Elasticsearch 介绍
概述
- 开源分布式搜索分析引擎
- 近实时(Near Real Time)
- 分布式存储/搜索/分析引擎
Solr 和 Splunk 提供的功能跟 Elasticsearch 很相似。但是 Elasticsearch 使用更加广泛,在搜索引擎中排名第一。
https://db-engines.com/en/ranking

起源
Elasticsearch 是起源于 Lucene。
- 基于 Java 语言开发的搜索引擎类库
- Lucene 具有高性能、易扩展的优点
- Lucene 的局限性:
- 只能基于 Java 语言开发
- 类库的接口学习曲线陡峭
- 原生并不支持水平扩展
2004 年 Shay Banon 基于 Lucene 开发了 Compass;
2010 年 Shay Banon 重写了 Compass,取名 Elasticsearch
- 支持分布式,可水平扩展
- 降低全文检索的学习曲线,可以被任何编程语言调用
Elastic 产品生命周期结束日期
分布式架构
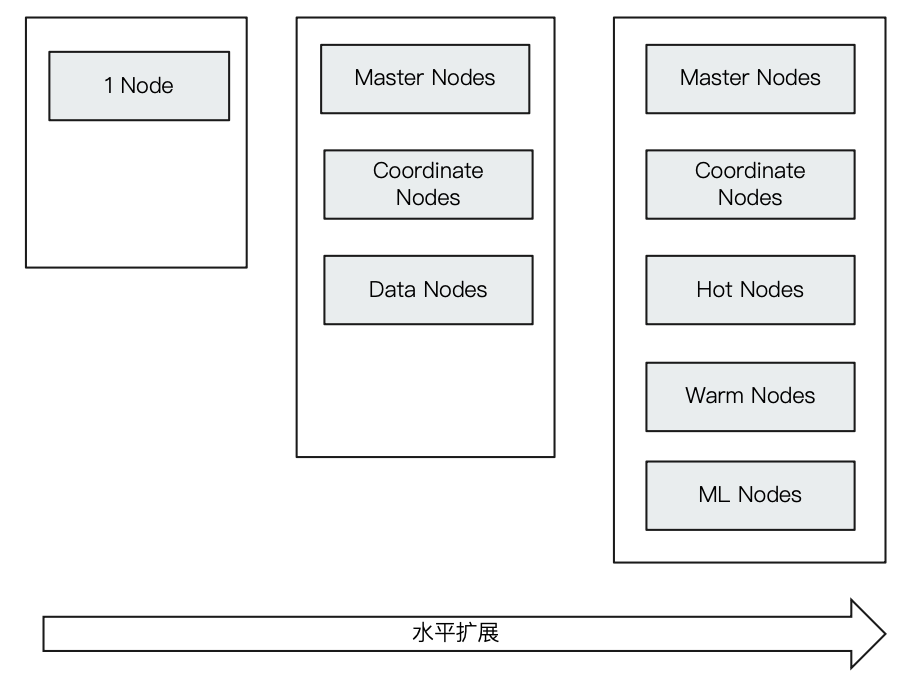
- 集群规模可以从单个扩展至数百个节点
- 高可用 & 水平扩展
- 服务和数据两个维度
- 支持不同的节点类型
- 支持 Hot & Warm 架构(一般用于日志类型数据)
支持多种方式集成接入
多种编程语言的类库:https://www.elastic.co/guide/en/elasticsearch/client/index.html
![image-20240326152428393]()
RESTful API vs Transport API
- 9200 vs 9300 (建议使用 RESTful API)
JDBC & ODBC

主要功能
- 海量数据的分布式存储以及集群管理
- 服务与数据的高可用,水平扩展
- 近实时搜索,性能卓越
- 结构化 / 全文 / 地理位置 / 自动完成
- 海量数据的近实时分析
- 聚合功能
相比关系型数据库,Elasticsearch 提供了如模糊查询,搜索条件的算分第等关系型数据库所不擅长的功能,但是在事务性等方面,也不如关系型数据库来的强大。因此,在实际 生产环境中,需要考虑具体业务要求,综合使用。
不同版本的特性
Elastic 产品生命周期结束日期
5.x

6.x

7.x

ELK 家族成员及应用场景
Elastic Stack 包括 Elasticsearch, Kibana, Logstash, Beats 等一系列产品.
Elasticsearch 是核心引擎,提供了海量数据存储,搜索和聚合的能力.
Beats 是轻量的数据采集器,
Logstash用来做数据转换,
Kibana 则提供了丰富的可视化展现与分析的功能.

Logstash:数据处理管道
https://www.elastic.co/cn/logstash
- 开源的服务器端数据处理管道,支持从不同来源采集数据,转换数据,并将数据发送到不同的存储库中
- Logstash 诞生于 2009年,最初用来做日志的采集与处理,2013年被 Elasticsearch 收购
特性:
- 实时解析和转换数据
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段
- 可扩展
- 200 多个插件(日志/数据库/Arcsigh/Netflow)
- 可靠性安全性
- Logstash 会通过持久化队列来保证至少将运行中的事情传达一次
- 数据传输加密
- 监控
Kibana:可视化分析利器
https://www.elastic.co/cn/kibana
- Kibana 名字的含义 = Kiwifruit + Banana
- 数据可视化工具,帮助用户解开对数据的任何疑问
- 最早是基于 Logstash 的工具,2013 年加入 Elasticsearch
特性:
提供可视化图表:

通过机器学习,做异常检测

BEATS:轻量的数据采集器
https://www.elastic.co/cn/products/beats
使用 go 语言开发

X-Pack:商业化套件
https://www.elastic.co/pricing
https://www.elastic.co/cn/subscriptions
- 6.3 之前的版本,X-Pack 以插件方式安装
- X-Pack 开源以后,Elasticsearch & Kibana 支持 OSS 版和 Basic 两种版本(开源版本和免费版本)
- 部分 X-Pack 功能支持免费使用,6.8 和 7.1 开始,Security 功能免费
- OSS,Basic,黄金级,白金级
应用场景
Elastic Stack 主要被广泛使用于:搜索,日志管理,安全分析,指标分析,业务分析, 应用性能监控等多个领域
分为两大类:搜索和数据分析
- 网站搜索(门户网站、购物网站)/垂直搜索/代码搜索(github)
- 日志管理与分析/安全指标监控/应用性能监控/WEB抓取舆情分
日志管理
- 日志搜集
- 格式化分析
- 全文检索
- 风险告警

Elasticsearch 与数据库的集成

- 一种情况是单独使用 Elasticsearch 存储:简单,高效
- 以下情况可考虑与数据库集成:将数据写入数据库,然后使用同步机制,将数据同步到 Elasticsearch
- 与现有系统的集成
- 需考虑事务性
- 数据更新频繁
指标分析/日志分析

当数据量大的时候,需要引入缓冲层,例如 Redis、Kafka、RabbitMQ 这种具备削峰的队列,Logstash 将日志进行转化和聚合,存储到 Elasticsearch,基于持久化的数据,可以通过 Grafana、Kibana 做数据分析和展示。
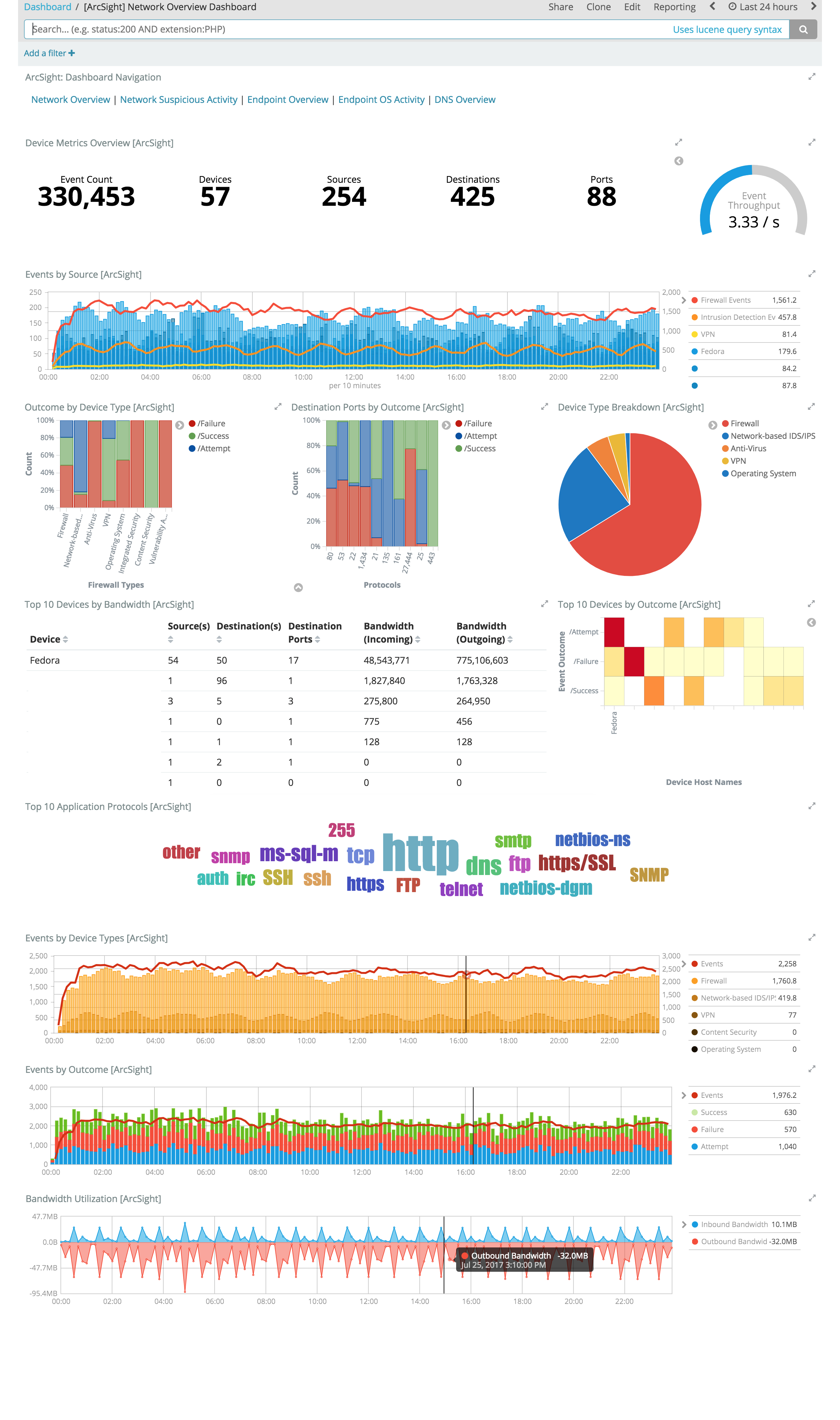
安全分析:集成 ArcSight
https://www.elastic.co/guide/en/logstash/current/arcsight-module.html#arcsight-module
Logstash ArcSight 模块能够轻松地将 ArcSight 数据与 Elastic Stack 集成。通过一个命令,该模块直接连接到 ArcSight Smart Connector 或事件代理,解析并索引安全事件到 Elasticsearch,并安装一套 Kibana 仪表板。

安装与简单配置
https://www.elastic.co/cn/downloads/elasticsearch
更加推荐使用 docker
文件目录结构

JVM 配置
- 修改 JVM -
config/jvm.options- 7.1 下载的默认设置是 1GB
- 配置的建议
- Xmx 和 Xms 设置成一样 (最小最大内存设置成一样)
- Xmx 不要超过内机器内存的 50%
- 内存总量不要超过 30GB:https://www.elastic.co/blog/a-heap-of-trouble
1 | # ps axuf|grep elasticsearch |
配置目录是 /etc/elasticsearch,修改里面的文件
1 | # vim jvm.options |
ps:
- 默认安装会打开
xpack.security,需要打开https页面,并且输入账号密码。可以关闭此功能。 - 如果打不开,可能是由于绑定地址为
localhost,而不是对外网口,修改配置文件/etc/elasticsearch/elasticsearch.yml中的network.host:为0.0.0.0
8.x 版本默认开启安装访问,需要进入 https,页面打开输入的账号密码需要手动设置:
1 | bin/elasticsearch-setup-passwords interactive |
需要输入多个用户的密码
1 | Please confirm that you would like to continue [y/N]y |
登录之后,显示节点信息
1 | { |
安装与查看插件
/_cat/plugins/?v 可以查看插件安装状态
进入到 es 的安装目录 /usr/share/elasticsearch,可通过 ps aux 查看
1 | # bin/elasticsearch-plugin list |
重启 Elasticsearch 后,浏览器中可以看到已安装

Elasticsearch 提供插件的机制对系统进行扩展
- Discovery Plugin
- Analysis Plugin
- Security Plugin
- Management Plugin
- Ingest Plugin
- Mapper Plugin
- Backup Plugin
开发机上运行多个实例
1 | ./bin/elasticsearch -d -E cluster.name=my_cluster -E node.name=node_1 -E path.data=node_1_data |
查看节点 /_cat/nodes?v
关闭进程通过 kill <pid>
Kibana 的安装与界面快速预览
https://www.elastic.co/guide/en/kibana/8.12/install.html
通过 5601 端口进入。
- 如果打不开,可能是由于绑定地址为
localhost,而不是对外网口,修改配置文件/etc/kibana/kibana.yml中的server.host:为0.0.0.0
页面打开之后,通过上面配置的账号密码登录。
默认会安装 APM,按照页面指令安装即可。
登录进去之后,在 Home - Try sample data - Other sample data sets 中,上传测试数据到 Elasticsearch 中。
在 Management - Dev Tools 页面,可以通过 Elasticsearch 命令操作,通过点击 help 可以查看快捷键。
Kibana Plugin
增强应用,以及一些图表功能
https://www.elastic.co/guide/en/kibana/current/kibana-plugins.html#known-kibana-plugins
1 | # ./bin/kibana-plugin |
Cerebro
一个 Elasticsearch 网页管理工具:https://github.com/lmenezes/cerebro
由于需要安装 Java 的环境,比较麻烦,这里推荐使用 docker
1 | docker run -p 9000:9000 --env-file env-ldap lmenezes/cerebro |
打开 9000 端口即可。
Logstash
https://www.elastic.co/cn/downloads/logstash
1 | bin/logstash -f logstash.conf |
下载测试集
https://grouplens.org/datasets/movielens/
也就是下载:https://files.grouplens.org/datasets/movielens/ml-25m.zip
编辑导入文件的配置文件 logstash.conf
1 | input { |
执行命令导入
1 | ./bin/logstash -f logstash.conf |
导入后,可以看到有 movies 的 index
/_cat/indices?v
1 | yellow open movies ay_XjQBsTpWoLszNQNPDgQ 1 1 62424 0 14.5mb 14.5mb 14.5mb |
基本概念
Elasticsearch 中有很多概念,例如 Document、Index 和 Type

可以理解为:
- Index 索引
- Type 类型
- Document 文档
- Node 节点
- Shard 分片
文档 Document
- Elasticsearch 是面向文档的,文档是所有可搜索数据的最小单位
- 日志文件中的日志项
- 一条数据
- 文档会被序列化成 JSON 格式,保存在 Elasticsearch 中
- JSON 对象由字段组成
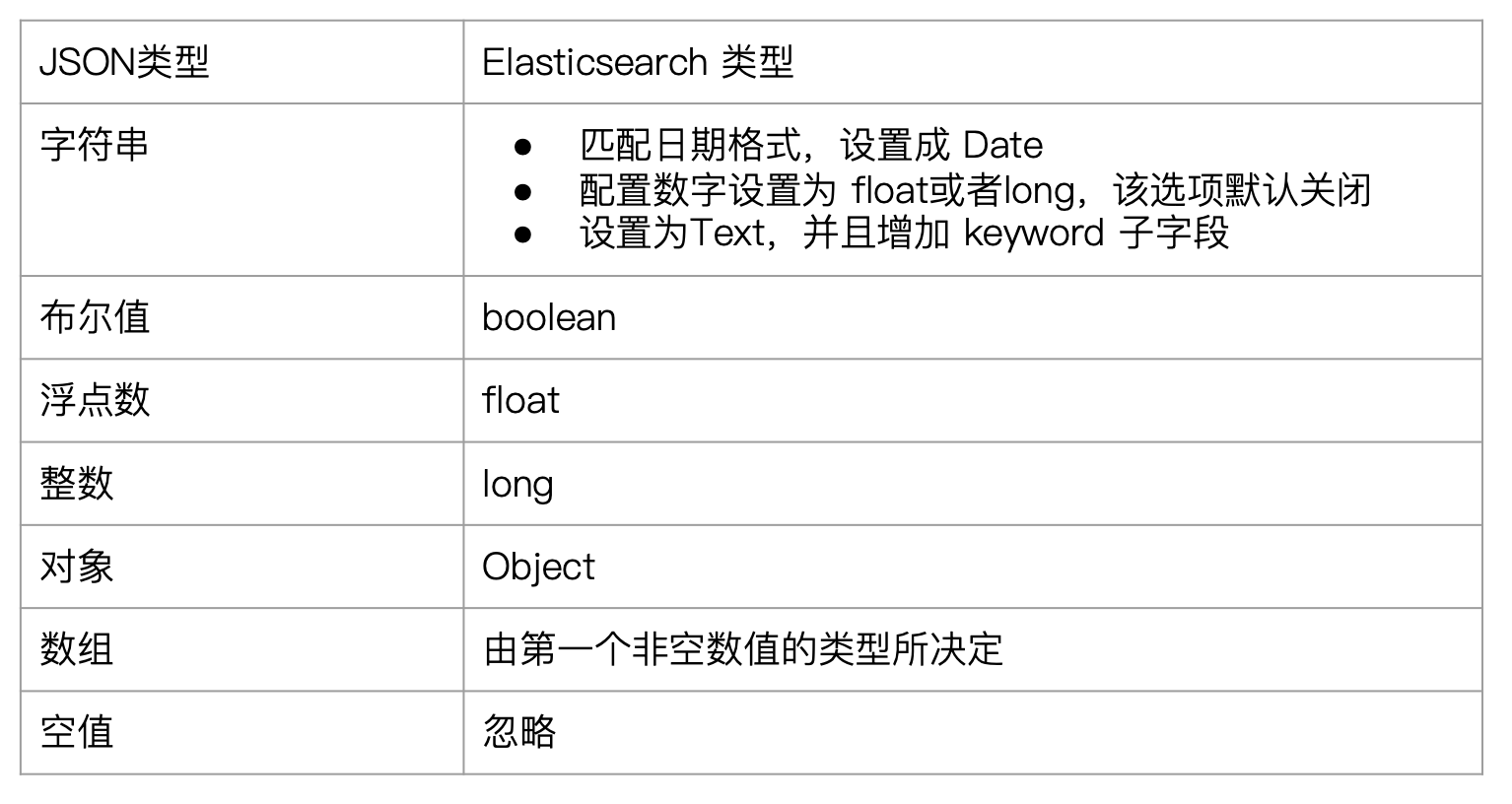
- 每个字段都有对应的字段类型(字符串/数值/布尔/日期/二进制/范围类型)
- 每个文档都有一个 Unique ID
- 可以指定 ID
- 通过 Elasticsearch 自动生成
JSON 文档
- 一个文档中包含一系列的字段,类似数据库表中一条记录
- JSON 文档,格式灵活,不需要预先定义格式
- 字段的类型可以指定或者通过 Elasticsearch 自动推算
- 支持数组/支持嵌套

文档的元数据
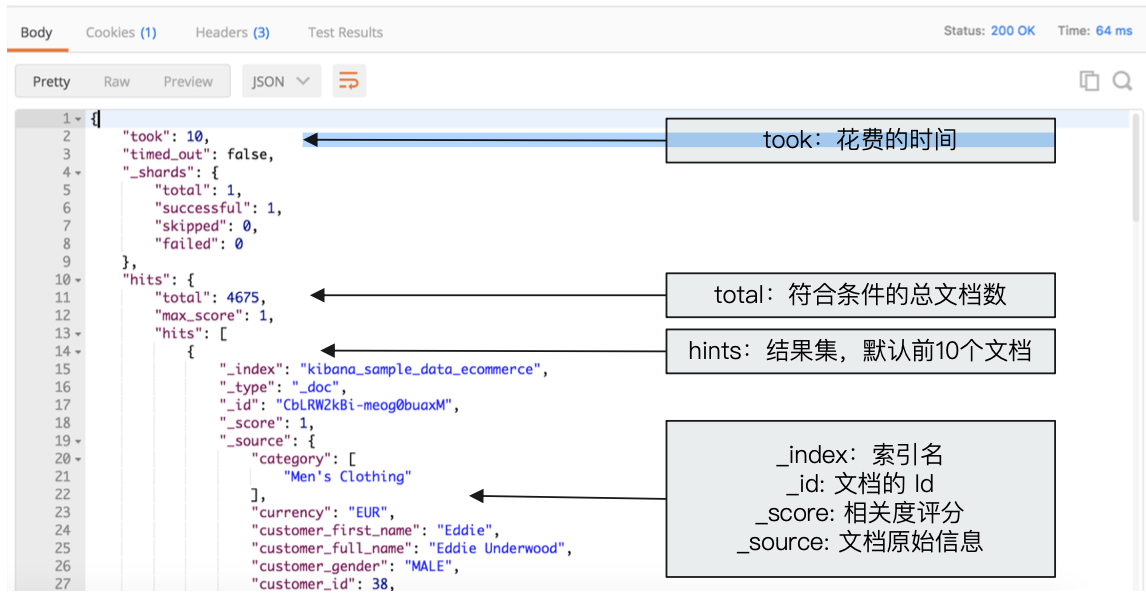
1 | { |
元数据:用于标注文档的相关信息
_index:文档所属的索引名_type:文档所属的类型名_id:文档唯一 id_source:文档的原始 JSON 数据_all:整合所有字段内容到该字段(目的是检索),已被废除_version:文档的版本信息(解决文档冲突)_score:相关性打分(查询结果算分)
索引 Index
Index:索引,是文档的容器,是一类文档的结合
- Index 体现了逻辑空间的概念:每个所有都有自己的 Mapping 定义,用于定义包含的文档的字段名和字段类型
Shard体现了物理空间的概念:索引中的数据分散在Shard上
索引的 Mapping 与 Setting
Mapping定义文档字段的类型Settings定义不同的数据分布
1 | GET /movies/_settings |
1 | GET /movies/_mapping |
索引的不同语意

例如:索引(动词)文档到 Elasticsearch 的索引(名词)中
- 名词:一个 Elasticsearch 集群中,可以创建很多个不同的缩影
- 动词:保存一个文档到 Elasticsearch 的过程也叫作缩影 (Indexing)
- ES 中,指的是创建一个倒排索引的过程
- 名词:例如一个 B 数索引,一个倒排索引
类型 Type
在 7.0 之前,一个 Index 可以设置多个 Types,每个 Type 下有相同类型的文档;
从 6.0 开始,Type 已经被 Deprecated。7.0 开始,一个索引只能创建一个 Type - _doc
1 | { |
抽象与类比
| RDBMS | Elasticsearch |
|---|---|
| Table | Index(Type) |
| Row | Document |
| Column | Field |
| Schema(表定义) | Mapping |
| SQL | DSL |
传统关系型数据库和 Elasticsearch 的区别和侧重点:
- Elasticsearch:Schemaless /相关性/高性能全文检索
- RDBMS:事务性 /
Join
REST API
很容易被各种语言调用

一些基本的 API
indices- 创建 Index:
PUT Movies - 查看所有 Index:
_cat/indices
- 创建 Index:
1 | # 获取 Index 信息 |
集群
作为分布式系统,需要具备高可用性和可扩展性
- 高可用性:
- 服务可用性:允许有节点停止服务
- 数据可用性:部分节点丢失,不会丢失数据
- 可扩展性
- 请求量提升 / 数据的不断增长(将数据分布到所有节点上)
分布式特性
- 优势
- 存储的水平扩容
- 提高系统的可用性,部分节点停止服务,整个集群的服务不受影响
- 架构
- 不同的集群通过不同的名字来区分,默认名字
elasticsearch - 通过配置文件修改,或者在命令行中
-E cluster.name=xxx进行设定 - 一个集群可以有一个或者多个节点
- 不同的集群通过不同的名字来区分,默认名字
节点
节点是一个 Elasticsearch 的实例:
- 本质上就是一个 Java 进程
- 一台机器上可以运行多个 Elasticsearch 进程,但是生产环境一般建议一台机器上只运行一个 Elasticsearch 实例
每一个节点都有名字,通过配置文件配置,或者启动时候 -E nodel.name=node1 指定
每一个节点在启动之后,会分配一个 UID,保存在 data 目录下
Master Node & Master eligible Node
- 每个节点启动后,默认就是一个 Master eligible 节点
- 可以设置配置文件
node.master: false禁止
- 可以设置配置文件
- Master-eligible 节点可以参加选主流程,成为 Master 节点
- 当第一个节点启动时,它会将自己选举成 Master 节点
- 每个节点上都保存了集群的状态,只有 Master 节点才能修改集群的状态信息
- 集群状态(Cluster State),维护了一个集群中必要的信息
- 所有的节点信息
- 所有的索引和其相关的 Mapping 与 Setting 信息
- 分片的路由信息
- 任意节点都能修改信息会导致数据的不一致性
- 集群状态(Cluster State),维护了一个集群中必要的信息
Data Node
可以保存数据的节点,叫作 Data Node。负责保存分片数据,在数据扩展上起到了至关重要的作用。(当集群无法保存现有数据时,可以给集群添加一个数据节点来解决这个问题)
Coordinating Node
- 负责接受 Client 的请求,将请求分发到合适的节点,最终把结果汇集到一起
- 每个节点默认都起到了 Coordinating Node 的职责
Hot & Warm Node
Hot 节点是配置比较高的节点,有比较好的内存和CPU,Warm 节点用于存储旧数据,配置较低。
不同硬件配置的 Data Node,用来实现 Hot & Warm 架构,降级集群部署的成本。
Machine Learning Node
负责跑机器学习的 Job,用来做异常检测
Tribe Node
未来版本会被(Cluster Search 功能)淘汰,
(5.3 开始使用 Cross Cluster Search)Tribe Node 连接到不同的 Elasticsearch 集群,并且支持将这些集群当成一个单独的集群处理。
配置节点类型
开发环境中一个节点可以承担多种角色
- 性能好
- 根据不同的机器分配不同的性能
生产环境中,应该设置单一的角色的节点(dedicated node)

分片
分片分为 Primary Shar(主分片)和 Replica Shard(副本)
- 主分片,用以解决数据水平扩展的问题,通过主分片,可以将数据分布到集群内的所有节点之上
- 一个分片是一个运行的 Lucene 的实例
- 主分片数在索引(Index)创建时指定,后续不允许修改,除非 Reindex
- 副本,用以解决数据高可用的问题,分片是主分片的拷贝
- 副本分片数,可以动态调整
- 增加副本数,还可以在一定程度上提高服务的可用性(读取的吞吐)
一个三节点的集群中,blogs 索引的分片分布情况
1 | PUT /blog |
创建 Index 时,会创建三个分片,以及每一个主分片对应一个副本,一共六个分片,相同分片不会分布到同一个节点上。

如果此时增加一个节点,那么六个分片会分布到四个节点上,一定程度增加系统可用性。
分片的设定
对于生产环境中分片的设定,需要提前做好容量规划。
- 分片数设置过小
- 导致后续无法增加节点实现水平扩展
- 单个分片的数据量太大,导致数据重新分配耗时
- 分片数设置过大,7.0 开始,默认主分片设置成1(从 5 改成 1),解决了
over-sharding的问题- 影响搜索结果的相关性打分,影响统计结果的准确性
- 单个节点上过多的分片,会导致资源浪费,同时也会影响性能
查看集群健康状况
1 | GET /_cluster/health |
- Green:主分片与副本都正常分配
- Yellow:主分片全部正常分配,有副本分片未能正常分配
- Red:有主分片未能分配
- 例如,当服务器的磁盘容量超过 85% 时,创建了一个新的索引
还可以通过一些工具查看集群节点的状态,例如前面的 Cerebro,或者浏览器插件:https://chromewebstore.google.com/detail/elasticvue/hkedbapjpblbodpgbajblpnlpenaebaa
节点状态:


分片状态:

当关闭节点 node_1


再关闭一个节点(Master 节点),会导致选举无法满足半数,导致 Master 无法产生,集群无法正常工作。
文档的基本操作
CRUD 与批量操作
文档的 CRUD
Index 创建
1 | PUT my_index/_doc/1 |
Type 名,约定都用 _doc。
PUT 如果 ID 存在,会全局覆盖更新(可以理解为删除现有的文档,再创建新的文档,版本会增加)
1 | PUT my_index/_doc/1 |
自动创建 id
1 | POST my_index/_doc |
Index 和 Create 不一样的地方:
- 如果文档不存在,就索引新的文档
- 否则现有文档会被删除,新的文档被索引,版本号 +1
Create 创建
1 | PUT my_index/_create/3 |
如果 ID 已经存在,会失败
Read 获取
1 | GET my_index/_doc/1 |
- 找到文档,返回 HTTP 200
- 文档元信息
- 包含版本信息,同一个 ID 的文档,即使被删除,
_version也会不断增加 _source中默认包含了文档的所有原始信息
- 包含版本信息,同一个 ID 的文档,即使被删除,
- 文档元信息
- 找不到文档,返回 HTTP 404
Update 更新
1 | POST my_index/_update/1 |
文档必须已经存在,更新只会对相应字段做增量修改
- Update 方法不会删除原来文档的字段,而是实现真正的数据更新(其实真实逻辑也是删除整个文档,然后局部替换,再创建)
- POST 方法 Payload 需要包含在
doc中
ps:es 中没有更新,只有删除再创建。
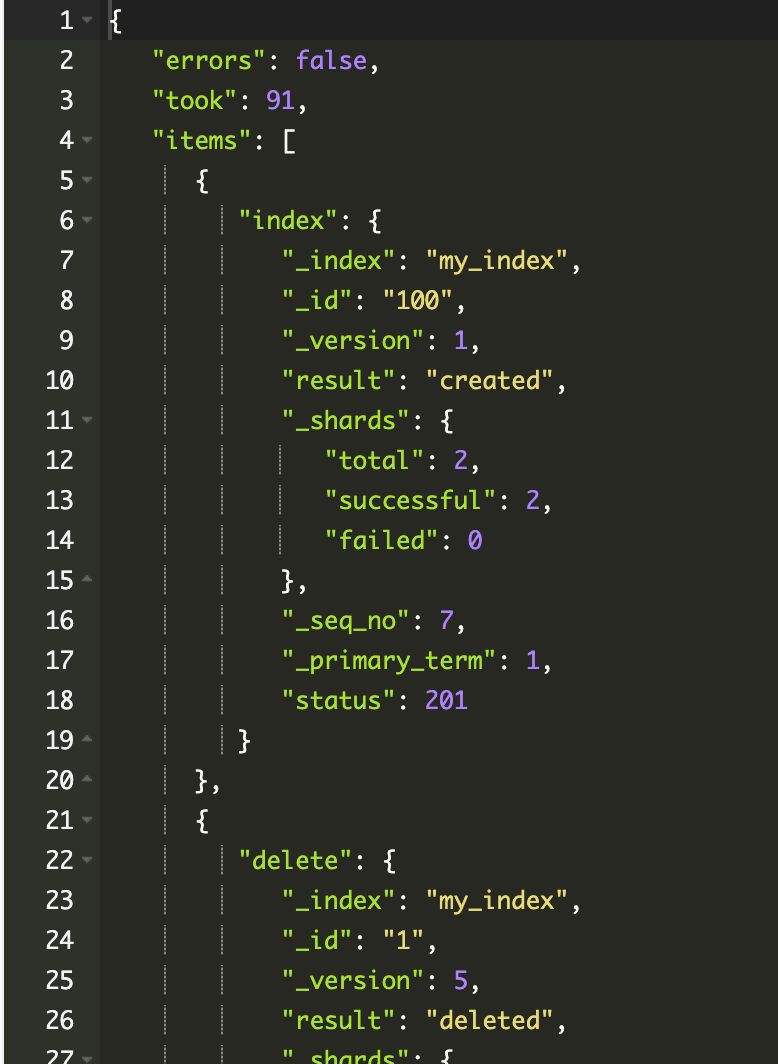
批量操作
在请求 ES 时经过网络操作,比较消耗性能,此时可以通过 Bulk 将多个操作一次性发送到服务端。
每次批量操作,数据量不宜过大,以免引发性能问题
批量多操作 Bulk
- 支持在一次 API 调用中,对不同的索引进行操作
- 支持四种类型操作
- Index
- Create
- Update
- Delete
- 可以在 URI 中指定 Index,也可以在请求的 Playload 中指定
- 操作中单条操作失败,并不会影响其他操作
- 返回结果包括了每一条操作执行的结果
1 | POST _bulk |
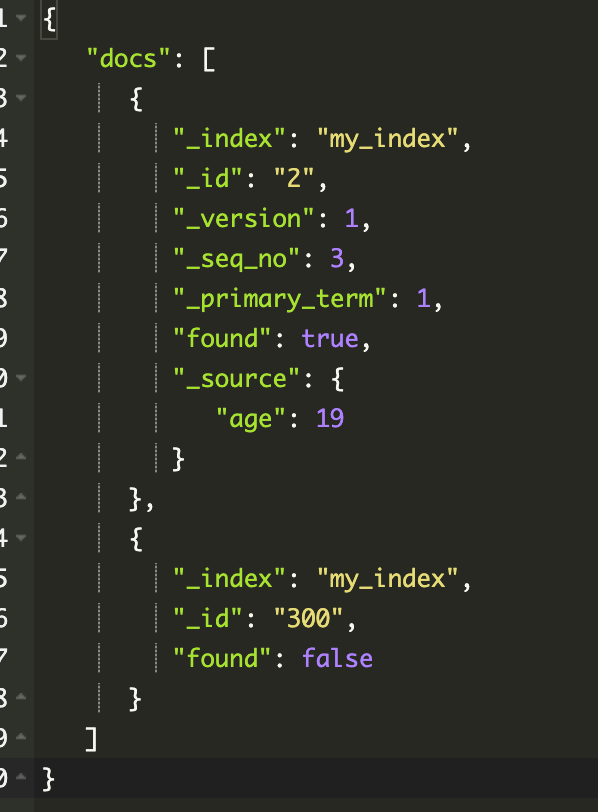
批量读取 mget
1 | GET _mget |
批量查询 msearch
1 | POST /my_index/_msearch |
返回结果就是执行多个检索条件的返回结果
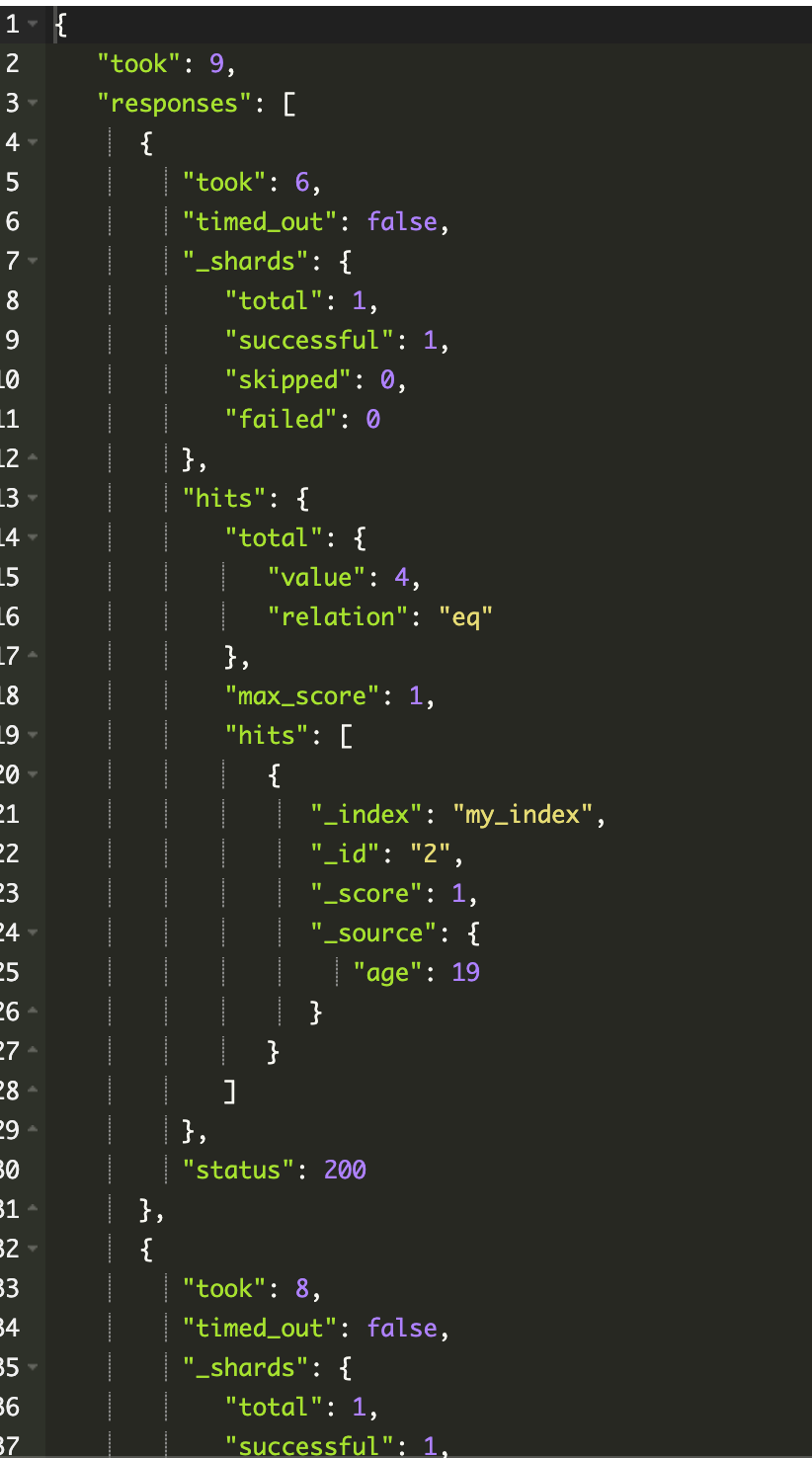
常见错误返回

倒排索引
倒排索引可以理解为通过内容查找到文件。
例如用图书和搜索引擎的类比:
- 图书:
- 正排索引 - 目录页
- 倒排索引 - 索引页
- 搜索引擎
- 正排索引 - 文档 ID 到文档内容和单词的关联
- 倒排索引 - 单词到文档 ID 的关系
正排索引和倒排索引

核心组成
倒排索引包含两个部分:
- 单词词典(Term Dictionary):记录所有文档的单词,记录单词到倒排列表的关联关系
- 单词词典一般比较大,可以通过 B+ 数或哈希拉链法实现,以满足高性能的插入与查询
- 倒排列表(Posting List):记录了单词对应的文档结合,由倒排索引项组成
- 倒排索引项(Posting)
- 文档 ID
- 词频 TF:该单词在文档中出现的次数,用于相关性评分
- 位置(Position):单词在文档中分词的位置。用于语句检索(Phrase query)
- 偏移(Offset):记录单词的开始结束位置,实现高亮显示
- 倒排索引项(Posting)
例如 Elasticsearch 这个单词对应的 倒排列表:

- Elasticsearch 的 JSON 文档中的每个字段,都有自己的倒排索引
- 可以指定对某些字段不做索引
- 优点:节省存储空间
- 缺点:字段无法被搜索
通过 Analyzer 进行分词
Analysis 与 Analyzer
- Analysis:文本分析,也叫分词,就是将文本转换成一系列单词(
term/token)的过程。 - Analysis:是通过 Analyzer(分词器) 来实现的
- 可使用 Elasticsearch 内置的分词器,或者按需定制化分词器
- 出了在数据写入时转换词条,匹配 Query 语句时也需要用相同的分词器对查询语句进行分析

例如,将 Elasticsearch Server 这段词,分为 elasticsearch、server 两个小写单词。
Analyzer 的组成
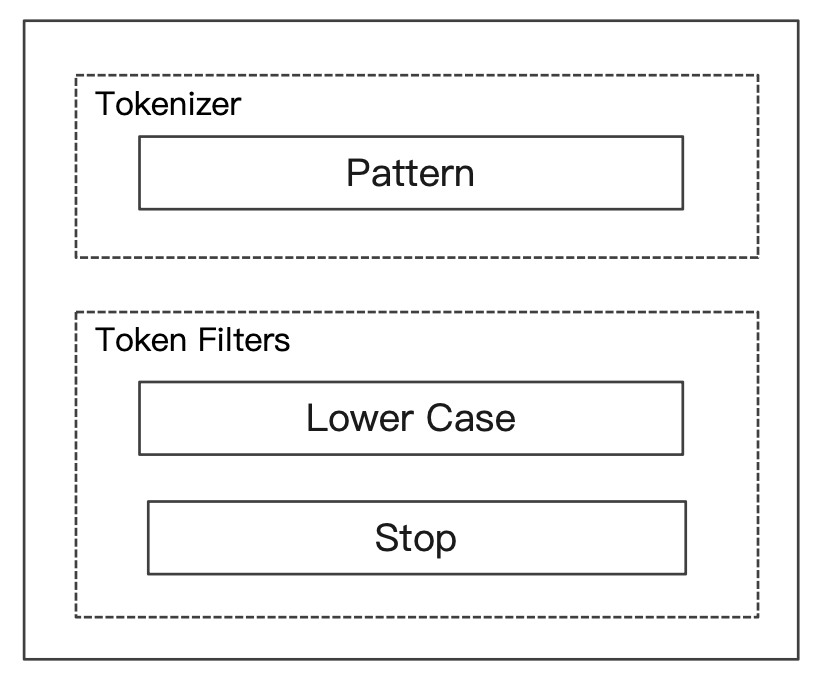
分词器是专门处理分词的组件,Analyzer 由三部分组成
- Character Filters(针对原始文本处理,例如去除
html标签)/ Tokenizer(按照规则切分为单词,例如通过空格切分)/ Token Filter(将切分的单词进行加工,例如小写,删除stopwords,增加同义词)
分词过程如下:

Elasticsearch 的分词器
Elasticsearch 除了提供内置的分词器,还提供自定义分词器

指定分词器进行测试
1 | POST /_analyze |
指定索引的字段进行测试
1 | POST movies/_analyze |
自定义分词器进行测试
1 | POST /_analyze |
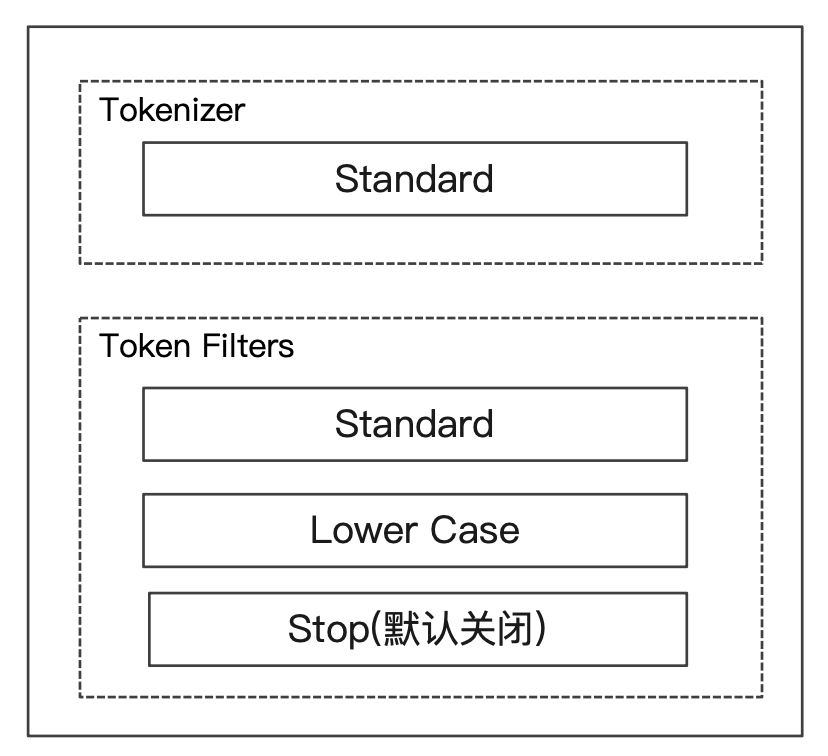
Standard Analyzer
- 默认分词器
- 按词切分
- 小写处理
Simple Analyzer
- 按照非字母切分,非字母的都被去除
- 小写处理

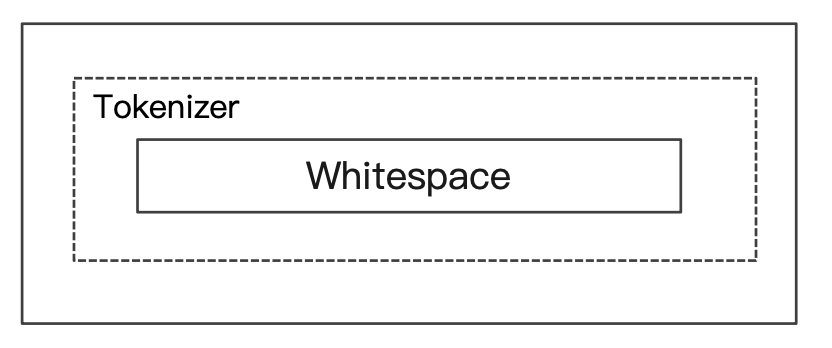
Whitespace Analyzer
- 按照空格切分
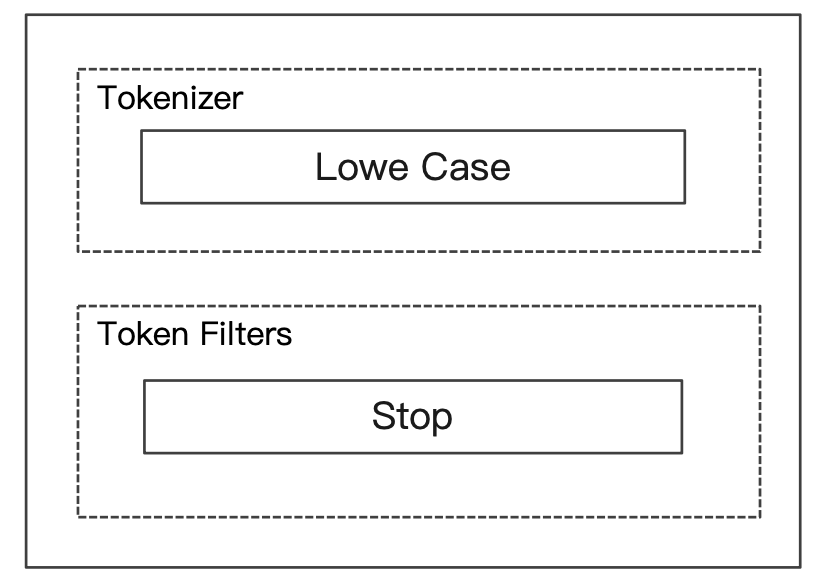
Stop Analyzer
- 相比 Simple Analyzer 多了 stop filter
- 会把
the,a、is等修饰性词语去除
Keyword Analyzer
- 不分词,直接将输入当一个
term输出
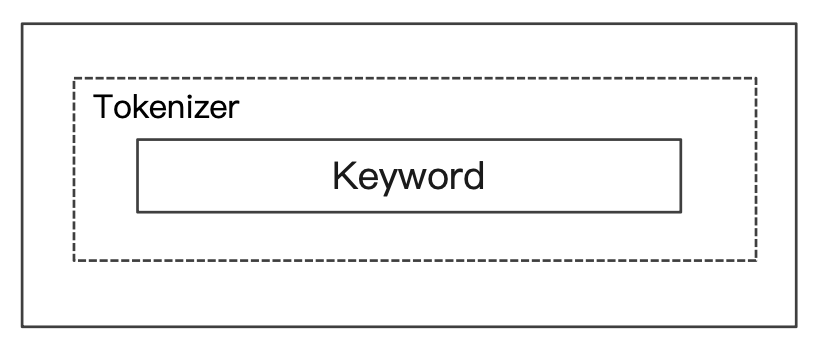
Pattern Analyzer
- 通过正则表达式进行分词
- 默认是
\W+,非字符的符号进行分隔
Language Analyzer
通过指定语言来进行分词

例如
1 | POST /_analyze |
中分分词的难点
- 中文句子,切分成一个一个词(不是一个个字)
- 英文中,单词有自然的空格作为分隔
- 一句中文,在不同的上下文,有不同的理解
- 例如:
这个苹果,不大好吃相比这个苹果,不大,好吃
- 例如:
- 还有一些无法分词
- 例如:
他说的确实在理
- 例如:
ICU Analyzer
通过 plugin 安装
1 | bin/elasticsearch-plugin install analysis-icu |
提供了 Unicode 的支持,更好的支持亚洲语言。
1 | POST /_analyze |
更多的中文分词器
- IK:支持自定义词库,支持热更新分词字典
- https://github.com/infinilabs/analysis-ik
- THULAC:
- 清华大学自然语言处理和社会人文计算实验室的一套中文分词器
- https://github.com/microbun/elasticsearch-thulac-plugin
Search API
查询 API 分为两种:
- URI Search:也就是在 URL 中使用查询参数
- Request Body Search:使用 Elasticsearch 提供的,基于 JSON 格式的更加完备的 Query Domain Specific Language (DSL)
指定查询的索引
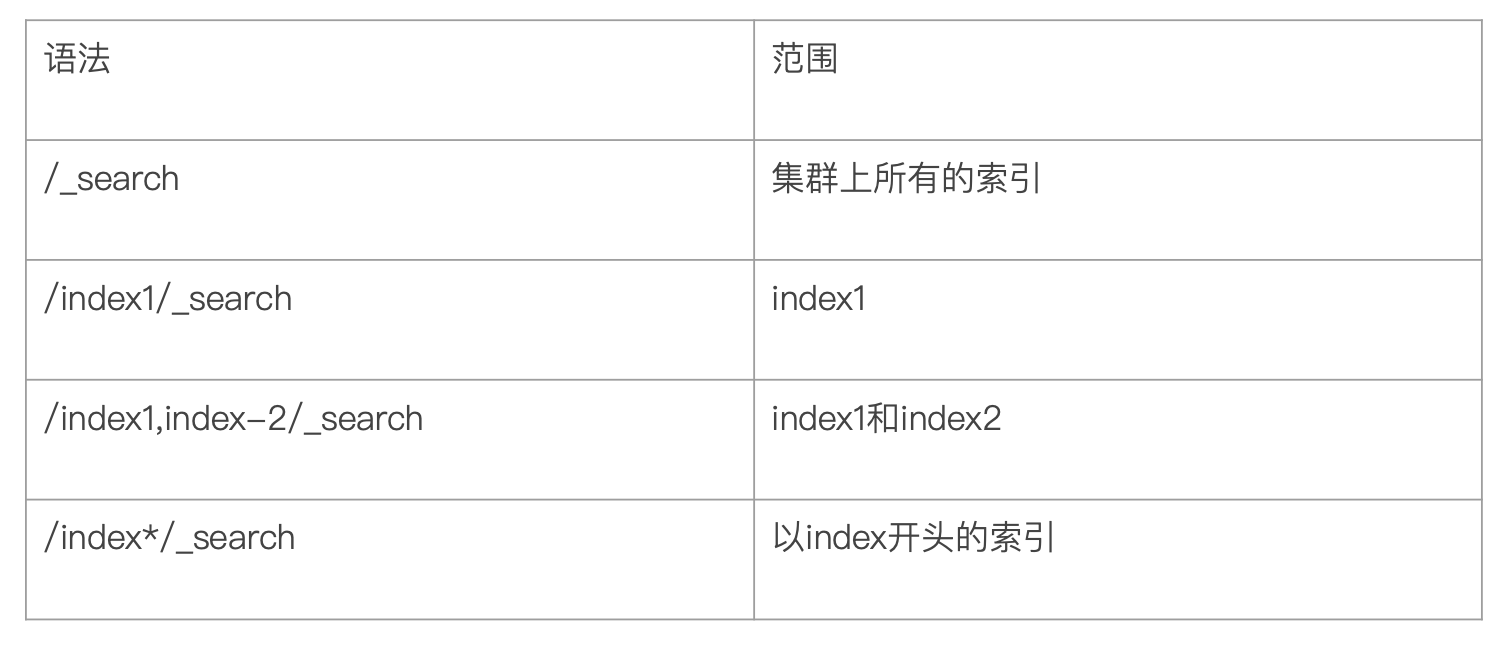
提供所有 Index 检索,也提供多个 Index 搜索,以及提供 前缀Index 搜索
URI 查询
- 使用
q,指定查询字符串 query string syntax,KV 键值对
例如:

Request Body
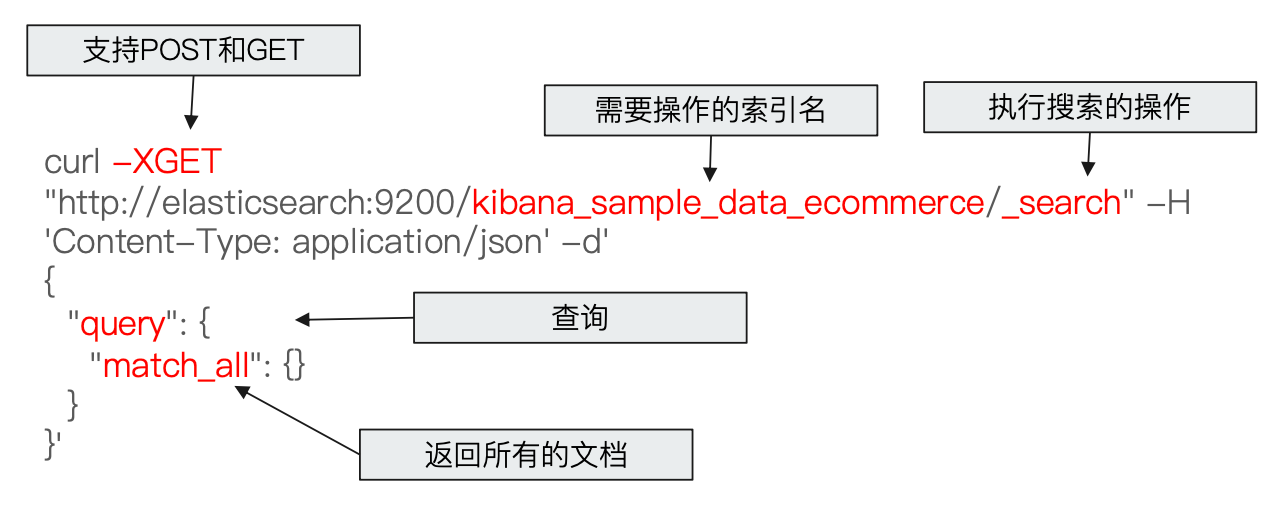
Ps:es 查询时支持使用 POST 和 GET,GET 支持携带 Body
搜索 Response
搜索的相关性 Relevance
- 搜索时用户和搜索引擎的对话
- 用户关心的是搜索结果的相关性
- 是否可以找到所有相关的内容
- 有多少不相关的内容被返回了
- 文档的打分是否合理
- 结合业务需求,平衡结果排名
Web 搜索
- Page Rank 算法
- 不仅仅是内容
- 竞价排名的排序
- 更重要的是内容的可信度
电商搜索
- 搜索引起扮演销售的角色
- 提高用户购物体验
- 提升网站销售业绩
- 去库存
衡量相关性
Information Retrieval
- Precision(查准率):尽可能返回较少的无关文档
- Recall(查全率):尽量返回较多的相关文档
- Ranking:是否能够按照相关度进行排序
Precision & Recall
查准率和查全率的计算方式:
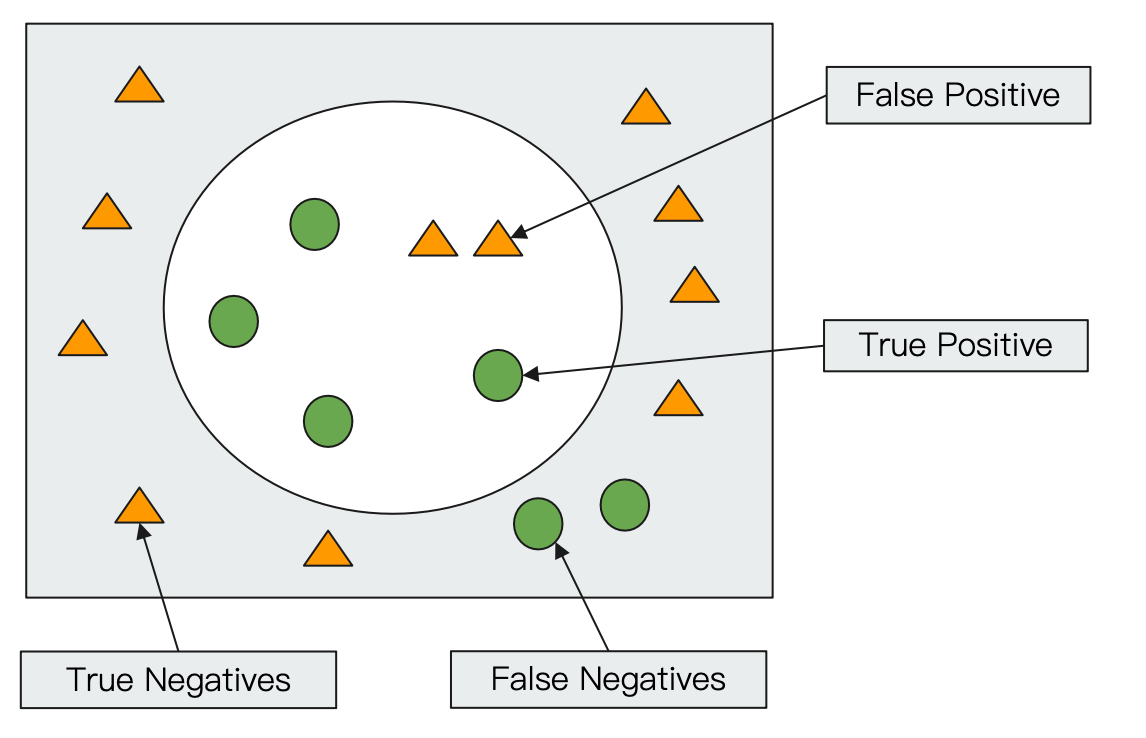
- Precision - True Positive / 全部返回的结果(True and False Positives)
- Recall - True Positive / 所有应该返回的结果(True positives + False Negtives)
使用 Elasticsearch 时,需要通过查询和相关的参数改善搜索的 Precision 和 Recall
Search
URI Search
通过 URI 参数实现搜索的目的
1 | GET movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10&timeout=1s |
q:指定查询语句,使用 Query String Syntaxdf:默认字段(也叫做查询字段),不指定时,代表查询所有字段sort:指定字段排序from,size:用于分页profile:可以查看查询是如何被执行的
1 | "profile": { |
一些语法
指定字段 和 泛查询
指定字段是指定某个字段作为检索条件;泛查询指的是所有字段作为检索条件
1 | # 指定字段 |
通过 profile 可以看到查询细节,包含了所有字段
1 | "description": "ConstantScore((log.file.path.keyword:2012 | event.original.keyword:2012 | id.keyword:2012 | log.file.path:2012 | id:2012 | year:[2012 TO 2012] | genre:2012 | @version:2012 | @version.keyword:2012 | event.original:2012 | genre.keyword:2012 | title.keyword:2012 | title:2012))", |
Term 和 Phrase
例如:
- Term:
Beautiful Mind等效于Beautiful OR Mind - Phrase:
"Beautiful Mind"等效于Beautiful AND Mind。Phrase查询,还要求前后顺序保持一致
1 | GET movies/_search?q=title:(Beautiful Mind) # 使用括号代表分组是一个组 |
1 | # 使用括号代表分组是一个组,如果不分组,会变成 |
分组与引号
- 分组:
title:(Beautiful Mind),代表是一个组,作为查询条件 - 引号:
title:"Beautiful Mind",代表是一个 Phrase 查询
布尔操作
AND / OR / NOT 或者 && / || / !
- 必须大写
title:(Beautiful AND Mind) 代表必须两个都有
1 | GET movies/_search?q=title:(Beautiful AND Mind) |
分组操作
+表示must-表示must_not
title:(+Beautiful -Mind) 代表 必须有 Beautiful 以及必须没有 Mind
范围查询
使用区间表示:[] 闭区间,{} 开区间
- 闭区间代表包括
- 开区间代表不包括
1 | GET movies/_search?q=year:{1980 TO 1981] |
算数符号
1 | GET movies/_search?q=year:>2000 |
通配符查询
通配符查询效率低,占用内存大,不建议使用,特别是放在最前面。
?代表 1 个字符,*代表 0 或多个字符
1 | GET movies/_search?q=title:M?nd |
正则表达式
1 | GET movies/_search?q=title:[bt]oy |
模糊匹配与近似查询
1 | GET movies/_search?q=title:beautif~1 |
Request Body Search
将查询语句通过 HTTP Request Body 发送给 Elasticsearch。使用 Query DSL
1 | GET movies/_search?q=2012&df=title&sort=year:desc&from=0&size=10&timeout=1s |
分页
- From 默认从 0 开始,返回 10 个结果
- 获取靠后的翻页成本较高
排序
- 最好在 数字型 和 日期型 字段上排序
- 因为对于多值类型或分析过的字段排序,系统会选一个值,无法得知该值
过滤
1 | GET movies/_search |
- 如果
_source没有存储,那就只返回匹配的文档的元数据 - 支持通配符
["*name*", "desc*"]
脚本字段
1 | GET movies/_search |
脚本一般用于检索结果需要做额外操作,例如 排除、替换、计算 一些内容
查询表达式
match 全文检索
有且只有一个字段,并且会分词,默认是 OR 关系
1 | GET movies/_search |
Match Phrase
可以多字段检索,也会分词,单词之间是 AND 关系,并且位置顺序也影响搜索结果
1 | GET movies/_search |
query_string
类似 URI Query,可以指定多个字段,可以使用复杂的查询表达式,不分词
1 | GET movies/_search |
Simple Query String Query
- 类似 Query String,但是会忽略错误的语法,同时只支持部分查询语法
- 不支持 AND OR NOT,会当作字符串处理
- Term 之间默认的关系是 OR,可以指定 Operator
- 支持部分逻辑
+替代 AND|替代 OR-提到 NOT
1 | GET movies/_search |
Mapping
Mapping 类似数据库中的 schema 的定义,作用如下:
- 定义索引中的字段的名称
- 定义字段的数据类型,例如字符串,数字,布尔
- 字段,倒排索引的相关配置(Analyzed or Not Analyzed,Analyzer:定义是否被索引,被分词,以及指定分词器)
Mapping 会把 JSON 文档映射成 Lucene 所需要的扁平格式
一个 Mapping 属于一个索引的 Type
- 每个文档都属于一个 Type
- 一个 Type 有一个 Mapping 定义
- 7.0 开始,不需要在 Mapping 定义中指定 type 信息
字段数据类型
- 简单类型
- Text / Keyword
- text 用于全文搜索,会分词
- keyword 用于精确匹配,不会分词
- Date
- Integer / Floating
- Boolean
- IPv4 & IPv6
- Text / Keyword
- 复杂类型一对象和嵌套对象
- 对象类型 / 嵌套类型
- 特殊类型
- geo_point & geo_shape / percolator
Dynamic Mapping
- 在写入文档时候,如果索引不存在, 会自动创建索引
- Dynamic Mapping 的机制,使得我们无需手动定义Mappings。 Elasticsearch 会自动根据文档信息,推算出字段的类型
- 但是有时候会推算的不对,例如地理位置信息
- 当类型如果设置不对时,会导致一些功能无法正常运行,例如 Range 查询
1 | GET movies/_mapping |
类型的自动识别
更改 Mapping 字段类型的情况
两种情况:
- 新增加字段
- Dynamic 设为
true时,一旦有新增字段的文档写入,Mapping 也同时被更新 - Dynamic 设为
false,Mapping 不会被更新,新增字段的数据无法被索引, 但是信息会出现在_source中 - Dynamic 设置成 Strict,文档写入失败
- Dynamic 设为
- 对已有字段,一旦已经有数据写入,就不再支持修改字段定义
- Lucene 实现的倒排索引,一旦生成后,就不允许修改
- 如果希望改变字段类型,必须 Reindex APl,重建索引
原因:
- 如果修改了字段的数据类型,会导致已被索引的数据无法被搜索
- 但是如果是增加新的字段,就不会有这样的影响
设置 Dynamic Mappings

1 | PUT test1 |
- 当 dynamic 被设置成 false 时候,存在新增字段的数据写入,该数据可以被索引, 但是新增字段被丢弃
- 当设置成 Strict 模式时候,数据写入直接出错
显式 Mapping 设置与常见参数介绍
1 | PUT test1 |
自定义 mapping 的一些建议:
- 可以参考 API 手册,纯手写
- 为了减少输入的工作量,减少出错概率,可以依照以下步骤
- 创建一个临时的 index,写入一些样本数据
- 通过访问 Mapping APl 获得该临时文件的动态 Mapping 定义
- 修改后,使用该配置创建你的索引
- 删除临时索引
控制当前字段是否被索引
Index:控制当前字段是否被索引。默认为true。如果设置成 false,该字段不可被搜索

设置成 false 不会创建倒排索引,也会节省开销。
Index 选项
四种不同级别的 Index Options 配置,可以控制倒排索引记录的内容:
- docs - 记录 doc id
- freqs - 记录 doc id 和 term frequencies
- positions -记录 doc id / term frequencies / term position
- offsets - doc id / term frequencies / term posistion / character offects
Text 类型默认记录 postions,其他默认为 docs
记录内容越多,占用存储空间越大

null_value
空值处理

- 需要对 Null 值实现搜索
- 只有 Keyword 类型支持设定 Null_value
copy_to
将一个字段的倒排索引拷贝到另外一个字段(这个字段不存在),供检索使用,但是不影响原始文档。

_all在 es 7中被copy_to所替代- 满足一些特定的搜索需求
copy_to将字段的数值拷贝到目标字段,实现类似_all的作用copy_to的目标字段不出现在_source中
数组类型
Elasticsearch 中不提供专门的数组类型。但是任何字段,都可以包含多个相同类类型的数值

多字段特性及配置自定义 Analyzer
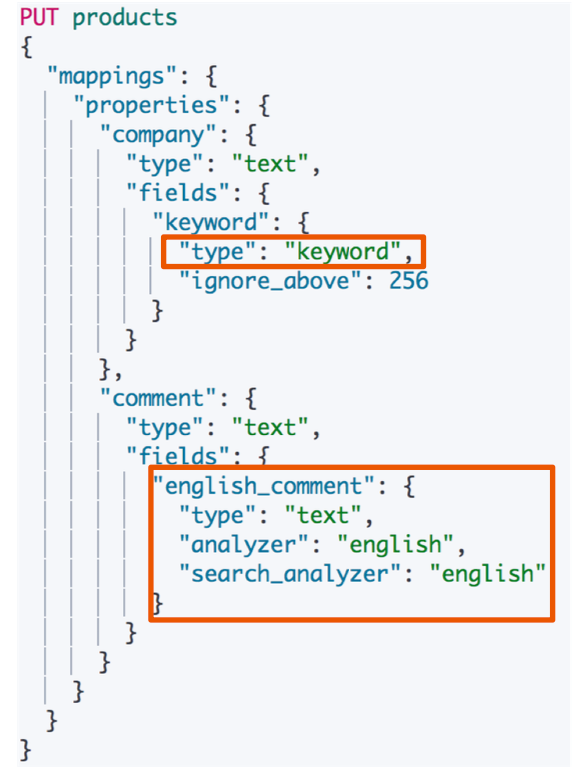
- 多字段特性
- 厂商名字实现精确匹配
- 增加一个 kewword 字段
- 使用不同的 analyzer
- 不同语言
- pinyin 字段的搜索
- 还支持为搜索和索引指定不同的 analyzer
- 厂商名字实现精确匹配
Exact Values vs Full Text
精确值和全文本的比较
- Exact Value: 包括数字 / 日期 / 具体一个字符串(例如 “Apple Store”) ,不需要分词处理
- Elasticseach 中的 Kewword
- 全文本,非结构化的文本数据,需要分词处理
- Elasticsearch 中的 text
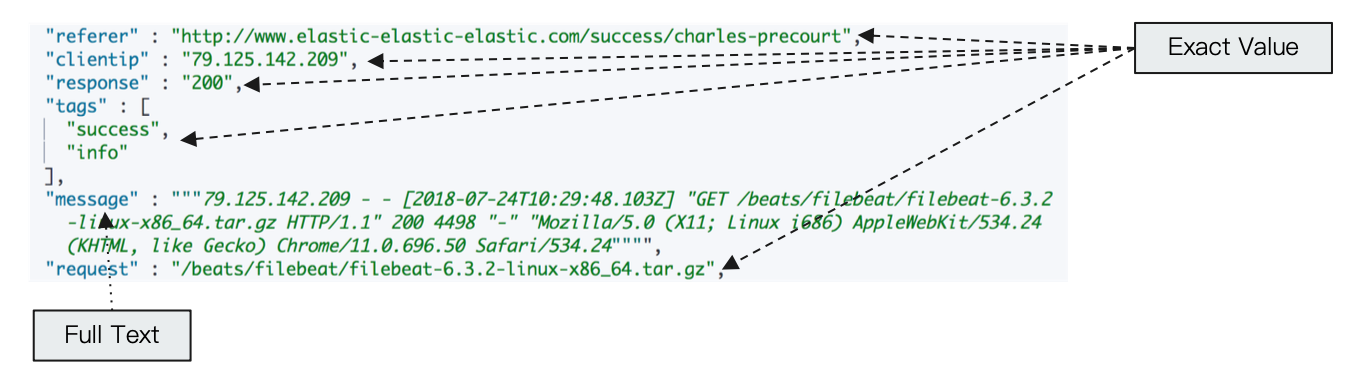
Exact Values 不需要被分词
Elasticsearch 为每一个字段创建一个倒排索引,Exact Value 在索引时,不需要做特殊的分词处理。

自定义分词
当 Elasticsearch 自带的分词器无法满足时,可以自定义分词器,通过自组合不同的组件实现
- Character Filter
- Tokenizer
- Token Filter
Character Filter
- 在 Tokenizer 之前对文本进行处理,例如增加删除及替换字符。可以配置多个 Character Filters。会影响 Tokenizer 的 position 和 offset 信息
- 一些自带的 Character Filters
- HTML strip:出除 html 标签
- Mapping:字符串替换
- Pattem replace:正则匹配替换
Tokenizer
- 将原始的文本按照一定的规则,切分为词 (term or token)
- Elasticsearch 内置的 Tokenizers
- whitespace / standard / uax_urlemail / patter / keyword / path hierarchy
- 可以用 Java 开发插件,实现自己的 Tokenizer
Token Filter
- 将 Tokenizer 输出的单词(term),进行增加,修改,删除
- 自带的 Token Filters
- lowercase / stop / synonym(添加近义词)
设置一个 Custom Aanlyzer
自定义一个 Analyzer,通过自定义一些分词器,组合成 Analyzer

Index Template 和 Dynamic Template
如果集群上的索引越来越多,例如为日志每天创建一个索引。使用多个索引可以更好的管理数据,提高性能。
Index Template
帮助你设定 Mappings 和 Settings,并按照一定的规则, 自动匹配到新创建的索引之上 。
- 模版仅在一个索引被新创建时,才会产生作用。
- 修改模版不会影响已创建的索引
- 你可以设定多个索引模版,这些设置会被
merge在一起 - 你可以指定
order的数值,控制merging的过程
例如两个 Index Templates

如果索引名称是 test 开头,则会以第二个索引覆盖第一个索引的配置。
Index Template 的工作方式
当一个索引被新创建时
- 应用 Elasticsearch 默认的 settings 和 mappings
- 应用
order数值低的 Index Template 中的设定 - 应用
order高的 Index Template 中的设定,之前的设定会被覆盖 - 应用创建索引时,用户所指定的 Settings 和 Mappings,并覆盖之前模版中的设定
Dynamic Template
根据 Elasticsearch 识别的数据类型,结合字段名称,来动态设定字段类型,例如:
- 所有的字符串类型都设定成 Keyword,或者关闭 keyword 字段
is开头的字段都设置成booleanlong_开头的都设置成long类型

- Dynamic Tempate 是定义在在某个索引的 Mapping 中
- Template有一个名称
- 匹配规则是一个数组
- 为匹配到字段设置 Mapping
匹配规则参数

match_mapping_type: 匹配自动识别的字段类型, 如string,boolean等match,unmatch: 匹配字段名path_match,path_unmatch- 需要注意数组中的顺序
聚合分析
聚合:将搜索结果通过大小聚合到不同的组中,用于进一步检索

- Elasticsearch 除搜索以外,提供的针对 ES 数据进行统计分析的功能
- 实时性高
- Hadoop (T+1)
- 通过聚合,我们会得到一个数据的概览,是分析和总结全套的数据,而不是寻找单个文档
- 购物网站上检索出来鞋子不同尺寸的结果数量
- 尖沙咀和香港岛的客房数量
- 不同的价格区间,可预定的经济型酒店和五星级酒店的数量
- 高性能,只需要一条语句,就可以从 Elasticsearch 得到分析结果
- 无需在客户端自己去实现分析逻辑
Kibana 可视化报表 - 聚合分析

- 客户的地理位置分布
- 订单增长情况
集合的分类
- Bucket Aggregation:一些列满足特定条件的文档的集合
- Metric Aggregation:一些数学运算,可以对文档字段进行统计分析
- Pipeline Aggregation:对其他的聚合结果进行二次聚合
- Matrix Aggregration:支持对多个字段的操作并提供一个结果矩阵
Bucket & Metric

- Metric:一系列的统计方法,例如 SQL 中的 COUNT
- Bucket:一组满足条件的文档,例如 SQL 中的 GROUP
Bucket:

- 一些例子
- 杭州属于浙江 /一个演员属于男或女性
- 嵌套关系:杭州属于浙江属于中国属于亚洲
- Elasticsearch 提供了很多类型的 Bucket, 帮助你用多种方式划分文档
- Term & Range(时间 / 年龄区间 / 地理位置)
Metric:
- Metric 会基于数据集计算结果,除了支持在字段上进行计算,同样也支持在脚本(painless script)产生的结果之上进行计算
- 大多数 Metric 是数学计算,仅输出一个值
- min / max / sum / avg / cardinality
- 部分 metric 支持输出多个数值
- stats / percentiles / percentile_ranks
例如使用 Bucket 查看航班目的地的统计信息

加入 Metric,查看航班目的地的统计信息,增加均价,最高最低价格
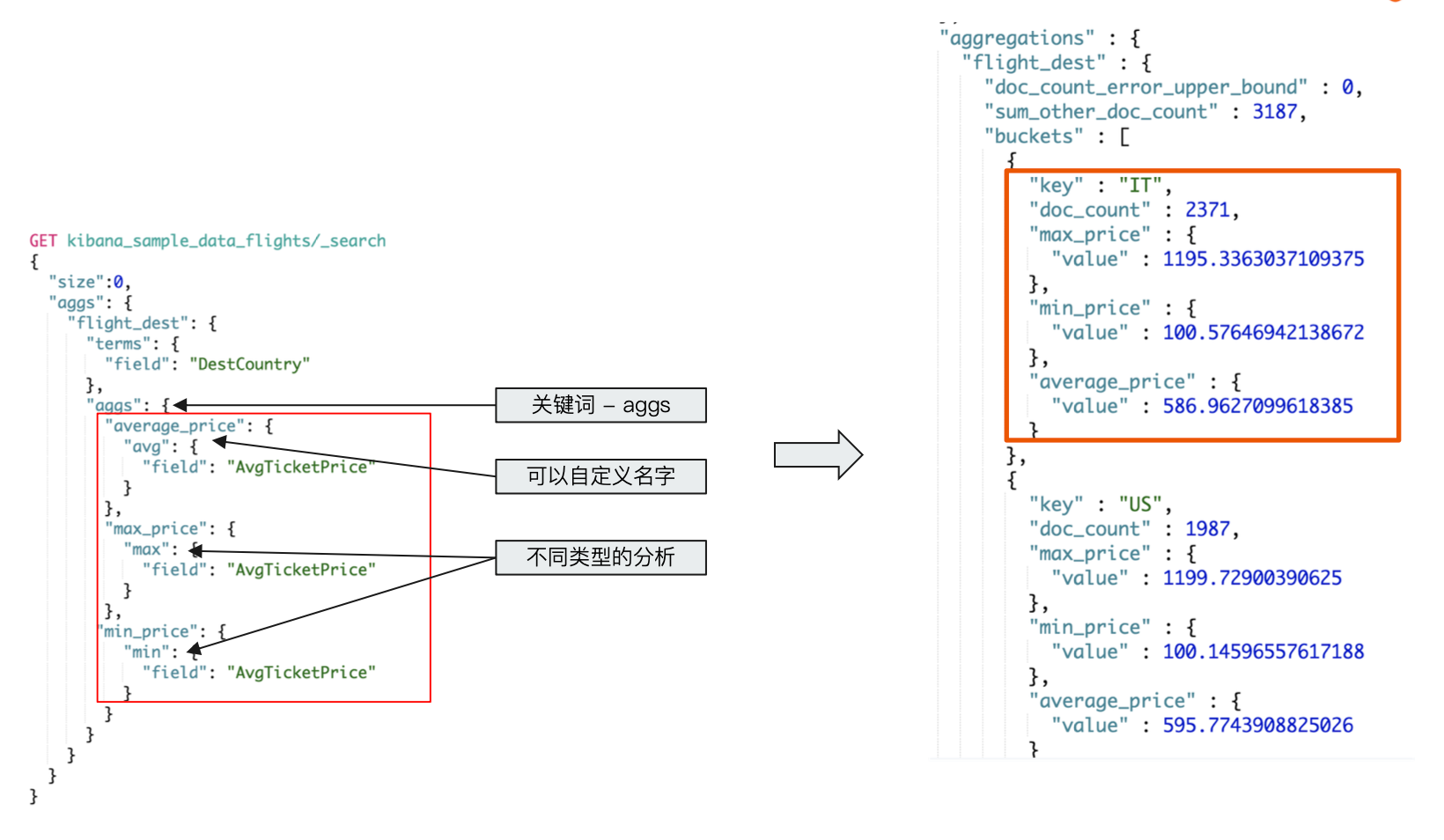
嵌套
查看航班目的地的统计信息,平均票价,以及天气状况
