Elasticsearch 搜索、聚合和数据建模
基于词项和基于全文的检索
基于 Term 的查询
Term 的重要性: Term 是表达语意的最小单位。搜索和利用统计语言模型进行自然语言处理都需要处理 Term
特点:
- Term Level Query: Term Query / Range Query / Exists Query / Prefix Query / Wildcard Query
- 在ES中,Term 查询,对输入 不做分词,会将输入作为一个整体。在倒排索引中查找准确的词项,并且使用相关度算分公式为每个包含该词项的文档进行 相关度算分 一例如
Apple Store - 可以通过 Constant Score 将查询转换成一个 Filtering,避免算分,并利用缓存,提高性能
例如文档:

检索语句 1: iPhone、2: iphone、3: 搜索 value

由于写入 Index 时,会自动使用动态 Mapping 自动识别数据,字符串的数据都会被分词存储,也就是变换小写,去掉间隔符号,分割成单词。
term 检索不会分词,因此 iPhone 无法搜索到,需要使用 iphone 搜索。同理,搜索语句 3 也无法搜索到。
多字段 Mapping 和 Term 查询
默认情况下,text 类型多字段特性,除了会存储分词单词外,还有不分词的 keyword 子字段,可以通过不分词的字段查询

复合查询
Constant Score 转为 Filter
- 将 Query 转成 Filter,忽略TF-IDF 计算,避免相关性算分的开销
- Filter 可以有效利用缓存

结果返回的算分都是一样
基于全文的查询
基于全文本的查找:
- Match Query / Match Phrase Query / Query String Query
特点:
- 索引和搜索时都会进行分词,查询字符串先传递到一个合适的分词器,然后生成一个供查询的词项列表
- 查询时候,先会对输入的查询进行分词,然后每个词项逐个进行底层的查询,最终将结果进行合并。
- 并为每个文档生成一个算分。一例如查
Matrix reloaded,会查到包括Matrix或者reload的所有结果。 - 如果搜索的字段是
.keyword,搜索时会被转换为term query
查询结果如下:

Operator

Minimum_should_match

Match Phrase Query

Match Query 查询过程

- 基于全文本的查找
- Match Query / Match Phrase Query / Query String Query
- 基于全文本的查询的特点
- 索引和搜索时都会进行分词,查询字符串先传递到一个合适的分词器,然后生成一个供查询的词项列表
- 查询会对每个词项逐个进行底层的查询,再将结果进行合并。并为每个文档生成一个算分
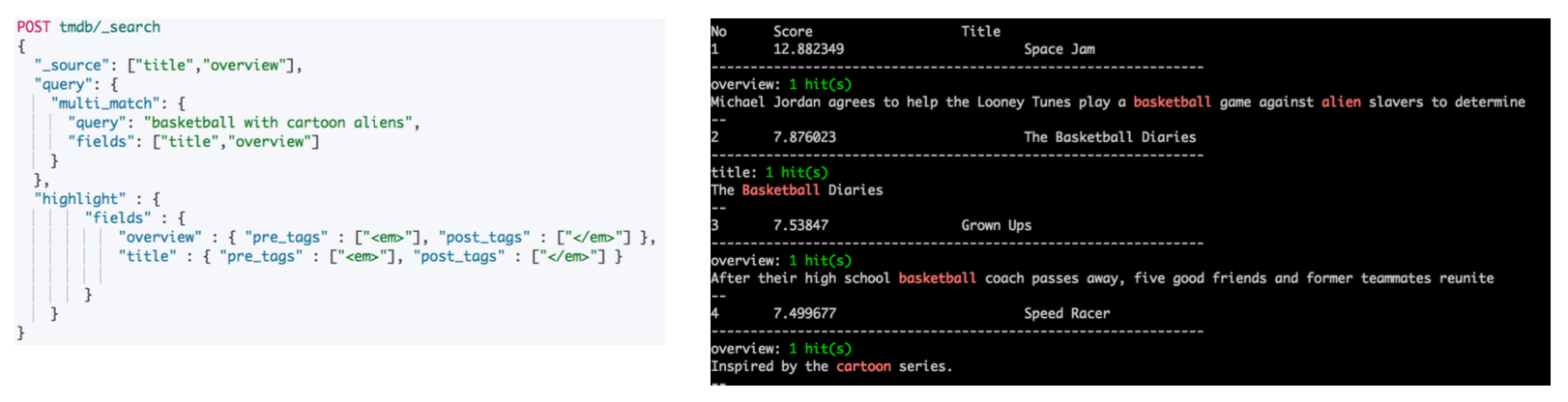
Highlight 结果高亮
结构化搜索
结构化数据
结构化搜索 (Structured search) 是指对结构化数据的搜索
- 日期,布尔类型和数字都是结构化的
文本也可以是结构化的。
- 如彩色笔可以有离散的颜色集合:红 (red) 绿 (green)、蓝(blue)
- 一个博客可能被标记了标签,例如,分布式 (distributed) 和搜索 (search)
- 电商网站上的商品都有 UPCs(通用产品码 Universal Product Codes) 或其他的唯一标 识,它们都需要遵从严格规定的、结构化的格式。
ES 中的结构化搜索
- 布尔,时间,日期和数字这类结构化数据:
- 有精确的格式,我们可以对这些格式进行逻辑操作
- 包括比较数字或时间的范围,或判定两个值的大小
- 结构化的文本可以做精确匹配或者部分匹配
- Term 查询 Prefix 前缀查询
- 结构化结果只有“是”或“否”两个值
- 根据场景需要,可以决定结构化搜索是否需要打分
布尔值
通过 filter 跳过算分

数字
使用 Range

- gt 大于
- lt小于
- gte 大于等于
- Ite 小于等于
日期
例如大于等于当前时间减去一年

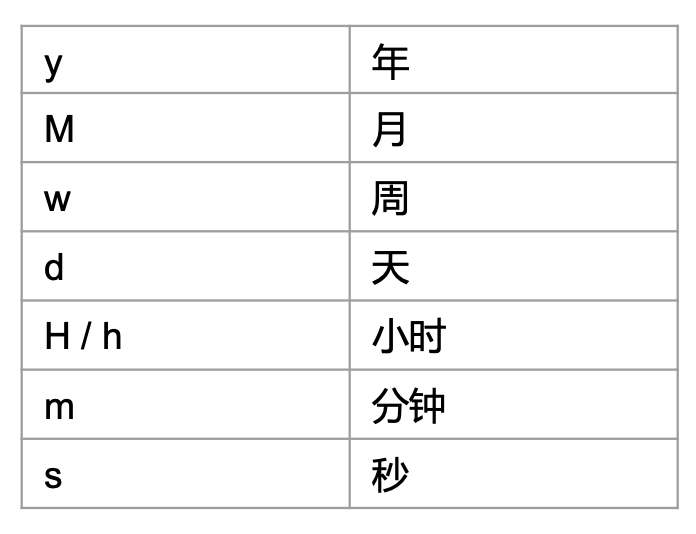
Date Math Expressions :2024-01-01 00:00:00||+1M
处理空值

查找多个精确值

包含而不是相等
term 检索多值是,是包含关系,而不是相等关系

如果要完全相等,解决方案:增加一个 genre_count 字段进行计数。会在组合 bool query 给出解决方法
检索的相关性算分
相关性: Relevance
- 搜索的相关性算分,描述了一个文档和查询语句匹配的程度。ES 会对每个匹配查询条件的结果进行算分
_score - 打分的本质是排序,需要把最符合用户需求的文档排在前面。ES5 之前,默认的相关性算分采用 TF-IDF,现在采用 BM 25
例如:

说明文档 2,3 都含有搜索的词,相关性高
TF-IDF
词频 TF
- Term Frequency:检索词在一篇文档中出现的频率
- 检索词出现的次数除以文档的总字数
- 度量一条查询和结果文档相关性的简单方法:简单将搜索中每一个词的TF 进行相加
- TF(区块链)+TF(的)+TF(应用)
- Stop Word
的在文档中出现了很多次,但是对贡献相关度几乎没有用处,不应该考虑他们的TF
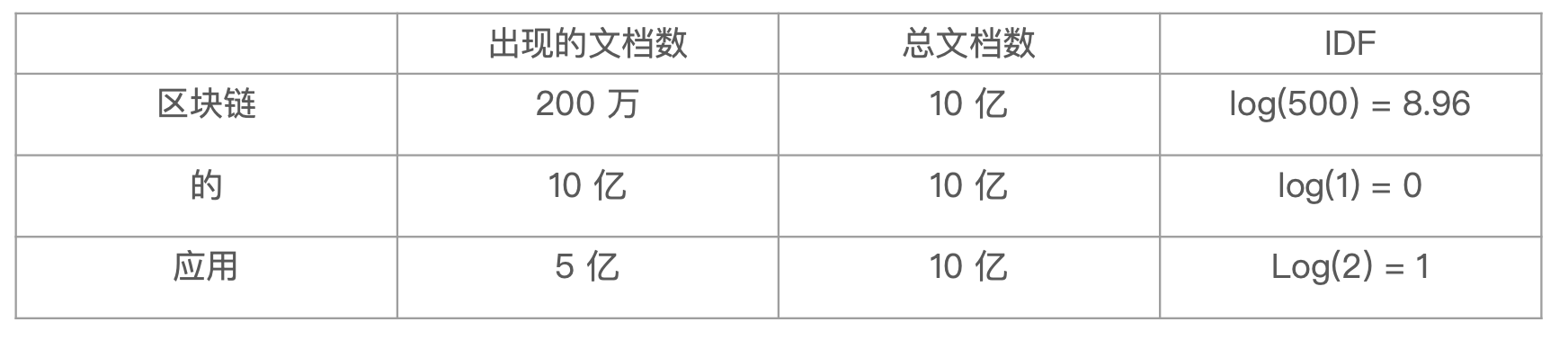
逆文档频率 IDF
- DF:检索词在所有文档中出现的频率
- 区块链 在相对比较少的文档中出现
- 应用 在相对比较多的文档中出现
- Stop Word 文档中出现
- Inverse Document Frequency:简单说 =
log(全部文档数/检索词出现过的文档总数) - TF-IDF 本质上就是将TF 求和变成了加权求和
TF(区块链)* IDF(区块链)+ TF(的)* IDF(的)+ TF(应用)* IDF(应用)
TF-IDF 的概念
- TF-IDF 被公认为是信息检索领域最重要的发明
- 除了在信息检索,在文献分类和其他相关领域有着非常广泛的应用
- IDF 的概念,最早是剑桥大学的 斯巴克.琼斯 提出
- 1972年一“关键词特殊性的统计解释和它在文献检索中的应用”
- 但是没有从理论上解释 IDF 应该是用
log(全部文档数/检索词出现过的文档总数),而不是其他函数。也没有做进一步的研究
- 1970,1980年代萨尔顿和罗宾近进行了进一步的证明和研究,并用香农信息论做了证明
- https://www.staff.city.ac.uk/~sbrp622/papers/foundations_bm25_review.pdf
- 现代搜索引擎,对 TF-IDF 进行了大量细微的优化
Lucene 中的 TF-IDF 评分公式
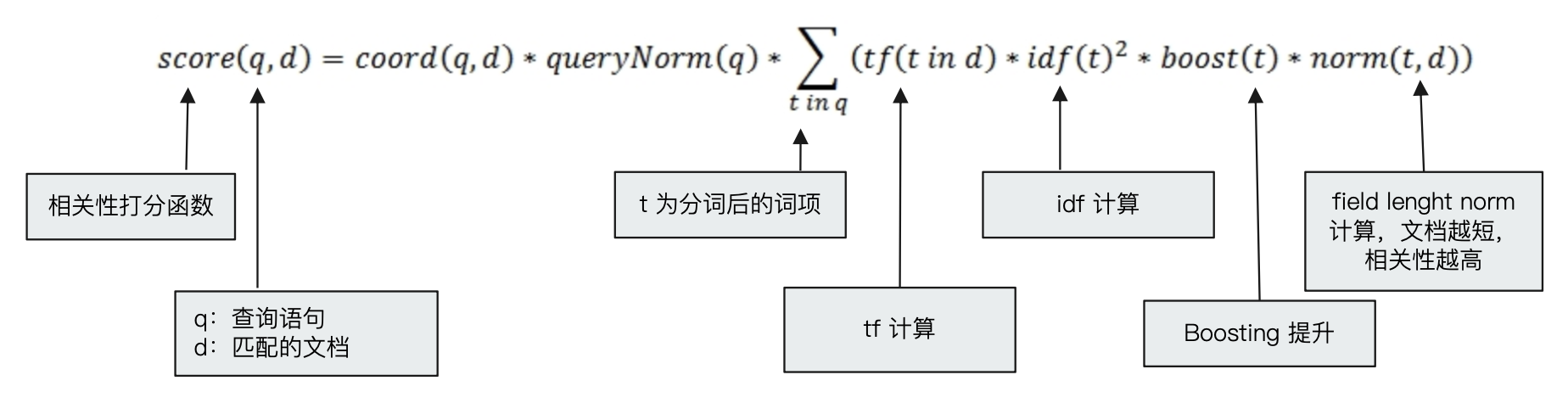
BM 25
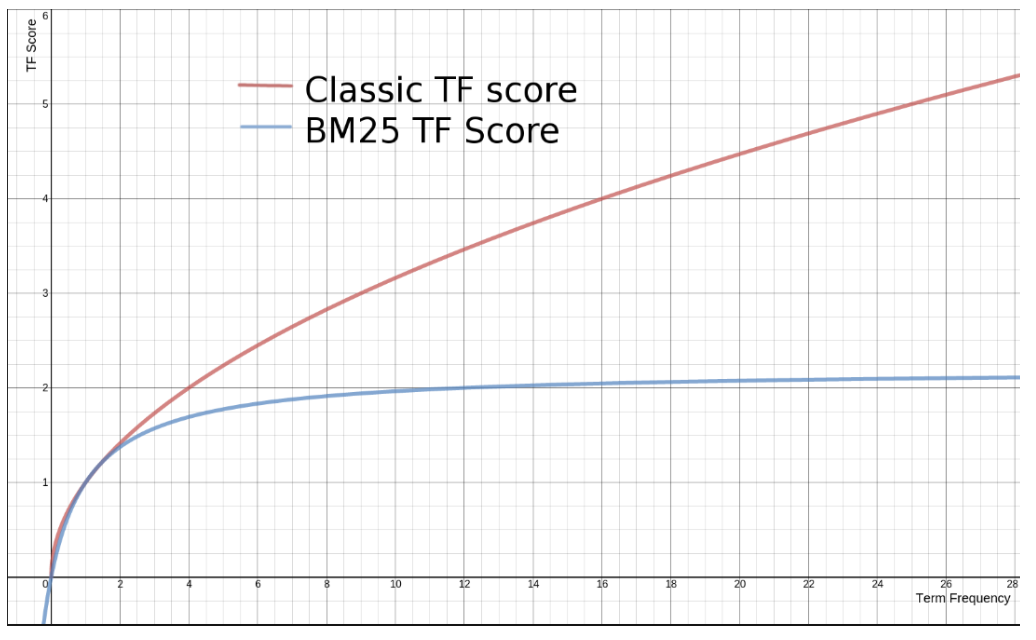
从 ES 5 开始,默认算法改为 BM 25 。
和经典的 TF-IDF 相比,当 T 无限增加时, BM 25算分会趋于一个数值(前者会过度增长)
定制 Similarity

公式:
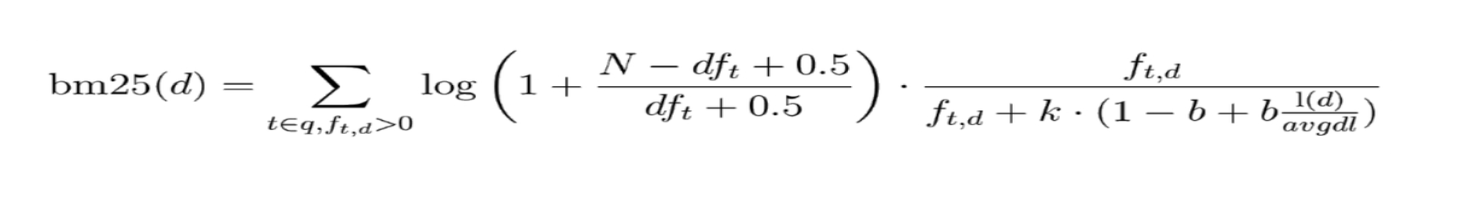
K 默认值是1.2,数值越小,饱和度越高
b默认值是 0.75(取值范围 0-1),0 代表禁止 Normalization
通过 Explain API 查看 TF-IDF

1 | "_explanation": { |
Boosting Relevance
符合查询 Boosting Query

- Boosting 是控制相关度的一种手段
- 索引,字段或查询子条件
- 参数 boost 的含义
- 当
boost > 1时,打分的相关度相对性提升 - 当
0 < boost < 1时,打分的权重相对性降低 - 当
boost < 0时,贡献负分
- 当
测试相关性
需要理解原理 + 多分析 + 多调整测试
- 技术分为道和术两种
- 道:原理和原则
- 术:具体的做法,具体的解法
- 关于搜索,为了有一个好的搜索结果。除了真正理解背后的原理,更需要多加实践与分析
- 单纯追求“术”,会一直很辛苦。只有掌握了本质和精髓之“道”,做事才能游刃有余
- 要做好搜索,除了理解原理,也需要坚持去分析一些不好的搜索结果。只有通过一定时间的积累, 才能真正有所感觉
- 总希望一个模型,一个算法,就能毕其功于一役,是不现实的
检测并且理解用户行为
- 不要过度调试相关度
- 而要监控搜索结果,监控用户点击最顶端结果的频次
- 将搜索结果提高到极高水平,唯一途径就是
- 需要具有度量用户行为的强大能力
- 可以在后台实现统计数据,比如,用户的查询和结果,有多少被点击了
- 哪些搜索,没有返回结果
Query & Filtering 与多字符串多字段查询
Query Context & Filter Context
例如一个高级查询的界面

- 高级搜索的功能:支持多项文本输入,针对多个字段进行搜索。
- 搜索引擎一般也提供基于时间,价格等条件的过滤
- 在 Elasticsearch 中,有 Query 和 Filter 两种不同的 Context
- Query Context: 相关性算分
- Filter Context: 不需要算分( Yes or No) ,可以利用 Cache, 获得更好的性能
Bool 查询
适用于多条件查询的情况
- 一个 bool 查询,是一个或者多个查询子句的组合
- 总共包括 4 种子句。其中2 种会影响算分,2 种不影响算分
- 相关性并不只是全文本检索的专利,也适用于 yes | no 的子句,匹配的子句越多,相关性评分越高。
- 如果多条查询子句被合并为一条复合查询语句,比如
bool查询,则每个查询子句计算得出的评分会被合并到总的相关性评分中。

查询语法

- 子查询可以任意顺序出现
- 可以嵌套多个查询
- 如果你的 bool 查询中,没有 must 条件, should 中必须至少满足一条查询
解决 包含而不是相等 的问题

解决方案:增加一个 genre count 字段进行计数
从业务角度,按需改进 Elasticsearch 数据模型

Filter Context
不影响算分

Query Context
影响算分

Bool 嵌套

通过设置minimum_should_match参数,您可以控制至少有多少个should子句需要匹配才能使整个bool查询被视为匹配成功。
实现了 should not 的逻辑
查询语句影响相关度
查询语句的结构,会对相关度算分产生影响

- 同一层级下的竞争字段,具有有相同的权重
- 通过嵌套 bool 查询,可以改变对算分的影响
控制字段的 Boosting

- Boosting 是控制相关度的一种手段
- 索引,字段或查询子条件
- 参数 boost 的含义
- 当
boost >1时,打分的相关度相对性提升 - 当
0 < boost <1时,打分的权重相对性降低 - 当
boost < 0时,贡献负分
- 当
Boosting Query
将符合条件的往前排列(打分高),符合另外一个条件的往后排列(打分低)

例如此时需要将 Apple 的产品往前排列,可以使用 Boosting Query

检索结果:

单字符传多字段查询
单字符传查询:Dis Max Query

- Google 只提供一个输入框,查询相关的多个字段
- 支持按照价格,时间等进行过滤
例如:

- 博客标题
- 文档 1中出现 Brown
- 博客内容
- 文档1中出现了 Brown
- Brown fox 在文档 2 中全部出现,并且保持和查询一致的顺序 (目测相关性最高)
算分过程:
- 查询 should 语句中的两个查询
- 加和两个查询的评分
- 乘以匹配语句的总数
- 除以所有语句的总数
查询结果及分析:

可以看到,由于文档 1 多个字段中都出现了 brown,相比之下,文档 2 只有 body 中出现 brown 和 fox,文档 1 打分更高。
Disjunction Max Query 查询
上例中,title 和 body 相互竞争,不应该将分数简单叠加,而是应该找到单个最佳匹配的字段的评分
Disjunction Max Query:将任何与任一查询匹配的文档作为结果返回。采用字段上最匹配的评分最终评分返回

计算结果是 文档2 更高。
最佳字段查询调优

有一些情况下,同时匹配 title 和 body 字段的文档比只与一个字段匹配的文档的相关度更高。
但 disjunction max query 查询只会简单地使用单个最佳匹配语句的评分 _score 作为整体评分。例如上面,两个最佳的分数是一样的。
此时可以通过 Tie Breaker 参数调整

- 获得最佳匹配语句的评分_score
- 将其他匹配语句的评分与 tie _breaker 相乘
- 对以上评分求和并规范化
Tier Breaker 是一个介于 0-1 之间的浮点数。0 代表使用最佳匹配;1代表所有语句同等重要。
Multi Match
使用多字段查询的三种常见:
- 最佳字段 (Best Fields)
- 当字段之间相互竞争,又相互关联。例如 title 和 body 这样的字段。评分来自最匹配字段
- 多数字段 (Most Fields)
- 处理英文内容时:
- 一种常见的手段是,在主字段(English Analyzer),抽取词干,加入同义词,以匹配更多的文档。
- 相同的文本,加入子字段(Standard Analyzer),以提供更加精确的匹配。
- 其他字段作为匹配文档提高相关度的信号。匹配字段越多则越好
- 处理英文内容时:
- 混合字段(Cross Field)
- 对于某些实体,例如人名,地址,图书信息。需要在多个字段中确定信息,单个字段只能作为整体的一部分。希望在任何这些列出的字段中找到尽可能多的词
Multi Match Query

- Best Fields 是默认类型,可以不用指定
- minimum should match 等参数可以传 递到生成的
query中
一些案例:
英文分词器,导致精确度降低,时态信息丢失

由于使用英语分词器,两个文档都会以相同频率匹配,但是第一个文档更短,所以打分更高。
使用多数字段匹配解决

- 用广度匹配字段 title 包括尽可能多的文档(以提升召回率),同时又使用字段
title.std作为信号将相关度更高的文档置于结果顶部。 - 每个字段对于最终评分的贡献可以通过自定义值
boost来控制。比如,使title字段更为重要, 这样同时也降低了其他信号字段的作用:

跨字段搜索

- 无法使用 Operator (当需要所有的词都出现时,无法使用
operator增加条件) - 可以用
copy_to解决,但是需要额外的 存储空间
还可以使用跨字段搜索

- 支持使用 Operator
- 与
copy_to相比,其中一个优势就是它可以在搜索时为单个字段提升权重。
多语言及中文分词与检索
自然语言与查询 Recall
- 当处理人类自然语言时,有些情况,尽管搜索和原文不完全匹配,但是希望搜到一些内容
- Quick brown fox 和 fast brown fox Jumping fox 和 Jumped foxes
- 一些可采取的优化
- 归一化词元:清除变音符号,如
role(o三声) 的时候也会匹配role - 抽取词根:清除单复数和时态的差异
- 包含同义词
- 拼写错误:拼写错误,或者同音异形词
- 归一化词元:清除变音符号,如
混合多语言的挑战
- 一些具体的多语言场景
- 不同的索引使用不同的语言
- 同一个索引中,不同的字段使用不同的语言
- 一个文档的一个字段内混合不同的语言
- 混合语言存在的一些挑战
- 词干提取:以色列文档,包含了希伯来语,阿拉伯语, 俄语和英文
- 不正确的文档频率一英文为主的文章中,德文算分高(稀有)
- 需要判断用户搜索时使用的语言,语言识别 (Compact Language Detector)
- 例如,根据语言,查询不同的索引
分词的挑战
- 英文分词:
You‘re分成一个还是多个?Half-baked 是否切分? - 中文分词
- 分词标准:哈工大标准中,姓和名分开。HanLP 是在一起的。具体情况需制定不同的标准
- 歧义(组合型歧义,交集型歧义,真歧义)
- 中华人民共和国
- 美国会通过对台售武法案
- 上海仁和服装厂
中文分词方法的演变
字典法
- 查字典一最容易想到的分词方法 (北京航空大学的梁南元教授提出)
- 一个句子从左到右扫描一遍。遇到有的词就标示出来。找到复合词,就找最长的
- 不认识的字串就分割成单字词
- 最小词数的分词理论一哈工大王晓龙博士把查字典的方法理论化
- 一句话应该分成数量最少的词串
- 遇到二义性的分割,无能为力(例如:“发展中国家”/“上海大学城书店”)
- 用各种文化规则来解决二义性,都并不成功
基于统计法的机器学习算法
- 统计语言模型一1990年前后,清华大学电子工程系郭进博士
- 解决了二义性问题,将中文分词的错误率降低了一个数量级。概率问题,动态规划 + 利用维特比算 法快速找到最佳分词
- 基于统计的机器学习算法
- 这类目前常用的是算法是HMM、CRF、SVM、深度学习等算法。比如 Hanlp 分词工具是基于CRF 算法以CRF为例,基本思路是对汉字进行标注训练,不仅考虑了词语出现的频率,还考虑上下文, 具备较好的学习能力,因此其对岐义词和未登录词的识别都具有良好的效果。
- 随着深度学习的兴起,也出现了基于神经网络的分词器,有人尝试使用双向LSTM+CRF实现分词器, 其本质上是序列标注,据报道其分词器字符准确率可高达97.5%
中文分词器现状
- 中文分词器以统计语言模型为基础,经过几十年的发展,今天基本已经可以看作是一个已经解决的问题
- 不同分词器的好坏,主要的差别在于数据的使用和工程使用的精度
- 常见的分词器都是使用机器学习算法和词典相结合,一方面能够提高分词准确率,另一 方面能够改善领域适应性。
一些中文分词器
- HanLP :面向生产环境的自然语言处理工具包
- https://hanlp.com/
- https://github.com/KennFalcon/elasticsearch-analysis-hanlp
- IK 分词器
- https://github.com/infinilabs/analysis-ik
HanLP Analysis
例如分词效果:https://hanlp.com/semantics/functionapi/participle
安装方法
1 | ./bin/elasticsearch-plugin install https://github.com/KennFalcon/elasticsearch-analysis-hanlp/releases/download/v6.5.4/elasticsearch-analysis-hanlp-6.5.4.zip |
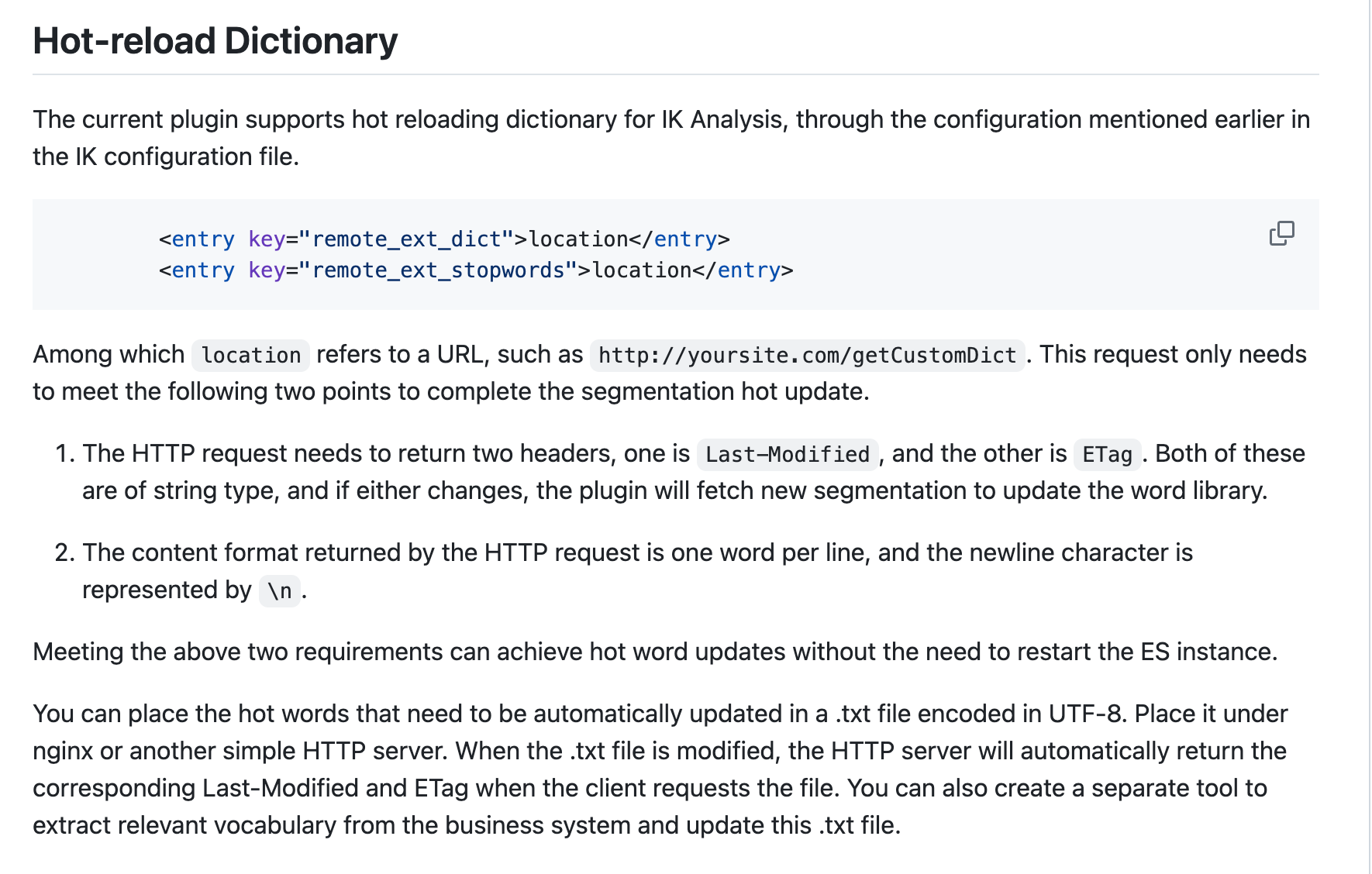
热更新:
在本版本中,增加了词典热更新,修改步骤如下:
a. 在 *ES_HOME*/plugins/analysis-hanlp/data/dictionary/custom 目录中新增自定义词典
b. 修改 hanlp.properties,修改 CustomDictionaryPath,增加自定义词典配置
c. 等待1分钟后,词典自动加载
注:每个节点都需要做上述更改
IK Analysis
https://github.com/infinilabs/analysis-ik
安装方法
1 | bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-ik/8.4.1 |
字典热更新
Pinyin Analysis
例如通过搜字母搜人的名字
https://github.com/infinilabs/analysis-pinyin
安装方法:
1 | bin/elasticsearch-plugin install https://get.infini.cloud/elasticsearch/analysis-pinyin/8.4.1 |
Search Template
解耦程序 & 搜索 DSL
- Elasticsearch 的查询语句
- 对相关性算分
- 查询性能都至关重要
- 在开发初期,虽然可以明确查询参数,但是往往还不能最终定义查询的DSL的具体结构
- 通过 Search Template 定义一个 Contract
- 各司其职,解耦
- 开发人员
- 搜索工程师
- 性能工程师
例如创建一个搜索模板
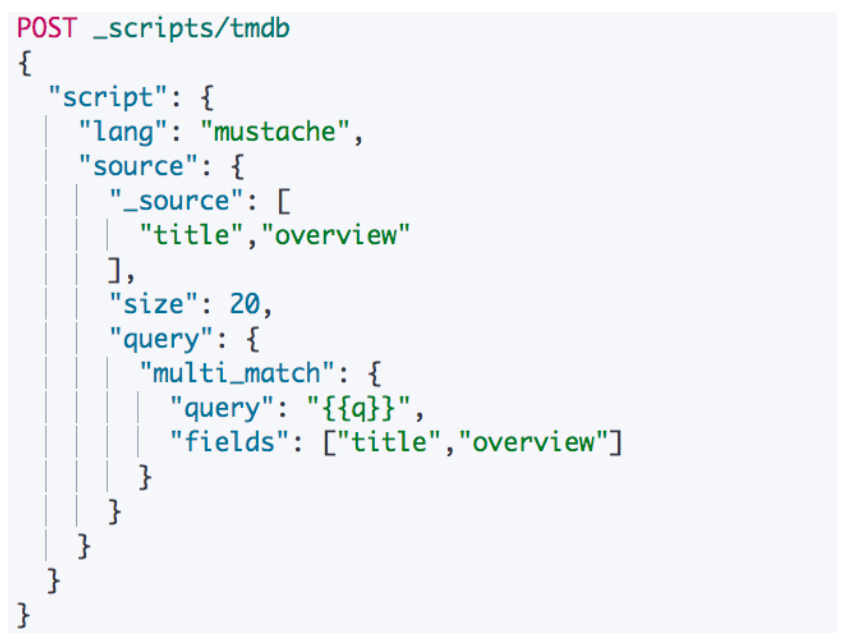
前端工程师在使用时,通过这个 Query 即可实现查询
使用 Search Template 进行查询
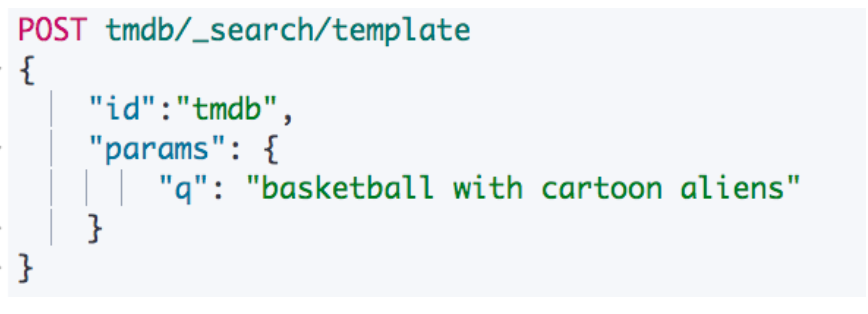
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-template.html
Index Alias
索引别名,可以实现零停机运维
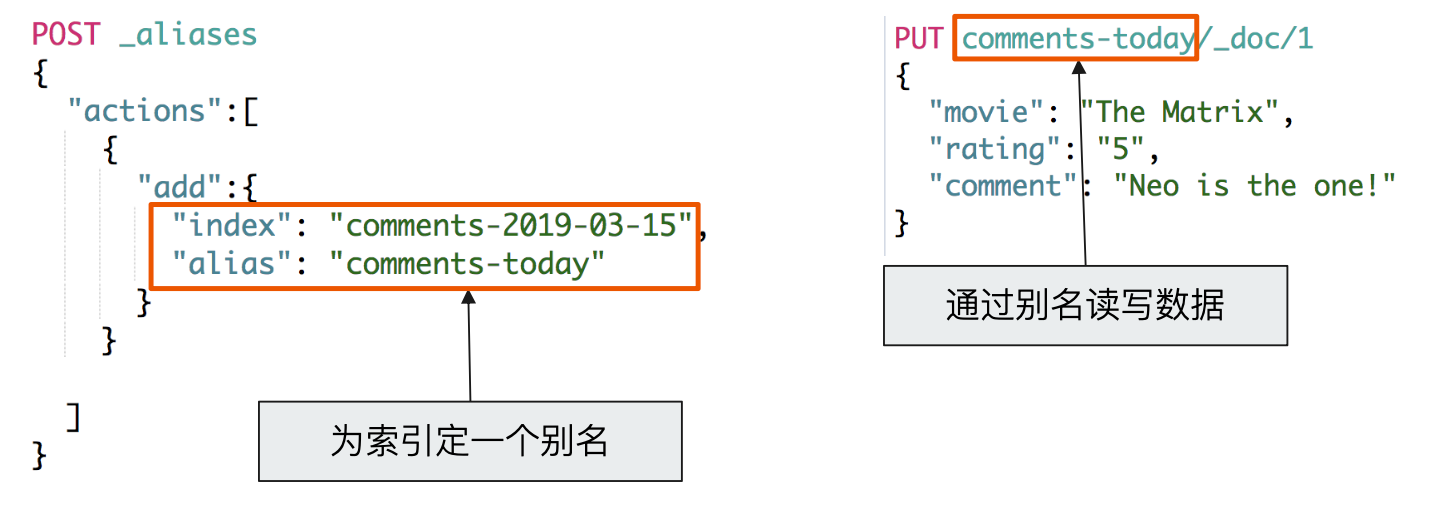
使用 Alias 创建不同查询的视图

后续使用 alias 的 index 进行搜索时,默认带有过滤条件

综合排序
通过 Function Score Query 优化算法
算法与排序:
- Elasticsearch 默认会以文档的相关度算分进行排序
- 可以通过指定一个或者多个字段进行排序
- 使用相关度算分(score)排序,不能满足某些特定条件
- 无法针对相关度,对排序实现更多的控制
Function Score Query:
可以在查询结束后,对每一个匹配的文档进行一系列的重新算分,根据新生成的分数进行排序。
- 提供了几种默认的计算分值的函数
- Weight:为每一个文档设置一个简单而不被规范化的权重
- Field Value Factor:使用该数值来修改
_score,例如将“热度”和“点赞数”作为算分的参考因素 - Random Score:为每一个用户使用一个不同的,随机算分结果
- 衰减函数:以某个字段的值为标准,距离某个值越近,得分越高
- Script Score:自定义脚本完全控制所需逻辑
实例
例如按受欢迎提升权重
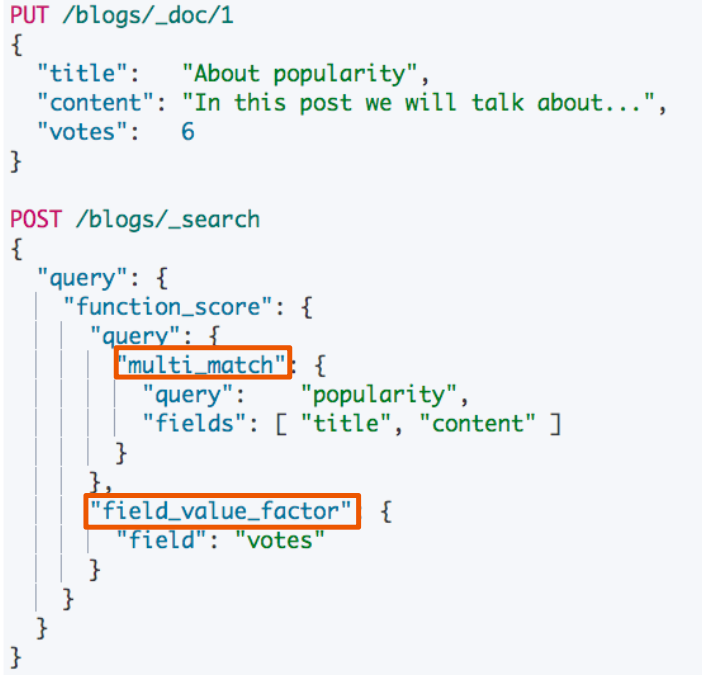
- 希望能够将点赞多的 blog,放在搜索列表相对靠前的位置。同时搜索的评分,还是要作为排序的主要依据
- 新的算分 =
老的算分*投票数- 投票数为 0 时,结果很靠后
- 投票数很大时,结果很靠前
使用 Modifier 平滑曲线

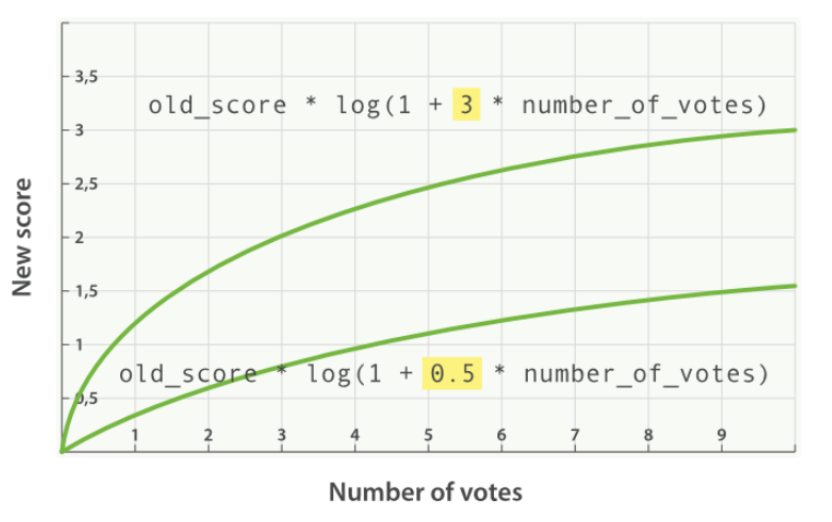
新的算分 = 老的算分 * log(1+投票数)
提供的 modifier 参数:

引入 Factor
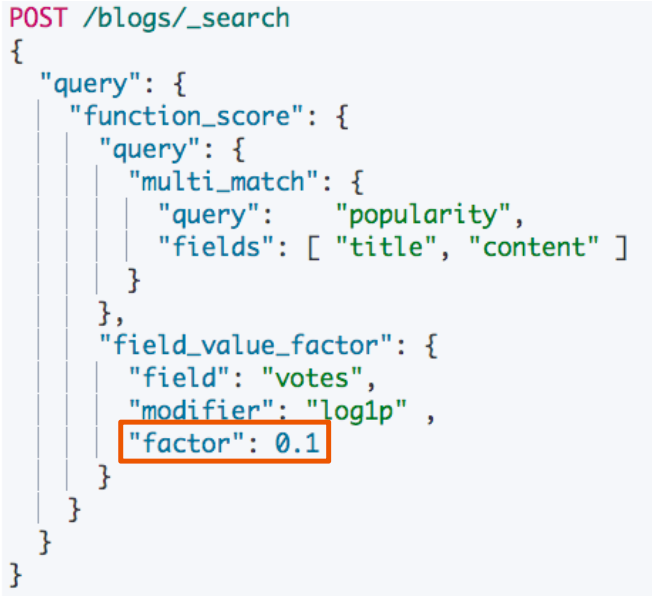
新的算分 = 老的算分 * log(1+factor * 投票数)
将 factor 从 3 到 0.5 的得分比较
Boost Mode 和 Max Boost
- Boost Mode
- Multiply:算分与函数值的乘积
- Sum:算分与函数的和
- Min / Max:算分与函数取最小 / 最大值
- Replace: 使用函数值取代算分
- Max Boost 可以将算分控制在一个最大值
一致性随机函数
以一个随机值对排名进行计算,随机值不变,计算结果也不变
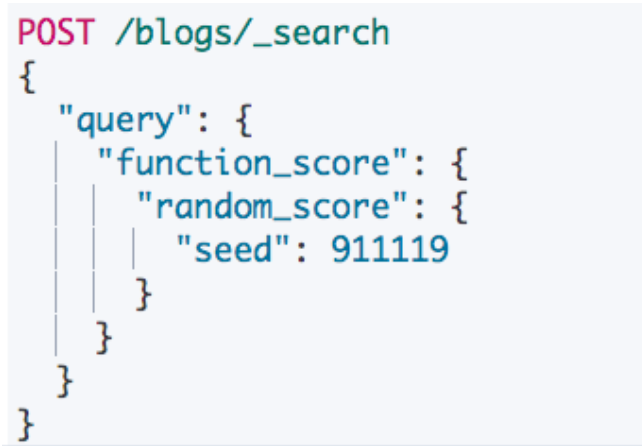
- 使用场景:网站的广告需要提高展现率
- 具体需求:让每个用户能看到不同的随机排名,但是也希望同一个用户访问时,结果的相对顺序,保持一致(Consistently Random)
Term & Phrase Suggester
搜索建议:例如在搜索引擎上输入的内容有错误拼写
- 现代的搜索引擎,一般都会提供 Suggest as you type 的功能
- 帮助用户在输入搜索的过程中,进行自动补全或者纠错。通过协助用户输入更加精准的关键词,提高后续搜索阶段文档匹配的程度
- 在 google 上搜索,一开始会自动补全。当输入到一定长度,如因为单词拼写错误无法补全, 日七士片、 就会开始提示相似的词或者句子
Elasticsearch Suggester API
- 搜索引擎中类似的功能,在 Elasticsearch 中是通过 Suggester API 实现的
- 原理:将输入的文本分解为 Token,然后在索引的字典里查找相似的 Term 并返回
- 根据不同的使用场景,Elasticsearch 设计了4 种类别的
- Suggesters Term & Phrase Suggester
- Complete & Context Suggester
Term Suggester

- Suggester 就是一种特殊类型的搜索。”text”里是 调用时候提供的文本,通常来自于用户界面上用户
- 输入的內容 用户输入的“lucen”是一个错误的拼写
- 会到指定的字段 “body”上搜索,当无法搜索到结果时 (
missing),返回建议的词
测试数据:

- 默认使用 standard 分词器
- 大写转小写
- rocks 和 rock 是两个词
Missing Mode
结果:

- 搜索
lucen rock:- 每个建议都包含了一个算分,相似性是通过 Levenshtein Edit Distance 的算法实现的。
- 核心思想就是一个词改动多少字符就可以和另外一个词一致。提供了很多可选参数来控制相似性的模糊程度。例如
max_edits
- 几种 Suggestion Mode
- Missing :如索引中已经存在,就不提供建议
- Popular:推荐出现频率更加高的词
- Always:无论是否存在,都提供建议
Popular Mode
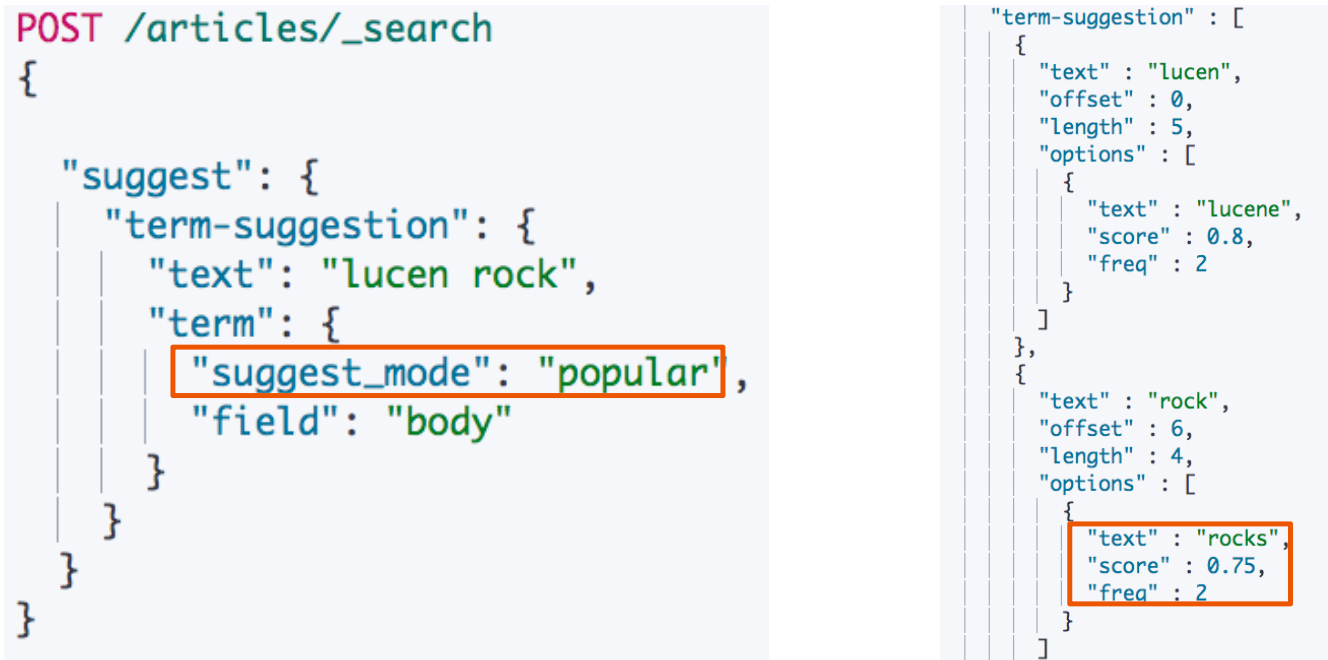
Sorting by Frequency & Prefix Length

- 默认按照 score 排序,也可以按照
frequency - 默认首字母不一致就不会匹配推荐,但是如果将
prefix_length设置为 0,就会为hock建议rock
Phrase Suggester
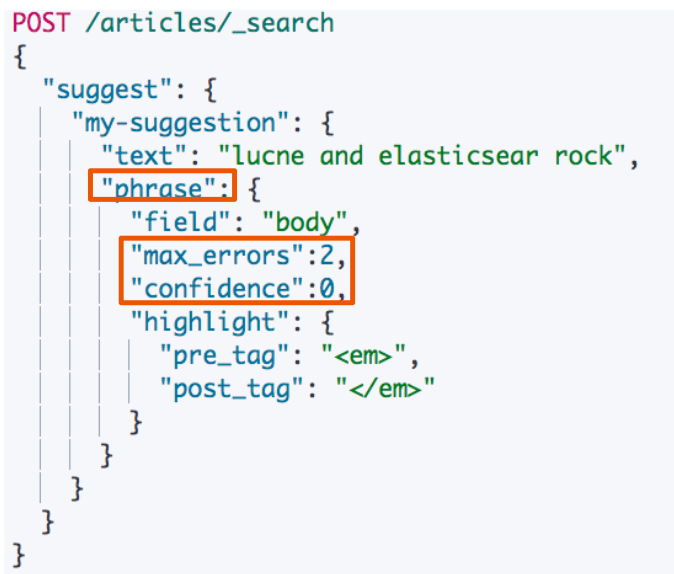
- Phrase Suggester:在 Term Suggester 上增加了一些额外的逻辑
- 通过一些参数控制范围
- Suggest Mode:missing, popular, always
- Max Errors:最多可以拼错的 Terms 数
- Confidence:限制返回结果数,默认为1
自动补全与基于上下文的提示
The Completion Suggester
- Completion Suggester 提供了 自动完成(Auto Complete) 的功能。用户每输入一个字符,就需要即时发送一个查询请求到后段查找匹配项
- 对性能要求比较苛刻。Elasticsearch 采用了不同的数据结构,并非通过倒排索引来完成。 而是将 Analyze 的数据编码成 FST 和索引一起存放。FST 会被 ES 整个加载进内存, 速度很快
- FST 只能用于前缀查找
使用步骤

- 定义 Mapping,使用
completion type - 索引数据
- 运行
suggest查询,得到搜索建议
例如创建数据:

搜索数据

Context Suggester
- Completion Suggester 的扩展
- 可以在搜索中加入更多的上下文信息,例如,输入
star- 咖啡相关:建议
Starbucks - 电影相关:
star wars
- 咖啡相关:建议
实现 Context Suggester:
- 可以定义两种类型的 Context
- Category:任意的字符串
- Geo:地理位置信息
- 实现 Context Suggester 的具体步骤
- 定制一个 Mapping
- 索引数据,并且为每个文档加入 Context 信息
- 结合 Context 进行 Suggestion 查询
定义 Mapping

- 增加 Contexts
- type
- name
索引数据:

通过不同的上下文,自动提示:
通过指定上下文 coffee,推荐的结果是 starbucks

精准度和召回率
- 精准度
- Completion > Phrase > Term
- 召回率
- Term > Phrase > Completion
- 性能
- Completion > Phrase > Term
跨集群搜索
水平扩展的痛点
- 单集群:当水平扩展时,节点数不能无限增加
- 当集群的 meta 信息(节点,索引,集群状态)过多,会导致更新压力变大,单个 Active Master 会成为性能瓶颈,导致整个集群无法正常工作
- 早期版本,通过 Tribe Node 可以实现多集群访问的需求,但是还存在一定的问题
- Tribe Node 会以 Client Node 的方式加入每个集群。集群中 Master 节点的任务变更需要 Tribe Node 的回应才能继续
- Tribe Node 不保存 Cluster State 信息,一旦重启,初始化很慢
- 当多个集群存在索引|重名的情况时,只能设置一种 Prefer 规则
在 Elasticsearch 中,Tribe Node(部落节点)是一种特殊类型的节点,用于连接多个独立的 Elasticsearch集群,并允许将它们视为一个逻辑集群进行查询。Tribe Node 可以用来跨多个独立集群执行全局搜索、索引数据、执行聚合操作等。
以下是 Tribe Node 的一些关键特点和用途:
跨集群搜索:Tribe Node 可以连接多个独立的 Elasticsearch 集群,并将它们视为一个逻辑集群。这使得用户可以在多个集群中执行全局搜索,而无需直接与每个集群进行通信。
全局索引数据:Tribe Node 允许在多个集群之间索引数据,这意味着您可以将数据索引到一个集群中,然后通过 Tribe Node 将其复制到其他集群中。
集中化管理:通过 Tribe Node,您可以集中管理多个集群的索引、搜索和其他操作,而无需直接与每个集群进行交互。
跨集群聚合:Tribe Node 还允许在多个集群中执行聚合操作,从而汇总来自不同集群的数据并生成全局聚合结果。
需要注意的是,从 Elasticsearch 7.0 版本开始,Tribe Node 已被标记为废弃,不建议在生产环境中使用。相反,推荐使用跨集群搜索功能(Cross-Cluster Search)来实现类似的功能,它提供了更安全和可靠的方式来搜索多个集群。
总的来说,Tribe Node 是用于连接多个独立 Elasticsearch 集群并以逻辑集群方式进行操作的一种机制。如果您有任何其他关于 Tribe Node 或 Elasticsearch 的问题,请随时告诉我!
跨集群搜索:Cross Cluster Search
- 早期 Tribe Node 的方案存在一定的问题,现已被 Deprecated
- Elasticsearch 5.3引入了跨集群搜索的功能(Cross Cluster Search),推荐使用
- 允许任何节点扮演 federated 节点,以轻量的方式,将搜索请求进行代理
- 不需要以 Client Node 的形式加入其他集群
在 Elasticsearch 中,”federated” 节点通常指的是一种能够连接多个 Elasticsearch 集群并在一个集群中执行全局搜索的节点。这种节点允许您在一个集群中搜索多个远程集群中的数据,从而实现集中化的搜索和分析操作。
与 Tribe Node 不同,federated 节点通常是指通过一些插件或者特定的配置来实现集成多个 Elasticsearch 集群的功能,而非 Elasticsearch 官方提供的原生功能。这种方法通常提供了更灵活的方式来连接和搜索多个集群。
使用 federated 节点可以实现以下功能:
全局搜索:在一个集群中搜索多个远程集群中的数据,实现全局搜索的目的。
集中化管理:通过 federated 节点,您可以集中管理多个集群的搜索和索引操作,而无需直接与每个集群进行通信。
跨集群查询:执行跨集群的查询和聚合操作,从而汇总来自不同集群的数据并生成全局结果。
需要注意的是,federated 节点通常是通过第三方插件或者自定义配置来实现的,并不是 Elasticsearch 官方提供的功能。因此,具体实现和功能可能会因使用的插件或配置而异。
配置(每个集群上都需要执行)

执行搜索

跨集群搜索

集群分布式模型及选主与脑裂问题
分布式特性
- Elasticsearch 的分布式架构带来的好处
- 存储的水平扩容,支持 PB 级数据
- 提高系统的可用性,部分节点停止服务,整个集群的服务不受影响
- Elasticsearch 的分布式架构
- 不同的集群通过不同的名字来区分,默认名字
elasticsearch - 通过配置文件修改,或者在命令行中
-E cluster.name=xxx进行设定
- 不同的集群通过不同的名字来区分,默认名字
节点
- 节点是一个 Elasticsearch 的实例
- 其本质上就是一个 JAVA 进程
- 一台机器上可以运行多个 Elasticsearch 进程,但是生产环境一般建议一台机器上就运行一个 Elasticsearch 实例
- 每一个节点都有名字,通过配置文件配置,或者启动时候
-E node.name=xxx指定 - 每一个节点在启动之后,会分配一个 UID,保存在 data 目录下
Coordinating Node
- 处理请求的节点,叫 Coordinating Node
- 路由请求到正确的节点,例如创建索引的请求,需要路由到 Master 节点
- 所有节点默认都是 Coordinating Node
- 通过将其他类型设置成 False,使其成为 Dedicated Coordinating Node
Data Node
- 可以保存数据的节点,叫做 Data Node
- 节点启动后,默认就是数据节点。可以设置
node.data: false禁止
- 节点启动后,默认就是数据节点。可以设置
- Data Node 的职责
- 保存分片数据。在数据扩展上起到了至关重要的作用(由 Master Node 决定如何把分片分发到数据节点上)
- 通过增加数据节点
- 可以解决数据水平扩展和解决数据单点问题
Ingest Node
- 用于在数据进入索引之前对数据进行预处理、转换和丰富操作。
- 数据预处理:Ingest Node 可以用于对数据进行各种预处理操作,比如解析、转换、标准化、丰富数据等。这有助于减轻索引时的负担,提高数据质量和一致性。
- 插件化处理:Ingest Node 支持使用预定义的处理器(processors)来执行各种操作,如 grok、date、geoip 等。您还可以编写自定义处理器来满足特定需求。
- 性能优化:通过在数据进入索引之前进行处理,Ingest Node 可以减少索引时的工作量,提高性能并减少对索引过程的影响。
- 灵活配置:您可以在索引模板中定义 Ingest Node pipeline,并将其应用于特定索引或索引模式,从而实现对不同类型数据的不同处理流程
- 实时处理:Ingest Node 的处理是实时的,即数据进入节点后会立即应用处理步骤,而不是等待后续索引过程。
Master Node
- Master Node 的职责
- 处理创建,删除索引等请求 / 决定分片被分配到哪个节点 / 负责索引的创建与删除
- 维护并且更新 Cluster State
- Master Node 的最佳实践
- Master 节点非常重要,在部署上需要考虑解决单点的问题
- 为一个集群设置多个 Master 节点 / 每个节点只承担 Master 的单一角色
Master Eligible Nodes & 选主流程
- 一个集群,支持配置多个 Master Eligible 节点。这些节点可以在必要时(如 Master 节点出现故障,网络故障时)参与选主流程,成为 Master 节点
- 每个节点启动后,默认就是一个 Master eligible 节点
- 可以设置
node.master: false禁止
- 可以设置
- 当集群内第一个 Master eligible 节点启动时候,它会将自己选举成 Master 节点
选主流程:
- 互相 Ping 对方,Node Id 低的会成为被选举的节点
- 其他节点会加入集群,但是不承担 Master 节点的角色。一旦发现被选中的主节点丢失, 就会选举出新的 Master 节点
集群状态
- 集群状态信息(Cluster State),维护了一个集群中,必要的信息:
- 所有的节点信息
- 所有的索引和其相关的 Mapping 与 Setting 信息
- 分片的路由信息
- 在每个节点上都保存了集群的状态信息
- 但是,只有 Master 节点才能修改集群的状态信息,并负责同步给其他节点
- 因为,任意节点都能修改信息会导致 Cluster State 信息的不一致

脑裂问题
- Split-Brain,分布式系统的经典网络问题,当出现网络问题,一个节点和其他节点无法连接
- Node 2 和 Node 3 会重新选举 Master
- Node 1 自己还是作为 Master,组成一个集群,同时更新 Cluster State
- 导致2个 master,维护不同的 cluster state。当网络恢复时,无法选择正确恢复

避免脑裂问题
- 限定一个选举条件,设置
quorum(仲裁),只有在 Master eligible 节点数大于等于quorum时,才能进行选举- Quorum =
(master节点总数 / 2) + 1- 当3个 master eligible 时,设置
discovery.zen.minimum_master_nodes为 2,即可避免脑裂
- 当3个 master eligible 时,设置
- 从 7.0 开始,无需这个配置
- 移除
minimum_master_nodes参数,让 Elasticsearch 自己选择可以形成仲裁的节点。 - 典型的主节点选举现在只需要很短的时间就可以完成。集群的伸缩变得更安全、更容易,并且可能造成丢失数据的系统配置选项更少了。
- 节点更清楚地记录它们的状态,有助于诊断为什么它们不能加入集群或为什么无法选举出主节点
- 移除
- Quorum =
配置节点类型
一个节点默认情况下是一个 Master eligible, data and ingest node:

分片与集群的故障转移
Primary Shard:提升系统存储容量
- 分片是 Elasticsearch 分布式存储的基石
- 主分片
- 副本分片
- 通过主分片,将数据分布在所有节点上
- Primary Shard,可以将一份索引的数据,分散在多个 Data Node 上,实现存储的水平扩展
- 主分片(Primary Shard)数在索引创建时候指定,后续默认不能修改,如要修改,需重建索引
Replica Shard:提高数据可用性
- 数据可用性
- 通过引入副本分片(Replica Shard) 提高数据的可用性。一旦主分片丢失,副本分片可以 Promote 成主分片。
- 副本分片数可以动态调整,每个节点上都有完备的单独一个分片。
- 如果不设置副本分片,一旦出现节点硬件故障,就有可能造成数据丢失
- 相同分片 ID 的主副分片不能同时存储在一个节点上
- 提升系统的读取性能
- 副本分片由主分片(Primary Shard)同步。
- 通过支持增加 Replica 个数,一定程度可以提高读取的吞吐量
调整副分片数量
1 | PUT /your_index/_settings |
分片数的设定
- 如何规划一个索引的主分片数和副本分片数
- 主分片数过小:例如创建了1个 Primary Shard 的 Index
- 如果该索引增长很快,集群无法通过增加节点实现对这个索引的数据扩展
- 主分片数设置过大:
- 导致单个 Shard 容量很小,引发一个节点上有过多分片,影响性能
- 副本分片数设置过多,会降低集群整体的写入性能
- 主分片数过小:例如创建了1个 Primary Shard 的 Index
单节点集群
1 | PUT tmdb |
此时单节点上有三个分片,但是另外 3 个副分片无法分配,导致索引状态和集群状态都为黄色。

增加一个数据节点

- 集群状态转为绿色
- 集群具备故障转移能力
- 尝试着将 Replica 设置成 2 和 3, 查看集群的状况
再增加一个数据节点

- 集群具备故障转移能力
- Master 节点会决定分片分配到哪个节点
- 通过增加节点,提高集群的计算能力
故障转移

- 3 个节点共同组成
- 包含了 1个索引,索引设置了 3个 Primary Shard 和1 个 Replica
- 节点 1是 Master 节点,节点意外出现故障。集群重新选举 Master 节点
- Node 3 上的
RO提升成PO,集群变黄 RO和R1重新分配,集群变绿
集群健康状态
1 | GET /_cluster/health |
- Green:健康状态,所有的主分片和副本分片都可用
- Yellow:亚健康,所有的主分片可用,部分副本分片不可用
- Red:不健康状态,部分主分片不可用
文档分布式存储
文档存储在分片上:
- 文档会存储在具体的某个主分片和副本分片上:
- 例如文档1,会存储在 PO 和 RO 分片上
- 文档到分片的映射算法
- 确保文档能均匀分布在所用分片上,充分利用硬件资源,避免部分机器空闲,部分机器繁忙
- 潜在的算法
- 随机 Round Robin。当查询文档1,分片数很多,需要多次查询才可能查到文档1
- 维护文档到分片的映射关系,当文档数据量大的时候,维护成本高
- 实时计算,通过文档 1,自动算出,需要去那个分片上获取文档
文档到分片的路由算法
算法:shard = hash(_routing) % number_of_primary_shards
- Hash 算法确保文档均匀分散到分片中
- 默认的
_routing值是文档 id - 可以自行制定
routing数值,例如用相同国家的商品,都分配到指定的shard - 设置 Index Settings 后,Primary 数,不能随意修改的根本原因

更新一个文档

- 客户端将更新请求发送到某个节点(这个节点一定是 Coordinating 节点)
- 该节点通过 hash 计算分片存在的节点,
- 将请求路由过去
- 对应存储分片的节点将文档删除
- 再创建新文档(无论是局部更新还是整体更新,都是删除然后替换),更新 version,同时将请求转发到副本节点上
- 将处理结果返回给 Coordinating 节点
- Coordinating 节点将结果响应给客户端
删除一个文档

- 客户端发送删除请求到 Coordinating 节点
- Coordinating 节点计算 hash 确定分片节点以及将请求路由到对应节点
- 存储对应主分片的节点将文档删除
- 存储对应分片的节点请求副分片所在节点,删除副本
- 存储副分片的节点将文档删除,并且返回响应给存储主分片的节点
- 存储主分片的节点将删除结果返回给 Coordinating 节点
- Coordinating 节点将响应返回给客户端
分片及其生命周期
Elasticsearch 中最小工作单元是分片。
分片的内部原理
- 什么是 ES 的分片
- ES 中最小的工作单元 / 是一个 Lucene 的 Index
- 一些问题:
- 为什么 ES 的搜索是近实时的(1秒后被搜到)
- ES 如何保证在断电时数据也不会丢失
- 为什么删除文档, 并不会立刻释放空间
倒排索引不可变性
- 倒排索引采用 Immutable Design,一旦生成,不可更改
- 不可变性,带来了的好处如下:
- 无需考虑并发写文件的问题,避免了锁机制带来的性能问题
- —旦读入内核的文件系统缓存,便留在哪里。只要文件系统存有足够的空间,大部分请求就会直接请求内存,不会命中磁盘,提升了很大的性能
- 缓存容易生成和维护 / 数据可以被压缩
- 不可变更性,带来了的挑战:如果需要让一个新的文档可以被搜索,需要重建整个索引。
Lucene Index

- 在 Lucene 中,单个倒排索引文件被称为 Segment。
- Segment 是自包含的,不可变更的。
- 多个 Segments 汇总在一起,称为 Lucene 的 Index,其对应的就是 ES 中的 Shard
- 当有新文档写入时,会生成新 Segment,查询时会同时查询所有 Segments,并且对结果汇总。
- Lucene 中有一个文件,用来记录所有 Segments 信息,叫做 Commit Point
- 删除的文档信息,保存在
.del文件中
Refersh

- 将 Index buffer 写入 Segment 的过程叫 Refresh,Refresh 不执行
fsync(指的是同步文件系统) - 操作 Refresh 频率:默认1秒发生一次,可通过
index.refresh_interval配置 - Refresh 后, 数据就可以被搜索到了(这也是为什么 Elasticsearch 被称为近实时搜索)
- 如果系统有大量的数据写入,那就会产生很多的 Segment
- Index Buffer 被占满时,会触发 Refresh,默认值是 JVM 的10%
Transaction Log

- Segment 写入磁盘的过程相对耗时,借助文件系统缓存,Refresh 时,先将 Segment 写入缓存以开放查询
- 为了保证数据不会丢失:
- 在 Index 文档时,同时写 Transaction Log,
- 高版本开始,Transaction Log 默认落盘,每个分片有一个 Transaction Log
- 在 ES Refresh 时,Index Buffer 被清空, Transaction log 不会清空
- 当服务异常退出,再启动时,会从 Transaction Log 中恢复数据
Flush

- ES Flush & Lucene Commit
- 调用 Refresh, Index Buffer 清空并且 Refresh
- 调用
fsync,将缓存中的 Segments 写入磁盘 - 清空(删除) Transaction Log •
- 默认 30 分钟调用一次
- Transaction Log 满(默认 512 MB)也会调用
Merge
- Segment 很多,需要被定期被合并,作用是:
- 减少 Segments
- 删除已经删除的文档
- ES 和 Lucene 会自动进行 Merge 操作
- 也可以调用请求
POST my_index/_forcemerge
- 也可以调用请求
剖析分布式查询及相关性算分
分布式搜索的运行机制
- Elasticsearch 的搜索,会分两阶段进行
- 第一阶段:Query
- 第二阶段:Fetch
- 步骤:Query-then-Fetch
Query 阶段

- 用户发出搜索请求到 ES 节点。
- 节点收到请求 后,会以 Coordinating 节点的身份,在 6 个主副分片中随机选择 3个分片,发送查询请求
- 被选中的分片执行查询,进行排序
- 然后,每个分片都会返回
From + Size个排序后的文档 Id 和排序值给 Coordinating 节点
Fetch 阶段

- Coordinating Node 会将 Query 阶段,从每个分片获取的排序后的文档 Id 列表,重新进行排序
- 选取
From到From + Size个文档的 Id 以multi get请求的方式,到相应的分片获取详细的文档数据
Query Then Fetch 潜在的问题
- 性能问题
- 每个分片上需要查的文档个数 = from + size
- 最终协调节点需要处理:
number_of_shard * (from+size) - 深度分页(会出现性能问题)
- 相关性算分
- 每个分片都基于自己的分片上的数据进行相关度计算。相关性算分在分片之间是相互独立。
- 这会导致打分偏离的情况,特别是数据量很少时。
- 当文档总数很少的情况下,如果主分片大于 1,主分片数越多,相关性算分会越不准
解决不准的方法
- 数据量不大的时候,可以将主分片数设置为1
- 当数据量足够大时候,只要保证文档均匀分散在各个分片上,结果一般就不会出现偏差
- 使用 DFS Query Then Fetch
- 搜索的 URL 中指定参数
_search?search_type=dfs_query_then_fetch - 到每个分片把各分片的词频和文档频率进行搜集,然后完整的进行一次相关性算分, 耗费更加多的 CPU 和内存,执行性能低下,一般不建议使用
- 搜索的 URL 中指定参数
排序及 Doc Values & Field Data
排序
当指定排序之后,搜索结果的算分值为 null

- Elasticsearch 默认采用相关性算分对结果进行降序排序
- 可以通过设定
sort参数,自行设定排序 - 如果
sort参数中不指定_score参数,算分为Null
多字段排序

- 组合多个条件
- 优先考虑写在前面的排序
- 支持对相关性算分进行排序
对 Text 类型排序
默认无法对 Text 类型排序

排序的过程
- 排序是针对字段原始内容进行的。倒排索引无法发挥作用
- 需要用到正排索引。通过文档 Id 和字段快速得到字段原始内容
- Elasticsearch 有两种实现正排索引的方法
- Fielddata
- Doc Values (列式存储,对 Text 类型无效)
Doc Values vs Field Data

打开 Fielddata

- 默认关闭,可以通过 Mapping 设置打开。修改设置后,即时生效,无需重建索引
- 其他字段类型不支持,只支持对 Text 进行设定
- 打开后,可以对 Text 字段进行排序。但是是对分词后的 term 排序,所以,结果往往无法满足预期,不建议使用
- 部分情况下打开,满足一些聚合分析的特定需求
关闭 Doc Values

- 默认启用,可以通过 Mapping 设置关闭
- 增加索引的速度
- 减少磁盘空间
- 如果重新打开,需要重建索引
- 什么时候需要关闭:明确不需要做排序及聚合分析
获取 Doc Values & Fielddata 中存储的内容
1 | PUT tmp_users |
- Text 类型的不支持 Doc Values
- Text 类型打开
Fielddata后,可以查看分词后的数据
分页与便利
From / Size

- 默认情况下,查询按照相关度算分排序,返回前 10 条记录
- 容易理解的分页方案
- From:开始位置
- Size:期望获取文档的总数
分布式系统中深度分页的问题

- ES 天生就是分布式的。查询信息,但是数据分别保存在多个分片,多台机器上,ES 天生就需要满足排序的需要(按照相关性算分)
- 当一个查询:From = 990, Size =10
- 会在每个分片上先都获取 1000 个文档。
- 然后, 通过 Coordinating Node 聚合所有结果。
- 最后再通过排序选取前1000 个文档。
- 页数越深,占用内存越多。
- 为了避免深度分页带来的内存开销。ES 有一个设定,默认限定到 10000个文档 Index。
max_result_window
Search After 避免深度分页

- 避免深度分页的性能问题,可以实时获取下一页文档信息
- 不支持指定页数 (From)
- 只能往下翻
- 第一步搜索需要指定
sort,并且保证值是唯一的 (可以通过加入_id保证唯一性) - 然后使用上一次,最后一个文档的 sort 值进行查询
Search After 解决深度分页的原理

- 假定 Size 是10
- 当查询 990 -1000
- 通过唯一排序值定位,将每次要处理的文档数都控制在 10
Scroll API

指定快照时间 5min,保存返回的快照 ID。下次查询时,指定这个快照 ID,会返回一个新的快照 ID 和一个文档,后续使用时,用上一次的结果中的快照 ID 替换,返回下一个文档
- 创建一个快照,有新的数据写入以后,无法被查到
- 每次查询后,输入上一次的 Scroll Id
不同的搜索类型和使用场景
- Regular
- 需要实时获取顶部的部分文档。例如查询最新的订单
- Scroll
- 需要全部文档,例如导出全部数据
- Pagination
- From 和 Size
- 如果需要深度分页,则选用 Search After
处理并发读写操作
并发控制的必要性

两个 Web 程序同时更新某个文档,如果缺乏有效的并发,会导致更改的数据丢失。
- 悲观并发控制
- 假定有变更冲突的可能。会对资源加锁,防止冲突。例如数据库行锁
- 乐观并发控制
- 假定冲突是不会发生的,不会阻塞正在尝试的操作。
- 如果数据在读写中被修改,更新将会失败。
- 应用程序决定如何解决冲突,例如重试更新,使用新的数据,或者将错误报告给用户
ES 采用的是乐观并发控制
乐观并发控制

- ES 中的文档是不可变更的:
- 如果你更新一个文档,会将就文档标记为删除
- 同时增加一个全新的文档。
- 同时文档的 version 字段加1
- 内部版本控制
If_sea_no + If_primary_term
- 使用外部版本(使用其他数据库作为主要数据存储,数据库中也含有
version字段)version + version_type=external
if_seq_no 和 if_primary_term 要匹配
1 | POST tmp_users/_doc/RlTliI4BnDRtFsWPtR7G?if_seq_no=0&if_primary_term=1 |
version id 要大于当前 id,并且更新后 version 为 version id
1 | POST tmp_users/_doc/RlTliI4BnDRtFsWPtR7G?version=5&version_type=external |
聚合分析
Bucket & Metric 聚合分析及嵌套聚合

Metric:一些系列的统计方法
Bucket:一组满足条件的文档
Aggregation 语法
Aggregation 属于 Search 的一部分。一般情况下,建议将其 Size 指定为 0

例如统计最大值、最小值、平均值

Metric Aggregation
- 单值分析:只输出一个分析结果
- min, max, avg, sum
- Cardinality (类似 distinct Count):去重计数个数
- 多值分析:输出多个分析结果
- stats, extended stats:统计
- percentile, percentile rank :百分位
- top hits (排在前面的示例)
Bucket Aggregation

- 按照一定的规则,将文档分配到不同的桶中,从而达到分类的目的
- ES提供的一些常见的 Bucket Aggregation:
- Terms:根据单词分桶
- 数字类型:根据数据分桶
- Range / Data Range :根据数字范围、时间范围分桶
- Histogram / Date Histogram:直方图(可以理解为固定区间)分桶
- 支持嵌套:也就在桶里再做分桶
Terms Aggregation
text字段需要打开fielddata,才能进行 Terms Aggregation (这是由于 terms 需要分词)- Keyword 默认支持
doc_values - Text 需要在 Mapping 中
enable,会按照分词后的结果进行分
- Keyword 默认支持
Cardinality Aggregation
类似 SQL 中的 Distinct

优化 Terms 聚合的性能

https://www.elastic.co/guide/en/elasticsearch/reference/8.13/tune-for-search-speed.html#_warm_up_global_ordinals
1 | PUT index |
在这个字段需要经常被聚合,同时不断有新的文档产生时可以打开预加载,可以提升聚合速度。
Range & Histogram 聚合
- 按照数字的范围,进行分桶
- 在 Range Aggregation 中,可以自定义 Key
例如:按照工资的 Range 分桶;按照工资的间隔 (Histogram) 分桶
Bucket + Metric Aggregation
- Bucket 聚合分析允许通过添加子聚合分析来进一步分析,子聚合分析可以是
- Bucket
- Metric
例如:按照工作类型进行分桶,并统计工资信息;先按照工作类型分桶,然后按性别分桶,并统计工资信息
Pipeline 聚合分析
对聚合分析再做一次聚合分析。
例如 min_bucket:在员工数最多的工种里,找出平均工资最低的工种

Pipeline
- 管道的概念:支持对聚合分析的结果,再次进行聚合分析
- Pipeline 的分析结果会输出到原结果中,根据位置的不同,分为两类
- Sibling:结果和现有分析结果同级(如上)
- Max, min, Avg & Sum Bucket
- Stats, Extended Status Bucket
- Percentiles Bucket
- Parent:结果内嵌到现有的聚合分析结果之中
- Derivative (求导)
- Cumultive Sum(累计求和)
- Moving Function(滑动窗口)
- Sibling:结果和现有分析结果同级(如上)
Parent Pipeline:Derivative
例如,按照年龄,对工资进行求导(看工资发展的趋势)

聚合的作用范围及排序
作用范围

- ES 聚合分析的默认作用范围是 query 的查询结果集
- 同时 ES还支持以下方式改变聚合的作用范围
- Filter
- Post_Filter
- Global
Filter

Post_Filter

- 是对聚合分析后的文档进行再次过滤
- Size 无需设置为 0
- 使用场景
- 一条语句,获取聚合信息 + 获取符合条件的文档
Global

排序

- 指定 order,按照 count 和 key 进行排序
- 默认情况,按照 count 降序排序
- 指定 size,就能返回相应的桶
基于子聚合的值排序

- 基于子聚合的数值进行排序
- 使用子聚合,Aggregation name
聚合的精准度问题
分布式系统的近似统计算法

当数据量不大,ES 通过有限数据计算,可以满足进准度。
当分片上文档数量过大,ES 会通过近似计算来提高精确度,但是有些情况下,依然有准确度问题。
Min 聚合分析的执行流程

Min 聚合很准确,计算每个分片的最小值。
Terms Aggregation 返回值

- 在 Terms Aggregation 的返回中有两个特殊的数值:
doc_count_error_upper_bound:被遗漏的term分桶,包含的文档(有可能的结果数,越大说明越不准确,例如下面示例中有可能的最大值)sum_other_doc_count:除了返回结果bucket的terms以外,其他terms的文档总数(总数-返回的总数,越大说明可能越不准确)
Terms 聚合分析的执行流程

例如:

从两个分片获取最大个数的前三名:
- 分片1 返回的前三名是 A:6/ B:4/ C:4
- 分片 2 返回的前三名是 A:6/ B:2/ D:3
- 相加之后的结果是 A:12/ B:6/ C:4,这个结果是不准确的
分片 1 中可能被遗漏的最大数是 4,分片 2 中可能被遗漏的最大数是 3,doc_count_error_upper_bound = 4 + 3 = 7;
返回的结果总数,减去最终结果总数,sum_other_doc_count = (17 + 12) - (12 + 6 + 4) = 7;
解决 Terms 不准的问题
通过提升 shard_size 的参数

- Terms 聚合分析不准的原因,数据分散在多个分片上,Coordinating Node 无法获取数据全貌
- 解决方案1:当数据量不大时,设置 Primary Shard 为 1;实现准确性
- 方案2:在分布式数据上,设置
shard_size参数,提高精确度- 原理:每次从 Shard 上额外多获取数据,提升准确率
shard_size 设定
- 调整 shard size 大小,降低
doc_count_error_upper_bound来提升准确度- 增加整体计算量,提高了准确度,但会降低响应时间
- Shard Size 默认大小设定
shard size = size * 1.5 + 10
https://www.elastic.co/guide/en/elasticsearch/reference/8.13/search-aggregations-bucket-terms-aggregation.html#search-aggregations-bucket-terms-aggregation-shard-size
打开 show_term_doc_count_error

对象及 Nested 对象
对象主要应用于数据的关联关系
例如:
- 博客 / 作者 / 评论
- 银行账户有多次交易记录
- 客户有多个银行账户
- 目录文件有多个文件和子目录
关系型数据库的范式化设计

- 范式化设计(Normalization)的主要目标是“减少不必要的更新”
- 副作用:一个完全范式化设计的数据库会经常面临
查询缓慢的问题- 数据库越范式化,就需要 Join 越多的表
- 范式化节省了存储空间,但是存储空间却越来越便宜
- 范式化简化了更新,但是数据
读取操作可能更多
反范式化 Denormalization
- 反范式化设计
- 数据
Flattening,不使用关联关系,而是在文档中保存冗余的数据拷贝
- 数据
- 优点:无需处理 Joins 操作,数据读取性能好
- Elasticsearch 通过压缩
_source字段,减少磁盘空间的开销
- Elasticsearch 通过压缩
- 缺点:不适合在数据频繁修改的场景
- 一条数据(用户名)的改动,可能会引起很多数据的更新
在 Elasticsearch 中处理关联关系
- 关系型数据库,一般会考虑 Normalize 数据;在 Elasticsearch,往往考虑 Denormalize 数据
- Denormalize 的好处:
- 读的速度变快
- 无需表连接
- 无需行锁
- Denormalize 的好处:
- Elasticsearch 并不擅长处理关联关系。我们一般采用以下四种方法处理关联:
- 对象类型
- 嵌套对象(Nested Object)
- 父子关联关系(Parent / Child)
- 应用端关联
对象类型
例如在博客 Index 中,文档包含作者信息

对象类型:在每一博客的文档中都保留作者的信息
如果作者信息发生变化,需要修改相关的博客文档
好处是查询过程简单:

包含对象数组的文档
例如:

搜索时,如果错落查询,理论上不应该查询到,但是实际上可以查询得到:

还是可以搜索出来,这是因为:
- 存储时,内部对象的边界并没有考虑在内,JSON 格式被处理成扁平式键值对的结构
- 当对多个字段进行查询时,导致了意外的搜索结果
- 可以用 Nested Data Type 解决这个问题

Nested Data Type

- Nested 数据类型:允许对象数组中的对象被独立索引
- 使用 nested 和 properties 关键字,将所有 actors 索引到多个分隔的文档
- 在内部,Nested 文档会被保存在两个 Lucene 文档中,在查询时做 Join 处理
嵌套查询

在内部,Nested 文档会被保存在两个 Lucene 文档中,会在查询时做 Join 处理

嵌套聚合

父子关系
对象和 Nested 对象的局限性:每次更新,需要重新索引整个对象(包括根对象和嵌套对象)
ES 提供了类似关系型数据库中 Join 的实现。使用 Join 数据类型实现,可以通过维护 Parent / Child 的关系,从而分离两个对象
- 父文档和子文档是两个独立的文档
- 更新父文档无需重新索引子文档。子文档被添加,更新或者删除也不会影响到父文档和其他的子文档
例如博客和作者,这两者可以作为一个独立的文档。
定义父子关系的几个步骤:
- 设置索引的 Mapping
- 索引父文档
- 索引子文档
- 按需查询文档
操作过程
设置 Mapping

索引父文档

索引子文档

- 父文档和子文档必须存在相同的分片上
- 确保查询
join的性能
- 确保查询
- 当指定子文档时候,必须指定它的父文档 ld
- 使用 route 参数来保证,分配到相同的分片
支持的查询
- 查询所有文档
- Parent ld 查询:通过父ID查询子文档
- Has Child 查询
- Has Parent 查询
使用 hash_child 查询

- 返回父文档
- 通过对子文档进行查询
- 返回具有相关子文档的父文档
- 父子文档在相同的分片上,因此 Join 效率高
使用 has_parent 查询

- 返回相关的子文档
- 通过对父文档进行查询
- 返回所有相关子文档
使用 parent_id 查询

- 返回所有相关子文档
- 通过对父文档 Id 进行查询
- 返回所有相关子文档
访问子文档
指定父文档 routing 参数

更新子文档
更新子文档不会影响到父文档

嵌套对象 vs 父子文档

Update By Query & Reindex API
使用场景:
- 一般在以下几种情况时,我们需要重建索引
- 索引的 Mappings 发生变更:字段类型更改,分词器及字典更新
- 索引的 Settings 发生变更:索引的主分片数发生改变
- 集群内,集群间需要做数据迁移
- Elasticsearch 的内置提供的 API
- Update By Query:在现有索引上重建
- Reindex: 在其他索引上重建索引
Update By Query
例如:为索引增加子字段

- 改变 Mapping,增加子字段,使用英文分词器
- 此时尝试对子字段进行查询
- 虽然有数据已经存在,但是没有返回结果

- 执行 Update By Query
- 尝试对 Multi-Fields 查询查询
- 可以搜索到结果
Reindex API
更改已有字段类型的 Mappings

- ES不允许在原有 Mapping 上对字段类型进行修改
- 只能创建新的索引,并且设定正确的字段类型,再重新导入数据

将数据从 source 写入到 dest 的索引
- Reindex API 支持把文档从一个索引拷贝到另外一个索引
- 使用 Reindex APl 的一些场景
- 修改索引的主分片数
- 改变字段的 Mapping 中的字段类型
- 集群内数据迁移 / 跨集群的数据迁移
Reindex 注意点
重新索引要求在源中的所有文档启用 _source。
在调用 _reindex 之前,应该配置目标为所需状态。重新索引不会复制源或其关联模板的设置。映射、分片计数、副本等必须提前配置好。
Reindex requires
_sourceto be enabled for all documents in the source.The destination should be configured as wanted before calling
_reindex. Reindex does not copy the settings from the source or its associated template.Mappings, shard counts, replicas, and so on must be configured ahead of time.
OP Type

_reindex只会创建不存在的文档- 文档如果已经存在,会导致版本冲突
跨集群 Reindex

目的地端需要修改 elasticsearch.yml,并且重启节点

查看 Task API
异步 reindex 时,可以查看任务状态


- Reindx API 支持异步操作,执行只返回 Task Id
POST reindex?wait_forcompletion=false
Ingest Pipeline 与 Painless Script
例如有如下需求,后期需要对 Tags 进行 Aggregation 统计
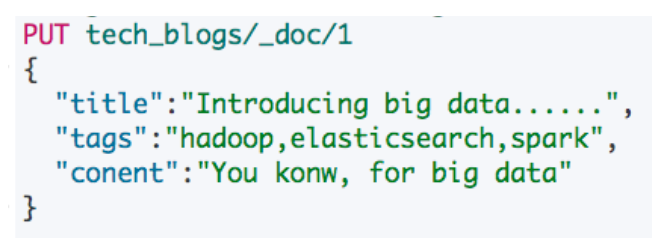
Tags 字段中,逗号分隔的文本应该是数组,而不是一个字符串
Ingest Node
- Elasticsearch 5.0 后,引入的一种新的节点类型。默认配置下,每个节点都是 Ingest Node
- 具有预处理数据的能力,可拦截 Index 或 Bulk API 的请求
- 对数据进行转换,并重新返回给 Index 或 Bulk API
- 无需 Logstash,就可以进行数据的预处理,例如:
- 为某个字段设置默认值;
- 重命名某个字段的字段名;
- 对字段值进行 Split 操作
- 支持设置 Painless 脚本,对数据进行更加复杂的加工
Pipeline & Processor
- Pipeline:管道会对通过的数据(文档),按照顺序进行加工
- Processor:Elasticsearch 对一些加工的行为进行了抽象包装
- Elastiosearch 有很多内置的 Processors。也支持通过插件的方式,实现自己的 Processor
使用 Pipeline 切分字符串
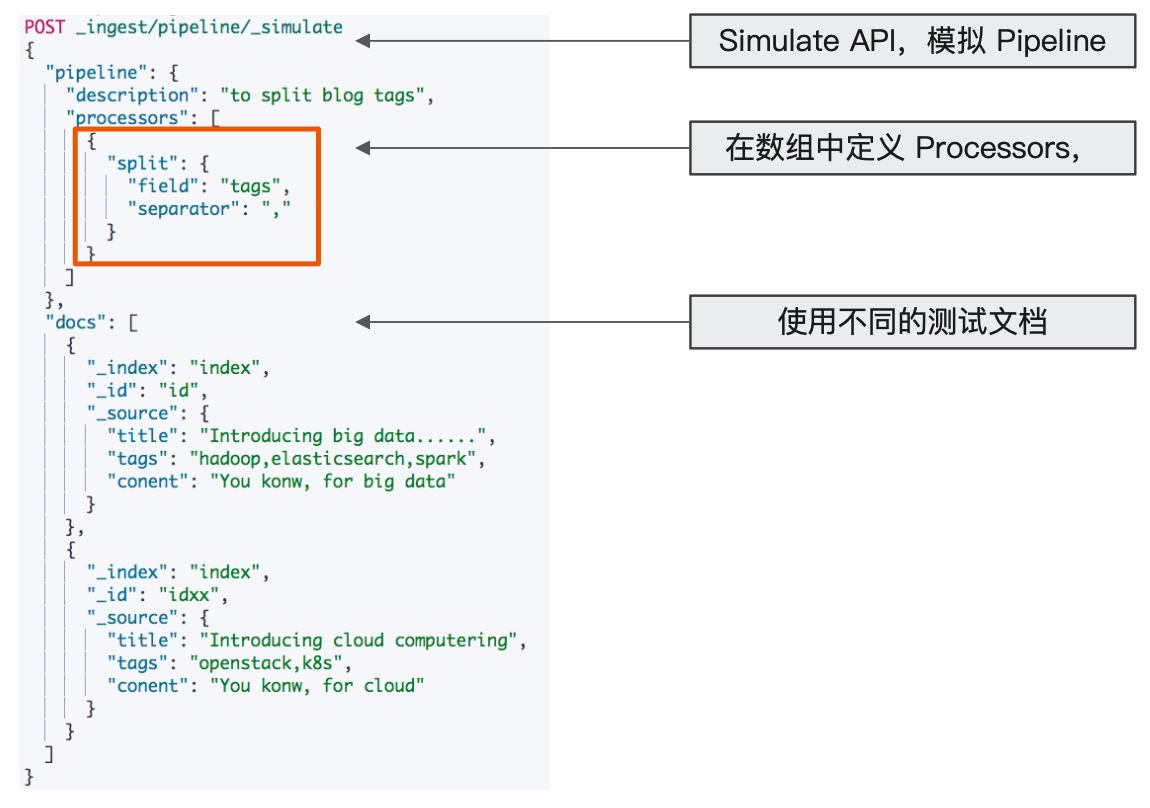
问文档增加字段

Pipeline API

例如添加 Pipeline 并测试

Index & Update By Query

一些内置 Processors
https://www.elastic.co/guide/en/elasticsearch/reference/8.13/processors.html#ingest-process-category-data-enrichment
- Split Processor (例:将给定字段值分成一个数组)
- Remove / Rename Processor (例:移除一个重命名字段)
- Append (例: 为商品增加一个新的标签)
- Convert (例:将商品价格,从字符串转换成 float 类型)
- Date / JSON(例:日期格式转换,字符串转 JSON 对象)
- Date Index Name Processor (例:将通过该处理器的文档,分配到指定时间格式的索引中)
- Fail Processor (一旦出现异常,该 Pipeline 指定的错误信息能返回给用户)
- Foreach Process(数组字段,数组的每个元素都会使用到一个相同的处理器)
- Grok Processor(日志的日期格式切割)
- Gsub / Join / Split(字符串替换 / 数组转字符串 / 字符串转数组)
- Lowercase Upcase (大小写转换)
Ingest Node vs Logstash
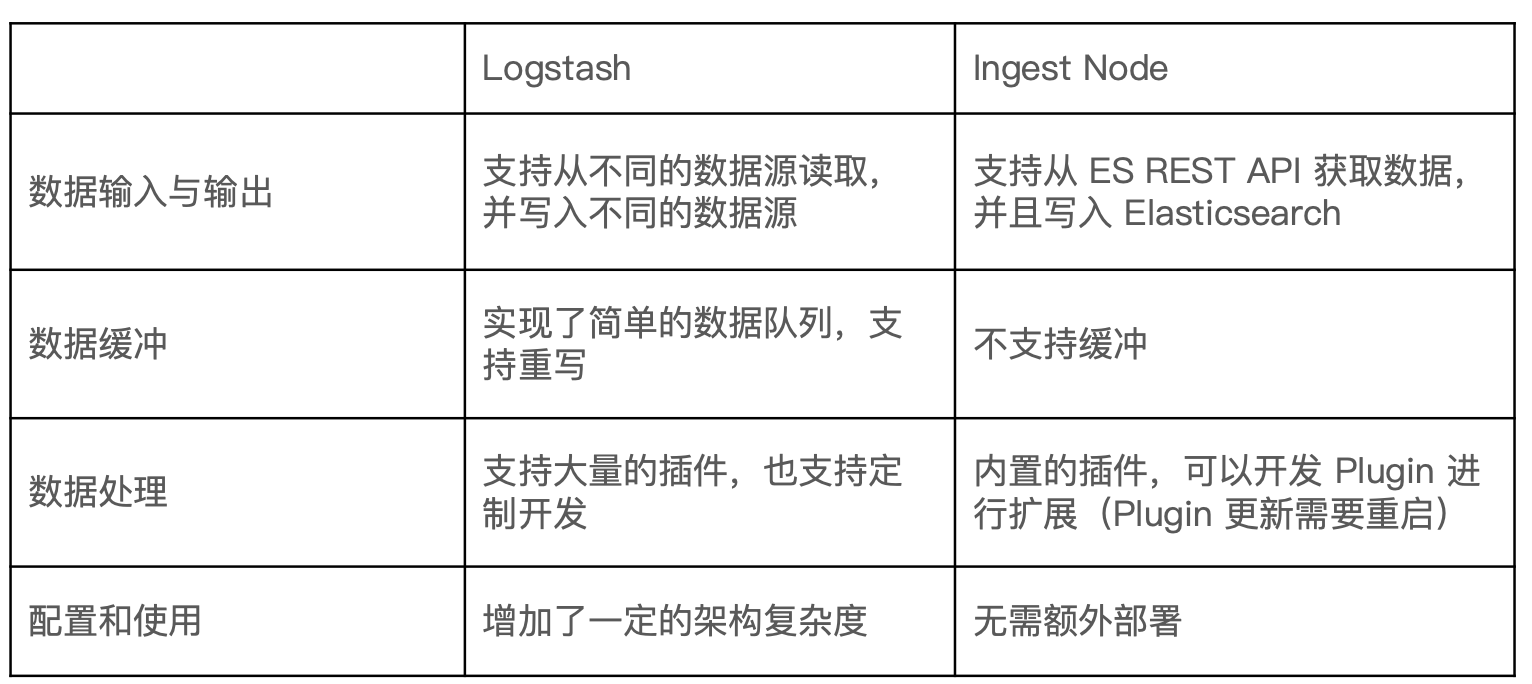
我应该使用 Logstash 还是 Elasticsearch 采集节点呢?
Painless 的用途
自 Elasticsearch 5.x 后引入,专门为 Elasticsearch 设计,扩展了 Java 的语法。
6.0 开始,ES 只支持 Painless。Groowy、JavaScript 和 Python 都不再支持。
Painless 支持所有 Java 的数据类型及 Java API 子集
Painless Script 具备以下特性
- 高性能、安全
- 支持显示类型或者动态定义类型
用途:
- 可以对文档字段进行加工处理
- 更新或删除字段,处理数据聚合操作
- Script Field:对返回的字段提前进行计算
- Function Score:对文档的算分进行处理
- 在 Ingest Pipeline 中执行脚本
- 在 Reindex APl, Update By Query 时,对数据进行处理
通过 Painless 脚本访问字段
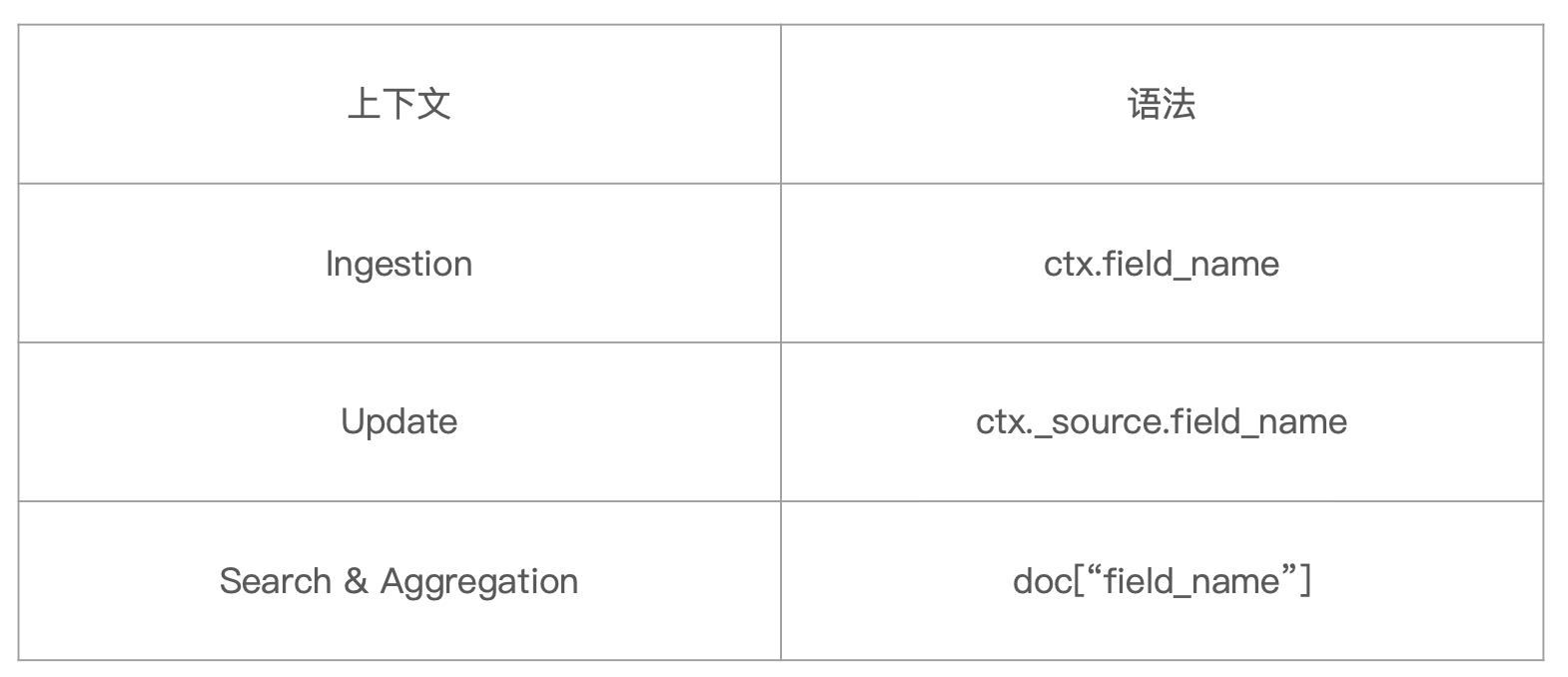
例如在 Ingestion 中使用脚本:
判断 content 字段是否存在,如果存在,则将 content_length 字段的值设置为长度

又例如:文档更新计数

又例如搜索时的 script 字段
通过 doc['field_name'] 访问数据
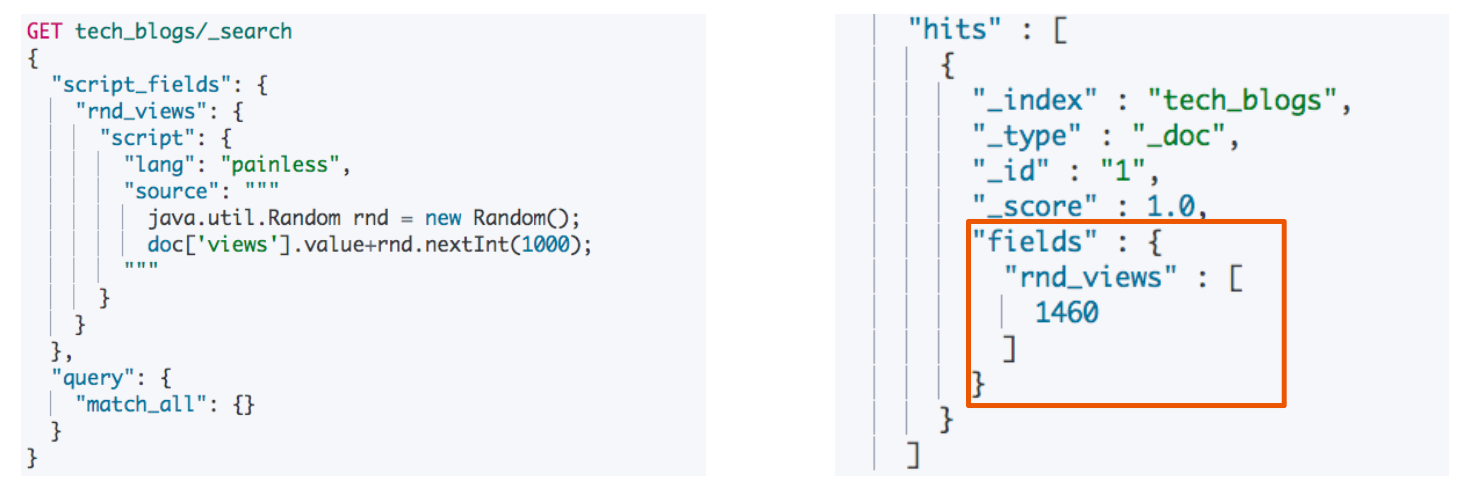
Script:Inline vs Stored
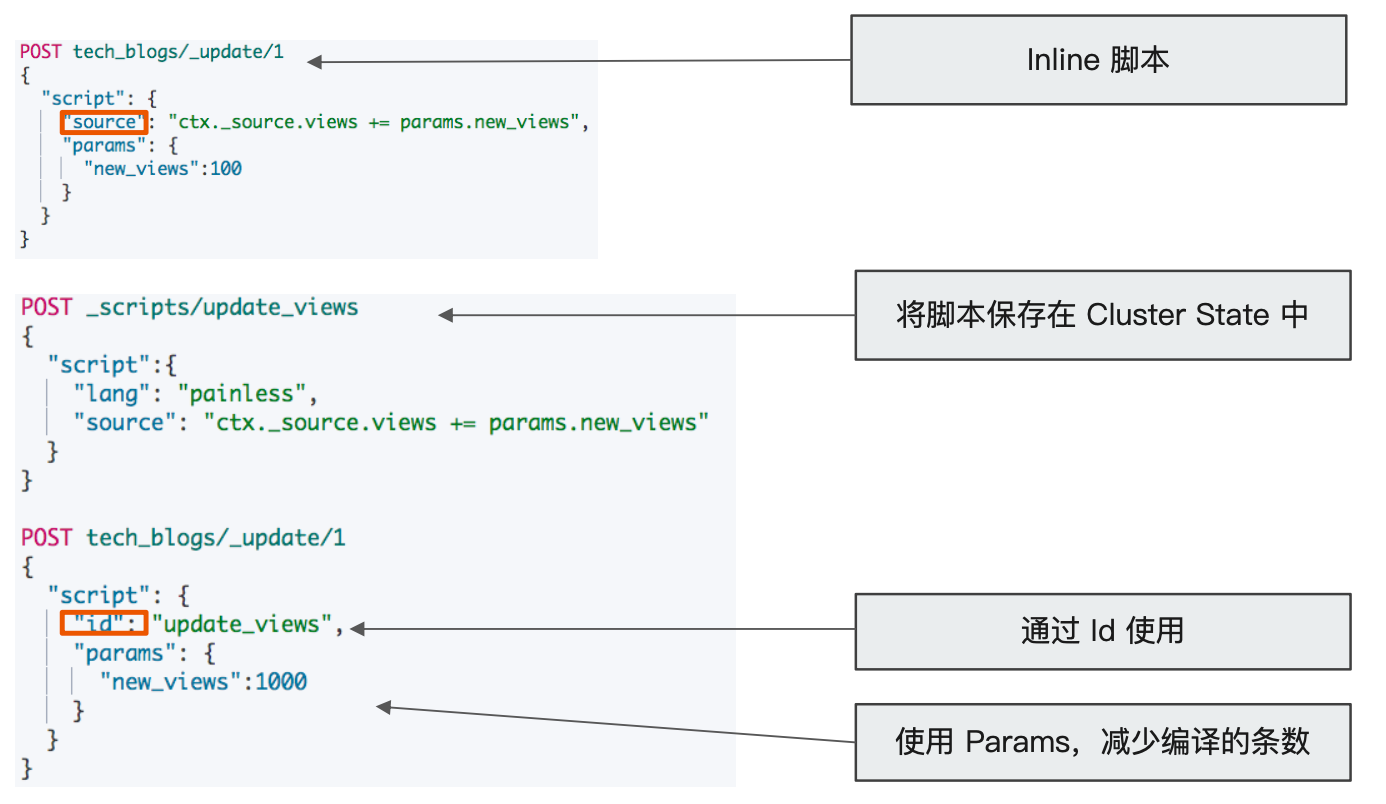
脚本缓存
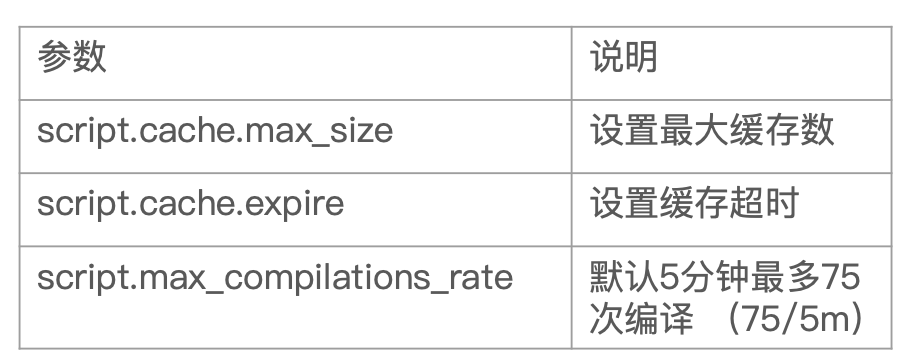
- 编译的开销相较大
- Elasticsearch 会将脚本编译后缓存在 Cache 中
- Inline scripts 和 Stored Scripts 都会被缓存
- 默认缓存 100 个脚本
数据建模
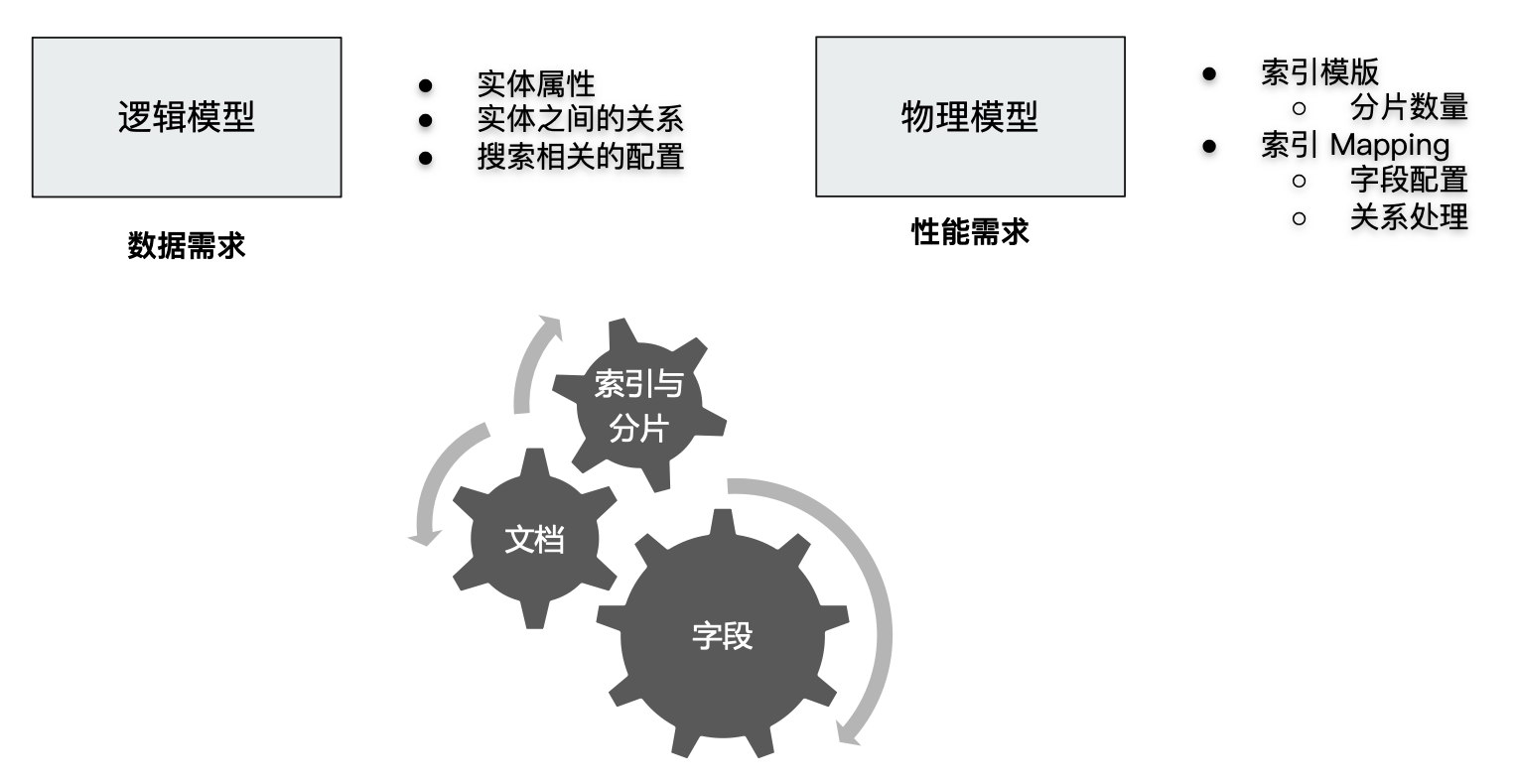
数据建模(Data modeling),是创建数据模型的过程
- 数据模型是对真实世界进行抽象描述的一种工具和方法,实现对现实世界的映射
- 博客 / 作者 / 用户评论
- 三个过程:概念模型 =>逻辑模型 =>数据模型(第三范式)
- 数据模型:结合具体的数据库,在满足业务读写性能等需求的前提下,确定最终的定义
功能需求 + 性能需求
对字段进行建模
- 字段类型
- 是否要搜索及分词
- 是否要聚合及排序
- 是否要额外的存储
字段类型:Text vs Keyword
- Text
- 用于全文本字段,文本会被 Analyzer 分词
- 默认不支持聚合分析及排序。需要设置 fielddata 为 true
- Keyword
- 用于 id,枚举及不需要分词的文本。例如电话号码、email地址、手机号码、邮政编码、性别等
- 适用于 Filter(精确匹配),Sorting 和 Aggregations
- 设置多字段类型
- 默认会为文本类型设置成 text,并且设置一个 keyword 的子字段
- 在处理人类语言时,通过增加 英文,拼音 和 标准 分词器,提高搜索结构
字段类型:结构化数据
- 数值类型
- 尽量选择贴近的类型。例如可以用 byte,就不要用 long
- 枚举类型
- 设置为 keyword。即便是数字,也应该设置成 keyword,获取更加好的性能
- 其他
- 日期 / 布尔 / 地理信息
检索
- 如不需要检索,排序和聚合分析
- Enable 设置成 false
- 如不需要检索
- Index 设置成 false
- 对需要检索的字段,可以通过如下配置,设定存储粒度
- Index_options / Norms:不需要归一化数据时,可以关闭(以达到磁盘存储的目的)
聚合及排序
- 如不需要检索、排序和聚合分析
- Enable 设置成 false
- 如不需要排序或者聚合分析功能
- Doc_values / fielddata 设置成 false
- 更新频繁,聚合查询频繁的 keyword 类型的字段
- 推荐将
eager_globalordinals设置为 true(可以利用缓存特性,提升性能)
- 推荐将
额外的存储
- 是否需要专门存储当前字段数据
- Store 设置成 true,可以存储该字段的原始内容
- 一般结合
_source的enabled为false时候使用
- Disable:
_source:节约磁盘;适用于指标型数据- 一般建议先考虑增加压缩比
- 无法看到
_source字段,无法做Relndex,无法做Update - Kibana 中无法做 discovery
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-store.html#mapping-store
默认情况下,字段值被索引以便进行搜索,但它们不会被存储。这意味着该字段可以被查询,但无法检索原始字段值。通常这并不重要。字段值已经是 _source 字段的一部分,默认情况下会被存储。如果您只想检索单个字段或几个字段的值,而不是整个 _source,则可以通过源过滤来实现。在某些情况下将字段存储起来可能是有意义的。例如,如果您有一个包含标题、日期和非常大内容字段的文档,则可能希望仅检索标题和日期,而无需从大型 _source 字段中提取这些字段:
案例
图书的索引
- 书名
- 简介
- 作者
- 发行日期
- 图书封面(默认映射成 text 类型,而且增加子字段 keyworld)

优化字段设定

图书的索引
- 书名:支持全文和精确匹配
- 简介:支持全文
- 作者:精确值
- 发行日期:日期类型
- 图书封面:精确值
需求变更
- 新需求:增加图书内容的字段。并要求能被搜索同时支持高亮显示
- 新需求会导致
_source的内容过大- Source Filtering 只是传输给客户端时进行过滤,Fetch 数据时,ES 节点还是会传输
_source中的数据
- Source Filtering 只是传输给客户端时进行过滤,Fetch 数据时,ES 节点还是会传输
- 解决方法
- 关闭
_source - 将每个字段的
store设置成 true
- 关闭

解决字段过大引发的性能问题
- 返回结果不包含
_source字段 - 对于需要显示的信息,可以在在查询中指定
stored fields - 禁止
_source字段后,还是支持使用 highlights APl, 高亮显示 content 中匹配的相关信息

Mapping 字段的相关设置
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-params.html
- Enabled:设置成
false,仅做存储,不支持搜索和聚合分析(数据保存在_source中,依然可以看到) - Index:是否构倒排索引。设置成 false,无法被搜索,但还是支持
aggregation,并出现在_source中 - Norms:如果字段用来过滤和聚合分析,可以关闭,节约存储
- Doc_values :是否启用
doc_values, 用于排序和聚合分析 - Field_data:如果要对 text 类型启用排序和聚合分析,fielddata 需要设置成 true
- Store:默认不存储,数据默认存储在
_source。 - Coerce:默认开启,是否开启数据类型的自动转换(例如,字符串转数字)
- Multifields:多字段特性
- Dynamic:true / false / strict,控制 Mapping 的自动更新
一些相关的 API
- Index Template & Dynamic Template
- 根据索引的名字匹配不同的 Mappings 和 Settings
- 可以在一个 Mapping 上动态的设定字段类型
- Index Alias
- 无需停机,无需修改程序,即可进行修改
- Update By Query & Reindex
最佳实践
处理关联关系

Kibana 支持
- Kibana 目前暂对 nested 类型和 parent/child 类型支持不太好
- 如果需要使用 Kibana 进行数据分析,在数据建模时仍需对嵌套和父子关联类型作出取舍
避免过多字段
- 一个文档中,最好避免大量的字段
- 过多的字段数不容易维护
- Mapping 信息保存在 Cluster State 中,数据量过大,对集群性能会有影响(Cluster State 信息需要和所有的节点同步)
- 删除或者修改数据需要 reindex
- 默认最大字段数是 1000,可以设置
index.mapping.total_fields.limit限定最大字段数。
什么原因会导致文档中有成百上千的字段:不同格式的数据存入一个 index 中,并且 Dynamic 参数被打开
Dynamic vs Strict
- Dynamic(生产环境中,尽量不要打开 Dynamic)
- true:未知字段会被自动加入
- false:新字段不会被索引。但是会保存在
_source - strict:新增字段不会被索引,文档写入失败
- Strict:可以控制到字段级别
例如字段过多的问题
Cookie Service 的数据写入 es

- 来自 Cookie Service 的数据
- Cookie 的键值对很多
- 当 Dynamic 设置为 True
- 同时采用扁平化的设计,必然导致字段数量的膨胀
解决方案:Nested Object & Key Value
使用嵌套数据类型,通过类型和值两个字段存储

数据写入:

数据查询:

通过 Nested 对象保存 Key/Value 的一些不足:
- 可以减少字段数量,解决 Cluster State 中保存过多 Meta 信息的问题,但是:
- 导致查询语句复杂度增加
- Nested 对象,不利于在 Kibana 中实现可视化分析
避免正则查询
- 问题:
- 正则,通配符查询,前缀查询属于 Term 查询,但是性能不够好
- 特别是将通配符放在开头,会导致性能的灾难
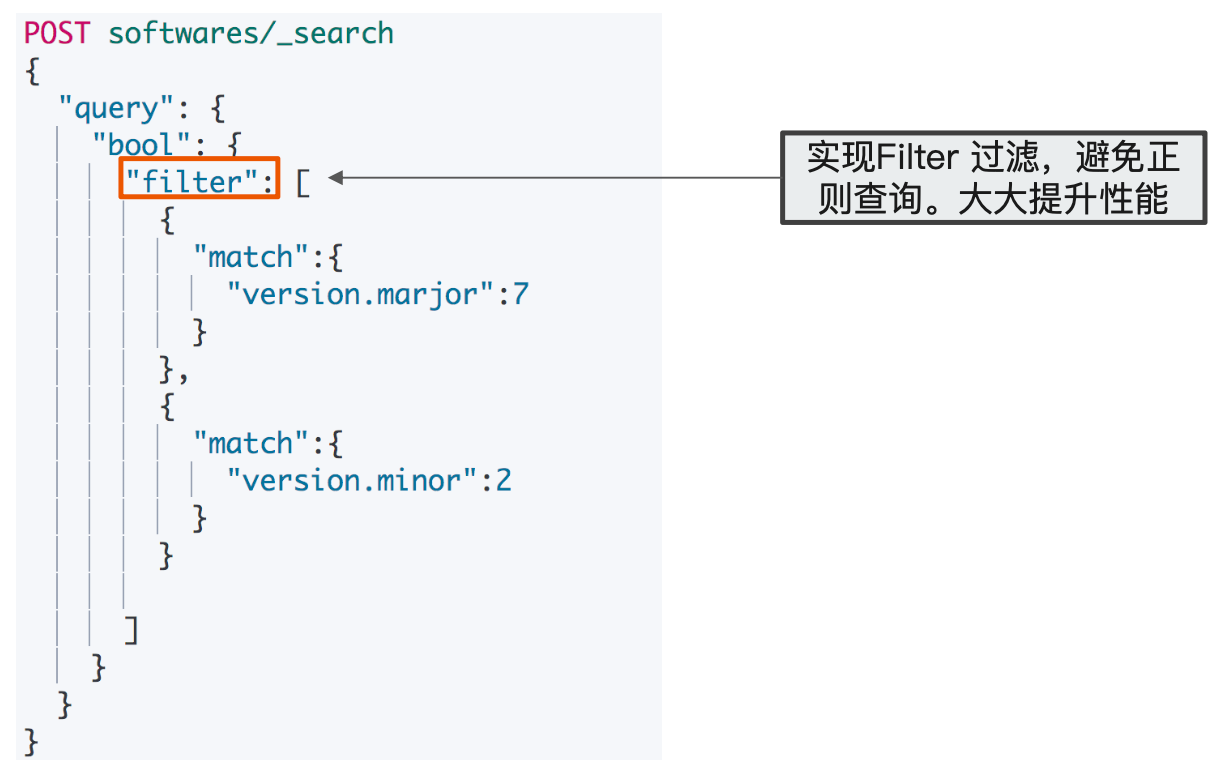
- 案例:
- 文档中某个字段包含了 Elasticsearch 的版本信息,例如 version:
7.1.0 - 搜索所有是 bug fix 的版本?每个主要版本号所关联的文档?
- 文档中某个字段包含了 Elasticsearch 的版本信息,例如 version:
解决方案:将字符串转换为对象

搜索过滤,利用缓存,性能更好
避免空值引起的聚合不准
例如获取平均值时,有 null 值时,结果不对

利用 null_value 解决空值问题(例如设置为 1,也可以设置为 0)

为索引的 Mapping 加入 Meta 信息
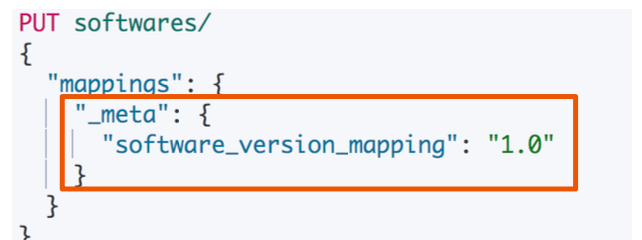
- Mappings 设置非常重要,需要从两个维度进行考虑
- 功能:搜索,聚合,排序
- 性能:存储的开销;内存的开销;搜索的性能
- Mappings 设置是一个迭代的过程
- 加入新的字段很容易 (必要时需要
update_by_query) - 更新删除字段不允许(需要 Reindex 重建数据)
- 最好能对 Mappings 加入 Meta 信息,更好的进行版本管理
- 可以考虑将 Mapping 文件上传 git 进行管理
- 加入新的字段很容易 (必要时需要