分布式事务
分布式事务
例如经典转账问题:
支付宝账户表:A(id, user_id, amount)
余额宝账户表:B(id, user_id, amount)
用户的 user_id = 1,从支付宝转账1万块到余额宝分为两个步骤:
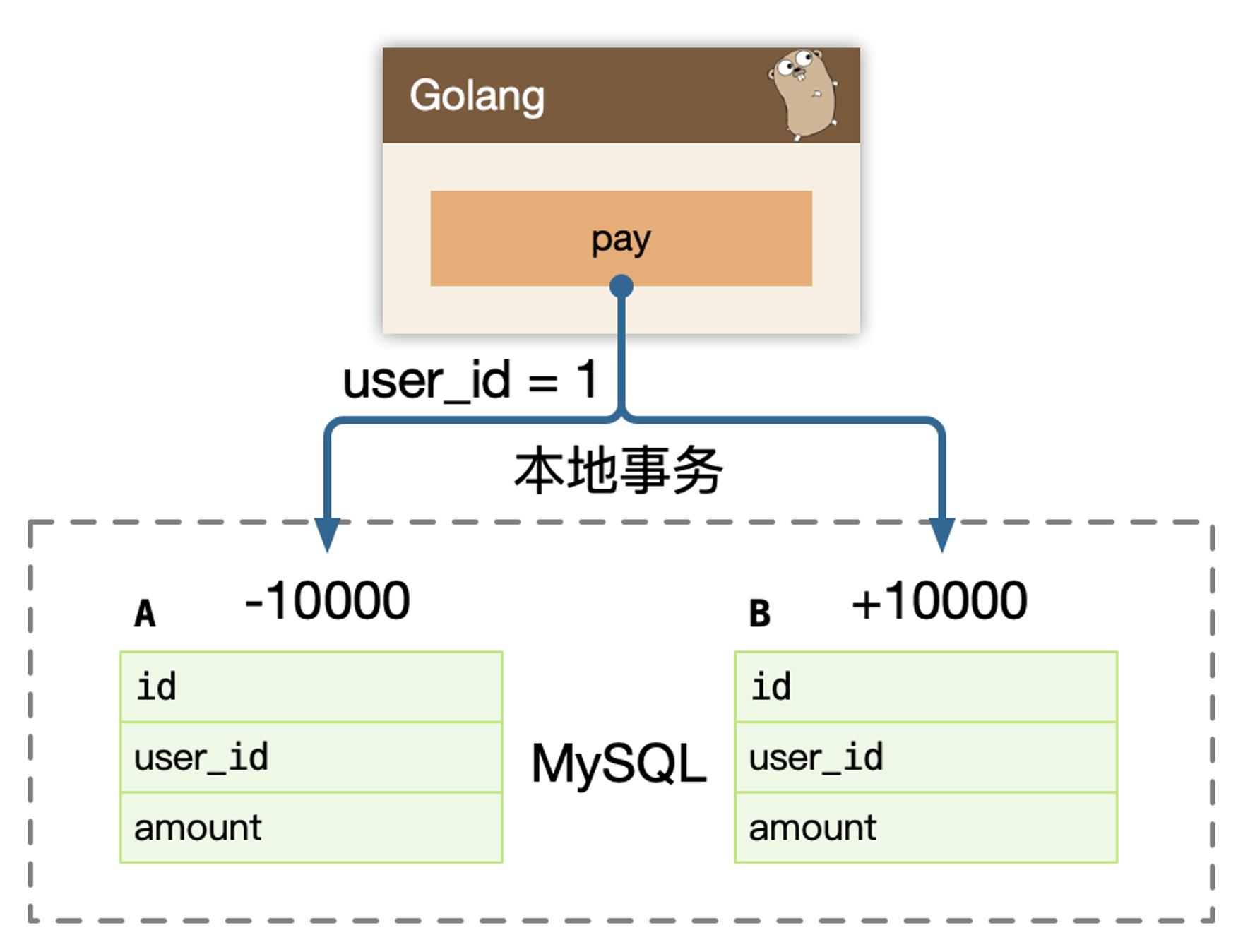
支付宝表扣除 1万:
UPDATE A SET amount = amount - 10000 WHERE user_id = 1;余额宝表增加 1万:
UPDATE B SET amount = amount + 10000 WHERE user_id = 1;
要保证数据一致性,则需要开启事务。
单个数据库,可以保证 ACID 使用数据库事务。
随着系统变大,进行了微服务架构的改造,因为每个微服务独占了一个数据库实例,从 user_id = 1,发起的转账动作,跨越了两个微服务:pay 和 balance 服务。

需要保证,跨多个服务的步骤数据一致性:
- 微服务
pay的支付宝表扣除 1万; - 微服务
balance的余额包表增加 1万;
每个系统都对应一个独立的数据源,且可能位于不同机房,同时调用多个系统的服务很难保证同时成功,这就是跨服务分布式事务的问题。
系统应该能保证每个服务自身的 ACID,基于这个假设,事务消息解决分布式事务问题。
事务消息
例如北京很有名的姚记炒肝,点了炒肝并付了钱后,他们并不会直接把你的炒肝给你,往往是给你一张小票,然后让你拿小票到出货区排队去取。
这是将付钱和取货两个动作分开。其中一个很重要的原因是为了使他们接待能力增强(并发量更高)。
只要这张小票在,用户最终是能拿到炒肝的。同理转账服务也是如此。
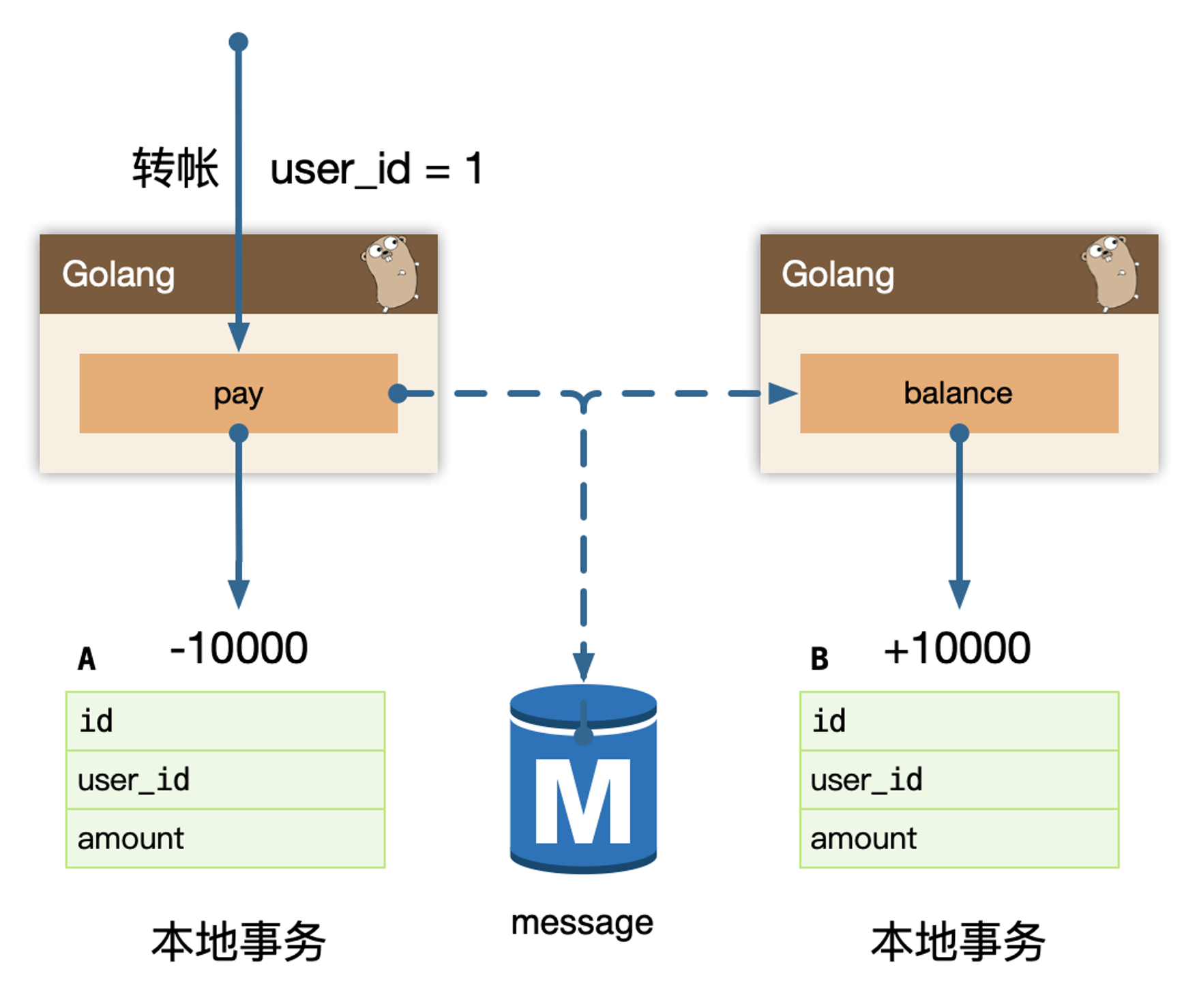
当支付宝账户扣除 1万后,我们只要生成一个凭证(消息)即可,这个凭证(消息)上写着让余额宝账户增加1万,只要这个凭证(消息)能可靠保存,最终是可以拿着这个凭证(消息)让余额宝账户增加1万的,即我们能依靠这个凭证(消息)完成最终一致性。
问题的关键就是可靠的保存消息凭证。
要解决消息可靠存储,实际上需要解决的问题是:本地的 MySQL 存储和 message 存储的一致性问题。
Transactional outbox:事务投递箱Polling publisher:从原始生产方拖消息Transaction log tailing:binlog订阅2PC Message Queue:二阶段提交
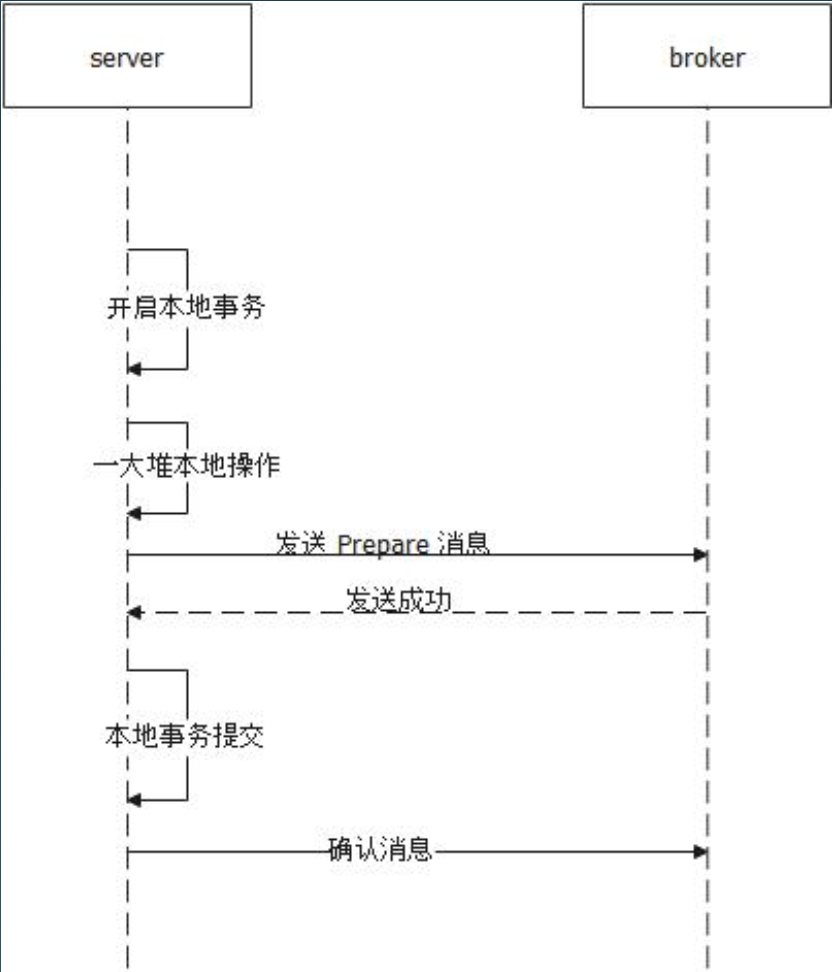
事务消息一旦被可靠的持久化,整个分布式事务,变为了最终一致性,消息的消费才能保障最终业务数据的完整性,所以要尽最大努力,把消息送达到下游的业务消费方,称为:Best Effort。只有消息被消费,整个交易才能算是完整完结。
大多数事务消息都是利用二阶段提交来实现,例如 RabbitMQ 的事务消息机制是二阶段提交 + 事务回查。
Best Effort
尽最大努力交付,主要用于在这样一种场景:不同的服务平台之间的事务性保证。
比如在电商购物,使用支付宝支付;又比如玩网游的时候,通过 App Store 充值。
拿购物为例,电商平台与支付平台是相互独立的,隶属于不同的公司,即使是同一个公司也很可能是独立的部门。
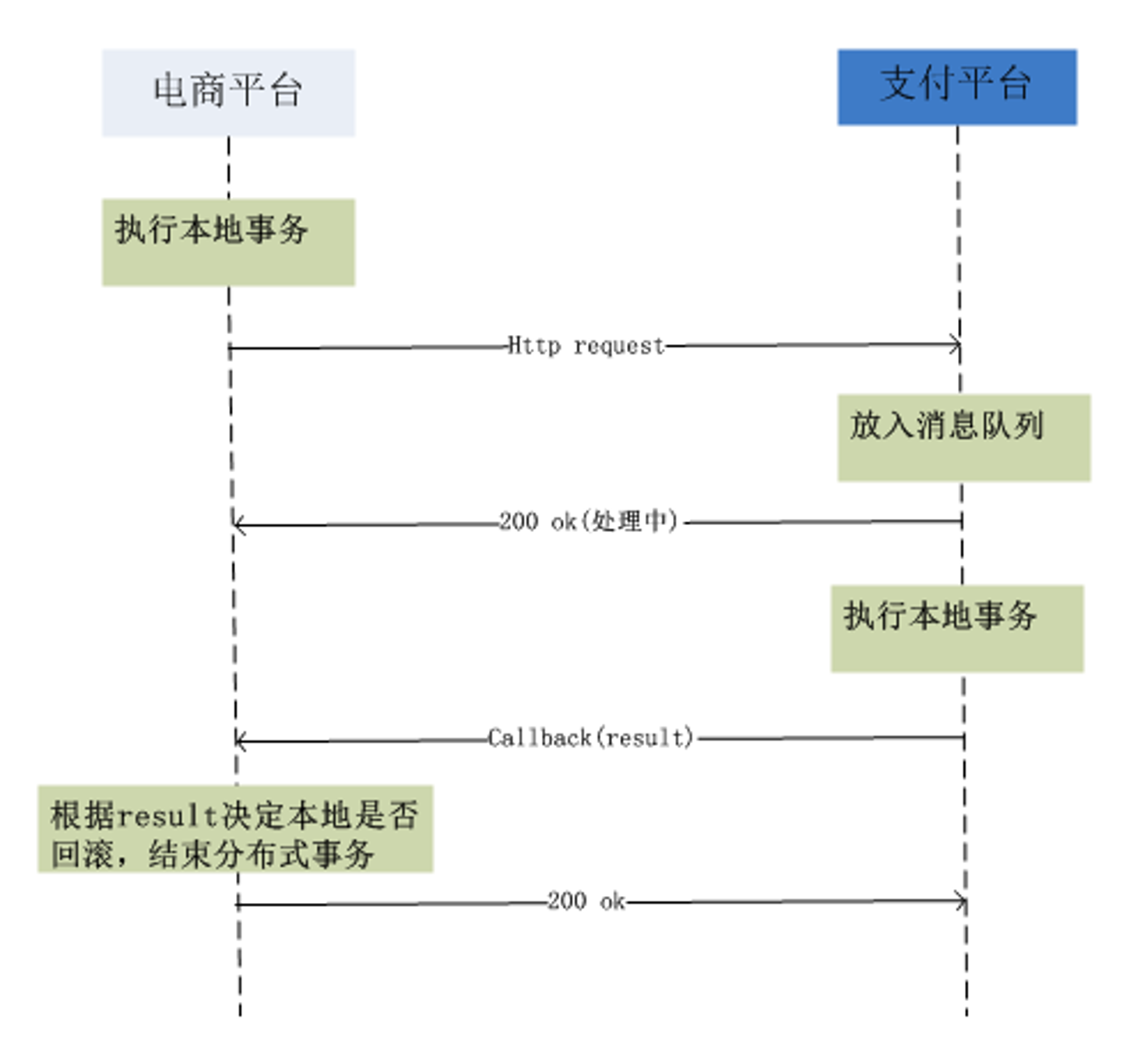
做过支付宝交易接口的同学都知道,我们一般会在支付宝的回调页面和接口里,解密参数,然后调用系统中更新交易状态相关的服务,将订单更新为付款成功。
同时,只有当我们回调页面中输出了
success字样或者标识业务处理成功相应状态码时,支付宝才会停止回调请求。否则,支付宝会每间隔一段时间后,再向客户方发起回调请求,直到输出成功标识为止。
需要注意,回调接口需要处理幂等,当交付平台重复回调接口,发送请求成功信息时,可以避免出现产生多次交易成功的情况。
Transactional outbox
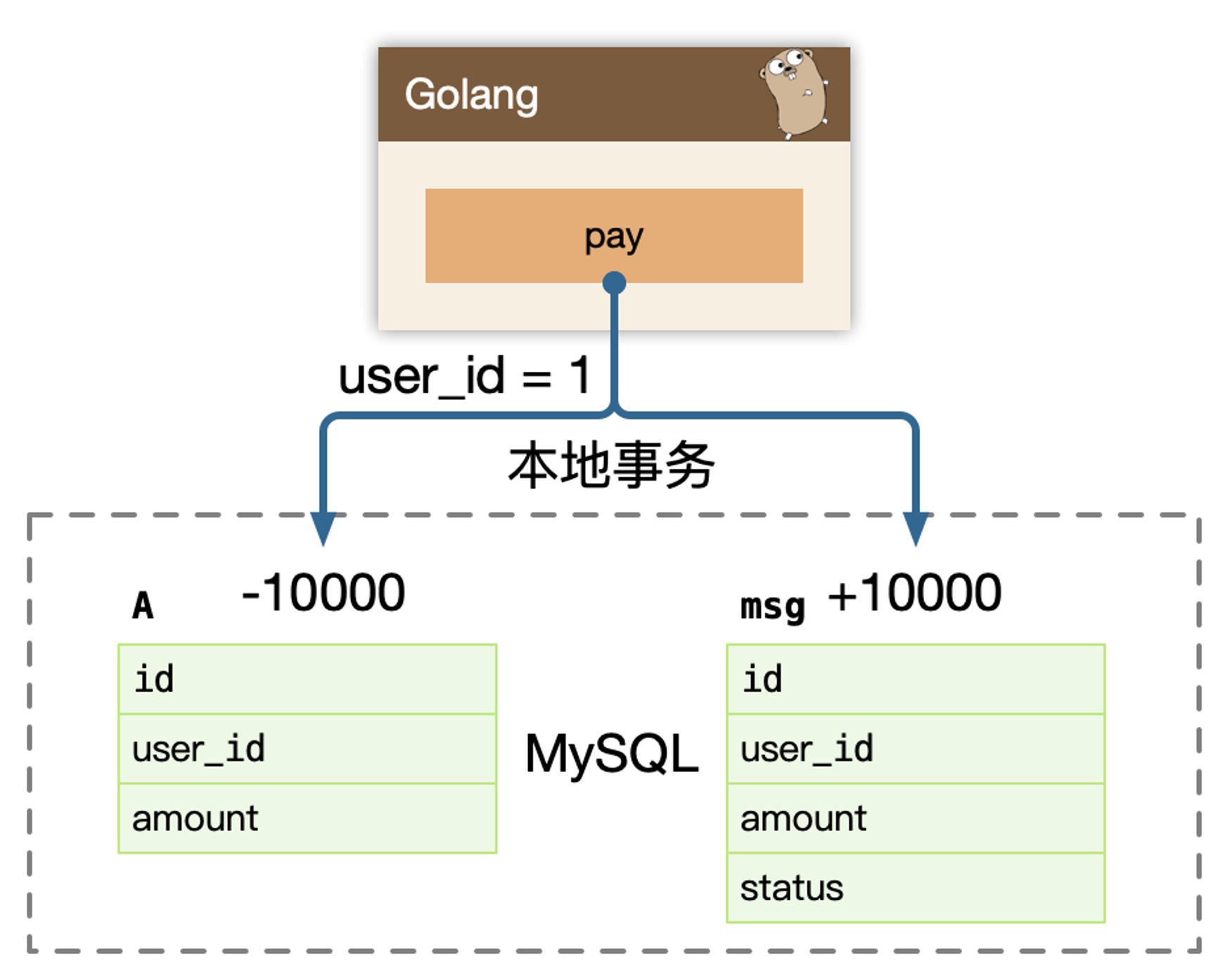
Transactional outbox(事务型收件箱),支付宝在完成扣款的同时,同时记录消息数据,这个消息数据与业务数据保存在同一数据库实例里(消息记录表表名为 msg)
1 | BEGIN TRANSACTION |
上述事务能保证只要支付宝账户里被扣了钱,消息一定能保存下来。当上述事务提交成功后,我们想办法将此消息通知余额宝,余额宝处理成功后发送回复成功消息,支付宝收到回复后删除该条消息数据。余额宝处理成功之后回调,修改消息状态。当然,除了在交易的时候调用余额宝的接口,还需要定期轮询消息表,以防一些消息漏掉没有发送给余额宝。
Polling publisher
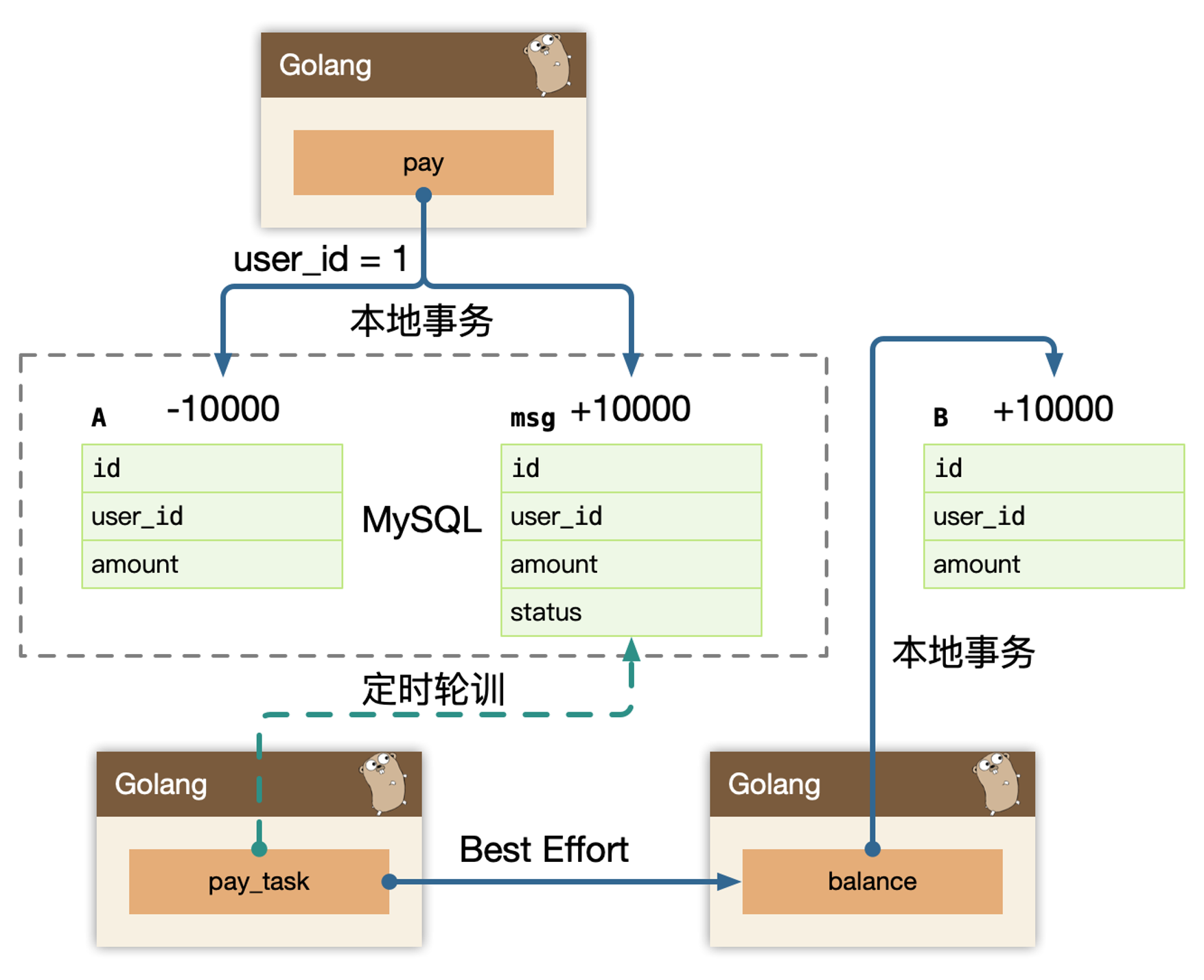
Polling publisher,我们定时的轮询 msg 表,把 status = 1 的消息统统拿出来消费,可以按照自增 id 排序,保证顺序消费。在这里我们独立了一个 pay_task 服务,把拖出来的消息 publish 给我们消息队列,balance 服务自己来消费队列,或者直接 rpc 发送给 balance 服务。同步调用成功之后,再修改数据库 status。
实际我们第一个版本的 archive-service 在使用 CQRS 时,就用的这个模型,Pull 的模型,从延迟来说不够好,Pull 太猛对 Database 有一定的压力,Pull 频次低了,延迟比较高。
缺陷:
- 定时操作,也就是会有延迟
- 如果要减少延迟,那么频次会很高,数据库查询压力大
Transaction log tailing
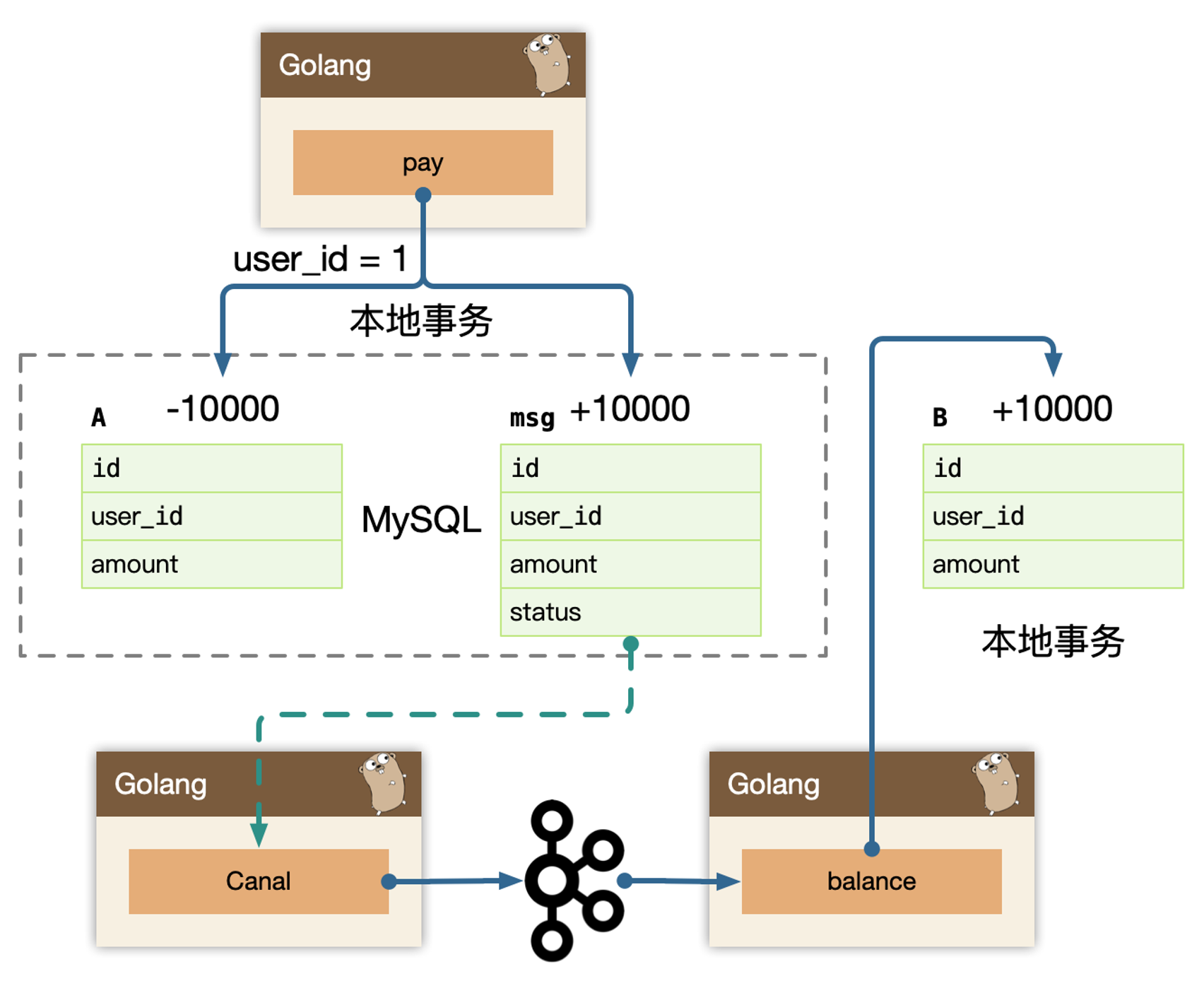
Transaction log tailing,上述保存消息的方式使得消息数据和业务数据紧耦合在一起,从架构上看不够优雅,而且容易诱发其他问题。
有一些业务场景,可以直接使用主表被 canal 订阅使用,有一些业务场景自带这类 message 表,比如订单或者交易流水,可以直接使用这类流水表作为 message 表使用。这样就不需要轮询查询数据库,甚至订阅订单表和流水表的话,可以不需要 msg 表。(一般这种用法叫作 CDC,Change Data Capture,用于捕获和跟踪数据库中发生的数据变更。)
使用 canal 订阅以后,是实时流式消费数据,在消费者 balance 或者 balance-job 必须努力送达到。
所有努力送达的模型,必须是先预扣(预占资源)的做法。
幂等
还有一个很严重的问题就是消息重复投递,如果相同的消息被重复投递两次(或者获取消息消费了两次),那么我们余额宝账户将会增加 2万而不是 1万了。
为什么相同的消息会被重复投递?比如余额宝处理完消息 msg 后,发送了处理成功的消息给支付宝,正常情况下支付宝应该要删除消息 msg,但如果支付宝这时候悲剧的挂了,重启后一看消息 msg 还在,就会继续发送消息 msg。
消息队列一般都有两种模式:至少一次消费(ack);至多一次消费。
全局唯一
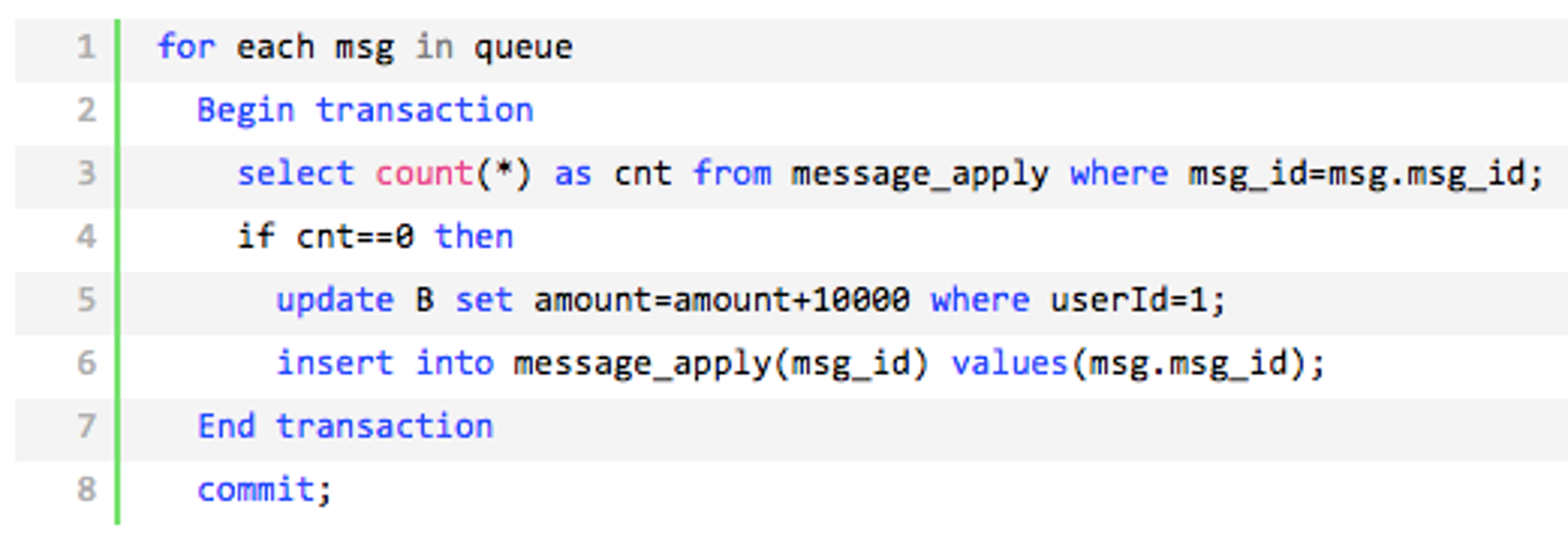
ID+ 去重表在余额宝这边增加消息应用状态表
msg_apply,通俗来说就是个账本,用于记录消息的消费情况,每次来一个消息,在真正执行之前,先去消息应用状态表中查询一遍,如果找到说明是重复消息,丢弃即可,如果没找到才执行,同时插入到消息应用状态表(同一事务)版本号
2PC
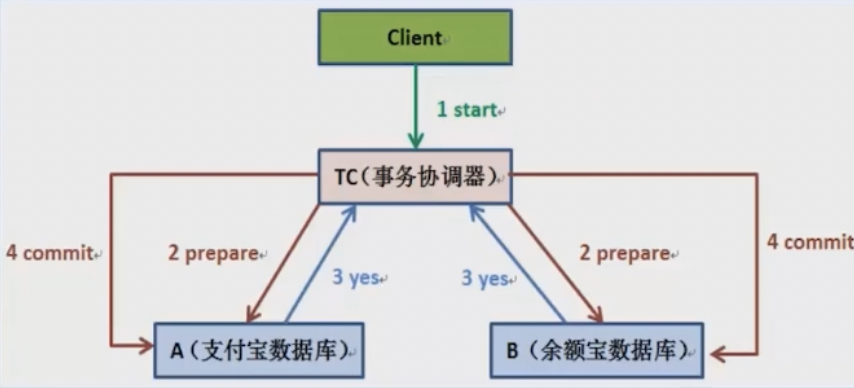
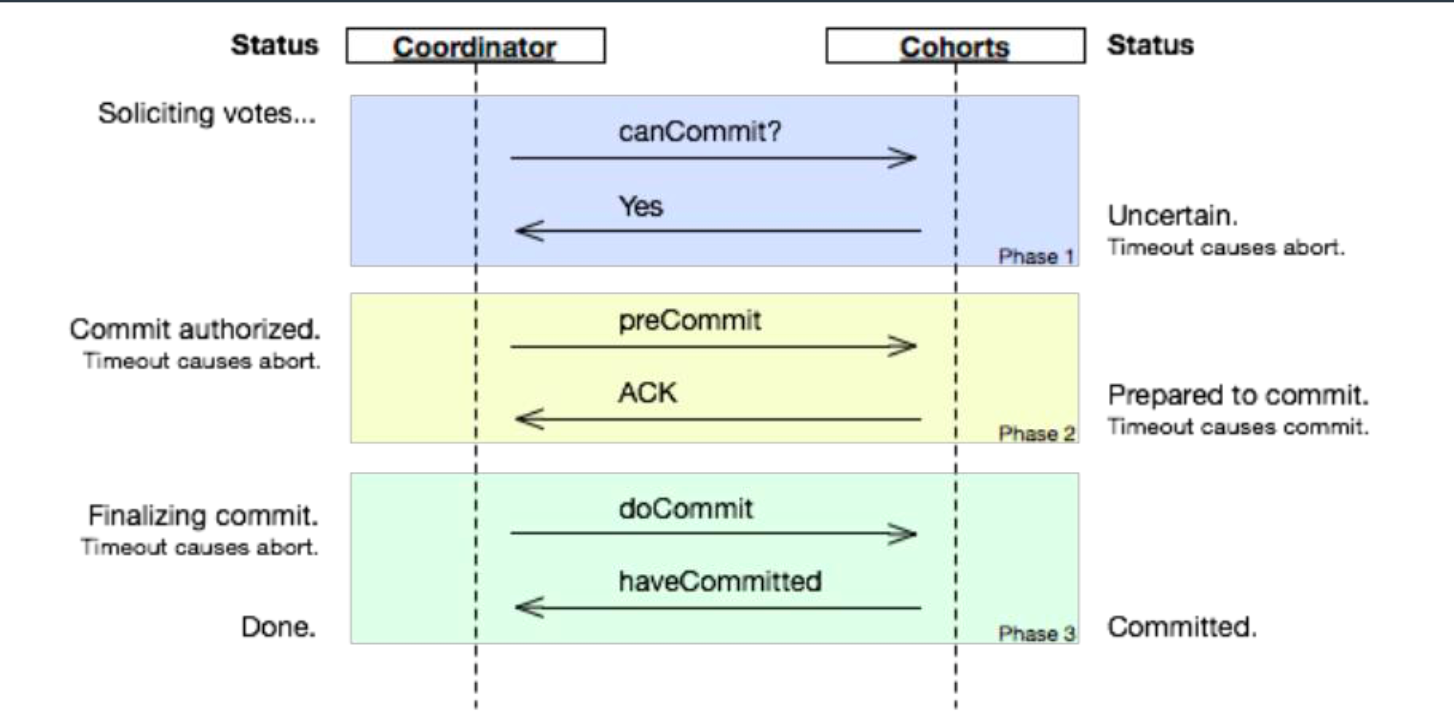
两阶段提交协议(Two Phase Commitment Protocol)中,涉及到两种角色。
- 一个事务协调者(
coordinator):负责协调多个参与者进行业务投票及提交(回滚) - 多个事务参与者(
participants):即本地事务执行者
总共处理步骤有两个:
- 投票阶段(
voting phase):协调者将通知事务参与者准备提交或取消事务,然后进入表决过程。参与者将告知协调者自己的决策:同意(事务参与者本地事务执行成功,但未提交)或取消(本地事务执行故障); - 提交阶段(
commit phase):收到参与者的通知后,协调者再向参与者发出通知,根据反馈情况决定各参与者是否要提交还是回滚;
差不多的还有三阶段提交
2PC Message Queue
二阶段提交消息队列

Seata 2PC
Seata 实现 2PC 与传统 2PC 的差别

- 架构层次方面:传统
2PC方案的RM实际上是在数据库层,RM本质上就是数据库自身,通过XA协议实现,而Seata的RM是以jar包的形式作为中间件层部署在应用程序这一侧的。 - 两阶段提交方面:传统
2PC无论第二阶段的决议是commit还是rollback,事务性资源的锁都要保持到Phase2完成才释放。而Seata的做法是在Phase1就将本地事务提交,这样就可以省去Phase2持锁的时间,整体提高效率。
TCC
TCC 是 Try、Confirm、Cancel 三个词语的缩写,TCC 要求每个分支事务实现三个操作:预处理 Try、确认Confirm、撤销 Cancel。
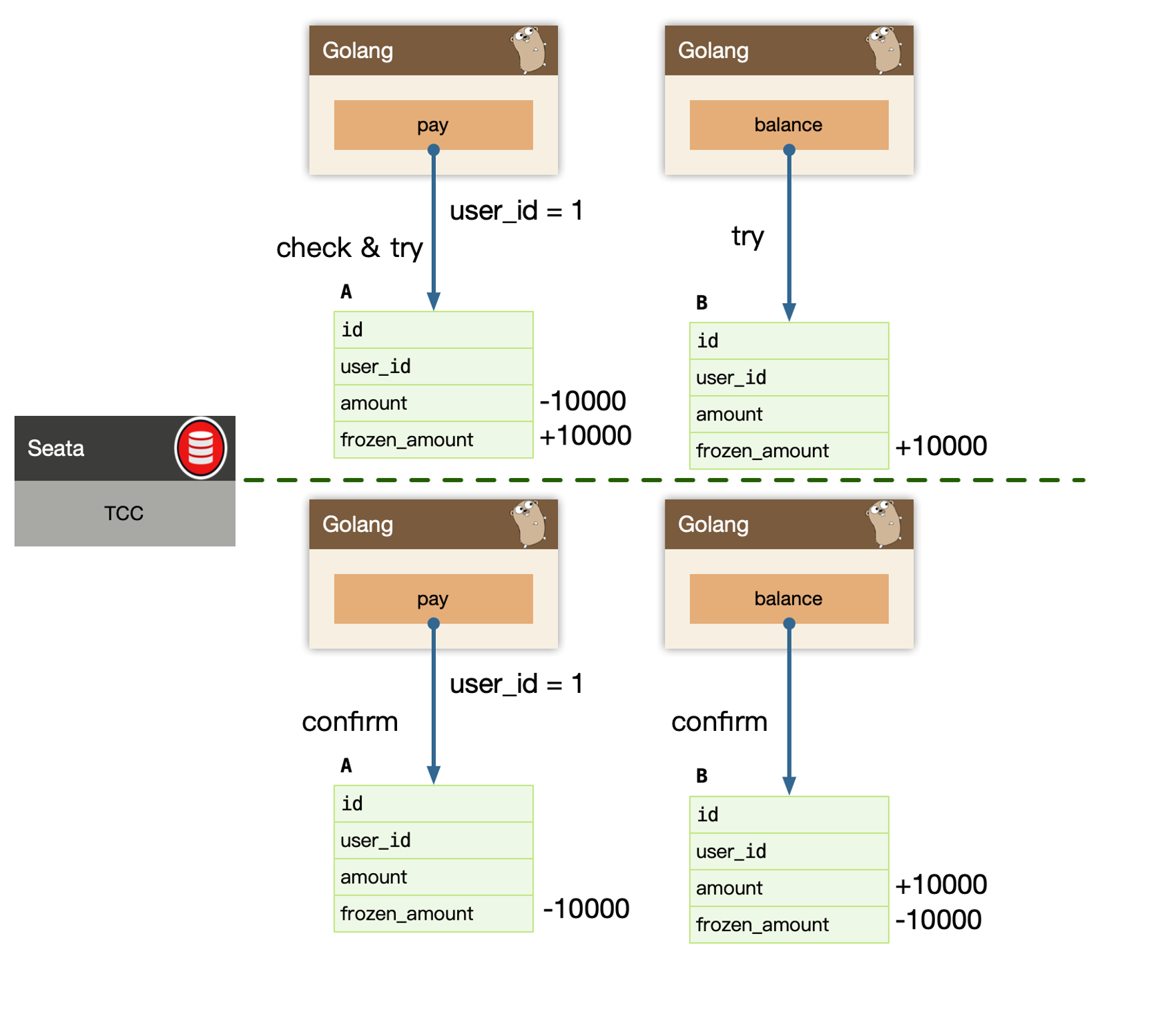
Try 操作做业务检查及资源预留,Confirm 做业务确认操作,Cancel 实现一个与 Try 相反的操作即回滚操作。
TM 首先发起所有的分支事务 Try 操作,任何一个分支事务的 Try 操作执行失败,TM 将会发起所有分支事务的 Cancel 操作,若 Try 操作全部成功,TM 将会发起所有分支事务的 Confirm 操作,其中 Confirm/Cancel 操作若执行失败,TM 会进行重试。
需要注意:
- 幂等:避免网络原因产生的多次请求
- 空回滚:
try失败的时候,再回滚,需要特殊处理; - 防悬挂:例如先
cancel比try到达,导致乱序,这个时候应该停止交易;
微服务
除了上面的服务内部实现分布式事务,在微服务层面,也有一些分布式事务的解决方案:
Event sourcing:事件驱动,将所有的操作落盘到一张表,然后读取数据库的这张表。Saga:A服务发送消息给kafka,B订阅,类似与一种编排服务,可以同步请求。
推荐阅读
Seata实战-分布式事务简介及demo上手
面试必问:分布式事务六种解决方案
分布式事务有这一篇就够了
漫画:什么是分布式事务?
Pattern: Event sourcing
Pattern: Saga
Pattern: Polling publisher
Pattern: Transaction log tailing