Go网络编程
网络通信协议
互联网的核心是一些列协议,总称为 互联网协议(Internet Protocol Suite),证实这一些协议规定了电脑如何连接和组网。
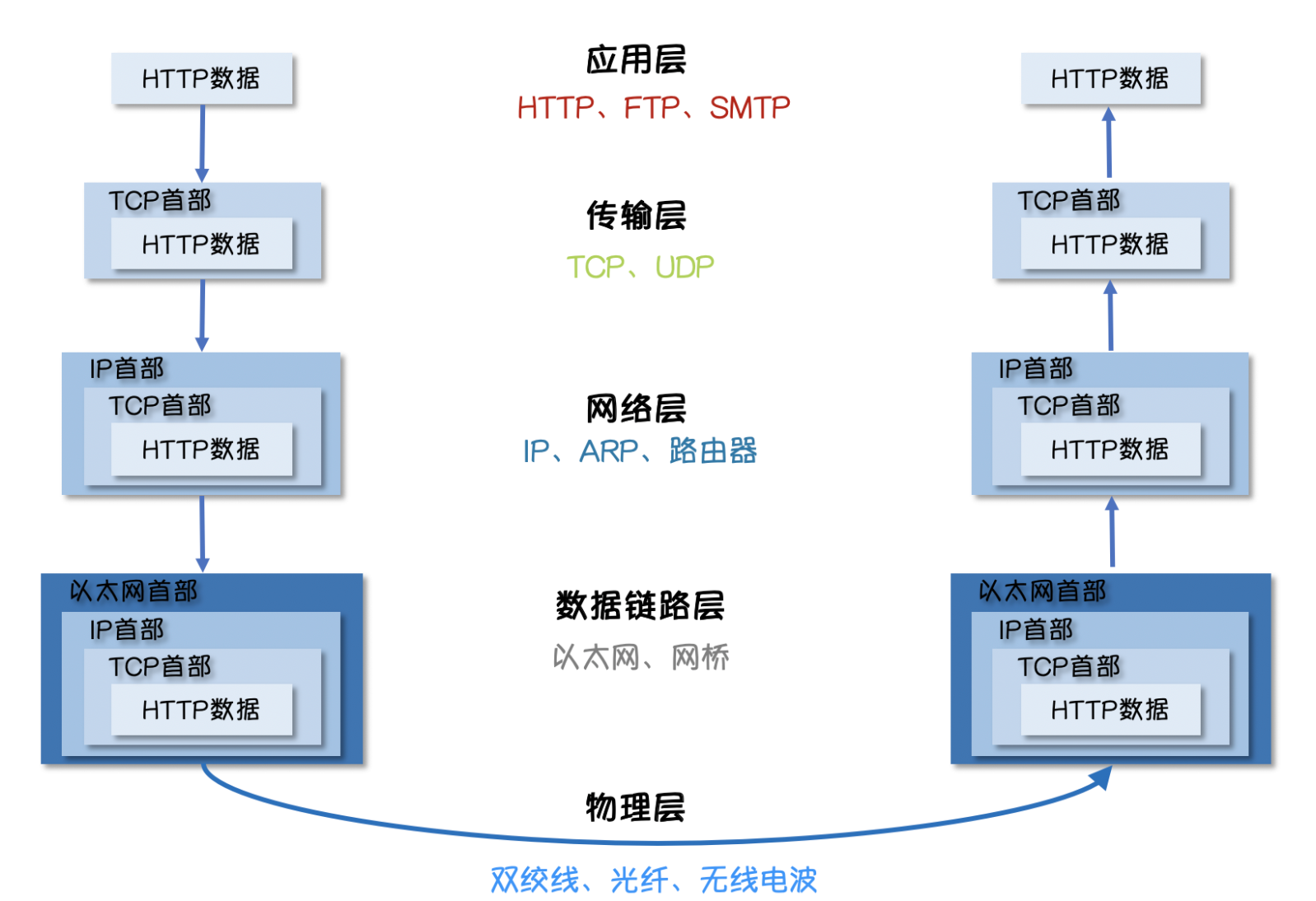
主要协议分为:
Socket- 接口抽象层
TCP/UDP- 面向连接(可靠)/ 无连接(不可靠)
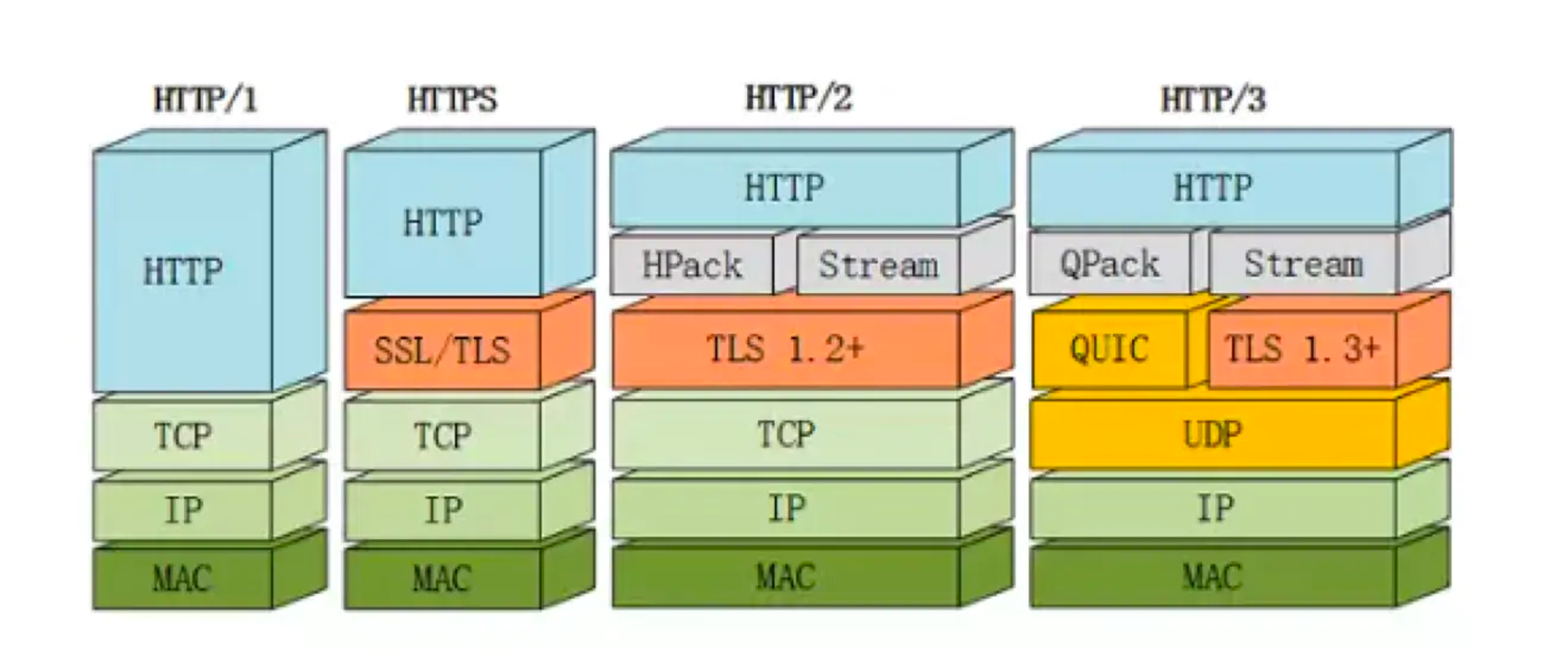
HTTP1.1/HTTP2/QUIC(HTTP3)(HTTP 1.1 是一个请求一个包,连接被占用;HTTP2 可以一个连接发送多个包;HTTP3解决当一个包堵的时候不影响后续包)- 超文本传输协议
Socket 抽象层
应用程序通常通过 套接字 向网络发出请求或者应答网络请求。
一种通用的面向流的网络接口。
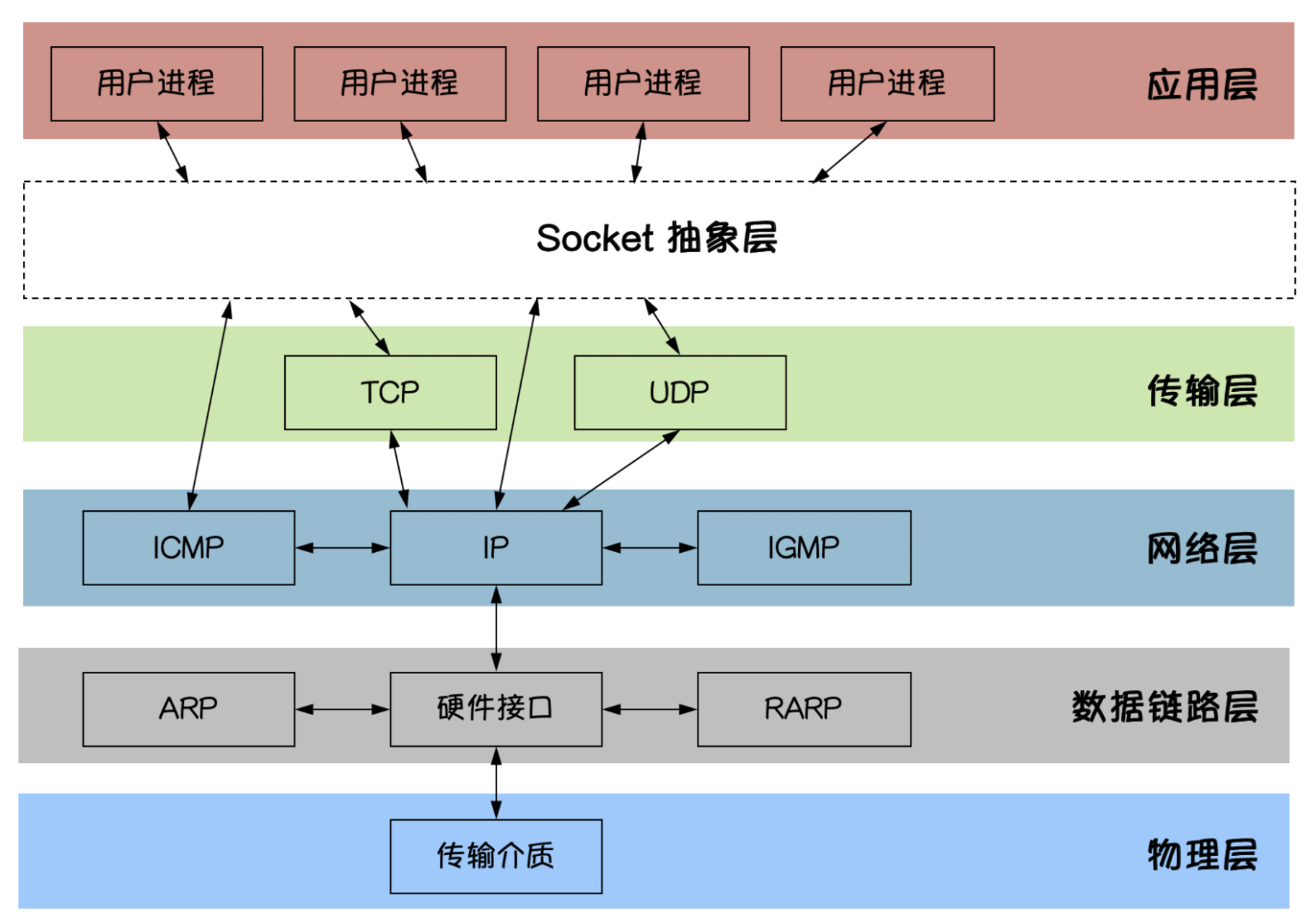
主要操作:
- 建立、接受连接
- 读写、关闭、超时
- 获取地址、端口
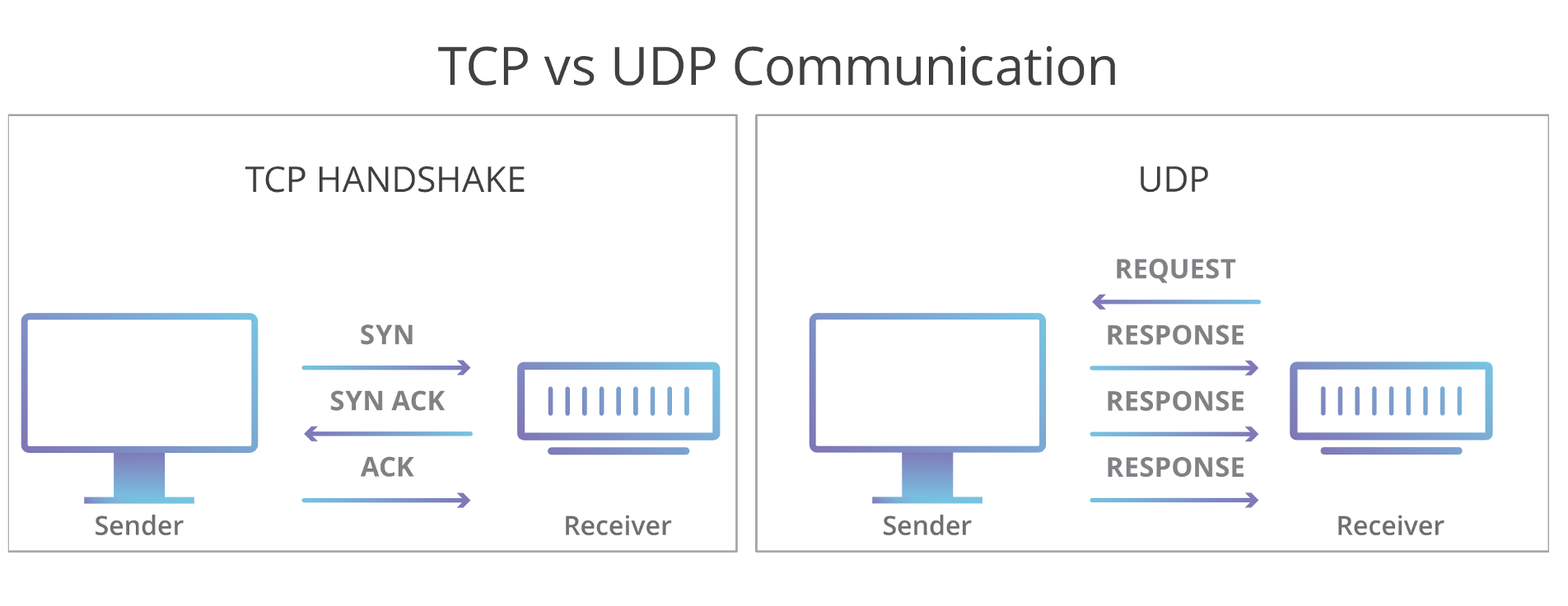
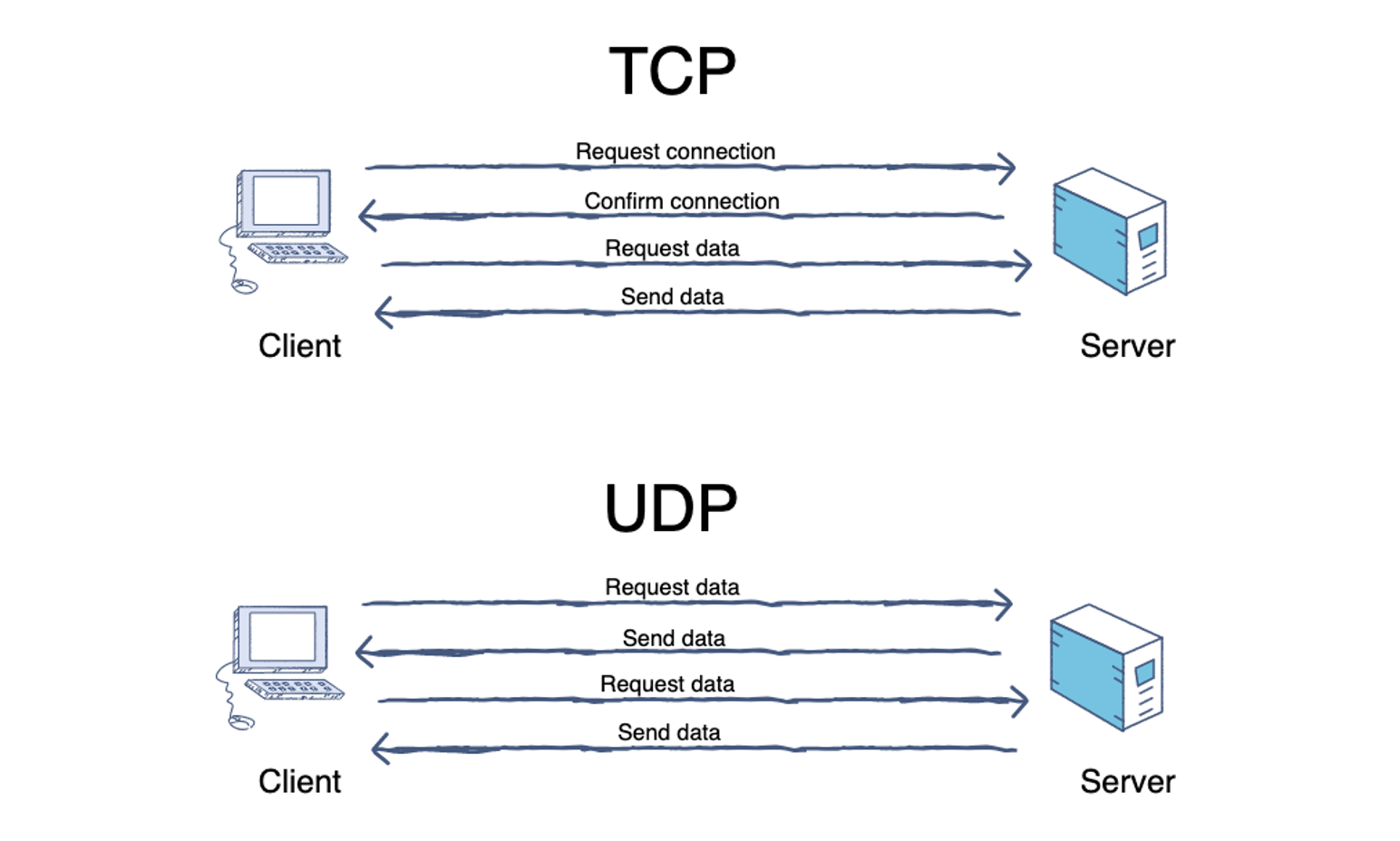
TCP
可靠连接,面向连接的协议。
TCP/IP(Transmission Control Protocol/Internet Protocol),即传输控制协议/网间协议,是一种面向连接(连接导向)的】可靠的、基于字节流的传输层(Transport layer)通信协议,因为是面向连接的协议。
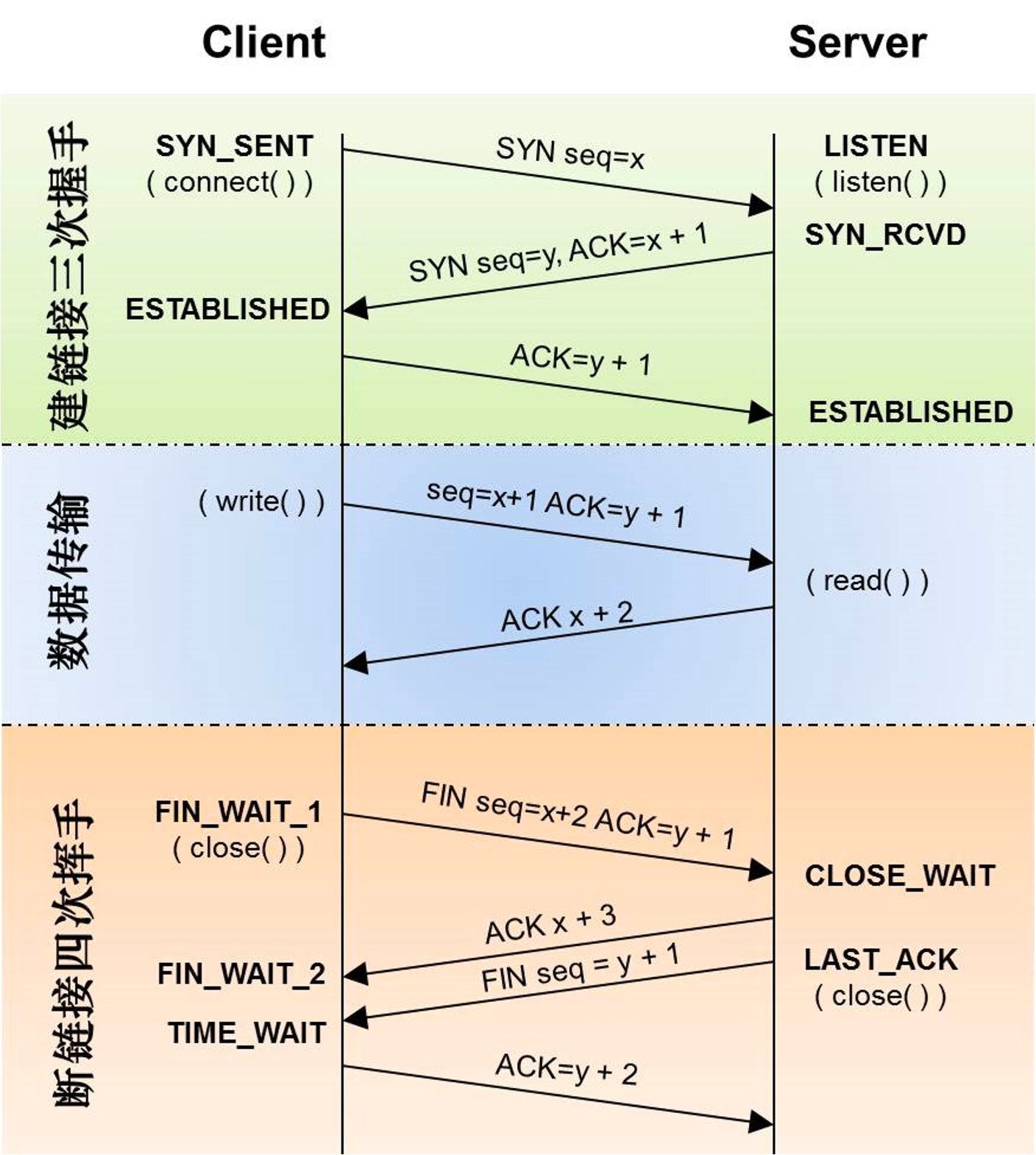
服务端流程:
- 监听端口
- 接收客户端请求建立连接
- 创建
goroutine处理连接
客户端流程:
- 建立与服务端的连接
- 进行数据收发
- 关闭连接
UDP
不可靠连接,允许广播或多播
UDP协议(User Datagram Protocol)中文名称是用户数据报协议,是 OSI(Open Sysetm Interconnection,开放式系统互联)参考模型中一种无连接的传输层协议。
一个简单的传输层协议:
- 不需要建立连接
- 不可靠的、没有时序的通信
- 数据报有长度(
65535-20 = 65515) - 支持多播和广播
- 低延迟,实时性比较好(但是国内有些设备
UDP会降级,导致一些丢包) - 应用于视频直播、游戏同步
HTTP
超文本传输协议
HTTP(HyperText Transfer Protocol)是互联网上应用最为广泛的一种网络协议,它详细规定了浏览器和万维网服务器之间互相通信的规则,通过因特网传送万维网文档的数据传送协议。
1 | GET / HTTP/1.1 |
请求报文
1 | Method: HEAD/GET/POST/PUT/DELETE |
响应报文
1 | 状态行(200/400/500) |
一些运维工具
1 | nload |
演进
HTTP 发展史:
- 1991 年发布初代
HTTP/0.9版本 - 1996 年发布
HTTP/1.0版本 - 1997 年发布
HTTP/1.1版,是到今天为止传输最广泛的版本 - 2015 年发布了
HTTP/2.0版,优化了HTTP/1.1的性能和安全性 - 2018 年发布了
HTTP/3.0版,使用UDP取代TCP协议
HTTP2:
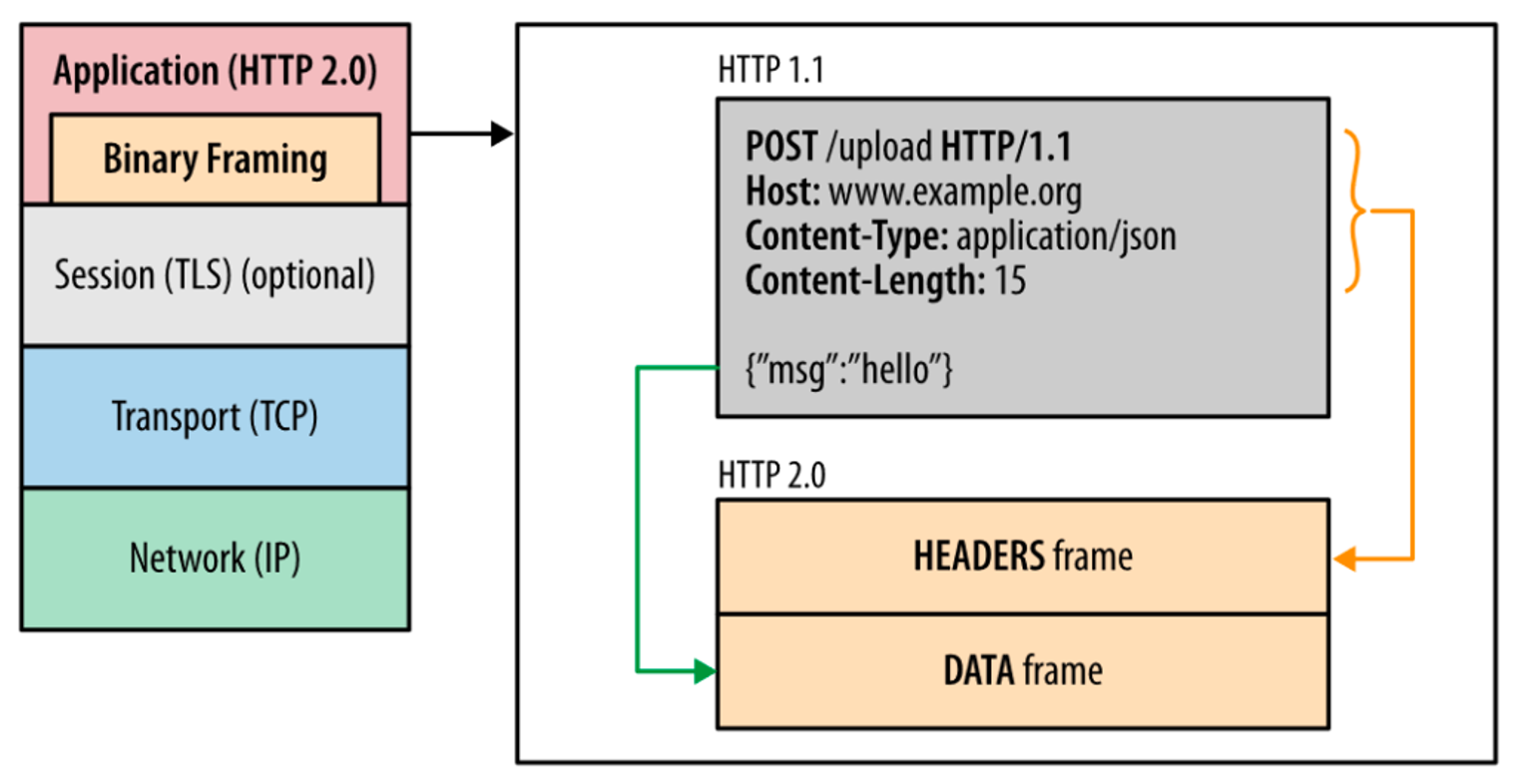
- 二进制分帧,按帧方式传输
- 多路复用,代替原来的序列和阻塞机制
- 头部压缩,通过
HPACK压缩格式(例如 header 中不变的一些信息,传过一次之后,没有变化则可以不用传) - 服务器推送,服务端可以主动推送资源
HTTP/3:
- 连接建立延时低,一次往返可建立
HTTPS连接 - 改进的拥塞控制,高效的重传确认机制
- 切换网络保持连接,从 4G 切换到 WI-FI 不用重建连接
Go 网络编程
基础概念:
Socket: 数据传输Encoding:内容编码(Content-Type: Application/json)Session:连接会话状态(虚拟的概念,表示客户端服务端建立连接之后)C/S模式:通过客户端实现双端通信B/S模式:通过浏览器即可完成数据的传输
简单例子:
- 通过
TCP/UDP实现网络通信
网络轮询器:
- 多路复用模型
- 多路复用模块
- 文件描述符
Goroutine唤醒
TCP简单例子
服务端
1 | func main() { |
处理逻辑
1 | func handleConn(conn net.Conn) { |
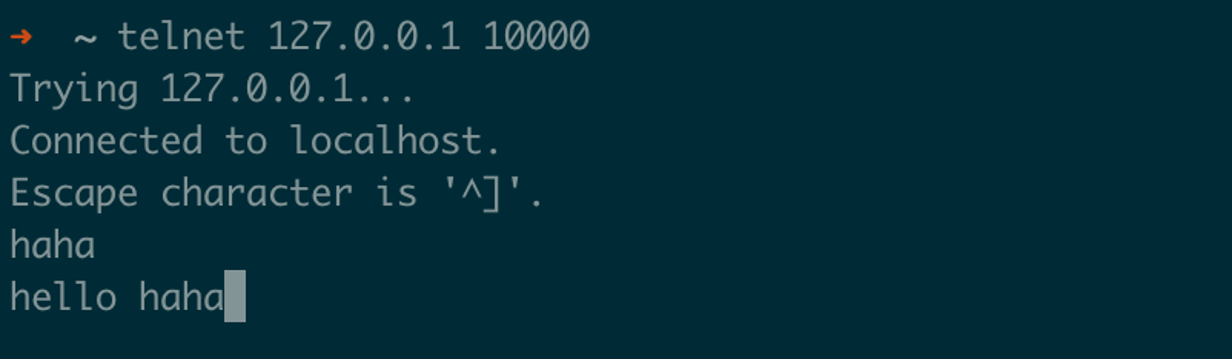
客户端,直接使用 telnet 连接
UDP简单例子
1 | func main() { |

I/O 模型
Linux 下主要的 I/O 模型分为:
- Blocking IO - 阻塞 IO
- Nonblocking IO - 非阻塞IO
- IO multiplexing - IO 多路复用(
select,poll,epoll) - Signal-driven IO - 信号驱动式 IO (注册一个
signal,基于拦截到信号通知)(异步阻塞) - Asynchronous IO - 异步IO (注册
callback,例如redis处理bgsave使用aio)
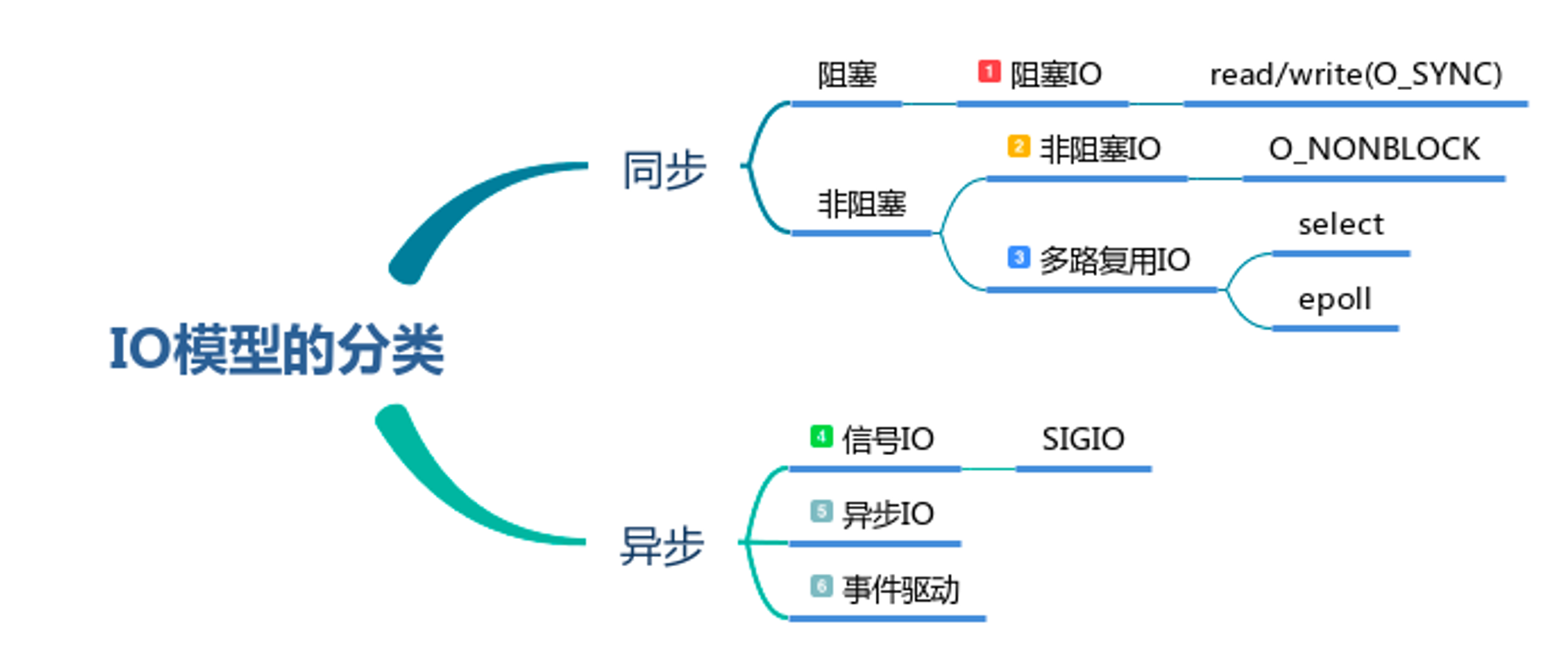
同步:调用端会一直等待服务端响应,直到返回结果;
异步:调用端会发起调用之后会立刻返回,不会等待服务端响应
阻塞:服务端返回结果之前,客户端线程会被挂起,此时线程不可被 CPU 调度,线程暂停运行
非阻塞:在服务端返回前,函数不会阻塞调用端线程,而会立刻返回
IO多路复用
Go 语言采用 IO多路复用 模型处理 IO 操作,但是他没有选择常见的系统调用 select。虽然 select 也可以提供 IO 多路复用能力,但是使用它有较多的限制:
- 监听能力有限 - 最多只能监听 1024 个文件描述符;
- 内存拷贝开销大 - 需要维护一个较大的数据结构存储文件描述符,该结构需要拷贝到内核中;
- 时间复杂度
O(n)- 返回准备就绪的事件个数后,需要遍历所有的文件描述符;
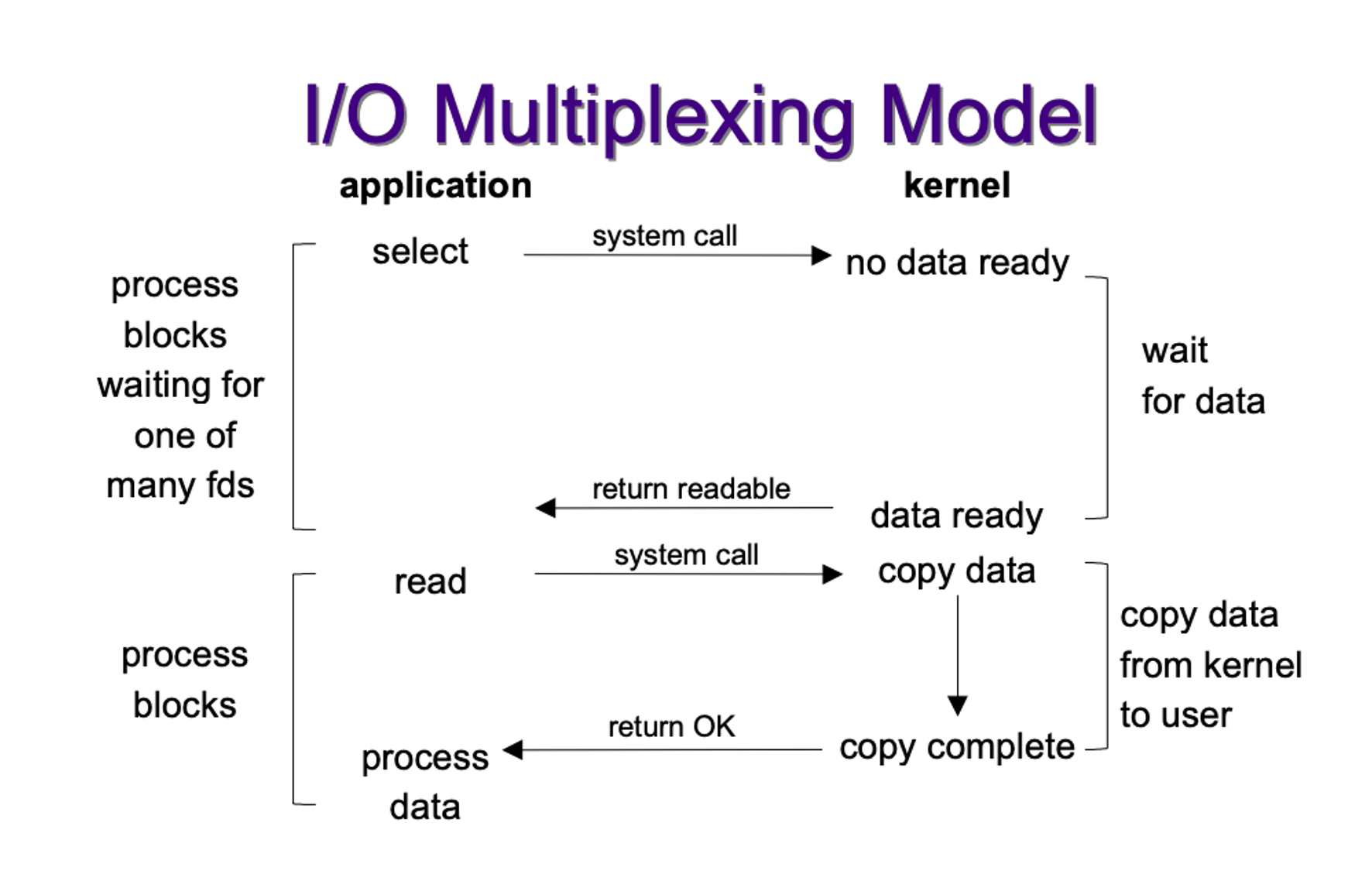
IO 多路复用:进程阻塞于 select,等待多个 IO 中的任意一个变为可读,select 调用返回,通知响应 IO 可以读。它可以支持单线程响应多个请求这种模式。
多路复用模块
为了提高 IO多路复用的性能,不同的操作系统也都实现了自己的 IO 多路复用函数,例如: epoll、kqueue 和 evport 等。
Go 语言为了提高在不同操作系统上的 IO 操作性能,使用平台特定的函数实现了多个版本的网络轮询模块:
1 | src/runtime/netpoll_epoll.go |
Goim 长连接 TCP 编程
使用长连接做一个聊天室。
概览
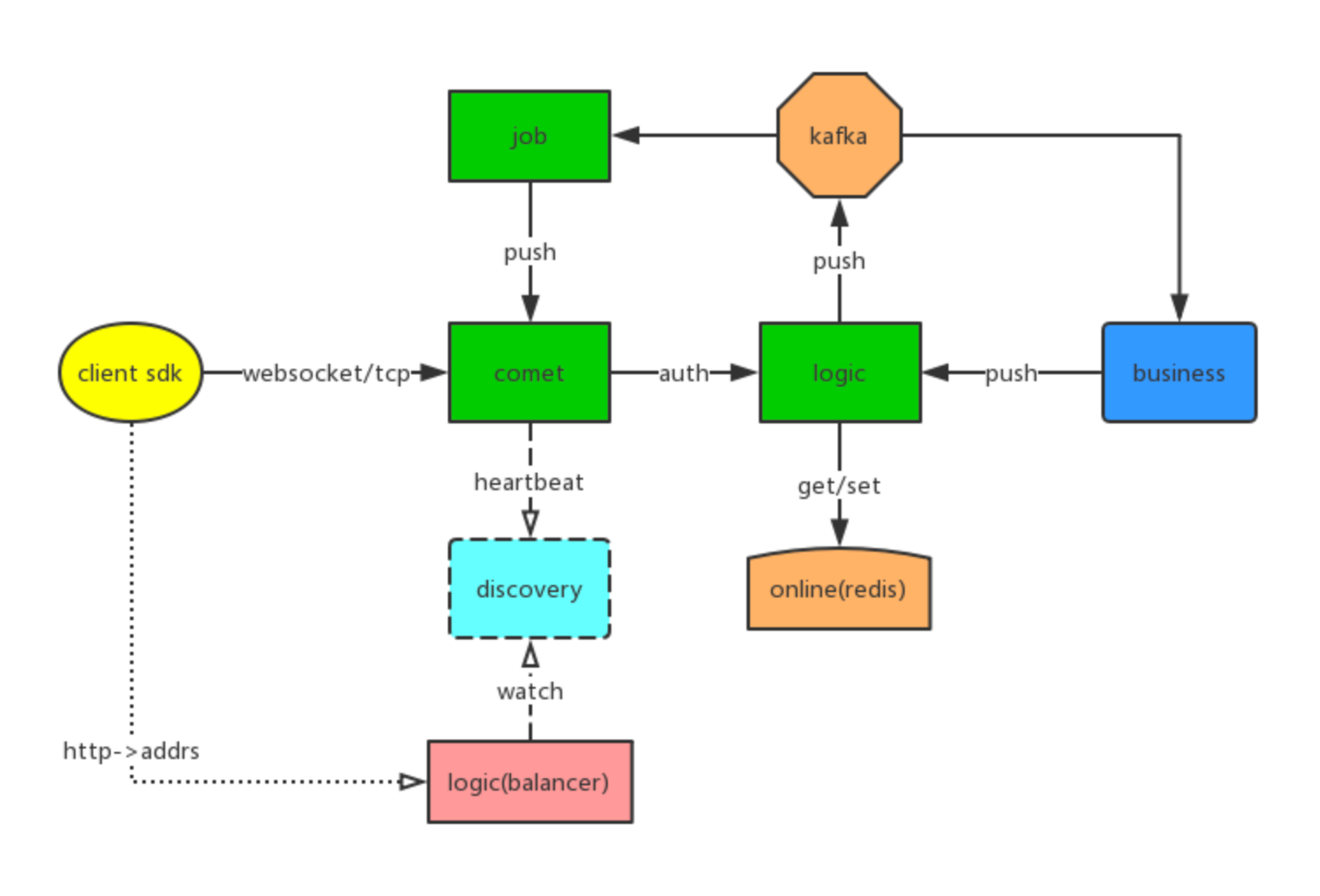
Comet
长连接管理层,主要是监听外网
TCP/Websocket端口,并且通过设备 ID 进行绑定Channel实现,以及实现了Room合适直播等大房间消息广播(逻辑上将一些用户组合在一起)。专门管理网络层连接。为了满足超大连接量,一般直接使用物理机。Logic
逻辑层,监控连接
Connect、Disconnect实现,可自定义鉴权,进行记录Session信息(设备 ID、
ServerID、用户ID),业务可以通过设备 ID、用户ID、RoomID、全局广播进行消息推送。Job
通过消息队列的进行推送削峰处理,并把消息推送到对应 Comet 节点。
Redis
存储用户id或者设备id对应的
comet上
各个模块之间,通过 gRPC 进行通信。
协议设计
一般分为两个部分:头部(header)和身体(body)
header:一般存放和协议相关的元数据,例如魔数(做比较粗略的校验,例如几个字段的长度)、协议版本、数据长度(可以解析出body)body:请求内容
常见头部字段:
- 魔数:没啥实际作用,一般就是用来标记某个协议,用作报文快速检测
- 版本:用于版本控制,使得服务端和客户端可以做到前后兼容
- 长度:标记消息有多长。(为了保障传输性能,网卡在发包的时候,会将很多数据包组合在一起发送,接收端需要进行分割,否则会出现粘包现象。使用长度就可以知道当前数据的完整长度。)
message id:用于标记请求,一般只有在特殊的时候(例如多路复用)才会启用- 如果说一个请求发出去之后,
TCP连接被goroutine一直持有,那么messgae id是不需要的。但是如果允许TCP上请求并发发送,那么就需要。
- 如果说一个请求发出去之后,
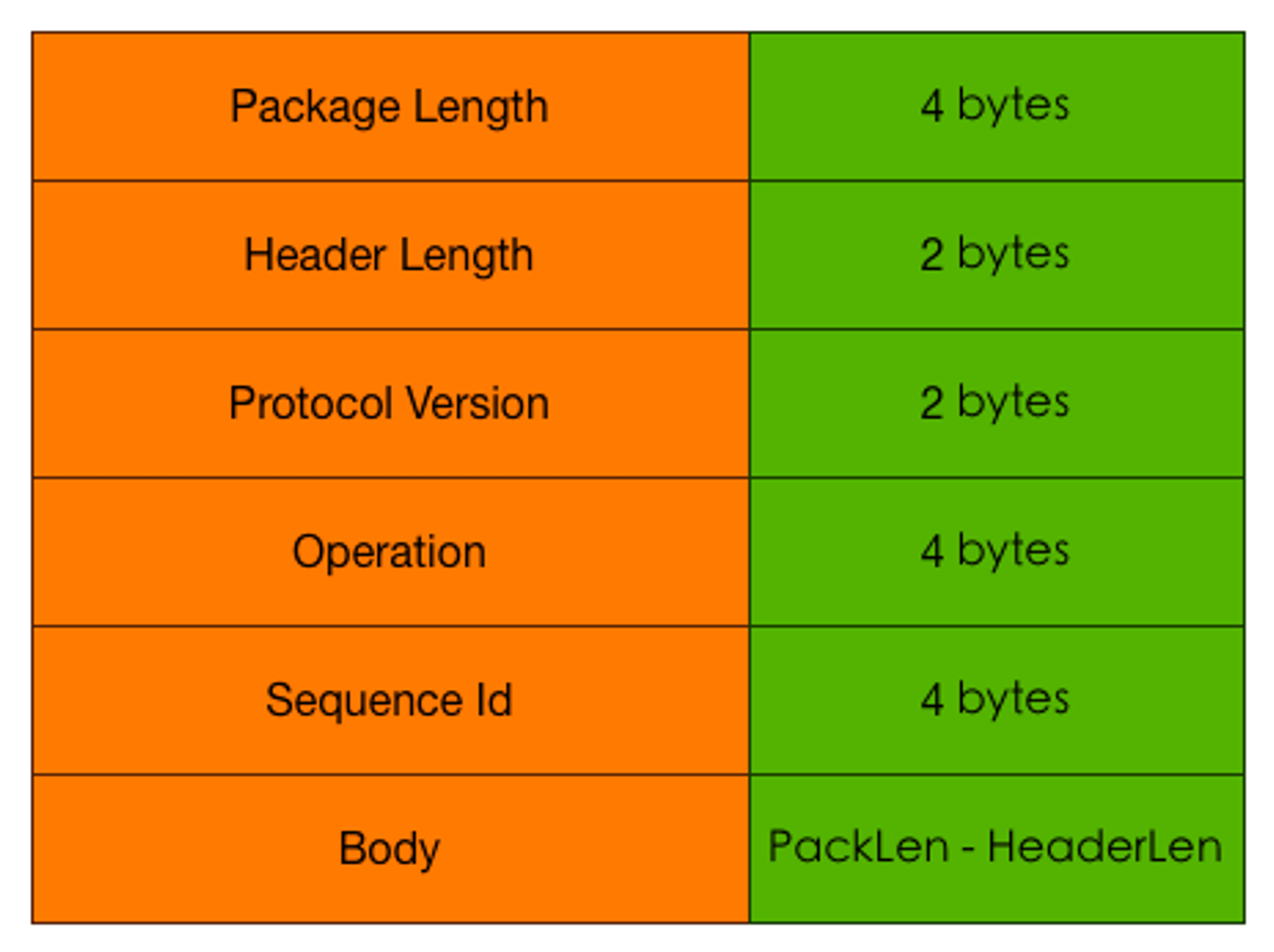
主要以包/针方式:
- Package Length,包长度,避免
tcp粘包 - Header Length,头长度
- Protocol Version,协议版本
- Operation,操作码
- Sequence 请求序列号ID,避免出现由于处理消息顺序不一致导致的问题
- Body,包内容
使用 encoding/binary 包编码成字节序,将 int32 转换为包中占用 4 byte 的数据。
Operation可以是:
- Auth:TCP 建联之后发送的第一个包
- Heartbeat
- Message
Sequence:
- 按请求、响应对应递增ID
粘包
在计算机网络中,粘包(Packet Sticking)是指发送方在发送数据时将多个较小的数据包粘合在一起发送,而接收方在接收数据时将这些数据包作为一个较大的数据块接收的现象。
粘包问题通常出现在基于流式传输协议(如TCP)的通信中。由于网络传输的特性,发送方在发送数据时可能会将多个较小的数据包合并成一个较大的数据块进行发送。而接收方在接收数据时,可能会一次性接收到多个数据包,导致粘包现象。
造成粘包问题的原因有多种,包括网络延迟、缓冲区大小设置不合理、发送方连续发送数据等。这种现象在高负载、高并发的网络环境中较为常见。
粘包问题可能会导致接收方无法正确解析数据,从而造成数据解析错误或数据处理异常。为了解决粘包问题,常见的方法包括:
定长消息:发送方在发送数据时,将每个数据包固定长度,接收方按照固定长度进行拆包。适用于简单的网路协议,或者很低层的通讯协议,例如
MTU分隔符消息:发送方在数据包之间添加特定的分隔符,接收方根据分隔符进行拆包。一般结合转义符来使用,例如
HTTP是按照特殊分隔符分割消息头部包含长度信息:发送方在每个数据包的头部添加表示数据包长度的信息,接收方根据长度信息进行拆包。
使用消息边界:发送方在每个数据包之间添加消息边界标识,接收方根据消息边界进行拆包。
实际应用中,根据具体的需求和协议,可以选择适合的方法来解决粘包问题,以确保数据的正确传输和解析。
边缘节点
Comet 长连接连续节点,通常部署在距离用户比较近,通过 TCP 或者 WebSocket 建立连接,并且通过应用层 Heartbeat 进行保活检测,保证连接可用性。
节点之间通过云 VPC 专线通信,按地区部署分布。
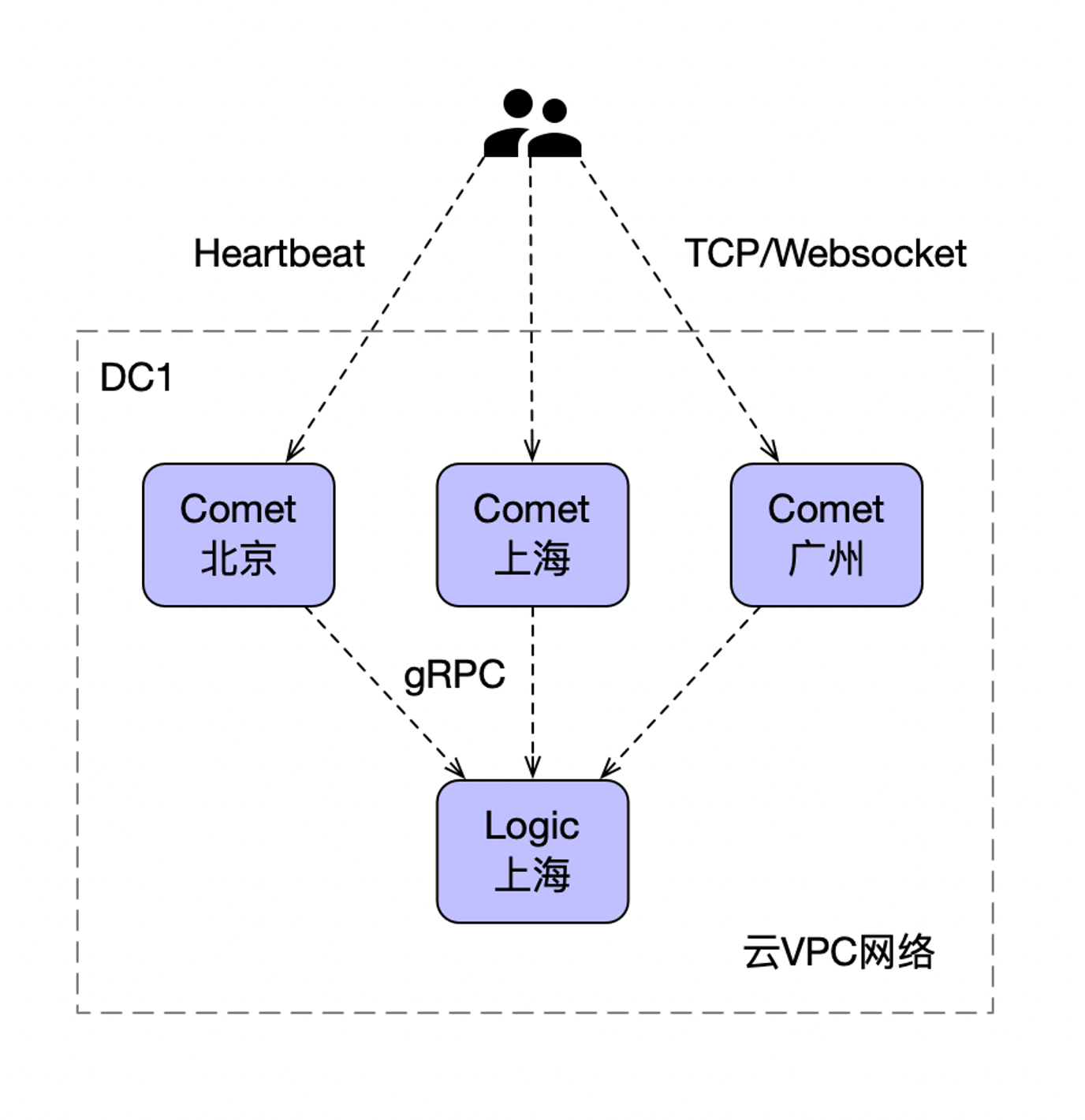
国内:
- 华北(北京)
- 华中(上海、杭州)
- 华南(广州、深圳)
- 华西(四川)
国外:
- 香港、日本、美国、欧洲
全国范围内的连接需要考虑负载均衡,而且长连接的负载均衡无法直接使用四层负载均衡。
负载均衡
长连接负载均衡比较特殊,需要按一定的负载算法进行分配节点(也无法直接通过 DNS 来实现负载均衡),可以通过 HTTPDNS 方式,请求获取到对应的节点 IP 列表,例如,返回固定数量 IP,按一定的权重或者最少连接数进行排序(可以有内部逻辑来实现负载均衡,例如连接用户数量),客户端通过 IP 逐个重试链接;
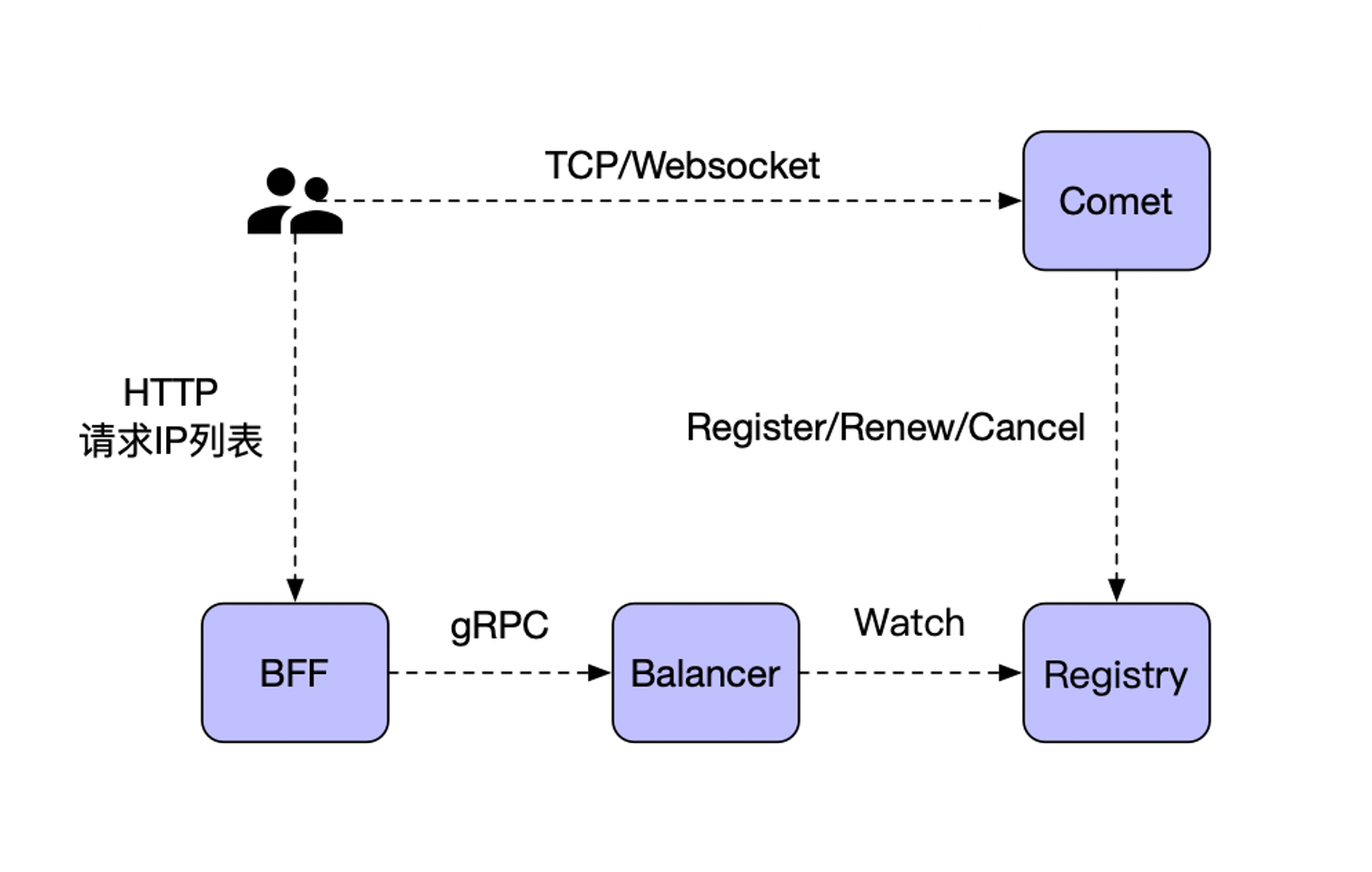
- Comet 注册 IP 地址,以及节点权重,定时
Renew当前节点连接数量; Balancer按地区经纬度计算,按最近地区(经纬度)提供Comet节点IP列表,以及权重计算排序;BFF返回对应的长连接节点IP,客户端可以通过IP直接连;- 客户端按返回
IP列表顺序,逐个连接尝试建立长连接;
心跳保活机制
长连接断开的原因:
- 长连接所在的进程被杀死
NAT超时- 网络状态发生变化,如移动网络 、 WI-FI 切换、断开、重连
- 其他不可抗因素(网络状态差、DHCP 的租期等等)
高效维持长连接方案
- 进程保活(防止进程被杀死,特别是移动端设备,一些厂商会维护热本应用,也可以考虑 APP 之间相互拉活)
- 心跳保活(防止
NAT超时,client发送pingpong包,单向保活即可) - 断线重连(断网以后重新连接网络)
自适应心跳时间
- 心跳可选区间,
[ min = 60s, max = 300s] - 心跳增加步长,
step = 30s,减少耗电 - 心跳周期探测,
success = current + step、fail = current - step,当出现丢包等情况导致心跳失败,则降低周期
用户鉴权和 Session 信息
用户鉴权,在长连接建立成功后,需要先进行连接鉴权,并且绑定对应的会话信息;
client 与 comet 建立连接之后,Comet 将注册信息转发到 Logic 进行 Auth。Comet 负责与 client 建立连接,并且维护连接。
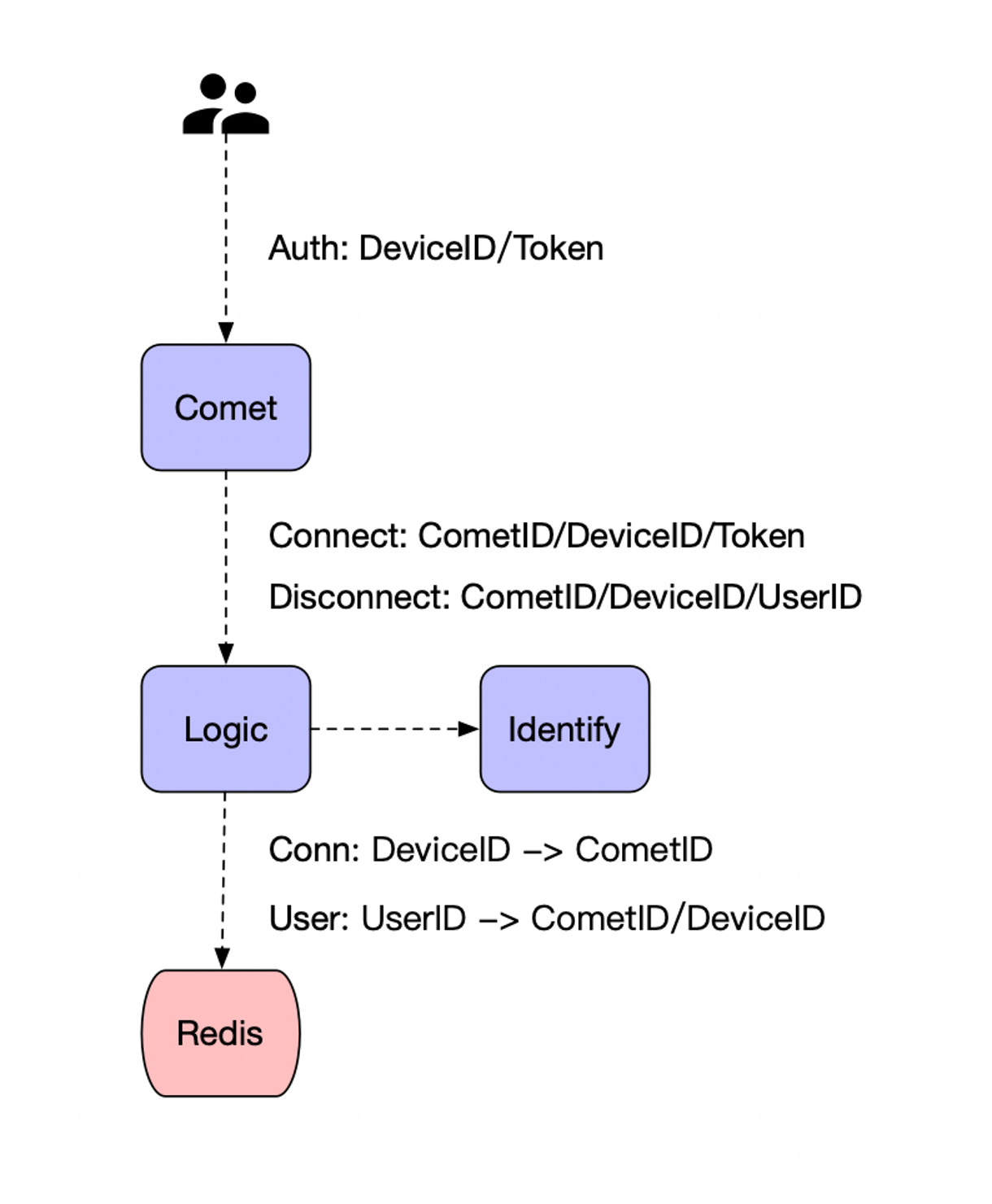
Connect,建立连接进行鉴权,保存 Session 信息:
DeviceID,设备唯一IDToken,用户鉴权Token,认证得到用户IDComet,连接所在Comet节点
Disconnect,断开连接,删除对应 Session 信息:
DeviceID,设备唯一 IDCometID,连接所在Comet节点UserID,用户ID
Session,会话信息通过 Redis 保存连接路由信息:
- 连接维度,通过设备
ID找到所在Comet节点 - 用户维度,通过用户
ID找到对应的连接和Comet所在节点
当两个用户 P2P 发送消息,首先将消息发送到 Comet,由 Comet 将消息转发到 Logic,再由 job 处理的时候查询接受者所在 Comet,将消息转发到 对应Comet。
连接的时候也可以实现一些安全防护,例如使用不同的 ip + token 进行连接攻击,可以在七层做特殊格式 token 进行七层cc
Comet
Comet 长连接层,实现连接管理和消息推送:
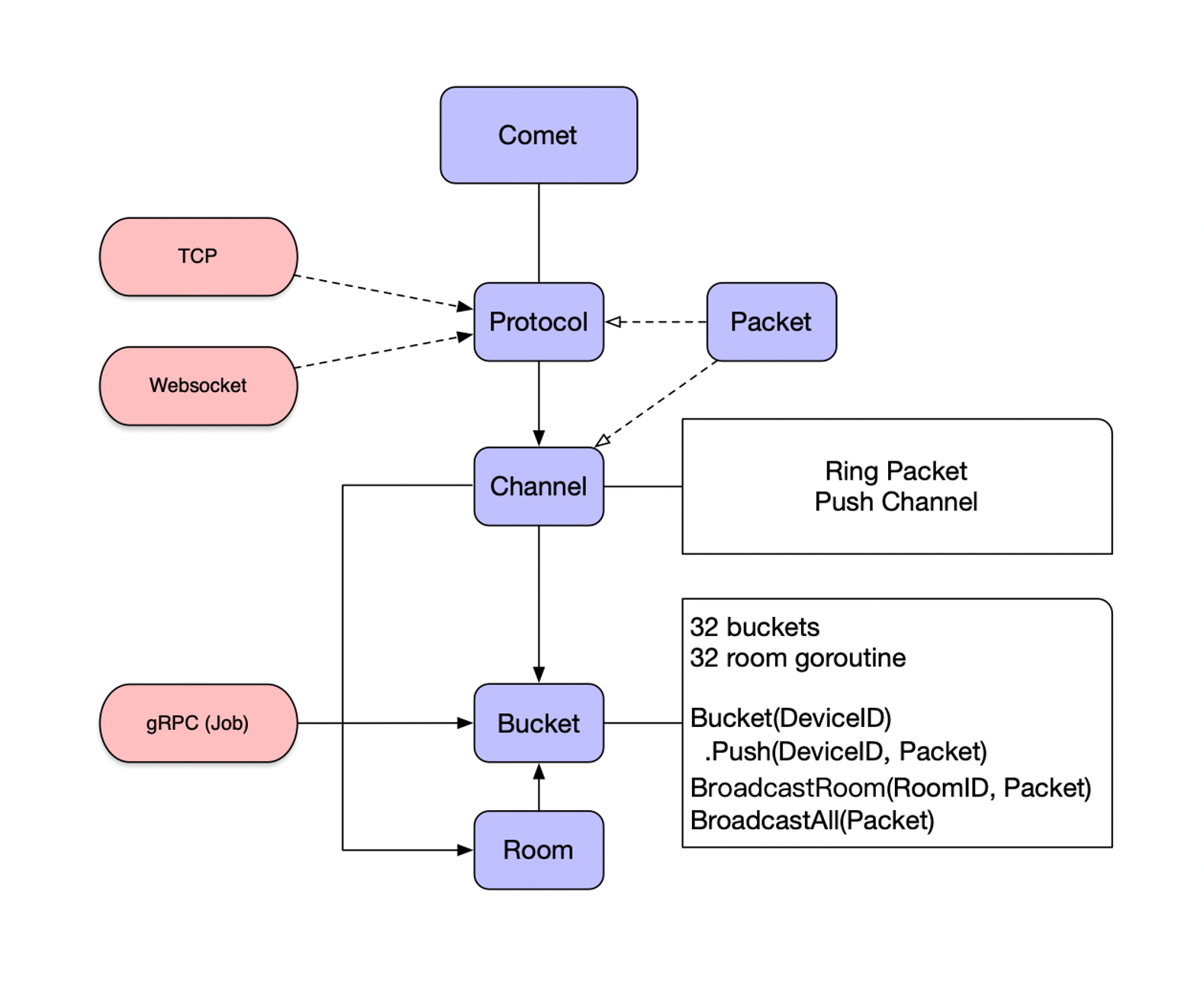
Protocol,TCP/Websocket协议监听;Packet,长连接消息包,每个包都有固定长度;Channel,消息管道相当于每个连接抽象,最终TCP/Websocket中的封装,进行消息包的读写分发,使用两个goroutine,分别处理读和写;Bucket,连接通过DeviceID进行管理,用于读写锁拆解,并且实现房间消息推送,类似Nginx Worker;Room,房间管理通过RoomID进行管理,通过双链表进行Channel遍历推送消息,这样的好处是当用户退出房间,将链表的指针替换即可;为了避免房间人数过多时导致发送消息慢,需要将Room打散成Bucket的粒度;
每个 Bucket 都有独立的 Goroutine 和读写锁优化:
1 | type Buckets struct { |
Logic
Logic 业务逻辑层,处理连接鉴权、消息路由、用户会话管理;
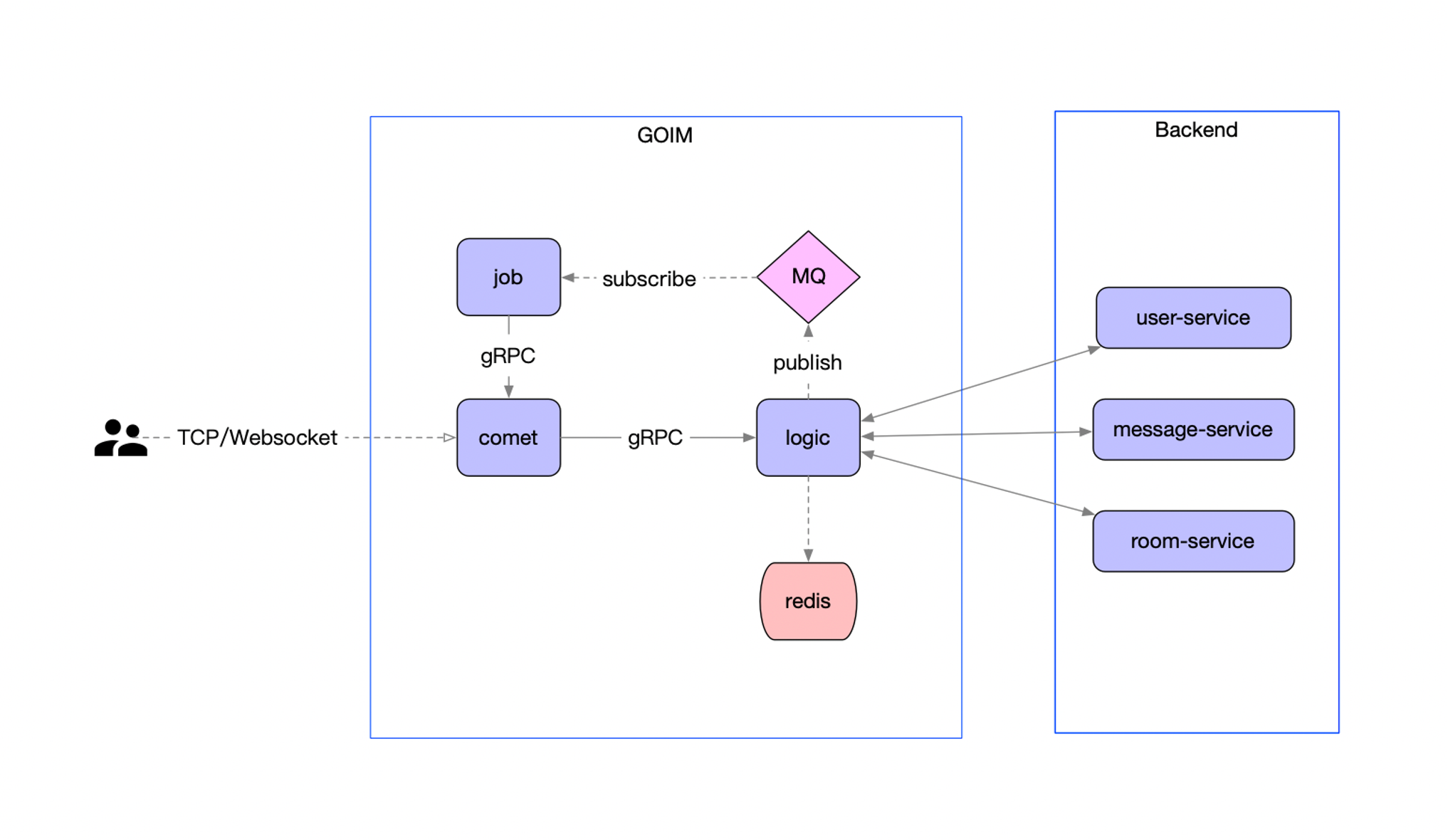
主要分为三层:
sdk,通过TCP/Websocket建立长连接,进行重连、心跳保活;goim,主要负责连接管理,提供消息长连接能力;backend,处理业务逻辑,对推送消息过滤,以及持久化相关等;也依赖一些backend的服务
Job
业务通过对应的推送方式,可以对连接设备、房间、用户ID进行推送,通过 Session 信息定位到所在的 Comet 连接节点,并通过 Job 推送消息;
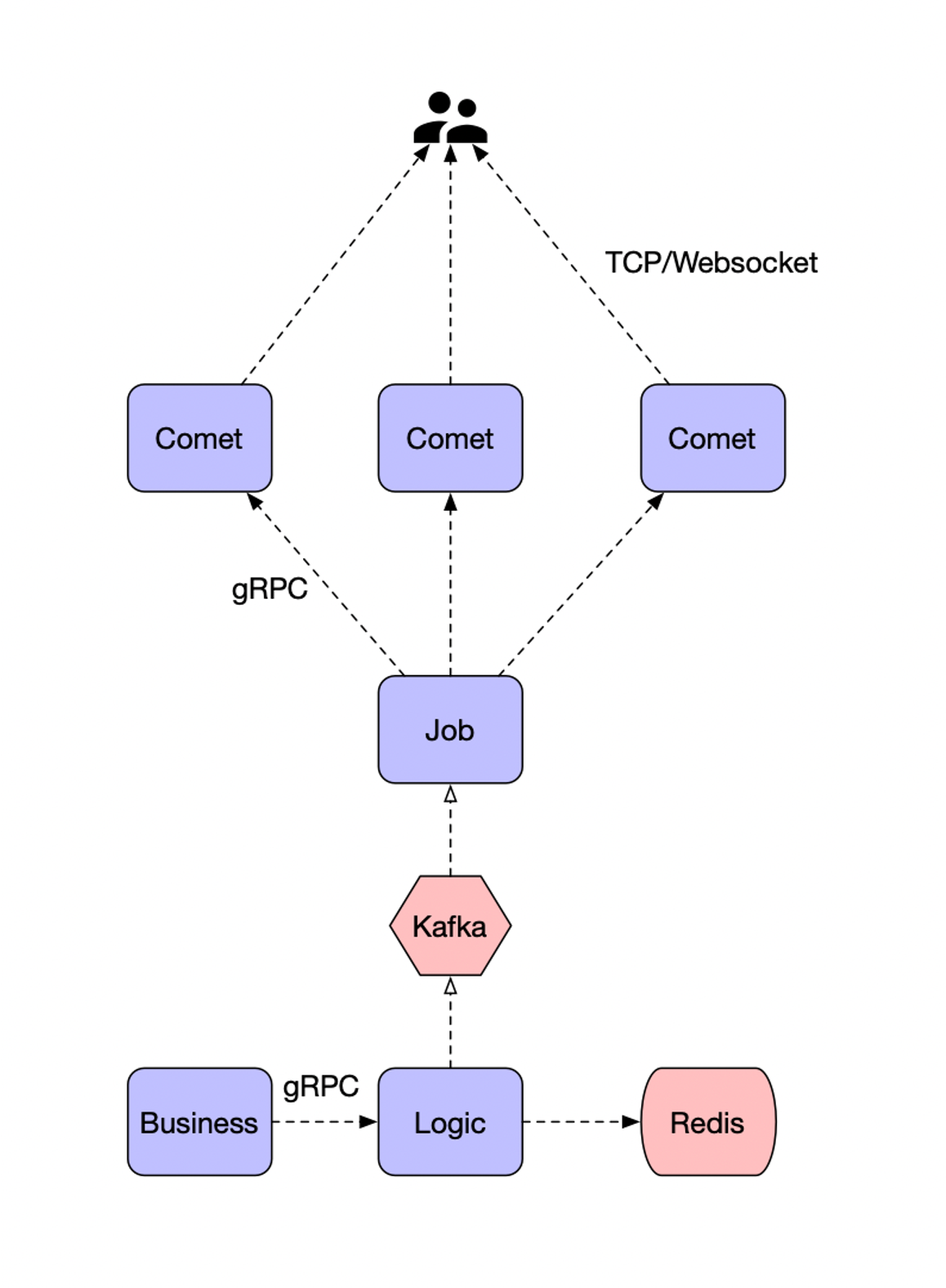
通过 Kafka 进行推送削峰,保证消息逐步推送成功;
在 Push 到 Kafka 的时候,查询到用户信息之后,消费时就不需要再次查询,降低查询压力负载。
另外,推送到大型房间(或者所有房间)的消息,可以不需要根据RoomID具体推送,而是推送到所有的 Comet 节点。
支持的多种推送方式:
Push(DeviceID,Message)Push(UserID,Message)Push(RoomID,Message)Push(Message)
推拉结合
在长连接中,如果想把消息通知所有人,主要有两种模式:
一种是自己拿广播通知所有人,这个叫推模式;
一种是有人主动来找你要,这个叫拉模式;
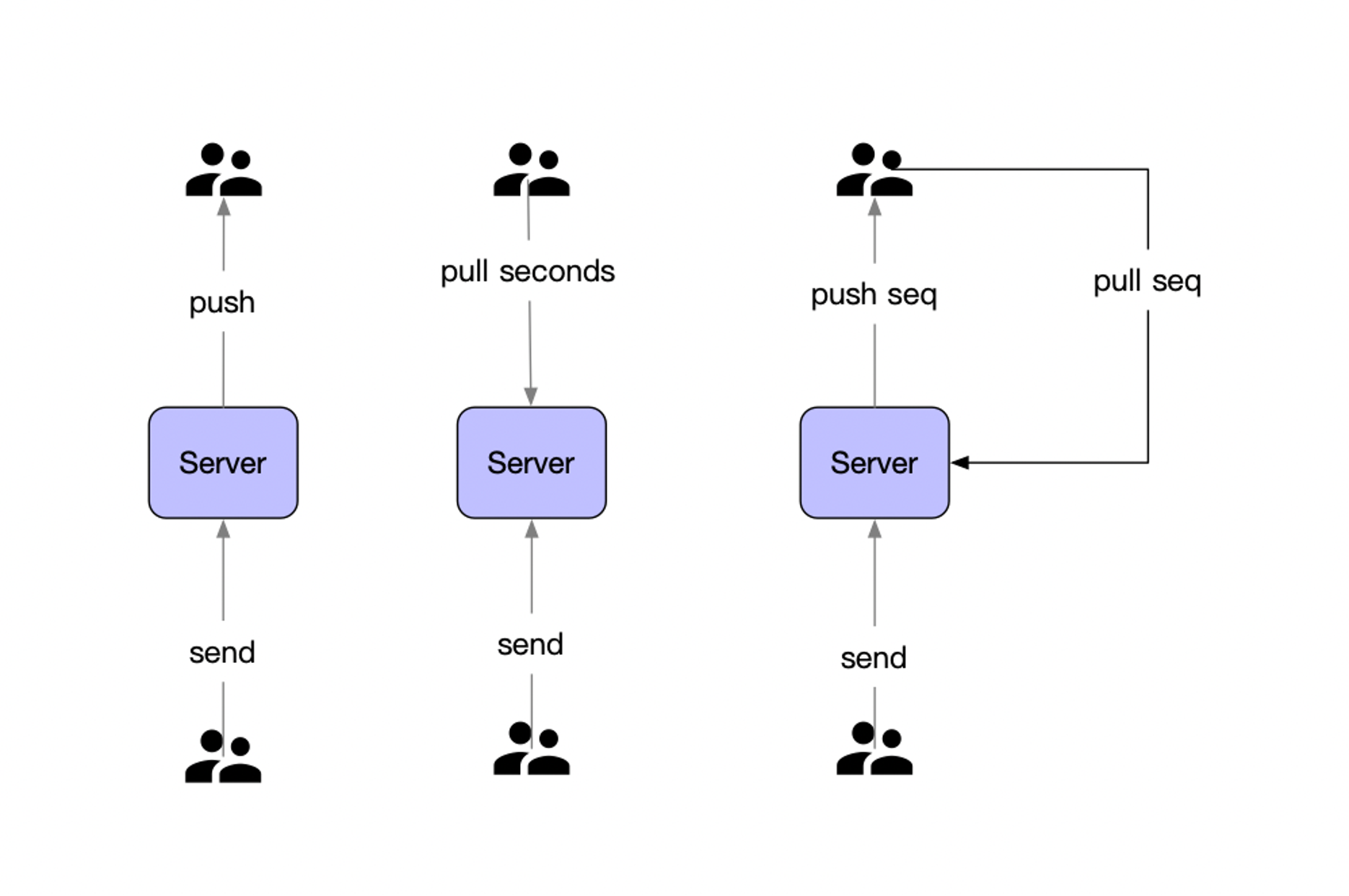
在业务系统中,通常会有三种可能的做法:
- 推模式,有新消息时服务器主动推给客户端;
- 拉模式,由前端主动发起拉取消息的请求;
- 推拉结合模式,有新消息实时通知,客户端再进行新的消息摘取;
读写扩散
一般消息系统中,通常会比较关注消息存储;主要进行考虑读、写扩散,也就是性能问题;
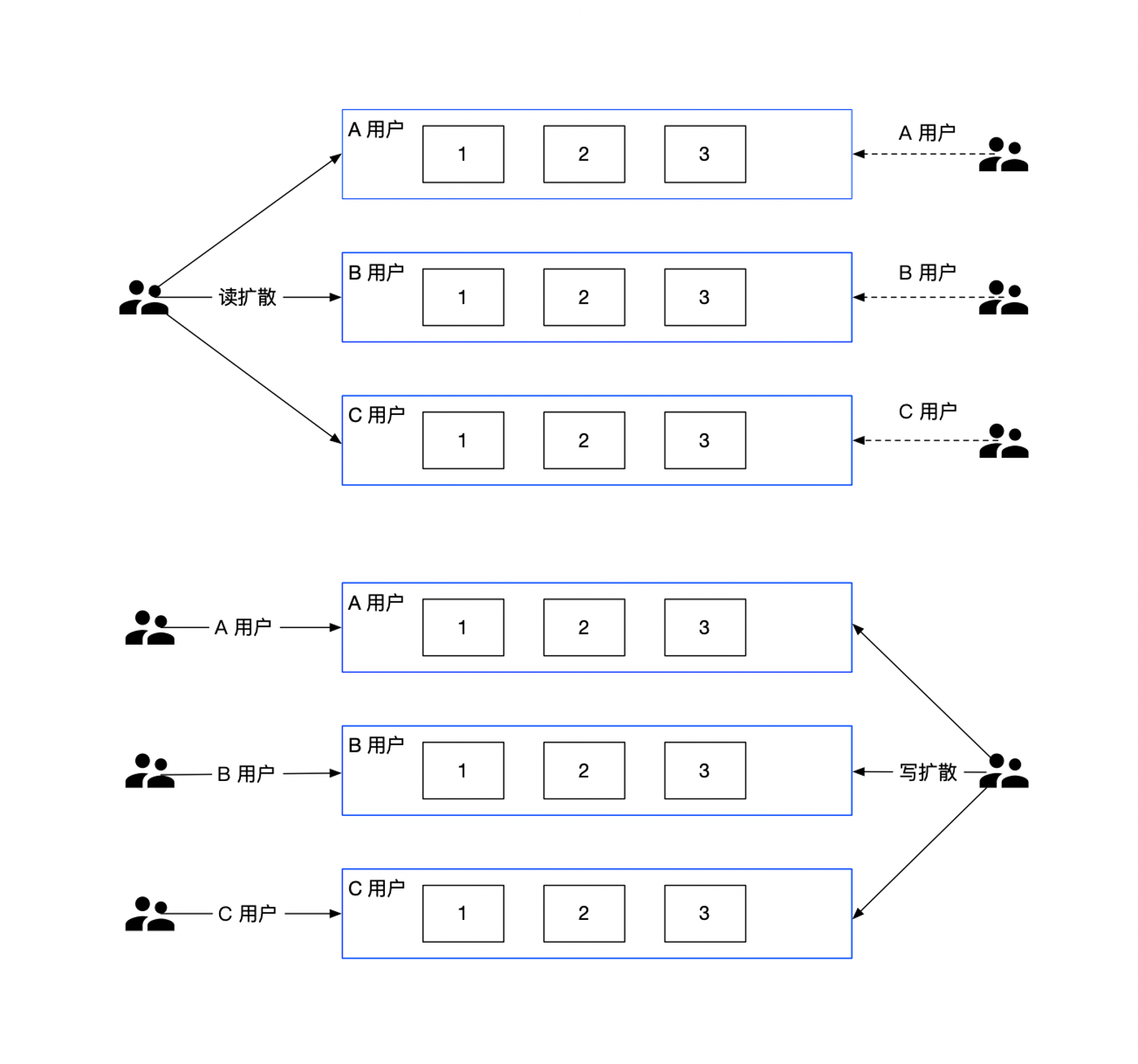
在不同场景,可能选择不同的方式:
- 读扩散,在 IM 系统里的读扩散通常是每两个相关联的人就有一个信箱,或者每个群一个信箱;
- 优点:写操作(发消息)很轻量,只用写自己信箱
- 缺点:读操作(读消息)很重,需要读所有人信箱
- 写扩散,每个人都只从自己的信箱里读取消息,但写(发消息)的时候需要所有人写一份
- 优点:读操作很轻量
- 缺点:写操作很重,尤其是对于群聊来说
唯一 ID 设计
唯一 ID,需要保证全局唯一,绝对不会出现重复的 ID,且 ID 整体趋势递增。
通常情况下,ID 的设计主要有以下几大类:
- UUID
- 基于
Snowflake的 ID 生成方式,雪花算法 - 基于申请 DB 步长的生成方式
- 基于 Redis 或者 DB 的自增 ID 生成方式
- 特殊的规则生成唯一 ID,发号器
雪花算法
雪花(Snowflake)是一种网络服务,用于在简单保证的前提下大规模生成唯一的 ID 号。
Snowflake,is a network service for generating unique ID numbers at high scale with some simple guarantees.
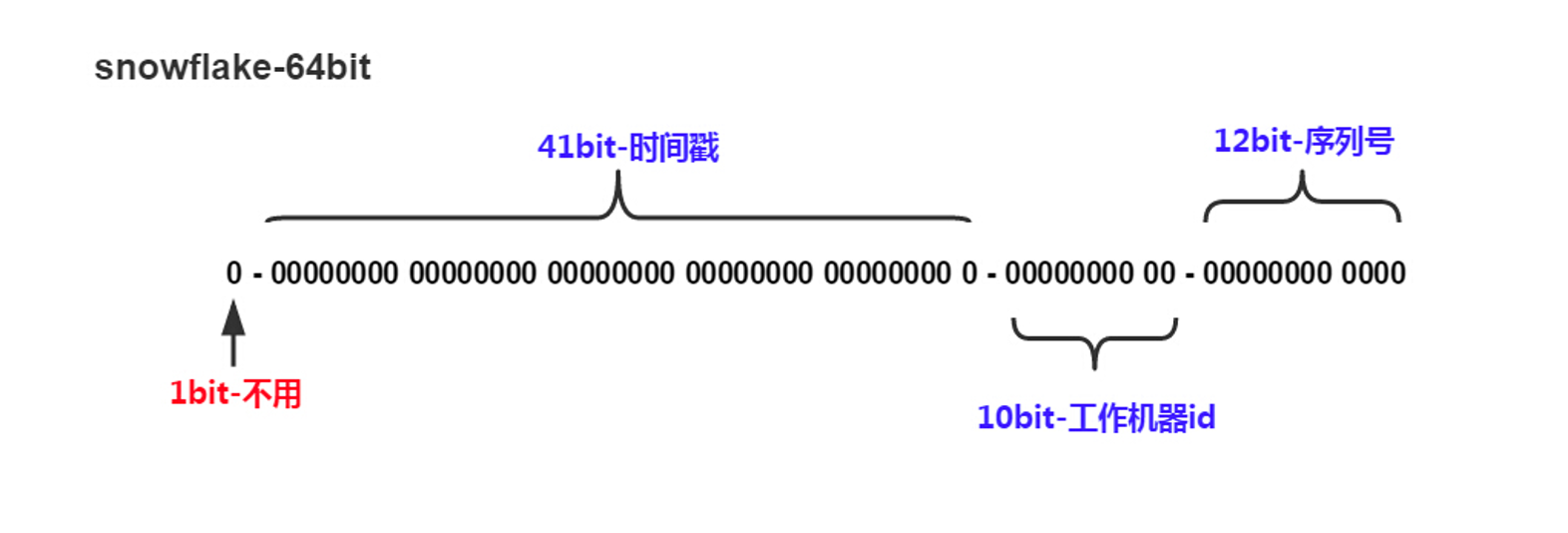
ID 由以下部分组成:
- time - 41 bits (millisecond precision w/ a custom epoch gives us 69 years):时间戳,保证递增
- configured machine id - 10 bits - gives us up to 1024 machines:机器id
- sequence number - 12 bits - rolls over every 4096 per machine (with protection to avoid rollover in the same ms):序列号,可以让同一时间、同一机器生成大量的id
Sonyflake
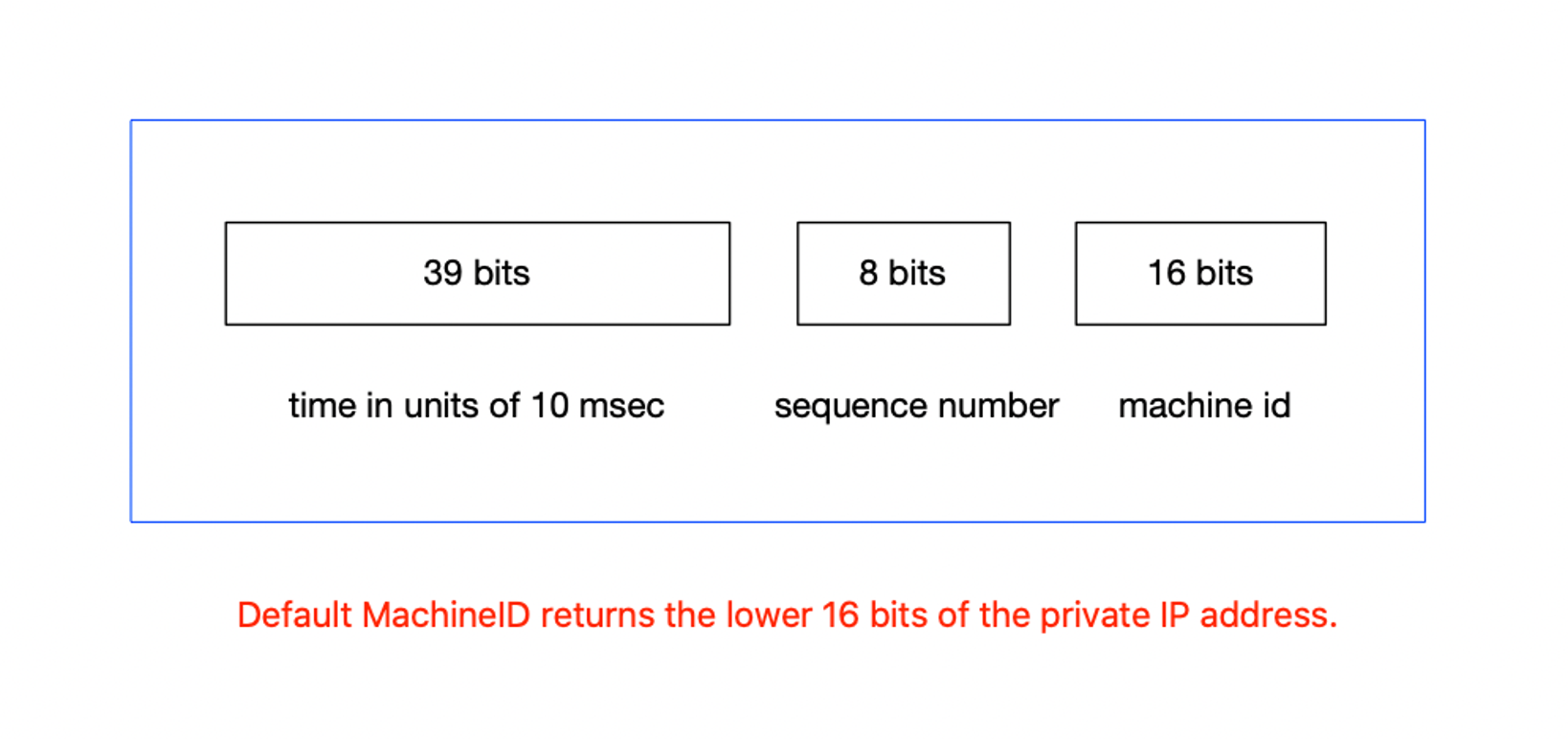
Sonyflake,is a distributed unique ID generator inspired by Twitter’s Snowflake.
id is composed of:
- 39 bits for time in units of 10 msec
- 8 bits for a sequence number
- 16 bits for a machine id
As a result, Sonyflake has the following advantages and disadvantages:
- The lifetime (174 years) is longer than that of Snowflake (69 years)
- It can work in more distributed machines (2^16) than Snowflake (2^10)
- It can generate 2^8 IDs per 10 msec at most in a single machine/thread (slower than Snowflake)
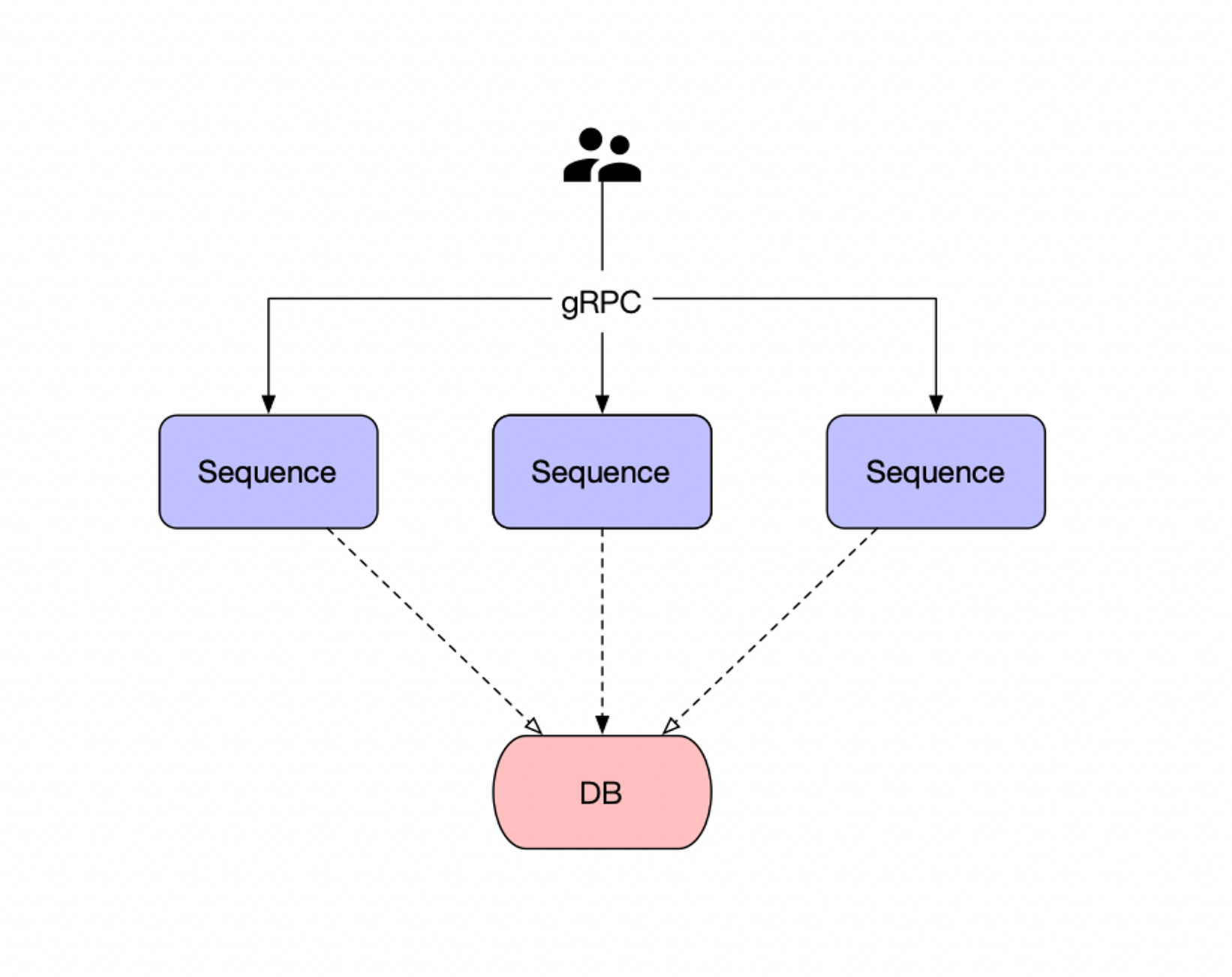
ID生成器
基于步长递增的分布式 ID 生成器,可以生成基于递增,并且比较小的唯一 ID;
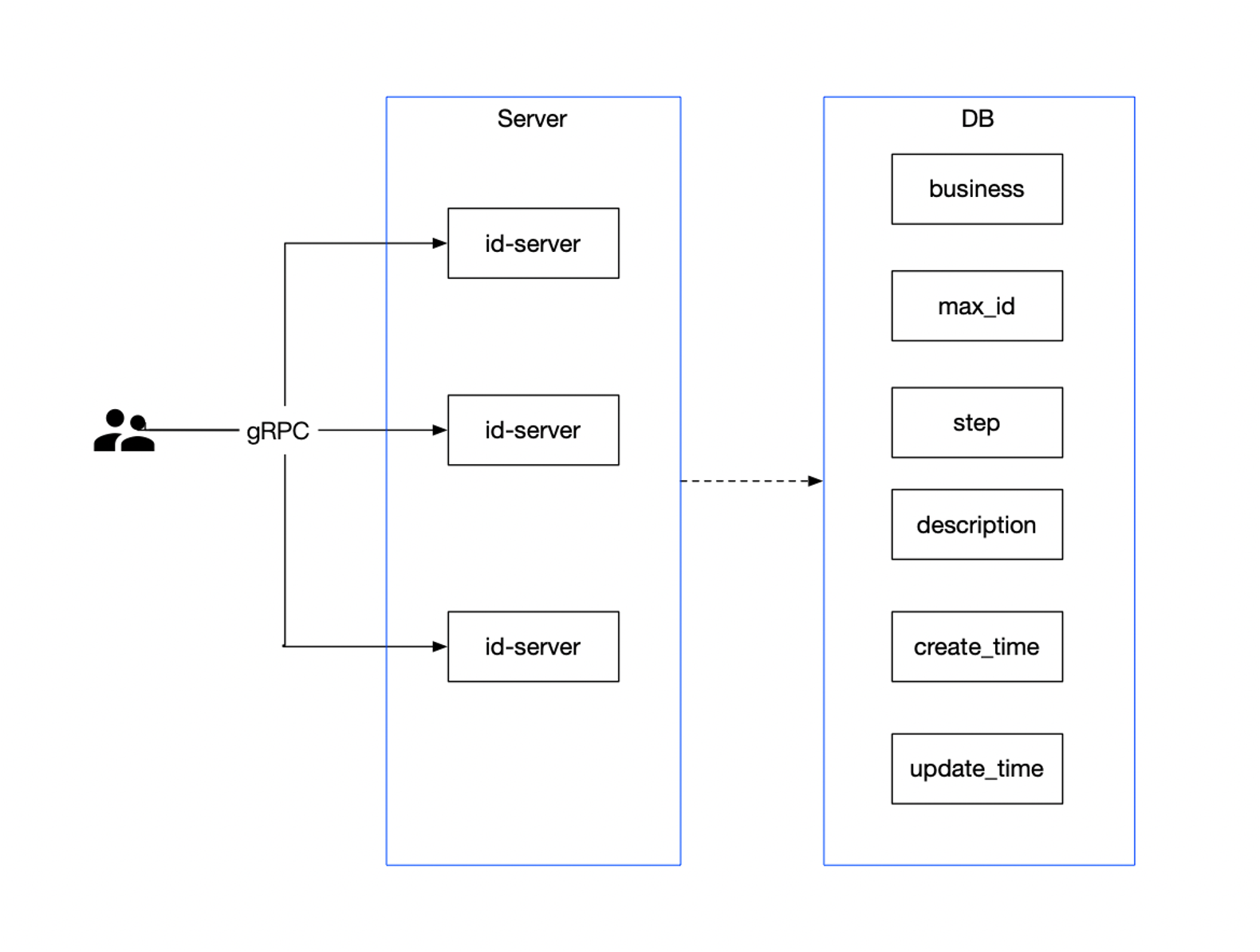
服务主要分为:
- 通过 gRPC 通信,提供 ID 生成接口,并且携带业务标记,为不同业务分配ID;
- 部署多个
id-server服务,通过数据库进行申请 ID 步长,并且持久化最大的 ID,例如,每次批量获取 1000 到内存中,可以减少对 DB 的压力; - 数据库记录分配的业务 MAX_ID 和对应
Step,供Sequence请求获取;
IM 私信系统
在聊天系统中,几乎每个人都在使用聊天应用,并且对消息及时性要求也非常高;

对消息也需要有一致性保证;
并且都有着丰富的多媒体传输功能:
- 1 on 1:私聊
- Group Chat:群聊
- Online presence:显示在线状态
- Multiple device support:多设备支持(多设备同步消息,也需要服务端记录已同步的消息版本号)
- Push nofifications:推送通知
聊天系统中,主要是客户端和服务端之间进行通信;
客户端可以是 Android、iOS、Web 应用;
通常客户端之间不会进行直接通信,可是客户端链接到服务端进行通信;

服务端需要支持:
- 接收各个客户端消息
- 消息转发到对应的人
- 用户不在线,存储新消息
- 用户上线,同步所有新消息
聊天系统中,最重要的是通信协议,如何有保证地及时送达消息;
一般来看移动端基本都是通过长连接方式实现,而 Web 端可以使用 HTTP、Websocket 实现实时通信;
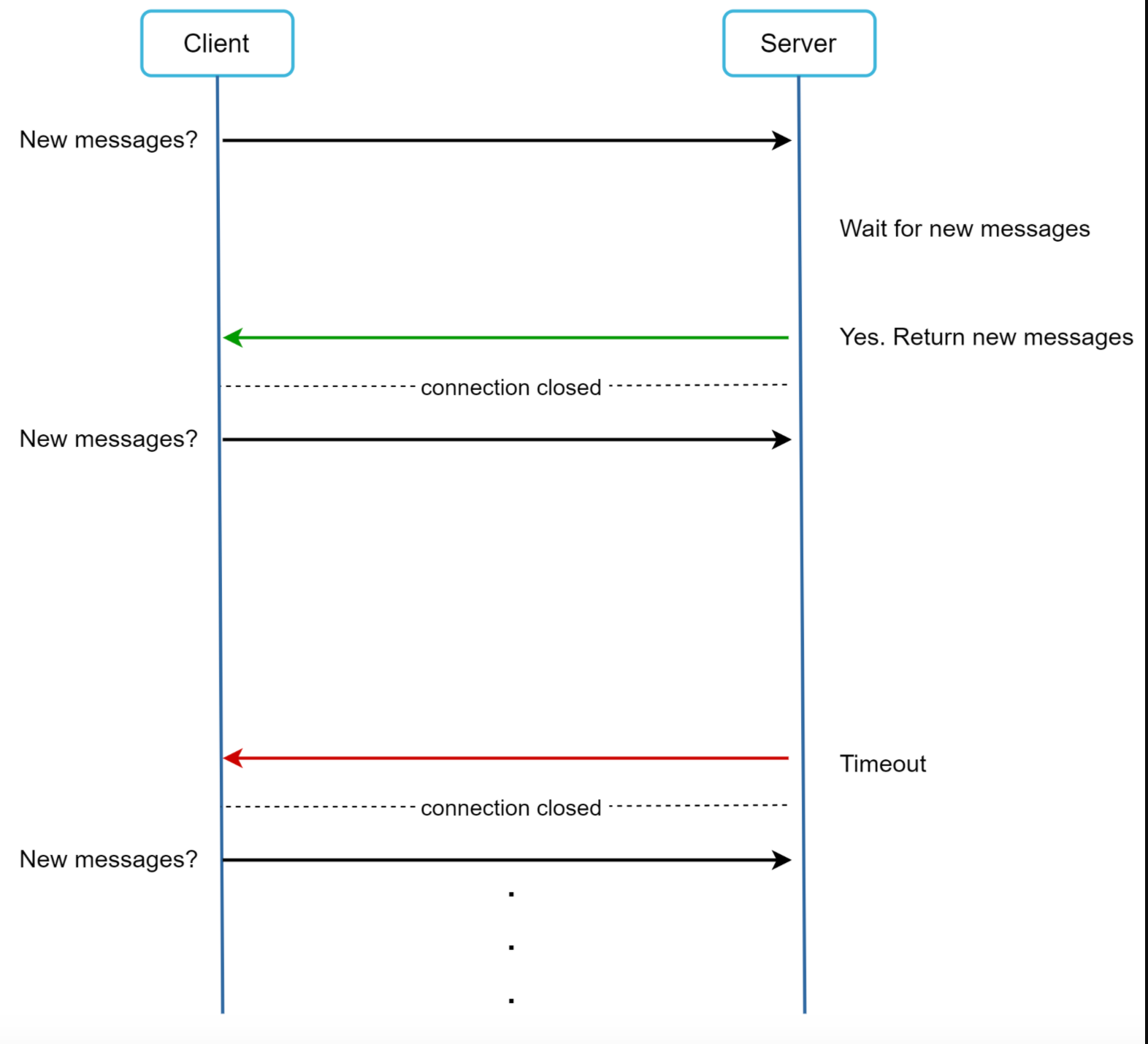
通用通信方式:
- HTTP 定时轮询
- HTTP 长轮询
- WebSocket
- TCP
在聊天系统中,有着很多用户、消息功能,比如:登录、注册、用户信息,可以通过 HTTP API 方式;
消息、群聊、用户状态,可以通过实时通信方式;
可能集成一些三方的服务,比如小米、华为推送、APNs 等;
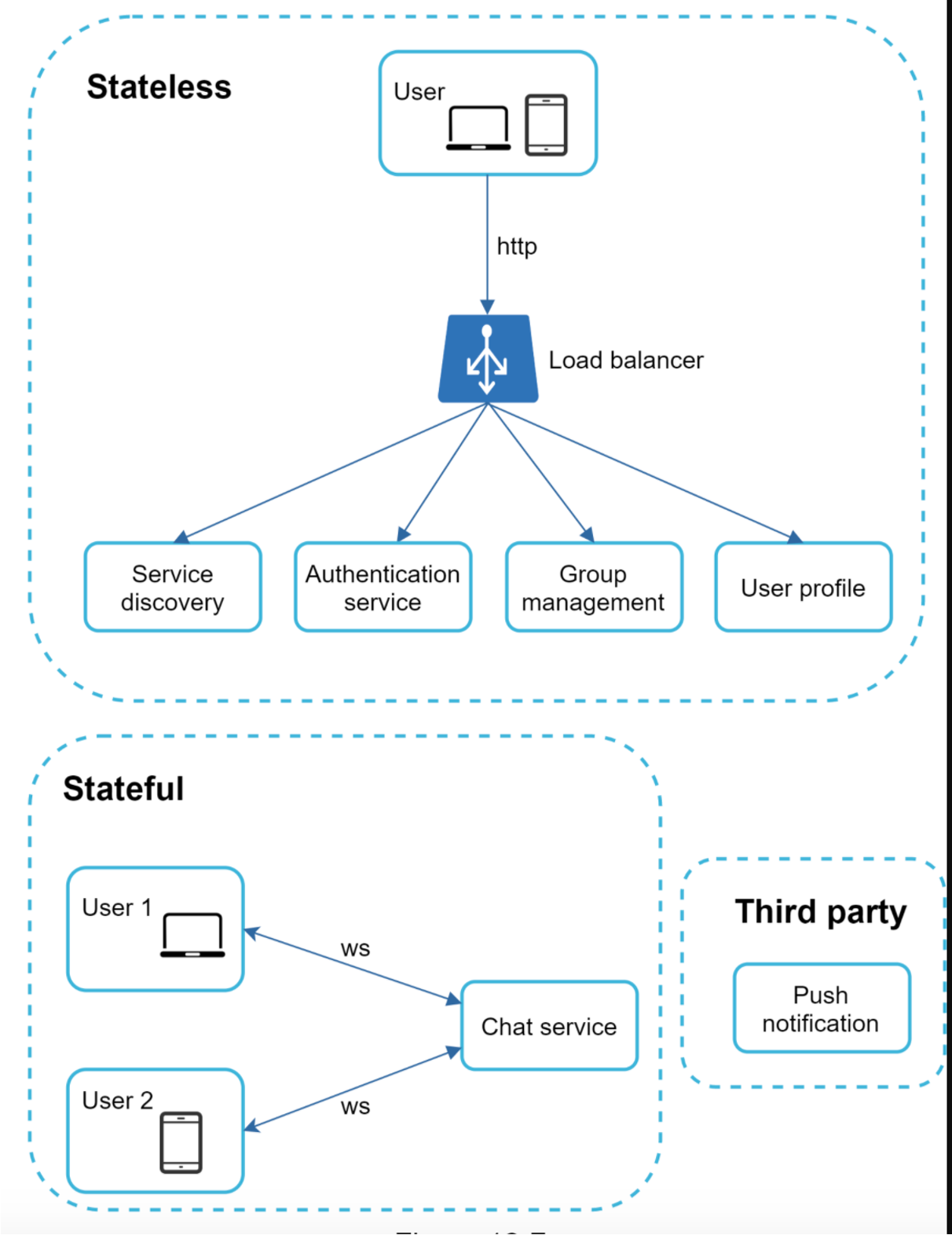
所以,主要服务可为三大类:
- 无状态服务:登录、注册、获取用户信息、验证、群管理
- 有状态服务:群聊、消息、获取用户状态
- 第三方集成:推送、APNs
聊天系统中,Goim 主要角色是 Real time service,实现对 连接 和 状态 的管理:
可以通过 API servers 进行系统之间的解耦;
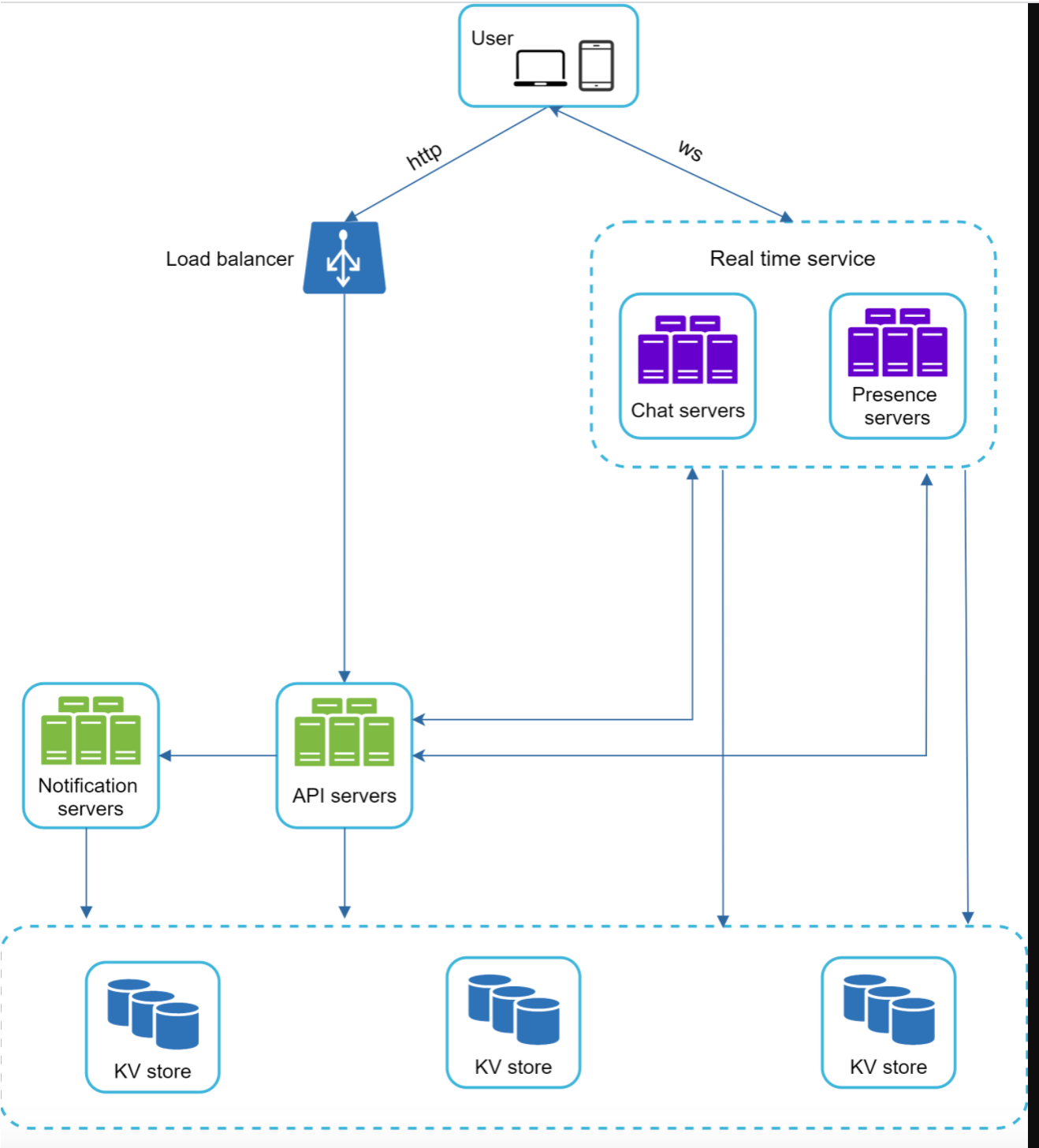
各个服务的主要功能为:
- 聊天服务进行消息的发送和接收
- 在线状态服务管理用户在线和离线
- API 服务处理用户登录、注册、修改信息
- 通知服务器发送推送通知(
Notification) - 通过 KV 存储进行存储、查询聊天信息
聊天系统中,消息存储是最主要的,通常会有海量的消息需要存储,可以想到关系数据库还是 NoSQL 数据库;
而关系数据库主要进行存储用户信息,好友列表,群组信息,通过主从、分片基本满足;
由于消息存储比较单一,可以通过 KV 存储(也需要支持排序和过滤,有些也需要支持索引);


KV 存储消息的好处:
- 水平扩展
- 延迟低
- 访问成本低
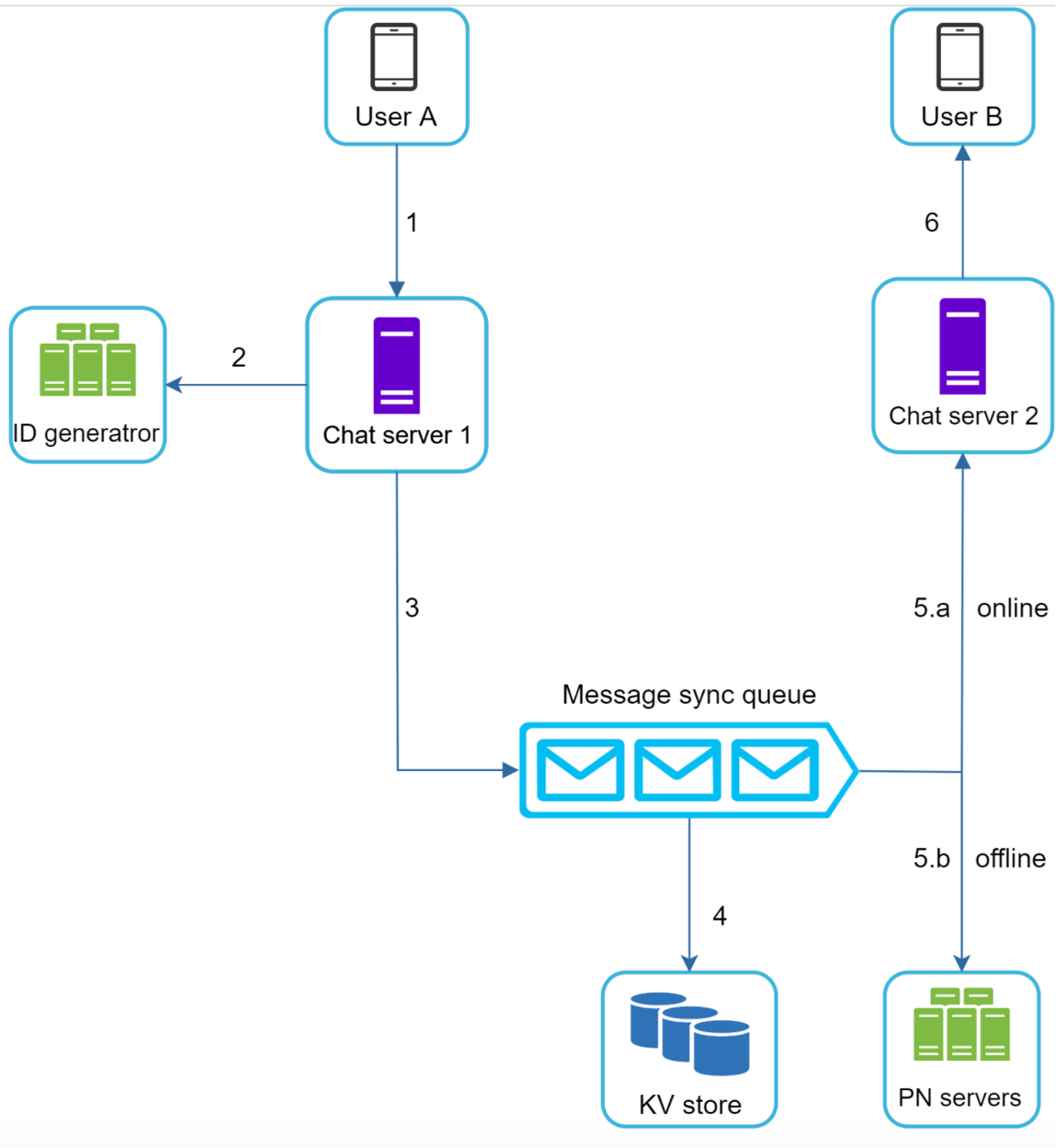
一对一聊天,主要的消息发送流程:
- 用户 A 向聊天服务器发送消息给用户 B
- 聊天服务从生成器获取消息 ID
- 聊天服务将消息发送到消息队列
- 消费保存在 KV 存储中
- 如果用户在线,则转发消息给用户(客户端在冷启动或者热启动的时候,定时同步,保障消息不丢失。)
- 如果用户不在线,则转发到通知服务 (Notification)
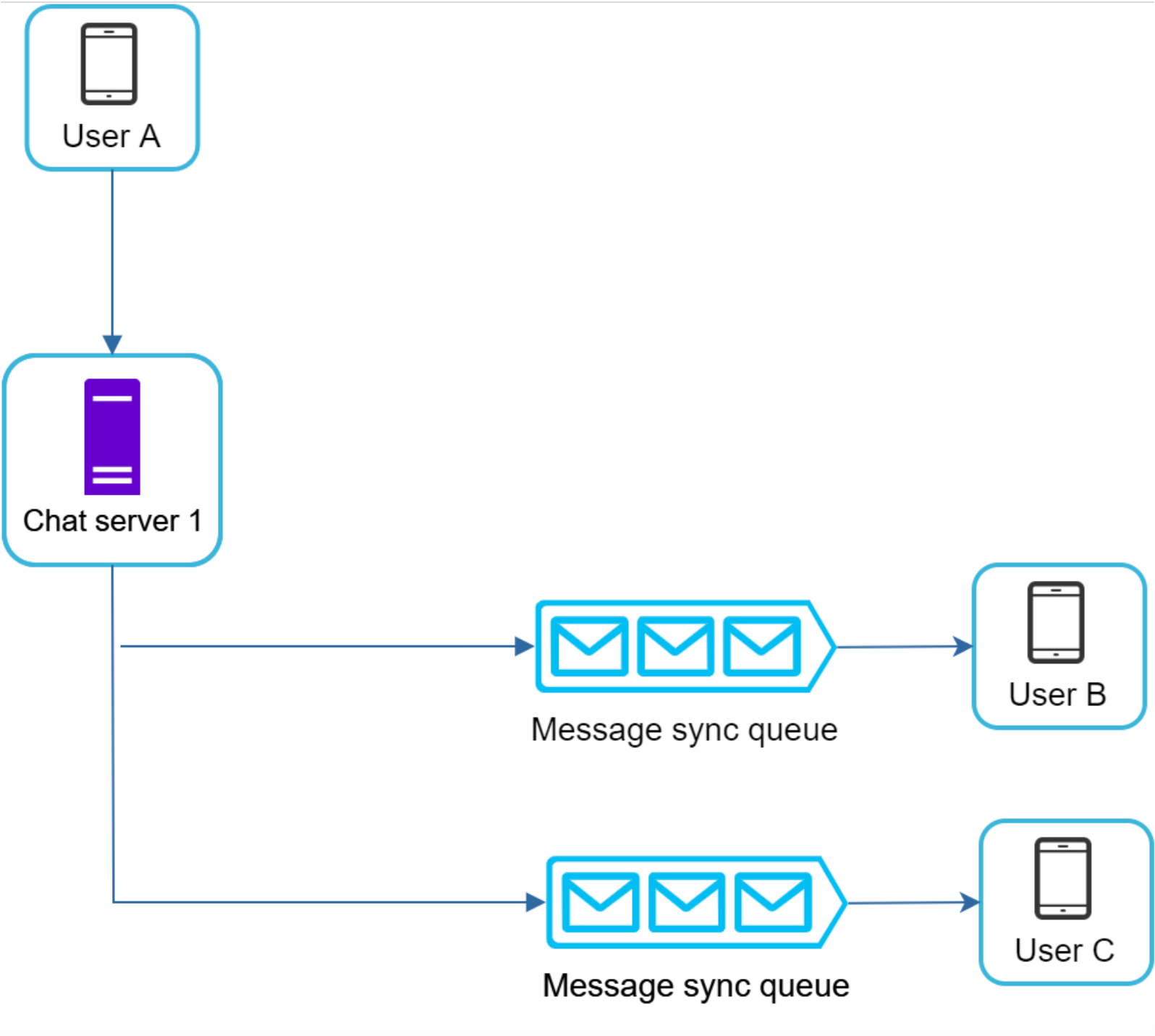
群聊,较为复杂,通常有多写、多读两种方式;
单信箱(多写),每个用户都保存一份消息:
- 消息同步流程比较简单,每个客户端仅需要读取自己的信箱,即可获取新消息
- 当群组比较小时,成本也不是很高,例如微信群通常为 500 用户上限
- 对数组数量无上限
多信箱(多读),每个群仅保存一份消息:
- 用户需要同时查询多个信箱(可以优化一下只获取活跃的群)
- 如果信箱比较多,查询成本比较高
- 需要控制用户已加入的群组上限
References
6.6 网络轮询器
Go语言基础之网络编程
Android微信智能心跳方案
如何设计一个亿级消息量的 IM 系统
Leaf:美团分布式ID生成服务开源
系统调优,你所不知道的TIME_WAIT和CLOSE_WAIT
Java核心(五)深入理解BIO、NIO、AIO
从无到有:微信后台系统的演进之路
Design A Chat System