分布式缓存
缓存选型
Memcache
Memcache 提供简单的 kv cache 存储,value 大小不超过 1MB。一般将 Memcache 作为大文本或者简单的 kv 结构使用。
Memcache 使用了 slab 的方式做内存管理(可以理解为分块,一开始申请一个非常大的联系内存块,然后逐步分为比较小的块),存在一定的浪费,如果大量接近的 item,建议调整 Memcache 参数来优化每一个 slab 增长的 ratio(增长因子),可以通过设置 slab_automove & slab_reassign 开启 Memcache 的动态/手动 move slab,防止某些 slab 热点导致内存足够的情况下引发 LRU。(例如大量的小数据占用大量的小 slab ,放入大数据的时候虽然显示有内存,但是实际上没有连续的内存空间,此时会导致内存回收)
大部分情况下,简单 KV 推荐使用 Memcache,吞吐和响应都足够好。
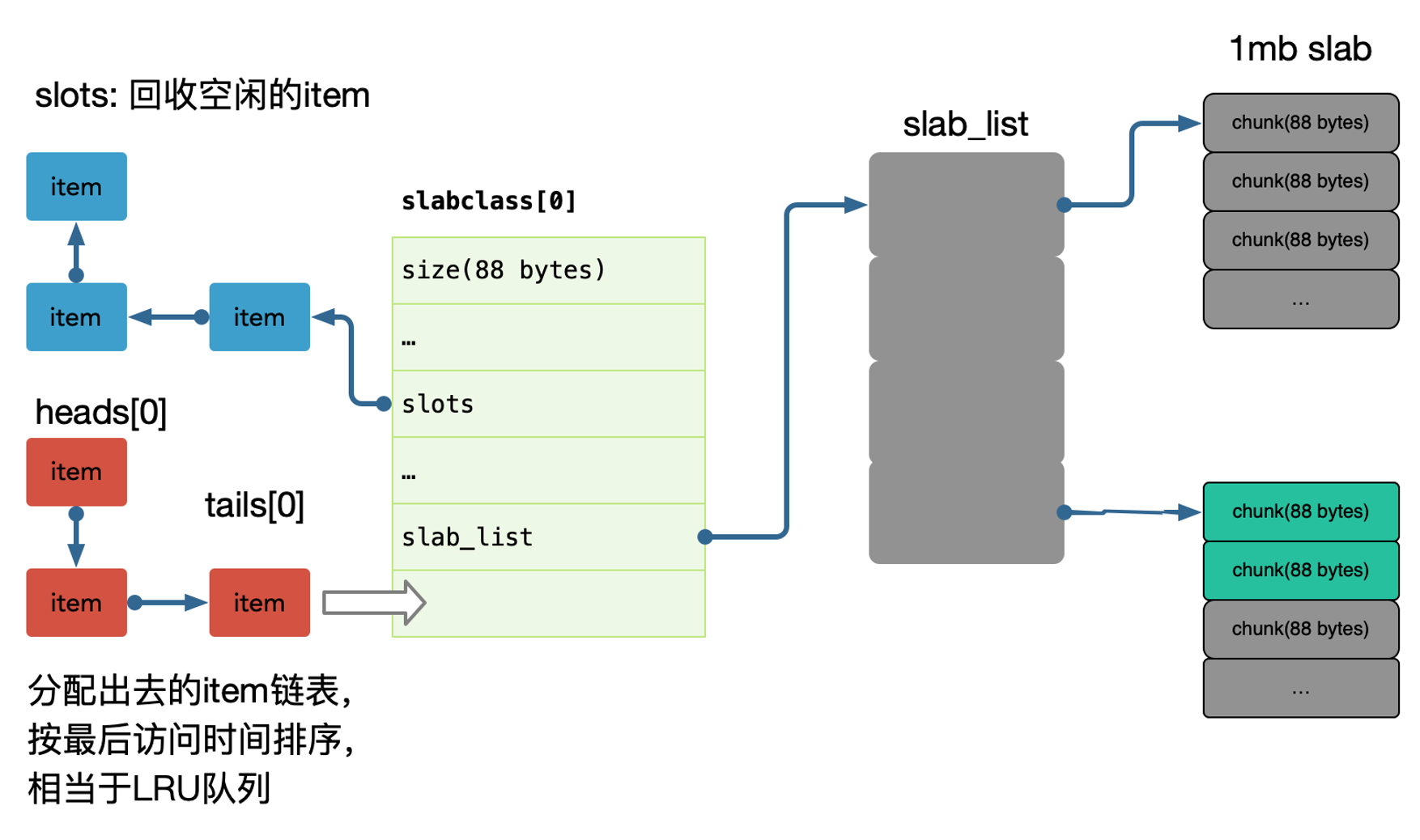
每个 slab 包含若干个大小为 1M 的内存页,这些内存又被分割成多个 chunk,每个 chunk 存储一个 item:
在 Memcache 启动初始化时,每个 slab 都预分配一个 1M 的内存页,由 slabs_preallocate 完成(也可将相应代码注释掉关闭预分配功能)。
chunk 的增长因子由 -f 指定,默认 1.25,起始大小为 48 字节。
内存池有很多设计,可以参考:nginx ngx_pool_t,tcmalloc 的设计等等。
Redis
Redis 有丰富的数据类型,支持增量方式的修改部分数据,比如排行榜、集合、数组等。
比较常见的方式是使用 Redis 作为数据索引,比如评论的列表 ID,播放历史的列表 ID 集合,关系链列表ID。
Redis 因为没有使用内存池,所以是存在一定的内存碎片的,一般会使用 jemalloc 来优化内存分配,需要编译时候使用 jemalloc 库代替 glib 的 malloc 使用。
Redis vs Memcache
Redis 和 Memcache 最大的区别其实是 redis 单线程(新版本多线程,一个线程负责IO读写,多个线程负责同时处理网络请求),memcache多线程,所以 QPS 可能两者差异不大,但是吞吐会有很大的差别,比如大数据 value 返回的时候,redis 的qps 会抖动下降的很厉害,因为单线程工作,其他查询进不来。(比如执行 keys * 等命令时)
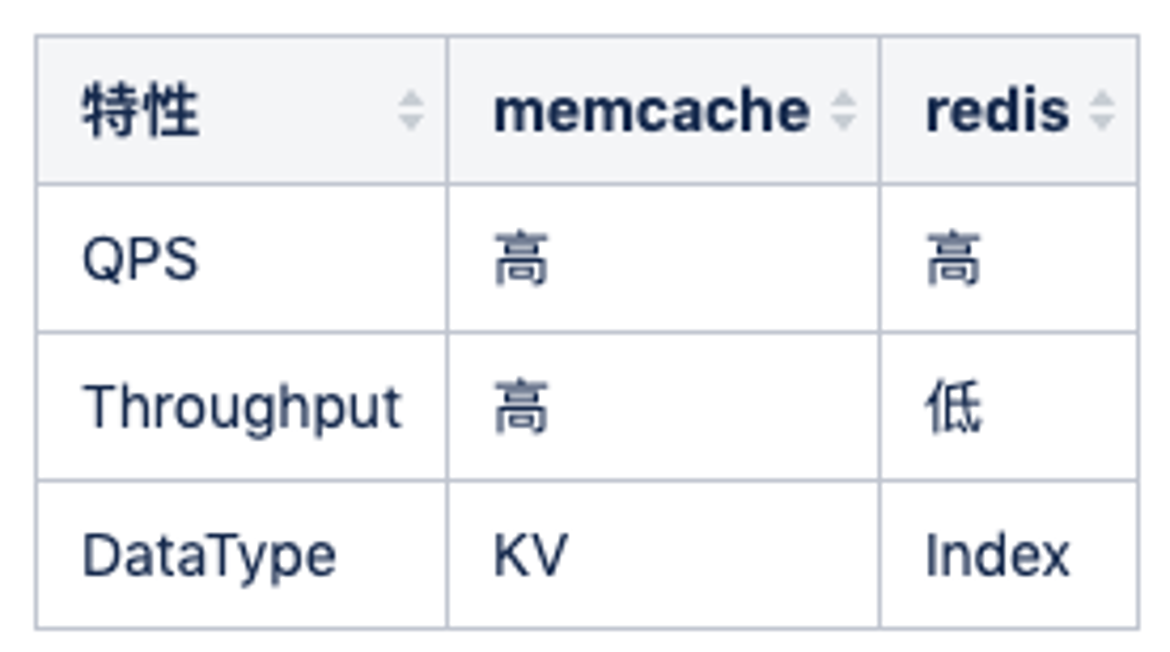
所以建议纯 kv 都走 memcache,比如关系链服务,可以使用 hashs 存储双向关系,也会使用 memcache 挡一层来避免 hgetall 导致吞吐下降的问题。(例如使用redis的hash,一次性全部取出来会影响redis,这时可以将数据通过protobuf序列化之后存储到memcache,当然,更新时也需要双删双改。)
在很多系统中可以看到多次使用 memcache + redis 双缓存设计。
Porxy
早期使用 twemproxy 作为缓存代理(类似于在 client 到 redis 之间有一层代理,代理实现将数据均分给不同的后端 redis 节点),但是在使用上有如下一些痛点:
- 单进程单线程模型和
redis类似,在处理一些大key的时候可能出现io瓶颈; - 二次开发成本难度高,难以于公司运维平台进行深度集成;
- 不支持自动伸缩,不支持
aotorebalance,增删节点需要重启才能生效 - 运维不友好,没有控制面板
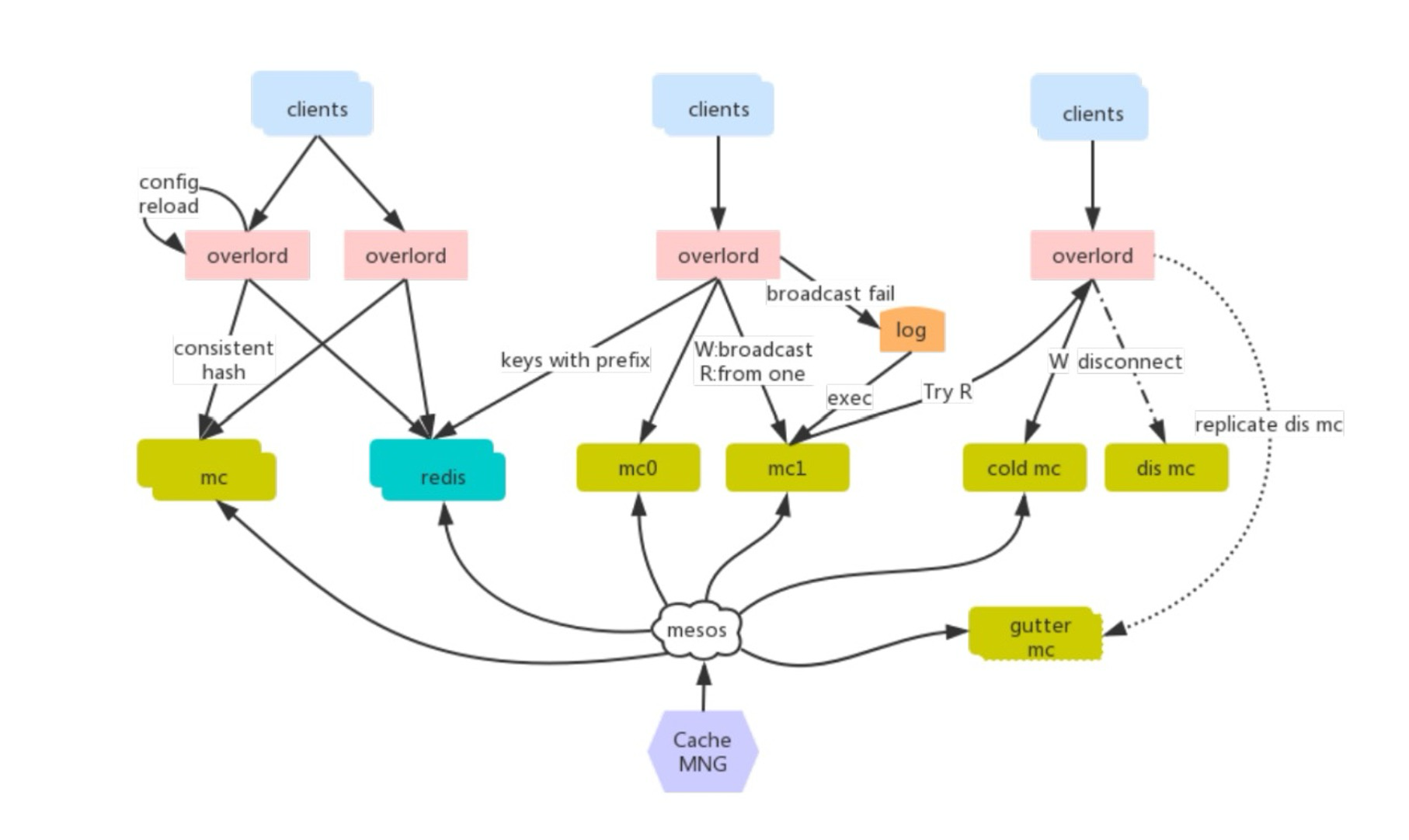
业界开源的其他代理工具:
codis:只支持redis协议,且需要使用patch版本的redismcrouter:只支持memcache协议,C开发,与运维集成开发难度高;
从集中式访问缓存到 Sidecar 访问缓存:
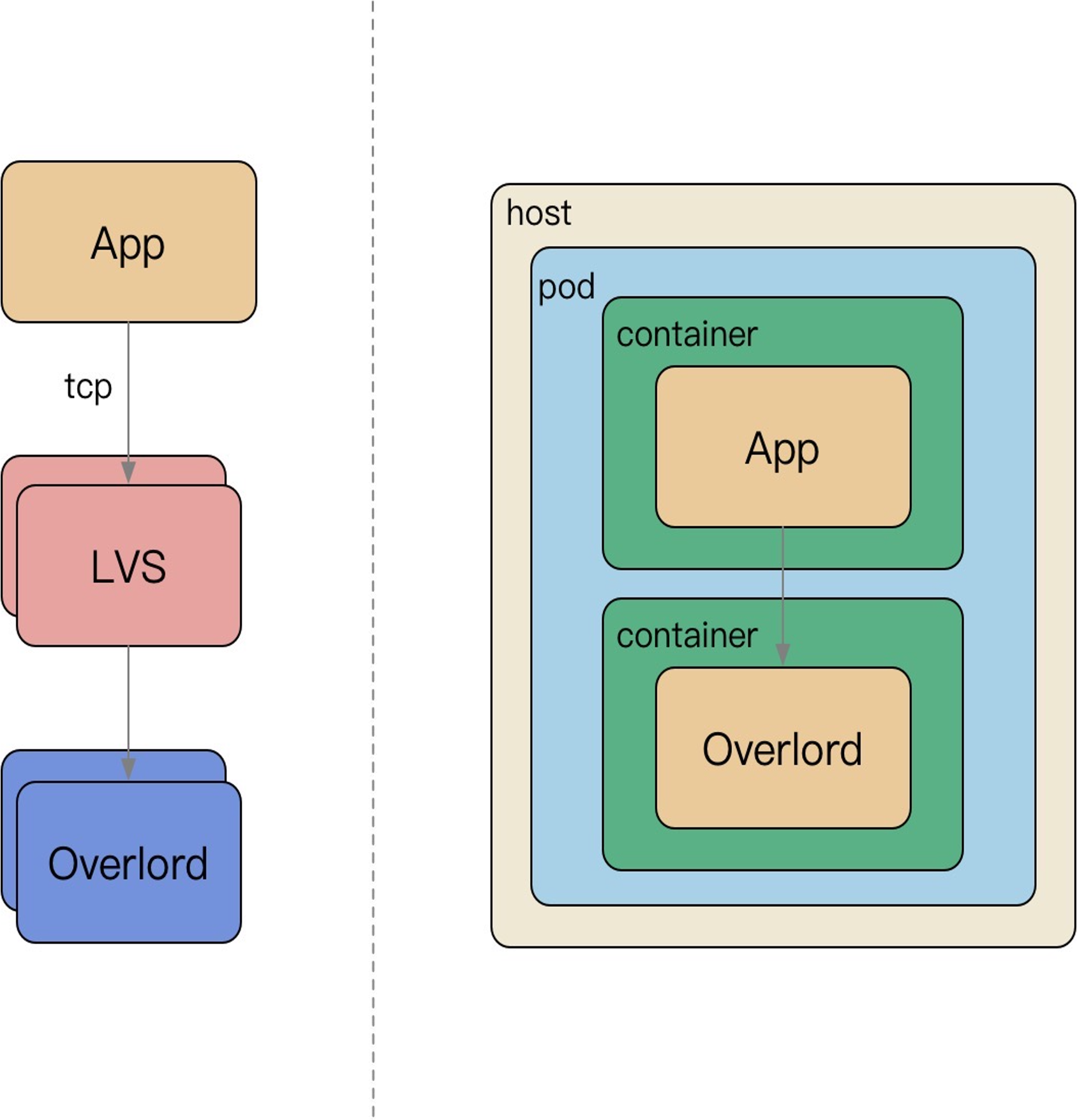
- 微服务强调去中心化,使用
Overload这种Sidecar访问存储 LVS运维困难,容易流量热点,随下游扩容儿扩容,链接不均衡等问题,去掉LVS这样的四层负载均衡Sidecar伴生容器随App容器启动而启动,配置简化;
一致性 Hash
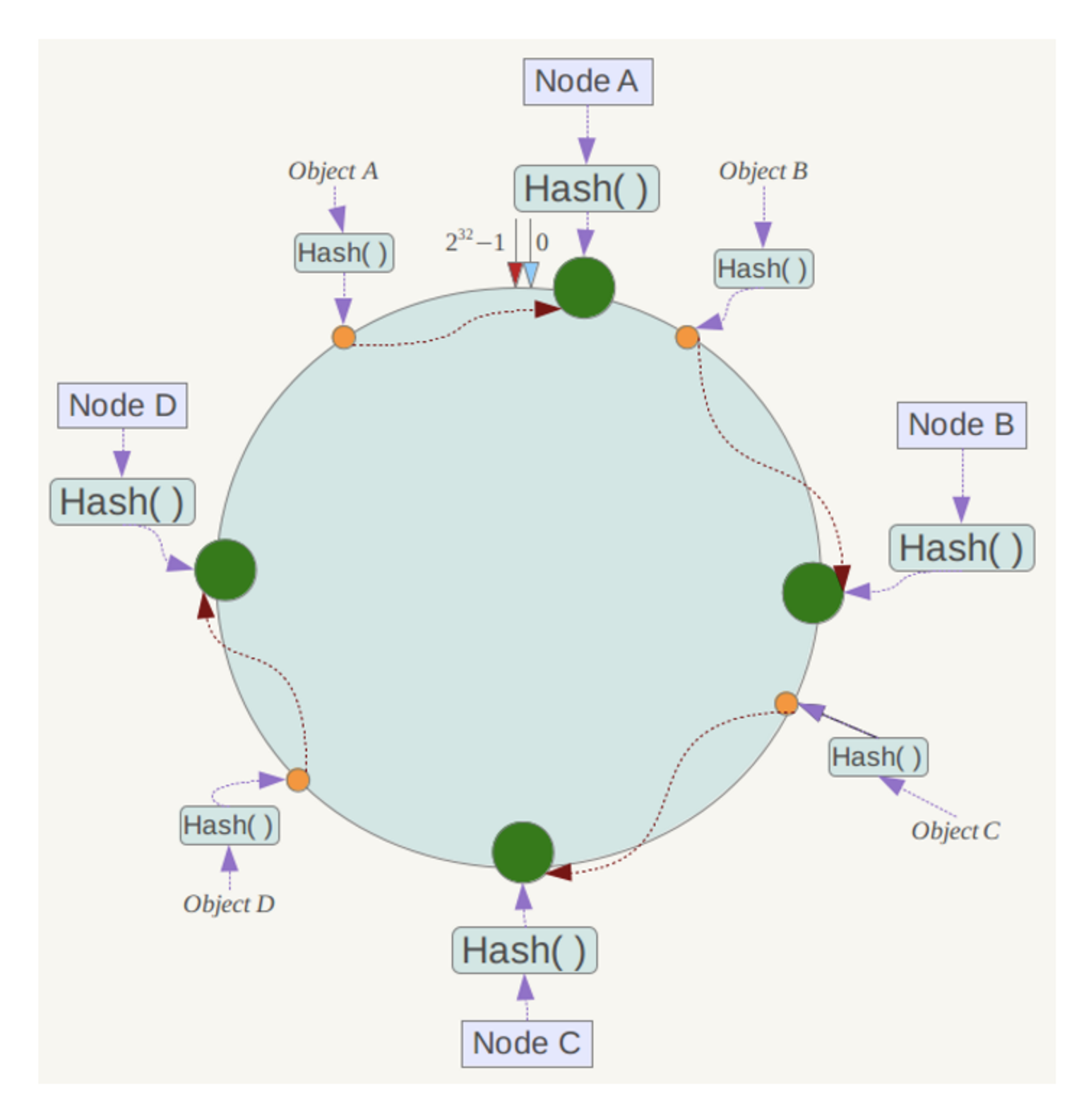
一致性 hash 是将数据按照特征值映射到一个首尾相连的 hash 环上,同时也将节点(按照 IP 地址或者机器名 hash)映射到这个环上。
对于数据,从数据在环上的位置开始,顺时针找到第一个节点即为数据的存储点。
余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但 Consistent Hashing 中,只有在园(continuum)上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响。
- 平衡性(
Balance):尽可能分布到所有的缓冲中去 - 单调性(
Monotonicity):单调性是指如果已经有了一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲区加入到系统中,那么哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲区中去,而不会被映射到旧的缓冲集合中的其他缓冲区。 - 分散性(
Spread):相同内容被存储到不同缓冲中去,降低了系统存储的效率,需要尽量降低分散性 - 负载(
Load):哈希算法应能够尽量降低缓冲的负载 - 平滑性(
Smoothness):缓存服务器的数目平滑改变和缓存对象的平滑改变是一致的
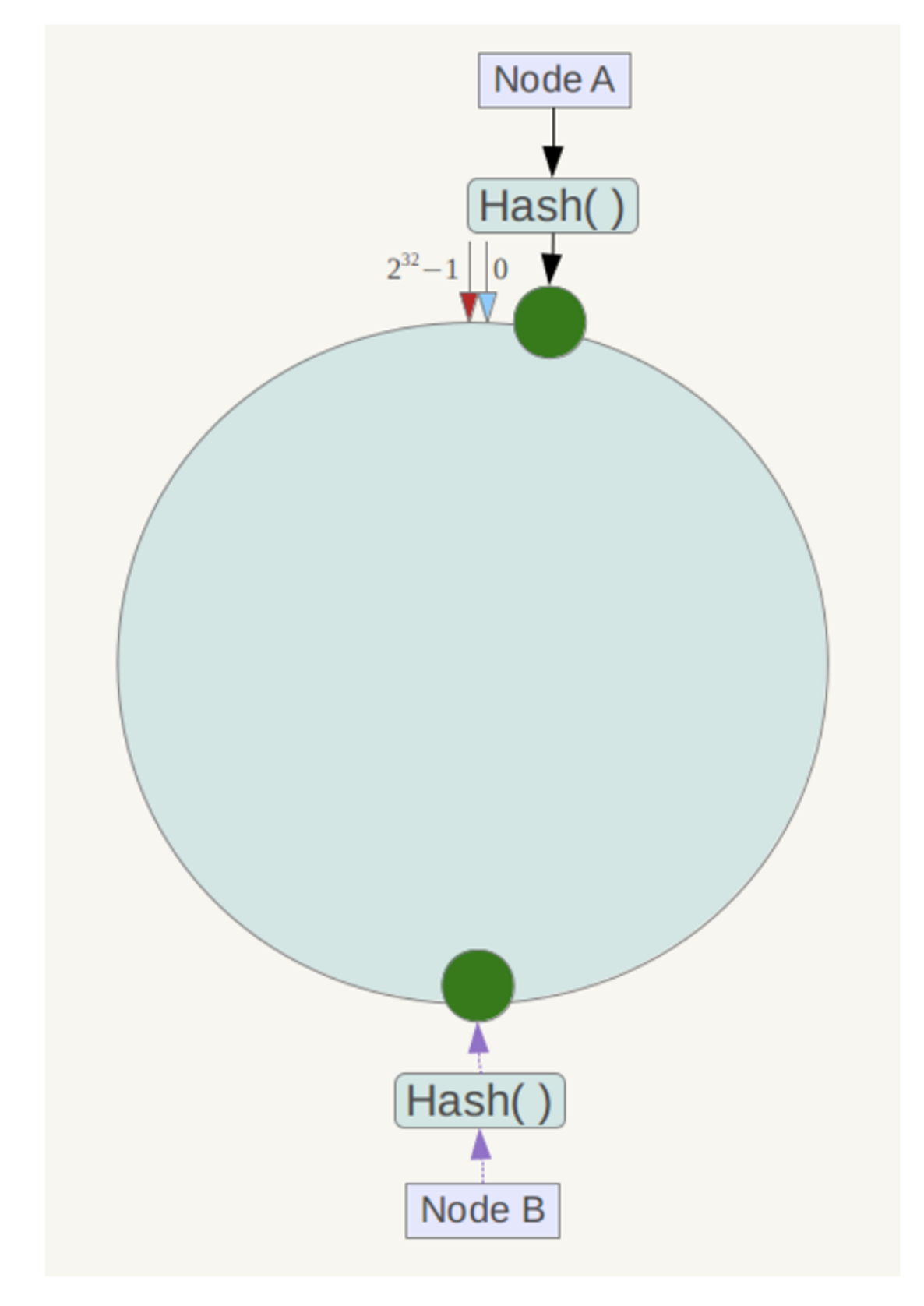
一致性哈希算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜问题。
此时必然造成大量数据集中到 Node A 上,而只有极少量会定位到 Node B上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。
具体做法可以在服务器 IP 或主机名的后面增加编号来实现。
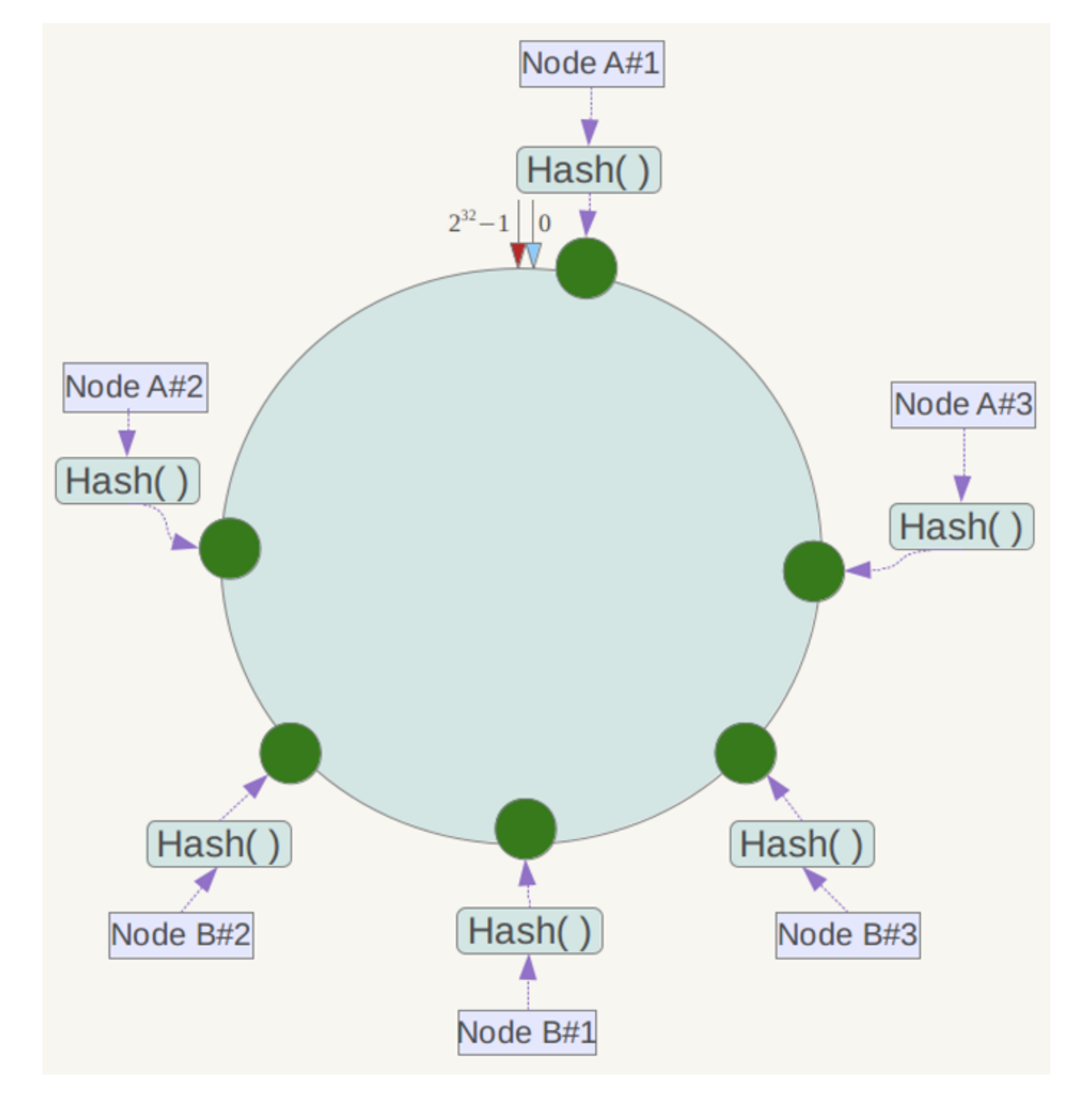
例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算。
Node A#1、Node A#2、Node A#3,Node B#1、Node B#1、Node B#1 的哈希值,于是形成六个虚拟节点。
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到Node A#1、Node A#2、Node A#3三个虚拟节点的数据均定位到 Node A 上,这样就解决了服务节点少时数据倾斜的问题。
参考微信红包的写合并优化:微信红包系统架构的设计和优化分享
在网关层,使用一致性 hash,对红包 ID 进行分片,命中到某一个逻辑服务器处理,在进程内做写操作的合并,减少存储层的单行锁争用。
如果红包的范围扩大,用户量非常多,避免造成一个服务器出现热点,还可以使用有界负载一致性hash:学界 | 谷歌推出有界负载的一致性哈希算法,解决服务器负载均衡问题
即严格控制每个服务器的最大负载,在节点过载时,请求漂到下一个节点。
Hash
数据分片的 hash 方式也是这个思路,即按照数据的某一特征(Key)来计算哈希值,并将哈希值与系统中的节点建立映射关系,从而将哈希值不同的数据分布到不同的节点上。
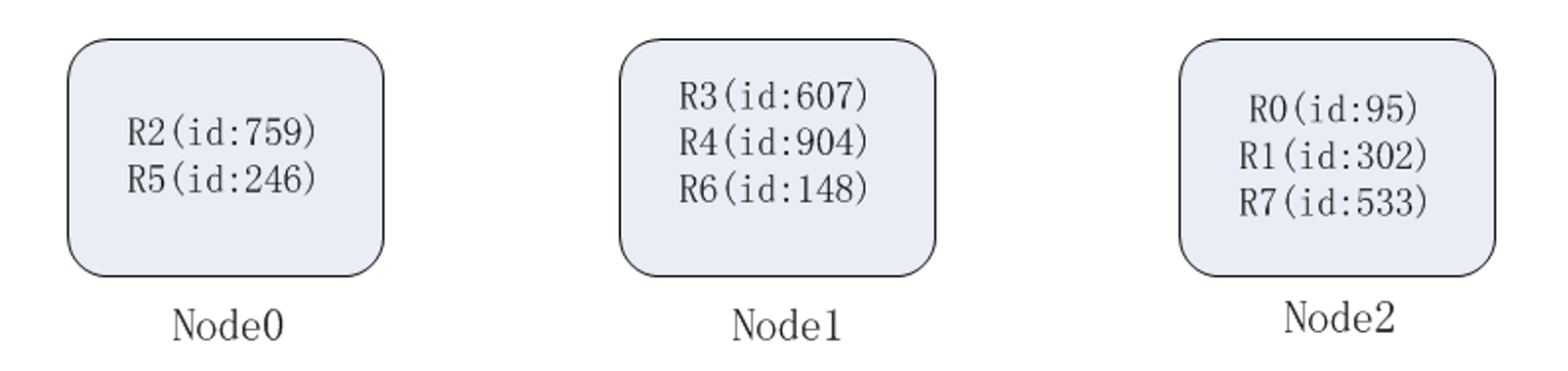
按照hash方式做数据分片,映射关系非常简单;需要管理的元数据也非常之少,只需要记录节点的数据以及 hash 方式就行了。
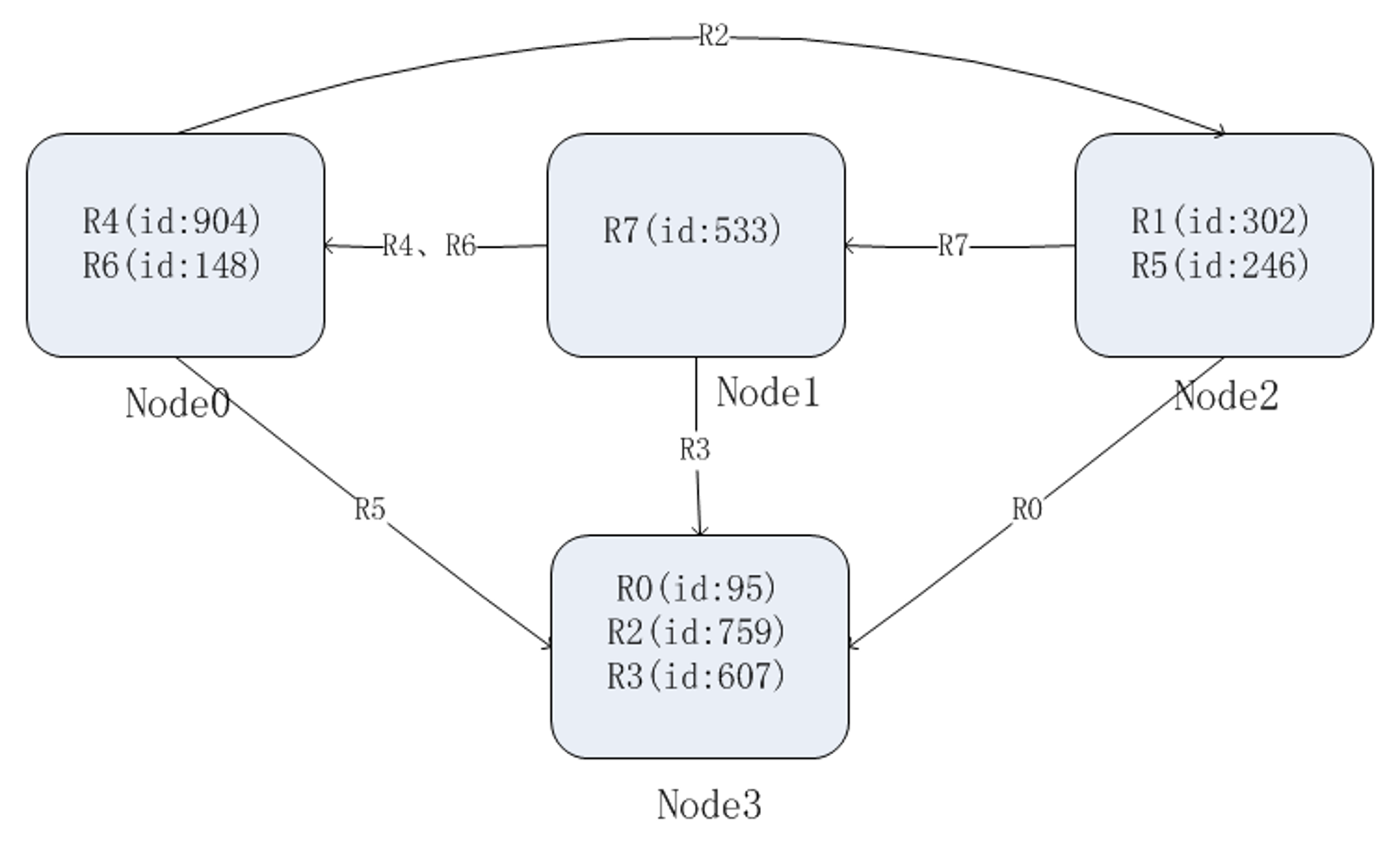
当加入或者删除一个节点的时候,大量的数据需要移动。比如在这里增加一个节点 N3,因此 hash 方式变为了 mod 4。
均衡问题:原始数据的特征值分布不均匀,导致大量的数据集中到一个物理节点上;第二,对于可修改的记录数据,单条记录的数据变大。
高级玩法是抽象 slot,基于 Hash 的 Slot Sharding,例如 Redis-Cluster。
Slot
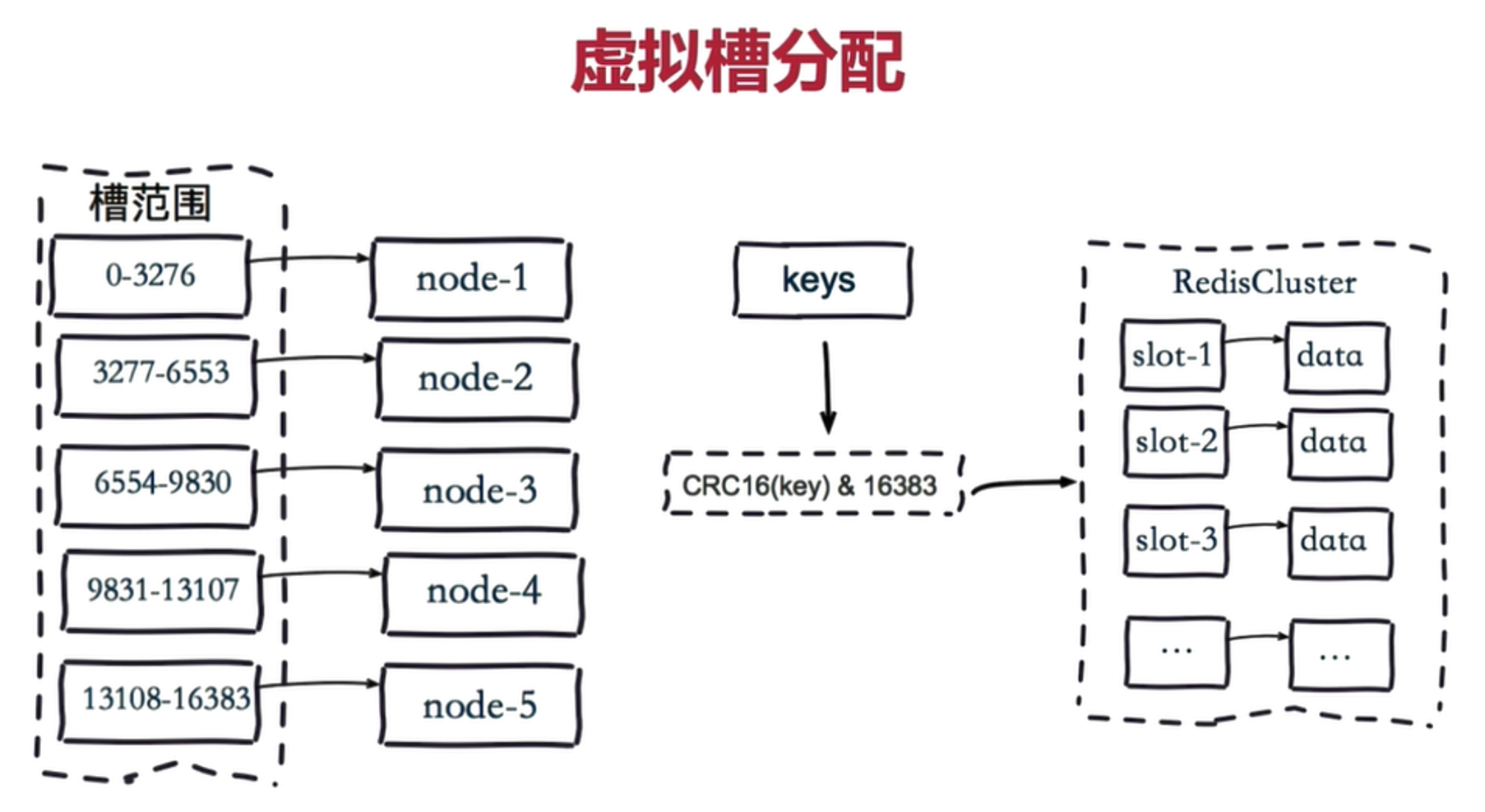
redis-cluster 把 16384 槽按照节点数量进行平均分配,由节点进行管理。
对每个 key 按照 CRC16 规则进行 hash 运算,把 hash 结果对16384 进行取余,把余数发送给 redis 节点。
需要注意的是:Redis Cluster 的节点之间会共享消息,每个节点都会知道是哪个节点负责哪个范围内的数据槽。
好处是扩容和锁容的时候,数据迁移很方便。
缓存模式
数据一致性
Storage 和 Cache 同步更新容易出现数据不一致。
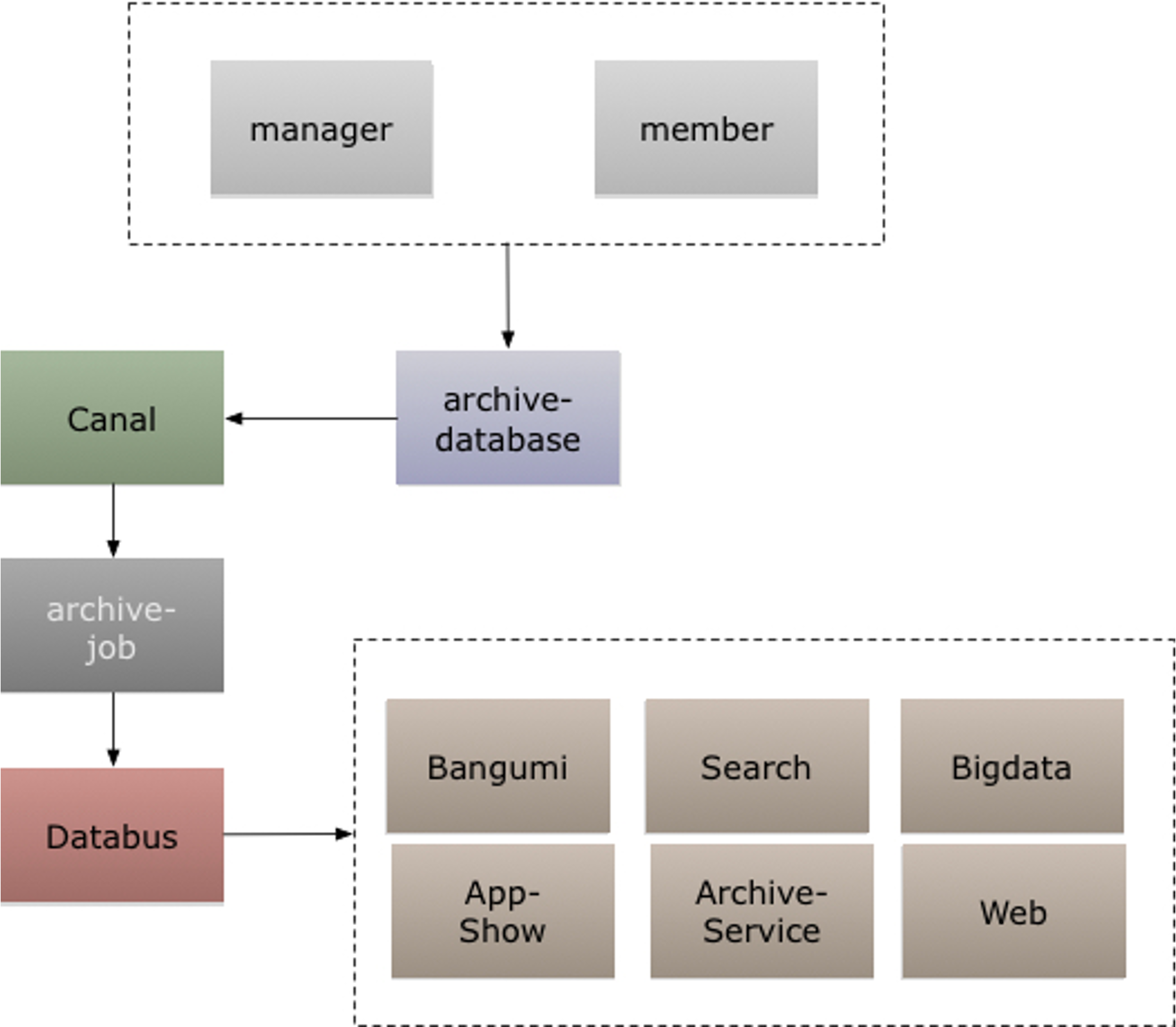
模拟 MySQL Slave做数据复制,再把消息投递到 Kafka,保证至少一次消费:
- 同步操作 DB
- 同步操作 Cache
- 利用
Job消费信息,重新补偿一次缓存操作,保证缓存一致性
保证时效性和一致性。
Cache Aside 模型中,读缓存 Miss 的回填操作,和修改数据同步更新缓存,包括消息队列的异步补偿缓存,都无法满足 Happens Before,会存在相互覆盖的情况。
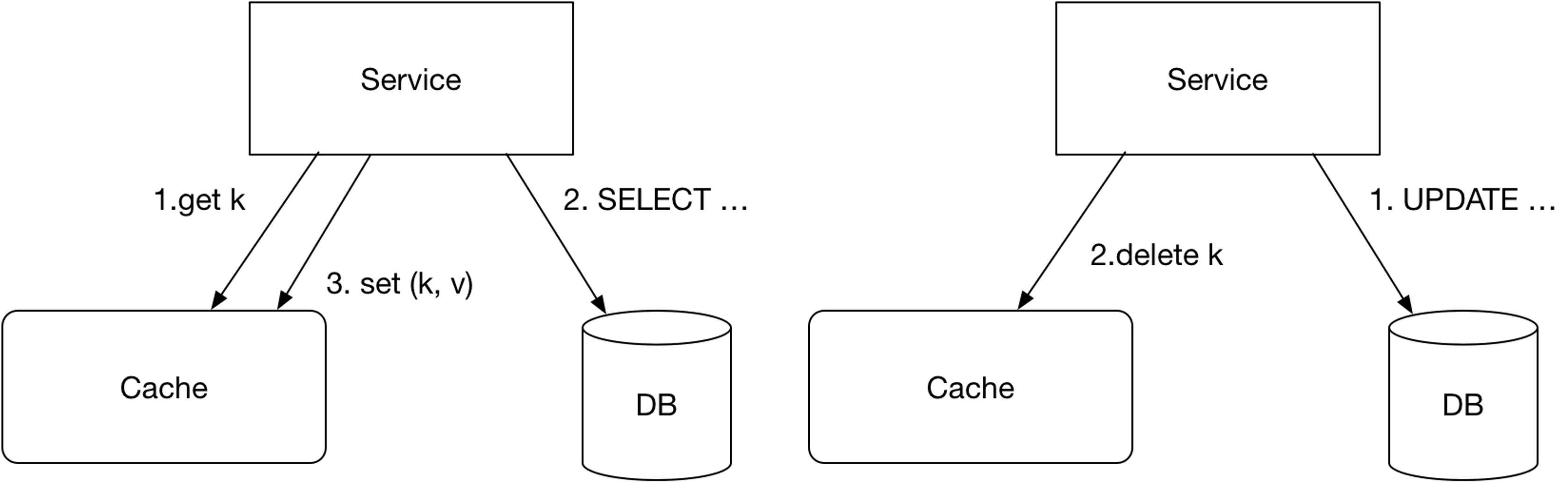
可能出现这种情况,A 操作读取的时候,cache 中没有,因此读取的 DB,读取到的 v1,B操作 DB 更新对象,需要更新 Cache 成 v2,而且订阅 binlog 的时候,可能收到删除操作,可能出现binlog 先消费,导致更新cache,由于无法保证谁先谁后(Happens Before),因此会出现缓存和DB数据不一致的情况。
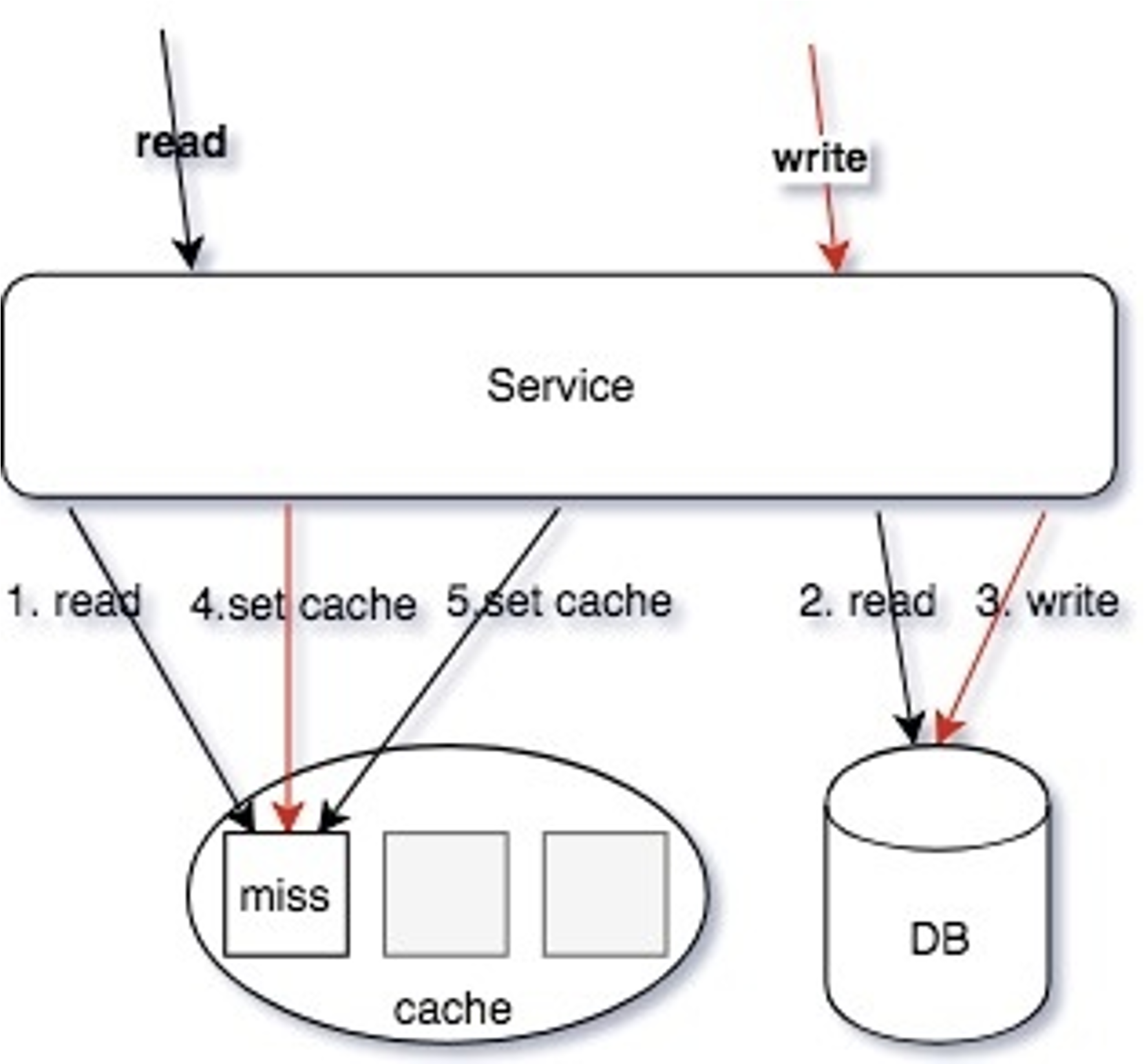
读/写同时操作:
- 读操作,读缓存,缓存
miss - 读操作,读
DB,读取到数据 - 写操作,更新
DB数据 - 写操作,
SET/DELETE Cache(可Job异步操作) - 读操作,
Set操作数据回写缓存(可Job异步操作)
这种交互下,由于4和5操作步骤是设置缓存,导致写入的值互相覆盖;并且操作的顺序性不确定,从而导致 cache 存在脏缓存的情况。
可以优化成下面这样:
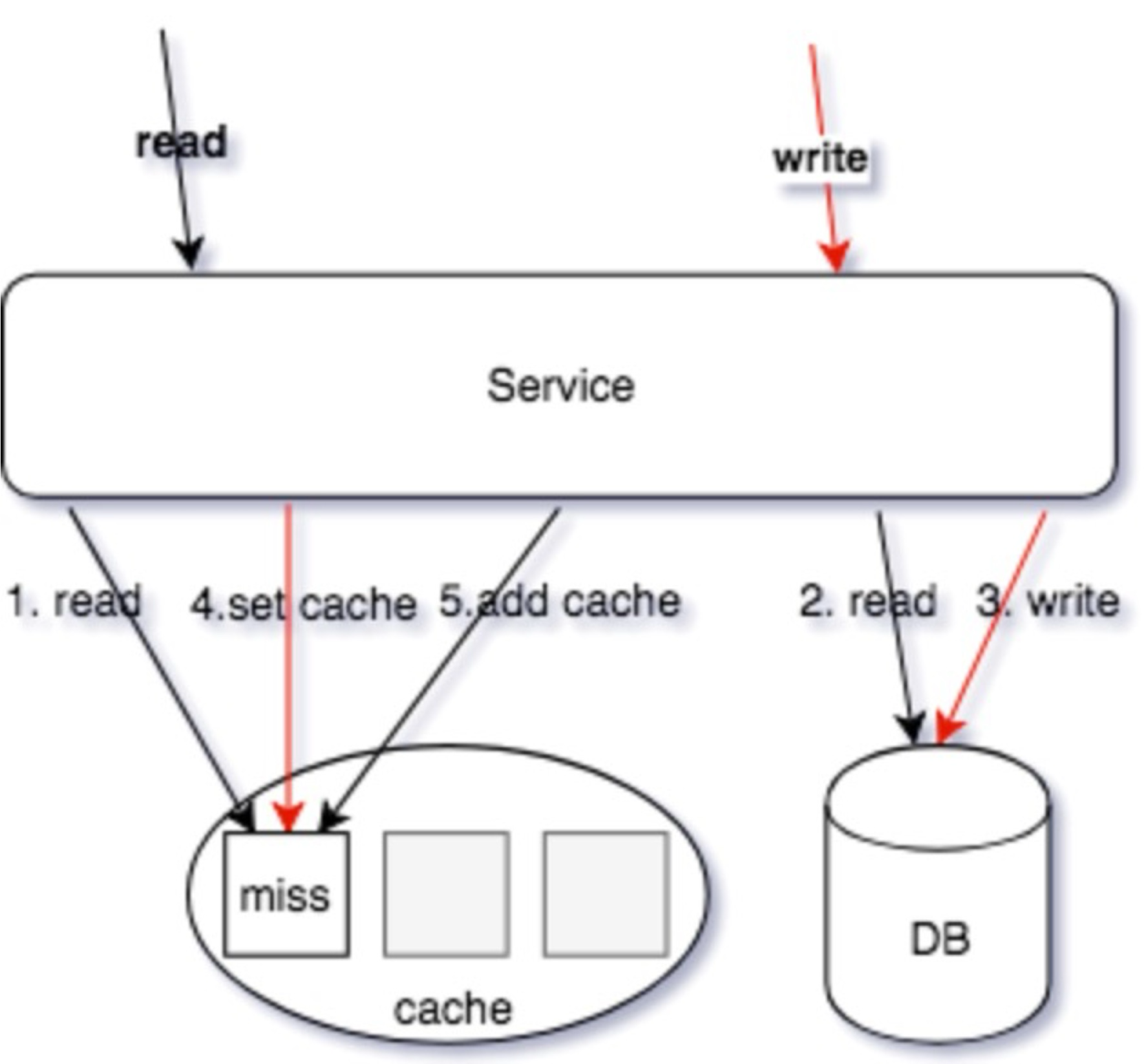
读/写同时操作:
- 读操作,读缓存,缓存
miss - 读操作,读 DB,读取到数据
- 写操作,更新 DB 数据
- 写操作,
Set Cache(可Job异步操作,Redis可以使用SETNX操作) - 读操作,
ADD操作数据回写缓存(可Job异步操作,Redis可以使用SETNX操作)
写操作使用 SET 操作命令,覆盖写缓存;读操作,使用 ADD 操作回写 MISS 数据,从而保证写操作的最新数据不会被读操作的回写数据覆盖。
多级缓存
微服务拆分细粒度原子业务下的整合服务(聚合服务),用于提供粗粒度的接口,以及二级缓存加速,减少扇出的 RPC 网络请求,减少延迟。
例如一些服务需要由很多下游服务的结果拼凑,很容易出现扇出大量读请求。这个时候就可以使用多级缓存,减少读取请求。
最重要是保证多级缓存的一致性:
- 清理的优先级是有要求的,先优先清理下游,再上游;
- 下游的缓存
expire要大于上游,避免穿透回源
微服务是分久必合,合久必分,适当的微服务合并也是不错的做法,再使用 DDD 思想以及良好的目录结构组织方式,区分不同的 Usecase。
热点缓存
对于热点缓存 key,按照如下思路解决:
小表广播,从
RemoteCache提升为LocalCache,App定时刷新,甚至可以让运营平台支持广播刷新Localcache主动监控防御预热,比如直播房间页高在线情况下直接外挂服务主动防御,监控服务通知 App 将某个热点数据直接缓存到
LocalCache基础库框架支持热点发现,自动短时的
short-live cache多
Cluster支持,一个服务有多个cluster![image-20231103113121092]()
多
Key设计:使用多副本,减少节点热点的问题- 使用多副本
ms_1,ms_2,ms_3每个节点保存一份数据,使得请求分散到多个节点,避免单节点热点问题。
- 使用多副本
建立多个 Cluster,和微服务、存储等一起组成一个 Region。
这样相当于是用空间换时间:
同一个 key 在每一个 fontend cluster 都可能有一个 copy,这样会带来 consistency 的问题,但是这样能够降低 latency 和提高 avaliability。利用 MySQL Binlog消息 anycast 到不同集群的某个节点清理或者更新缓存;
当业务频繁更新的时候,cache 频繁过期,会导致命中率低,stale sets
如果应用程序层可以忍受稍微过期一点的数据,针对这点可以进一步降低系统负载。当一个 key 被删除的时候(delete 请求或者 cache 爆棚清理空间了),它被放到一个临时的数据结构里,会再续上比较短的一段时间(避免大热 key 被删掉之后,立马有大量的请求穿透缓存,可以先设置删除 flag 做软删,新的cache没有构建时,先用过期数据)。当有请求进来的时候会返回这个数据并标记为 Stale。对于大部分应用场景而言,Stale Value 是可以忍受的。(需要改 memcache、Redis 源码,或者基础库支持)
穿透缓存
singlefly
对关键字进行一致性
hash,使其某一个维度的key一定命中某个节点,然后在节点内使用互斥锁,保证归并回源,但是对于批量查询无解;分布式锁(不推荐,容易出错。)
设置一个
locl key,犹且只有一个人成功,并且返回,交由这个人来执行回源操作,其他候选者轮询cache这个local key,如果不存在去读取数据缓存,hit就返回,miss继续抢锁;队列(推荐,虽然复杂,但是效果好)
如果
cache miss,交由队列聚合一个key,来load数据回写缓存,对于miss当前请求可以使用singlefly保证回源,如评论架构实现。适合回源加载数据重的任务,比如评论miss只返回第一页,但是需要构建完成评论数据索引。lease通过加入
lease机制,可以很好避免这两个问题,lease是64-bit的token,与客户端请求的key绑定,对于过时设置,在写入时验证lease,可以解决这个问题;对于thundering herd,每个key 10s分配一次,当client在没有获取到lease时,可以稍微等一下再访问cache,这时往往cache中已有数据。(需要基础库支持 & 修改cache源码)
缓存技巧
Incast Congestion 广播阻塞
如果网路中的包太多,就会发生 Incast Congestion 的问题(可以理解为,network 有很多 switch,router 之类的,一旦一次性发一堆包,这些包同时到达 switch,这些 switch 可能无法及时处理)。
应对这个问题就是不要让大量包在同一时间送出去,在客户端限制每次发出去的包的数量(具体体现就是客户端弄个队列,限制一次性发送的数量,将高频、小包,合并成低频、大包)。
每次发送的包的数量称为 Window size。这个值太小的话,发送太慢,自然延迟会变高;这个值太大,发送的包太多提升 network switch 负载,这样可能发生比如丢包之类的情况,可能被当作 cache miss,这样延迟也会变高。所以这个值需要调整,一般会在 proxy 层面实现。(类似于 TCP 的滑动窗口机制。)
小技巧
易读性的前提下,
key设置尽可能小,减少资源的占用,redis value可以用int就不要用string,对于小N的value,redis内部有shared_obejct缓存拆分
key。主要是用在redis使用hashes情况下。同一个hashes key会落到同一个redis节点,hashes过大的情况下会导致内存及请求分布的不均匀。考虑对hashes进行拆分为小的hashes,使得节点内存均匀及避免单节点请求热点。空缓存设置。对于部分数据,可能数据库始终为空,这时应该设置空缓存,避免每次请求都缓存
miss直接打到DB。空缓存保护策略
读失败后的写缓存策略。(降级后一般读失败不触发回写缓存)
序列化使用
protobuf,尽可能减少size工具化胶水代码,直接生成
![image-20231106150535964]()
memcache 小技巧
flag使用:标识compress、encoding、large value等;memcache支持gets,尽量读取,尽可能的pipeline,减少网络往返- 使用二进制协议,支持
pipeline delete,UDP读取、TCP更新;
redis 小技巧
增量更新一致性:
EXPIRE(先续期)、ZADD/HSET等,保证索引结构体务必存在的情况下去操作新增数据;BITSET:存储每日登录用户,单个标记位置(boolean),为了避免单个BITSEET过大或者热点,需要使用region sharding,比如按照mid求余%和/10000,商为key,余数作为offset;List:抽奖的奖池、顶弹幕,用于类似Stack PUSH/POP操作;Sortedset:翻页、排序、有序的集合,杜绝zrange或者zrevrange返回的集合过大;Hashs:过小的时候会使用压缩列表、过大的情况容易导致rehash内存浪费,也杜绝返回hgetall,对于小结构体,建议直接使用memcache KV;String:SET的EX/NX等KV扩展指令,SETNX可以用于分布式锁、SETEX聚合了SET+EXPIRE;Sets:类似Hashs,无Value,去重等;尽可能的
PIPELINE指令,但是避免集合过大;避免超大
Value,导致影响其他的读写请求;
参考
Redis 集群中的纪元(epoch)
一万字详解 Redis Cluster Gossip 协议
微信红包系统架构的设计和优化分享
Improving load balancing with a new consistent-hashing algorithm
浅谈分布式存储系统数据分布方法
一致性哈希算法(一)- 问题的提出
高可用Redis:Redis Cluster
CRDT 简介