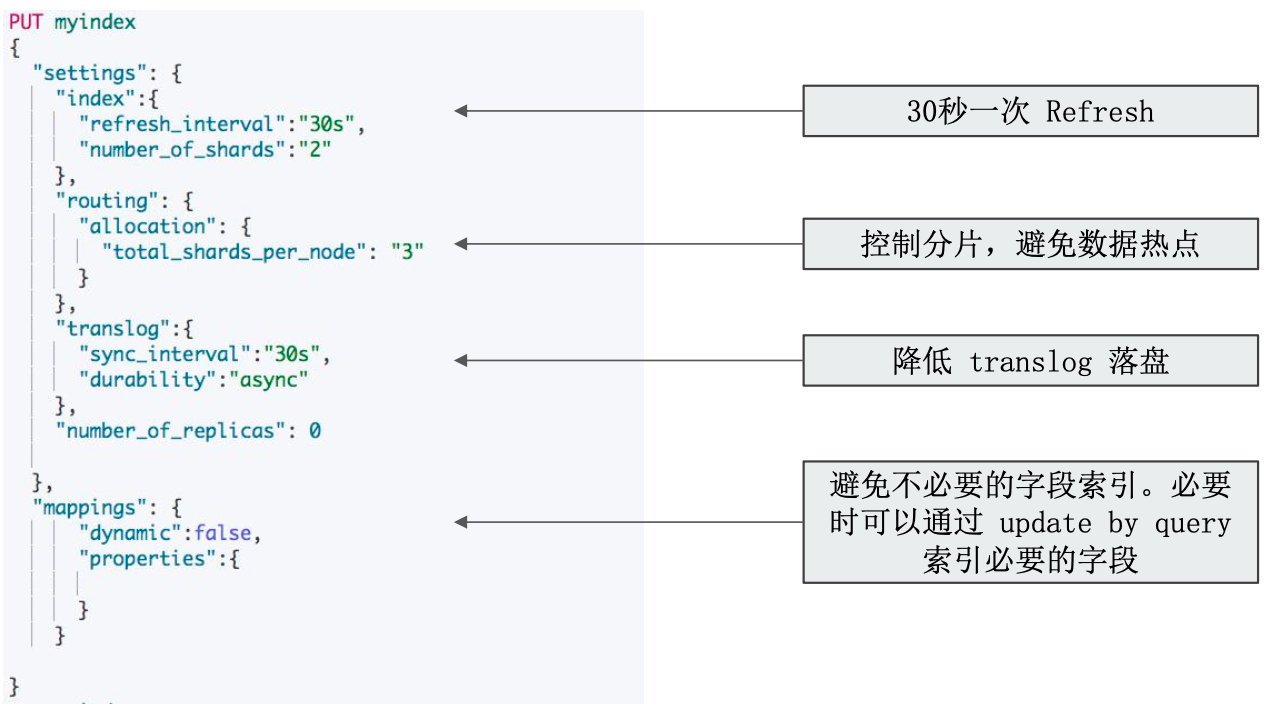
Elasticsearch 集群管理
集群身份认证与用户鉴权
如果 es 安全功能没有打开,很容易引起数据泄露。
- Elasticsearch 在默认安装后,不提供任何形式的安全防护(老版本)
- 错误的配置信息导致公网可以访问 ES 集群
- 在
elasticsearch.yml文件中,server.host被错误的配置为0.0.0.0
- 在
数据安全性的基本需求
- 身份认证
- 鉴定用户是否合法
- 用户鉴权
- 指定那个用户可以访问哪个索引
- 传输加密
- 日志审计
一些免费的方案
设置 Nginx 反向代理,通过 Nginx 实现身份认证功能
安装免费的 Security 插件
- Search Guard:https://search-guard.com/
- ReadOnly REST:https://github.com/sscarduzio/elasticsearch-readonlyrest-plugin
X-Pack 的 Basic 版
从 ES 6.8 & ES 7.0 开始,Security 纳入 x-pack 的 Basic 版本中,免费使用一些基本的功能
https://www.elastic.co/cn/elastic-stack/security
Authentication 身份认证
- 认证体系的几种类型
- 提供用户名和密码
- 提供秘钥或 Kerberos 票据
- Realms: X-Pack 中的认证服务
- 内置 Realms (免费)
- File / Native(用户名密码保存在 Elasticsearch 的索引中)
- 外部 Realms (收费)
- LDAP / Active Directory / PKI / SAML / Kerberos
- 内置 Realms (免费)
RBAC 用户鉴权
RBAC:Role Based Access Control,定义一个角色,并分配一组权限
权限包括索引级,字段级,集群级的不同的操作,然后通过将角色分配给用户,使得用户拥有这些权限
- User: The authenticated User
- Role: A named set of permissions
- Permission:A set of one or more privileges against a secured resource
- Privilege:A named group of 1 or more actions that user may execute against a secured resource
Privilege
- Cluster Privileges
- all / monitor / manager / manage_index / manage_index_template / manage_ rollup
- Indices Privileges
- all / create / create_index / delete / delete_index / index / manage / read / write / view_index_metadata
创建内置的用户和角色

使用 Security API 创建用户

开启并配置 X-Pack 的认证与鉴权
修改配置文件,打开认证与授权
1
./bin/elasticsearch -d -E cluster.name=my_cluster -E node.name=node_1 -E path.data=node_1_data -E xpack.security.enabled=true
创建默认的用户和分组(内置的用户和角色)
1
./bin/elasticsearch-password interactive
当集群开启身份认证之后,配置 Kibana,在 Kibana 的管理页面中创建角色和用户
配置 Kibana
1 | vim config/kibana.yml |
集群内部间的安全通信
加密通讯
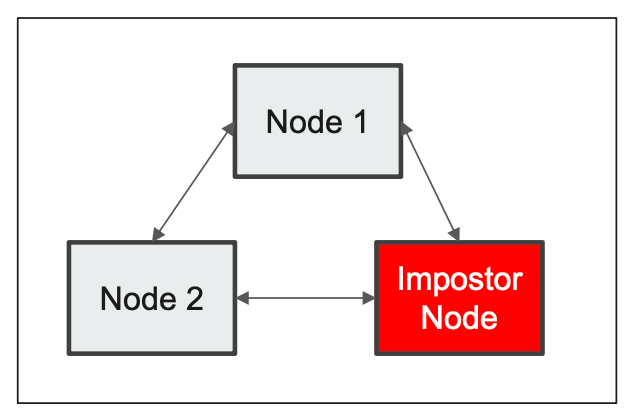
- 加密数据:避免数据抓包,敏感信息泄漏
- 验证身份:避免 Impostor Node (为止来源的节点)
- 否则会泄露 Data / Cluster State
为节点创建证书
- TLS:TLS 协议要求 Trusted Certificate Authority (CA) 签发的 X.509 的证书
- 证书认证的不同级别
- Certificate:节点加入需要使用相同 CA 签发的证书
- Full Verification:节点加入集群需要相同 CA 签发的证书,还需要验证 Host name 或 IP 地址
- No Verification:任何节点都可以加入,开发环境中用于诊断目的
生成节点证书
https://www.elastic.co/guide/en/elasticsearch/reference/8.13/configuring-tls.html
1 | # 创建 ca 文件 |
配置节点间通讯
1 | xpack.security.transport.ssl.enabled: true |
https://www.elastic.co/guide/en/elasticsearch/reference/8.13/security-settings.html#transport-tls-ssl-settings
集群与外部系统的安全通信
明文传输容易被抓包
安全机制需要通过 HTTPS
配置 Elasticsearch for HTTPS
1 | xpack.security.http.ssl.enabled: true |
配置 Kibana 连接 Elasticsearch HTTPS
1 | config/kibana.yml |
配置 HTTS 访问 Kibana
1 | # 基于 ca 给节点签发证书的公钥和私钥 |
常见的集群部署方式
节点类型
不同角色的节点:
- Master eligible:主节点以及备选主节点,用于保存 index 分片信息
- Data:数据节点,用于存放索引
- Ingest:数据预处理
- Coordinating:接受和处理请求
- Machine Learning:机器学习
在开发环境中,一个节点可承担多种角色
在生产环境中, 根据数据量,写入和查询的吞吐量,选择合适的部署方式
建议设置单一角色的节点 (dedicated node)
节点参数配置
一个节点在默认情况会下同时扮演:master eligible, data node 和 ingest node
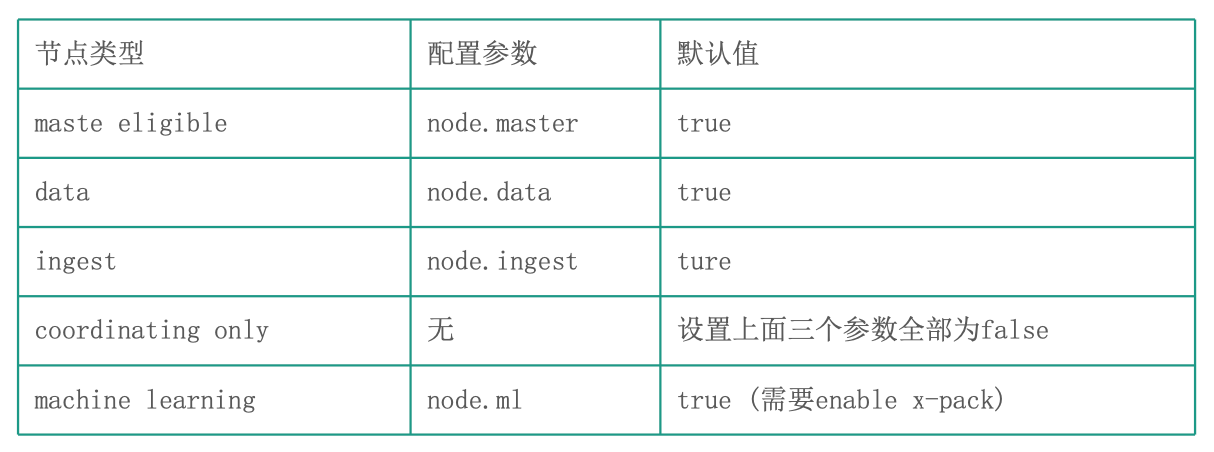
单一职责的节点
一个节点只承担一个角色

单一角色:职责分离的好处
- Dedicated master eligible nodes:负责集群状态(cluster state)的管理
- 使用低配置的 CPU, RAM 和磁盘
- Dedicated data nodes:负责数据存储及处理客户端请求
- 使用高配置的 CPU, RAM 和磁盘
- Dedicated ingest nodes:负责数据处理
- 使用高配置 CPU;中等配置的RAM;低配置的磁盘
Dedicate Coordinating Only Node (Client Node)
配置:将 Master, Data, Ingest 都配置成 False
- Medium/High CUP; Medium/High RAM; Low Disk
生产环境中,建议为一些大的集群配置 Coordinating Only Nodes
- 扮演 Load Balancers,降低 Master 和 Data Nodes 的负载
- 负责搜索结果的 Gather(收集结果) / Reduce(去掉不对的结果)
- 有时候无法预知客户端会发送怎么样的请求
- 大量占用内存的结合操作,一个深度聚合可能会引发 0OM
Dedicate Master Node
从高可用&避免脑裂的角度出发:
- 一般在生产环境中配置3 台
- 一个集群只有1 台活跃的主节点
- 负责分片管理,索引创建,集群管理等操作
如果和数据节点或者 Coordinate 节点混合部署:
- 数据节点相对有比较大的内存占用
- Coordinate 节点有时候可能会有开销很高的查询,导致 00M
- 这些都有可能影响 Master 节点,导致集群的不稳定
基本部署:增加节点,水平扩展
当磁盘容量无法满足需求时,可以增加数据节点: 磁盘读写压力大时,增加数据节点

水平扩展:Coordinating Only Node
当系统中有大量的复杂查询及聚合时候,增加 Coordinating 节点,增加查询的性能

读写分离

在集群中部署 Kibana
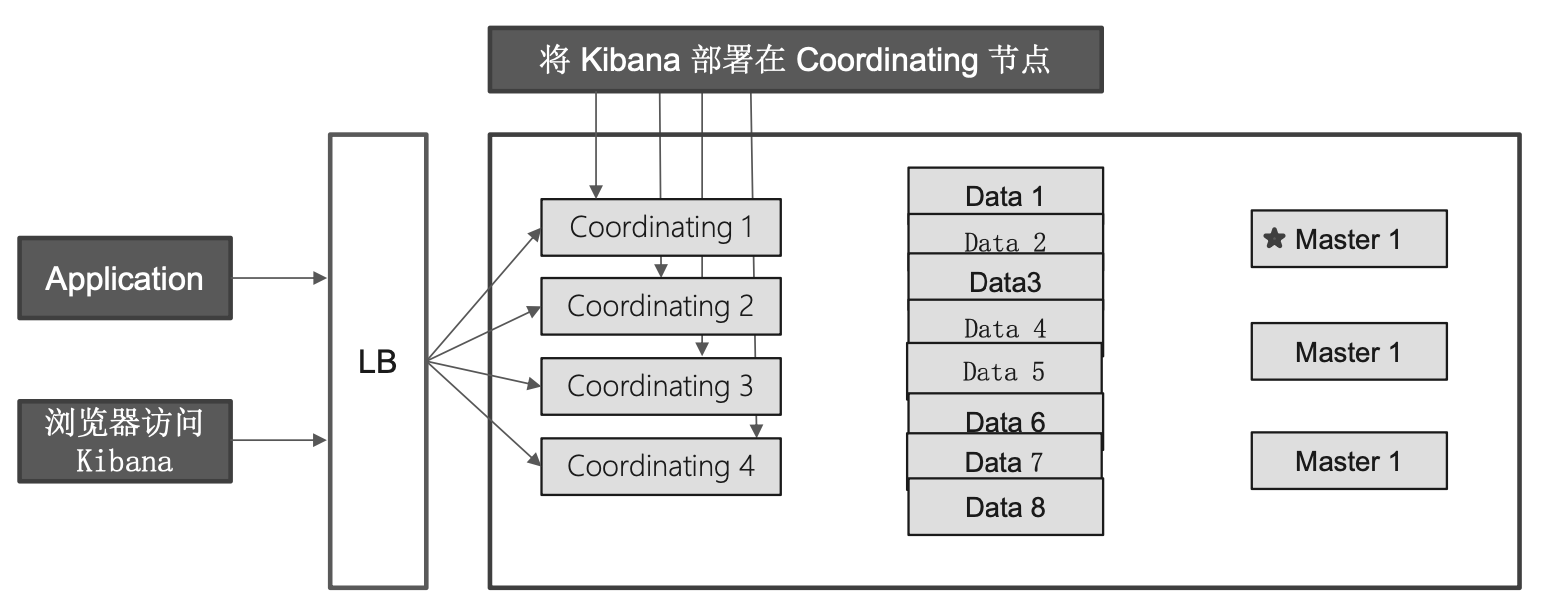
异地多活的部署
集群处在三个数据中心;数据三写;GTM 分发读请求

Hot & Warm 架构与 Shard Filtering
日志类应用的部署架构:
通过不同的硬件配置,存放热点数据和冷数据
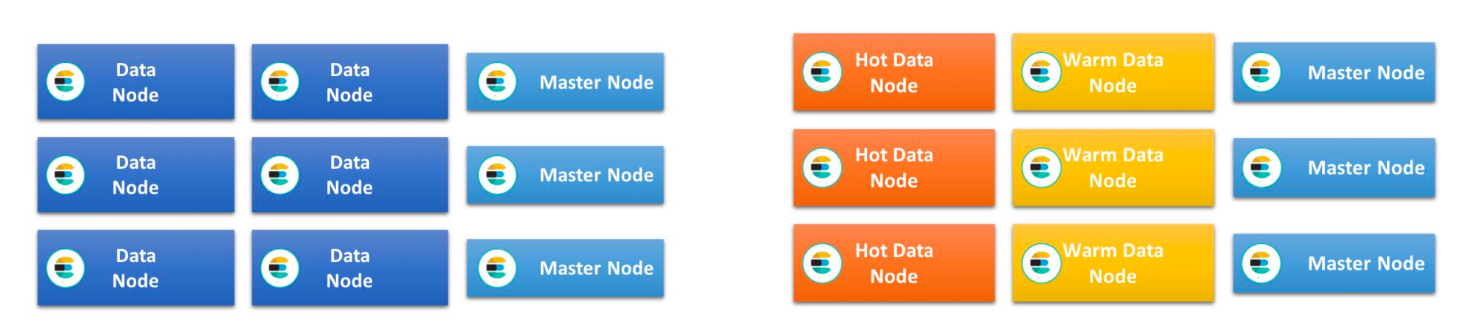
Hot & Warm Architecture
Hot & Warm Architecture :
- 数据通常不会有 Update 操作;适用于 Time based 索引数据(生命周期管理),同时数据量比较大的场景。
- 引入 Warm 节点,低配置大容量的机器存放老数据,以降低部署成本
两类数据节点,不同的硬件配置:
- Hot 节点(通常使用 SSD):索引有不断有新文档写入。通常使用 SSD
- Warm 节点(通常使用 HDD):索引不存在新数据的写入;同时也不存在大量的数据查询
Hot Nodes
用于数据的写入:
- Indexing 对 CPU 和 IO 都有很高的要求。所以需要使用高配置的机器
- 存储的性能要好。建议使用 SSD
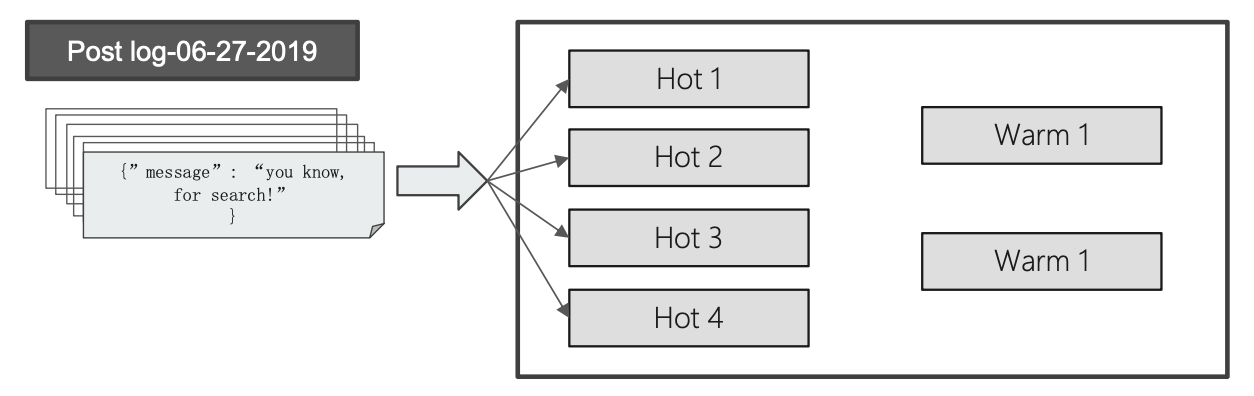
Warm Nodes
用于保存只读的索引,比较旧的数据
- 通常使用大容量的磁盘(通常是 Spining Disks)
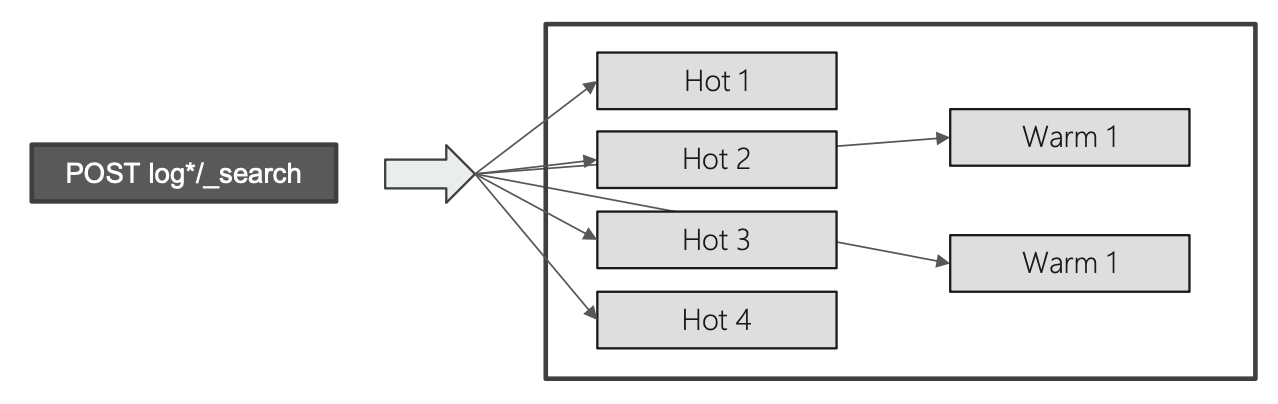
配置 Hot & Warm Architecture
使用 Shard Filtering,步骤分为以下几步:
- 标记节点 (Tagging)
- 配置索引到 Hot Node
- 配置索引到 Warm 节点
标记节点
需要通过 node.attr 来标记一个节点:
- 节点的 attribute 可以是任何的 key/value
- 可以通过
elasticsearch.yml或者通过- E命令指定
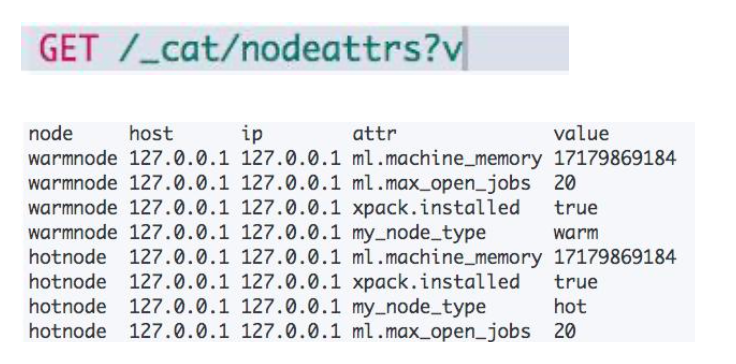
配置 Hot 数据
创建索引时候,指定将其创建在 hot 节点上
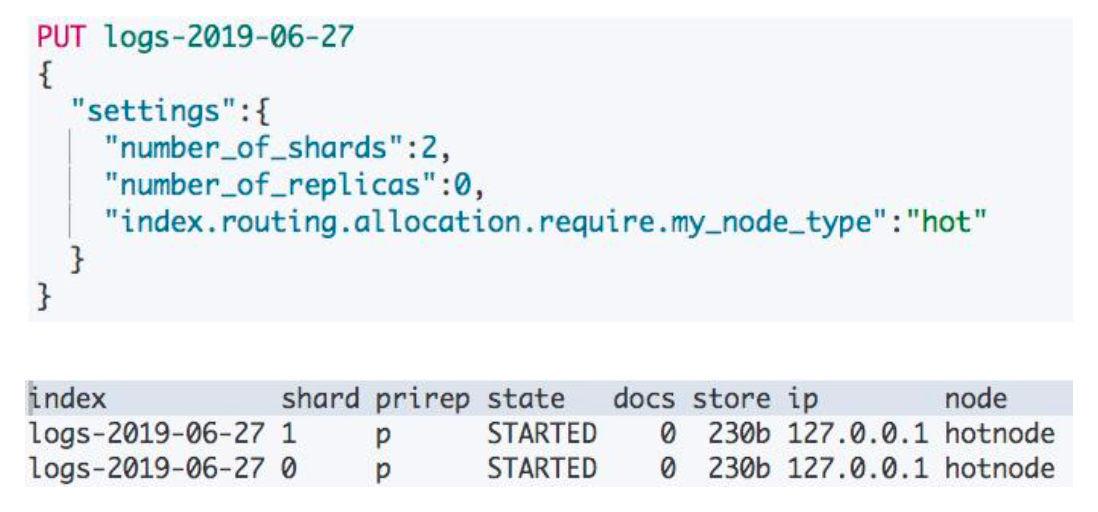
旧数据移动到 Warm 节点
index.routing.allocation 是一个索引级的 dynamic setting,可以通过 API 在后期进行设定:
- Curator / Index Life Cycle Management Tool
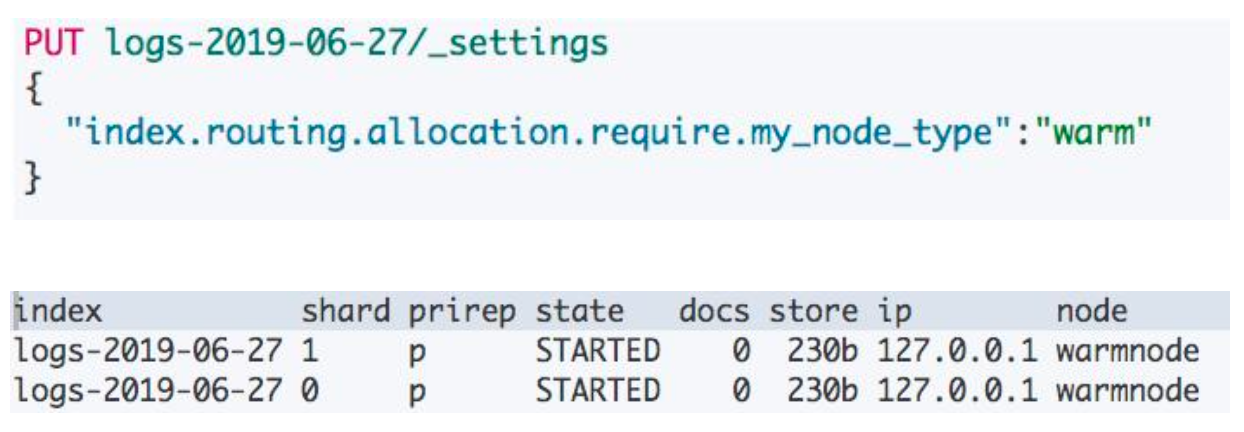
Rack Awareness
ES 的节点可能分布在不同的机架:
- 当一个机架断电,可能会同时丢失几个节点
- 如果一个索引相同的主分片和副本分片,同时在这个机架上,房有可能导致数据的丢失
- 通过 Rack Awareness 的机制, 就可以尽可能避免将同一个索引的主副分片同时分配在一个机架的节点上
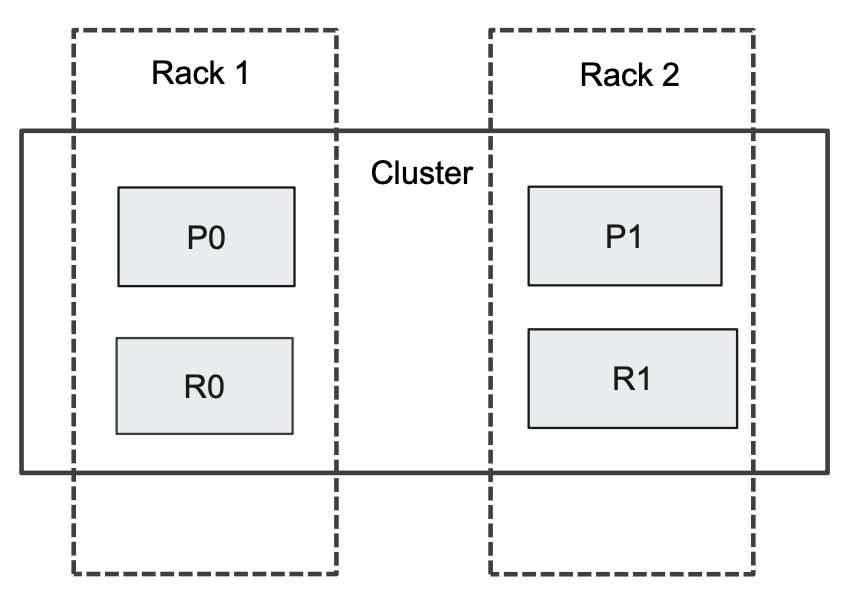
标记 Rack 节点 + 配置集群
1 | ./bin/elasticsearch -d -E cluster.name=my_cluster -E node.name=node_1 -E path.data=node_1_data -E node.attr.my_rack_id=rack1 |
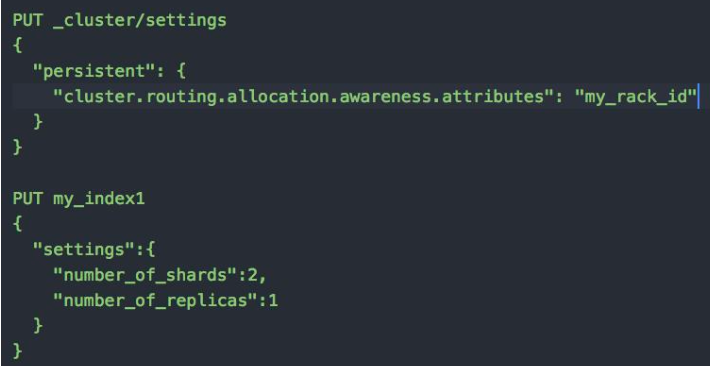
Forced Awareness
当两台机器都在 rack 上时,让主副分片不分配在一个 rack 上。
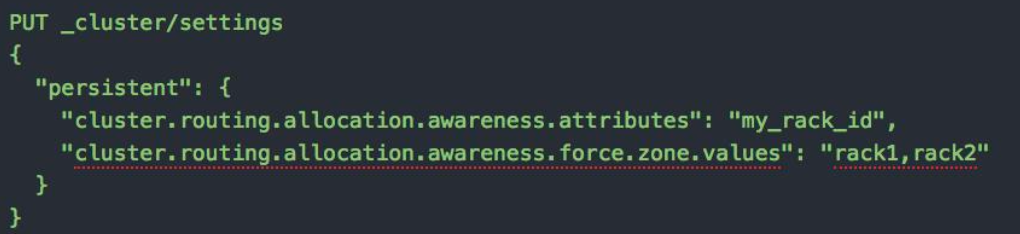
rack1,rack2:代表主副分片要分在这两个 rack 上
当只有 rack1 时,副本分片无法分配
Shard Filtering
node.attr:标记节点index.routing.allocation:分配索引到节点
分片设定及管理
单个分片
- 7.0 开始,新创建一个索引时,默认只有一个主分片(早版本是 5)
- 单个分片,查询算分,聚合不准的问题都可以得以避免
- 单个索引,单个分片时候,集群无法实现水平扩展
- 即使增加新的节点,无法实现水平扩展
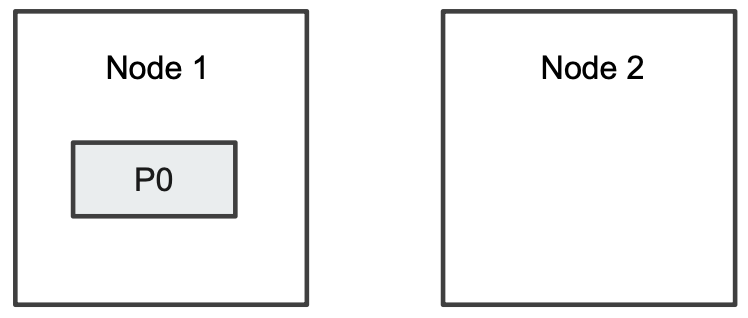
两个分片
- 集群增加一个节点后,Elasticsearch 会自动进行分片的移动,也叫 Shard Rebalancing
如何设计分片数
- 当分片数〉节点数时
- 一旦集群中有新的数据节点加入,分片就可以自动进行分配
- 分片在重新分配时,系统不会有 downtime
- 多分片的好处:一个索引如果分布在不同的节点,多个节点可以并行执行
- 查询可以并行执行
- 数据写入可以分散到多个机器
例如案例1:
- 每天 1 GB 的数据,一个索引一个主分片,一个副本分片
- 需保留半年的数据,接近 360 GB 的数据量,
案例2:
- 5 个不同的日志,每天创建一个日志索引。每个日志索引创建 10 个主分片
- 保留半年的数据
5 * 10 ** 30 * 6 = 9000个分片
分片过多所带来的副作用
- Shard 是 Elasticsearch 实现集群水平扩展的最小单位
- 过多设置分片数会带来一些潜在的问题
- 每个分片是一个 Lucene 的索引,会使用机器的资源。过多的分片会导致额外的性能开销
- Lucene Indices / File descriptors / RAM / CPU
- 每次搜索的请求,需要从每个分片上获取数据
- 分片的 Meta 信息由 Master 节点维护。过多,会增加管理的负担。
- 每个分片是一个 Lucene 的索引,会使用机器的资源。过多的分片会导致额外的性能开销
- 经验值:控制分片总数在 10w 以内
如何确定主分片数
- 从存储的物理角度看
- 日志类应用,单个分片不要大于 50GB
- 搜索类应用,单个分片不要超过 20GB
- 为什么要控制分片存储大小
- 提高 Update 的性能
- Merge 时,减少所需的资源
- 丢失节点后,具备更快的恢复速度 / 便于分片在集群内 Rebalancing
如何确定副本分片数
- 副本是主分片的拷贝
- 提高系统可用性:相应查询请求,防止数据丢失
- 需要占用和主分片一样的资源
- 对性能的影响
- 副本会降低数据的索引速度:有几份副本就会有几倍的 CPU 资源消耗在索引上(也就是创建数据时要写入多份)
- 会减缓对主分片的查询压力,但是会消耗同样的内存资源
- 如果机器资源充分,提高副本数,可以提高整体的查询 QPS
调整分片总数设定,避免分配不均衡
https://www.elastic.co/guide/en/elasticsearch/reference/current/allocation-total-shards.html
ES 的分片策略会尽量保证节点上的分片数大致相同
- 扩容的新节点没有数据,导致新索引集中在新的节点
- 热点数据过于集中,可能会产生新能问题
对集群进行容量规划
容量规划:
- 一个集群总共需要多少个节点?一个索引需要设置几个分片?
- 规划上需要保持一定的余量,当负载出现波动,节点出现丢失时,还能正常运行
- 做容量规划时,一些需要考虑的因素
- 机器的软硬件配置
- 单条文档的尺寸 / 文档的总数据量 / 索引的总数据量(Time base 数据保留的时间)/ 副本分片数
- 文档是如何写入的(Bulk的尺寸)
- 文档的复杂度,文档是如何进行读取的(怎么样的查询和聚合)
评估业务的性能需求
- 数据吞吐及性能需求
- 数据写入的吞吐量,每秒要求写入多少数据?
- 查询的吞吐量?
- 单条查询可接受的最大返回时间?
- 了解你的数据
- 数据的格式和数据的 Mapping
- 实际的查询和聚合长的是什么样的
常见用例
- 搜索:固定大小的数据集
- 搜索的数据集增长相对比较缓慢
- 日志:基于时间序列的数据
- 使用 ES 存放日志与性能指标。数据每天不断写入,增长速度较快
- 结合 Warm Node 做数据的老化处理
硬件配置
- 选择合理的硬件,数据节点尽可能使用 SSD
- 搜索等性能要求高的场景,建议 SSD
- 按照
1:10的比例配置内存和硬盘
- 按照
- 日志类和查询并发低的场景,可以考虑使用机械硬盘存储
- 按照
1:50的比例配置内存和硬盘
- 按照
- 单节点数据建议控制在 2TB 以内,最大不建议超过 5TB
- JM 配置机器内存的一半,JVM 内存配置不建议超过 32G
部署方式
- 按需选择合理的部署方式
- 如果需要考虑可靠性高可用,建议部署 3 台 dedicated 的 Master 节点
- 如果有复杂的查询和聚合,建议设置 Coordinating 节点
一些案例
案例 1:唱片信息库 / 产品信息
- 一些特性
- 被搜索的数据集很大,但是增长相对比较慢(不会有大量的写入)。更关心搜索和聚合的读取性能
- 数据的重要性与时间范围无关。关注的是搜索的相关度
- 估算索引的的数据量,然后确定分片的大小
- 单个分片的数据不要超过 20 GB
- 可以通过增加副本分片,提高查询的吞吐量
解决方案:拆分索引
- 如果业务上有大量的查询是基于一个字段进行 Filter,该字段又是一个数量有限的枚举值
- 例如订单所在的地区
- 如果在单个索引有大量的数据,可以考虑将索引拆分成多个素引
- 查询性能可以得到提高
- 如果要对多个索引进行查询,还是可以在查询中指定多个索引得以实现
- 如果业务上有大量的查询是基于一个字段进行 Filter,该字段数值并不固定
- 可以启用 Routing 功能,按照 filter 字段的值分布到集群中不同的 shard,降低查询时相关的 shard, 提高 CPU 利用率
案例 2:基于时间序列的数据
- 相关的用案
- 日志 / 指标 / 安全相关的 Events
- 與情分析
- 一些特性
- 每条数据都有时间戳;文档基本不会被更新(日志和指标数据)
- 用户更多的会查询近期的数据;对旧的数据查询相对较少
- 对数据的写入性能要求比较高
解决方案:创建基于时间序列的索引
- 创建 time-based 索引
- 在索引的名字中增加时间信息
- 按照每天 / 每周 / 每月的方式进行划分
- 带来的好处
- 更加合理的组织索引,例如随着时间推移,便于对索引做的老化处理
- 利用 Hot & Warm Architecture
- 备份和删除以及删除的效率高。( Delete By Query 执行速度慢,底层不也不会立刻释放空间,而 Merge 时又很消耗资源)
- 更加合理的组织索引,例如随着时间推移,便于对索引做的老化处理
写入时间序列的数据:基于 Date Math 的方式
- 优势:容易使用
- 劣势:如果时间发生变化,需要重新部署代码
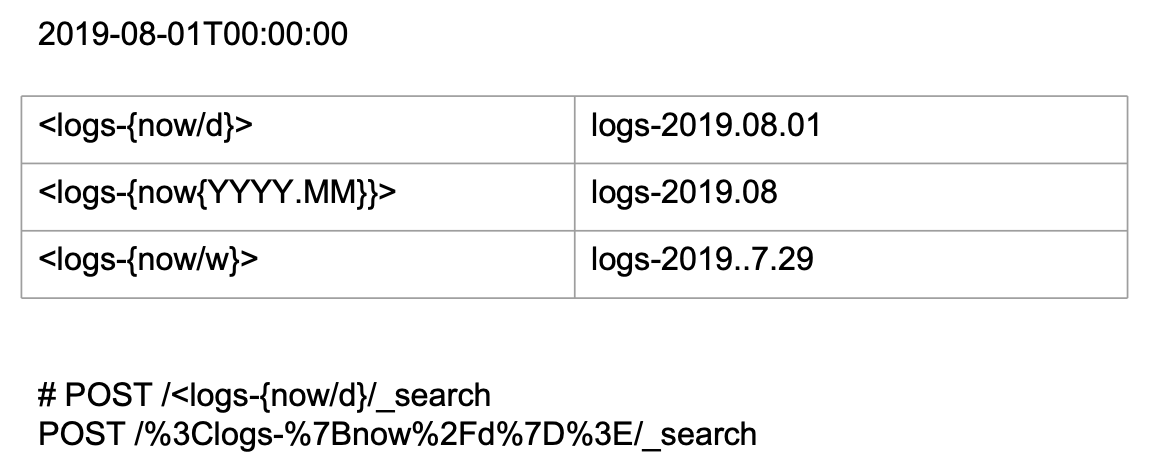
写入时间序列的数据:基于 Index Alias
Time-based 索引
- 创建索引,每天 / 每周 / 每月
- 在索引的名字中增加时间信息
- 需要每天执行一下命令,创建新的 Index,设置 alias

集群扩容
- 增加 Coordinating / Ingest Node
- 解决 CPU 和内存开销的问题
- 增加数据节点
- 解决存储的容量的问题
- 为避免分片分布不均的问题,要提前监控磁盘空间,提前清理数据或增加节点(70%)
在私有云上管理 Elasticsearch 的一些方法
管理单个集群
- 集群容量不够时,需手工增加节点
- 有节点丢失时,手工修复或更换节点
- 确保 Rack Awareness
- 集群版本升级;数据备份;滚动升级
- 完全手动,管理成本高
- 无法统一管理,例如整合变更管理等
手动操作管理成本比较高
https://www.elastic.co/cn/pricing

ECE
Elastic Cloud Enterprise:帮助你管理多个 Elasticsearch 集群
https://www.elastic.co/cn/ece
- 通过单个控制台,管理多个集群
- 支持不同方式的集群部署(支持各类部署) / 跨数据中心 / 部署 Anti Affinity
- 统一监控所有集群的状态
- 图形化操作
- 增加删除节点
- 升级集群
- 滚动更新
- 自动数据备份
基于 Kubernetes 的方案
- 基于容器技术,使用 Operator 模式进行编排管理
- 配置,管理监控多个集群
- 支持 Hot & Warm
- 数据快照和恢复
https://www.elastic.co/cn/elastic-cloud-kubernetes

Kubernetes CRD
https://www.elastic.co/cn/downloads/elastic-cloud-kubernetes
构建自己的管理系统
- 基于虚拟机的编排管理方式
- Puppet Infrastructure(Puppet / Elasticsearch Puppet Module / Foreman)
- Workflow based Provision & Management
- 基于 Kubernetes 的容器化编排管理方式
- 基于 Operator 模式
- Kubernetes 一 Customer Resource Definition
将 Elasticsearch 部署在 Kubernetes
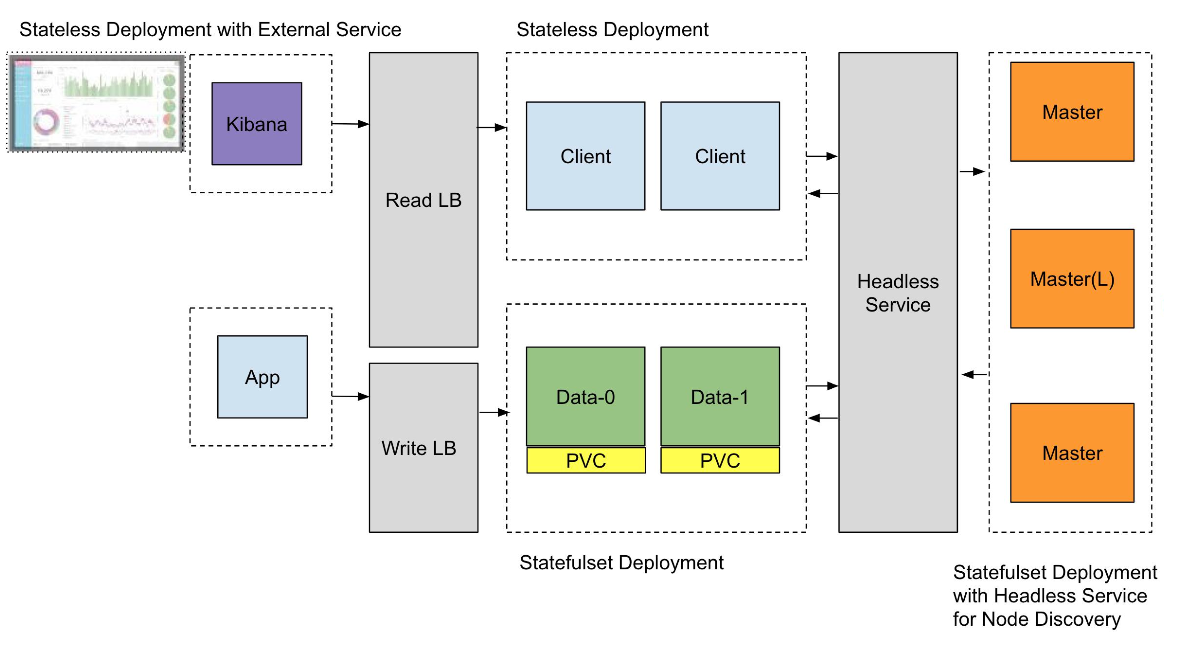
Kubernetes Operator 模式
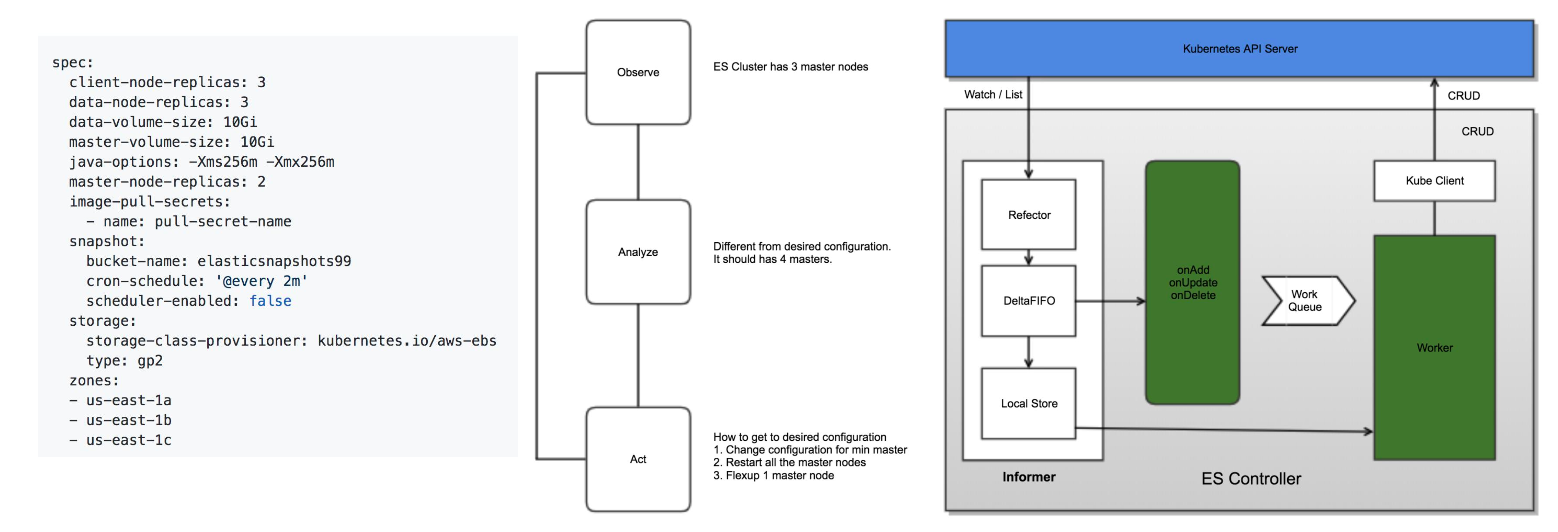
Operator SDK
https://github.com/operator-framework/operator-sdk
在公有云上管理与部署 Elasticsearch
Elastic Cloud
Elastic Cloud 可以免费试用
https://www.elastic.co/cn/cloud
国内也有公有云产商支持。
https://www.aliyun.com/product/bigdata/elasticsearch
https://cloud.tencent.com/product/es
理解集群的配置
- 基于虚拟机的编排管理方式
- Puppet Infrastructure (Puppet / Elasticsearch Puppet Module / Foreman)
- Workflow based Provision & Management
- 基于 Kubernetes 的容器化编排管理方式
- 基于 Operator 模式
- Kubernetes 一 Customer Resource Definition
生产环境常用配置和上线清单
Development vs. Production Mode
从 ES 5 开始,支持 Development 和 Production 两种运行模式
- 开发模式
- 生产模式
Bootstrap Checks
- 一个集群在 Production Mode 时,启动时必须通过所有 Bootstrap 检测,否则会启动失败
- Bootstrap Checks 可以分为两类:JVM & Linux Checks
- Linux Checks 只针对 Linux 系统

https://www.elastic.co/guide/en/elasticsearch/reference/master/bootstrap-checks.html
JVM 设定
- 从ES6开始,只支持 64 位的 JVM
- 配置
config / jvm.options
- 配置
- 避免修改默认配置
- 将内存 Xms 和 Xmx 设置成一样,避免 heap resize 时引发停顿
- Xmx 设置不要超过物理内存的 50%(剩下的 50% 会交给 Lucene 进行全文检索);单个节点上,最大内存建议不要超过 32 G 内存:A Heap of Trouble: Managing Elasticsearch’s Managed Heap
- 生产环境,JVM 必须使用 Server 模式
- 关闭 JVM Swapping
集群的 API 设定
静态设置和动态设定
- 静态配置文件尽量简洁;按照文档设置所有相关系统参数。
elasticsearch.yml配置文件中尽量只写必备参数,一些特殊参数可以通过命令行指定
其他的设置项可以通过 API 动态进行设定。
- 动态设定分 transient 和 persistent 两种, 都会覆盖 elasticsearch.yaml 中的设置
- Transient 在集群重启后会丢失
- Persistent 在集群中重启后不会丢失
- 动态设定分 transient 和 persistent 两种, 都会覆盖 elasticsearch.yaml 中的设置

四中配置的优先级,优先级越小约高,高优先级的设置可以覆盖低优先级设置

系统设置
参照文档 Important System Configuration

最佳实践
网络
- 单个集群不要跨数据中心进行部署(不要使用 WAN)
- 节点之间的 hops 越少越好
- 如果有多块网卡,最好将 transport 和 http 绑定到不同的网卡,并设置不同的防火墙 Rules
- 按需为 Coordinating Node 或 Ingest Node 配置负载均衡
内存设定计算实例
- 内存大小要根据 Node 需要存储的数据来进行估算
- 搜索类的比例建议: 1:16
- 日志类: 1:48 - 1:96 之间
- 总数据量 1T, 设置一个副本 = 2T 总数据量
- 如果搜索类的项目,每个节点
31G * 16 = 496G( 1 个分片最大的硬盘容量),加上预留空间。所以每个节点最多 400G 数据,至少需要 5 个数据节点 - 如果是日志类项目,每个节点
31G * 50 = 1550GB( 1 个分片最大的硬盘容量),2 个数据节点即可
- 如果搜索类的项目,每个节点
存储
推荐使用 SSD,使用本地存储(Local Disk)。避免使用 SAN / NFS / AWS / Azure filesystem
可以在本地指定多个
path.data,以支持使用多块磁盘ES 本身提供了很好的 HA 机制;无需使用 RAID 1/5/10
可以在 Warm 节点上使用 Spinning Disk,但是需要关闭 Concurrent Merges
index.merge.scheduler.max_thread_count: 1Trim 你的 SSD(调优):Is your Elasticsearch “Trimmed”?
服务器硬件
- 建议使用中等配置的机器,不建议使用过于强劲的硬件配置
- Medium machine over large machine
- 不建议在一台服务器上运行多个节点(避免节点故障产生较大影响)
集群设置
Throttles 限流
- 为 Relocation 和 Recovery 设置限流,避免过多任务对集群产生性能影响
- Recovery
- 用于控制在集群中同时进行的分片恢复操作的并发数量:
cluster.routing.allocation.node_concurrent_recoveries: 2
- 用于控制在集群中同时进行的分片恢复操作的并发数量:
- Relocation
- 用于控制在集群中同时进行的分片重新平衡(rebalance)操作的并发数量:
cluster.routing.allocation.cluster_concurrent_rebalance: 2
- 用于控制在集群中同时进行的分片重新平衡(rebalance)操作的并发数量:
关闭 Dynamic Indexes
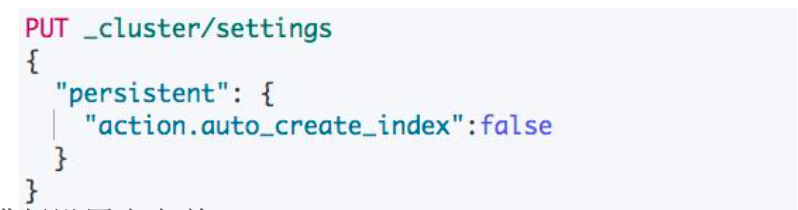
动态索引(Dynamic Indexes)是指在 Elasticsearch 中,索引可以根据文档的属性自动创建而无需预先定义索引的映射。
关闭动态索引的目的是避免数据写入时自动创建索引对集群产生的影响
可以考虑关闭动态索引创建的功能(创建 Index 需要手动设置 mapping)
![image-20240330174144556]()
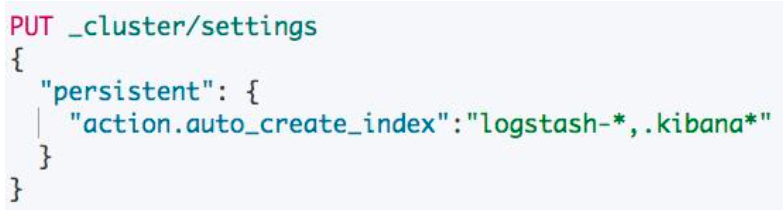
或者通过模版设置白名单
![image-20240330174157492]()
安全设定
- 为 Elasticsearch 和 Kibana 配置安全功能
- 打开 Authentication & Authorization
- 实现索引和和字段级的安全控制
- 节点间通信加密
- Enable HTTPS
- Audit logs:https://www.elastic.co/guide/en/elasticsearch/reference/current/enable-audit-logging.html#enable-audit-logging
监控 Elasticsearch 集群
Elasticsearch Stats 相关的 API
Elasticsearch 提供了多个监控相关的 API
- Node Stats:
_nodes/stats_nodes/thread_pool_nodes/stats/thread_pool_cat/thread_pool?v_nodes/hot_threads
- Cluster Stats:
_cluster/stats - Index Stats:
index_name/_stats
Elasticsearch Task API
- 查看 Task 相关的 API
- Pending Cluster Tasks API:
GET _cluster/pending_tasks - Task Management API:
GET _tasks(可以用来 Cancel 一个 Task)
- Pending Cluster Tasks API:
- 监控 Thread Pools
GET _nodes/thread_poolGET _nodes/stats/thread_poolGET _cat/thread_pool?vGET _nodes/hot_threads
The Index & Query Slow Log
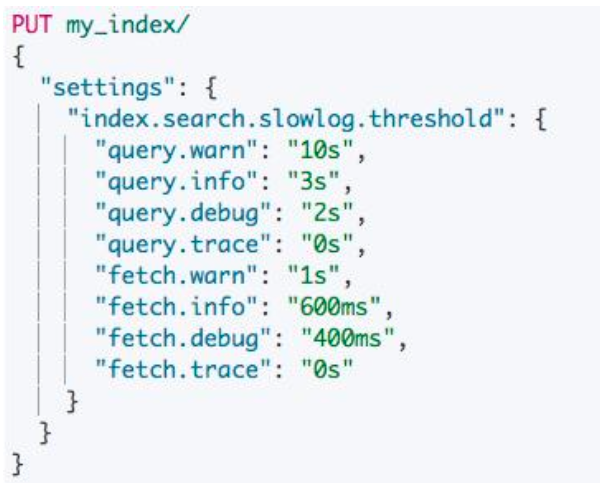
- 支持将分片上, Search 和 Fetch 阶段的慢 查询写入文件
- 支持为 Query 和 Fetch 分别定义阈值
- 索引级的动态设置,可以按需设置,或者通过 Index Template 统一设定
- Slog log 文件通过
log4j2.properties配 置
创建监控 Dashboard
- 开发 Elasticsearch plugin,通过读取相关的监控 API,将数据发送到 ES,或者 TSDB
- 使用 Metricbeats 搜集相关指标
- 使用 Kibana 或 Grafana 创建 Dashboard
- 可以开发 Elasticsearch Exporter,通过 Prometheus 监控 Elasticsearch 集群
诊断集群的潜在问题
集群运维所面临的挑战
- 用户集群数量多,业务场景差异大
- 使用与配置不当,优化不够
- 如何让用户更加高效和正确的使用 ES
- 如何让用户更全面的了解自己的集群的使用状况
- 发现问题滞后,需要防患于未然
- 需要 “有迹可循”,做到 “有则改之,无则加勉”
- Elastic 有提供 Support Diagnostics Tool:https://github.com/elastic/support-diagnostics,当集群出现问题时,通过运行命令收集指标,帮助对问题进行定位和诊断
集群绿色
集群绿色并不意味着足够好:
- 绿色只是其中一项指标。显示分片是否都已正常分配
- 监控指标多并且分散
- 指标的含义不够明确直观
- 问题分析定位的门槛较高
- 需要具备专业知识
指标分析的好处:
- 防患于未然,避免集群奔溃
- Master 节点 / 数据节点当机:负载过高,导致节点失联
- 副本丢失,导致数据可靠性受损
- 集群压力过大,数据写入失败
- 提升集群性能
- 数据节点负载不均衡(避免单节点瓶颈) / 优化分片,segment 合并
- 规范操作方式(利用别名 / 避免 Dynamic Mapping 引发过多字段,对索引的合理性进行管控)
诊断工具的作用
https://gitcode.com/elastic/support-diagnostics/overview#run-requirements?utm_source=csdn_github_accelerator
集群中索引的诊断内容:
- 索引的总数是否过大
- 是否存在字段过多的情况
- 索引的分片个数是否设置合理
- 单个节点的分片数是否过多
- 数据节点之间的负载偏差是否过大
- 冷热数据分配是否正确(例如,Cold 节点上的索引是否设置成只读)
可以得到判断:
- 集群健康状态,是否有节点丢失
- 索引合理性
- 索引总数不能过大 / 副本分片尽量不要设置为 0 / 主分片尺寸检测 / 索引的字段总数(Dynamic Mapping 关闭) / 索引是否分配不均衡 / 索引 segment 大小诊断分析
- 资源使用合理性
- CPU 内存和 磁盘的使用状况分析 / 是否存在节点负载不平衡 / 是否需要增加节点
- 业务操作合理性
- 集群状态变更频率,是否在业务高峰期有频繁操作
- 慢查询监控与分析
一些诊断工具
阿里云:https://help.aliyun.com/zh/es/user-guide/overview-4
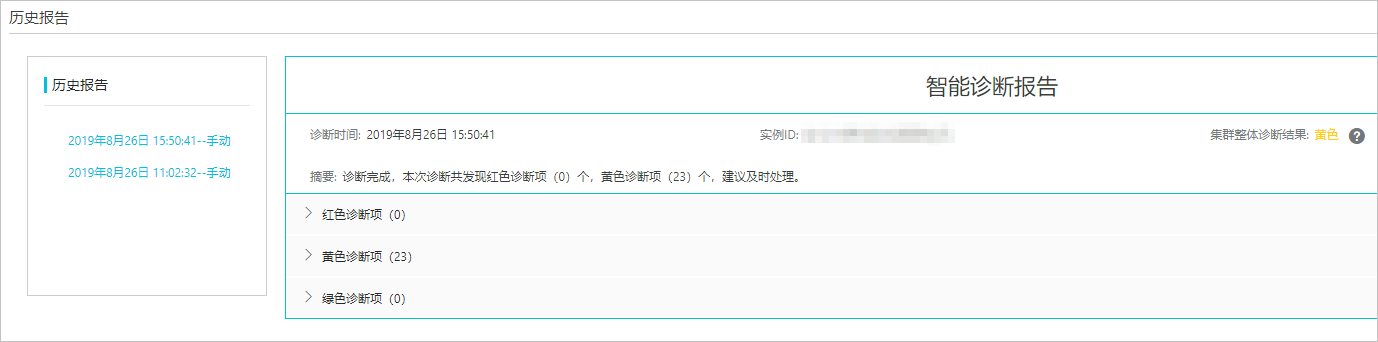
多维度检测,构建自己的诊断工具:
解决集群 Yellow 与 Red 的问题

- 分片健康
- 红:至少有一个主分片没有分配
- 黄:至少有一个副本没有分配
- 绿:主副本分片全部正常分配
- 索引健康: 最差的分片的状态
- 集群健康: 最差的索引的状态
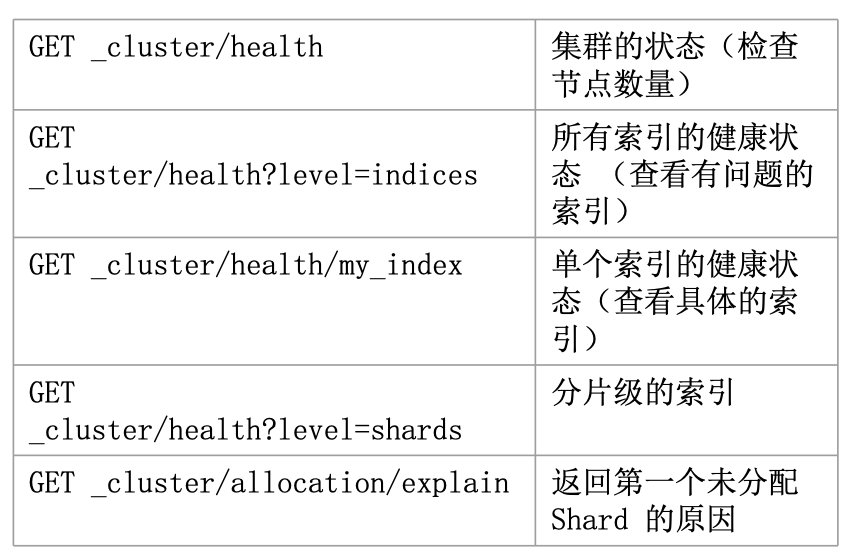
Health 相关的 API
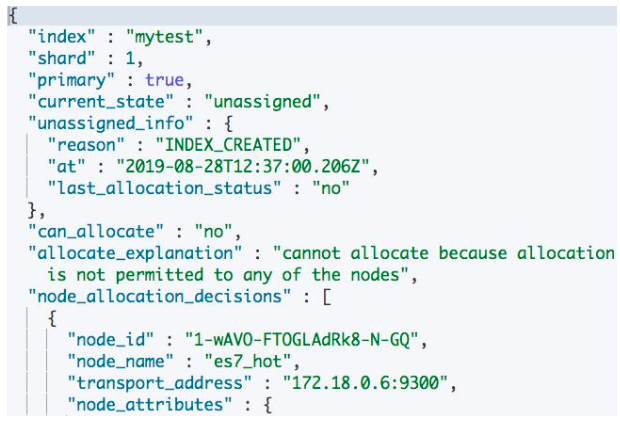
例如有一个分片没有被分配:
集群变红和变黄
比如一些错误的设置,可能会导致索引变红,例如索引无法分配到节点上;也可能会导致变黄,例如副本分片无法分配在主分片所在节点上。
可以先通过 GET _cluster/health?level=indices 定位到具体索引,然后通过 GET _cluster/allocation/explain发现创建索引失败的问题。
分片没有被分配的一些原因
- INDEX_CREATE:创建索引导致。在索引的全部分片分配完成之前,会有短暂的 Red,不一定代表有问题
- CLUSTER_RECOVER:集群重启阶段,会有这个问题
- INDEX_REOPEN:Open 一个之前 Close 的索引
- DANGLING_INDEX_IMPORTED:一个节点离开集群期间,有索引被删除。这个节点重新返回时,会导致 Dangling 的问题(此时将该索引再删除一次即可解决)
更多分片没有被分配的原因:https://www.elastic.co/guide/en/elasticsearch/reference/8.13/cat-shards.html#cat-shards
常见问题与解决方法
- 集群变红,需要检查是否有节点离线。如果有,通常通过重启离线的节点可以解决问题
- 由于配置导致的问题,需要修复相关的配置(例如错误的
affi属性,错误的副本数)- 如果是测试的索引,可以直接删除
- 因为磁盘空间限制,分片规则(Shard Filtering)引发的,需要调整规则或者增加节点
- 对于节点返回集群,导致的 dangling 变红,可直接删除 dangling 索引
问题总结
- Red & Yellow 是集群运维中常见的问题
- 除了集群故障,一些创建,增加副本等操作, 都会导致集群短暂的 Red 和 Yellow,所以监控和报警时需要设置一定的延时
- 通过检查节点数,使用 ES 提供的相关 API, 找到真正的原因
- 可以指定 Move 或者 Reallocate 分片
例如:将分片从一个 node 移动到另外一个 node

集群读写性能优化
集群写性能优化
- 写性能优化的目标:增大写吞吐量(Events Per Second),越高越好
- 客户端:多线程,批量写
- 可以通过性能测试,确定最佳文档数量
- 多线程:需要观察是否有 HTTP 429 返回,实现 Retry 以及线程数量的自动调节
- 服务器端:单个性能问题,往往是多个因素造成的。需要先分解问题,在单个节点上进行调整并且结合测试,尽可能压榨硬件资源,以达到最高吞吐量
- 使用更好的硬件。观察 CPU / IO Block
- 线程切换 / 堆栈状况
服务器端优化写入性能的一些手段
- 降低IO操作
- 使用 ES 自动生成的文档 Id(自己指定 ID 写入时会先有一个 GET 操作)
- 一些相关的 ES 配置,如 Refresh Interval
- 降低 CPU 和存储开销
- 减少不必要分词
- 避免不需要的 doc_values
- 文档的字段尽量保证相同的顺序,可以提高文档的压缩率
- 尽可能做到写入和分片的均衡负载,实现水平扩展
- Shard Filtering
- Write Load Balancer
- 调整 Bulk 线程池和队列
优化写入性能
- ES 的默认设置,已经综合考虑了数据可靠性,搜索的实时性质,写入速度,一般不要盲目修改
- 一切优化,都要基于高质量的数据建模
关闭无关的功能

- 只需要聚合不需要搜索, Index 设置成 false
- 不需要算分, Norms 设置成 false
- 不要对字符串使用默认的 dynamic mapping。字段数量过多,会对性能产生比较大的影响,而且还会产生
keyword的子类型 - Index_options 控制在创建倒排索引时,哪些内容会被添加到倒排索引中。优化这些设置,一定程度可以节约 CPU
- 关闭
_source,减少 IO 操作(适合指标型数据,因此需要平衡)
针对性能的取舍
如果需要追求极致的写入速度,可以牺牲数据可靠性及搜索实时性以换取性能:
- 牺牲可靠性:将副本分片设置为 0,写入完毕再调整回去
- 牺牲搜索实时性:增加 Refresh Interval 的时间
- 牺牲可靠性:修改 Translog 的配置
数据写入的过程
- Refresh:将文档先保存在 Index buffer 中, 以 refresh_interval 为间隔时间,定期清空 buffer,生成 segment,借助文件系统缓存的特性,先将 segment 放在文件系统缓存中,并开放查询,以提升搜索的实时性
- Translog:Segment 没有写入磁盘,即便发生了宕机,重启后,数据也能恢复,ES 6.0 之后默认配置是每次请求都会落盘
- Flush:
- 删除旧的 translog 文件
- 生成 Segment 并写入磁盘
- 更新 commit point 并写入磁盘
- ES 自动完成,可优化点不多
Refresh Interval
降低 Refresh 的频率:
- 增加 refresh_interval 的数值。默认为 1s ,如果设置成 -1 ,会禁止自动 refresh
- 避免过于频繁的 refresh,而生成过多的 segment 文件
- 但是会降低搜索的实时性(文档从写入到能够被搜索到的时间间隔增加)
- 增大静态配置参数
indices.memory.index_buffer_size- 默认是 10%, 会导致自动触发 refresh
Translog
降低写磁盘的频率,但是会降低容灾能力(没有刷盘时宕机,会产生数据丢失):
index.translog.durability:默认是 request,每个请求都落盘。设置成 async,异步写入index.translog.sync_interval设置为 60s,每分钟执行一次index.translog.flush_threshod_size: 默认 512mb,可以适当调大。 当 translog 超过该值,会触发 flush
分片设定
- 副本在写入时设为 0,完成后再增加
- 合理设置主分片数,确保均匀分配在所有数据节点上
index.routing.allocation.total_share_per_node:限定每个索引在每个节点上可分配的总分片数- 5 个节点的集群。 索引有 5 个主分片,1 个副本,应该如何设置?
(5 + 5) / 5 = 2,此时每个索引在每个节点上可分配的总分片数是 2 个,一个主分片,一个副本分片- 生产环境中要适当调大这个数字,避免有节点下线时,分片无法正常迁移
Bulk,线程池和队列大小
- 客户端
- 单个 bulk 请求体的数据量不要太大,官方建议大约 5-15mb
- 写入端的 bulk 请求超时需要足够长,建议 60s 以上
- 写入端尽量将数据轮询打到不同节点。
- 服务器端
- 索引创建属于计算密集型任务,应该使用固定大小的线程池来配置。来不及处理的放入队列,线程数应该配置成 CPU 核心数 +1 ,避免过多的上下文切换
- 队列大小可以适当增加,不要过大,否则占用的内存会成为 GC 的负担
一个索引设定的例子
集群读性能优化
尽量 Denormalize 数据
反规范化数据,可以获得最佳性能
- Elasticsearch != 关系型数据库
- 尽可能 Denormalize 数据,从而获取最佳的性能
- 使用 Nested 类型的数据。查询速度会慢几倍
- 使用 Parent / Child 关系。查询速度会慢几百倍
数据建模
- 尽量将数据先行计算,然后保存到 Elasticsearch 中。尽量避免查询时的 Script 计算
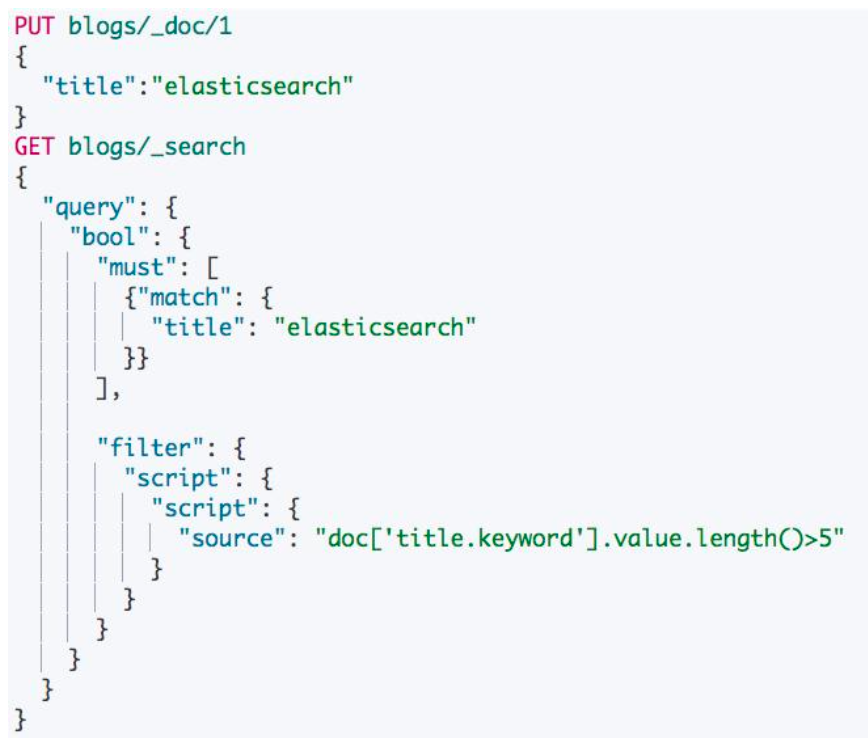
- 尽量使用 Filter Context,利用缓存机制,减少不必要的算分
- 结合 profile,explain API 分析慢查询的问题,持续优化数据模型
- 严禁使用
*开头通配符 Terms 查询
- 严禁使用
避免查询时脚本
可以在 Index 文档时,使用 Ingest Pipeline,计算并写入某个字段
常见的查询性能问题
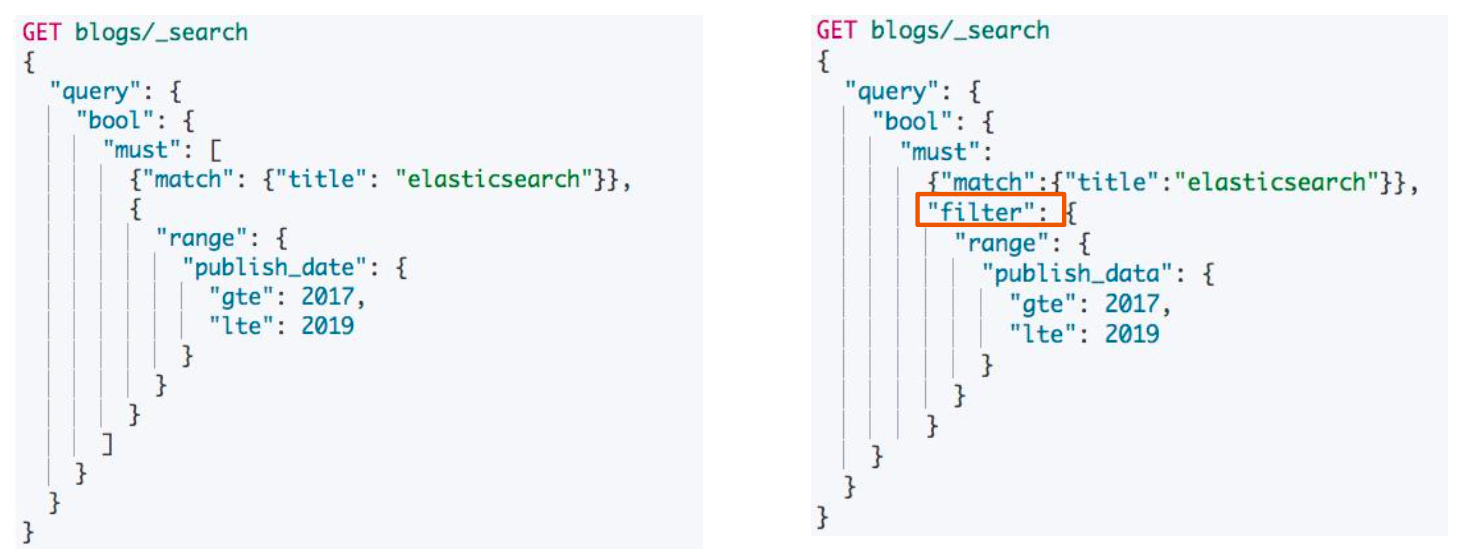
使用 Query Context
使用 filter 进行过滤,通过缓存提高性能
聚合文档消耗内存
- 聚合查询会消耗内存,特别是针对很大的数据集进行聚合运算
- 如果可以控制聚合的数量,就能减少内存的开销
- 当需要使用不同的 Query Scope,可以使用 Filter Bucket

通配符开始的正则表达
通配符开头的正则,性能非常糟糕,需避免使用

优化分片
- 避免 Over Sharing
- 一个查询需要访问每一个分片,分片过多,会导致不必要的查询开销
- 结合应用场景,控制单个分片的尺寸
- Search: 20GB
- Logging: 40GB
- Force-merge Read-only 索引
- 使用基于时间序列的索引,将只读的索引进行 force merge,减少 segment 数量
读性能优化
影响查询性能的一些因素
- 数据模型和索引配置是否优化
- 数据规模是否过大,通过 Filter 减少不必要的数据计算
- 查询语句是否优化
集群压力测试
- 压力测试的目的
- 容量规划 / 性能优化 / 版本间性能比较 / 性能问题诊断
- 确定系统稳定性,考察系统功能极限和隐患
- 压力测试的方法与步骤
- 测试计划(确定测试场景和测试数据集)
- 脚本开发
- 测试环境搭建(不同的软硬件配置) & 运行测试
- 分析比较结果
测试目标 & 测试数据
测试目标:
- 测试集群的读写性能
- 做集群容量规划
- 对 ES 配置参数进行修改,评估优化效果
- 修改 Mapping 和 Setting,对数据建模进行优化,并测试评估性能改进
- 测试 ES 新版本,结合实际场景和老版本进行比较,评估是否进行升级
测试数据:
- 数据量
- 数据分布
测试脚本
ES 本身提供了 REST API,所以,可以通过很多传统的性能测试工具:
- Load Runner (商业软件,支持录制 + 重放 + DSL)
- JMeter (Apache 开源,Record & Play)
- Gatling (开源,支持写 Scala 代码 + DSL)
专门为 Elasticsearch 设计的工具
- ES Pref & Elasticsearch-stress-test
- Elastic Rally
ES Rally
Elastic 官方开源,基于 Python 3 的压力测试工具
- https://github.com/elastic/rally
- 性能测试结果比较: https://elasticsearch-benchmarks.elastic.co/
功能介绍
- 自动创建,配置,运行测试,并且销毁 ES 集群
- 支持不同的测试数据的比较,也支持将数据导入 ES 集群,进行二次分析
- 支持测试时指标数据的搜集,方便对测试结果进行深度的分析
Rally 的安装以及入门
安装运行
- Python3.4+ 和 pip3 / JDK8 / git1.9+
- 运行
pip3 install esrally - 运行 esrally configure
运行
- 运行
esrally –distribution-version=7.1.0 - 运行 1000 条测试数据:
esrally –distribution-version=7.1.0 --test-mode
Rally 基本概念讲解
- Tournament – 定义测试目标,由多个 race 组成
- Esrally list races
- Track – 赛道:测试数据和测试场景与策略
- https://github.com/elastic/rally-tracks
esrally list tracks
- Car– 执行测试方案
- 不同配置的 es 实例
- Award – 测试结果和报告
Benchmark Reports
压测的流程
- Pipeline 指的是压测的一个流程
esrally list pipelines
- 默认的流程
- From-source-complete
- From-source-skip-build
- From-distribution
- Benchmark-only (对已有的集群进行测试)
自定义 & 分布式测试
- Car
- https://esrally.readthedocs.io/en/latest/car.html
- 使用自建的集群
- Track
- 自带的测试数据集: Nyc_taxis 4.5 G / logging 1.2G
- 更多的测试数据集: https://github.com/elastic/rally-tracks
- 分布式测试
- https://esrally.readthedocs.io/en/latest/recipes.html#recipe-distributed-load-driver
实例
比较不同的版本的性能
- 测试
esrally race --distribution-version=6.0.0 --track=nyc_taxis --challenge=append-no-conflicts --user-tag="version:6.0.0”esrally race --distribution-version=7.1.0 --track=nyc_taxis --challenge=append-no-conflicts --user-tag="version:7.1.0"
- 比较结果
esrally list racesesrally compare --baseline=[6.0.0 race] --contender=[7.1.0 race]
比较不同 Mapping 的性能
- 测试
esrally race --distribution-version=7.1.0 --track=nyc_taxis --challenge=append-no-conflicts --user-tag="enableSource:true" --include-tasks="type:index”- 修改:
benchmarks/tracks/default/nyc_taxis/mappings.json,修改_source.enabled为false esrally race --distribution-version=7.1.0 --track=nyc_taxis --challenge=append-no-conflicts --user-tag="enableSource:false" --include-tasks="type:index
- 比较
esrally compare --baseline=[enableAll race] --contender=[disableAll race]
测试现有集群的性能
- 测试
esrally race --pipeline=benchmark-only --target-hosts=127.0.0.1:9200 --track=geonames --challenge=append-no-conflicts
段合并优化及注意事项
Lucene Index 原理回顾:
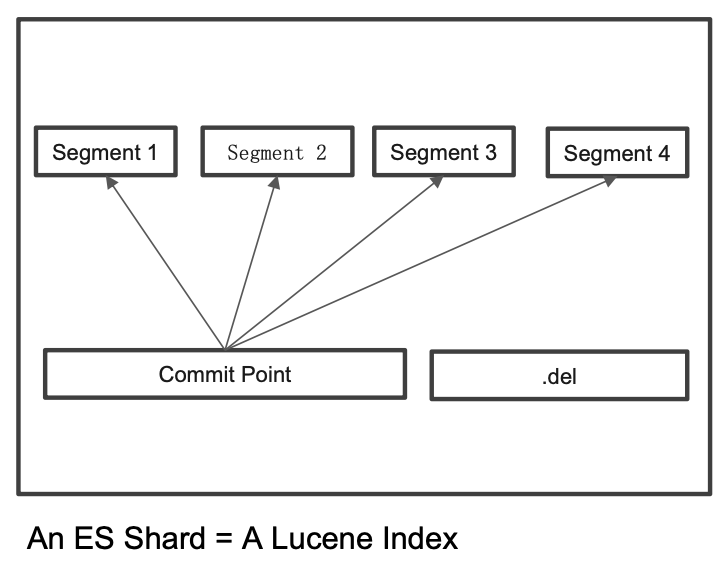
- 在 Lucene 中,单个倒排索引文件被称为 Segment。Segment 是自包含的,不可变更的。 多个 Segments 汇总在一起,称为 Lucene 的 Index,其对应的就是 ES 中的 Shard
- 当有新文档写入时,并且执行 Refresh,就会 会生成一个新 Segment。 Lucene 中有一个文件,用来记录所有 Segments 信息,叫做 Commit Point。查询时会同时查询所有 Segments,并且对结果汇总。
- 删除的文档信息,保存在
.del文件中,查询后会进行过滤。 - Segment 会定期 Merge,合并成一个,同时删除已删除文档
Merge 优化
- ES 和 Lucene 会自动进行 Merge 操作
- Merge 操作相对比较重,需要优化,降低对系统的影响
- 优化点一:降低分段产生的数量 / 频率
- 可以将 Refresh Interval 调整到分钟级别
indices.memory.index_buffer_size(默认是 10%)- 尽量避免文档的更新操作
- 优化点二:降低最大分段大小,避免较大的分段继续参与 Merge,节省系统资源。(最终会有多个分段)
index.merge.policy.segments_per_tier,默认为 10, 越小需要越多的合并操作index.merge.policy.max_merged_segment,默认 5 GB, 操作此大小以后,就不再参与后续的合并操作
Force Merge
- 当 Index 不再有写入操作的时候,建议对其进行 force merge
- 提升查询速度
- 减少内存开销

- 最终分成几个 segments 比较合适?
- 越少越好,最好可以 force merge 成 1 个,但是,Force Merge 会占用大量的网络,IO 和 CPU
- 如果不能在业务高峰期之前做完,就需要考虑增大最终的分段数
- Shard 的大小
index.merge.policy.max_merged_segment的大小
缓存及使用 Circuit Breaker 限制内存使用
Inside the JVM Heap
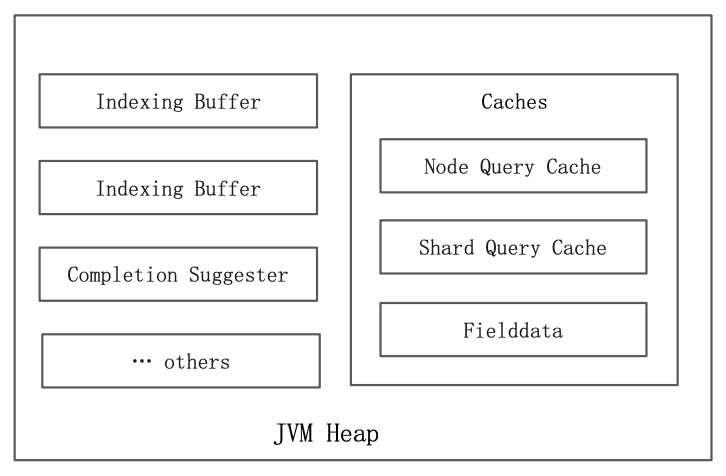
Elasticsearch 的缓存主要分成三大类:
- Node Query Cache (Filter Context)
- Shard Query Cache (Cache Query的结果)
- Fielddata Cache
Node Query Cache
每一个节点有一个 Node Query 缓存
- 由该节点的所有 Shard 共享,只缓存 Filter Context 相关内容
- Cache 采用 LRU 算法
静态配置,需要设置在每个 Data Node 上
- Node Level: indices.queries.cache.size: “10%”
- Index Level:
index.queries.cache.enabled: true
Shard Request Cache
- 缓存每个分片上的查询结果
- 只会缓存设置了
size=0的查询对应的结果。不会缓存 hits。但是会缓存 Aggregations 和 Suggestions
- 只会缓存设置了
- Cache Key
- LRU 算法,将整个 JSON 查询串作为 Key,与 JSON 对象的顺序相关
- 静态配置
- 数据节点:
indices.requests.cache.size: "1%"
- 数据节点:
Fielddata Cache
- 除了 Text 类型,默认都采用
doc_values。节约了内存- Aggregation 的 Global ordinals 也保存在 Fielddata cache 中
- Text 类型的字段需要打开 Fileddata 才能对其进行聚合和排序
- Text 经过分词,排序和聚合效果不佳,建议不要轻易使用
- 配置
- 可以控制
indices.fielddata.cache.size,避免产生 GC (默认无限制)
- 可以控制
缓存失效
- Node Query Cache
- 保存的是 Segment 级缓存命中的结果。Segment 被合并后,缓存会失效
- Shard Request Cache
- 分片 Refresh 时候,Shard Request Cache 会失效。如果 Shard 对应的数据频繁发生变化,该缓存的效率会很差
- Fielddata Cache
- Segment 被合并后,会失效
管理内存的重要性
- Elasticsearch 高效运维依赖于内存的合理分配
- 可用内存一半分配给 JVM,一半留给操作系统,缓存索引文件
- 内存问题,引发的问题
- 长时间 GC,影响节点,导致集群响应缓慢
- OOM, 导致丢节点
诊断内存状况
- 查看各个节点的内存状况
GET _cat/nodes?vGET _nodes/stats/indices?prettyGET _cat/nodes?v&h=name,queryCacheMemory,queryCacheEvictions,requestCacheMemory,requestCacheHitCount,request_cache.miss_countGET _cat/nodes?h=name,port,segments.memory,segments.index_writer_memory,fielddata.memory_size,query_cache.memory_size,request_cache.memory_size&v
一些常见的内存问题
案例 1:Segments 个数过多,导致 full GC
- 现象:集群整体响应缓慢,也没有特别多的数据读写。但是发现节点在持续进行 Full GC
- 分析:查看 Elasticsearch 的内存使用,发现
segments.memory占用很大空间 - 解决:通过 force merge,把 segments 合并成一个。
- 建议:
- 对于不在写入和更新的索引,可以将其设置成只读
- 同时,进行 force merge 操作
- 如果问题依然存在,则需要考虑扩容
- 此外,对索引进行 force merge ,还可以减少对 global_ordinals 数据结构的构建,减少对 fielddata cache 的开销
案例 2:Field data cache 过大,导致 full GC
- 现象:集群整体响应缓慢,也没有特别多的数据读写。但是发现节点在持续进行 Full GC
- 分析:查看 Elasticsearch 的内存使用,发现
fielddata.memory.size占用很大空间。同时,数据不存在写入和更新,也执行过 segments merge。 - 解决:将
indices.fielddata.cache.size设小,重启节点,堆内存恢复正常 - 建议:
- Field data cache 的构建比较重,Elasticsearch 不会主动释放,所以这个值应该设置的保守一些。
- 如果业务上确实有所需要,可以通过增加节点,扩容解决
案例 3:复杂的嵌套聚合,导致集群 full GC
- 现象:节点响应缓慢,持续进行 Full GC
- 分析:导出 Dump 分析。发现内存中有大量 bucket 对象,查看日志,发现复杂的嵌套聚合
- 解决:优化聚合
- 建议:
- 在大量数据集上进行嵌套聚合查询,需要很大的堆内存来完成。
- 如果业务场景确实需要,则需要增加硬件进行扩展。
- 同时,为了避免这类查询影响整个集群,需要设置 Circuit Breaker 和
search.max_buckets的数值
Circuit Breaker
包含多种断路器,避免不合理操作引发的 OOM,每个断路器可以指定内存使用的限制:
- Parent circuit breaker:设置所有的熔断器可以使用的内存的总量
- Fielddata circuit breaker:加载 fielddata 所需要的内存
- Request circuit breaker:防止每个请求级数据结构超过一定的内存(例如聚合计算的内存)
- In flight circuit breaker:Request中的断路器
- Accounting request circuit breaker:请求结束后不能释放的对象所占用的内存
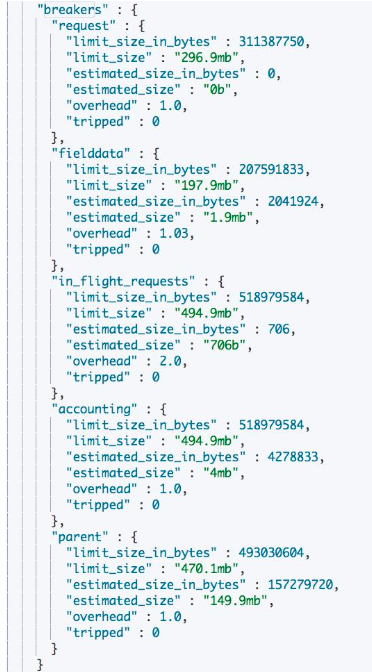
Circuit Breaker 统计信息
通过 GET /_nodes/stats/breaker? 查看所有 Circuit Breaker 的状况
- Tripped 大于 0, 说明有过熔断
- Limit size 与 estimated size 约接近,越可能引发熔断
在实际运维过程中,千万不要触发了熔断,就盲目调大参数,有可能会导致集群出问题,也不因该盲目调小,需要进行评估。
- 建议将集群升级到 7.x,更好的 Circuit Breaker 实现机制
- 增加了
indices.breaker.total.use_real_memory配置项,可以更加精准的分析内存状况,避免 OOM - 使用真实内存断路器提高节点弹性
- 增加了
一些运维相关的建议
集群的生命周期管理
- 预上线
- 评估用户的需求及使用场景
- 数据建模
- 容量规划
- 选择合适的部署架构
- 性能测试
- 上线
- 监控流量
- 定期检查潜在问题 (防患于未然,发现错误的使用方式,及时增加机器)
- 对索引进行优化(Index Lifecycle Management),检测是否存在不均衡而导致有部分节点过热
- 定期数据备份 / 滚动升级
- 下架前监控流量,实现 Stage Decommission
部署的建议
- 根据实际场景,选择合适的部署方式,选择合理的硬件配置
- 搜索类
- 日志/指标
- 部署要考虑,反亲和性(Anti-Affinity)
- 尽量将机器分散在不同的机架。例如,3 台 Master 节点必须分散在不同的机架上
- 善用 Shard Filtering 进行配置
使用要遵循一定的规范
- Mapping:
- 生产环境中索引应考虑禁止 Dynamic Index Mapping,避免过多字段导致 Cluster State 占用过多
- 禁止索引自动创建的功能,创建时必须提供 Mapping 或通过 Index Template 进行设定
- 设置 Slowlogs,发现一些性能不好,甚至是错误的使用 Pattern
- 例如:错误的将网址映射成 keyword,然后用通配符查询。应该使用 Text,结合 URL 分词器
- 严禁一切
*开头的通配符查询
对重要的数据进行备份
如果集群运行在 Cloud 上,云提供商会提供备份功能
- 集群备份
- https://www.elastic.co/guide/en/elasticsearch/reference/8.13/snapshot-restore.html
定期更新到新版本
- ES 在新版本中会持续对性能作出优化、提供更多的新功能
- Circuit breaker 实现的改进
- 修复一些已知的 bug 和安全隐患
ES 的版本
- Elasticsearch 的版本格式是: X.Y.Z
- X: Major
- Y: Minor
- Z: Patch
- Elasticsearch 可以使用上一个主版本的索引,例如:
- 7.x 可以使用 6.x / 7.x 不支持使用 5.x
- 5.x 可以使用 2.x
Rolling Upgrade v.s Full Cluster Restart
对于升级,ES 提供两种方式:
- Rolling Upgrade
- 没有 Downtime
- https://www.elastic.co/guide/en/elastic-stack/8.13/upgrading-elastic-stack.html
- Full Cluster Restart
- 集群在更新期间不可用
- 升级更快
Full Restart 的步骤
- 停止索引数据,同时备份集群
- Disable Shard Allocation (Persistent)
- 执行 Synced Flush
- 关闭并更新所有节点
- 先运行所有 Master 节点 / 再运行其他节点
- 等集群变黄后打开 Shard Allocation

运维时经常使用的命令
移动分片
- 从一个节点移动分片到另外一个节点
- 使用场景:
- 当一个数据节点上有过多 Hot Shards,可以通过手动分配分片到特定的节点解决

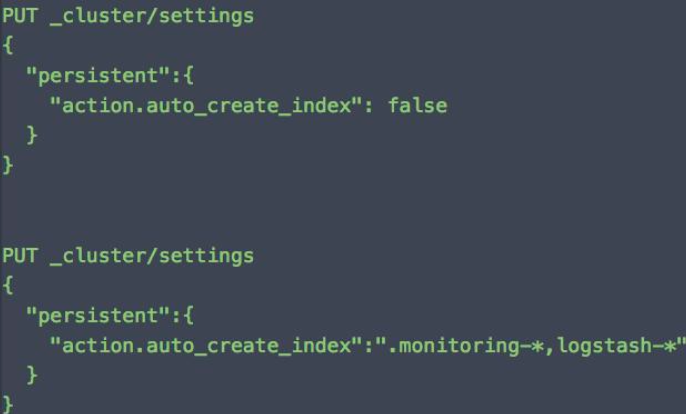
从集群中移除一个节点
使用场景:当你想移除一个节点,或者对一个机器进行维护。同时你又不希望导致集群的颜色变黄或者变红
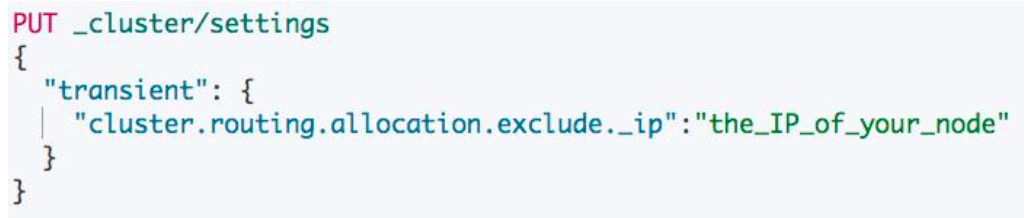
控制 Allocation 和 Recovery
使用场景:控制 Allocation 和 Recovery 的速率

Synced Flush
使用场景:需要重启一个节点。
- 通过 synced flush,可以在索引上放置一个 sync ID。这样可以提供这些分片的 Recovery 的时间

清空节点上的缓存
使用场景:节点上出现了高内存占用。可以执行清除缓存的操作。这个操作会影响集群的性能,但是会避免你的集群出现 OOM 的问题

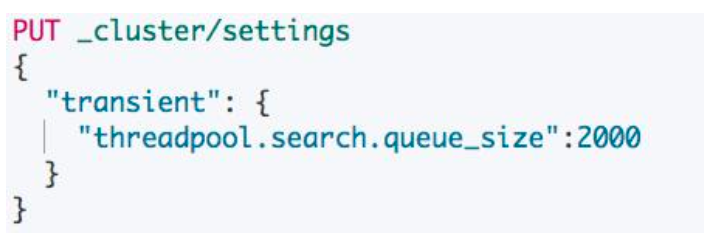
控制搜索的队列
使用场景:当搜索的响应时间过长,看到有 reject 指标的增加,都可以适当增加该数值
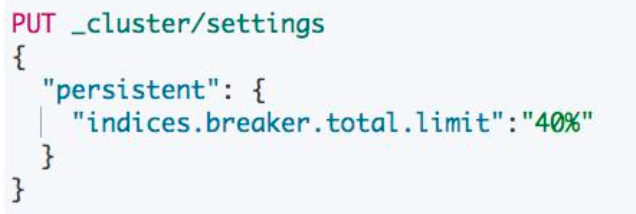
设置 Circuit Breaker
使用场景:设置各类 Circuit Breaker。避免 OOM 的发生。
运维建议
- 了解用户场景,选择合适部署
- 定期检查,发现潜在问题
- 对重要的数据进行备份
- 保持版本升级
使用 Shrink 与 Rollover API 管理索引
索引管理 API:https://www.elastic.co/guide/en/elasticsearch/reference/8.13/indices.html

- Open / Close Index:索引关闭后无法进行读写,但是索引数据不会被删除
- Shrink Index:可以将索引的主分片数收缩到较小的值
- Split Index:可以扩大主分片个数
- Rollover Index:类似 Log4J 记录日志的方式,索引尺寸或者时间超过一定值后,创建新的
- Rollup Index:对数据进行处理后,重新写入,减少数据量
Open / Close Index API
- 索引关闭后,对集群的相关开销基本降低为 0
- 但是无法被读取和搜索
- 当需要的时候,可以重新打开
Shrink API
- ES 5.x 后推出的一个新功能,使用场景
- 索引保存的数据量比较小,需要重新设定主分片数
- 索引从 Hot 移动到 Warm 后,需要降低主分片数
- 会使用和源索引相同的配置创建一个新的索引,仅仅降低主分片数(相比 reindex 的方式性能更好,是以硬链接的方式移动到新索引)
- 源分片数必须是目标分片数的倍数。如果源分片数是素数,目标分片数只能为 1
- 如果文件系统支持硬链接,会将 Segments 硬连接到目标索引,所以性能好
- 完成后,可以删除源索引
https://www.elastic.co/guide/en/elasticsearch/reference/8.13/indices-shrink-index.html

- 分片必须只读
- 所有的分片必须在同一个节点上(使用 affi 设置到一个节点上)
- 集群健康状态为 Green

Split API
https://www.elastic.co/guide/en/elasticsearch/reference/8.13/indices-split-index.html


- 目标索引不得存在。
- 源索引的主分片数量必须少于目标索引。
- 目标索引中的主分片数量必须是源索引中主分片数量的倍数。
- 处理拆分过程的节点必须有足够的空闲磁盘空间来容纳现有索引的第二个副本。
一个时间序列索引的实际场景
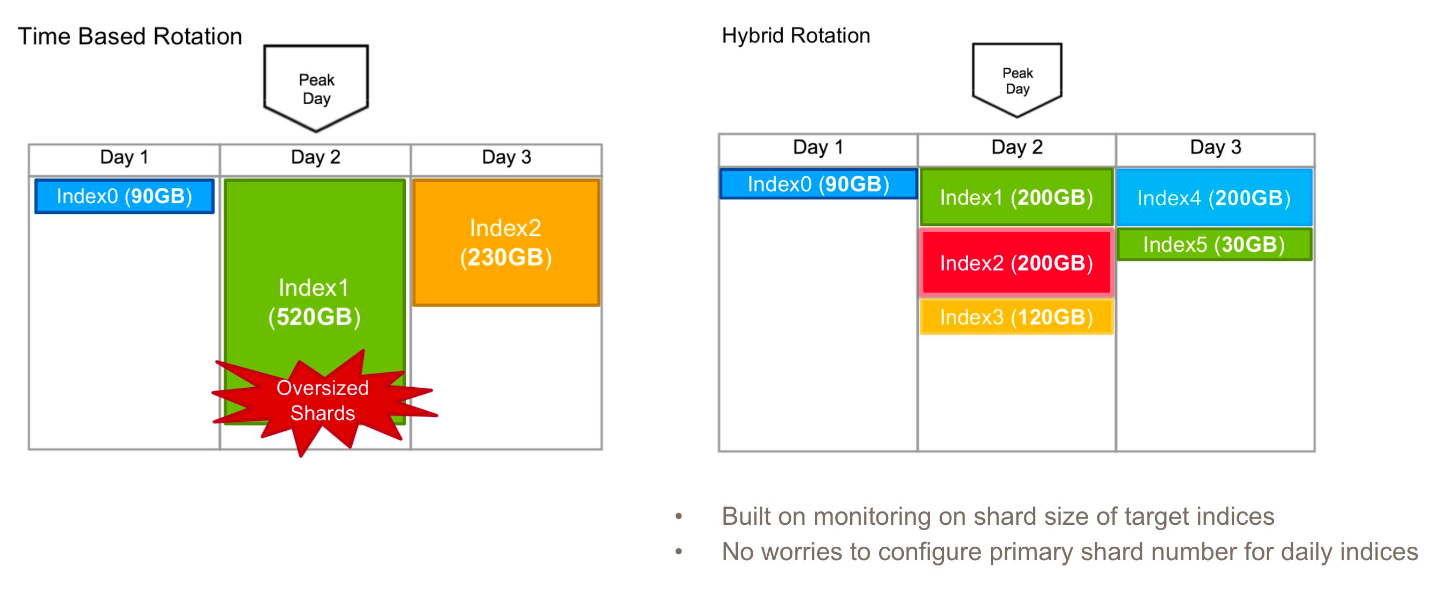
当一个索引超过一定大小时,需要创建下一个索引
Rollover API
当满足一系列的条件,Rollover API 支持将一个 Alias 指向一个新的索引
- 存活的时间
- 最大文档数
- 最大的文件尺寸
应用场景
- 当一个索引数据量过大
一般需要和 Index Lifecycle Management Policies 结合使用
- 只有调用 Rollover API 时,才会去做相应的检测。ES 并不会自动去监控这些索引

索引全生命周期管理及工具介绍
时间序列的索引
- 特点
- 索引中的数据随着时间,持续不断增长
- 按照时间序列划分索引的好处 & 挑战
- 按照时间进行划分索引,会使得管理更加简单。例如,完整删除一个索引,性能比 delete by query 好
- 如何进行自动化管理,减少人工操作
- 从 Hot 移动到 Warm
- 定期关闭或者删除索引
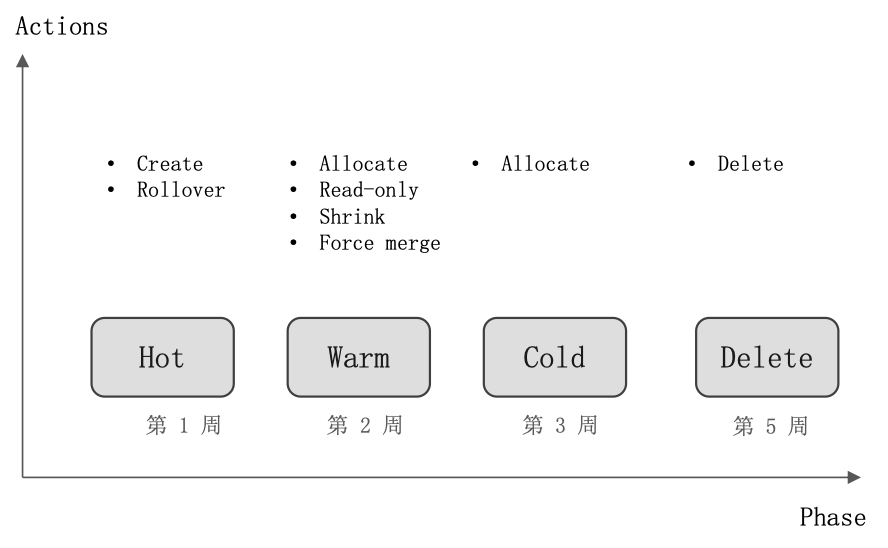
索引生命周期常见的阶段

- Hot: 索引还存在着大量的读写操作
- Warm:索引不存在写操作,还有被查询的需要
- Cold:数据不存在写操作,读操作也不多
- Delete:索引不再需要,可以被安全删除
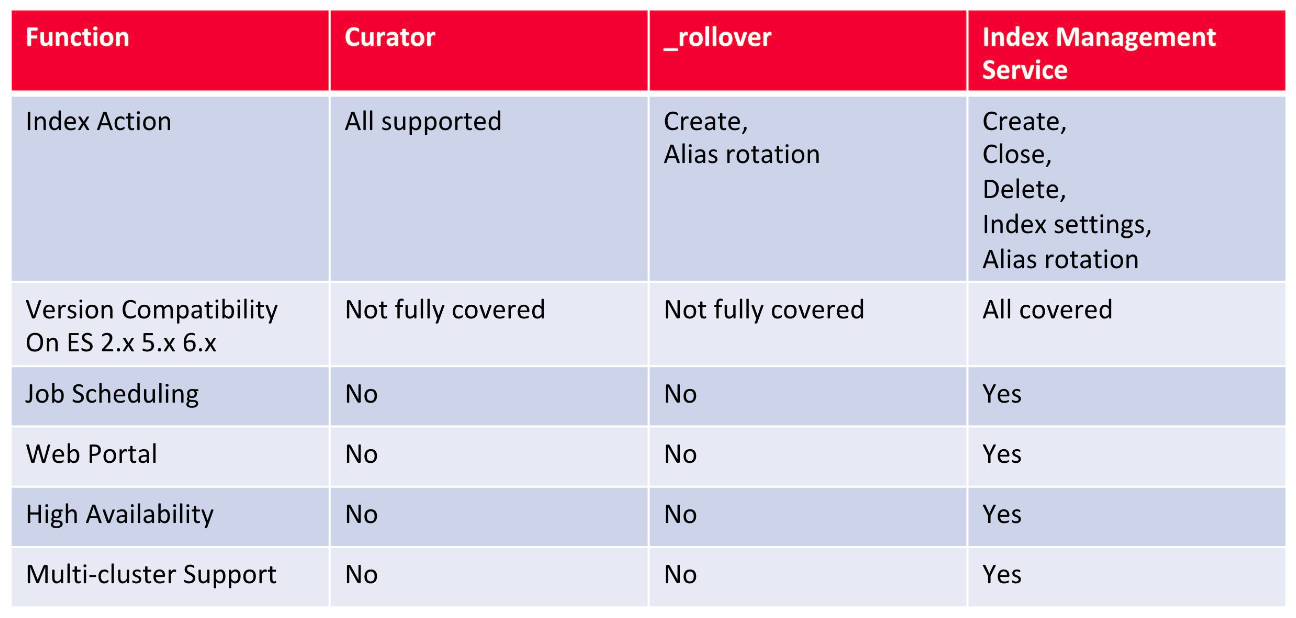
Elasticsearch Curator
https://www.elastic.co/guide/en/elasticsearch/client/curator/current/index.html
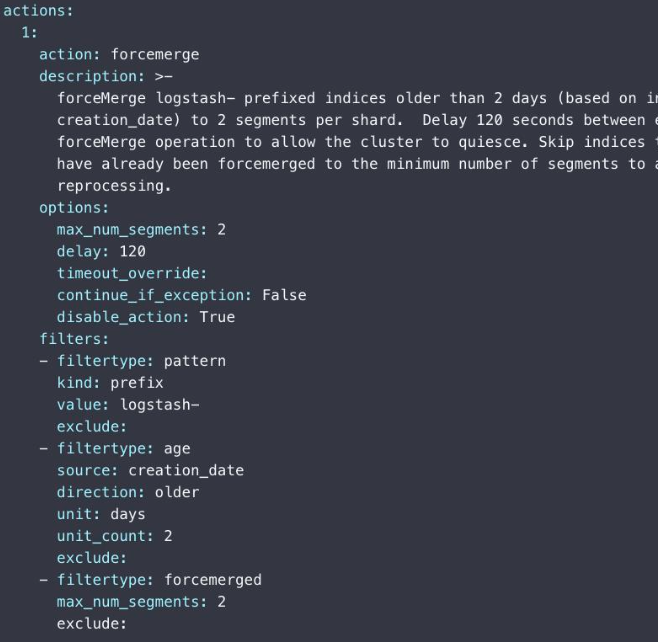
- Elastic 官方推出的工具
- 基于 python 的命令行工具
- 配置 Actions
- 内置 10 多种 Index 相关的操作
- 每个动作可以顺序执行
- Filters
- 支持各种条件,过滤出需要操作的索引
eBay Lifecycle Management Tool
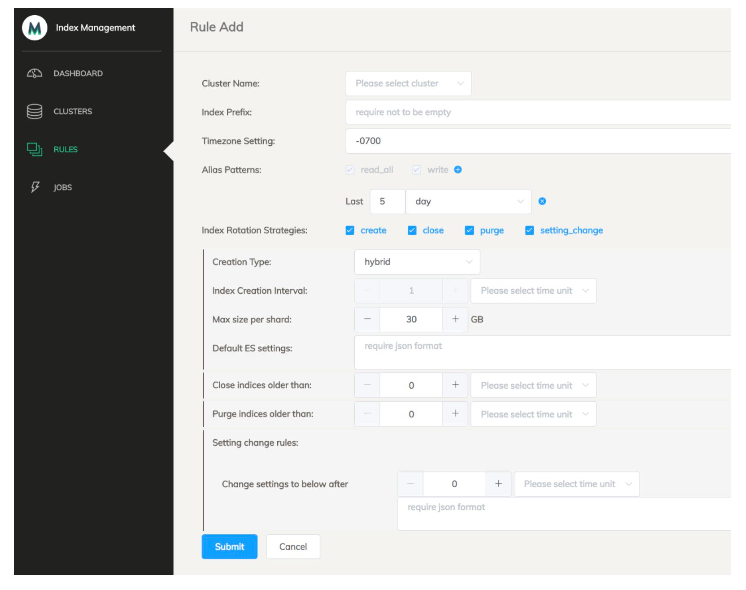
- eBay Pronto team 自研图形化工具
- 支持 Curator 的功能
- 一个界面,管理多个 ES 集群
- 支持不同的 ES 版本
- 支持图形化配置
- Job 定时触发
- 系统高可用
工具比较
Index Lifecycle Management
https://www.elastic.co/guide/en/elasticsearch/reference/current/index-lifecycle-management.html
Elasticsearch 6.6 推出的新功能:
- 基于 X-Pack Basic License,可免费使用
ILM 概念:
- Policy
- Phase
- Action
ILM Policy
- 集群中支持定义多个 Policy
- 每个索引可以使用相同或不相同的 Policy
Index Lifecycle Policies 图形化界面
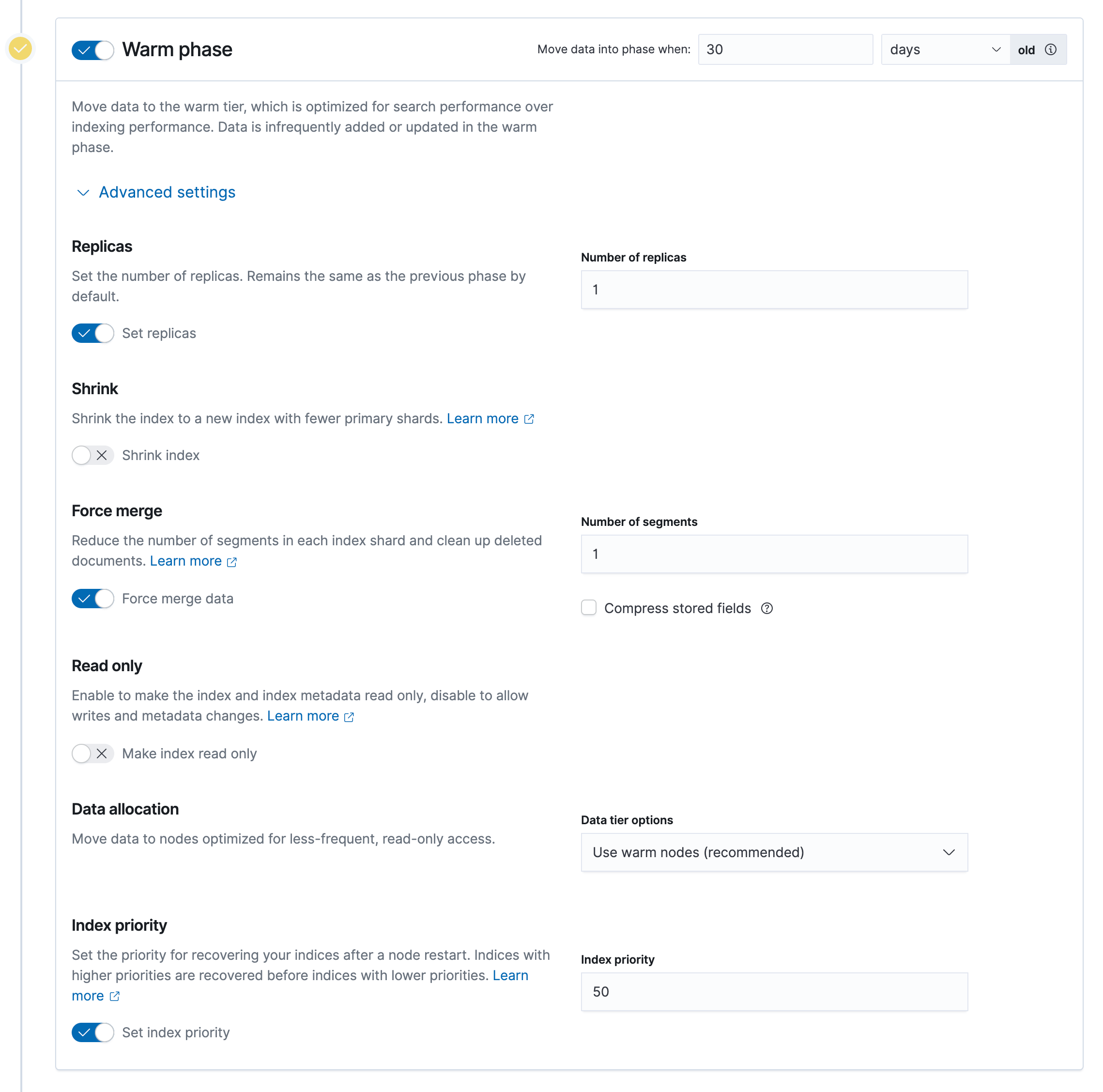
- 通过 Kibana Management 设定
- Hot phase 是必须要的
- 可以 enable rollover
- 其他 Phase 按需设定
- Watch-history-ilm policy
- 创建 7 天后自动删除
集群 Backup & Restore
集群的备份与恢复
https://www.elastic.co/guide/en/elasticsearch/reference/current/snapshot-restore.html
备份可以分为三大块:

注册 Repository
配置文件和调用接口两种方式:
1 | #在 elasticsearch.yml 加入相关的配置 |
还支持 Amazon S3, HDFS, Google Cloud Storage 等存储方式
创建快照和恢复
1 | # 创建一个snapshot |
快照的版本兼容