Elasticsearch 利用 ELK 做大数据分析
Logstash 入门及架构介绍
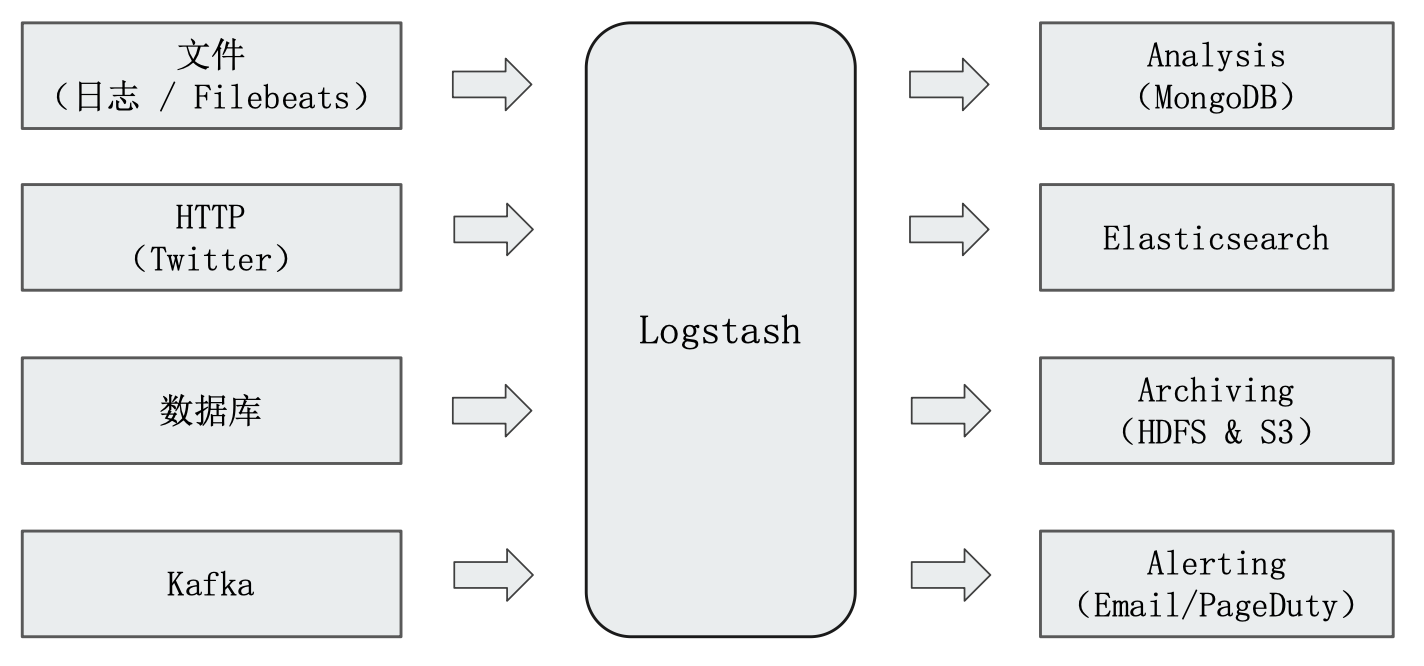
Logstash:ELT 工具 / 数据搜集处理引擎。支持 200 多个插件
Logstash Concepts
Logstash 的概念:
- Pipeline
- 包含了 input-filter-output 三个阶段的处理流程
- 插件生命周期管理
- 队列管理
- Logstash Event
- 数据在内部流转时的具体表现形式。数据在 input 阶段被转换为 Event,在 output 被转化成目标格式数据
- Event 其实是一个 Java Object,在配置文件中,对 Event 的属性进行增删改查
Logstash 架构简介
Codec(Code / Decode):将原始数据 decode 成 Event;将 Event encode 成目标数据
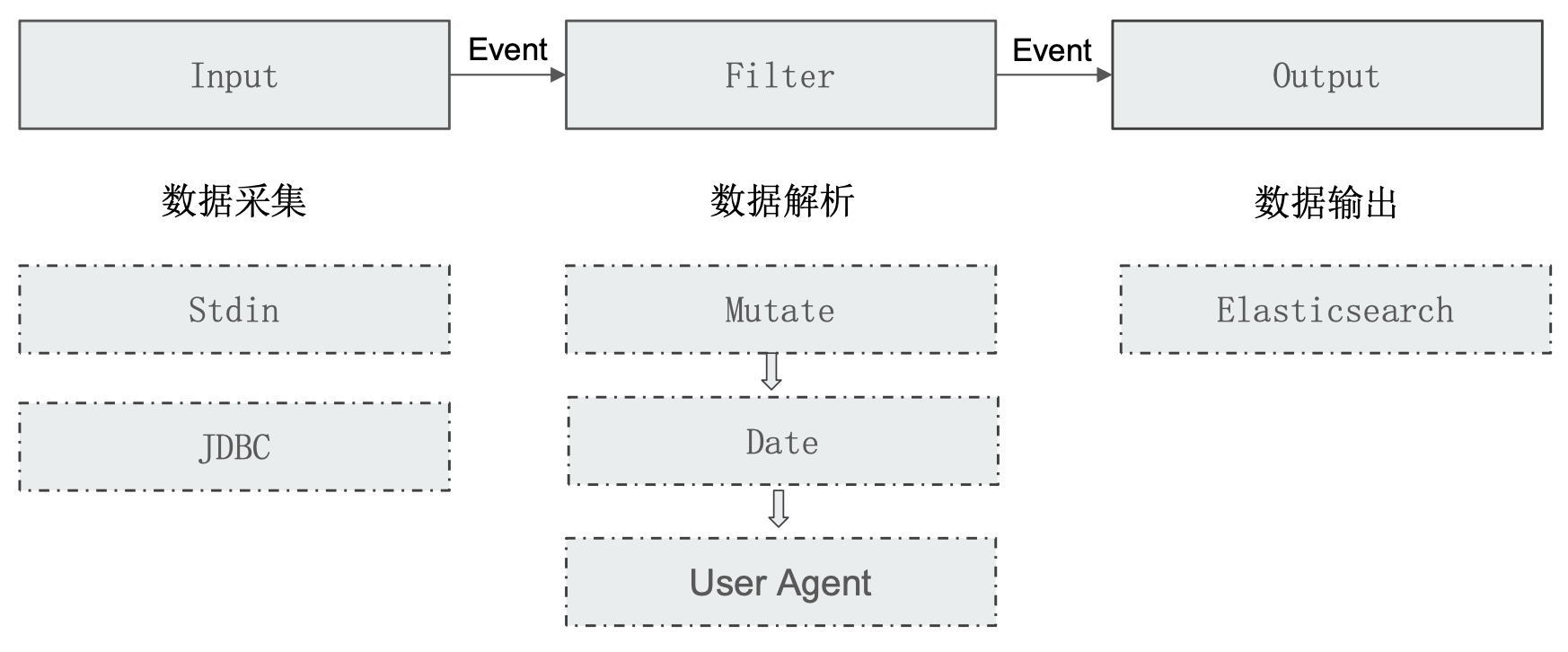
Logstash 配置文件结构
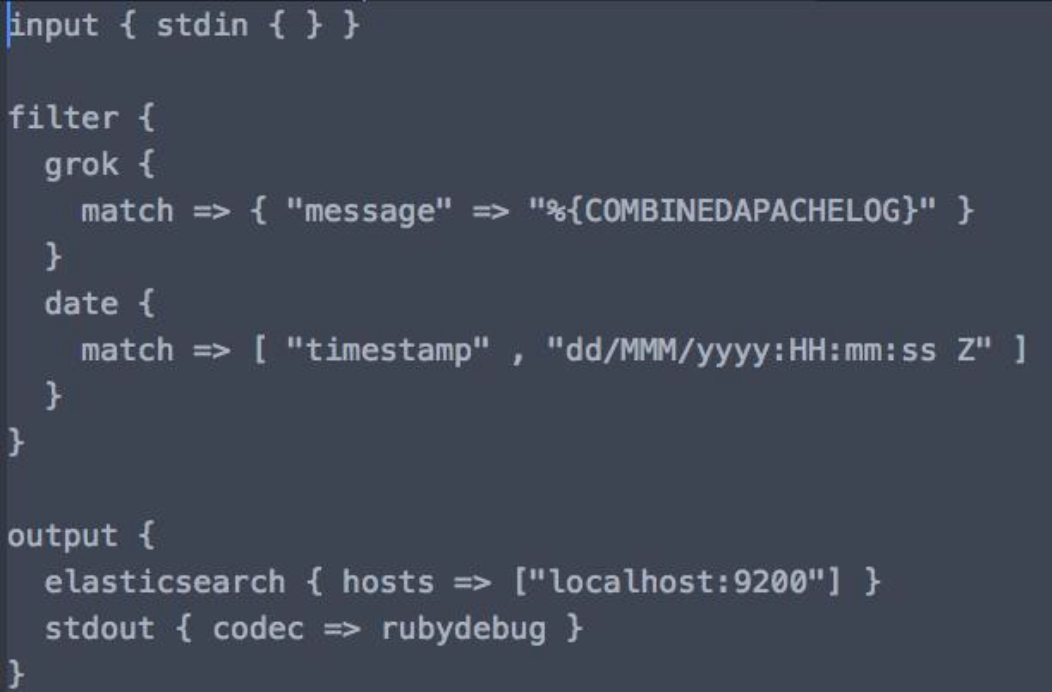
bin/logstash –f demo.conf- Pipeline
- Input / Filter / Output
- Codec
- Line / json
Input Plugins
一个 Pipeline 可以有多个 input 插件:https://www.elastic.co/guide/en/logstash/8.13/input-plugins.html
- Stdin / File
- Beats / Log4J / Elasticsearch / JDBC / Kafka / Rabbitmq / Redis
- JMX / HTTP / Websocket / UDP / TCP
- Google Cloud Storage / S3
- Github / Twitter
Output Plugins
- 将 Event 发送到特定的目的地,是 Pipeline 的最后一个阶段
- 常见 Output Plugins:https://www.elastic.co/guide/en/logstash/8.13/output-plugins.html
- Elasticsearch
- Email / Pageduty
- Influxdb / Kafka / Mongodb / Opentsdb / Zabbix ○ Http / TCP / Websocket
Codec Plugins
- 将原始数据 decode 成 Event;将 Event encode 成目标数据
- 内置的 Codec Plugins:https://www.elastic.co/guide/en/logstash/8.13/codec-plugins.html
- Line / Multiline
- JSON / Avro / Cef (ArcSight Common Event Format)
- Dots / Rubydebug
Filter Plugins
- 处理 Event
- 内置的 Filter Plugins:https://www.elastic.co/guide/en/logstash/8.13/filter-plugins.html
- Mutate – 操作 Event 的字段
- Metrics – Aggregate metrics
- Ruby – 执行 Ruby 代码
Queue
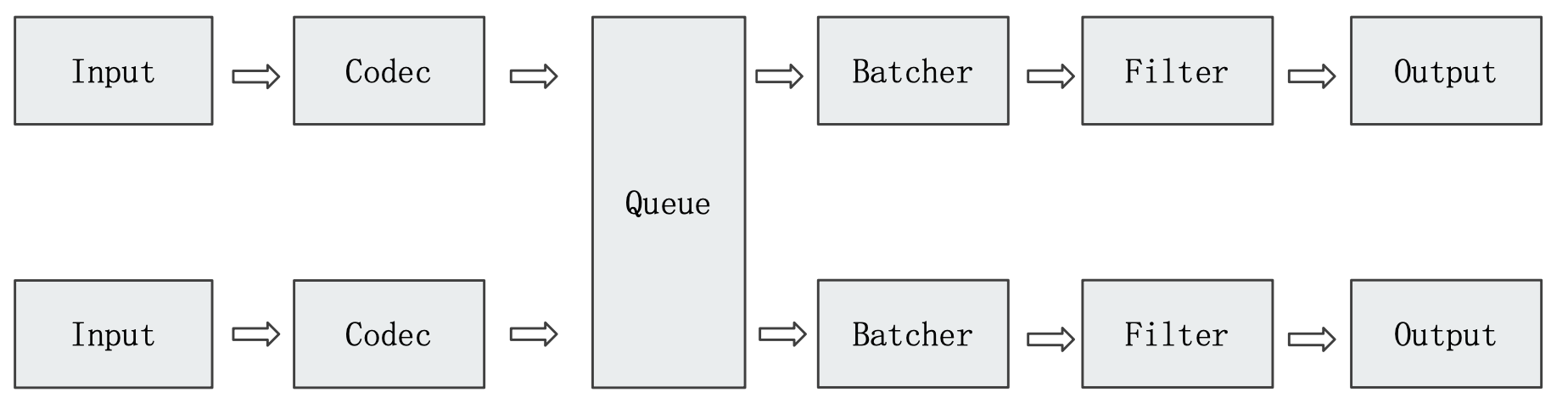
多 Pipelines 实例
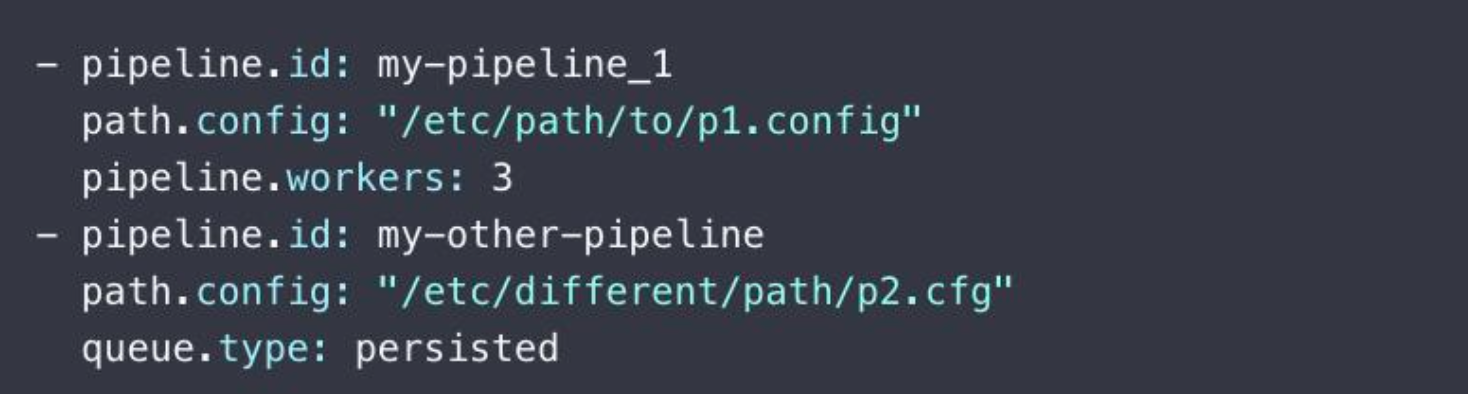
pipeline.works: Pipeline 线程数,默认是 CPU 核数pipeline.batch.size:Batcher 一次批量获取等待处理的文档数,默认 125。需结合 jvm.options调节pipeline.batch.delay:Batcher 等待时间
Logstash Queue
- In Memory Queue
- 进程 Crash,机器宕机,都会引起数据的丢失
- Persistent Queue
- Queue.type.persisted (默认是 memory)
- Queue.max_bytes: 4gb
- 机器当机,数据也不会丢失;数据保证会被消费;可以替代 Kafka 等消息队列缓冲区的作用
- Queue.type.persisted (默认是 memory)
https://www.elastic.co/guide/en/logstash/8.13/resiliency.html
Codec Plugin Demo
Single Line:

Multiline:
设置参数:
- Pattern:设置行匹配的正则表达式
- What:如果匹配成功,那么匹配行属于上一个事件还是下一个事件
- Previous / Next
- Negate true / false:是否对 pattern 结果取反
- True / False
异常日志:


Input Plugin Demo
File:
- 支持从文件中读取数据,如日志文件
- 文件读取需要解决的问题
- 只被读取一次。重启后需要从上次读取的位置继续(通过 sincedb 实现)
- 读取到文件新内容,发现新文件
- 文件发生归档操作(文档位置发生变化,日志 rotation),不能影响当前的内容读取
Filter Plugin Demo
Filter Plugin 可以对 Logstash Event 进行各种处理,例如解析,删除字段,类型转换
- Date:日期解析
- Dissect:分割符解析
- Grok:正则匹配解析
- Mutate:处理字段。重命名,删除,替换
- Ruby:利用 Ruby 代码来动态修改 Event
Mutate:
- 对字段做各种操作
- Convert 类型转换
- Gsub 字符串替换
- Split / Join / Merge 字符串切割,数组合并字符串,数组合并数组
- Rename 字段重命名
- Update / Replace 字段内容更新替换
- Remove_field 字段删除
利用 JDBC 插件导入数据到 Elasticsearch
同步数据库数据到 Elasticsearch
需求:将数据库中的数据同步到 ES,借助 ES 的全文搜索,提高搜索速度
- 需要把新增用户信息同步到 Elasticsearch 中
- 用户信息 Update 后,需要能被更新到 Elasticsearch
- 支持增量更新
- 用户注销后,不能被 ES 所搜索到
JDBC Input Plugin & 设计实现思路
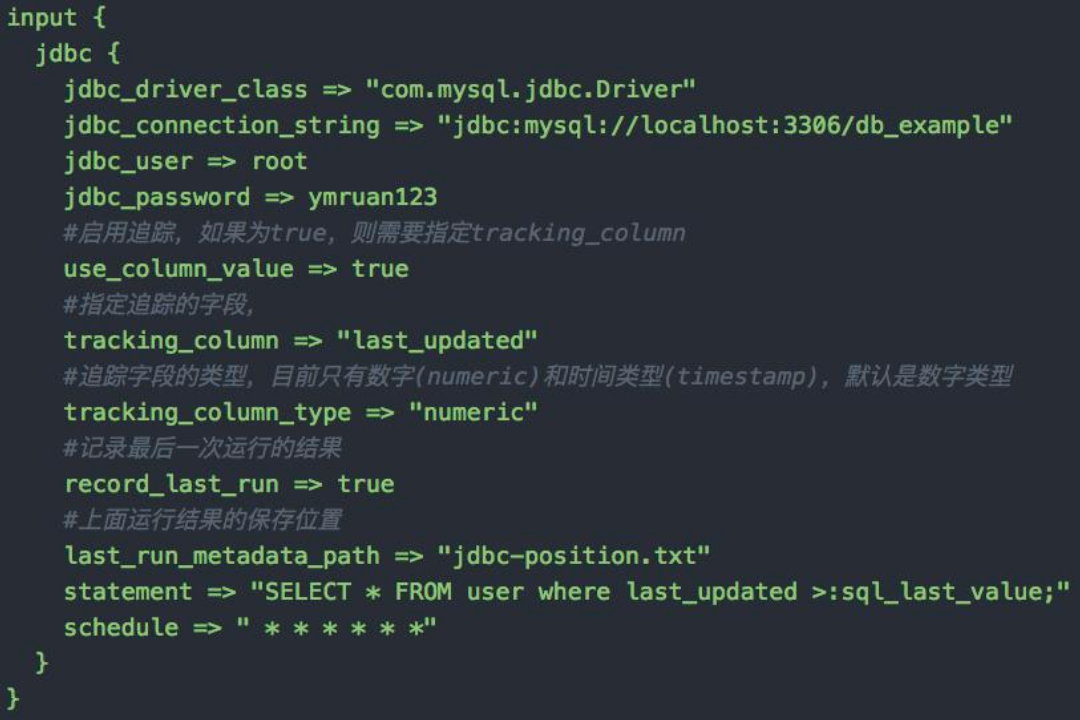
- 支持通过 JDBC Input Plugin 将数据从数据库从读到 Logstash
- 需要自己提供所需的 JDBC Driver
- Scheduling
- 语法来自 Rufus-scheduler
- 扩展了 Cron,支持时区
- State
- Tracking_column / sql_last_value
demo:https://spring.io/guides/gs/accessing-data-mysql
Beats 介绍

- Light weight data shippers
- 以搜集数据为主
- 支持与 Logstash 或 ES 集成
- 全品类 / 轻量级 / 开箱即用 / 可插拔 / 可扩展 / 可视化
Metricbeat 简介
- 用来定期搜集操作系统,软件的指标数据
- Metric v.s Logs
- Metric:可聚合的数据,定期搜集
- Logs:文本数据,随机搜集
- Metric v.s Logs
- 指标存储在 Elasticsearch 中,可以通过 Kibana 进行实时的数据分析
Metricbeat 组成
- Module
- 搜集的指标对象,例如不同的操作系统,不同的数据库,不同的应用系统
- Metricset
- 一个 Module可以有多个 metricset
- 具体的指标集合。以减少调用次数为原则进行划分
- 不同的 metricset 可以设置不同的抓取时长
Module
- Metricbeat 提供了大量的开箱即用的 Module
- https://www.elastic.co/guide/en/beats/metricbeat/8.13/metricbeat-modules.html
- 通过执行
metricbeat module list查看 - 通过执行
metricbeat moudle enable module_name定制
Metricsets
每个 Module 都有自己的 metricsets,以 System Module 为例
- core
- CPU
- disk IO
- filesystem
- load
- memory
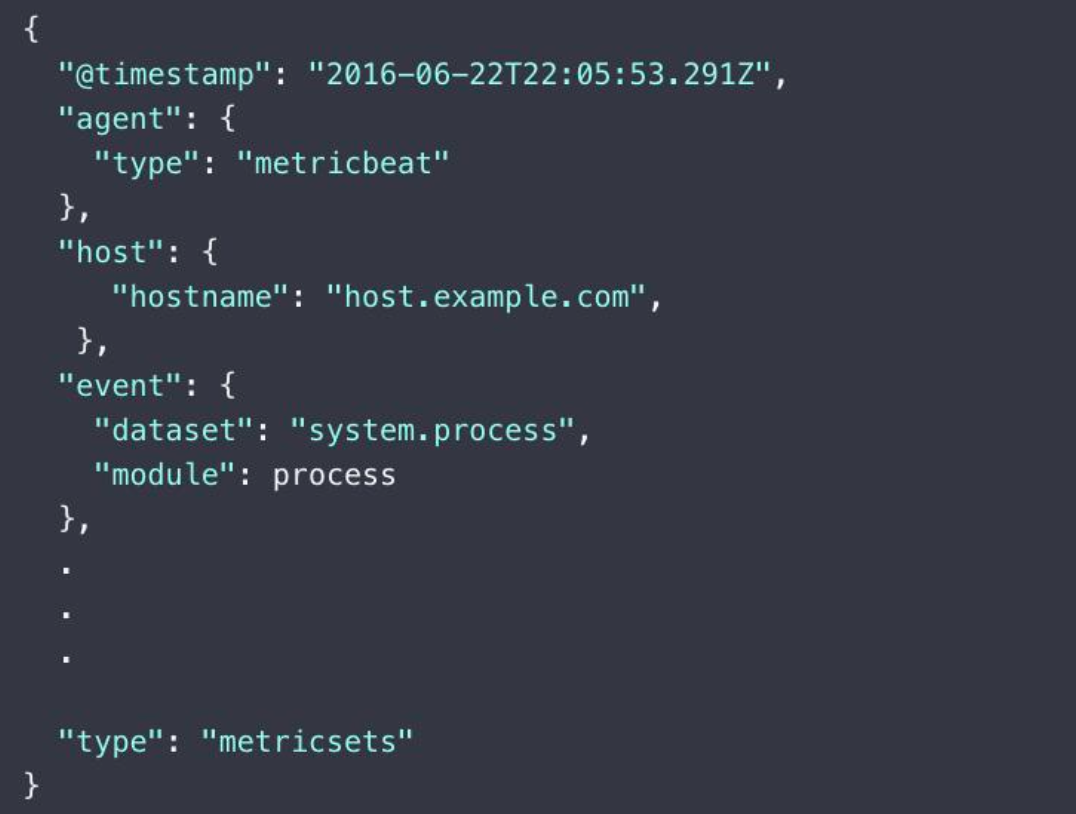
Metricbeat Event
Packetbeat
- Packetbeat - 实时网络数据分析,监控应用服务器之间的网络流量
- 常见抓包工具 - Tcpdump /wireshark
- 常见抓包配置 - Pcap 基于 libpcap,跨平台 / Af_packet 仅支持 Linux,基于内存映射嗅探,高性能
- Packetbeat 支持的协议
- ICMP / DHCP / DNS / HTTP / Cassandra / Mysql / PostgresSQL / Redis / MongoDB / Memcache /
TLS
- ICMP / DHCP / DNS / HTTP / Cassandra / Mysql / PostgresSQL / Redis / MongoDB / Memcache /
- Network flows:抓取记录网络流量数据,不涉及协议解析
https://www.elastic.co/guide/en/beats/packetbeat/current/packetbeat-installation-configuration.html
使用 Index Pattern 配置数据
给图表展示和数据分析做准备
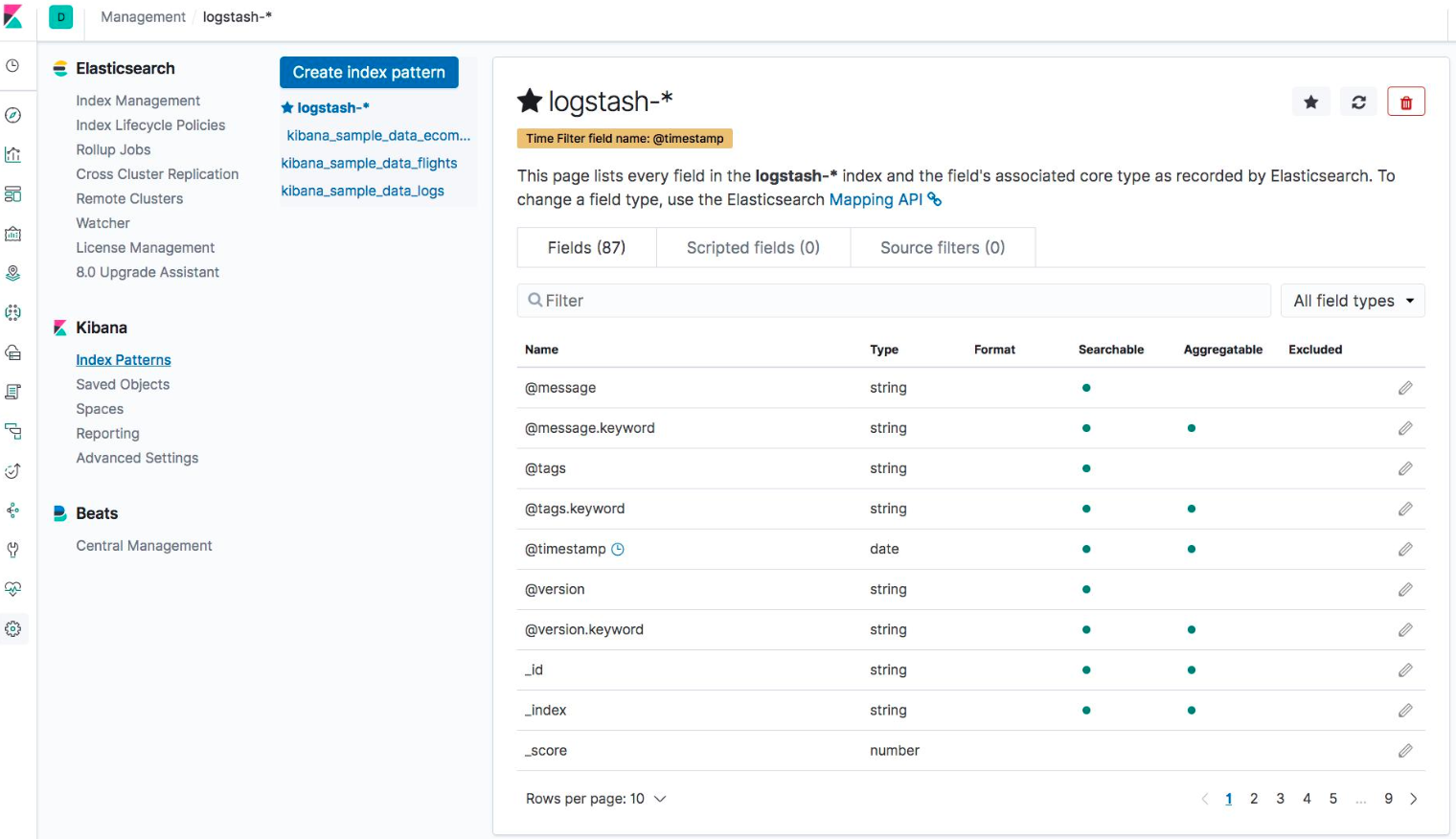
- Management
- Index Patterns / Saved Objects (导出备份)
- Created Index Pattern (Save As default Pattern)
- Fields: Type,Searchable/Aggregation / Format(Number / Image)
- Script Fields
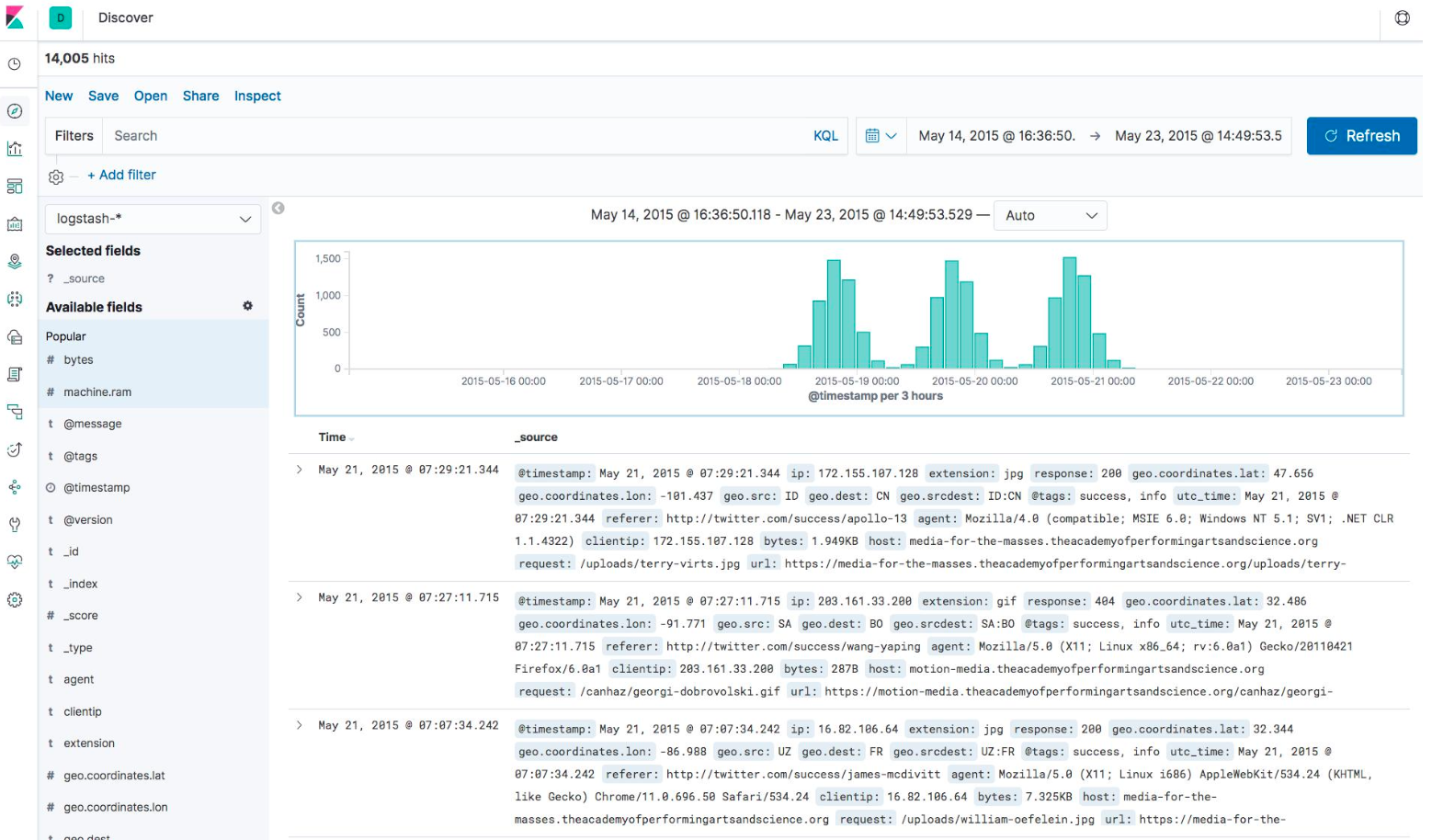
使用 Kibana Discovery 探索数据
Discovery:
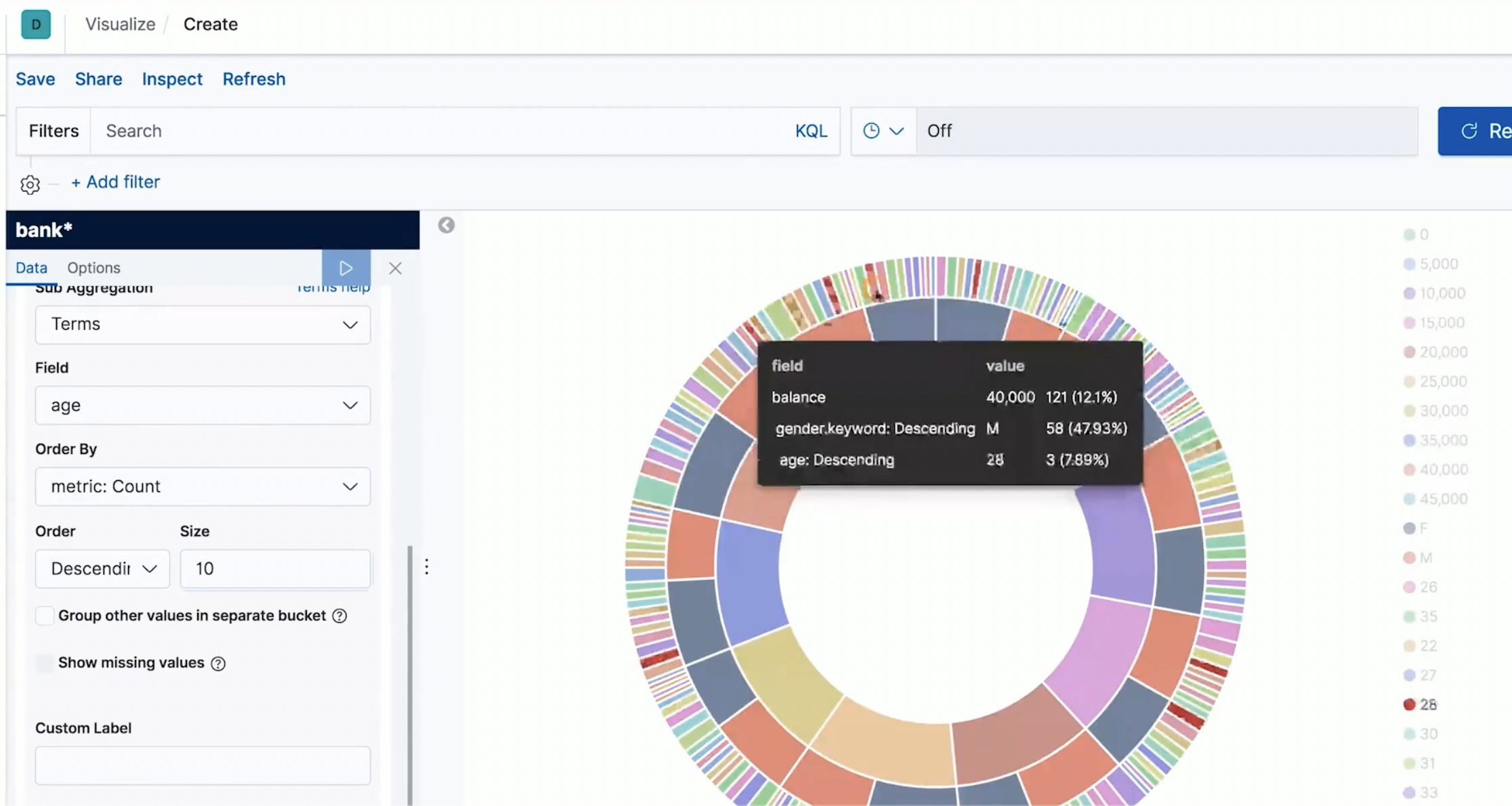
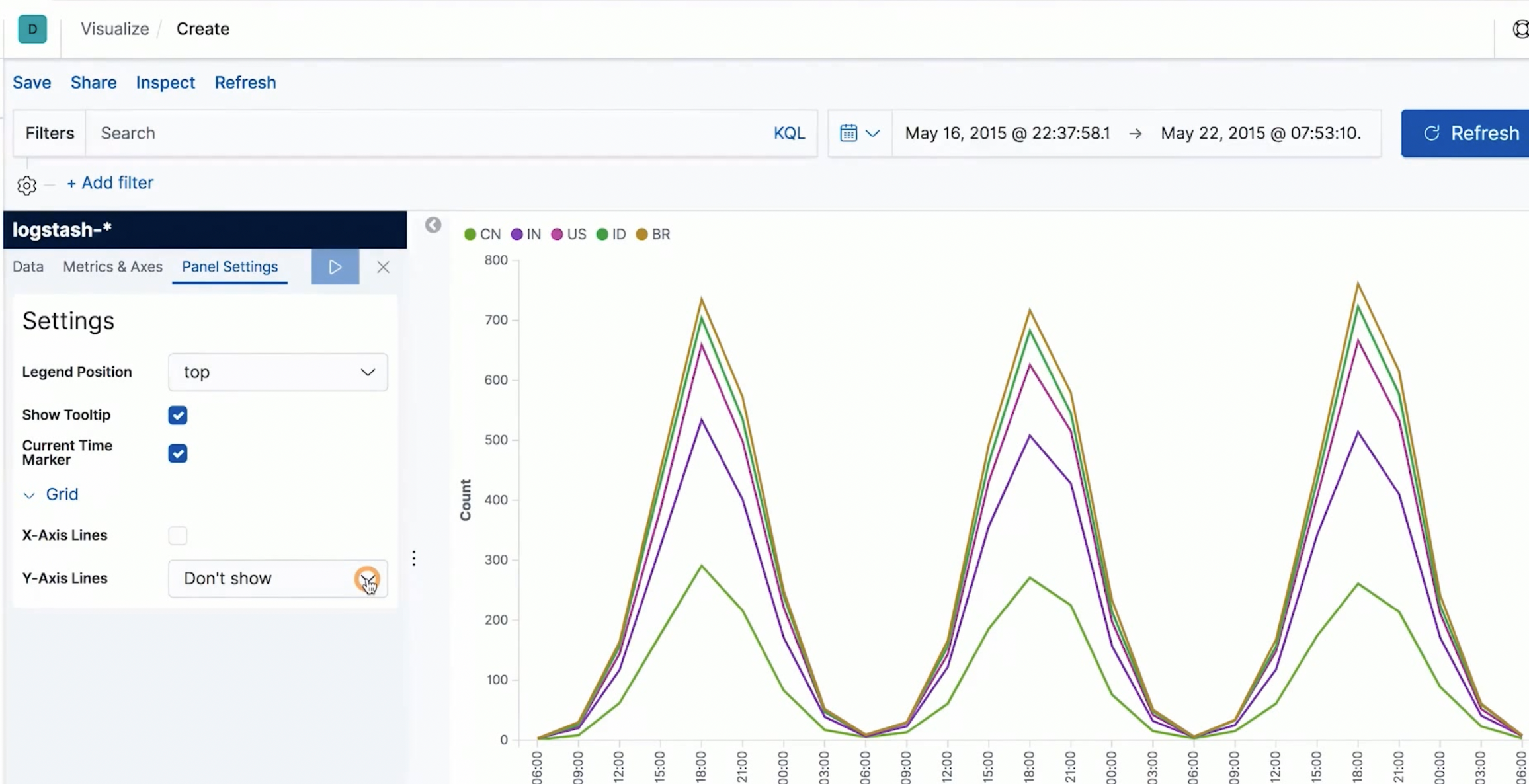
基本可视化组件介绍 Visualize
使用内置数据搭建可视化的 Visualize 页面
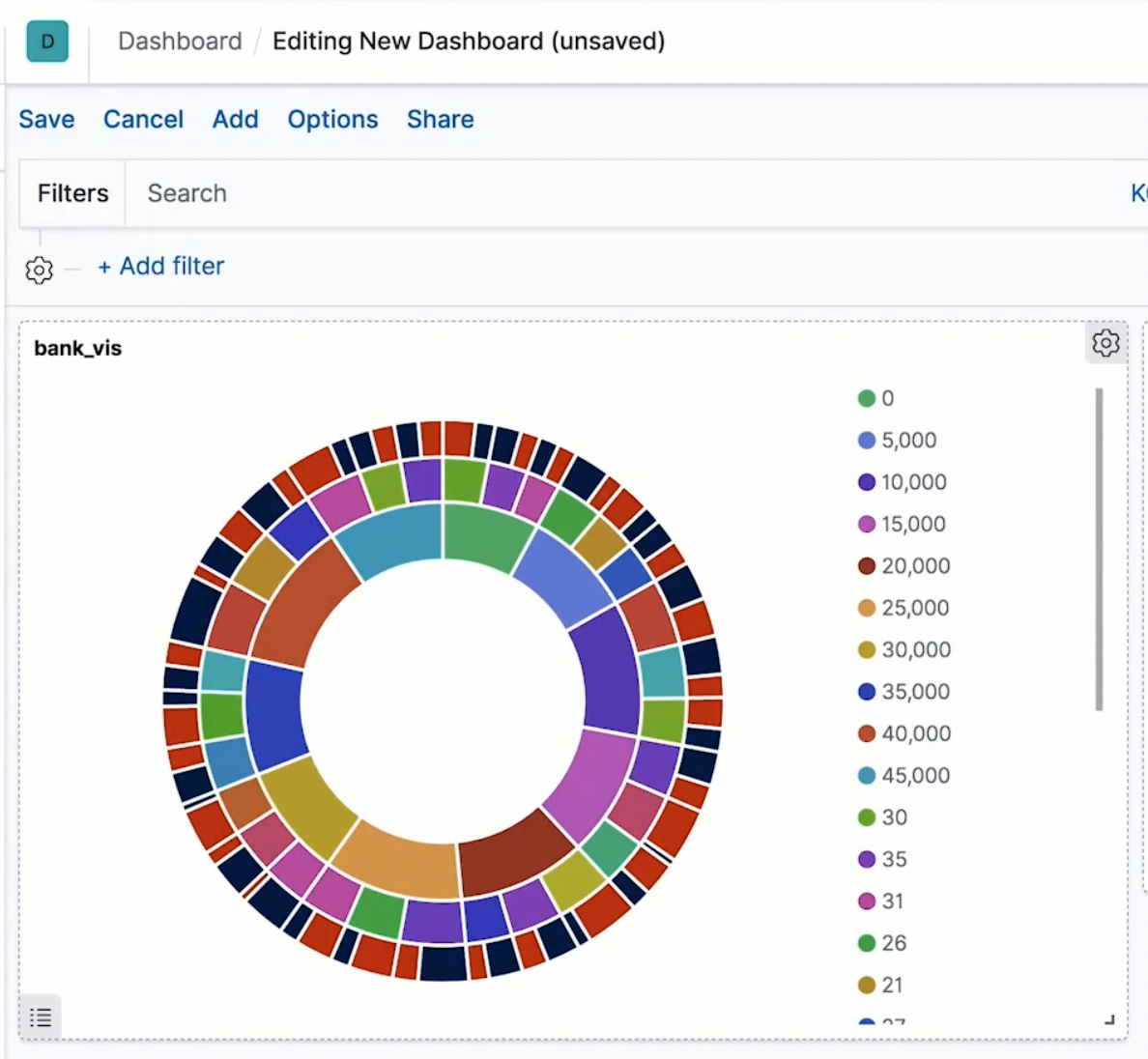
- 账户存款
- Pie Chart (Inspector)
- 日志相关
- Area Chart (X 轴 Y 轴, 顺序,etc)
- Bar Chart
构建 Dashboard
Dashboard 是一组相关主题的可视化组件
用 Monitoring 和 Alerting 监控 Elasticsearch 集群
X-Pack Monitoring:
- X-Pack 提供了免费集群监控的功能
- 使用 Elasticsearch 监控 Elasticsearch
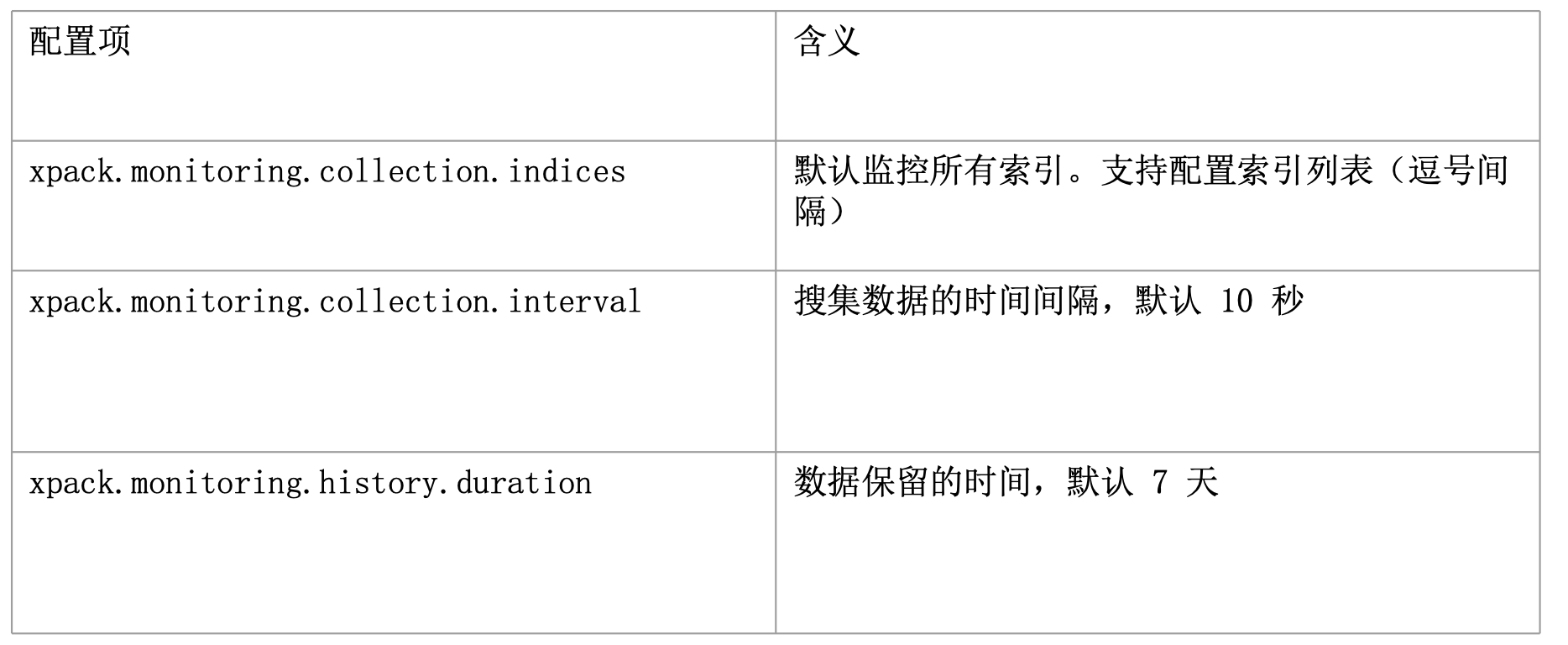
Xpack.monitoring.collection.interval默认设置 10 秒
- 在生产环境中,建议搭建 dedicated 集群用于 ES 集群的监控。有以下几个好处
- 减少负载和数据
- 当被监控集群出现问题,还能看到监控相关的数据
https://www.elastic.co/guide/en/elasticsearch/reference/current/monitoring-settings.html#monitoring-settings
配置 Monitoring
Watcher for Alerting
- 需要 Gold 账户
- 一个 Watcher 由 5个部分组成
- Trigger – 多久被触发一次(例如:5 分钟触发一次)
- Input – 查询条件(在所有日志索引中查看 “ERROR” 相关)
- Condition –查询是否满足条件(例如:大于 1000 条返回)
- Actions – 执行相关操作(例如:发送邮件)
Overall
Kinaba:Stack Monitoring
Oveview:
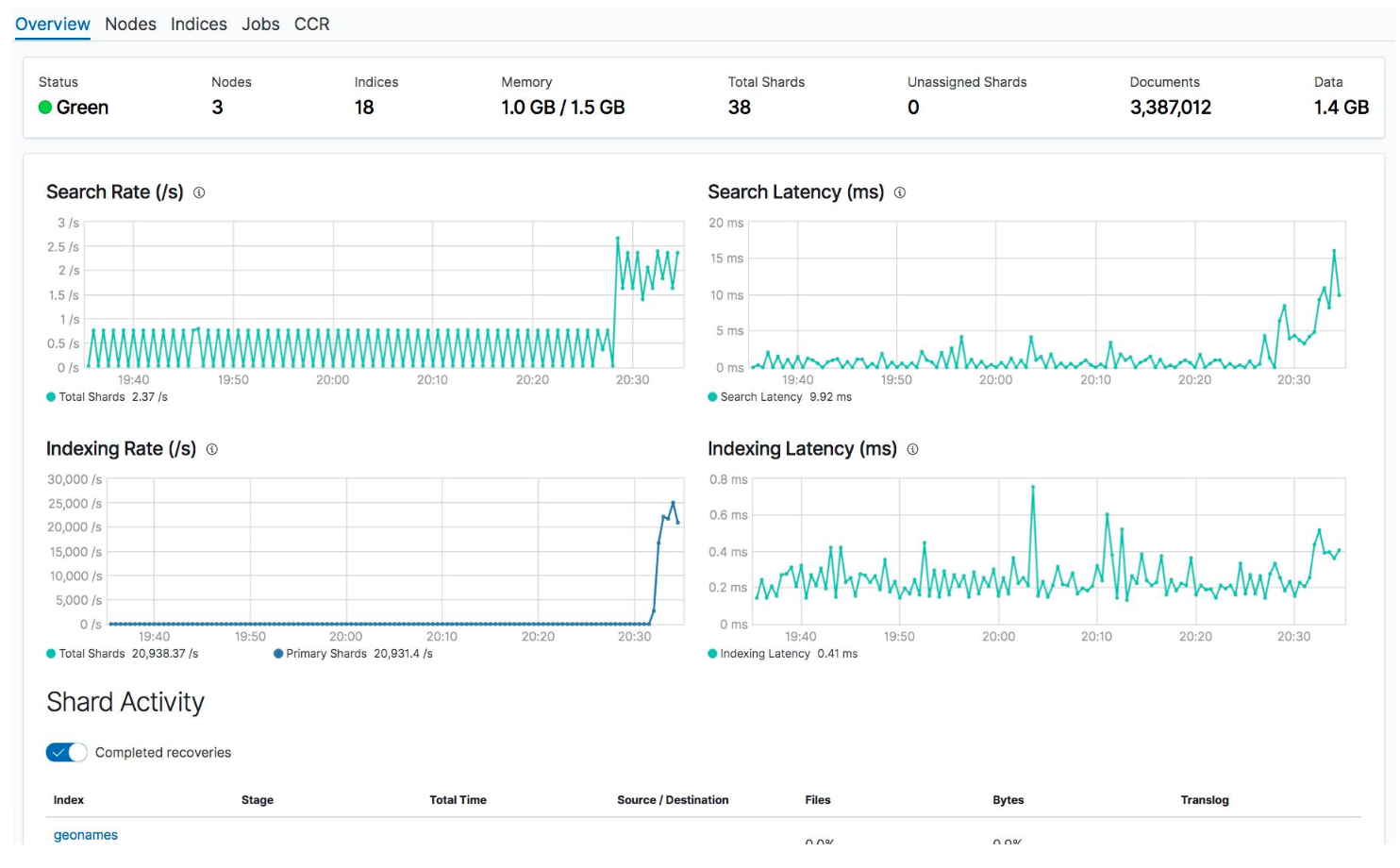
Nodes:
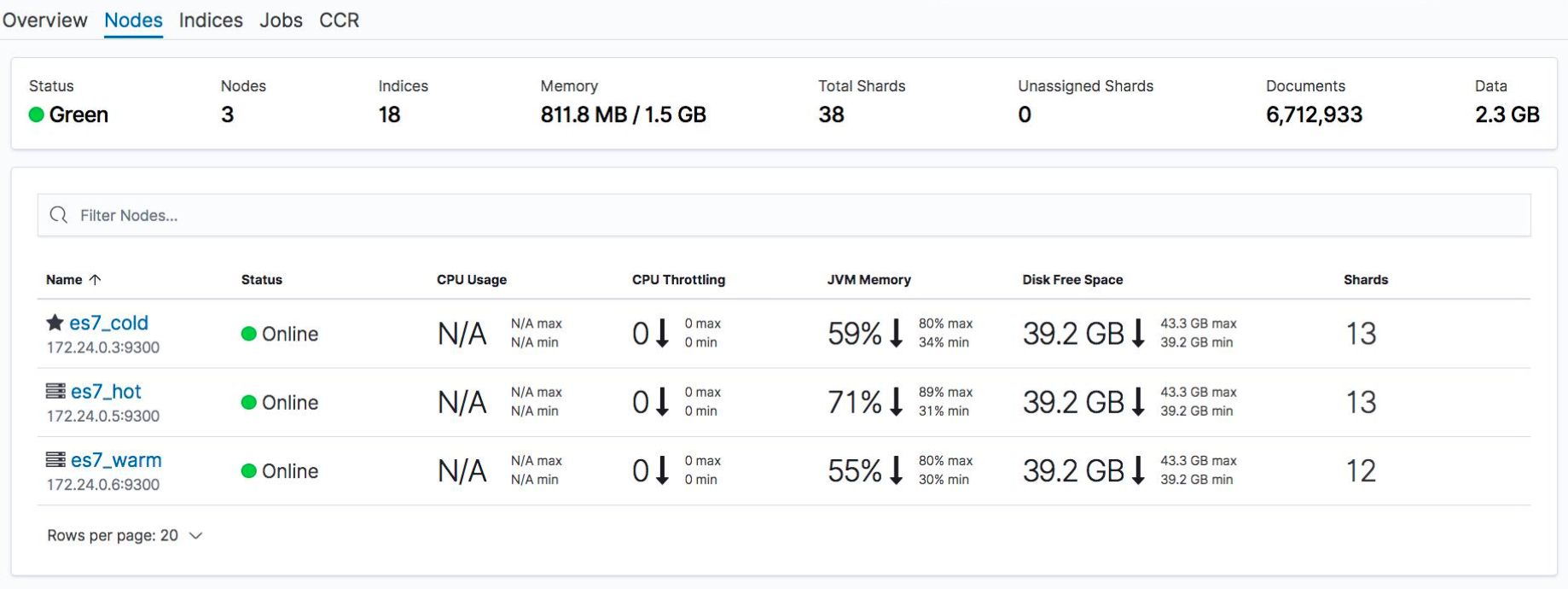
Index
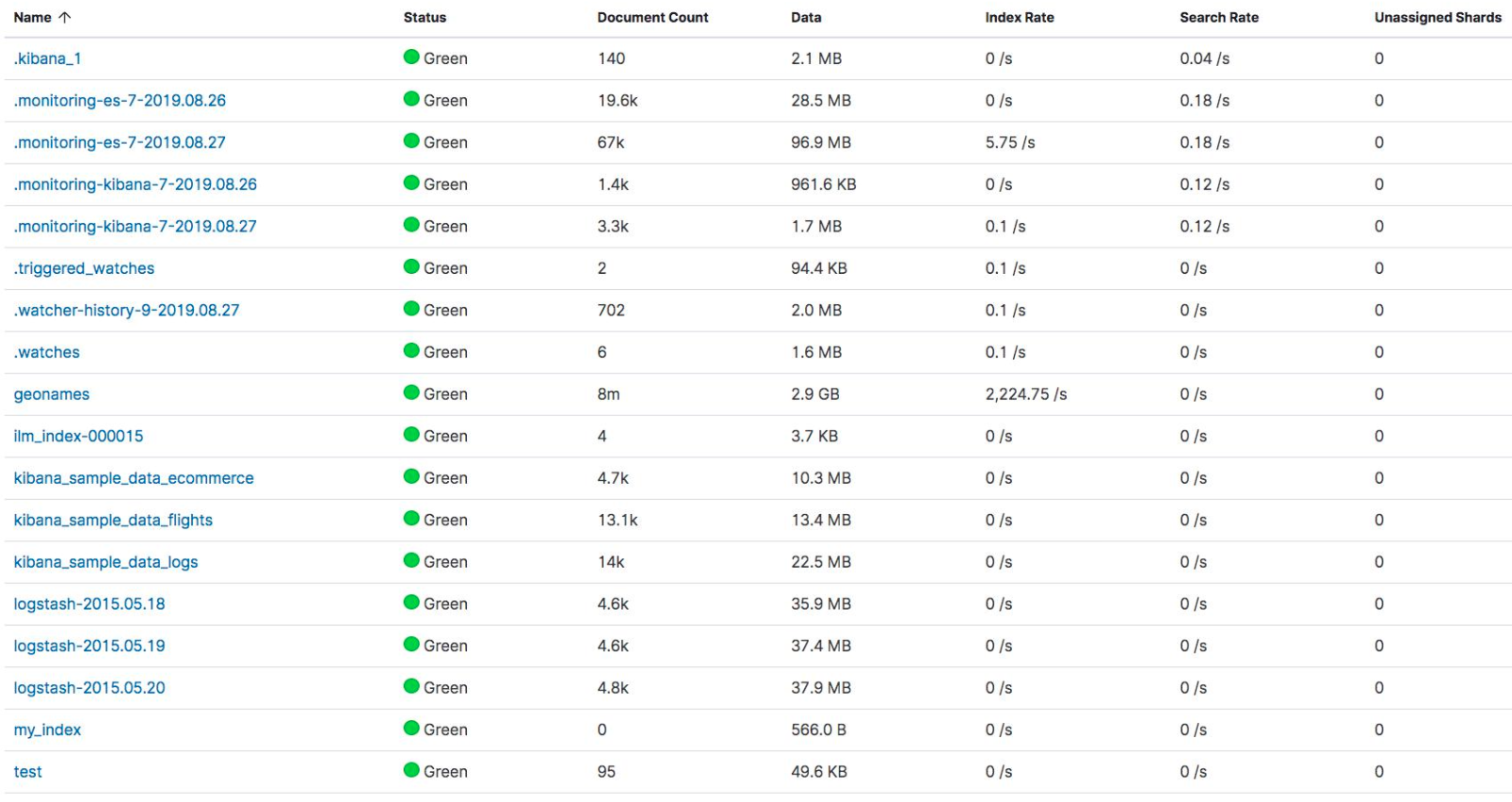
Index Level
用 APM 进行程序性能监控
Elastic 全栈监控
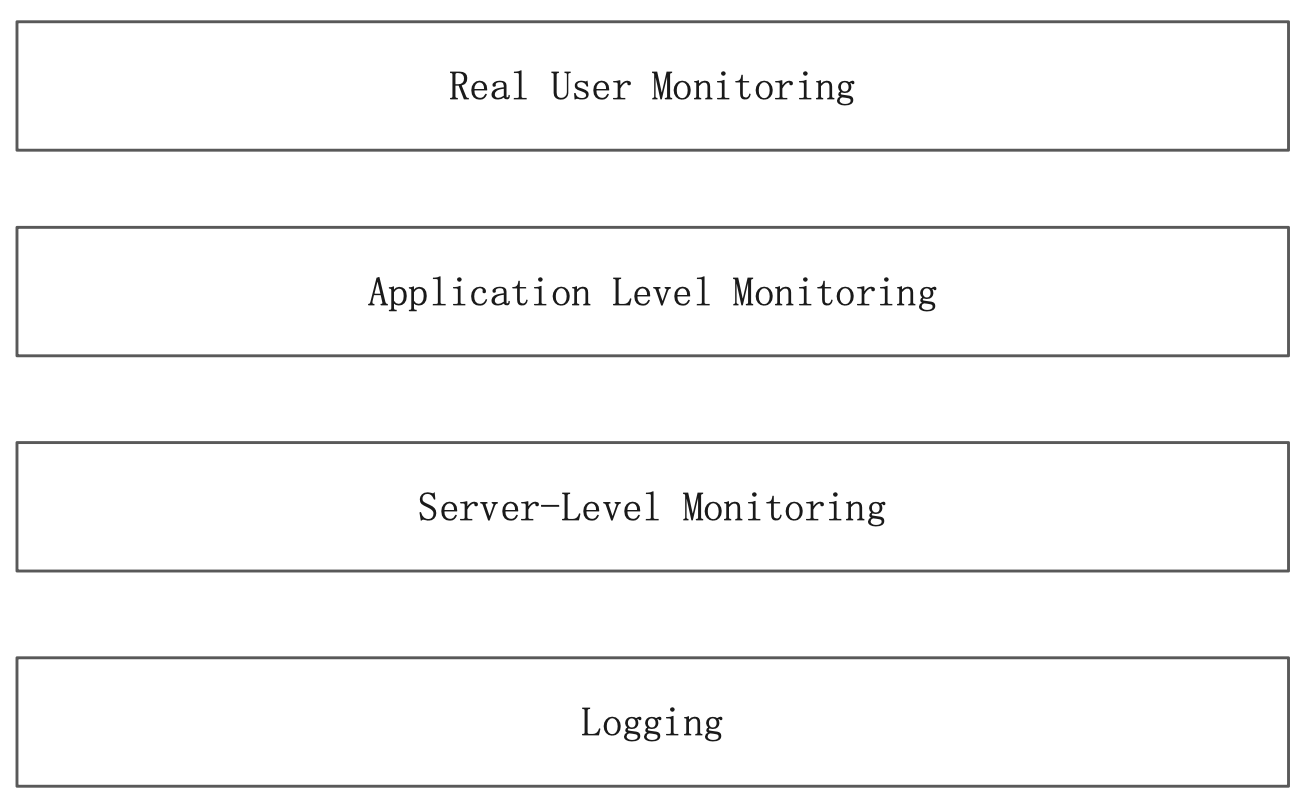
APM 提供用户操作层面的监控。
核心应用指标:
- 请求响应时间
- 未处理的错误及异常
- 可视化调用关系
- 发现性能瓶颈
- 代码下钻
APM
https://www.elastic.co/cn/observability/application-performance-monitoring

APM 如何整合到 Elastic Stack
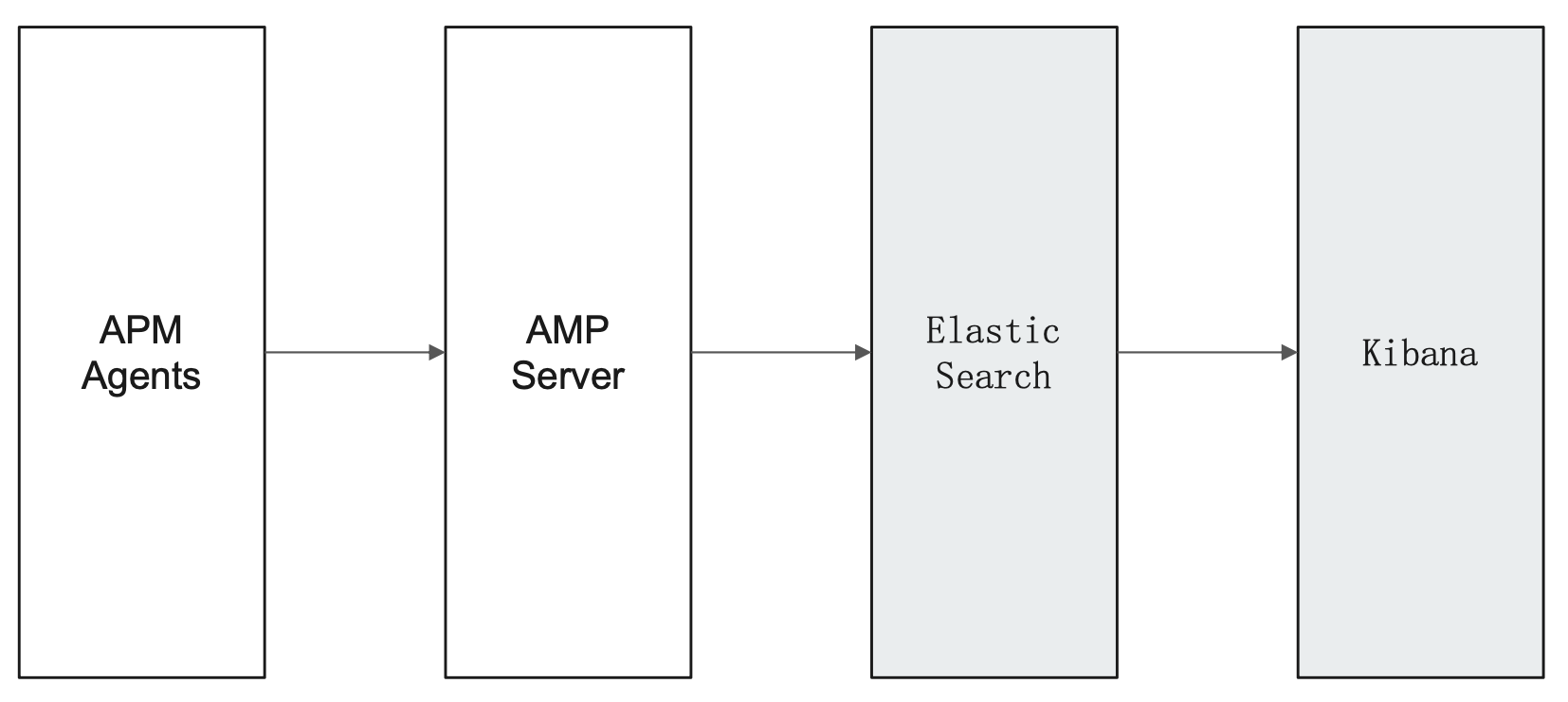
安装文档:https://www.elastic.co/guide/en/apm/index.html
用机器学习实现异常检测
用机器学习异常检测所解决的问题,主要是解决一些基于规则或者 Dashboard 难以实时发现的问题,例如:
- IT 运维
- 如何知道系统正常运行 / 如何调节阈值触发合适的报警 / 如何进行归因分析
- 信息安全
- 哪些用户构成了内部威胁 / 系统是否感染了病毒
- 物联网 / 数据采集监控
- 工厂和设备是否正常运营
什么是正常:
- 随着时间的推移,某个个体一直表现出一致的行为
- 某个个体和他的同类比较,一直表现出和其他个体一致的行为
什么是异常:
- 和自己比 - 个体的行为发生了急剧的变化
- 和他人比 - 个体明显区别于其他的个体

很多时候判定异常需要一定的指导。
相关术语
- Elastic 平台的机器学习功能
- Elastic 的ML,主要针对时序数据的异常检测和预测
- 非监督机器学习
- 不需要使用人工标签的数据来学习,仅仅依靠历史数据自动学习
- 贝叶斯统计
- 一种概率计算方法,使用先验结果来计算现值或者预测未来的数值
- 异常检测
- 异常代表的是不同的,但未必代表的是坏的 / 定义异常需要一些指导,从哪个方面去看
如何学习 正常:
- 观察不同的人每天走路的步数,由此预测明天他会走多少步
- 需要观察不同的人,需要观察多久?
- 一天/一周/一个月/一年/十年
- 直觉: 观察的数据多,你的预测越准确
- 使用这些观察来创建一个模型
- 概率分布函数:使用这个模型找出什么事几乎不可能的事件
机器学习帮你自动挑选模型
- 使用成熟的机器学习技术,挑选适合数据的正确的统计模型
- 更好的模型 = 更好的异常检测 = 更少的误报和漏报
- 出现在低概率区域,发现异常
模型与需要考虑任何的周期
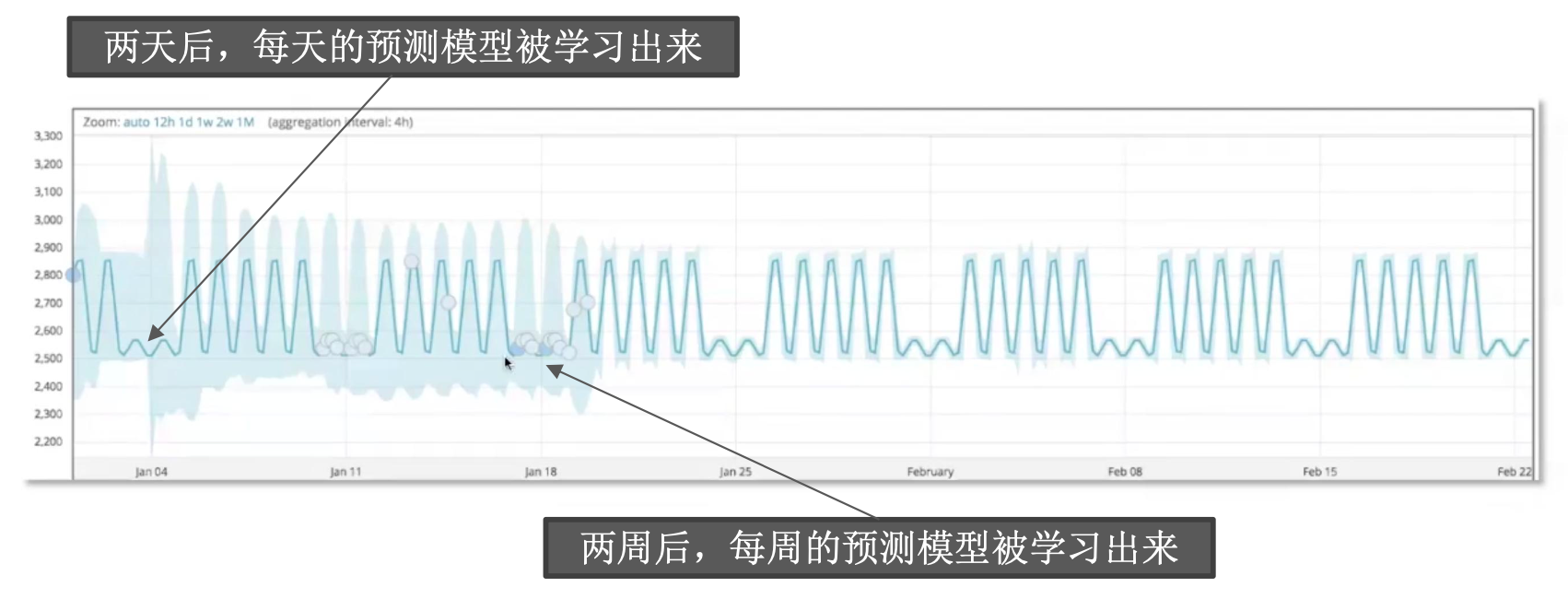
周期选择:
- 需要一定周期的学习,才能使的置信区间的范围更小
- 时间太长:影响因素太多,导致随机分布
- 时间太短:完全是随机波动
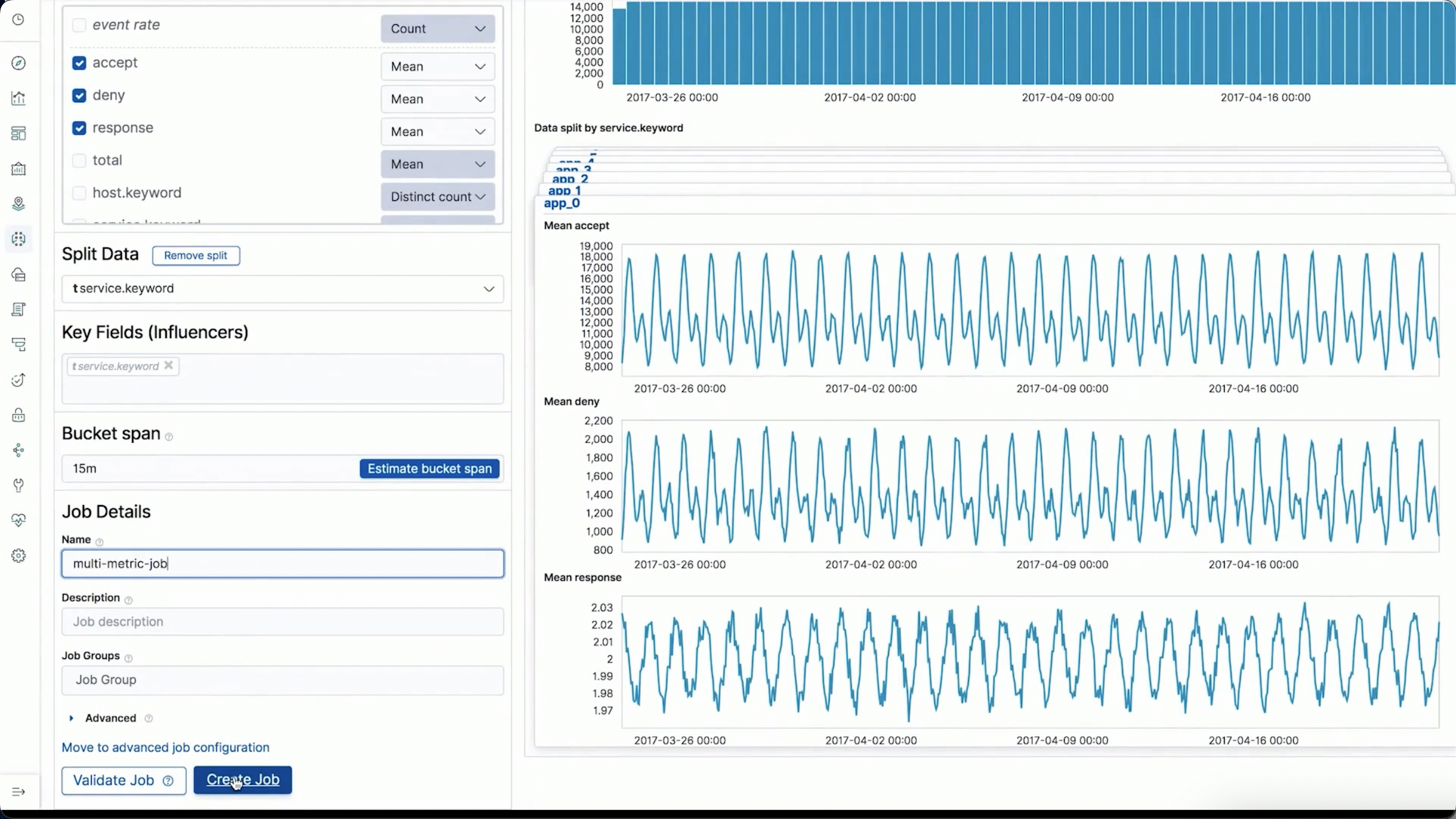
ES ML:单指标 / 多指标 / 种群分析
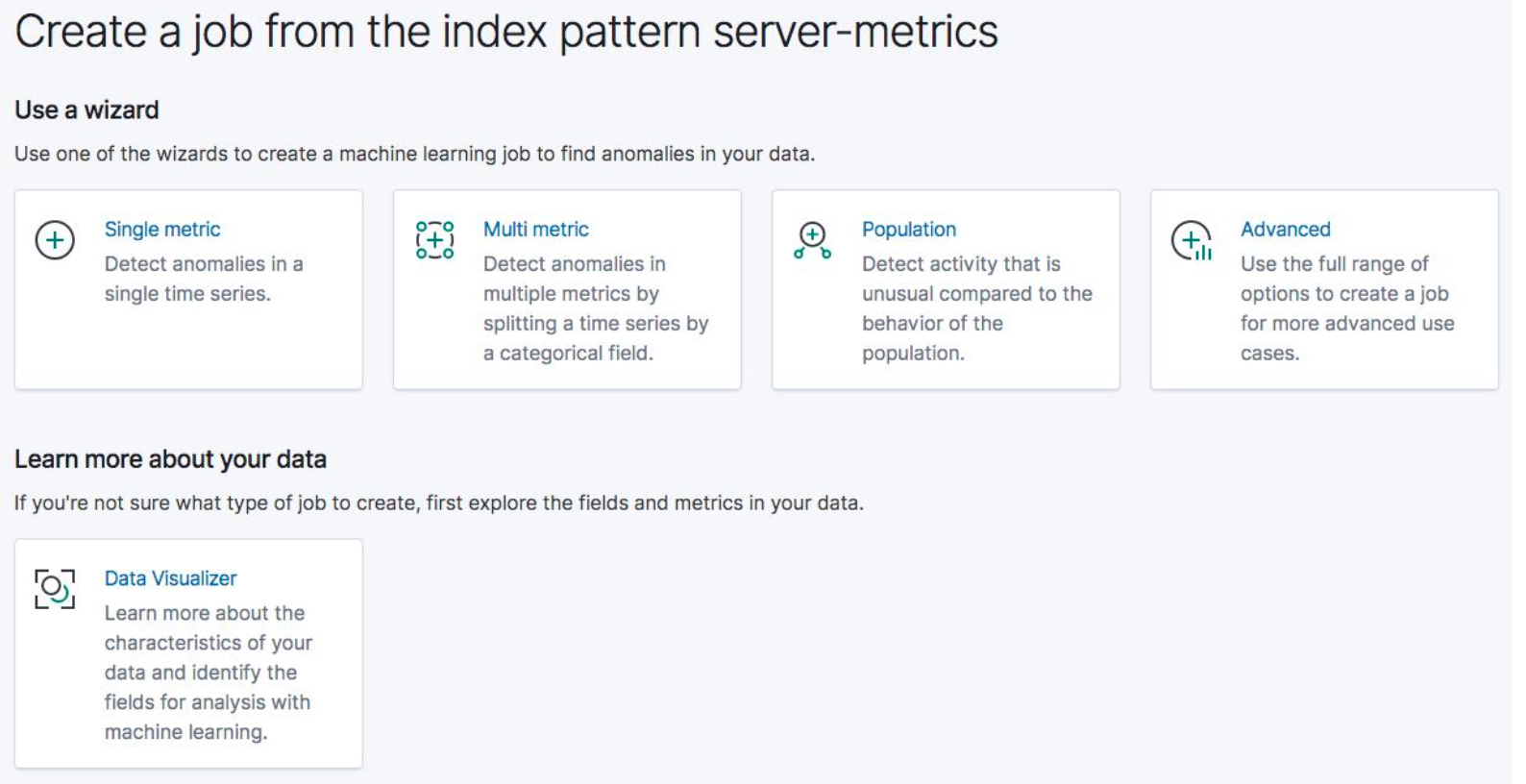
单指标任务
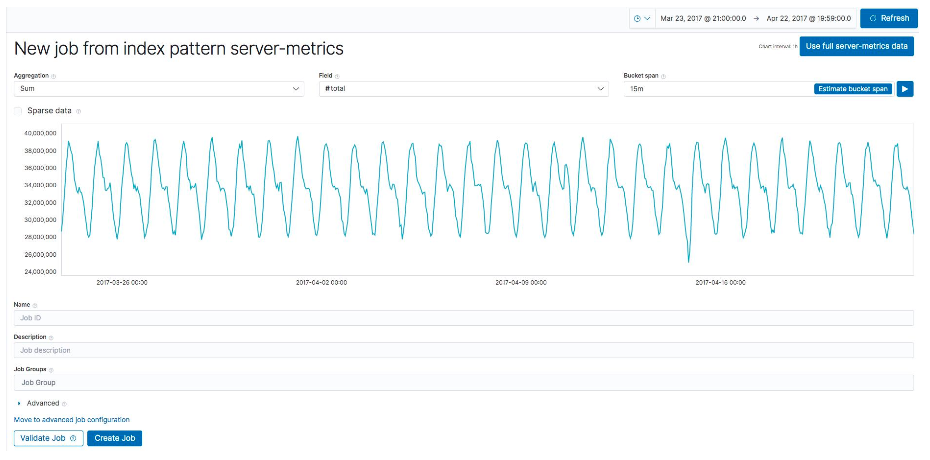
- Create New Job
- 选择 Index Pattern,选择 Fare quote
- 选择单指标任务
- Aggregation
- Field
- Bucket Span (取决于用户的数据业务 / 数据的采样时间 / 波动情况 / 需要预测的频率,做一个桶的时间分隔)
- Use full data
多指标检测
- 多个指标
- 按照某个字段进行分类
- 什么是影响因子
- 影响因子是一个字段
- 这个字段从逻辑分析上看,是可能造成异常的原因
- 不一定必须是一个检测器,但是这个字段通常能够被用于区分数据
- 对影响因子也可以打分,打分是基于其多大程度会影响到异常
种群分析
- 如何分析
- 种群之间比较
- 不和自己的过去比较
- 适用情景
- 个体具备高 Cardinality
- 少数个体从时间上是稀疏的
- 作为整体看,群体行为是均匀的
- 不适用的场景
- 个体的行为各自都不相同
用 Elastic Stack 进行日志管理
日志的重要性
- 为什么重要
- 运维:医生给病人看病。日志就是病人对自己的陈述
- 恶意攻击,恶意注册,刷单,恶意密码猜测
- 挑战
- 关注点很多,任何一个点都有可能引起问题
- 日志分散在很多机器,出了问题时,才发现日志被删了
- 很多运维人员是消防员,哪里有问题去哪里
集中化日志管理

Filebeat 简介
简介:
- A log data shipper for local files
- 读取日志文件,Filebeat 不做数据的解析,加工处理
- 日志是非结构化数据
- 需要进行处理后,以结构化的方式保存到 Elasticsearch
- 保证数据至少被读取一次
- 处理多行数据,解析 JSON 格式 ,简单的过滤
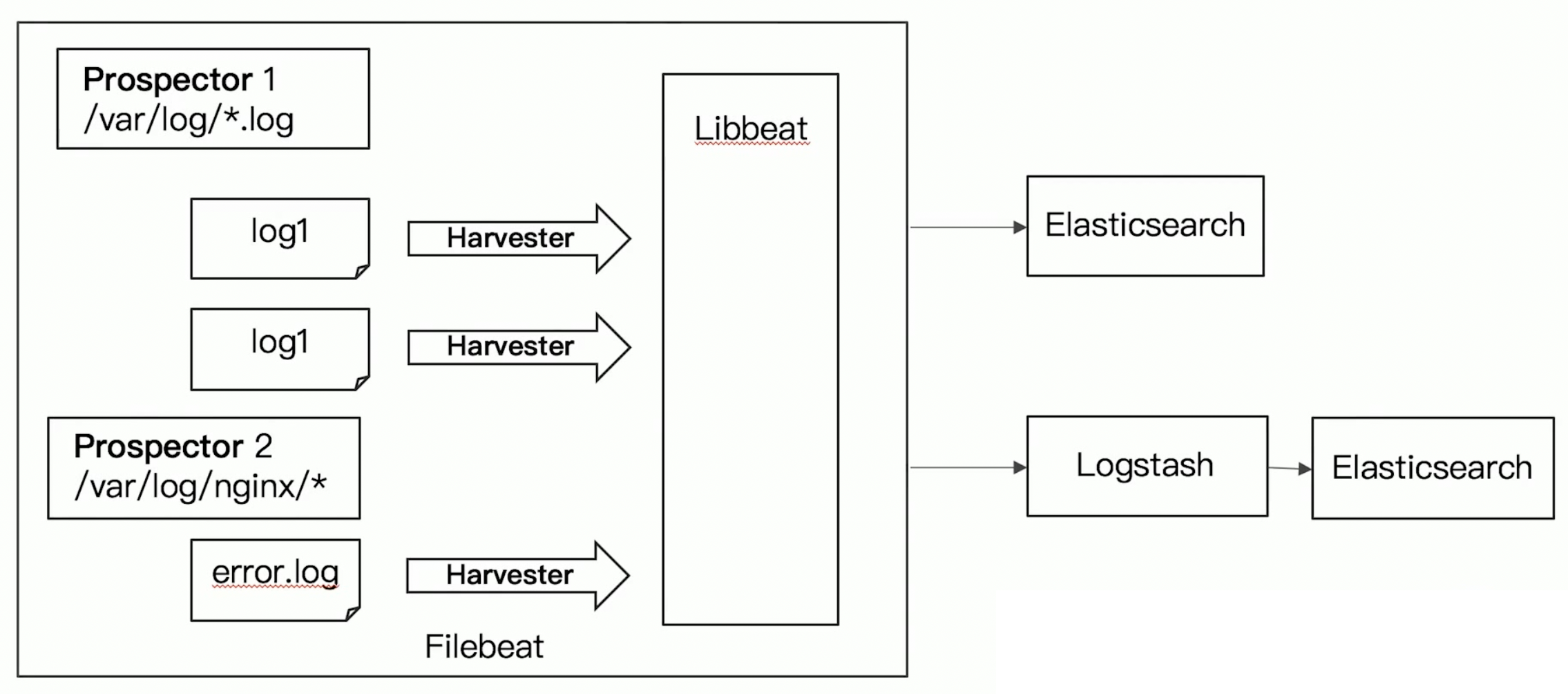
Filebeat 执行流程
- 定义数据采集:Prospector 配置。通过 filebeat.yml
- 建立数据模型::Index Template
- 建立数据处理流程:Ingest Pipeline
- 存储并提供可视化分析:ES + Kibana Dashboard
Modules 开箱即用
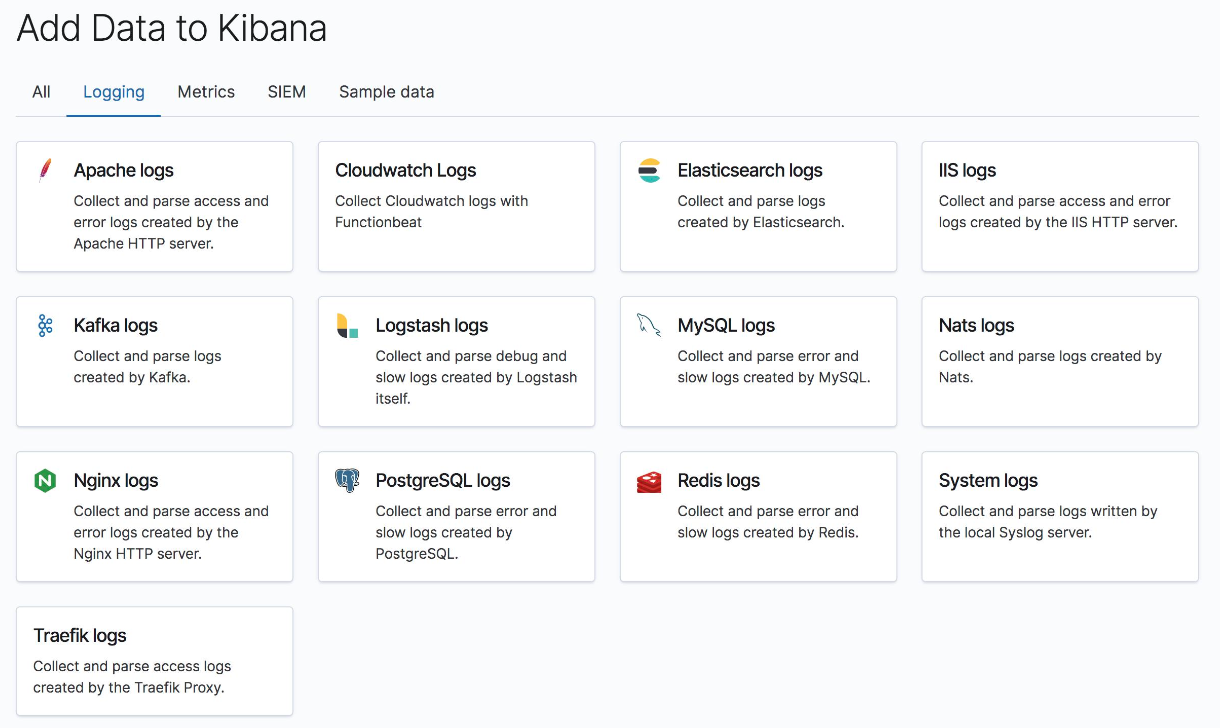
- 大量开箱即用的日志模块
- 简化使用流程
- 减少开发的投入
- 最佳参考实践
- 一些命令
./filebeat modules list./Filebeat modules enable nginx
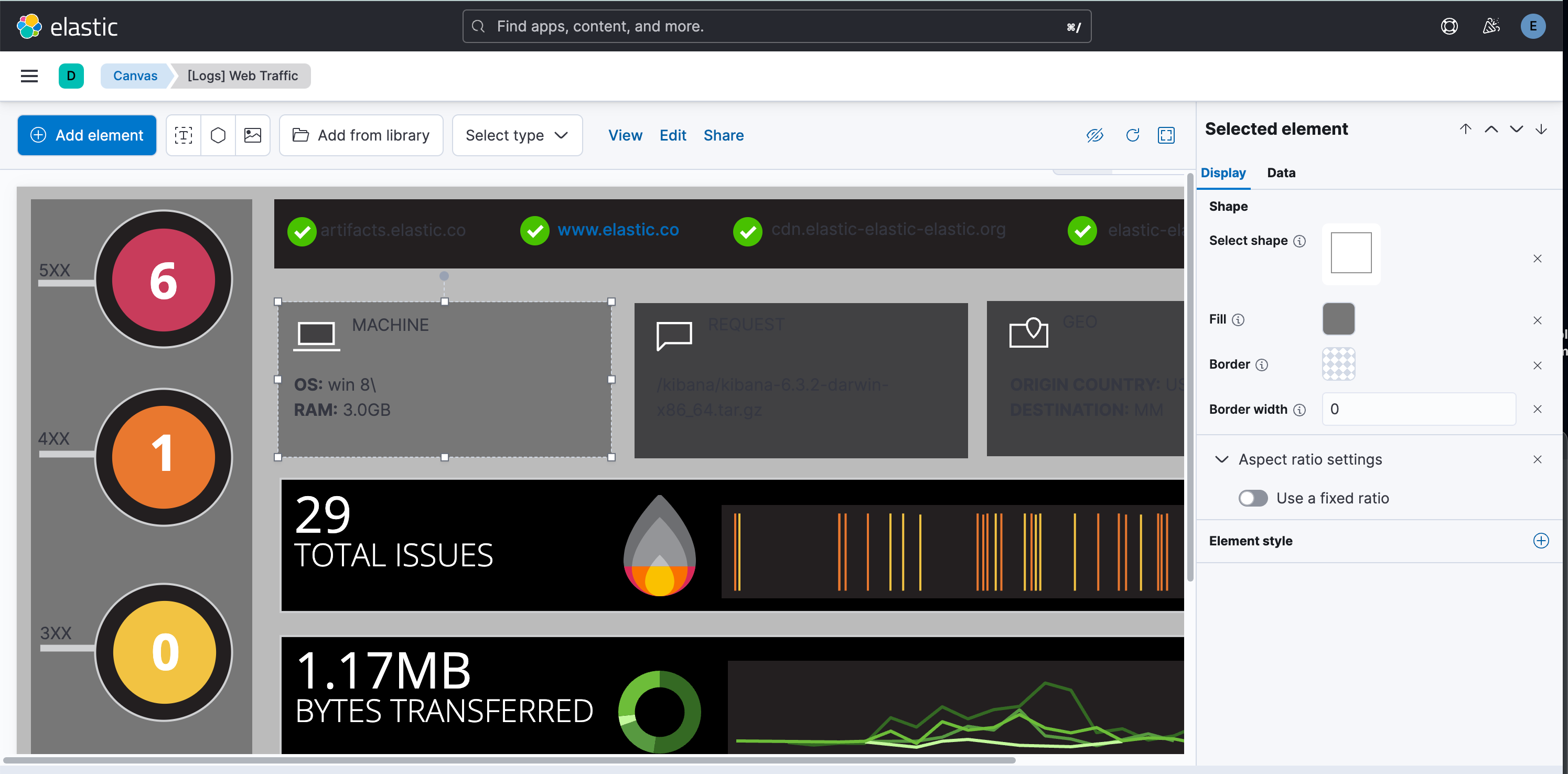
用 Canvas 进行数据的实时展示
https://www.elastic.co/guide/en/kibana/current/canvas.html
实时展示数据,并且达到完美像素级要求:
- 用更加酷炫的方式,演绎你的数据
- 基于 ES 实现准实时的数据分析
- 更好的想法,更大的屏幕
- 品牌宣传,会议大屏
- 高度定制化
- 调色板 / CSS / 拖放元素
个性化方式展现你的数据:
- 公司的 Logo
- 符合公司的配色方案以及设计元素
- Kibana 中免费提供
案例
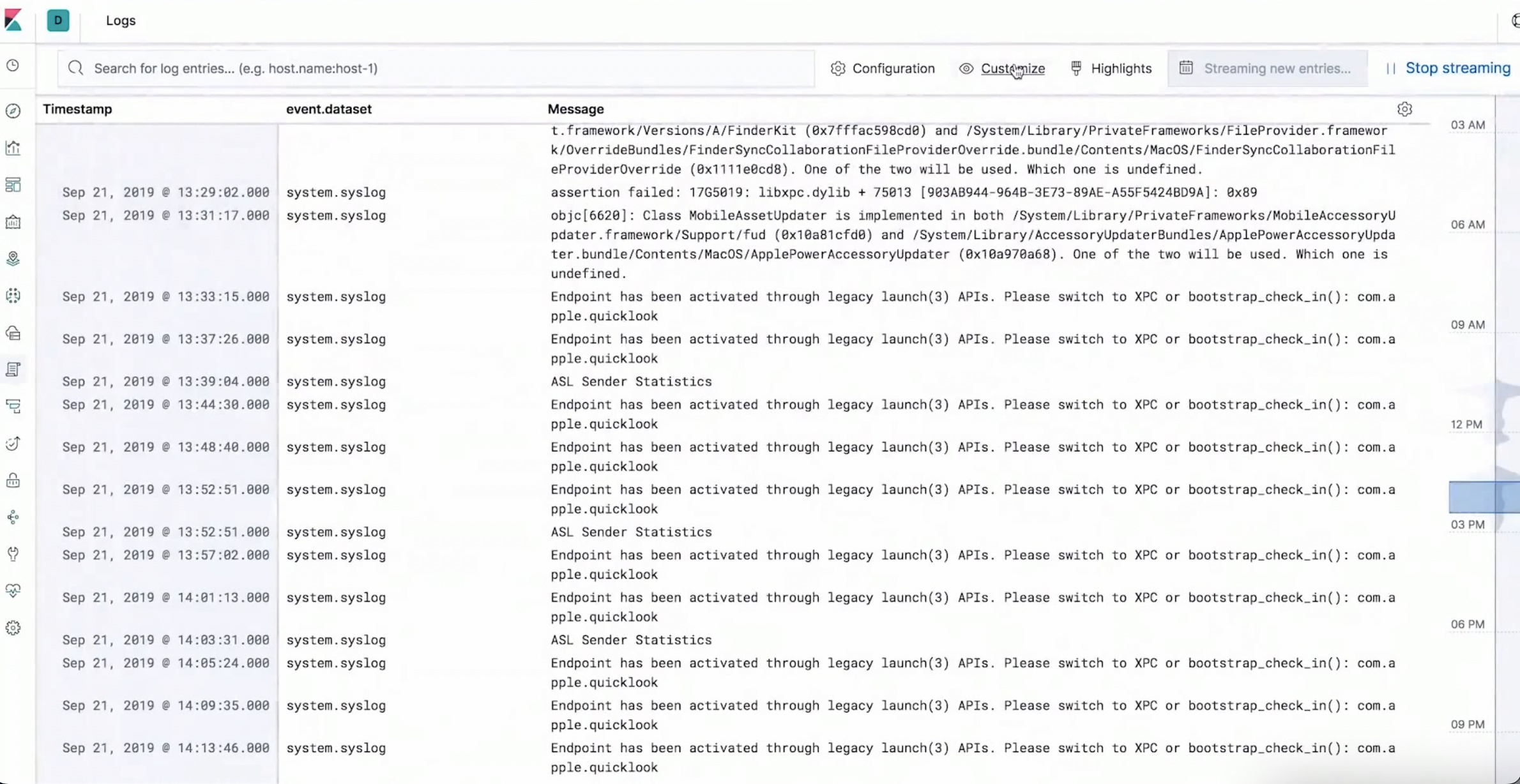
日志分析:
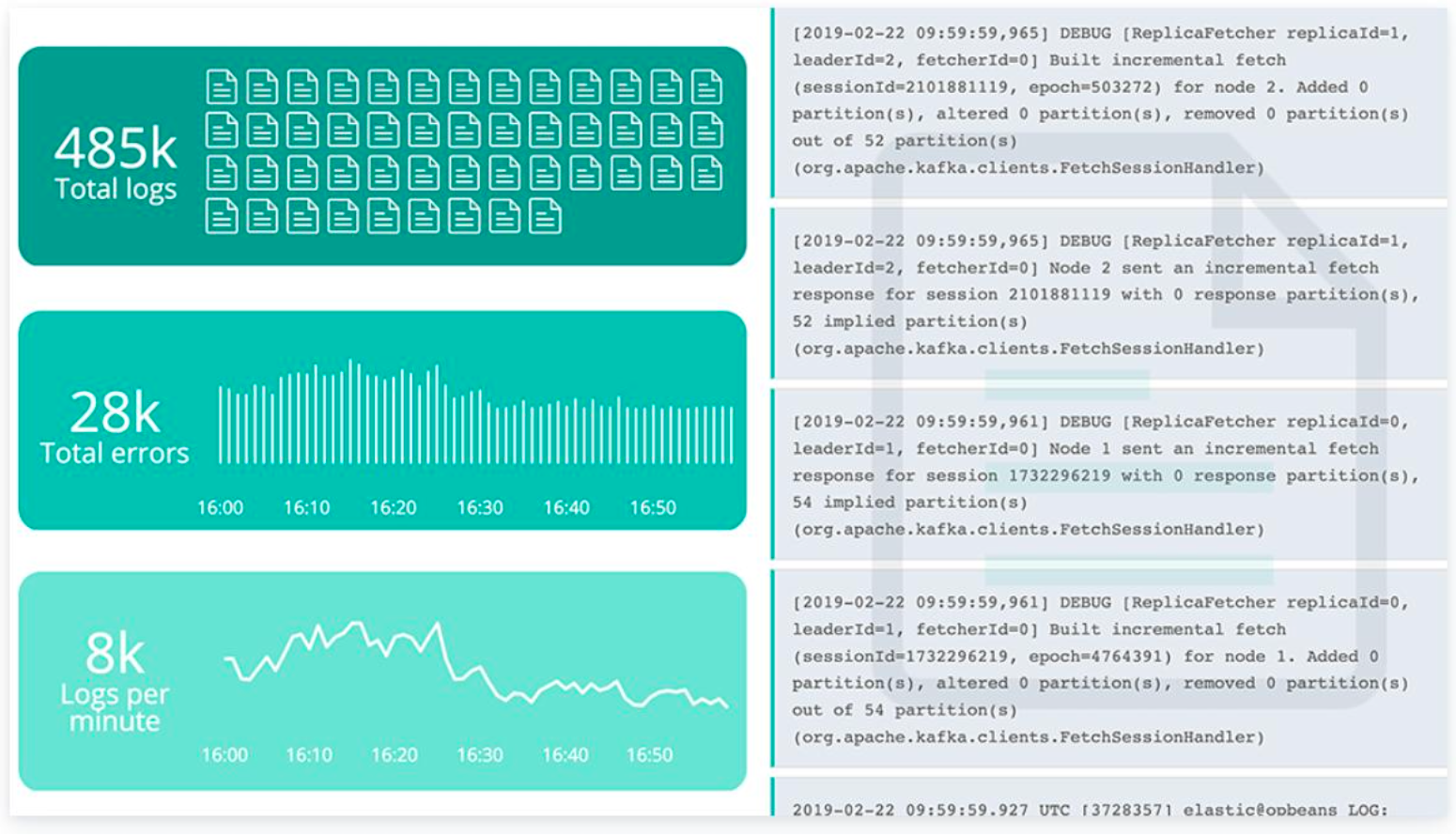
基础设施监控
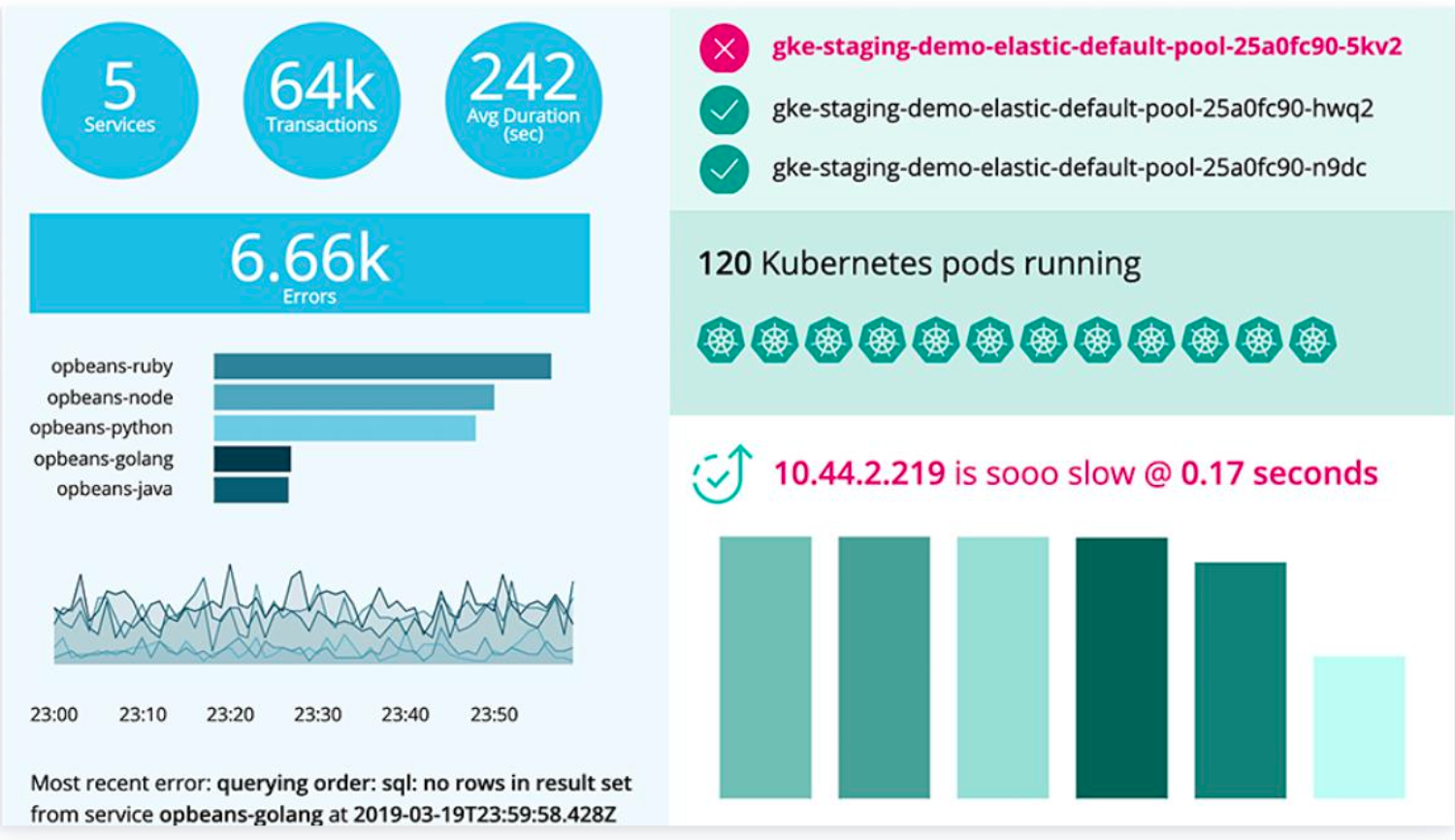
APM
安全运维

业务分析
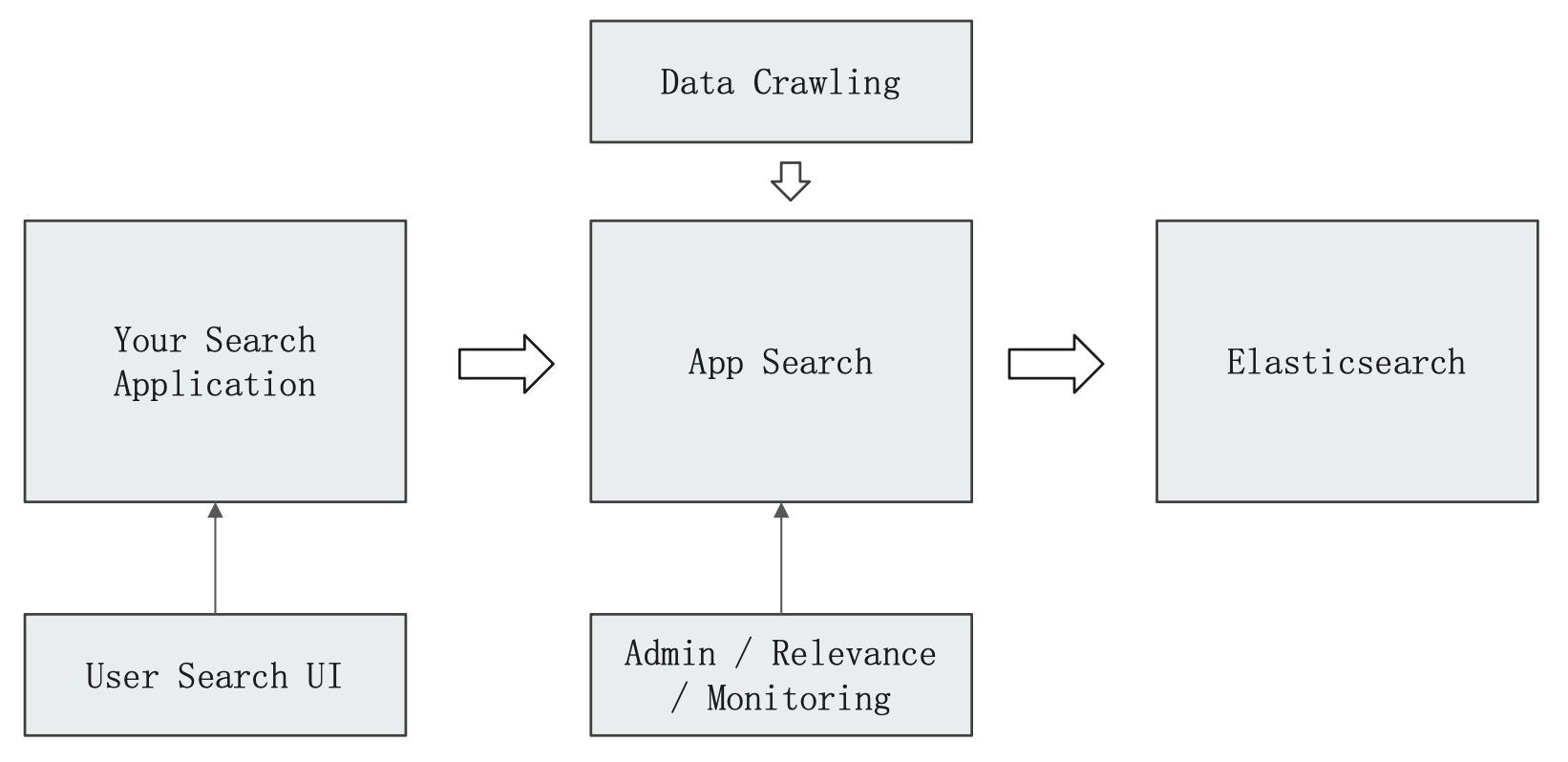
Elastic App Search
Elastic 的 Swiftype 团队推出了一款强大的新搜索产品供开发人员使用。这款新产品名为 App Search,是一种搜索即服务解决方案,简化了为各种软件应用构建丰富搜索体验的过程 — 从电子商务网站到 SaaS 应用再到移动应用。
https://www.elastic.co/cn/webinars/elastic-app-search-overview-and-demo
https://www.elastic.co/guide/en/app-search/current/index.html
架构: