Kubernetes 生产化集群的管理
计算节点相关
生产环境需要稳定性、安全性和可维护性,在硬件、kernel 上需要做一些考量。
生产化集群的考量
计算节点:
- 如何批量安装和升级计算节点的操作系统
- 如何管理配置计算节点的网络信息
- 如何管理不同
SKU(Stock Keeping Unit)的计算节点,例如有的节点带有GPU,有的节点不带 - 如何快速下架故障的计算节点
- 如何快速扩缩容集群的规模
控制平面:
- 如何在主节点上下载、安装和升级控制平面组件及其所需的配置文件
- 如何确保集群所需的其他插件,例如
CoreDNS、监控系统等部署完成 - 如何准备控制平面组件的各种安全证书
- 如何快速升级或者回滚控制平面组件的版本
操作系统选择
操作系统的评估与选择
- 通用操作系统
UbuntuCentOSFedora
- 专为容器优化的操作系统
- 最小化操作系统
CoreOSRedHat AtomicSnappy Ubuntu CoreRancherOS
- 最小化操作系统
面对市面上可选的多种操作系统,需要针对性做技术选型。
操作系统的评估与选择
- 操作系统评估和选型的标准
- 是否有生态系统
- 成熟度
- 内核版本
- 对运行时的支持
Init System- 包管理和系统升级
- 安全
生态系统与成熟度
- 容器优化操作系统的游戏
- 小
- 原子级升级和回退
- 更高的安全性
- 小
| Centos | Ubuntu | CoreOS | Atomic* | Snappy | RancherOS | |
|---|---|---|---|---|---|---|
| 通用操作系统 | 容器优化 | 容器优化 | 容器优化 | 容器优化 | 容器优化 | |
| 生态系统和成熟度 | 成熟 | 成熟 | 最早的容器优化操作系统,不过公司体量小,目前已被收购 | Red Hat 出品,品质保证 | Canonical 出品,最初为移动设备设计 | 相对较新,RancherOS 中运行的所有服务都是 docker 容器 |
最终推荐 Atomic,主要原因是不可变原则,并且可以将 rpm 包以 ostree 的方式提供,在启动的时候注入,通过 ostree 生成不同的操作系统,逻辑与 dockerfile 非常类似。
云原生的原则
可变基础设施的风险
- 在灾难发生的时候,难以重新构建服务。持续过多的手工操作,缺乏记录,会导致很难由标准初始化后的服务器来重新构建起等效的服务
- 在服务运行过程中,持续的修改服务器,就犹如程序中的可变变量的值发生变化而引入的状态不一致的并发风险。这些对于服务器的修改,同样会引入中间状态,从而导致不可预知的问题
不可变基础设施(
immutable infrastructure)避免一些额外动作影响线上业务逻辑,以及一些手动操作没有覆盖生产环境导致异常问题。
- 不可变的容器镜像
- 不可变的主机操作系统
Atomic
- 由
Red Hat支持的软件包安装系统 - 多种
DistroFedoraCentOSRHEL
- 优势
- 不可变操作系统,面向容器优化的基础设施
- 灵活和安全性较好
- 只有
/etc和/var可以修改,其他目录均为只读
- 基于
rpm-ostree管理系统包rpm-ostree是一个开源项目,使得生产系统中构建镜像非常简单- 支持操作系统升级和回滚的原子操作
- 不可变操作系统,面向容器优化的基础设施
最小化主机操作系统
原则:
- 最小化主机操作系统
- 只安装必要的工具
- 必要:支持系统运行的最小工具集
- 任何调试工具,比如性能排查,网络排查工具,均可以后期以容器形式运行
- 意义
- 性能
- 稳定性
- 安全保障
操作系统构建流程

- 将
rpm源拉取快照 - 通过
rpm-ostree将rpm源构建出ostree包,提供ostree服务 - 物理机在启动时候,通过
kickstart调用ostree命令 - 虚拟机(例如
OpenStack),通过Packer Builder将ostree构建成OpenStack支持的方式 - 需要做调试时,在节点上通过拉起容器进行调试,避免最小化操作系统被一些工具污染
ostree
提供一个共享库(libostree)和一些列命令行(非常类似 git)
提供与 git 命令行一致的体验,可以提交或者下载一个完整的可启动的文件系统数
提供将 ostree 部署进 bootloader 的机制
https://github.com/ostreedev/ostree/blob/main/src/boot/dracut/module-setup.sh
1 | install() { |
构建 ostree
rpm-ostree基于
treefile将rpm包构建成为ostree管理ostree以及bootloader配置treefilerefer:分支名(版本,CPU 架构)repo:rpm package repositoriespackages:待安装组件将
rpm构建成ostree1
# rpm-ostree compose tree --unified-core --cachedir=cache --repo=./build-repo /path/to/treefile.json
通过
treefile构建最小化镜像。
treefile 示例:
1 | { |
加载 ostree
初始化项目
1
ostree admin os-init centos-atomic-host
导入
ostree repo,指定ostree源1
ostree remote add atomic http://ostree.svr/ostree
![image-20240131174007070]()
拉取
ostree,将构建好的ostree拉到本地1
ostree pull atomic centos-atomic-host/8/x86_64/standard
部署
os1
ostree admin deploy --os=centos-atomic-host centos-atomic-host/8/x86_64/standard --karg='root=/dev/atomicos/root'

操作系统加载
- 物理机
- 物理机通常需要通过
foreman启动,foreman通过pxe boot,并加载kickstart kickstart通过ostree deploy即可完成操作系统的部署
- 物理机通常需要通过
- 虚拟机
- 需要通过镜像工具将
ostree构建成qcow2格式,vhd、raw等模式
- 需要通过镜像工具将
生产环境遭遇过的陷阱
一些早期碰到的问题。
cluoud-init 0.7.7bug阻止 node 在初始化过程中的静态网络配置
Docker 1.9.1bug当
docker实例日志快速输出时,会发生内存泄漏Kernel panicin4.4.6Cgroup创建和销毁过程中,会产生kernel panicrootfs分区大小rootfs无空间会导致docker无法启动- 导致
rootfs占满的情况CICD中的Maven build会把下载的lib放在/tmp- 用户
Dockerlogs日志过快,导致一个log rotation周期内日志文件撑爆硬盘
- 导致
需要定制化的操作系统参数
- 比如
Elasticsearch需要max_map_count >= 262144,但操作系统默认值为65535,我们需要在创建Node的时候就apply这个配置
- 比如
节点资源管理
NUMA Node
Non-Uniform Memory Access (不对等内存访问)是一种内存访问方式,是为多处理器计算机设计的内存架构

CPU 通过 FSB 总线与内存交互,但是 Core2 访问内存是通过 QPI + FSB ,相对而言性能是较低的。一些性能调优会通过判断进程正在运行的 Core 做就近迁移,避免内存远程访问。
节点资源管理
- 状态汇报
- 资源预留:例如预留给
systemd、kebelet运行 - 防止节点资源耗尽的防御机制驱逐:例如 Pod 将磁盘耗尽、inode 耗尽、端口耗尽、文件句柄耗尽,节点通过防御机制驱逐这种 Pod 以自保
- 容器和系统资源的配置
状态上报
kubelet 周期性地向 API Server 进行汇报,并更新节点的相关健康和资源使用信息。
节点基础信息,包括
IP地址、操作系统、内核、运行时、kubelet、kube-proxy版本信息1
2
3
4
5
6
7
8
9
10
11
12# kubectl get nodes master -o yaml
nodeInfo:
architecture: amd64
bootID: 29d745d8-b0c0-4eb7-ac29-b8734d40ef3f
containerRuntimeVersion: docker://19.3.5
kernelVersion: 5.15.15-1.el7.x86_64
kubeProxyVersion: v1.16.15
kubeletVersion: v1.16.15
machineID: 844b4cb679ee439dab4948ec571eef48
operatingSystem: linux
osImage: CentOS Linux 7 (Core)
systemUUID: 00000000-0000-0000-0000-ac1f6b145e7c节点资源信息包括
CPU、内存、HugePage、临时存储、GPU等注册设备,以及这些资源中可以分配给容器使用的部分1
2
3
4
5
6
7
8
9
10
11
12
13
14allocatable: # 可分配资源
cpu: "56"
ephemeral-storage: 456005072Ki
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 131726028Ki
pods: "110"
capacity: # 资源总和
cpu: "56"
ephemeral-storage: 466490832Ki
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 131726028Ki
pods: "110"调度器在为
Pod选择节点时会将机器的状态信息作为依据1
2
3
4
5
6
7conditions: # 节点状态信息汇总
- lastHeartbeatTime: "2024-02-01T03:31:37Z"
lastTransitionTime: "2023-05-30T03:06:38Z"
message: kubelet has sufficient memory available
reason: KubeletHasSufficientMemory
status: "False"
type: MemoryPressure
| 状态 | 状态的意义 |
|---|---|
| Ready | 节点是否健康 |
| MemoryPressure | 节点是否存在内存压力 |
| PIDPressure | 节点是否存在比较多的进程 |
| DiskPressure | 节点是否存在磁盘压力 |
| NetworkUnavailable | 节点网络配置是否正确 |
Lease
在早期版本 kubelet 的状态上报直接更新 node 对象,而上报的信息包含状态信息和资源信息,因此需要传输的数据包较大,给 APIServer 和 etcd 造成的压力较大。
后引入 Lease 对象(租约)用来保存健康信息(状态信息和资源信息通常变化不会很频繁,只有健康信息需要重点关注),在默认 40s 的 nodeLeaseDurationSeconds 周期内,若 Lease 对象没有被更新,则对应节点可以被判定为不健康
1 | # kubectl get leases.coordination.k8s.io -A |
资源预留
计算节点除用户容器外,还存在很多支撑系统运行的基础服务,譬如 systemd、journald、sshd、dockerd、Containerd、kubelet 等。
为了使服务进程能够正常运行,要确保他们在任何时候都可以获取足够的系统资源,所以我们要为这些系统进程预留资源。
kubelet 可以通过众多启动参数为系统预留 CPU、内存、PID 等资源,比如 systemReserved、KubeReserved 等。
Capacity 和 Allocatable
容量资源(Capacity)是指 kubelet 获取的计算节点当前的资源信息。
- CPU 是从
/proc/cpuinfo文件中获取的节点 CPU 核数 memory是从/proc/memoryinfo中获取的节点内存大小ephemeral-storage是指节点根分区的大小
资源可分配额(Allocatable)是用户 Pod 可用的资源,是资源容量减去分配给系统的资源的剩余部分。
1 | allocatable: |
节点可分配资源(allocatable) = 节点的资源容量(capacity)- kube-reserved - system-reserved - `eviction
| 节点的资源容量(capacity) | |||
|---|---|---|---|
| kube-reserved | system-reserved | eviction-threshold | 可用资源(allocatable) |
节点磁盘管理
系统分区
nodefs默认:
/var/lib/kubelet/pods/- 工作目录和容器日志
容器运行时分区
imagefsdocker:/var/lib/docker/overlay2/containerd:/var/lib/containerd/io.containerd.snapshotter.v1.overlayfs/- 用户镜像和容器可写层
- 容器运行时分区是可选的,可以合并到系统分区中
驱逐管理
kubelet会在系统资源不够时中止一些容器进程,以空出系统资源,保证节点的稳定性- 但由
kubelet发起的驱逐只停止Pod的所有容器进程,并不会直接删除Pod(作为审计用,后续需要手动清理)Pod的status.phase会被标记为Failedstatus.reason会被设置为Evictedstatus.message则会记录被驱逐的原因
资源可用额监控
kubelet依赖内嵌的开源软件cAdvisor,周期性检查节点资源使用情况(新版本会替换掉,由kubelet自身获取,主要是通过Cgroup)CPU是可压缩资源,根据不同进程分配时间配额和权重,CPU可被多个进程竞相使用(针对一些无法压缩的进程,则需要针对性调优)- 驱逐策略是基于磁盘和内存资源用量进行的,因为两者属于不可压缩的资源,当此类资源使用耗尽时将无法再申请
| 检查类型 | 说明 |
|---|---|
| memory.avaliable | 节点当前的可用内存 |
| nodefs.avaliable | 节点根分区的可使用磁盘大小 |
| nodefs.inodesFree | 节点根分区的可使用 inode |
| imagefs.inodesFree | 节点运行时分区的可使用 inode |
| imagefs.avaliable | 节点运行时分区的可使用磁盘大小 节点如果没有运行时分区,就不会有相应的资源监控 |
驱逐策略
kubelet 获得节点的可用额信息后,会结合节点的容量信息来判断当前节点运行的 Pod 是否满足驱逐条件。
驱逐条件可以是绝对值或百分比,当监控资源的可使用额少于设定的数值或百分比时,kubelet 就会发起驱逐操作。
kubelet 参数 evictionMinimumReclaim 可以设置每次回收的资源的最小值,以防止小资源的多次回收。
| kubelet 参数 | 分类 | 驱逐方式 |
|---|---|---|
| evictionSoft | 软驱逐 | 当检测到当前资源达到软驱逐的阈值时,并不会立即启动驱逐操作,而是要等待一个宽限期。 这个宽限期选取 EvictionSoftGracePeriod 和 Pod 指定的 TerminationGracePeriodSeconds 中较小的值。 |
| evictionHard | 硬驱逐 | 没有宽限期,一旦检测到满足硬驱逐的条件,就直接中止容器来释放紧张资源 |
kubectl explain pod.spec.terminationGracePeriodSeconds
1 | # /usr/bin/kubelet --help |
基于内存压力的驱逐
memory.avaiable 表示当前系统的可用内存情况。
kubelet 默认设置了 memory.available < 100Mi 的硬驱逐条件。
当 kubelet 检测到当前节点可用内存资源紧张并满足驱逐条件时,会将节点的 MemoryPressurce 状态设置为 True,调度器会阻止 BestEffort Pod 调度到内存承压的节点。(也就是禁止调度)
kubelet 启动对内存不足的驱逐操作时,会依照如下的顺序选取目标 Pod:
- 判断
Pod所有容器的内存使用量总和是否超出了请求的内存量,超出请求资源的Pod会成为被选目标(QoS)kubectl explain pod.status.qosClass - 查询
Pod的调度优先级,低优先级的Pod被优先驱逐(优先级)kubectl explain pod.spec.priorityClassName - 计算
Pod所有容器的内存使用量和Pod请求的内存量的差值,差值越小,越不容易被驱逐。(同等优先级情况下,再按照内存使用量进行排序)
基于磁盘压力的驱逐
以下任何一项满足驱逐条件时,它会将节点的 DiskPressure 状态设置为 True,调度器不会再调度任何 Pod 到该节点上
nodefs.avaliable:可用空间nodefs.inodesFree:判断inode够不够imagefs.availableiamgefs.inodesFree
驱逐行为:(按照 nodefs 和 imagefs 是否放在一起做区分)
- 有容器运行时分区
nodefs达到驱逐阈值,那么kubelet删除已经退出的容器imagefs达到驱逐阈值,那么kubelet删除所有未使用的镜像
- 无容器运行时分区
kubelet同时删除未运行的容器和未使用的镜像
回收已经退出的容器和未使用的镜像后,如果节点依然满足驱逐条件,kubelet 就会开始驱逐正在运行的 Pod ,进一步释放磁盘空间。
- 判断 Pod 的磁盘使用量是否超过请求的大小,超出请求资源的 Pod 会成为备选目标
- 查询 Pod 的调度优先级,低优先级的 Pod 优先驱逐
- 根据磁盘使用超过请求的数量进行排序,差值越小,越不容易被驱逐
容器和资源配置
Pod 的 QoS 级别是根据其容器的资源请求和限制来确定的。如果容器的资源请求和限制相等,则 Pod 被标记为 Guaranteed 级别。如果容器的资源请求小于限制,则 Pod 被标记为 Burstable 级别。如果容器没有设置资源请求和限制,则 Pod 被标记为 BestEffort 级别。
针对不同 QoS Class 的 Pod,Kubernetes 按如下 Hierarchy 组织 cgroup 中的 CPU 子系统(内存同理)
1 | # cd /sys/fs/cgroup/cpu/kubepods.slice/ |
Guaranteed 则是一个单独的目录。

CPU CGroup 配置
| CGroup 类型 | 参数 | QoS 类型 | 值 |
|---|---|---|---|
| 容器的 CGroup | cpu.shares | BestEffort | 2(最小值) |
| Burstable | requests.cpu X 1024 | ||
| Guaranteed | requests.cpu X 1024 | ||
| cpu.cfs_quota_us | BestEffort | -1(不限制) | |
| Burstable | limits.cpu X 100 | ||
| Guaranteed | limits.cpu X 100 | ||
| Pod 的 CGroup | cpu.shares | BestEffort | 2 |
| Burstable | Pod 所有容器(requests.cpu X 1024)之和 | ||
| Guaranteed | Pod 所有容器(requests.cpu X 1024)之和 | ||
| cpu.cfs_quota_us | BestEffort | -1 | |
| Burstable | Pod 所有容器(limits.cpu X 100)之和 | ||
| Guaranteed | Pod 所有容器(limits.cpu X 100)之和 |
容器和资源配置
针对不同 QoS Class 的 Pod,Kubernetes 按如下 Hierarchy 组织 cgroup 中的 Memory 子系统
1 | # ls -ltra /sys/fs/cgroup/memory/kubepods.slice/ |
Guaranteed 则是一个单独的目录。

内存 CGroup 配置
| CGroup 类型 | 参数 | QoS 类型 | 值 |
|---|---|---|---|
| 容器的 CGroup | memory.limit_in_bytes | BestEffort | 9223372036854771712(最大值) |
| Burstable | limits.memory | ||
| Guaranteed | limits.memory | ||
| Pod 的 CGroup | memory.limit_in_bytes | BestEffort | 9223372036854771712 |
| Burstable | Pod 所有容器(limits.memory)之和 | ||
| Guaranteed | Pod 所有容器(limits.memory)之和 |
OOM Killer 行为
- 系统的 OOM
Killer可能会采取 OOM 的方式来中止某些容器的进程,进行必要的内存回收操作 - 而系统根据进程的
oom_score来进行优先级排序,选择待终止的进程,且进程的oom_score越高,越容易被终止 - 进程的
oom_score是根据当前进程使用的内存占节点总内存的比例值乘以 10,再加上oom_score_adj综合得到的 - 而容器进程的
oom_score_adj正是kubelet根据memory.request进行设置的
| Pod QoS 类型 | oom_score_adj |
|---|---|
| Guaranteed | -997 |
| BestEffort | 1000 |
| Burstable | min(max(2, 1000-(1000 x memoryRequestBytes) / machineMemoryCapacityBytes), 999) |
也就是优先杀死 BestEffort 中对内存占用较高的进程。
1 | # crictl ps | grep nginx |
测试对 CPU 的校验和准入行为
定义一个 Pod,并将该 Pod 中的 nodeName 属性直接写成集群中的节点名
将 Pod 的 CPU 的资源设置为超出计算节点的 CPU 的值
创建该 Pod
1 | apiVersion: v1 |
1 | Events: |
可以看到,pod 被拒绝创建。
日志管理
节点上需要通过运行 logrotate 的定时任务对系统服务日志进行 rotate 清理,以防止系统服务日志占用大量的磁盘空间。
logrotate的执行周期不能过长,以防日志短时间内大量增长- 同时配置日志的
rotate条件,在日志不占用太多空间的情况下,保证有足够的日志可供查看 Docker- 出了基于系统
logrotate管理日志,还可以依赖Docker自带的日志管理功能来设置容器日志的数量和每个日志文件的大小 Docker写入数据之前会对日志大小进行检查和rotate操作,确保日志文件不会超过配置的数量和大小
- 出了基于系统
Containerd- 日志的管理是通过
kubelet定期(默认为 10s)执行du命令,来检查容器日志的数量和文件的大小的。 - 每个容器日志的大小和可以保留的文件个数,可以通过
kubelet的配置参数container-log-max-size和container-log-max-files进行调整
- 日志的管理是通过
Docker 卷管理
- 在构建容器镜像时,可以在
Dockerfile中通过VOLUME指令声明一个存储卷,目前 Kubernetes 尚未将其纳入管控范围,不建议使用。 - 如果容器进程在可写层或
emptyDir卷进行大量读写操作,就会导致磁盘I/O过高,从而影响其他容器进程甚至系统进程。(所有的容器都使用同一个运行时目录) Docker和Containerd运行时都基于CGroup v1。对于块设备,只支持对Direct I/O限速,而对于Buffer I/O还不具备有效的支持。因此,针对设备限速的问题,目前还没有完美的解决方案,对于特殊I/O需求的容器,建议使用独立的磁盘空间。(期待CGroup v2来解决)
网络资源
由网络插件通过 Linux Traffic Control 为 Pod 限制带宽
可利用 CNI 社区提供的 bandwidth 插件
1 | apiVersion: v1 |
进程数
kubelet 默认不限制 Pod 可以创建的子进程数量,但可以通过启动参数 podPidsLimit 开启限制,还可以由 reserved 参数为系统进程预留进程数。
kubelet通过系统调用周期性地获取当前系统的 PID 的使用量,并读取/proc/sys/kernel/pid_max,获取系统支持的 PID 上限- 如果当前的可用进程数少于设定阈值,那么
kubelet会将节点对象的PIDPressure标记为 True kube-schedule在进行调度时,会从备选节点中对处于NodeUnderPIDPressure状态的节点进行过滤
节点异常检测
Kubernetes 集群可能存在的问题
- 基础架构守护程序问题:NTP 服务关闭
- 硬件问题:CPU,内存或磁盘损坏
- 内核问题:内核死锁,文件系统损坏
- 容器运行时问题:运行时守护程序无响应
- …
当 Kubernetes 中节点发生上述问题,在整个集群中,Kubernetes 服务组件并不会感知以上问题,就会导致 Pod 仍会调度至问题节点。
node-problem-detector (NPD)
为了解决上面的问题,社区引入了守护进程 node-problem-detector,从各个守护进程收集节点问题,并使它们对上游层可见。
Kubernetes 节点诊断的工具,可以将节点的异常上报,例如:
- Runtime 无响应
- Linux Kernel 无响应
- 网络插件
- 文件描述符异常
- 硬件问题如 CPU,内存或者磁盘故障
故障分类
| Problem Daemon Types | NodeCondition | Description | Configs |
|---|---|---|---|
| 系统日志监控 | KernelDeadlock ReadonlyFilesystem FrequentKubeletRestart FrequentDockerRestart FrequentContainerdRestart | 通过监控系统日志来汇报问题并输出系统指标数据 | filelog, kmsg, kernel abrt system |
| CustomPluginMonitor | 按需定义 | 自定义插件监控允许用户自定义监控脚本,并运行这些脚本来进行监控 | 比如 npt 服务监控 |
| HealthChecker | KubeletUnhealthy ContainerRuntimeUnhealthy | 针对 kubelet 和运行时的健康检查 | kubelet docker containerd |
问题汇报手段
node-problem-detector 通过设置 NodeCondition 或者创建 Event 对象来汇报问题
NodeCondition:针对永久性故障,会通过设置NodeCondition来改变节点状态Event:临时故障通过Event来提醒相关对象,比如通知当前节点运行的所有 Pod
安装
按照教程:
https://helm.sh/docs/intro/install/
https://github.com/kubernetes/node-problem-detector
1 | helm repo add deliveryhero https://charts.deliveryhero.io/ |
或者手动安装:
1 | helm repo add deliveryhero https://charts.deliveryhero.io/ |
改镜像
1 | vi node-problem-detector/values.yaml |
镜像源从 regisry.k8s.io 改为 k8s.mirror.nju.edu.cn
安装
1 | helm install npd ./node-problem-detector |
1 | # kubectl get daemonsets.apps |
测试,在节点的 kmsg 中刷入日志
1 | sudo sh -c "echo 'kernel: BUG: unable to handle kernel NULL pointer dereference at TESTING' >> /dev/kmsg" |
1 | kubectl logs -f npd-node-problem-detector-sv7hx --tail 10 |
在节点的 event 中
1 | # kubectl describe nodes master |
测试,刷入 blocked 类型日志
1 | sudo sh -c "echo 'kernel: INFO: task docker:20744 blocked for more than 120 seconds.' >> /dev/kmsg" |
在节点的 condition 中
1 | # kubectl get node master -o yaml |
NPD 只负责捕获异常状态,因此,还需要有监控系统做对应运维操作。
使用插件 Pod 启动 NPD
如果你使用的是自定义集群引导解决方案,不需要覆盖默认配置,可以利用插件 Pod 进一步自动化部署。
创建 node-stick-detector.yaml,并在控制平面节点上保存配置到插件 Pod 的目录 /etc/kubernetes/addons/node-problem-detector。Kubernetes 会自动去扫描这个 addons 目录安装插件。
NPD 的异常处理行为
NPD 只负责获取异常事件,并修改
node conditino,不会对节点状态和调度产生影响1
2
3
4
5
6- lastHeartbeatTime: "2024-02-17T09:04:43Z"
lastTransitionTime: "2024-02-17T09:04:43Z"
message: 'kernel: INFO: task docker:20744 blocked for more than 120 seconds.'
reason: DockerHung
status: "True"
type: KernelDeadlock需要自定义控制器,监听 NPD 汇报的
condition,taint node,阻止pod调度到故障节点问题修复后,重启 NPD Pod 来清理错误事件
需要人为操作,修复好节点之后,删除 NPD Pod 。
常用节点问题排查手段
通常建议使用运维 pod 来做排查手段,并且给足够的权限
ssh 到内网节点
- 创建一个支持
ssh的pod - 并通过负载均衡器转发
ssh请求
查看日志
针对 systemd 拉起的服务:
journalctl -afu kubelet -S "2024-02-02 00:00:00"-u unit:对应的systemd拉起的组件,如kubelet-f follow:跟踪最新日志-a show all:实现所有日志列-S since:从某一时间开始
对于标准的容器日志:
kubectl logs -f nginx-deployment-5759c4887d-gv98m -c nginx指定容器名 和 Pod 名称
kubectl logs -f --all-containers nginx-deployment-5759c4887d-gv98m打印 Pod 内所有容器的日志
kubectl logs -f nginx-deployment-5759c4887d-gv98m --previous查看 Pod
crash时上一个 Pod 的日志
如果容器日志被 shell 转储到文件,则需通过 exec
kubectl exec -it nginx-deployment-5759c4887d-gv98m -- tail -f /var/log/nginx/error.log
基于 extended resource 扩展节点资源
扩展资源
扩展资源是 kubernetes.io 域名之外的标准资源名称。它们使得集群管理员能够颁布非 Kubernetes 内置资源,而用户可以使用它们。
自定义扩展资源无法使用 kubernetes.io 作为资源域名。
管理扩展资源
- 节点级扩展资源
- 节点级扩展资源绑定到节点
- 设备插件管理的资源
- 发布在各节点上由设备插件所管理的资源,如 GPU,智能网卡等
为节点配置资源
- 集群操作员可以向 API 服务器提交 PATCH HTTP 请求,以在集群中节点的
status.capacity中为其配置可用数量 - 完成此操作后,节点的
status.capacity字段中将包含新资源 kubelet会异步地对status.allocatable字段执行自动更新操作,使之包含新资源- 调度器在评估 Pod 是否适在某节点上执行时会使用节点的
status.allocatable值,在更新节点容量使之包含新资源之后和请求该资源的第一个 Pod 被调度到该节点之间,可能会有短暂的延迟。 - 例如注册扩展自定义的扩展资源
将 ~/.kube/config 中的 client-key-data 和 client-certificate-data 作为 key 和 crt
1 | echo xxx | base64 -d > admin.key |
可以看到额外资源
1 | allocatable: |
使用扩展资源
1 | apiVersion: apps/v1 |
通过 yaml 文件创建资源,可以看到由于节点资源不足的报错
1 | Events: |
将 reclaimed-cpu 的数量改为 2 即可。
集群层面的扩展资源
- 可选择由默认调度器管理资源,默认调度器像管理其他资源一样管理扩展资源
Request与Limit必须一致,因为 Kubernetes 无法确保扩展资源的超售- 而且给会给客户带来变动压力
- 更常见的场景是,由调度器扩展程序(Scheduler Extenders)管理,这些程序处理资源消耗和资源配额
- 修改调度器策略配置
ignoredByScheduler字段可配置调度器不要检查自定义资源 - 在波谷时,监控机器的负载,将资源通过扩展资源进行管理,将一些
Job使用扩展资源进行调度
1 | { |
构建和管理高可用资源
在多节点、集群环境下管理 Kubernetes 生产系统。
Kubernetes 高可用层级

- 基础架构管理:提供计算资源的管理平台,在数据中心中安装部署服务器,作为计算节点、网络节点、存储节点,对应的,还需要管理操作系统,以及一些安全相关的策略,例如
iptables、firewalld、selinux,以及容器运行时,一般选择containerd - Kubernetes 本身管理:包括集群管理,每一个物理节点管理等
- 在数据平面和控制平面有不同的插件和组件,控制平面服务于应用程序,控制平面服务与应用管理,控制平面除了 Kubernetes 自带的一些核心组件,还有有社区提供的插件例如
cni,针对一些特殊场景有自定义的用户空间控制器,以及基于告警系统的平台管理 - 对接企业公共服务,面向企业,搭配企业 DNS 实现外部域名访问等
高可用的数据中心
- 多地部署
- 每个数据中心需要划分成具有独立供电、制冷、网络设备的高可用区
- 每个高可用区管理独立的硬件资产,包括机架、计算节点、存储、负载均衡器、防火墙等硬件设备
Node 的生命周期管理
运营 Kubernetes 集群,不仅仅是集群搭建那么简单,运营需要对集群中所有节点的完整生命周期负责。
- 集群搭建
- 集群扩容、缩容
- 集群销毁(很少)
- 无论是集群搭建还是扩容,核心是 Node 的生命周期管理
- Onboard
- 物理资产上架
- 操作系统安装
- 网络配置
- Kubernetes 组件安装
- 创建 Node 对象
- 故障处理
- 临时故障:重启大法
- 永久故障:机器下架
- Offboard
- 删除 Node 对象
- 物理资产下载,送修、报废
- Onboard
主机管理
- 选定哪个版本的系统内核、哪个发行版、安装哪些工具集、主机网络如何规划等
- 日常的主机镜像升级更新也可能是造成服务不可用的因素之一
- 主机镜像更新可以通过
A/B系统 OTA(Over The Air) 升级方式进行分别使用 A、B 两个存储空间,共享一份用户数据。在升级过程中,OTA 更新即往其中一个存储空间写入升级包,同时保证了另一个系统可以正常运行,而不会打断用户。如果 OTA 失败,那么设备会启动到 OTA 之前的磁盘分区,并且仍然可以使用。
更加推荐这种方式,不仅有安全保证,还可以批量进行。
- 主机镜像更新可以通过
生产化集群管理
- 如何设定单个集群规模
社区声明单一集群可支持 5000 节点,在如此规模的集群中,大规模部署应用是有诸多挑战的。应该更多还是更少?如何权衡?
可以采用在 Pod 内搭建 git,然后使用 Pod 拉取代码构建。避免频繁创建 Pod
- 如何根据地域划分集群:(
etcd集群部署,选主、心跳)- 不同地域的计算节点划分到同一集群
- 将同一地域的节点划分到同一集群
- 如何规划集群的网络
- 企业办公环境、测试环境、预生产环境和生产环境应如何进行网络分离
- 不同租户之间应如何进行网络隔离
- 如何自动化搭建集群
- 如何自动化搭建和升级集群,包括自动化部署控制平面和数据平面的核心组件
- 如何与企业的公共服务集成
企业公共服务
- 需要与企业认证平台集成,这样企业用户就能通过统一认证平台接入 Kubernetes 集群,而无须重新设计和管理一套用户系统
- 集成企业的域名服务、负载均衡服务,提供集群服务对企业外发布的访问入口
- 在与企业的公共服务集成时,需要考虑它们的服务是否可靠
- 对于不能异步调用的请求,采用同步调用需要设置合理的超时时间
- 过长的超时时间,会延迟结果等待时间,导致整体的链路调用时间延长,从而降低整体的 TPS
- 有些失败是短暂的、偶然的(比如网络抖动),进行重试即可。而有些失败是必然的,重试反而会造成调用请求量放大,加重对调用系统的负担
控制平面的高可用保证
- 针对大规模的集群,应该为控制平面组件划分单独节点,减少业务容器对控制平面容器或守护进程的干扰和资源抢占
- 控制平面所在的节点,应确保在不同机架上,以防止因为某些机架的交换机或电源出问题,造成所有的控制面节点都无法工作
- 保证控制平面的每个组件有足够的 CPU、内存和磁盘资源,过于严苛的资源限制会导致系统效率低下,降低集群可用性
- 应尽可能地减少或消除外部依赖。在 Kubernetes 初期版本中存在较多 Cloud Provider API 的调用,导致在运营过程中,当 Cloud Provider API 出现故障时,会使得 Kubernetes 集群也无法正常工作
- 应尽可能地将控制平面和数据平面解耦,确保控制平面组件出现故障时,将业务影响降到最低
- Kubernetes 还有一些核心插件,是以普通的 Pod 形式加载运行的,可能会被调度到任意工作节点,与普通应用竞争资源。这些插件是否正常运行也决定了集群的可用性
高可用集群

多节点选择专门的 master ,避免控制面流量被数据流量影响。
集群安装方法比较
| 安装工具 | 方法 | 优势 | 缺点 |
|---|---|---|---|
| 二进制 | 下载二进制文件,并通过设置 systemd 来管理 | 灵活度强 | 复杂,需要关心每一个组件的配置 对系统服务的依赖性过多 |
| kubeadm | kubeadm 是一个搭建集群的命令行工具 管理节点通过 kubeadm init 初始化 计算节点通过 kubeadm join 加入 |
相比二进制,控制面板组件的安装和配置被封装起来了 管理集群的生命周期,比如升级,证书管理等 |
操作系统层面的配置无自动化 运行时安装配置等复杂步骤依然是必须的 CNI 插件等需要手工安装 |
| kubespray | 通过 Ansible-playbook 完成集群搭建 | 自动完成操作系统层面的配置 利用了 kubeadm 作为集群管理工具 |
缺少基于声明式 API 的支持 |
| KOPS | 基于声明式 API 的集群管理工具 | 基于社区标准的 Cluster API 进行集群管理 节点的操作系统安装等全自动化 |
与云环境深度集成 灵活性差 |
综合来看,在商业化能力不够的情况下,安装大型集群推荐使用 kubespray 的方式。
目前社区推广的事 KOPS 的方式,但是需要与云环境定制开发。
用 Kubespray 搭建高可用集群

通过 ansible 和 kubadm 实现自动化安装。
基于声明式 API 管理集群
集群管理不仅仅包括集群搭建,还有更多功能需要支持
- 集群扩缩容
- 节点健康检查和自动修复
- Kubernetes 升级
- 操作系统升级
云原生场景中集群应该按照我们的期望的状态运行,这意味着我们应该将集群管理建立在声明式 API 的基础之上。
Kubernetes Cluster API

参与角色
管理集群
管理 workload 集群的集群,用来存放 Cluster API 对象的地方
可同时管理多个集群
Workload集群- 真正开放给用户用来运行应用的集群,由管理集群管理
Infrastructure provider- 提供不同云的基础架构管理,包括计算节点、网络等。目前流行的公有云多与 Cluster API 集成了
Bootstrap provider- 证书生成
- 控制面组件安装和初始化,监控节点的创建
- 将主节点和计算节点加入集群
Control plane- Kubernetes 控制平面组件
涉及模型
Machine- 计算节点,用来描述可以运行 Kubernetes 组件的机器对象(注意与 Kubernetes Node)的差异
- 一个新
Machine被创建以后,对应的控制器会创建一个计算节点,安装好操作系统并更新Machine的状态 - 当一个
Machine被删除后,对应的控制器会删除掉该节点并回收计算资源 - 当
Machine属性被更新以后(比如 Kubernetes 版本更新),对应的控制器会删除旧节点并创建新节点
Machine Immutability(In-place Upgradevs.Replace)- 不可变基础架构
MachineDeployment- 提供针对
Machine和MachineSet的声明式更新,类似于 Kubernetes Deployment(声明式思想统一)
- 提供针对
MachineSet- 维护一个稳定的机器集合,类似 Kubernetes
ReplicaSet
- 维护一个稳定的机器集合,类似 Kubernetes
MachineHealthCheck- 定义节点应该被标记为不可用的条件
用 cluster API 管理集群
使用 kind 部署 Kubernetes on Docker

KubeadmControlPlane
一些配置

MachineDeployment
一些配置

MachineHealthCheck
一些配置

日常运营中的节点问题归类
可自动修复的问题
- 计算节点
downPing不通TCP probe失败- 节点上的所有应用都不可达
不可自动修复的问题
- 文件系统损坏
- 磁盘阵列故障
- 网盘挂载问题
- 其他硬件故障
kernel出错,core dumps
其他问题
- 软件 Bug
- 进程锁死,或者
memory/CPU竞争问题 - Kubernetes 组件出问题
kubelet/kube-proxy/Docker/Salt
故障检测和自动恢复
当创建 Compute 节点时,允许定义 Liveness Probe
- 当
livenessProbe失败时,ComputeNode的ProbePassed设置为false
在 Prometheus 中,已经有 Node Level 的 alert,抓取 Prometheus 中的 alert
1 | spec: |
设定自动恢复规则
- 大多数情况下,重启大法(
Restart operator) - 如果重启不行就重装(
reprovision) - 重装不行就重修(
breakfix)
探活失败示例:
Cluster Autoscaler
每一个厂商都有自己的一套 cluster aotoscaler 方法,但是原理都差不多。
工作机制
- 扩容:
- 由于资源不足,
pod调度失败,即有pod一直处于Pending状态
- 由于资源不足,
- 缩容
node的资源利用率较低时,持续10分钟低于50%- 此
node上存在的pod都能被重新调度到其他node上运行

Cluster Autoscaler 架构
Autoscaler:核心模块,负责整体扩缩容功能
Estimator:负责评估计算扩容节点,数量以及是否支持扩容
Simulator:负责模拟调度,计算缩容节点,资源以及调度之后是否可以运行
Cloud-Provider:与云交互进行节点的增删操作,每个支持 CA 的主流厂商都实现自己的 plugin 实现动态缩放
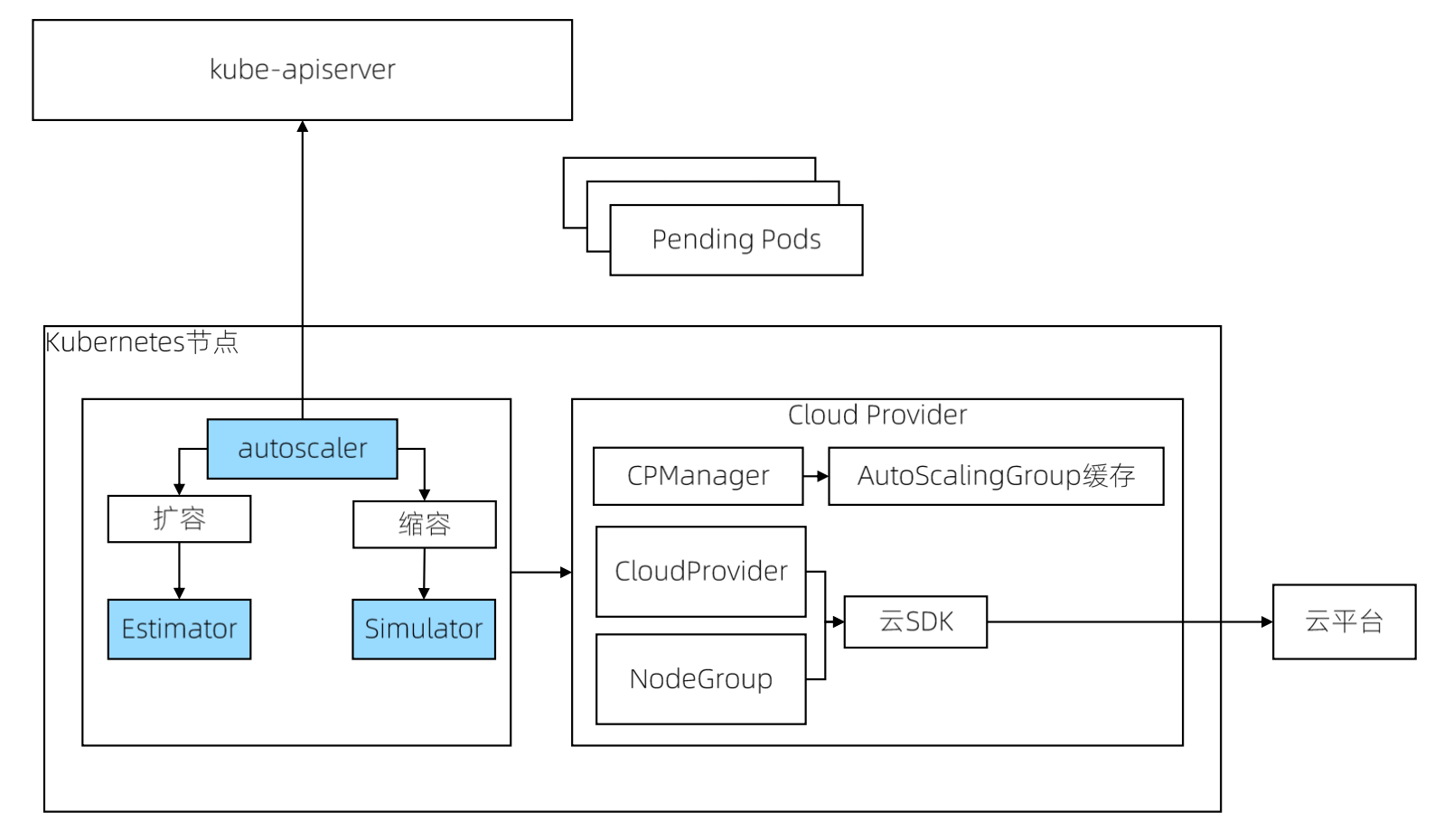
Cluster Autoscaler 的扩展机制
为了自动创建和初始化 Node,Cluster Autoscaler 要求 Node 必须属于某个 Node Group,比如:
GCE/GKE中的Managed instance groups(MIG)AWS中的Autoscaling GroupsCluster API Node
当集群中有多个 Node Group 时,可以通过 --expander=<option> 选项配置选择 Node Group 的策略,支持如下四种方式:
random:随机选择most-pods:选择容量最大(可以创建最多Pod)的Node Groupleast-waste:以最小浪费原则选择,即选择有最少可用资源的Node Groupprice:选择最便宜的Node Group
附加资料
代码:
https://github.com/kubernetes/autoscaler
Cluster API 与 Cluster Autoscaler 的整合
https://cluster-api.sigs.k8s.io/tasks/automated-machine-management/autoscaling
集群管理实践案例分享
cluster API 出现之前,一些厂商都有自己的管理方式。

设备模型通过不同的区域、数据中心、机架。机器上架之后,注册到集群中。
设备通过集群模型进行抽象资源化,通过划分到不同的节点池,用于后续扩容缩容使用。
如果是虚拟化 Openstack 则通过 api 启动 node,是物理机则使用 kickstart ,使用 OSImage 定义操作系统
声明式集群配置
通过 yaml 文件声明节点信息,salt 安装

声明式扩容
定义 NodePool 定义资源副本数,通过 NodePool Controller 创建 ComputeNode 描述节点信息,Provision Controller 与 provider 交互创建虚拟机,安装 Kubernetes 。

声明式持续发布
操作系统或者 Kubernetes 组件更新时,通过 ClusterDeployment 的方式一个一个节点更新节点(直接更换,而不是升级)。好处是方便,坏处是缓慢。
可以优化成只有操作系统更新时才更换节点,Kubernetes 更新时只更新部署。

自定义插件 - 声明式集群管理对象
也就是 Kubernetes on Kubernetes

多租户集群管理
多租户集群,核心还是基于 Cluster API
租户
- 租户是指一组拥有访问特定软件资源权限的用户集合,在多租户环境中,它还包括共享的应用、服务、数据和各项配置等
- 多租户集群必须将租户彼此隔离,以最大限度地减少租户与租户、租户与集群之间的影响
- 集群须在租户之间公平地分配集群资源。通过多租户共享集群资源,可以有效地降低集群管理成本,提高整体集群的资源利用率。
认证 - 实现多租户的基础
- 租户管理首选需要识别访问的用户是谁,因此用户身份认证是多租户的基础
- 权限控制,如允许合法登录的用户访问、拒绝非法登录的用户访问或提供有限的匿名访问
- Kubernetes 可管理两类用户
- 用来标识和管理系统组件的 ServiceAccount
- 外部用户的认证,需要通过 Kubernetes 的认证扩展来对接企业、提供商的认证服务,为用户验证、操作授权、资源隔离等提供基础
隔离
除认证、授权这些基础条件外,还要能够保证用户的工作负载彼此之间有尽可能安全的隔离,减少用户工作负载之间的影响。通常从权限、网络、数据三个方面对不同用户进行隔离。
- 权限隔离
- 普通用户的容器默认不具有
priviledged、sys_admin、net_admin等高级管理权限,以阻止对宿主机及其其他用户的容器进行读取、写入等操作
- 普通用户的容器默认不具有
- 网络隔离
- 不同的
Pod,运行在不同的Network Namespace中,拥有独立的网络协议栈。Pod之间只能通过容器开放的端口进行通信,不能通过其他方式进行访问。例如使用iptables
- 不同的
- 数据隔离
- 容器之间利用
Namespace进行隔离。不同Pod的容器,运行在不同的MNT、UTS、PID、IPC Namespace上,相互之间无法访问对方的文件系统、进程、IPC等信息;同一个Pod的容器,其mnt、PID Namespace也不共享
- 容器之间利用
租户隔离手段
基于 Namespace 实现隔离

Namespace:Namespace属于且仅属于一个租户- 权限定义:定义内容包括命名空间中的
Role与RoleBinding。这些资源表示目前租户在归属于自己的命名空间中定义了什么权限、授权给了哪些租户的成员 Pod安全策略:特殊权限指集群级的特定资源定义 -PodSecurityPolicy。它定义了一系列工作负载与基础设施之间、工作负载与工作负载之间的关联关系,并通过命名空间的 RoleBinding 完成授权- 网络策略:基础设施层面为保障租户网络的隔离机制提供了一系列默认策略,以及租户自己定制的用户租户应用彼此访问的策略
Pod、Service、PersistentVolumeClaim等命名空间资源:这些定义表示租户的应用落地到 Kubernetes 中的实体
权限隔离

- 基于
Namespace的权限隔离- 创建一个
namespace-admin ClusterRole,拥有所有对象的所有权限 - 为用户开辟新
namespace,并在该namespace创建rolebinding绑定namespace-admin ClusterRole,用户即可拥有当前namespace所有对象操作权限
- 创建一个
- 自动化解决方案
- 当
Namespace创建时,通过mutatingwebhook将namespace变形,将用户信息记录至namespace annotation - 创建一个控制器,监控
namespace,创建rolebinding为该用户绑定namespace-admin的权限
- 当
Quota 管理

开启
ResourceQuota准入插件在用户
namespace创建ResourceQuota对象进行限额配置
1 | apiVersion: v1 |
1 | # kubectl describe quota |
节点资源隔离
通过为节点设置不同 taint 来识别不同租户的计算资源
不同租户在创建 Pod 时,增加 Toleration 关键字,确保其能调度至某个 taint 的节点。
references
Compose server
node-problem-detector