Kubernetes 生产化运维
镜像仓库
生产化的过程核心是 CI/CD,这两者都非常依赖镜像。
镜像仓库
镜像仓库(Docker Registry)负责存储、管理和分发镜像。
镜像仓库管理多个 Repository,Repository 通过命名来区分。每个 Repository 包含一个或多个镜像,镜像通过镜像名称和标签(Tag)来区分。

容器镜像最终是一个 tar 包,在镜像仓库中存储两个内容,一个是元数据,记录镜像的 manifest,一个是镜像包。
客户端拉取镜像时,要指定三要素:
- 镜像仓库:要从哪一个镜像仓库拉取镜像,通常通过 DNS 或 IP 地址来确定一个镜像仓库,如
hub.docker.com Repository:组织面,如xxx.com- 镜像名称 + 标签:如
nginx:latest
镜像仓遵循 OCI 的 Distribution Spec
适配规范:
| HTTP Verb | URL | 功能 |
|---|---|---|
| GET | /v2/ | 检查镜像仓库实现的规范、版本 |
| GET | /v2/_catalog | 获取仓库列表 |
| GET | /v2/ |
获取一个仓库下所有的标签 |
| PUT | /v2/ |
上传镜像 manifest 信息 |
| DELETE | /v2/ |
删除镜像 |
| GET | /v2/ |
获取一个镜像的 manifest 信息 |
| GET | /v2/ |
获取一个镜像的文件层 |
| POST | /v2/ |
启动一个镜像的上传 |
| PUT | /v2/ |
结束文件层上传 |
数据和块文件
镜像由元数据和块文件两部分组成,镜像仓库的核心职能就是管理这两项数据。
元数据:
- 元数据用于描述一个镜像的核心信息,包含镜像的镜像仓库、仓库、标签、校验码、文件层、镜像构建描述等信息
- 通过这些信息,可以从抽象层面完整地描述一个镜像:它是如何构建出来的、运行过什么构建命令、构建的每一个文件层的校验码、打的标签、镜像的校验码等
1
2
3docker inspect busybox
# 以及 crictl 更加详细
cricrl inpecti busybox块文件(
blob)- 块文件是组成镜像的联合文件层的实体,每一个块文件是一个文件层,内部包含对应文件层的变更

镜像仓库就是管理这一堆元数据和一堆 blob,一个镜像有一份元数据,有多份 blob,每一份 blob 就是一层。
镜像仓库
共有镜像仓库
优势
- 开放:任何开发都可以上传、分享镜像到共有镜像仓库中
- 便捷:开发者可以非常方便地搜索、拉取其他开发者的镜像,避免重复造轮子
- 免运维:开发者只需要关注应用开发,不必关心镜像仓库的更新、升级、维护等
- 成本低:企业或开发者不需要购买硬件、解决方案来搭建镜像仓库,也不需要团队来维护
劣势:
- 可能会限流
- 无法满足一些无外网的环境
- 有些时候可能需要翻墙
私有镜像仓库
- 优势
- 隐私性:企业的代码和数据是企业的私有资产,不允许随意共享到公共平台
- 敏感性:企业的镜像会包含一些敏感信息,如密钥信息、令牌信息等。这些敏感信息严禁暴露到企业外部
- 网络连通性:企业的网络结构多种多样,并非所有环境都可以访问互联网
- 安全性:而在企业环境中,若使用一些含有漏洞的依赖包,则会引入安全隐患
- 优势
Harbor
主流的镜像仓有:docker、coreos、harbor。
Harbor 是 VMware 开源的企业级镜像仓库,目前已是 CNCF 的毕业项目。它拥有完整的仓库管理、镜像管理、基于角色的权限控制、镜像安全扫描集成、镜像签名等。

Harbor 提供的服务
Harbor核心服务:提供Harbor的核心管理服务API,包括仓库管理、认证管理、授权管理、配置管理、项目管理、配额管理、签名管理、副本管理等Harbor Portal:Harbor的Web界面Registry:Registry负责接收客户端的pull/push请求,其核心为docker/Distribution- 副本控制器:
Harbor可以以主从模式来部署镜像仓库,副本控制器将镜像从主镜像服务分发到从镜像服务 - 日志收集器:收集各模块的日志
- 垃圾回收控制器:回收日常操作中删除镜像记录后遗留在块存储中的孤立块文件
Harbor 架构

Harbor 安装
1 | helm repo add harbor https://helm.goharbor.io |
1 | # kubectl get pod |
配置 /etc/hosts 增加域名
1 | vim /etc/hosts |
配置证书
打开管理页面:https://192.168.239.128:30003/
账号/密码:admin/Harbor12345
https://192.168.239.128:30003/harbor/projects/1/repositories
点击下载证书

创建目录,并将证书放在对应目录中。
1 | mkdir /etc/docker/certs.d/core.harbor.domain |
Docker 登录
1 | docker login -u admin -p Harbor12345 core.harbor.domain |
或者使用另外一种不安全的方式,忽略证书
1 | vim /etc/docker/daemon.json |
修改一个镜像的 tag,推送到 harbor 上
1 | # docker tag 350b164e7ae1 core.harbor.domain/library/pause |
在 pod 中,镜像存储的地方位于 harbor-registry-5dc97c74d6-gzfwp 中
1 | # 元数据存放于 |
harbor 的信息存储于数据库中
1 | # 进入pod |
一些数据库表以及它们的作用:
projects表:存储Harbor中的项目信息,包括项目名称、描述等。repositories表:存储Harbor中的镜像仓库信息,包括仓库名称、所属项目、创建时间等。tags表:存储Harbor中镜像标签的信息,包括标签名称、关联的镜像ID、大小等。manifests表:存储Harbor中镜像的清单信息,包括镜像ID、标签、创建时间等。labels表:存储Harbor中标签的信息,用于对镜像进行分类和标记。users表:存储Harbor用户的信息,包括用户名、密码哈希、邮箱等。roles表:存储Harbor中角色的信息,用于权限管理。permissions表:存储Harbor中权限的信息,用于定义用户或角色对资源的访问权限。
Harbor Demo Server
可以注册和使用共有 harbor 仓库。https://demo.goharbor.io/
一些特性:
Demo Server2 天清理一次数据(镜像只保留2天)
不能
push超过100Mb的镜像不能使用管理功能
PortalHttps://demo.goharbor.io/harbor/projects
镜像使用
1
2
3docker login demo.goharbor.io
docker build -t demo.goharbor.io/your-project/test-image .
docker push demo.goharbor.io/your-project/test-image
Harbor 高可用架构

通过修改 chart 里面的配置,可以搭建 harbor 高可用集群。
Harbor 的用户管理
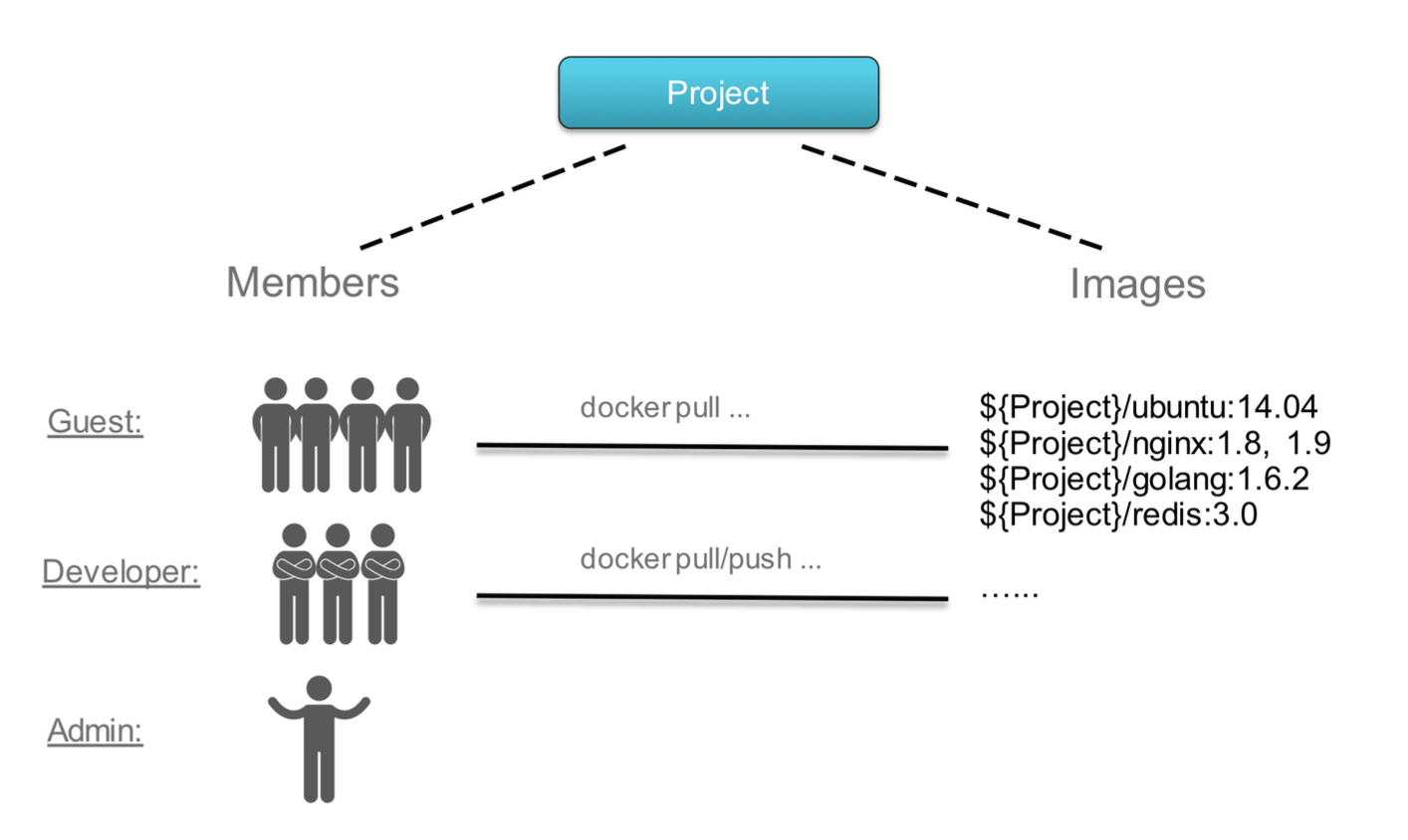
harbor 的用户管理可以通过不同的用户赋予不同权限实现管理机制。
垃圾回收
镜像删除时,blob 文件不会被删除,只有 manifest 会被删掉。因为 docker 特性,blob 可能会作为多个镜像的基础镜像,不删除是为了避免影响其他镜像。
需要通过垃圾回收机制来删除不用的 blob,进而回收存储空间

本地镜像加速 Dragonfly
Dragonfly 是一款基于 P2P 的智能镜像和文件分发工具,阿里主导。
它旨在提高文件传输的效率和速率,最大限度地利用网络带宽,尤其是在分发大量数据时。当需要拉取镜像时,先从 df 本地缓存中拉取。
- 应用分发
- 缓存分发
- 日志分发
- 镜像分发
优势
- 基于
P2P的文件分发 - 非侵入式支持所有类型的容器技术
- 机器级别的限速
- 被动式
CDN - 高度一致性
- 磁盘保护和高效
IO - 高性能
- 自动隔离异常
- 对文件源无压力
- 支持标准
HTTP头文件 - 有效的
Registry鉴权并发控制 - 简单易用
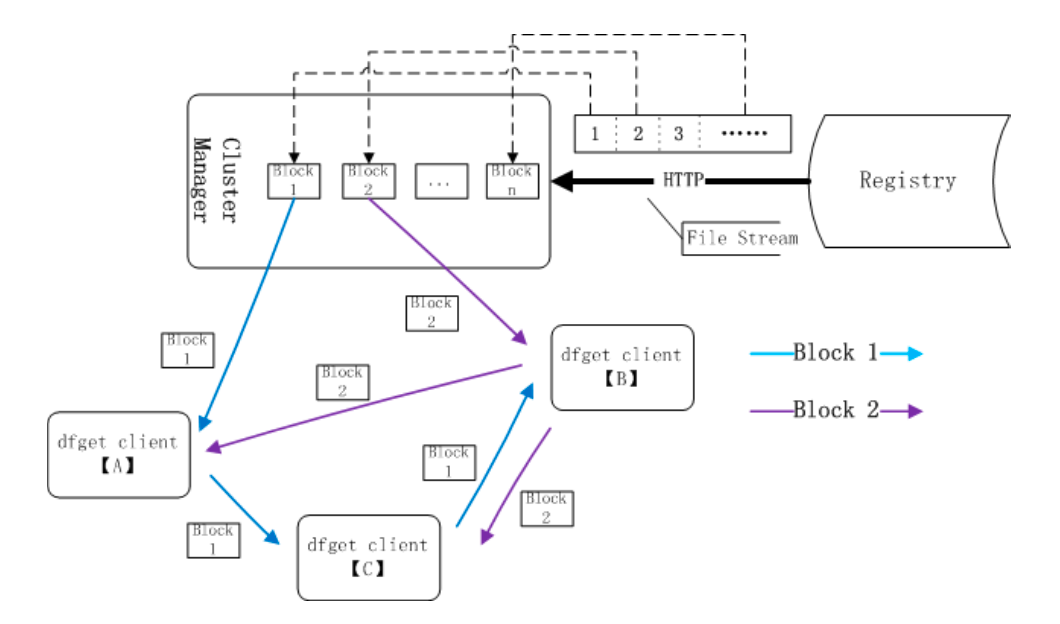
镜像下载流程
dfget proxy 也称为 dfdaemon,会拦截来自 docker pull 或 docker push 的 HTTP 请求,然后使用 dfget 来处理那些跟镜像分层相关的请求。

- 主机
docker从某一个dfget proxy节点中拉取镜像,proxy节点可能有成千上万台 cluster manager用于维护整个分发集群,daemon用于在拉取镜像时,会先将请求发送到proxy- 当代理中没有对应镜像,
dfget proxy请求cluster manager cluster manager将请求转发到主镜像仓库,主仓库将镜像的manifest下发到cluster managercluster manager将blob下发到proxy,而且可能不同proxy会下发不同层proxy在拉取其他层时,则会 P2P 其他proxy,请求不会到cluster manager,通过这种方式减少主镜像仓库的压力
每个文件会被分成多个分块,并在对等节点之间传输。
镜像安全
镜像安全的最佳实践
- 构建指令问题
- 避免在构建镜像时,添加密钥,
Token等敏感信息(配置与代码应分离)
- 避免在构建镜像时,添加密钥,
- 应用依赖问题
- 应尽量避免安装不必要的依赖
- 确保依赖无安全风险,一些长时间不更新的基础镜像的可能面临安全风险,比如基于
openssl1.0,只支持tls1.0等
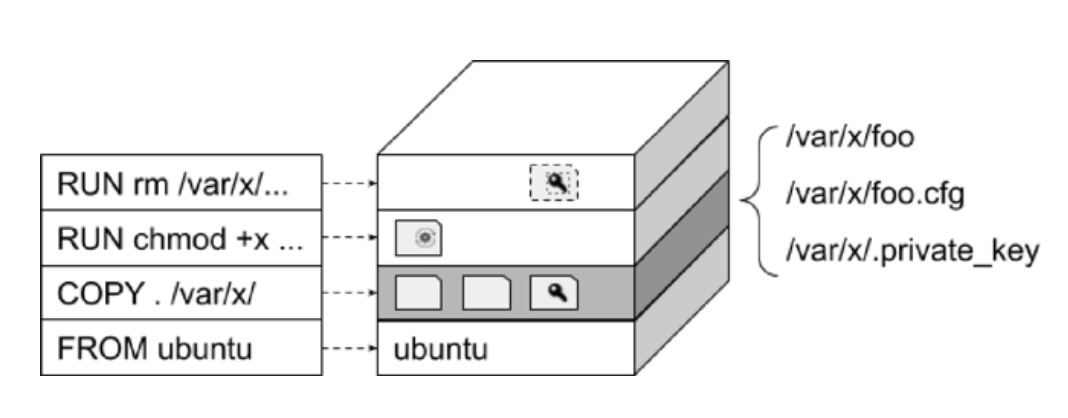
- 文件问题
- 在构建镜像时,除应用本身外,还会添加应用需要的配置文件、模板等,在添加这些文件时,会无意间添加一些包含敏感信息或不符合安全策略的文件到镜像中
- 当镜像中存在文件问题时,需要通过引入该文件的构建指令行进行修复,而不是通过追加一条删除指令来恢复(基于
overlay删除操作并不能完全清理文件)
镜像扫描 Vulnerability Scanning
镜像扫描通过扫描工具或扫描服务对镜像进行扫描,来确定镜像是否安全
- 分析构建指令、应用、文件、依赖包
- 查询 CVE 库、安全策略
- 检测镜像是否安全,是否符合企业的安全标准
镜像策略准入控制
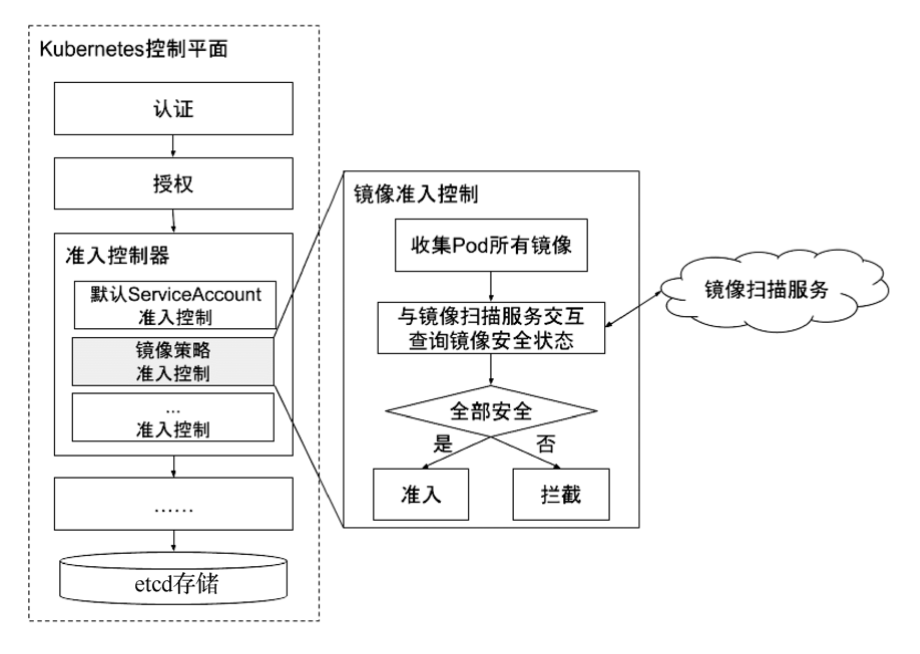
镜像准入控制是在部署 Pod、更新 Pod 时,对 Pod 中的所有镜像进行安全验证以放行或拦截对 Pod 的操作(也就是 ImagePolicyWebhook):
- 放行:
Pod中所有的镜像都安全,允许此次的操作,Pod成功被创建或更新 - 拦截:
Pod中的镜像未扫描,或已经扫描但存在安全漏洞,或不符合安全策略,Pod无法被创建或更新
扫描镜像
- 镜像扫描服务从镜像仓库拉取镜像
- 解析镜像的元数据
- 解压镜像的每一个文件层
- 提取每一层所包含的依赖包、可运行程序、文件列表、文件内容扫描
- 将扫描结果与 CVE 字典、安全策略字典进行匹配,以确认最终镜像是否安全
镜像扫描服务
| 供应商 | Anchore | Aqua | Twistlock | Clair | Qualys |
|---|---|---|---|---|---|
| 镜像文件扫描 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 多 CVE 库支持 | 支持 | 支持 | 支持 | 支持 | 支持 |
| 是否开源 | 是 | 部分 | 是 | ||
| 商业支持 | 支持 | 支持 | 支持 | 支持 | |
| 可定制安全策略 | 支持 | 支持 | |||
| 镜像仓库支持 | Harbor | Quay、Harbor |
一般 harbor 搭配 Clair 使用。
Clair 架构

前端有 API,有通知机制,有后端存储,以及一些做比较的引擎。
基于 Kubernetes 的 DevOps
传统运维模式
- 缺乏一致性环境(用户环境和实验室环境可能有差别)
- 平台与应用部署相互割裂(基于虚拟化平台,应用层相对于基础平台不可见)
- 缺乏工具链支持(特别是 CD,没有统一的发布平台)
- 缺乏统一的灰度发布管理
- 缺乏统一监控能力和持续运维能力(没有
cgroup的管理能力)

建立持续交付的服务体系
传统的开发运维模式下,存在的问题:
- 从需求到版本上线中间是个黑箱子,风险不可控;
- 开发设计时未过多考虑运维,导致后续部署及维护的困难;
- 开发各自为政,烟囱式开发,未考虑共享重用、联调,开发的资产积累不能快速交移到运维手中;
应对以上问题,通常倡导的解决之道是:运维前移,统一运维,建立持续交付服务体系。
基于 Docker 的开发模式驱动持续集成
- 开发测试环境容器化
- 持续集成容器化
- 应用交付容器化
本地代码写好之后,(CI/CD)持续构建、持续部署到线上环境再进一步测试。
DevOps 流程定义
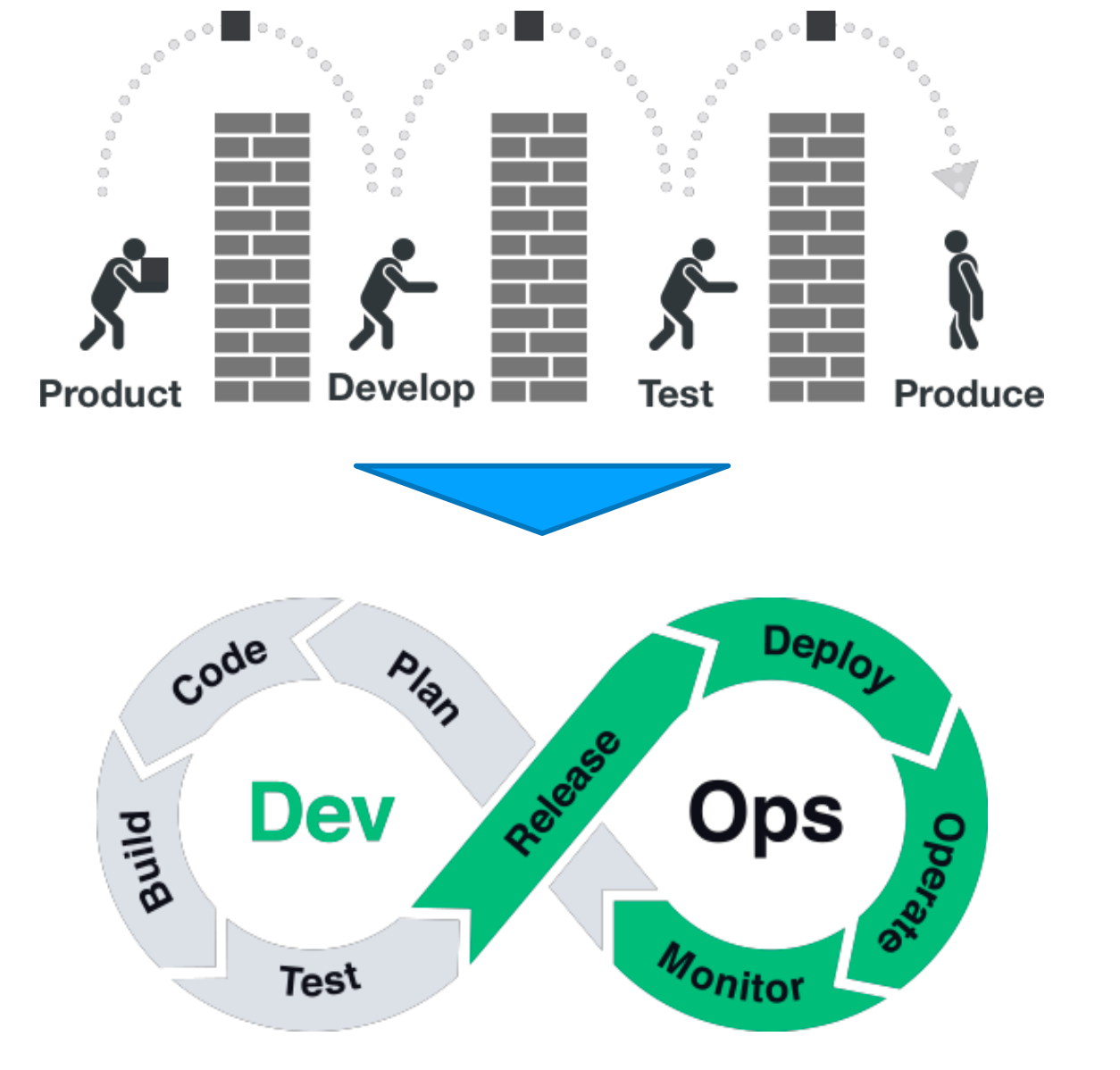
从传统的 产品 -> 研发 -> 测试 -> 产品 的开发流程,到目前的 DevOps,开发和运维一体化。
Dev 和 Ops 的边界定义
Programming vs. Engineering
Programming:编程,更多的是系统设计和编码实现,也就是写逻辑和业务代码Engineering:工程,包含更大范围概念,除了功能层面的实现,还需为运维服务,产品功能落地(压测、部署脚本、异常排查、监控等)
定义 production readiness
Function ready vs. Production ready
Function Ready只是交付的软件产品从功能层面满足需求定义Production Ready除了功能就绪还包含LnP测试通过,压力测试,满足性能需求- 用户手册完成,用户可按照用户手册使用既定功能
- 管理手册完成,运维人员可以依照管理手册部署,升级产品并解决现网问题
- 监控,包括:
- 组件健康状态检查(
UP) - 性能指标(
Metrics) - 基于性能指标,定义
alert rule,在系统故障或缓慢时,发送告警信息给运维人员 Assertion,定期测试某功能并检查结果,比如每小时创建service,测试vip连通性
- 组件健康状态检查(
单体架构下的人员配置
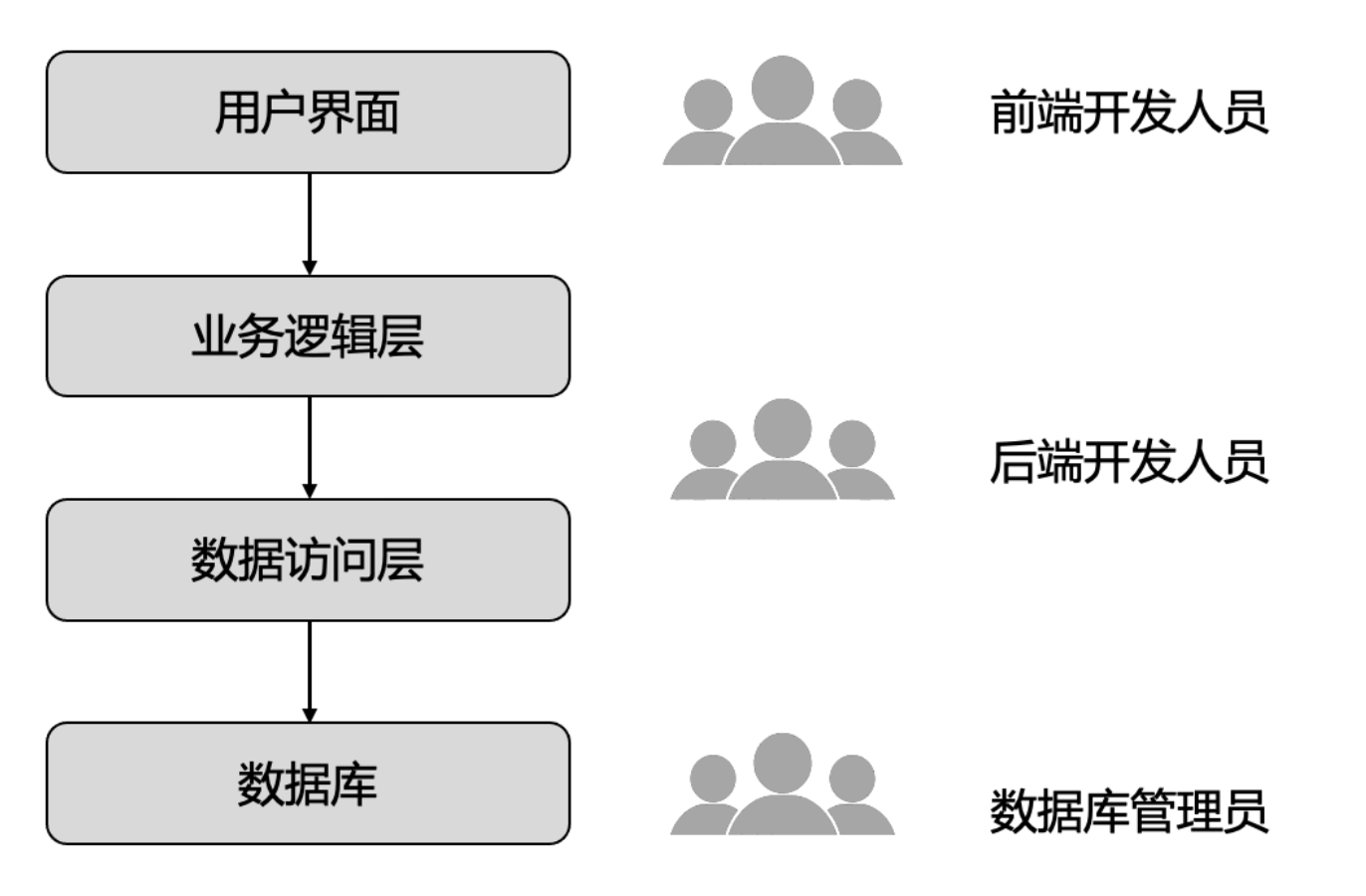
三层架构:UI -> 业务逻辑 -> 数据库。前后端分离架构。
在开发过程中,需要前端开发人员和后端开发人员做任务拆分和排期。当需要排查问题时,他们需要有全局的视图,而这往往是理想化的。
微服务架构下的人员配置
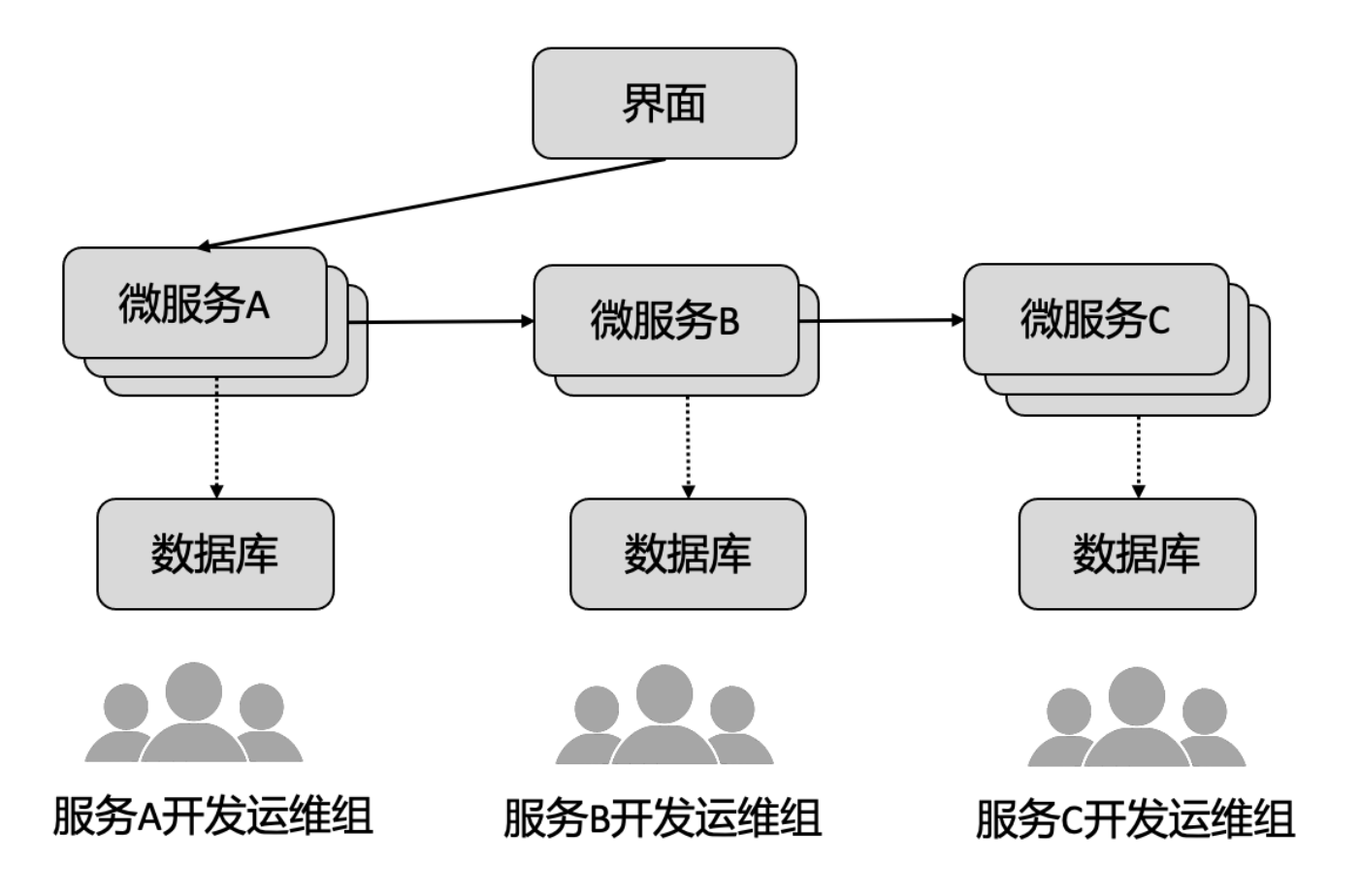
基于不同的微服务有不同的开发运维组,专门负责一个微服务。他们不需要全局化,专注于当前的微服务,定义好服务边界,以及上下游关系。
DevOps 下的人员划分

DevOps 持续迭代的环形结构。
此组织结构的优缺点
优势:
- 一个架构师负责整个产品的规划,使得产品更规范,产品进化不同的
Program由不同PO负责端到端,从需求到生产系统部署,保证solution质量 - 研发和运营统一,一个最大的作用是研发可以深刻理解现网痛苦,对功能需求的设计和优先级定义有极大帮助
Function readyVs.Production readyProgrammingVs.Engineering- 更具连续性
问题:
- 传统运营和开发的冲突并非消失,而是转变为了运营经理和架构以及
PO之间的冲突 - 运营轮值导致生产系统权责不明确
- 轮值期间期待不出故障
- 对于出现的故障缺少端对端的跟踪,可能问题还没处理结束,已经要交接给下一个人了
- 对于生产系统的积累问题,如故障节点,无人专职处理,导致比较多的故障节点堆积
- 对于生产系统的配置,无统一规划,每个人可能用不同的配置打到相同的目的
Dev自主权过高导致Dev可以偷偷加功能并部署到生产
理想中的 DevOps
Dev 和 Ops 需要权责划分,可以有 overlap,同时做部署,同时做计划,但 Dev 应侧重功能开发,Ops 偏重生产系统运维。
Ops 参与到版本规划流程中,并为一个功能能不能 release 和 deploy 把关
DevPlanCodeBuildTestReleaseDeploy
OpsDeployOperateMonitorPlan
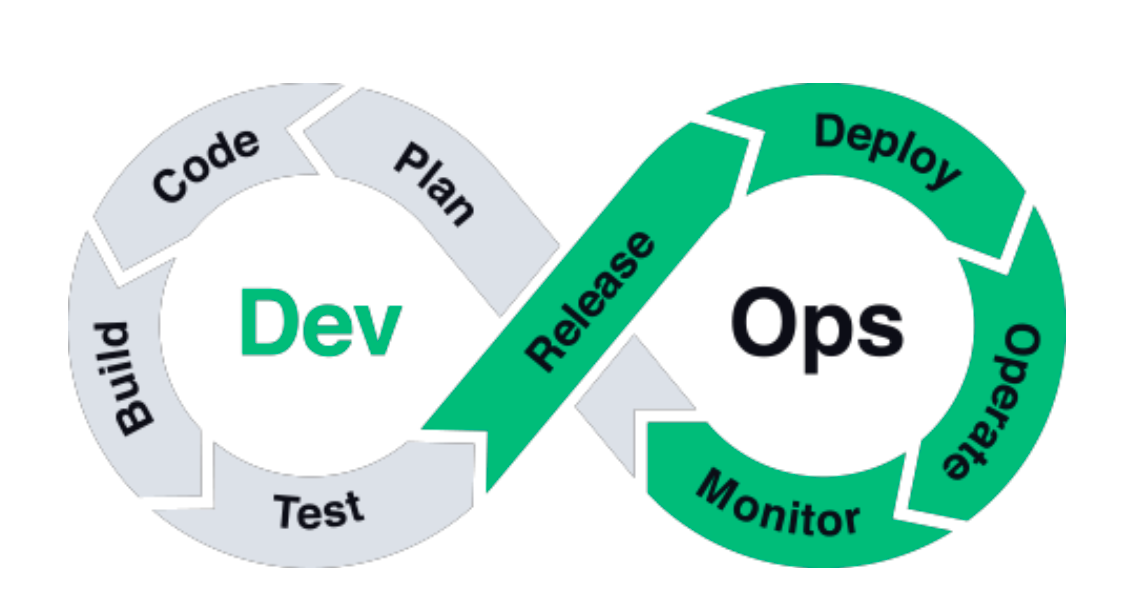
案例
产品愿景
产品愿景的定义有多个目的:
- 统一团队思想,让团队成员知道我们要往哪里去,这有助于让团队专注于交付产品价值
- 长期愿景往往是有野心的,能对团队成员起到激励作用,比如 业界尖端技术 往往能刺激团队成员努力自我提升
- 该愿景应该是团队成员的共识,是所有人的共同理想
- 愿景要产生真正的价值,是真正建立在对当前业务痛点的充分理解基础之上的
长期愿景:
- 基于业界尖端技术打造下一代流量管理平台
产品价值:
- 节省时间成本,负载均衡上架时间从数月降低到分钟级
- 移除供应商依赖问题,出现生产系统故障不再依赖供应商上门调试
- 构建一套统一模型管理所有业务场景,降低系统集成成本
- 全自动化,减少手工操作,降低维护人力成本
- 故障检测和根因分析能力,快速定位故障,提升可用性
产品路线图定义
而项目执行需要有明确时间线的近期目标,因此需要将产品价值转化成可控的产品需求。产品需求的输入包括新功能和当前产品的功能缺陷等,产品经理需要与核心团队一道定义近期(比如 2-3 个季度)的产品核心功能,并定义近期产品版本需要包含的功能。
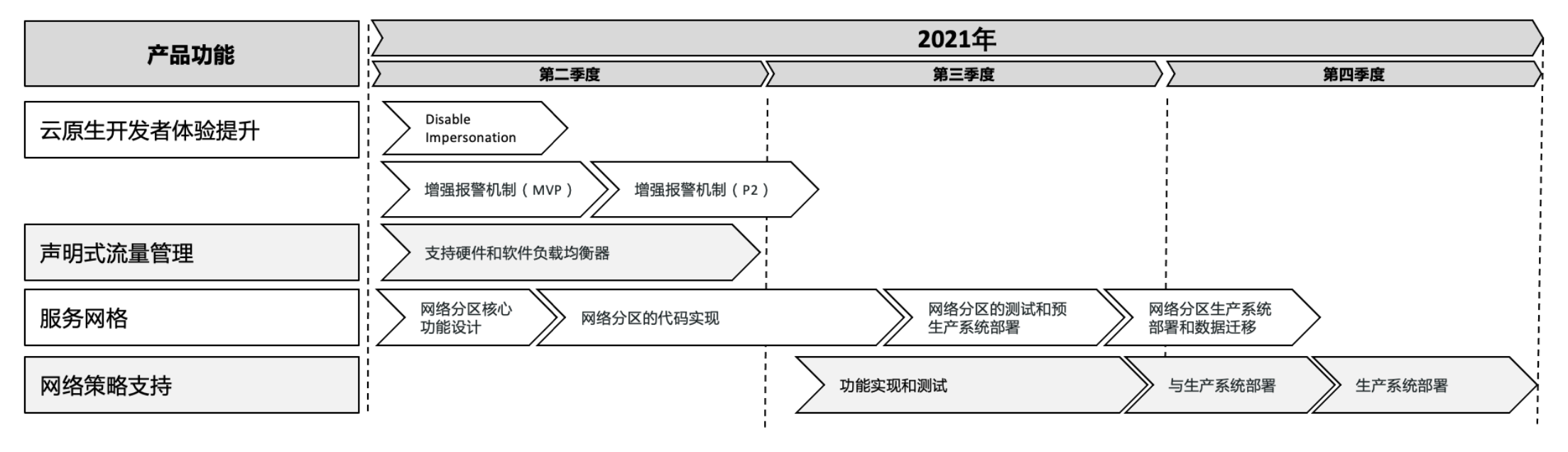
- 团队成员可以聚焦每个极度的功能
- 外部团队可以明确季度交付产出,可以更好的配合
- 产品团队可以明确能对外提供能力的时间节点
敏捷开发

大概 2周 一个Spring,部署原型之后,开启下一个 Spring,可以在开发和迭代过程中规划,逐步靠近产品交付状态。
DevOps 流程概览
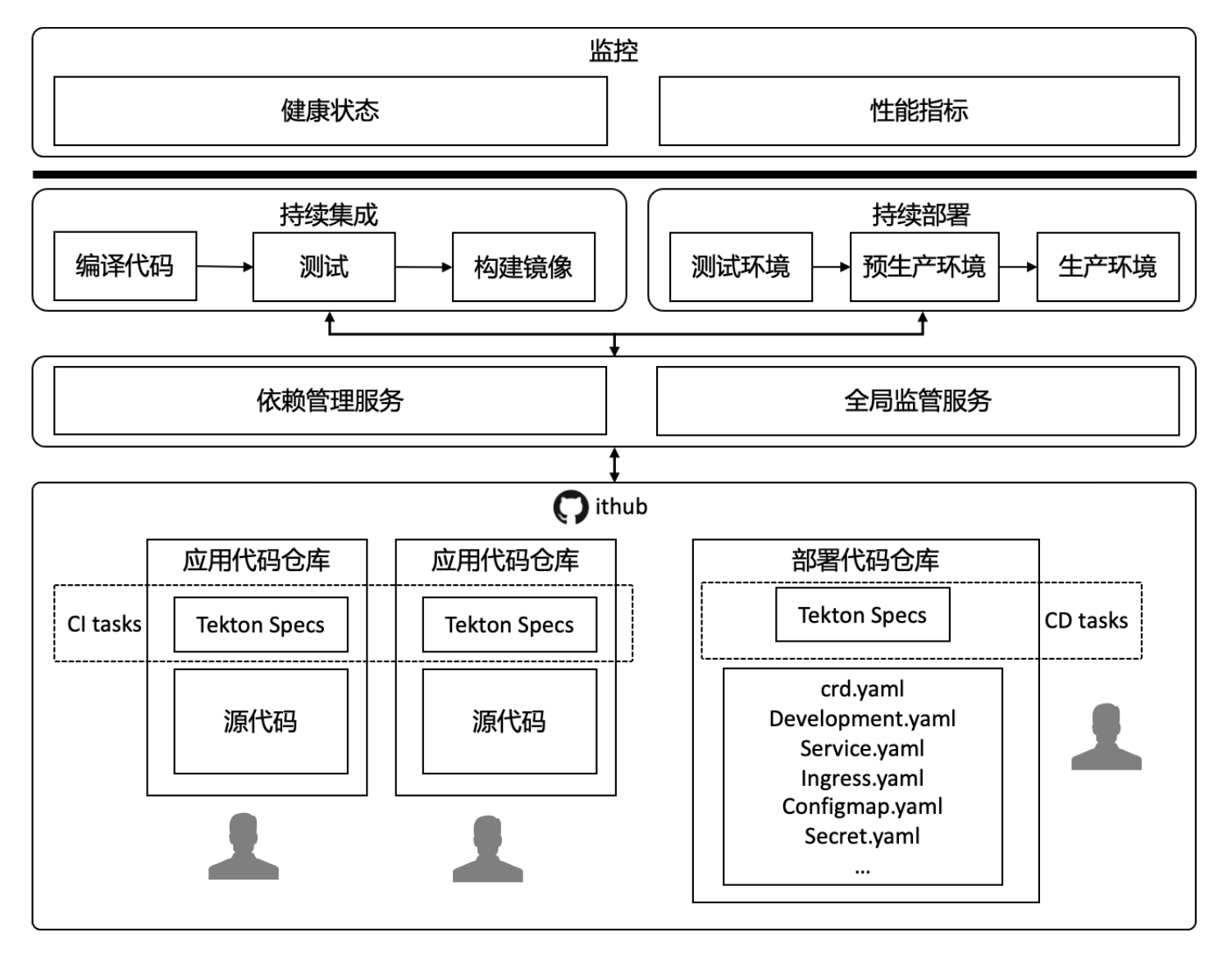
在代码仓库里面设置 WebHook,通过一些 CI 平台,在提交代码后,持续构建。
通过部署代码仓库,定义 yaml 格式的 spec,将应用部署到平台,持续部署。
代码分支管理
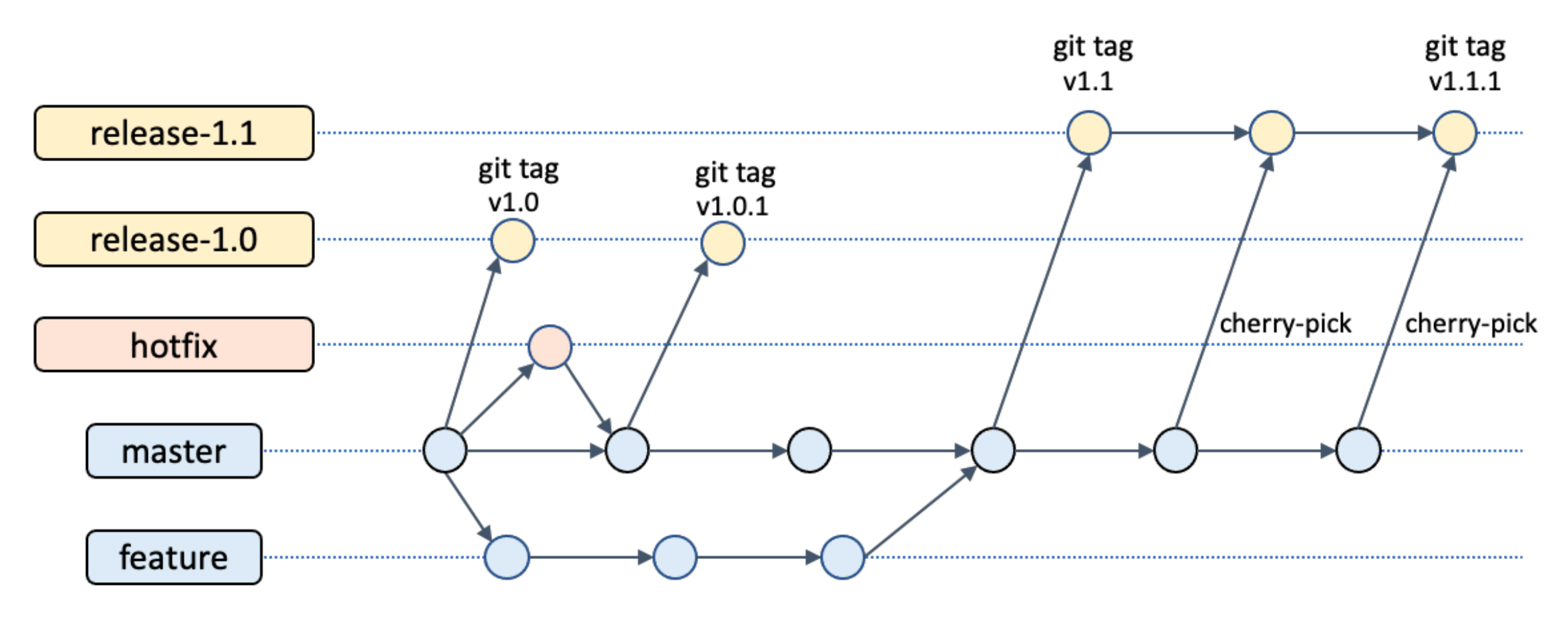
master:主要开发分支feature:开发分支,某个功能的分支。当功能完成,合并到master,开始进行流水线,编译、测试等,通过之后,审核代码,通过之后,合并到masterhotfix:一些bug修复分支release-1.0:发布正式版本时,避免版本变更,会从master上拉取一个分支,例如release-1.0,release-1.1的分支,拉取发布后,打tag。版本不会一成不变,可能需要加一些功能,此时release分支和master分支并行开发,此时的开发过程是在feature分支开发完后,合并到master,然后cherry-pick到release分支。
持续集成
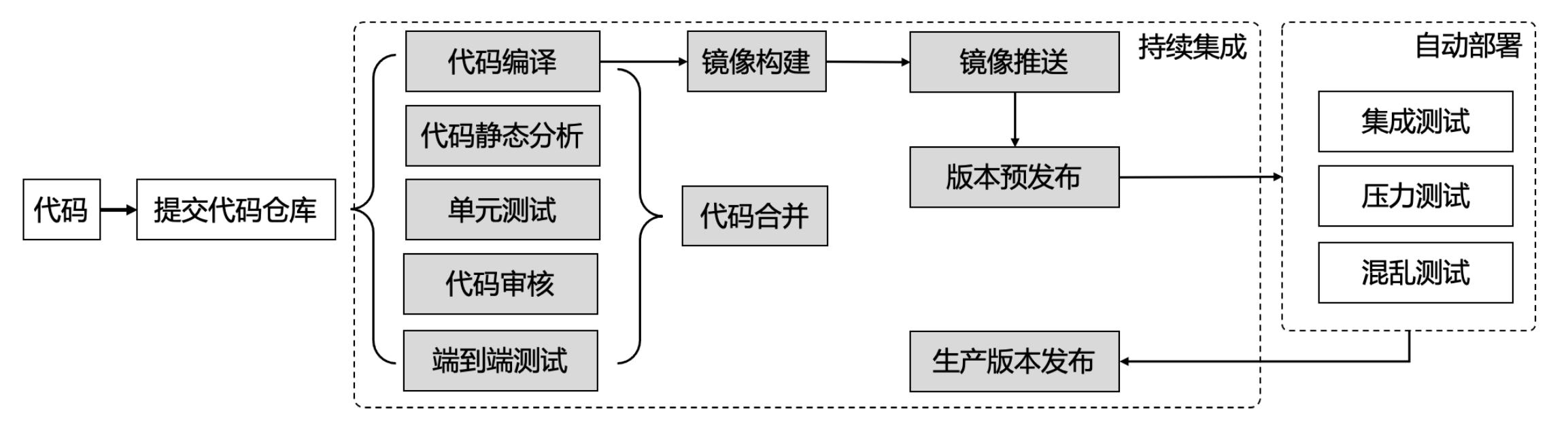
持续集成是在测试、合并、构建、镜像推送。
持续部署

持续部署是在部署、线上测试、预生产、生产。
GitOps
替代线上环境调试,通过 Git 修改源代码配置,触发持续部署,确保部署过程的健壮性。

基于 GitHub Action 的自动化流水线
基于公共 GitHub 的 action 构建流水线
- 低成本
GitHub目前为项目提供免费构建流水线,可满足日常构建需求
- 免运维
- 无需自己构建流水线(有现成的很多流水线),
GitHub提供小量构建请求(每天次数有限)
- 无需自己构建流水线(有现成的很多流水线),
- 易构建
GitHub action非常容易构建,只需点击几次按钮,即可完成GitHub提供了一系列内建action,社区有大量可复用的action
- 易集成
- 无需配置
GitHub Webhook即可完成与PR的联动
- 无需配置
Action 的创建
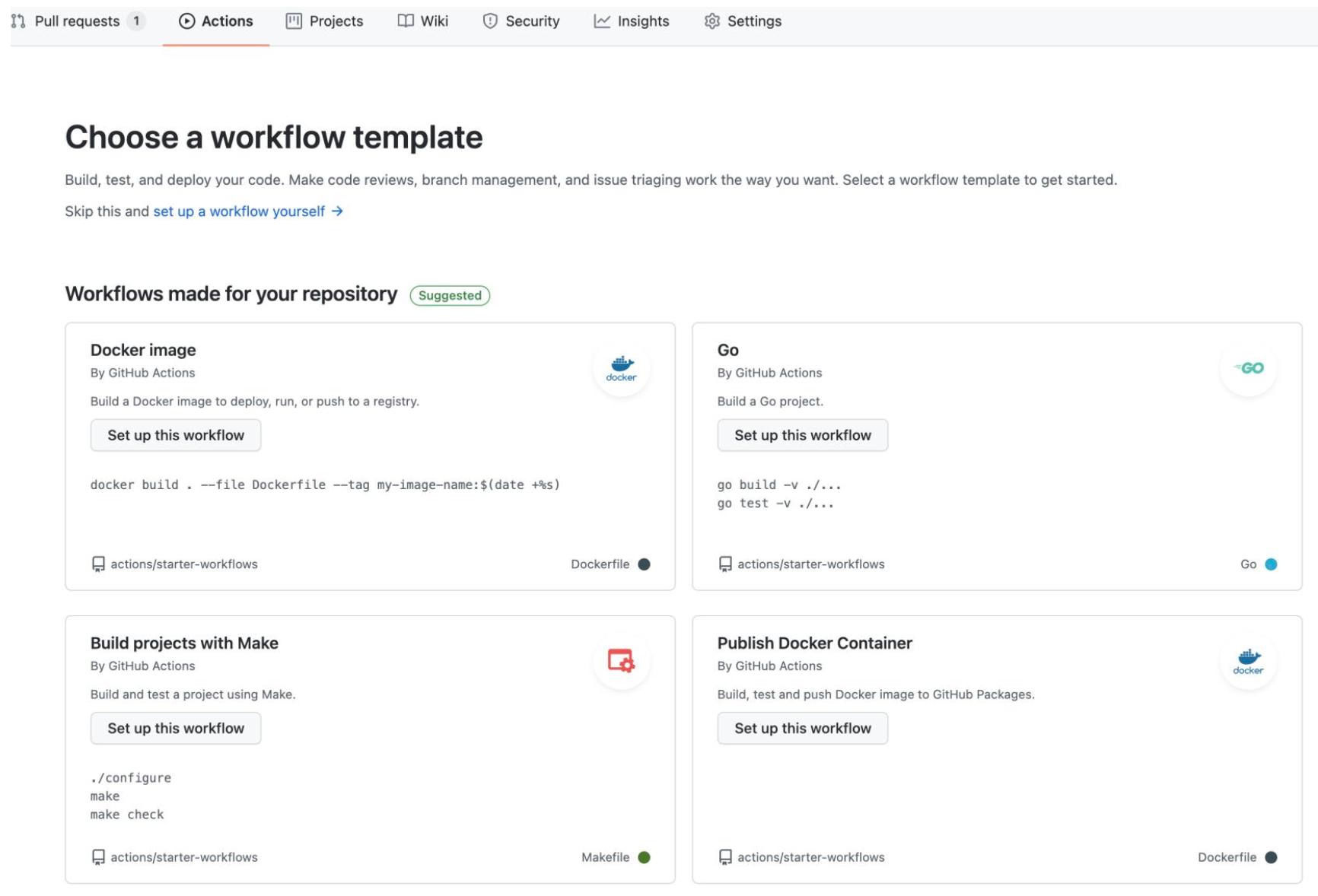
Action 细节
xxx/.github/workflows/go.yml
1 | name: Go |
基于 Jenkins 的自动化流水线
私有环境,使用 Jenkins,没有 action 支持。

Kubernetes CI&CD 完整流程
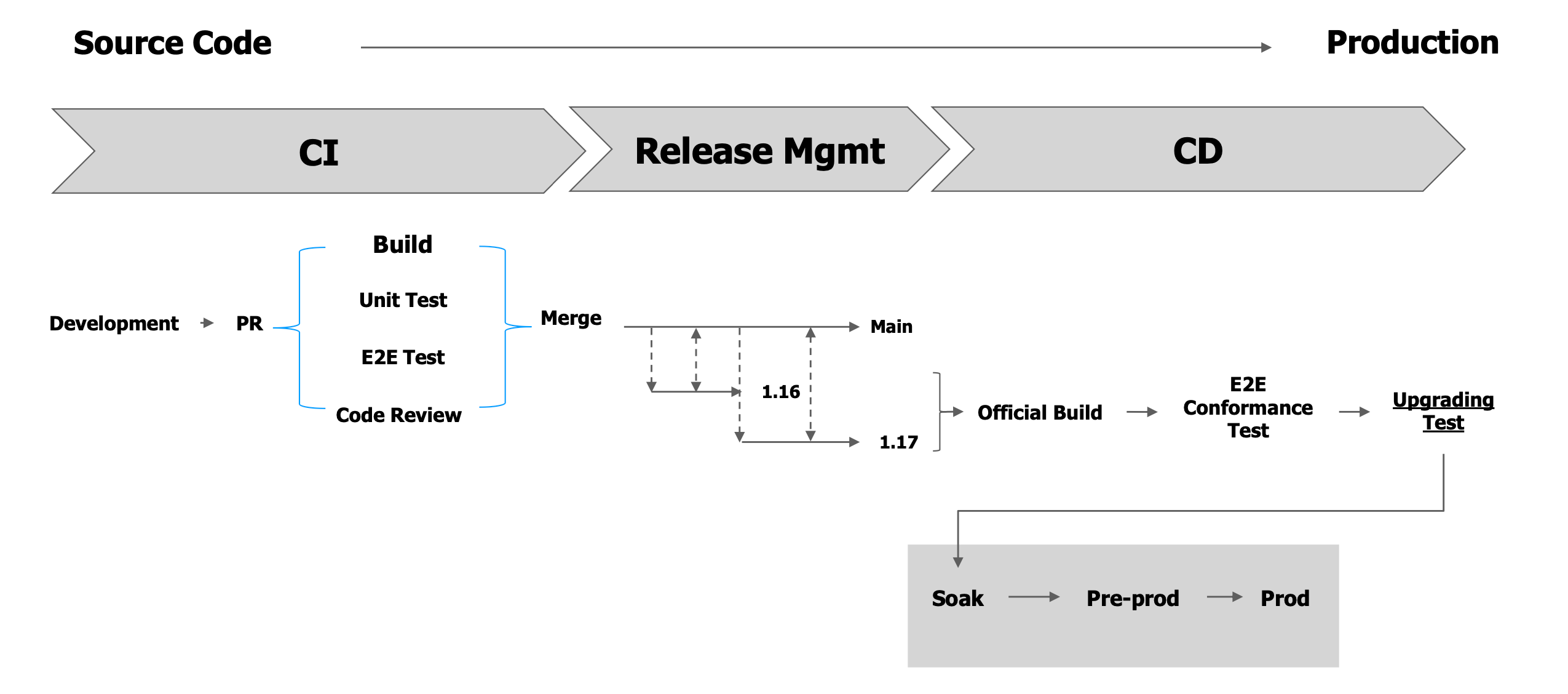
持续集成容器化
最主要解决的问题是保证 CI 构建环境和开发构建环境的统一。
使用容器作为标准的构建环境,将代码库作为 Volume 挂载进构建容器。
由于构建结果是 Docker 镜像,所以要在构建容器中执行 docker build 命令,需要注意 DIND 的问题。
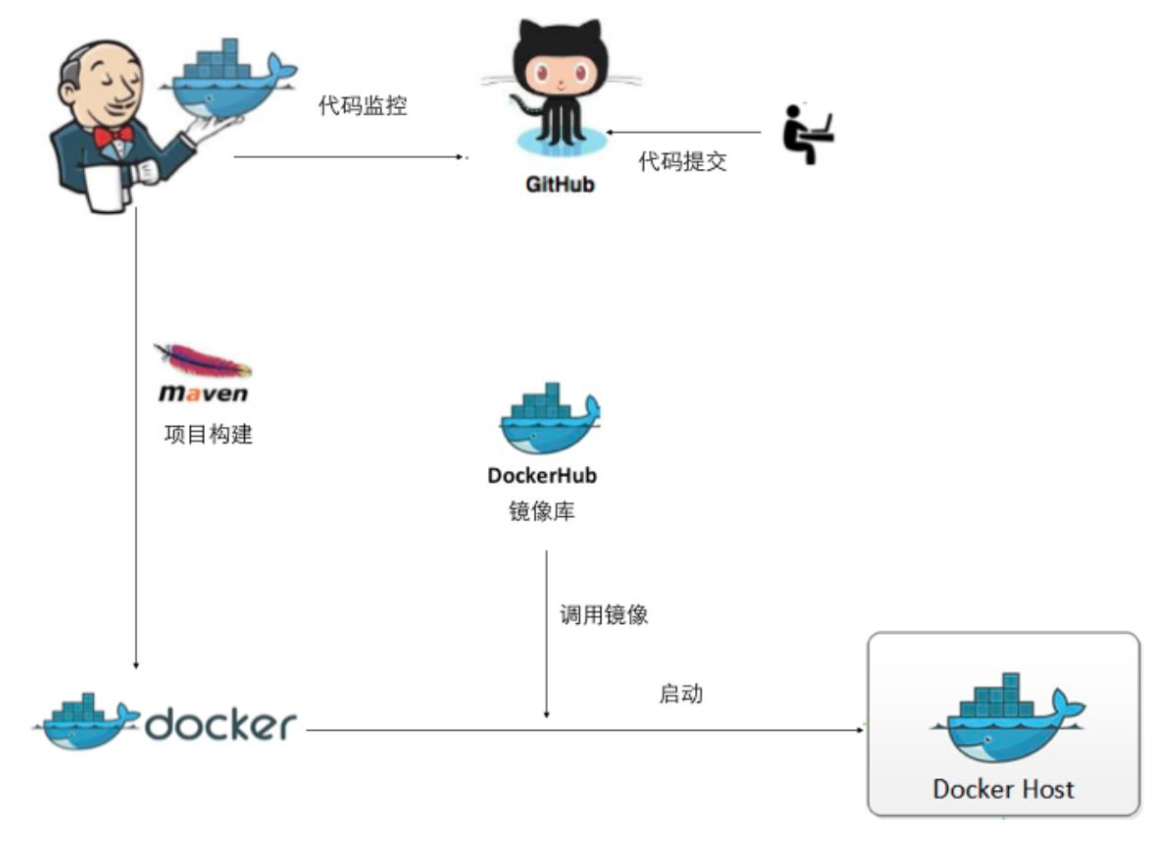
基于 Kubernetes 的持续集成
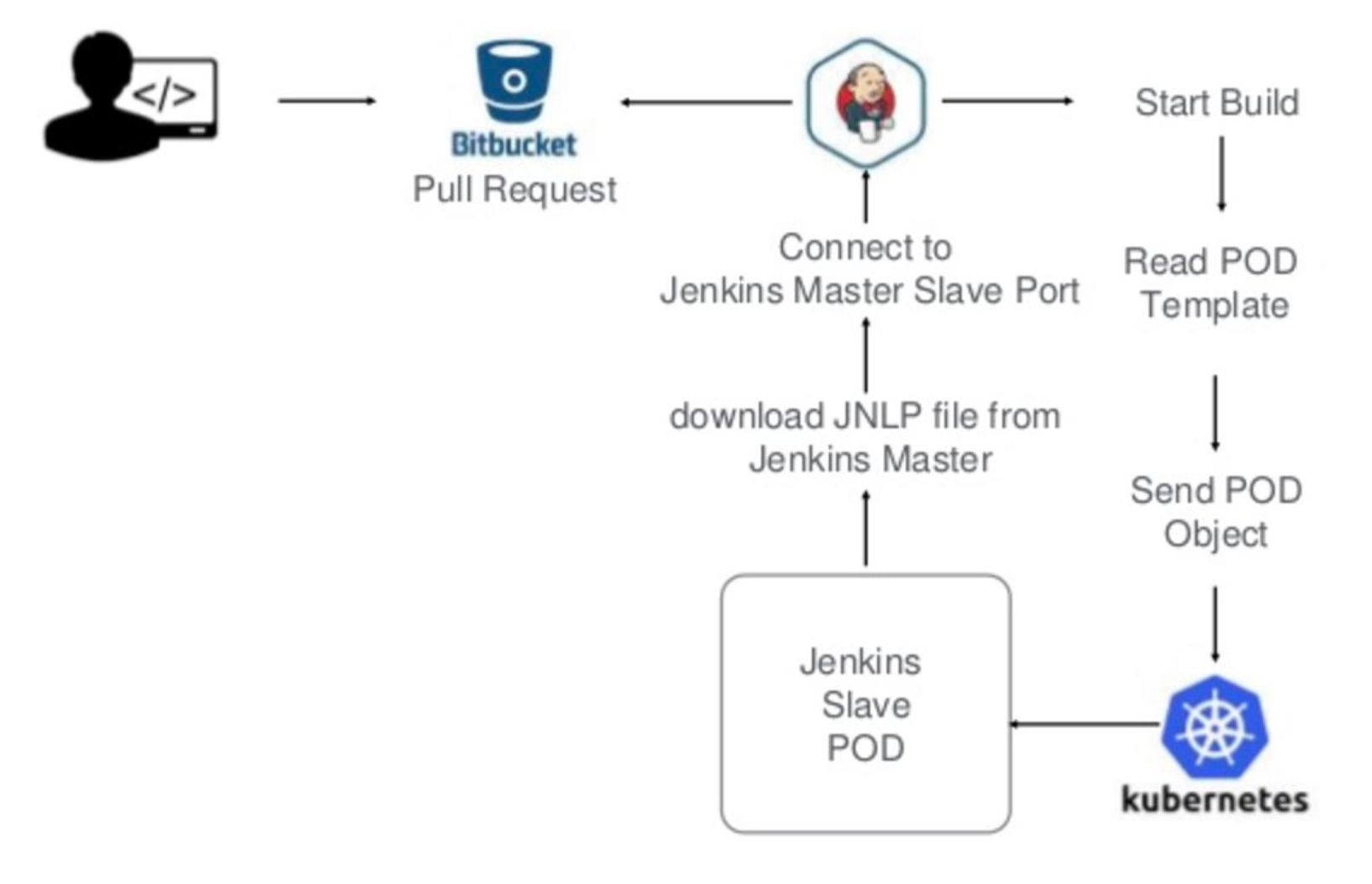
Jenkins 上可以通过插件的形式支持 Kubernetes。
Docker in Docker 问题展开
当 Jenkins 在 Docker 中时,需要操作 Docker 实现构建和测试。
方法1
docker in docker :在 Docker 做一层 Docker
早期尝试:https://github.com/jpetazzo/dind (archived)
官方支持:https://hub.docker.com/_/docker/
1 | docker run --privileged --name some-docker -d \ |
可能引入的问题:https://jpetazzo.github.io/2015/09/03/do-not-use-docker-in-docker-for-ci/
Long story short: if your use case really absolutely mandates Docker-in-Docker, have a look at sysbox, it might be what you need.
方法2
mount host docker.socket:将主机的 Docker socket mount 到容器中。
docker run -v /var/run/docker.socket:/var/run/docker.sock
但是这样会有风险,相当于一些不利的操作会影响主机的 Docker。
方法3
Kaniko:谷歌主导的,在 Tokton 里面使用的非常广泛
https://github.com/GoogleContainerTools/kaniko
1 | echo -e 'FROM alpine \nRUN echo "created from standard input"' > Dockerfile | tar -cf - Dockerfile | gzip -9 | docker run \ |
构建基于 Kubernetes 的 Jenkins Pipeline
sa.yaml
1 |
|
jenkins.yaml
1 | apiVersion: apps/v1 |
安装,在 default 的 ns 中安装
1 | kubectl create -f sa.yaml |
查看管理员密码
1 | kubectl logs -f jenkins-0 |
登录,并初始化

安装 plugin

等待安装完成。
生产环境安装步骤:
- Image 准备:基于 Jenkins 官方 Image 安装自定义插件
- https://github.com/jenkinsci/kubernetes-plugin
- 默认安装 Kubernetes
plugin
- 默认安装 Kubernetes
- https://github.com/jenkinsci/docker-inbound-agent (archived)
- 如果需要做
docker build,则需要自定义Dockerfile,安装docker binary,并且把host的docker.socketmount进container
- 如果需要做
- https://github.com/jenkinsci/kubernetes-plugin
- Jenkins 配置的保存
- 需要创建
PVC,以便保证在 Jenkinsmaster pod出错时,新的 Kubernetespod可以mount同样的工作目录,保证配置不丢失 - 可以通过
Jenkins scm plugin把Jenkins配置保存至GitHub
- 需要创建
- 创建 Kubernetes
spec
Jenkins 的配置
Cloud provider 配置
在 Jenkins System Config 选择点击 Cloud,并选择 Kubernetes
创建 Kubernetes ServiceAccount,并在 Kubernetes 对应的 namespace 授予 namespace admin 权限
指定 Jenkins slave 的 image
按需指定 volume mount,如需在 slave container 内部执行 docker 命令,则需要 mount /var/run/docker.socket
创建 Jenkins Job
- Git Integration
- Jenkins webhook on GitHub
- Git review /merge Bot
- Build Job
- Git clone code
- Build binary
- Build Docker image
- Push Docker image to hub
- Testing
- UT /UT Coverage
- E2E
- Conformance
- Conformance Slow
- LnP
安装 Kubernetes 插件
如上图
- 菜单 Mange Jenkins -> Manage Plugins -> Available
- 查找并安装 Kubernetes
- 选择 Kubernetes,点击 install without restart
- 等待安装完成
配置 Cloud Provider
这个过程相当于配置一个 pod
菜单 Manage Jenkins -> Manage Node and Cloud -> Configure Cloud
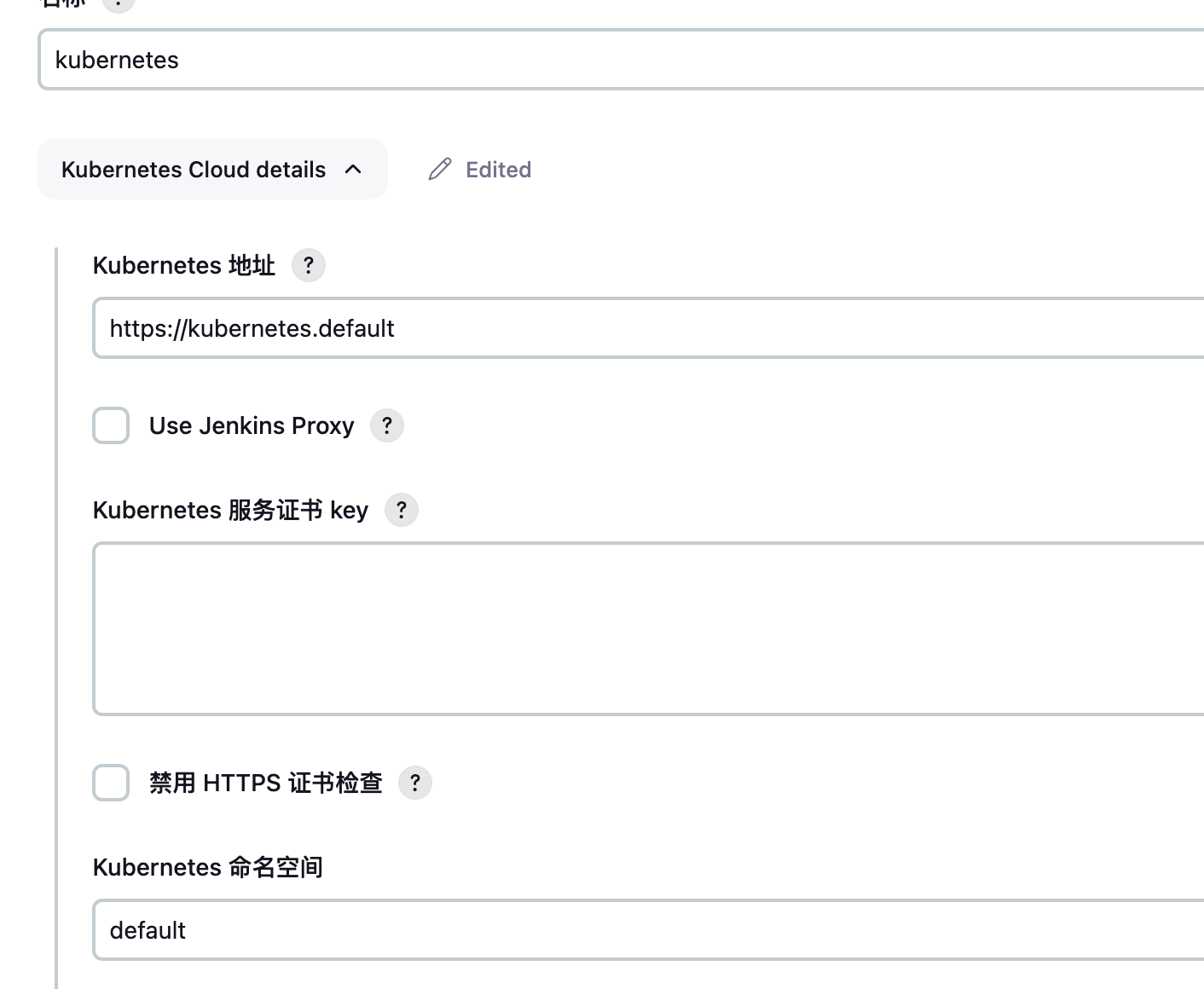
Add a new cloud:
KubernetesKubernetes URL:
https://kubernetes.defaultKubernetes Namespace:
default![image-20240221202735345]()
新版本镜像不用指定凭证。
Test connection
![image-20240221212805080]()
Jenkins URL:
http://jenkins![image-20240221202934729]()
PodTemplate
![image-20240221202949790]()
Add Container // 新版本 Jenkins 会默认用社区镜像启动
jnlp slave(官方提供),可以通过定义同名容器覆盖Name:
jnlpNamespace:
defaultLabels:
jnlp-slave![image-20240221203105548]()
Name:
jnlpImage:
jenkins/inbound-agentCommand: “”
Arguments to pass to the command: ${computer.jnlpmac} ${computer.name}
![image-20240221203500129]()
save




Create a Job and test
Dashboard -> Create Item -> Freestyle project
![image-20240221203613978]()
Restrict where this project can be run
Label Expression:
jnlp-slave![image-20240221203702064]()
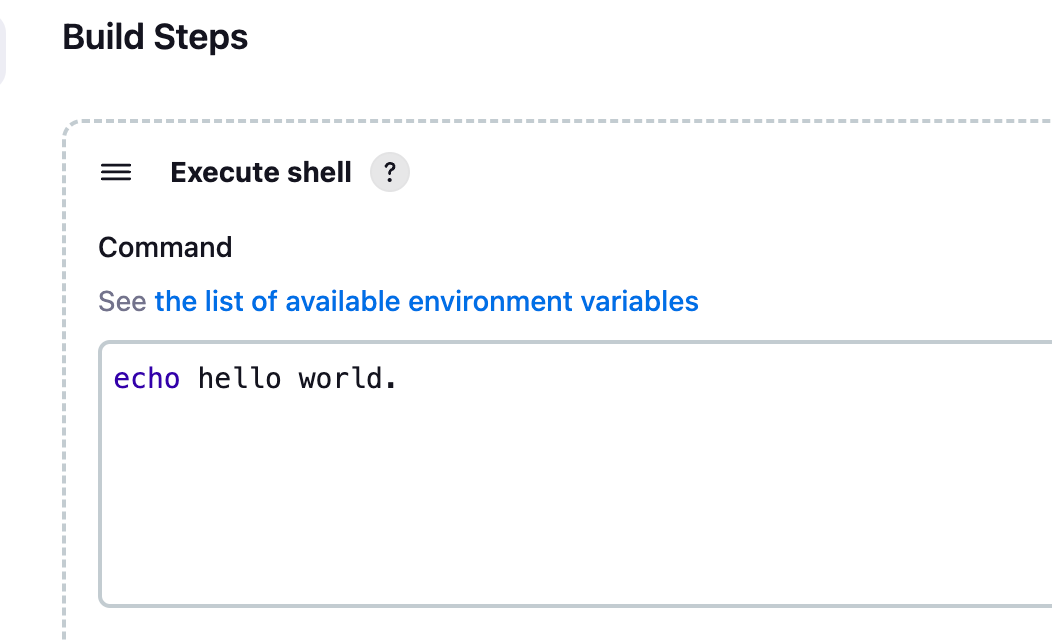
Build Steps-> Add build step -> Execute shell
echo hello world.![image-20240221203755950]()
Build Now
查看 jenkins slave pod:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22# kubectl get pod -n default -w
NAME READY STATUS RESTARTS AGE
jenkins-0 1/1 Running 0 15m
jnlp-1lfzc 0/1 Pending 0 0s
jnlp-1lfzc 0/1 Pending 0 0s
jnlp-1lfzc 0/1 ContainerCreating 0 0s
jnlp-1lfzc 0/1 ContainerCreating 0 1s
jnlp-1lfzc 1/1 Running 0 2s
jnlp-1lfzc 1/1 Terminating 0 8s
jnlp-1lfzc 1/1 Terminating 0 9s
jnlp-1lfzc 0/1 Terminating 0 9s
jnlp-1lfzc 0/1 Terminating 0 10s
* 查看 job log
```sh
Building remotely on jnlp-c7xtm (jnlp-slave) in workspace /home/jenkins/agent/workspace/test
[test] $ /bin/sh -xe /tmp/jenkins2725200252626615934.sh
+ echo hello world.
hello world.
Finished: SUCCESS

Tokton
https://tekton.dev/
Jenkins 的不足
- 基于脚本的
Job配置复用率不足,而且slave个数有限制- Jenkins 等工具的流水线作用通常基于大量不可复用的脚本语言,如何提高代码复用率
- 代码调用困难,几千条代码调试也麻烦
- 如何让流水线作业的配置更好地适应云原生场景的需求越来越急迫
基于声明式 API 的流水线 - Tekton
面向云原生对象
自定义
Tekton 对象是高度自定义的,可扩展性极强。平台工程师可预定义可重用模块以详细的模块目录提供,开发人员可在其他项目中直接引用。
可重用
Tekton 对象的可重用性强,组件只需一次定义,即可被组织内的任何人在任何流水线都可重用。使得开发人员无需重复造轮子即可构建复杂流水线。例如
task和cluster task,相互引用。可扩展性
Tekton 组件目录(
Tekton Catalog)是一个社区驱动的 Tekton 组件的存储仓库。任何用户可以直接从社区获取成熟的组件并在此之上构建复杂流水线,也就是当你要构建一个流水线时,很可能你需要的所有代码和配置都可以从Tekton Catalog直接拿下来复用,而无需重复开发。标准化
Tekton 作为 Kubernetes 集群的扩展安装和运行,并使用业界公认的 Kubernetes 资源模型;Tekton 作业以 Kubernetes 容器形态执行
规模化支持
只需增加 Kubernetes 节点,即可增加作业处理能力。Tokton 的能力可依照集群规模随意扩充,无需重新定义资源分配需求或者重新定义流水线。
Tekton 核心组件
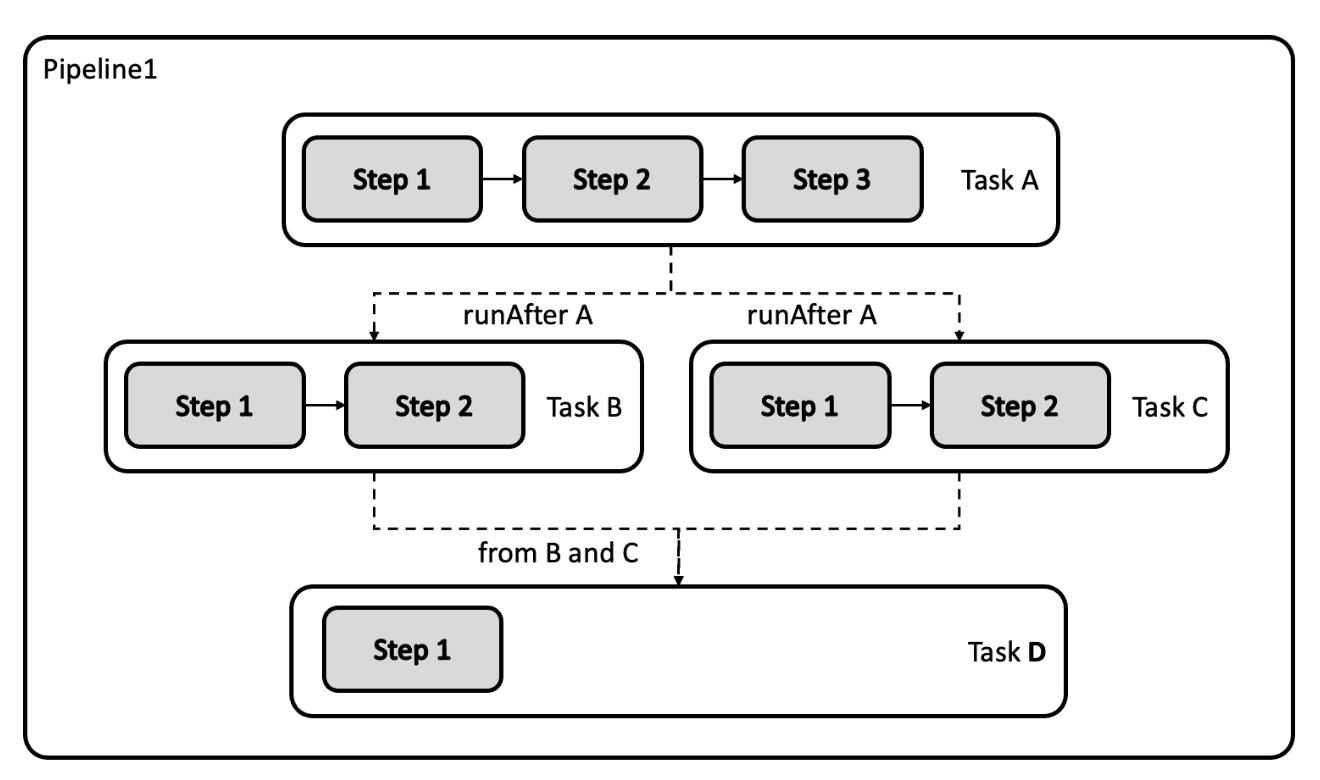
Pipeline:对象定义了一个流水线作业,一个 Pipeline 对象由一个或数个 Task 对象组成。
Task:一个可独立运行的任务,如获取代码,编译,或者推送镜像等等,当流水线被运行时,Kubernetes 会为每个 Task 创建一个 Pod。一个 Task 由多个 Step 组成,每个 Step 体现为这个 Pod 中的一个容器。
安装
1 | // tekton 核心组件 |
镜像如果下载不下来,则将镜像源地址从 gcr.io 改成 gcr.lank8s.cn,亲测可用
1 | # kubectl get pod |
示例
一些 crd
1 | # kubectl get crd | grep tekton |
taskrun-hello.yaml
1 | apiVersion: tekton.dev/v1beta1 |
task-hello.yaml
1 | apiVersion: tekton.dev/v1beta1 |
1 | # 创建 task |
1 | # kubectl describe pod hello-run-r69nz-pod-86btx |
输入输出资源
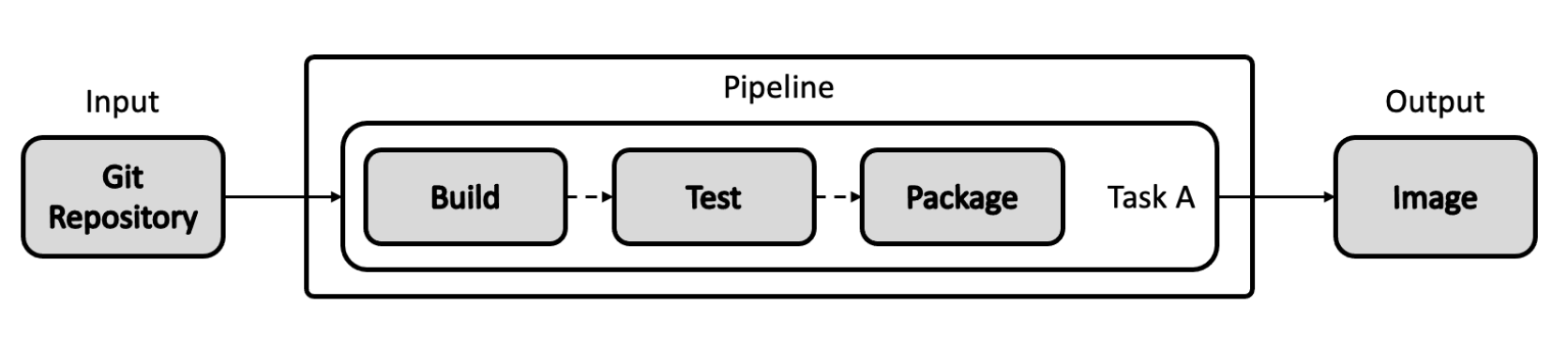
Pipeline 和 Task 对象可以接收 git reposity,pull request 等资源作为输入,可以将 Image,Kubernetes Cluster,Storage,CloudEvent 等对象作为输出。
事件触发的自动化流水线
EventListener
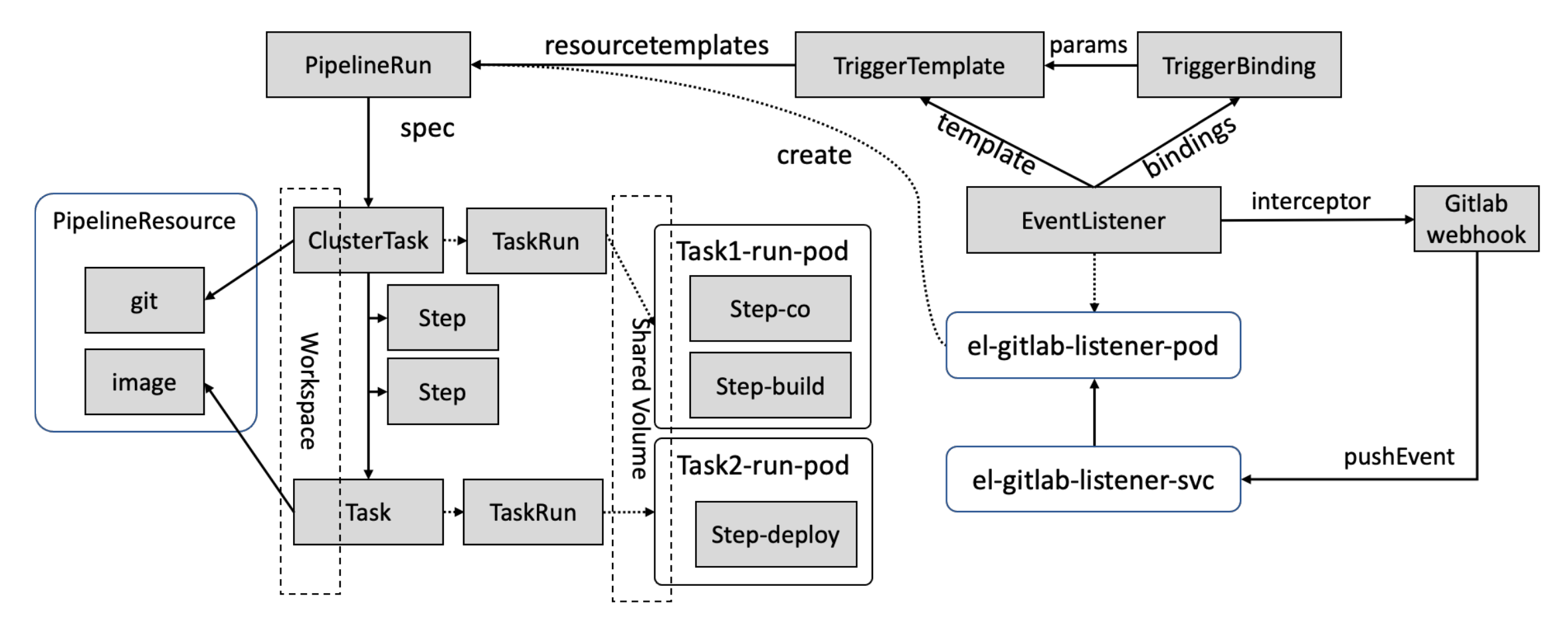
EventListener:
事件监听器,该对象核心属性是 interceptors 拦截器,该拦截器可监听多种类型的事件,比如监听来自 GitLab 的 Push 事件。
当该 EventListener 对象被创建以后,Tekton 控制器会为该 EventListener 创建 Kubernetes Pod 和 Service,并启动一个 HTTP 服务以监听 Push 事件。
当用户在 GitHub 项目中设置 webhook 并填写该 EventListener 的服务地址以后,任何人针对被管理项目发起的 Push 操作,都会被 EventListener 捕获。
EventListener
1 | apiVersion: triggers.tekton.dev/v1alpha1 |
TriggerTemplate
1 | apiVersion: triggers.tekton.dev/v1alpha1 |
GitLab Webhook
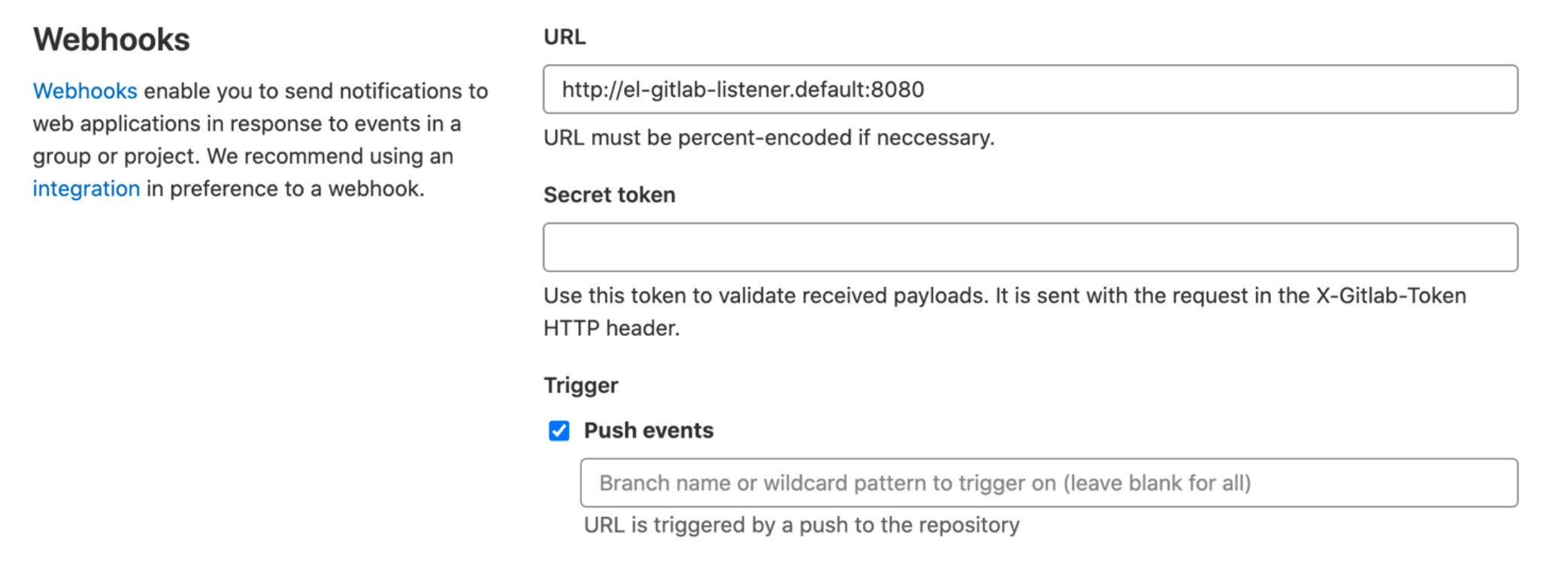
只需在 GitLab 中的被管理项目中设置一个 Webhook,以确保该项目中的事件通知会发送至 EventListener 的服务地址即可。
Argo CD
https://github.com/argoproj/argo-cd
https://argo-cd.readthedocs.io/en/stable/
Argo CD 是用于 Kubernetes 的声明性 GitOps 连续交付工具。
选择 Argo CD 的理由:
- 应用程序定义,配置和环境应为声明性的,并受版本控制
- 应用程序部署和生命周期管理应该是自动化的,可审核的且易于理解的
argo cd 架构
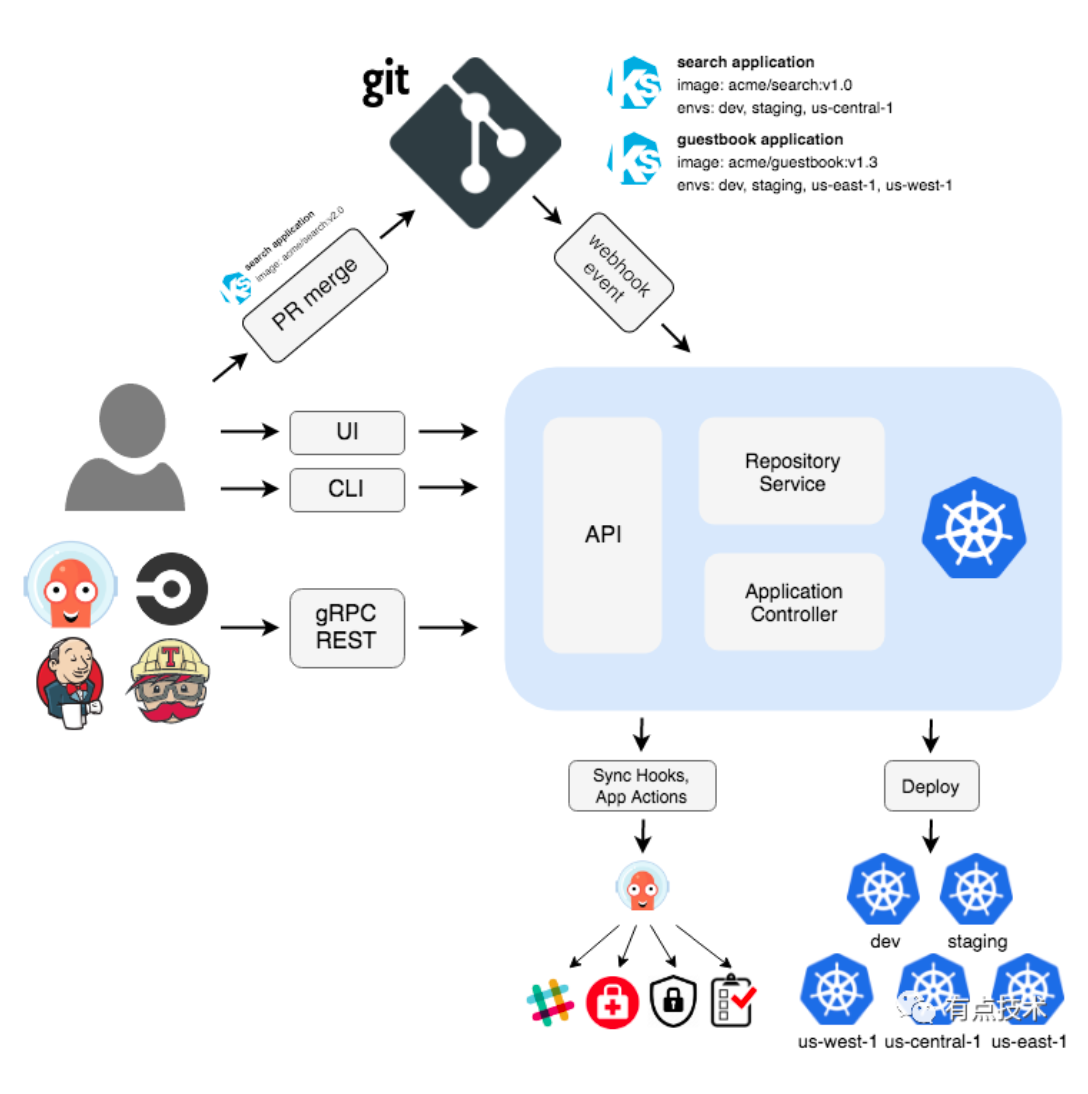
- Argo CD 被实现为 Kubernetes 控制器,该控制器连续监视正在运行的应用程序,并将当前的活动状态与所需的目标状态(在 Git 存储库中指定)进行比较
- 其活动状态偏离目标状态的已部署应用程序被标记为
OutOfSync - Argo CD 报告并可视化差异,同时提供了自动或手动将实时状态同步回所需目标状态的功能
- 在 Git 存储库中对所需目标状态所做的任何修改都可以自动应用并反映在指定的目标环境中。
安装 argocd
1 | kubectl create namespace argocd |
确保 argocd-service service 类型为 NodePort
访问 argocd 控制台
用户名:admin
密码 kubectl get secret -n argocd argocd-initial-admin-secret -o yaml
Argued 的适用场景
- 低成本的
Gitops利器 - 多集群管理
- 不同目的集群:测试,集成,预生产,生产
- 多生产集群管理
监控和日志
数据系统构建
- 日志收集与分析
- 监控系统构建
日志系统的价值
- 分布式系统的日志查看比较复杂,因为多对节点的系统,要先找到正确的节点,才能看到想看的日志。日志系统把整个集群的日志汇总在一起,方便查看
- 因为节点上的日志滚动机制,如果由应用打印太多日志,如果没有日志系统,会导致关键日志丢失
- 日志系统的重要意义在于解决,节点出错导致不可访问,进而丢失日志的情况
常用数据系统构建模式
- 数据收集
- Push:客户端往服务端推送
- Pull:服务端在客户端上拉取
- 预处理
- 去重:日志重复出现的时候去重
- 塑形:日志格式标准化,方便后续做过滤查询和内容补充
- Enrich-ment
- 存储
- TSDB
- Hadoop
- 按需查询
- 查询特定需求的日志
- 告警
- 分析
- 奇异点分析
- 统计分析
- 预测分析
日志收集系统 Loki
https://github.com/grafana/loki
https://grafana.com/oss/loki/
Grafana Loki 是可以组成功能齐全的日志记录堆栈的一组组件。
- 与其他日志记录系统不同,Loki 是基于仅索引有关日志的元数据的想法而构建的:标签
- 日志数据本身被压缩并存储在对象存储(例如 S3 或 GCS)中的块中,甚至存储在文件系统本地
- 小索引和高度压缩的块简化了操作,并大大降低了 Loki 的成本
基于 Loki 的日志收集系统
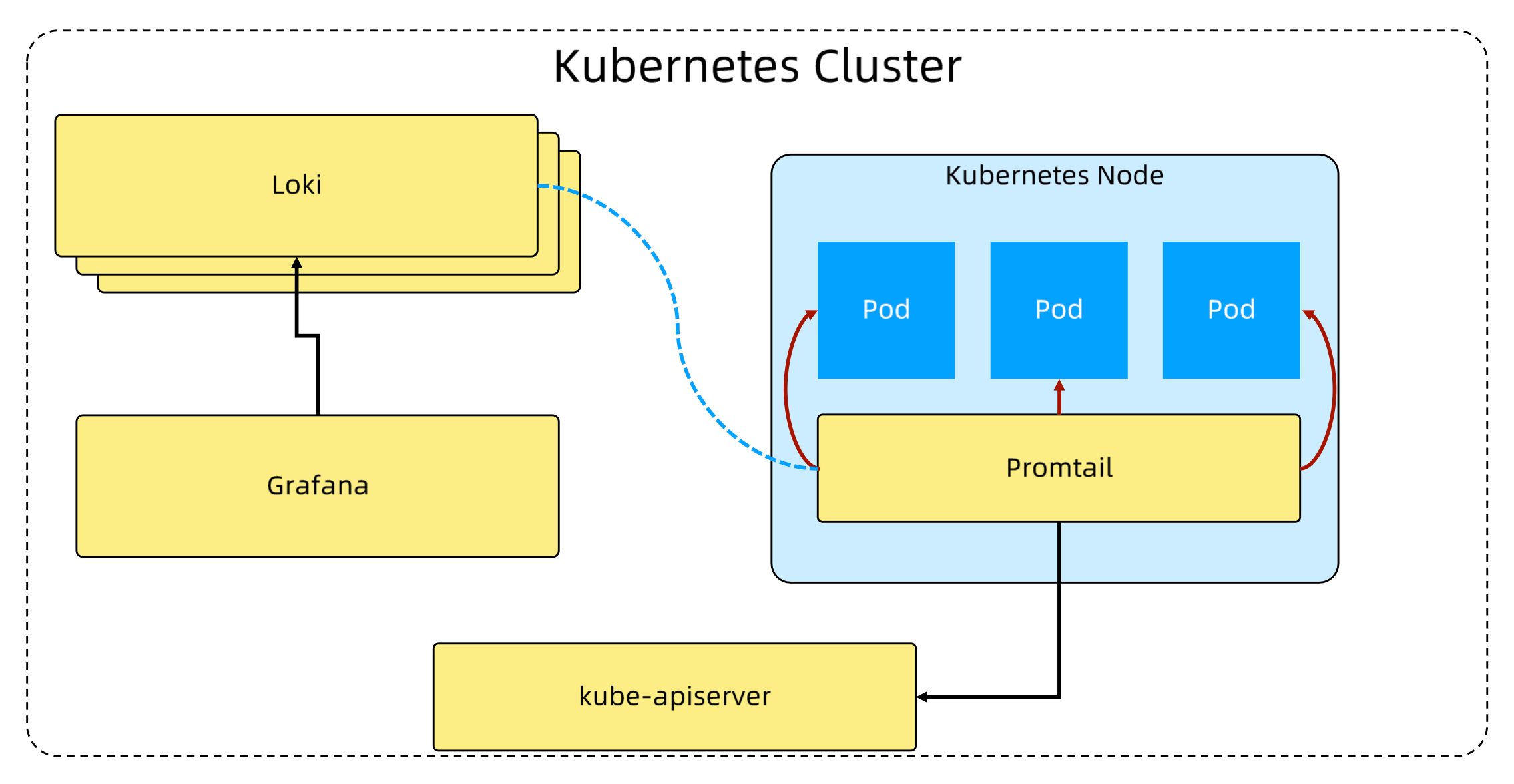
Loki-stack 子系统
- Promtail
- 将容器日志发送到 Loki 或者 Grafana 服务上的日志收集工具
- 发现采集目标以及给日志流添加上
Label,然后发送给 Loki - Promtail 的服务发现是基于 Prometheus 的服务发现机制实现的,可以查看
configmap loki-promtail了解细节
- Loki
- Loki 是可以水平扩展、高可用以及支持多租户的日志聚合系统
- 使用和 Prometheus 相同的服务发现机制,将标签添加到日志流中而不是构建全文索引
- Promtail 接收到的日志和应用的 metrics 指标就具有相同的标签集
- Grafana
- Grafana 是一个用于监控和可视化观测的开源平台,支持非常丰富的数据源
- 在 Loki 技术栈中它专门用来展示来自 Prometheus 和 Loki 等数据源的时间序列数据
- 允许进行查询、可视化、报警等操作,可以用于创建、探索和共享数据 Dashboard
Loki 架构
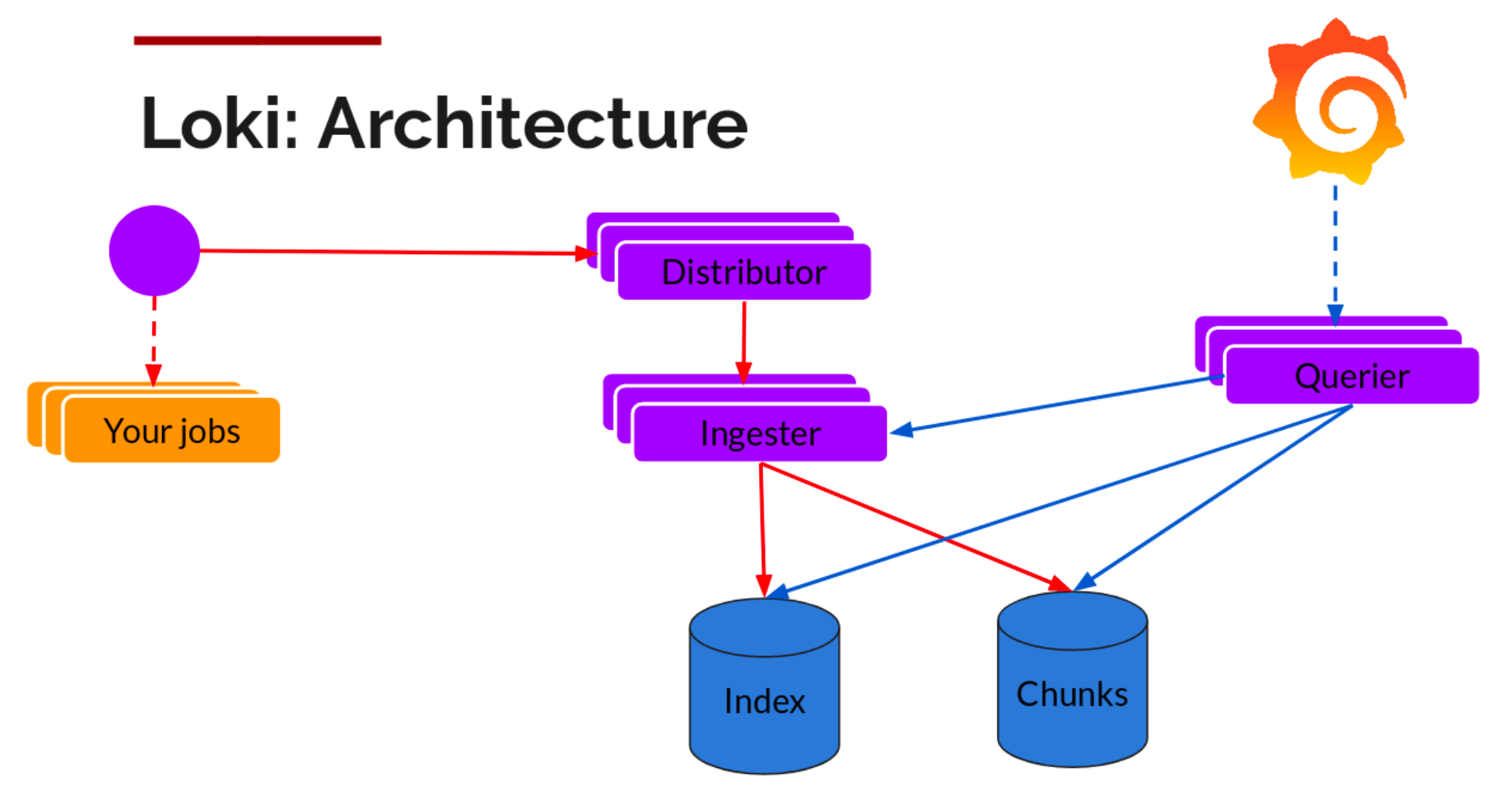
Loki 组件
Distributor(分配器)- 分配器服务负责处理客户端写入的日志
- 一旦分配接收到日志数据,它就会把它们分成若干批次,并将它们并行地发送到多个采集器去
- 分配器通过
gRPC和采集器进行通信 - 它们是无状态的,基于一致性哈希,我们可以根据实际需要对他们进行扩缩容
Ingester(采集器)- 采集器服务负责将日志数据写入长期存储的后端(
DynamoDB、S3、Cassandra等等) - 采集器会校验采集的日志是否乱序
- 采集器验证接收到的日志行是按照时间戳递增的顺序接收的,否则日志行将被拒绝并返回错误
- 采集器服务负责将日志数据写入长期存储的后端(
Querier(查询器)- 查询器服务负责处理
LogQL查询语句来评估存储在长期存储中的日志数据
- 查询器服务负责处理
安装 Loki stack
https://grafana.com/docs/loki/latest/setup/install/helm/install-monolithic/
1 | helm repo add grafana https://grafana.github.io/helm-charts |
在 Kubernetes 集群中的日志系统
日志收集上之后,可以通过简易日志(非详细日志,一般云厂商都免费提供),做一些图表。
在生产中的问题
存在的问题
- 利用率低
- 日志大多数目的是给管理员做问题分析用的,但管理员更多的是登陆点到节点或者
pod里做分析,因为日志分析知识整个分析过程中的一部分,所以很多时候顺手就把日志看了
- 日志大多数目的是给管理员做问题分析用的,但管理员更多的是登陆点到节点或者
Beats出现过锁住文件系统,docker container无法删除的情况- 与监控系统相比,日志系统的重要度稍低
- 出现过多次因为日志滚动太快而使得日志收集占用太大网络带宽的情况
监控系统
为什么监控,监控什么内容?
- 对自己系统的运行状态了如指掌,有问题及时发现,而不让用户先发现我们系统不能使用
- 我们也需要知道我们的服务运行情况。例如,
slowsql处于什么水平,平均响应时间超过200ms的占比由百分之多少
我们为什么需要监控我们的服务?
需要监控工具来提醒我服务出现了故障,比如通过监控服务的负载来决定扩容或缩容。
如果机器普遍负载不高,则可以考虑是否缩减一下机器规模,如果数据库连接经常维持在一个高位水平,则可以考虑一下是否可以进行拆库处理,优化一下架构
监控还可以帮助进行内部通知,尤其是对安全比较敏感的行业,比如证券银行等。比如服务器受到攻击时,我们需要分析事件,找到根本原因,识别类似攻击,发现没有发现的被攻击的系统,甚至完成取证等工作
监控目的
- 减少宕机时间
- 扩展和性能管理
- 资源计划
- 识别异常事件
- 故障排除、分析
在 Kubernetes 集群中的监控系统
目前基本上是 Prometheus 一家独大。
https://prometheus.io/docs/introduction/overview/
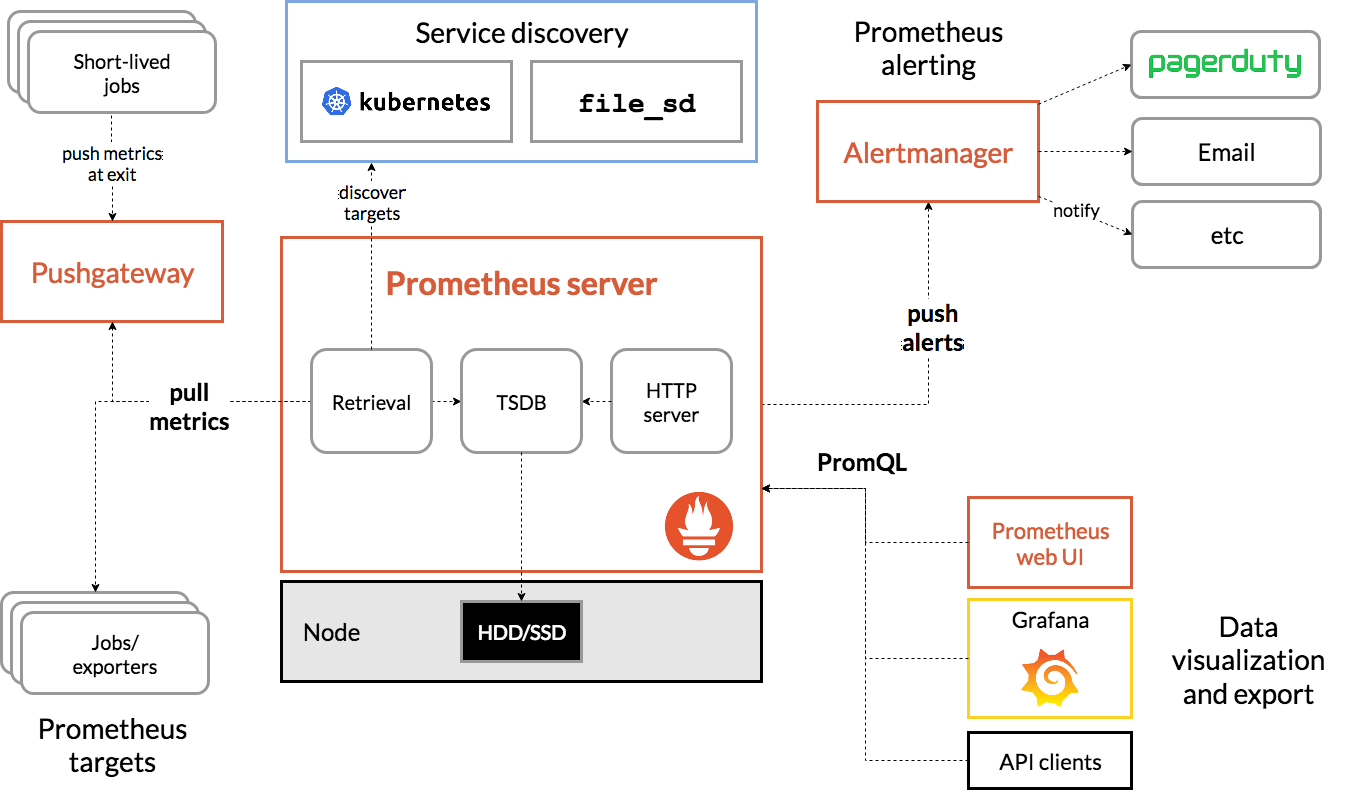
在 Kubernetes 集群中的监控系统
每个节点的 kubelet(集成了 cAdvisor)会收集当前节点 host 上所有信息,包括 cpu、内存、磁盘等。
Prometheus 会 pull 这些信息,给每个节点打上标签来区分不同的节点。(大部分是 pull 的模式,但是也有 push 模式)

在 Kubernetes 中汇报指标
应用 pod 需要声明上报指标端口和地址,声明之后,Prometheus 会自动采集。
1 | apiVersion: v1 |
应用启动时,需要注册 metrics
https://github.com/prometheus/client_golang/tree/main/prometheus/promhttp
1 | http.Handle("/metrics", promhttp.Handler()) |
注册指标
1 | prometheus.MustRegister(version.NewCollector(constants.Loki)) |
代码中输出指标
1 | managerMetrics := NewManagerMetrics(false, nil, constants.Cortex) |
在 Kubernetes 集群中的监控系统
Kubernetes 的 control panel,包括各种 controller 都原生的暴露 Prometheus 格式的 metrics
1 | func newMetrics(registerer prometheus.Registerer) *metrics { |
Prometheus 中的指标类型
Counter(计数器)Counter类型代表一种样本数据单调递增的指标,即只增不减,除非监控系统发生了重置
Gauge(仪表盘)Gauge类型代表一种样本数据可以任意变化的指标,即可增可减
Histogram(直方图)Histogram在一段时间范围内对数据进行采样(通常是请求持续时间或响应大小等),并将其计入可配置的存储桶(bucket)中,后续可通过指定区间筛选样本,也可以统计样本总数,最后一般将数据展示为直方图- 样本的值分布在
bucket中的数量,命名为<basename>_bucket{ le = "<上边界>"} - 所有样本值的大小总和,命名为
<basename>_sum - 样本总数,命名为
<basename>_count。值和<basename>_bucket{ le = "+ Inf"}相同
Summary(摘要)- 与
Histogram类型类似,用于表示一段时间内的数据采样结果(通常是请求持续时间或响应大小等),但它直接存储了分位数(通过客户端计算,然后展示出来),而不是通过区间来计算 - 它们都包含了
<basename>_sum和<basename>_count指标 - Histogram 需要通过
<basename>_bucket来计算分位数,而 Summary 则直接存储了分位数的值
- 与
Prometheus Query Language
histogram_quantile(0.95,sum(rate(httpserver_execution_latency_seconds_bucket[5m])) by (le))hsitogram是直方图,httpserver_execution_latency_seconds_bucket是直方图指标,是将httpserver处理请求的时间放入不同的桶内,其表达的是落在不同时长区间的响应次数by(le),是将采集的数据按桶的上边界分组rate(httpserver_execution_latency_seconds_bucket[5m]),计算的是五分钟内的变化率sum(),是将所有指标的变化率总计0.95,是取95分位
综上:
上述表达式计算的是 httpserver 处理请求时,95% 的请求在 5 分钟内,在不同响应时间区间的处理的数量的变化情况。
在 Kubernetes 集群中的监控系统
Grafana Dashboard

开启告警
修改 Prometheus 配置文件 prometheus.yml,添加以下配置:
1 | rule_files: |
在目录 /etc/prometheus/rules/ 下创建告警文件 hoststats-alert.rules 内容如下:
1 | groups: |
或者:
1 | groups: |
构建支撑生产的监控系统
Metrics- 收集数据
Alert- 创建告警规则,如果告警规则被触发,则按不同严重程度告警
Assertion- 以一定时间间隔,模拟客户行为,操作 Kubernetes 对象,并断言成功,如果不成功则按严重程度告警
来自生产系统的经验分享
Prometheus 需要大内存和存储
- 最初
prometheus经常发生OOM kill - 在提高指定的资源以后,如果发生
crash或者重启,prometheus需要30分钟以上的时间来读取数据进行初始化
Prometheus 是运营生产系统过程中最重要的模块
- 如果
prometheus宕机,则没有任何数据和告警,管理员无法感知系统状况
References
CONTINUOUS INTEGRATION(CI) / CONTINUOUS DELIVERY(CD) PIPELINE : USE CASES