Kubernetes 控制平面组件:生命周期管理和服务发现
深入理解 Pod 的生命周期
如何优雅的管理 Pod 的完整生命周期

Pod 的不同状态代表处于不同的生命周期
Pod 状态机

当有组件出现故障时,就会出现 Unknown 的状态。
Pod Phase
kubectl get pod csi-cephfsplugin-provisioner-865b98f797-wx6mv -o yaml 可以查看 Pod 不同阶段的信息
1 | status: |
Pod Phase:
Pending:待调度Running:正常运行Succeeded:正常运行结束Failed:异常退出Unknown:由于某个插件异常,例如当csi插件被卸载,原先使用这个csi插件的 Pod 就会出现Unknown
kubectl get pod 显示的状态信息是由 podstatus 的 conditions 和 phase 计算出来的
查看
pod细节1
kubectl get pod $podname -o yaml
查看 pod 相关事件
1
kubectl describe pod $podname
Pod 状态计算细节
| kubectl get pod 返回的状态 | Pod Phase | Conditions |
|---|---|---|
| Completed | Succeeded | |
| ContainerCreating | Pending | |
| CrashLoopBackOff | Running | Container exits(一般是由于业务异常) |
| CreateContainerConfigError | Pending | Configmap “test” not found secret “my-secret” not found |
| ErrImagePull ImagePullBackOff Init:ImagePullBackOff InvalidImageName |
Pending | Back-off pulling image |
| Error | Failed | restartPolicy: Never container exits with Error(not 0) |
| Evicted | Failed | Message: ‘Usage of EmptyDir volume “myworkdir” exceeds the limit “40Gi”.’ reason: Evicted |
| Init: 0/1 | Pending | Init containers don’t exit |
| Init: CrashLoopBackOff/ Init: Error |
Pending | Init container crashed (exit with not 1) |
| OOMKilled | Running | Containers are OOMKilled |
| StartError | Running | Containers cannot be started |
| Unknown | Running | Node NotReady |
| OutOfCpu OutOfMemory |
Failed | Scheduled, but it cannot pass kubelet admit |
如何确保 Pod 的高可用
- 避免容器进程被终止,避免 Pod 被驱逐
- 设置合理的
resource.memory limits防止容器进程被 OOMKill - 设置合理的
emptydir.sizeLimit并且确保数据写入不超过emptyDir的限制,防止Pod被驱逐
- 设置合理的
Pod 的 QoS 分类
- [Qos & Quota]
Guaranteed、BustableandBestEffort
从高到低:
Guaranteed:代表 Pod 调度到这个节点之后,可以确保这个节点上的资源可用,保障limits的资源量Pod的每个容器都设置了资源 CPU 和内存需求Limits和requests的值完全一致1
2
3
4
5
6
7
8
9
10
11
12spec:
containers:
...
resources:
limits:
cpu: 700m
memory: 200Mi
requests:
cpu: 700m
memory: 200Mi
...
qosClass: Guaranteed
Burstable:可以保证requests的,无法保证limits里面的至少一个容器设置了
CPU或内存requestPod的资源需求不符合Guaranteed QoS的条件,也就是requests和limits不一致1
2
3
4
5
6
7
8
9
10spec:
containers:
...
resources:
limits:
memory: 200Mi
requests:
memory: 100Mi
...
qosClass: Burstable
BestEffort:不保证任何资源Pod中的所有容器都未指定CPU或内存资源需求requests1
2
3
4
5
6spec:
containers:
...
resources: {}
...
qosClass: BestEffort
当计算节点检测到内存压力时,Kubernetes 会按 BestEffort -> Burstable -> Guaranteed 的顺序依次驱逐 Pod
1 | ~ kubectl get pod air-matrix-service-5b6f74d96f-jwl5k -o yaml | grep qosClass |
质量保证 Guaranteed,Burstable and BestEffort
定义 Guaranteed 类型的资源需求来保护你的重要 Pod
认真考量 Pod 需要的真实需求并设置 limit 和 resource,这有利于将集群资源利用率控制在合理范围并减少 Pod 被驱逐的现象。
尽量避免将生产 Pod 设置为 BestEffort,但是对测试环境来讲,BestEffort Pod 能确保大多数应用不会因为资源不足而处于 Pending 状态。(使用压力测试来预估应用资源)
Burstable 适用于大多数场景。
基于 Taint 的 Evictions
NotReady Node
当 Node 上有 NotReady 的 Taint
1 | spec: |
Kubernetes 为 Pod 自动增加的 Tolerating
1 | tolerations: |
可能出现的情况以及解决方案:
- 节点临时不可达
- 网络分区
kubelet,contained不工作- 节点重启超过了
15分钟
- 增大
tolerationSeconds以避免被驱逐(例如节点可能重启,默认的 15 分钟可能不够,导致 Pod 被驱逐)- 特别是依赖于本地存储状态的有状态应用
健康检查探针
健康探针类型分为
livenessProbe- 探活,当检查失败时,意味着该应用进程已经无法正常提供服务,
kubelet会终止该进程并按照restartPolicy决定是否重启
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20apiVersion: v1
kind: Pod
metadata:
name: liveness1
spec:
containers:
- name: liveness
image: centos
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
# 30s 之后会删掉。Pod 会正常运行 30s,30s 后,探活失败,Pod 会重启(restartPolicy 一般是 Always)
livenessProbe:
exec: # 通过命令行判断就绪状态
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10 # 10s 之后开始探针检测
periodSeconds: 5- 探活,当检查失败时,意味着该应用进程已经无法正常提供服务,
readinessProbe- 就绪状态检查,当检查失败时,意味着应用进程正在运行,但因为某些原因不能提供服务,
Pod状态会被标记为NotReady
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17apiVersion: v1
kind: Pod
metadata:
name: http-probe
spec:
containers:
- name: http-probe
image: nginx
readinessProbe:
httpGet:
### this probe will fail with 404 error code
### only httpcode between 200-400 is retreated as success
path: /healthz
port: 80
initialDelaySeconds: 30
periodSeconds: 5
successThreshold: 2Pod 状态
1
2
3
4
5
6- lastProbeTime: null
lastTransitionTime: "2024-01-25T08:41:01Z"
message: 'containers with unready status: [http-probe]'
reason: ContainersNotReady
status: "False"
type: ContainersReady- 就绪状态检查,当检查失败时,意味着应用进程正在运行,但因为某些原因不能提供服务,
startupProbe- 在初始化阶段(
Ready之前)进行的健康检查,通常用来避免过于频繁的监测影响应用启动
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19apiVersion: v1
kind: Pod
metadata:
name: initial-delay
spec:
containers:
- name: initial-delay
image: centos
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 300; rm -rf /tmp/healthy; sleep 600
startupProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 30 # 等30s 之后判断文件是否存在
periodSeconds: 5- 在初始化阶段(
这三种探针一般搭配使用,让应用在准备时和启动时有足够的时间。
探针方法包括
ExecAction:在容器内部运行指定命令,当返回码为 0 时,探测结果为成功TCPSocketAction:由kubelet发起,通过TCP协议检查容器IP和端口,当端口可达时,探测结果为成功HTTPGetAction:由kubelet发起,对Pod的IP和指定端口以及路径进行HTTPGet操作,当返回码为200-400之间时,探测结果为成功
1
2
3
4
5
6
7
8
9
10
11readinessProbe:
httpGet:
path: /healthz
port: 80
httoHeaders:
- name: X-Custom-Header
value: Awesome
initialDelaySeconds: 30
periodSeconds: 5
successThreshold: 2
timeoutSeconds: 1
探针属性
| parameters | Description |
|---|---|
| initialDelaySeconds | Defaults to 0 seconds. Minimum value is 0. 推迟时间 |
| periodSeconds | Defaults to 0 seconds. Minimum value is 1. 间隔 |
| timeoutSeconds | Defaults to 1 seconds. Minimum value is 1. 请求超时时间 |
| successThreshold | Defaults to 1. Must be 1 for liveness. Minimum value is 1. 判定成功的连续成功次数 |
| failureThreshold | Defaults to 3. Minimum value is 1. 判定失败的连续失败次数 |
ReadinessGates
Readiness允许在 Kubernetes 自带的Pod Conditions之外引入自定义的就绪条件- 新引入的
readinessGatescondition需要为True状态后,加上内置的Conditions,Pod 才可以为就绪状态 - 该状态应该由某控制器修改
1 | apiVersion: v1 |
1 | status: |
虽然状态是 Running ,但是这个 Pod 不会接受和处理流量。一般用于服务需要其他外部服务可以正常访问才接受流量。
1 | # kubectl get svc |
Post-start 和 Pre-Stop Hook
优雅启动
启动钩子:用于在服务启动后,提供服务前做预先处理。
1 | kubectl explain pod.spec.containers.lifecycle.postStart |
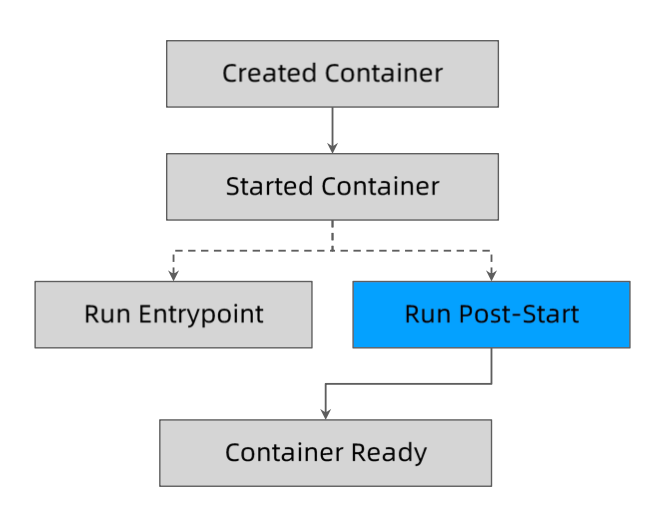
postStart 结束之前,容器不会被标记为 running 状态。
1 | apiVersion: v1 |
无法保证 postStart 脚本和容器的 Entrypoint (指的是 Docker 镜像中的 Entrypoint )哪个先执行。
优雅终止
在容器终止之前,执行的脚本。执行完了之后(不执行完不发送后面的信号),再给容器中的进程发送 SIGTERM,然后再发送 SIGKILL。(给容器先发送信号,让容器可以捕捉到并且自己处理一些终止逻辑,然后才终止。)

Pre-stop 和 SIGKILL 之间的间隔时间可以通过 terminationGracePeriodSeconds 设置。
1 | spec: |
Grace period 默认值:terminationGracePeriodSeconds = 30
1 | apiVersion: v1 |
杀死这个容器时,先执行 preStop,然后发送 SIGTERM 信号,由于 SIGTERM 会被忽略,所以会等待 60s,再发送 SIGKILL 信号。容器内进程忽略 SIGTERM 信号,收到 SIGKILL,进程终止。
1 | apiVersion: v1 |
退出时,执行 nginx -s quit,也就是在优雅终止。
1 | 2024/01/25 09:55:24 [notice] 1#1: start worker process 31 |
只有当 Pod 被终止时,Kubernetes 才会执行 preStop 脚本,这意味着当 Pod 完成或容器退出时,preStop 脚本不会被执行。
terminationGracePeriodSeconds 的分解
terminationGracePeriodSeconds 包括两部分,一部分是 PreStop 到 SIGTERM 阶段,另一部分是 SIGTERM 到 SIGKILL 阶段,两个阶段加起来的时间是 terminationGracePeriodSeconds。

Terminating Pod 的误用


bash/sh 会忽略 SIGTERM 信号量,因此 kill -SIGTERM 会永远超时,若应用使用 bash/sh 作为 Entrypoint,则应避免过长的 grace period。例如上图,无论是 Docker 镜像里面使用 bash/sh 还是在 k8s 的 command 中调用 shell 脚本,都应注意,不然会一直等待 grace period 的时长之后,进程才会终止。
| Time Taken by PreStop (duration 1) |
Time Taken by kill -SIGTERM (duration 2) |
Total Time |
|---|---|---|
| Timeout: grace period < grace period |
Time out: grace period - duration 1 cannot be killed |
Grace period |
Terminating Pod 的经验分享
terminationGracePeriodSeconds 默认时长 30s。
如果不关心 Pod 的终止时长,那么无需采取特殊措施。
如果希望快速终止应用进程,那么可采取如下方案:
- 在
preStopscript中主动退出进程 - 在主容器进程中使用特定的初始化进程
优雅的初始化进程应该:
- 正确处理系统信号量,将信号量转发给子进程
- 在主进程退出之前,需要先等待并确保所有子进程退出
- 监控并清理孤儿子进程
推荐使用:https://github.com/krallin/tini
在 Kubernetes 上部署应用的挑战
资源规划
- 每个实例需要多少计算资源
CPU/GPUMemory
- 超售需求以及
QoS Class - 每个实例需要多少存储资源
- 大小
- 本地还是网络存储盘
- 读写性能
Disk I/O
- 网络需求
- 整个应用总体
QPS和带宽
- 整个应用总体
存储带来的挑战
多容器之间共享存储,最简方案是 emptyDir
带来的挑战:
emptyDir需要控制sizelimit,否则无限扩张的应用会撑爆主机磁盘导致主机不可用,进而导致大规模集群故障emptyDir size limit生效以后,kubelet会定期对容器目录执行du操作,会导致些许的性能影响(满了之后会驱逐这个Pod,后面kubelet更新了,不使用du操作)size limit达到以后,Pod会被驱逐,原Pod的日志配置等信息会消失
应用配置
传入方式,不会固定到容器中,否则修改配置需要重新打镜像
Environment VariablesVolume Mount
数据来源
ConfigMapSecretDownward API:也就是将 Pod 信息注入容器内部,例如上面两种,环境变量和卷挂载,也可以是一些其他信息例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19volumes:
- name: kube-api-access-vhbrx
projected:
defaultMode: 420
sources:
- serviceAccountToken:
expirationSeconds: 3607
path: token
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
数据应该如何保存

| 存储卷类型 | 容器重启后是否存在 | Pod 重建后数据是否存在 | 是否有大小控制 | 注意 |
|---|---|---|---|---|
| emptyDir | 是 | 否 | 是 | 如果被调度到其他节点,数据会消失 |
| hostPath | 是 | 否 | 否 | 需要额外权限控制 如果被调度到其他节点,也会消失 |
| Local volume | 是 | 否 | 是 | 无备份 |
| Network volume | 是 | 是 | 是 | |
| rootFS | 否 | 否 | 否 | 不要写任何数据 |
注意控制日志写入速度,防止操作系统在配置日志回滚窗口期内把硬盘写满。
容器应用可能面临的进程中断
系统问题类型:
kubelet升级影响:
- 不重建容器,无影响
- 重建容器,则
Pod进程会被重启,服务会收到影响(kubelt通过hash算法唯一确认一个容器,升级可能导致算法变更)
建议:(升级之前查看
updatelog, 细化影响)- 冗余部署
- 跨故障域部署
主机操作系统升级;节点手工重启
影响:
- 节点重启
Pod进程会被终止数分钟(10分钟左右)
建议:
- 跨故障域部署
- 增加
Liveness,Readiness探针 - 设置合理的
NotReadynode的Toleration时间,在重启节点过程中不被重新调度
节点下架,送修
影响:
- 节点会
drain(优雅的驱逐节点),重启或者从集群中删除 Pod进程会被终止数分钟
建议:
- 跨故障域部署
- 利用
Pod distruption budget(Pod最多有几个实例不为 Ready,应用层和基础架构层通过这个约束来,当drain节点的时候,会被阻拦) 避免节点被drain导致Pod被意外删除而影响业务 - 利用
preStop script做数据备份等操作
- 节点会
节点长时间下线
影响:
Pods will be down for about 10 minutes
建议:
- 跨故障域部署
- 设置合理的
NotReadynode的Toleration时间
节点崩溃
影响:
Pod进程会被终止15分钟左右
建议:
- 跨故障域部署
高可用部署方式
需要注意:
多少实例
更新策略
maxSurge:更新时,先不杀掉老版本,先拉取新版本的个数maxUnavailable(需要考虑ResourceQuota的限制):用于保护应用,最大不可用的 Pod 个数,当达到满足个数,就不会继续升级
深入理解
PodTemplateHash导致的应用的易变性,比如更换label时,可能导致hash变更,也导致Pod重建
服务发现
由于 Pod 的不稳定性,例如在节点驱逐或是异常时,Pod 的 IP 地址会变化,Pod 名称会变化,因此需要引入服务发现实现 Pod 稳定的访问。
服务发布
服务发布需要提供的功能:
需要把服务发布至集群内部或者外部,服务的不同类型
ClusterIP(Headless):``cluster` 对应服务生成一个虚拟 IPNodePort:IP 之外,额外增加一个端口LoadBalancer:在外部的负载均衡器上配置IP,通过访问这个IP实现负载均衡。由这个外部的负载均衡决定请求转发到哪个PodExternalName:通过域名绑定一个外部服务地址
证书管理(https)和七层负载均衡的需求
需要 gRPC 负载均衡:gRPC 是基于 HTTP/2,会复用 TCP 连接,需要在应用层实现负载均衡
DNS 需求(服务发布时,通过域名绑定,使用更加简便)
与上下游服务的关系
服务发布的挑战
kube-dns
DNS TTL问题:每次DNS的请求都会携带一个对应的TTL,减少域名服务器的压力;但是坏处是变更无法及时生效。
Service
ClusterIP只能对内Kube-proxy支持的iptables/ipvs规模有限IPVS的性能和生产化问题kube-proxy的drift问题(多节点下一致性问题)- 频繁的
Pod变动(spec change,failover,crashloop)导致LB频繁变更 - 对外发布的
Service需要与企业ELB集成 - 不支持
gRPC - 不支持自定义
DNS和高级路由功能
Ingress:外部流量进入集群的方式
Spec的成熟度
其他可选方案或多或少都有一些问题,无法全面覆盖。
跨地域部署
需要多少实例
如何控制失败域,部署在几个地区,AZ,集群?
如何进行精细的流量控制
如何做按地域的顺序更新
如何回滚
微服务架构下的高可用挑战
服务发现
- 微服务架构是由一系列职责单一的细粒度服务构成的分布式网状结构,服务之间通过轻量机制进行通信,这时候必然引入一个服务注册发现问题,也就是说服务提供方要注册通告服务地址,服务的调用方要能发现目标服务。
- 同时服务提供方一般以集群方式提供服务,也就引入了负载均衡和健康检查问题。
互联网架构发展历程

- 单一网页阶段:一个后端服务即可提供服务
- 负载均衡和高可用阶段:使用
nginx做转发或者代理 - L4/L7 层负载均衡阶段:通过硬件 LB 实现负载均衡,更好的管理和接收所有的流量
- 多个 L4 负载均衡阶段:通过路由(或者其他技术)将流量转发到不同的 L4 负载均衡器
- 多数据中心阶段
理解网络包格式
例如一个 HTTP 请求的数据包格式:

负载均衡的目的:简化的讲,获取的数据包之后,修改数据包的包头,修改其中的目标地址以及目标端口,将数据包转发到对应服务器上。
集中式 LB 服务发现
在集群外部,加一层 LB
- 在服务消费者和服务提供者之间有一个独立的
LB(硬件级别集中式负载均衡器,所有的请求流量都从这个负载均衡器进来) LB上所有服务的地址映射表,通常由运维配置注册- 当服务消费方调用某个目标服务时,它向
LB发起请求,由LB以某种策略(比如Round-Robin)做负载均衡后将请求转发到目标服务 LB一般具备健康检查能力,能自动摘除不健康的服务实例- 服务消费方通过
DNS发现LB,运维人员为服务配置一个DNS域名,这个域名指向LB

- 集中式
LB方案实现简单,在LB上也容易做集中式的访问控制,这一方案目前还是业界主流 - 集中式
LB的主要问题是单点问题,所有服务调用流量都经过LB,当服务数量和调用量大的时候,LB容易成为瓶颈,且一旦LB发生故障对整个系统的影响是灾难性的 LB在服务消费方和服务提供方之间增加了一跳(hop),有一定性能开销
进程内 LB 服务发现
集中式 LB 有一些缺陷,例如某个流量较大时会占满带宽。因此,一些常见下引入进程内 LB 服务发现
- 进程内
LB方案将LB的功能以库的形式集成到服务消费方进程里面,该方案也被称为客户端负载方案。 - 服务注册表(
Service Registry)配合支持服务自注册和自发现,服务提供方启动时,首先将服务地址注册到服务注册表(同时定期报心跳到服务注册表以表明服务的存活状态)。 - 服务消费方要访问某个服务时,它通过内置的
LB组件向服务注册表查询(同时缓存并定期刷新)目标服务地址列表,然后以某种负载均衡策略选择一个目标服务地址,最后向目标服务发起请求。 - 这一方案对服务注册表的可用性(
Availability)要求很高,一般采用能满足高可用分布式一致的组件(例如Zookeeper,Consul,etcd等)来实现。
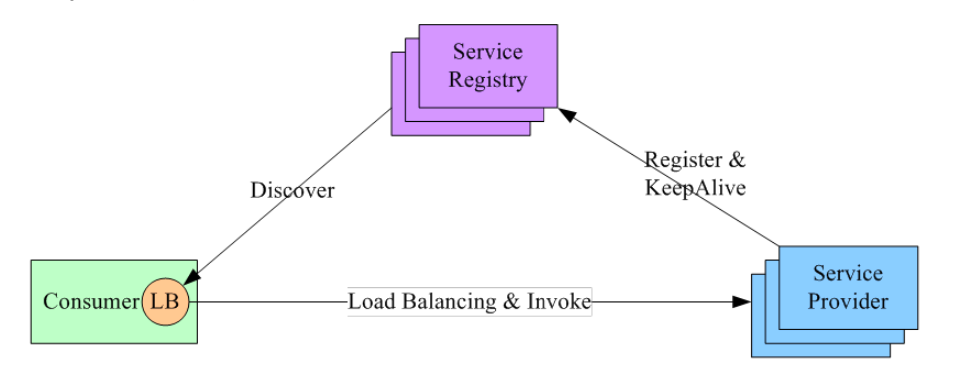
- 进程内 LB 是一种分布式模式,LB 和服务发现能力被分散到每一个服务消费者的进程内部,同时服务消费方和服务提供方之间是直接调用,没有额外开销,性能比较好。该方案以客户端(
Client Library)的方式集成到服务调用方进程里面,如果企业内有多种不同的语言栈,就要配合开发多种不同的客户端,有一定的研发和维护成本。(一般会集中在中间件中,例如gRPC) - 一旦客户端跟随服务调用方发布到生产环境中,后续如果要对客户库进行升级,势必要求服务调用方修改代码并重新发布,所以该方案的升级推广有不小的阻力。
独立 LB 进程服务发现
- 针对进程内 LB模式的不足而提出的一种折中方案,原理和第二种方案基本类似
- 不同之处是,将 LB 和服务发现功能从进程内移出来,变成主机上的一个独立进程,主机上的一个或者多个服务要访问目标服务时,他们都通过同一主机上的独立 LB 进程做服务发现和负载均衡(
sidecar的方式) - LB 独立进程可以进一步与服务消费方进行解耦,以独立集群的形式提供高可用的负载均衡服务
- 这种模式可以称之为真正的 软负载(
Soft Load Balancing)

- 独立 LB 进程也是一种分布式方案,没有单点问题,一个
LB进程挂了只影响该主机上的服务调用方 - 服务调用方和 LB 之间是进程间调用,性能好
- 简化了服务调用方,不需要为不同语言开发客户库(使用 SDK 替换为本地进程间通信),
LB的升级不需要服务调用方改代码 - 不足是部署较复杂,环节多,出错调试排查问题不方便
负载均衡
- 系统的扩展可分为纵向(垂直)扩展(实例增加资源)和横向(水平)扩展(增加实例个数)
- 纵向扩展:是从单机的角度通过增加硬件处理能力,比如
CPU处理能力,内存容量,磁盘等方面,实现服务器处理能力的提升,不能满足大型分布式系统(网站),大流量,高并发,海量数据的问题 - 横向扩展:通过添加机器来满足大型网站服务的处理能力。比如:一台机器不能满足,则增加两台或者多台机器,共同承担访问压力,这就是典型的集群和负载均衡架构(横向扩展需要预先提供优雅终止和优雅启动)
- 纵向扩展:是从单机的角度通过增加硬件处理能力,比如
- 负载均衡的作用(解决的问题):
- 解决并发压力,提高应用处理性能,增加吞吐量,加强网络处理能力
- 提供故障转移,实现高可用
- 通过添加或减少服务器数量,提供网站伸缩性,扩展性
- 安全防护,负载均衡设备上做一些过滤,黑白名单等处理
DNS 负载均衡
最早的负载均衡技术,利用域名解析实现负载均衡,在 DNS 服务器,配置多个 A 记录,这些 A 记录对应的服务器构成集群。

优点:
- 使用简单
- 负载均衡工作,交给 DNS 服务器处理,省掉了负载均衡服务器维护的麻烦
- 提高性能
- 可以支持基于地址的域名解析,解析成距离用户最近的服务器地址,可以加快访问速度,改善性能
缺点:
- 可用性差
- DNS 解析是多级解析,新增/修改 DNS 后,解析时间较长
- 解析过程中,用户访问网站将失败
- 扩展性差
- DNS 负载均衡的控制权在域名商那里,无法对其做更多的改善和扩展
- 一般是轮询解析结果,并不能起到真正的负载均衡效果
- 维护性差:
- 也不能反映服务器的当前运行状态;
- 支持的算法少;
- 不能区分服务器的差异,不能根据系统与服务的状态来判断负载
负载均衡技术概览
Envoy(数据面)/Istio(控制面)对应的
LB技术:TLS terminationL7 path forwarding,redirectingURL/Header rewrite
对应 OSI 层次模型中的第 7 层,应用层(例如
nginx转发,拆解出HTTP的报文header中的数据以及配置,获取具体需要转发到的节点)Kube Services/Kube-ProxyELB ProviderIP分配IP路由网络策略
三层隧道
对应的
LB技术:- 网络地址转换(
NAT):改原始包的包头目标地址和源地址 - 隧道技术(
Tunnel):在原始包的基础上封装一层
对应
OSI层次模型中的第 4 层,传输层- 数据链路层修改
MAC地址进行负载均衡 - 响应数据包直接返回给用户浏览器
对应
OSI层次模型中的第 2 层,链路层- 网络地址转换(
具体使用几层负载均衡技术,可以根据实际情况来决定。例如如果所有服务都在同一个二层网络,则可以使用链路层的 LB 技术。
网络地址转换
网络地址转换(Network Address Translation,NAT)通常通过修改数据包的源地址(Source NAT)或目标地址(Destination NAT)来控制数据包的转发行为。

新建 TCP 连接
为记录原始客户端 IP 地址,负载均衡功能不仅要进行数据包的源地址修改,同时要记录原始客户端 IP 地址,基于简单的 NAT 无法满足此需求,于是衍生出了基于传输层协议的负载均衡的另一种方案– TCP/UDP Termination 方案

链路层负载均衡
- 在通信协议的数据链路层修改
MAC地址进行负载均衡 - 数据分发时,不修改
IP地址,指修改目标MAC地址,配置真实物理服务器集群所有机器虚拟IP和负载均衡服务器IP地址一致,达到不修改数据包的源地址和目标地址,进行数据分发的目的 - 实际处理服务器 IP 和数据请求目的
IP一致,不需要经过负载均衡服务器进行地址转换,可将相应数据包直接返回给用户浏览器,避免负载均衡服务器网卡带宽成为瓶颈。也称为直接路由模式(DR模式)

隧道技术
负载均衡中常用的隧道技术是 IP over IP,其原理是保持原始数据包 IP 头不变,在 IP 头外层增加额外的 IP 包头后转发给上游服务器。
上游服务器接收 IP 数据包,解开外层 IP 包头后,剩下的是原始数据包。
同样的,原始数据包中的目标 IP 地址要配置在上游服务器中,上游服务器处理完数据请求以后,响应包通过网关直接返回给客户端。
Service 对象
Service Selector- Kubernetes 允许将
Pod对象通过标签Label进行标记,并通过Service Selector定义基于Pod标签的过滤规则,以便选择服务的上游应用实例
- Kubernetes 允许将
PortsPorts属性中定义了服务的端口、协议目标端口等信息
1 | apiVersion: v1 |
Endpoint 对象
创建 svc 对象
1 | apiVersion: v1 |
1 | # kubectl get svc nginx-basic -o yaml |
当
Service的selector不为空时,KubernetesEndpoint Controller会侦听服务创建事件,创建与Service同名的Endpoint对象1
2
3kubectl get endpoints
NAME ENDPOINTS AGE
nginx-basic <none> 3s # ENDPOINTS 是空的,代表无法通过 svc 访问到 Pod创建一个无法正常
ready的deployment1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
readinessProbe: # ready 设置
exec:
command:
- cat
- /tmp/healthy # 5s 之后获取一个不存在的 文件,获取到状态才 ready
initialDelaySeconds: 5
periodSeconds: 51
2
3# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-6b5b456bdb-vghq2 0/1 Running 0 26sselector能够选取的所有PodIP都会被配置到address属性中- 如果此时
selector所对应的filter查询不到对应的Pod,则address列表为空 - 默认配置下,如果此时对应的
Pod为not ready状态,则对应的PodIP只会出现在subsets的notReadyAddress属性中,这意味着对应的Pod还没准备好提供服务,不能作为流量转发的目标 - 如果设置了
PublishNotReadyAddress为true,则无论Pod是否就绪都会被加入readyAddress list
- 如果此时
1 | # kubectl get endpoints nginx-basic -o yaml |
endpoint 可以理解为 svc 和 pod 之间的中间对象,维护所有 pod 对应的 IP。一个 svc 可以映射多个 pod,一个 pod 也可以同时被多个 svc 映射,所以 pod 和 svc 之间的关系是多对多,endpoint 的作用就是维护多对多的关系。
例如增加一个 Pod
1 | # kubectl scale deployment nginx-deployment --replicas 2 |
在其中一个 pod 中创建文件
1 | # kubectl exec -it nginx-deployment-6b5b456bdb-dv97r -- touch /tmp/healthy |
PublishNotReadyAddress 语义
1 | kubectl explain service.spec.publishNotReadyAddresses |
kube-proxy 会监听 svc 和 endpoint,并且通过调用接口,在每个节点上都创建出对应转发关系,每个节点的 Pod 和主机之间,都可以通过 svc 互通。
这样会引发其他的问题,在集群规模变得很大的时候,任何一个 Pod\SVC 的变动都会引发 endpoint 的变动,导致同步数据流量占用巨大。因此社区提出一个新的对象,endpointSlice。
EndpointSlice 对象
- 当某个
Service对应的backend Pod较多时,Endpoint对象就会因保存的地址信息过多而变得异常庞大 Pod状态的变更会引起Endpoint的变更,Endpoint的变更会被推送至所有节点,从而导致持续占用大量网络带宽EndpointSlice对象,用于对Pod较多的Endpoint进行切片,切片大小可以自定义- 切片之后,当
Pod发生变动,只会推送部分变动的endpoint信息到所有节点的endpoint
1 | # kubectl get endpointslices.discovery.k8s.io |
不定义 Selector 的 Service
1 | apiVersion: v1 |
创建出来后,不会产生 endpoint
1 | kubectl get svc |
- 用户创建了
Service但不定义SelectorEndpoint Controller不会为该Service自动创建Endpoint- 用户可以手动创建
Endpoint对象,并设置任意IP地址到Address属性 - 访问该服务的请求会被转发至目标地址
- 通过该类型服务,可以为集群外的一组
Endpoint创建服务
这个功能可以用于使用集群外部服务,并且由 svc 自动实现负载均衡。
Service、Endpoint 和 Pod 的对应关系

svc 的目的是让外部服务访问 clusterIP:port ,由 svc 通过 LB 将流量转发到背后的 Pod。
Service 类型
ClusterIPService的默认类型,服务被发布至仅集群内部可见的虚拟IP地址上- 在
API Server启动时,需要通过--service-cluster-ip-range参数配置虚拟IP地址段,API Server中有用于分配IP地址和端口的组件,当该组件捕获Service对象并创建事件时,会从配置的虚拟IP地址段中取一个有效的IP地址,分配给该Service对象
NodePort- 在
API Server启动时,需要通过--node-port-range参数配置nodePort的范围,同样的,API Server组件会捕获Service对象并创建事件,即从配置好的nodePort范围取一个有效端口,分配给该Service(默认 30000 - 32000) - 每个节点的
kube-proxy会尝试在服务分配的nodePort上建立监听器接收请求,并转发给服务对应的后端Pod实例
- 在
LoadBalancer- 企业数据中心一般会采购一些负载均衡器,作为外网请求进入数据中心内部的统一流量入口
- 针对不同的基础架构云平台,Kubernetes Cloud Manager 提供支持不同供应商
API的Service Controller。如果需要在 OpenStack 云平台上搭建 Kubernetes 集群,那么只需要提供一份openstack.rc,OpenStack Service Controller 即可通过调用LBaaS API完成负载均衡配置 - 使用
LoadBalancer后,流量会从LoadBalancer进来,转发到对应Pod
Service 类型不是并列关系,而是包含关系,从下到上,一层一层包含。
其他类型服务
Headless Service1
2
3
4
5
6
7
8
9
10
11
12apiVersion: v1
kind: Service
metadata:
name: nginx-headless
spec:
ClusterIP: None # 指定 None 代表 Headless,不需要负载均衡配置,
ports:
- port: 80
protocol: TCP
name: http
selector:
app: nginxHeadless服务是用户将clusterIP显示定义为None的服务。无头的服务意味着 Kubernetes 不会为该服务分配统一入口,包括
clusterIP,nodePort等一般用于
StatefulSet服务,给每一个Pod创建一个独立的Service入口ExternalName Service1
2
3
4
5
6
7
8apiVersion: v1
kind: Service
metadata:
name: my-service
namespace: prod
spec:
type: ExternalName
externalName: tencent.com为一个服务创建别名,一般用于访问外部服务或者给内部服务做替换。
Service Topology
- 一个网络调用的延迟受客户端和服务器所处位置的影响,两者是否在同一节点、同一机架、同一可用区、同一数据中心,都会影响参与数据传输的设备数量
- 在分布式系统中,为保证系统的高可用,往往需要控制应用的错误域(
Failure Domain),比如通过反亲和性配置,将一个应用的多个副本部署在不同机架,甚至不同的数据中心 - Kubernetes 提供通用标签标记节点所处的物理位置,如:
1 | topology.kubernetes.io/zone: us-west2-a |
Service 引入了
topologyKeys属性,可以通过如下设置来控制流量,只会将流量转发到某个节点或者优先转发到某个节点1
2
3
4
5
6
7
8
9
10
11
12
13apiVersion: v1
kind: Service
metadata:
name: nodelocal
spec:
ports:
- port: 80
protocol: TCP
name: http
selector:
app: nginx
topologyKeys:
- "kubernetes.io/hostname" # 硬性,按照 topologyKeys 执行当本节点有对应 Pod 才转发请求,否则直接拒绝1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16apiVersion: v1
kind: Service
metadata:
name: prefer-nodelocal
spec:
ports:
- port: 80
protocol: TCP
name: http
selector:
app: nginx
topologyKeys: # 软性,按照 topologyKeys 指定的顺序层级来优先转发,最终 * 兜底
- "kubernetes.io/hostname"
- "topology.kubernetes.io/zone"
- "topology.kubernetes.io/region"
- "*"- 当 topologyKeys 设置为
["kubernetes.io/hostname"]时,调用服务的客户端所在节点上如果有服务实例正在运行,则该实例处理请求,否则,调用失败。 - 当 topologyKeys 设置为
["kubernetes.io/hostname", "topology.kubernetes.io/zone", "topology.kubernetes.io/region"]时,若同一节点有对应的服务实例,则请求会优先转发至该实例。否则,顺序查找当前zone及当前region是否有服务实例,并将请求按顺序转发。 - 当 topologyKeys 设置为
["topology.kubernetes.io/zone", "*"]时,请求会被优先转发至当前 zone 的服务实例。如果当前 zone 不存在服务实例,则请求会被转发至任意服务实例。
- 当 topologyKeys 设置为
kube-proxy
每台机器上都运行一个 kube-proxy 服务,它监听 API Server 中 service (负载均衡 IP 和对应 endpoint )和 endpoint ( Pod 信息)的变化情况,并通过 iptables 等来为服务配置负载均衡(仅支持 TCP 和 UDP)
kube-proxy 可以直接运行在物理机上,也可以以 static pod 或者 DaemonSet 的方式运行。
kube-proxy 当前支持一下几种实现:
userspace:最早的负载均衡方案,它在用户空间监听一个端口,所有服务通过iptables转发到这个端口,然后在其内部负载均衡到实际的 Pod。该方式最主要的问题是效率低,有明显的性能瓶颈(内核态 网卡处理 -> 用户态 kube-proxy -> 内核态 转发到对应网口)iptables:目前推荐的方案,完全以iptables规则的方式来实现service负载均衡。该方式最主要的问题是在服务多的时候产生太多的iptables规则,非增量式更新会引入一定的时延,大规模情况下有明显的性能问题(通过kernel中的netfilter处理,netfileter包含了iptables和ipvs)ipvs:为解决iptables模式的性能问题,v 1.8 新增了ipvs模式,采用增量式更新,并可以保证service更新期间连接保持不断开winuserspace:同userspace,但仅工作在windows上
Linux 内核处理数据包:Netfilter 框架
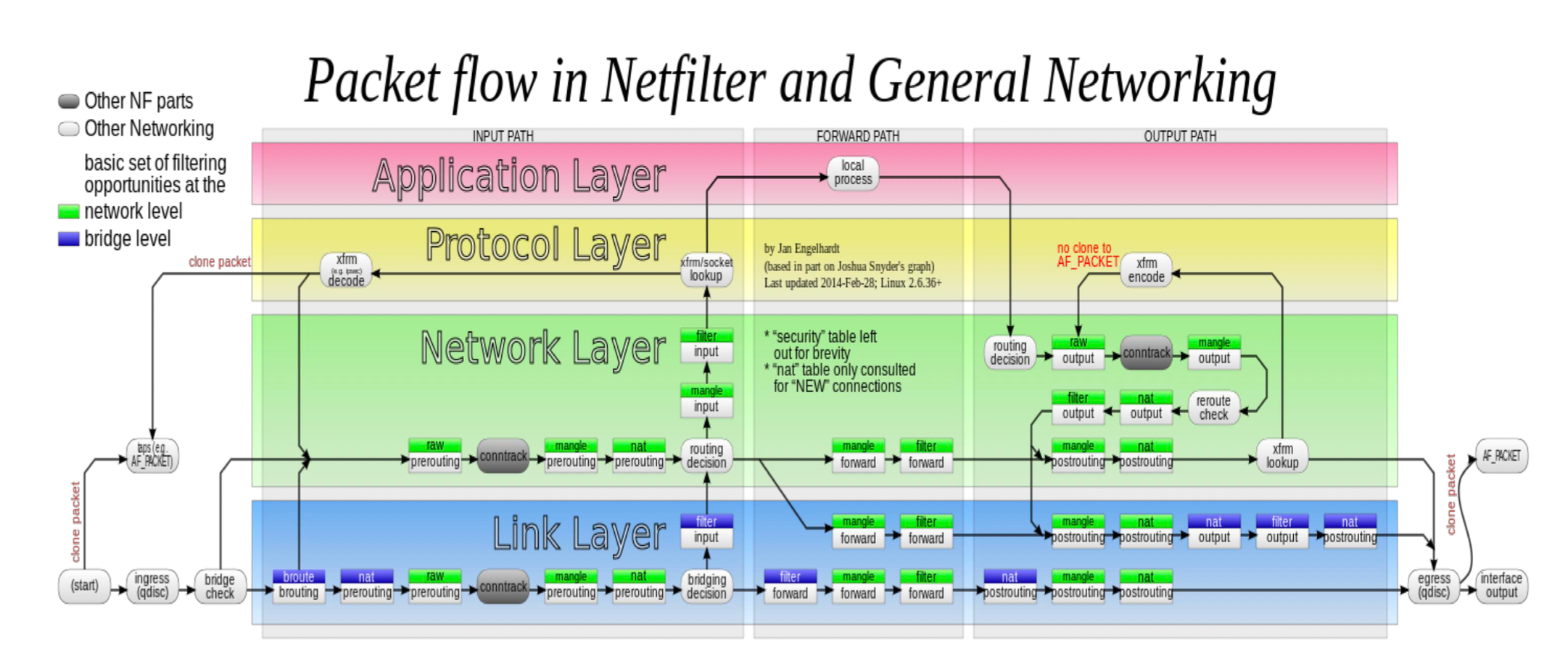
- 数据包在内核中处理会通过很多
hook(图中绿白色),ipatbles通过接口配置这些hook - 内核处理可以在多个层级中实现不同的处理方式,可以在不同层进行过滤、转发,例如
nat在 网络层prerouting时实现
Netfilter 和 iptables

网卡接收到数据包之后,通过硬件中断提醒 CPU
避免每次都有数据包都进入硬中断,影响效率,CPU 通过生产者消费者模型,让
kernel的一个进程ksoftirqd处理软中断,进程在 kernel 中构造数据包buffer,buffer中包含包头和数据信息1
2
3ps -ef | grep -i irq
root 9 2 0 01:24 ? 00:00:02 [ksoftirqd/0]
root 18 2 0 01:24 ? 00:00:03 [ksoftirqd/1]将
buffer交由Netfiler处理,Netfilter读取iptables的规则,判断是否nat以及是否访问本机,如果不是则FORWARD处理
iptables
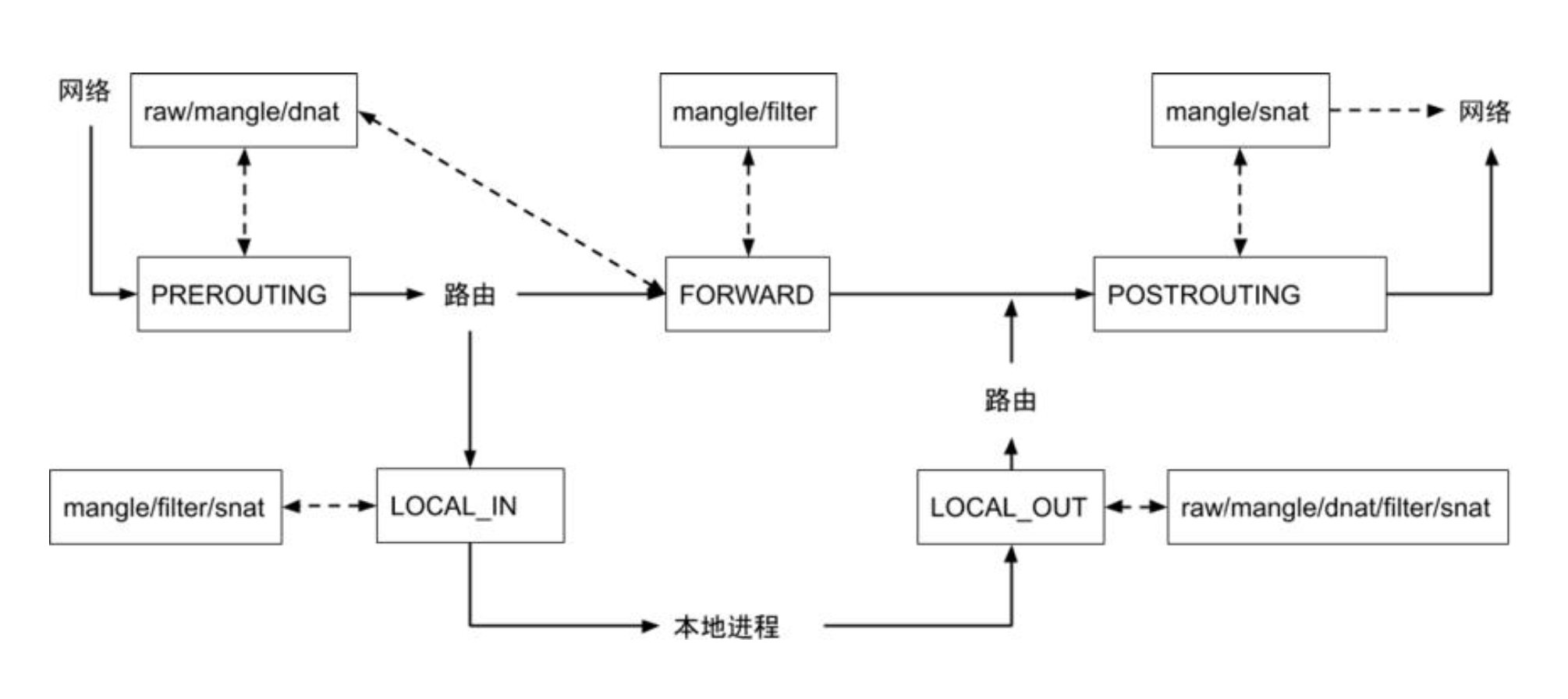
五链(链:chain, 包括 PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING)四表(manager、nat、filter、raw)
- 数据包进来,在 PREROUTING 中可以通过
dnat做转换,dnat是转换目标 IP 和端口 - 通过路由规则判断是访问本机还是访问其他地址
- 如果访问其他地址,则通过 FORWARD 将数据转发出去
- 本地进程可以通过
LOCAL_OUT将请求转发到其他地址,也是通过snat表实现
iptables 支持的锚点
| Table/chain | PREROUTING | INPUT | FORWARD | OUTPUT | POSTROUTING |
|---|---|---|---|---|---|
| raw | 支持 | 支持 | |||
| mangle | 支持 | 支持 | 支持 | 支持 | 支持 |
| dnat | 支持 | 支持 | |||
| filter | 支持 | 支持 | 支持 | ||
| snat | 支持 | 支持 | 支持 |
简单解释:例如上面的 nginx ,在 iptables 中生成的条目
1 | -A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES |
-A代表添加,PREROUTING代表在PREROUTING这个chain中添加一条规则;-m是注释-j是jump,代表跳转到KUBE-SERVICES
也就是出口和入口的流量,都会交给 KUBE-SERVICES 处理
过滤 nginx 的 svc 地址(svc 的地址只会记录在 iptables 里面,不会绑定到任何的网卡上,因此 ping 不会有响应)
1 | -A KUBE-SERVICES -d 10.1.39.38/32 -p tcp -m comment --comment "practice/nginx-basic:http cluster IP" -m tcp --dport 80 -j KUBE-SVC-6QMKDF5V6IOJPWNA |
-d是目标地址-p是协议--dport是目标端口 也是跳转到KUBE-SVC-6QMKDF5V6IOJPWNA
1 | -A KUBE-SVC-6QMKDF5V6IOJPWNA ! -s 10.244.0.0/16 -d 10.1.39.38/32 -p tcp -m comment --comment "practice/nginx-basic:http cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ |
多条规则,会从上到下,匹配到则直接处理。
第一条,当源地址不是 10.244.0.0/16 ,目标地址是 10.1.39.38/32 ,协议是 tcp,目标端口协议是 tcp,端口是 80,则交由 KUBE-MARK-MASQ 这个 chain 处理
第二条,交由 KUBE-SEP-2Q45Q4BWORYFEJSP 处理
1 | -A KUBE-SEP-2Q45Q4BWORYFEJSP -s 10.244.34.94/32 -m comment --comment "practice/nginx-basic:http" -j KUBE-MARK-MASQ |
第一条,如果源是 10.244.34.94/32,交由 KUBE-MARK-MASQ 处理
第二条,如果是 tcp 协议的包,且目标协议是 tcp,则交由 DNAT 处理,转发到目标 10.244.34.94:80 (也就是状态为 ready 的 pod)
如果将 pod 的 readinessProbe 去掉,并且副本数改为 3 个
1 | kubectl get pod -o wide |
iptables-save 查看 iptables
1 | -A KUBE-SVC-6QMKDF5V6IOJPWNA ! -s 10.244.0.0/16 -d 10.1.39.38/32 -p tcp -m comment --comment "practice/nginx-basic:http cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ |
可以看到,转发给 3 个 Pod 的过程其实是通过随机数实现,转发到第一个节点有 33% 的概率,如果没有转发到,则转发到第二个节点的概率是 50%,如果也没有命中,则转发给第三个节点。
可以看到这个负载均衡策略是比较简单的,就是随机轮询。同理,三个 pod 一个 svc 就有很多条数,如果上千个 pod 则每个节点的条目会非常多,在匹配的时候效率也会很慢。因此 iptables 并不适合大规模集群(iptables 本意也不是大规模控制,设计时也没有考虑这种情况),因此后续需要通过 ipvs 来解决这些问题。
kube-proxy 工作原理

每个节点上的 kube-proxy 通过监听 kube-apiserver 的信息,将 ClusterIP 规则、NodePort 规则、LB IP规则添加到 iptables 中(不是增量添加,而是全局覆盖)。
通常来讲,LB 是使用外部 LB 硬件设备,当指定了外部 LB 并且创建了对应 LB 类型的 svc,svc 会带有对应 IP 和 port,通过节点 label 设定规则,外部 LB 设备虽然无法直接访问 ClusterIP,社区解决方案是在 LB 上 nat 之后,流量请求到集群,集群通过 label 将流量转发到对应 node,在 node 上通过 iptables 判断转发到哪个 PodIP。
Kubernetes iptables 规则

iptables 示例
1 | # iptables -L |
IPVS

ipvs 只有三个 hook 点:LOCAL_IN、FORWARD、LOCAL_OUT,因此,当有外部访问 cluster IP(集群中跨主机通信) 时,无法在 PREROUTING 中判断请求是否在本机,需要在路由中处理。
所以,ipvs 会在本机创建一个虚拟网卡,配置相应路由,接收请求,转发到 LOCAL_IN 进行处理。
从 iptables 切换到 ipvs,修改 configmap
1 | # kubectl edit cm kube-proxy -n kube-system |
手动删除 kube-proxy 的 Pod
1 | kubectl delete pod kube-proxy-d9hnp kube-proxy-mkn6x kube-proxy-wmt5w -n kube-system |
更新 iptables 的 nat 表
1 | # iptables -F -t nat |
下载 ipvsadm 名称查看
1 | ipvsadm -L -n |
由于 ipvs 在 POSROUTING 中没有锚点,在 Pod 跨主机通信时,为了让接收者能够回包(也就是接收端有回来的路由),依然需要包伪装,因此需要 iptables 配合使用,通过 ipset 封装数据包
1 | # ipset -L |
通过聚合一些相同类型的 IP、协议、端口,减少 iptables 里面的条目。
端口信息:
1 | 10: kube-ipvs0: <BROADCAST,NOARP> mtu 1500 qdisc noop state DOWN group default |
IPVS 支持的锚点和核心函数
| HOOK | 函数 | 核心函数 | Priority |
|---|---|---|---|
| NF_INET_LOCAL_IN | ip_vs_reply4 | ip_vs_out | NF_IP_PRI_NAT_SRC - 2 |
| NF_INET_LOCAL_IN | ip_vs_remote_request4 | ip_vs_in | NF_IP_PRI_NAT_SRC - 1 |
| NF_INET_LOCAL_OUT | ip_vs_local_reply4 | ip_vs_out | NF_IP_PRI_NAT_DST + 1 |
| NF_INET_LOCAL_OUT | ip_vs_local_request4 | ip_vs_in | NF_IP_PRI_NAT_DST + 2 |
| NF_INET_FORWARD | ip_vs_forward_icmp | ip_vs_in_icmp | 99 |
| NF_INET_FORWARD | Ip_vs_reply4 | ip_vs_out | 100 |
域名服务
- Kubernetes
Service通过虚拟 IP 地址或者节点端口为用户应用提供访问入口 - 然而这些 IP 地址和端口是动态分配的,如果用户重建一个服务,其分配的
clusterIP和nodePort,以及LoadBalancerIP都是会变化的,我们无法把一个可变的入口发布出去供他人访问 - Kubernetes 提供了内置的域名服务,用户定义的服务会自动获得域名,而无论服务重建多少次,只要服务名不可改变,其对应的域名就不会改变
CoreDNS
CoreDNS 包含一个内存态 DNS,以及与其他 controller 类似的控制器
CoreDNS 的实现原理是,控制器监听 Service 和 Endpoint 的变化并配置 DNS,客户端 Pod 在进行域名解析时,从 CoreDNS 中查询服务对应的地址记录
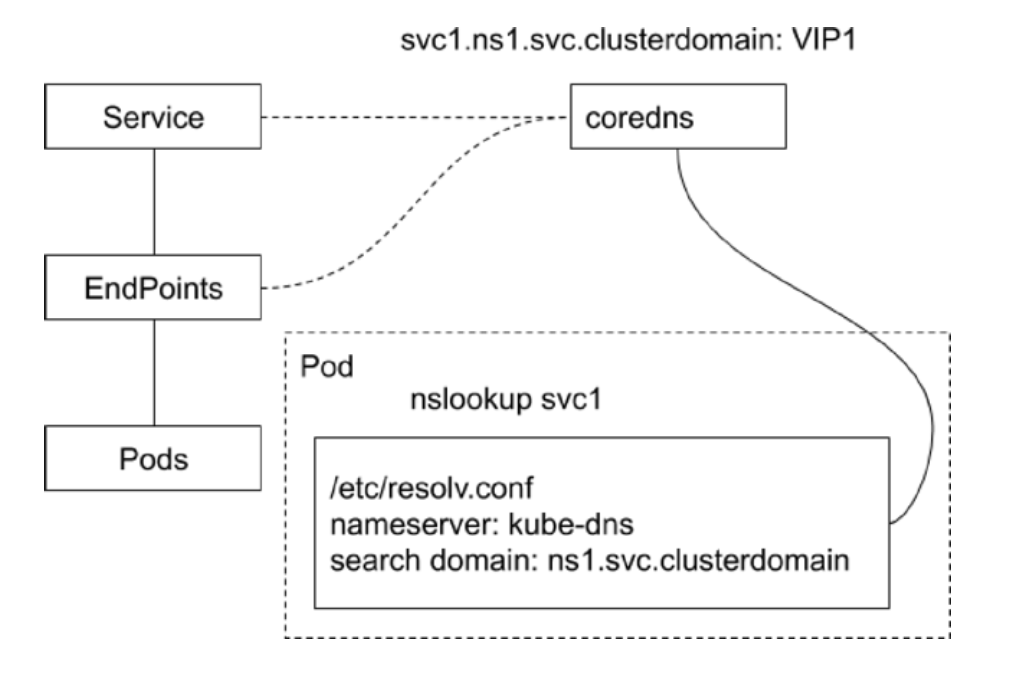
也就是监听 svc 和 endpoint 的变化,将 svc1.ns1.svc.clusterdomain 作为 A 记录写入内存中的 dns 记录中,指向 svc 对应的 ip。
在客户端中,使用 coredns 的方法是在 /etc/resolv.conf 中写入 coredns 的 ip
1 | # cat /etc/resolv.conf |
ndots:5:指的是解析的域名的 . 号的个数,如果小于 5 个,则使用上面 search 作为后缀补充,例如如果解析的是
1 | nginx-basic |
实际会解析
1 | nginx-basic.practice.svc.cluster.local |
如果解析不出来,则会换第二个拼接然后解析
dns 指向的是 coredns 的 svc IP
1 | # kubectl get svc -n kube-system |
当使用 coredns 作为 dns 解析可以解析出来
1 | # kubectl get pod -n kube-system -o wide |
如果需要解析外网,例如 www.baidu.com ,pod 会首先在 coredns 中查询,coredns 中会往上游查询:
1 | # kubectl get cm coredns -n kube-system -o yaml |
不同类型服务的 DNS 记录
- 普通
ServiceClusterIP、NodePort、LoadBalancer类型的Service都拥有API Server分配的ClusterIP,CoreDNS会为这些Service创建FQDN格式为$svcname.$namespace.svc.$clusterdomain: clusterIP的A记录及PTR记录,并为端口创建SRV记录
Headless Service- 顾名思义,无头,是用户在
Spec显式置顶ClusterIP为None的Service,对于这类Service,API Service不会为其分配ClusterIP。CoreDNS为此类Service创建多条A记录,并且目标为每个就绪的PodIP - 另外,每个
Pod会拥有一个FQDN格式为$podname.$svcname.$namespace.svc.$clusterdomain的 A 记录指向PodIP
- 顾名思义,无头,是用户在
ExternalName Service- 此类
Service用来引用一个已经存在的域名,CoreDNS会为该Service创建一个CName记录指向目标域名
- 此类
Kubernetes 中的域名解析
Kubernetes
Pod有一个DNS策略相关的属性DNSPolicy,默认值是ClusterFirst,这个默认值会修改 Pod 的resolv.conf如果是
default,则会使用主机上的resolv.conf如果是
None,则可以使用自己配置的dns1
2
3
4
5
6
7
8
9
10
11spec:
dnsPolicy: "None"
dnsConfig:
nameservers:
- 1.2.3.4
searchs:
- xx.ns1.svc.cluster.local
- xx.daemon.com
options:
- name: ndots
values: "2"Pod 启动后的
/etc/resolv.conf会被改写,所有的地址解析优先发送至CoreDNS
1 | cat /etc/resolv.conf |
- 当 Pod 启动时,同一
Namespace的所有Service都会以环境变量的形式设置到容器内
关于 DNS 的落地实践
Kubernetes 作为企业基础架构的一部分,Kubernetes 服务也需要发布到企业 DNS,需要定制企业 DNS 控制器
- 对于 Kubernetes 中的服务,在企业
DNS同样创建A/PTR/SRV records(通常解析地址是LoadBalancer VIP) - 针对
Headless service,在PodIP可全局路由的前提下,按需创建DNS records Headless service的 DNS 记录,应该按需创建,否则对企业DNS冲击过大
如果使用企业 DNS 全部托管,这种方式会有些问题:
- 虽然
dns服务端可以设置ttl,会影响客户端解析时效性 - 如果
ttl设置为 0 ,那么dns服务端压力会非常大 - 另外客户端也会有
dns缓存,也会影响解析时效性
服务在集群内通过 CoreDNS 寻址,在集群外通过企业 DNS 寻址,服务在集群内外有统一标识。
例如 coredns 的配置
1 | apiVersion: v1 |
Kubernetes 中的负载均衡技术
- 基于
L4的服务:也就是五元组(源IP、源端口、协议、目标IP、目标端口)- 基于
iptables/ipvs的分布式四层负载均衡技术 - 多种
Load Balancer Provider提供与企业现有ELB的整合 kube-proxy基于iptablesrules为 Kubernetes 形成全局统一的distributed load balancerkube-proxy是一种mesh,Internal Client无论通过podip,nodeport还是LBVIP都经由kube-proxy跳转至pod- 属于 Kubernetes
core
- 基于
- 基于
L7的Ingress:应用层级别,例如nginx、envoy- 基于七层应用层,提供更多功能:通过请求的
header TLS termination:安全,将https解密成httpL7 path forwardingURL/http header rewrite- 与采用 7 层软件紧密相关
- 基于七层应用层,提供更多功能:通过请求的
Service 中的 Ingress 的对比
基于
L4的服务- 每个应用独占
ELB,浪费资源 - 为每个服务动态创建
DNS记录,频繁的DNS更新 - 支持
TCP和UDP,业务部门需要启动HTTPS服务,自己管理证书
![image-20240126163710182]()
- 每个应用独占
基于
L7的Ingress- 多个应用共享
ELB,节省资源 - 多个应用共享一个
Domain,可采用静态DNS配置 TLS termination发生在Ingress层,可集中管理证书- 更多复杂性,更多的网络
hop
![image-20240126163807240]()
- 多个应用共享

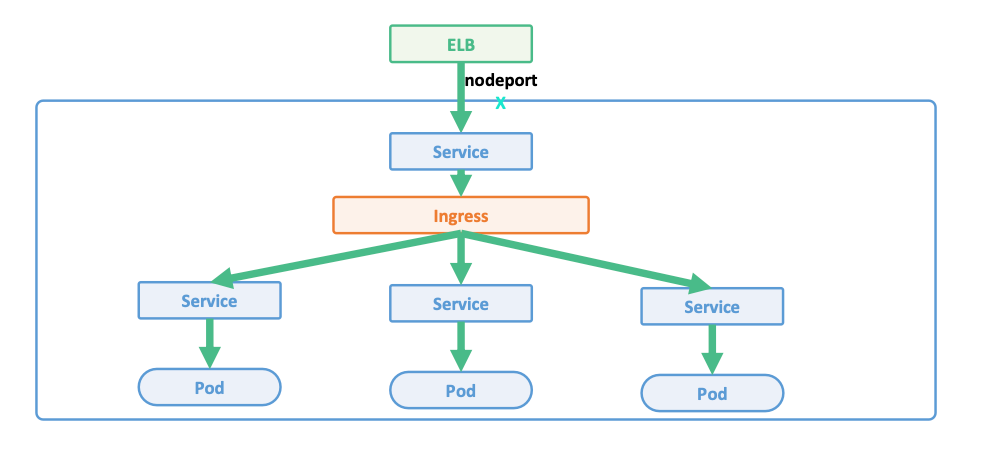
Ingress
安装部署:https://kubernetes.github.io/ingress-nginx/deploy/
1 | wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.8.2/deploy/static/provider/cloud/deploy.yaml |
由于 registry.k8s.io 镜像拉不下来,因此需要将 yaml 下载下来,修改其中镜像地址,然后再部署
1 | image: registry.aliyuncs.com/google_containers/nginx-ingress-controller:v1.8.1 |
1 | kubectl get pod -n ingress-nginx |
切换默认 ns 为 ingress-nginx
1 | # kubectl exec -it ingress-nginx-controller-88b784f6-s86db ps aux |
其中 ingress-nginx-controller 有两个进程,一个是 controller,检测 ingress 配置变化,一个是 nginx,转发流量
1 | kubectl get svc |
默认创建一个LoadBalancer 类型的 svc ,提供给外部访问,对外提供的统一入口是 31994
1 | # kubectl get svc ingress-nginx-controller -o yaml |
创建证书
如果需要通过 IP 访问而不是域名,需要将 DNS 设置为 *
1 | openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=xiaoyeshiyu.com/O=xiaoyeshiyu" -addext "subjectAltName = DNS:xiaoyeshiyu.com" |
通过证书,创建 secret
1 | kubectl create secret tls xiaoyeshiyu-tls --cert=./tls.crt --key=./tls.key |
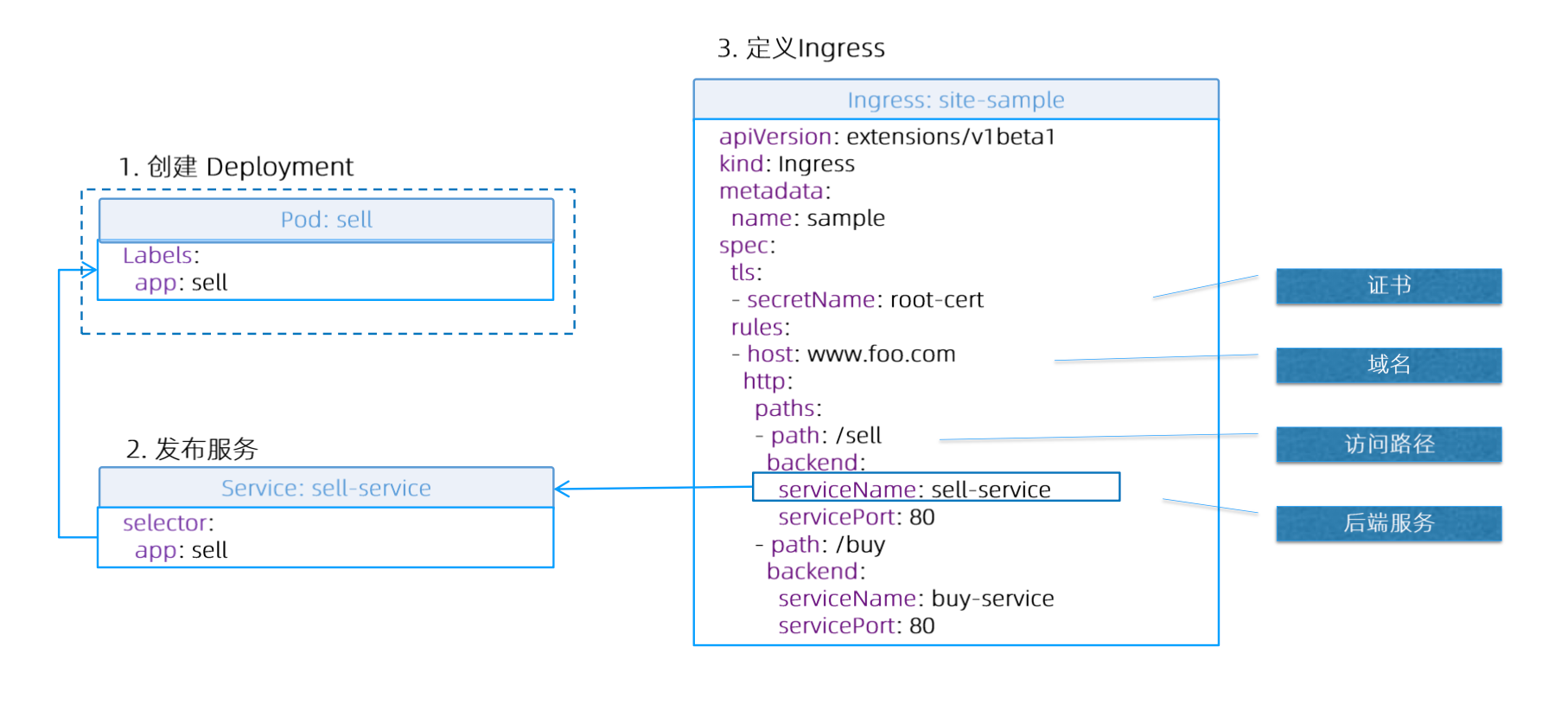
创建 ingress 对象,要指定为要转发出去的 svc 的 ns
1 | # cat ingress.yaml |
创建 Ingress
1 | # kubectl create -f ingress.yaml |
查看对象
1 | # kubectl get ingresses.networking.k8s.io |
访问
1 | # curl -H "Host: xiaoyeshiyu.com" https://192.168.239.128:31495 -v -k |
IngressIngress是一层代理- 负责根据
hostname和path将流量转发到不同的服务上,使得一个负载均衡器用于多个后台应用 - Kubernetes
IngressSpec是转发规则的集合
Ingress Controller- 确保实际状态(
Actual)与期望状态(Desired)一致的ControlLoop Ingress Controller确保- 负载均衡配置
- 边缘路由配置
- DNS 配置
- 确保实际状态(
ingress 的局限性:
tls:版本、加密方式- 无法通过
http的header做区分 - 无法改写
http的header、URL
对于这些附加功能,在 ingress 的 spec 已经完善确定的情况下,会加在 annotation 里面,实现一些简单的功能
1 | Name Description Values |
但是即使 annotation 里面实现了一些功能,依然无法具备 L7 下所有的能力,因此社区提供 service-api 的一堆模型,以及其他扩展的项目,例如数据层面的 envoy 和更加推荐的 Istio
传统应用网络拓扑
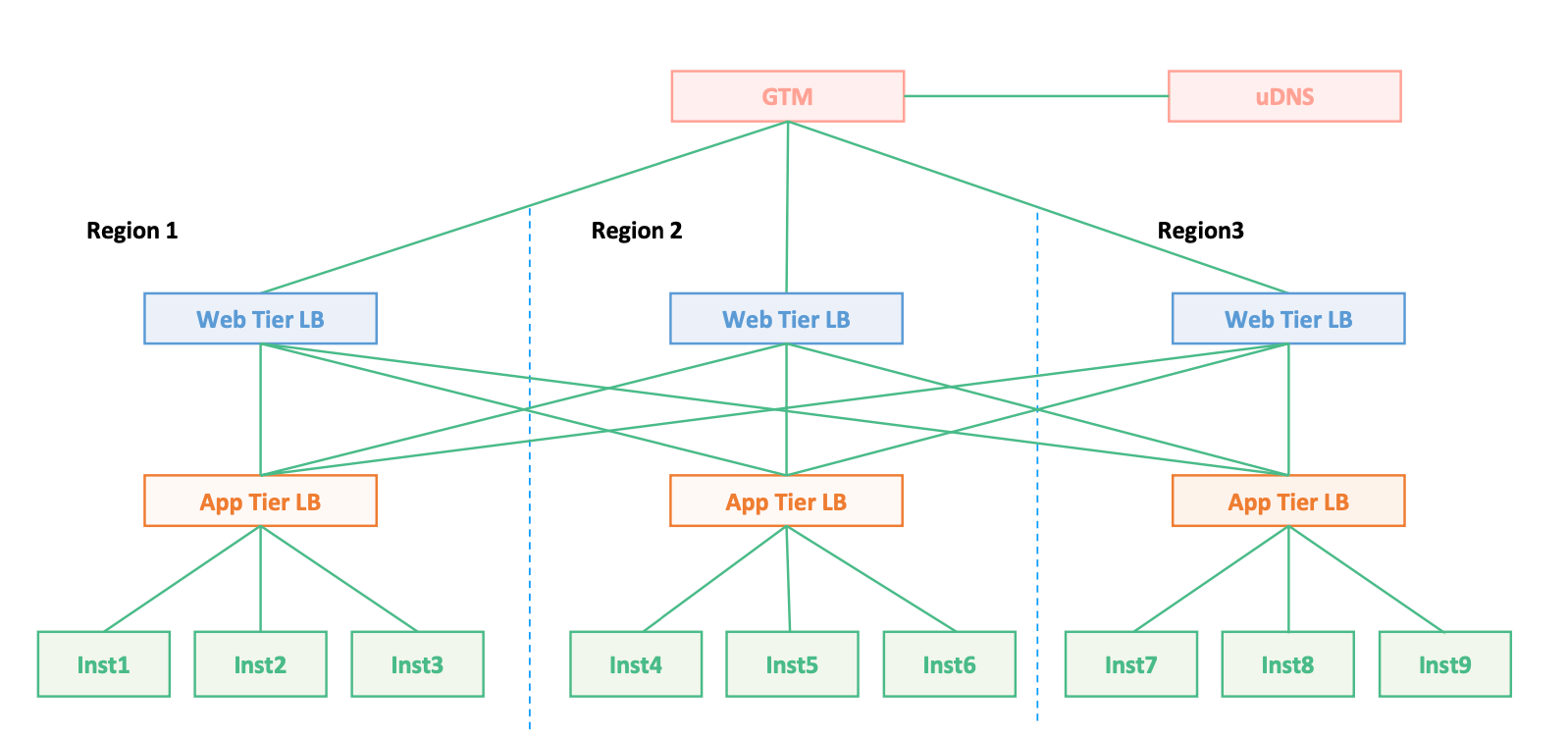
一般的架构模式是 3 个实例(如果一个卡在发布,这时坏了一个,还有一个可以正常工作),为了实现高可用,在本区域通过 APP Tier LB 实现高可用。
这种情况下,如果通过 dns 做转发,当区域级别异常时,可能由于 DNS 有缓存,继续将流量转发到异常节点。此时可以在区域内加一层 Web Tier LB,正常情况下将 99% 的流量转发到本机房,1% 的流量转发到其他区域机房。当机房故障,则将所有流量均分到另外两个区域,实现故障瞬间恢复。
三步构建 Ingress Controller
针对不同的业务场景,构建符合业务的 Ingress Controller
复用 Kubernetes
LoadBalancer接口staging/src/k8s.io/cloud-provider/cloud.go1
2
3
4
5
6
7type LoadBalancer interface {
GetLoadBalancer(ctx context.Context, clusterName string, service *v1.Service) (status *v1.LoadBalancerStatus, exists bool, err error)
GetLoadBalancerName(ctx context.Context, clusterName string, service *v1.Service) string
EnsureLoadBalancer(ctx context.Context, clusterName string, service *v1.Service, nodes []*v1.Node) (*v1.LoadBalancerStatus, error)
UpdateLoadBalancer(ctx context.Context, clusterName string, service *v1.Service, nodes []*v1.Node) error
EnsureLoadBalancerDeleted(ctx context.Context, clusterName string, service *v1.Service) error
}定义
Informer,监控ingress,secret,service,endpoint的变化,加入相应的队列:生产者![image-20240126164536689]()
启动
worker,遍历ingress队列:消费者- 为
Ingress Domain创建LoadBalancer service,依赖service controller创建ingress vip - 为
Ingress Domain创建DNS A record并指向Ingress VIP - 更新
Ingress状态
- 为

为什么需要构建 SLB 方案
- 成本
- 硬件
LB价格昂贵 - 固定的
tech refresh周期
- 硬件
- 配置管理
LB设置的onboard/offboard由不同team管理- 不同设备
API不一样,不支持L7 API - 基于传统的
ssh接口,效率低下 Flexup/down以及Migration复杂
- 部署模式
- 1 + 1 模式
- 隔离性差
ebay案例分享
亟待解决的问题
- 负载均衡配置
- 7 层方案(选型之后,实现
ingress controller)Envoyvs.Nginxvs.Haproxy
- 4 层方案(使用
nat则改包头,使用tunnel则加包头)- 抛弃传统
HLB的支持,用IPVS取代
- 抛弃传统
- 7 层方案(选型之后,实现
- 边缘路由配置(提供四层 LB,将本机的路由发布出去)
IngressVIP 通过BGP协议发布给TOR
- DNS 配置(一台节点上有非常多的域名)
IngressVIP 通过BGP协议发布给TOR
需要解决问题:如何让 domain 用户自定义后台应用的访问地址,如何优化访问路径
L4 Provicer:Citrix NetScaler
IPVS插件:- 基于
IPAM分配VIP - 将
VIP绑定至IPVS Directors - 创建
IP tunnel - 通过
BGP发布VIP路由
- 基于
L7 Provider:
envoy- 基于
Envoy提供L7 Path forwarding - 可以提供
TLS Termination - 基于
upstream的Istio实现配置管理和热加载 - 基于
Istio实现Service Mesh
- 基于
DNS Provider:DNS
- 创建 DNS 记录
- 为多个
cluster的ingressVIP 生成相同的 DNS 记录实现 DNS 联邦
Ingress Controller:
Ingress- 编排控制器
- 为
Ingress创建service object,将LB配置委派给service controller - 创建
configmap为每个ingress创建envoy配置 - 创建 L7
pod的deployment加载envoy集群 - 生成 DNS 记录
L4 集群架构
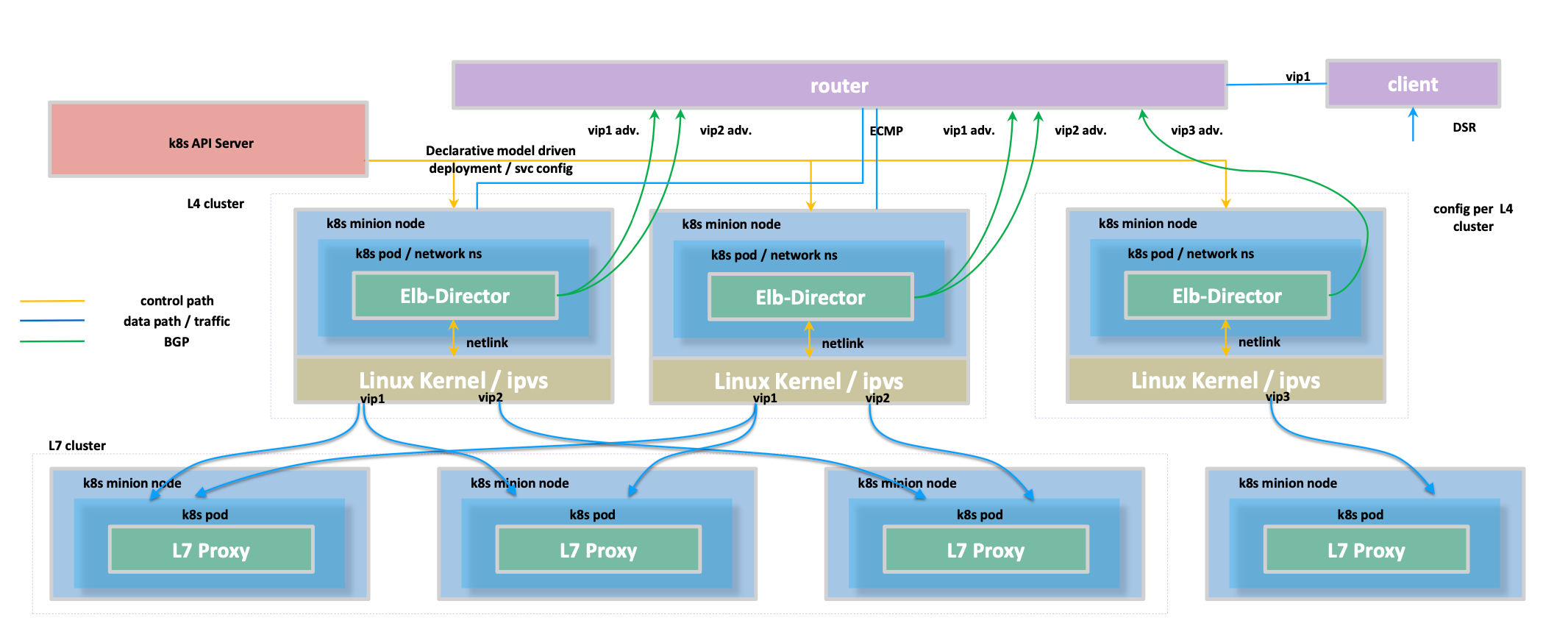
四层 Elb-Director 在集群的某几个特殊节点上,这几个 ELB 节点通过 BGP 与外部路由器宣告本地路由,外部路由器通过路由指向以及路由条目上的条数判断优先转发。
ELB 上的 IP 是虚拟 IP,使用 tunnel 将 IP 进行封装,IP-in-IP ,ELB 上获取数据包之后,将虚拟 IP 转换成底层 Pod IP,转发到 L7 LB。
ELB 上主要用于数据包告诉转发以及负载均衡,主要使用 Linux Kernel 进行封包,使用 ipvs 实现负载均衡。
L7 集群架构

L7 Porxy 将流量分发给后面的 Pod,会用到一些长连接,拆出请求,获得响应之后封装发给上层。
数据流

三层路由转发,通过外部封装一层源地址和目标地址,实现可路由转发。
跨大陆的互联网调用

边缘加速:使用场景是跨大陆访问,例如用户端到核心机房,TCP 三次握手以及墙的问题会往往会导致访问超时。使用 CDN 加速可以将一些静态资源推送到全球范围的 CDN,用户在使用时通过域名解析解析到到就近 CDN 机房,而不需要请求到数据中心机房。
互联网路径的不确定性
使用 CDN 就是为了解决互联网路径的不确定性。例如加拿大的两个城市访问美国的路径可能不是同一条。
玻斯到美国

墨尔本到美国

一般可以通过统计用户活跃度,将用户集中划分到区域,在某个区域里面部署一套边缘节点,用于加速。
边缘加速方案综述
- 在全球业务需求较大的城市创建边缘数据中心
- 2017 年在建阿姆斯特丹,悉尼等 8 个城市
- 迷你型数据中心,每个 site 15 台服务器
- 在边缘数据中心搭建 Kubernetes 集群
- 部署纯软件的
ingress组件- 启动
Ingress Controller完成Ingress配置 IPVS负责VIP绑定,4 层负载均衡以及一致性哈希Envoy把TLS terminate在边缘节点,并提供L7路由转发BGP协议将VIP发布给路由器
- 启动
- 规划
Ingress规则- 手工创建
endpoint指向数据中心的应用 - 创建
Ingress并指向endpoint对应的service
- 手工创建
边缘加速组件

用户先通过域名解析到就近边缘节点,在边缘节点上有一些缓存,存储静态文件,同时通过 L7 Terminator 将 HTTPS 的请求转成明文。
在边缘节点和 CDN 之间有专线 MTBB,流量更加稳定和安全。
对网络路径的优化
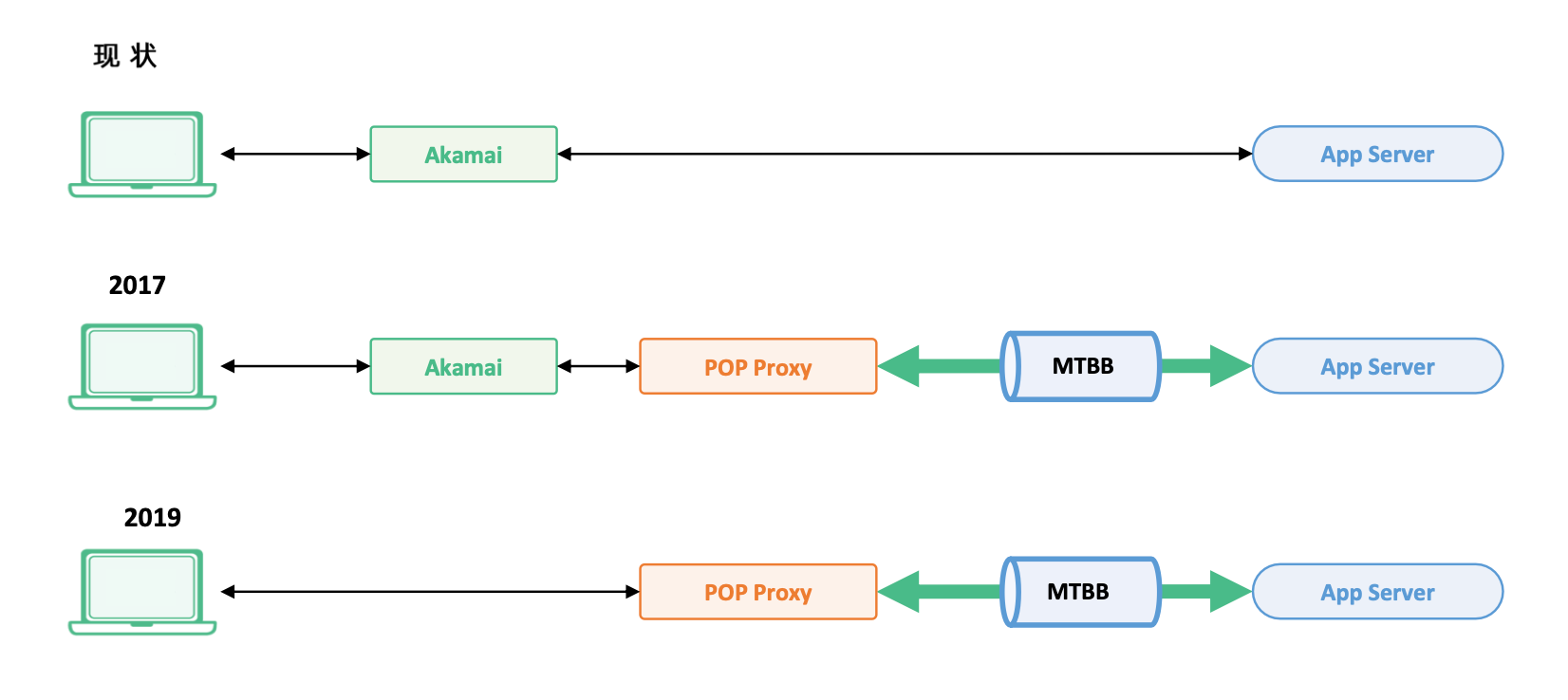
优化路径:
- 通过 CDN 服务提供商到数据中心;
- CDN 访问边缘节点,边缘节点通过专线与数据中心通信;
- 去掉 CDN 服务提供商,通过边缘节点与用户直接接入;(还需要一些安全加固,例如
DDoS)
不同方案的响应时间对比
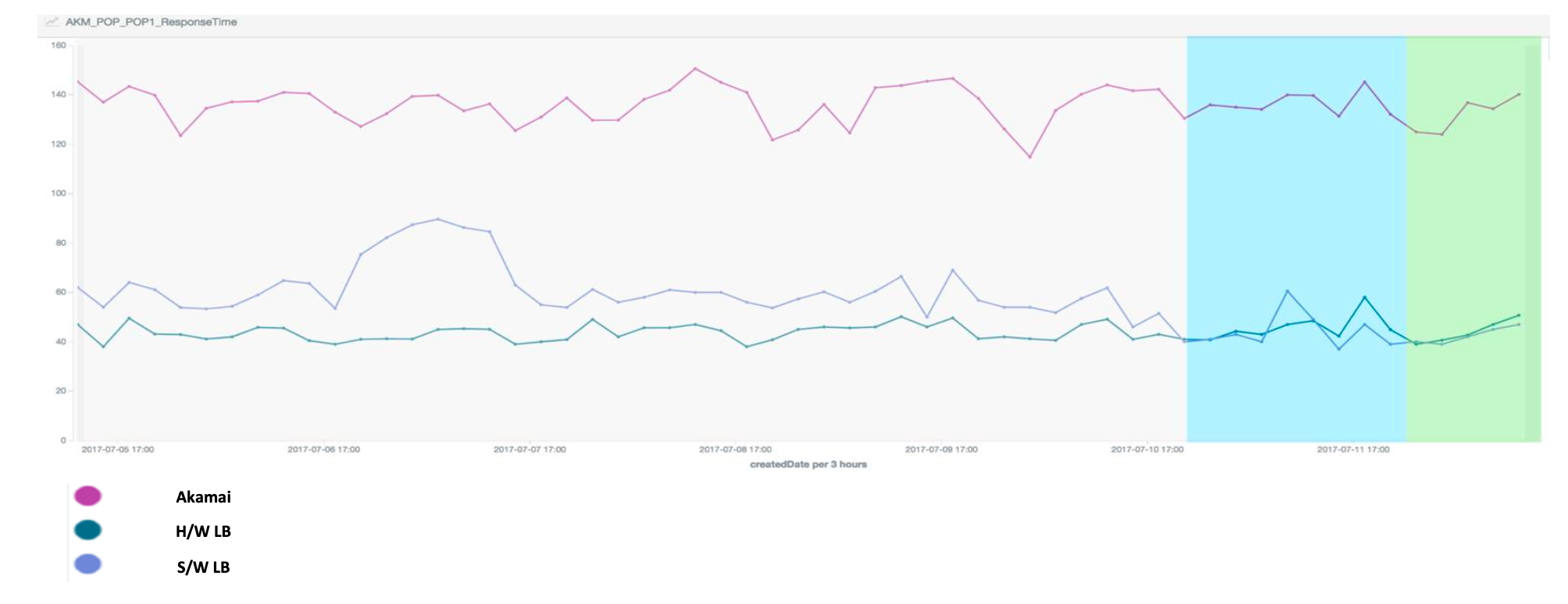
通过方案转换,访问速度提高 100ms。
Reference
Enterprise-Class Availability, Security, and Visibility for Apps