Go的concurrency之goroutine
进程和线程
进程和线程的区别对于理解Goroutine很重要。
操作系统会为该应用程序创建一个进程。
- 作为一个应用程序,它像一个为所有资源而运行的容器。这些资源包括内存地址空间、文件句柄、设备和线程。
线程是操作系统调度的一种执行路径,用于在处理器上执行在函数中编写的代码。
- 一个进程从一个线程开始,即主线程,当该线程终止时,进程终止,这是由于主线程是应用程序的原点
- 然后,主线程可以依次启动更多的线程,而这些线程可以启动更多的线程
无论线程属于哪个进程,操作系统都会安排线程在可用处理器上运行。每个操作系统都有自己的算法来做出这些决定。
并发和并行
Go语言层面支持的go关键字,可以快速的让一个函数创建为goroutine,可以认为main函数就是作为goroutine执行的。
操作系统调度线程在可用处理器上运行,Go运行时调度goroutines在绑定到单个操作系统线程的逻辑处理器中运行(P)。
即使使用这个单一的逻辑处理器和操作系统线程,也可以调度数十万goroutine以惊人的效率和性能并发运行。
Concurrency is not Parallelism.
并发不是并行。
并行是指两个或多个线程,同时在不同的处理器上执行代码。如果将运行时配置为使用多个逻辑处理器(CPU core),则调度程序将在这些逻辑处理器之间分配 goroutine,这将导致 goroutine在不同的操作系统线程上运行。
但是,要获得真正的并行性,需要在具有多个物理处理器的计算机上运行程序。
否则,goroutine将针对单个物理处理器并发运行,即使 Go 运行时,使用多个逻辑处理器。
例如:
案例1
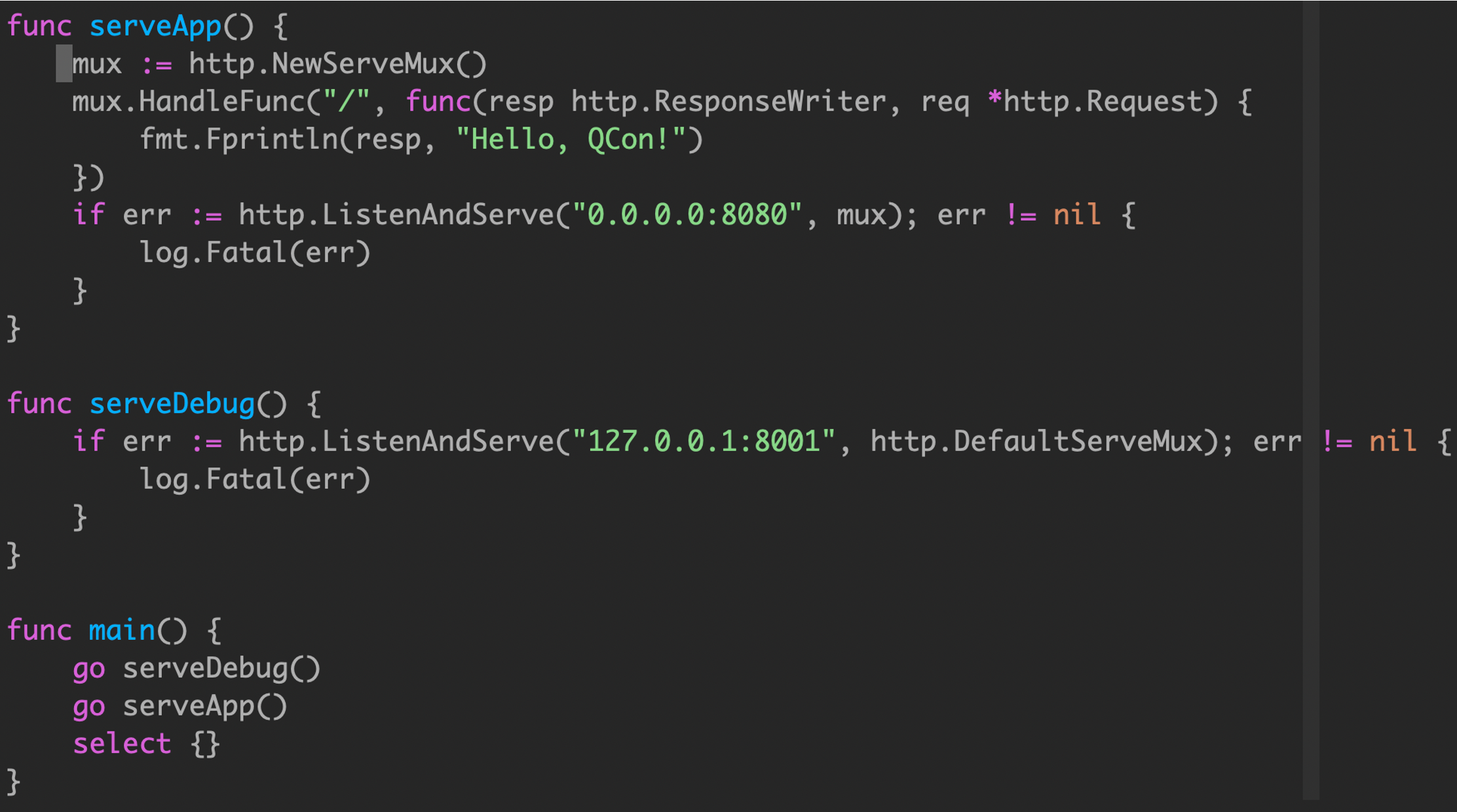
开启 HTTP 服务,通过监听某个接口实现访问。
示例1
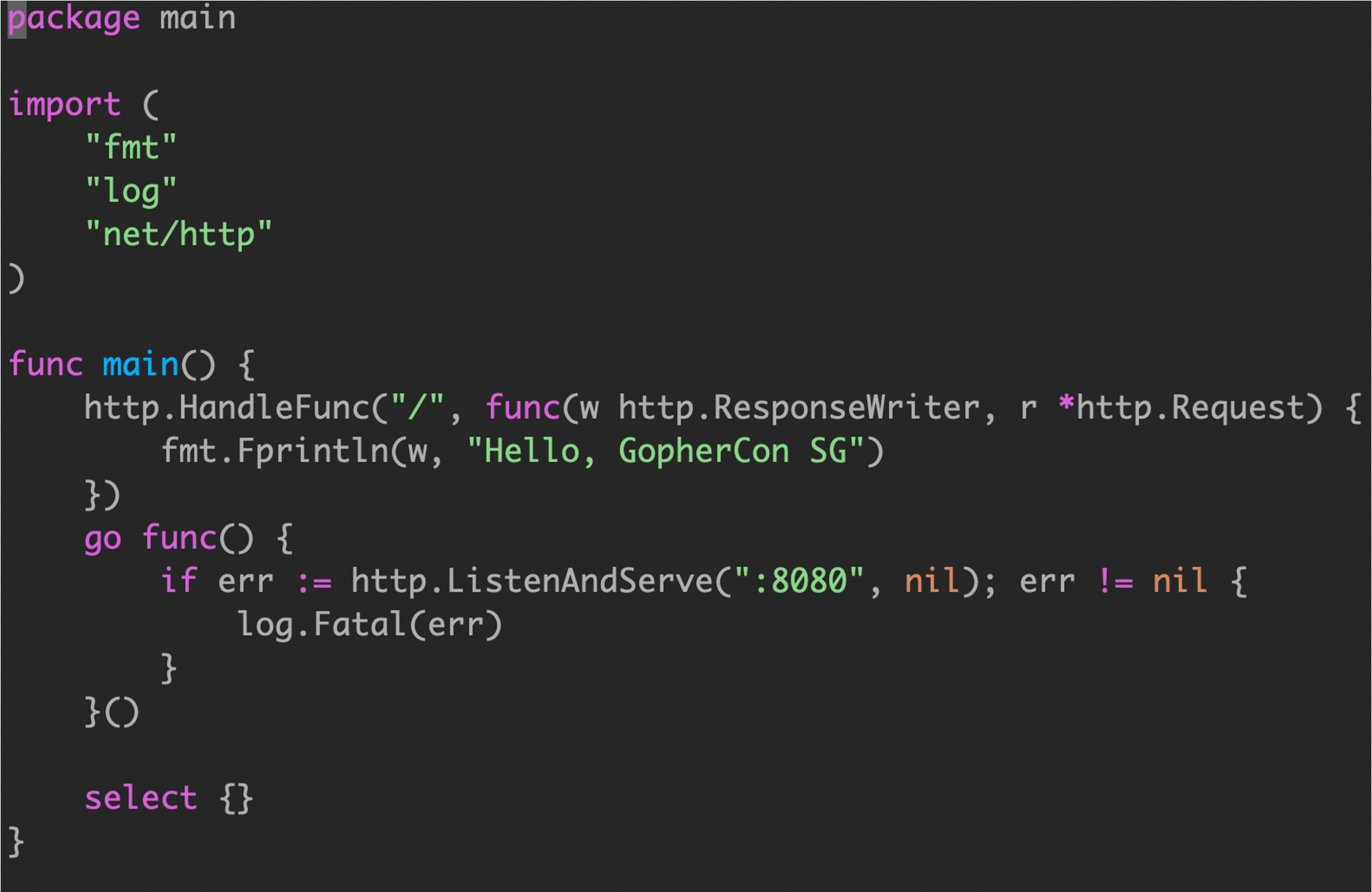
空 select 语句将永远阻塞。
通过关键字 go启动一个HTTP服务。
但是上述代码有一个问题:如果 HTTP 服务异常,协程退出,但是 main 函数不会退出。
如果你的 goroutine 在从另一个 goroutine 获得结果之前,无法取得进展,那么通常情况下,你自己去做这项工作,比委派它(go func())更简单。
者通常消除了将结果从 goroutine 返回到其启动器所需的大量状态跟踪和 chan 操作。
示例2
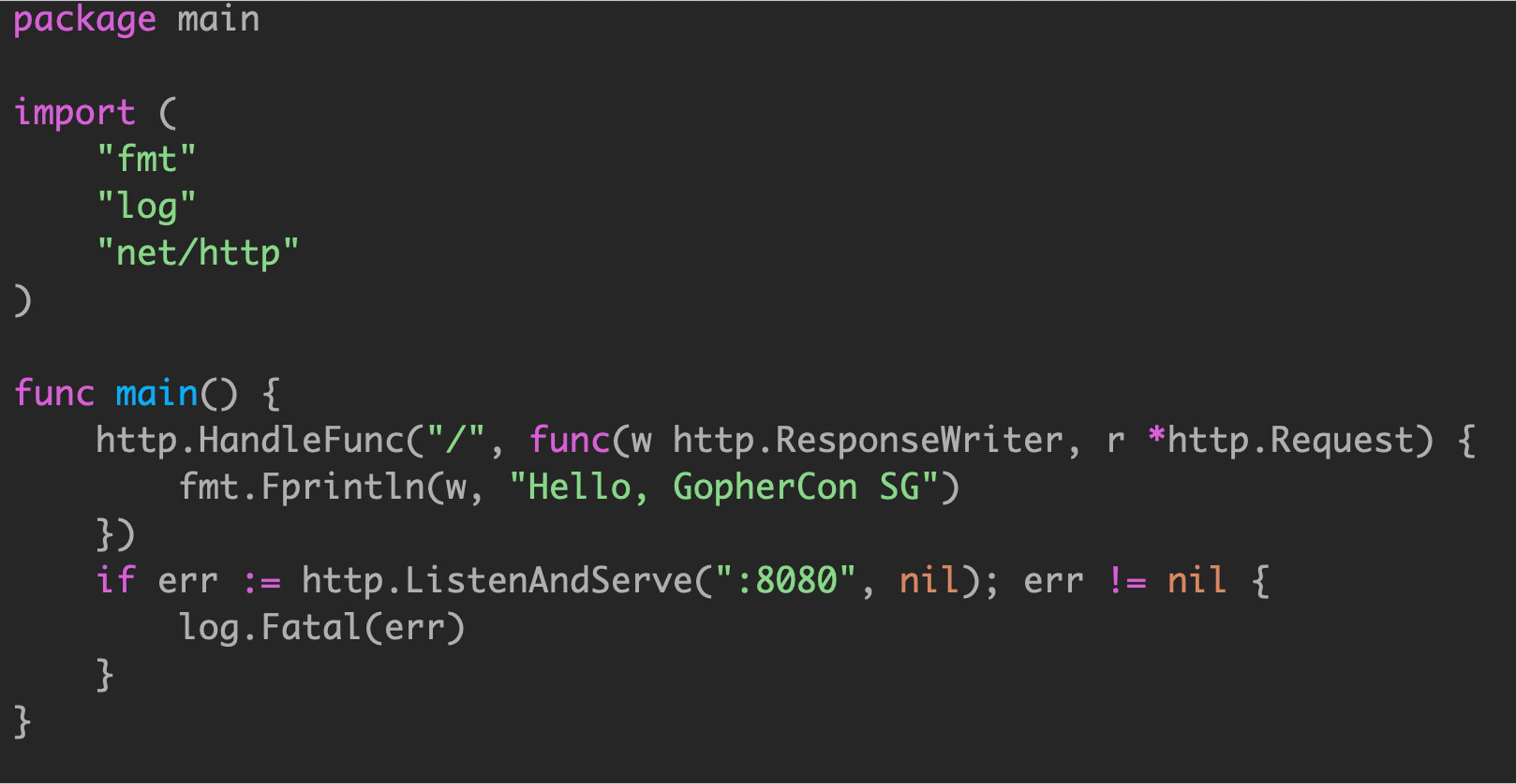
但是实际情况下,main函数不一定只会有一个goroutine需要阻塞,例如 main中需要监听多个端口。
示例3
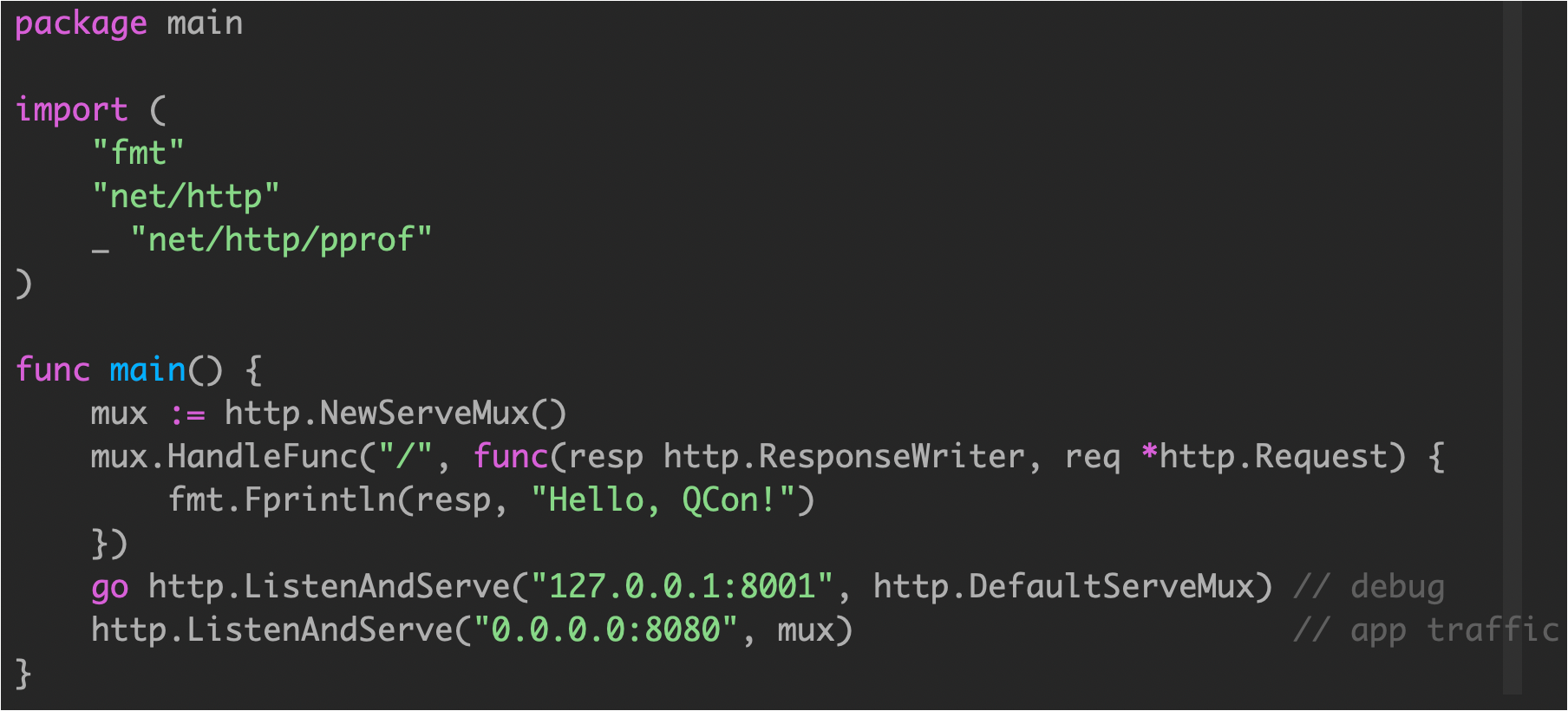
在 8080 端口处理通常的 HTTP 请求,8001 端口用于访问 /debug/pprof 端点。
这种启动方式跟例子1一样,都无法获取 goroutine 状态。
Never start a goroutine without knowning when it will stop
如果不知道 goroutine 什么时候结束,那么就不应该启动这个 goroutine。
示例4
将案例3进行优化。通过将 serverApp 和 serveDebug 处理程序分解为各自的函数,将它们与 main.main 解耦,而且遵循上面的建议,并确保 serveApp 和 serveDebug 将它们的并发性留给调用者。
如果 serveApp 返回,则 main.main 将返回导致程序关闭,只能靠类似 supervisor 进程管理来重新启动。
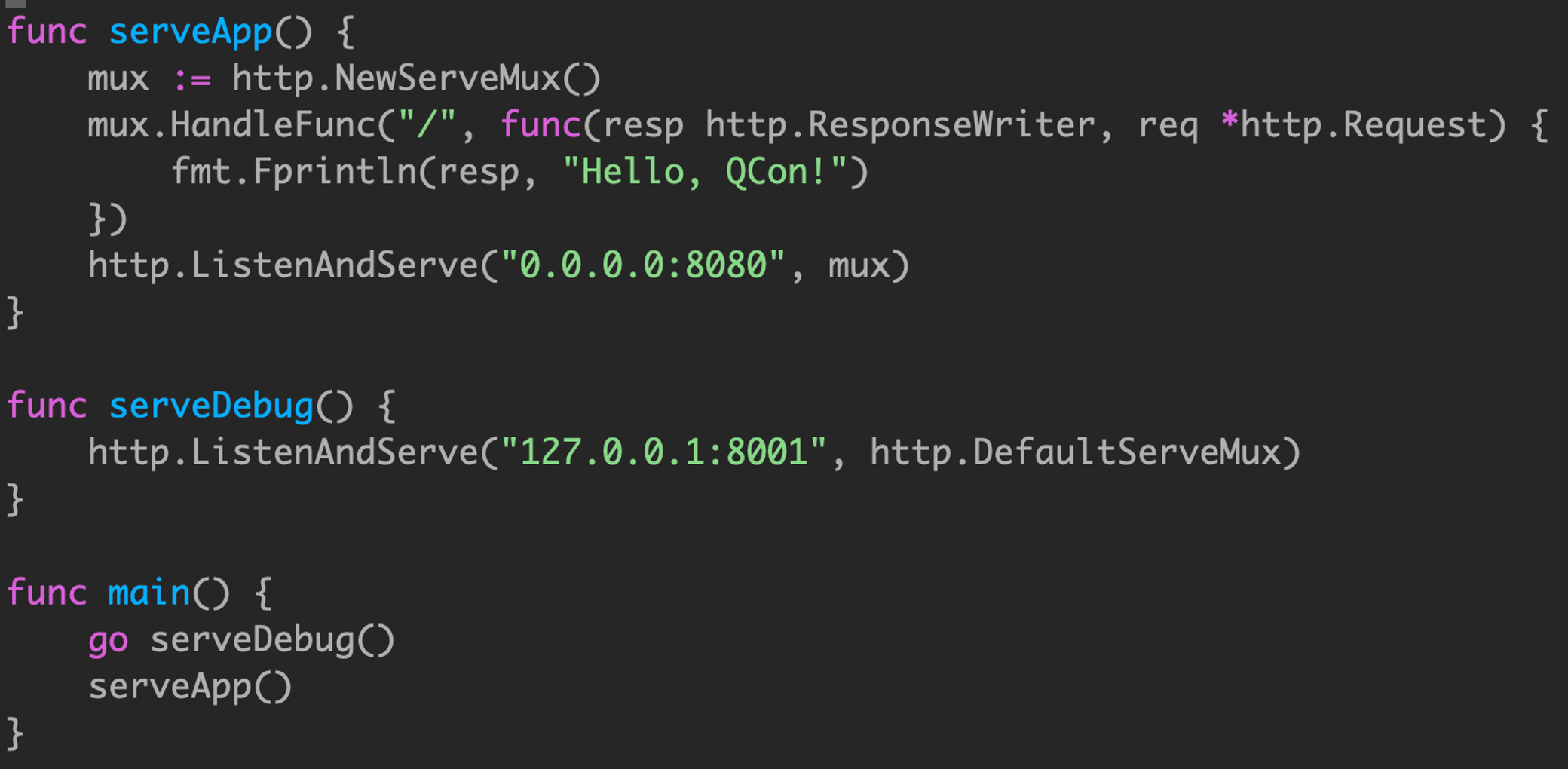
然而,serveDebug 是在一个单独的 goroutine 中运行的,如果它返回,那么所在的 goroutine 将退出,而程序的其余部分继续运行。由于 /debug 处理程序很久以前就停止工作,所以其他调用者会很不高兴地发现他们无法在需要时从应用程序中获取统计信息。
并且需要注意,这种 busy work 应该是自身执行,而不是在内部实现 go func(),并且阻塞。外部如果调用,除非看代码,不然无法感知到阻塞状态。
ListenAndServer 返回 nil error,最终 main.main无法退出
log.Fatal 调用了 os.Exit,会无条件终止程序;defer 不会被调用。
log.Fatal只能在main.main中或者init函数中使用。
示例5
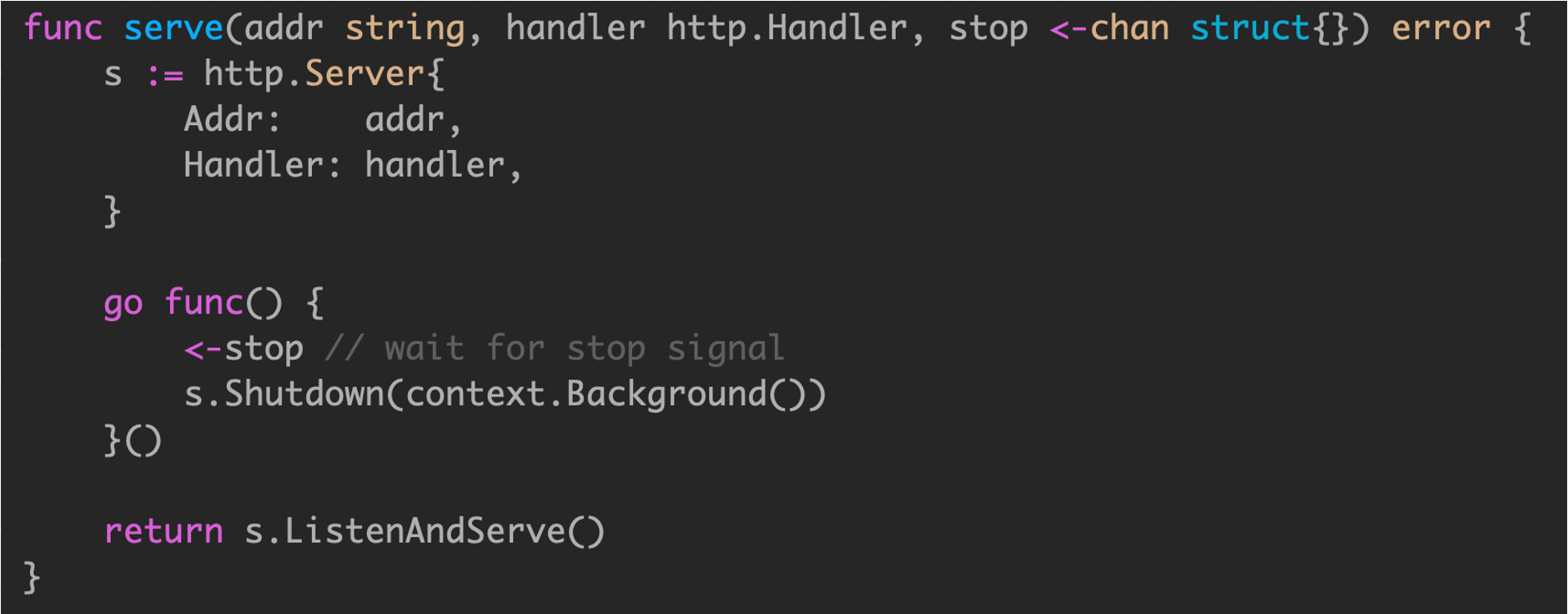
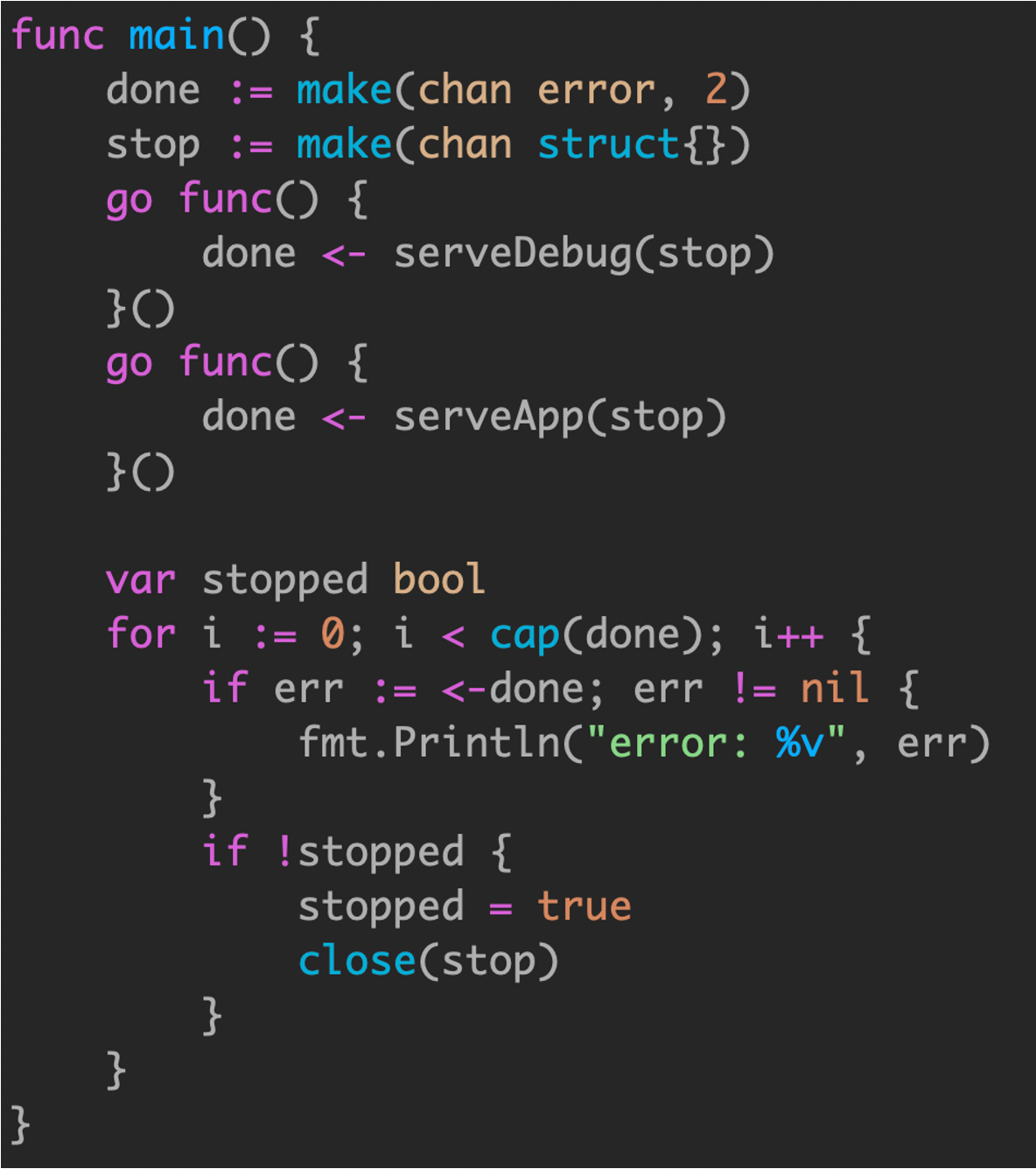
通过 channel 实现服务状态监控,并且安全退出。
https://github.com/da440dil/go-workgroup
案例2
把并行交给调用者
获取大量数据,是否一次性返回。
示例1
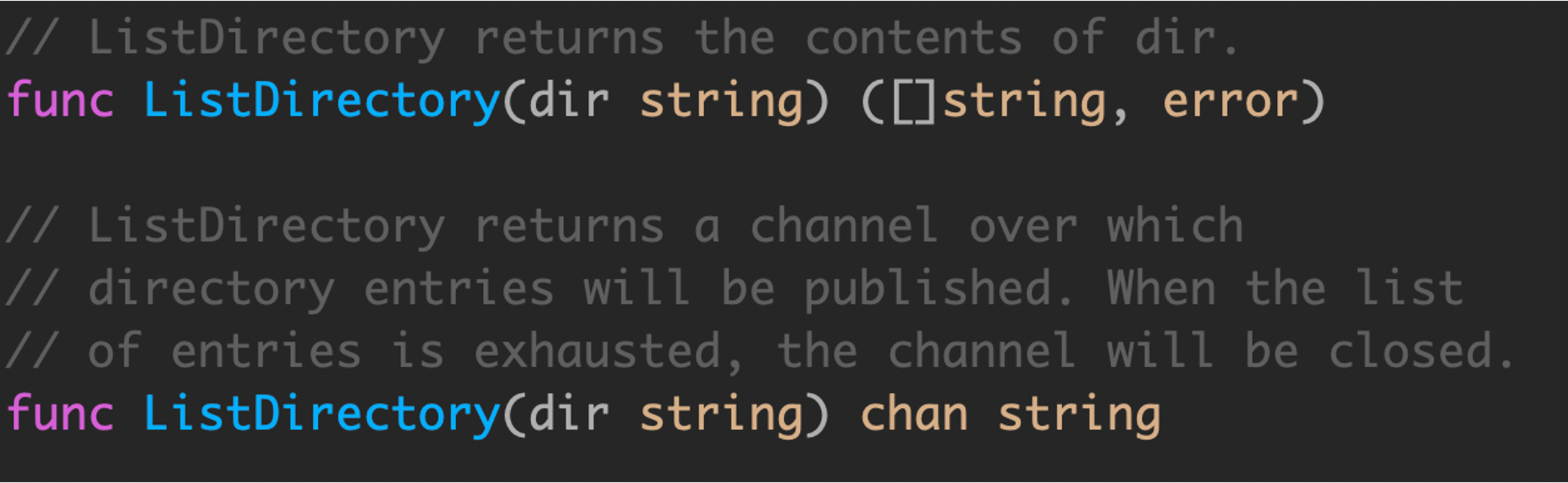
- 将目录赌气到一个
slice中,然后返回整个切片,如果出现错误,则返回错误。这是同步调用的,ListDirectory的调用方会阻塞,直到读取所有目录条目。根据目录大小,这可能需要很长时间,并且可能会分配大量内存来构建目录条目名称的slice。 ListDirectory返回一个chan string,将通过该chan传递目录。当通道关闭时,表示不再有目录。(可以通过range知道channel是否关闭,或者通过第二个值ok判断channel是否关闭。)由于在ListDirectory返回后发生通道的填充,ListDirectory可能内部启动goroutine来填充通道。
ListDirectory chan 版本还有两个问题:
- 通过使用一个关闭的
chan作为不再需要处理的项目的信号,ListDirectory无法告诉调用者通过chan返回的项目集不完整,因为中途遇到了错误。调用方无法区分空目录于完全从目录读取的错误之间的区别。这两种方法都会导致从ListDirectory返回的通道会立即关闭。 - 调用者必须继续从通道读取,直到它关闭。(例如已经获取到需要的目录,后面已经不需要,如果不消费完,生产者会堵住,可能导致
chan泄露。)因为这是调用者直到开始填充通道的goroutine已经停止的唯一方法。这对ListDirectory的使用是一个严重的限制,调用者必须花时间从通道读取数据,即使它可能收到了它想要的答案。对于大中型目录,它可能在内存使用方面更为高效,但这种方法并不比原始的基于slice的方法快。
示例2
使用函数式编程解决这个问题

filepath.WalkDir也是类似的模型。如果函数启动 goroutine ,则必须向调用方提供显示停止该 goroutine 的方法。通常,将异步执行函数的决定权交给该函数的调用方更容易。
go1.19.6/src/path/filepath/path.go
1 | func WalkDir(root string, fn fs.WalkDirFunc) error { |
/go1.19.6/src/os/os_test.go
1 | if err := filepath.WalkDir("./testdata/dirfs", func(path string, d fs.DirEntry, err error) error { |
案例3
在启用 goroutine 时,一定要注意生命周期,避免 goroutine 泄露。
示例1
在下面的例子中,goroutine 泄露可以在 code review 快速识别出来。不幸的是,生产代码中的 goroutine 泄露通常很难找到。
比如下面的代码:
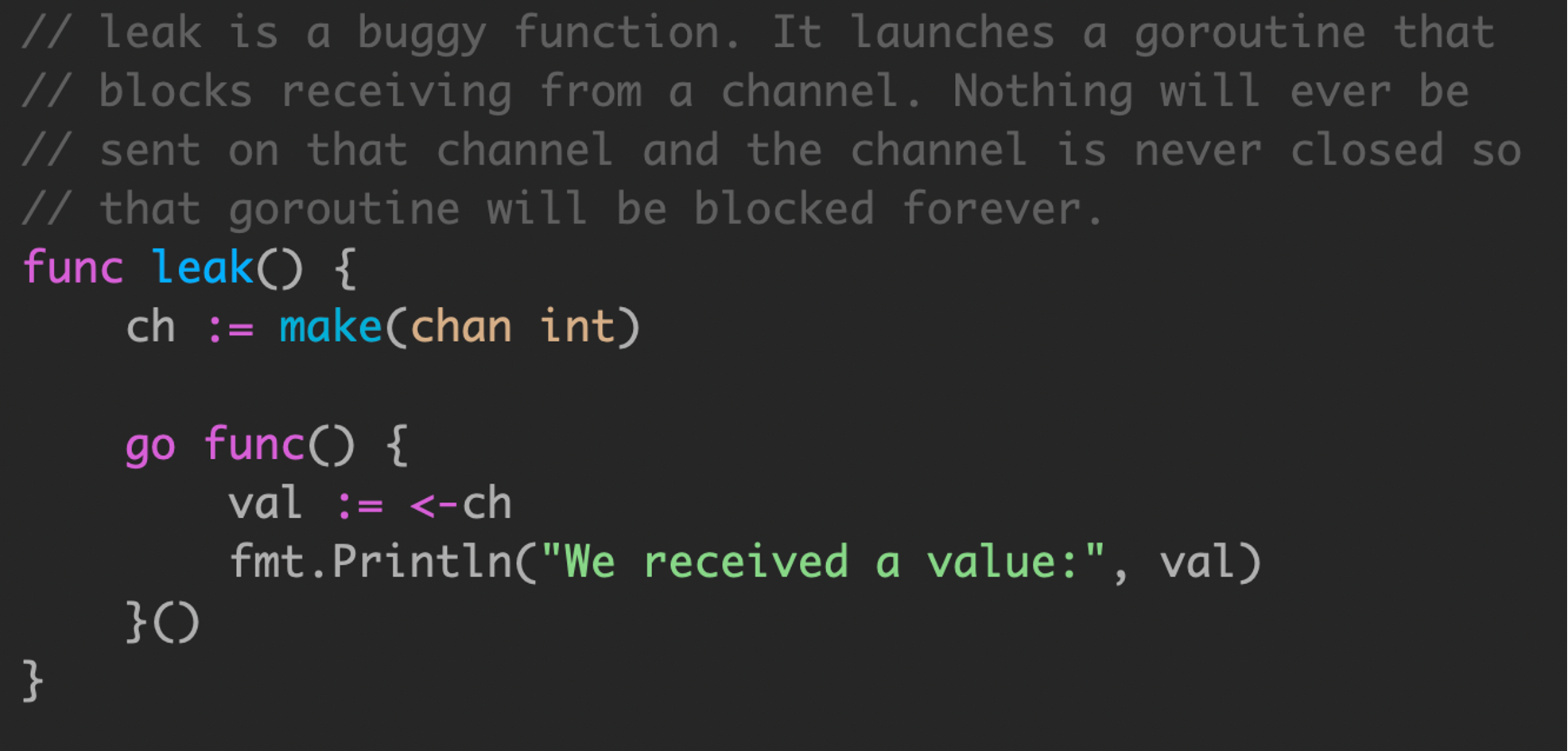
由于 ch 是一个局部变量,不会有其他的调用者往 ch 中发送数据,因此 go func() 中的内容永远不会执行到,这会产生 channel 泄漏。
示例2
协程的执行需要注意是否能控制结束,例如
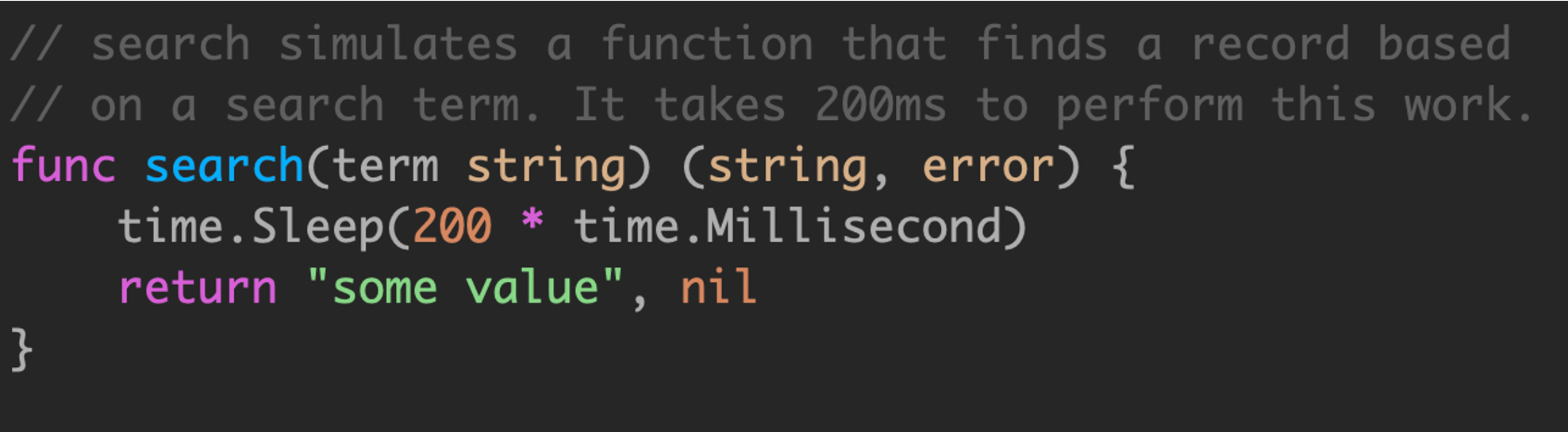
search 函数是一个模拟实现,模拟长时间运行的操作,例如数据库大数据量查询或者 rpc 调用。
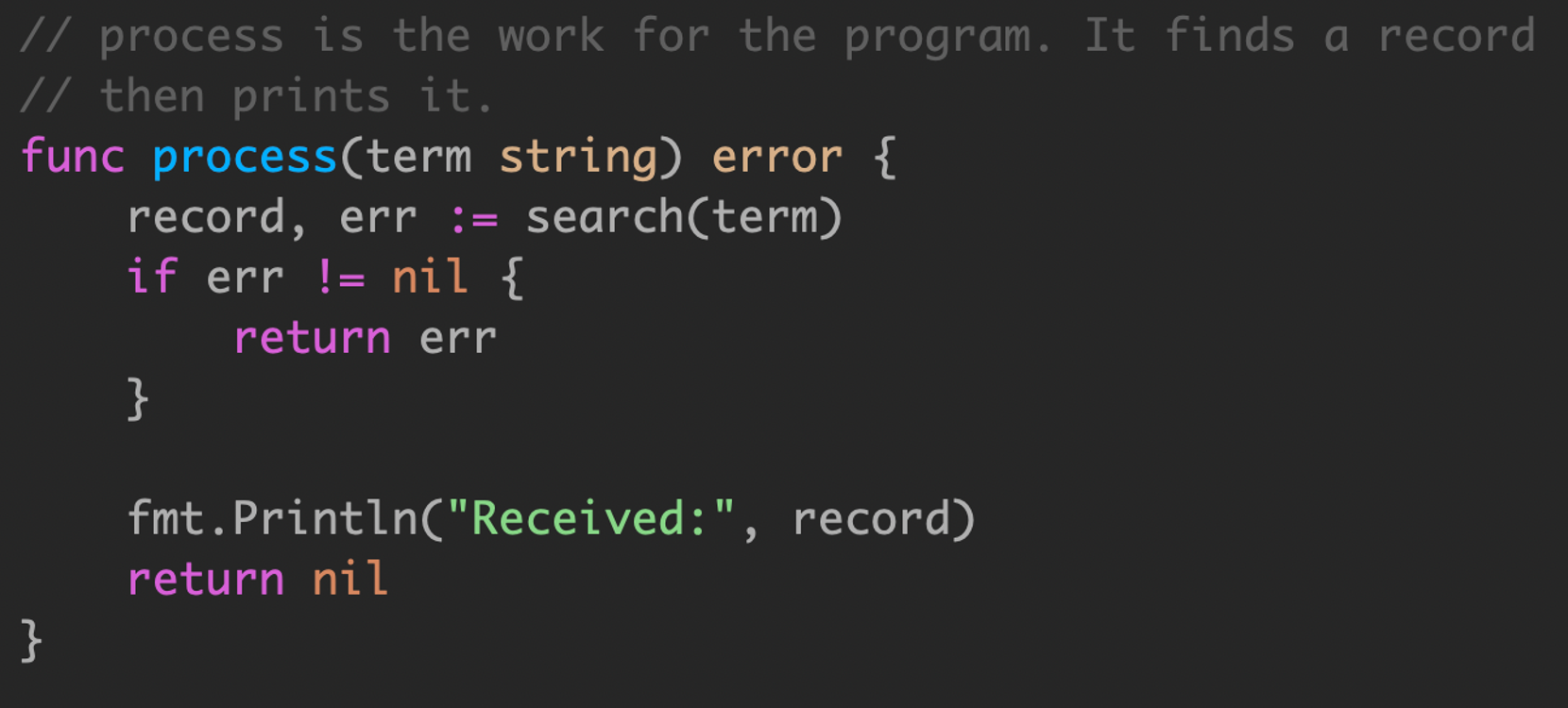
process 函数接受调用者参数,调用 search ,对于某些应用程序,顺序调用产生的延迟可能是不可接受的。
这里需要注意,例如这个请求是在 goroutine 中,由于无法确定 search 函数的耗时,也无法获取到执行状态,可能会造成 goroutine 泄漏。
这里就可以通过 context 实现超时控制。
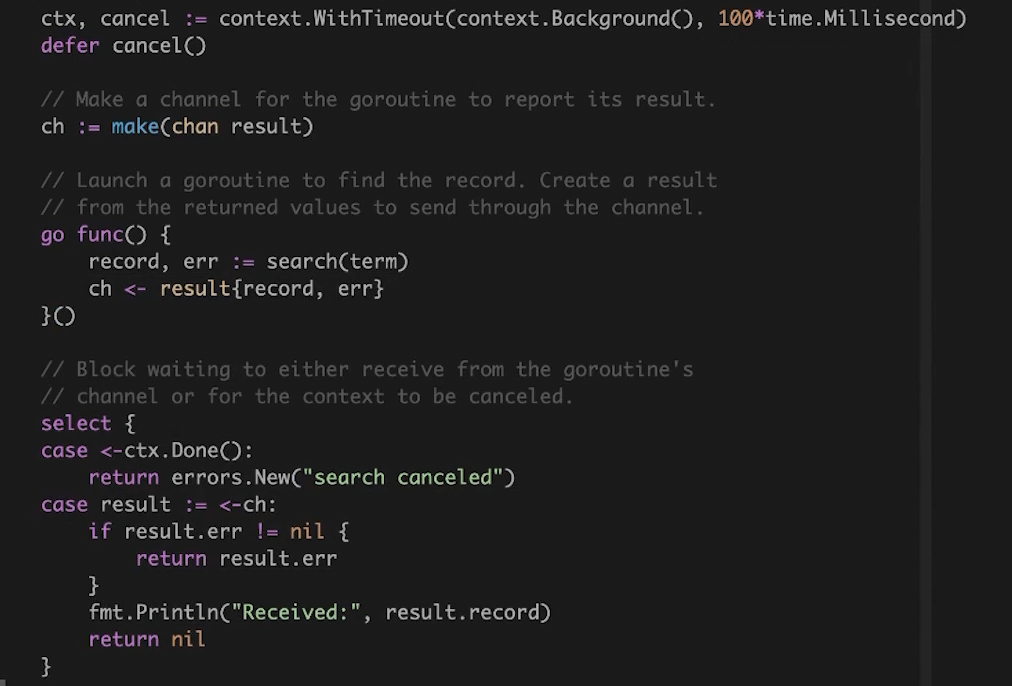
案例4
由于处理goroutine ,导致一些未完成的工作。
示例1
例如使用服务端埋点来跟踪记录一些事件,或者使用日志等服务
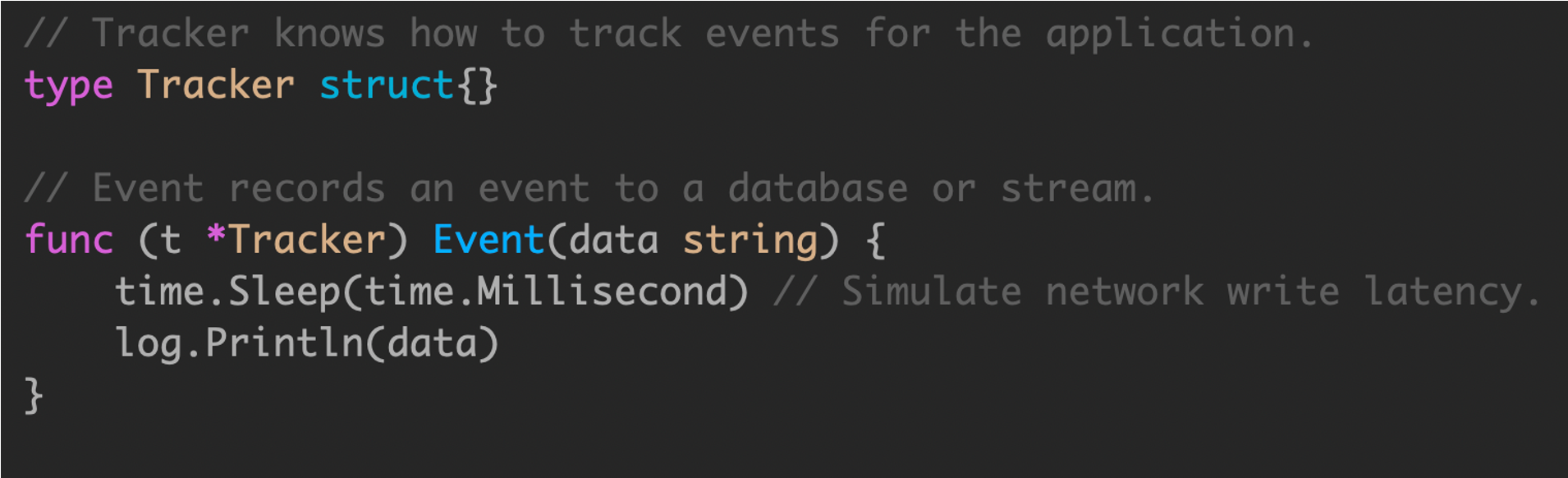
由于这类埋点属于旁路逻辑,通常会使用 goroutine 实现
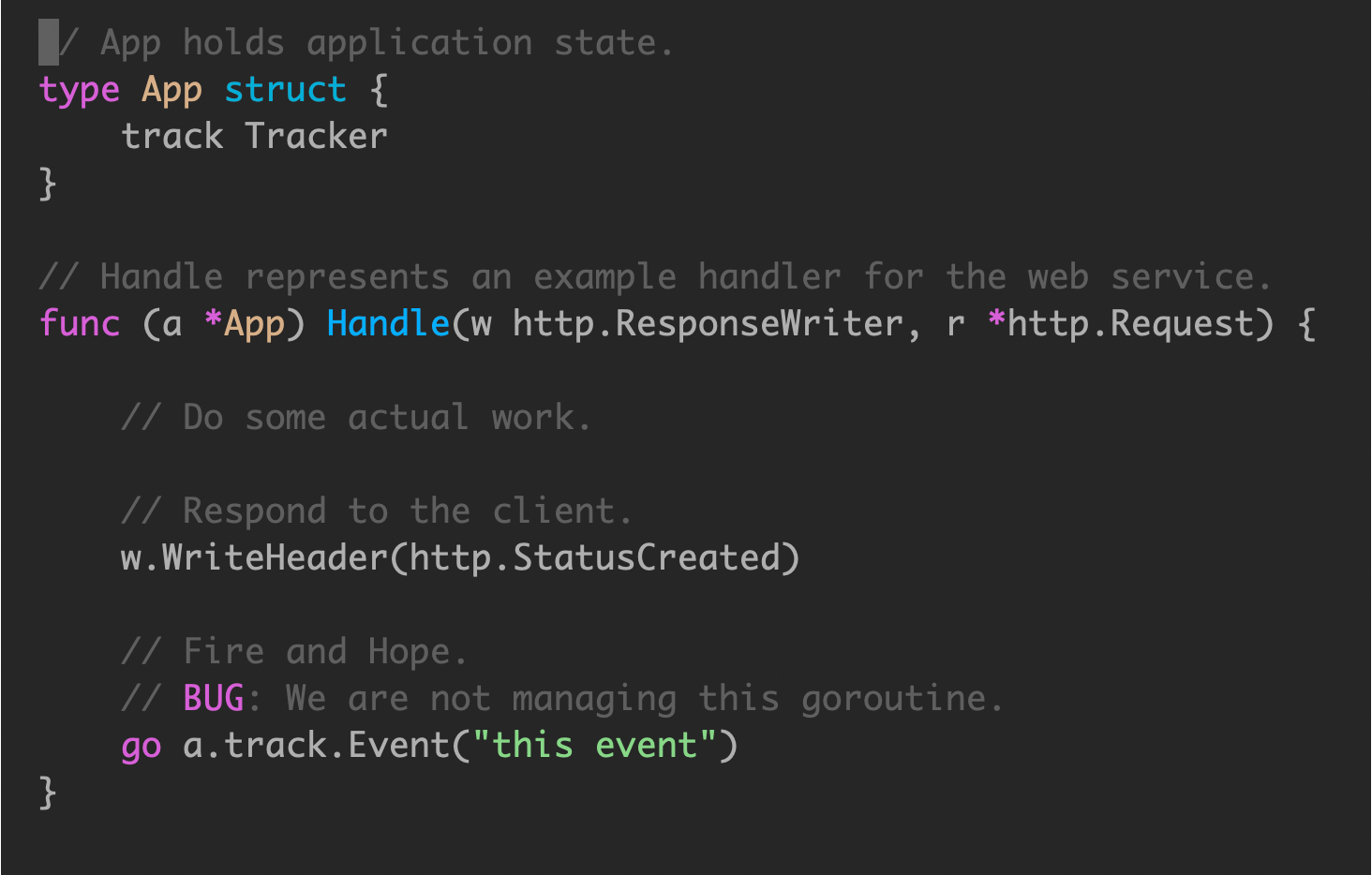
这种写法会有一个问题,无法保证创建的 goroutine 声明周期管理,会导致常见问题,在服务关闭的时候,有一些事件、日志会丢失。
示例2
使用 sync.WaitGroup 来追踪每一个创建的 goroutine
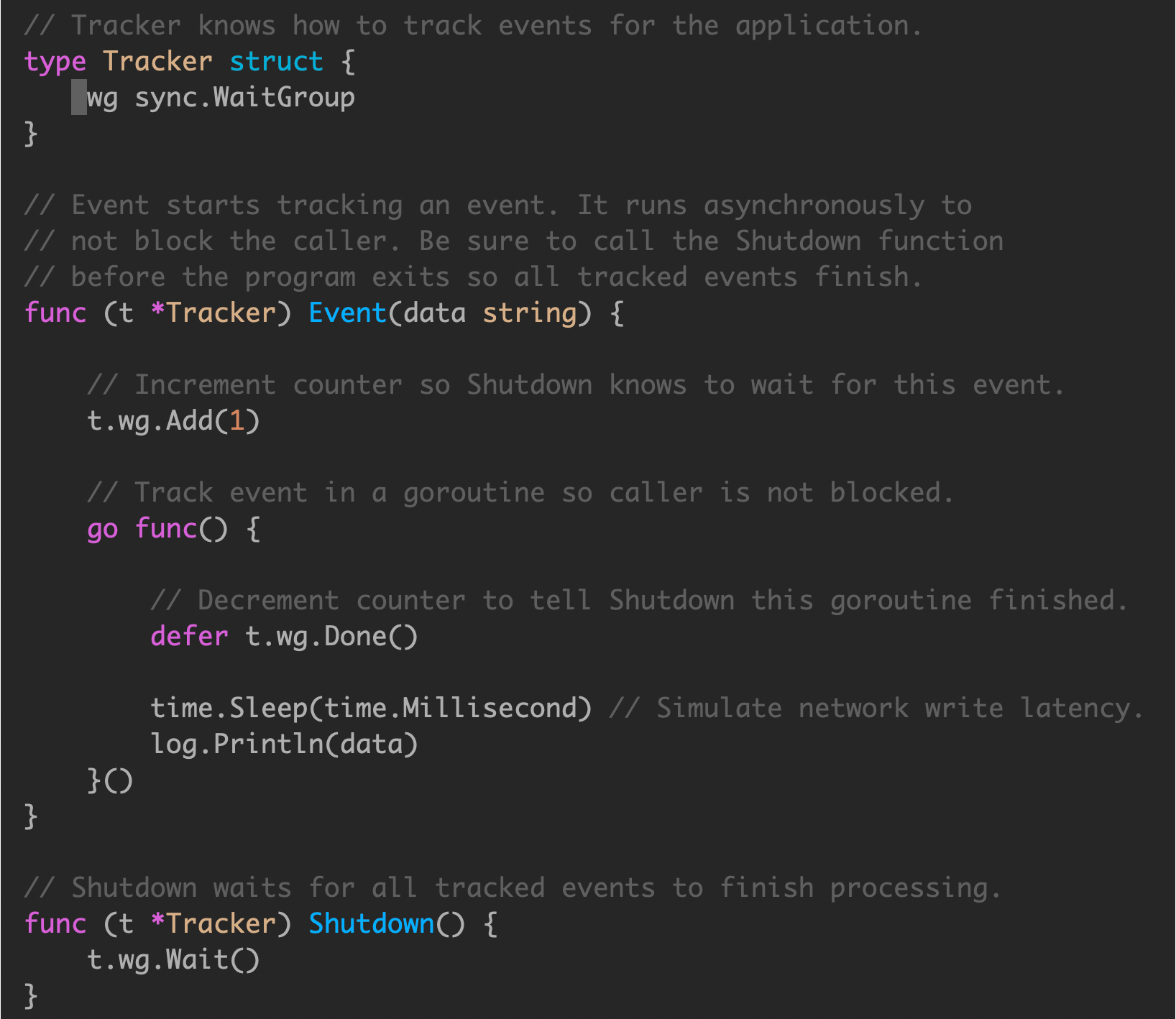
调用一次,增加一个 wg
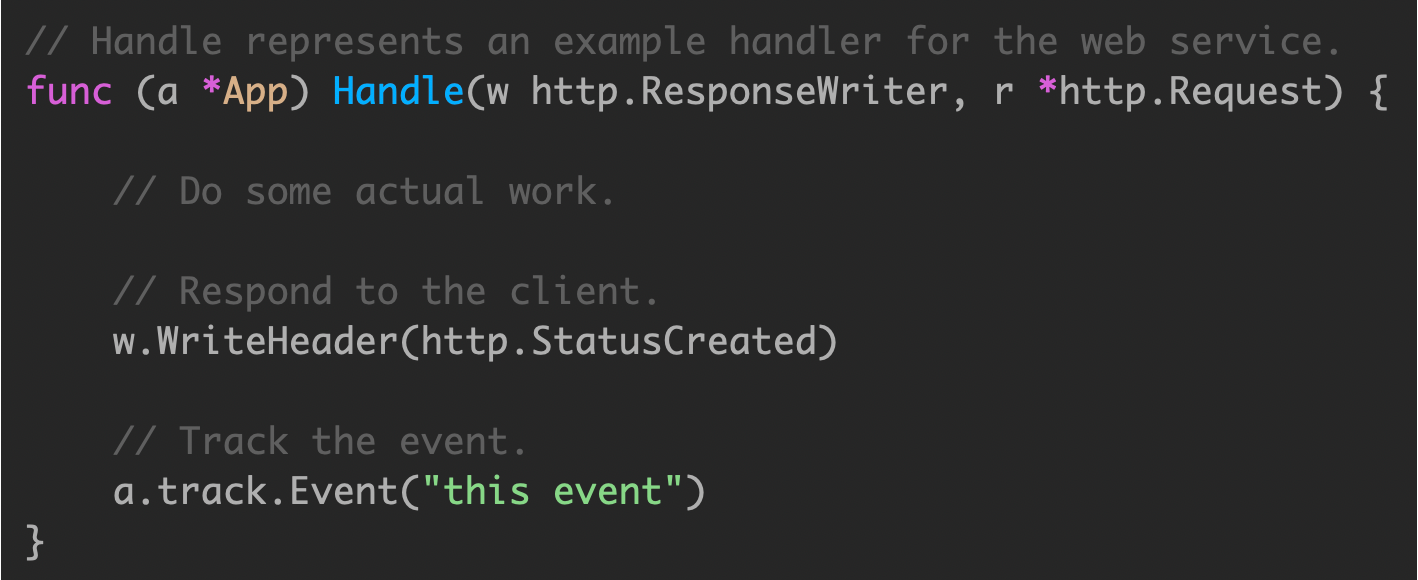
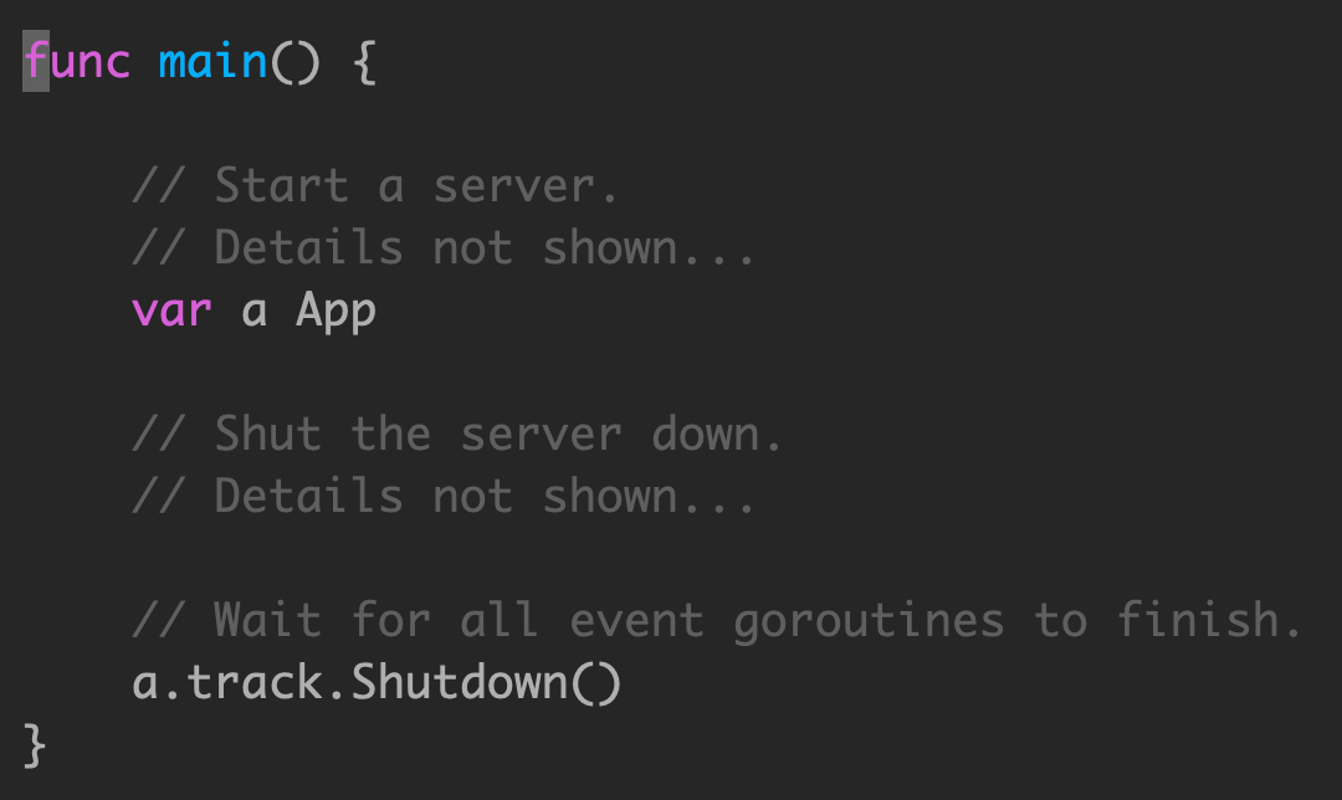
在退出时,使用 waitgroup ,保证所有的 goroutine 全部退出。
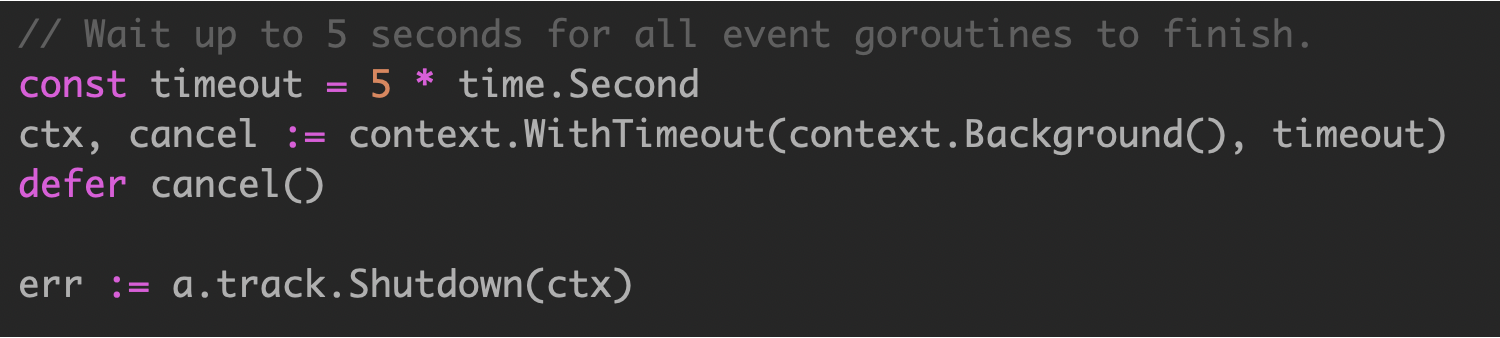
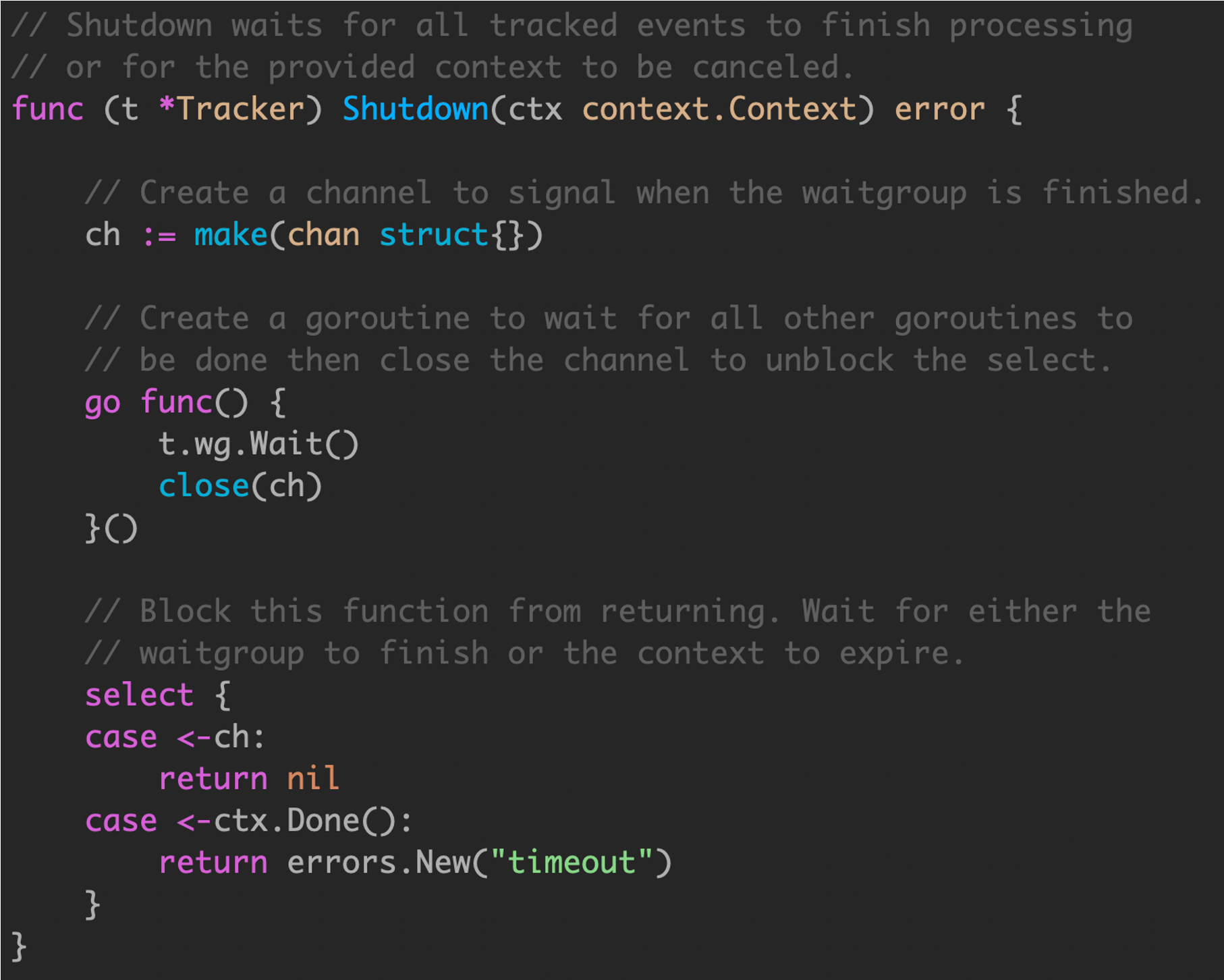
使用时,将 wg.Wait() 操作托管到其他 goroutine ,owner goroutine 使用 context 处理超时。
但是,在一个高并发情况下,这样开启 goroutine 的成本是比较大的。
示例3
通过 channel 的生产和消费,避免大量 goroutine ,同时通过 channel 跨协程通信,管控生命周期。
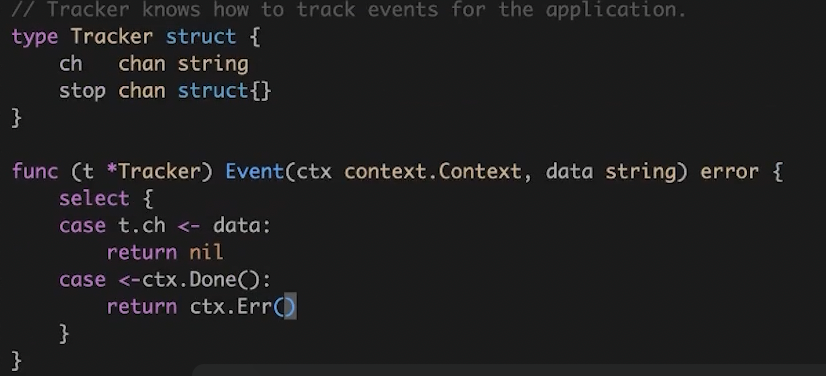
生产消息,往 channel 中丢数据。
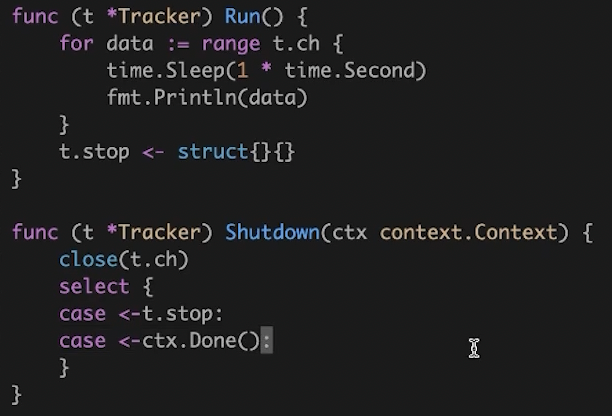
消费消息使用 goroutine 开启消费协程。
通过 shutdown ,既可以超时控制,也可以自身控制。
参考文献
Goroutine Leaks - The Forgotten Sender
Concurrency Trap #2: Incomplete Work
Concurrency, Goroutines and GOMAXPROCS
Concurrency