缓存
缓存
缓存相比于存储,应该是高性能的,缺点则是易失效的。
使用缓存,其实是选择高性能,而放弃一致性。一般缓存的实现方案是使用内存,要么使用本地内存作为缓存,要么使用Redis这种内存数据库作为分布式缓存。
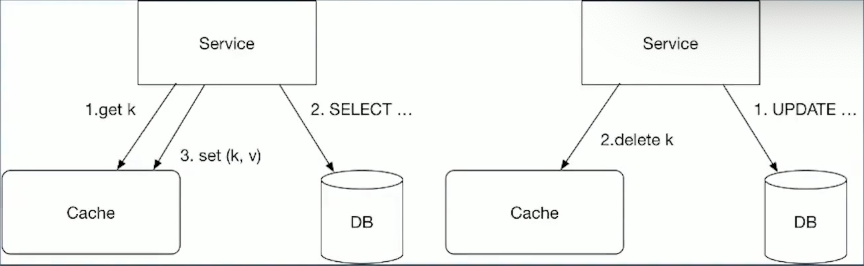
同步更新方案,数据一致性
先同步持久化,再操作cache
往往最好的选择是优先更新持久化,然后再同步操作cache。
这个方案虽然可能出现更新数据库之后,操作cache失败,导致数据不一致,因此cache中的数据需要设置过期时间,过期之后,获取到的数据就是新的。
相比先更新cache再更新持久化,如果更新持久化失败,客户看到的数据会是错误的数据。
先同步持久化的方式,可以保证数据最终一致性。
短暂不一致的情况
获取到cache之后马上更新
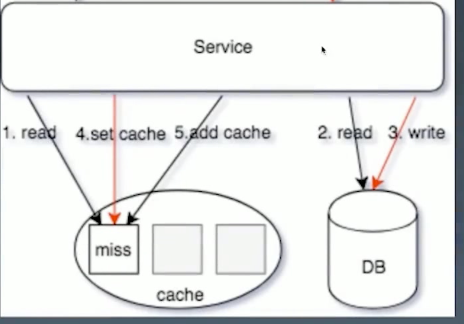
但是可能出现另外一种情况:
- 一个进程获取
cache miss,从db中获取数据 - 另外一个进程更新数据(可异步,例如cannel),在
cache中删除这个空的cache - 第一个进程将
cache miss的key放到cache中
这种情况下,就会造成数据不一致的现象。
同时更新
还有一种情况,就是多个线程同时set cache,由于无法确定更新之后,往cache中set的线程顺序(一般进程的顺序不会有很大的影响)
删缓存还是更新缓存
删除缓存:更新DB中的数据之后,将cache中的数据删除;缺点是如果出现热key,影响会很大。解决方案是不删除,而是将这个key的ttl改短,是否使用交由业务层决定。
更新缓存:更新DB中的数据之后,再更新cache,通过MQ或者Binlog保证最终一致性;缺点是无法保证发生顺序,可能出现ABA的现象,先获取A,然后刷新下变成B,然后刷新下变成C
版本号
版本号和使用从库做标签类似。
当cache miss的时候,生成一个版本号,set DB之后回填,通过新的版本号判断是否是旧数据。
这个就可以解决脏数据被写入的情况。同时还需要通过双删的做法,保证数据正确性。
多级缓存
在微服务场景下,可能出现下层支撑服务和上层业务服务之间,都需要使用缓存,为了降低服务之间调用频率,经常会在上下游都使用缓存,实现多级缓存。
多级缓存需要注意:
- 清理优先级:先清理下游,再清理上游;避免出现清理上游之后,马上有上游进程cache miss之后将下游数据set到上游缓存
- 下游缓存的expire要大于上游,里面穿透回源;避免出现上游数据过期之后,cache miss时查询下游,出现缓存穿透
热点缓存
对于热点缓存key,可以按照如下思路:
- 小表广播,从
Remote Cache提升为LocalCache,App定时更新,甚至可以支持广播刷新LocalCache - 主动监控防御预热,比如一些大表高更新的情况下,直接外挂服务主动防御,将Remote Cache变成Local Cache
- 基础库框架支持热点发现,自动短时的short-live cache,实现在滑动窗口内自有统计的cache,将Remote Cache提升为Local Cache
- 在大架构层面,使用多集群思路,每个集群使用独立cache,避免热key,增加冗余能力
- 多key设计,使用多副本,减小节点热点的问题
- 使用多副本ms_1,ms_2,ms_3每个节点保存一份数据,使得请求分散到多个节点,避免单点热点问题。一般可以通过中间件实现,多节点hash之后平均请求
穿透缓存
singlefly
对关键字进行一致性hash,使其某一个维度的key一定命中某个节点,然后在节点内使用互斥锁,保证归并回源,但是对于批量查询无解。获取到互斥锁的线程,获取到结果,广播给所有其他线程。
分布式锁
设置一个lock key,有且只有一个进程成功并且发挥,交由这个进程来执行回源操作,其他候选者轮询cache这个lock key,如果不存在就读数据库,hit就返回,miss继续抢锁。
队列
如果cache miss,交由队列聚合一个key,来load数据会写缓存,对于miss当前请求可以使用singlefly保证回源,如评论架构实现,适合回源加载数据重的任务,比如评论miss只返回第一页,但是需要构建完成评论数据索引。相比直接使用singlefly的进程写入缓存要轻量。
lease,租约
通过加入lease机制,可以很好避免这两个问题,lease是64-bit的token,与客户端请求的key绑定,对于过时设置,在写入时验证lease,可以解决这个问题:对于thundering hard,每个key10s分配一次,当client在没有获取到lease时,可以稍微等一下再访问cache,这时往往cache中已有数据。(基础库支持&修改cache源码)
缓存技巧
小技巧
- 易读性的前提下,key设置尽可能小,减少资源占用,redis value可以用int就不要用string,比如存储指针,对于小于N的value,redis内部有shared object缓存
- 拆分key,主要用在redis使用hashes情况下,同一个hashes key会落到同一个redis节点,hashes过大的情况下,会导致内存以及请求分布的不均匀。考虑对hash进行拆分为小的hash,使得节点内存均匀及避免单节点请求热点。
- 空缓存设置,对于部分数据,可能数据库使用为空,这时应该设置空缓存,避免每次请求都缓存miss,直接击穿缓存到DB;也可以在业务层判断过滤
- 空缓存保护策略
- 读失败后的写缓存策略(降级后一般读失败不触发回写缓存)
- 序列化使用protobuf而不是json,尽可能减少size
- 工具化浇水代码,比如使用go generate 生成代码
Redis 小技巧
- 增量更新一致性:EXPIRE、ZADD/HSET 等,保证索引结构体务必存在的情况下去操作新增数据。避免出现先判断没有过期,然后ZADD时又出现过期的情况,可以先增加过期时间,然后ZADD
- BITSET:存储每日登录用户,单个标记位置(boolean),为了避免单个BITSET过大或者热点,需要使用region sharding,比如按照mid求余%和1/10000,商为key、余数作为offset
- List:抽奖的奖池、顶弹幕,用于类似Stack PUSH/POP操作
- SortedSet:翻页、排序、有序的集合,杜绝zrange或者zrevrange返回的集合过大
- Hashs:过小的时候会使用压缩列表、过大的情况容易导致rehash内存浪费,也杜绝返回hgetall,对于小结构体,建议直接使用memcache KV;
- String:SET的EX/NX等KV扩展指令,SETNX可以用于分布式锁、SETNX聚合了SET+EXPIRE
- Sets:类似Hashs,无value,去重等
- 尽可能的PIPELINE指令,但是避免集合过大
- 避免超大Value
分布式缓存
分布式缓存是一种常见的技术,用于提高系统的性能和可扩展性。以下是几种常见的分布式缓存实现方案:
Memcached:Memcached 是一种常用的开源分布式内存对象缓存系统。它以键值对的形式存储数据,并使用哈希算法将数据分布到多个节点上。Memcached 提供了简单而高效的缓存机制,适用于许多应用场景。
Redis:Redis 是另一种流行的开源内存数据存储系统,它支持键值对、列表、集合等多种数据结构,并提供了丰富的功能和灵活的配置选项。Redis 的分布式特性通过使用主从复制和分片技术来实现,可以将数据分布到多个节点上以提高性能和可用性。
Apache Kafka:尽管 Kafka 主要被用作消息队列系统,但它也可以用作分布式缓存。Kafka 提供了高吞吐量、持久化存储和分布式复制等特性,可以用于缓存大量的数据,并支持多个消费者并行读取。
Hazelcast:Hazelcast 是一个开源的内存数据网格解决方案,它提供了分布式缓存和分布式计算的功能。Hazelcast 可以将数据存储在内存中,并通过分布式算法将数据分散到多个节点上。它还提供了事务支持和集群管理功能。
这些是常见的分布式缓存实现方案,每个方案都有其特点和适用场景。选择适合你的需求的方案时,需要考虑数据一致性、可用性、性能要求以及系统的复杂性等因素。
Redis 特点
单线程处理读写请求。多线程下,也是单线程处理读写,其他的线程处理磁盘读写。
集群下,Redis 使用一致性哈希算法(Consistent Hashing)来实现分布式缓存的数据分片和负载均衡。一致性哈希算法的主要思想是将缓存键(Key)通过哈希函数映射到一个固定大小的哈希环上,然后将节点(缓存服务器)也映射到同一个哈希环上。
以下是 Redis 一致性哈希算法的基本原理和步骤:
构建哈希环:将所有的缓存节点(服务器)通过哈希函数映射到一个固定大小的哈希环上,形成一个环状结构。
映射缓存键:将要缓存的键(Key)通过同样的哈希函数映射到哈希环上的一个位置。
定位节点:从映射到的位置开始,沿着哈希环顺时针查找,找到第一个遇到的节点。这个节点就是负责缓存该键的节点。
数据分片:将缓存的数据分散存储在不同的节点上,每个节点负责一部分数据。
节点变动处理:当添加或移除节点时,只会影响到环上的少部分键的映射,大部分键的映射仍然保持不变。这样可以避免大规模数据迁移的开销。
通过使用一致性哈希算法,Redis 可以实现动态的节点扩展和收缩,而不需要重新分配大部分数据。这样可以使缓存系统具备高可用性和可扩展性。
需要注意的是,一致性哈希算法并不能完全解决数据倾斜(数据在节点上分布不均匀)的问题。为了解决数据倾斜,可以使用虚拟节点(Virtual Nodes)来增加节点的数量,使数据更加均匀地分布在各个节点上。
缓存一致性
一致性无法满足的情况大部分是在更新数据和获取的数据不一致。
- 更新数据更新之后,先逐条更新
redis,同时更新sql。 - 监听
sql的binlog,再次更新redis。
解决方法:产生数据不一致,可以在数据查询时更新redis,使用nx更新。在更新数据是,使用set覆盖。
那么,更新sql之后,是使用删除redis里面的key还是更新key?
- 更新key可能会出现的问题是两个更新,无法确定前后,导致数据不一致
- 删除key可能会出现的问题是热key被删除之后,请求会打到数据库
有一种方式是,redis过期之后,在数据上加一个tag,在获取到缓存之后,能够知道这个key过期,需要请求数据库。
分布式事务
分布式事务,指的是:跨表,跨集群,跨服务的事务。(直白来说,就是跨进程)
分布式理论:
- ACID:原子、一致性、持久化、事务隔离。
- CAP:满足分布式的三大要素,但是C(一致性)和A(可用性)不能同时满足。
- BASE:CAP理论的进一步扩充
分布式事务方案的一种思路:使用插件或者说代理,让代理作为中间件,实现事务。比如 Seata
分布式式事务实现方案
实现方案:
- 方案1、服务a生成一张伴随表,记录中间处理状态,服务b任务完成,回调服务a,服务a将半生表中的字段删除,或者更新字段。
- 方案2、服务b定期查询服务a的伴随表,处理任务,处理成功之后,更新b服务的表,b服务作为新的服务状态表。这个方案,会定时查询表,可能会对数据库有压力。
- 方案3、伴随表的binlog变更订阅推送到kafka,消费者更新本地事务。
通过消息队列实现分布式事务
需要解决的问题有幂等。
幂等
消息重复投递,或者重复消费。通过全局唯一ID+去重表。
做法1、启一个本地事务,查询伴随表,是否存在这个id,如果不存在,则插入这个任务id(或者叫流水号),创建这个任务,并且在伴随表中插入这个字段。
也可以通过状态判断、或者通过版本号来解决。
二阶段提交协议
发送方
- 先发送消息
perpared,再执行本地事务,事务成功,再发送commit_message确认消息; - 可以确保消息一定会成功发送到消息队列中,第二步或者第三步失败,消息队列会反向请求业务消息是否确认,如果本地事务异常,则丢弃消息。
接收方
- 接受消息,处理本地事务,处理成功,ack消息。
- 这个过程需要在接收方处理幂等性。
TCC
try confirm cancel:也就是事务的三个分支,预处理try,确认confirm,撤销cancel。
例如,预处理阶段,可以在表中新增一个冻结字段,描述资源变化。在两个服务中都做一个冻结。
确认阶段,两个服务均按照逻辑处理,处理成功,则确认。处理失败,则撤销,通过冻结字段进行撤销。
这个过程需要注意:
空回滚:try失败,也就是什么都没有执行,需要能支持回滚。
防悬挂:如果因为一些原因,cancel比try先到达,操作乱序的情况下,应该取消本次事务。