Go的concurrency之sync
共享内存
Share Memory By Communicating
传统的线程模型(通常在编写 Java、C++ 和 Python 程序时使用)程序员在线程之间通信需要使用共享内存。通常,共享数据结构由锁保护,线程将争用这些锁来访问数据。在某些情况下,通过使用线程安全的数据结构(如 Python 的 Queue),这会变得更容易。
Go 的并发原语 goroutines 和 channels 为构造并发软件提供了一种优雅而独特的方法。 Go 没有显式地使用锁来协调对共享数据的访问,而是鼓励使用 chan 在 goroutine 之间传递对数据的引用(通常是指针)。这种方法确保在给定的时间只有一个 goroutine 可以访问数据。
通过 channel ,共享内存。
Do not communicate by sharing memory; instaed, share memory by communicating,
数据竞态
Detecting Race Conditions With Go
Data race 是两个或多个 goroutine 访问同一个资源(如变量或数据结构),并尝试对该资源进行读写而不考虑其他 goroutine。这种类型的代码可以创建最疯狂和最随机的 bug。通常需要大量的日志记录和运气才能找到这些类型的 bug。
早在2013年6月份的Go 1.1 中,Go 工具引入了一个 race detector。竞态检测器是在构建过程中内置到程序中的代码。然后,一旦程序运行,它就能够检测并报告它发现的任何竞争条件。这个工具非常酷,并且在识别罪魁祸首的代码方面作了令人难以置信的工作。
1 | go build -race // 编译时使用-race标志来启用race detector |
案例1
1 | package main |
例如上述代码,在 goroutine 中使用 Counter++ ,同时赋值。
通过编译可以看到 Counter++ 不是原子的
1 | go tool compile -N -l -S main.go // 生成汇编代码 main.o |
go 1.4 go build -gcflags -S main.go
1 | 0x0022 00034 (code/test1.go:24) MOVQ "".Counter+0(SB),BX |
i++ 其实是分为三个步骤,先是赋值,然后自增这个赋值,然后把值赋值回去。
三行汇编代码在执行以增加计数器,这三行汇编代码看起来很像原始的 Go 代码。在这三行汇编代码之后可能有一个上下文切换。尽管程序现在正在运行,但从技术上讲,这个 bug 仍然存在。虽然 Go 代码看起来像是在安全地访问资源,而实际上底层的程序集代码根本就不安全。
其实是相当于
1 | for count := 0; count < 2; count++ { |
通过竞态检测工具,可以看到上面的代码在不同的 goroutine 中有同时读写的行为,检测到代码的争用条件。如果查看 race conditoin 报告下面,可以看到程序的输出:全局计数器变量的值为4。
go 1.4 go build -race && ./main
1 | ================== |
如果不好复现,可以让 goroutine 执行久一点,手动增加一点时间
1 | func Routine(id int) { |
正常的过程应该是两个 goroutine 有先后顺序
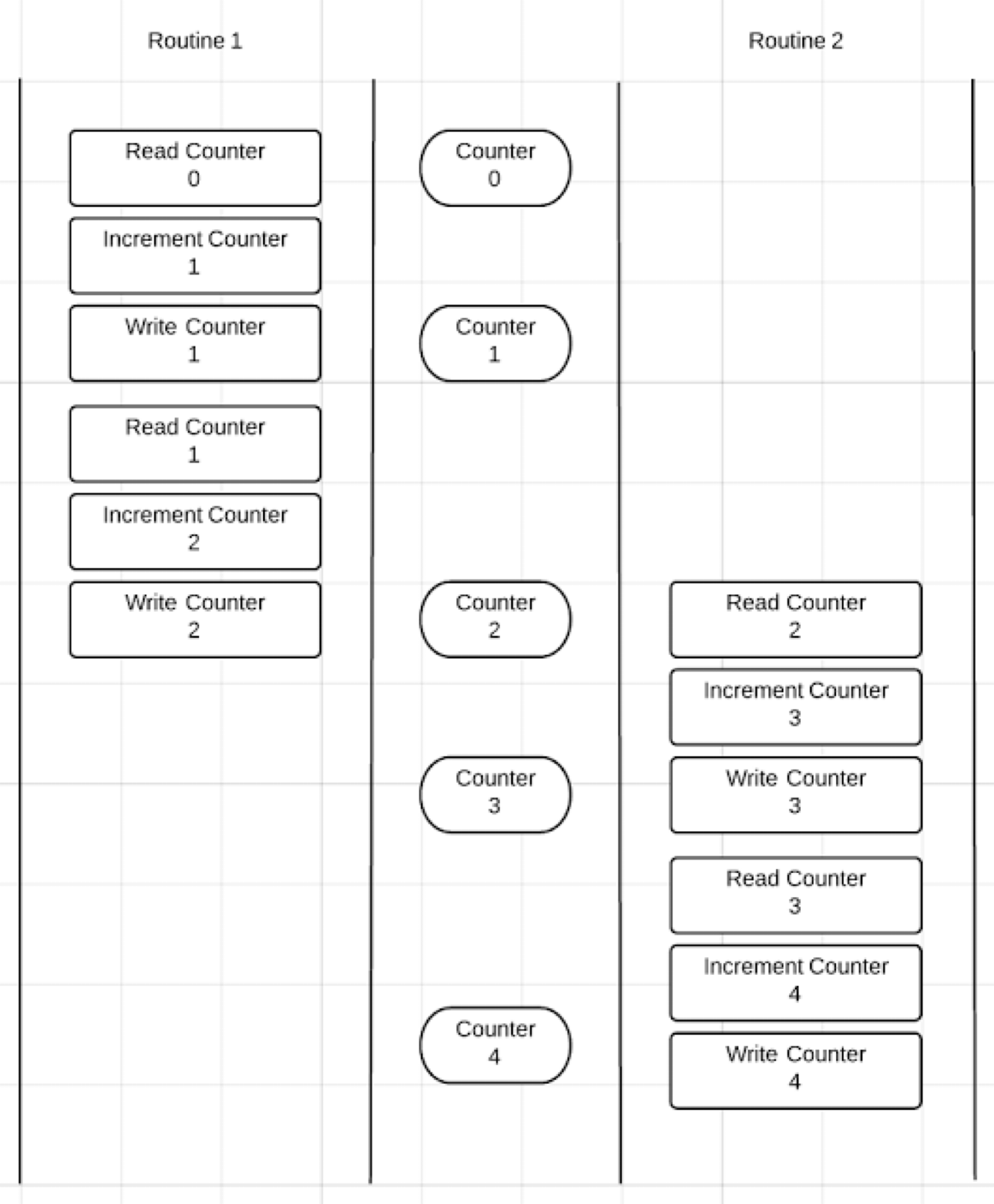
此时,应该使用 Go 同步语义:Mutex
案例2
这里修改 Ben 将id去掉,将 Ben 和 Jerry 的内存布局设置成一样。
1 | package main |
在机器字 single machine word(例如 x86_64 的系统上,8字节是最小计算单元)的赋值上,应该是原子赋值,为啥 -race 会乱报。
例如上面的代码,maker 是一个 interface,指针类型占用8个字节,在 loop0 和 loop1 中通过 goroutine 循环调用,在 goroutine 中无法保证调用顺序,因此会有数据竞态。ben 和 jerry 都是指针类型,也是8个字节,
执行之后的效果。
go 1.4 env GOMAXPROCS=2 go run main.go
1 | Ben says, "Hello my name is Ben" |
但是对于 Golang 来说,interface 是有两部分。
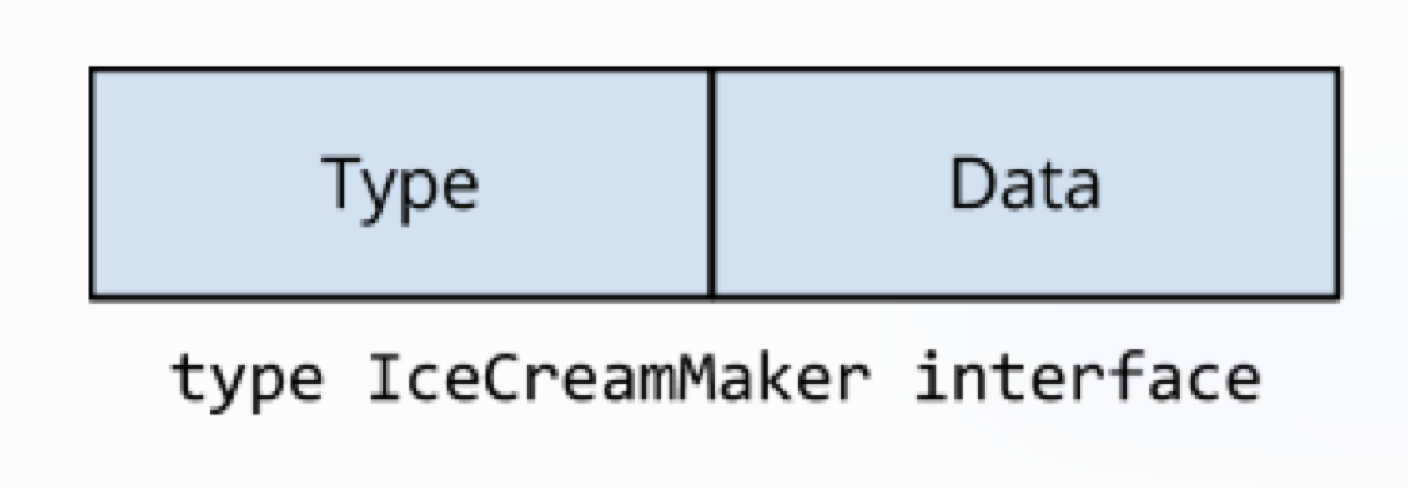
Type 指向实现了接口的 struct ,Data 指向了实际的值(也就是一个是类型,一个是值)。

Data 作为通过 interface 中任何方法调用的接受方传递。
对于语句 var maker IceCreamMaker = ben,编译器将生成执行以下操作的代码
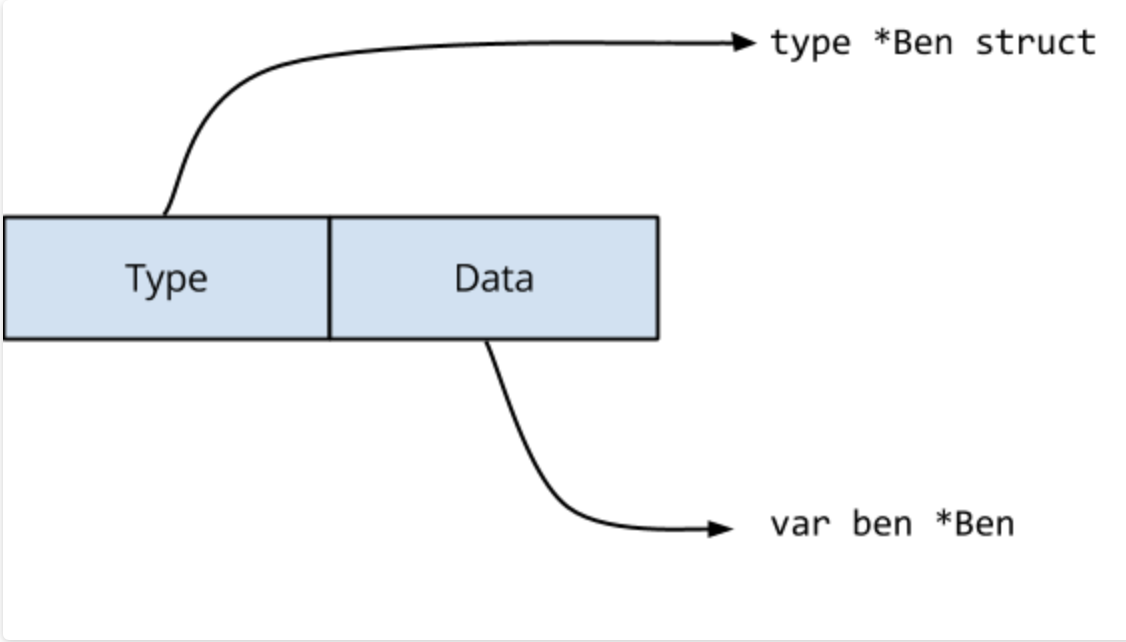
当 loop1() 执行 maker = jerry 语句时,必须更新接口值的两个字段。
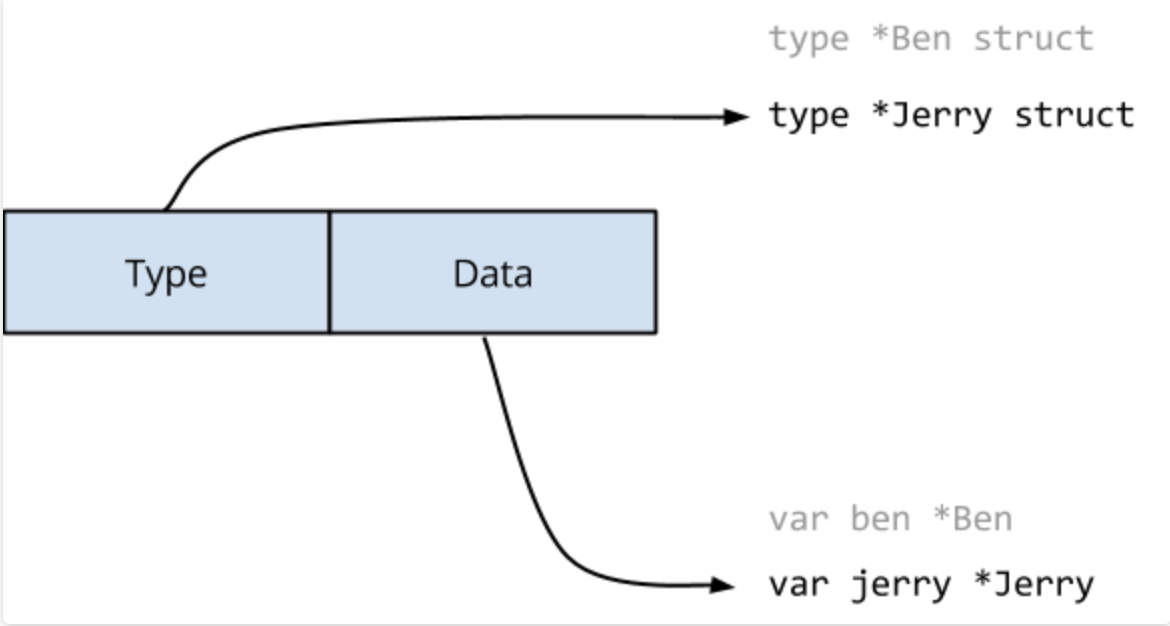
很有可能在实际执行的过程中,会出现 Type 和 Data 指向的是不同的字段。
Go memory model 提到过:表示下如单个machine word将是原子的,但 interface 内部是两个 machine word 的值。另一个 goroutine 可能在更改接口值时观察到它的内容。
在这个例子中, Ben 和 Jerry 内存结构布局是相同的,因此它们在某种意义上是兼容的。如果它们的内存布局不同,会发生什么混乱。(比如。Ben 字段的 id )
1 | package main |
go 1.4 env GOMAXPROCS=2 go run main.go
1 | Ben says, "Hello my name is Ben" |
如果是一个普通的指针、map、slice 可以安全的更新吗?
虽然是一样的8个字节的 machine word ,与 Jerry 是相同大小,兼容的。
但是:
没有安全的 data race(safe data race)。要么是没有 data race ,要么其操作未定义。
- 原子性:操作不可分割,例如 machine word
- 可见性:指针内部操作,无法确定内部操作是否是原子的。例如上面的 interface ,多个 goroutine 操作的时候,可能不同的 goroutine 操作(或者读取)到的不是同一份数据上的 type 和 data 。
案例3
例如下面的代码
1 | package main |
cfg 作为包级全局对象,在这个例子中被多个 goroutine 同时访问(一个 goroutine 写入,另外一个 goroutine 读取(打印)),因此这里存在 data race,会看到不连续的内存输出。
go 1.4 env GOMAXPROCS=2 go run main.go
1 | &{[2351 2352 3643 3697 3698 3700]} |
go 1.4 go build -race
1 | ================== |
我们想到使用Go 语义解决。
- Mutex:互斥锁
- RWMutex:读写锁
- Atomic:原子操作
sync包
原子操作
sync.Atomic VS sync.Mutex
例如上述代码,在读多写少的情况下,可以使用读写锁,相比互斥锁效率更高。
但是与更加轻量级的原子操作相比,读写锁的效率不如原子操作。
读写锁:
写入的时候加写锁;读取的时候用读锁。
1 | package main |
原子操作:
写入的时候使用原子操作存储数据,读取的时候将数据拷贝出来。
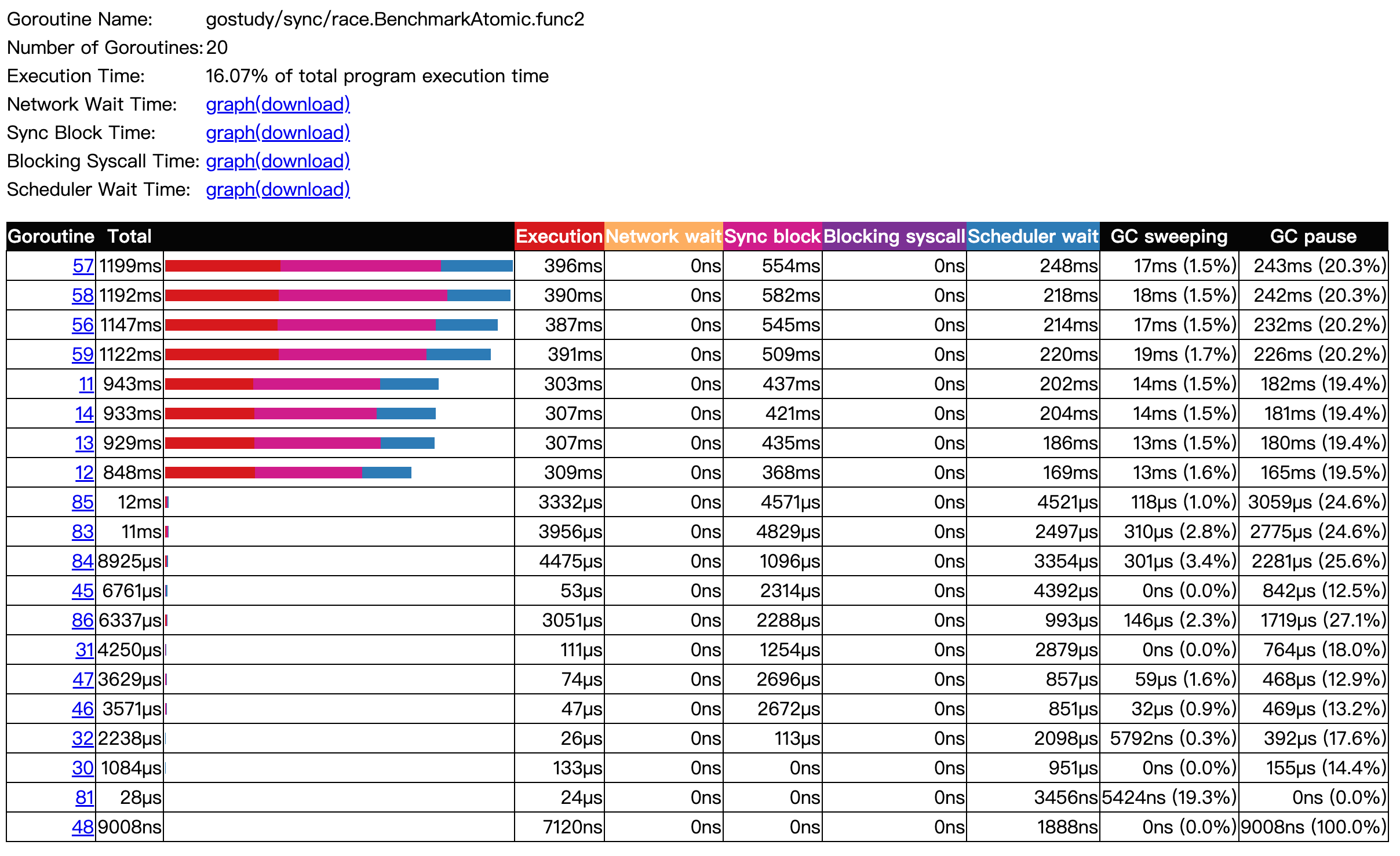
1 | func BenchmarkAtomic(b *testing.B) { |
使用 Benchmark 测试出结果,Mutex相对更重。
go test -bench=.
1 | goos: darwin |
因为涉及到更多的 goroutine 之间的上下文切换 pack blocking goroutine,以及唤醒 goroutine。
env GOMAXPROCS=4 go test -trace trace.out -bench .
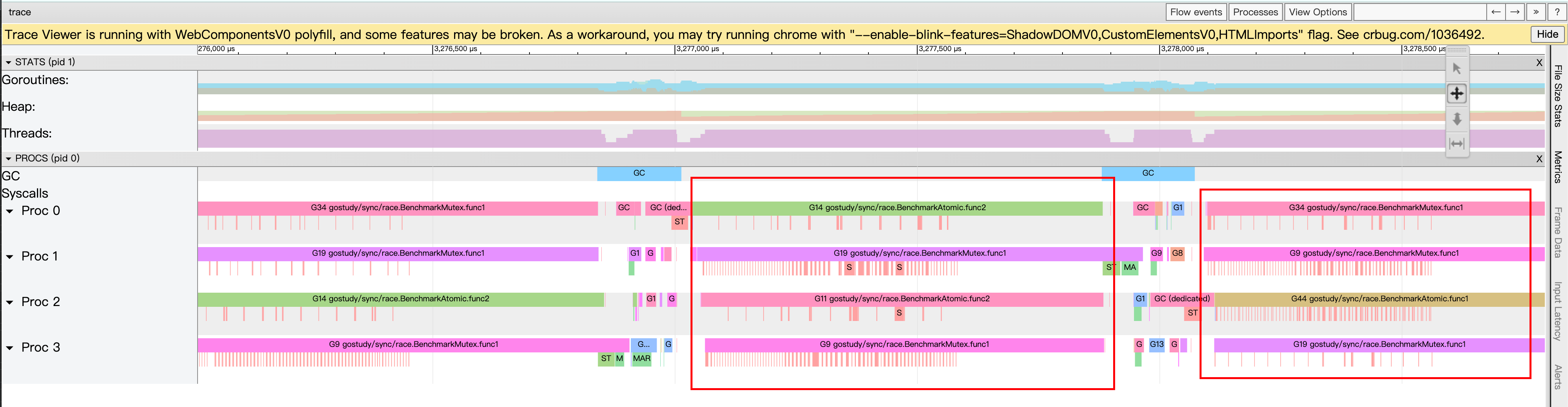
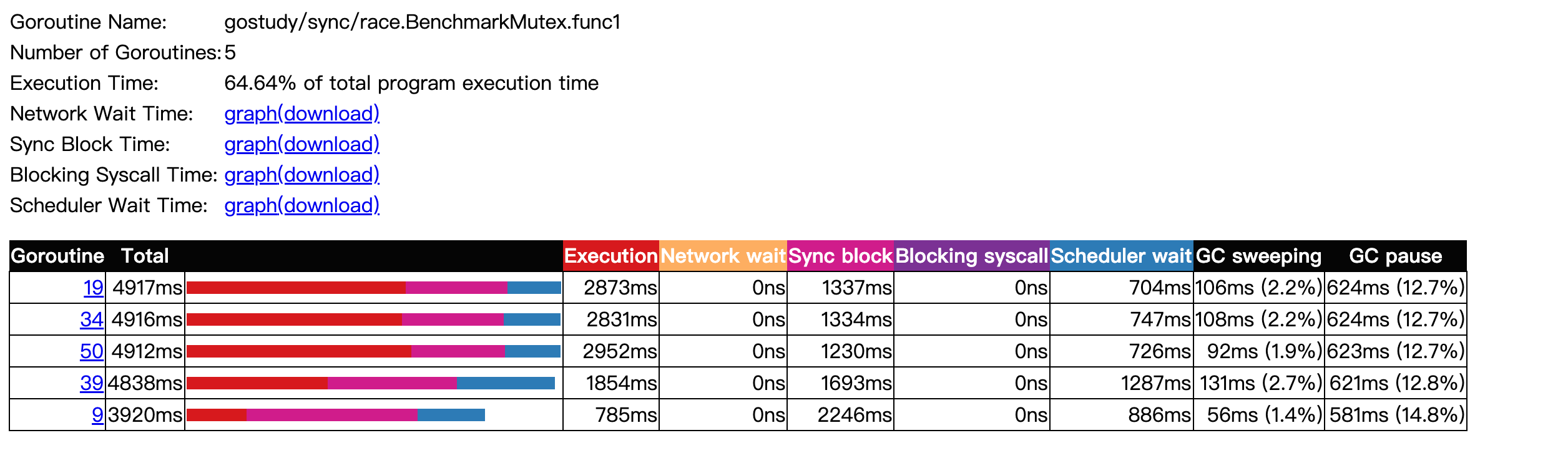
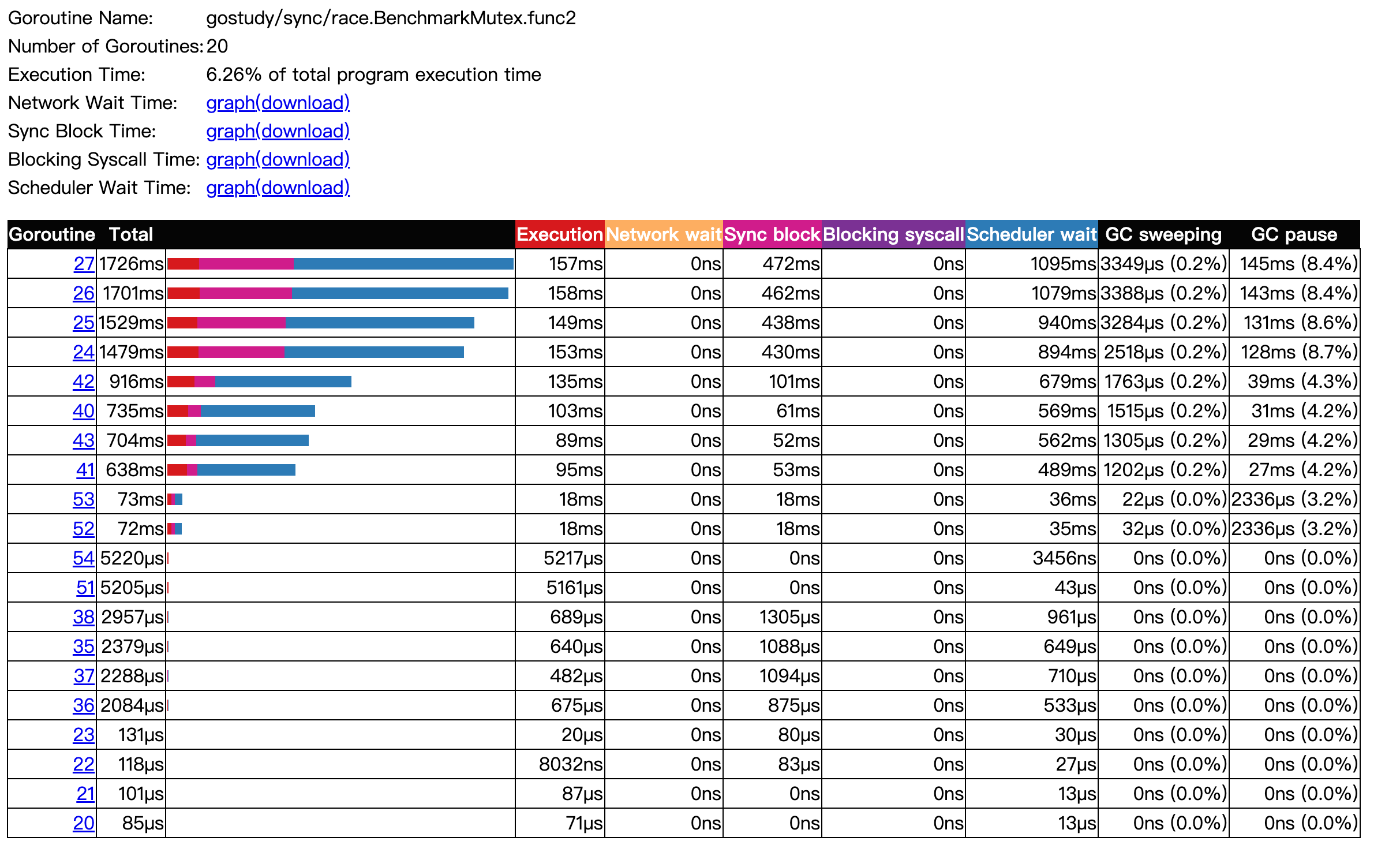
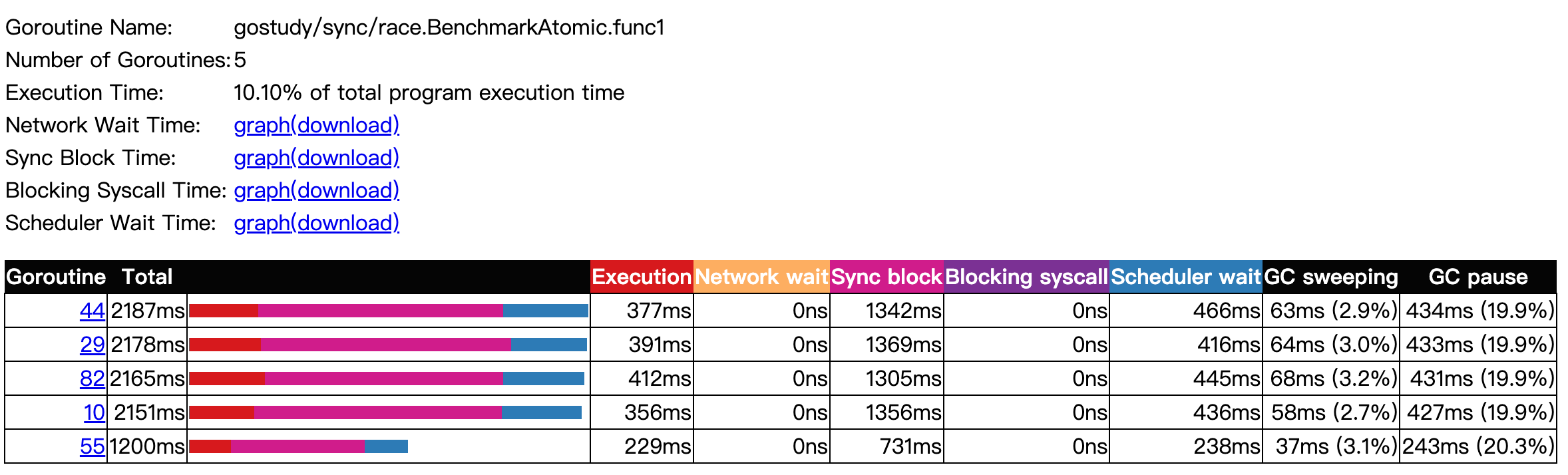
COW
Copy-On-Write (写时复制)思路在微服务降级或者 local cache 场景中经常使用。写时复制指的是,写入操作时复制全量老数据到一个新的对象中,携带上本次新写的数据,之后利用原子替换( atomic.Value),更新调用者的变量。来完成无锁访问共享数据。
例如定期(每10s加载一次最新数据),使用原子操作 store 数据,使用的时候,从 atomic 中读取出来。
但是需要注意,可能会出现读取出来的数据是 v1 的。
1 | package main |
又例如读取配置,实时生效。
1 | package main |
互斥锁
Mutex
1 | package main |
这个案例基于两个 goroutine :
- goroutine 1 持有锁 100ms
- goroutine 2 每 100ms 持有一次锁
都是100ms 的周期,但是由于 goroutine 1 不断的请求锁,可预期它会频繁的持续锁的状态。
基于 Go 1.8 循环 10次,下面是锁的请求占用分布:

Mutex 被 g1 获取了 700 多万次,而 g2 只获取了 10 次。这是非常不公平的。(占用时间长,而且还获得锁的概率高)
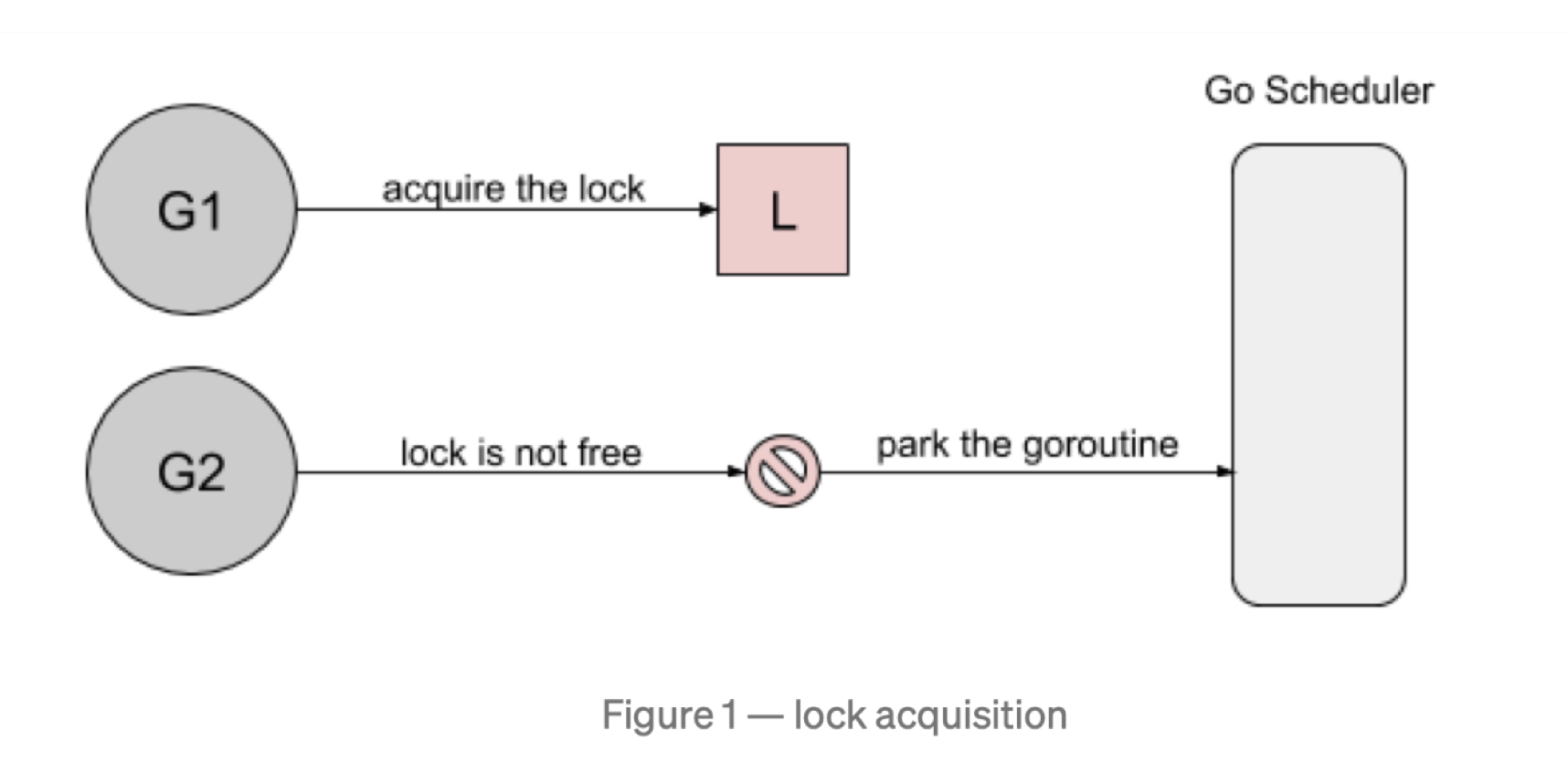
首先,goroutine1 将获得锁,并休眠 100ms。当 goroutine2 试图获取锁是,它将被添加到锁的队列中- FIFO顺序(先进先出),goroutine 将进入等待状态(Parking)。
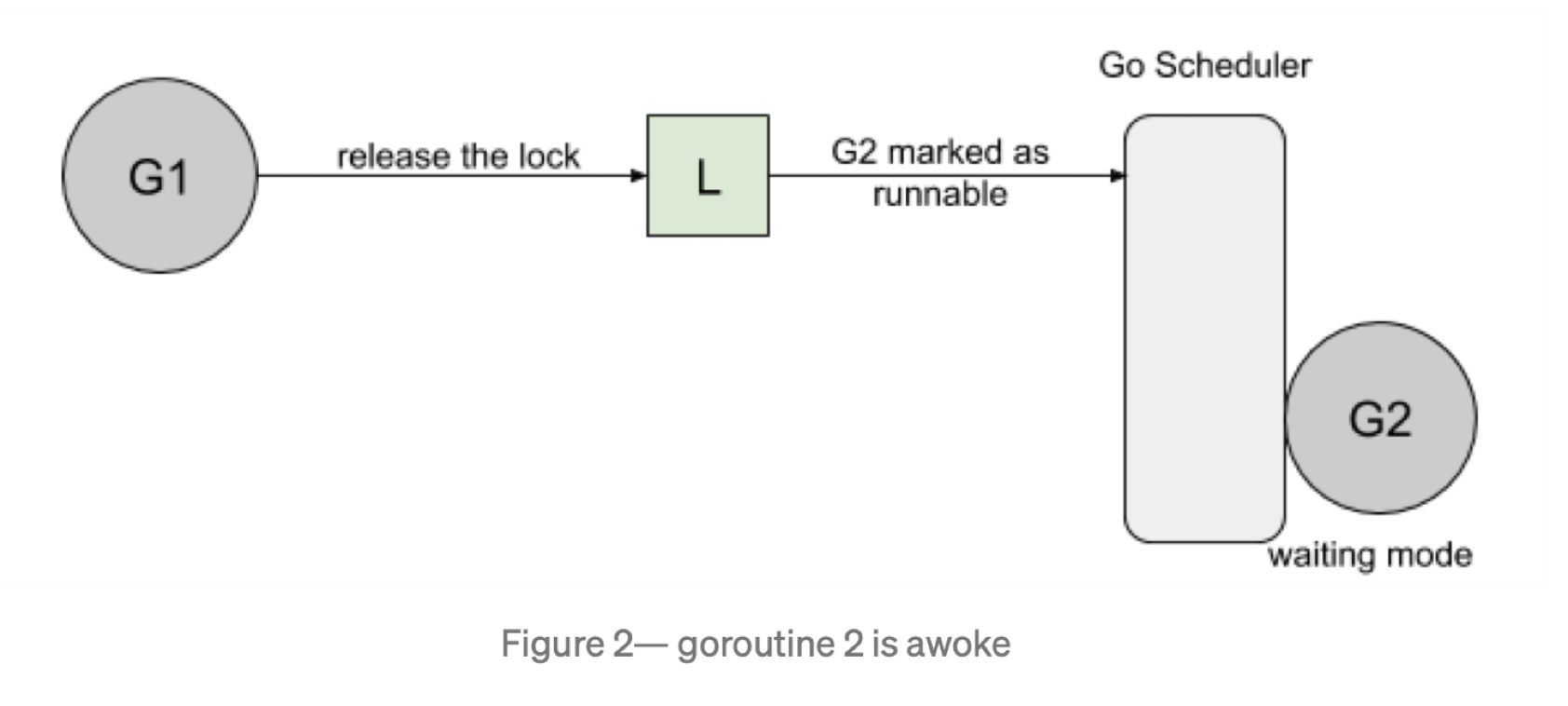
然后,当 goroutine1 完成它的工作时,它将释放锁。此版本将通知队列,唤醒 goroutine2 ,goroutine2 将被通知队列唤醒 goroutine2 。goroutine2 将被标记为可运行的,并且正在等待 Go 调度程序在线程上运行。
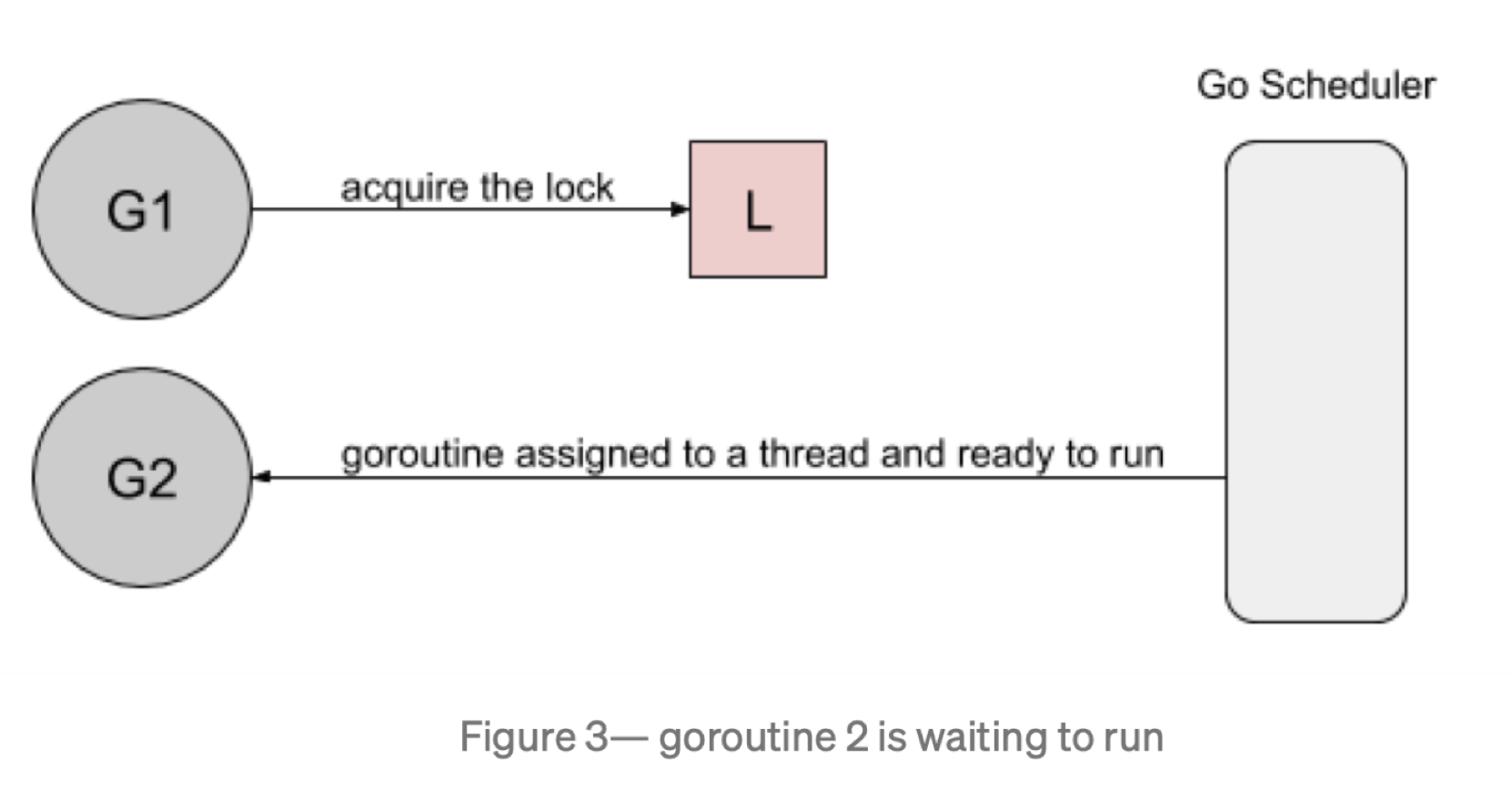
然而,当 goroutine2 等待运行时,goroutine1 将再次请求锁。
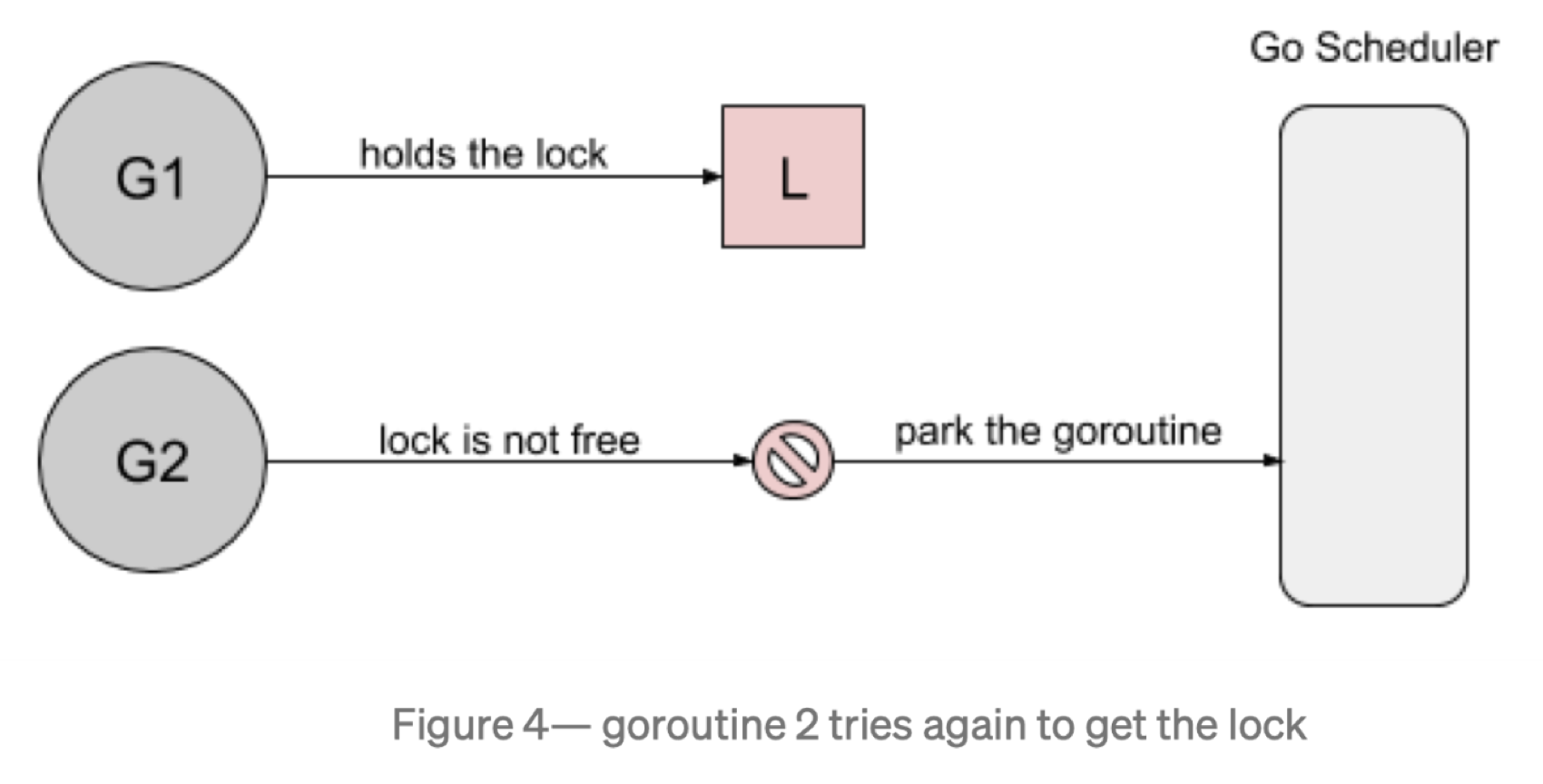
goroutine2 尝试去获取锁,结果发现锁又被人持有了,它自己继续进入到等待模式。
这是由于新请求锁的 goroutine 具有优势(g1):它正在 CPU 上执行,缩放锁之后,立马竞争,再次获得锁。
Mutex锁的实现
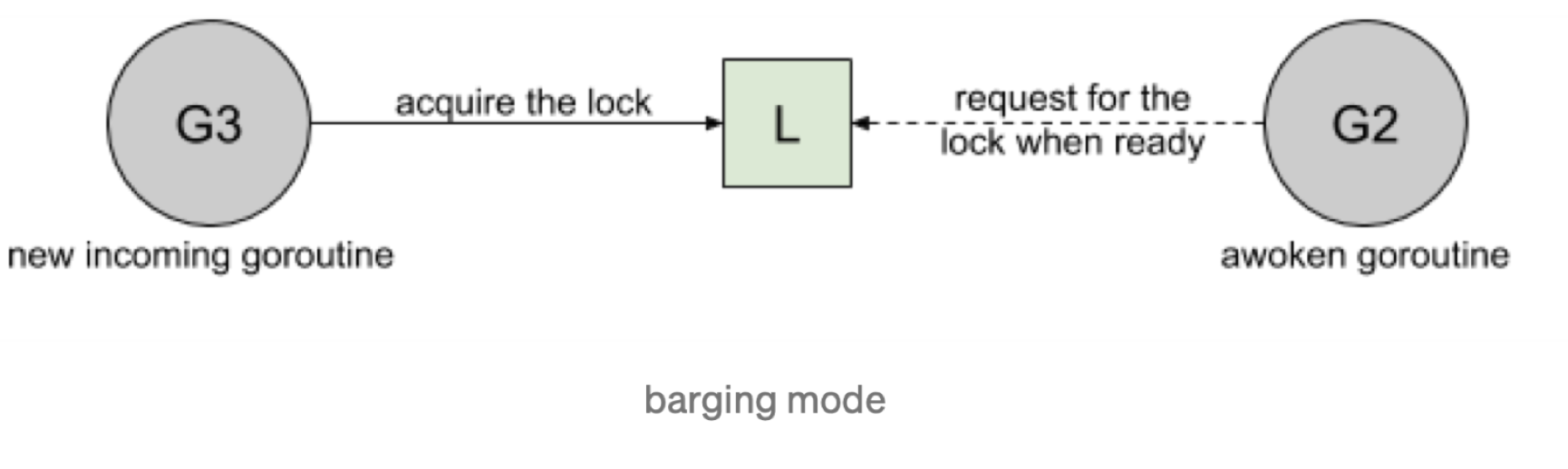
- Barging:这种模式时为了提高吞吐量,当锁被释放时,它会唤醒第一个等待者,然后把锁给第一个等待者或者给第一个请求锁的人。
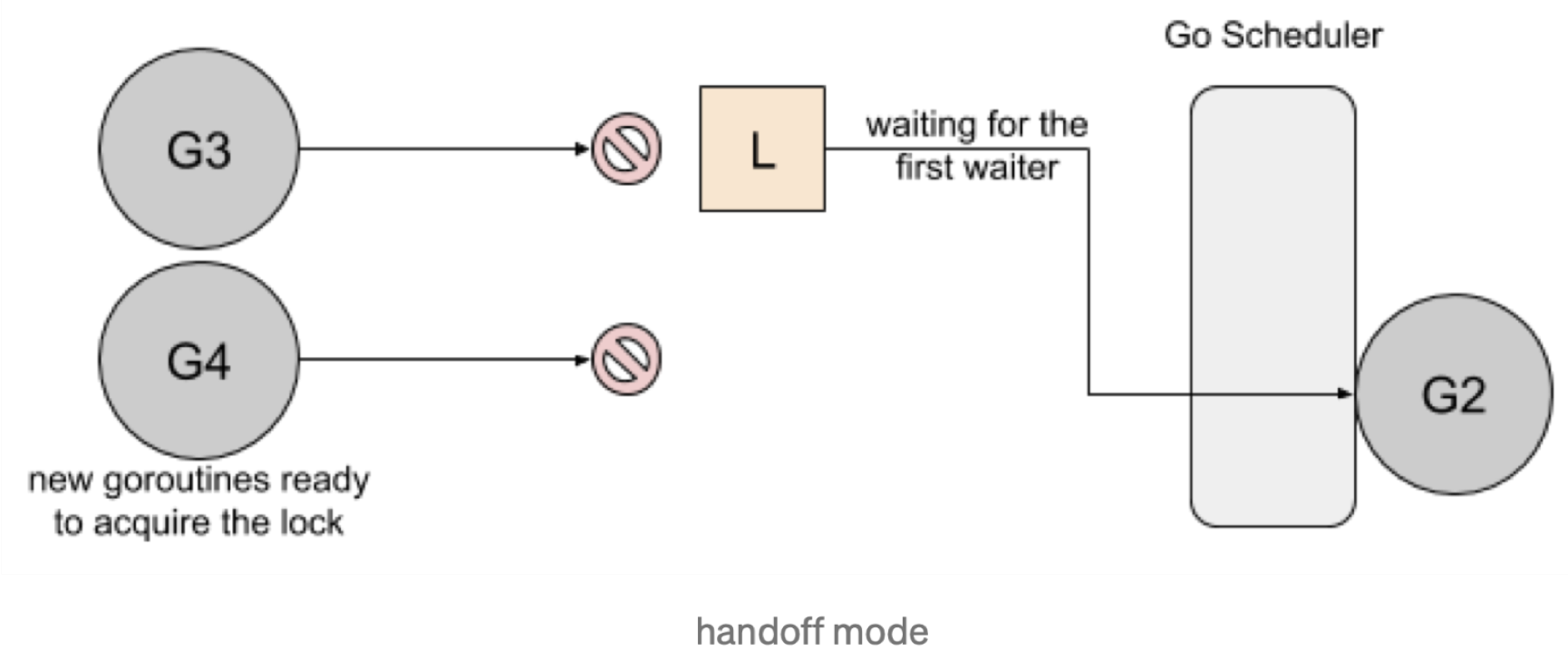
- Handsoff:当锁释放时,锁会一直持有直到第一个等待者准备好获取锁。它降低了吞吐量,因为锁被持有,即使另一个 goroutine 准备获取它。降低吞吐,提高公平。
一个互斥锁的 handsoff 会完美地平衡两个 goroutine 之间的锁分配,但是会降低性能,因为它会迫使第一个 goroutine 等待锁。
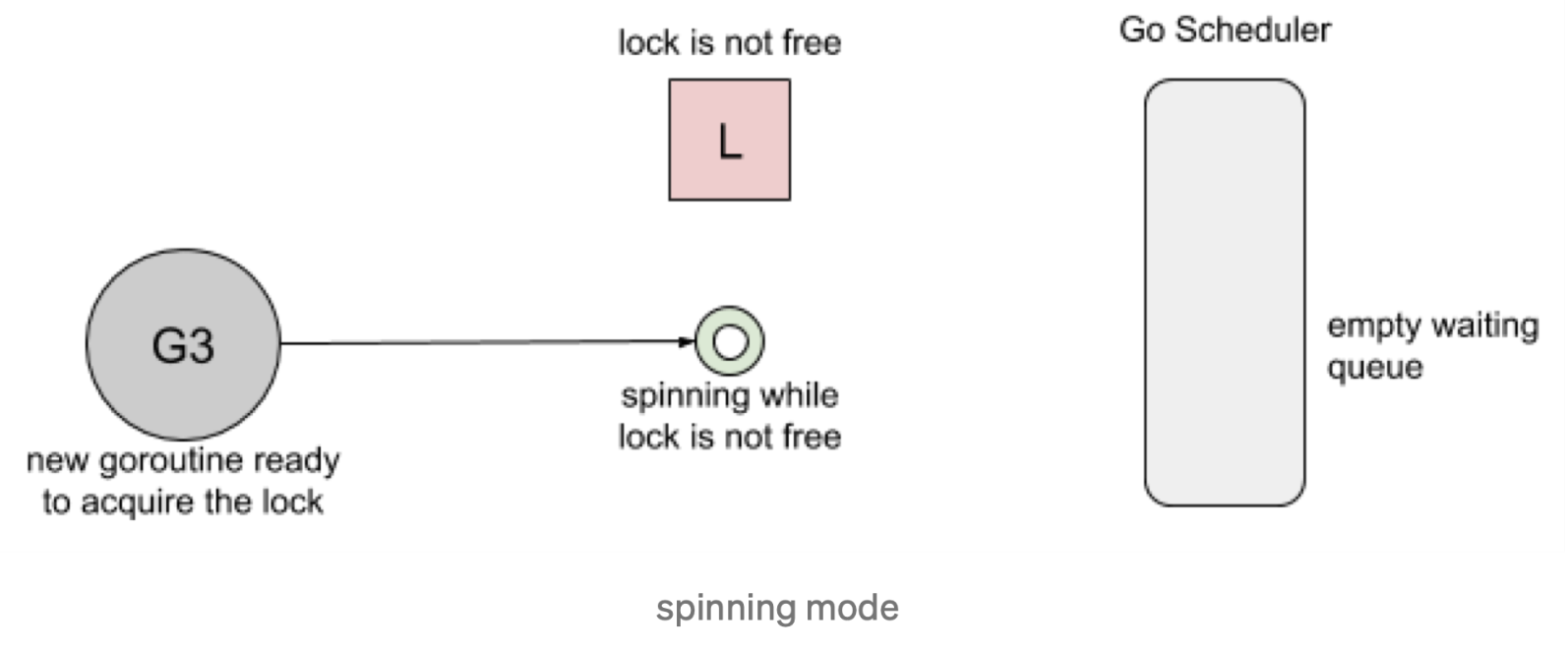
- Spining:自旋,在等待队列为空或者应用程序重度使用锁时效果不错。Parking( goroutine 进入等待队列 ) 和 Unparking(goroutine 从等待队列中被唤醒) goroutine 有不低的性能成本开销,相比自旋来说要慢得多。
Go 1.8使用了 Barging 和 Spining 的结合实现。当试图获取已经被持有的锁时,如果本地队列为空,并且 P 的数量大于1, goroutine 将自旋几次(用一个 P 旋转会阻塞程序)。自旋后,goroutine park。在程序高频使用锁的情况下,它充当了一个快速路径。
Go 1.9 通过增加一个新的饥饿模式来解决先前的公平和开销问题。该模式将会在释放时出发 handsoff。所有等待锁超过 1ms 的goroutine(也被成为有界等待)将被诊断为饥饿。当被标记为饥饿状态时,unlock 方法会 handsoff 把锁直接仍给第一个等待者。
在饥饿模式下,自旋也被停用,因为传入的 goroutine 将没有机会获取为下一个等待者保留的锁。(这样让等待的 goroutine 一定会拿到锁。)

这是由于锁在自旋的过程中,为了保证公平,一段时间没有拿到锁(1ms),会进入饥饿态,进而加大获得锁的概率。
errgroup
把一个复杂的任务,尤其时依赖多个微服务 rpc 需要聚合数据的任务,分解为依赖和并行,依赖的意思为:需要上游 a 的数据才能访问下游 b 的数据进行组合。但是并行的意思为:分解为多个小任务并行执行,最终等全部执行完毕。
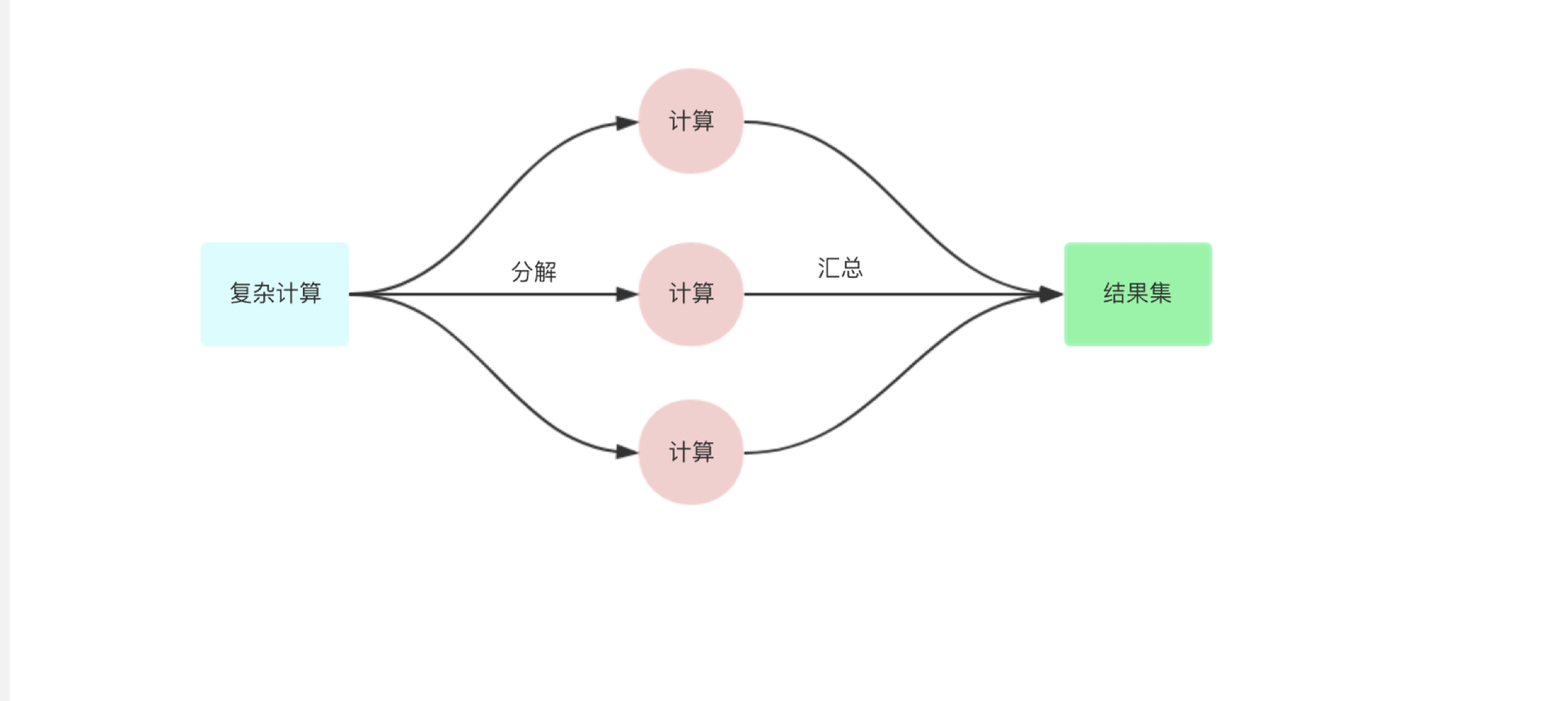
可以使用errgroup
核心原理:利用 sync.Waitgroup 管理,并行执行的 goroutine
优势:
- 并行工作流
- 错误处理 或者 优雅降级
- context 传播和取消
- 利用局部变量 + 闭包
示例
一些注意事项:
- 处理panic
- 派生其他的 goroutine
- 不管有没有报错,都继续执行(避免 context cancel 掉其他的 goroutine )
- 使用 context,而且还在作用域之外使用
Pool
sync.Pool 的场景时用来保存和复用临时对象,以减少内存分配,降低 GC 压力 (Request-Driven 特别合适)。

Get 返回 Pool 中的任意一个对象。如果 Pool 为空,则调用 New 函数返回一个新创建的对象。
放进 Pool 中的对象,会在说不准什么时候被回收到。所以如果事先 Put 进去 100个对象,下次 Get 的时候可能 Pool 是空的。这个特性的一个好处就在于不用担心 Pool 会一直增长,因为 Go 已经帮你在 Pool 中做了回收机制。
因此 sync.Pool 里面只能方能被任意回收的对象,例如内存,套接字,文件DF之类的,而不能放连接池,例如连接池放进去,被GC,则会出现内存泄露。
这个清理过程时在每次垃圾回收之前做的。之前每次 GC 时都会清空 pool,而在 1.13 版本中引入 victim cache ,会将 pool 内数据拷贝一份,避免 GC 将其清空,即使没有引用的内容也可以保留最多两轮 GC。
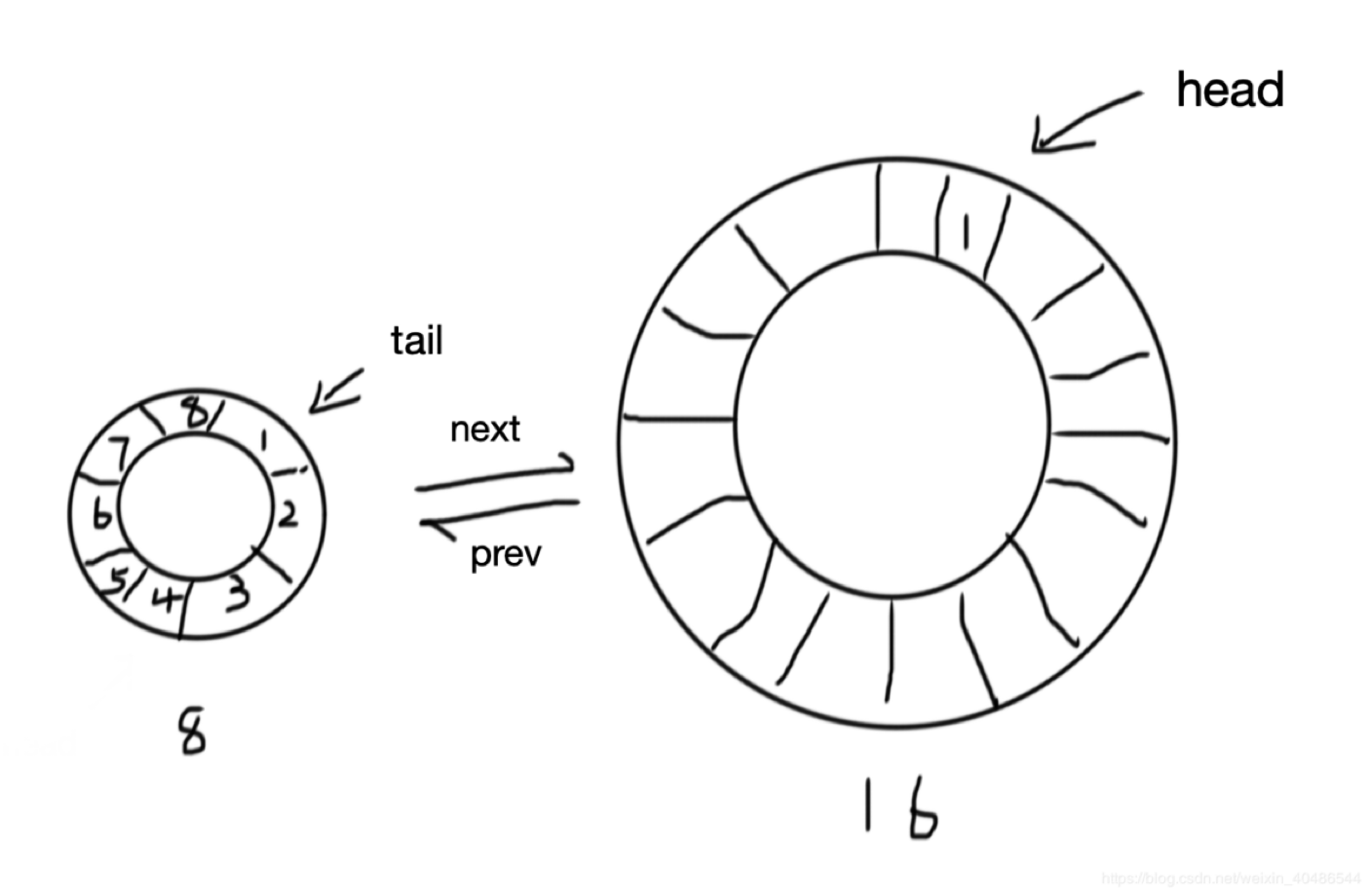
Pool 内部使用环, ring buffer (定长 FIFO)+ 双向链表的方式,头部只能写入,尾部可以并发读取的形式。生成的时候,如果 ring 中存在对象,则直接从尾部读取,如果没有则生成。 写入的时候从头部写入。
踩坑和技巧
sync.XXX
不要在参数里面传递sync.XXX
要么是调用者自己决定,例如方法
要么是方法内部使用
sync.Once
一般会用于比较重的资源的初始化
Double check,在
LoadOrStore()方法返回对象和bool,代表返回老的对象还是新的对象,在方法内部,在加锁的时候,需要注意多个 goroutine 可能会产生冲突,因此需要double check1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17type SafeMap struct {
mutex sync.RWMutex
m map[string]interface{}
}
func (s *SafeMap) LoadOrStore(key string, newValue interface{}) (val interface{}, loaded bool) {
s.mutex.RLock()
val, ok := s.m[key]
s.mutex.RUnlock()
if ok { // 判断OK的时候,就可能有别的 goroutine store新的数据
return val, true
}
s.mutex.Lock()
defer s.mutex.Unlock()
s.m[key] = newValue // 上面的读锁释放后,下面的可能会有多个goroutine store 值
return newValue, false
}使用 double check
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15func (s *SafeMap) LoadOrStore(key string, newValue interface{}) (val interface{}, loaded bool) {
s.mutex.RLock()
val, ok := s.m[key]
s.mutex.RUnlock()
if ok { // 判断OK的时候,就可能有别的 goroutine store新的数据
return val, true
}
s.mutex.Lock()
defer s.mutex.Unlock()
if val, ok = s.m[key]; ok { // 使用double check,虽然可以优化成只加一个互斥锁,但是这种方式不影响在可以读到数据的情况下的性能
return val, true
}
s.m[key] = newValue // 上面的读锁释放后,下面的可能会有多个goroutine store 值
return newValue, false
}也就是 check and do something
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15func (s *SafeMap) CheckAndDoSomething() {
s.mutex.Lock()
// check and do something
s.mutex.Unlock()
}
func (s *SafeMap) CheckAndDoSomething1() {
s.mutex.RLock()
// first check
s.mutex.RUnlock()
s.mutex.Lock()
defer s.mutex.Unlock()
// check and do something
}LoadAndStore 释放资源
在 Load 资源前面需要注意,如果资源创建之后没有 Store 到
map中,需要手动回收,不然会给GC压力。1
2
3
4
5
6
7
8
9
10
11
12
13func TestSafeMap_LoadAndStore(t *testing.T) {
m := &SafeMap{
m: map[string]interface{}{},
}
for i := 0; i < 10; i++ {
go func() {
conn := &connection{}
nc, _ := m.LoadOrStore("hello", conn) // store 进去的 conn 可以正常使用,但是没有 store 进去的 conn 会被丢弃
_ = nc.(*connection).send()
}()
}
}因此,需要根据返回的是否使用
map中的对象,来决定对象是否需要回收1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16func TestSafeMap_LoadAndStore(t *testing.T) {
m := &SafeMap{
m: map[string]interface{}{},
}
for i := 0; i < 10; i++ {
go func() {
conn := &connection{}
nc, loaded := m.LoadOrStore("hello", conn) // store 进去的 conn 可以正常使用,但是没有 store 进去的 conn 会被丢弃
if loaded { // 判断是否是从 map 中 load 的对象
_ = nc.(*connection).Close()
}
_ = nc.(*connection).send()
}()
}
}减轻重量对象创建时的资源
比如一些链接创建的时候会比较重量,因此在创建对象的时候可以传入一个创建函数,在具体需要使用的时候才创建。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18type valProvider func() interface{}
func (s *SafeMap) LoadOrStore(key string, p valProvider) (val interface{}, loaded bool) {
s.mutex.RLock()
val, ok := s.m[key]
s.mutex.RUnlock()
if ok { // 判断OK的时候,就可能有别的 goroutine store新的数据
return val, true
}
s.mutex.Lock()
defer s.mutex.Unlock()
if val, ok = s.m[key]; ok { // 使用double check,虽然可以优化成只加一个互斥锁,但是这种方式不影响在可以读到数据的情况下的性能
return val, true
}
newValue := p() // 在需要创建的时候才会创建,让对象更加轻量
s.m[key] = newValue // 上面的读锁释放后,下面的可能会有多个goroutine store 值
return newValue, false
}这种做法也可以优雅的解决前面创建对象时没有 Load 需要手动回收的问题。
Limiter 限流器
1
2
3
4
5
6
7
8
9type Limiter struct {
limit int // 当前处理请求的上限
handler func(req interface{}) interface{} // 处理请求逻辑
}
// Reject bool 返回值表示究竟有没有执行
func (l Limiter) Reject(req interface{}) (interface{}, bool) {
}v1版本,加锁处理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15type Limiter struct {
limit int // 当前处理请求的上限
handler func(req interface{}) interface{} // 处理请求逻辑
mutex sync.Mutex
}
// Reject bool 返回值表示究竟有没有执行
func (l *Limiter) Reject(req interface{}) (interface{}, bool) {
l.mutex.Lock()
defer l.mutex.Unlock()
res := l.handler(req)
return res, true
}这个版本没有意义,只有一个 goroutine 可以处理请求,也一直都不会拒绝其他请求。
下一个版本,将请求从串行改为可并发
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29package main
import (
"sync"
)
type Limiter struct {
limit int // 当前处理请求的上限
handler func(req interface{}) interface{} // 处理请求逻辑
mutex sync.Mutex
cnt int // 当前正在处理的请求数
}
// Reject bool 返回值表示究竟有没有执行
func (l *Limiter) Reject(req interface{}) (interface{}, bool) {
l.mutex.Lock()
if l.cnt < l.limit {
l.cnt++
l.mutex.Unlock() // 释放锁,让其他的 goroutine 可以处理
res := l.handler(req)
l.mutex.Lock() // 加锁,处理完之后,要减去当前处理的
defer l.mutex.Unlock()
l.cnt--
return res, true
}
l.mutex.Unlock()
return nil, false
}但是这个版本很繁琐。而且一定要加锁,这里优化一下,使用读写锁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40package main
import (
"sync"
)
type Limiter struct {
limit int // 当前处理请求的上限
handler func(req interface{}) interface{} // 处理请求逻辑
mutex sync.RWMutex
cnt int // 当前正在处理的请求数
}
// Reject bool 返回值表示究竟有没有执行
func (l *Limiter) Reject(req interface{}) (interface{}, bool) {
l.mutex.RLock()
if l.cnt > l.limit { // 如果经常命中这个分支,那么性能要好一些
l.mutex.RUnlock()
return nil, false
}
l.mutex.RUnlock()
// 再加写锁
l.mutex.Lock()
if l.cnt > l.limit {
l.mutex.Unlock()
return nil, false
}
l.cnt++
l.mutex.Unlock() // 释放锁,让其他的 goroutine 可以处理
res := l.handler(req)
l.mutex.Lock() // 加锁,处理完之后,要减去当前处理的
defer l.mutex.Unlock()
l.cnt--
return res, true
}频繁加锁,代码繁琐,而且性能不好,可以通过
atomic实现更加轻量的效果。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26package main
import (
"sync"
"sync/atomic"
)
type Limiter struct {
limit int64 // 当前处理请求的上限
handler func(req interface{}) interface{} // 处理请求逻辑
mutex sync.RWMutex
cnt *int64 // 当前正在处理的请求数
}
// Reject bool 返回值表示究竟有没有执行
func (l *Limiter) Reject(req interface{}) (interface{}, bool) {
if atomic.LoadInt64(l.cnt) > l.limit { // 先获取一次
return nil, false
}
atomic.AddInt64(l.cnt, 1) // 没有超过阈值,则+1
defer atomic.AddInt64(l.cnt, -1)
res := l.handler(req)
return res, true
}改用
atomic更加简洁,但是,当多个 goroutine 同时通过第一次判断时,第二次就无法准确哦按端请求数量,还需要 double check 一下。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30package main
import (
"sync"
"sync/atomic"
)
type Limiter struct {
limit int64 // 当前处理请求的上限
handler func(req interface{}) interface{} // 处理请求逻辑
mutex sync.RWMutex
cnt *int64 // 当前正在处理的请求数
}
// Reject bool 返回值表示究竟有没有执行
func (l *Limiter) Reject(req interface{}) (interface{}, bool) {
if atomic.LoadInt64(l.cnt) > l.limit { // 先获取一次
return nil, false
}
// double check
cnt := atomic.AddInt64(l.cnt, 1)
defer atomic.AddInt64(l.cnt, -1)
if cnt > l.limit {
return nil, false
}
res := l.handler(req)
return res, true
}这个代码还可以更加简洁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26package main
import (
"sync"
"sync/atomic"
)
type Limiter struct {
limit int64 // 当前处理请求的上限
handler func(req interface{}) interface{} // 处理请求逻辑
mutex sync.RWMutex
cnt *int64 // 当前正在处理的请求数
}
// Reject bool 返回值表示究竟有没有执行
func (l *Limiter) Reject(req interface{}) (interface{}, bool) {
cnt := atomic.AddInt64(l.cnt, 1)
defer atomic.AddInt64(l.cnt, -1)
if cnt > l.limit {
return nil, false
}
res := l.handler(req)
return res, true
}单向幂等修改
比如关闭服务器的时候,方filter拒绝所有的新请求。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24package main
import (
"sync/atomic"
)
type filter struct {
// 处理请求
handler func(req interface{}) interface{}
// 0 代表不拒绝,不为0代表拒绝
reject int32
}
func (f *filter) Handler(req interface{}) (interface{}, bool) {
if atomic.LoadInt32(&f.reject) > 0 { // 每一个请求都检验
return nil, false
}
return f.handler(req), true
}
func (f *filter) RejectNewRequest() {
atomic.StoreInt32(&f.reject, 1)
}但是,这个逻辑可以直接使用并发操作,直接修改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20package main
type filter struct {
// 处理请求
handler func(req interface{}) interface{}
// 0 代表不拒绝,不为0代表拒绝
reject int32
}
func (f *filter) Handler(req interface{}) (interface{}, bool) {
if f.reject > 0 { // 每一个请求都检验
return nil, false
}
return f.handler(req), true
}
func (f *filter) RejectNewRequest() {
f.reject = 1
}只要接受可见性的短暂延迟,就没啥问题。
锁保护资源
使用锁保护资源的时候,需要将锁和资源结合在一起
1
2
3
4// PublicResource 永远不知道用户拿了它会干啥
// 即使调用者不使用 PublicResourceLock 也没有办法
var PublicResource interface{}
var PublicResourceLock sync.Mutex推荐写法
1
2
3
4
5
6
7
8
9
10type safeResource struct {
resource interface{}
lock sync.Mutex
}
func (s *safeResource) DoSomething() {
s.lock.Lock()
defer s.lock.Unlock()
s.resource
}不用锁,如何实现线程安全。
可以使用使用分割线,第一部分写入,第二部分读取使用。两个部分不会同时使用 goroutine 即可
1
2
3
4
5
6
7
8
9
10
11type Registry struct {
resources map[string]interface{}
}
func (r *Registry) Register(name string, resource interface{}) {
r.resources[name] = resource
}
func (r *Registry) Get(name string) (interface{}, error) {
return r.resources[name], nil
}使用的时候,先注册(不能并发写入),然后使用的时候可以安全并发读取。
可见性
在多核CPU上,由于CPU有本地缓存,导致其他CPU要通过读屏障和写屏障获取到最新数据
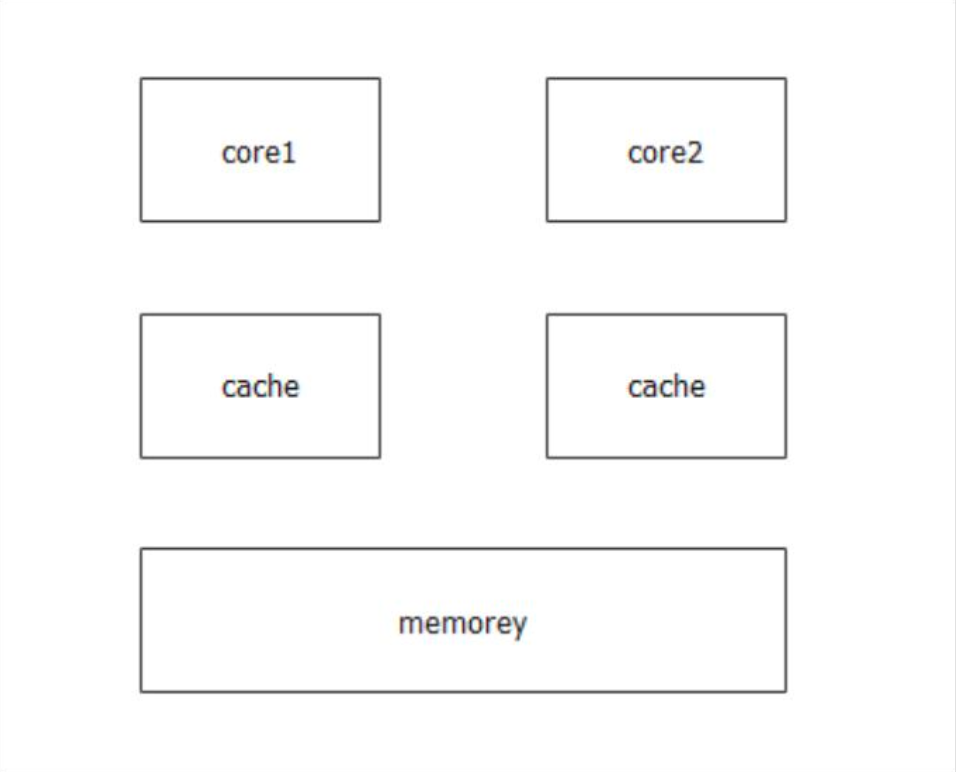
这个架构其实与本地存储非常像
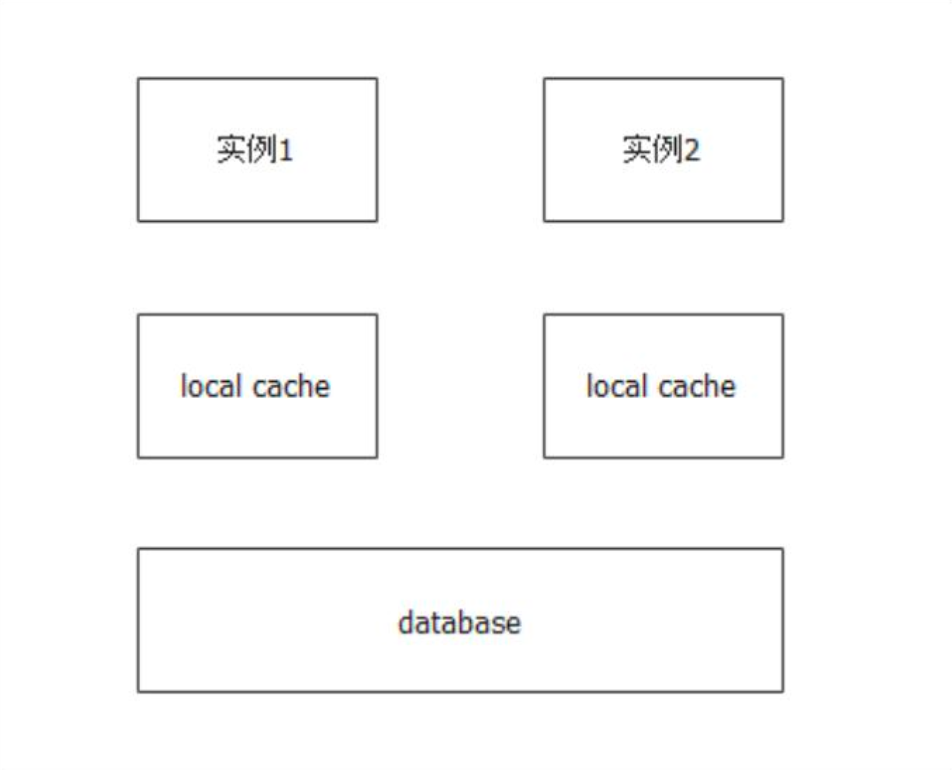
- 如果只是修改本地缓存,别的实例肯定感知不到
- 如果修改了班底缓存,还写回去了数据库,别的实例也不一定能看到,因为它们自身缓存还没过期
- 写回去数据库之后,还要通知别的实例让缓存过期,重新加载
理解锁
这可能是最容易理解的 Go Mutex 源码剖析

一些面试题
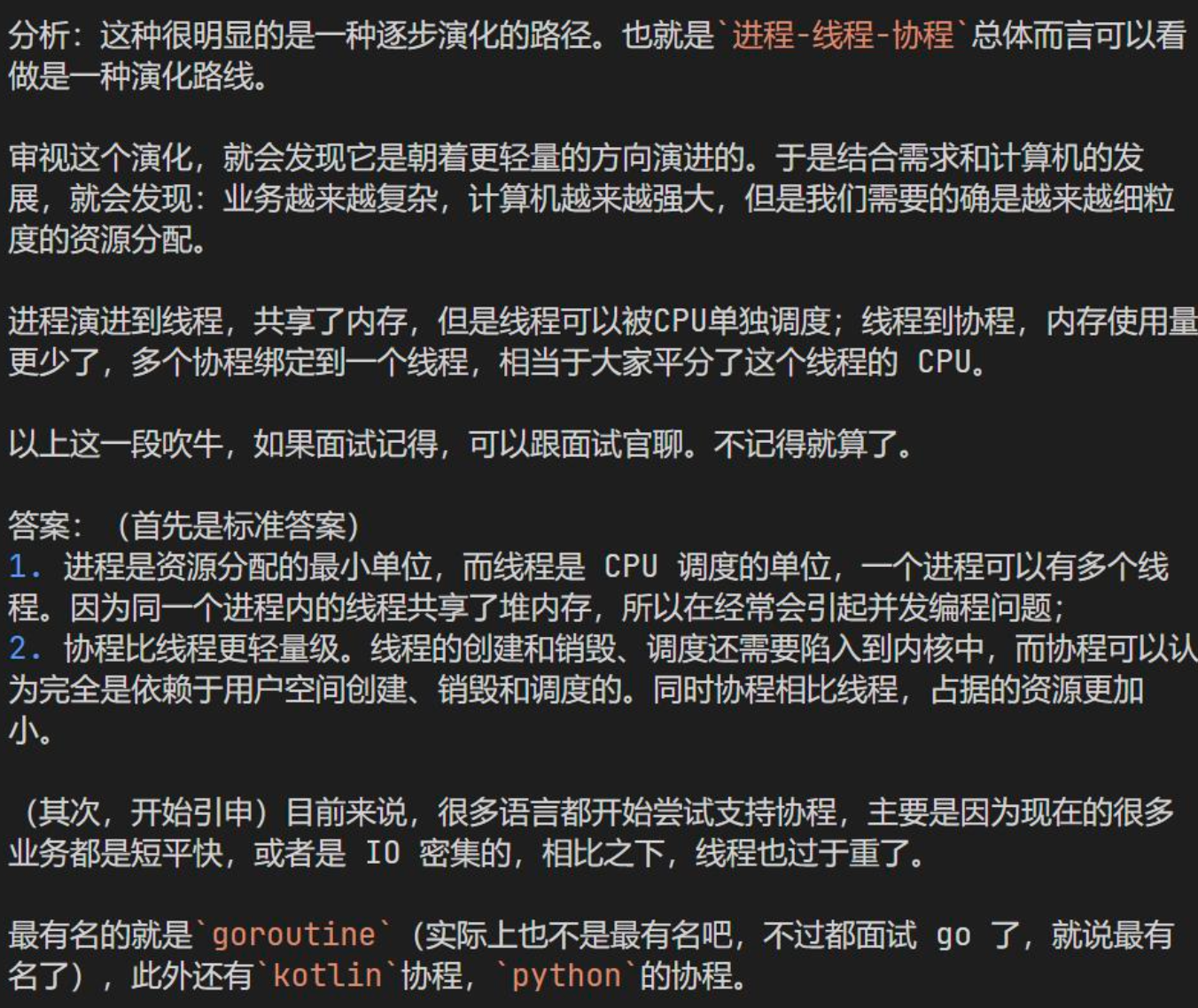
进程、线程和协程的不同
![image-20230924223924892]()
为什么引入协程
![image-20231018112824649]()
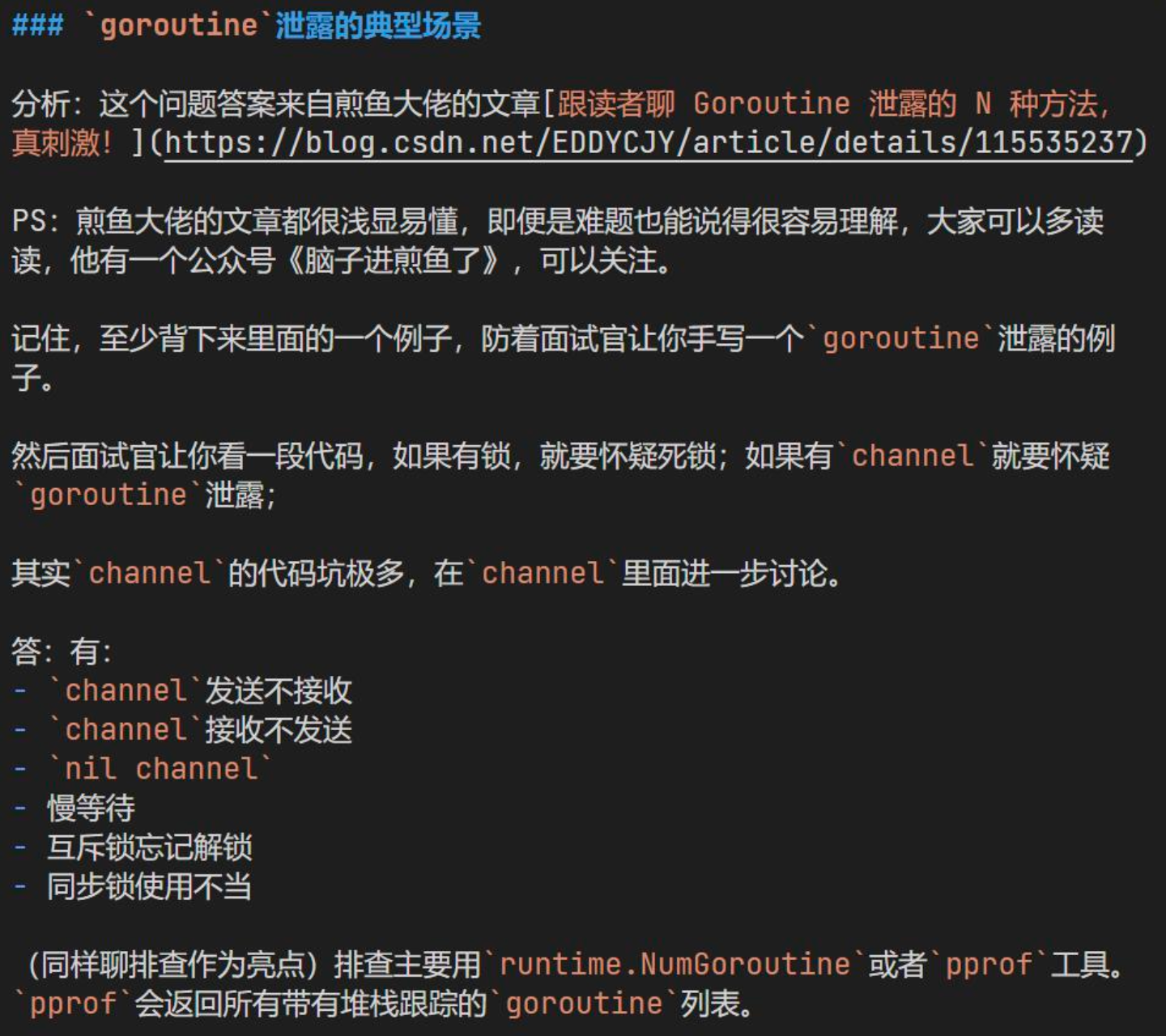
goroutine 泄露的典型场景
![image-20231018112846040]()
跟读者聊 Goroutine 泄露的 N 种方法,真刺激!
怎么避免 goroutine 泄露
![image-20231018112912780]()
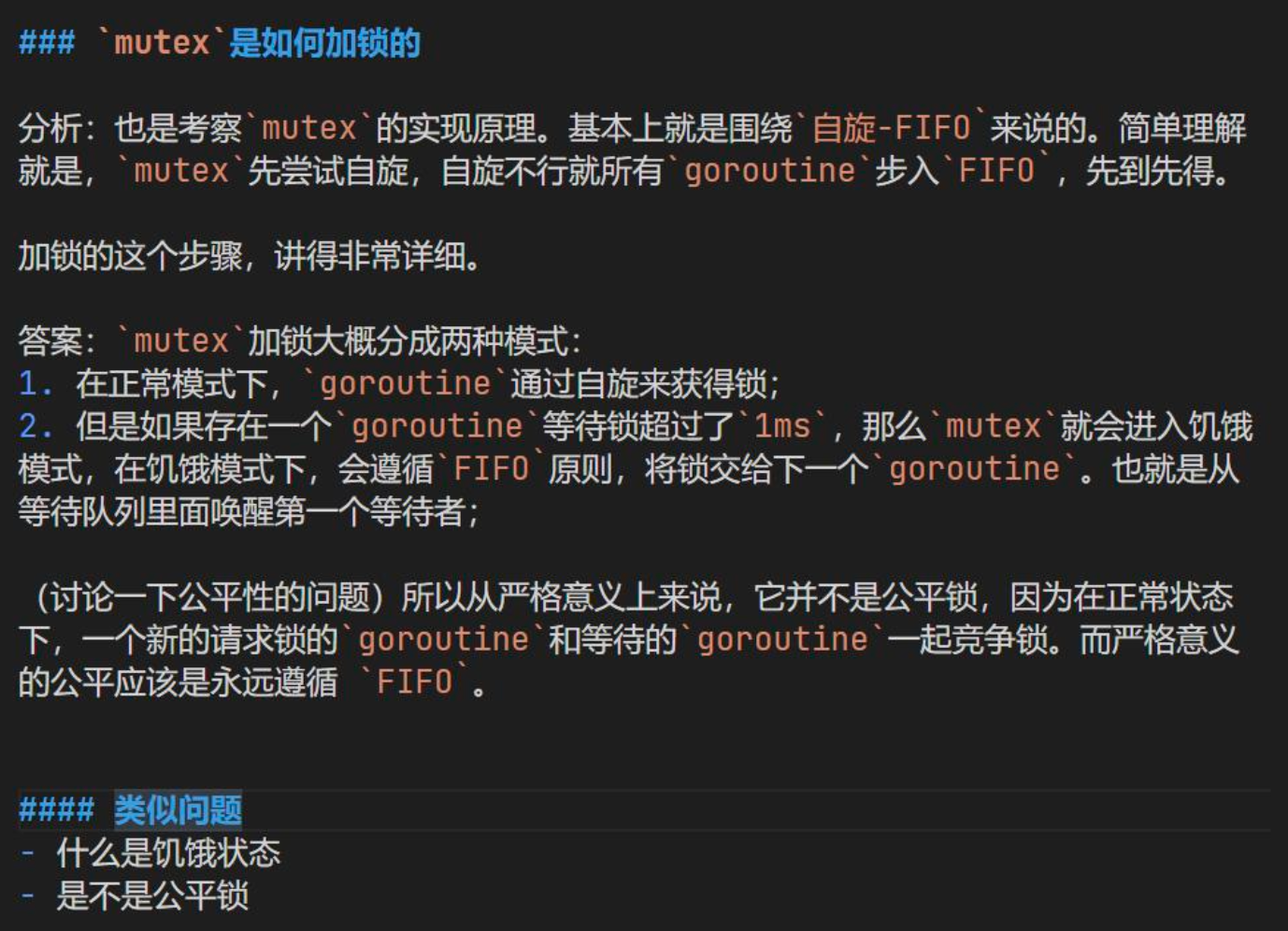
mutex 加锁
![image-20230924225652184]()


推荐阅读
If aligned memory writes are atomic, why do we need the sync/atomic package?
Introducing the Go Race Detector
Ice cream makers and data races
Ice Cream Makers and Data Races Part II
Go: How to Reduce Lock Contention with the Atomic Package
Go: Discovery of the Trace Package
Go: Mutex and Starvation
medium 无法看完整内容推荐使用 https://canererden.com/blog/2023/unlock-medium/
PS:好像有方法说用 twitter 也可以突破限制。