Zookeeper 学习笔记
基础
ZooKeeper 是一个分布式的,开放源码的分布式应用程序协同服务。
ZooKeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
概述
发展历史
ZooKeeper 最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协同,但是这些系统往往都存在分布式单点问题。
所以,雅虎的开发人员就开发了一个通用的无单点问题的分布式协调框架,这就是ZooKeeper。ZooKeeper 之后在开源界被大量使用,下面列出了 3 个著名开源项目是如何使用 ZooKeeper:
- Hadoop:使用 ZooKeeper 做 Namenode的高可用。
- HBase:保证集群中只有一个 master,保存
hbase:meta表的位置,保存集群中的 RegionServer 列表。 - Kafka:集群成员管理,controller 节点选举。
应用场景
典型应用场景:
- 配置管理(configuration management)
- DNS 服务
- 组成员管理(HBase:groupmembership)
- 各种分布式锁
ZooKeeper 适用于存储和协同相关的关键数据,不适合用于大数据量存储。
实现 Master-Worker 协同
master-worker 架构
master-work 是一个广泛使用的分布式架构。 master-work架构中有一个 master 负责监控 worker 的状态,并为worker分配任务。
在任何时刻,系统中最多只能有一个master,不可以出现两个master的情况,多个master共存会导致脑裂。
系统中除了处于active状态的master还有一个bakcupmaster,如果activemaster失败了,backupmaster可以很快的进入active状态。
master实时监控worker的状态,能够及时收到worker成员变化的通知。master在收到worker成员变化的时候,通常重新进行任务的重新分配。

示例1- HBase

HBase采用的是master-worker的架构。HMBase是系统中的master,HRegionServer是系统中的worker。
HMBase监控HBaseCluster中worker的成员变化,把region分配给各个HRegionServer 。系统中有一个HMaster处于active状态,其他HMaster处于备用状态。
示例2-Kafka

一个Kafka集群由多个broker组成,这些borker是系统中的worker。Kafka会从这些worker选举出一个controller,这个controlle是系统中的master,负责把topic partition分配给各个broker。
示例3- HDFS

HDFS采用的也是一个master-worker的架构,NameNode是系统中的master,DataNode是系统中的worker。
NameNode用来保存整个分布式文件系统的metadata,并把数据块分配给cluster中的DataNode进行保存。
使用ZooKeeper实现master-worker

- 使用一个临时节点
/master表示 master。master 在行使 master 的职能之前,首先要创建这个 znode。如果能创建成功,进入 active 状态,开始行使 master 职能。否则的话,进入 backup 状态,使用 watch 机制监控/master。假设系统中有一个active master 和一个 backup master。如果 active master 失败,它创建的/master就会被 ZooKeeper 自动删除。这时 backup master 就会收到通知,通过再次创建 /master 节点成为新的 active master。 - worker 通过在 /workers 下面创建临时节点来加入集群。
- 处于 active 状态的 master 会通过 watch 机制监控 /workers 下面 znode 列表来实时获取 worker 成员的变化。
服务说明
应用使用 ZooKeeper 客户端库使用 ZooKeeper 服务。
ZooKeeper 客户端负责和 ZooKeeper 集群的交互。

数据模型

ZooKeeper 的数据模型是层次模型(Google Chubby也是这么做的)。
层次模型常见于文件系统。层次模型和 key-value 模型是两种主流的数据模型。
ZooKeeper 使用文件系统模型主要基于以下两点考虑:
- 文件系统的树形结构便于表达数据之间的层次关系。
- 文件系统的树形结构便于为不同的应用分配独立的命名空间(namespace)。
ZooKeeper 的层次模型称作 data tree。Data tree 的每个节点叫作 znode。不同于文件系统,每个节点都可以保存数据。每个节点都有一个版本(version)。版本从 0 开始计数。
data tree 示例

在上图所示的 data tree 中有两个子树,一个用于应用1(/app1)和另一个用于应用2(/app2)。
应用1的子树实现了一个简单的组成员协议:每个客户端进程 pi 创建一个znode p_i 在 /app1 下,只要 /app1/p_i 存在就代表进程 pi 在正常运行。
data tree 接口
ZooKeeper 对外提供一个用来访问 data tree 的简化文件系统 API:
- 使用 UNIX 风格的路径名来定位 znode,例如 /A/X 表示 znode A的子节点 X。
- znode 的数据只支持全量写入和读取,没有像通用文件系统那样支持部分写入和读取。
- data tree 的所有 API 都是 wait-free 的,正在执行中的 API 调用不会影响其他 API 的完成。
- data tree 的 API 都是对文件系统的 wait-free 操作,不直接提供锁这样的分布式协同机制。但是 data tree 的 API 非常强大,可以用来实现多种分布式协同机制。
znode分类
一个 znode 可以使持久性的,也可以是临时性的:
- 持久性的 znode (
PERSISTENT):ZooKeeper 宕机,或者 client 宕机,这个 znode 一旦创建就不会丢失。 - 临时性的 znode (
EPHEMERAL):ZooKeeper 宕机了,或者 client 在指定的 timeout 时间内没有连接 server,都会被认为丢失。
znode 节点也可以是顺序性的。每一个顺序性的 znode 关联一个唯一的单调递增整数。这个单调递增整数是 znode 名字的后缀。如果上面两种 znode 具备顺序性,又有以下两种 znode:
持久顺序性的 znode(
PERSISTENT_SEQUENTIAL): znode 除了具备持久性 znode 的特点之外,znode 的名字具备顺序性。临时顺序性的 znode(
EPHEMERAL_SEQUENTIAL): znode 除了具备临时性 znode 的特点之外,znode的名字具备顺序性。
ZooKeeper 主要有以上 4 种 znode。
入门
安装
https://zookeeper.apache.org/
- 唯一的依赖是 JDK7+。
- 到 https://zookeeper.apache.org/releases.html 下载 ZooKeeper,目前的最新版是 3.9.2。(推荐使用迅雷)
- 把 apache-zookeeper-3.9.2-bin.tar.gz 解压到一个本地目录 (目录名最好不要包含空格和中文)。
- 进入 apache-zookeeper-3.9.2-bin 目录中,根据示例配置文件创建 conf/zoo.cfg。
cp zoo_sample.cfg zoo.cfg - 配置以下环境变量,以便操作
1 | export ZOOKEEPER_HOME="$HOME/xxx/apache-zookeeper-3.9.2-bin" |
启动
注意两个配置:
1 | dataDir=/tmp/zookeeper # 表示数据存储目录,存放日志文件和快照文件;建议修改,tmp 目录重启会清空 |
使用 zkServer.sh start 启动 ZooKeeper 服务。
1
2
3
4
5# zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /root/mitaka/apache-zookeeper-3.9.2-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED检查 ZooKeeper 日志是否有出错信息。
1
grep -E -i "((exception)|(error))" zookeeper-root-server-master.out
检查 ZooKeeper 数据文件。
1
2
3
4
5
6
7# tree .
.
├── version-2
│ └── snapshot.0 # 快照文件
└── zookeeper_server.pid # 生命文件
1 directory, 2 files检查 ZooKeeper 是否在 2181 端口上监听。
1
2# netstat -tanple | grep 2181
tcp6 0 0 :::2181 :::* LISTEN 0 52999 3764/java
zkCli.sh 一些常用命令
执行 zkCli.sh 进入 zk 交互命令行
1 | help # 打印帮助 |
实现一个锁
分布式锁要求:如果锁的持有者宕了,锁可以被释放。
ZooKeeper 的 ephemeral 节点恰好具备这样的特性。
终端1:
1 | create -e /lock # -e 表示临时 znode |
终端 2
1 | create -e /lock # 加锁出现报错 |
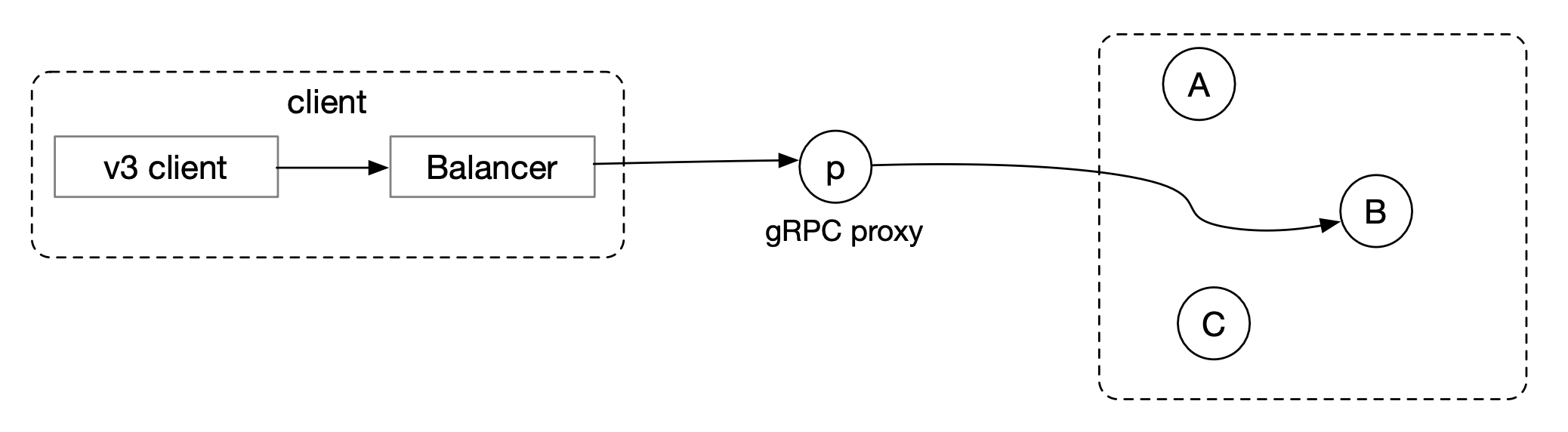
总体架构
应用使用 ZooKeeper 客户端库使用 ZooKeeper 服务。 ZooKeeper 客户端负责和 ZooKeeper 集群的交互。
ZooKeeper 集群可以有两种模式:standalone 模式和 quorum 模式。
- 处于 standalone 模式的 ZooKeeper 集群只有一个独立运行的 ZooKeeper 节点(会有单点故障)
- 处于 quorum 模式的 ZooKeeper 集群包换多个 ZooKeeper 节点。

Session
ZooKeeper 客户端库和 ZooKeeper 集群中的节点创建一个 session。客户端可以主动关闭 session。另外如果ZooKeeper 节点没有在 session 关联的 timeout 时间内收到客户端的数据的话, ZooKeeper 节点也会关闭 session。
另外 ZooKeeper 客户端库如果发现连接的 ZooKeeper 出错,会自动的和其他 ZooKeeper 节点建立连接。

Quorum模式
处于 Quorum 模式的 ZooKeeper 集群包含多个 ZooKeeper 节点。
下图的 ZooKeeper 集群有 3 个节点,其中节点 1 是 leader 节点,节点 2 和节点 3 是 follower 节点。
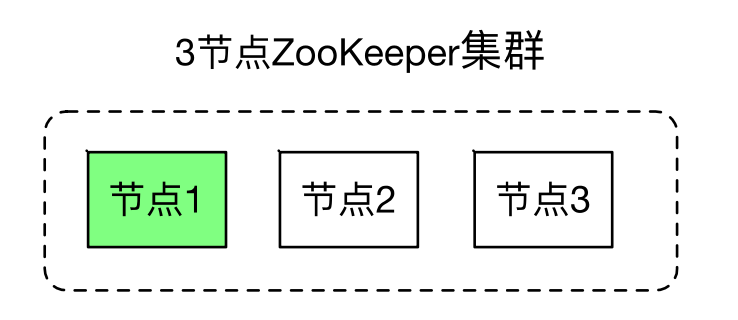
leader 节点可以处理读写请求,follower 只可以处理读请求。 follower 在接到写请求时会把写请求转发给 leader 来处理。
数据一致性
- 可线性化(Linearizable)写入:先到达 leader 的写请求会被先处理,leader 决定写请求的执行顺序。
- 客户端 FIFO 顺序:来自给定客户端的请求按照发送顺序执行。
3节点 quorum 模式集群
在一台服务器上运行三个进程模拟 quorum 集群,需要准备 3 个配置文件:
节点 1 配置文件改动:
1 | dataDir=/root/mitaka/apache-zookeeper-3.9.2-bin/data1 |
节点 2 配置文件改动:
1 | dataDir=/root/mitaka/apache-zookeeper-3.9.2-bin/data2 |
节点 3 配置文件改动:
1 | dataDir=/root/mitaka/apache-zookeeper-3.9.2-bin/data3 |
在三个 data 目录中创建 myid 文件,其中存放对应节点的 id
1 | vim data1/myid |
使用以下命令依次启动每个进程:
1 | zkServer.sh start-foreground zoo1.cfg |
start-foreground 选项 zkServer.sh 在前台运行,把日志直接打到 console。如果把日志打到文件的话,这三个 zkServer.sh 会把日志打到同一个文件。
节点日志:
第一个进程启动时,由于其他进程没有启动,日志中可以看到
1 | 2024-04-01 15:40:59,188 [myid:] - WARN [QuorumConnectionThread-[myid=1]-2:o.a.z.s.q.QuorumCnxManager@401] - Cannot open channel to 2 at election address /127.0.0.1:4445 |
其他节点启动后,可以看到选举过程
1 | 2024-04-01 15:42:21,657 [myid:] - INFO [QuorumPeer[myid=1](plain=[0:0:0:0:0:0:0:0]:2181)(secure=disabled):o.a.z.s.q.QuorumPeer@906] - Peer state changed: following |
节点 1 变成 following,节点 2 变成 leading。
客户端连接
1 | zkCli.sh -server 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183 |
从日志中可以看到与 2182 端口,也就是节点 2 建立连接
1 | 2024-04-01 15:49:41,305 [myid:127.0.0.1:2182] - INFO [main-SendThread(127.0.0.1:2182):o.a.z.ClientCnxn$SendThread@998] - Socket connection established, initiating session, client: /127.0.0.1:43608, server: localhost/127.0.0.1:2182 |
关闭节点 2
1 | [zk: 127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183(CONNECTED) 0] 2024-04-01 15:50:42,511 [myid:127.0.0.1:2182] - WARN [main-SendThread(127.0.0.1:2182):o.a.z.ClientCnxn$SendThread@1285] - Session 0x200005092d90000 for server localhost/127.0.0.1:2182, Closing socket connection. Attempting reconnect except it is a SessionExpiredException. |
客户端自动与 2181 端口也就是节点 1 建立连接
开发
通过 Java 语言作为客户端与 ZooKeeper 交互。
https://zookeeper.apache.org/doc/r3.9.2/javaExample.html
https://github.com/go-zookeeper/zk
API
ZooKeeper 类
ZooKeeper Java 代码主要使用 org.apache.zookeeper.ZooKeeper 这个类使用 ZooKeeper 服务。
1 | ZooKeeper(connectString, sessionTimeout, watcher) |
connectString:使用逗号分隔的列表,每个 ZooKeeper 节点是一个host:port对,host 是机器名或者 IP 地址,port 是 ZooKeeper 节点使用的端口号。 会任意选取 connectString 中的一个节点建立连接。sessionTimeout:session timeout 时间。watcher:用于接收到来自 ZooKeeper 集群的所有事件。
ZooKeeper 主要方法
create(path, data, flags)创建一个给定路径的 znode,并在 znode 保存data[]的数据,flags 指定 znode 的类型。delete(path, version):如果给定 path 上的 znode 的版本和给定的 version 匹配,删除 znode。exists(path, watch):判断给定 path 上的 znode 是否存在,并在 znode 设置一个 watch。getData(path, watch):返回给定 path 上的 znode 数据,并在 znode 设置一个 watch。setData(path, data, version):如果给定 path 上的 znode 的版本和给定的 version 匹配,设置 znode 数据。getChildren(path, watch):返回给定 path 上的 znode 的孩子 znode 名字,并在 znode 设置一个 watch。sync(path):把客户端 session 连接节点和 leader 节点进行同步。
方法说明
- 所有获取 znode 数据的 API 都可以设置一个 watch 用来监控 znode 的变化。
- 所有更新 znode 数据的 API 都有两个版本: 无条件更新版本和条件更新版本。如果 version 为 -1,更新为条件更新。否则只有给定的 version 和 znode 当前的 version 一样,才会 进行更新,这样的更新是条件更新。
- 所有的方法都有同步和异步两个版本。同步版本的方法发送请求给 ZooKeeper 并等待服务器的响应。异步版本把请求放入客户端的请求队列,然后马上返回。异步版本通过 callback 来接受来 自服务端的响应。
代码异常处理
所有同步执行的 API 方法都有可能抛出以下两个异常:
KeeperException: 表示 ZooKeeper 服务端出错。KeeperException 的子类 ConnectionLossException 表示客户端和当前连接的 ZooKeeper 节点断开了连接。网络分区 和 ZooKeeper 节点失败都会导致这个异常出现。
发生此异常的时机可能是在 ZooKeeper 节点处 理客户端请求之前,也可能是在 ZooKeeper 节点处理客户端请求之后。
出现 ConnectionLossException 异常之后,客户端会进行自动重新连接,但是我们必须要检查我们 以前的客户端请求是否被成功执行。
InterruptedException:表示方法被中断了。我们可以使用Thread.interrupt()来中断 API 的执行。
数据读取 API
示例 - getData
有以下三个获取 znode 数据的方法:
byte[] getData(String path, boolean watch, Stat stat)同步方法。如果 watch 为 true,该 znode 的状态变化会发送给构建 ZooKeeper 是指定的 watcher。
void getData(String path, boolean watch, DataCallback cb, Object ctx)
异步方法。cb 是一个 callback,用来接收服务端的响应。ctx 是提供给 cb 的 context。 watch 参数的含义和方法 1 相同。void getData(String path, Watcher watcher, DataCallback cb, Object ctx)异步方法。 watcher 用来接收该 znode 的状态变化。
数据写入 API
示例 - setData
Stat setData(String path, byte[] data, int version)同步版本。如果 version 是 -1,做无条件更新。如果 version 是非 0 整数,做条件更新。
void setData(String path, byte[] data, int version, StatCallback cb, Object ctx)异步版本。
watch
watch 提供一个让客户端获取最新数据的机制。如果没有 watch 机制,客户端需要不断的轮询 ZooKeeper 来查看是否有数据更新,这在分布式环境中是非常耗时的。
客户端可以在读取数据的时候设置一个 watcher,这样在数据更新时,客户端就会收到通知。

条件更新
设想用 znode /c 实现一个 counter,使用 set 命令来实现自增 1 操作。条件更新场景:

- 客户端1把/c更新到版本1,实现/c的自增1。
- 客户端2把/c更新到版本2,实现/c的自增1。
- 客户端 1 不知道 /c 已经被客户端 2 更新过了,还用过时的版本 1 是去更新 /c,更新失败。如果客户端 1 使用的是无条件更新,/c 就会更新为 2,没有实现自增 1 。
使用条件更新可以避免对数据基于过期的数据进行数据更新操作。
分布式队列
通过 ZooKeeper Recipes 实现一个分布式队列
https://zookeeper.apache.org/doc/r3.5.5/recipes.html#sc_recipes_Queues
设计

使用路径为 /queue 的 znode 下的节点表示队列中的元素。
/queue 下的节点都是顺序持久化 znode。
这些 znode 名字的后缀数字表示了对应队列元素在队列中的位置。
Znode 名字后缀数字越小,对应队列元素在队列中的位置越靠前。
offer 方法
offer 方法在 /queue 下面创建一个顺序 znode。
因为 znode 的后缀数字是 /queue 下面现有 znode 最大后缀数字加 1,所以该 znode 对应的队列元素处于队尾。(也就是持久的顺序节点)
element 方法
element 方法返回队尾的一个元素。
element 方法有以下两种返回的方式,要么里面没有元素,队列为空;要么有元素,返回最上面的一个元素:
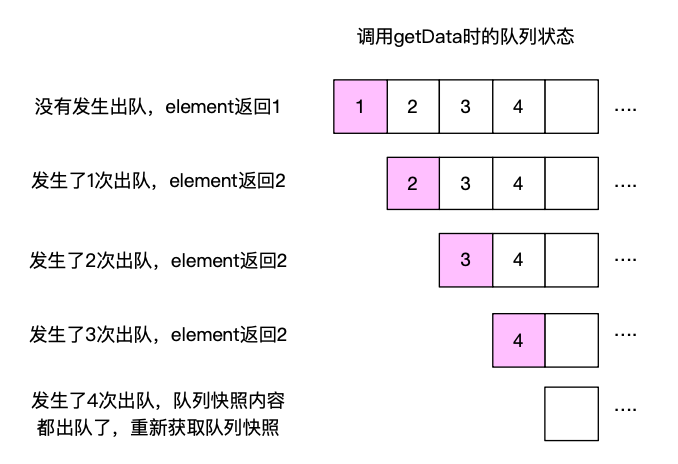
throw new NoSuchElementException():因为 element 方法读取到了队列为空的状态,所以抛出 NoSuchElementException 是正确的。return zookeeper.getData(dir+"/"+headNode, false, null): childNames 保存的是队列内容的一个快照。这个 return 语句返回快照中还没出队。如果队列快照的元素都出队了,重试。
remove 方法
remove 方法返回队尾的元素,并且将这个元素从队尾中删除。
remove 方法和 element 方法类似。值得注意的是 getData 的成功执行不意味着:出队成功,原因是该队列元素可能会被其他用户出队。
1 | byte[] data = zookeeper.getData(path, false, null); |

分布式锁
使用 ZooKeeper Recipes 实现分布式锁
https://zookeeper.apache.org/doc/r3.5.5/recipes.html#sc_recipes_Locks
设计
使用临时顺序 znode 来表示获取锁的请求,创建最小后缀数字 znode 的用户成功拿到锁。

避免羊群效应(herd effect)
把锁请求者按照后缀数字进行排队,后缀数字小的锁请求者先获取锁。如果所有的锁请求者都 watch 锁持有者,当代表锁请求者的 znode 被删除以后,所有的锁请求者都会通知到,但是只有一个锁请求者能拿到锁。这就是羊群效应。
为了避免羊群效应,每个锁请求者 watch 它前面的锁请求者。每次锁被释放,只会有一个锁请求者会被通知到。这样做还让锁的分配具有公平性,锁定的分配遵循先到先得的原则。

选举
通过 ZooKeeper Recipes 实现选举功能
https://zookeeper.apache.org/doc/r3.5.5/recipes.html#sc_leaderElection
设计
使用临时顺序 znode 来表示选举请求,创建最小后缀数字 znode 的选举请求成功。在协同设计上和分布式锁是一样的,不同之处在于具体实现。不同于分布式锁,选举的具体实现对选举的各个阶段做了监控。

使用 Apache Curator 简化 ZooKeeper 开发
Apache Curator 是 Apache ZooKeeper 的 Java 客户端库。
Curator 项目的目标是简化ZooKeeper 客户端的使用。例如,要自己处理 ConnectionLossException 。
另外 Curator 为常见的分布式协同服务提供了高质量的实现。
Apache Curator 最初是 Netflix 研发的,后来捐献给了 Apache 基金会,目前是 Apache 的 顶级项目。
Curator 技术栈
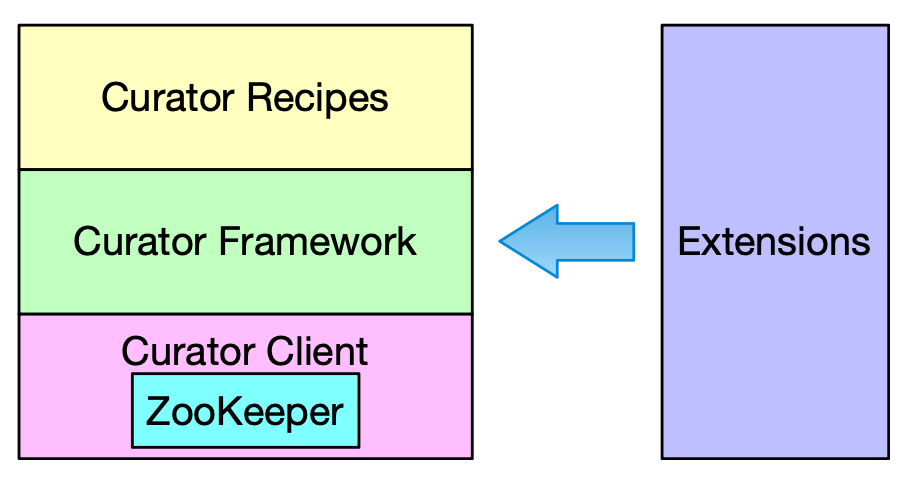
- Client:封装了ZooKeeper类,管理和 ZooKeeper 集群的连接,并提供了重建 连接机制。
- Framework:为所有的ZooKeeper操作提供了重试机制,对外提供了一个 Fluent 风格的 API 。
- Recipes:使用framework实现了大量的 ZooKeeper 协同服务。
- Extensions:扩展模块。
Client
初始化一个 client 分成两个步骤:
- 创建 client
- 启动 client
以下是两种创建 client 的方法:

Fluent 风格 API

运维
安装配置一个生产环境
配置项
ZooKeeper 的配置项在 zoo.cfg 配置文件中配置, 另外有些配置项可以通过 Java 系统属性来进行配置。
ZooKeeper 有很多配置项,比较重要的有:
- clientPort:ZooKeeper 对客户端提供服务的端口。
- dataDir:来保存快照文件的目录。如果没有设置 dataLogDir ,事务日志文件也会保存到这个目录。
- dataLogDir:用来保存事务日志文件的目录。因为 ZooKeeper 在提交一个事务之前,需要保证事务日志记录的落盘,所以需要为 dataLogDir 分配一个独占的存储设备。
ZooKeeper 节点硬件要求
给 ZooKeeper 分配独占的服务器,要给 ZooKeeper 的事务日志分配独立的存储设备。(提交事务之前要落盘,所以对磁盘性能有要求)
- 内存:ZooKeeper 需要在内存中保存 data tree 。对于一般的 ZooKeeper 应用场景,8G 的内存足够了。
- CPU:ZooKeeper 对 CPU 的消耗不高,只要保证 ZooKeeper 能够有一个独占的 CPU 核即可,所以使用一个双核的 CPU 。
- 存储:因为存储设备的写延迟会直接影响事务提交的效率,建议为 dataLogDir 分配一个独占的 SSD 盘。
日志配置文件
ZooKeeper 使用 SLF4J 版本 1.7 作为其日志基础设施。默认情况下,ZooKeeper 随 LOGBack 作为日志后端一起提供,但您可以使用任何其他支持的日志框架。
ZooKeeper 默认的 logback.xml 文件位于 conf 目录中。Logback 要求 logback.xml 要么在工作目录(即运行 ZooKeeper 的目录)中,要么可以从类路径访问到。
1 | <property name="zookeeper.console.threshold" value="INFO" /> |
监控
The Four Letter Words
一组检查 ZooKeeper 节点状态的命令。
每个命令由四个字母组成,可以通过 telnet 或 ncat 使用客户端端口向 ZooKeeper 发出命令。
4lw.commands.whitelist : (Java system property: zookeeper.4lw.commands.whitelist) New in 3.5.3: A list of comma separated Four Letter Words commands that user wants to use. A valid Four Letter Words command must be put in this list else ZooKeeper server will not enable the command. By default the whitelist only contains “srvr” command which zkServer.sh uses. The rest of four-letter word commands are disabled by default: attempting to use them will gain a response “…. is not executed because it is not in the whitelist.” Here’s an example of the configuration that enables stat, ruok, conf, and isro command while disabling the rest of Four Letter Words command:
https://zookeeper.apache.org/doc/r3.9.2/zookeeperAdmin.html#sc_4lw

例如,在配置文件中加入 whitelist
1 | # echo ruok | ncat localhost 2181 |
JMX
ZooKeeper 很好的支持了 JMX ,大量的监控和管理工作多可以通过 JMX 来做。
QuorumPeerMain starts a ZooKeeper server, JMX management beans are also registered which allows management through a JMX management console. The ZooKeeper JMX document contains details on managing ZooKeeper with JMX. See the script bin/zkServer.sh, which is included in the release, for an example of starting server instances. 8. Test your deployment by connecting to the hosts: In Java, you can run the following command to execute simple operations:
QuorumPeerMain启动了一个ZooKeeper服务器,还注册了JMX管理bean,可以通过JMX管理控制台进行管理。ZooKeeper JMX文档包含有关使用JMX管理ZooKeeper的详细信息。查看发布中包含的示例启动服务器实例的脚本bin/zkServer.sh。8. 通过连接到主机测试您的部署:在Java中,您可以运行以下命令执行简单操作:
https://zookeeper.apache.org/doc/r3.9.2/zookeeperJMX.html
跨区域部署
通过 ZooKeeper Observer 实现跨区域部署
ZooKeeper 处理写请求时序

- ZooKeeper 处理写请求,收到请求的节点(节点 1)会先转发到 Leader 节点(节点 2)
- Leader 节点发送预处理请求(Prepose)到所有其他节点(而不是超过半数)
- 收到其他节点收到后进行相应(Accept)
- Leader 节点收到其他节点(超过半数)相应后,给其他节点发送确认(Commit)请求
- 收到写请求的节点(节点 1)收到确认请求后,响应给客户端
Observer
Observer 和 ZooKeeper 机器其他节点唯一的交互是接收来自 leader 的 inform 消息,更新自己的本地存储,不参与提交和选举的投票过程。
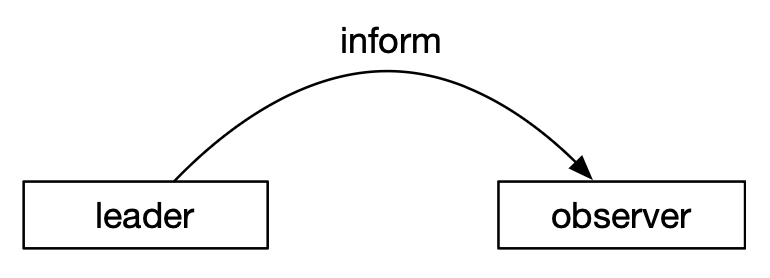
写性能提升
Observer 和 ZooKeeper 机器其他节点唯一的交互是接收来自 leader 的 inform 消息,更新自己的本地存储,不参与提交和选举的投票过程。因此可以通过往集群里面添加 Observer 节点来提高整个集群的读性能。

例如上图,节点 1 作为 Observer 节点,收到写入请求后,不参加数据写入的投票过程。
集群主节点写入完成后,同步到 Observer 节点,Observer 节点本地完成数据一致。
应用场景 - 跨数据中心部署
例如需要部署一个北京和香港两地都可以使用的 ZooKeeper 服务。
要求北京和香港的客户端的读请求的延迟都低。因此,需要在北京和香港都部署 ZooKeeper 节点。
假设 leader 节点在北京。那么每个写请求要涉及 leader 和每个香港 follower 节点之间的 propose 、ack 和 commit 三个跨区域消息。香港节点到北京节点需要跨互联网,延迟高

解决的方案是把香港的节点都设置成 observer 。 上面提的 propose 、ack 和 commit 消息三个消息就变成了 inform 一个跨区域消息消息。
1 | server.1=127.0.0.1:3333:3334 |
dynamic reconfiguration
通过动态配置实现不中断服务的集群成员变更
当需要手动集群成员调整时,操作步骤:
- 停止整个 ZooKeeper 现有集群。
- 更改配置文件 zoo.cfg 的 server.n 项。
- 启动新集群的 ZooKeeper 节点。
此时需要停止 ZooKeeper 服务。
同时,可能会导致已经提交的数据写入被覆盖。
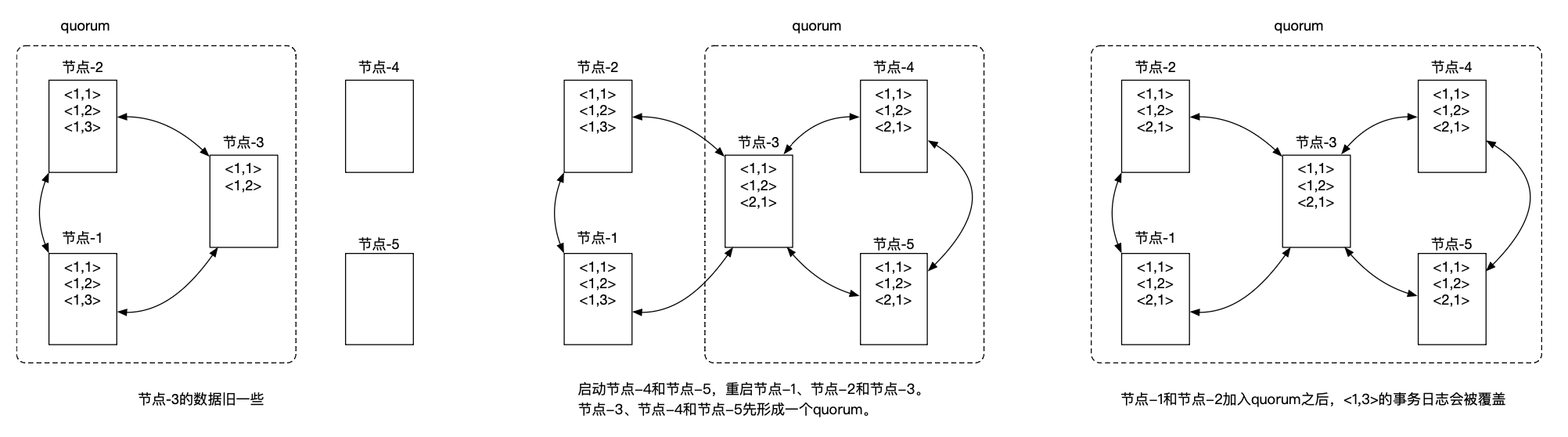
当重启时,一些节点上数据没有被同步,如果重启后,这部分节点行程选举群,那么老数据会同步新数据。
3.5.0 新特性
dynamic reconfiguration:动态配置,可以在不停止 ZooKeeper 服务的前提下,调整集群成员。
https://zookeeper.apache.org/doc/r3.9.2/zookeeperReconfig.html
The ZooKeeper Java and C API were extended with getConfig and reconfig commands that facilitate reconfiguration. Both commands have a synchronous (blocking) variant and an asynchronous one. We demonstrate these commands here using the Java CLI, but note that you can similarly use the C CLI or invoke the commands directly from a program just like any other ZooKeeper command.
ZooKeeper Java 和 C API 已经扩展了 getConfig 和 reconfig 命令,以便进行重新配置。这两个命令都有同步(阻塞)和异步的变体。我们在这里使用 Java CLI 演示这些命令,但请注意您也可以类似地使用 C CLI 或直接从程序中调用这些命令,就像任何其他 ZooKeeper 命令一样。

示例:

内部数据文件
本地存储架构

上图中 3、4、5 就是 zxid
zxid
- 每一个对 ZooKeeper data tree 都会作为一个事务执行。
- 每一个事务都有一个 zxid。
- zxid 是一个 64 位的整数(Java long 类型)。
- zxid 有两个组成部分,高 4 个字节保存的是 epoch,低 4 个字节保存的是 counter 。

日志文件
通过查看事务日志文件(Transaction Logs)可以看到里面的 zxid 信息
1 | # zkTxnLogToolkit.sh log.1 |
快照
通过快照文件(Snapshots)查看 ZooKeeper 里面的内容
1 | # zkSnapShotToolkit.sh snapshot.12 |
Epoch 文件
当 ZooKeeper 以单节点的方式运行不会有 Epoch 文件,以集群的方式运行则会有。
1 | # ls -ltrah |
开发进阶
实现服务发现
服务发现主要应用于微服务架构和分布式架构场景下。在这些场景下,一个服务通常需要松耦合的多个组件的协同才能完成。服务发现就是让组件发现相关的组件。服务发现要提供的功能有以下3点:
- 服务注册。
- 服务实例的获取。
- 服务变化的通知机制。
Curator 有一个扩展叫作 curator-x-discovery。curator-x-discovery 基于 ZooKeeper 实现了服务发现。
curator-x-discovery 设计
使用一个 base path 作为整个服务发现的根目录。 在这个根目录下是各个服务的的目录。服务目录下面是服务实例。实例是服务实例的 JSON 序列化数 据。服务实例对应的 znode 节点可以根据需要设置成持久性、临时性和顺序性。

核心接口
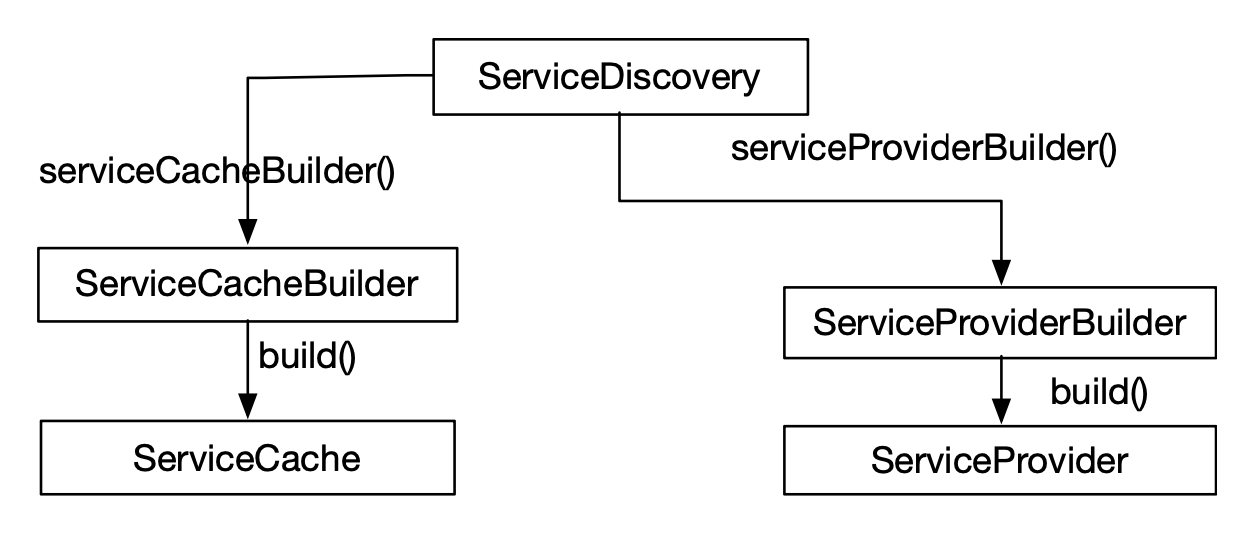
左图列出了服务发现用户代码要使用的 curator-x-discovery 接口。最主要的有下三个接口:
ServiceProvider:在服务 cache 之上支持服务发现操作,封装了一些服务发现策略。ServiceDiscovery:服务注册,也支持直接访问 ZooKeeper 的服务发现操作。ServiceCache:服务cache。
ServiceInstance
用来表示服务实例的 POJO,除了包含一些服务实例常用的成员之外,还提供一个 payload 成员让用户存自定义的信息。
ServiceDiscovery
从一个 ServiceDiscovery ,可以创建多个 ServiceProvider(返回服务端的服务的服务列表) 和多个 ServiceCache(返回本地缓存的服务列表) 。

ServiceProvider
ServiceProvider 提供服务发现 high-level API 。
ServiceProvider 是封装 ProviderStraegy 和 InstanceProvider 的 facade 。
InstanceProvider 的数据来自一个服务 Cache 。服务 cache 是 ZooKeeper 数据的一个本地 cache ,服务 cache 里面的数据可能会比 ZooKeeper 里面的数据旧一些。(目的时为了提高性能,当然牺牲了可用性,但是可以在客户端上做容错来解决)
ProviderStraegy 提供了三种策略: 轮询, 随机和 sticky 。

ServiceProvider 除了提供服务发现的方法( getInstance:根据服务特点返回一个实例 和 getAllInstances:返回所有实例 )以外,还通过 noteError 提供了一个让服务使用者把服务使用情况反馈给 ServiceProvider 的机制。
ZooKeeper 交互
ServiceDiscovery 提供的服务注册方法是对 znode 的更新操作,服务发现方法是 znode 的读取操作。 同时它也是最核心的类,所有的服务发现操作都要从这个类开始。
另外服务 Cache 会接受来自 ZooKeeper 的更新通知,读取服务信息(也就是读取 znode 信息)。
类的说明
ServiceDiscovery、ServiceCache、ServiceProvider 说明
- 都有一个对应的 builder。这些 builder 提供一个创建这三个类的 fluent API。
- 在使用之前都要调用 start 方法。
- 在使用之后都要调用 close 方法。close 方法只会释放自己创建的资源,不会释放上游关联的资源。 例如 ServiceDiscovery 的 close 方法不会去调用 CuratorFramework 的 close 方法。
Node Cache
Node Cache 是 curator 的一个 recipe ,用来本地 cache 一个 znode 的数据。
Node Cache 通过监控一个 znode 的 update / create / delete 事件来更新本地的 znode 数据。
用户可以在 Node Cache 上面注册一个 listener 来获取 cache 更新的通知。
相比直接通过 ZooKeeper 创建 listener,一个 listener 只能监听依次,cache 的 listener 可以持续监听
Path Cache
Path Cache 和 Node Cache 一样,不同之处是在于 Path Cache 缓存一个 znode 目录下所有子节点。
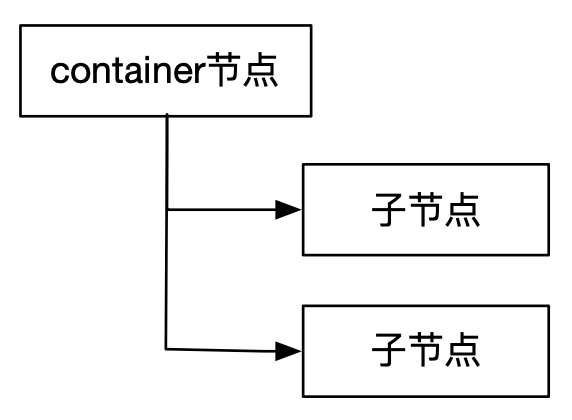
container 节点
container 节点是一种新引入的 znode ,目的在于下挂子节点。
当一个 container 节点的所有子节点被删除之后,ZooKeeper 会删除掉这个 container 节点。
服务发现的 base path 节点和服务节点就是 containe 节点。
ServiceCacheImpl
ServiceCacheImpl 使用一个 PathChildrenCache 来维护一个 instances 。这个 instances也是对 znode 数据的一个 cache

ServiceProviderImpl
如下图所示,ServiceProviderImpl 是多个对象的 facade 。

curator-x-discovery-server 扩展
curator-x-discovery-server 是基于 curator-x-discovery 实现的对外提供服务发现的 HTTP API。
他的 HTTP API 是基于 JAX-RS 研发的。
总结
curator-x-discovery 在系统质量和影响力和 ZooKeeper 相比还是有很大差距的,但是提供的服务发现的功能还是很完备的。
如果我们的服务发现场景和 curator-x-discovery 匹配,就可以直接用它或者扩展它。curator-x-discovery-server 本身实现的功能很少,不建议使用,完全可以自己实现类似的功能。
进行 ZooKeeper API 开发,建议以下的 SDK 使用优先顺序: curator recipes -> curator framework -> ZooKeeper API 。
Kafka
Kafka 使用 ZooKeeper 实现了大量的协同服务。如果检查一个 Kafka 使用的 ZooKeeper ,会发现大量的 znode :

ZooKeeper Directories 对一些关键的 ZooKeeper 使用有一个说明。
Broker Node Registry 是用来保存 Kafka 集群的 Kafka 节点,是典型的组成员管理协同服务。
安装 Kafka 集群
使用 Confluent 的发行版
- 从 https://www.confluent.io/download/ 下载社区版
confluent-community-7.6.0.tar.gz - 在一个节点上的
etc/kafka/zookeeper.properties文件中配置一下dataDir,在etc/kafka/server.properties配置log.dirs、broker.id和zookeeper.connect。 - 把 confluent-7.6.0 目录
rsync到其他节点。在其他节点上更新broker.id,创建dataDir目录和log.dirs目录。
broker 注册演示
- 启动 standalone 的 ZooKeeper 服务。
- 打开 zookeeper-shell,运行
ls /。 - 启动一个 Kafka 服务,使用 zookeeper-shell 检查
/brokers/ids下的内容。 - 再启动一个 Kafka 服务,使用 zookeeper-shell 检查
/brokers/ids下的内容。 - 杀掉一个 Kafka 服务,使用 zookeeper-shell 检查
/brokers/ids下的内容。
multi API
ZooKeeper 的 multi 方法提供了一次执行多个 ZooKeeper 操作的机制。多个 ZooKeeper 操作作为一个整体执行,要么全部成功,要么全部失败。类似于事务的概念。
另外 ZooKeeper 还提供了一个 builder 风格的 API 来使用 multi API 。
Kafka 的源代码就使用到了 multi API,二次开发 Kafka 时可以一并替换。
总结
Kafka 在逐渐减少对 ZooKeeper 的依赖:
- 在老的版本中,committed offsets 是保存在 Kafka 中的。
- 未来 Kafka 还有计划完全移除对 ZooKeeper 的依赖。
Kafka 使用 ZooKeeper 的方式值得我们依赖。
在我们刚开始一个分布式系统的时候,我们可以把协同数据都给 ZooKeeper 来管理,迅速让系统上线。如果在系统的后续使用中要对协同数据进行定制化处理,我们可以研发自己的协同数据机制来代替 ZooKeeper 。
比较 ZooKeeper、etcd和 Chubby
Paxos 协议
Paxos 算法是一个一致性算法,作用是让 Asynchronous non-Byzantine Model 的分布式环境中的 各个 agent 达成一致。
打一个比方,7 个朋友要决定晚上去哪里吃饭。一致性算法就是保证要么这 7 个朋友达成一致选定一个地方去吃饭,要么因为各种异常情况达不成一致,但是不能出现一些朋友选定一个地方,另外一些朋友选定另外一个地方的情况。
Asynchronous non-Byzantine Model
一个分布式环境由若干个 agent 组成,agent 之间通过传递消息进行通讯:
- agent以任意的速度速度运行,agent 可能失败和重启。但是 agent 不会出 Byzantine fault(在不同观察者中呈现不同症状的任何故障)。
- 消息需要任意长的时间进行传递,消息可能丢失,消息可能会重复。但是消息不会 corrupt(不会篡改后又发出来)。
agent 角色
- client:发送请求给 Paxos 算法服务。
- proposer:发送 prepare 请求和 accept 请求。
- acceptor:处理 prepare 请求和 accept 请求。
- learner:获取一个 Paxos 算法实例决定的结果。
伪代码

- Phase 1: Prepare(准备阶段):
- 提议者向大多数接受者发送提案编号(proposal number,提案编号通常由两部分组成:提议者的标识符和一个递增的序列号)。
- 如果接受者收到的提案编号比自己见过的提案编号大,则接受提案,并向提议者发送已经接受的提案编号和对应的提案内容(如果有)。
- Phase 2: Accept(接受阶段):
- 如果提议者收到大多数接受者的响应,且这些响应中没有任何比自己提出的提案编号更大的提案,则提议者可以发送自己的提案内容给接受者。
- 接受者收到提议者的提案后,如果没有接受过更大编号的提案,则接受该提案,通知提议者和其他接受者。
算法描述
一个 Paxos 算法实例正常运行的前提是大多数 acceptor 正常运行。换句话说就是 Paxos 提供允许少数 accepter 失败的容错能力。

算法的消息流
以下是一个 Paxos 算法实例的完成的消息流:

Replicated State Machine
Replicated State Machine:复制状态机,Paxos 算法可以用来实现复制状态机的一致性算法模块。
这里面的状态机是一个 KV 系统。通过复制状态机可以把它变成一个容错的 3 节点分布式 KV 系统。下面是处理 z=6 这个写操作的过程:
- 客户端3发送一个 z=6 请求给节点3的一致性算法模块。
- 节点3的一致性算法发起一个算法实例。
- 如果各个节点的一致性算法模块能一起达成一致,节点3把 z=6 应用到它的状态机,并把结果返回给客户端3。

MultiPaxos
基本的 Paxos 算法在决定一个值的时候需要的执行两个阶段,这涉及大量消息交换。
MultiPaxos 算法的提出就是为了解决这个问题。
MultiPaxos 保持一个长期的 leader,这样决定一个值只需要执行第二阶段。
一个典型的 Paxos 部署通常包括奇数个服务器,每个服务器都有一个 proposer ,一个 acceptor 和一个 learner 。
Chubby
Chubby 是一个分布式锁系统,广泛应用于 Google 的基础架构中,例如知名的 GFS 和 Bigtable 都用 Chubby 来做协同服务。(使用 Chubby 选举 Master)
ZooKeeper 借鉴了很多 Chubby 的设计思想,所以它们之间有很多相似之处。
系统架构

- 一个 Chubby 的集群叫作一个 cell,cell 由多个 replica 实例组成,其中一个 replica 是整个 cell 的 master 。所有的 读写请求只能通过 master 来处理。
- 应用通过引入 Chubby 客户端库来使用 Chubby 服务。 Chubby 客户端在和 master 建立 session 之后,通过发 RPC
给 master 来访问 Chubby 数据。 - 每个客户端维护一个保证数据一致性的 cache
数据模型

Chubby 使用的是层次数据模型,可以看做一个简化的 UNIX 文件系统:
- Chubby 不支持部分内容的读写。
- Chubby 不支持 link:不支持硬链接(hard links)或符号链接(symbolic links)的功能。
- Chubby 不支持依赖路径的文件权限。
不同于 ZooKeeper ,Chubby 的命名空间是由多个 Chubby cell 构成的,例如上图中 /ls 下包含多个 Cell。
Chubby API
与 ZooKeeper 不同,Chubby 的 API 有一个文件句柄的概念。
Open():唯一使用路径名访问文件的API,其他API都使用一个文件句柄。Close():关闭文件句柄。Poison():取消文件句柄上正在进行的操作,主要用于多线程场景。- 文件操作API:
GetContentsAndStat(),SetContents(),Delete()。 - 锁API:
Acquire(),TryAcquire(),Release(),GetSequencer(),SetSequencer(),CheckSequencer()。
和 ZooKeeper 一样,Chubby 的 API 提供了事件通知机制、API 的异步和同步版本。
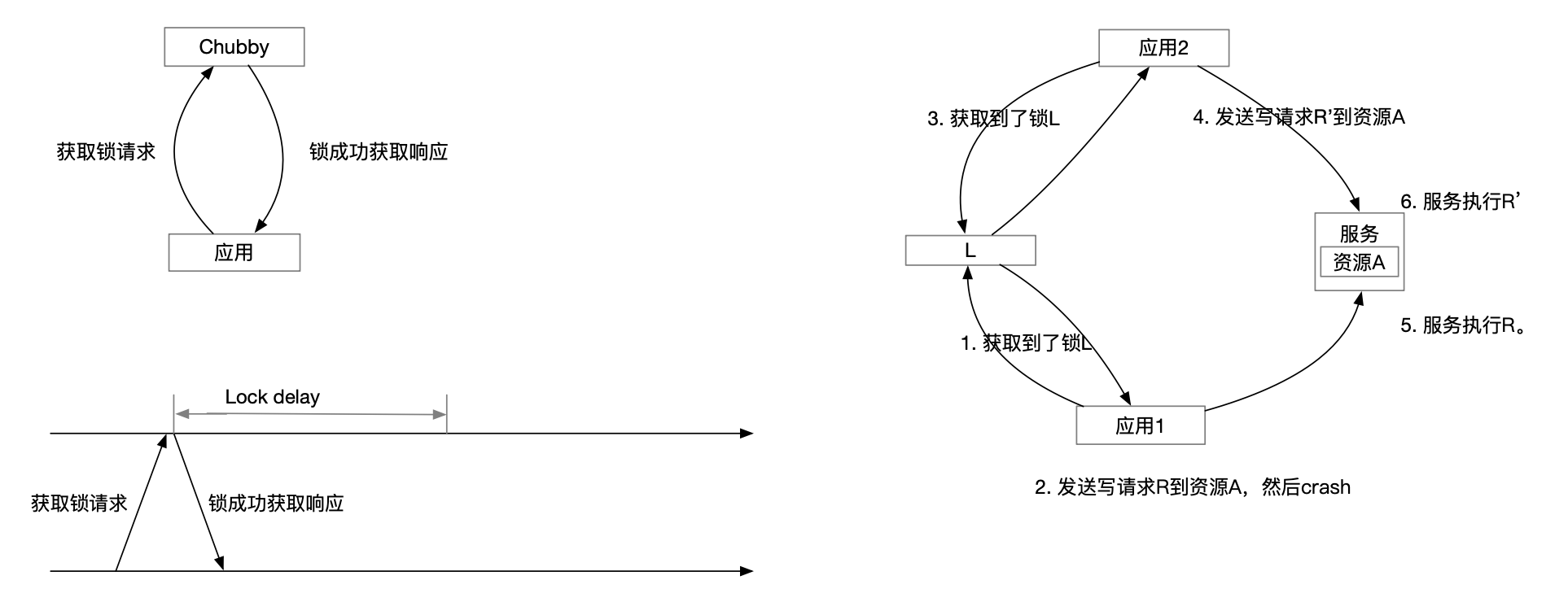
Locking
Chubby 使用 Advisory locking。
由于通信的不确定性和各种节点失败,分布式环境中的锁是非常复杂的。
例如在下图所示的场景中,Chubby 锁 L 用来保护资源 A ,但是会出现操作请求执行顺序颠倒的情况。

解决方案 1:Sequencer:时序控制器
一个锁持有者可以使用 GetSequencer() API 向 Chubby 请求一个 sequencer 。
之后锁持有者发送访问资源的请求时,把 sequencer 一起发送给资源服务。
资源服务会对 sequencer 进行验证,如果验证失败,就拒绝资源访问请求。sequencer 包含的数据有锁的名称、锁的模式和 lock generation number 。

ZooKeeper 锁 recipe 里面表示锁请求的 znode 的序列号可以用作 sequencer ,从而也可以实现解决方案 1。
解决方案 2:lock delay
如果锁 L 的持有者失败了或者访问不到 Chubby cell 中的节点了,Chubby 不会立刻处理对锁 L 的请求。
Chubby 会等一段时间(默认1分钟)才会把锁 L 分配给其他的请求。
这样也可以保证应用 2 在更晚的时刻获得到锁 L ,从而在更晚的时刻发送请求 R' ,保证 R 先于 R' 执行。
cache
Chubby 的客户端维护一个 write-through 的 cache,能保证 cache 中的数据和 Chubby 节点上的数据是一致的。
master 只有在所有的 cache 失效之后(收到客户端 cache invalidation 的响应或者客户端的 lease 失效了),才进行文件更新操作。
lease 是客户端维持 session 有效的时间段。如果过了这段时间,客户端还没有 renew lease 的话,客户端停止任何 Chubby 的操作,并断开 session 。
ZooKeeper 没有办法提供和 Chubby 一样的 cache 。 原因是 ZooKeeper 是先更新再发通知,没有办法避免 cache 中有旧数据。
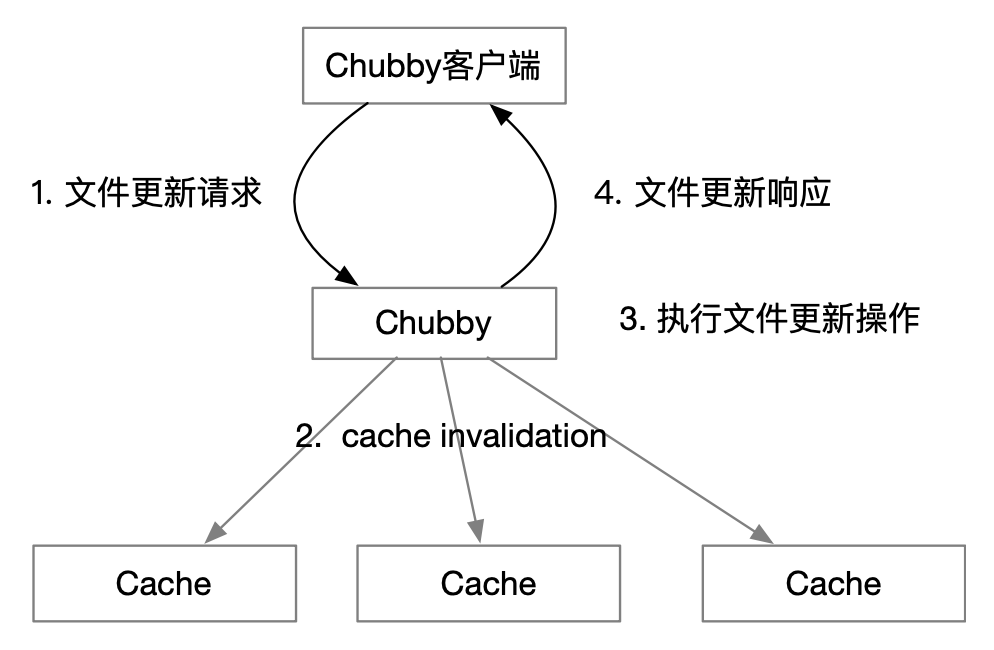
对比
相同之处:
- Chubby 的文件相当于 ZooKeeper 的 znode。Chubby 的文件和 znode 都是用来存储少量数据。
- 都只提供文件的全部读取和全部写入。
- 都提供类似 UNIX 文件系统的 API。
- 都提供接收数据更新的通知,Chubby 提供 event 机制,ZooKeeper 提供 watch 机制。
- 它们的客户端都通过一个 session 和服务器端进行交互。
- 写操作都是通过
leader/master来进行。 - 都支持持久性和临时性数据。
- 都使用复制状态机来做容错。
不同之处:
| Chubby | ZooKeeper |
|---|---|
| Chubby 内置对分布式锁的支持。 | ZooKeeper 本身不提供锁,但是可以基于 ZooKeeper 的基本操作来实现锁。 |
| 读操作也必须通过 master 节点来执行。相应的,Chubby 保证的数据一致性强一些,不会有读到旧数据的问题。 | 读操作可以通过任意节点来执行。相应的,ZooKeeper 保证的数据一致性弱一些,有读到旧数据的问题。 |
| Chubby 提供一个保证数据一致性的 cache 。有文件句柄的概念。 | ZooKeeper 不支持文件句柄,也不支持 cache,但是可以通过 watch 机制来实现 cache 。但是这样实现的 cache 还是有返回旧数据的问题。 |
| Chubby 基本操作不如 ZooKeeper 的强大。 | ZooKeeper 提供更强大的基本操作,例如对顺序性节点的支持,可以用来实现更多的协同服务。 |
| Chubby 使用 Paxos 数据一致性协议。 | ZooKeeper 使用 Zab 数据一致性协议。 |
虽然 Chubby 允许 Followers 节点处理读取请求,但在某些情况下,特别是在需要确保数据一致性的情况下,读取请求可能会被转发到 Leader 节点进行处理。这样可以确保客户端读取到的数据是最新的,并且避免读取到旧数据。
在 Chubby 中,数据的一致性是通过类似于 Paxos 的一致性算法来实现的。Chubby 使用版本号和 lease 机制来确保数据的一致性和可靠性。具体来说:
- 版本号机制:Chubby 中的数据对象具有版本号,每次写入操作都会增加版本号。这样可以确保新写入的数据会覆盖旧数据,从而避免读取到旧数据的情况。
- Lease 机制:Chubby 中的客户端在读取或写入数据时需要获取一个 lease,这个 lease 会在一段时间内保持有效。只有持有有效 lease 的客户端才能读取或写入数据。当 lease 过期时,客户端需要重新获取 lease 才能继续操作。这样可以避免客户端读取到过期的数据。
为了确保客户端不会读取到旧数据,客户端在读取数据时会与 Chubby 的 Leader 节点交互,并通过版本号验证确保读取的数据是最新的。客户端的版本号会与 Leader 节点进行交互验证,以确保读取的数据是最新的。
Raft 协议解析
Raft 是目前使用最为广泛的一致性算法。例如新的协同服务平台 etcd 和 Consul 都是使用的 Raft 算法。
在 Raft 出现之间,广泛使用的一致性算法是 Paxos 。Paxos 的基本算法解决的是如何保证单一客户端操作的一致性,完成每个操作需要至少两轮的消息交换。
和 Paxos 不同,Raft 有 leader 的概念。Raft 在处理任何客户端操作之前必须选举一个 leader,选举一个 leader 需要至少一轮的消息交换。但是在选取了 leader 之后,处理每个客户端操作只需要一轮消息交换。
Raft 论文描述了一个基于 Raft 的复制状态机的整体方案,例如 Raft 论文描述了日志复制、选举机制和成员变更等这些复制状态机的各个方面。
相反 Paxos 论文只是给了一个一致性算法,基于 Paxos 的系统都要自己实现这些机制。
基于 Raft 的复制状态机系统架构
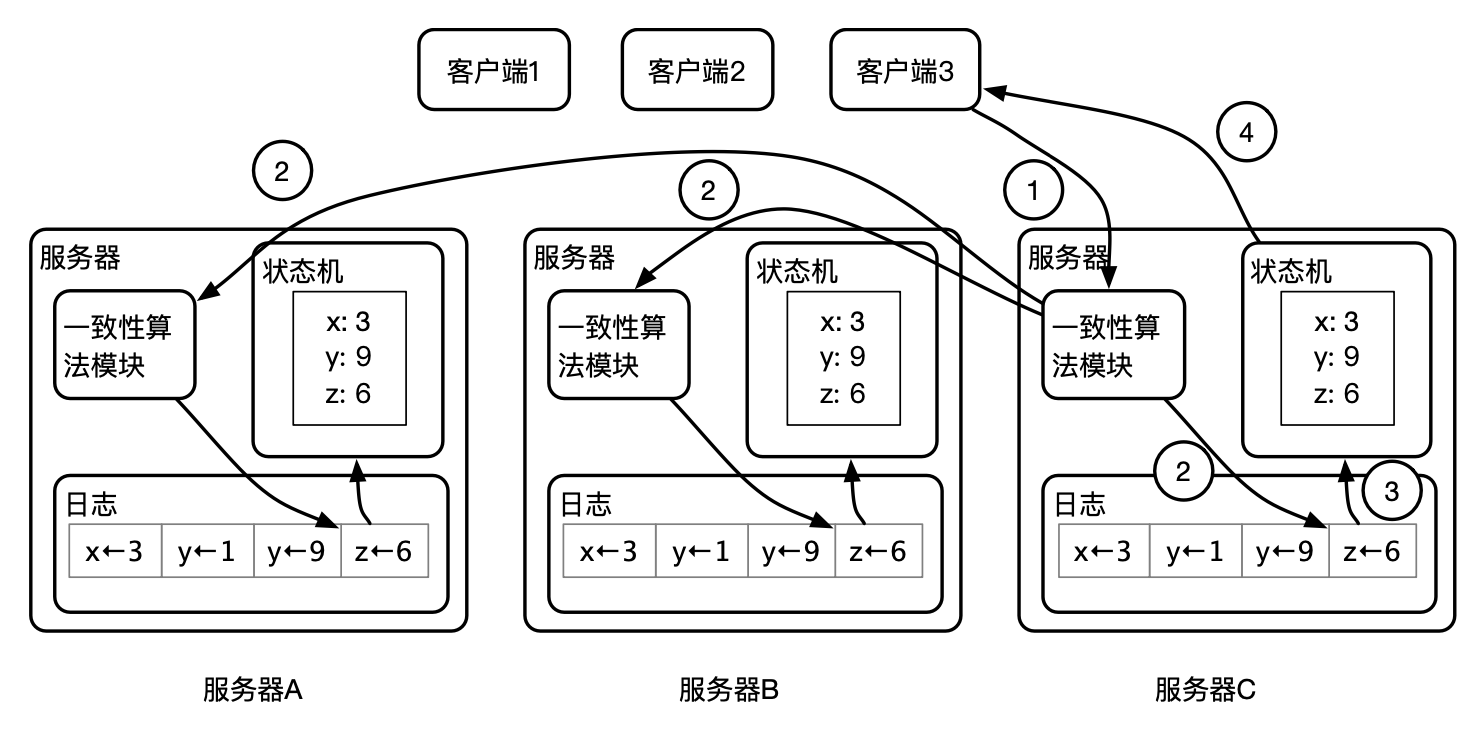
上图展示了执行一条客户端写命令的过程 ( z←6 表示把 6 写入 z ):
- 客户端 3 发送一个状态机命令 z←6 给服务器 C 的一致性算法模块。
- 一致性算法模块把状态机命令写入服务器 C 的日志,同时发送日志复制请求给服务器 A 和服务器 B 的一致性算法模块。服务器 A 和服务器 B 的一致性算法模块在接收到日志复制请求之后,分别在自己的服务器上写入日志,然后回复服务器 C 的一致性算法模块。
- 服务器 C 的一致性算法模块在收到服务器 A 和 B 对日志复制请求的回复之后,并等待大多数节点(超过半数节点)确认已经复制了这条日志,让状态机执行来自客户端的命令。
- 服务器 C 的状态机把命令执行结果返回给客户端 3 。
Raft 日志复制
一个 Raft 集群包括若干服务器。
服务器可以处于以下三种状态:leader 、follower 和 candidate。只有 leader 处理来自客户端的请求。
follower 不会主动发起任何操作,只会被动的接收来自 leader 和 candidate 的请求。在正常情况下,Raft 集群中有一个 leader ,其他的都是 follower 。 leader 在接受到一个写命令之后,为这个命令生成一个日志条目,然后进行日志复制。
leader 通过发送 AppendEntries RPC 把日志条目发送给 follower ,让 follower 把接收到的日志条目写入自己的日志文件。另外 leader 也会把日志条目写入自己的日志文件。日志复制保证 Raft 集群中所有的服务器的日志最终都处于同样的状态。
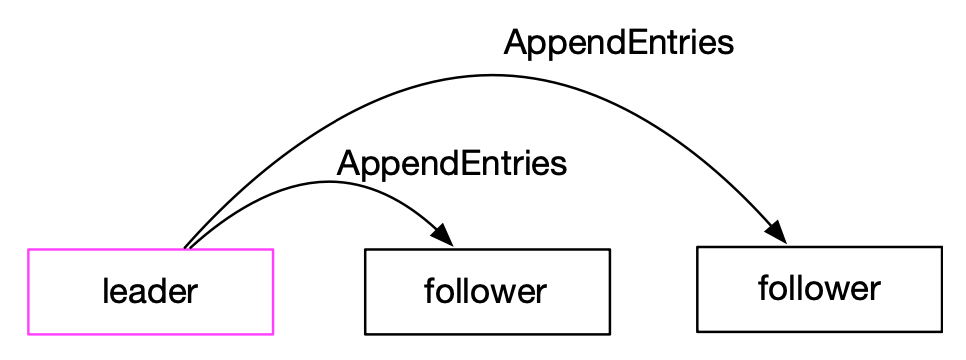
Raft 的日志复制对应的就是 Paxos 的 accept 阶段,它们是很相似的。
日志条目的提交
leader 只有在超过半数 Follow 请求被提交以后,才可以在状态机执行客户端请求。提交意味着集群中多数服务器完成了客户端请求的日志写入,这样做是为了保证以下两点:
- 容错:在数量少于 Raft 服务器总数一半的 follower 失败的情况下,Raft 集群仍然可以正常处理来自客户端的请求。
- 确保重叠:一旦 Raft Leader 响应了一个客户端请求,即使出现 Raft 集群中少数服务器的失败,也会有一个服务器包含所有以前提交的日志条目。
Raft 日志复制示例
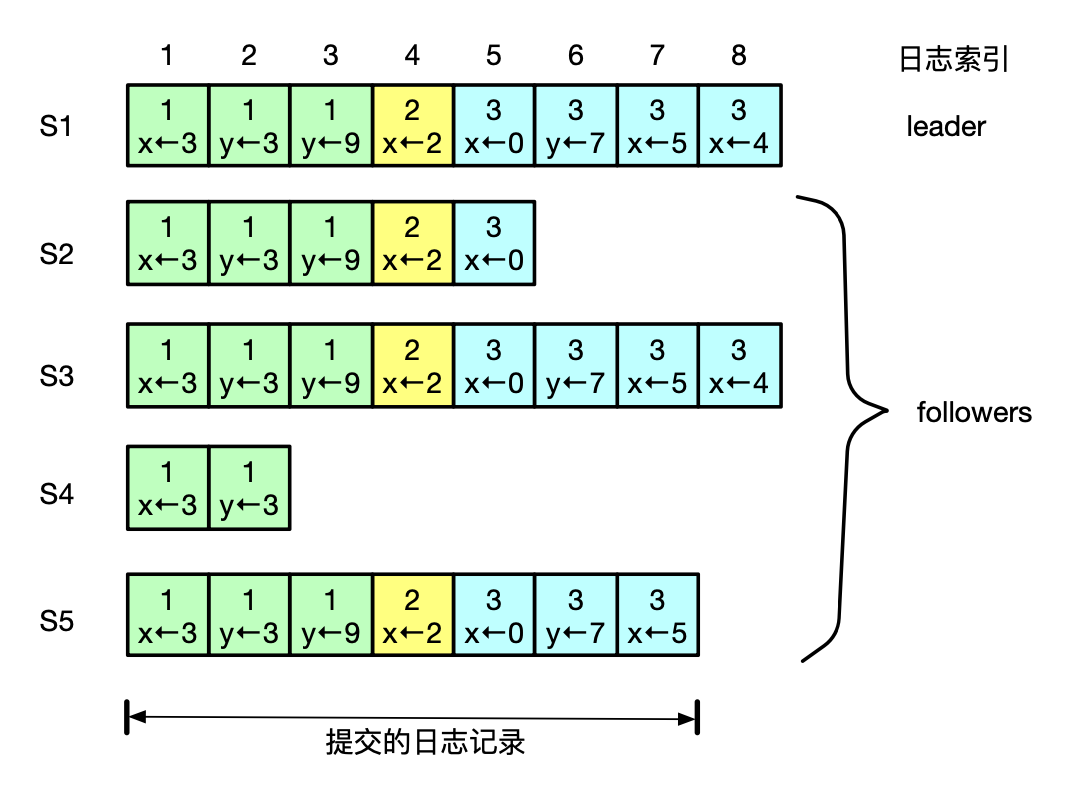
上图表示的是一个包括 5 个服务器的 Raft 集群的日志格式。
S1 处于 leader 状态,其他的服务器处于 follower 状态。此时,由于 x<-5 的日志条目被大部分节点写入日志,因此,直到 x<-5 可以被提交到状态机。
每个日志条目由一条状态机命令和创建这条日志条目的 leader 的 term。
每个日志条目有对应的日志索引,日志索引表示这条日志在日志中的位置。
Raft 集群中提交的日志条目是 S5 上面 的所有日志条目,因为这些日志条目被复制到了集群中的大多数服务器。
Raft 选举算法
Raft 使用心跳机制来触发 leader 选取。
一个 follower 只要能收到来自 leader 或者 candidate 的有效 RPC ,就会一直处于 follower 状态。
leader 在每一个 election timeout 向所有 follower 发送心跳消息来保持自己的 leader 状态。
如果 follower 在一个 election timeout 周期内没有收到心跳信息,就认为目前集群中没有 leader。此时 follower 会对自己的 currentTerm 进行加一操作,并进入 candidate 状态,发起一轮投票。它会给自己投票并向其他所有的服务器发送 RequestVote RPC ,然后会一直处于 candidate 状态,直到下列三种情形之一发生:
- 这个 candidate 赢得了选举 。
- 另外一台服务器成为了 leader 。
- 一段时间之内没有服务器赢得选举。
在这种情况下,candidate 会再次发起选举。
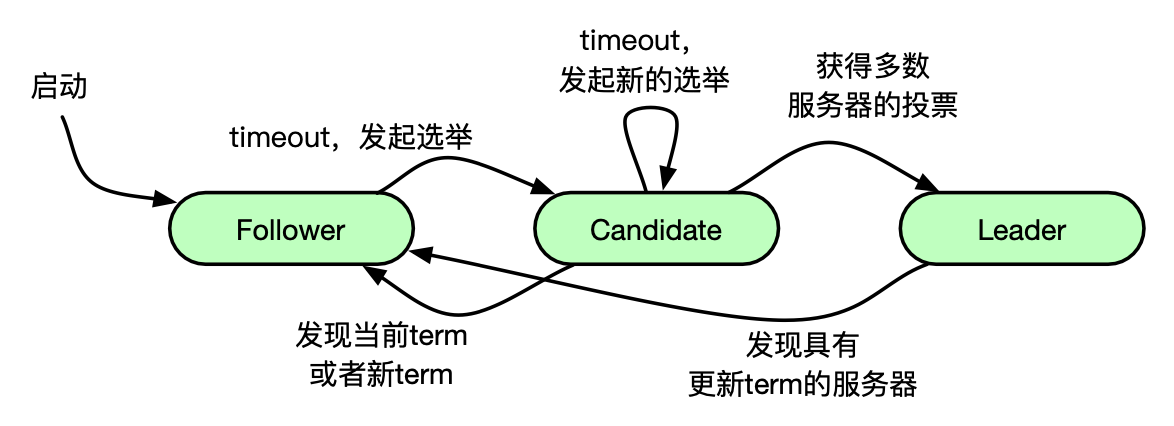
Raft 的选举对应的就是 Paxos 的 prepare 阶段,它们是很相似的。
日志匹配
Raft 日志条目具备以下日志匹配属性:
- 如果两个服务器上的日志条目有的相同索引和 term ,那么这两个日志条目存储的状态机命令是一样的。
- 如果两个服务器上的日志条目有的相同索引和 term ,那么这两个日志从头到这个索引是完全一样的。
如果 Raft 处于复制状态,每个 follower 的日志是 leader 日志的前缀,显然日志匹配属性是满足的。在一个新的 leader 出来之后,follower 的日志可能和 leader 的日志一致,也可能处于以下三种不一致状态:
- follower 与 leader 相比少一些日志条目。
- follower 与 leader 相比多一些日志条目。
- 包含(1)和(2)两种不一致情况。
例如在下图中:
- follower (a) 和 follower (b) 属于不一致情况 1,比 leader 少
- follower (c) 和 follower(d) 属于不一致情况 2,比 leader 多
- follower (e) 和 follower (f) 属于不一致情况 3,比 leader 有少有多
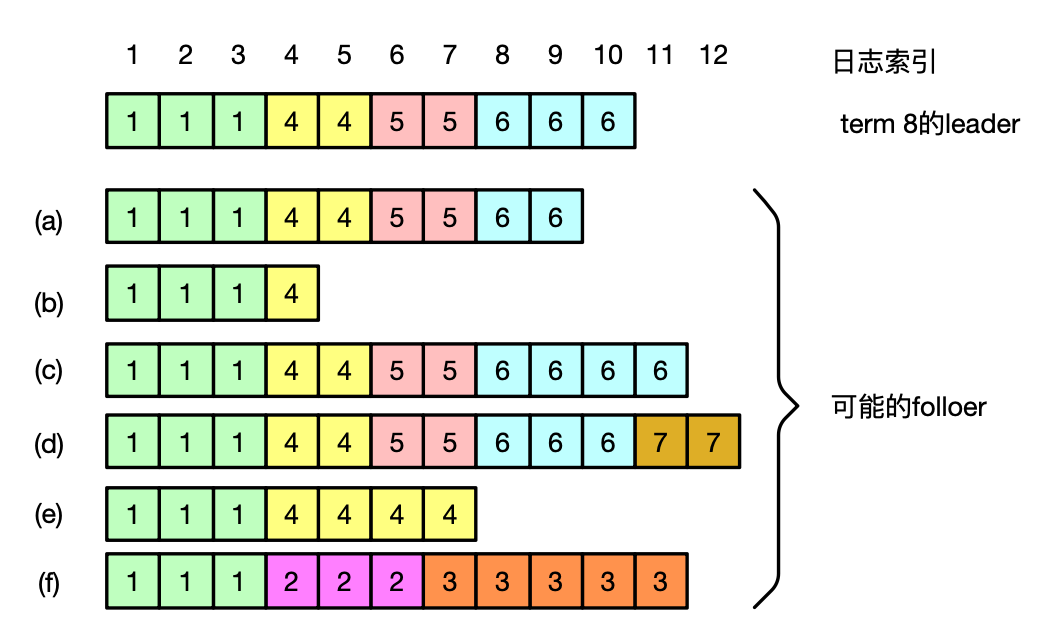
确保一致性的方案
如何保证一个新 term 的 leader 保存了所有提交的日志条目?
以下三点保证新 term 的 leader 保存了所有提交的日志条目:
- 日志条目只有复制到了多个多个服务器上,才能提交。
- 一个 candidate 只有赢得了多个服务器的 vote ,才能成为 leader 。
- 并且要求只有 candidate 的日志比自己的新的时候才能 vote 。
下图的 Raft 集群有 5 个服务器:S1、S2、S3、S4、S5:
- S1 是 leader。
- S1 把一条日志复制了 S1、S2 和 S3 之后, 提交这一条日志。
- 以后发生了选举,S5 成了新 term U 的 leader。
- 上面两点保证一定有一个服务器收到了这条日志并参与了 term U 的投票,这里是 S3。
- 第 2 点又保证 S5 的日志比 S3 的新,所以 S5 必定保存了这条日志。
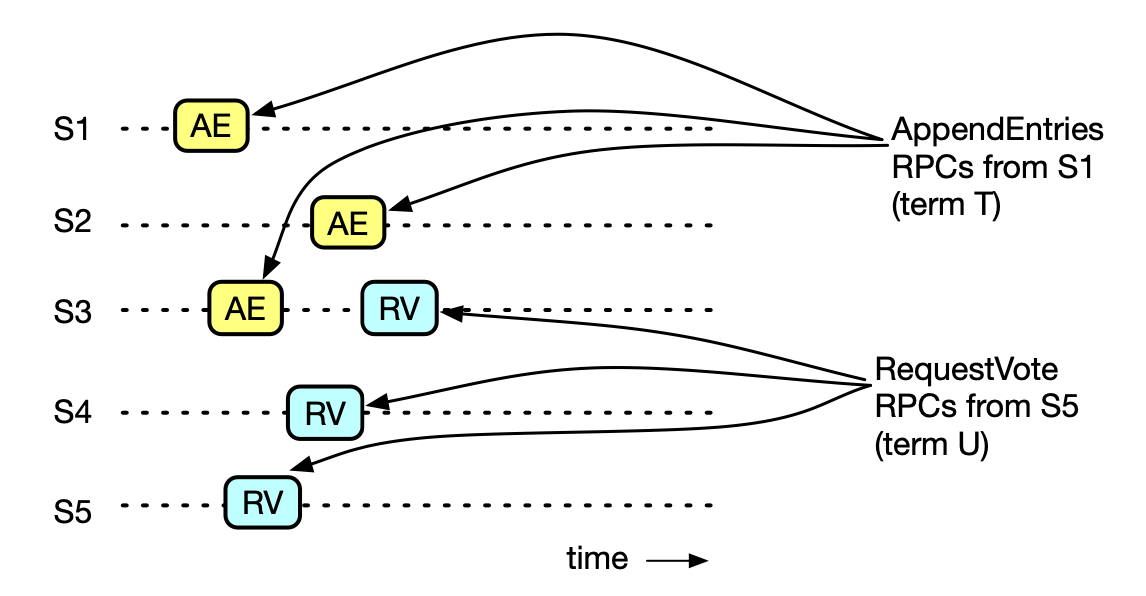
状态机命令的提交点
前面说过,一条日志在被复制到多个服务器之后就可以提交。但这是一种不准确的说法。
下图解释了为什么 leader 不能靠检查一条日志是否复制了到了大多数服务器上来确定旧 term 的日志条目是否已经提交。
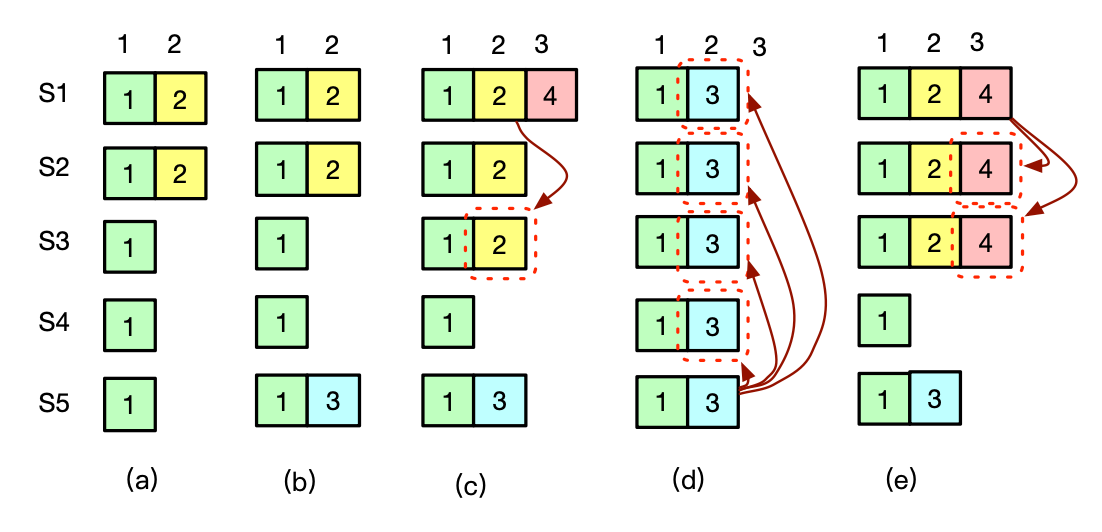
准确的说法:Raft 不会通过计算旧 term 的日志条目被复制到了多少台服务器来决定是否它已经被提交,只有当前 term 的日志条目提交状态可以这么决定。
如果当前 term 的日志条目被提交,那么基于日志匹配属性,我们知道之前的日志条目也都被间接的提交了。
集群成员更新
我们把 Raft 集群中的机器集合称为集群配置。到目前位置,我们都假定集群配置是固定的。
但在实际环境中,我们会经常需要更改配置,例如更换故障的机器或者更改日志的复制级别。我们希望 Raft 集群能够接受一个集群配置变更的请求,然后自动完成集群变更。
而且在集群配置的变更中,Raft 集群可以继续提供服务。另外集群配置的变更还要做到一定程度的容错。
Raft 提供一个两阶段的集群成员更新机制。
etcd
etcd 是一个高可用的分布式 KV 系统,可以用来实现各种分布式协同服务。
etcd 采用的一致性算法是 raft,基于 Go 语言实现。
etcd 最初由 CoreOS 的团队研发,目前是 Could Native 基金会的孵化项目。
为什么叫 etcd:etc 来源于 UNIX 的 /etc 配置文件目录,d 代表 distributed system。
应用场景
典型应用场景:
- Kubernetes 使用
etcd来做服务发现和配置信息管理。 - Openstack 使用
etcd来做配置管理和分布式锁。 - ROOK 使用
etcd研发编排引擎。
etcd 和 ZooKeeper 覆盖基本一样的协同服务场景。
ZooKeeper 因为需要把所有的数据都要加载到内存,一般存储几百 MB 的数据。
etcd 使用 bbolt 存储引擎,可以处理几个 GB 的数据。
MVCC
etcd 的数据模型是 KV模型,所有的 key 构成了一个扁平的命名空间,所有的 key 通过字典序排序。
整个 etcd 的 KV 存储维护一个递增的 64 位整数。
etcd 使用这个整数位为每一次 KV 更新分配一个 revision(基于 64 位整数)。每一个 key 可以有多个 revision。每一次更新操作都会生成一个新的 revision。删除操作会生成一个 tombstone 的新的 revision。
如果 etcd 进行了 compaction,etcd 会对 compaction revision 之前的 key-value 进行清理。
整个 KV 上最新的一次更新操作的 revision 叫作整个 KV 的 revision。
| Key | CreateRevision | ModRevision | Version | Value |
|---|---|---|---|---|
| foo | 10 | 10 | 1 | one |
| foo | 10 | 11 | 2 | two |
| foo | 10 | 12 | 3 | three |
CreateRevision 是创建 key 的 revision;
ModRevsion 是更新 key 值的 revision;
Version 是 key 的版本号,从 1 开始。
状态机
可以把 etcd 看做一个状态机。
Etcd 的状态是所有的 key-value,revision 是状态的编号,每一个状态转换是若干个 key 的更新操作。
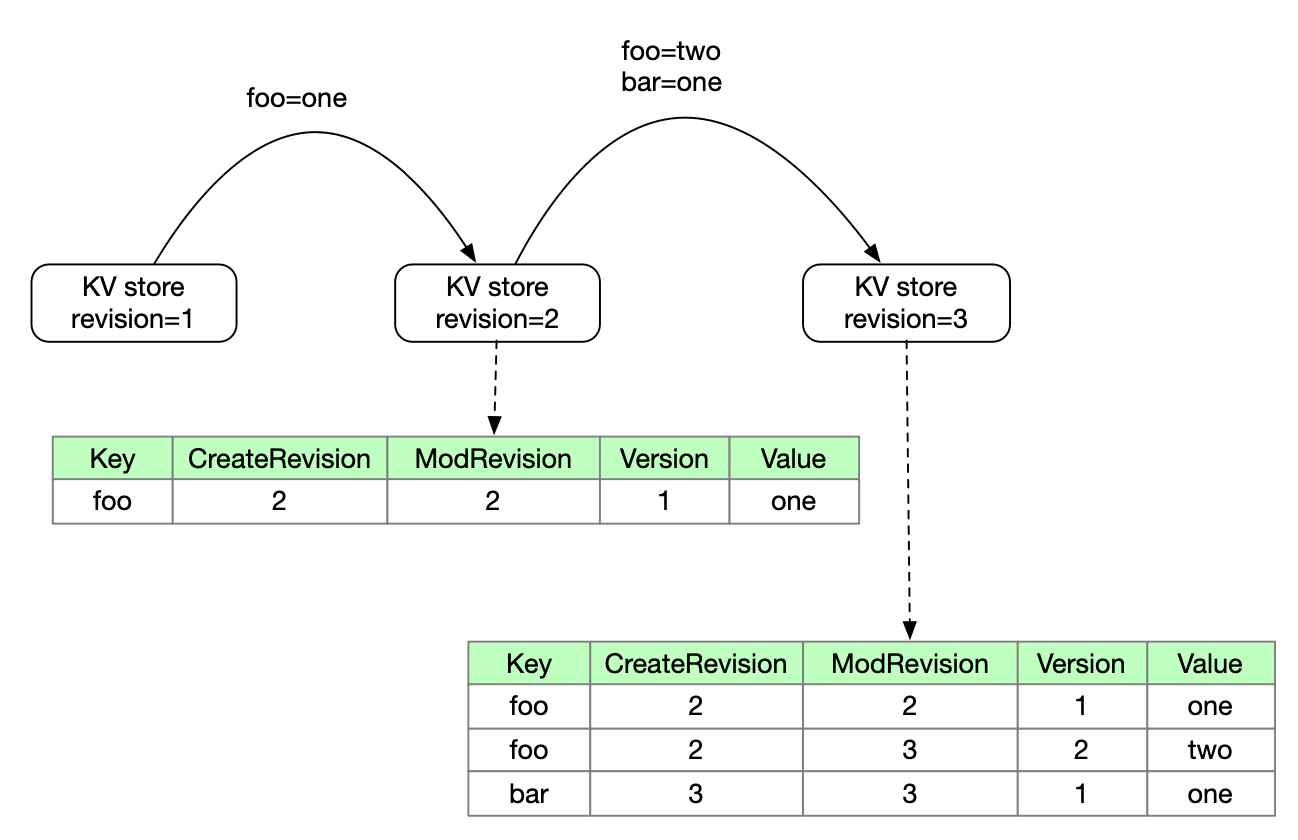
- 最开始没有数据,此时系统的
reversion为 1; - 创建变量
foo值为one,此时 KV store 的reversion加 1,为 2;foo的 CreateRevision 为 2,表示创建时的 reversion,ModRevision 为 2,表示更改时的 reversion 为 2,Version 为 1,代表这是这个值的第一个版本 - 现在将 foo 改为 two,并且创建一个 bar 值为 one;此时 KV store 加 1,为 3;
- foo 的 ModReversion 变为 3,表示更新这个值时的 reversion 为 3,version 为 2,表示这个值的第二个版本(foo 的 value 是一个列表,存储多个版本的信息,老版本的信息也会存储)
- bar 同理
数据存储
- etcd 使用 bbolt 进行 KV 的存储。bbolt 使用持久化的
B+tree保存 key-value。- 三元组 (major、sub、type)是
B+tree的 key, - major 是的 revision,
- sub 用来区别一次更新中的各个 key,
- type 保存可选的特殊值(例如 type 取值为 t 代表这个三元组对应的是一个 tombstone)。
- 这样做的目的是为加速某一个 revision 上的 range 查找。
- 三元组 (major、sub、type)是
- 另外 etcd 还维护一个
in-memory的B-tree索引,这个索引中的 key 是 key-value 中的 key 。
内存中的 value 存储的是 value 的当前 value,revision 信息是存储在 etcd 的持久化存储 bbolt 中
安装配置
安装配置 etcd 的步骤:
https://github.com/etcd-io/etcd/releases
1 | # etcd 有多个版本,通过环境变量确定版本 |
一篇文章带你搞懂 etcd 3.5 的核心特性
使用 etcdctl
在 {db-dir} 目录运行 etcd 启动 etcd 服务,让后在另外一个终端运行:
etcdctl put foo bar:写入键值etcdctl get foo:通过键获取值etcdctl del foo:删除键值
etcdctl get "" --prefix=true 可以用来扫描 etcd 的所有数据。
etcdctl del "" --prefix=true 可以用来删除 etcd 中的所有数据。
使用 etcd HTTP API
除了使用 etcdctl 工具访问 etcd,我们可以使用 etcd HTTP Rest API。
http POST http://localhost:2379/v3/kv/put <<< '{"key": "Zm9v", "value": "YmFy"}'1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17HTTP/1.1 200 OK
Access-Control-Allow-Headers: accept, content-type, authorization
Access-Control-Allow-Methods: POST, GET, OPTIONS, PUT, DELETE
Access-Control-Allow-Origin: *
Content-Length: 114
Content-Type: application/json
Date: Tue, 02 Apr 2024 03:14:34 GMT
Grpc-Metadata-Content-Type: application/grpc
{
"header": {
"cluster_id": "14841639068965178418",
"member_id": "10276657743932975437",
"raft_term": "2",
"revision": "5"
}
}http POST http://localhost:2379/v3/kv/range <<< '{"key": "Zm9v"}'1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27HTTP/1.1 200 OK
Access-Control-Allow-Headers: accept, content-type, authorization
Access-Control-Allow-Methods: POST, GET, OPTIONS, PUT, DELETE
Access-Control-Allow-Origin: *
Content-Length: 219
Content-Type: application/json
Date: Tue, 02 Apr 2024 03:15:03 GMT
Grpc-Metadata-Content-Type: application/grpc
{
"count": "1",
"header": {
"cluster_id": "14841639068965178418",
"member_id": "10276657743932975437",
"raft_term": "2",
"revision": "5"
},
"kvs": [
{
"create_revision": "2",
"key": "Zm9v",
"mod_revision": "5",
"value": "YmFy",
"version": "4"
}
]
}
Zm9v 是 foo 的 base64 编码, YmFy 是 bar 的 base64 编码。
和 etcdctl 相比,etcd HTTP API 返回的数据更多,可以帮助我们学习 etcd API 的行为。
etcd API 的 KV 部分
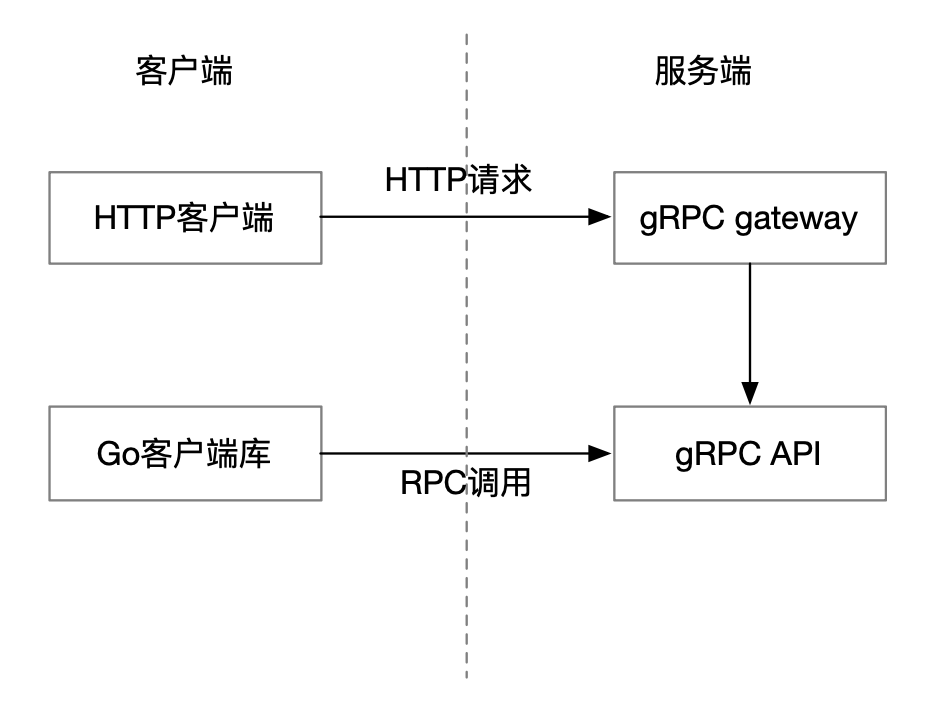
etcd 使用 gRPC 提供对外 API。
Etcd 官方提供一个 Go 客户端库。 Go 客户端库是对 gRPC 调用的封装, 对于其他常见语言也有第三方提供的客户端库。
另外 etcd 还用 gRPC gateway 对外提供了 HTTP API。可见 etcd 提供了丰富的客户端接入方式。
ZooKeeper 的 RPC 是基于 jute 的,客户端只有 Java 版和 C 语言版,接入方式相少一些。
和 ZooKeeper 的客户端库不同,etcd 的客户端不会自动和服务器端建立一个 session,但是可以使用 Lease API 来实现 session。
etcd API
etcd 使用 gRPC 提供对外 API。etcd 的 API 分为三大类:
- KV:key-value 的创建、更新、读取和删除。
- Watch:提供监控数据更新的机制。
- Lease:用来支持来自客户端的 keep-alive 消息。(Lease 允许用户为特定的键值对分配一个时间段,在这段时间内,该键值对将保持有效。一旦 Lease 过期,与该 Lease 相关的键值对将被自动删除。)
Response Header
所有的 RPC 响应都有一个 response header,Protobuf response header 包含以下信息:
cluster_id:创建响应的 etcd 集群 ID。member_id:创建响应的 etcd 节点 ID。revision:创建响应时 etcd KV 的 revision。raft_term:创建响应时的 raft term。
KeyValue
Key-value 是 etcd API 处理的最小数据单元,一个 Protobuf KeyValue 消息包含如下信息:
key:key 的类型为字节 slice。create_revision:key-value 的创建 revision。mod_revision:key-value 的修改 revision。version:key-value 的版本,从 1 开始。value:value 的类型为字节 slice。lease:和 key-value 关联的 leaseID。0 代表没有关联的 lease。
Key Range
key range [key, range_end) 代表从 key (包含) 到 range_end (不包含) 的 key 的区间。etcd API 使用可以 range 来检索 key-value。
[x,x+'\x00')代表单个 keya,例如['a','a\x00)代表单个key 'a'。对应 ZooKeeper,可以用['/a', '/a\x00')表示/a这个节点。[x,x+1)代表前缀为 x 的 key,例如['a','b)代表所有前缀为b的 key。对应 ZooKeeper, 可以用['/a/', '/a0')来表示目录/a下所有的子孙节点,但是没有办法使用 range 表示/a下的所有孩子节点。['\x00','\x00')代表整个的 key 空间。[a,'\x00')代表所有不小于 a(非\x00)的 key。
KV 服务
KV 服务主要包含以下 API:
Range:返回 range 区间中的 key-value。Put:写入一个 key-value。DeleteRange:删除 range 区间中的 key-value。Txn:提供一个 If/Then/Else 的原子操作,提供了一定程度的事务支持。
Range 和 DeleteRange 操作的对象是一个 key range,Put 操作的对象是单个的 key, Txn 的 If 中进行比较的对象也是单个的 key。
Range API
etcd 的 Range 默认执行 linearizable read(线性化读取,读取到最新数据,但性能不好),但是可以配置成 serializable read(串行化读取,可能读取到旧数据,但是性能好)。
ZooKeeper 的数据读取 API 只支持 serializable read。
etcd API 的 Watch 和 Lease 部分
Txn API
Txn 是 etcd kv 上面的 If/Then/Else 原子操作。如果 If 中的多个 Compare 的交为 true,执行 Then 中的若干 RequestOp,否则执行 Else 中的若干 RequestOp。
- 多个 Compare 可以使用多个 key。
- 多个 RequestOp 可以用来操作不同的 key,后面的 RequestOp 能读到前面 RequestOp 的执行结果。所有的更新 RequestOp 对应一个 revision。不能有多个更新的 RequestOp 操作一个 key。
Txn API 提供一个更新整个 etcd kv 的原子操作。Txn 的 If 语句检查 etcd kv 中若干 key 的状态,然后根据检查的结果更新整个 etcd kv。
Txn API 语法图
下图是简化的 Txn API 语法图。因为你缺少某个语句和语句为空是等价的,省略了缺少 If 语句、Then 语句和 Else 语句的情况。
- 如果 Then 为空或者 Else 为空,Txn 只有一个分支。
- 如果 If 为空的话,If 的结果为 true。
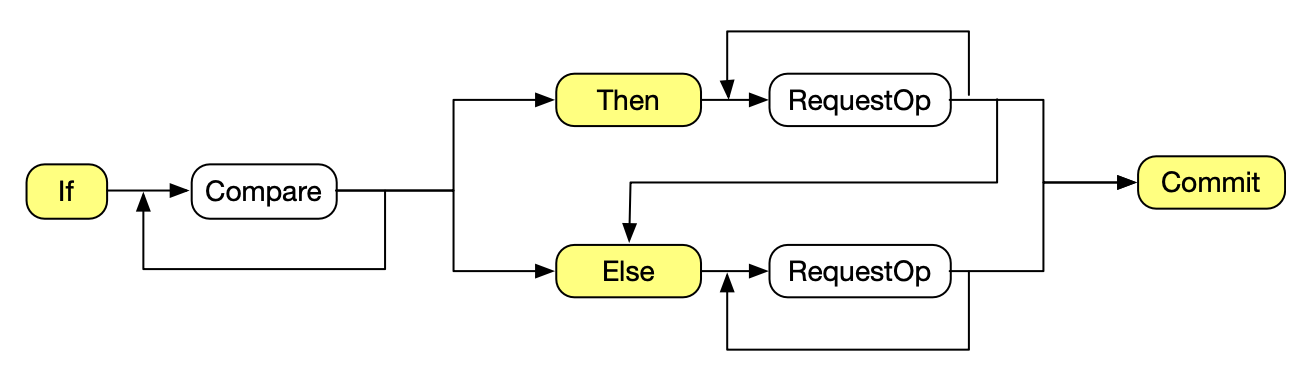
ZooKeeper 对应 etcd Txn API 的 API 是条件更新。条件更新对应的语法图如下图所示。
可以看出 Txn 要比条件更新灵活很多。条件更新只能对一个节点 A 的版本做比较,如果比较成功对 A 节点做 setData 或者 delete 操作。

ZooKeeper 另外还有一个 Transaction API,可以原子执行一个操作序列,但是没有 Txn API 的条件执行操作的机制。
1 | func TestTxn(t *testing.T) { |
1 | func TestTxnOpOrder(t *testing.T) { |
1 | func TestTxnMultis(t *testing.T) { |
Watch API
Watch API 提供一个监控 etcd KV 更新事件的机制。etcd Watch 可以从一个历史的 revision 或者当前的 revision 开始监控一个 key range 的更新。
ZooKeeper 的 Watch 机制只能监控一个节点的当前时间之后的更新事件,但是 ZooKeeper 的 Watch 支持提供了对子节点更新的原生支持。
etcd 没有对应的原生支持,但是可以用通过一个 key range 来监控一个目录下所有子孙的更新。
1 | func TestOneWatch(t *testing.T) { |
1 | func TestTwoWatches(t *testing.T) { |
Lease API
Lease 是用来检测客户端是否在线的机制。
客户端可以通过发送 LeaseGrantRequest 消息向 etcd 集群申请 lease,每个 lease 有一个 TTL(time-to-live)。
客户端可以通过发送 LeaseKeepAliveRequest 消息来延长自己的的 lease。
如果 etcd 集群在 TTL 时间内没有收到来自客户端的 keep alive 消息,lease 就会过期。另外客户端也可以通过发送 LeaseRevokeRequest 消息给 etcd 集群来主动的放弃自己的租约。
可以把一个 lease 和一个 key 绑定在一起。在 lease 过期之后,关联的 key 会被删除,这个删除操作会生成一个 revision。
客户端可以通过不断发送 LeaseKeepAliveRequest 来维持一个和 etcd 集群的 session。和 lease 关联的 key 和 ZooKeeper 的临时性节点类似。
1 | func TestLeaseWithKeepAliveOnce(t *testing.T) { |
使用 etcd 实现分布式队列
队列基础
队列是一种 FIFO 的数据结构。
队列首先可以用来保存元素入队的顺序,图的广度优先搜索算法就是用队列来保存访问节点的顺序。队列还可以用来做生产者和消费者的处理,把同步操作异步化。
并发队列支持的入队和出队操作的并发执行,例如 Java 的 BlockingQueue。
分布式队列也是一种并发队列,但是分布式队列的生产者和消费者可以是独立的 agent。
例如 Kafka 就 是一个分布式消息队列。

设计
使用 key 为某一固定前缀(例如 queue/)来表示队列中的元素。 ModRevision 的大小表示元素在队列中的位置,小的在队列前面,大的在队列后面。

设计思想和 ZooKeeper 的分布式队列是一样的。
ZooKeeper 的 recipe 中使用顺序号表示队列元素的位置。
etcd 的 ModRevision 和 ZooKeeper 的顺序号都是代表了数据创建顺序,都可以代表元素的入队时间。(但是这种做法可能会出现时间戳一样导致冲突,可以通过重试解决)
1 | // putNewKV attempts to create the given key, only succeeding if the key did |
出队操作
如果两个 agent A 和 B 进行入队操作的时候恰好使用了同样的时间戳,其中一个 agent 的入队操作就会失败。但是发生这种情况的概率是很低的,所以不用影响分布式队列的实际使用。发生这种情况的时候,入队失败的 agent 进行重试。
ZooKeeper 实现的队列没上述问题,原因在于它使用了 ZooKeeper 自己分配的序列号来命名队列元素。
1 | // Dequeue returns Enqueue()'d elements in FIFO order. If the queue is empty, Dequeue blocks until elements are |
使用 etcd 实现分布式锁
排它锁(Mutex)基础
Mutex 用来保证只有一个 agent 运行在临界区。在单机环境,可以使用 CAS 指令来实现 Mutex。
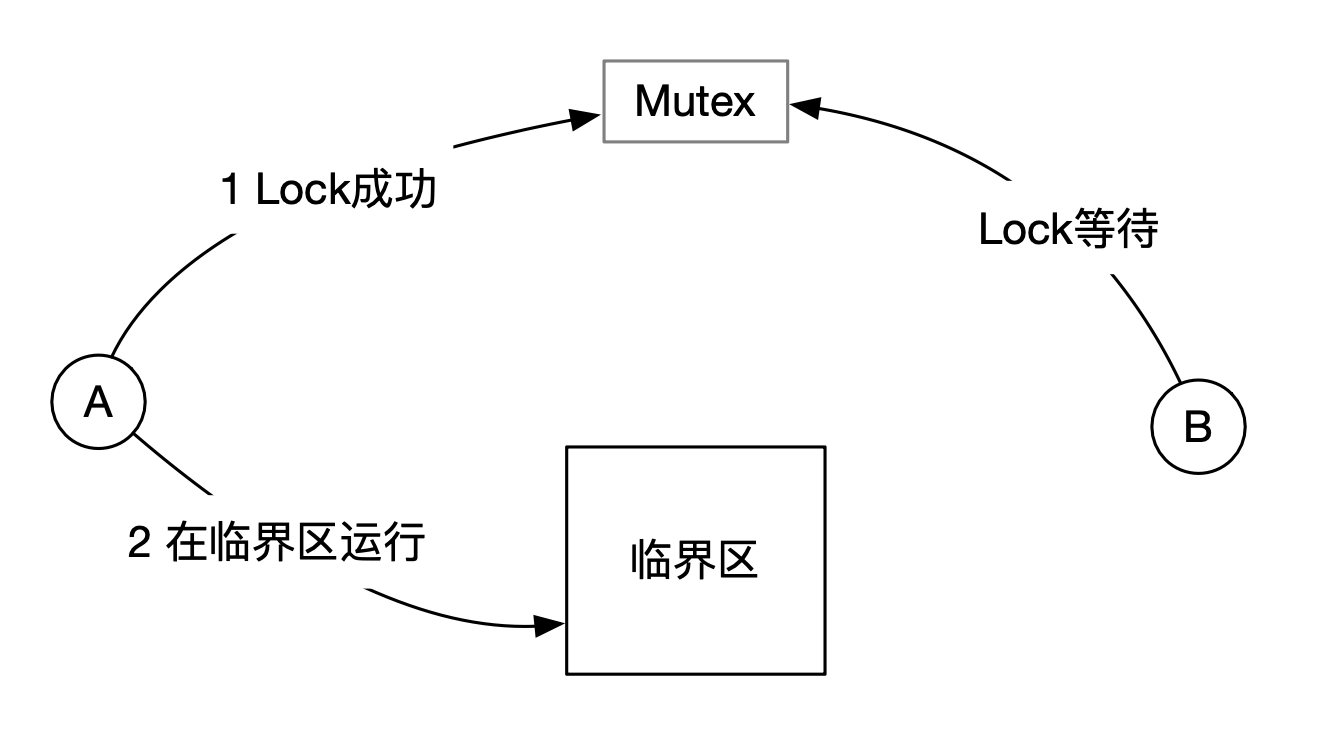
分布式排它锁
一个分布式 Mutex 除了需要类似 CAS 指令的机制以外,还需要处理持有锁的 agent 失败的情况。
如果持有者的 agent 失败了,需要一个心跳机制自动释放 Mutex。
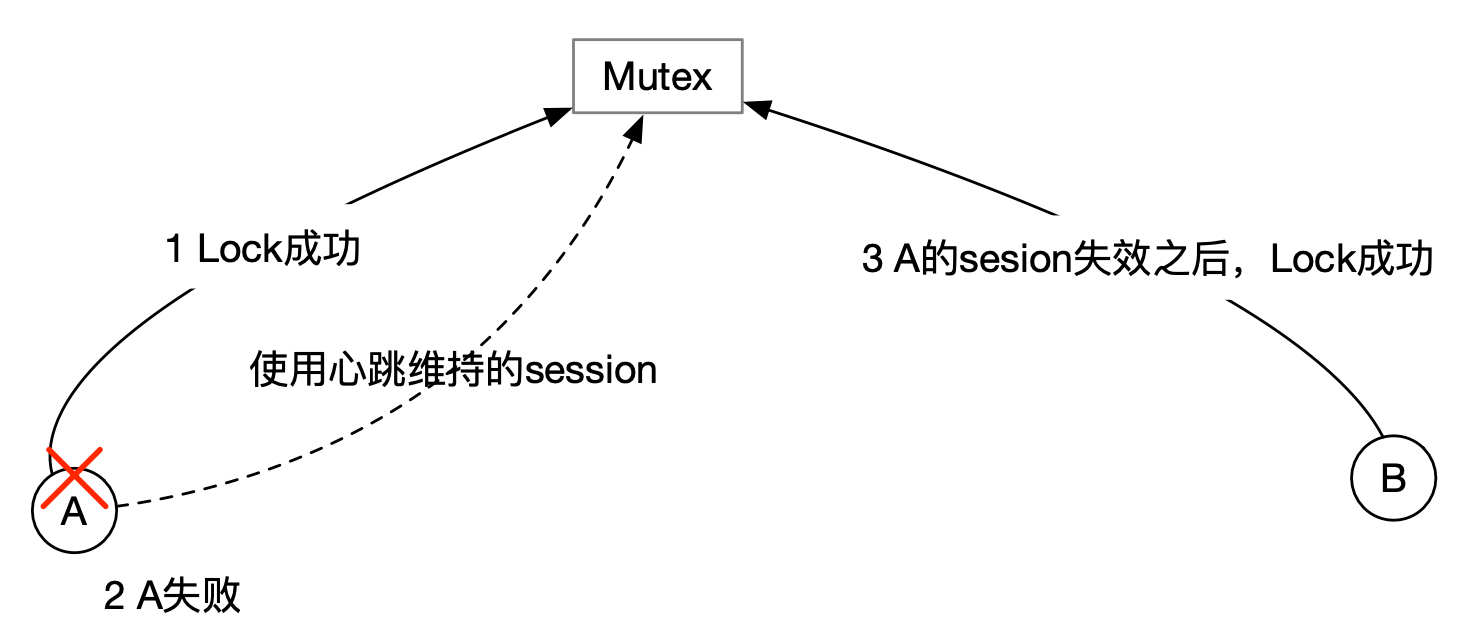
设计
使用 key 为某一固定前缀(例如 /lock/)的 key-value 来表示锁请求。
每个表示锁请求的 key 都和 lease 关联,这样在所持有者失败的情况下,相关的 key 会被自动删除,从而释放锁。
代表锁请求的 key 的 CreateRevision 越小,越先获得锁。CreateRevision 最小的锁请求可以成功获取锁。
为了避免羊群效应,每个等待的锁请求 watch 它前面的锁请求。

设计思想和 ZooKeeper 的分布式锁是一样的。ZooKeeper 的 recipe 中使用顺序号表示队列元素的位置。
etcd 的 CreateRevision 和 ZooKeeper 的顺序号都是代表了数据创建顺序,都可以代表锁请求的先后顺序。
1 | type Mutex struct { |
搭建一个 etcd 生产环境
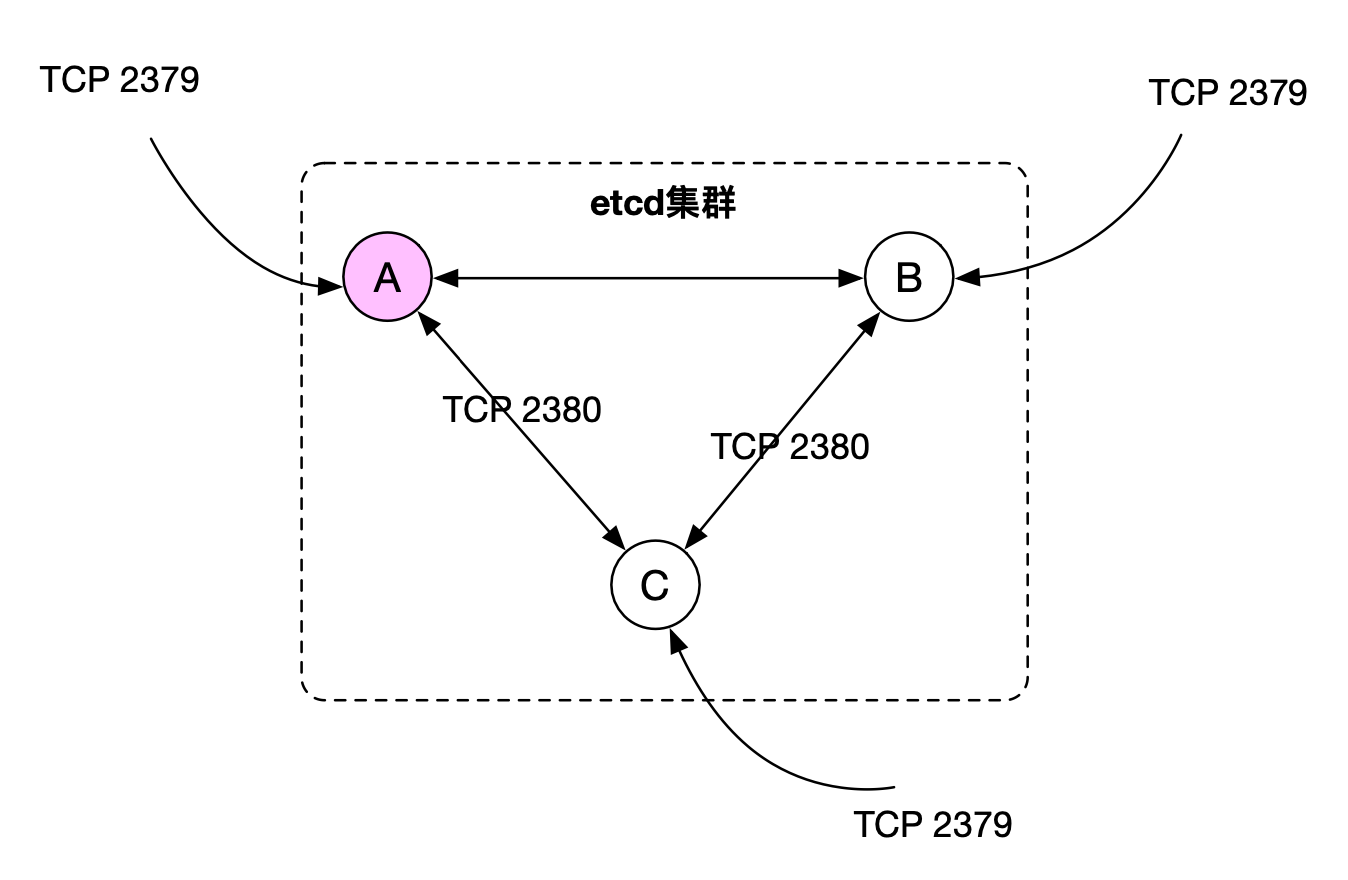
etcd 集群:一个 etcd 集群通常由奇数个节点组成。
节点之间默认使用 TCP 2380 端口进行通讯,每个节点默认使用 2379 对外提供 gRPC 服务。
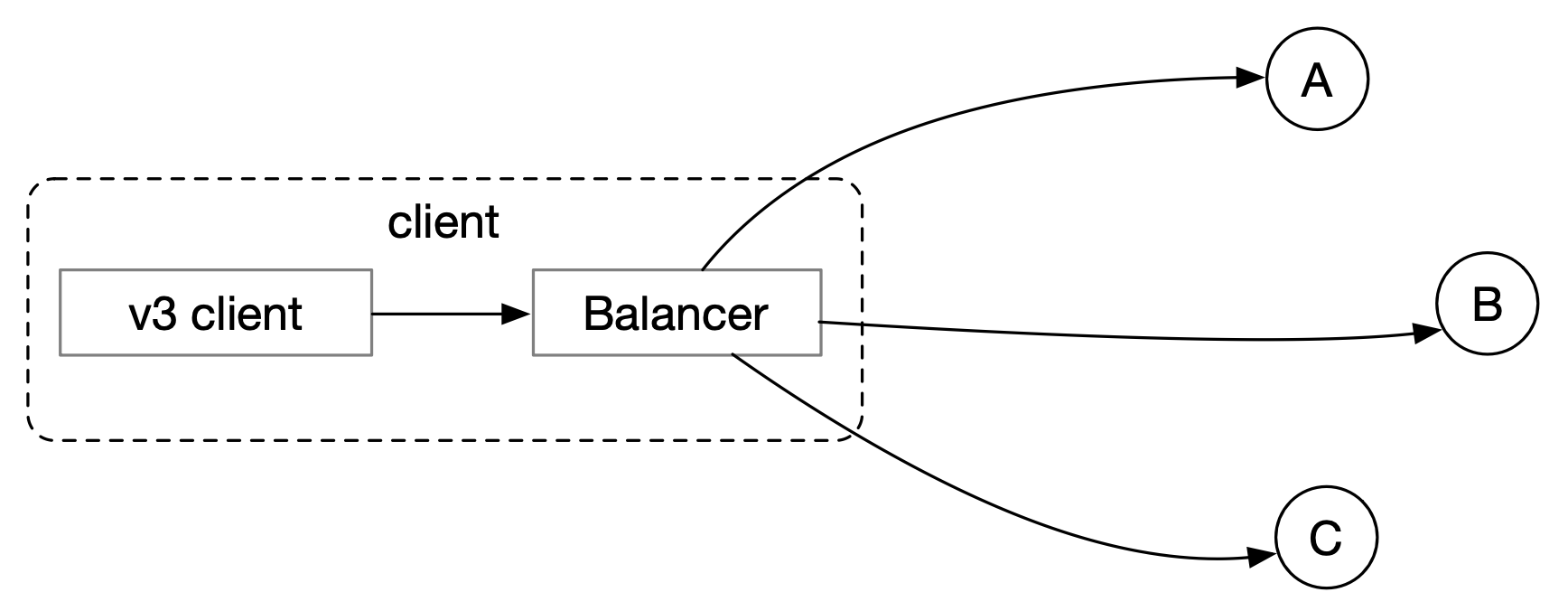
clientv3-grpc1.23 架构
客户端有一个内置的 balancer。这个 balancer 和每一个 etcd 集群中的节点预先建立一个 TCP 连接。
balancer 使用轮询策略向集群中的节点发送 RPC 请求。
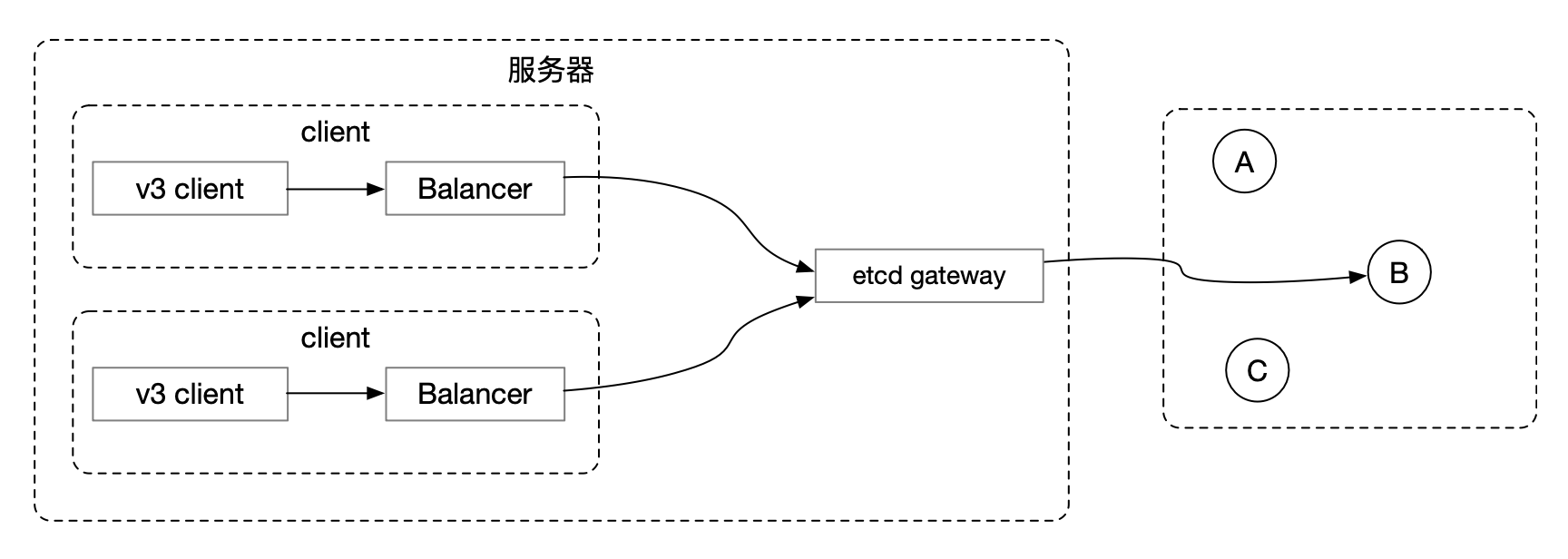
etcd gateway
etcd gateway 是一个4层代理。客户端可以通过 etcd gateway 访问 etcd 集群中的各个节点。
这样在集群中成员节点发生变化,只要在 etcd gateway 上面更新一次 etcd 集群节点访问地址就可以了,用不重要每个客户端都更新。
对于来自客户端的每一个 TCP 连接,etcd gateway 采用轮询方式的选择一个 etcd 节点,把这个 TCP 连接代理到这个节点上。
gRPC proxy
gRPC proxy 是一个7层代理,可以用来减少 etcd 集群的负载。
gRPC proxy 除了合并客户端的 watch API 和 lease API 的请求,并且会 cache 来自 etcd 集群的响应。
gRPC proxy 会随机的选取选取集群中的一个节点建立连接。如果当前连接的节点失败, gRPC proxy 才会切换到集群中 另外一个节点。
配置一个3节点的集群
启动一个3节点的 etcd 集群和一个 gPRC proxy 的步骤:
- 安装 Go1.13
- 使用
go get github.com/mattn/goreman安装 goreman - 编辑 Procfile
https://github.com/etcd-io/etcd/blob/master/Procfile
1 | # Adapted https://github.com/etcd-io/etcd/blob/master/Procfile |
动态添加删除节点
可以使用 etcdctl member 命令动态添加和删除节点。
比较 ZooKeeper 和 etcd
ZooKeeper 和 etcd 都是优秀的分布式协同服务平台,都有很大的生态圈。
- ZooKeeper更成熟,系统更稳定,文档更加完备。在大数据生态,ZooKeeper是首选。如果研发首选语言是基于 JVM 的,建议 ZooKeeper。
- etcd的架构更先进一些。在云计算领域,etcd是首选。如果研发首选语言是Go,建议etcd。
实现原理和源码解读
存储数据结构之 B-tree
B-tree 的应用十分广泛,尤其是在关系型数据库领域,下面列出了一些知名的 B-tree 存储引擎:
- 关系型数据库系统 Oracle、SQL Server、MySQL 和 PostgreSQL 都支持 B-tree。
- WiredTiger 是 MongoDB 的默认存储引擎,开发语言是 C,支持 B-tree。
- BoltDB:Go 语言开发的 B-tree 存储引擎,etcd 使用 BoltDB 的 fork bbolt。
存储引擎一般用的都是 B+tree,但是存储引擎界不太区分 B-tree 和 B+tree,说 B-tree 的时候其实一般指的是 B+tree。
硬要说区别就是 B-tree 指的是节点上除了有索引信息,还有数据信息,而 B+tree 枝干节点上只有索引信息,叶子节点上有索引信息和数据信息。
平衡二叉搜索树
平衡二叉搜索树是用来快速查找 key-value 的有序数据结构。
平衡二叉搜索树适用于内存场景(指的是所有节点都存放在内存中国),但是不适用于于外部存储(节点信息存放在外部存储中,查询到一个节点需要从外部存储中获得信息)。原因在于每访问一个节点都要访问一次外部存储,而访问外部存储是非常耗时的。
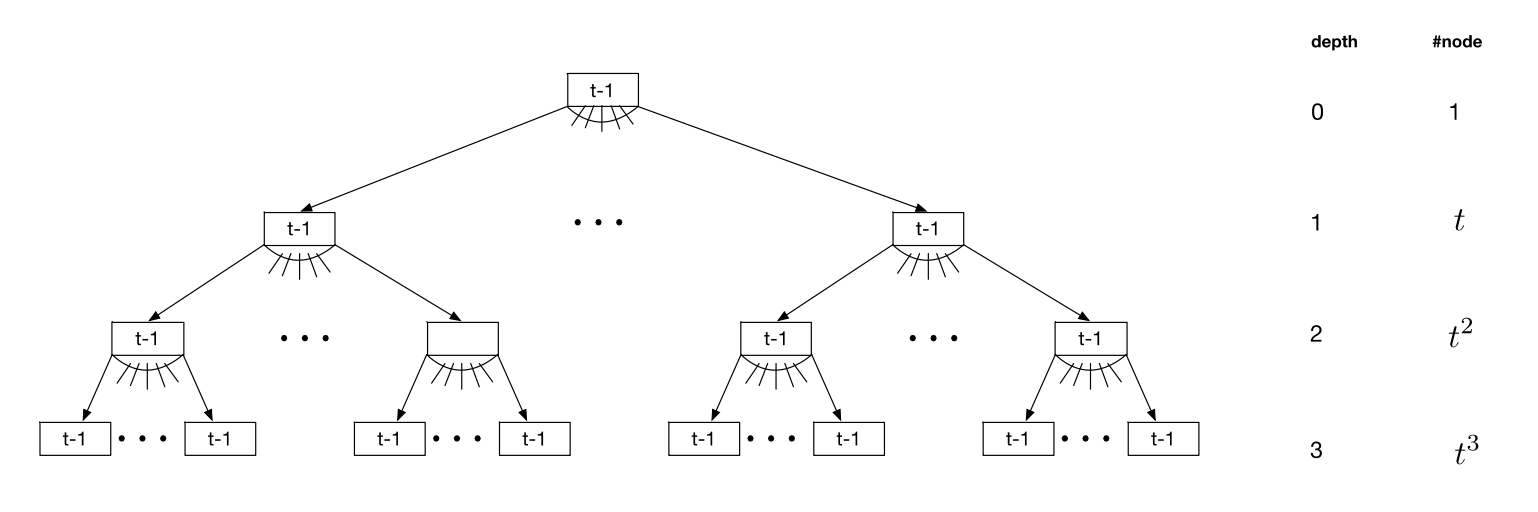
要减少访问外部存储的次数,就要减少树的高度,要减少树的高度就要增加一个节点保存 key 的个数。B-tree 就是用增加节点中 key 个数的方案来减少对外部存储的访问。
B-tree
B-tree 是一种平衡搜索树。
每一个 B-tree 有一个参数 t,叫做 minimum degree。每一个节点的 degree 在 t 和 2t 之间。
下图是一个每个节点的 degree 都为 t 的 B-tree。如果 t 为 1024 的话,下面的 B-tree 可以保存 1G 多的 key 值。
因为 B-tree 的内部节点通常可以缓存在内存中,访问一个 key 只需要访问一次外部存储。
B-tree 和平衡二叉搜索树的算法复杂度一样的,但是减少了对外部存储的访问次数。
B-tree 特点
- 所有的节点添加都是通过节点分裂完成的。
- 所有的节点删除都是通过节点合并完成。
- 所有的插入都发生在叶子节点。
- B-tree 的节点的大小通常是文件系统 block 大小的倍数,例如 4k,8k 和 16k。(例如 MySQL 中 InnoDB 存储引擎的默认页大小是 16KB)
B+tree
为了让 B-tree 的内部节点可以具有更大的 degree,可以规定内部节点只保存 key,不保存 value。这样的 B-tree 叫作 B+tree。
另外通常会把叶子节点连成一个双向链表,方便 key-value 升序和降序扫描。
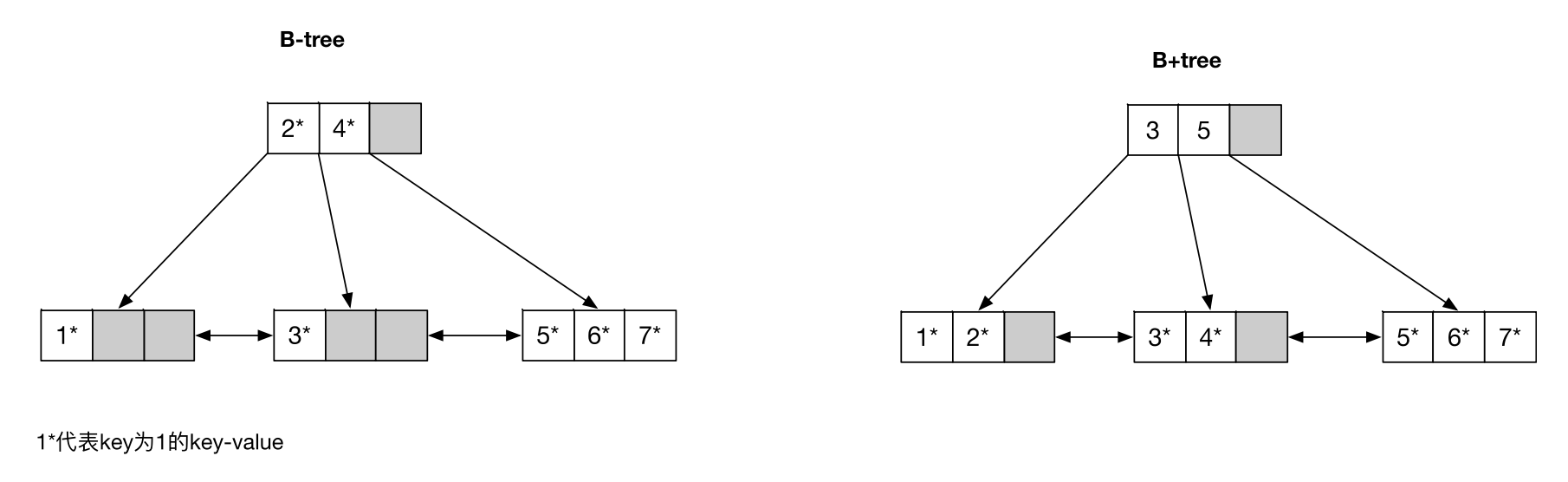
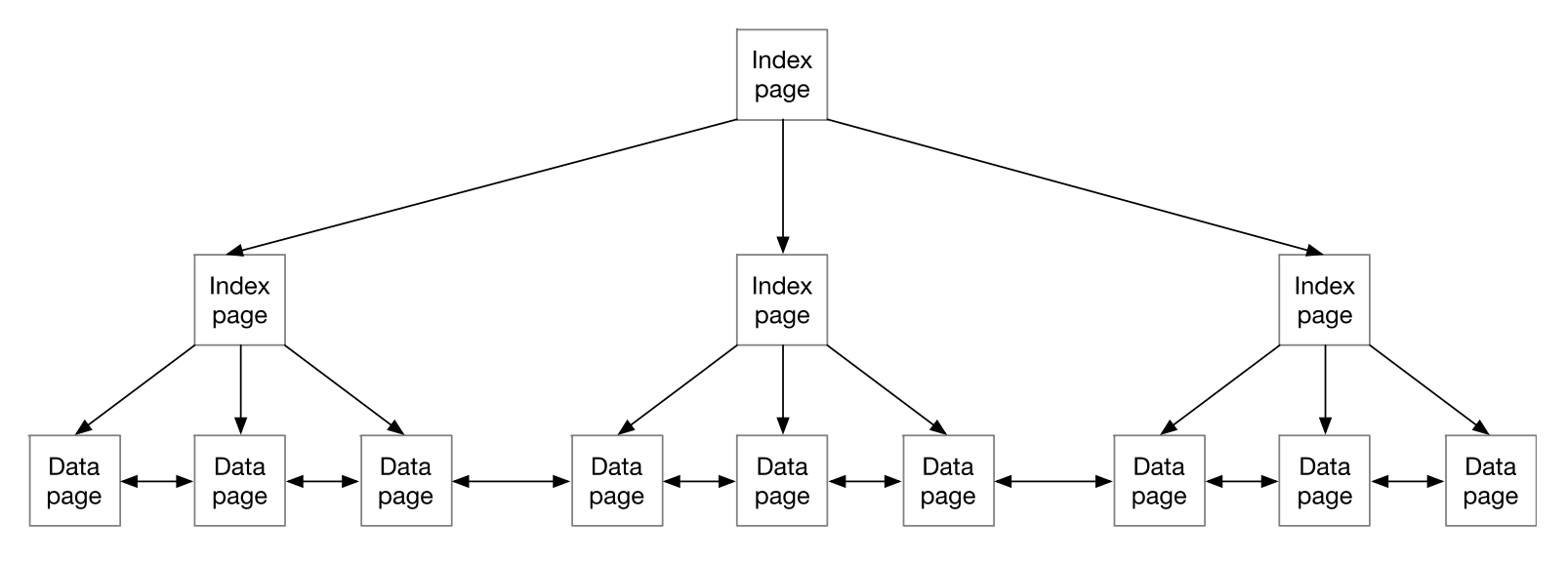
B+tree 索引
大部分关系型数据库表的主索引都是用的 B+tree。B+tree 的叶子节点叫作 data page,内部节点叫作 index page。
存储数据结构之 LSM
Log Structured Merge-tree(LSM):是另外一种广泛使用的存储引擎数据结构。
LSM 是在 1996 发明的,但是到了 2006 年从 Bigtable 开始才受到关注。
LSM 架构
一个基于 LSM 的存储引擎有以下 3 部分组成:
Memtable:保存有序 KV 对的内存缓冲区。- 多个
SSTable:保存有序 KV 对的只读文件。 - 日志:事务日志。
LSM 存储 MVCC 的 key-value。每次更新一个 key-value 都会生成一个新版本,删除一个 key-value 会生成一个 tombstone 的新版本。

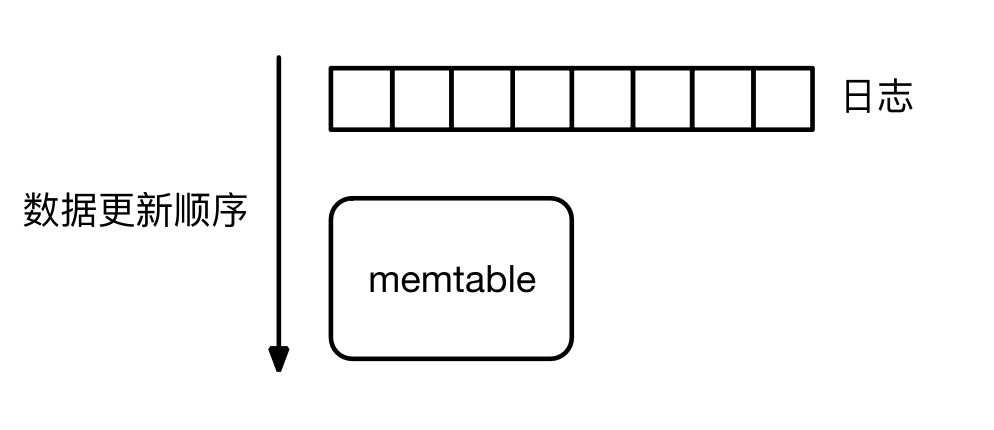
LSM 写操作
一个写操作首先在日志中追加事务日志,然后把新的 key-value 更新到 Memtable。LSM 的事务是 WAL
日志。
LSM 读操作
在由 Memtable 和 SSTable 合并成的一个有序 KV 视图上进行 Key 值的查找。
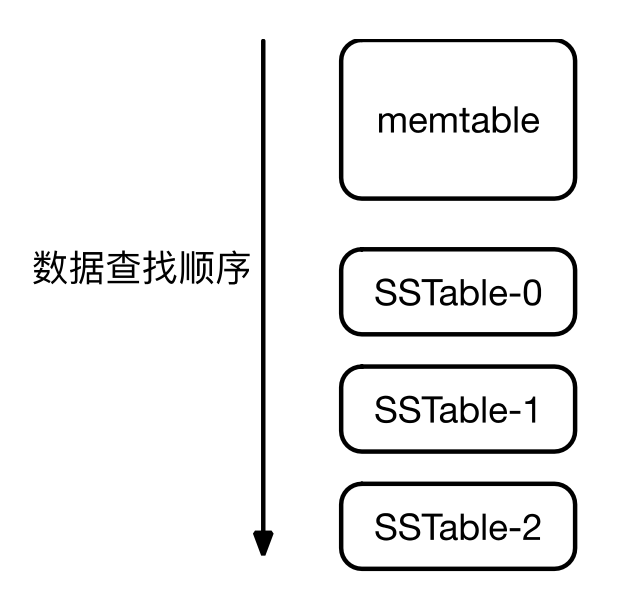
例如在上图所示的 LSM 中,要查找一个 key a:
在 memtable 中查找,如果查找到,返回。否则继续。
在 SSTable-0 中查找,如果查找到,返回。否则继续。
在 SSTable-1 中查找,如果查找到,返回。否则继续。
在 SSTable-2 中查找,如果查找到,返回。否则返回空值。
Bloom Filter
使用 Bloom filter 来提升 LSM 数据读取的性能。
Bloom filter 是一种随机数据结构,可以在 O(1) 时间内判断一个给定的元素是否在集合中。False positive 是可能的,既 Bloom filter 判断在集合中的元素有可能实际不在集合中,但是 false negative 是不可能的。
Bloom filter 由一个 m 位的位向量和 k 个相互独立的哈希函数 h1,h2,…,hk 构成。
- 这些 hash 函数的值范围是 {1,…,m}。
- 初始化 Bloom filter 的时候把位向量的所有的位都置为 0。
- 添加元素 a 到集合的时候,把维向量 h1(a), h2(a), hk(a) 位置上的位置为 1。
- 判断一个元素 b 是否在集合中的时候,检查把维向量 h1(b), h2(b), … ,hk(a) 位置上的位是否都为 1。
- 如果这些位都为 1,那么认为 b 在集合中;否则认为 b 不在集合之中。
下图所示的是一个 m 为 14,k 为 3 的 Bloom filter。

下面是计算 False positive 概率的公式(n 是添加过的元素数量):
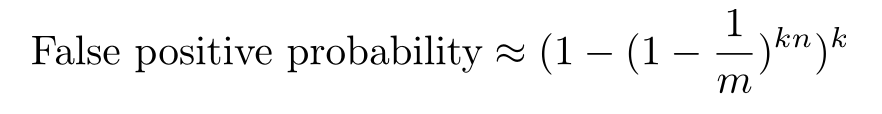
Compaction
如果我们一直对 memtable 进行写入,memtable 就会一直增大直到超出服务器的内部限制。所以我们需要把 memtable 的内存数据放到 durable storage 上去,生成 SSTable 文件,这叫做 minor compaction。

- Minor compaction:把 memtable 的内容写到一个 SSTable。目的是减少内存消耗,另外减少数据恢复时需要从日志读取的数据量。
- Merge compaction:把几个连续 level 的 SSTable 和 memtable 合并成一个 SSTable。目的是减少读操作要读取的 SSTable 数量。
- Major compaction:合并所有 level 上的 SSTable 的 merge compaction。目的在于彻底删除 tombstone 数据,并释放存储空间。
基于 LSM 的存储引擎
下面列出了几个知名的基于 LSM 的存储引擎:
LevelDB:开发语言是 C++,Chrome 的 IndexedDB 使用的是 LevelDB。RocksDB:开发语言是 C++,RocksDB 功能丰富,应用十分广泛,例如 CockroachDB、TiKV 和 Kafka Streams 都使用了它。Pebble:开发语言是 Go,应用于 CockroachDB。BadgerDB:一种分离存储 key 和 value 的 LSM 存储引擎。WiredTiger:WiredTiger 除了支持 B-tree 以外,还支持 LSM。
存储引擎的放大指标(Amplification Factors)
对比存储引擎的三个指标:
- 读放大(read amplification):一个查询涉及的外部存储读操作次数。如果我们查询一个数据需要做 3 次外部存储读取,那么读放大就是 3。
- 写放大(write amplification):写入外部存储设备的数据量和写入数据库的数据量的比率。如果我们对数据库写入了 10MB 数据,但是对外部存储设备写入了 20BM 数据,写放大就是 2。
- 空间放大(space amplification):数据库占用的外部存储量和数据库本身的数据量的比率。如果一个 10MB 的数据库占用了 100MB,那么空间放大就是 10。
比较 B-tree 和 LSM
LSM 和 B-tree 在 Read amplification(读放大),Write amplification(写放大)和 Space amplification(空间放大)这个三个指标上的区别:
| LSM | B+/-Tree | |
|---|---|---|
| 读放大 | 一个读操作要对多个 level 上的 SSTable 进行读操作。 | 一个 key-value 的写操作涉及一个数据页的读操作,若干个索引页的读操作。 |
| 写放大 | 一个 key-value 值的写操作要在多级的 SSTable 上进行。 | 一个 key-value 的写操作涉及数据页的写操作,若干个索引页的写操作。 |
| 空间放大 | 在 SSTable 中存储一个 key-value 的多个版本。 | 索引页和页 fragmentation。 |
LSM 和 B+-Tree 在性能上的比较:
- 写操作:LSM 上的一个写操作涉及对日志的追加操作和对 memtable 的更新(顺序 IO)。但是在 B+-Tree 上面,一个写操作对若干个索引页和一个数据页进行读写操作,可能导致多次的随机 IO。所以 LSM 的写操作性能一般要比 B+-Tree 的写操作性能好。
- 读操作:LSM 上的一个读操作需要对所有 SSTable 的内容和 memtable 的内容进行合并 。但是在 B+-Tree 上面,一个读操作对若干个索引页和一个数据页进行读操作 。所以 B+-Tree 的读操作性能一般要比 LSM 的读操作性能好。
本地存储技术总结
数据的随机读写 vs 顺序读写
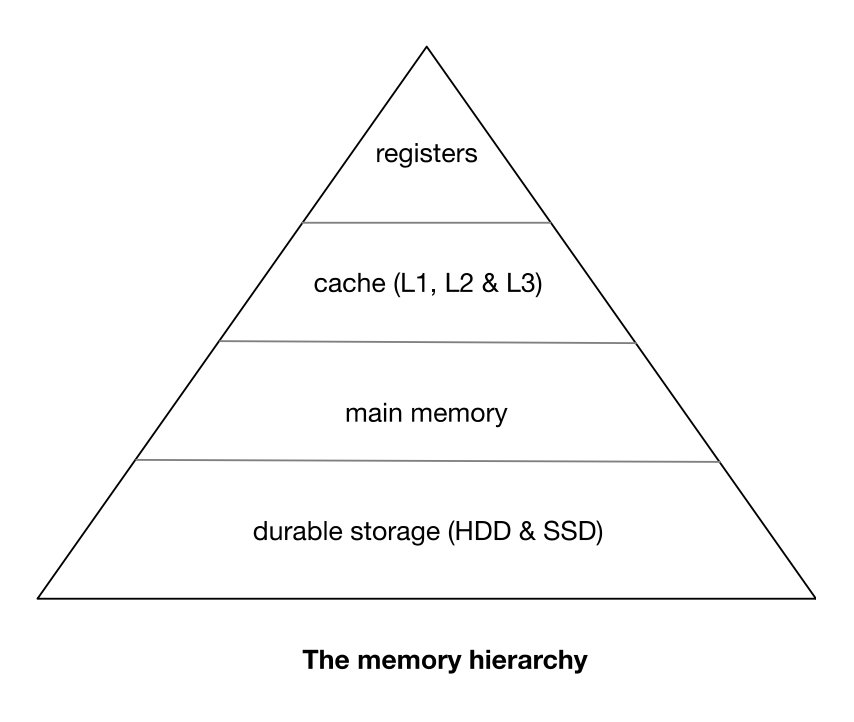
在上图的 memory hierarchy,越往下的存储方式容量越大延迟越大,越往上容量越小延迟越小。
对 main memory 和 durable storage 的数据访问,顺序读写的效率都要比随机读写高。
例如 HDD 的 seek time 通常在 3 到 9ms 之前,所以一个 HDD 一秒最多支持 300 多次随机读写。
虽然 SSD 和 main memory 的随机读写效率要比 HDD 好的多,顺序读写的效率仍然要比随机读写高。
所以我们设计存储系统的时候,要尽量避免随机读写多使用顺序读写。
文件系统基础知识
ext4 文件系统
ext4 是 Linux 系统上广泛使用的文件系统。
下图列的是 ext4 文件系统 inode 的结构。
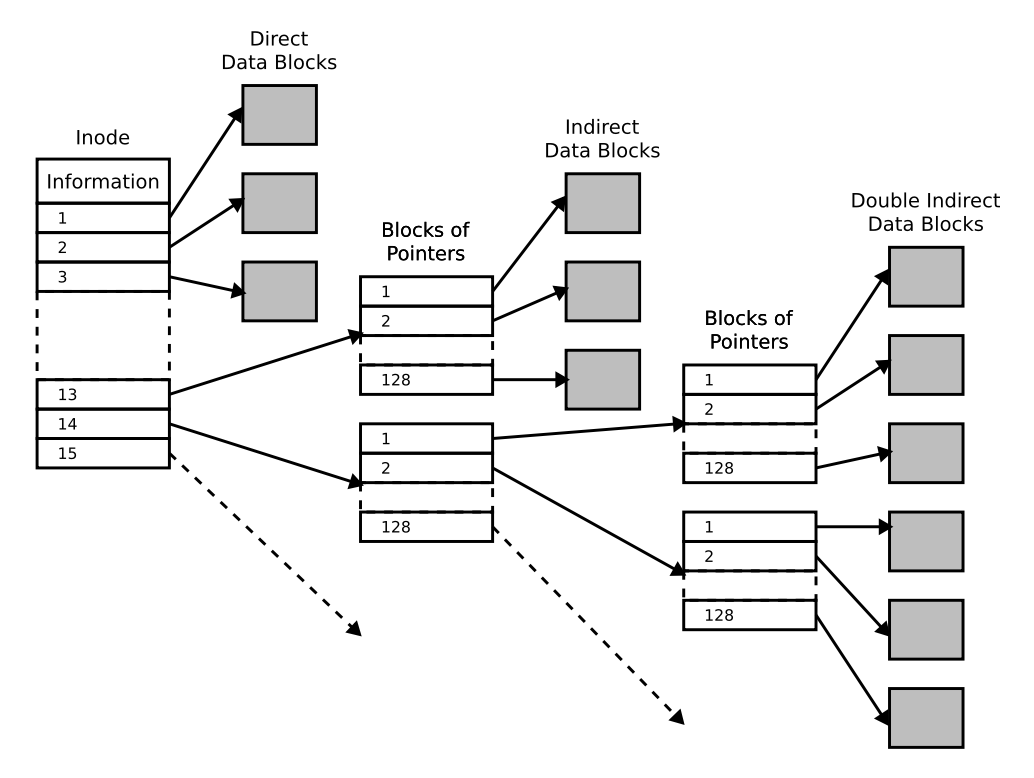
其中 information (元数据 inode)包括文件的 size,last access time 和 last modification time 等。文件的 inode 和 data block 存储在存储设备的不同位置。
文件系统 API
访问文件内容是 read 和 write 两个系统调用。
除非使用了 O_DIRECT 选项,read 和 write 操作的都是 block 的 buffer cache,Linux OS 会定期把 dirty block 刷新到 durable storage 上去。
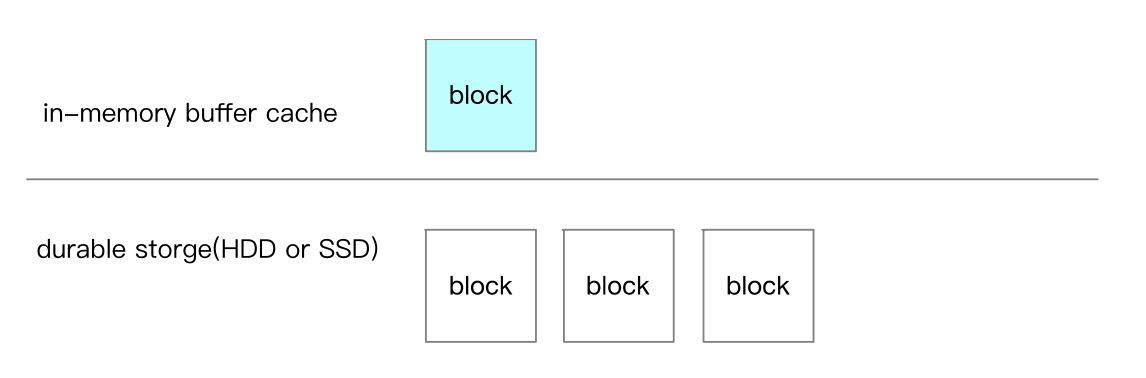
设计可靠的存储系统要求把内容实际写到 durable storage 上去。
下面的这两个系统调用提供了把 buffer cache 的内容手动刷新到 durable storage 的机制:
- fsync:把文件的数据 block 和 inode 的 metadata 刷新到 durable storage。
- fdatasync:把文件的数据 block 刷新到 durable storage。只有修改过的 metadata 影响后面的操作才把 metadata 也刷新到 durable storage。
Write Ahead Logging
保证 durable storage 写入的原子性
我们在 write 调用之后调用 fsync/fdatasync,文件系统通常可以保证对一个 block 写入的原子性。
如果我们的一个数据写入包含对多个 block 的写入。要保证这样整个写入的原子性,就需要另外的机制。
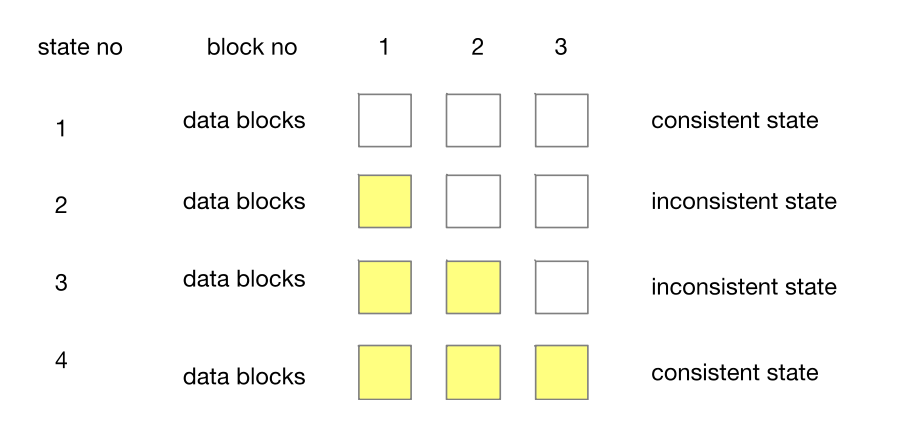
例如在上图中,我们要对 3 个 data block 进行写入。
如果我们依次对这些 block 写入,如果在写入 block1 之后发生 crash,数据就会处于状态 2。
在状态 2 中,block1 保存旧数据、block2 和 block3 保存旧数据,数据是不一致的。
Write Ahead Logging(WAL)
WAL 是广泛使用的保证多 block 数据写入原子性的技术。
WAL 就是在对 block 进行写入之前,先把新的数据写到一个日志。只有在写入 END 日志并调用 sync API,才开始对 block 进行写入。
如果在对 block 进行写入的任何时候发生 crash,都可以在重启的使用 WAL 里面的数据完成 block 的写入。

另外通过使用 WAL,我们在提交一个操作之前只需要进行文件的顺序写入,从而减少了包含多 block 文件操作的数据写入时延。
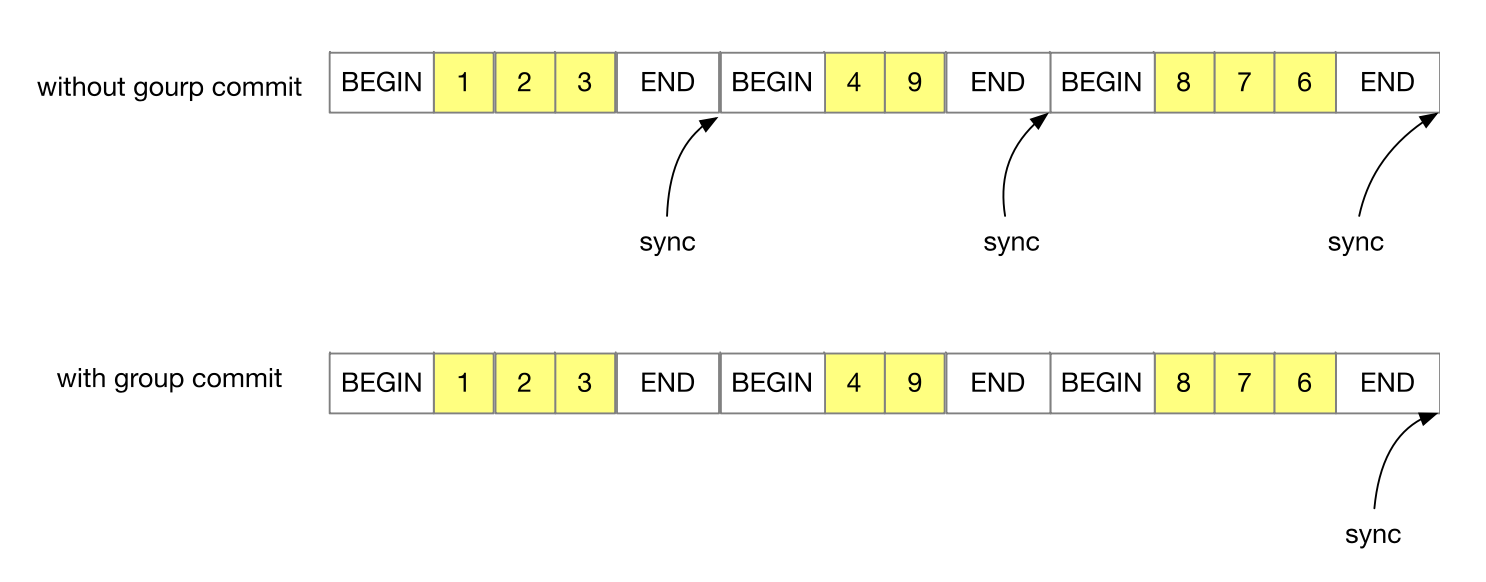
WAL 优化1:Group Commit
上面的 WAL 方案中每次写入完 END 日志都要调用一次耗时的 sync API,会影响系统的性能。
为了解决这个问题,我们可以使用 group commit。group commit 就是一次提交多个数据写入,只有在写入最后一个数据写入的 END日志之后,才调用一次 sync API。
WAL 优化2:File Padding
在往 WAL 里面追加日志的时候,如果当前的文件 block 不能保存新添加的日志,就要为文件分配新的 block,这要更新文件 inode 里面的信息(例如 size)。
如果我们使用的是 HHD 的话,就要先 seek 到 inode 所在的位置,然后回到新添加 block 的位置进行日志追加。
为了减少这些 seek,我们可以预先为WAL 分配 block。例如 ZooKeeper 就是每次为 WAL 分配 64MB 的 block。

WAL 优化3:快照
如果我们使用一个内存数据结构加 WAL 的存储方案,WAL 就会一直增长。这样在存储系统启动的时候,就要读取大量的 WAL 日志数据来重建内存数据。
快照可以解决这个问题。
快照是应用 WAL 中从头到某一个日志条目产生的内存数据结构的序列化,例如下图中的快照就是应用从 1 到 7 日志条目产生的。
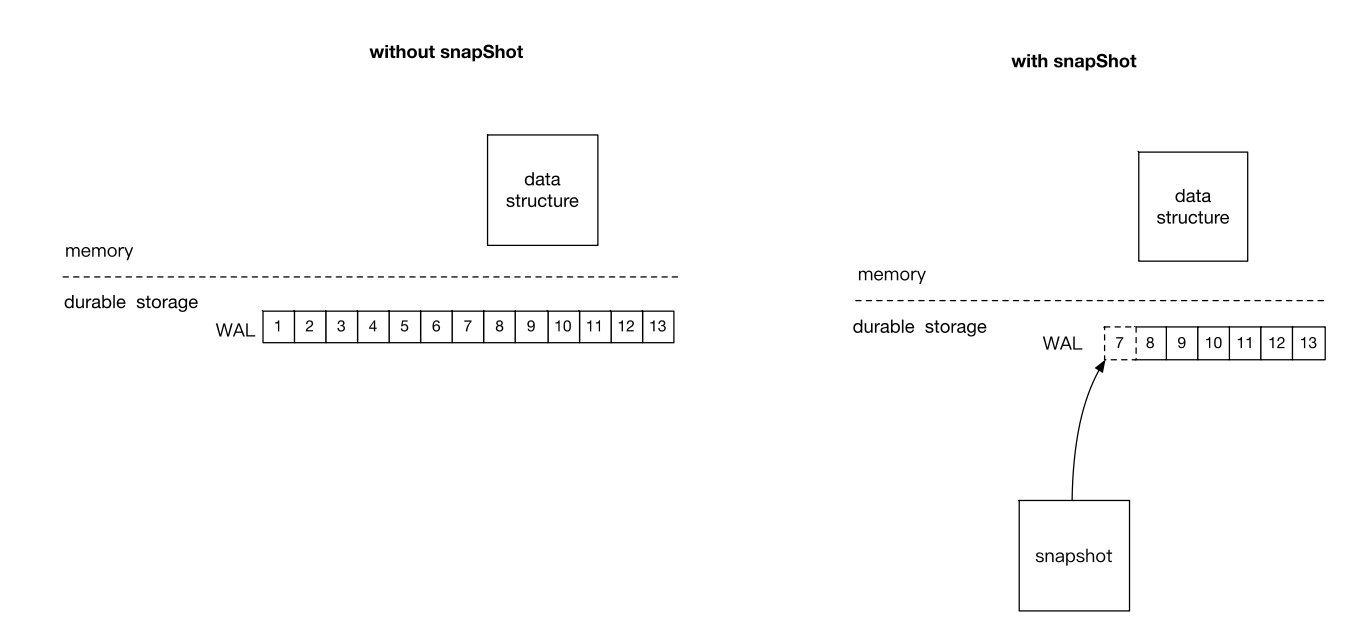
除了解决启动时间过长的问题之外,快照还可以减少存储空间的使用。
WAL 的多个日志条目有可能是对同一个数据的改动,通过快照,就可以只保留最新的数据改动。
数据序列化
现在有众多的数据序列化方案,下面列出一些比较有影响力的序列化方案:
- JSON:基于文本的序列化方案,方便易用,没有 schema,但是序列化的效率低,广泛应用于 HTTP API 中。
- BSON:二进制的 JSON 序列化方案,应用于 MongoDB。
- Protobuf:Google 研发的二进制的序列化方案,有 schema,广泛应用于 Google 内部,在开源界也有广泛的应用(例如 gRPC)。
- Thrift:Facebook 研发的和 Protobuf 类似的一种二进制序列化方案,是 Apache 的项目。
- Avro:二进制的序列化方案,Apache 项目,在大数据领域用的比较多。
研发本地存储
研发一个高效的本地存储引擎需要该领域的专家级技术,所以不建议自己从 0 开始研发。
目前开源界有众多的本地存储引擎,建议直接使用现有的方案。如果现有的开源方案不能满足要求,可以在这些方案的基础之上进行二次开发。
ZooKeeper本地存储源码解析
序列化
ZooKeeper 使用的序列化方案是 Apache Jute。
zooKeeper.jute 包含所有数据的 schema ,Jute 编译器通过编译 jute 文件生成 Java 代码。生成的所有 Java 类实现 Record 接口。
下面列出了序列化的核心接口和类。 Jute 的序列化底层使用的是 Java DataInput 的编码方案。
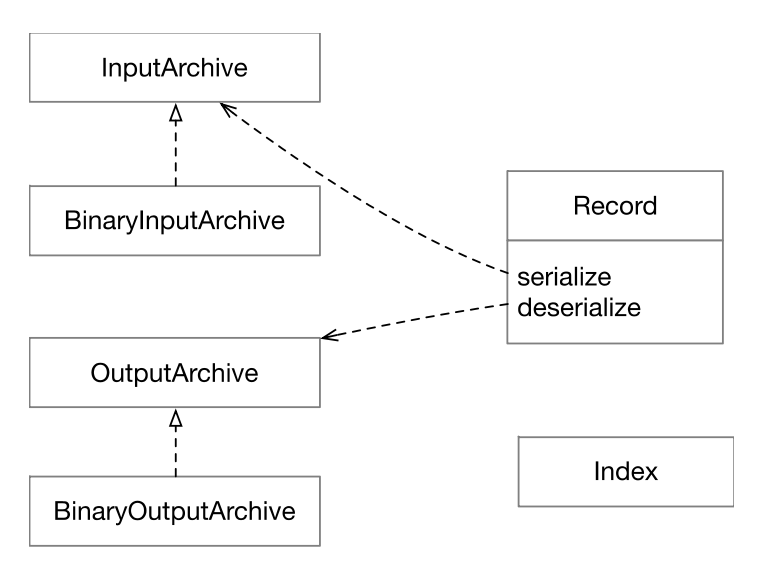
InputArchive:反序列化;
OutputArchive:序列化;
本地存储架构
ZooKeeper 的本地存储采用的是内存数据结构加 WAL 的方案。
ZooKeeper 的 WAL 叫作事务日志(transaction log).
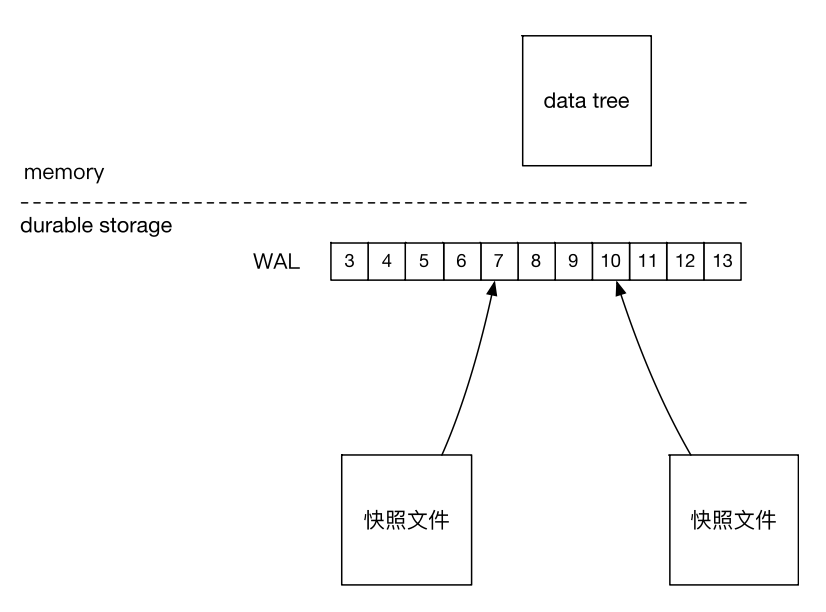
核心接口和类
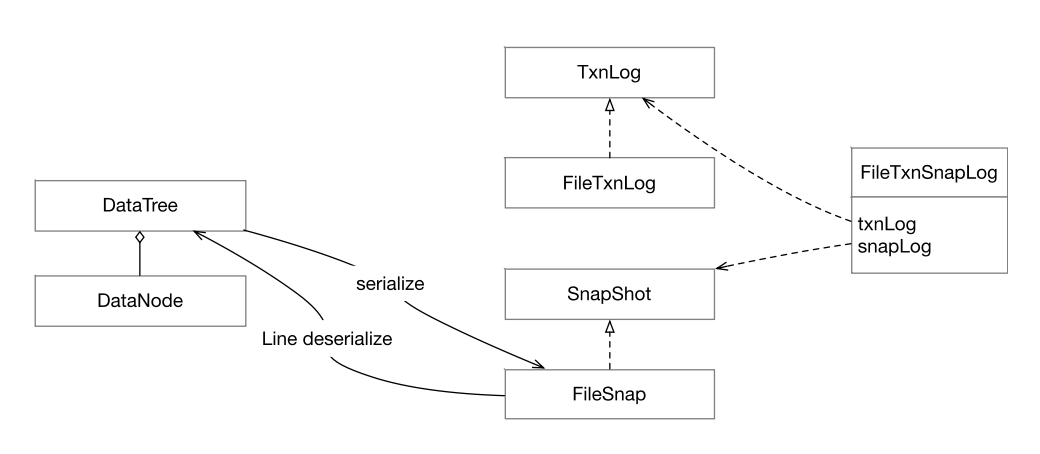
- TxnLog: 接口类型,提供读写事务日志的API。
- FileTxnLog: 基于文件的 TxnLog 实现。
- Snapshot: 快照接口类型,提供序列化、反序列化、访问快照的 API。
- FileSnap: 基于文件的 Snapsho 实现。
- FileTxnSnapLog: TxnLog和 SnapShot 的封装。
- DataTree: ZooKeeper 的内存数据结构,是有所有 znode 构成的树。
- DataNode: 表示一个 znode。
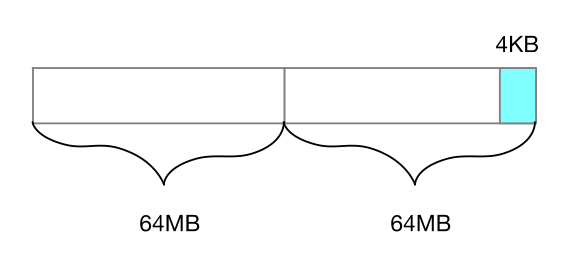
File Padding
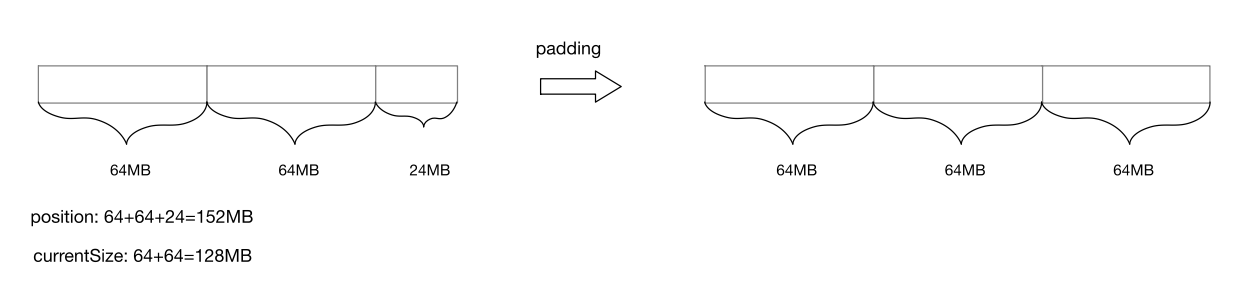
当 file channel 的 position 在 currentSize 结束为止的 4KB 范围之内是进行 padding。
如果 position 已经超出了 currentSize,基于 position 进行空间扩容。
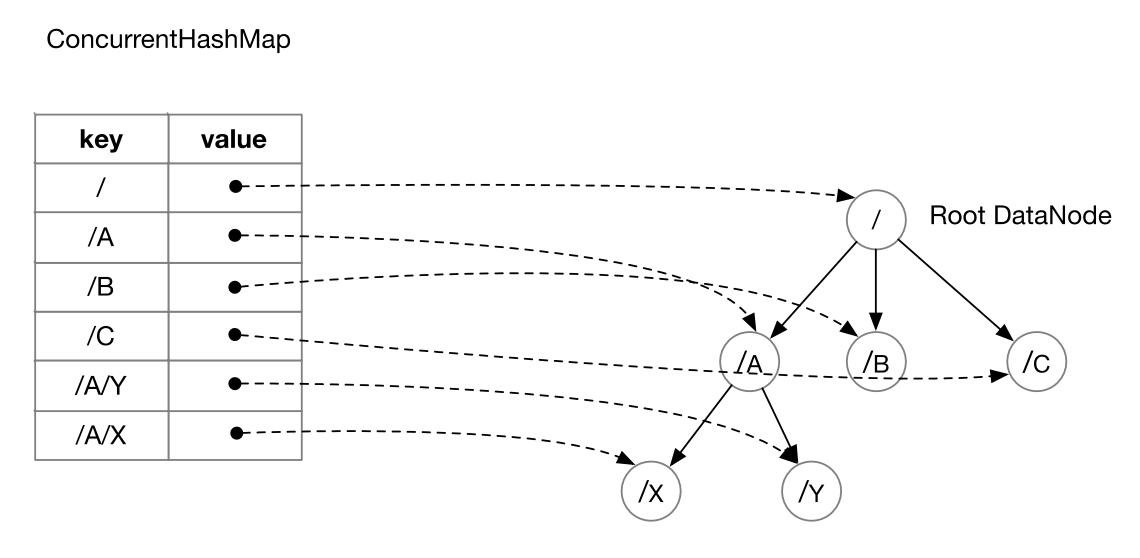
DataTree
DataNode 有一个成员叫作 children,children 保存该 DataNode 的子节点名字,可以从根节点开始通过 children 遍历所有的节点。
只有在序列化 DataTree 的时候才会通过 children 进行 DataTree 的遍历。其他对 DataNode 的访问都是通过 DataTree 的成员 nodes 来进行的。
nodes 是一个ConcurrentHashMap,保存的是 DataNode 的 path 到 DataNode 的映射。
快照
- 序列化:从根 DataNode 开始做前序遍历,依次把 DataNode 写入到快照文件中。
- 反序列化:从头开始顺序读取快照文件的内容,建立 DataTree。因为在序列化的时候使用的是前序遍历,会先反序列化到父亲节点再反序列化孩子节点。因此,在创建新的 DataNode 的同时,可以把新的 DataNode 加到它的父亲节点的 children 中去。

网络编程基础
TCP/IP 协议栈
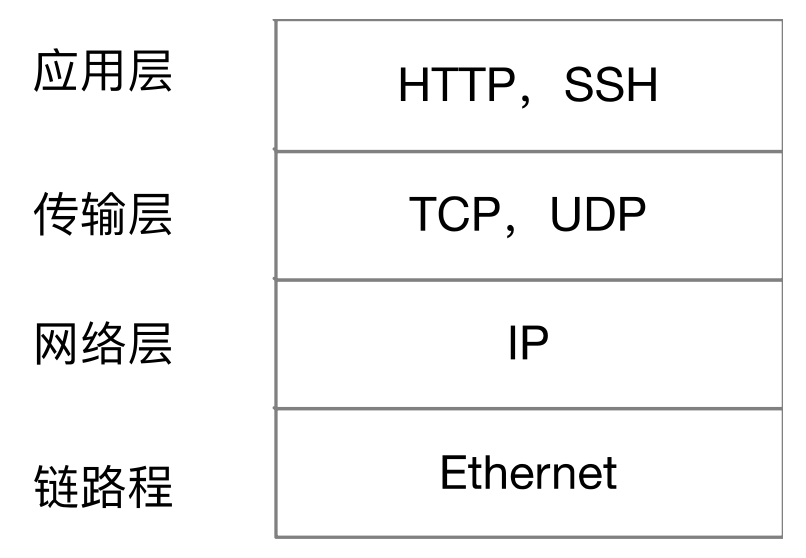
使用的传输层协议就是 TCP。
Endianness
在网络编程中,不同计算机体系结构可能使用不同的字节序。当不同字节序的计算机之间进行数据交换时,就会出现字节序不匹配的问题,导致数据解释错误。为了解决这个问题,网络编程中通常需要进行字节序的转换,确保数据在传输过程中能够被正确解释。
常见的解决方法是使用网络字节序(Network Byte Order),通常采用大端序作为网络字节序。在 C 语言中,可以使用函数 htons() 和 htonl() 来将主机字节序转换为网络字节序;使用函数 ntohs()和 ntohl() 将网络字节序转换为主机字节序。
Java 使用的是 big-endian,x86 使用的是 little-endian,TCP/IP 使用的是 big-endian。
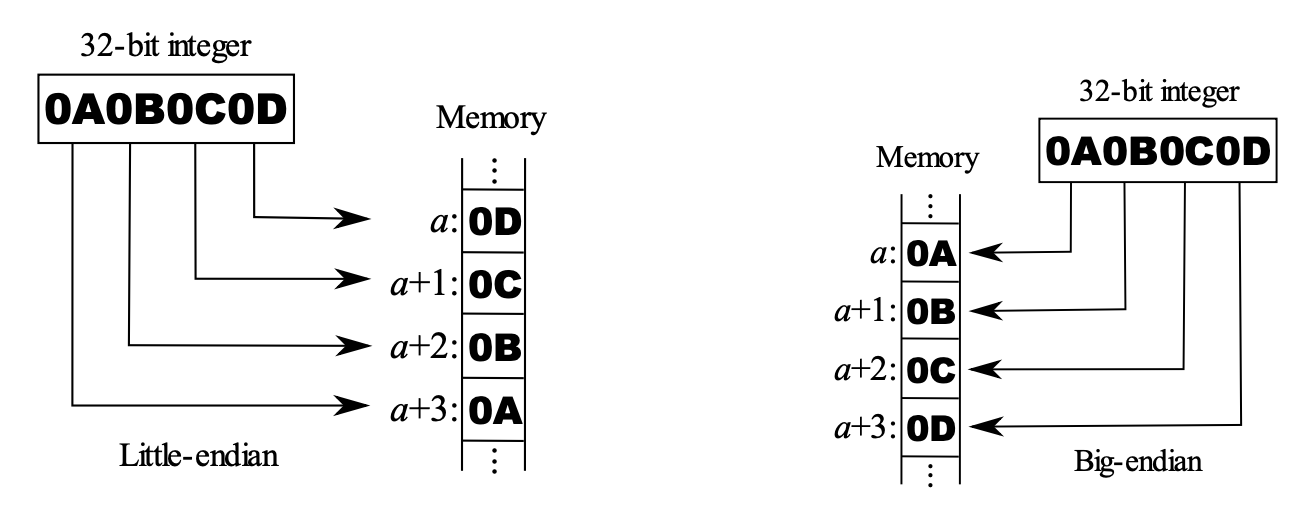
小端序(Little Endian):在小端序中,数据的低位字节存储在低地址,高位字节存储在高地址。换句话说,数据的低位字节排在高位字节的前面。
大端序(Big Endian):在大端序中,数据的高位字节存储在低地址,低位字节存储在高地址。换句话说,数据的高位字节排在低位字节的前面。
TCP socket 和 connection
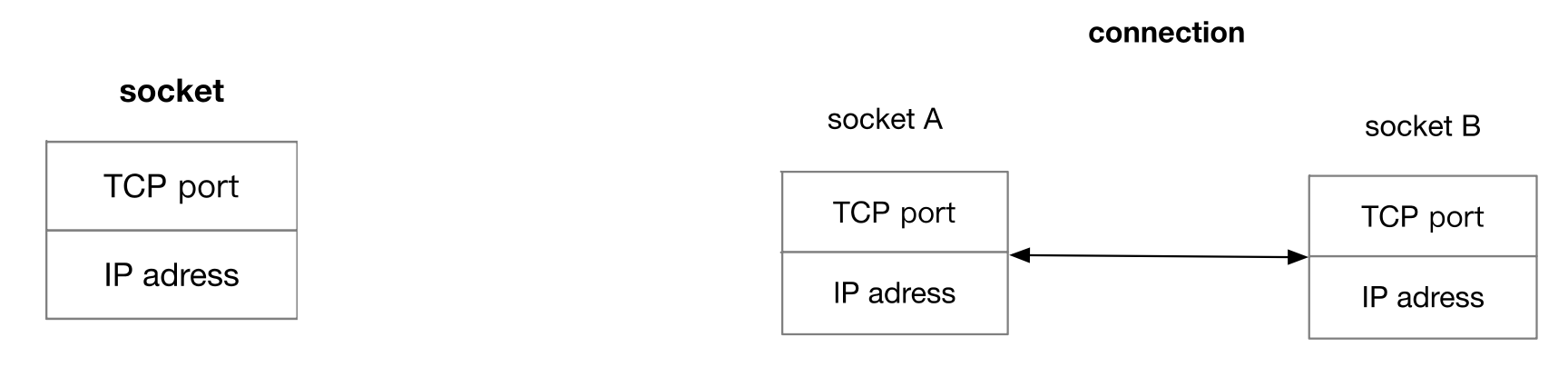
socket:用来表示网络中接收和发送数据的一个 endpoint,由 IP 地址和 TCP 端口号组成。
connection:表示两个 endpoint 之间进行数据转述的一个通道,由代表两个 endpoint 的 socket 组成。
Socket编程API
发送和接受数据API:
ssize_t write(int fd, const void *buf, size_t count)ssize_t read(int fd, void *buf, size_t count)
返回值大于等于 0,表示发送和接收的字节数;
返回值 -1 表示API调用失败,errno 里面会保存相应的错误码。
perror() API可以用来输出 errno 表示的错误。

例如读取和写入 3 个字节的数据。
client端socket编程
socket(): 创建一个数据传输 socket。getsockopt() /setsockopt(): 获取和设置 socket 的选项。connect():建立 TCP 连接。close():关闭 socket,释放资源。

server 端 socket 编程
socket(): 创建一个用于监听的 socket。bind(): 把socket和一个网络地址关联起来。listen():开始监听连接请求。accept():接受一个连接,返回一个用于数据传输的socket。
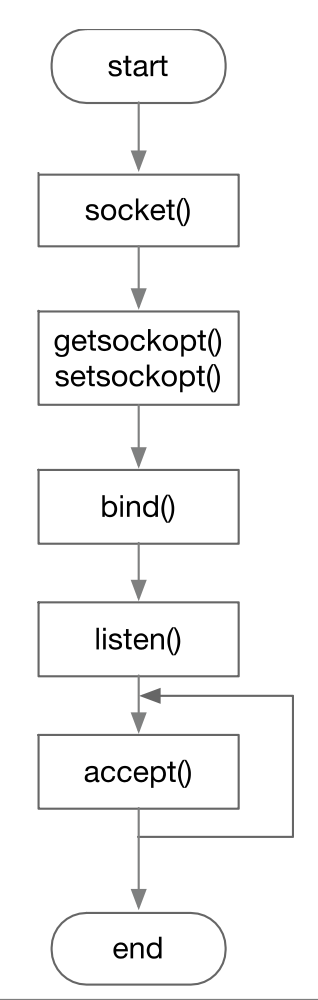
Java Socket编程
Java 区分用于数据传输的 socket 和监听的 socket,用 Socket 这个类表示前者,用 ServerSocket 这个类表示后者。
Socket的 getOutputStream() 返回的 OutputStream 用于发送数据,Socket的 getInputStream() 返回的 InputStream 用于接收数据。
ServerSocket没有 listen 方法, listen 是自动被执行的。
事件驱动的网络编程
阻塞IO的服务架构
这种架构使用一个进程处理一个 connection,Apache HTTP server 的 Prefork MPM 就是采用的这种架构。
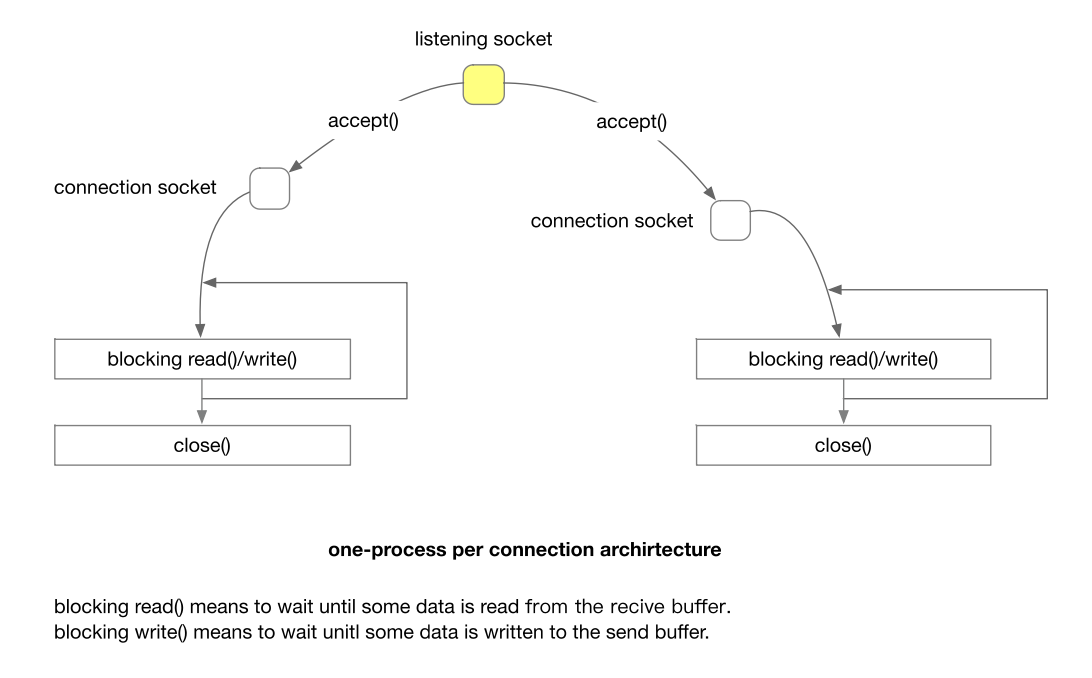
- 阻塞读取意味着等待直到从接收缓冲区中读取一些数据。
- 阻塞写入意味着等待直到将一些数据写入发送缓冲区。
这种架构的问题在于进程和 connection 的不匹配,connection 是一种 lightweight 的 OS 资源,而 process 是一种heavyweight 的 OS 资源。
- Connection(连接)是指通信通道或连接,用于在计算机系统中传输数据。在网络编程中,连接通常指代网络连接,比如 TCP 连接或者数据库连接等。连接通常被认为是”轻量级”资源,因为它主要包含了一些状态信息和缓冲区,占用的系统资源相对较少。当创建连接时,系统会分配一些内存用于维护连接的状态,但这种开销相对较小。
- Process(进程)是指正在运行的程序的实例,它包含了程序的代码、数据、堆栈等信息。进程是操作系统中的一个”重量级”资源,因为它需要分配更多的系统资源,如内存空间、CPU 时间片等。每个进程都有独立的内存空间,需要维护进程控制块等数据结构,因此创建和维护进程的开销相对较大。
事件驱动的网络编程架构
epoll API
epoll提供以下3个API:
epoll_create1:创建 epoll 文件描述符。epoll_wait:等待和 epoll 文件描述符关联的 I/O 事件。epoll_ctl:设置 epoll 文件描述符的属性,更新文件描述符和 epoll 文件描述符的关联。
EPOLL 事件的两种模型:Level Triggered (LT) 水平触发和 Edge Triggered (ET) 边沿触发 。默认是水平触发。
- Level Triggered (LT) 水平触发:
- 在 LT 模式下,当文件描述符上有数据可读或可写时,epoll_wait() 将返回并通知应用程序。
- 如果应用程序没有读取所有数据或者写入缓冲区已满,下次调用 epoll_wait() 时仍然会返回该文件描述符。
- LT 模式下,如果文件描述符上的事件没有完全处理,epoll_wait() 会持续通知应用程序该事件。
- Edge Triggered (ET) 边沿触发:
- 在 ET 模式下,epoll_wait() 仅在文件描述符状态发生变化时返回,并通知应用程序。
- 应用程序需要立即处理该事件,否则下次调用 epoll_wait() 时不会再次返回该文件描述符。
- ET 模式要求应用程序在每次事件到来时必须处理完整,否则可能错过部分事件。
事件驱动的网络编程架构
使用一个 event loop 进行网络数据的发送和接收。
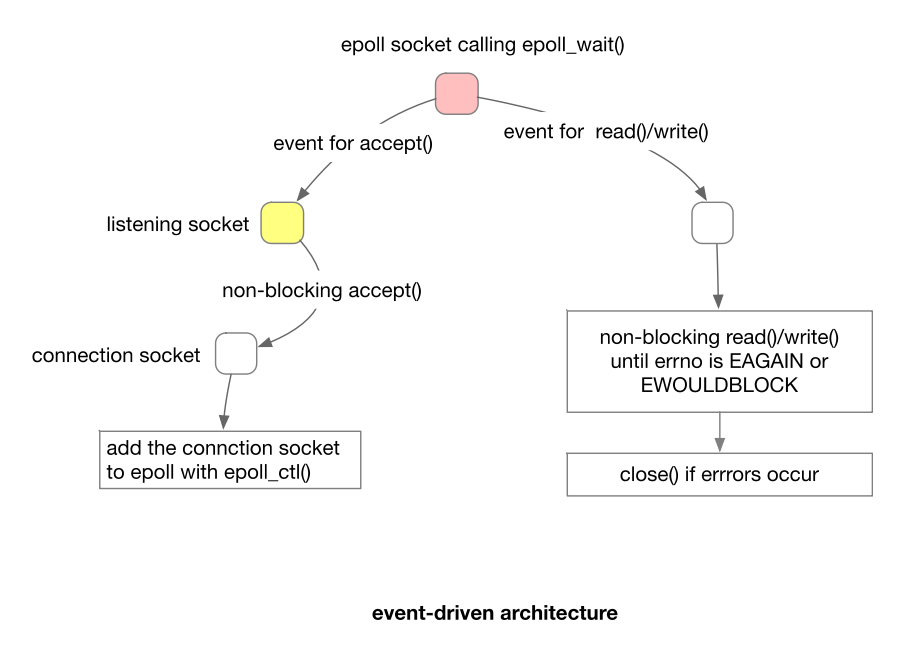
优点:
- 避免了大量创建 process 的 OS 资源消耗。
- 减少了耗时的 context switch。(进程切换的上下文)
缺点:事件驱动的编程麻烦一些。
ZooKeeper的客户端网络通信
RPC网络数据结构
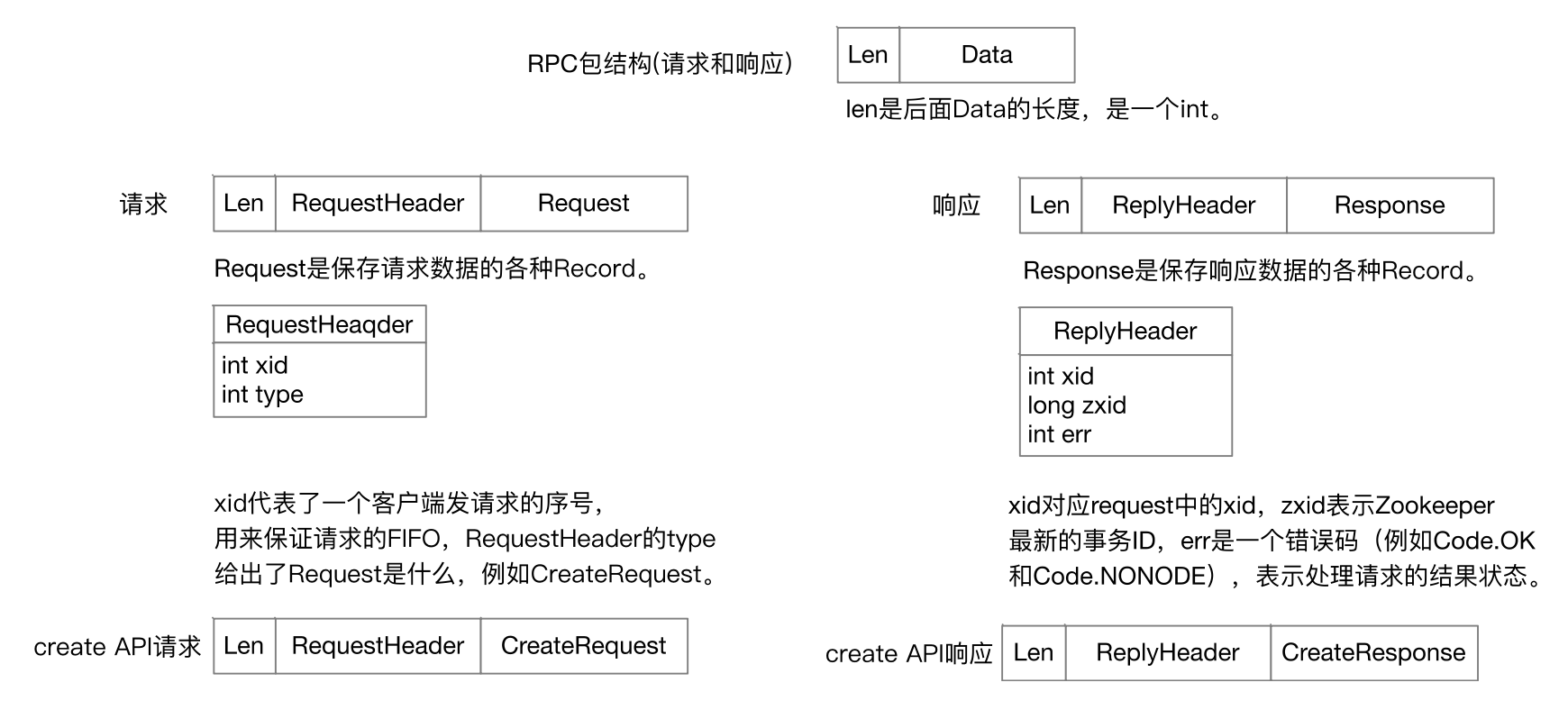
ZooKeeper网络通信概述
支持两种事件驱动编程模型,一种是Java NIO,一种是Netty。核心接口和类如下:
- ZooKeeper:用户使用的ZooKeeper客户端库核心类。
- ClientCnxn: 负责和多个ZooKeeper节点的一个建立网络连接,包含ZooKeeper RPC的处理逻辑。
- ClientCnxnSocket: 网络通信的high level逻辑。
- ClientCnxnSocketNetty: 实际进行TCP socket的网络通信。
- StaticHostProvider: 提供一个ZooKeeper节点列表。
RPC方法流程
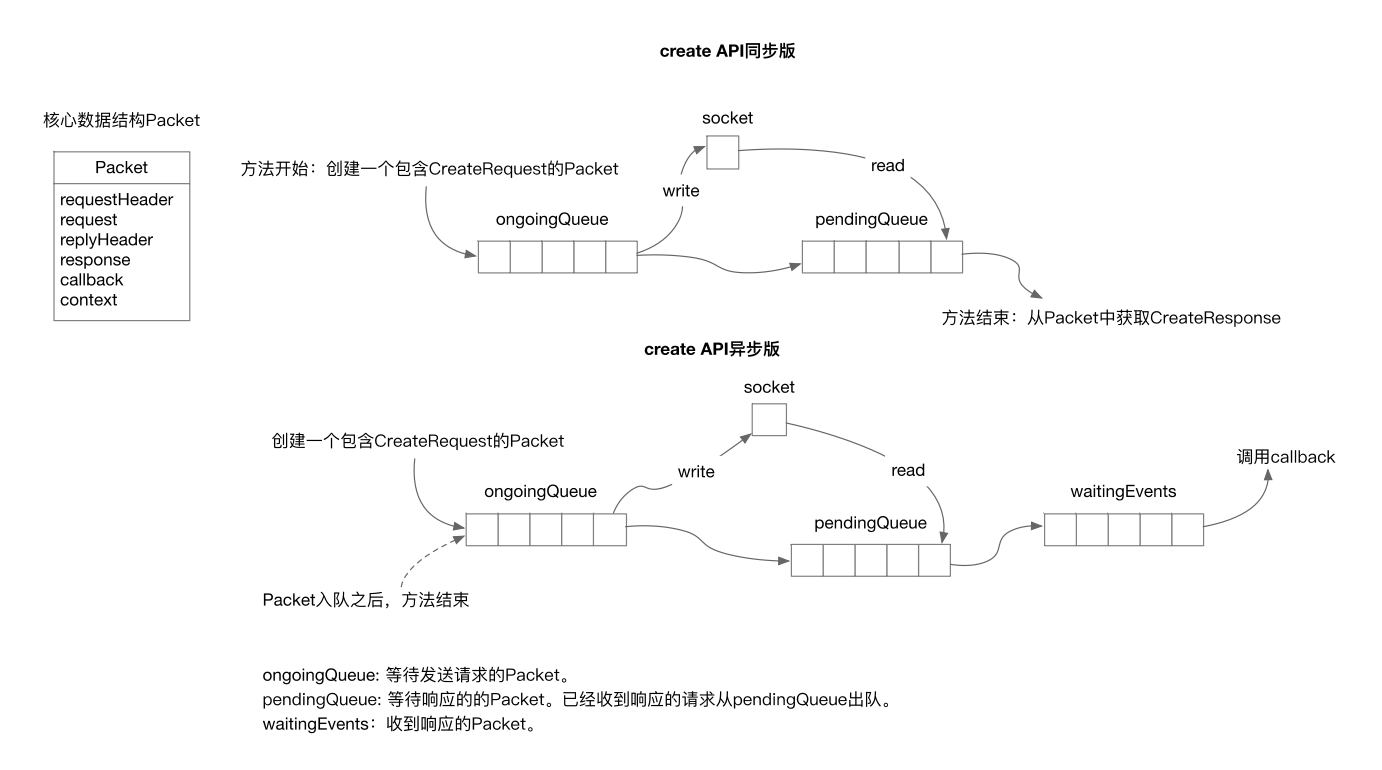
Standalone的ZooKeeper处理客户端请求
事务日志:
PrepRequestProcessor会为每一个客户端写请求生成一个事务,对ZooKeeper in-memory DataTree更新的时候应的不是原始的写请求,而是对应的事务记录。
事务记录都是幂等的,多次应用一个事务记录不会影响结构的正确性。

ZooKeeper 的事务日志是每个事务包含一条记录的 REDO 日志,日志记录是 physical 的。
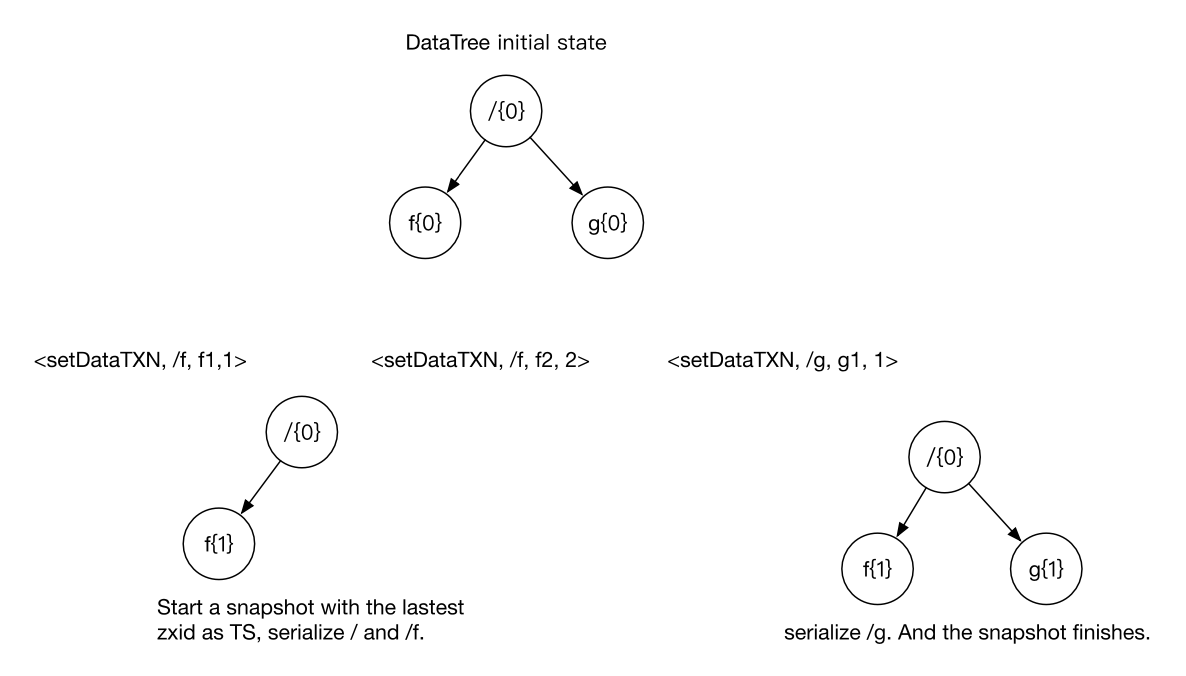
Fuzzy Snapshot
ZooKeeper可以在同时处理客户端请求的时候生成snapshot。snapshot开始时候DataTree上面最新的zxid叫作snapshot的TS。
ZooKeeper的snapshot不是一个数据一致的DataTree,但是在snapshot上面应用比TS新的事务记录之后得到的DataTree是数据一致的。
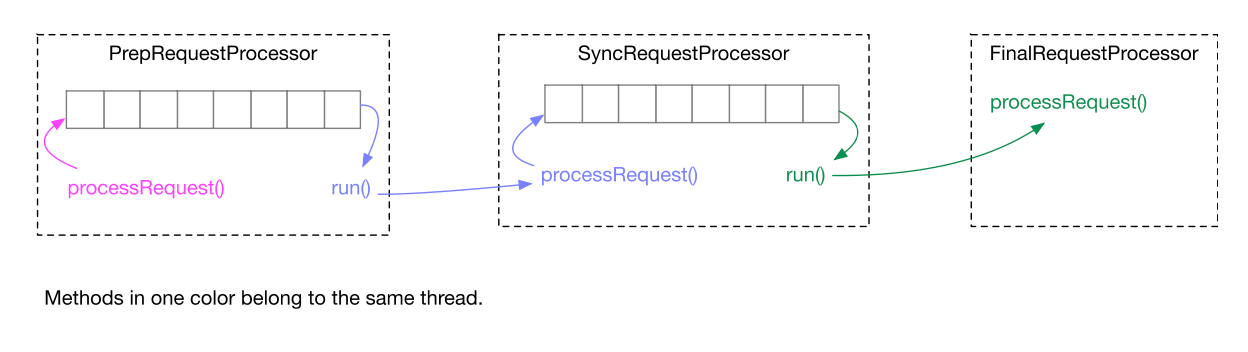
Quorum模式下ZooKeeper节点的Request Processor Pipeline
Standalone模式下ZooKeeper如何保证数据一致性的:
ZooKeeper数据一致性:
- 全局可线性化(Linearizable)写入: ZooKeeper节点决定写请求的执行顺序。
- 客户端 FIFO 顺序:来自一个客户端的请求按照发送顺序执行。
Standalone模式下的以下两点保证了以上的数据一致性:
- TCP协议保证了请求在网络上进行传输的先后顺序。
- Request processor pipeline的每个阶段都是单线程的。
第2点导致FinalRequestProcessor对DataTree的访问都是串行的,性能不好。
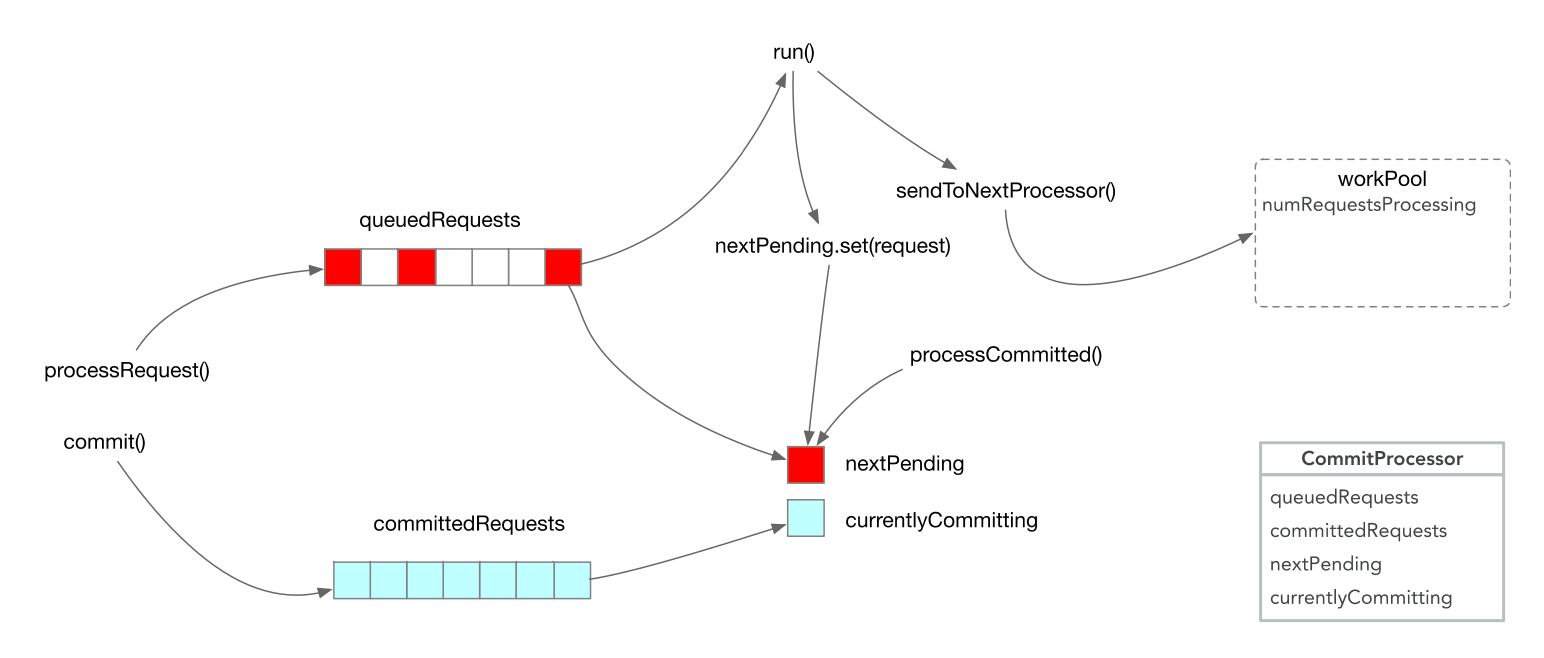
Quorum模式下ZooKeeper使用以下3点保证数据一致性:
- 每一个ZooKeeper节点都按照zxid的把事务记录应用到DataTree上面。
- 来自一个session的请求按照FIFO的顺序执行。
- 在处理一个写请求的时候,不能处理任何其他请求。
这样做的好处是允许DatatTree并行执行读操作。Quorum模式下,保证第2点和第3点的是CommitProcessor。
CommitProcessor核心逻辑
下图是CommitProcessor处理请求的核心逻辑:
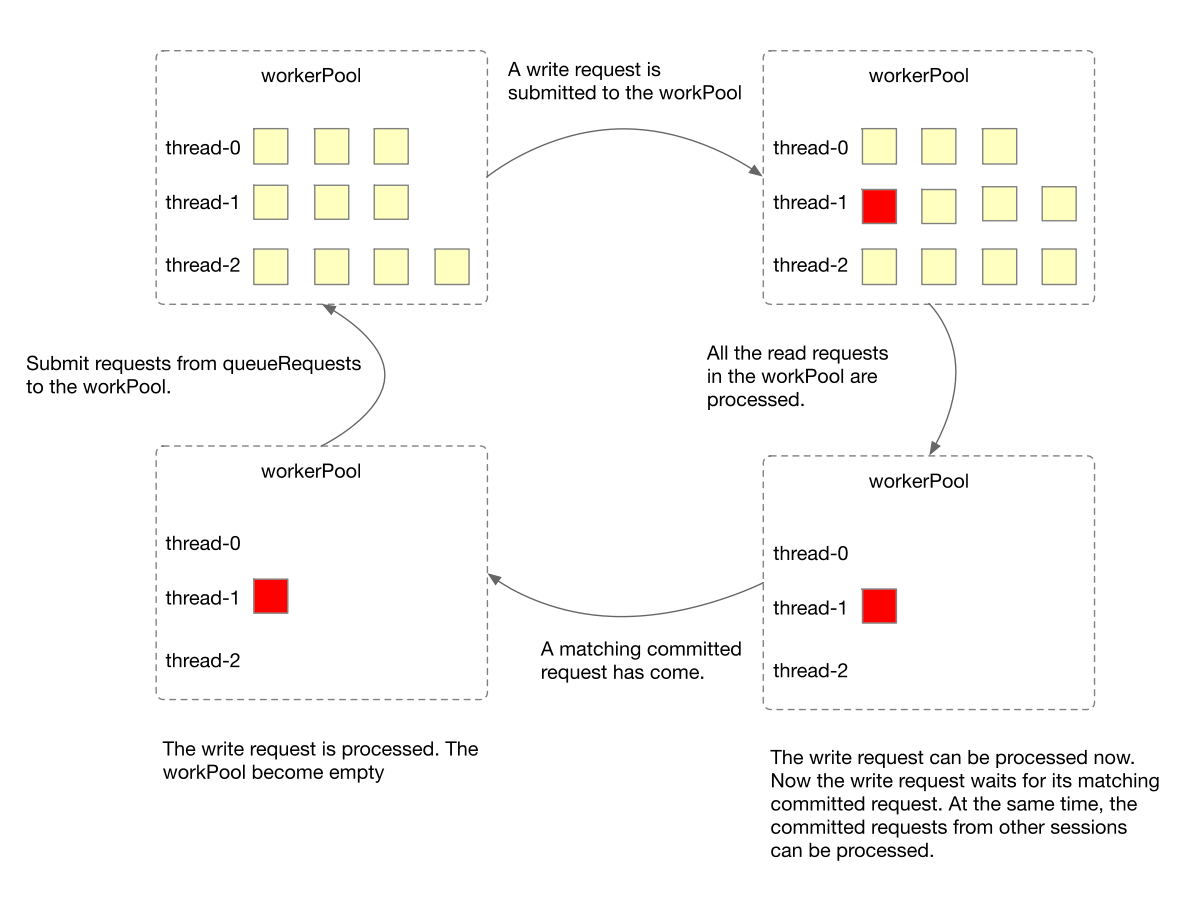
workPool状态图
workPool处于两个重要状态:
- 并行处理读请求。
- 处理一个写请求。
ZooKeeper Leader节点选举
Leader Election算法
一个 vote 的由 voteId 和 voteZxid 组成。对于 vote(voteId, voteZxid) 和 vote(mySid, myZxid),如果以下两个条件中有一个成立,就认为前者比后者新:
voteZxid > myZxidvoteZxid == myZxid and voteId > mySid
Leader Election算法
一个 ZooKeeper 节点通过向所有的节点发送 vote(voteId,voteZxid) 开始选举, voteId 是节点自己的 ID(mySid),voteZxid 是节点上最新的 zxid(myZxid)。
一个节点在接收到 vote(voteId,voteZxid) 之后如果发现 vote(voteId,voteZxid) 比 vote(mySid, myZxid)新,就让 mySid = voteId 和 myZxid = voteZxid,并把 vote(voteId,voteZxid) 发送给所有的 ZooKeeper 节点。否则的话,什么也不用做。
这个算法保证参与选举的具有最新 zxid 的节点赢得选举。在选举结束之后,一个 follower 节点和 leader 节点同步状态之后才可以开始处理来自客户端的请求。
Leader Election示例(happy case)
下图是一个3节点集群选举一个leader的时序图:
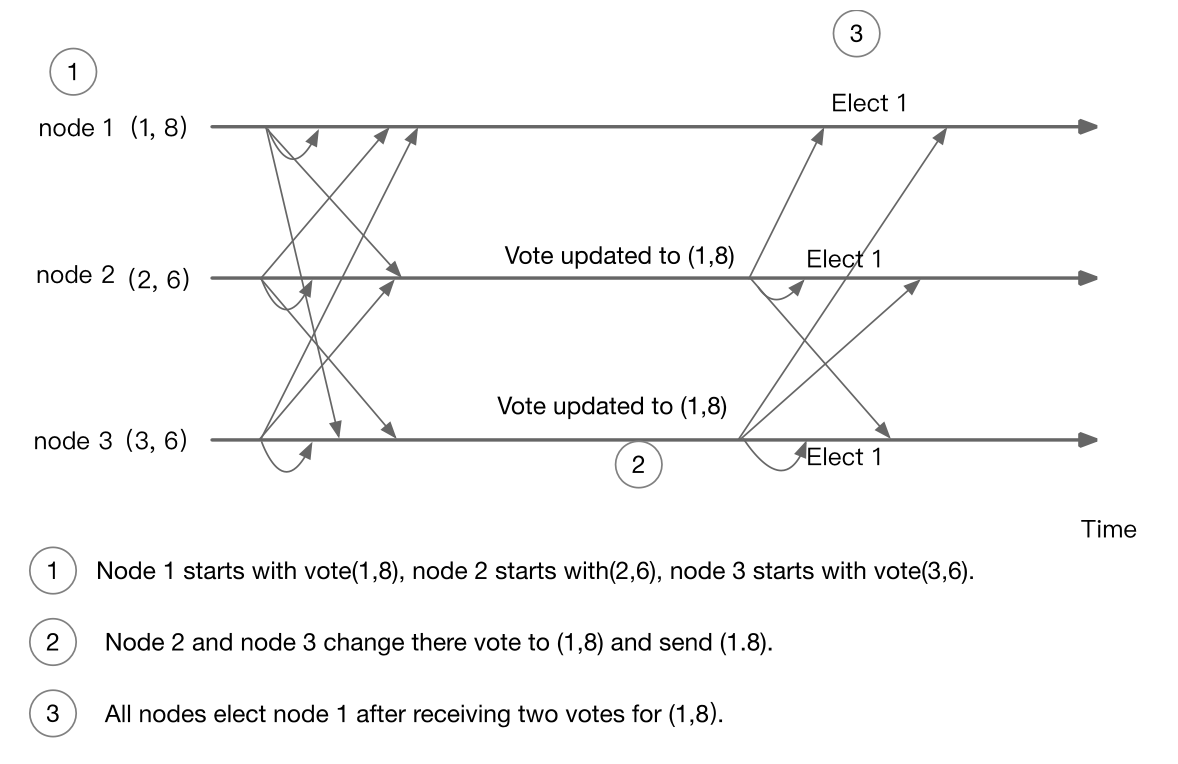
Leader Election示例(unhappy case)
下面的时序图展示了长时间的消息发送延迟导致选举出两个 leader 的 unhappy case:
由于网络延迟,导致 node 2 先后将 node 3 和 node 1 选举为 leader。
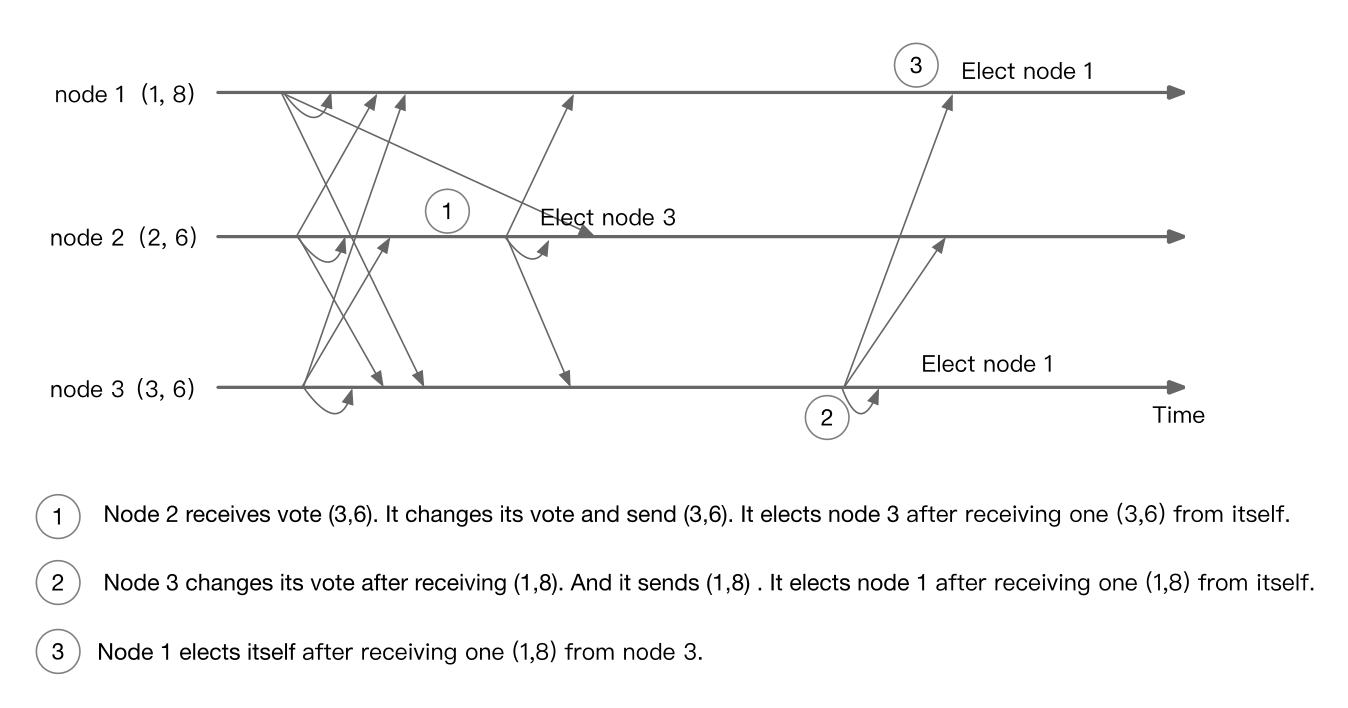
在这种情况之下,node 3 不会响应来自 node 2 的请求,node 2 会在 timeout 之后重试。node 2 在 timeout 之前没有办法处理请求。
使用finalizeWait来避免unhappy case
一个节点在获得一个 vote 的 quorum 之后,在完成选举之前会等待一段时间。
如果在这段时间收到更新的 vote,继续执行选举算法。
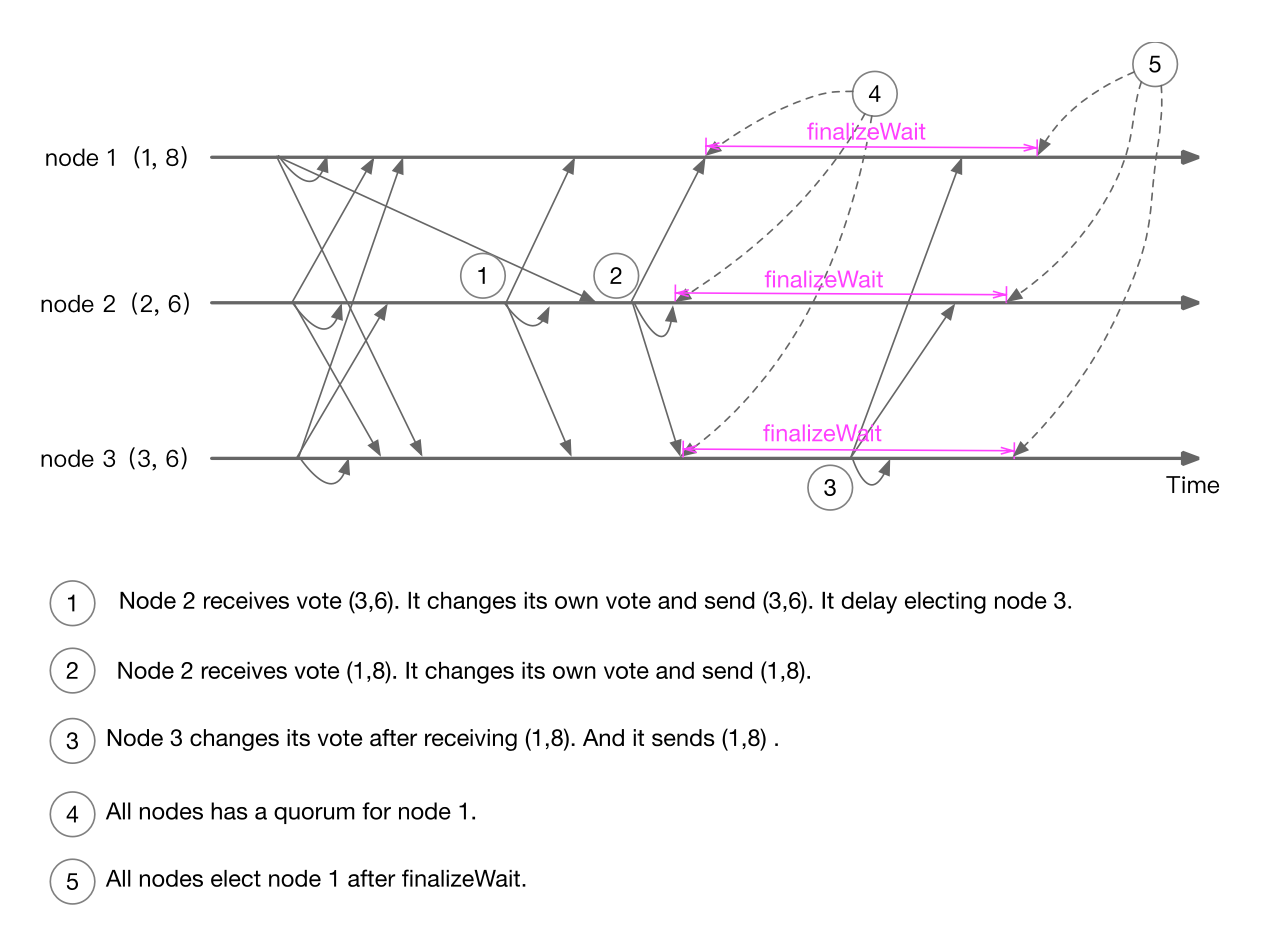
node 2 先后投票给 node 3 和 node 1;node 3 收到自己和 node 2 的票后进入 finalizeWait,在这个过程中收到 node 1 的选举请求,投票给 node 1,node 1 票数过半,进入 finalizeWait,最后 node 1 成为 Leader
Leader Election的网络通信
ZooKeeper使用一个专门的TCP端口进行 Leader Election的网络通信。负责这一部分工作的类是 QuorumCnxManager,使用的是 Java 的 Socket 编程,没有使用 NIO 和 Netty 。
Zab协议
Zab(ZooKeeper Atomic Broadcast)协议
ZooKeeper 处理写请求需要经过 Zab 协议
Zab 协议有以下3个步骤组成:
- Leader 发送 PROPOSAL 给集群中所有的节点(包括自己)。
- 节点在收到 PROPOSAL 之后,把 PROPOSAL 落盘,发送一个 ACK 给 Leader。
- Leader 在收到大多数节点的 ACK 之后,发送 COMMIT 给集群中所有的节点。

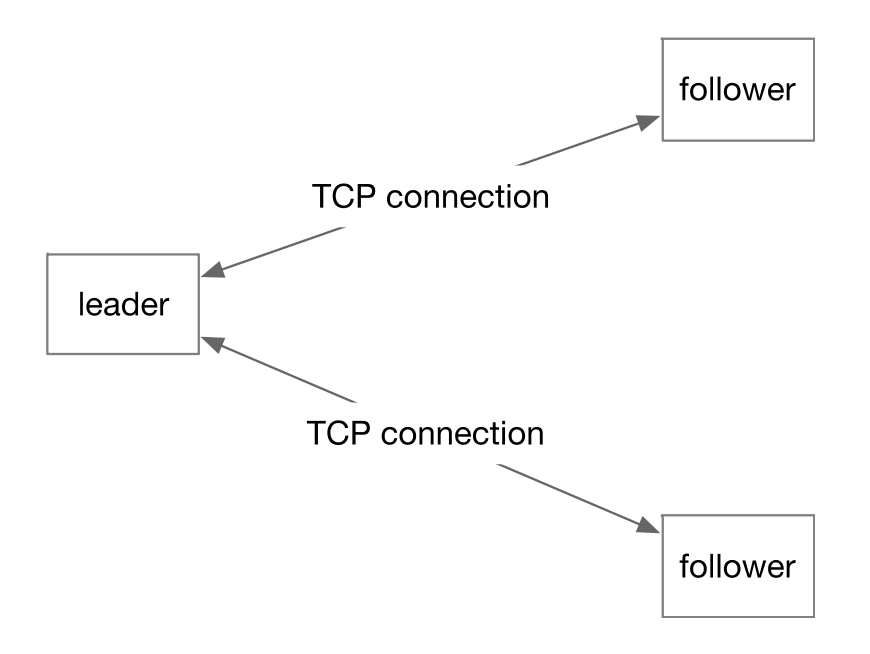
Quorum网络通信
Leader会在一个quorum TCP socket 地址上面监听,每一个 follower 节点会和 leader 节点上在这些地址上面建立一个连接。之后 leader 和 follower 之间的 quorum 通信都通过这些建立的连接来进行。
这一部分的研发也没有使用 NIO 和 Netty,使用的 socket 通信。
客户端和服务器端交互:Watch和Session
客户端的 ZKWatchManager 和服务器端的 WatchManager 都是 Watch 的注册表。
如果当前和客户端连接的 ZooKeeper 节点宕机,客户端在和另外一个 ZooKeeper 节点建立连接时会使用 ZKWatchManager 在新节点上面重建 WatchManager。
Session核心数据结构和逻辑
为了高效的管理大量的 session,ZooKeeper 使用桶的机制进行 session 过期。
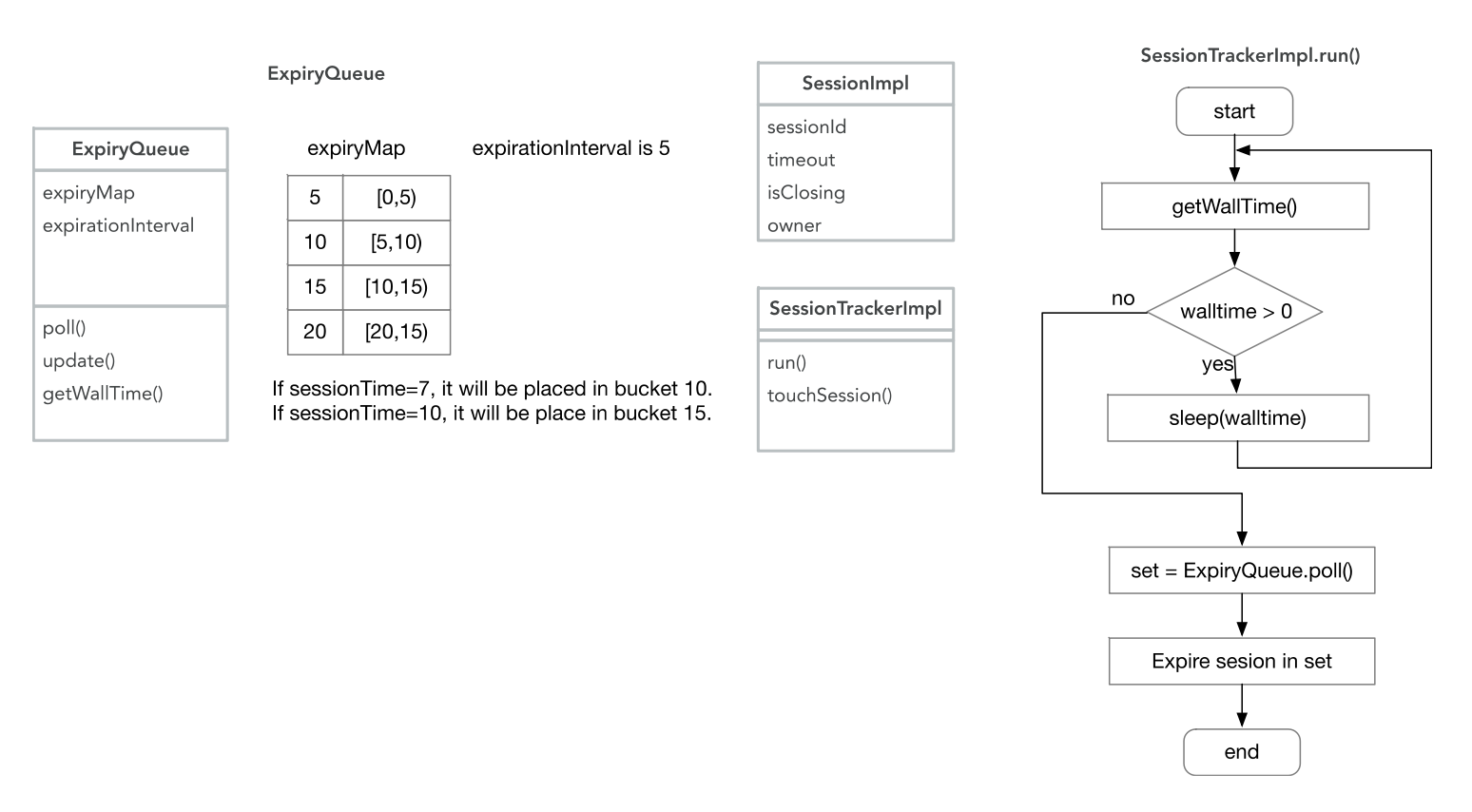
从客户端到服务器端的心跳
为了维持客户端到ZooKeeper节点的session,如果在一段时间内客户端不需要向服务器端发送请求,客户端需要向服务器发送心跳消息PING。