将应用迁移至Kubernetes平台
应用接入最佳实践
应用上云原生的重要一步就是容器化,在容器化过程中可能会猜到一些坑,以及碰到一些挑战。
应用容器化
目标
- 稳定性
- 可用性
- 性能
- 安全
四个目标,缺一不可。
从多纬度思考高可用的问题:
- 单个实例视角
- 资源需求
- 配置管理
- 数据保存
- 日志和指标收集
- 应用视角
- 冗余部署(高可用)
- 部署实例个数
- 负载均衡
- 健康检查
- 服务发现
- 监控
- 故障转移
- 扩缩容
- 安全视角
- 镜像安全
- 应用安全
- 数据安全
- 通讯安全
应用容器化的思考
- 应用本身
- 启动速度(是否适合云原生)
- 健康检查
- 启动参数
- Dockerfile
- 基础镜像的选择
- 基础镜像越小越好(可以在
Pod里面插一个debug的container,以保障主container越小越好)
- 基础镜像越小越好(可以在
- 需要安装
Utilitylib越少越安全,但是越多越方便,因此需要有取舍
- 进程数量(一个容器最好一个进程)
- 分清楚主次,由主次关系决定状态的主程序(例如是监控进程是主进程还是应用进程是主进程)
Fork bomb的危害
- 代码(应用程序)和配置分离
- 配置如何管理
- 环境变量
- 配置文件
- 配置如何管理
- 分层的控制(层数越多,效率越低)
Entrypoint
- 基础镜像的选择
一个坑:GOMAXPROCS 的设置。https://github.com/uber-go/automaxprocs
容器额外开销和风险
Log driver,云原生推荐日志打到标准输出里面(stdout、stderr),k8s会读取标准输出,转储到本地文件。Blocking mode:当应用打出大量的日志情况下,可能出现日志阻塞,进而影响业务进程Non blocking mode:当应用打出大量的日志情况下,为了不阻塞,会直接丢弃日志
- 共用
kernel:- 系统参数配置共享,比如
es会设置一些特殊的系统参数 - 进程数共享 -
Fork bomb fd数共享- 主机磁盘共享
- 系统参数配置共享,比如
容器化应用的资源监控
容器中看到的资源是主机资源
topJava runtime.GetAvailableProcesses()(老版本不对,新版本已经改进)cat /proc/cpuinfo,Go 和 Java 都依赖这个信息,因此会导致协程数量不正确。https://github.com/uber-go/automaxprocscat /proc/meminfodf -k
解决方案
查询
/proc/1/cgroup是否包含kubepods关键字(docker关键字不可靠)1
0::/kubepods-besteffort-pod0bb596ea_ee65_4440_a7d4_abadd882c92e.slice:cri-containerd:0650a2afd5fb6343ed2975c21115482fa016730ca0fa7d922ec419e3fa1768b0
可以看到,使用
containerd时,没有docker关键字包含此关键字,则表明是运行在 Kubernetes 之上
内存开销
查看容器真实的内存资源
- 配额
cat /sys/fs/cgroup/memory/memory.limit_in_bytes
- 用量
cat /sys/fs/cgroup/memory/memory.usage_in_bytes
CPU
查看容器真实的 CPU 资源
配额,
分配的 CPU 个数 = quota / period,quota = -1代表besteffortcat /sys/fs/cgroup/cpu/cpu.cfs_quota_uscat /sys/fs/cgroup/cpu/cpu.cfs_period_us
用量
cat /sys/fs/cgroup/cpuacct/cpuacct.usage_percpu(按 CPU 区分)1
2$ cat /sys/fs/cgroup/cpuacct/cpuacct.usage_percpu
16687899693 18340627949 17484230028 20110312336 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0cat /sys/fs/cgroup/cpuacct/cpuacct.usage1
2$ cat /sys/fs/cgroup/cpuacct/cpuacct.usage
72673556129
其他方案
lxcfs:https://github.com/lxc/lxcfs- 通过
so挂载的方式,使容器获得正确的资源信息
- 通过
Kata:https://katacontainers.io/ Kubernetes 调用 kata 的runtime而不是容器的runtimeVM中跑container,使用虚拟机隔离容器,默认会给Kata分配额外资源
Virtlet:https://github.com/Mirantis/virtlet- 直接启动
VM,就与容器无关
- 直接启动
对应用造成的影响
JavaConcurrent GC ThreadHeap Size- 线程数不可控
Node.js- 多线程模式启动的
Thread数量过多,导致OOM Kill
- 多线程模式启动的
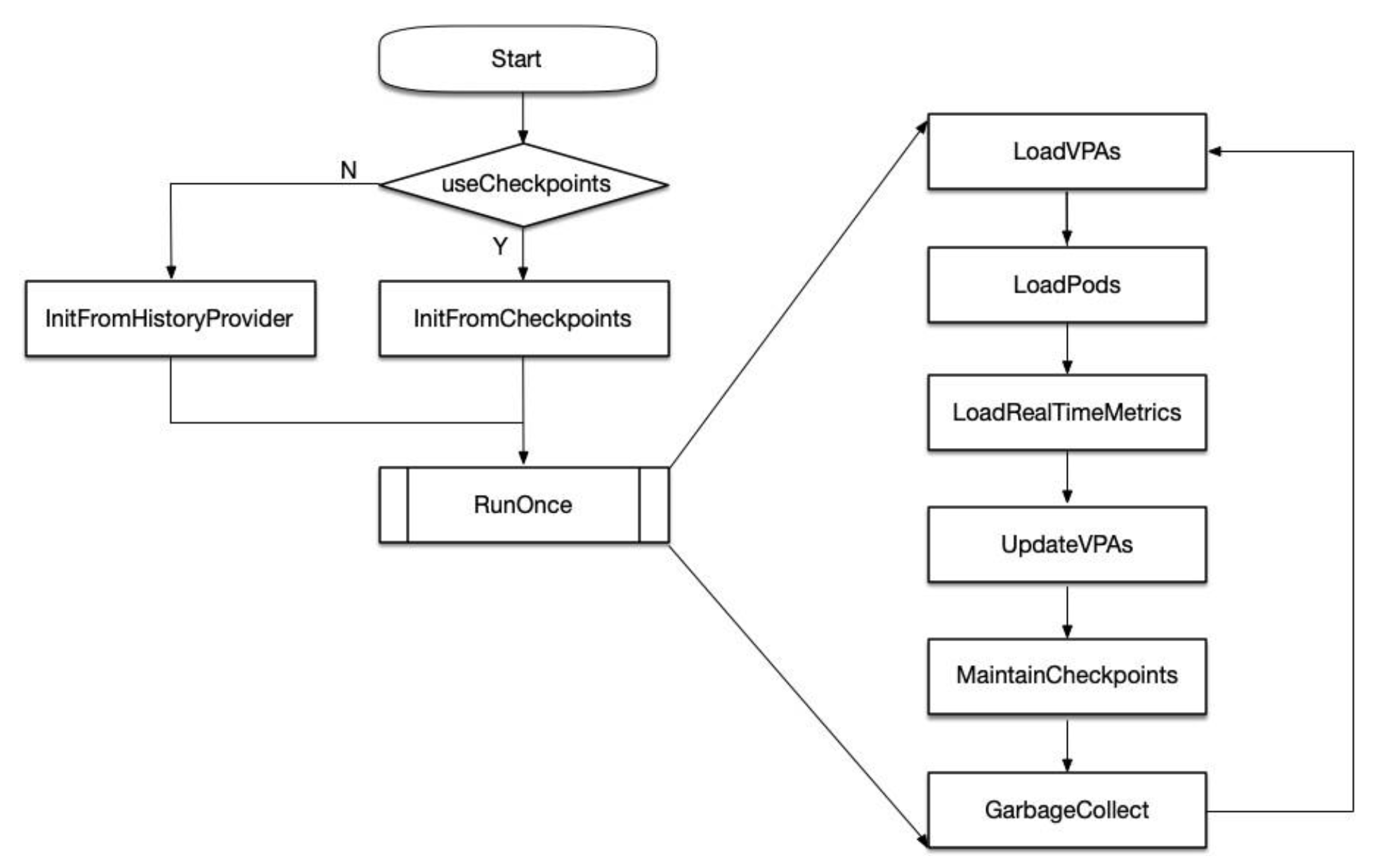
将应用迁移至 Kubernetes
Pod spec
- 初始化需求(
init container):容器初始化需求 - 主
container的个数 - 权限问题,
Privilege和SecurityContext(PSP) - 共享哪些
Namespace(PID,IPC,NET,UTS,MNT) - 配置管理
- 优雅终止
- 健康检查
Liveness ProbeReadiness Probe
DNS策略以及对resolv.conf的影响imagePullPolicy Image拉取策略
Probe 误用会造成严重后果
例如:https://access.redhat.com/solutions/6626611
1 | readinessProbe: |
出现多个僵尸进程
1 | 1000650+ 4140953 10918 0 Oct20 ? 00:00:00 [curl] <defunct> |
这是由于主进程被杀死,但是没有处理子进程的能力,导致子进程成为僵尸进程。
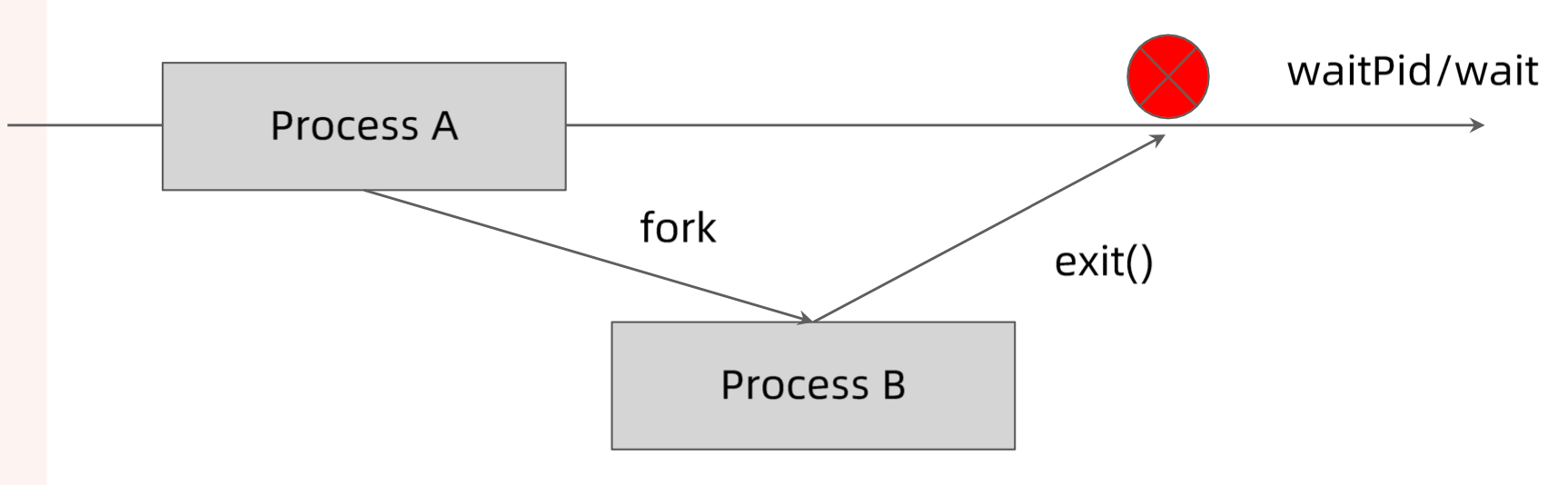
后果:可能耗尽节点所有的 PID
如何防止 PID 泄露
单进程容器
合理的处理多进程容器
- 容器的初始化进程必须负责清理
fork出来的所有子进程 - 开源方案
Tinihttps://github.com/krallin/tini采用
Tini作为容器的初始化进程(PID=1),容器中僵尸进程的父进程会被置为11
2
3
4
5
6
7
8
9# Add Tini
ENV TINI_VERSION v0.19.0
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /tini
RUN chmod +x /tini
ENTRYPOINT ["/tini", "--"]
# Run your program under Tini
CMD ["/your/program", "-and", "-its", "arguments"]
# or docker run your-image /your/program ...
- 容器的初始化进程必须负责清理
如果不采用特殊初始化进程
- 建议采用
HTTPCheck作为Probe - 为
exec Probe设置合理的超时时间
- 建议采用
在 Kubernetes 上部署应用的挑战
资源规划::
- 每个实例需要多少计算资源
CPU/GPUMemory
- 超售需求
- 每个实例需要多少存储资源
- 大小
- 本地还是网盘
- 读写性能
Disk IO
- 网络需求
- 整个应用总体
QPS和带宽
- 整个应用总体
Pod 的数据管理
Local-ssd:独占的本地磁盘,独占IO,固定大小,读写性能高Local-dynamic:基于LVM,动态分配空间,效率低
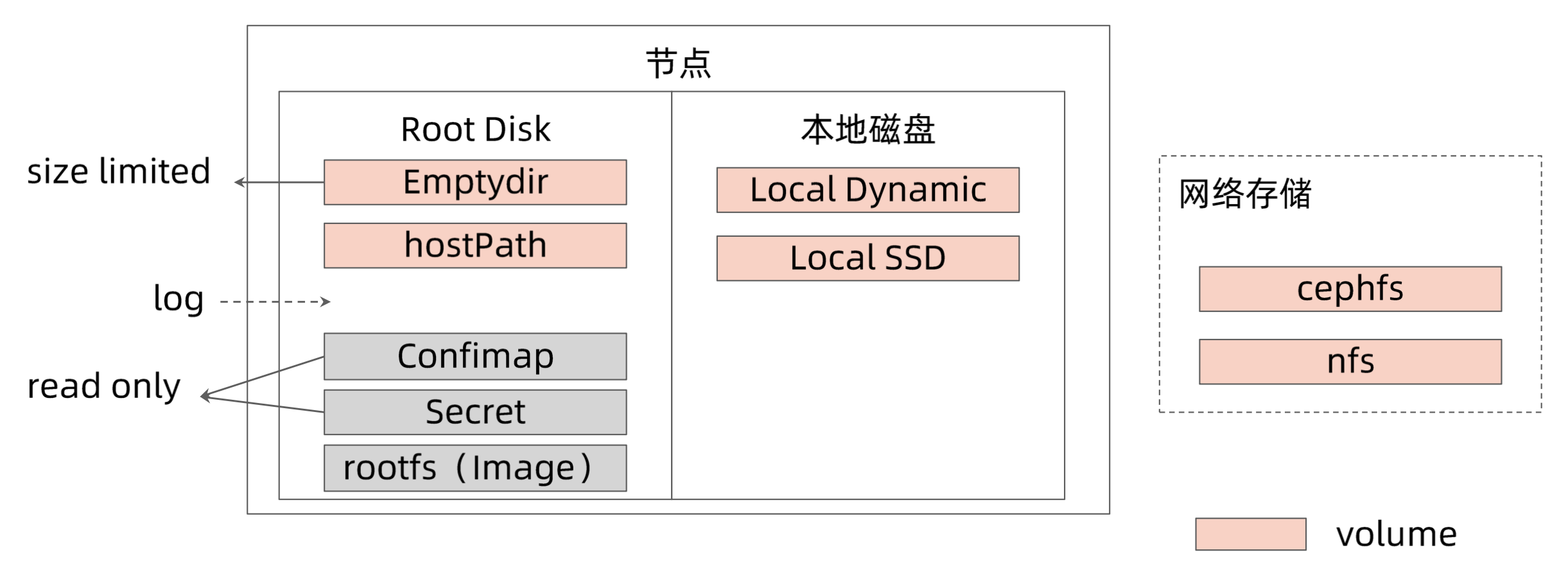
我的数据应该保存在哪里
| 存储卷类型 | 是应用进程重启后数据是否存在 | Pod 重新调度后数据是否存在 | 容量限制 | 注意 |
|---|---|---|---|---|
| emptydir | Yes | No | Yes | 推荐,进一步了解 emptydir 的 size limit 行为 |
| hostPath | Yes | No | No | 需要额外权限,不建议普通应用使用,多开放给节点管理员 |
| local ssd/dynamic | Yes | No | Yes. Quota |
无备份 |
| 网络存储 | Yes | Yes | Yes Quota |
依赖与网络存储稳定性 |
| 容器 rootfs | No | No | No | 不要写数据 |
不要短时间内打印过多日志,以防在日志滚动之前节点磁盘就被耗光。
应用配置
传入方式
Environment VariablesVolume Mount
数据来源
ConfigmapSecretDownward API
高可用部署
- 需要多少实例?
- 如何控制失败域,部署在几个地区,AZ,集群?
- 如何进行精细的流量控制?
- 如何做按地域的顺序更新?
- 如何回滚?
如何应对基础架构的影响
| 系统管理员 | 应用 | 类型 | 影响 | 建议 |
|---|---|---|---|---|
| 自主中断 | 自主中断 | kubelet 升级 | 大部分情况容器不会受影响 | |
| 自主中断 | 非自主中断 | kubelet 升级 | 某些版本更新会重建 container Pods 会在秒级重建,业务恢复速度依赖应用启动速度 |
多实例部署 故障域控制,跨节点跨机架部署 |
| 自主中断 | 非自主中断 | kubelet 或者运行时无响应 | 如果是短时无响应,应用不应该受影响 如果是长时间无响应,需要驱逐 Pod |
故障域控制,跨节点跨机架部署 合理的健康探针 设置合理的 toleration seconds |
| 自主中断 | 非自主中断 | 节点替换 | 节点会被 dran 掉,节点会被删除 Pod 会被驱逐 |
故障域控制,跨节点跨机架部署 使用 PDB 与基础架构约定驱逐策略 使用 preStop 备份关键数据 |
| 自主中断 | 非自主中断 | 节点重启 | Pod 会失效数分钟 | 故障域控制,跨节点跨机架部署 设置合理的 toleration seconds |
| 非自主中断 | 非自主中断 | 节点 Crash | Pod 会在 15 分钟后被驱逐 Pod 会失效 15 分钟以上 |
故障域控制,跨节点跨机架部署 |
PodDisruptionBudget
Pod 能够被打算的预算值。
PDB 是为了自主中断时保障应用的高可用。
在使用 PDB 时,你需要弄清楚你的应用类型以及你想要的应对措施:
- 无状态应用
- 目标:至少有
60%的副本Available - 方案:创建
PDB Object,指定minAvailable为60%,或者maxUnavailable为40%
- 目标:至少有
- 单实例的有状态应用
- 目标:终止这个实例之前必须提前通知客户并取得同意
- 方案:创建
PDB Object,并设置maxUnavailable为0
- 多实例的有状态应用:
- 目标:最少可用的实例数不能少于某个数
N,例如etcd - 方案:设置
maxUnavailable = 1或者minAvailable = N,分别允许每次只删除一个实例和每次删除expected_replicas - minAvailable个实例
- 目标:最少可用的实例数不能少于某个数
基础架构与应用团队的约束
基础架构团队:在移除一个节点时,应遵循如下流程
将
node设置为不可调度kubectl cordon <node name>执行
node drain排空节点,将其上运行的Pod平滑迁移至其他节点kubectl drain <node name>
应用开发人员:针对敏感应用,可定义 PDB 来确保应用不会被意外中断
1 | apiVersion: policy/v1 |
部署方式
- 实例个数
- 更新策略
MaxSurgeMaxUnavailable(需要考虑ResourceQuota的限制)
- 深入理解
PodTemplateHash导致的应用的易变性
服务发布
需要把服务发布至集群内部或者外部,服务的不同类型:
ClusterIP(Headless)NodePortLoadBalancerExternalName
证书管理和七层负载均衡的需求
需要 gRPC 负载均衡如何做,使用 SVC 无法满足。
DNS 需求
与上下游服务的关系
服务发布的挑战
kube-dns- DNS TTL 问题
ServiceClusterIP只能对内kube-proxy支持的iptables/ipvs规模有限IPVS的性能和生产化问题kube-proxy的drift问题- 频繁的
Pod变动(spec change,failover,crashLoop)导致LB频繁变更 - 对外发布的
Service需要与企业ELB即成 - 不支持
gRPC - 不支持自定义
DNS和高级路由功能
IngressSpec要depracate
无状态应用管理
Replicaset副本集用什么
Pod模板创建多少个实例?replicas: 2
Deployment描述的是部署过程
版本管理
1
2
3
4
5metadata:
annotations:
deployment.kubernetes.io/revision: "1"
spec:
revisionHistoryLimit: 10滚动升级策略
1
2
3
4
5
6spec:
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
有状态应用管理
Statefulset
与 deployment 相比,多了 Volume claim template
1 | volumeClaimTemplates: |
随着业务的发展,单个服务的 sts 已经无法满足需求,例如 MySQL 集群化,需要实现数据同步,这个时候就需要 Operator。
有状态应用 - Operator
创建 Operator 的关键是 CRD(自定义资源)的设计。
Kubernetes 对象是可扩展的,扩展的方式有
基于原生对象
- 生成
types对象,并通过client-go生成相应的clients,lister,informer - 实现对象的
registry backend,即定义对象任何存储进etcd - 注册对象的
schema至apiserver - 创建该对象的
apiserver声明,注册该对象所对应的api handler
基于原生对象往往需要通过
aggregation apiserver把不同对象组合起来。- 生成
基于
CRD- 在不同应用业务环境下,对于平台可能有一些特殊的需求,这些需求可以抽象为 Kubernetes 的扩展资源,而 Kubernetes 的
CRD(CustomResourceDefinition)为这样的需求提供了轻量级的机制,保证新的资源的快速注册和使用 - 在更老的版本中,
TPR(ThirdPartyResource)是与CRD类似的概念,但是在1.9以上的版本中被弃用,而CRD则进入的beta状态
- 在不同应用业务环境下,对于平台可能有一些特殊的需求,这些需求可以抽象为 Kubernetes 的扩展资源,而 Kubernetes 的
如何使用 CRD
用户向 Kubernetes API 服务注册一个带有特定 schema 的资源,并定义相关 API
- 注册一系列该资源的实例
- 在 Kubernetes 的其他资源对象中引用这个新注册资源的对象实例
- 用户自定义的
controller例程需要对这个引用进行释义和实施,让新的资源对象达到预期的状态
基于 CRD 的开发过程
借助 Kubernetes RBAC 和 authentication 机制来保证该扩展资源的 security、access control、authentication 和 multitenancy。
将扩展资源的数据存储到 Kubernetes 的 etcd 集群。
借助 Kubernetes 提供的 controller 模式开发框架,实现新的 controller,并借助 APIServer 监听 etcd 集群关于该资源的状态并定义状态变化的处理逻辑。
该功能可以让开发人员扩展添加新功能,更新现有的功能,并且可以自动执行一些管理任务,这些自定义的控制器就像 Kubernetes 原生的组件一样,Operator 直接使用 Kubernetes API 进行开发,也就是说他们可以根据这些控制器内部编写的自定义规则来监控集群、更改 Pods/Services、对正在运行的应用进行扩缩容。
控制器模式
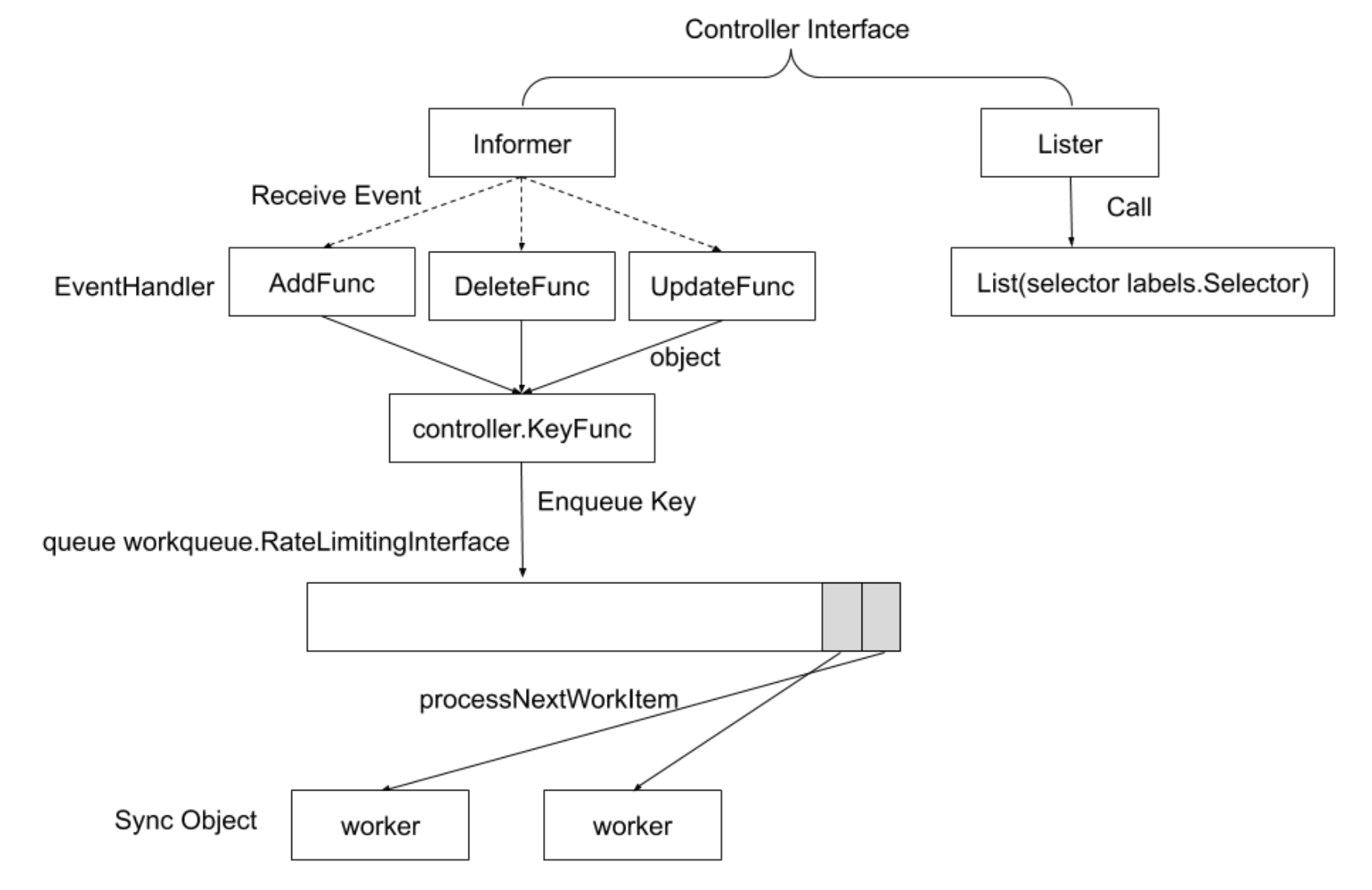
控制器代码示例
k8s 源码 pkg/controller/daemon/daemon_controller.go
1 | daemonSetInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{ |
主要逻辑是消费者从队列中获取数据之后的处理。
安装 kubebuilder
https://github.com/kubernetes-sigs/kubebuilder
下载至本地
https://github.com/kubernetes-sigs/kubebuilder/releases
1 | # download kubebuilder and install locally. |
Kubebuilder
辅助生成 CRD
https://book.kubebuilder.io/quick-start.html
1 | mkdir -p ~/projects/guestbook |
修改 Spec,增加一个 Image 字段
1 | // GuestbookSpec defines the desired state of Guestbook |
生成 CRD 的 yaml 文件
1 | make manifests |
修改消费者代码,监听到 Guestbook 对象时的操作逻辑
1 | func (r *GuestbookReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { |
声明 CRD
1 | make install |
部署 controller 到 k8s 集群上
1 | make deploy |
或者本地运行消费者,进行调试
1 | make run |
查看每个节点是否都生成一个 Pod
创建项目
运行下面的命令创建项目
kubebuilder init --domain=example.com
该命令生成如下文件:
go.mod:依赖管理Makefile:编译文件PROJECT:kubebuilder为生成新组建的元数据配置
有状态应用的复杂性讨论
有状态应用部署示例 - MySQL
高可用部署
- 构建
Galera cluster,提供多活高可用 MySQL 集群(性能就不高,但是可用性强,多地同时都是master,就近读写) - 多实例跨集群/跨机架/跨主机/跨地域
- 一般高可用的方案,都离不开分布式下的理论因素,例如基于
paxos协议实现数据同步 - 如果不管数据一致性,当数据出现冲突时,则需要选择一种方案或者人工介入
- 构建
持久化存储
- 需要为每个 Pod 创建 PVC 并
mount - 读写性能保证
local dynamic作为数据盘,cephfs作为备份盘
- 需要为每个 Pod 创建 PVC 并
有状态应用的复杂配置
- 与无状态应用不一样,MySQL 需要复杂配置以完成
galara集群的构建/etc/mysql/conf.d/galera.cnf
- 与无状态应用不一样,MySQL 需要复杂配置以完成
配置细节
1 | #Configuration the First Node(Primary Component) |
启动顺序
- 在
Primary Component节点上运行mysqld_bootstrap
- 在其他节点上运行
systemctl start mysql
- 发生了什么
- 当节点第一次启动时,会自动生成 UUID 以代表当前节点身份
- 启动后,
galera会在数据目录生成gvwstate.dat文件,该文件内容记录Primary Component的UUID以及连接到当前Primary Component的节点的UUID - 如果
Primary Component出现故障,则剩余节点会重新选择新的Primary Component - 若该文件已经存在,则无需额外执行
bootstrap命令启动Primary Component,可依次规则编写Operator在多个节点构建此文件
1 | my_uuid: d3124bc8-1605-11e4-aa3d-ab44303c044a |
健康检查
MySQL 提供健康检查 API
- 检查集群成员是否能接受查询请求
SHOW GLOBAL STATUS LIKE 'wsrep_ready';
- 检查节点是否与其他节点网络互通
SHOW GLOBAL STATUS LIKE 'wsrep_connected';
- 检查节点自场次查询结束后接收到的查询请求数量,如果结果为非 0,意味着写请求不能立即处理
SHOW STATUS LIKE 'wsrep_local_recv_queue_avg';
健康检查应该影响 Pod 的 readiness probe,在进行版本升级时,确保大多数集群节点状态一致。
数据备份
推荐为 MySQL 创建不同类型的 volume
Local volume用来做数据盘Network volume用来做数据备份
创建 cronjob,每天将数据备份至 backup 目录
- 备份文件为
一键恢复能力
- 导入备份目录的
sql file
版本发布和故障转移
针对配置了 Local disk 的 Pod,当发生因版本变更而引发的 Pod 重建时,新 Pod 在进行调度时,调度器会查询 Pod 挂载的 volume 所在节点,并将新 Pod 优先调度至该节点,此场景不涉及到数据恢复。
其开销与 MySQL 进程重启相差不大。
版本发布和故障转移
如果节点出现故障,如硬件故障,Kubernetes 的 Evict Manager 会将该 Pod 从故障节点驱逐,Operator 应确保新 Pod 会被重新构建。而新 Pod 会被调度至新节点,此场景等价于替换 MySQL 中的少数节点。
galera集群中的少数 MySQL 节点替换,不涉及到数据迁移,galera会确保新节点的数据同步
若整个 MySQL 集群需要做数据恢复,则应该从 backup 目录对应的网络 volume 恢复数据。此时可选择:
- 只恢复单一节点数据:配置简单
- 恢复所有节点数据:恢复速度快
与基础架构的 Contract
PodDisruptionBudget
一些 Operator 的推荐
https://github.com/operator-framework/awesome-operators?tab=readme-ov-file
https://operatorhub.io/
Spec 管理神器 - Helm
官方文档自带中文:https://helm.sh/zh/docs/
什么是 Helm
Helm 特性
- Helm chart 是创建一个应用实例的必要的配置组,也就是一堆 Spec
- 配置信息被归类为模板(
Template)和值(Value),这些信息经过渲染生成最终的对象 - 所有配置可以被打包进一个可以发布的对象中
- 一个
release就是一个有特定配置的chart的实例
Helm 的组件
Helm client
- 本地
chart开发 - 管理
repository - 管理
release - 与
helm library交互- 发送需要安装的
chart - 请求升级或者卸载存在的
release
- 发送需要安装的
Helm library
- 负责与 APIServer 交互,并提供以下功能
- 基于
chart和configuration创建一个release - 把 chart 安装进 Kubernetes,并提供相应的
release对象 - 升级和卸载
- Helm 采用 Kubernetes 存储所有配置信息,无需自己的数据库
- 基于
Kubernetes Helm 架构
Helm 的目标
从头创建 chart
把 chart 打包成压缩文件(tgz)
与 chart 的存储仓库交互(chart repository)
Kubernetes 集群中的 chart 安装与卸载
管理用 Helm 安装的 release 的生命周期
Helm 的安装
下载:https://github.com/helm/helm/releases
1 | tar -zxvf helm-v3.0.0-linux-amd64.tar.gz |
或者

Helm chart 的基本使用
创建一个 chart
1 | helm create myapp |
复用已存在的成熟的 Helm release
针对 Helm release repo 的操作
1
2
3
4helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm repo list
helm search repo grafana从 remote repo 安装 Helm chart
1
helm upgrade --install loki grafana/loki-stack
拉取 chart
1
2helm pull grafana/loki-stack
helm upgrade --install loki ./loki-stack
metrics-server
Aggregated APIServer
在 apiserver 中设定一些 apiserver 不由 kubelet 管理,集成到 Aggregated APIServer 里面。
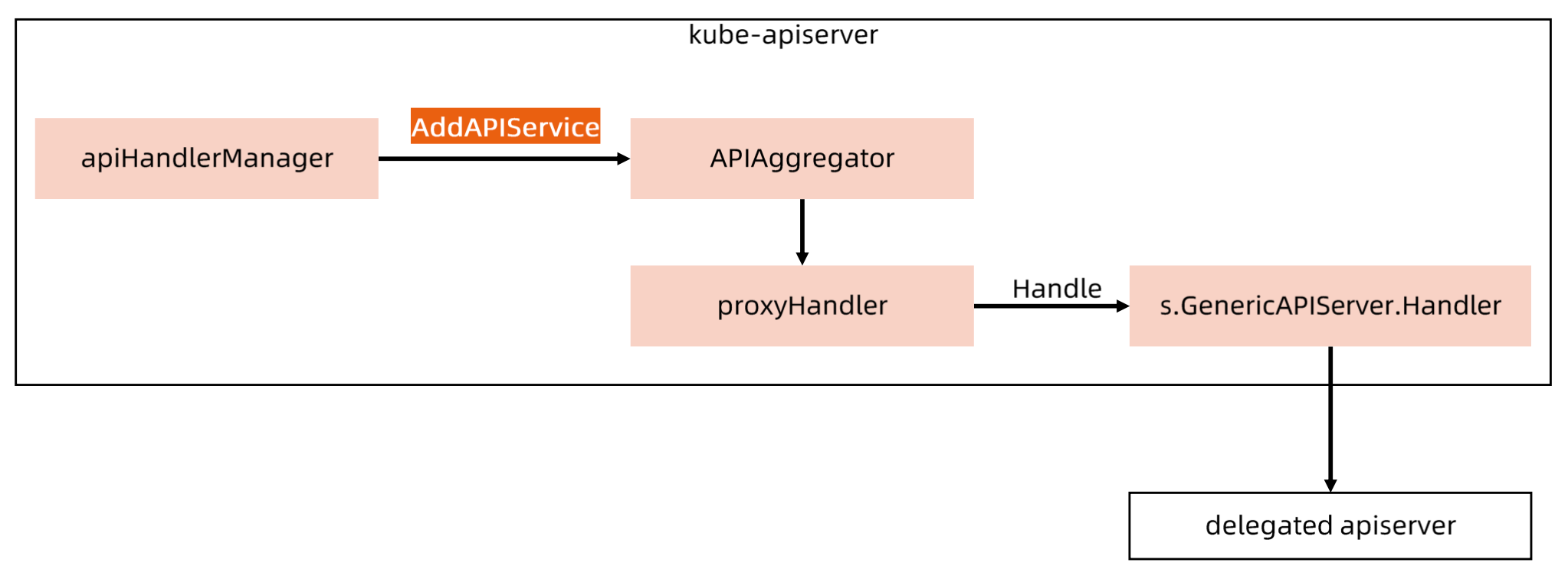
Metrics-Server
metrics-server 是 Kubernetes 监控体系中的核心组件之一,它负责从 kubelet 收集资源指标,然后对这些指标监控数据进行聚合(依赖 cube-aggregator),并在 Kubernetes APIServer 中通过 Metrics API(/apis/metrics.k8s.io/)公开暴露它们,但是 metrics-server 只存储最新的指标数据(CPU/Memory)。
kube-apiserver 要能访问到 metrics-server;
需要 kube-apiserver 启用聚合层;
组件要有认证配置并且绑定到 metrics-server;
Pod/Node 指标需要由 Summary API 通过 kubelet 公开。
请求响应流程:
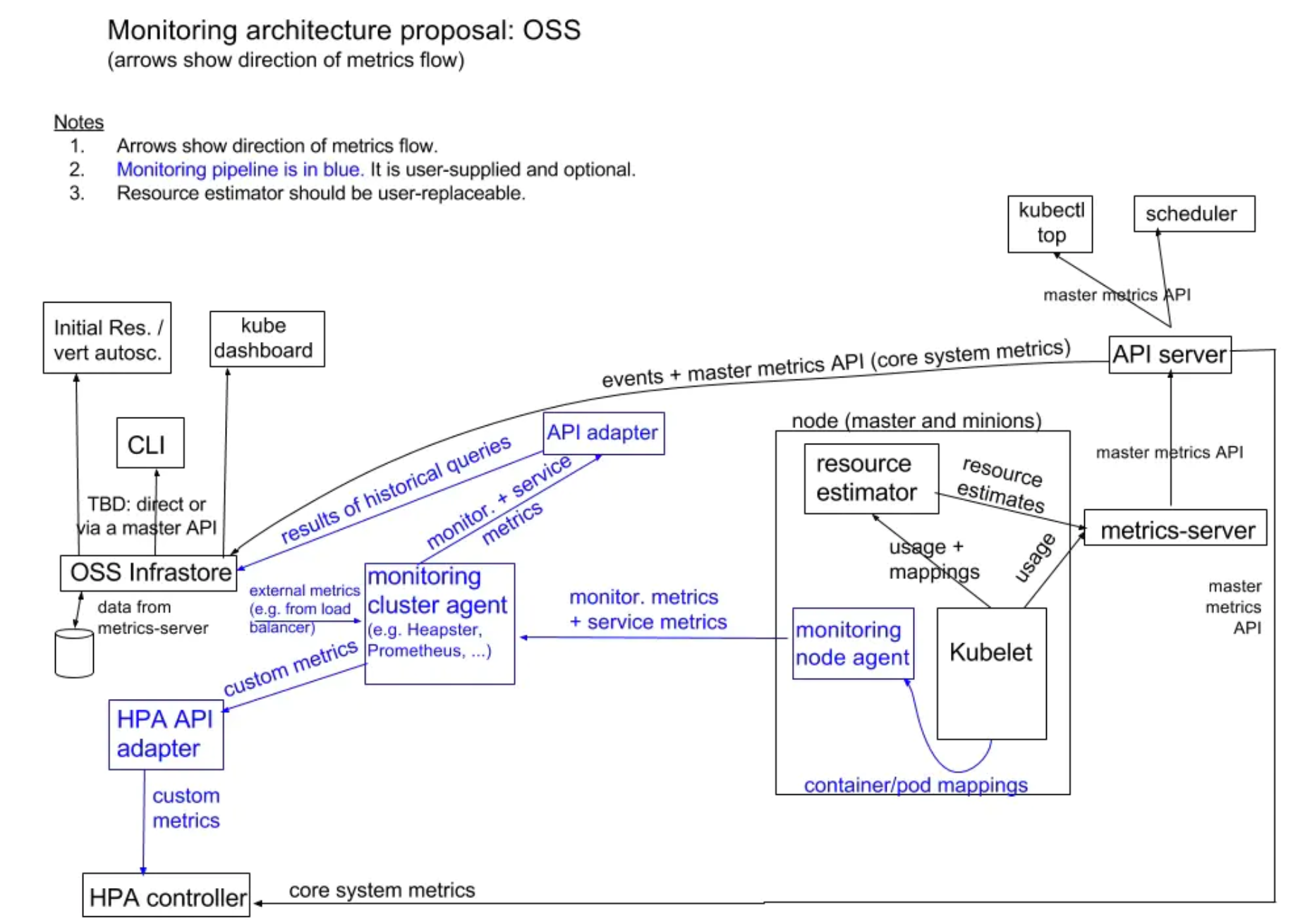
Metrics-server 的本质
https://github.com/kubernetes-sigs/metrics-server
安装:
1 | kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml |
踩坑:
修改 deployment 的内容
1 | # 修改镜像地址,避免镜像拉不下来 |
将质保数据转换成 metrics.k8s.io 的 api 调用返回值
1 | # kubectl top node |
自动扩容缩容 - HPA
横向伸缩和纵向伸缩
- 应用扩容是指在应用接收到的并发请求已经处于其处理请求极限边界的情形下,扩展处理能力而确保应用高可用的技术手段
Horizontal Scaling- 所谓横向伸缩是指通过增加应用实例数量分担负载的方式来提升应用整体处理能力的方式,例如增加副本数。
Vertical Scaling- 所谓纵向伸缩是指通过增加单个应用实例资源以提升单个实例处理能力,进而提升应用整体处理能力的方式,例如增加 CPU/内存。
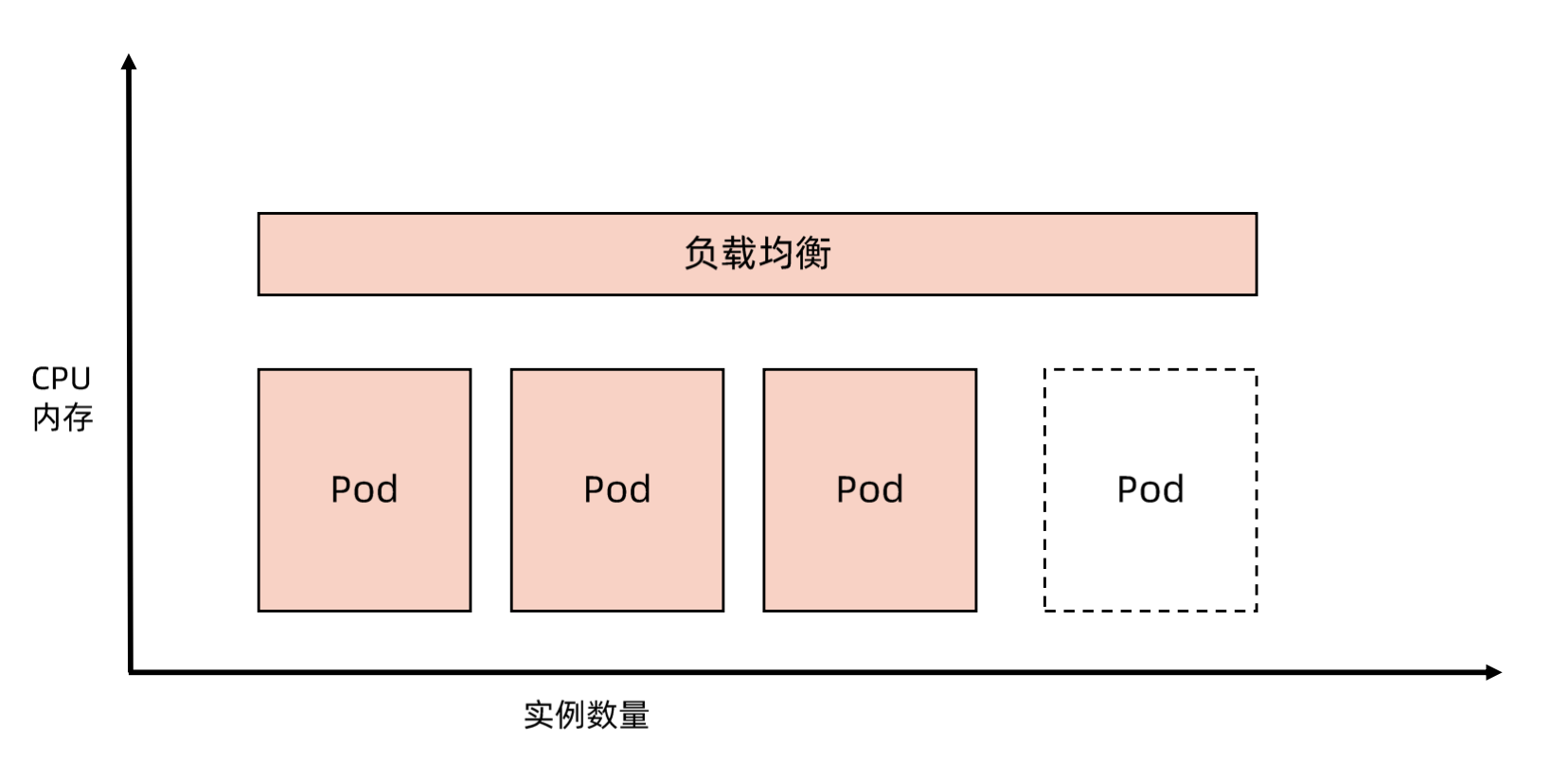
理解云原生的弹性能力
Kubernetes 提供了横向扩展和纵向扩展的能力:
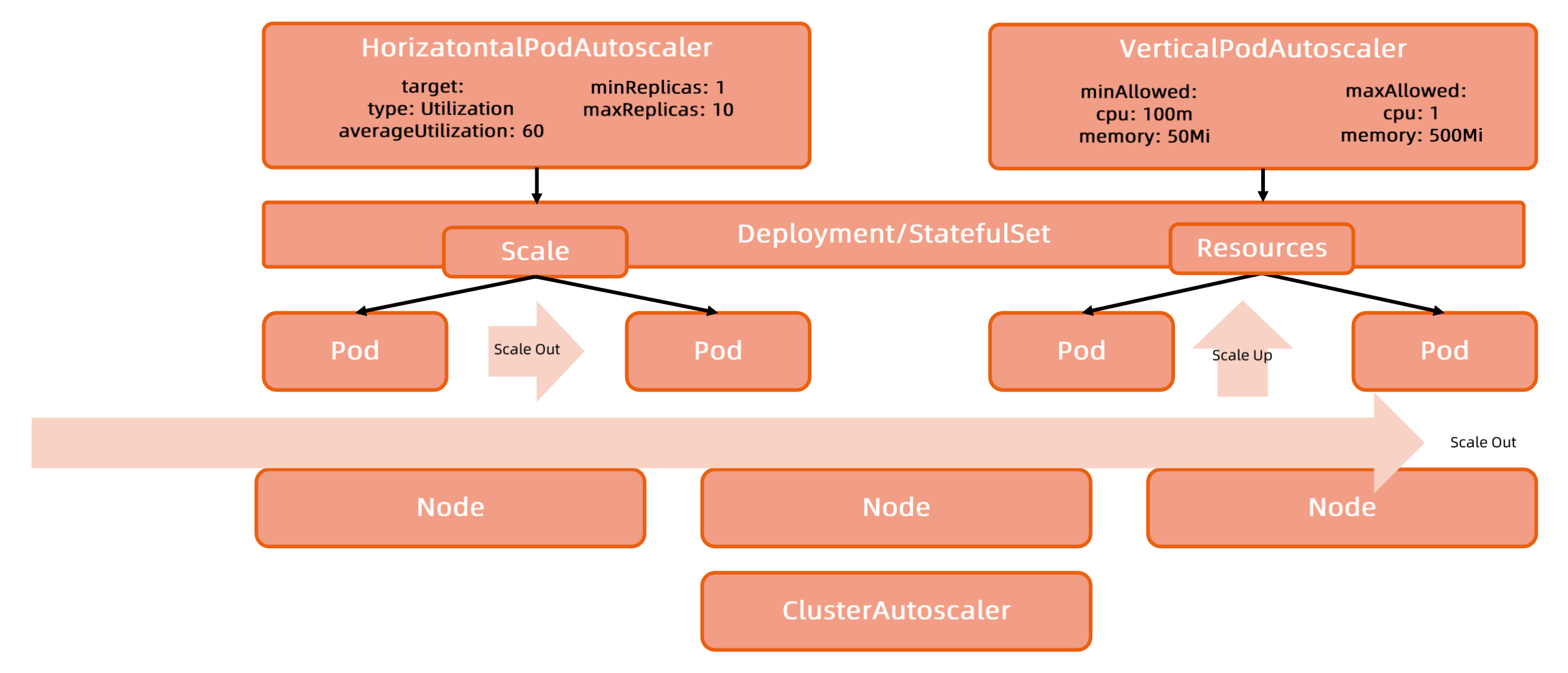
比如横向:超过 60% 的 CPU 使用率,资源从 metrics 收集。
HPA
- HPA(
Horizontal Pod Autoscaler)是 Kubernetes 的一种资源对象,能够根据某些指标对在statefulSet、replicaSet、deployment等集合中的 Pod 数量进行横向动态伸缩,使运行在上面的服务对指标的变化有一定的自适应能力。 - 因节点计算资源固定,当 Pod 调度完成并运行以后,动态调整计算资源变得较为困难,因为横向扩展具有更大优势,HPA 时扩展应用能力的第一选择。
- 多个冲突的 HPA 同时创建到同一个应用的时候会有无法预期的行为,因此需要小心维护 HPA 规则。
- HPA 依赖于
Metrics-Server
HPA Spec
v1 版本示例,只支持 CPU 和内存,没有扩展性,已经不满足需求
1 | apiVersion: autoscaling/v1 |
v2 版本示例,支持一些扩展能力,例如 QPS 等
1 | apiVersion: autoscaling/v2beta2 |
HPA 支持的指标类型
对于按 Pod 统计的资源指标(如 CPU),控制器从资源指标 API 中获取每一个 HorizontalPodAutoscaler 指定的 Pod 的度量值,如果设置了目标使用率,控制器获取每个 Pod 中的容器资源使用情况,并计算资源使用率。如果设置了 target 值,将直接使用原始数据(不再计算百分比)。
如果 Pod 使用自定义指示,控制器机制与资源指标类似,区别在于自定义指标只使用原始值,而不是使用率。
如果 Pod 使用对象指标和外部指标(每个指标描述一个对象信息)。这个指标将直接根据目标设定值相比较,并生成一个上面提到的扩缩比例。在 autoscaling/v2beta2 版本 API 中,这个指标也可以根据 Pod 数量平分后再计算。
HPA 指标
Resource 是 Kubernetes 默认支持的资源类型,CPU、内存等
Pod 类型这种类型默认不收集,需要定义指标。
1 | # Resource 类型的指标 |
1 | # Pods 类型的指标 |
对象类型
1 | type: Object |
算法细节
https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/
HPA 算法非常简单
1 | 期望副本数 = ceil[当前副本数 * (当前指标 / 期望指标)] |
当前度量值为 200m,目标设定值为 100m,那么由于 200.0/100.0 == 2.0,副本数量将会翻倍。
如果当前指标为 20m,副本数量将会减半,因为 50.0/100.0 == 0.5。
如果计算出的扩缩比例接近 1.0(根据 –horizontal-pod-autoscaler-tolerance 参数全局配置的容忍值,默认为 0.1),将会放弃本次扩缩。
扩容时比较激进,缩容时比较保守。
滚动升级时扩缩
当你为一个 Deployment 配置自动扩缩时,你要为每个 Deployment 绑定一个 HorizontalPodAutoscaler.
HorizontalPodAutoscaler 管理 Deployment 的 replicas 字段。
Deployment Controller 负责设置下层 ReplicaSet 的 replicas 字段,以便确保在上线及后续过程副本个数合适。
想一想:为什么 deploymentSpec 中的 replicas 字段的类型为 *int,而不是 int ,这是出于零值的考量,使用指针,可以区别没有填写或是填写零值,避免在升级过程中造成影响。
冷却/延迟支持
当使用 HorizontalPodAutoscaler 管理一组副本扩缩时,有可能因为指标动态的变化造成副本数量频繁的变化,有时这被称为抖动(Thrashing)。例如在 Pod 启动的时候,对内存占用较高,避免这个时候计算资源使用率产生影响。
–horizontal-pod-autoscaler-downscale-stabilization:设置缩容冷却时间窗口长度。
水平 Pod 扩缩器能够记住过去建议的负载规模,并仅对此时间窗口内的最大规模执行操作。
默认值是 5 分钟(5m0s)。
扩缩策略
在 Spec 字段的 behavior 部分可以指定一个或多个扩缩策略。当指定多个策略时,默认选择允许更改最多的策略。下面的例子展示了缩容时的行为:
1 | behavior: |
HPA 练习
安装 metrics-server(本质上是一个 aggregate Server)
https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
php-apache.yaml
1 | apiVersion: apps/v1 |
hpa.yaml
1 | apiVersion: autoscaling/v2 |
启动应用
创建
php-server1
kubectl apply -f https://k8s.io/examples/application/php-apache.yaml
设置 HPA 规则
1
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
或者使用
yaml文件定义1
kubectl apply -f hpa.yaml
查看 HPA Spec
1
2
3
4
5
6
7
8
9
10
11
12
13
14spec:
maxReplicas: 10
metrics:
- resource:
name: cpu
target:
averageUtilization: 50
type: Utilization
type: Resource
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
测试 HPA
为服务器加压
1
2
3# 在单独的终端中运行它
# 以便负载生成继续,你可以继续执行其余步骤
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"现在执行:
1
2# 准备好后按 Ctrl+C 结束观察
kubectl get hpa php-apache --watch一分钟时间左右之后,通过以下命令,我们可以看到 CPU 负载升高了;例如:
1
2NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 305% / 50% 1 10 1 3m观测
top pod,可以发现当podcpu利用率大于500m的时候,会创建更多pod出来分担压力停止
load-generator以后,等待一段时间,pod数量会降为一个1
2NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 11m
HPA 存在的问题
基于指标的弹性由滞后效应,因为弹性控制器操作的链路过长。应用使用出现阈值 -> cAdvisor 采集 -> 上报到 kubelet -> metrics 采集。这几个链路走下来可能已经过了一两分钟。
从应用负载超出阈值到 HPA 完成扩容之间的时间差包括:
- 应用指标数据已经超出阈值;
HPA定期执行指标收集滞后效应;HPA控制Deployment进行扩容的时间;Pod调度,运行时启动挂载存储和网络的时间;- 应用启动到服务就绪的时间。
很可能在突发流量出现时,还没完成弹性扩容,既有的服务实例已经被流量击垮。
自动扩容缩容 - VPA
https://github.com/kubernetes/autoscaler
VPA 全称 Vertical Pod Autoscaler,即垂直 Pod 自动扩缩容,它根据容器资源使用率自动设置 CPU 和内存的 request,从而允许在节点上进行适当的调度,以便为每个 Pod 提供适当的资源。它既可以缩小过度请求资源的容器,也可以根据其使用情况随时提升资源不足的容量。
使用 VPA 的意义:
- Pod 资源用其所需,提升集群节点使用效率;
- 不必运行基准测试任务来确定 CPU 和内存请求的合适值;
- VPA 可以随时调整 CPU 的内存请求,无需人为操作,因此可以减少维护时间
注意:
VPA 目前还没有生产就绪,在使用之前需要了解资源调节对应用的影响。
VPA 架构图

VPA 组件
- VPA 引入了一种新型的 API 资源:
VerticalPodAutoscaler - VPA
Recommender监视所有 Pod,不断为它们计算新的推荐资源,并将推荐值存储在 VPA 对象中。它使用来自Metrics-Server的集群中所有 Pod 的利用率和 OOM 事件。 - 所有 Pod 创建请求都通过 VPA
Admission Controller - VPA
Updater时负责 Pod 实时更新的组件。如果 Pod 在Auto模式下使用VPA,则Updater可以决定使用推荐器资源对其进行更新 History Storage是一个存储组件(如Prometheus),它使用来自API Server的利用率信息和 OOM(与推荐器相同的数据)并将其持久存储- VPA 更新模式:
Off:Updater 不工作Auto:Updater 会工作,
VPA 工作原理
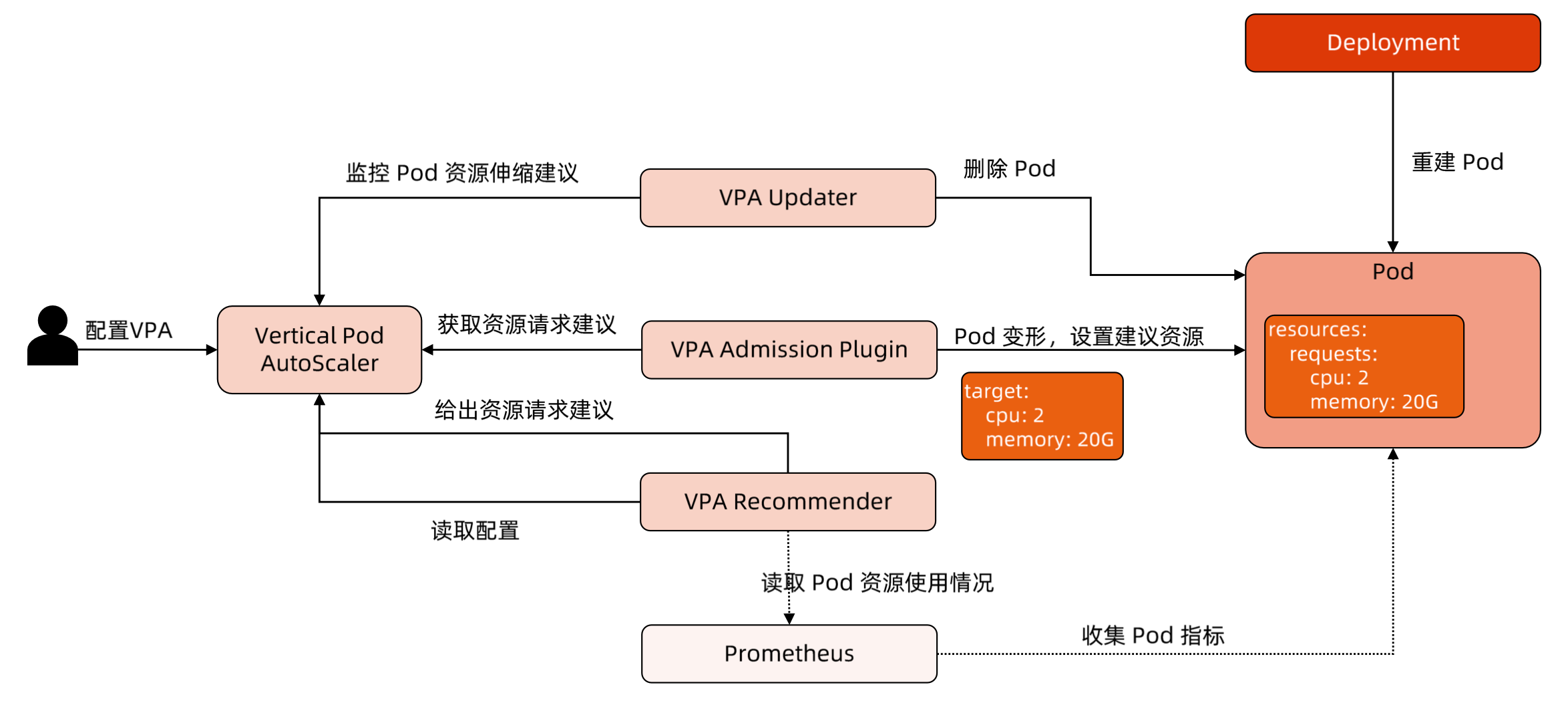
Recommender 通过读取 Prometheus 获取 Pod 资源使用情况,从 Metrics 中读取当前指标,给出建议,通过 Admission Updater 删除 Pod,然后创建 Pod 时经过 Admission Plugin 变形,修改 Resource,重建 Pod。
Recommender 设计理念
推荐模型(MVP)假设内存和 CPU 利用率时独立的随机变量,其分布等于过去 N 天观察到的变量(推荐值为 N=8 以捕获每周峰值,以一周为一个周期)。
- 对于
CPU,目标时将容器使用率超过请求的高百分比(例如95%)时的时间部分保持在某个阈值(例如1%的时间)以下。在此模型中,CPU 使用率 被定义在短时间间隔内测量的平均值。测量间隔越短,针对尖峰、延迟敏感的工作负载的建议质量就越高。最小合理分辨率为1/min,推荐为1/sec - 对于内存,目标是将特定窗口内容器使用率超过请求的概率保持在某个阈值以下(例如,
24小时内低于1%)。窗口必须很长(≥ 24小时)以确保由OOM引起的驱逐不会明显影响(a)服务应用程序的可用性(b)批处理计算的进度(更高级的模型可以允许用户指定 SLO 来控制它)
主要流程
Checkpoints:将采集到的数据做统计和分布,用于后续算法推荐。
滑动窗口与半衰指数直方图
Recommender 的资源推荐算法主要受 Google AutoPilot moving window (滑动窗口和半衰期,时间节点越近权重越高)推荐器的启发,假设 CPU 和 Memory 消耗时独立的随机变量,其分布等于过去 N 天观察到的变量分布(推荐值为 N = 8 以捕获每周业务容器峰值)。
https://research.google/pubs/autopilot-workload-autoscaling-at-google-scale/
https://dl.acm.org/doi/pdf/10.1145/3342195.3387524
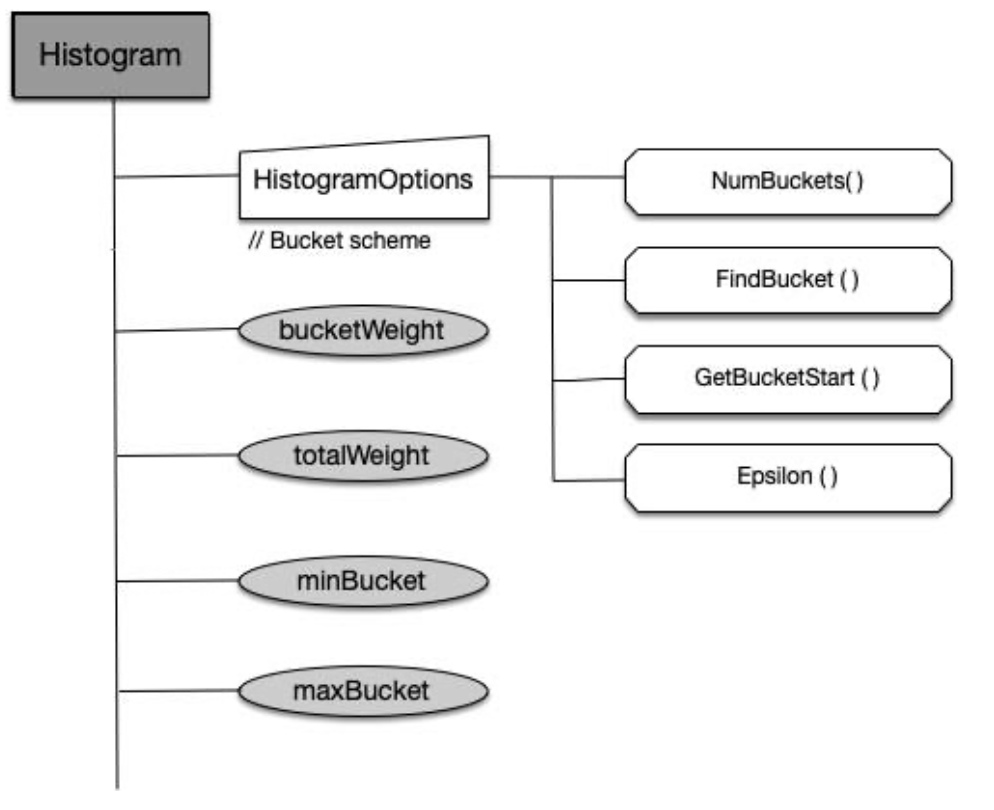
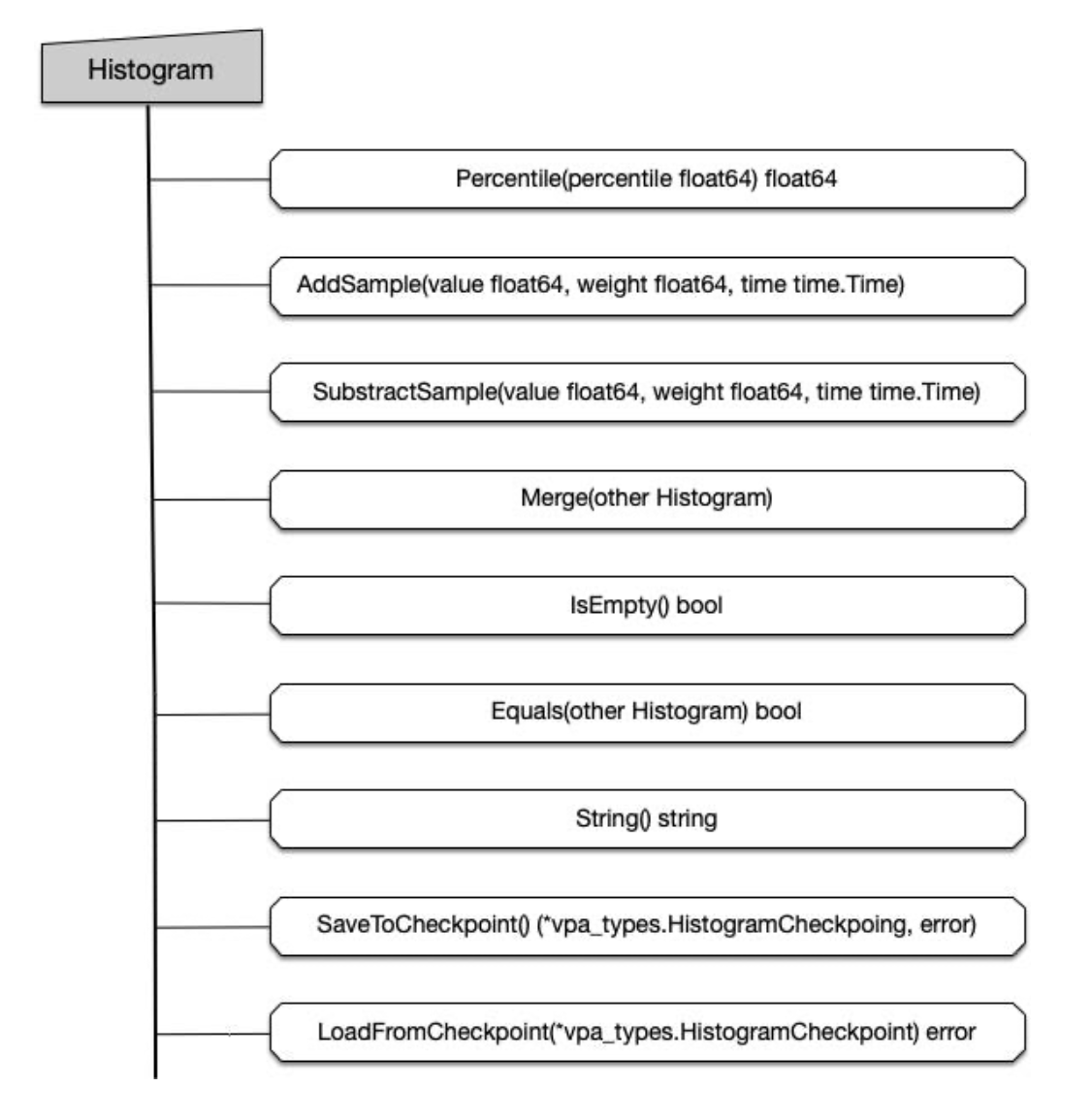
Recommender 组件获取资源消耗实时数据,存到相应资源对象 CheckPoint 中。CheckPoint CRD 资源本质上是一个直方图。
直方图统一对外提供的接口
直方图数据范围
| Resource | minBucket | maxBucket | rate |
|---|---|---|---|
| cpu | 0.01 cores | 1000 cores | 5% |
| memory | 10 MB | 1 TB | 5% |
从第1个桶(cpu:0 ~ 0.01 core)开始,到最后一个桶。
半衰期和权重系数
- 为每个样本数据权重乘上指数
2^((sampleTime - referenceTimestamp) / halfLife),以保证较新的样本被赋予更高的权重,而较老的样本随时间推移权重逐步衰减。 - 默认情况下,每
24h为一个半衰期,即每经过24h,直方图中所有样本的权重(重要性)衰减为原来的一半。 - 当指数过大时,
referenceTimestamp就需要向前调整,以避免浮点乘法计算时向上溢出。CPU使用量样本对应的权重是基于容器CPU request值确定的。当CPU request增加时,对应的权重也随之增加。- 而
Memory使用量样本对应的权重固定为1.0。
操作 VPA
1 | git clone https://github.com/kubernetes/autoscaler.git |
1 | # This config creates a deployment with two pods, each requesting 100 millicores |
Get all pods->
Get live pods->
Get pods managed by vpa && evictable ->
Add to updater queue->
If
(within recommend range && no oom) || (oom but resourcediff==0)-> no updateelse pods enqueue with priority->
Sort by priority ->
Kill with ratelimit configured in command line parameter
VPA 总结
VPA 的成熟度还不足
- 更新正在运行的
Pod资源配置时 VPA 的一项实验性功能,会导致Pod的重建和重启,而且有可能会被调度到其他的节点上。(目前社区在讨论可以动态修改 Pod Spec,但是目前没有落地) - VPA 不会驱逐没有在副本控制器管理下的 Pod。目前对于这类 Pod,
Auto模式等同于Initial模式。 - 目前 VPA 不能和监控 CPU 和内存度量的
Horizontal Pod Autoscaler(HPA)同时运行,除非 HPA 只监控其他定制化的或者外部的资源度量。 - VPA 使用
admission webhook作为其准入控制器。如果集群中有其他的admission webhook,需要确保它们不会与 VPA 发生冲突。准入控制器的执行顺序定义在APIServer的配置参数中。 - VPA 会处理出现的绝大多数
OOM(Out Of Memory)的事件,但不保证所有的场景下都有效。 - VPA 的性能还没有在大型集群中测试过。
- VPA 对 Pod 资源
requests的修改制可能超过实际的资源上限,例如节点资源上限、空闲资源或资源配额,从而造成 Pod 处于Pending状态无法被调度。同时使用集群自动伸缩(ClusterAutoscaler)可以一定程度上解决这个问题。 - 多个 VPA 同时匹配同一个 Pod 会造成未定义的行为。
如何解决社区基础弹性能力不足的问题
弹性的意义
| 目标 | 方法 | 流程 | 工具 |
|---|---|---|---|
| 增效 | 研发效能 | DevOps | Continuous Integration & Continuous Deployment |
| 将本 | 资源效能 | FinOps | Cloud Resource Analytics and Economics |
https://www.finops.org/introduction/what-is-finops/
https://github.com/gocrane/crane
成本优化的关键路径
核心时理解成本:
成本时业务稳定性跟资源利用率的矛盾
大多数稳定性都是由冗余换来的
成本时业务投入跟技术投入的矛盾
就一个人力,投入业务还是投入优化
成本还是企业内不同组织/角色的矛盾
业务团队 vs 资源团队
云业务的去中心化部署和运维为成本管理带来挑战
可以通过技术手段和组织手段减少矛盾
开启降本之路
- 天时 - 云原生技术的日趋成熟
- 地利 - 统一上云
- 人和 - 思想统一
| 思想统一 | 流程驱动 | 工具链支撑 | 成本优化 |
|---|---|---|---|
| FinOps | 云原生成熟度模型 | 弹性 服务定级 质量保证 |
统一思想 - FinOps
报表-建议-实施操作
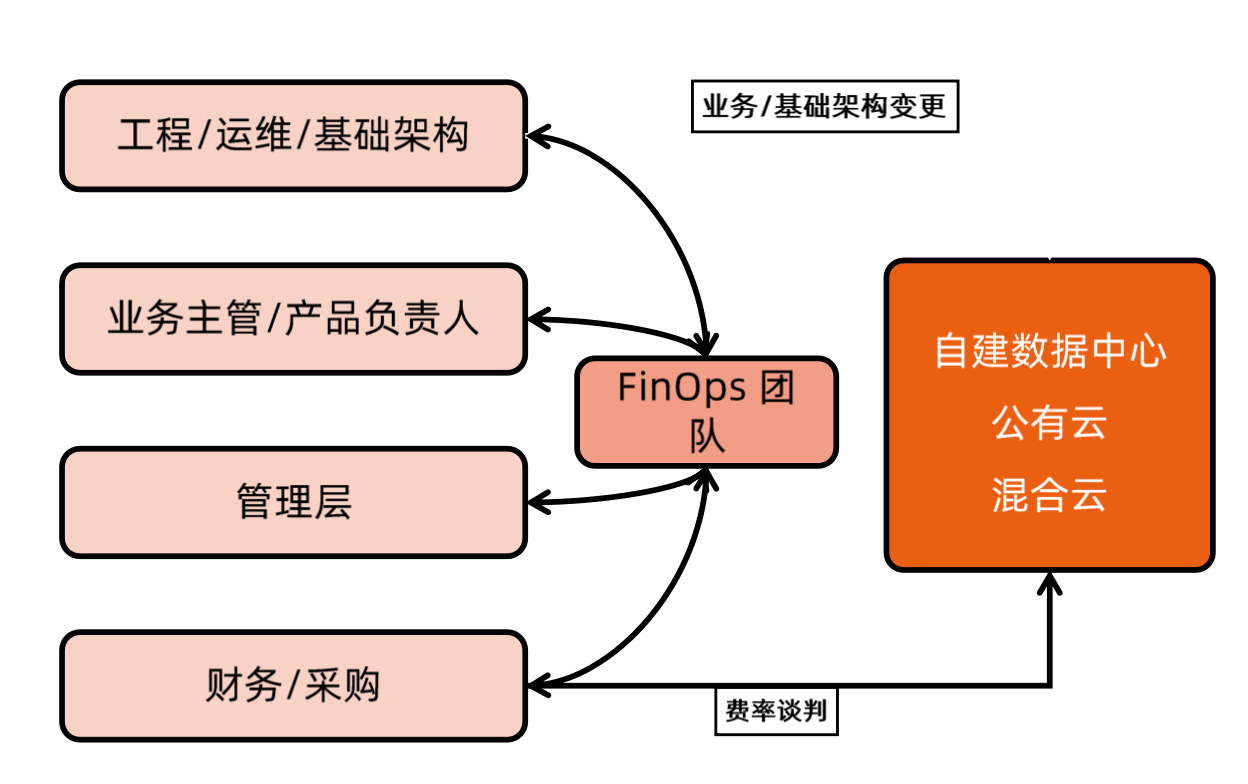
- FinOps 基金会隶属于 Linux 基金会,致力推进企业的云资产管理
- FinOps 核心是确保企业在云中花费的每一分钱都获得最大价值
流程建设 - 云原生成熟度模型
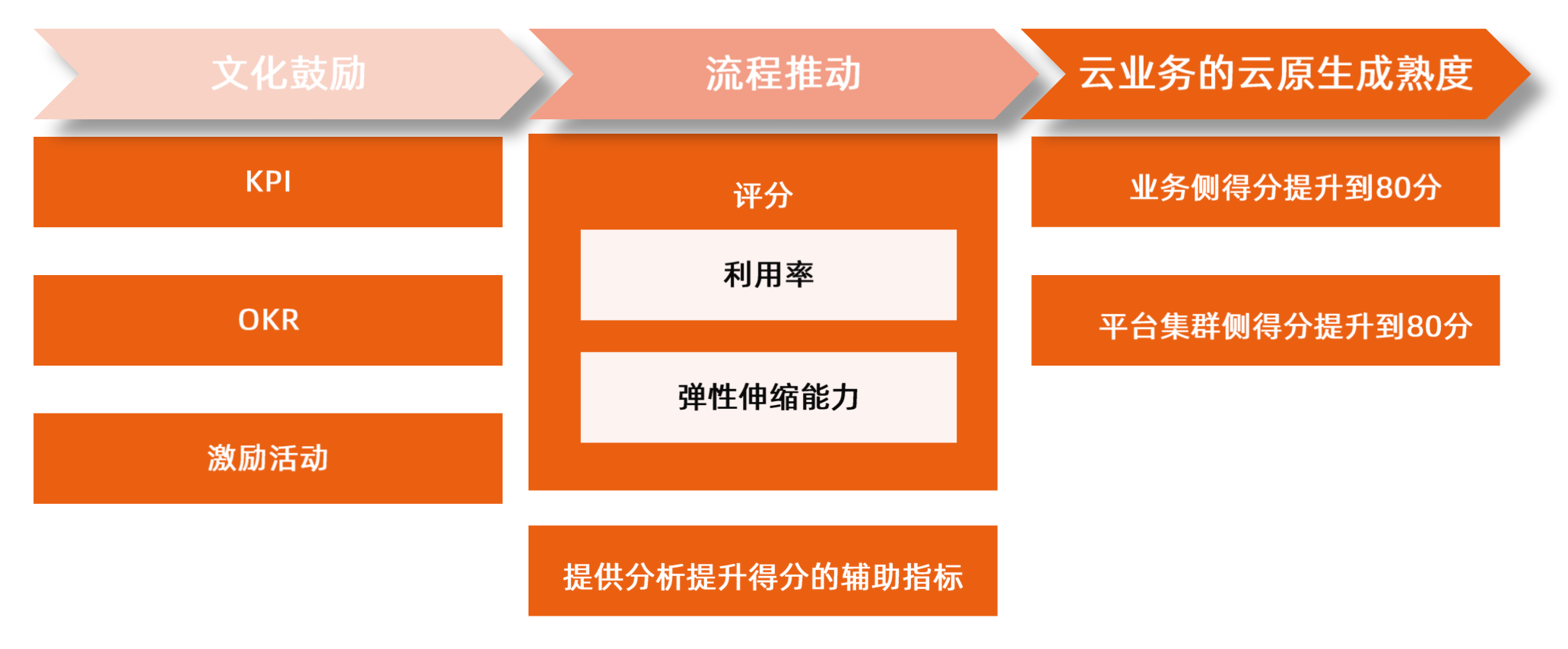
业务侧 Workload 评分
| 指标 | 规则 |
|---|---|
| Workload 利用率得分 | 以每天 Workload 的利用率(used / request 总量)峰值作为打分基础 1. 利用率大于等于 50% 得 100 分 2. 利用率小于 50%:分数 = 利用率 * 100 / 50 注:峰值不去毛刺 |
| Workload 弹性得分 | * Workload 每天 Pod 数计算:按 10 分钟聚合每个 Workload 的 Pod 个数 * Pod 信息按分钟上报,每天 1440 个点,取 10 分钟聚合数据作为 Pod 数据来规避偶尔的上报丢失情况 * 如某天 Pod 数目发生变化,且满足(max - min) > max * 5% 且(max - min)>1,则本日弹性计数为 1,否则为 0 1. 若 30 天内总计弹性计数 < 2,则弹性得分记为 0 2. 如果 30 天内弹性计数 = 2,则弹性得分记为 60,滞后弹性计数每 +1,弹性得分 +5,满分 100 3. 利用率得分 90 分以上,弹性免考核,弹性得分直接记为 100 4. Pod 树小于 3 个的,默认弹性设置为 60 分 |
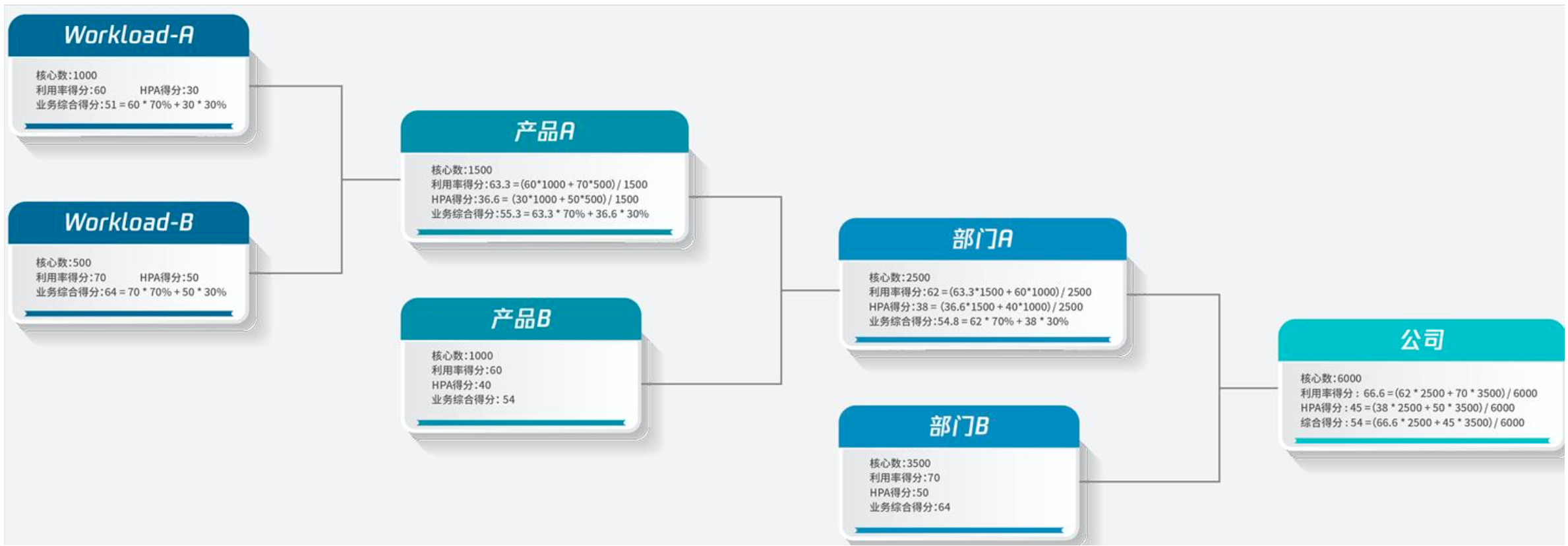
| Workload 总和得分 | 单 Workload 总和得分 = (利用率得分 * 70% + HPA 得分 * 30%) * 该 Workload 的 request)/ 该业务所有 Workload 总 request |
| 业务总和得分 | Sum(单 Workload 综合得分) |
业务侧 Workload 评分 - 辅助指标
| 指标 | 说明 | 建议 |
|---|---|---|
| Pod 伸缩比 | 该指标会计算各 Workload 的 limit 配置与 request 配置的比例 | 建议业务根据实际使用情况,适当降低 request 配置、提升 limit 配置。从而提升 Pod 的伸缩比 |
| 大核心占比 | 统计 Request 配置大于 16 核的 Pod 核心数占比 | 建议业务降低 Request 的配置,提升 Workload 的资源利用率及可调度性 |
| 容器平均核心 | 统计 Pod Request 配置平均核心数 | 建议业务降低 Request 的配置,提升 Workload 的资源利用率及可调度性 |
| CPU:Memory | 统计 CPU 与 Memory 的比值(Memory 单位为 GB) | 建议业务降低 CPU 与 Memory 配比,提示资源利用效率 |
| CPU:Memory 过高的占比 | 统计 CPU 与 Memory 的比值Memory 单位为 GB) 超过 1:4 的 Pod CPU 占比 |
建议业务降低 CPU 与 Memory 配比,提示资源利用效率 |
平台集群评分
| 指标 | 规则 |
|---|---|
| 集群利用率得分 | 以每天集群的率用率峰值作为打分基础 1. 利用率大于等于 50% 得 100 分; 2. 利用率小于 50%:分数 = 利用率 * 100 / 50 注:峰值不去毛刺 |
| 集群 CA 得分 CA(Cluster Autoscaler) |
1. 集群在云梯侧开启了 CA 功能可得 60 分 上述得分规则未考虑集群的规模及实际利用率情况,在执行过程中发现了业务频繁刷分的现象 |
集群 CAB 得分规则补充,降低刷分行为对排行榜的影响:

辅助指标
| 指标 | 规则 |
|---|---|
| 超卖率 | 集群可分配核心数 / 集群机器总核心数 |
| 装箱率 | 集群所有 Workload Request CPU 总核心数 / 集群机器总核心数 |
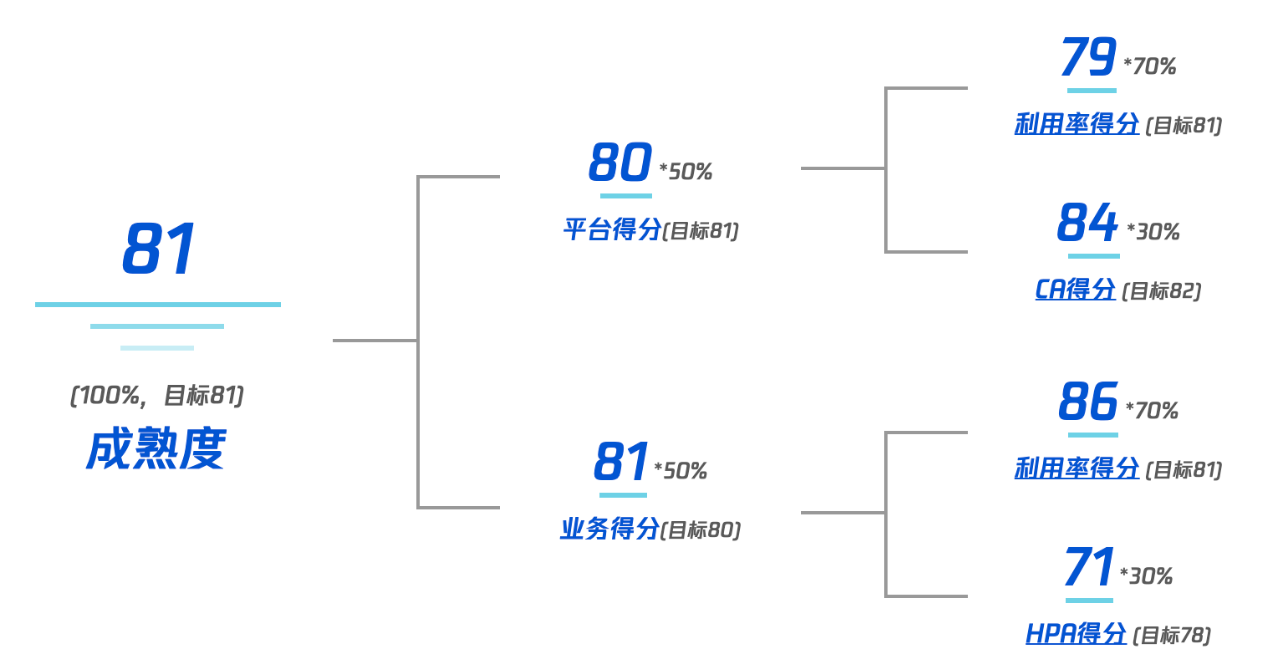
成熟度指标计算公式
总成熟度得分 = 业务侧得分 * 50% + 平台侧得分 * 50%
驱动力
计数交流层面
业务上云经验研讨
外部云原生技术推广福利
团队及个人荣誉层面
资源优惠层面

云成熟度模型成效
涌现了一大批先进个人和团队
推动了云原生最佳实践的广泛认可和研讨
最佳实践对外输出,提升行业知名度
资源利用率极大提升
Crane - 工具链打通
Cloud Resource Analytics and Economics
云财务管理的一站式解决方案
开源项目:https://github.com/gocrane
https://github.com/gocrane/crane/blob/main/README_zh.md

- 多维的成本展示
- 精确的浪费识别
- 基于云原生成熟度模型的评估体系
- 可靠的弹性
- 分级业务的质量保证
- 智能弹性和成本优化
Crane 高层架构
Predictor 驱动整个生态系统
- 成本趋势展示
- 基于预测的资源回收与再分配
- 基于预测的智能弹性
基线能力
- 基于业务优先级的主动回避
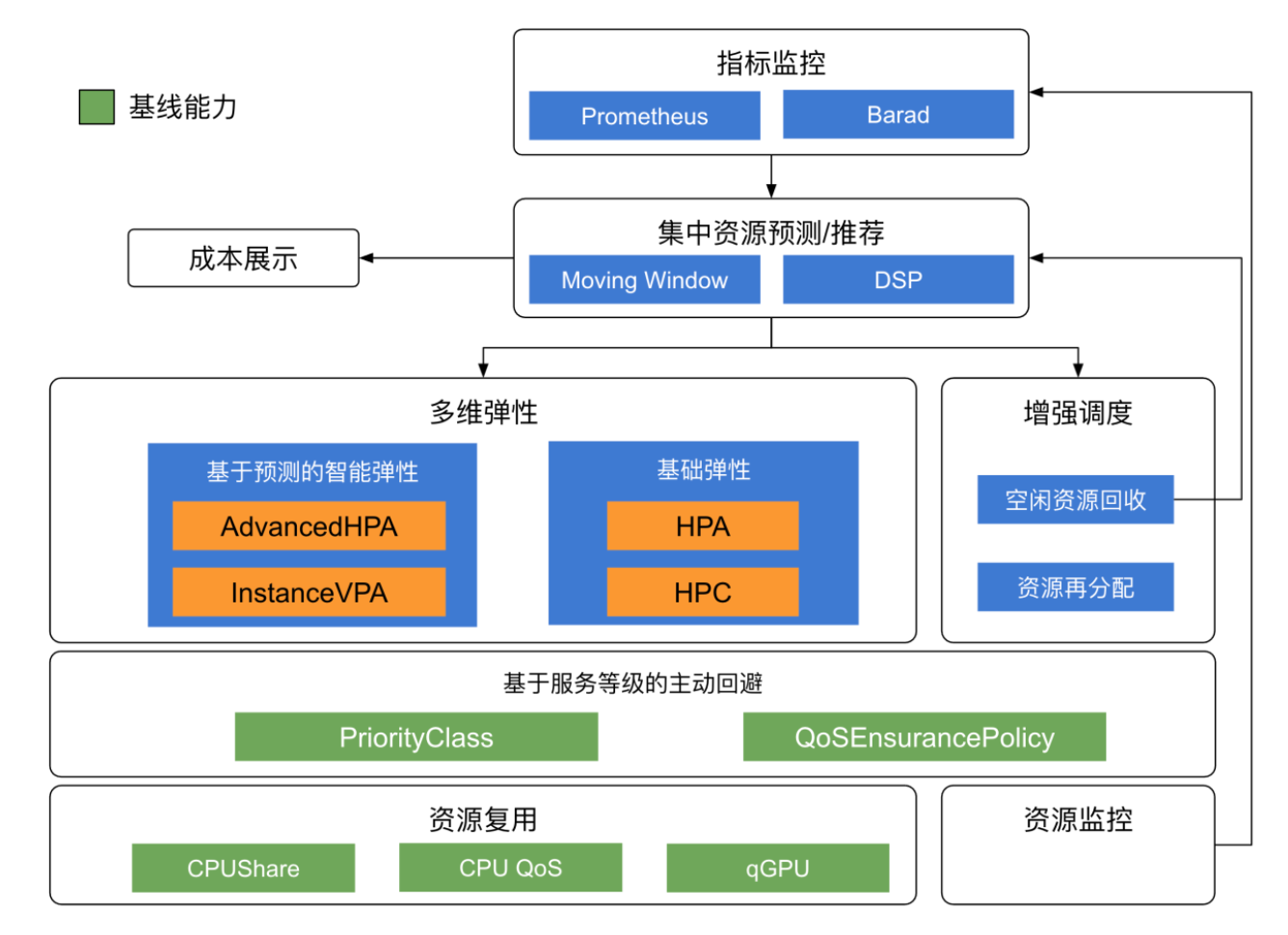
资源预测
多数据源支持:例如 Prometheus
可扩展的资源质保
可自定义的算法
基于声明式 API 的预测
TimeSeriesPrediction对象定义资源预测规则- 预测结果按
PodGroup汇聚,作为弹性能力的输入 - 预测结果按
Node汇聚,作为节点资源回收器的输入
- 预测结果按

多维的成本展示
基于预测结果的资源用量趋势分析:
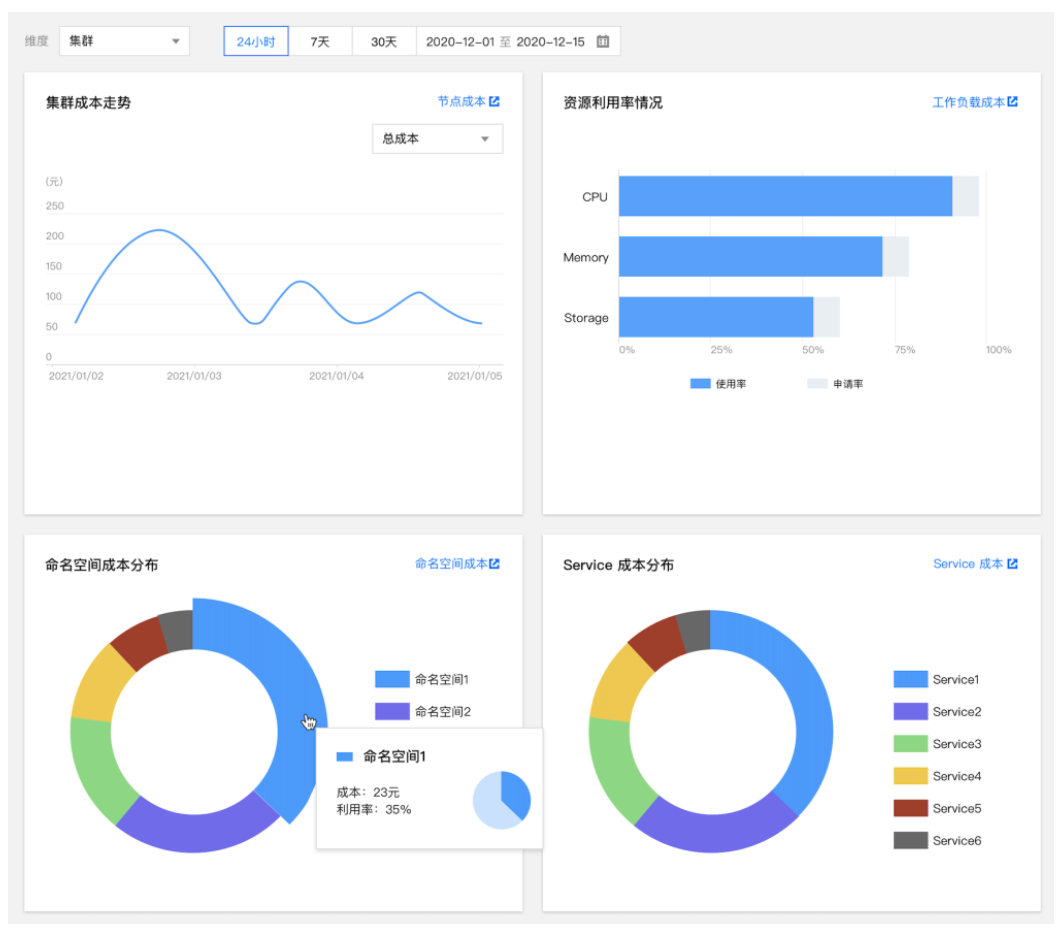
基于 FinOps 理念的成本展示
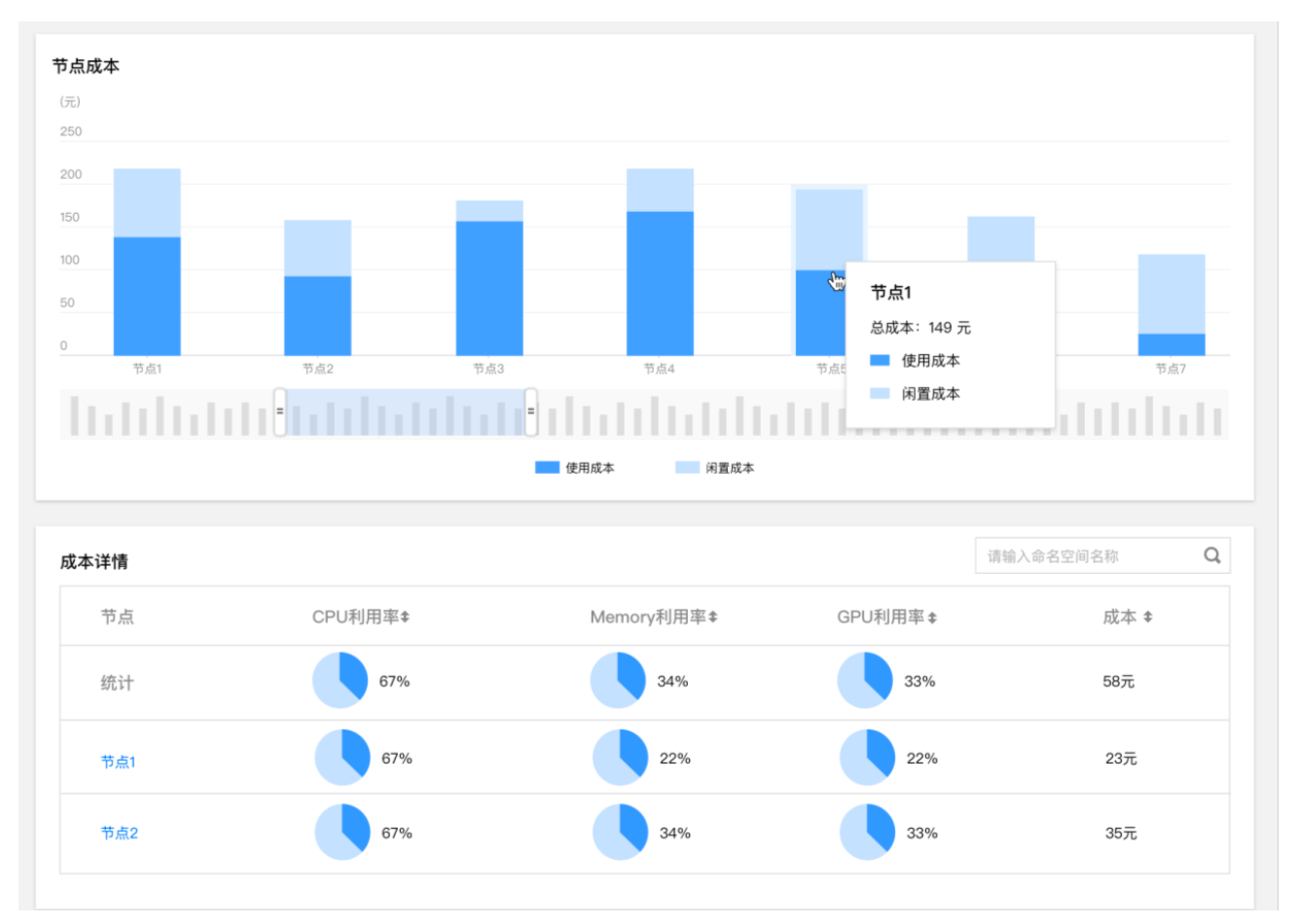
精准的浪费识别
闲置资源识别
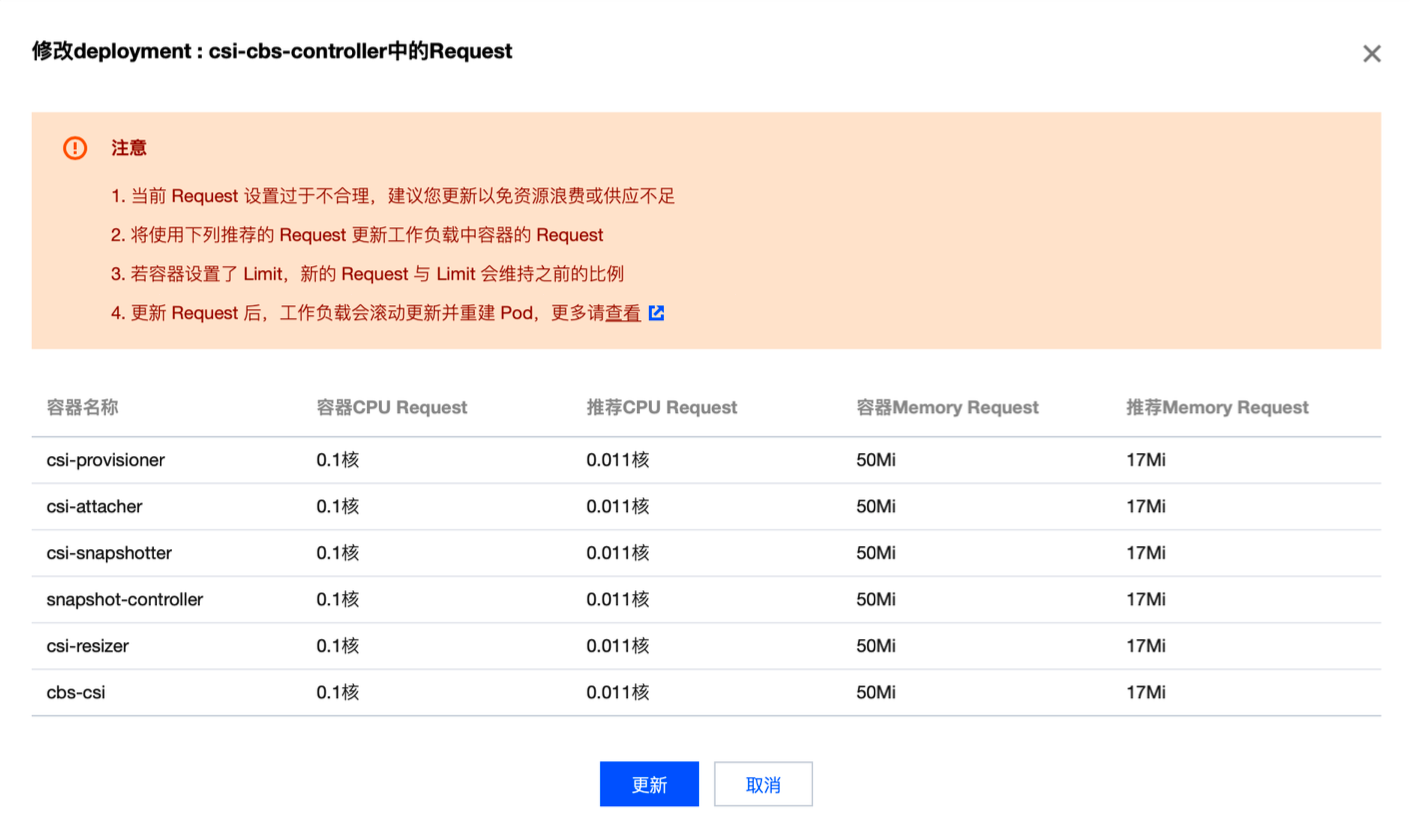
资源浪费识别和基于预测结果的 Request 推荐
云原生成熟度模型的产品化支持
常规优化手段
- 弹性
- 按作业负载动态调节实例副本数或单实例的资源上
- 负载高峰扩容以保证业务服务等级
- 负载低谷缩容以回收资源减少浪费
- 按作业负载动态调节实例副本数或单实例的资源上
- 混部
- 在负载低谷运行离线作业以提升总体资源利用率
- TKE-Scheduler 专为离线场景优化:gang-scheduling、all-or-nothing,10x 性能提升
社区原生弹性能力的不足
HPA
- 业务指标驱动,指标的滞后导致业务突发流量时来不及弹性
VPA
- 资源需求时 Pod 对象中的不可变属性,VPA 纵向调整资源后,Pod 需要重建,而实现场景中,Pod 重建时大量业务不可接受的。
CA
- 当集群资源不足时,CA 可按照既定规则扩容集群节点,但这对基础架构层面的空闲资源和可靠性都有极高的要求
AHPA - 基于预测的横向伸缩

- 引入
AdvancedHorizontalPodAutoscaler对象,该对象关联TimeSeriesPrediction和 HPA Metric-Adapter通过External Metric Provider方式注册到k8s集群中,并将TimeSeriesPrediction.Status中的预测结果转化为External MetricsHPA-Controller通过External Metric API从Metric-Adapter获取应用的预测指标,该指标驱动 HPA 行为
IVPA - 基于扩展资源回收的实时纵向伸缩
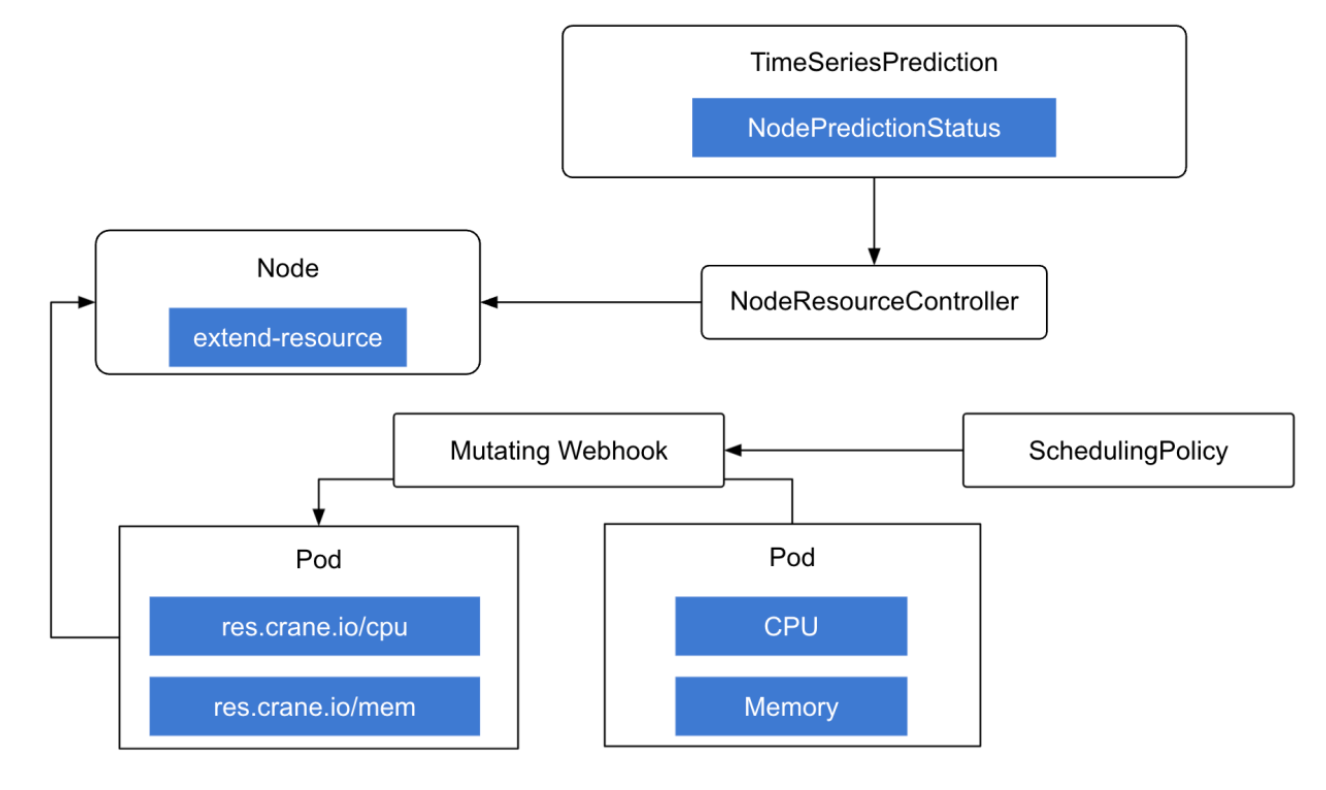
Craned 中的 NodeResourceController 控制器基于预测结果将空闲资源更新至节点 extend-resource。
引入 SchedulingPolicy 对象,为特定 ProrityClass 定义资源转化策略。
基于 Mutating Webhook,将特定 PriorityClass 的 Pod 中的资源请求转化为 extend-resource,实现回收资源再利用。
资源回收再利用可以被认为时广义的实时动态 VPA 能力(InstanceVerticalPodAutoscaler)
基于分布式云虚拟节点计数的集群弹性
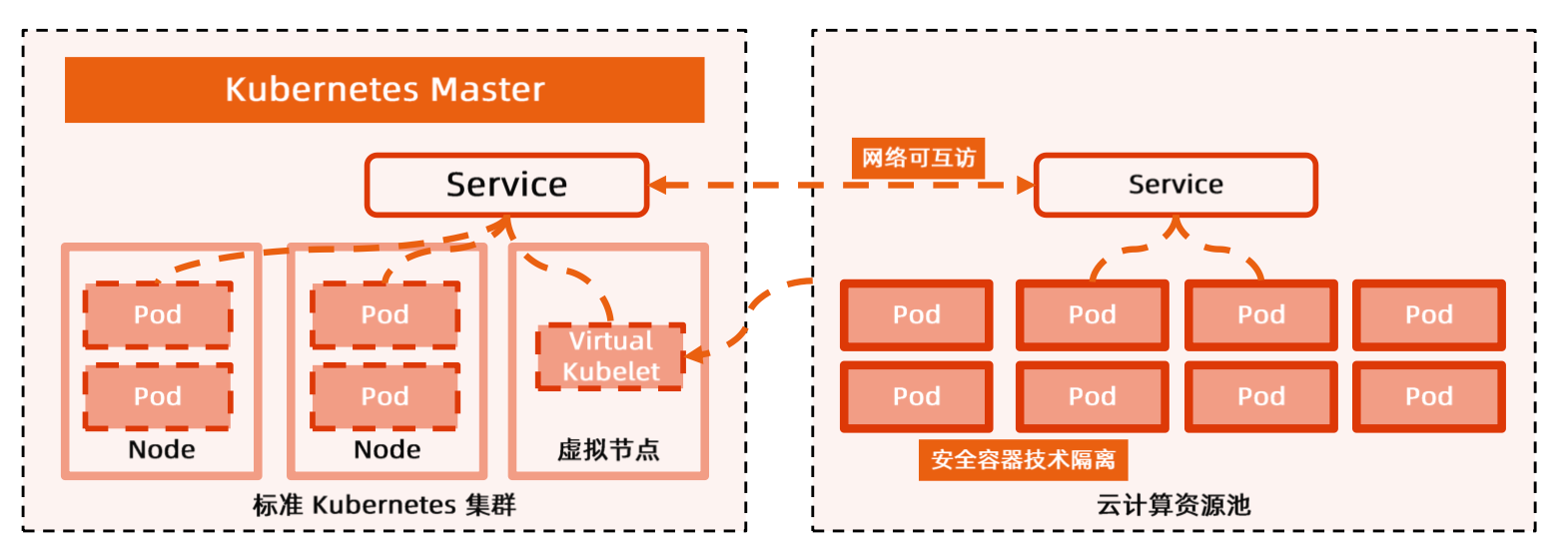
支持在标准 k8s 集群添加虚拟节点,虚拟节点打通弹性容器(EKS)的资源池,可将 Pod 调度为无服务器的弹性容器:
- 集群资源不足时,自动把 Pod 扩容到虚拟节点上;集群资源充足时,会优先缩容虚拟节点上的 Pod
- 每分钟支持快速扩容超过
1000 Pod - 虚拟节点上的 Pod 与集群内所有资源(
Service、Pod)网络互通 - 虚拟节点上的 Pod 兼容 Kubernetes 集群原生
Service机制
服务质量保证 - 安心拉升资源利用率的秘密
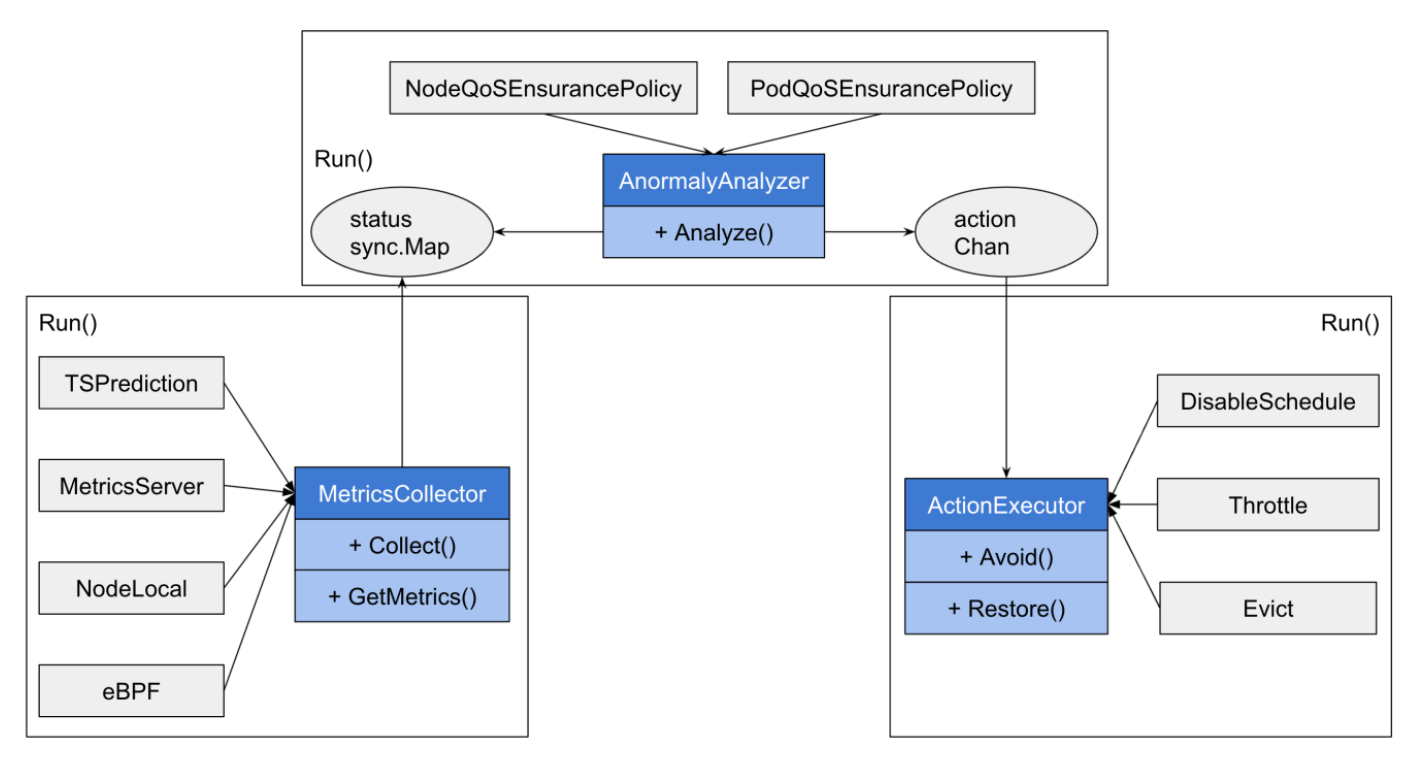
配合 PriorityClass 为业务 定级。
针对节点水位和业务 SLO 进行多纬度异常指标检测。
当检测指标出现异常时,按预定义优先级进行主动回避,确保高优任务 SLO。
资源隔离 - OS 隔离 - RQSM 框架

支持开源 kernel 隔离/ QoS
- CPU:
cgroup cpuset/cpu - HT:
thread silbings - Memory:
cgroup memory limit、reclaim - BLK:
cgroup DIO read/write、Buffered IO read、weight、xfs/ext4 dis quota - Network:
tc egress、优先级流控TC HTB qdisc
References
lxcfs 是什么? lxcfs 实现对容器资源视图隔离的最佳实践
crane
What is FinOps?