-- 创建视图 -- 针对单表 CREATEVIEW vu_emp1 ASSELECT emp_id,fname FROM employee; -- 字段的别名会作为视图中的别名出现 CREATEVIEW vu_emp2 ASSELECT emp_id `id`,fname `name` FROM employee; -- 别名的第二种方式,定义的名称与SELECT的名称需要一一对应 CREATEVIEW vu_emp3(id,`name`) ASSELECT emp_id ,fname FROM employee;
-- 使用视图 SELECT*FROM vu_emp6;
-- 查询在表中不存在的字段 CREATEVIEW vu_emp6 AS SELECTmax(start_date),dept_id FROM employee GROUPBY dept_id;
-- 针对多表 CREATEVIEW vu_emp_dept1 AS SELECT employee.emp_id,employee.fname,department.name FROM employee JOIN department ON employee.dept_id = department.dept_id; SELECT*FROM vu_emp_dept1 ORDERBY emp_id;
-- 利用视图对数据进行格式化 CREATEVIEW vu_emp_dept2 AS SELECT employee.emp_id,CONCAT(employee.fname,' ',employee.lname,' =》 ',department.`name`) emp_info FROM employee JOIN department ON employee.dept_id = department.dept_id; SELECT*FROM vu_emp_dept2; DESC vu_emp_dept2;
-- 基于视图创建视图 CREATEVIEW vu_emp7 ASSELECT emp_id,fname,dept_id FROM employee; CREATEVIEW vu_emp8 ASSELECT fname,dept_id FROM vu_emp7; SELECT*FROM vu_emp8;
查看视图
1 2 3 4 5 6 7 8
-- 查看数据库的表对象、视图对象 SHOW TABLES; -- 查看视图结构 DESC vu_emp1; -- 查看视图的属性信息 SHOWTABLE STATUS LIKE'vu_emp1'; -- 查看视图详细定义信息 SHOWCREATEVIEW vu_emp1;
-- 删除视图中的数据,会导致表中的数据删除 DELETEFROM vu_emp7 WHERE emp_id =18; -- 删除表中的数据也会导致视图中的数据删除 DELETEFROM employee WHERE emp_id =19;
-- 更新视图中的数据 -- 一般情况下,视图中的数据可以更新,视图中数据更新会导致表中数据也更新 UPDATE vu_emp7 SET dept_id =3WHERE emp_id =1; -- 有时候不能更新视图中的数据,例如表中没有对应字段,例如最大值 CREATEVIEW vu_emp9 ASSELECTmax(start_date) max_date,dept_id FROM employee GROUPBY dept_id; SELECT*FROM vu_emp9; -- The target table vu_emp9 of the UPDATE is not updatable UPDATE vu_emp9 SET max_date =2000-01-01WHERE dept_id =1; -- 删除同样不行 The target table vu_emp9 of the DELETE is not updatable DELETEFROM vu_emp9 WHERE dept_id =1;
-- 修改、删除视图 DESC vu_emp1; -- 方式1,重新创建 CREATEOR REPLACE VIEW vu_emp1 ASSELECT emp_id,lname FROM employee WHERE start_date >'2002-01-01'; -- 方式2,更新 ALTERVIEW vu_emp1 ASSELECT emp_id,lname FROM employee WHERE start_date >'2002-01-01';
SHOW TABLES; -- 删除视图 DROPVIEW vu_emp9; DROPVIEW IF EXISTS vu_emp8;
-- 当表删除,视图查询会报错 SELECT*FROM mitaka_test1; CREATEVIEW vu_mita1 ASSELECT id,last_name FROM mitaka_test1; SELECT*FROM vu_mita1; DROPTABLE mitaka_test1; -- View 'mitaka.vu_mita1' references invalid table(s) or column(s) or function(s) or definer/invoker of view lack rights to use them SELECT*FROM vu_mita1;
-- 局部变量 -- 1. 使用 DECLARE 声明 -- 2. 必须放在BEGIN END中 -- 3. DECLARE 的方式声明的局部变量必须声明在 BEGIN 中的首行位置 CREATEPROCEDURE get_max_start_date() BEGIN -- 声明局部变量 DECLARE a INTDEFAULT0; DECLARE b CHAR(20); -- 赋值 SET a =1; SET b ='name'; SELECT lname INTO b FROM employee WHERE emp_id = a; -- 使用 SELECT a,b; END; -- 调用存储过程 CALL get_max_start_date();
-- 条件判断 CREATEPROCEDURE test_if() BEGIN -- 声明局部变量 DECLARE stu_name VARCHAR(15); -- 使用 IF 结构 IF stu_name ISNULL THENSELECT'stu_name is null'; END IF; END; -- 调用 CALL test_if();
-- 二选一 CREATEPROCEDURE test_if2() BEGIN DECLARE email VARCHAR(25) DEFAULT'[email protected]'; IF email ISNULL THENSELECT'email is null'; ELSESELECT'email is not null'; END IF; END; -- 调用 CALL test_if2();
-- 多选一 CREATEPROCEDURE test_if3() BEGIN DECLARE age INTDEFAULT20; IF age >40 THENSELECT'中年'; ELSEIF age >20 THENSELECT'青年'; ELSESELECT'少年'; END IF; END; CALL test_if3();
CASE
情况一:类似于switch
1 2 3 4 5 6 7 8 9 10 11 12 13 14
-- CASE CREATEPROCEDURE test_case1() BEGIN DECLARE var INTDEFAULT2; CASE var WHEN1THENSELECT'var = 1'; WHEN2THENSELECT'var = 2'; WHEN3THENSELECT'var = 3'; ELSESELECT'other value'; ENDCASE; END; -- 调用 CALL test_case1();
情况二:类似于多重if
1 2 3 4 5 6 7 8 9 10
CREATEPROCEDURE test_case2() BEGIN DECLARE var INTDEFAULT10; CASE WHEN var >=100THENSELECT'var 3位数'; WHEN var >=10THENSELECT'var 2位数'; ELSESELECT'个位数'; ENDCASE; END; CALL test_case2();
LOOP
循环语句主要由四个部分组成:
初始化条件
循环条件
循环体
迭代条件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
CREATEPROCEDURE test_loop() BEGIN -- 初始化条件 DECLARE num INTDEFAULT1; loop_label: LOOP -- 循环体和迭代条件 SET num = num +1; -- 循环条件 IF num >10THEN LEAVE loop_label; END IF; END LOOP loop_label; SELECT num; END; -- 调用 CALL test_loop();
WHILE
1 2 3 4 5 6 7 8 9 10 11 12 13
CREATEPROCEDURE test_while() BEGIN -- 初始化条件 DECLARE num INTDEFAULT0; -- 循环条件 WHILE num <10 DO -- 循环体和迭代条件 SET num = num +1; END WHILE; SELECT num; END; -- 执行 CALL test_while();
REPEAT
1 2 3 4 5 6 7 8 9 10 11 12 13
CREATEPROCEDURE test_repeat() BEGIN -- 初始化条件 DECLARE num INTDEFAULT0; REPEAT -- 循环体和迭代条件 SET num = num +1; -- 循环条件 UNTIL num >10END REPEAT; SELECT num; END; -- 执行 CALL test_repeat();
CREATEPROCEDURE test_leave(IN num INT) begin_label:BEGIN IF num <=0 -- 跳出begin THEN LEAVE begin_label; ELSEIF num =1 THENSELECTmax(start_date) FROM employee; ELSEIF num =2 THENSELECTmin(start_date) FROM employee; ELSE SELECT'null'; END IF; END; -- 调用 CALL test_leave(3);
ITERATE:只能使用在循环体内,表示跳过当前循环,进入下次循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
CREATEPROCEDURE test_iterate(IN num INT) BEGIN DECLARE size INTDEFAULT0; loop_label: LOOP SET num = num -1; IF num <=0THEN -- 跳出loop LEAVE loop_label; ELSEIF num %2=0THENSET size = size +1; -- 跳过此次loop,进入下次loop ELSE ITERATE loop_label; END IF; END LOOP loop_label; SELECT size; END; -- 调用 CALL test_iterate(10);
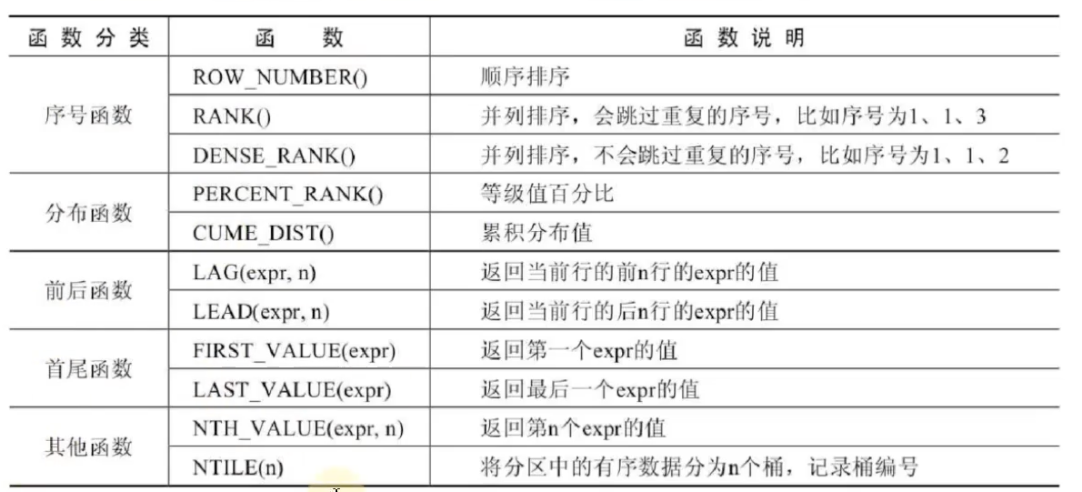
-- RANK(),并列排序,会跳过重复的序号 SELECTRANK() over -- 通过 dept_id 分区,通过 start_date 排序,将分区和降序的结果序号作为row_num (PARTITIONBY dept_id ORDERBY start_date) AS row_num, emp_id,start_date,dept_id FROM employee;
1 2 3 4 5 6 7 8 9 10
-- DENSE_RANK(),并列排序,不会跳过重复的序号 SELECTDENSE_RANK() over -- 通过 dept_id 分区,通过 start_date 排序,将分区和降序的结果序号作为row_num (PARTITIONBY dept_id ORDERBY start_date) AS row_num, emp_id,start_date,dept_id FROM employee;
-- 窗口函数的另外一种写法,将窗口函数作为一个 window 声明 SELECTDENSE_RANK() over w AS row_num, emp_id,start_date,dept_id FROM employee window w AS (PARTITIONBY dept_id ORDERBY start_date);
分布函数
1 2 3 4 5 6 7 8 9 10
-- PERCENT_RANK() 等级值百分比,(rank - 1) / (rows - 1) SELECTRANK() OVER w AS r, PERCENT_RANK() OVER w AS pr, emp_id,start_date,dept_id FROM employee window w AS (PARTITIONBY dept_id ORDERBY start_date DESC);
-- CUME_DIST() 查询小于或等于的比例 SELECTCUME_DIST() OVER w AS c, emp_id,start_date,dept_id FROM employee window w AS (PARTITIONBY dept_id ORDERBY start_date DESC);
前后函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
-- 查询前一个员工的start_date SELECTLAG(start_date,1) OVER w AS pre_start_date, emp_id,start_date,dept_id FROM employee window w AS (PARTITIONBY dept_id ORDERBY start_date DESC); -- 可以作为一个子函数,实现差值 SELECT pre_start_date,DATEDIFF(pre_start_date,start_date) AS diff_start_date, emp_id,start_date,dept_id FROM ( SELECTLAG(start_date,1) OVER w AS pre_start_date, emp_id,start_date,dept_id FROM employee window w AS (PARTITIONBY dept_id ORDERBY start_date DESC))t
-- 查询后一个员工的start_date SELECTLEAD(start_date,1) OVER w AS behind_start_date, emp_id,start_date,dept_id FROM employee window w AS (PARTITIONBY dept_id ORDERBY start_date DESC);
首位函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14
-- 查询分组后最头一个的start_date,可以用来获取差值 SELECTFIRST_VALUE(start_date) OVER w AS first_start_date, emp_id,start_date,dept_id FROM employee window w AS (PARTITIONBY dept_id ORDERBY start_date DESC); -- 查询分组后最尾部一个的start_date,可以用来获取差值
-- LAST_VALUE是获取当前行与之前行的比较,因此获取到的是本行的 SELECTLAST_VALUE(start_date) OVER w AS last_start_date, emp_id,start_date,dept_id FROM employee window w AS (PARTITIONBY dept_id ORDERBY start_date DESC); -- 正确用法 SELECTLAST_VALUE(start_date) OVER w AS last_start_date, emp_id,start_date,dept_id FROM employee window w AS (PARTITIONBY dept_id ORDERBY start_date DESCrowsbetween unbounded preceding and unbounded following);
其他函数
1 2 3 4 5 6 7 8 9
-- 获取start_date排名第三的start_date SELECTNTH_VALUE(start_date,3) OVER w AS3th_start_date, emp_id,start_date,dept_id FROM employee window w AS (PARTITIONBY dept_id ORDERBY start_date DESC);
-- 将分组后的数据,再次平均分组, SELECTNTILE(3) OVER w AS nt, emp_id,start_date,dept_id FROM employee window w AS (PARTITIONBY dept_id ORDERBY start_date DESC);
-- 普通公用表表达式 -- 查看员工所在部门的信息 SELECT*FROM department WHERE dept_id IN ( -- 使用子查询 SELECT dept_id FROM employee); -- 将子查询替换成公用表表达式 -- 声明公用表表达式,需要与调用一起使用 WITH cte_emp AS ( SELECTDISTINCT dept_id FROM employee ) -- 使用公用表表达式 SELECT*FROM department d JOIN cte_emp c ON d.dept_id = c.dept_id;
递归公用表表达式
递归公用表表达式除了普通公用表表达式的特点之外,还可以自己调用自己。
1 2 3 4 5 6 7 8 9 10
-- 递归公用表表达式 -- 例如查询出有下属后,下属还有的下属 WITHrecursive cte_emp AS ( SELECT emp_id,lname,superior_emp_id,1AS n FROM employee WHERE emp_id =1-- 种子查询,先取老板 -- UNIONALL SELECT a.emp_id,a.lname,a.superior_emp_id,n+1FROM employee AS a JOIN cte_emp ON -- 递归查询,找出递归公用表表达式的人为领导的人,也就是老板的下属,递归查询下属的下属 (a.superior_emp_id = cte_emp.emp_id)) SELECT emp_id,lname FROM cte_emp WHERE n >=3;
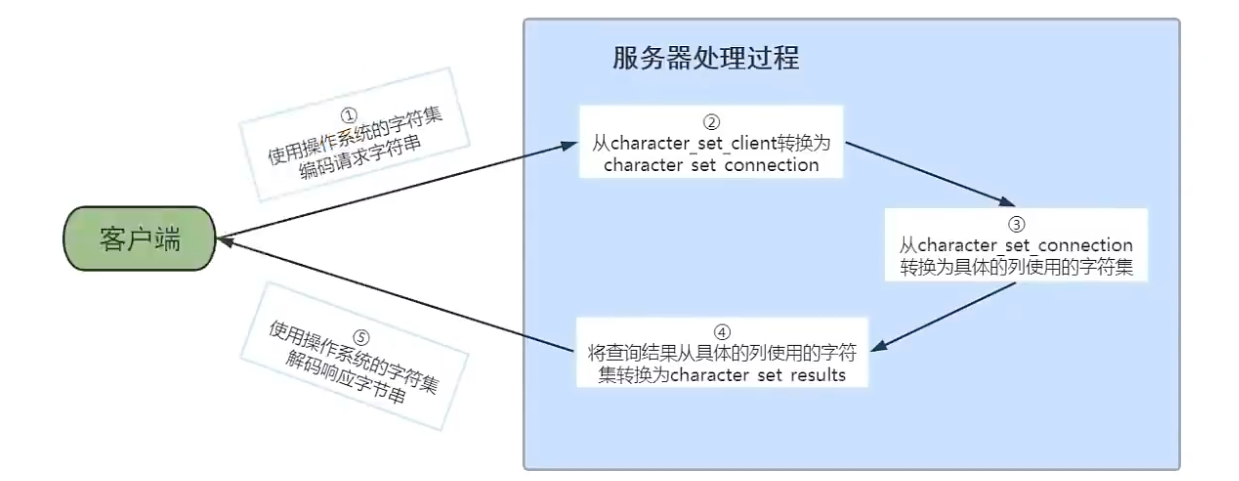
-- 一次性设置传输的字符集 SET NAMES utf8mb4; -- 想等于 SET character_set_client = utf8mb4; SET character_set_connection = utf8mb4; SET character_set_results = utf8mb4;
-rw-r----- 1 mysql mysql 2.4K Nov 11 14:26 myisam1_539.sdi // 元数据,列的信息:列名,属性,约束等 -rw-r----- 1 mysql mysql 1.0K Nov 11 14:26 myisam1.MYI // 索引 -rw-r----- 1 mysql mysql 0 Nov 11 14:26 myisam1.MYD // 数据
使用InnoDB引擎(默认),表文件如下
1
-rw-r----- 1 mysql mysql 327680 Jul 16 09:42 time_zone_name.ibd // 列的结构:列名,属性,约束等,以及数据(如果存储在独立表空间)
InnoDB还提供系统表空间,查看配置,是否存在系统表空间还是独立表空间
1 2
SHOW VARIABLES LIKE'innodb_file_per_table'; -- ON 代表使用独立表空间,OFF代表使用系统表空间
-- 权限带有 WITH GRANT OPTION 则代表可以将权限赋予其他用户 SHOW GRANTS; SHOW GRANTS FORCURRENT_USER; SHOW GRANTS FORCURRENT_USER(); -- 查看某个用户的权限 SHOW GRANTS FOR'user01'@'127.0.0.1';
desc db; +-----------------------+---------------+------+-----+---------+-------+ | Field | Type |Null| Key |Default| Extra | +-----------------------+---------------+------+-----+---------+-------+ | Host |char(255) |NO| PRI |||-- 主机 | Db |char(64) |NO| PRI |||-- 表 |User|char(32) |NO| PRI |||-- 用户 | Select_priv | enum('N','Y') |NO|| N || | Insert_priv | enum('N','Y') |NO|| N || | Update_priv | enum('N','Y') |NO|| N || | Delete_priv | enum('N','Y') |NO|| N || | Create_priv | enum('N','Y') |NO|| N || | Drop_priv | enum('N','Y') |NO|| N || | Grant_priv | enum('N','Y') |NO|| N || | References_priv | enum('N','Y') |NO|| N || | Index_priv | enum('N','Y') |NO|| N || | Alter_priv | enum('N','Y') |NO|| N || | Create_tmp_table_priv | enum('N','Y') |NO|| N || | Lock_tables_priv | enum('N','Y') |NO|| N || | Create_view_priv | enum('N','Y') |NO|| N || | Show_view_priv | enum('N','Y') |NO|| N || | Create_routine_priv | enum('N','Y') |NO|| N || | Alter_routine_priv | enum('N','Y') |NO|| N || | Execute_priv | enum('N','Y') |NO|| N || | Event_priv | enum('N','Y') |NO|| N || | Trigger_priv | enum('N','Y') |NO|| N || +-----------------------+---------------+------+-----+---------+-------+ 22rowsinset (0.01 sec)
表tables_priv,体现表中的权限
1 2 3 4 5 6 7 8 9 10 11 12 13 14
desc tables_priv; +-------------+-----------------------------------------------------------------------------------------------------------------------------------+------+-----+-------------------+-----------------------------------------------+ | Field | Type |Null| Key |Default| Extra | +-------------+-----------------------------------------------------------------------------------------------------------------------------------+------+-----+-------------------+-----------------------------------------------+ | Host |char(255) |NO| PRI ||| | Db |char(64) |NO| PRI ||| |User|char(32) |NO| PRI ||| | Table_name |char(64) |NO| PRI ||| | Grantor |varchar(288) |NO| MUL ||| |Timestamp|timestamp|NO||CURRENT_TIMESTAMP| DEFAULT_GENERATED onupdateCURRENT_TIMESTAMP| | Table_priv |set('Select','Insert','Update','Delete','Create','Drop','Grant','References','Index','Alter','Create View','Show view','Trigger') |NO|||| | Column_priv |set('Select','Insert','Update','References') |NO|||| +-------------+-----------------------------------------------------------------------------------------------------------------------------------+------+-----+-------------------+-----------------------------------------------+ 8rowsinset (0.02 sec)
表columns_priv,体现列的权限
1 2 3 4 5 6 7 8 9 10 11 12 13
desc columns_priv; +-------------+----------------------------------------------+------+-----+-------------------+-----------------------------------------------+ | Field | Type |Null| Key |Default| Extra | +-------------+----------------------------------------------+------+-----+-------------------+-----------------------------------------------+ | Host |char(255) |NO| PRI ||| | Db |char(64) |NO| PRI ||| |User|char(32) |NO| PRI ||| | Table_name |char(64) |NO| PRI ||| | Column_name |char(64) |NO| PRI ||| |Timestamp|timestamp|NO||CURRENT_TIMESTAMP| DEFAULT_GENERATED onupdateCURRENT_TIMESTAMP| | Column_priv |set('Select','Insert','Update','References') |NO|||| +-------------+----------------------------------------------+------+-----+-------------------+-----------------------------------------------+ 7rowsinset (0.01 sec)
表procs_priv,存储过程和存储函数的权限
1 2 3 4 5 6 7 8 9 10 11 12 13 14
desc procs_priv; +--------------+----------------------------------------+------+-----+-------------------+-----------------------------------------------+ | Field | Type |Null| Key |Default| Extra | +--------------+----------------------------------------+------+-----+-------------------+-----------------------------------------------+ | Host |char(255) |NO| PRI ||| | Db |char(64) |NO| PRI ||| |User|char(32) |NO| PRI ||| | Routine_name |char(64) |NO| PRI ||| | Routine_type | enum('FUNCTION','PROCEDURE') |NO| PRI |NULL|| | Grantor |varchar(288) |NO| MUL ||| | Proc_priv |set('Execute','Alter Routine','Grant') |NO|||| |Timestamp|timestamp|NO||CURRENT_TIMESTAMP| DEFAULT_GENERATED onupdateCURRENT_TIMESTAMP| +--------------+----------------------------------------+------+-----+-------------------+-----------------------------------------------+ 8rowsinset (0.01 sec)
角色
MySQL 8.0引入的新功能,角色是权限的集合,可以给角色添加或移除权限,给用户赋予角色之后,用户就拥有角色中包含的权限。
管理角色
1 2 3 4 5 6 7 8 9 10 11 12 13
-- 创建角色 CREATE ROLE 'manager'@'%'; CREATE ROLE 'boss'@'%'; -- 给角色赋予权限 GRANTSELECT,UPDATEON dbtest1.*TO'manager'; GRANTALL PRIVILEGES ON dbtest1.*TO'boss'; -- 查看角色的权限 SHOW GRANTS FOR'manager'@'%'; SHOW GRANTS FOR'boss'@'%'; -- 回收角色的权限 REVOKEUPDATEON dbtest1.*FROM'manager'; -- 删除角色 DROP ROLE 'boss';