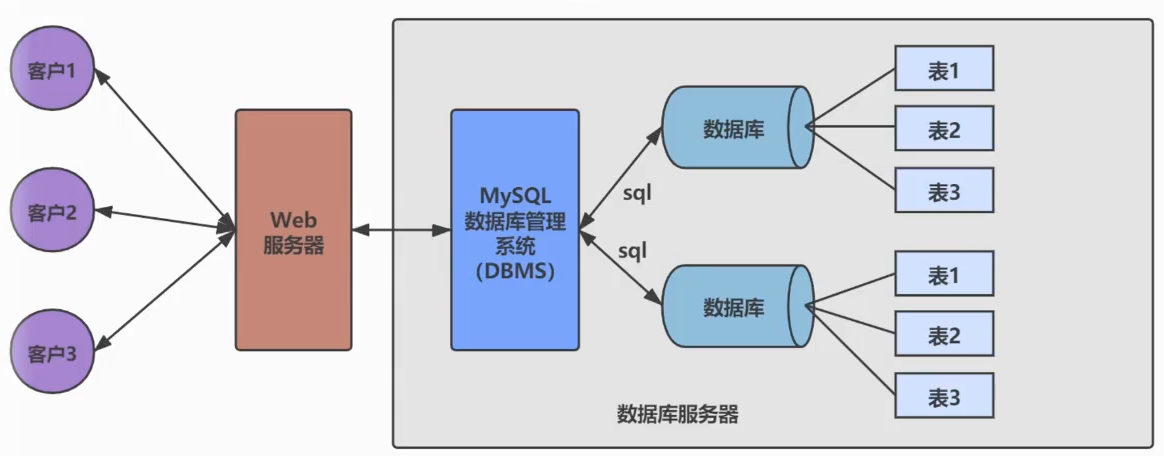
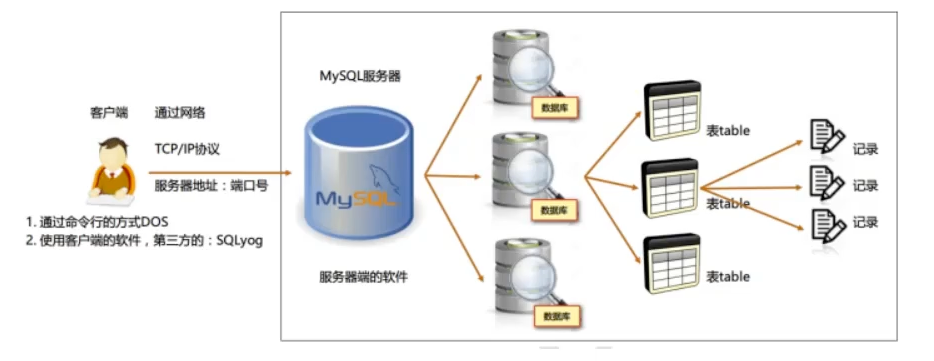
数据库概述 使用数据库的原因是需要将数据保存到磁盘上,做持久化存储,对于有一些有关系型的数据,为了方便后续查找,更加适合存储在数据库中。
相关概念
DB:Database,数据库,存储数据的仓库,本质是一个文件系统,保存了一些列有组织的数据。
DBMS:Database Management System,数据库管理系统,是操作和管理数据库的软件,用户通过DBMS访问数据库中表内的数据。
SQL:Structured Query Language,结构化查询语言,专门用来与数据库通信的语言。
DB和DBMS的关系,DB类似于一个文件,DBMS则是用于操作这个文件的软件。
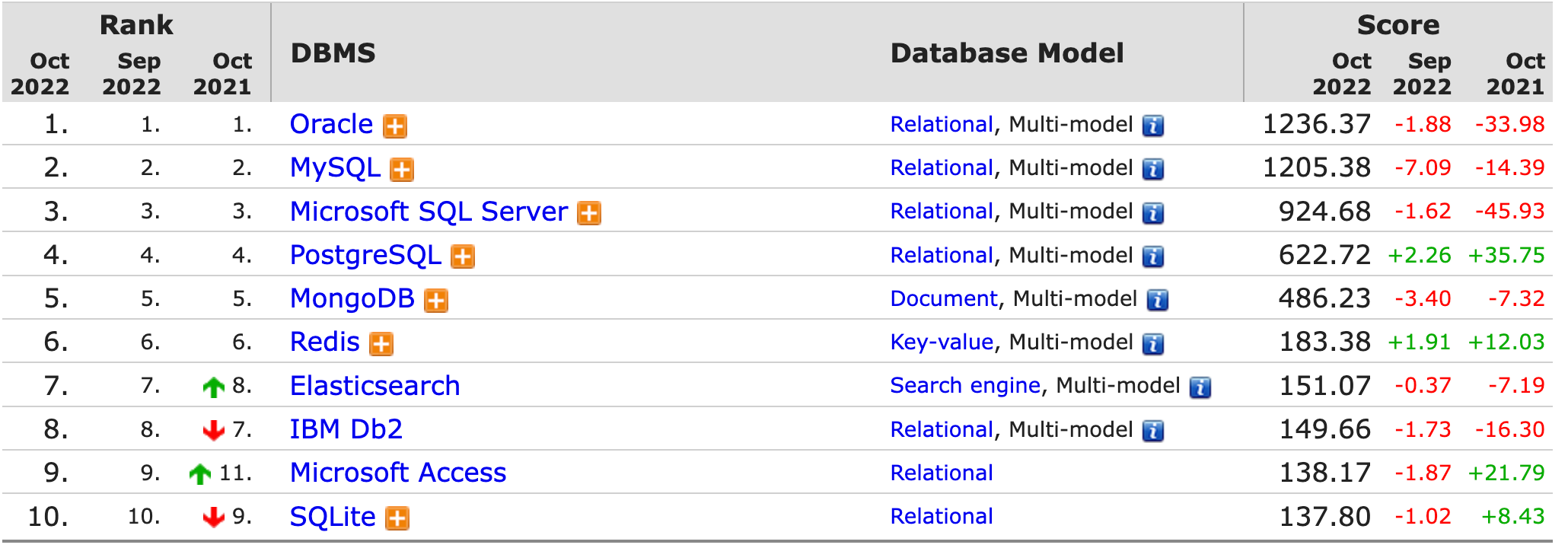
数据库管理系统排名
https://db-engines.com/en/ranking
MySQL MySQL是一个开源的关系型数据库管理系统 ,MySQL支持大型数据库,支持5000万条记录的数据仓库,32位系统表文件最大可支持4GB,64位操作系统最大的表文件为8TB。MySQL使用标准的SQL数据语言。
关系型数据库管理系统 关系型数据库RDBMS:把复杂的数据结构归结为简单的二元关系,即二维表格形式。
关系型数据库以**行row和 列column的形式存储数据,以便于用户理解,这一系列的行和列被称为 表table**,一组表组成了一个库database。
表与表之间的数据记录有关系relationship,各种实体及实体之间的各种联系均用 关系模型 来表示。关系型数据库 ,就是建立在关系模型 基础上的数据库。
关系型数据库的优势:
复杂查询:用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询
事务支持
非关系型数据库管理系统 非关系型数据库,可看成传统关系型数据库的功能阉割版本 ,基于键值对存储数据,不需要经过SQL层的解析,性能非常高 。减少不常用的功能,进一步提高性能。
非关系型数据库:
键值型数据库:通过Key-Value键值的方式存储数据,其中Key和Value可以是简单的对象,也可以是复杂的对象。Key作为唯一标识符,优点是查找速度快,缺点是无法使用条件过滤,如果要查找数据,则需要便利所有的键,会消耗大量计算。键值型数据库典型应用场景是作为内存缓存 。Redis是最流行的键值型数据库。
文档型数据库:在数据库中文档作为处理信息的基本单位,一个文档就相当于一条记录。文档数据库存放的文档,相当于键值数据库存放的值。MongoDB是最流行的文档数据库。
搜索引擎数据库:关系型数据库采用了索引提升检索效率,但是针对全文索引 效率较低。搜索引擎数据库时应用在搜索引擎领域的数据存储形式,由于搜索引擎会爬取大量的数据,并以特定的格式进行存储,这样在检索的时候才能保证性能最优。核心原理是“倒排索引”。例如Elasticsearch,Solr,Splunk等。
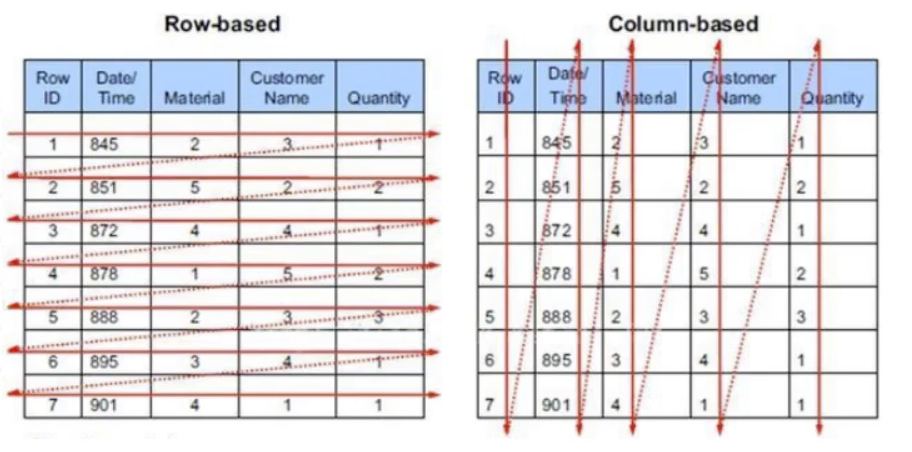
列式数据库:列式数据库时相当于行式存储的数据库,Oracle、MySQL等数据库采用的是行式存储(Row-based), 而列式数据库时将数据按照列存储到数据库中,好处是大量降低系统的I/O,适合于分布式文件系统,不足在于功能相对有限。例如HBase等
图形数据库:利用图这种数据结构存储了实体之间的关系。最典型的例子就是社交网络中人与人的关系,数据模型主要是以节点(对象)和边(关系)来实现,特点在于能高效的解决复杂的关系问题。例如Neo4J等。
NoSQL(not only SQL)对SQL做出了很好的补充,在一些不需要完整的关系型数据库功能中,使用性能更高、成本更低的非关系型数据库效果更好,例如日志收集、排行榜、定时器等。
RDBMS设计规则
关系型数据库的典型数据结构就是数据表 ,这些数据表的组成都是结构化的
将数据放到表中,表再放到库中
一个数据库中可以有多个表,每个表都有一个名字,用来标识自己,表名具有唯一性
表具有一些特性,这些特性定义了数据在表中如何存储,类似Java和Python中的类的设计,Go中结构体的设计。
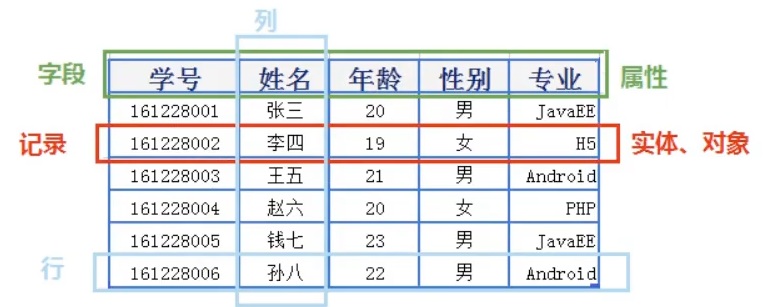
表、记录、字段
表的关联关系 表和表之间的数据有关系relationship,分为一对一关联、一对多关联、多对对关联、自我引用。
一对一关联 one-to-one 表A中的一个记录对应表B中的一个记录,一一对应。
例如将学生信息拆分成基础信息表和档案信息表,这两个表的记录是一一对应:
基础信息表:保存常用信息,例如学号、姓名、电话号码、班级等
档案信息表:保存不常用信息,例如学号、身份证号、家庭住址等
两种建表原则:
外键唯一:主表的主键和从表外键(唯一),形成主外键关系,外键唯一。
外键是主键:主表的主键和从表的主键,形成住外键关系。
一对多关系 one-to-many 表A中的一个记录,对应表B中的多个记录。
例如用户表和订单表,部门表和员工表
建表原则:
在从表(多方)创建一个字段,字段作为外键指向主表(一方)的主键
多对多关系 many-to-many 要表示多对多关系,必须创建第三张表,该表通常称为联接表 ,将多对多关系划分为两个一对多关系,将这两个表的主键都插入到第三张表中。
例如学生信息表和课程信息表,一个学生可以选择多门课程,一门课程中有很多学生,则需要一张选课信息表,记录学生学号和课程编号,形成多对多。
自我引用 self-reference 表A中某一个字段,需要引用同表中的一个字段,例如用户表中有上下级关系,上级需要引用同表中的另外一个用户。
MySQL安装 见官网:MySQL 8安装手册
MySQL四大版本
MySQL Community Server 社区版本,开源免费,自由下载,但不提供官方技术支持,适用于大多数普通用户MySQL Enterprise Edition 企业版本,需付费,不能在线下载,可以试用30天。MySQL Cluster 集群版,开源免费,用于架设集群服务器,将几个MySQL Server封装成一个Server,需要在社区版或企业版的基础上使用MySQL Cluster CGE 高级集群版,需要付费
这里使用容器版本,学习使用更加简单
1 docker run -itd --name mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql
Ps:如果是Linux上通过rpm包安装,则需要通过systemctl start mysqld启动服务,以及初始化过程中通过默认临时密码登录,以及修改用户密码。使用时需要注意防火墙以及SELinux。
由于学习使用,没有映射目录出来,仅仅将3306端口映射出来,可通过客户端连接。
另外,由于默认情况下,使用的localhost,因此可能出现远程连接报错的情况,一般有两种情况。
由于用户在远程主机上登录没有权限
1 2 create user root@% IDENTIFIED by '123456' ; flush privileges;
提示错误号码 2058
在MySQL 8版本中,更新了密码加密方式,解决方法是通过root登录
1 2 mysql - h127.0 .0 .1 - P3306 - uroot - p123456 alter user 'root' @'%' identified with mysql_native_password by '123456' ;
密码强度插件如果启用,可能由于密码123456太过简单报错。
插件配置信息在配置文件 /etc/my.cnf 中,也可以通过命令查看插件 SELECT * FROM mysql.component;,以及 SHOW VARIABLES LIKE '%validate_password%';
更多相关插件操作,MySQL 插件安装或卸载
创建表时需要注意,如果没有指定字符集,则会使用默认字符集,如果默认字符集不是utf8,则无法存储中文。
1 2 SHOW VARIABLES LIKE 'character_%' ; / / 查看字符集配置SHOW VARIABLES LIKE 'collation_%' ; / / 查看排序规则配置(在不同的字符集下比较规则)
SQL概述 SQL,Structured Query Language,结构化查询语言是一门语言,在功能上,主要分为3大类:
DDL:Data Definition Language,数据定义语言:定义数据库、表、视图、索引等数据库对象,还可以用来创建、删除、修改数据库和数据表的结构。关键字:CREATE、DROP、ALTER等
DCL:Data Control Language,数据控制语言:用于定义数据库、表、字段、用户的访问权限和安全级别,关键字:GRANT、REVOKE、COMMIT、ROLLBACK、SAVEPOINT等
DML:Data Manipulation Language,数据操作语言:用于添加、删除、更新和查询数据库记录,并检查数据完整性。关键字:INSERT、DELETE、UPDATE、SELECT
因为查询语句使用频繁,有些地方把查询语言单独作为一类,DQL,Data Query Language, 数据查询语言。
以及单独将COMMIT、ROLLBACK取出来作为一类TCL,Transaction Control Language,事务控制语言。
SQL语法规范 基本规则
SQL可以在一行或者多行,为了提高可读性,各自居分行写,必要时使用缩进
每条命令以;或\g或\G结束
三者区别:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 # 使用 ; mysql> show create table goods; + | Table | Create Table | + | goods | CREATE TABLE `goods` ( `id` int NOT NULL , `number` int DEFAULT NULL , PRIMARY KEY (`id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4 COLLATE = utf8mb4_0900_ai_ci | + 1 row in set (0.02 sec)# 使用 \g mysql> show create table goods\g + | Table | Create Table | + | goods | CREATE TABLE `goods` ( `id` int NOT NULL , `number` int DEFAULT NULL , PRIMARY KEY (`id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4 COLLATE = utf8mb4_0900_ai_ci | + 1 row in set (0.01 sec)# 使用 \G mysql> show create table goods\G * * * * * * * * * * * * * * * * * * * * * * * * * * * 1. row * * * * * * * * * * * * * * * * * * * * * * * * * * * Table : goods Create Table : CREATE TABLE `goods` ( `id` int NOT NULL , `number` int DEFAULT NULL , PRIMARY KEY (`id`) ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4 COLLATE = utf8mb4_0900_ai_ci 1 row in set (0.02 sec)
使用 ;和 \g一样,结果是按照列显示,但是是用 \G会变成行显示。
关键字不能被缩写也不能换行
字符串、日期时间类型的变量需要使用一对单引号 ''表示
列的别名,尽量使用双引号 ""表示
SQL编码建议
在Windows下大小写不敏感
在Linux下大小写敏感
数据库名、表名、表别名、变量名严格区分大小写
关键字、函数名、列名(或字段名)、列的别名(字段的别名)是忽略大小写的
建议采用统一规范
数据库名、表名、表别名、字段名、字段别名等都用小写
SQL关键字、函数名、绑定变量等都大写
更多规范,可查看阿里巴巴Java开发手册:MySQL 数据库 :
单行注释,使用 #,或者使用 -- ,-- 后有一个空格
多行注释,使用 /* ... */
查询语句 数据准备
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 # 学生表 create table Student(SId varchar (10 ),Sname varchar (10 ),Sage datetime,Ssex varchar (10 ));insert into Student values ('01' , '赵雷' , '1990-01-01' , '男' );insert into Student values ('02' , '钱电' , '1990-12-21' , '男' );insert into Student values ('03' , '孙风' , '1990-12-20' , '男' );insert into Student values ('04' , '李云' , '1990-12-06' , '男' );insert into Student values ('05' , '周梅' , '1991-12-01' , '女' );insert into Student values ('06' , '吴兰' , '1992-01-01' , '女' );insert into Student values ('07' , '郑竹' , '1989-01-01' , '女' );insert into Student values ('09' , '张三' , '2017-12-20' , '女' );insert into Student values ('10' , '李四' , '2017-12-25' , '女' );insert into Student values ('11' , '李四' , '2012-06-06' , '女' );insert into Student values ('12' , '赵六' , '2013-06-13' , '女' );insert into Student values ('13' , '孙七' , '2014-06-01' , '女' );# 科目表 create table Course(CId varchar (10 ),Cname nvarchar(10 ),TId varchar (10 ));insert into Course values ('01' , '语文' , '02' );insert into Course values ('02' , '数学' , '01' );insert into Course values ('03' , '英语' , '03' );# 教师表 create table Teacher(TId varchar (10 ),Tname varchar (10 ));insert into Teacher values ('01' , '张三' );insert into Teacher values ('02' , '李四' );insert into Teacher values ('03' , '王五' );# 成绩表 create table SC(SId varchar (10 ),CId varchar (10 ),score decimal (18 ,1 ));insert into SC values ('01' , '01' , 80 );insert into SC values ('01' , '02' , 90 );insert into SC values ('01' , '03' , 99 );insert into SC values ('02' , '01' , 70 );insert into SC values ('02' , '02' , 60 );insert into SC values ('02' , '03' , 80 );insert into SC values ('03' , '01' , 80 );insert into SC values ('03' , '02' , 80 );insert into SC values ('03' , '03' , 80 );insert into SC values ('04' , '01' , 50 );insert into SC values ('04' , '02' , 30 );insert into SC values ('04' , '03' , 20 );insert into SC values ('05' , '01' , 76 );insert into SC values ('05' , '02' , 87 );insert into SC values ('06' , '01' , 31 );insert into SC values ('06' , '03' , 34 );insert into SC values ('07' , '02' , 89 );insert into SC values ('07' , '03' , 98 );# 成绩等级表 CREATE TABLE score_grades(grade_level varchar (10 ),lowest_sal decimal (18 ,1 ),highest_sal decimal (18 ,1 ));INSERT INTO score_grades VALUES ('A' , 100 ,80 );INSERT INTO score_grades VALUES ('B' , 60 ,79 );INSERT INTO score_grades VALUES ('C' , 40 ,59 );INSERT INTO score_grades VALUES ('D' , 0 ,39 );
更多练习操作数据:
https://gitee.com/lzjcnb/test_db
Learning SQL
基本的查询语句 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 # SELECT 字段1 ,字段2 ,... FROM 表名 SELECT 1 ; + | 1 | + | 1 | + 1 row in set (0.01 sec)SELECT 1 + 1 ,3 * 2 FROM DUAL; # DUAL:伪表+ | 1 + 1 | 3 * 2 | + | 2 | 6 | + 1 row in set (0.00 sec)# SELECT * 查询所有字段 SELECT * FROM Student;+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 02 | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | | 03 | 孙风 | 1990 -12 -20 00 :00 :00 | 男 | | 04 | 李云 | 1990 -12 -06 00 :00 :00 | 男 | | 05 | 周梅 | 1991 -12 -01 00 :00 :00 | 女 | | 06 | 吴兰 | 1992 -01 -01 00 :00 :00 | 女 | | 07 | 郑竹 | 1989 -01 -01 00 :00 :00 | 女 | | 09 | 张三 | 2017 -12 -20 00 :00 :00 | 女 | | 10 | 李四 | 2017 -12 -25 00 :00 :00 | 女 | | 11 | 李四 | 2012 -06 -06 00 :00 :00 | 女 | | 12 | 赵六 | 2013 -06 -13 00 :00 :00 | 女 | | 13 | 孙七 | 2014 -06 -01 00 :00 :00 | 女 | + 12 rows in set (0.00 sec)SELECT Sname,Sage FROM Student;+ | Sname | Sage | + | 赵雷 | 1990 -01 -01 00 :00 :00 | | 钱电 | 1990 -12 -21 00 :00 :00 | | 孙风 | 1990 -12 -20 00 :00 :00 | | 李云 | 1990 -12 -06 00 :00 :00 | | 周梅 | 1991 -12 -01 00 :00 :00 | | 吴兰 | 1992 -01 -01 00 :00 :00 | | 郑竹 | 1989 -01 -01 00 :00 :00 | | 张三 | 2017 -12 -20 00 :00 :00 | | 李四 | 2017 -12 -25 00 :00 :00 | | 李四 | 2012 -06 -06 00 :00 :00 | | 赵六 | 2013 -06 -13 00 :00 :00 | | 孙七 | 2014 -06 -01 00 :00 :00 | + 12 rows in set (0.03 sec)SELECT Sname my_name,Sage AS my_age,Ssex "my_sex" FROM Student;+ | my_name | my_age | my_sex | + | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | | 孙风 | 1990 -12 -20 00 :00 :00 | 男 | | 李云 | 1990 -12 -06 00 :00 :00 | 男 | | 周梅 | 1991 -12 -01 00 :00 :00 | 女 | | 吴兰 | 1992 -01 -01 00 :00 :00 | 女 | | 郑竹 | 1989 -01 -01 00 :00 :00 | 女 | | 张三 | 2017 -12 -20 00 :00 :00 | 女 | | 李四 | 2017 -12 -25 00 :00 :00 | 女 | | 李四 | 2012 -06 -06 00 :00 :00 | 女 | | 赵六 | 2013 -06 -13 00 :00 :00 | 女 | | 孙七 | 2014 -06 -01 00 :00 :00 | 女 | + 12 rows in set (0.02 sec)SELECT DISTINCT Ssex FROM Student;+ | Ssex | + | 男 | | 女 | + 2 rows in set (0.02 sec) SELECT Sage,DISTINCT Ssex FROM Student;ERROR 1064 (42000 ): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'DISTINCT Ssex FROM Student' at line 1 SELECT DISTINCT Sage, Ssex FROM Student;+ | Sage | Ssex | + | 1990 -01 -01 00 :00 :00 | 男 | | 1990 -12 -21 00 :00 :00 | 男 | | 1990 -12 -20 00 :00 :00 | 男 | | 1990 -12 -06 00 :00 :00 | 男 | | 1991 -12 -01 00 :00 :00 | 女 | | 1992 -01 -01 00 :00 :00 | 女 | | 1989 -01 -01 00 :00 :00 | 女 | | 2017 -12 -20 00 :00 :00 | 女 | | 2017 -12 -25 00 :00 :00 | 女 | | 2012 -06 -06 00 :00 :00 | 女 | | 2013 -06 -13 00 :00 :00 | 女 | | 2014 -06 -01 00 :00 :00 | 女 | + 12 rows in set (0.02 sec)SELECT Sid,Cid,Score * 10 as all_score FROM SC;+ | Sid | Cid | all_score | + | 01 | 01 | 800.0 | | 01 | 02 | 900.0 | | 01 | 03 | 990.0 | | 02 | 01 | 700.0 | | 02 | 02 | 600.0 | | 02 | 03 | 800.0 | | 03 | 01 | 800.0 | | 03 | 02 | 800.0 | | 03 | 03 | 800.0 | | 04 | 01 | 500.0 | | 04 | 02 | 300.0 | | 04 | 03 | 200.0 | | 05 | 01 | 760.0 | | 05 | 02 | 870.0 | | 06 | 01 | 310.0 | | 06 | 03 | 340.0 | | 07 | 02 | 890.0 | | 07 | 03 | 980.0 | | 08 | 01 | NULL | + 19 rows in set (0.01 sec)SELECT Sid,Cid,IFNULL(Score,0 ) * 10 as all_score FROM SC;+ | Sid | Cid | all_score | + | 01 | 01 | 800.0 | | 01 | 02 | 900.0 | | 01 | 03 | 990.0 | | 02 | 01 | 700.0 | | 02 | 02 | 600.0 | | 02 | 03 | 800.0 | | 03 | 01 | 800.0 | | 03 | 02 | 800.0 | | 03 | 03 | 800.0 | | 04 | 01 | 500.0 | | 04 | 02 | 300.0 | | 04 | 03 | 200.0 | | 05 | 01 | 760.0 | | 05 | 02 | 870.0 | | 06 | 01 | 310.0 | | 06 | 03 | 340.0 | | 07 | 02 | 890.0 | | 07 | 03 | 980.0 | | 08 | 01 | 0.0 | + 19 rows in set (0.02 sec)SELECT '小学' ,Sname,Sage FROM Student;+ | 小学 | Sname | Sage | + | 小学 | 赵雷 | 1990 -01 -01 00 :00 :00 | | 小学 | 钱电 | 1990 -12 -21 00 :00 :00 | | 小学 | 孙风 | 1990 -12 -20 00 :00 :00 | | 小学 | 李云 | 1990 -12 -06 00 :00 :00 | | 小学 | 周梅 | 1991 -12 -01 00 :00 :00 | | 小学 | 吴兰 | 1992 -01 -01 00 :00 :00 | | 小学 | 郑竹 | 1989 -01 -01 00 :00 :00 | | 小学 | 张三 | 2017 -12 -20 00 :00 :00 | | 小学 | 李四 | 2017 -12 -25 00 :00 :00 | | 小学 | 李四 | 2012 -06 -06 00 :00 :00 | | 小学 | 赵六 | 2013 -06 -13 00 :00 :00 | | 小学 | 孙七 | 2014 -06 -01 00 :00 :00 | + 12 rows in set (0.01 sec)DESCRIBE Student; # 显示表中字段的详细信息+ | Field | Type | Null | Key | Default | Extra | + | SId | varchar (10 ) | YES | | NULL | | | Sname | varchar (10 ) | YES | | NULL | | | Sage | datetime | YES | | NULL | | | Ssex | varchar (10 ) | YES | | NULL | | + 4 rows in set (0.00 sec)DESC Student;+ | Field | Type | Null | Key | Default | Extra | + | SId | varchar (10 ) | YES | | NULL | | | Sname | varchar (10 ) | YES | | NULL | | | Sage | datetime | YES | | NULL | | | Ssex | varchar (10 ) | YES | | NULL | | + 4 rows in set (0.02 sec)
过滤数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 SELECT * FROM Student WHERE SSex = '男' ; # 列名大小写不敏感+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 02 | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | | 03 | 孙风 | 1990 -12 -20 00 :00 :00 | 男 | | 04 | 李云 | 1990 -12 -06 00 :00 :00 | 男 | + 4 rows in set (0.01 sec)SELECT * FROM Student WHERE Sage > '1990-1-20' AND Ssex = '男' ;+ | SId | Sname | Sage | Ssex | + | 02 | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | | 03 | 孙风 | 1990 -12 -20 00 :00 :00 | 男 | | 04 | 李云 | 1990 -12 -06 00 :00 :00 | 男 | + 3 rows in set (0.01 sec)
列的别名无法作为条件
1 2 SELECT Sage,Ssex as my_sex FROM student WHERE my_sex = '男' ;ERROR 1054 (42 S22): Unknown column 'my_sex' in 'where clause'
运算符 运算符用于算术、比较、逻辑、位运算
算数运算符 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 SELECT 100 ,100 + 0 ,100 -0 ,100 + 50 ,100 -50 + 30 ,10 + 20 * 3 ,10 / 3 ,100 -13.3 ,100 DIV 0 FROM DUAL; # 100 / 0 ,结果为null + | 100 | 100 + 0 | 100 -0 | 100 + 50 | 100 -50 + 30 | 10 + 20 * 3 | 10 / 3 | 100 -13.3 | 100 DIV 0 | + | 100 | 100 | 100 | 150 | 80 | 70 | 3.3333 | 86.7 | NULL | + 1 row in set , 1 warning (0.00 sec)SELECT 100 + '1' FROM DUAL; # 数字1 + | 100 + '1' | + | 101 | + 1 row in set (0.01 sec)SELECT 100 + 'a' FROM DUAL; # 将a作为数字0 处理+ | 100 + 'a' | + | 100 | + 1 row in set , 1 warning (0.01 sec)SELECT 100 + NULL FROM DUAL; # null 参与运算,结果为null + | 100 + NULL | + | NULL | + 1 row in set (0.01 sec)SELECT 12 % 3 ,10 % 2 ,12 % -5 ,-12 % 5 ,-12 % -5 FROM DUAL;+ | 12 % 3 | 10 % 2 | 12 % -5 | -12 % 5 | -12 % -5 | + | 0 | 0 | 2 | -2 | -2 | + 1 row in set (0.00 sec)
比较运算符 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 SELECT 1 = 1 ,1 = 2 ,1 = '1' , 1 = 'a' , 0 = 'a' FROM DUAL; # 数字和字符串比较,则将字符串转换为0 + | 1 = 1 | 1 = 2 | 1 = '1' | 1 = 'a' | 0 = 'a' | + | 1 | 0 | 1 | 0 | 1 | + 1 row in set , 2 warnings (0.01 sec)SELECT 'a' = 'a' , 'ab' = 'ab' ,'a' = 'b' ; # 字符串和字符串比较,则则按照ANSI比较规则,这里就是UTF-8 + | 'a' = 'a' | 'ab' = 'ab' | 'a' = 'b' | + | 1 | 1 | 0 | + 1 row in set (0.01 sec)SELECT 1 = NULL ,NULL = NULL ; # 只要有NULL 参与判断,结果为null + | 1 = NULL | NULL = NULL | + | NULL | NULL | + 1 row in set (0.01 sec)SELECT * FROM SC where Score = null ; # 此时不会返回任何条目,这是因为匹配结果返回null ,而不是1 ,Empty set (0.01 sec)SELECT * FROM SC where Score <=> null ;+ | SId | CId | score | + | 08 | 01 | NULL | + 1 row in set (0.03 sec)SELECT 2 <> 3 , 2 != 3 , 2 < 3 ,2 <= 3 ,2 > 3 ,2 >= 3 FROM DUAL;+ | 2 <> 3 | 2 != 3 | 2 < 3 | 2 <= 3 | 2 > 3 | 2 >= 3 | + | 1 | 1 | 1 | 1 | 0 | 0 | + 1 row in set (0.01 sec)SELECT LEAST('a' ,'v' ,'c' ),GREATEST('b' ,'d' ,'t' ) FROM DUAL;+ | LEAST('a' ,'v' ,'c' ) | GREATEST('b' ,'d' ,'t' ) | + | a | t | + 1 row in set (0.01 sec)SELECT LEAST(Sage,Sname) FROM Student;+ | LEAST(Sage,Sname) | + | 1990 -01 -01 00 :00 :00 | | 1990 -12 -21 00 :00 :00 | | 1990 -12 -20 00 :00 :00 | | 1990 -12 -06 00 :00 :00 | | 1991 -12 -01 00 :00 :00 | | 1992 -01 -01 00 :00 :00 | | 1989 -01 -01 00 :00 :00 | | 2017 -12 -20 00 :00 :00 | | 2017 -12 -25 00 :00 :00 | | 2012 -06 -06 00 :00 :00 | | 2013 -06 -13 00 :00 :00 | | 2014 -06 -01 00 :00 :00 | + 12 rows in set , 12 warnings (0.02 sec)SELECT * FROM Student WHERE Sage BETWEEN '1990-01-01' and '1994-12-12' ; # > 1990 -01 -01 AND < 1994 -12 -12 + | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 02 | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | | 03 | 孙风 | 1990 -12 -20 00 :00 :00 | 男 | | 04 | 李云 | 1990 -12 -06 00 :00 :00 | 男 | | 05 | 周梅 | 1991 -12 -01 00 :00 :00 | 女 | | 06 | 吴兰 | 1992 -01 -01 00 :00 :00 | 女 | + 6 rows in set (0.04 sec)SELECT * FROM Student WHERE Sage BETWEEN '1994-12-12' and '1991-01-01' ; # > 1994 -12 -12 AND < 1990 -01 -01 没有结果Empty set (0.02 sec)SELECT * FROM SC WHERE Score in (80 ,90 ); # Score = 80 or Score = 90 + | SId | CId | score | + | 01 | 01 | 80.0 | | 01 | 02 | 90.0 | | 02 | 03 | 80.0 | | 03 | 01 | 80.0 | | 03 | 02 | 80.0 | | 03 | 03 | 80.0 | + 6 rows in set (0.01 sec)SELECT * FROM SC WHERE Score NOT in (80 ,90 ); # Score != 80 and Score != 90 + | SId | CId | score | + | 01 | 03 | 99.0 | | 02 | 01 | 70.0 | | 02 | 02 | 60.0 | | 04 | 01 | 50.0 | | 04 | 02 | 30.0 | | 04 | 03 | 20.0 | | 05 | 01 | 76.0 | | 05 | 02 | 87.0 | | 06 | 01 | 31.0 | | 06 | 03 | 34.0 | | 07 | 02 | 89.0 | | 07 | 03 | 98.0 | + 12 rows in set (0.01 sec)SELECT * FROM Student WHERE Sname LIKE '%雷%' ; # % 号代表不确定个数的字符+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | + 1 row in set (0.01 sec)SELECT * FROM Student WHERE Sname LIKE '_雷%' ; # _号代表1 个字符+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | + 1 row in set (0.00 sec)SELECT * FROM Student WHERE Sname LIKE '\_雷%' ; # \转义Empty set (0.00 sec)SELECT * FROM Student WHERE Sname LIKE '$_雷%' ESCAPE '$' ; # 转义符为$Empty set (0.00 sec)SELECT * FROM Student Where Sname REGEXP '雷$' ;+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | + 1 row in set (0.02 sec)SELECT * FROM Student Where Sname RLIKE '雷$' ;+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | + 1 row in set (0.01 sec)
逻辑运算符 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 SELECT * FROM Student WHERE Sid = 1 XOR Sid = 2 ;+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 02 | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | + 2 rows in set (0.01 sec)SELECT * FROM Student WHERE Sid = 1 || Sid = 2 ;+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 02 | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | + 2 rows in set , 1 warning (0.01 sec)SELECT * FROM Student WHERE Sid = 1 AND Ssex = '男' ;+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | + 1 row in set (0.00 sec)SELECT * FROM Student WHERE Sid = 1 && Ssex = '男' ;+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | + 1 row in set , 1 warning (0.00 sec)SELECT * FROM Student WHERE NOT Sid = 1 && NOT Ssex = '男' ; + | SId | Sname | Sage | Ssex | + | 05 | 周梅 | 1991 -12 -01 00 :00 :00 | 女 | | 06 | 吴兰 | 1992 -01 -01 00 :00 :00 | 女 | | 07 | 郑竹 | 1989 -01 -01 00 :00 :00 | 女 | | 09 | 张三 | 2017 -12 -20 00 :00 :00 | 女 | | 10 | 李四 | 2017 -12 -25 00 :00 :00 | 女 | | 11 | 李四 | 2012 -06 -06 00 :00 :00 | 女 | | 12 | 赵六 | 2013 -06 -13 00 :00 :00 | 女 | | 13 | 孙七 | 2014 -06 -01 00 :00 :00 | 女 | + 8 rows in set , 1 warning (0.02 sec)SELECT * FROM Student WHERE Sid != 1 && Ssex != '男' ;+ | SId | Sname | Sage | Ssex | + | 05 | 周梅 | 1991 -12 -01 00 :00 :00 | 女 | | 06 | 吴兰 | 1992 -01 -01 00 :00 :00 | 女 | | 07 | 郑竹 | 1989 -01 -01 00 :00 :00 | 女 | | 09 | 张三 | 2017 -12 -20 00 :00 :00 | 女 | | 10 | 李四 | 2017 -12 -25 00 :00 :00 | 女 | | 11 | 李四 | 2012 -06 -06 00 :00 :00 | 女 | | 12 | 赵六 | 2013 -06 -13 00 :00 :00 | 女 | | 13 | 孙七 | 2014 -06 -01 00 :00 :00 | 女 | + 8 rows in set , 1 warning (0.03 sec)SELECT * FROM Student WHERE Sid = 1 XOR Ssex = '女' ;+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 05 | 周梅 | 1991 -12 -01 00 :00 :00 | 女 | | 06 | 吴兰 | 1992 -01 -01 00 :00 :00 | 女 | | 07 | 郑竹 | 1989 -01 -01 00 :00 :00 | 女 | | 09 | 张三 | 2017 -12 -20 00 :00 :00 | 女 | | 10 | 李四 | 2017 -12 -25 00 :00 :00 | 女 | | 11 | 李四 | 2012 -06 -06 00 :00 :00 | 女 | | 12 | 赵六 | 2013 -06 -13 00 :00 :00 | 女 | | 13 | 孙七 | 2014 -06 -01 00 :00 :00 | 女 | + 9 rows in set (0.01 sec)
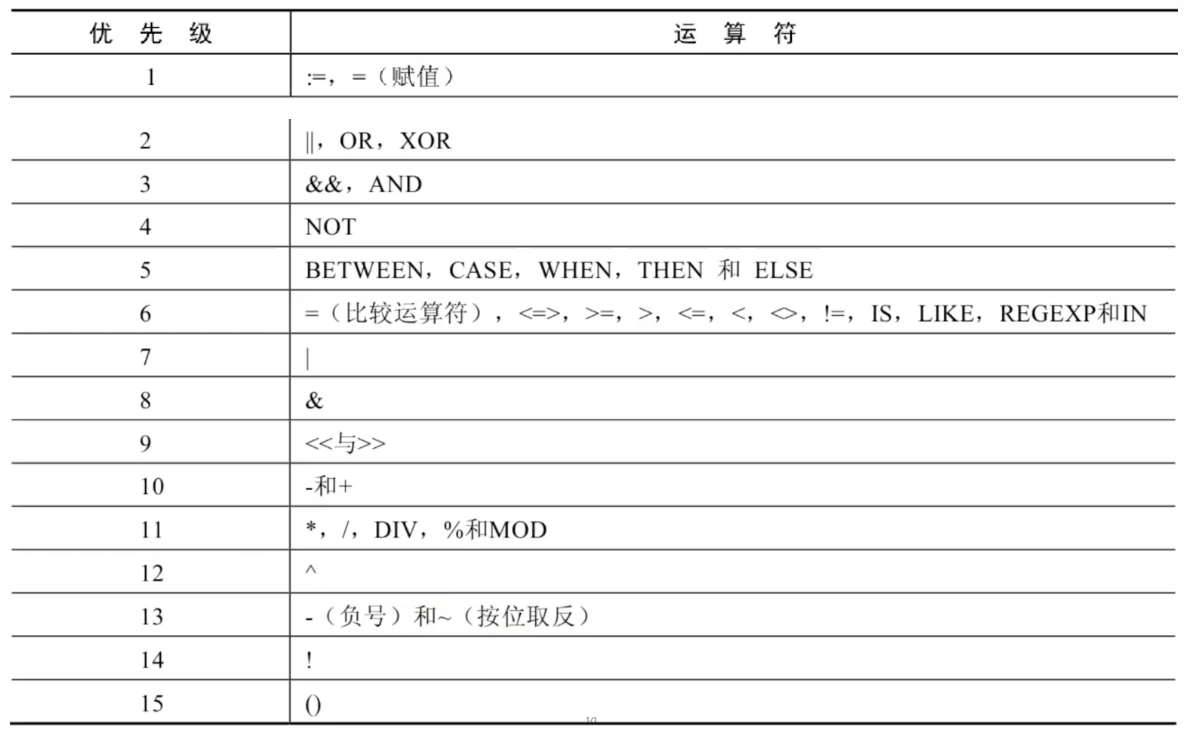
运算符优先级
数字编号越大,优先级越高,优先级高的运算符先进行计算。
位运算符 先将操作数变成二进制数,然后进行运算,再将计算结果从二进制转换成十进制
1 2 3 4 5 6 7 8 9 SELECT 7 & 4 ,7 | 4 ,3 ^ 3 ,10 & ~ 2 ,2 >> 1 ,2 << 1 FROM DUAL;+ | 7 & 4 | 7 | 4 | 3 ^ 3 | 10 & ~ 2 | 2 >> 1 | 2 << 1 | + | 4 | 7 | 0 | 8 | 1 | 4 | + 1 row in set (0.01 sec)
排序与分页 如果没有排序操作,默认按照数据添加的顺序排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 SELECT * FROM Student ORDER BY Sage;+ | SId | Sname | Sage | Ssex | + | 07 | 郑竹 | 1989 -01 -01 00 :00 :00 | 女 | | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 04 | 李云 | 1990 -12 -06 00 :00 :00 | 男 | | 03 | 孙风 | 1990 -12 -20 00 :00 :00 | 男 | | 02 | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | | 05 | 周梅 | 1991 -12 -01 00 :00 :00 | 女 | | 06 | 吴兰 | 1992 -01 -01 00 :00 :00 | 女 | | 11 | 李四 | 2012 -06 -06 00 :00 :00 | 女 | | 12 | 赵六 | 2013 -06 -13 00 :00 :00 | 女 | | 13 | 孙七 | 2014 -06 -01 00 :00 :00 | 女 | | 09 | 张三 | 2017 -12 -20 00 :00 :00 | 女 | | 10 | 李四 | 2017 -12 -25 00 :00 :00 | 女 | + 12 rows in set (0.02 sec)SELECT * FROM Student ORDER BY Sage ASC ;+ | SId | Sname | Sage | Ssex | + | 07 | 郑竹 | 1989 -01 -01 00 :00 :00 | 女 | | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 04 | 李云 | 1990 -12 -06 00 :00 :00 | 男 | | 03 | 孙风 | 1990 -12 -20 00 :00 :00 | 男 | | 02 | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | | 05 | 周梅 | 1991 -12 -01 00 :00 :00 | 女 | | 06 | 吴兰 | 1992 -01 -01 00 :00 :00 | 女 | | 11 | 李四 | 2012 -06 -06 00 :00 :00 | 女 | | 12 | 赵六 | 2013 -06 -13 00 :00 :00 | 女 | | 13 | 孙七 | 2014 -06 -01 00 :00 :00 | 女 | | 09 | 张三 | 2017 -12 -20 00 :00 :00 | 女 | | 10 | 李四 | 2017 -12 -25 00 :00 :00 | 女 | + 12 rows in set (0.01 sec)SELECT * FROM Student ORDER BY Sage DESC ;+ | SId | Sname | Sage | Ssex | + | 10 | 李四 | 2017 -12 -25 00 :00 :00 | 女 | | 09 | 张三 | 2017 -12 -20 00 :00 :00 | 女 | | 13 | 孙七 | 2014 -06 -01 00 :00 :00 | 女 | | 12 | 赵六 | 2013 -06 -13 00 :00 :00 | 女 | | 11 | 李四 | 2012 -06 -06 00 :00 :00 | 女 | | 06 | 吴兰 | 1992 -01 -01 00 :00 :00 | 女 | | 05 | 周梅 | 1991 -12 -01 00 :00 :00 | 女 | | 02 | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | | 03 | 孙风 | 1990 -12 -20 00 :00 :00 | 男 | | 04 | 李云 | 1990 -12 -06 00 :00 :00 | 男 | | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 07 | 郑竹 | 1989 -01 -01 00 :00 :00 | 女 | + 12 rows in set (0.01 sec)SELECT Sage,Ssex as my_sex FROM Student ORDER BY my_sex;+ | Sage | my_sex | + | 1991 -12 -01 00 :00 :00 | 女 | | 1992 -01 -01 00 :00 :00 | 女 | | 1989 -01 -01 00 :00 :00 | 女 | | 2017 -12 -20 00 :00 :00 | 女 | | 2017 -12 -25 00 :00 :00 | 女 | | 2012 -06 -06 00 :00 :00 | 女 | | 2013 -06 -13 00 :00 :00 | 女 | | 2014 -06 -01 00 :00 :00 | 女 | | 1990 -01 -01 00 :00 :00 | 男 | | 1990 -12 -21 00 :00 :00 | 男 | | 1990 -12 -20 00 :00 :00 | 男 | | 1990 -12 -06 00 :00 :00 | 男 | + 12 rows in set (0.00 sec)SELECT Sage,Ssex as my_sex FROM Student WHERE Sid > 10 ORDER BY my_sex;+ | Sage | my_sex | + | 2012 -06 -06 00 :00 :00 | 女 | | 2013 -06 -13 00 :00 :00 | 女 | | 2014 -06 -01 00 :00 :00 | 女 | + 3 rows in set (0.00 sec)SELECT * FROM Student ORDER BY Sage,Sid;+ | SId | Sname | Sage | Ssex | + | 07 | 郑竹 | 1989 -01 -01 00 :00 :00 | 女 | | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 04 | 李云 | 1990 -12 -06 00 :00 :00 | 男 | | 03 | 孙风 | 1990 -12 -20 00 :00 :00 | 男 | | 02 | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | | 05 | 周梅 | 1991 -12 -01 00 :00 :00 | 女 | | 06 | 吴兰 | 1992 -01 -01 00 :00 :00 | 女 | | 11 | 李四 | 2012 -06 -06 00 :00 :00 | 女 | | 12 | 赵六 | 2013 -06 -13 00 :00 :00 | 女 | | 13 | 孙七 | 2014 -06 -01 00 :00 :00 | 女 | | 09 | 张三 | 2017 -12 -20 00 :00 :00 | 女 | | 10 | 李四 | 2017 -12 -25 00 :00 :00 | 女 | + 12 rows in set (0.03 sec)
分页
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 SELECT * FROM Student LIMIT 0 ,4 ;+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 02 | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | | 03 | 孙风 | 1990 -12 -20 00 :00 :00 | 男 | | 04 | 李云 | 1990 -12 -06 00 :00 :00 | 男 | + 4 rows in set (0.00 sec)SELECT * FROM Student LIMIT 4 ;+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 02 | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | | 03 | 孙风 | 1990 -12 -20 00 :00 :00 | 男 | | 04 | 李云 | 1990 -12 -06 00 :00 :00 | 男 | + 4 rows in set (0.02 sec)SELECT * FROM Student LIMIT 4 ,4 ;+ | SId | Sname | Sage | Ssex | + | 05 | 周梅 | 1991 -12 -01 00 :00 :00 | 女 | | 06 | 吴兰 | 1992 -01 -01 00 :00 :00 | 女 | | 07 | 郑竹 | 1989 -01 -01 00 :00 :00 | 女 | | 09 | 张三 | 2017 -12 -20 00 :00 :00 | 女 | + 4 rows in set (0.01 sec)SELECT * FROM Student WHERE Ssex = '男' ORDER BY Sage LIMIT 0 ,4 ;+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 04 | 李云 | 1990 -12 -06 00 :00 :00 | 男 | | 03 | 孙风 | 1990 -12 -20 00 :00 :00 | 男 | | 02 | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | + 4 rows in set (0.01 sec)SELECT * FROM Student LIMIT 4 OFFSET 0 ;+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | | 02 | 钱电 | 1990 -12 -21 00 :00 :00 | 男 | | 03 | 孙风 | 1990 -12 -20 00 :00 :00 | 男 | | 04 | 李云 | 1990 -12 -06 00 :00 :00 | 男 | + 4 rows in set (0.01 sec)
多表查询 无法将表格关联起来时,如果需要查询某个学生某个学科的成绩,查询方式如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 SELECT * from Student WHERE Sname = '赵雷' ;+ | SId | Sname | Sage | Ssex | + | 01 | 赵雷 | 1990 -01 -01 00 :00 :00 | 男 | + 1 row in set (0.00 sec)SELECT * FROM Course WHERE Cname = '语文' ;+ | CId | Cname | TId | + | 01 | 语文 | 02 | + 1 row in set (0.00 sec)SELECT * FROM SC WHERE Sid = '01' AND Cid = '01' ;+ | SId | CId | score | + | 01 | 01 | 80.0 | + 1 row in set (0.01 sec)
这种查询方式是繁琐的,而且当查询条件是一个范围,查询过程会浪费很多资源和时间,所以需要使用多表查询
等值连接 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 SELECT Sname,Cname,score FROM Student,Course,SC;... 684 rows in set (0.01 sec)SELECT Sname,Cname,score FROM Student,Course,SC WHERE SC.SId = Student.Sid and SC.CId = Course.Cid;+ | Sname | Cname | score | + | 赵雷 | 英语 | 99.0 | | 赵雷 | 数学 | 90.0 | | 赵雷 | 语文 | 80.0 | | 钱电 | 英语 | 80.0 | | 钱电 | 数学 | 60.0 | | 钱电 | 语文 | 70.0 | | 孙风 | 英语 | 80.0 | | 孙风 | 数学 | 80.0 | | 孙风 | 语文 | 80.0 | | 李云 | 英语 | 20.0 | | 李云 | 数学 | 30.0 | | 李云 | 语文 | 50.0 | | 周梅 | 数学 | 87.0 | | 周梅 | 语文 | 76.0 | | 吴兰 | 英语 | 34.0 | | 吴兰 | 语文 | 31.0 | | 郑竹 | 英语 | 98.0 | | 郑竹 | 数学 | 89.0 | + 18 rows in set (0.01 sec)SELECT t1.Sname "姓名",t2.Cname "科目",t3.score "成绩" FROM Student t1,Course t2,SC t3 WHERE t3.SId = t1.Sid and t3.CId = t2.Cid;+ | 姓名 | 科目 | 成绩 | + | 赵雷 | 英语 | 99.0 | | 赵雷 | 数学 | 90.0 | | 赵雷 | 语文 | 80.0 | | 钱电 | 英语 | 80.0 | | 钱电 | 数学 | 60.0 | | 钱电 | 语文 | 70.0 | | 孙风 | 英语 | 80.0 | | 孙风 | 数学 | 80.0 | | 孙风 | 语文 | 80.0 | | 李云 | 英语 | 20.0 | | 李云 | 数学 | 30.0 | | 李云 | 语文 | 50.0 | | 周梅 | 数学 | 87.0 | | 周梅 | 语文 | 76.0 | | 吴兰 | 英语 | 34.0 | | 吴兰 | 语文 | 31.0 | | 郑竹 | 英语 | 98.0 | | 郑竹 | 数学 | 89.0 | + 18 rows in set (0.01 sec)
笛卡尔积
非等值连接 通过非等于条件连接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 SELECT t1.Sname "姓名",t2.Cname "科目",t3.score "成绩",t4.grade_level "等级" FROM Student t1,Course t2,SC t3,score_grades t4 WHERE t3.SId = t1.Sid and t3.CId = t2.Cid AND t3.score BETWEEN t4.lowest_sal AND t4.highest_sal;+ | 姓名 | 科目 | 成绩 | 等级 | + | 赵雷 | 语文 | 80.0 | A | | 赵雷 | 数学 | 90.0 | A | | 赵雷 | 英语 | 99.0 | A | | 钱电 | 语文 | 70.0 | B | | 钱电 | 数学 | 60.0 | B | | 钱电 | 英语 | 80.0 | A | | 孙风 | 语文 | 80.0 | A | | 孙风 | 数学 | 80.0 | A | | 孙风 | 英语 | 80.0 | A | | 李云 | 数学 | 30.0 | D | | 李云 | 英语 | 20.0 | D | | 李云 | 语文 | 50.0 | C | | 周梅 | 语文 | 76.0 | B | | 周梅 | 数学 | 87.0 | A | | 吴兰 | 语文 | 31.0 | D | | 吴兰 | 英语 | 34.0 | D | | 郑竹 | 数学 | 89.0 | A | | 郑竹 | 英语 | 98.0 | A | + 18 rows in set (0.02 sec)
自连接 表中一个字段属于同表中另外一个字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 SELECT emp.emp_id, emp.lname ,mgr.emp_id,mgr.lname FROM employee emp,employee mgr WHERE emp.superior_emp_id = mgr.emp_id;+ | emp_id | lname | emp_id | lname | + | 2 | Barker | 1 | Smith | | 3 | Tyler | 1 | Smith | | 4 | Hawthorne | 3 | Tyler | | 5 | Gooding | 4 | Hawthorne | | 6 | Fleming | 4 | Hawthorne | | 7 | Tucker | 6 | Fleming | | 8 | Parker | 6 | Fleming | | 9 | Grossman | 6 | Fleming | | 10 | Roberts | 4 | Hawthorne | | 11 | Ziegler | 10 | Roberts | | 12 | Jameson | 10 | Roberts | | 13 | Blake | 4 | Hawthorne | | 14 | Mason | 13 | Blake | | 15 | Portman | 13 | Blake | | 16 | Markham | 4 | Hawthorne | | 17 | Fowler | 16 | Markham | | 18 | Tulman | 16 | Markham | | 19 | Tulman | 16 | Markham | + 18 rows in set (0.02 sec)
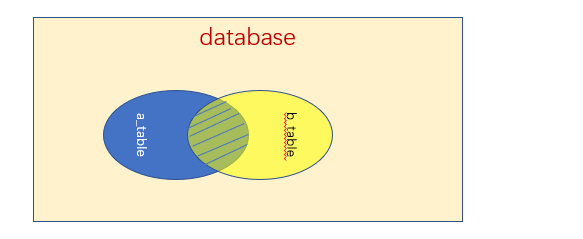
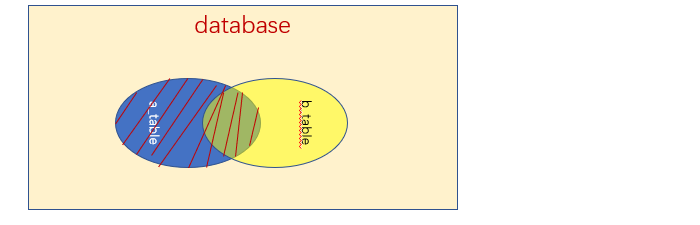
内连接 合并具有同一列的两个以上的表的行,结果集中不包含一个表与另一个表不匹配的行。上面的等值连接、非等值连接、自连接都属于内连接。
查询下图中a_table和b_table的集就是内连接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 SELECT lname,`name` FROM employee e JOIN department d on e.dept_id = d.dept_id; + | lname | name | + | Hawthorne | Operations | | Fleming | Operations | | Tucker | Operations | | Parker | Operations | | Grossman | Operations | | Roberts | Operations | | Ziegler | Operations | | Jameson | Operations | | Blake | Operations | | Mason | Operations | | Portman | Operations | | Markham | Operations | | Fowler | Operations | | Tulman | Operations | | Gooding | Loans | | Smith | Administration | | Barker | Administration | | Tyler | Administration | + 18 rows in set (0.01 sec)
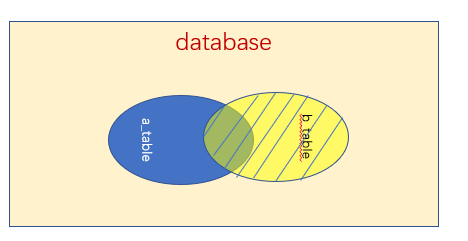
外连接 合并具有同一列的两个以上的表的行,结果集中除了包含一个表与另一个表匹配的行之外,还查询了左表或右表中不匹配的行
上图中,除了a_table和b_table的集之外,还包含a_table的左边部分或者包含b_table的右边部分,或者都包含,具体可以分为三类。
外连接的分类
左外连接:除了a_table和b_table的集之外,还包含a_table的左边部分,此时左边的表称为主表,右边的表称为从表
右外连接:除了a_table和b_table的集之外,还包含b_table的右边部分,此时右边的表称为主表,左边的表称为从表
满外连接:除了a_table和b_table的集之外,还包含a_table的左边部分和b_table的右边部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 SELECT emp_id,`name` FROM employee e LEFT JOIN department d ON e.dept_id = d.dept_id;+ | emp_id | name | + | 19 | NULL | | 4 | Operations | | 6 | Operations | | 7 | Operations | | 8 | Operations | | 9 | Operations | | 10 | Operations | | 11 | Operations | | 12 | Operations | | 13 | Operations | | 14 | Operations | | 15 | Operations | | 16 | Operations | | 17 | Operations | | 18 | Operations | | 5 | Loans | | 1 | Administration | | 2 | Administration | | 3 | Administration | + 19 rows in set (0.01 sec)SELECT emp_id,`name` FROM employee e RIGHT JOIN department d ON e.dept_id = d.dept_id;+ | emp_id | name | + | 4 | Operations | | 6 | Operations | | 7 | Operations | | 8 | Operations | | 9 | Operations | | 10 | Operations | | 11 | Operations | | 12 | Operations | | 13 | Operations | | 14 | Operations | | 15 | Operations | | 16 | Operations | | 17 | Operations | | 18 | Operations | | 5 | Loans | | 1 | Administration | | 2 | Administration | | 3 | Administration | | NULL | Test | + 19 rows in set (0.01 sec)SELECT emp_id,`name` FROM employee e FULL JOIN department d ON e.dept_id = d.dept_id;ERROR 1064 (42000 ): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'FULL JOIN department d ON e.dept_id = d.dept_id' at line 1
合并查询结果 由于MySQL不支持满外连接,是通过合并查询结果是实现
相比之下,UNION是在 UNION ALL的基础上,将两个查询结果的交集去重,会有性能损失,因此,更提倡使用UNION ALL
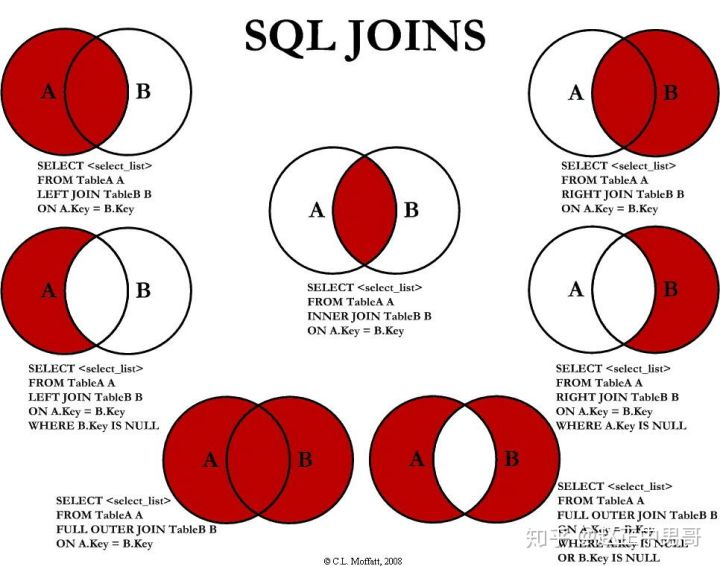
7中SQL JOINS的实现 通过 JOIN和 UNION,实现7种SQL JOINS
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 SELECT emp_id,d.name FROM employee e LEFT JOIN department d ON e.dept_id = d.dept_id;+ | emp_id | name | + | 19 | NULL | | 4 | Operations | | 6 | Operations | | 7 | Operations | | 8 | Operations | | 9 | Operations | | 10 | Operations | | 11 | Operations | | 12 | Operations | | 13 | Operations | | 14 | Operations | | 15 | Operations | | 16 | Operations | | 17 | Operations | | 18 | Operations | | 5 | Loans | | 1 | Administration | | 2 | Administration | | 3 | Administration | + 19 rows in set (0.00 sec)SELECT emp_id,d.name FROM employee e RIGHT JOIN department d ON e.dept_id = d.dept_id;+ | emp_id | name | + | 4 | Operations | | 6 | Operations | | 7 | Operations | | 8 | Operations | | 9 | Operations | | 10 | Operations | | 11 | Operations | | 12 | Operations | | 13 | Operations | | 14 | Operations | | 15 | Operations | | 16 | Operations | | 17 | Operations | | 18 | Operations | | 5 | Loans | | 1 | Administration | | 2 | Administration | | 3 | Administration | | NULL | Test | + 19 rows in set (0.00 sec)SELECT emp_id,d.name FROM employee e LEFT JOIN department d ON e.dept_id = d.dept_id WHERE d.dept_id IS NULL ;+ | emp_id | name | + | 19 | NULL | + 1 row in set (0.00 sec)SELECT emp_id,d.name FROM employee e RIGHT JOIN department d ON e.dept_id = d.dept_id WHERE e.dept_id IS NULL ;+ | emp_id | name | + | NULL | Test | + 1 row in set (0.02 sec)SELECT emp_id,d.name FROM employee e LEFT JOIN department d ON e.dept_id = d.dept_id UNION ALL SELECT emp_id,d.name FROM employee e RIGHT JOIN department d ON e.dept_id = d.dept_id WHERE e.dept_id IS NULL ;+ | emp_id | name | + | 19 | NULL | | 4 | Operations | | 6 | Operations | | 7 | Operations | | 8 | Operations | | 9 | Operations | | 10 | Operations | | 11 | Operations | | 12 | Operations | | 13 | Operations | | 14 | Operations | | 15 | Operations | | 16 | Operations | | 17 | Operations | | 18 | Operations | | 5 | Loans | | 1 | Administration | | 2 | Administration | | 3 | Administration | | NULL | Test | + 20 rows in set (0.00 sec)SELECT emp_id,d.name FROM employee e LEFT JOIN department d ON e.dept_id = d.dept_id WHERE d.dept_id IS NULL UNION ALL SELECT emp_id,d.name FROM employee e RIGHT JOIN department d ON e.dept_id = d.dept_id;+ | emp_id | name | + | 19 | NULL | | 4 | Operations | | 6 | Operations | | 7 | Operations | | 8 | Operations | | 9 | Operations | | 10 | Operations | | 11 | Operations | | 12 | Operations | | 13 | Operations | | 14 | Operations | | 15 | Operations | | 16 | Operations | | 17 | Operations | | 18 | Operations | | 5 | Loans | | 1 | Administration | | 2 | Administration | | 3 | Administration | | NULL | Test | + 20 rows in set (0.00 sec)SELECT emp_id,d.name FROM employee e LEFT JOIN department d ON e.dept_id = d.dept_id WHERE d.dept_id IS NULL UNION ALL SELECT emp_id,d.name FROM employee e RIGHT JOIN department d ON e.dept_id = d.dept_id WHERE e.dept_id IS NULL ;+ | emp_id | name | + | 19 | NULL | | NULL | Test | + 2 rows in set (0.00 sec)
SQL 99语法新特性
单行函数 将常用使用的代码封装出来作为函数,可以提高效率 和可维护性 。
从创建的角度,函数分为内置函数 和自定义函数 。内置函数为DBMS内置的函数,不同的DBMS,内置函数差别很大。自定义函数为用户自定义的函数。
从操作角度,函数分为单行函数 和多行函数(聚合函数、分组函数) 。单行函数为输入对象为单行,多行函数为输入对象为多行。
基本函数 https://www.w3school.com.cn/sql/sql_functions.asp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 SELECT ABS (-123 ),ABS (32 ),SIGN (-23 ),SIGN (43 ),PI(),CEIL (32.32 ),CEILING (-43.23 ),FLOOR (32.32 ), FLOOR (-43.23 ),MOD (12 , 5 ) FROM DUAL;+ | ABS (-123 ) | ABS (32 ) | SIGN (-23 ) | SIGN (43 ) | PI() | CEIL (32.32 ) | CEILING (-43.23 ) | FLOOR (32.32 ) | FLOOR (-43.23 ) | MOD (12 , 5 ) | + | 123 | 32 | -1 | 1 | 3.141593 | 33 | -43 | 32 | -44 | 2 | + 1 row in set (0.01 sec)SELECT RAND(),RAND(),RAND(10 ),RAND(10 ),RAND(-1 ), RAND(-1 ) FROM DUAL;+ | RAND() | RAND() | RAND(10 ) | RAND(10 ) | RAND(-1 ) | RAND(-1 ) | + | 0.5174580277106334 | 0.8552275140352803 | 0.6570515219653505 | 0.6570515219653505 | 0.9050373219931845 | 0.9050373219931845 | + 1 row in set (0.00 sec)SELECT ROUND(123.456 ),ROUND(123.456 ,2 ),ROUND(123.456 ,-2 ),TRUNCATE (123.456 ,2 ),TRUNCATE (123.456 ,-1 ),SQRT (7 ) FROM DUAL;+ | ROUND(123.456 ) | ROUND(123.456 ,2 ) | ROUND(123.456 ,-2 ) | TRUNCATE (123.456 ,2 ) | TRUNCATE (123.456 ,-1 ) | SQRT (7 ) | + | 123 | 123.46 | 100 | 123.45 | 120 | 2.6457513110645907 | + 1 row in set (0.00 sec)SELECT TRUNCATE (SQRT (7 ),2 ) FROM DUAL;+ | TRUNCATE (SQRT (7 ),2 ) | + | 2.64 | + 1 row in set (0.01 sec)SELECT RADIANS(90 ),RADIANS(60 ),DEGREES(2 * PI()) FROM DUAL;+ | RADIANS(90 ) | RADIANS(60 ) | DEGREES(2 * PI()) | + | 1.5707963267948966 | 1.0471975511965976 | 360 | + 1 row in set (0.01 sec)SELECT SIN (RADIANS(30 )),DEGREES(ASIN (1 )),TAN (RADIANS(45 )),DEGREES(ATAN (1 )) FROM DUAL;+ | SIN (RADIANS(30 )) | DEGREES(ASIN (1 )) | TAN (RADIANS(45 )) | DEGREES(ATAN (1 )) | + | 0.49999999999999994 | 90 | 0.9999999999999999 | 45 | + 1 row in set (0.02 sec)SELECT POW(2 , 5 ) , POWER (2 , 4 ), EXP (2 ) FROM DUAL;+ | POW(2 , 5 ) | POWER (2 , 4 ) | EXP (2 ) | + | 32 | 16 | 7.38905609893065 | + 1 row in set (0.01 sec)SELECT LN (EXP (2 )),LOG (EXP (2 )),LOG10 (10 ),LOG2(4 ) FROM DUAL;+ | LN (EXP (2 )) | LOG (EXP (2 )) | LOG10 (10 ) | LOG2(4 ) | + | 2 | 2 | 1 | 2 | + 1 row in set (0.01 sec)SELECT BIN(10 ),HEX(10 ),OCT(10 ) FROM DUAL;+ | BIN(10 ) | HEX(10 ) | OCT(10 ) | + | 1010 | A | 12 | + 1 row in set (0.00 sec)
字符串函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 SELECT ASCII('Abc' ),CHAR_LENGTH ('hello' ),CHAR_LENGTH ('我们' ),LENGTH('hello' ),LENGTH('我们' ) FROM DUAL;+ | ASCII('Abc' ) | CHAR_LENGTH ('hello' ) | CHAR_LENGTH ('我们' ) | LENGTH('hello' ) | LENGTH('我们' ) | + | 65 | 5 | 2 | 5 | 6 | + 1 row in set (0.00 sec)SELECT CONCAT(emp.lname,' worked hard with ' ,emp.title) "details" FROM employee `emp`;+ | details | + | Smith worked hard with President | | Barker worked hard with Vice President | | Tyler worked hard with Treasurer | | Hawthorne worked hard with Operations Manager | | Gooding worked hard with Loan Manager | | Fleming worked hard with Head Teller | | Tucker worked hard with Teller | | Parker worked hard with Teller | | Grossman worked hard with Teller | | Roberts worked hard with Head Teller | | Ziegler worked hard with Teller | | Jameson worked hard with Teller | | Blake worked hard with Head Teller | | Mason worked hard with Teller | | Portman worked hard with Teller | | Markham worked hard with Head Teller | | Fowler worked hard with Teller | | Tulman worked hard with Teller | | Tulman worked hard with Teller | + 19 rows in set (0.01 sec)SELECT CONCAT_WS('-' ,'HELP' ,'hello' ) FROM DUAL;+ | CONCAT_WS('-' ,'HELP' ,'hello' ) | + | HELP- hello | + 1 row in set (0.00 sec)SELECT INSERT ('helloworld' ,2 ,3 ,'aa111a' ),REPLACE('hello' ,'ll' ,'lm' ) FROM DUAL;+ | INSERT ('helloworld' ,2 ,3 ,'aa111a' ) | REPLACE('hello' ,'ll' ,'lm' ) | + | haa111aoworld | helmo | + 1 row in set (0.01 sec)SELECT UPPER ('abc' ),LOWER ('PDF' ) FROM DUAL;+ | UPPER ('abc' ) | LOWER ('PDF' ) | + | ABC | pdf | + 1 row in set (0.00 sec)SELECT LEFT ('hello' ,2 ),RIGHT ('begin' ,3 ),RIGHT ('begin' ,13 ) FROM DUAL;+ | LEFT ('hello' ,2 ) | RIGHT ('begin' ,3 ) | RIGHT ('begin' ,13 ) | + | he | gin | begin | + 1 row in set (0.00 sec)SELECT LPAD(123 ,10 ,'*' ),RPAD(123 ,10 ,'*' ) FROM DUAL;+ | LPAD(123 ,10 ,'*' ) | RPAD(123 ,10 ,'*' ) | + | * * * * * * * 123 | 123 * * * * * * * | + 1 row in set (0.01 sec)SELECT TRIM (' h e llo ' ),RTRIM(' h e llo ' ),LTRIM(' h e llo ' ),TRIM (' h e llo 00' FROM '0' ) FROM DUAL;+ | TRIM (' h e llo ' ) | RTRIM(' h e llo ' ) | LTRIM(' h e llo ' ) | TRIM (' h e llo 00' FROM '0' ) | + | h e llo | h e llo | h e llo | 0 | + 1 row in set (0.00 sec)SELECT REPEAT('hello' ,4 ),SPACE(5 ),STRCMP('bac' ,'def' ) FROM DUAL;+ | REPEAT('hello' ,4 ) | SPACE(5 ) | STRCMP('bac' ,'def' ) | + | hellohellohellohello | | -1 | + 1 row in set (0.01 sec)SELECT SUBSTR('hello' ,2 ,2 ),LOCATE('l' ,'hello' ),LOCATE('b' ,'hello' ),ELT(2 ,'a' ,'b' ,'c' ,'d' ),FIELD('mm' ,'gg' ,'mm' ,'mm' ),FIND_IN_SET('mm' ,'gg,mm,jj,mm' ) FROM DUAL;+ | SUBSTR('hello' ,2 ,2 ) | LOCATE('l' ,'hello' ) | LOCATE('b' ,'hello' ) | ELT(2 ,'a' ,'b' ,'c' ,'d' ) | FIELD('mm' ,'gg' ,'mm' ,'mm' ) | FIND_IN_SET('mm' ,'gg,mm,jj,mm' ) | + | el | 3 | 0 | b | 2 | 2 | + 1 row in set (0.01 sec)SELECT REVERSE('abc' ) FROM DUAL;+ | REVERSE('abc' ) | + | cba | + 1 row in set (0.00 sec)SELECT dept_id,NULLIF (LENGTH(lname),LENGTH(fname)) "common_name" FROM employee;+ | dept_id | common_name | + | 3 | 5 | | 3 | 6 | | 3 | 5 | | 1 | 9 | | 2 | 7 | | 1 | 7 | | 1 | 6 | | 1 | 6 | | 1 | 8 | | 1 | 7 | | 1 | 7 | | 1 | 7 | | 1 | 5 | | 1 | NULL | | 1 | 7 | | 1 | NULL | | 1 | 6 | | 1 | 6 | | NULL | 6 | + 19 rows in set (0.01 sec)
日期和时间 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 SELECT CURDATE(), CURTIME(), NOW(), SYSDATE()+ 0 , UTC_DATE(), UTC_DATE()+ 0 , UTC_TIME(), UTC_TIME()+ 8 FROM DUAL;+ | CURDATE() | CURTIME() | NOW() | SYSDATE()+ 0 | UTC_DATE() | UTC_DATE()+ 0 | UTC_TIME() | UTC_TIME()+ 8 | + | 2022 -10 -28 | 09 :14 :25 | 2022 -10 -28 09 :14 :25 | 20221028091425 | 2022 -10 -28 | 20221028 | 09 :14 :25 | 91433 | + 1 row in set (0.00 sec)SELECT UNIX_TIMESTAMP(),FROM_UNIXTIME(1666944191 ) FROM DUAL;+ | UNIX_TIMESTAMP() | FROM_UNIXTIME(1666944191 ) | + | 1666948475 | 2022 -10 -28 08 :03 :11 | + 1 row in set (0.00 sec)SELECT YEAR (CURDATE()), MONTH (CURDATE()), DAY (CURDATE()), HOUR (CURTIME()),MINUTE (NOW()) , SECOND (SYSDATE()) FROM DUAL;+ | YEAR (CURDATE()) | MONTH (CURDATE()) | DAY (CURDATE()) | HOUR (CURTIME()) | MINUTE (NOW()) | SECOND (SYSDATE()) | + | 2022 | 10 | 28 | 9 | 14 | 41 | + 1 row in set (0.01 sec)SELECT MONTHNAME('2021-10-26' ),DAYNAME('2021-10-26' ),WEEKDAY('2021-10-26' ),QUARTER(CURDATE()),WEEK(CURDATE()),DAYOFYEAR(NOW()),DAYOFMONTH(NOW()),DAYOFWEEK(NOW()) FROM DUAL;+ | MONTHNAME('2021-10-26' ) | DAYNAME('2021-10-26' ) | WEEKDAY('2021-10-26' ) | QUARTER(CURDATE()) | WEEK(CURDATE()) | DAYOFYEAR(NOW()) | DAYOFMONTH(NOW()) | DAYOFWEEK(NOW()) | + | October | Tuesday | 1 | 4 | 43 | 301 | 28 | 6 | + 1 row in set (0.00 sec)SELECT EXTRACT (SECOND FROM NOW()),EXTRACT (DAY FROM NOW()),EXTRACT (HOUR_MINUTE FROM NOW()),EXTRACT (QUARTER FROM NOW()) FROM DUAL;+ | EXTRACT (SECOND FROM NOW()) | EXTRACT (DAY FROM NOW()) | EXTRACT (HOUR_MINUTE FROM NOW()) | EXTRACT (QUARTER FROM NOW()) | + | 11 | 28 | 915 | 4 | + 1 row in set (0.01 sec)SELECT TIME_TO_SEC(CURTIME()),SEC_TO_TIME(29521 ) FROM DUAL;+ | TIME_TO_SEC(CURTIME()) | SEC_TO_TIME(29521 ) | + | 33320 | 08 :12 :01 | + 1 row in set (0.01 sec)SELECT DATE_ADD(NOW() ,INTERVAL 1 HOUR ),DATE_ADD(NOW() ,INTERVAL -1 HOUR ),DATE_SUB(NOW() ,INTERVAL -1 HOUR ),DATE_ADD(NOW() ,INTERVAL '1_1' YEAR_MONTH),DATE_ADD(NOW() ,INTERVAL '1_1' HOUR_MINUTE) FROM DUAL;+ | DATE_ADD(NOW() ,INTERVAL 1 HOUR ) | DATE_ADD(NOW() ,INTERVAL -1 HOUR ) | DATE_SUB(NOW() ,INTERVAL -1 HOUR ) | DATE_ADD(NOW() ,INTERVAL '1_1' YEAR_MONTH) | DATE_ADD(NOW() ,INTERVAL '1_1' HOUR_MINUTE) | + | 2022 -10 -28 10 :15 :33 | 2022 -10 -28 08 :15 :33 | 2022 -10 -28 10 :15 :33 | 2023 -11 -28 09 :15 :33 | 2022 -10 -28 10 :16 :33 | + 1 row in set (0.00 sec)SELECT ADDTIME(NOW(),20 ), SUBTIME(NOW(), 30 ), SUBTIME(NOW(), '1:1:3' ), DATEDIFF(NOW(), '2022-10-01' ), TIMEDIFF(NOW(), '2022-10-28 22:18:10' ), FROM_DAYS(366 ), TO_DAYS('0000-12-25' ), LAST_DAY(NOW()), MAKEDATE(YEAR (NOW()), 12 ), MAKETIME(10 ,21 ,23 ),PERIOD_ADD(20200101010101 , 10 ) FROM DUAL;+ | ADDTIME(NOW(),20 ) | SUBTIME(NOW(), 30 ) | SUBTIME(NOW(), '1:1:3' ) | DATEDIFF(NOW(), '2022-10-01' ) | TIMEDIFF(NOW(), '2022-10-28 22:18:10' ) | FROM_DAYS(366 ) | TO_DAYS('0000-12-25' ) | LAST_DAY(NOW()) | MAKEDATE(YEAR (NOW()), 12 ) | MAKETIME(10 ,21 ,23 ) | PERIOD_ADD(20200101010101 , 10 ) | + | 2022 -10 -28 09 :16 :32 | 2022 -10 -28 09 :15 :42 | 2022 -10 -28 08 :15 :09 | 27 | -13 :01 :58 | 0001 -01 -01 | 359 | 2022 -10 -31 | 2022 -01 -12 | 10 :21 :23 | 20200101010111 | + 1 row in set (0.00 sec)SELECT DATE_FORMAT(CURDATE(),'%Y-%M_%D' ),DATE_FORMAT(NOW(),'%Y-%m-%d' ),TIME_FORMAT(CURTIME(),'%h:%i:%s' ),DATE_FORMAT(NOW(),'%Y-%M-%D %h:%i:%S %W %w %T %t %r' ) FROM DUAL;+ | DATE_FORMAT(CURDATE(),'%Y-%M_%D' ) | DATE_FORMAT(NOW(),'%Y-%m-%d' ) | TIME_FORMAT(CURTIME(),'%h:%i:%s' ) | DATE_FORMAT(NOW(),'%Y-%M-%D %h:%i:%S %W %w %T %t %r' ) | + | 2022 - October_28th | 2022 -10 -28 | 09 :16 :35 | 2022 - October-28 th 09 :16 :35 Friday 5 09 :16 :35 t 09 :16 :35 AM | + 1 row in set (0.01 sec)SELECT STR_TO_DATE('2022-October-28th 08:23:55' ,'%Y-%M-%D %h:%i:%S' ) FROM DUAL;+ | STR_TO_DATE('2022-October-28th 08:23:55' ,'%Y-%M-%D %h:%i:%S' ) | + | 2022 -10 -28 08 :23 :55 | + 1 row in set (0.00 sec)SELECT GET_FORMAT(DATE , 'USA' ) FROM DUAL;+ | GET_FORMAT(DATE , 'USA' ) | + | % m.% d.% Y | + 1 row in set (0.01 sec)
流程控制函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 SELECT IF(1 > 0 ,'正确' ,'错误' ),IFNULL(NULL ,'空' ) FROM DUAL;+ | IF(1 > 0 ,'正确' ,'错误' ) | IFNULL(NULL ,'空' ) | + | 正确 | 空 | + 1 row in set (0.01 sec)SELECT CASE WHEN 1 > 2 THEN '错误' ELSE '正确' END "测试" FROM DUAL;+ | 测试 | + | 正确 | + 1 row in set (0.00 sec)
加密和解密 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 SELECT PASSWORD('123456' ) FROM DUAL;ERROR 1064 (42000 ): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '(' 123456 ') FROM DUAL' at line 1 SELECT MD5('123456' ),SHA('123456' ) FROM DUAL;+ | MD5('123456' ) | SHA('123456' ) | + | e10adc3949ba59abbe56e057f20f883e | 7 c4a8d09ca3762af61e59520943dc26494f8941b | + 1 row in set (0.01 sec)SELECT ENCODE('mitata' ,'mysql' ),DECODE('mitaka' ,'mysql' ) FROM DUAL;ERROR 1305 (42000 ): FUNCTION mitaka.ENCODE does not exist
其他函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 SELECT VERSION(),CONNECTION_ID(),DATABASE(),SCHEMA(),USER (),CURRENT_USER (),CHARSET('小夜时雨' ),COLLATION ('小夜时雨' ) from DUAL;+ | VERSION() | CONNECTION_ID() | DATABASE() | SCHEMA() | USER () | CURRENT_USER () | CHARSET('小夜时雨' ) | COLLATION ('小夜时雨' ) | + | 8.0 .31 | 13 | mitaka | mitaka | root@172 .17 .0 .1 | root@% | utf8mb4 | utf8mb4_0900_ai_ci | + 1 row in set (0.00 sec)SELECT FORMAT(123.12356 ,2 ) FROM DUAL;+ | FORMAT(123.12356 ,2 ) | + | 123.12 | + 1 row in set (0.01 sec)SELECT CONV(16 ,10 ,2 ) FROM DUAL;+ | CONV(16 ,10 ,2 ) | + | 10000 | + 1 row in set (0.00 sec)SELECT INET_ATON('192.168.1.1' ),INET_NTOA(3232235777 ) FROM DUAL;+ | INET_ATON('192.168.1.1' ) | INET_NTOA(3232235777 ) | + | 3232235777 | 192.168 .1 .1 | + 1 row in set (0.01 sec)SELECT BENCHMARK(100000 , MD5('mysql' )) FROM DUAL;+ | BENCHMARK(100000 , MD5('mysql' )) | + | 0 | + 1 row in set (0.05 sec)SELECT CHARSET('mitaka' ),CHARSET(CONVERT ('mitaka' USING 'utf8mb3' )) FROM DUAL;+ | CHARSET('mitaka' ) | CHARSET(CONVERT ('mitaka' USING 'utf8mb3' )) | + | utf8mb4 | utf8mb3 | + 1 row in set , 1 warning (0.01 sec)
聚合函数 对一组数据进行汇总的函数,输入的是一组数据的集合,输出的是单个值。聚合函数作用于一组数据,并对一组数据返回一个值。
常见的聚合函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 SELECT AVG (avail_balance),SUM (avail_balance),AVG (avail_balance) * 2844047 FROM account;+ | AVG (avail_balance) | SUM (avail_balance) | AVG (avail_balance) * 2844047 | + | 7114.769138 | 170754.46 | 20234737822.673504 | + 1 row in set (0.01 sec)SELECT SUM (fname),AVG (lname),SUM (start_date) FROM employee;+ | SUM (fname) | AVG (lname) | SUM (start_date) | + | 0 | 0 | 380383165 | + 1 row in set , 38 warnings (0.02 sec)SELECT MAX (avail_balance),MIN (avail_balance) FROM account;+ | MAX (avail_balance) | MIN (avail_balance) | + | 50000.00 | 0.00 | + 1 row in set (0.01 sec)SELECT MAX (fname),MIN (lname) FROM employee;+ | MAX (fname) | MIN (lname) | + | Thomas | Barker | + 1 row in set (0.01 sec)SELECT COUNT (emp_id),COUNT (fname),COUNT (2 * fname),COUNT (1 ),COUNT (* ) FROM employee;+ | COUNT (emp_id) | COUNT (fname) | COUNT (2 * fname) | COUNT (1 ) | COUNT (* ) | + | 19 | 19 | 19 | 19 | 19 | + 1 row in set (0.04 sec)SELECT COUNT (* ),COUNT (dept_id) FROM employee;+ | COUNT (* ) | COUNT (dept_id) | + | 19 | 18 | + 1 row in set (0.02 sec)SELECT AVG (avail_balance) , SUM (avail_balance) / COUNT (avail_balance) FROM account;+ | AVG (avail_balance) | SUM (avail_balance) / COUNT (avail_balance) | + | 7114.769138 | 7114.769138 | + 1 row in set (0.01 sec)
GROUP BY 分组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 SELECT open_emp_id,AVG (avail_balance),SUM (avail_balance) FROM account GROUP BY open_emp_id;+ | open_emp_id | AVG (avail_balance) | SUM (avail_balance) | + | 1 | 3485.321208 | 27882.57 | | 10 | 3051.617118 | 21361.32 | | 13 | 17756.750000 | 53270.25 | | 16 | 11373.386637 | 68240.32 | + 4 rows in set (0.01 sec)SELECT open_emp_id,product_cd,AVG (avail_balance),SUM (avail_balance) FROM account GROUP BY open_emp_id,product_cd;+ | open_emp_id | product_cd | AVG (avail_balance) | SUM (avail_balance) | + | 10 | CHK | 1657.885010 | 3315.77 | | 10 | SAV | 350.000000 | 700.00 | | 10 | CD | 4000.000000 | 8000.00 | | 13 | CHK | 1057.750000 | 1057.75 | | 13 | MM | 2212.500000 | 2212.50 | | 1 | CHK | 260.719999 | 782.16 | | 1 | SAV | 767.770020 | 767.77 | | 1 | MM | 7416.319824 | 14832.64 | | 16 | CHK | 16963.082458 | 67852.33 | | 1 | CD | 5750.000000 | 11500.00 | | 16 | SAV | 387.989990 | 387.99 | | 16 | BUS | 0.000000 | 0.00 | | 10 | BUS | 9345.549805 | 9345.55 | | 13 | SBL | 50000.000000 | 50000.00 | + 14 rows in set (0.01 sec)SELECT open_emp_id,product_cd,AVG (avail_balance),SUM (avail_balance) FROM account GROUP BY product_cd,open_emp_id;+ | open_emp_id | product_cd | AVG (avail_balance) | SUM (avail_balance) | + | 10 | CHK | 1657.885010 | 3315.77 | | 10 | SAV | 350.000000 | 700.00 | | 10 | CD | 4000.000000 | 8000.00 | | 13 | CHK | 1057.750000 | 1057.75 | | 13 | MM | 2212.500000 | 2212.50 | | 1 | CHK | 260.719999 | 782.16 | | 1 | SAV | 767.770020 | 767.77 | | 1 | MM | 7416.319824 | 14832.64 | | 16 | CHK | 16963.082458 | 67852.33 | | 1 | CD | 5750.000000 | 11500.00 | | 16 | SAV | 387.989990 | 387.99 | | 16 | BUS | 0.000000 | 0.00 | | 10 | BUS | 9345.549805 | 9345.55 | | 13 | SBL | 50000.000000 | 50000.00 | + 14 rows in set (0.01 sec)SELECT open_emp_id,product_cd,AVG (avail_balance),SUM (avail_balance) FROM account GROUP BY open_emp_id;ERROR 1055 (42000 ): Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'mitaka.account.product_cd' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode= only_full_group_by SELECT open_emp_id,AVG (avail_balance),SUM (avail_balance) FROM account GROUP BY open_emp_id WITH ROLLUP ;+ | open_emp_id | AVG (avail_balance) | SUM (avail_balance) | + | 1 | 3485.321208 | 27882.57 | | 10 | 3051.617118 | 21361.32 | | 13 | 17756.750000 | 53270.25 | | 16 | 11373.386637 | 68240.32 | | NULL | 7114.769138 | 170754.46 | + 5 rows in set (0.01 sec)SELECT open_emp_id,AVG (avail_balance),SUM (avail_balance) FROM account GROUP BY open_emp_id WITH ROLLUP ORDER BY open_emp_id ASC ;+ | open_emp_id | AVG (avail_balance) | SUM (avail_balance) | + | NULL | 7114.769138 | 170754.46 | | 1 | 3485.321208 | 27882.57 | | 10 | 3051.617118 | 21361.32 | | 13 | 17756.750000 | 53270.25 | | 16 | 11373.386637 | 68240.32 | + 5 rows in set (0.01 sec)
HAVING 用于过滤数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 SELECT open_emp_id,MAX (avail_balance) FROM account WHERE MAX (avail_balance) > 10000 GROUP BY open_emp_id;ERROR 1111 (HY000): Invalid use of group function SELECT open_emp_id,MAX (avail_balance) FROM account GROUP BY open_emp_id HAVING MAX (avail_balance) > 10000 ;+ | open_emp_id | MAX (avail_balance) | + | 13 | 50000.00 | | 16 | 38552.05 | + 2 rows in set (0.02 sec)SELECT open_emp_id,MAX (avail_balance) FROM account WHERE open_emp_id IN (13 ) GROUP BY open_emp_id HAVING MAX (avail_balance) > 10000 ;+ | open_emp_id | MAX (avail_balance) | + | 13 | 50000.00 | + 1 row in set (0.01 sec)SELECT open_emp_id,MAX (avail_balance) FROM account GROUP BY open_emp_id HAVING MAX (avail_balance) > 10000 AND open_emp_id IN (13 ) ;+ | open_emp_id | MAX (avail_balance) | + | 13 | 50000.00 | + 1 row in set (0.02 sec)
where 的 效率比 having 高,可依据SQL执行过程来确定
SQL执行过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 SELECT ...,DISTINCT (...),... FROM ...,... WHERE 不包含聚合函数的过滤条件 AND 连接表的条件 AND ...GROUP BY ...HAVING 包含聚合函数的过滤条件ORDER BY ... (ASC / DESC )LIMIT ... SELECT ...,DISTINCT (...),... FROM ... (LEFT / RIGHT ) JOIN ... ON 连接表的条件 (LEFT / RIGHT ) JOIN ... ON ... WHERE 不包含聚合函数的过滤条件 AND ...GROUP BY ...HAVING 包含聚合函数的过滤条件ORDER BY ... (ASC / DESC )LIMIT ...
每一个执行过程,会产生一个虚拟表,然后将这个虚拟表传入下一个步骤中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 FROM ...,... ON (LEFT / RIGHT ) JOIN ... ON ... (LEFT / RIGHT ) JOIN ... ON ... WHERE ... AND ...GROUP BY ...HAVING 包含聚合函数的过滤条件SELECT ...,...,... DISTINCT ORDER BY LIMIT ...
where在having之前执行,可以过滤掉很多数据,在后续过程中则不需要进行分组,因此效率更高。
子查询 查询需要从结果集中获取数据,或者从一个表中先计算得出一个数据结果,然后与这个数据结果进行比较。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 SELECT start_date FROM employee WHERE fname = 'Jane' ;+ | start_date | + | 2002 -05 -03 | + 1 row in set (0.01 sec)SELECT * FROM employee WHERE start_date > '2002-05-03' ;+ | emp_id | fname | lname | start_date | end_date | superior_emp_id | dept_id | title | assigned_branch_id | + | 2 | Susan | Barker | 2002 -09 -12 | NULL | 1 | 3 | Vice President | 1 | | 5 | John | Gooding | 2003 -11 -14 | NULL | 4 | 2 | Loan Manager | 1 | | 6 | Helen | Fleming | 2004 -03 -17 | NULL | 4 | 1 | Head Teller | 1 | | 7 | Chris | Tucker | 2004 -09 -15 | NULL | 6 | 1 | Teller | 1 | | 8 | Sarah | Parker | 2002 -12 -02 | NULL | 6 | 1 | Teller | 1 | | 10 | Paula | Roberts | 2002 -07 -27 | NULL | 4 | 1 | Head Teller | 2 | | 12 | Samantha | Jameson | 2003 -01 -08 | NULL | 10 | 1 | Teller | 2 | | 14 | Cindy | Mason | 2002 -08 -09 | NULL | 13 | 1 | Teller | 3 | | 15 | Frank | Portman | 2003 -04 -01 | NULL | 13 | 1 | Teller | 3 | | 17 | Beth | Fowler | 2002 -06 -29 | NULL | 16 | 1 | Teller | 4 | | 18 | Rick | Tulman | 2002 -12 -12 | NULL | 16 | 1 | Teller | 4 | | 19 | Rick | Tulman | 2002 -12 -12 | NULL | 16 | NULL | Teller | 4 | + 12 rows in set (0.01 sec)
此时需要执行两个查询语句,这个过程会消耗更多的网络资源,子查询就是可以将这两个查询语句合并成一个
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 SELECT e2.emp_id, e2.start_date FROM employee e1,employee e2 WHERE e2.start_date > e1.start_date AND e1.fname = 'Jane' ;+ | emp_id | start_date | + | 2 | 2002 -09 -12 | | 5 | 2003 -11 -14 | | 6 | 2004 -03 -17 | | 7 | 2004 -09 -15 | | 8 | 2002 -12 -02 | | 10 | 2002 -07 -27 | | 12 | 2003 -01 -08 | | 14 | 2002 -08 -09 | | 15 | 2003 -04 -01 | | 17 | 2002 -06 -29 | | 18 | 2002 -12 -12 | | 19 | 2002 -12 -12 | + 12 rows in set (0.01 sec)SELECT * FROM employee WHERE start_date > (SELECT start_date FROM employee WHERE fname = 'Jane' );+ | emp_id | fname | lname | start_date | end_date | superior_emp_id | dept_id | title | assigned_branch_id | + | 2 | Susan | Barker | 2002 -09 -12 | NULL | 1 | 3 | Vice President | 1 | | 5 | John | Gooding | 2003 -11 -14 | NULL | 4 | 2 | Loan Manager | 1 | | 6 | Helen | Fleming | 2004 -03 -17 | NULL | 4 | 1 | Head Teller | 1 | | 7 | Chris | Tucker | 2004 -09 -15 | NULL | 6 | 1 | Teller | 1 | | 8 | Sarah | Parker | 2002 -12 -02 | NULL | 6 | 1 | Teller | 1 | | 10 | Paula | Roberts | 2002 -07 -27 | NULL | 4 | 1 | Head Teller | 2 | | 12 | Samantha | Jameson | 2003 -01 -08 | NULL | 10 | 1 | Teller | 2 | | 14 | Cindy | Mason | 2002 -08 -09 | NULL | 13 | 1 | Teller | 3 | | 15 | Frank | Portman | 2003 -04 -01 | NULL | 13 | 1 | Teller | 3 | | 17 | Beth | Fowler | 2002 -06 -29 | NULL | 16 | 1 | Teller | 4 | | 18 | Rick | Tulman | 2002 -12 -12 | NULL | 16 | 1 | Teller | 4 | | 19 | Rick | Tulman | 2002 -12 -12 | NULL | 16 | NULL | Teller | 4 | + 12 rows in set (0.01 sec)
称谓的规范:外查询、内查询或者主查询,子查询
子查询在主查询之前一次执行完成
子查询的结果被主查询使用
注意:
子查询要在括号内
子查询放在比较条件的右侧
单行操作符对应单行子查询,多行操作符对应多行子查询
子查询通过两种分类方式可以进行分类
子查询返回结果数:
单行子查询:子查询结果只有1行
多行子查询:子查询结果可能有多个
子查询是否被执行多次
相关子查询:子查询条件会执行多次,与主查询条件有关联,例如查询全校学生成绩大于班级平均成绩,子查询条件需要与班级挂钩,每次查询都需要传入子查询进行查询
不相关子查询:子查询条件只执行一次,与主查询条件没有任何关联,例如查询全校学生成绩大于学校平均成绩,子查询条件与主查询条件无关,子查询只查询一次
单行子查询 单行操作符:= != > < >= <=
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 SELECT * FROM employee WHERE start_date > (SELECT start_date FROM employee WHERE fname = 'Jane' );+ | emp_id | fname | lname | start_date | end_date | superior_emp_id | dept_id | title | assigned_branch_id | + | 2 | Susan | Barker | 2002 -09 -12 | NULL | 1 | 3 | Vice President | 1 | | 5 | John | Gooding | 2003 -11 -14 | NULL | 4 | 2 | Loan Manager | 1 | | 6 | Helen | Fleming | 2004 -03 -17 | NULL | 4 | 1 | Head Teller | 1 | | 7 | Chris | Tucker | 2004 -09 -15 | NULL | 6 | 1 | Teller | 1 | | 8 | Sarah | Parker | 2002 -12 -02 | NULL | 6 | 1 | Teller | 1 | | 10 | Paula | Roberts | 2002 -07 -27 | NULL | 4 | 1 | Head Teller | 2 | | 12 | Samantha | Jameson | 2003 -01 -08 | NULL | 10 | 1 | Teller | 2 | | 14 | Cindy | Mason | 2002 -08 -09 | NULL | 13 | 1 | Teller | 3 | | 15 | Frank | Portman | 2003 -04 -01 | NULL | 13 | 1 | Teller | 3 | | 17 | Beth | Fowler | 2002 -06 -29 | NULL | 16 | 1 | Teller | 4 | | 18 | Rick | Tulman | 2002 -12 -12 | NULL | 16 | 1 | Teller | 4 | | 19 | Rick | Tulman | 2002 -12 -12 | NULL | 16 | NULL | Teller | 4 | + 12 rows in set (0.01 sec)
如果单行子查询结果为null,则不会返回任何行。如果多行子查询结果包含null,
1 2 3 SELECT * FROM employee WHERE start_date > (SELECT start_date FROM employee WHERE fname = 'mitaka' );Empty set (0.01 sec)
多行子查询 多行操作符:
IN等于列表中的任意一个;ANY需要和单行比较操作符一起使用,和子查询返回的某一个值比较; ALL:需要和单行比较符一起使用,和子查询返回的所有值比较; SOME:实际上是ANY的别名,作用相同,一般使用ANY。
多行子查询
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 SELECT * FROM employee WHERE start_date IN (SELECT start_date FROM employee WHERE superior_emp_id = 1 );+ | emp_id | fname | lname | start_date | end_date | superior_emp_id | dept_id | title | assigned_branch_id | + | 2 | Susan | Barker | 2002 -09 -12 | NULL | 1 | 3 | Vice President | 1 | | 3 | Robert | Tyler | 2000 -02 -09 | NULL | 1 | 3 | Treasurer | 1 | + 2 rows in set (0.00 sec)SELECT * FROM employee WHERE start_date > ANY (SELECT start_date FROM employee WHERE superior_emp_id = 1 );+ | emp_id | fname | lname | start_date | end_date | superior_emp_id | dept_id | title | assigned_branch_id | + | 1 | Michael | Smith | 2001 -06 -22 | NULL | NULL | 3 | President | 1 | | 2 | Susan | Barker | 2002 -09 -12 | NULL | 1 | 3 | Vice President | 1 | | 4 | Susan | Hawthorne | 2002 -04 -24 | NULL | 3 | 1 | Operations Manager | 1 | | 5 | John | Gooding | 2003 -11 -14 | NULL | 4 | 2 | Loan Manager | 1 | | 6 | Helen | Fleming | 2004 -03 -17 | NULL | 4 | 1 | Head Teller | 1 | | 7 | Chris | Tucker | 2004 -09 -15 | NULL | 6 | 1 | Teller | 1 | | 8 | Sarah | Parker | 2002 -12 -02 | NULL | 6 | 1 | Teller | 1 | | 9 | Jane | Grossman | 2002 -05 -03 | NULL | 6 | 1 | Teller | 1 | | 10 | Paula | Roberts | 2002 -07 -27 | NULL | 4 | 1 | Head Teller | 2 | | 11 | Thomas | Ziegler | 2000 -10 -23 | NULL | 10 | 1 | Teller | 2 | | 12 | Samantha | Jameson | 2003 -01 -08 | NULL | 10 | 1 | Teller | 2 | | 13 | John | Blake | 2000 -05 -11 | NULL | 4 | 1 | Head Teller | 3 | | 14 | Cindy | Mason | 2002 -08 -09 | NULL | 13 | 1 | Teller | 3 | | 15 | Frank | Portman | 2003 -04 -01 | NULL | 13 | 1 | Teller | 3 | | 16 | Theresa | Markham | 2001 -03 -15 | NULL | 4 | 1 | Head Teller | 4 | | 17 | Beth | Fowler | 2002 -06 -29 | NULL | 16 | 1 | Teller | 4 | | 18 | Rick | Tulman | 2002 -12 -12 | NULL | 16 | 1 | Teller | 4 | | 19 | Rick | Tulman | 2002 -12 -12 | NULL | 16 | NULL | Teller | 4 | + 18 rows in set (0.01 sec)SELECT * FROM employee WHERE start_date > ALL (SELECT start_date FROM employee WHERE superior_emp_id = 1 );+ | emp_id | fname | lname | start_date | end_date | superior_emp_id | dept_id | title | assigned_branch_id | + | 5 | John | Gooding | 2003 -11 -14 | NULL | 4 | 2 | Loan Manager | 1 | | 6 | Helen | Fleming | 2004 -03 -17 | NULL | 4 | 1 | Head Teller | 1 | | 7 | Chris | Tucker | 2004 -09 -15 | NULL | 6 | 1 | Teller | 1 | | 8 | Sarah | Parker | 2002 -12 -02 | NULL | 6 | 1 | Teller | 1 | | 12 | Samantha | Jameson | 2003 -01 -08 | NULL | 10 | 1 | Teller | 2 | | 15 | Frank | Portman | 2003 -04 -01 | NULL | 13 | 1 | Teller | 3 | | 18 | Rick | Tulman | 2002 -12 -12 | NULL | 16 | 1 | Teller | 4 | | 19 | Rick | Tulman | 2002 -12 -12 | NULL | 16 | NULL | Teller | 4 | + 8 rows in set (0.01 sec)
多行子查询结果中如果包含NULL,需要注意联合使用 NOT IN时
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 SELECT * FROM employee WHERE emp_id IN (SELECT superior_emp_id FROM employee WHERE assigned_branch_id = 1 );+ | emp_id | fname | lname | start_date | end_date | superior_emp_id | dept_id | title | assigned_branch_id | + | 1 | Michael | Smith | 2001 -06 -22 | NULL | NULL | 3 | President | 1 | | 3 | Robert | Tyler | 2000 -02 -09 | NULL | 1 | 3 | Treasurer | 1 | | 4 | Susan | Hawthorne | 2002 -04 -24 | NULL | 3 | 1 | Operations Manager | 1 | | 6 | Helen | Fleming | 2004 -03 -17 | NULL | 4 | 1 | Head Teller | 1 | + 4 rows in set (0.01 sec)SELECT * FROM employee WHERE emp_id NOT IN (SELECT superior_emp_id FROM employee WHERE assigned_branch_id = 1 );Empty set (0.03 sec)SELECT * FROM employee WHERE emp_id NOT IN (SELECT superior_emp_id FROM employee WHERE assigned_branch_id = 1 AND superior_emp_id IS NOT NULL );+ | emp_id | fname | lname | start_date | end_date | superior_emp_id | dept_id | title | assigned_branch_id | + | 2 | Susan | Barker | 2002 -09 -12 | NULL | 1 | 3 | Vice President | 1 | | 5 | John | Gooding | 2003 -11 -14 | NULL | 4 | 2 | Loan Manager | 1 | | 7 | Chris | Tucker | 2004 -09 -15 | NULL | 6 | 1 | Teller | 1 | | 8 | Sarah | Parker | 2002 -12 -02 | NULL | 6 | 1 | Teller | 1 | | 9 | Jane | Grossman | 2002 -05 -03 | NULL | 6 | 1 | Teller | 1 | | 10 | Paula | Roberts | 2002 -07 -27 | NULL | 4 | 1 | Head Teller | 2 | | 11 | Thomas | Ziegler | 2000 -10 -23 | NULL | 10 | 1 | Teller | 2 | | 12 | Samantha | Jameson | 2003 -01 -08 | NULL | 10 | 1 | Teller | 2 | | 13 | John | Blake | 2000 -05 -11 | NULL | 4 | 1 | Head Teller | 3 | | 14 | Cindy | Mason | 2002 -08 -09 | NULL | 13 | 1 | Teller | 3 | | 15 | Frank | Portman | 2003 -04 -01 | NULL | 13 | 1 | Teller | 3 | | 16 | Theresa | Markham | 2001 -03 -15 | NULL | 4 | 1 | Head Teller | 4 | | 17 | Beth | Fowler | 2002 -06 -29 | NULL | 16 | 1 | Teller | 4 | | 18 | Rick | Tulman | 2002 -12 -12 | NULL | 16 | 1 | Teller | 4 | | 19 | Rick | Tulman | 2002 -12 -12 | NULL | 16 | NULL | Teller | 4 | + 15 rows in set (0.00 sec)
相关子查询 子查询的执行依赖于外部查询,通常情况下是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次主查询,子查询都要重新计算一次,这样的自查阿勋就称之为关键子查询 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 SELECT account_id,avail_balance,product_cd,open_branch_id FROM account `a1` WHERE a1.avail_balance > (SELECT AVG (avail_balance) FROM account `a2` WHERE open_branch_id = a1.open_branch_id);+ | account_id | avail_balance | product_cd | open_branch_id | + | 12 | 5487.09 | MM | 1 | | 15 | 10000.00 | CD | 1 | | 17 | 5000.00 | CD | 2 | | 22 | 9345.55 | MM | 1 | | 24 | 23575.12 | CHK | 4 | | 27 | 9345.55 | BUS | 2 | | 28 | 38552.05 | CHK | 4 | | 29 | 50000.00 | SBL | 3 | + 8 rows in set (0.01 sec)SELECT a.account_id,a.avail_balance,a.product_cd,a.open_branch_id FROM account a,(SELECT open_branch_id,AVG (avail_balance) avg_avail_balance FROM account GROUP BY open_branch_id) avg_open_branch_id WHERE a.open_branch_id = avg_open_branch_id.open_branch_id AND a.avail_balance > avg_open_branch_id.avg_avail_balance;+ | account_id | avail_balance | product_cd | open_branch_id | + | 12 | 5487.09 | MM | 1 | | 15 | 10000.00 | CD | 1 | | 17 | 5000.00 | CD | 2 | | 22 | 9345.55 | MM | 1 | | 24 | 23575.12 | CHK | 4 | | 27 | 9345.55 | BUS | 2 | | 28 | 38552.05 | CHK | 4 | | 29 | 50000.00 | SBL | 3 | + 8 rows in set (0.03 sec)SELECT emp_id,dept_id FROM employee e ORDER BY (SELECT `name` FROM department d WHERE e.dept_id = d.dept_id);+ | emp_id | dept_id | + | 19 | NULL | | 3 | 3 | | 2 | 3 | | 1 | 3 | | 5 | 2 | | 13 | 1 | | 18 | 1 | | 17 | 1 | | 16 | 1 | | 15 | 1 | | 14 | 1 | | 12 | 1 | | 11 | 1 | | 10 | 1 | | 9 | 1 | | 8 | 1 | | 7 | 1 | | 6 | 1 | | 4 | 1 | + 19 rows in set (0.01 sec)
子查询可以使用的位置:除了 GROUP BY 和 LIMIT 之外,其他位置可以声明子查询。
EXISTS 和 NOT EXISTS 关联查询通常会和EXISTS操作符一起使用,用来检查子查询中是否存在满足条件的行。
如果子查询中不存在满足条件的行:
如果子查询中存在满足条件的行:
NOT EXISTS 关键字表示,如果不存在某种条件,则返回TRUE,否则返回FALSE
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 SELECT DISTINCT e2.emp_id,e2.fname,e2.superior_emp_id FROM employee e1 JOIN employee e2 ON e1.superior_emp_id = e2.emp_id ;+ | emp_id | fname | superior_emp_id | + | 1 | Michael | NULL | | 3 | Robert | 1 | | 4 | Susan | 3 | | 6 | Helen | 4 | | 10 | Paula | 4 | | 13 | John | 4 | | 16 | Theresa | 4 | + 7 rows in set (0.01 sec)SELECT e1.emp_id,e1.fname,e1.superior_emp_id FROM employee e1 WHERE e1.emp_id IN (SELECT superior_emp_id FROM employee e2);+ | emp_id | fname | superior_emp_id | + | 1 | Michael | NULL | | 3 | Robert | 1 | | 4 | Susan | 3 | | 6 | Helen | 4 | | 10 | Paula | 4 | | 13 | John | 4 | | 16 | Theresa | 4 | + 7 rows in set (0.01 sec)SELECT e1.emp_id,e1.fname,e1.superior_emp_id FROM employee e1 WHERE EXISTS (SELECT * FROM employee e2 WHERE e1.emp_id = e2.superior_emp_id);+ | emp_id | fname | superior_emp_id | + | 1 | Michael | NULL | | 3 | Robert | 1 | | 4 | Susan | 3 | | 6 | Helen | 4 | | 10 | Paula | 4 | | 13 | John | 4 | | 16 | Theresa | 4 | + 7 rows in set (0.01 sec)SELECT e1.emp_id,e1.fname,e1.superior_emp_id FROM employee e1 WHERE NOT EXISTS (SELECT * FROM employee e2 WHERE e1.emp_id = e2.superior_emp_id);+ | emp_id | fname | superior_emp_id | + | 2 | Susan | 1 | | 5 | John | 4 | | 7 | Chris | 6 | | 8 | Sarah | 6 | | 9 | Jane | 6 | | 11 | Thomas | 10 | | 12 | Samantha | 10 | | 14 | Cindy | 13 | | 15 | Frank | 13 | | 17 | Beth | 16 | | 18 | Rick | 16 | | 19 | Rick | 16 | + 12 rows in set (0.02 sec)
创建和管理表 数据存储过程总共有4步,分别是创建数据库 、确认字段 、创建数据表 、插入数据 。
数据库名称、表名称只能由数字、字母、下划线组成。
数据库名、表名、字段名等对象名中不要包含空格。
数据库不能重名,同一个数据库中表不能重名,同一个表中字段不能重名。
保持字段名和类型的一致性:当一个字段出现在多个表中,需要保持该字段在多张表中的数据类型一致。
创建和管理数据库 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 CREATE DATABASE mitaka1;Query OK, 1 row affected (0.03 sec) CREATE DATABASE mitaka2 CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;Query OK, 1 row affected (0.01 sec) CREATE DATABASE IF NOT EXISTS mitaka1;Query OK, 1 row affected, 1 warning (0.01 sec) CREATE DATABASE IF NOT EXISTS mitaka3 CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci;Query OK, 1 row affected, 1 warning (0.00 sec) SHOW databases;+ | Database | + | employees | | information_schema | | mitaka | | mitaka1 | | mitaka2 | | mitaka3 | | mysql | | mytest | | performance_schema | | sys | + 10 rows in set (0.01 sec)SHOW CREATE DATABASE mitaka1;+ | Database | Create Database | + | mitaka1 | CREATE DATABASE `mitaka1` | + 1 row in set (0.00 sec)USE mitaka; Database changed show tables;SELECT DATABASE() FROM DUAL;+ | DATABASE() | + | mitaka | + 1 row in set (0.01 sec)SHOW TABLES FROM mitaka;ALTER DATABASE mitaka2 CHARACTER SET utf8;Query OK, 1 row affected, 1 warning (0.02 sec) DROP DATABASE mitaka1;Query OK, 0 rows affected (0.02 sec) DROP DATABASE IF EXISTS mitaka2;Query OK, 0 rows affected (0.03 sec)
数据类型 数据类型也就是表中的字段类型:
数字:
类型
举例
整数
TINYINT, SMALLINT, MEDIUMINT, INT或者INTEGER , BIGINT
浮点
FLOAT, DOUBLE
定点数类型
DECIMAL
位类型
BIT
日期时间:
类型
举例
日期时间
YEAR, TIME, DATE , DATETIME, TIMESTAMP
字符串:
类型
举例
文本
CHAR , VARCHAR , TINYEXT, TEXT, MEDIUMTEXT, LONGTEXT
枚举类型
ENUM
集合类型
SET
二进制字符串类型
BINARY, VARBINARY, TINYBLOB, BLOB, MEDIUMBLOB, LONGBLOB
JSON类型
JSON对象,JSON数组
空间数据类型
类型
举例
空间数据类型
单值:GEOMETRY, POINT, LINESTRING, POLYGON
创建表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 CREATE TABLE IF NOT EXISTS mytable1 (id INT , name VARCHAR (15 ), hire_date DATE ); Query OK, 0 rows affected, 1 warning (0.02 sec) SHOW CREATE TABLE mytable1;+ | Table | Create Table | + | mytable1 | CREATE TABLE `mytable1` ( `user_id` varchar (20 ) DEFAULT NULL , `id` int DEFAULT NULL , `name` varchar (30 ) DEFAULT (_utf8mb4'aaa' ), `email` varchar (20 ) DEFAULT NULL , `hire_date` date DEFAULT NULL ) ENGINE= InnoDB DEFAULT CHARSET= utf8mb4 COLLATE = utf8mb4_0900_ai_ci | + 1 row in set (0.01 sec)DESC mytable1;+ | Field | Type | Null | Key | Default | Extra | + | user_id | varchar (20 ) | YES | | NULL | | | id | int | YES | | NULL | | | name | varchar (30 ) | YES | | _utf8mb4'aaa' | DEFAULT_GENERATED | | email | varchar (20 ) | YES | | NULL | | | hire_date | date | YES | | NULL | | + 5 rows in set (0.01 sec)CREATE TABLE IF NOT EXISTS mytable2 AS SELECT id,name,hire_date FROM mytable1;Query OK, 0 rows affected (0.04 sec) Records: 0 Duplicates: 0 Warnings: 0 CREATE TABLE IF NOT EXISTS mytable3 AS SELECT e1.id new_id,e2.id old_id FROM mytable1 e1 JOIN mytable2 e2 ON e1.id = e2.id;Query OK, 0 rows affected, 1 warning (0.01 sec)
修改表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 ALTER TABLE mytable1 ADD salary DOUBLE (10 ,2 );Query OK, 0 rows affected, 1 warning (0.03 sec) Records: 0 Duplicates: 0 Warnings: 1 ALTER TABLE mytable1 ADD user_id2 VARCHAR (20 ) FIRST ;Query OK, 0 rows affected (0.04 sec) Records: 0 Duplicates: 0 Warnings: 0 ALTER TABLE mytable1 ADD email2 VARCHAR (20 ) AFTER name;Query OK, 0 rows affected (0.06 sec) Records: 0 Duplicates: 0 Warnings: 0 ALTER TABLE mytable1 MODIFY name VARCHAR (30 ) DEFAULT ('aaa' );Query OK, 0 rows affected (0.02 sec) Records: 0 Duplicates: 0 Warnings: 0 ALTER TABLE mytable1 CHANGE salary monthly_salary DOUBLE (100 ,2 );Query OK, 0 rows affected, 1 warning (0.03 sec) Records: 0 Duplicates: 0 Warnings: 1 ALTER TABLE mytable1 DROP COLUMN monthly_salary;Query OK, 0 rows affected (0.05 sec) Records: 0 Duplicates: 0 Warnings: 0
重命名表
1 2 3 4 5 6 7 RENAME TABLE mytable1 TO my_other_table1; Query OK, 0 rows affected (0.03 sec) ALTER TABLE my_other_table1 RENAME TO mytable1;Query OK, 0 rows affected (0.05 sec)
删除表
1 2 3 4 5 6 DROP TABLE mytable2;Query OK, 0 rows affected (0.04 sec) DROP TABLE IF EXISTS mytable3;Query OK, 0 rows affected (0.04 sec)
清空表
1 2 3 4 5 6 TRUNCATE TABLE mytable1;Query OK, 0 rows affected (0.06 sec) DELETE FROM mytable1;Query OK, 0 rows affected (0.01 sec)
清空表数据的两种方式对比 COMMIT:提交数据,一旦执行,则数据就永久保存在数据库中,意味着数据不可以回滚。
ROLLBACK:回滚数据,一旦执行,则可以实现数据的回滚,回滚到数据最近的一次COMMIT之后。
对于 TRUNCATE TABLE 和 DELETE FROM
相同点:都可以实现对表中所有数据清除,保留表结构
不同点:
TRUNCATE TABLE:一旦执行此操作,表中数据全部清除,同时,数据时不可以回滚的DELETE FROM:一旦执行此操作,表中数据可以全部清除(不带WHERE的条件),同时,数据是可以回滚的。
DDL 和 DML
DDL:一旦执行,就不可回滚
DML:默认情况下,一旦执行,不可回滚。但是,如果在执行DML之前,执行 SET AUTOCOMMIT = FALSE,则执行的DML操作就可以实现回滚。
通过DML的 DELETE FROM清空表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 COMMIT ;Query OK, 0 rows affected (0.00 sec) SELECT * FROM mytable2;+ | id | name | hire_date | + | 1 | mitaka | 2022 -11 -30 | + 1 row in set (0.00 sec)SET autocommit = FALSE ;Query OK, 0 rows affected (0.01 sec) DELETE FROM mytable2;Query OK, 1 row affected (0.00 sec) SELECT * FROM mytable2;Empty set (0.00 sec)ROLLBACK ;Query OK, 0 rows affected (0.03 sec) SELECT * FROM mytable2;+ | id | name | hire_date | + | 1 | mitaka | 2022 -11 -30 | + 1 row in set (0.01 sec)
通过DDL的 TRUNCATE mytable2;清空表
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 COMMIT ;Query OK, 0 rows affected (0.00 sec) SELECT * FROM mytable2;+ | id | name | hire_date | + | 1 | mitaka | 2022 -11 -30 | + 1 row in set (0.01 sec)SET autocommit = FALSE ;Query OK, 0 rows affected (0.01 sec) TRUNCATE mytable2;Query OK, 0 rows affected (0.04 sec) SELECT * FROM mytable2;Empty set (0.01 sec)ROLLBACK ;Query OK, 0 rows affected (0.01 sec) SELECT * FROM mytable2;Empty set (0.01 sec)
这是由于操作DDL之后,一定会执行COMMIT,这个COMMIT不受autocommit影响。
阿里开发规范:
truncate table比delete速度快,且占用系统和事务日志资源少,但truncate无事务且不触发trigger,有可能造成事故,故不建议在开发代码中使用词句。
说明:truncate table在功能上与不带where子句的delete语句相同。
在MySQL 8.0中,支持DDL事务性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 CREATE DATABASE mytest;Query OK, 1 row affected (0.02 sec) USE mytest; Database changed CREATE TABLE boo1(id int );Query OK, 0 rows affected (0.05 sec) DROP TABLE boo1,boo2;ERROR 1051 (42 S02): Unknown table 'mytest.boo2' show tables;+ | Tables_in_mytest | + | boo1 | + 1 row in set (0.02 sec)
增删改 增加数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 DESC employee_sub;+ | Field | Type | Null | Key | Default | Extra | + | id | int | YES | | NULL | | | fname | varchar (20 ) | NO | | NULL | | | lname | varchar (20 ) | NO | | NULL | | | start_date | date | NO | | NULL | | + 4 rows in set (0.00 sec)SELECT * FROM employee_sub;+ | id | fname | lname | start_date | + | 1 | mitaka | c | 2022 -01 -01 | ... + 23 rows in set (0.00 sec)
一条一条添加数据
1 2 3 4 5 6 7 8 9 10 11 12 INSERT INTO employee_sub VALUES (1 ,'mitaka' ,'x' ,'2022-10-10' );Query OK, 1 row affected (0.00 sec) INSERT INTO employee_sub(id,start_date,fname,lname) VALUES (2 ,'2022-10-10' ,'xiaoyeshiyu' ,'lname' );Query OK, 1 row affected (0.00 sec) INSERT INTO employee_sub VALUES (3 ,'a' ,'l' ,'2022-10-10' ),(4 ,'b' ,'l' ,'2022-10-10' );Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0
批量插入,也就是将查询结果插入进去
1 2 3 4 INSERT INTO employee_sub SELECT emp_id,fname,lname,start_date FROM employee;Query OK, 19 rows affected (0.02 sec) Records: 19 Duplicates: 0 Warnings: 0
注意:
关键字 VALUES也可以是 VALUE,不过 VALUES是规范
字符串、时间类型,需要使用单引号 ''
更新数据 1 2 3 4 5 6 7 8 9 10 11 UPDATE employee_sub SET start_date = '2022-10-11' WHERE id = 1 ;Query OK, 3 rows affected (0.01 sec) Rows matched: 4 Changed: 3 Warnings: 0 UPDATE employee_sub SET start_date = '2022-01-01' ,lname = 'c' WHERE id = 1 ;Query OK, 4 rows affected (0.01 sec) Rows matched: 4 Changed: 4 Warnings: 0
删除数据 1 2 3 4 5 6 DELETE FROM employee_sub WHERE id = 1 ;Query OK, 4 rows affected (0.00 sec)
总结 DML操作,默认情况下,执行完之后,就会自动提交数据。
如果希望执行完以后,不自动提交数据,则需要使用 set autocommit = false
MySQL 8新特性:计算列 当a列是1,b列式2,c列不需要手动插入,插入a列和b列之后,定义a+b的结果为c列的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 CREATE TABLE mytable3 (id INT , a INT , b INT , c INT GENERATED ALWAYS AS (a + b) VIRTUAL ); Query OK, 0 rows affected (0.06 sec) INSERT INTO mytable3(a,b) VALUES (1 ,2 ),(100 ,200 );Query OK, 2 rows affected (0.01 sec) Records: 2 Duplicates: 0 Warnings: 0 SELECT * FROM mytable3;+ | id | a | b | c | + | NULL | 1 | 2 | 3 | | NULL | 100 | 200 | 300 | + 2 rows in set (0.01 sec)
数据类型 数值类型 MySQL 支持所有标准 SQL 数值数据类型。
这些类型包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL 和 NUMERIC),以及近似数值数据类型(FLOAT、REAL 和 DOUBLE PRECISION)。
关键字INT是INTEGER的同义词,关键字DEC是DECIMAL的同义词。
BIT数据类型保存位字段值,并且支持 MyISAM、MEMORY、InnoDB 和 BDB表。
作为 SQL 标准的扩展,MySQL 也支持整数类型 TINYINT、MEDIUMINT 和 BIGINT。下面的表显示了需要的每个整数类型的存储和范围。
类型
大小
范围(有符号)
范围(无符号)
用途
TINYINT
1 Bytes
(-128,127)
(0,255)
小整数值
SMALLINT
2 Bytes
(-32 768,32 767)
(0,65 535)
大整数值
MEDIUMINT
3 Bytes
(-8 388 608,8 388 607)
(0,16 777 215)
大整数值
INT或INTEGER
4 Bytes
(-2 147 483 648,2 147 483 647)
(0,4 294 967 295)
大整数值
BIGINT
8 Bytes
(-9,223,372,036,854,775,808,9 223 372 036 854 775 807)
(0,18 446 744 073 709 551 615)
极大整数值
FLOAT
4 Bytes
(-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38)
0,(1.175 494 351 E-38,3.402 823 466 E+38)
单精度 浮点数值
DOUBLE
8 Bytes
(-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308)
0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308)
双精度 浮点数值
DECIMAL
对DECIMAL(M,D) ,如果M>D,为M+2,否则为D+2
高精度小数,依赖于M和D的值,默认是(10,0),M代表数字总长度,D代表小数点后数字长度。相比上面两个浮点数而言,DECIMAL更加精确,因此,在对浮点数有精度要求的情况下,应使用DECIMAL。
依赖于M和D的值
小数值
INT(5)代表显示宽度(而不是长度),也就是支持5位数显示,需要与 ZEROFILL一起使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 CREATE TABLE test_int2(f1 INT (5 ), f2 INT (5 ) ZEROFILL ); Query OK, 0 rows affected, 3 warnings (0.05 sec) INSERT INTO test_int2 VALUES (1 ,1 ),(123456 ,123456 );Query OK, 2 rows affected (0.02 sec) Records: 2 Duplicates: 0 Warnings: 0 SELECT * FROM test_int2;+ | f1 | f2 | + | 1 | 00001 | | 123456 | 123456 | + 2 rows in set (0.00 sec)
日期和时间类型 表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个”零”值,当指定不合法的MySQL不能表示的值时使用”零”值。
TIMESTAMP类型有专有的自动更新特性,将在后面描述。
类型
大小 ( bytes)
范围
格式
用途
DATE
3
1000-01-01/9999-12-31
YYYY-MM-DD
日期值
TIME
3
‘-838:59:59’/‘838:59:59’(在表示时间间隔时,可以使用负数)
HH:MM:SS
时间值或持续时间
YEAR
1
1901/2155
YYYY
年份值
DATETIME
8
‘1000-01-01 00:00:00’ 到 ‘9999-12-31 23:59:59’。可通过current_timestanp().now(),systime()函数生成。
YYYY-MM-DD hh:mm:ss
混合日期和时间值
TIMESTAMP
4
‘1970-01-01 00:00:01’ UTC 到 ‘2038-01-19 03:14:07’ UTC结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07 ,格林尼治时间 2038年1月19日 凌晨 03:14:07。可通过current_timestanp().now(),systime()函数生成。
YYYY-MM-DD hh:mm:ss
混合日期和时间值,时间戳
DATETIME和TIMESTAMP的区别:
TIMESTAMP存储空间小,因此表示的时间范围也比较小(在1970-2038之间)底层存储方式不同,TIMESTAMP底层存储的是毫秒,距离1970-01-01 00:00:00的毫秒值
两个日期比较大小或者日期计算时,TIMESTAMP更方便更快
TIMESTAMP与时区有关,TIMESTAMP会根据用户的时区不同,显示不同的结果,而DATETIME只能反应出插入时当地的时区,其他时区的人查看数据必然会有误差。
实际项目中,尽量使用DATETIME类型,因为这个数据类型包括了完整的日期和时间信息,取值范围也最大,使用起来比较方便。
此外,一般存储注册时间、商品发布时间等,不建议使用DATETIME存储,而是使用TIMESTAMP,因为DATETIME虽然直观,但是不便于计算。
字符串类型 字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
类型
大小
用途
CHAR
0-255 bytes
定长字符串,声明多少长度,存储时就占用多少空间。(1:1或1:3,根据字符集判断字节数),不写长度默认是1.
VARCHAR
0-65535 bytes
变长字符串,必须定义长度,最长为21845,因为1个中文占用3个字节。
TINYBLOB
0-255 bytes
不超过 255 个字符的二进制字符串
TINYTEXT
0-255 bytes
短文本字符串
BLOB
0-65 535 bytes(64KB)
二进制形式的长文本数据
TEXT
0-65 535 bytes
长文本数据
MEDIUMBLOB
0-16 777 215 bytes(16M)
二进制形式的中等长度文本数据
MEDIUMTEXT
0-16 777 215 bytes
中等长度文本数据
LONGBLOB
0-4 294 967 295 bytes(4G)
二进制形式的极大文本数据
LONGTEXT
0-4 294 967 295 bytes
极大文本数据
注意 :char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符。
CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同(select concat(c1,’****’) from test_char 这个命令可以看到字符串在右侧填充)。在存储或检索过程中不进行大小写转换。
CHAR和VARCHAR的比较:
CHAR(M):固定长度,空间上浪费存储空间,时间上效率高,适用于存储不大,速度要求高的场景
VARCHAR(M):可变长度,空间上节省存储空间,时间上效率低,使用与非CHAR的情况
情况1:存储很短的信息,应该用char
情况2:固定商都,比如使用uuid,使用char更合适
情况3:很频繁的改变column,因为varchar每次存储都要有额外的计算,得到长度等工作,如果一个column频繁改变,使用char更好
情况4:根据存储引擎决定:
MyISAM存储引擎和数据列:最好使用固定长度的数据列代替可变长度的数据列,使整个表竞态话,从而使数据检索更快,用空间换时间
MEMORY存储引擎和数据列:MEMORY数据表目前都是用固定长度的数据行存储,因此无论使用CHAR或VARCHAR都没有关系,都是作为CHAR处理
InnoDB存储引擎,建议使用VARCHAR类型。内部的行存储格式并没有区分固定长度和可变长度列(所有数据行都是用纸箱数据列值的头指针),而且主要影响性能的因素是数据行使用的存储总量 ,由于char平均占用的空间多余varchar,所以除了简短并且固定长度的,其他考虑varchar,这样节省空间,对磁盘I\O和数据存储总量比较好。
BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。
有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。由于实际存储长度不确定,因此MySQL不允许TEXT类型的字段做主键。遇到这种情况,可以使用CHAR(M)或VARCHAR(M)。
text和blob类型的数据删除后容易导致“空洞”,使得文件碎片比较多,所以频繁使用的表不建议包含TEXT类型字段,建议单独分出去用一个独立的表。
枚举类型
类型
大小
用途
ENUM
1个或2个字节,长度1<=L<=65535,当包含1255个成员,需要1个字节存储空间,包含25625535个成员,需要2个字节的存储空间,上限为65535个
固定值类型进行枚举
SET
根据成员个数,1<=L<=8占用1个字节,以此类推,最多64个成员占用8个字节。
选取多个枚举类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 CREATE TABLE `b` ( `k` ENUM('T' ,'F' ) NOT NULL ); Query OK, 0 rows affected (0.05 sec) INSERT INTO `b` (`k`) VALUES ('T' ), ('F' );Query OK, 2 rows affected (0.01 sec) Records: 2 Duplicates: 0 Warnings: 0 CREATE TABLE myset (col SET ('a' , 'b' , 'c' , 'd' ));/ / 新建表格Query OK, 0 rows affected (0.05 sec) INSERT INTO myset (col) VALUES ('a,d' ), ('d,a' ), ('a,d,a' ), ('a,d,d' ), ('d,a,d' );Query OK, 5 rows affected (0.02 sec) Records: 5 Duplicates: 0 Warnings: 0
数据类型总结 如果是整数,使用INT,如果是小数,使用DECIMAL(M,D),如果是日期,使用DATETIME。
任何字段如果是非负数,必须使用UNSIGENED
小数类型使用DECIMAL,禁止使用FLOAT和DOUBLE
字符串长度几乎相等,使用CHAR定长字符串类型
VARCHAR可变长字符串,不预先分配存储空间,长度不超过5000,如果长度大于此值定义字段类型为TEXT,独立出来一张表,用主键对应,避免影响其他字段索引效率
约束 数据完整性是指谁的精确性和可靠性,它是防止数据库中存在不符合语义规定的数据和防止因错误信息的输入输出造成无效操作或错误信息提出的。
SQL规范以约束的方式对表数据进行额外的条件限制:
实体完整性 Entity Intrgrity:一个表中,不能存在两条完全相同无法区分的记录,可以使用主键约束
域完整性Domain Integrity:例如年龄范围0-120,性别范围”男/女“
引用完整性Referential Integrity:例如员工所在部门,在部门表中要能找到这个部门
用户自定义完整性User-defined Integrity:例如用户名唯一、密码不能为空登,本部门经理的工资不得高于本部门职工的平均工资的5倍
表级的强制规定就是约束。可以在创建表时规定约束(CREATE TABLE语句),也可以在修改表时增加约束(ALTER TABLE),或者删除约束(ALTER TABLE)
约束分类:
约束字段个数:单列约束和多列约束
声明约束的位置:列级约束和表级约束
约束的作用:非空not null、唯一性约束unique、主键约束primary key、外键约束foregin key外键约束、检查约束check、默认值约束default
1 2 SELECT * FROM information_schema.table_constraints WHERE table_name = 'employees' ;
MySQL关键字
含义
NULL
数据列可包含NULL值,默认下,都可以为null
NOT NULL
数据列不允许包含NULL值,只能单独列设置,不能组合非空
DEFAULT
默认值
PRIMARY KEY
主键
AUTO_INCREMENT
自动递增,适用于整数类型
UNSIGNED
无符号
CHARACTER SET name
指定一个字符集(给表中的某个字段指定字符集)
非空约束 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 CREATE TABLE mitaka_test1 (id INT NOT NULL , last_name VARCHAR (15 ) NOT NULL , email VARCHAR (25 ), salary DECIMAL (10 ,2 ) ); Query OK, 0 rows affected (0.05 sec) INSERT INTO mitaka_test1 VALUES (1 ,'xiaoyeshiyu' ,'[email protected] ' ,2400 );Query OK, 1 row affected (0.02 sec) INSERT INTO mitaka_test1(id,email) VALUES (2 ,'[email protected] ' );"ERROR 1364 (HY000): Field 'last_name' doesn't have a default value" UPDATE mitaka_test1 SET last_name = NULL WHERE id = 1 ;ERROR 1048 (23000 ): Column 'last_name' cannot be null ALTER TABLE mitaka_test1 MODIFY email VARCHAR (25 ) NOT NULL ;Query OK, 0 rows affected (0.06 sec) Records: 0 Duplicates: 0 Warnings: 0 ALTER TABLE mitaka_test1 MODIFY email VARCHAR (25 );Query OK, 0 rows affected (0.08 sec) Records: 0 Duplicates: 0 Warnings: 0
唯一性约束 用来限制某个字段、列的值不能重复
同一个表可以有多个唯一性约束
唯一性约束可以用在多个列上,组成一个复合约束
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 CREATE TABLE test222(id INT UNIQUE , last_name VARCHAR (15 ), email VARCHAR (25 ) UNIQUE , salary DECIMAL (10 ,2 ), CONSTRAINT UNIQUE (email)); Query OK, 0 rows affected, 1 warning (0.07 sec) CREATE TABLE test2(id INT UNIQUE , last_name VARCHAR (15 ), email VARCHAR (25 ), salary DECIMAL (10 ,2 ), CONSTRAINT uk_test2_email UNIQUE (email)); Query OK, 0 rows affected (0.04 sec) DESC test2;+ | Field | Type | Null | Key | Default | Extra | + | id | int | YES | UNI | NULL | | | last_name | varchar (15 ) | YES | | NULL | | | email | varchar (25 ) | YES | UNI | NULL | | | salary | decimal (10 ,2 ) | YES | | NULL | | + 4 rows in set (0.01 sec)SELECT * FROM test2;UPDATE test2 SET salary = 3600 WHERE id = 3 ;Query OK, 0 rows affected (0.00 sec) Rows matched: 0 Changed: 0 Warnings: 0 INSERT INTO test2 VALUES (1 ,'m' ,'[email protected] ' ,3400 );Query OK, 1 row affected (0.02 sec) INSERT INTO test2 VALUES (2 ,'m' ,'[email protected] ' ,3500 );ERROR 1062 (23000 ): Duplicate entry '[email protected] ' for key 'test2.uk_test2_email' INSERT INTO test2 VALUES (4 ,'m' ,NULL ,3400 );Query OK, 1 row affected (0.01 sec) ALTER TABLE test2 ADD CONSTRAINT uk_test2_salary UNIQUE (salary);ERROR 1062 (23000 ): Duplicate entry '3400.00' for key 'test2.uk_test2_salary' Query OK, 0 rows affected (0.05 sec) Records: 0 Duplicates: 0 Warnings: 0 CREATE TABLE user1 (id INT , `name` VARCHAR (15 ), `password` VARCHAR (15 ), CONSTRAINT uk_user_name_pwd UNIQUE (`name`,`password`)); Query OK, 0 rows affected (0.04 sec) INSERT INTO user1 VALUES (1 ,'a' ,'a' );INSERT INTO user1 VALUES (1 ,'a' ,'b' );INSERT INTO user1 VALUES (1 ,'a' ,'a' );ALTER TABLE user1 DROP INDEX uk_user_name_pwd;
主键约束 用来唯一标识表中的一行记录。相当于唯一约束+非空约束的组合,主键约束不能重复也不能为NULL
一个表最多只能有一个主键约束,建立主键约束可以在列级别创建,也可以在表级别创建
主键约束对应表中的一列或多列(复合主键)
如果是多列组合的复合主键约束,则所有列都不能为空,并且组合的值不允许重复
MySQL的主键名总是PRIMARY,就算命名了主键约束也没用
当创建主键约束时,系统会默认在所在的列或列组合上建立对应的主键索引,如果删除主键约束,主键约束对应的索引就自动删除
需要注意,不要修改主键字段的值,因为主键是数据记录的唯一标识,修改主键的值就有可能破坏数据完整性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 CREATE TABLE test3(id INT PRIMARY KEY, last_name VARCHAR (15 ) PRIMARY KEY, salary DECIMAL (10 ,2 ), email VARCHAR (25 ) ); CREATE TABLE test3(id INT PRIMARY KEY, last_name VARCHAR (15 ), salary DECIMAL (10 ,2 ), email VARCHAR (25 ) ); SELECT * FROM information_schema.table_constraints WHERE table_name = 'test3' ;+ | CONSTRAINT_CATALOG | CONSTRAINT_SCHEMA | CONSTRAINT_NAME | TABLE_SCHEMA | TABLE_NAME | CONSTRAINT_TYPE | ENFORCED | + | def | mysql | PRIMARY | mysql | test3 | PRIMARY KEY | YES | + 1 row in set (0.02 sec)CREATE TABLE test4(id INT , last_name VARCHAR (15 ), salary DECIMAL (10 ,2 ), email VARCHAR (25 ), CONSTRAINT pk_test4_id PRIMARY KEY(id)); CREATE TABLE user3(id INT , `name` VARCHAR (15 ), `password` VARCHAR (15 ), PRIMARY KEY(`name`,`password`)); ALTER TABLE test6 ADD PRIMARY KEY(id);ALTER TABLE test6 DROP PRIMARY KEY;
自增列 某个字段的值自增,AUTO_INCREMENT。
一个表中最多只能有一个自增长列
当需要产生唯一标识符或顺序值时,可设置自增长列
自增长列约束的列必须是键列(主键列、唯一键列)
自增长约束的列的数据必须是整数类型
如果自增长列制定了0和null,会在当前最大值的基础上自增;如果自增列手动指定了具体值,则赋值为具体值。
auto increment自增不一定从1开始例如在表中插入第一条记录同时指定id为5,此后插入的记录id就会从6开始网上增。添加主键约束时,往往需要设置字段自增属性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 CREATE TABLE test7(id INT PRIMARY KEY auto_increment, last_name VARCHAR (15 ) ); INSERT INTO test7(last_name) VALUES ('m' );SELECT * FROM test7;INSERT INTO test7 VALUES (0 ,'a' );INSERT INTO test7 VALUES (NULL ,'a' );INSERT INTO test7 VALUES (8 ,'a' );DELETE FROM test7 WHERE id = 3 ;CREATE TABLE test8(id INT PRIMARY KEY, last_name VARCHAR (15 ) ); ALTER TABLE test8 MODIFY id INT auto_increment;ALTER TABLE test8 MODIFY id INT ;
外键约束 限制某个表的某个字段的引用完整性。FOREIGN KEY
例如员工表中的部门信息必须在部门表中存在。(员工表的部门id有外键约束,关联了部门表的主键id)
主表(父表):被引用的表,被参考的表;上例子中的部门表
从表(子表):引用别人的表,参考别人的表;上例子中的员工表
特点:
从表的外键列,比如引用、参考主表的主键或唯一约束的列;这是由于参考的值必须唯一。
创建约束时,不命名,默认名不是列名,而是自动产生一个外键名
创建表时就指定外键约束的话,需要先创建主表,再创建从表
删除表时,需要先删除从表,再删除住表
当主表的记录被从表参照时,主表的记录不允许删除,如果要删除数据,需要先删除从表中依赖该记录的数据,然后才可以删除主表的数据
在从表中指定外键约束,并且一个表可以建立多个外键约束
从表的外键列与主表被参照列的名字可以不相同,但是数据类型必须一样,逻辑意义一致,如果类型不一样,创建子表时,会出现报错
当创建外键约束时,系统默认会在所在的列上建立对应的普通索引 。但是索引名是列名,不是外键的约束名。(根据外键查询效率很高)删除外键约束后,必须手动删除 对应的索引
外键约束不能跨引擎使用。MySQL支持多种存储引擎,主表和从表不能跨引擎。因此,存储引擎也不能随意选择。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 CREATE TABLE dept1(dept_id INT , dept_name VARCHAR (15 ) ); CREATE TABLE emp1(emp_id INT PRIMARY KEY auto_increment, emp_name VARCHAR (15 ), department_id int , CONSTRAINT fk_emp1_dept_id FOREIGN KEY(department_id) REFERENCES dept1(dept_id)); ALTER TABLE dept1 ADD PRIMARY KEY(dept_id);DESC emp1;INSERT INTO emp1 VALUES (1 ,'m' ,1 );INSERT INTO dept1 VALUES (1 ,'sh' );DELETE FROM dept1 WHERE dept_id = 1 ;UPDATE dept1 SET dept_id = 2 WHERE dept_id = 1 ;CREATE TABLE dept2(dept_id INT PRIMARY KEY auto_increment, dept_name VARCHAR (15 ) ); CREATE TABLE emp2(emp_id INT PRIMARY KEY auto_increment, emp_name VARCHAR (15 ), department_id int ); ALTER TABLE emp2 ADD CONSTRAINT fk_emp2_dept_id FOREIGN KEY(department_id) REFERENCES dept2(dept_id);ALTER TABLE emp2 DROP CONSTRAINT fk_emp2_dept_id;SHOW INDEX FROM emp2;ALTER TABLE emp2 DROP INDEX fk_emp2_dept_id;
约束等级 约束等级限制主表修改时,从表是否或者如何同步修改。
Cascade方式:主表update、delete记录时,同步update、delete从表的匹配记录Set null方式:主表update、delete记录时,从表匹配的列设为null,但是要注意从表的外键列不能为not nullNo action方式:如果从表中有匹配的记录,则不允许对主表对应候选键进行update、delete操作Restrict方式:同no action,都是立即检查外键约束Set default方式:主表有变更时,从表将外键列设置成一个默认的值,但InnoDB不能识别。
如果没有指定等级,相当于Restrict方式。
对于外键约束,最好是采用 ON UPDATE CASCADE,ON DELETE RESTRICT的方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 CREATE TABLE dept3(dept_id INT PRIMARY KEY auto_increment, dept_name VARCHAR (15 ) ); CREATE TABLE emp3(emp_id INT PRIMARY KEY auto_increment, emp_name VARCHAR (15 ), department_id int , CONSTRAINT fk_emp3_dept_id FOREIGN KEY(department_id) REFERENCES dept3(dept_id) ON UPDATE CASCADE ON DELETE SET NULL ); INSERT INTO dept3 VALUES (1 ,'sh' );INSERT INTO emp3 VALUES (1 ,'m' ,1 ),(2 ,'m' ,1 );UPDATE dept3 SET dept_id = 2 WHERE dept_id = 1 ;SELECT * FROM emp3; DELETE FROM dept3 WHERE dept_id = 2 ;SELECT * FROM emp3;
使用场景
如果两个表有关系(一对一、一对多),是否一定要用外键约束
不是
建和不建外键约束有什么区别
建外键约束,操作(创建表、删除表、添加、修改、删除)会受到限制。
不建外键约束,操作(创建表、删除表、添加、修改、删除)不会受到限制,但是要保证数据的完整性,只能依靠开发者或是在代码层面限定。
建和不建外键约束和查询有没有关系
没有
MySQL中创建外键约束有成本,在大并发SQL操作外键约束会导致系统开销变得非常慢。
阿里开发约束:【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
级联:例如更新主表的id,从表的外键id也会更新,这就是级联更新。
使用外键和级联更适用于单机低并发,不适合分布式、高并发集群场景。级联更新是强阻塞,存在数据库更新风暴的风险;外键影响数据库的插入速度 。
检查约束 CHECK约束,检查某个字段的值是否符合要求,一般是值的范围。MySQL 5.7版本不支持,使用时不起作用。
1 2 3 4 5 6 7 8 CREATE TABLE test10(id INT , last_name VARCHAR (15 ), salary DECIMAL (10 ,2 ) CHECK (salary > 2000 ) ); INSERT INTO test10 VALUES (1 ,'m' ,1800 );
默认值约束 DEFAULT,给某个字段指定默认值,插入数据时,如果没有显示赋值,则赋值为默认值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 CREATE TABLE test11(id INT , last_name VARCHAR (15 ), salary DECIMAL (10 ,2 ) DEFAULT 2000 ); INSERT INTO test11(id,last_name,salary) VALUES (1 ,'m' ,3000 );INSERT INTO test11(id,last_name) VALUES (1 ,'m' );INSERT INTO test11(id,last_name,salary) VALUES (1 ,'m' ,NULL );SELECT * FROM test11;CREATE TABLE test12(id INT , last_name VARCHAR (15 ), salary DECIMAL (10 ,2 ) ); ALTER TABLE test12 MODIFY salary DECIMAL (10 ,2 ) DEFAULT 2000 ;ALTER TABLE test12 MODIFY salary DECIMAL (10 ,2 );
一般默认值约束会和非空约束联合使用,避免出现null,这是由于NULL值不好比较,只能用is null 或者is not null 比较;另外就是null值效率不高,没法提高索引效率。
推荐阅读:
50道SQL练习题及答案与详细分析
SQL的笛卡尔积
mysql5-7与mysql8-0关于with-rollup-order-by处理上的区别
Java开发手册
MySQL数据类型及字段属性