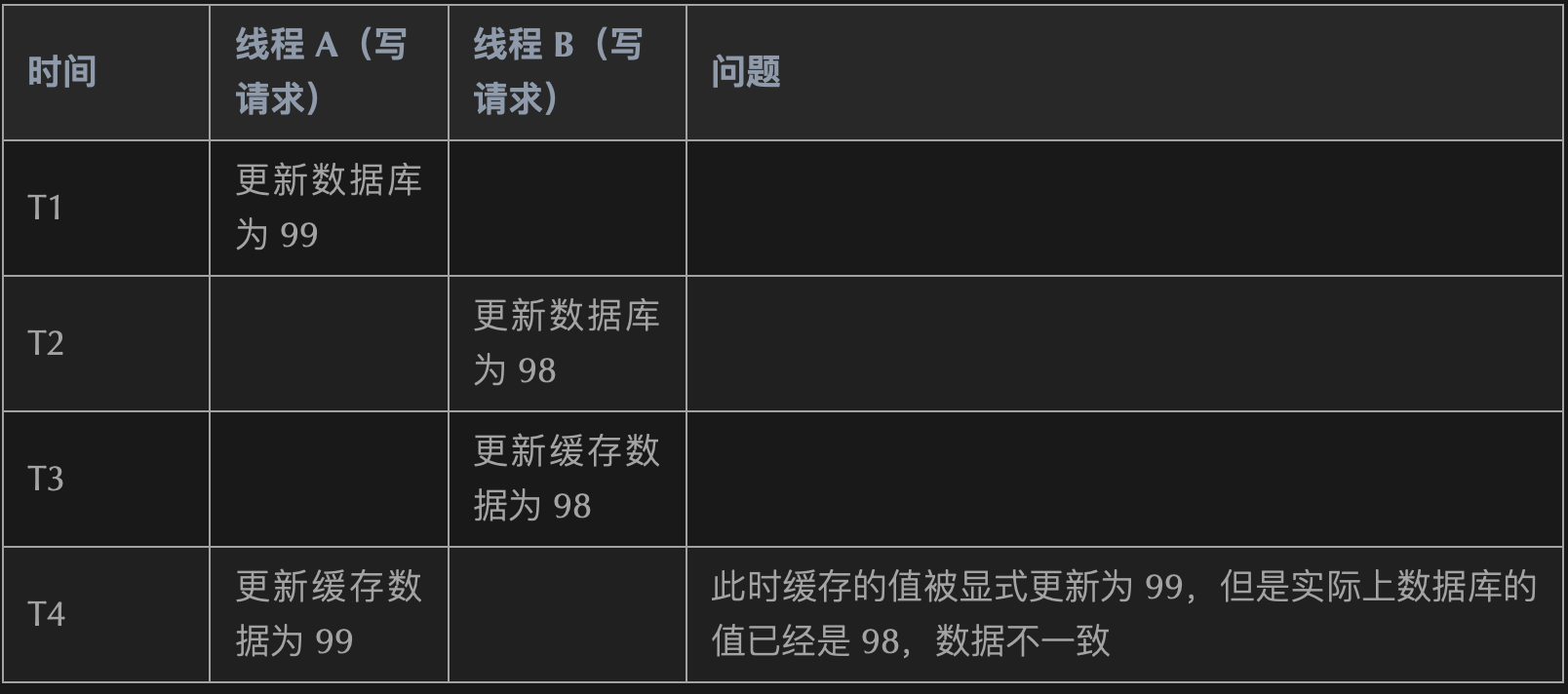
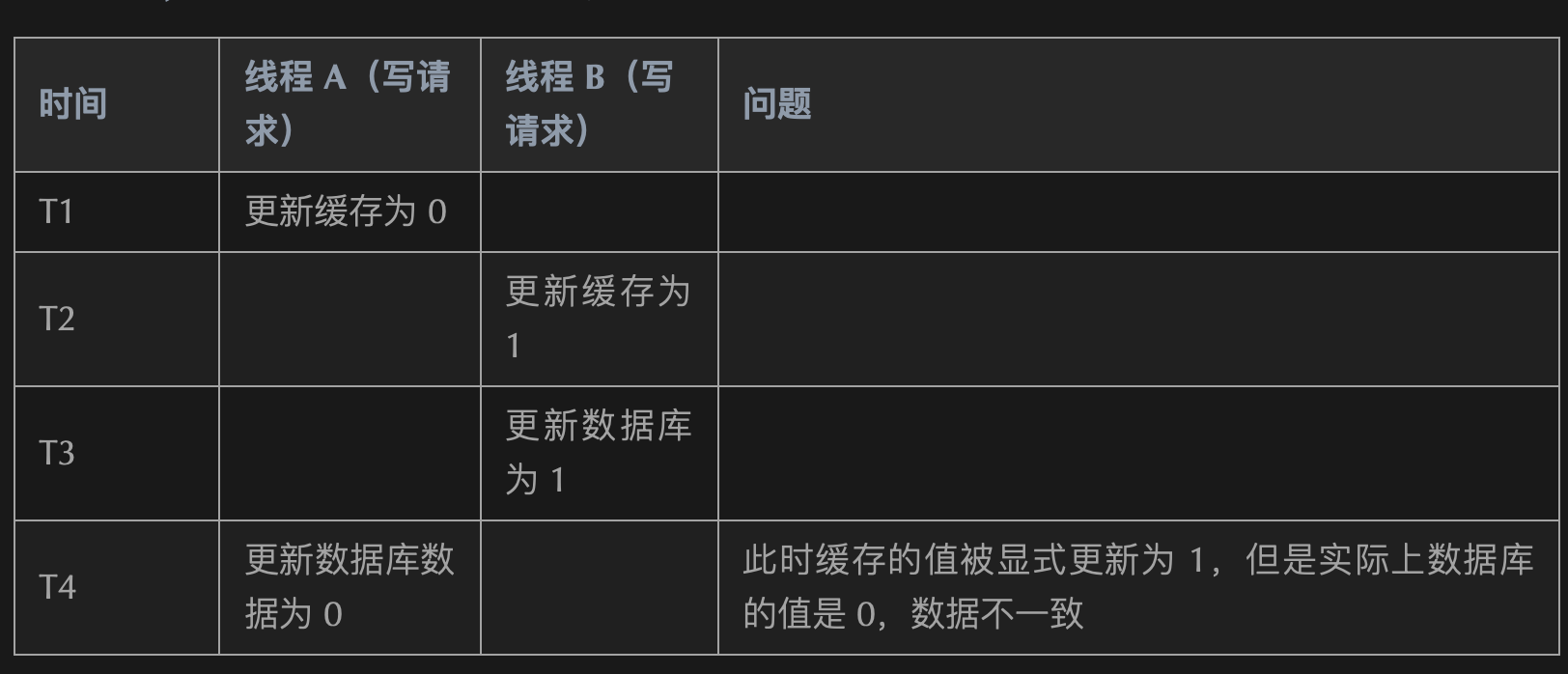
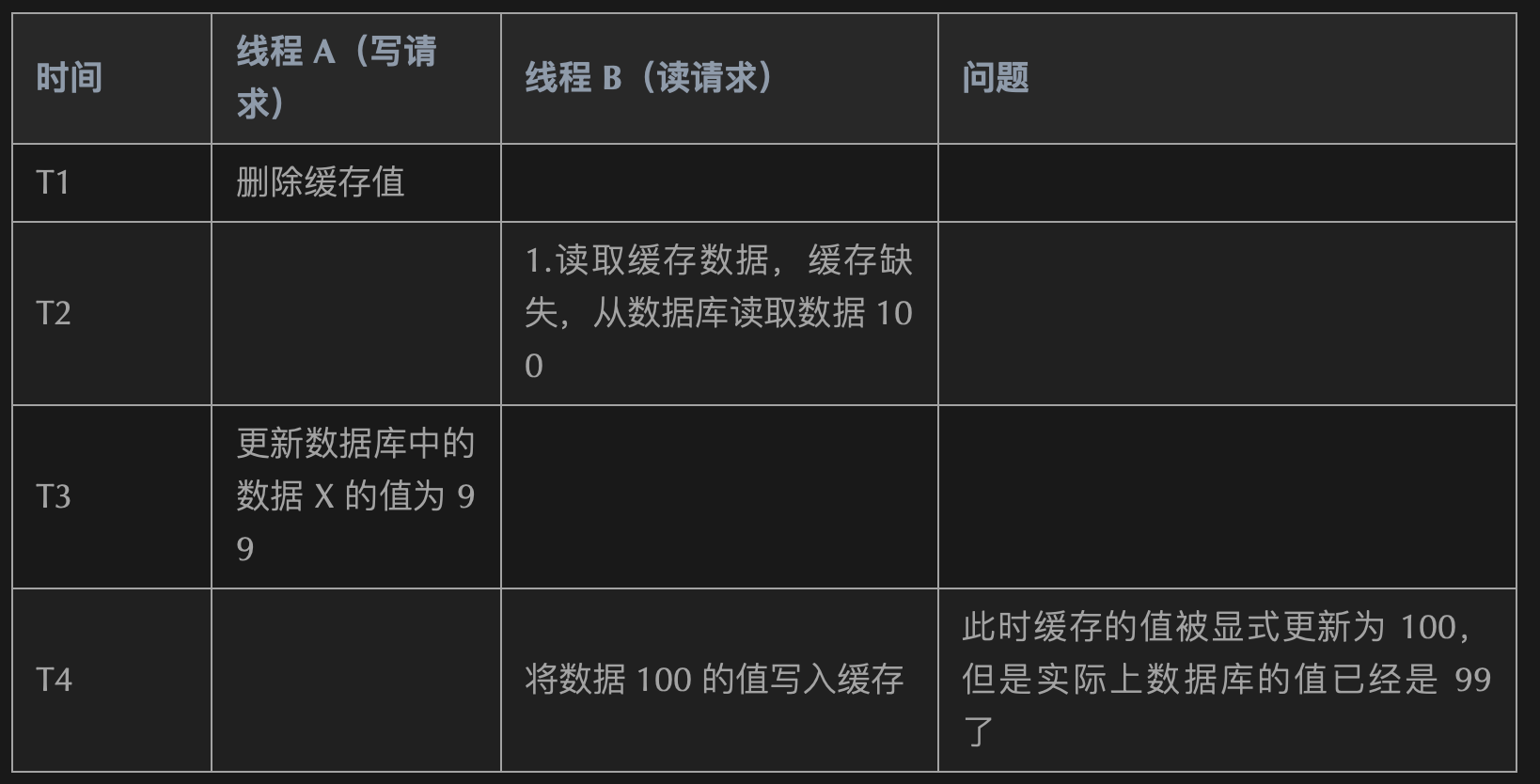
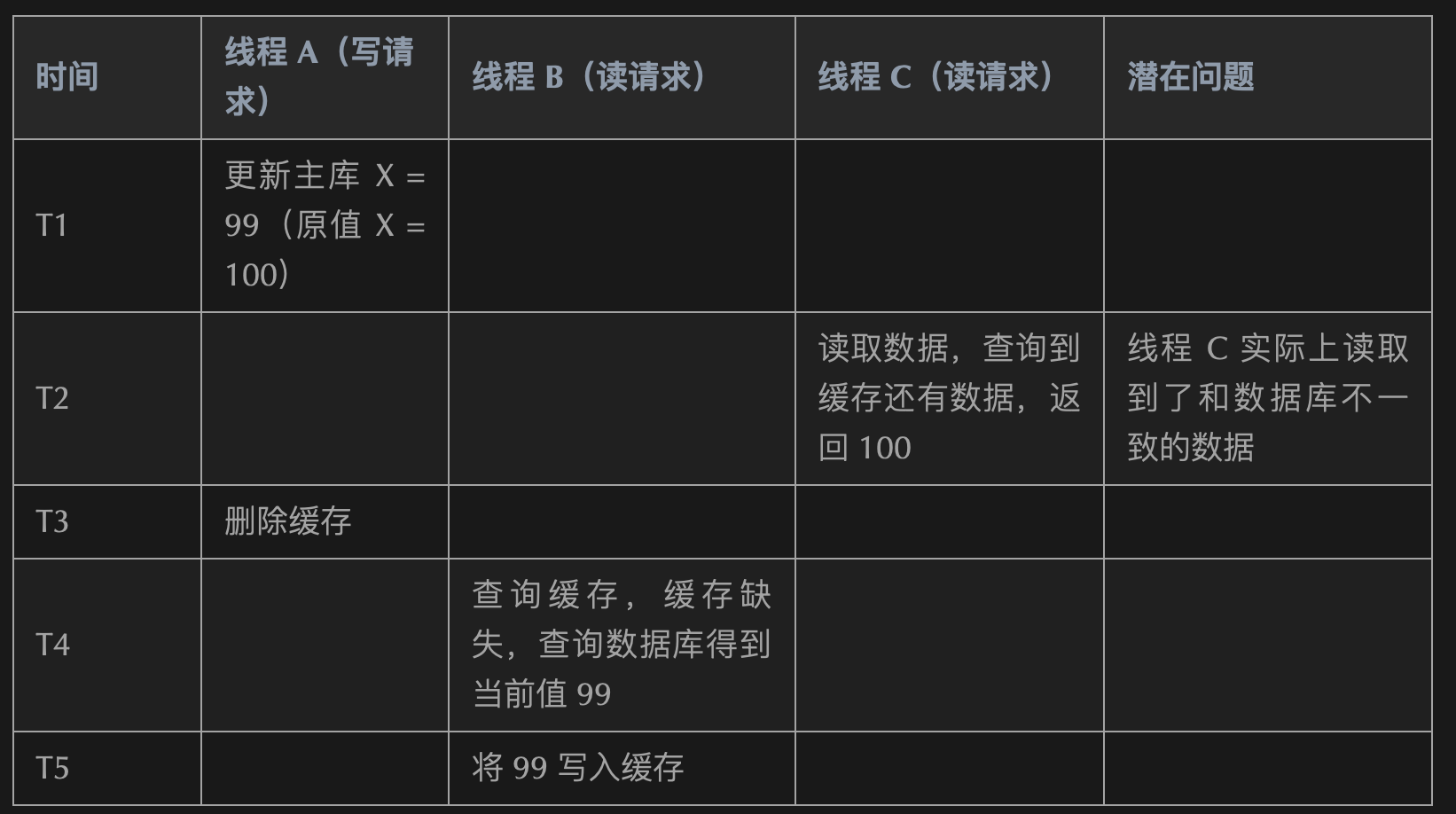
Unrecognized option or bad number of args for: '--big-keys' ➜ ~ redis-cli -h 127.0.0.1 -p 6379 --bigkeys # Scanning the entire keyspace to find biggest keys as well as # average sizes per key type. You can use -i 0.1 to sleep 0.1 sec # per 100 SCAN commands (not usually needed).
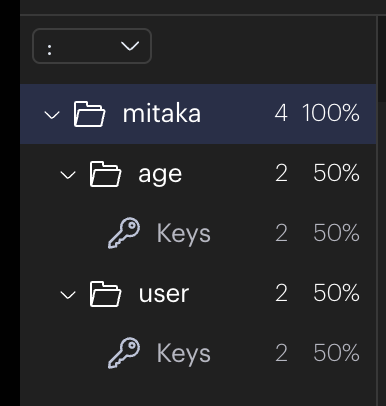
[00.00%] Biggest string found so far 'mitaka:age:2' with 2 bytes [00.00%] Biggest stream found so far 'stream1' with 44 entries [00.00%] Biggest string found so far 'mitaka:user:2' with 6 bytes
-------- summary -------
Sampled 9 keys in the keyspace! Total key length in bytes is 62 (avg len 6.89)
Biggest string found 'mitaka:user:2' has 6 bytes // 这个类型占用最大的内存 Biggest stream found 'stream1' has 44 entries
0 lists with 0 items (00.00% of keys, avg size 0.00) 0 hashs with 0 fields (00.00% of keys, avg size 0.00) 8 strings with 16 bytes (88.89% of keys, avg size 2.00) 1 streams with 44 entries (11.11% of keys, avg size 44.00) 0 sets with 0 members (00.00% of keys, avg size 0.00) 0 zsets with 0 members (00.00% of keys, avg size 0.00)
# Set a memory usage limit to the specified amount of bytes. # When the memory limit is reached Redis will try to remove keys # according to the eviction policy selected (see maxmemory-policy). maxmemory 100mb
# Optional ##########
# Evict any key using approximated LFU when maxmemory is reached. maxmemory-policy allkeys-lfu
# Enable active memory defragmentation. activedefrag yes
# Don't save data on the disk because we can afford to lose cached data. save ""
127.0.0.1:6379> MEMORY DOCTOR // 内存检查医生 Hi Sam, this instance is empty or is using very little memory, my issues detector can't be used in these conditions. Please, leave for your mission on Earth and fill it with some data. The new Sam and I will be back to our programming as soon as I finished rebooting. 127.0.0.1:6379> MEMORY MALLOC-STATS // 内存分配状态,Redis使用jemalloc分配内存 ___ Begin jemalloc statistics ___ Version: "5.2.1-0-g0" ... 省略部分信息
127.0.0.1:6379> MEMORY help 1) MEMORY <subcommand> [<arg> [value] [opt] ...]. Subcommands are: 2) DOCTOR 3) Return memory problems reports. 4) MALLOC-STATS 5) Return internal statistics report from the memory allocator. 6) PURGE 7) Attempt to purge dirty pages for reclamation by the allocator. 尝试清除脏页以供分配器回收。 8) STATS 9) Return information about the memory usage of the server. 返回有关服务器内存使用情况的信息。 10) USAGE <key> [SAMPLES <count>] 11) Return memory in bytes used by <key> and its value. Nested values are // 查看某个key占用的内存 12) sampled up to <count> times (default: 5, 0 means sample all). 13) HELP 14) Prints this help.
/* Insert an integer in the intset */ intset *intsetAdd(intset *is, int64_t value, uint8_t *success) { uint8_t valenc = _intsetValueEncoding(value); // 获取当前值编码 uint32_t pos; // 要插入的位置 if (success) *success = 1; // 判断成功或是失败
/* Upgrade encoding if necessary. If we need to upgrade, we know that * this value should be either appended (if > 0) or prepended (if < 0), * because it lies outside the range of existing values. */ if (valenc > intrev32ifbe(is->encoding)) { // 判断编码是否超过当前的encoding /* This always succeeds, so we don't need to curry *success. */ return intsetUpgradeAndAdd(is,value); // } else { /* Abort if the value is already present in the set. * This call will populate "pos" with the right position to insert * the value when it cannot be found. */ if (intsetSearch(is,value,&pos)) { if (success) *success = 0; return is; }
is = intsetResize(is,intrev32ifbe(is->length)+1); if (pos < intrev32ifbe(is->length)) intsetMoveTail(is,pos,pos+1); }
/* Upgrades the intset to a larger encoding and inserts the given integer. */ static intset *intsetUpgradeAndAdd(intset *is, int64_t value) { uint8_t curenc = intrev32ifbe(is->encoding); uint8_t newenc = _intsetValueEncoding(value); int length = intrev32ifbe(is->length); int prepend = value < 0 ? 1 : 0;
/* First set new encoding and resize */ is->encoding = intrev32ifbe(newenc); is = intsetResize(is,intrev32ifbe(is->length)+1);
/* Upgrade back-to-front so we don't overwrite values. * Note that the "prepend" variable is used to make sure we have an empty * space at either the beginning or the end of the intset. */ while(length--) _intsetSet(is,length+prepend,_intsetGetEncoded(is,length,curenc));
/* Set the value at the beginning or the end. */ if (prepend) _intsetSet(is,0,value); else _intsetSet(is,intrev32ifbe(is->length),value); is->length = intrev32ifbe(intrev32ifbe(is->length)+1); return is; }
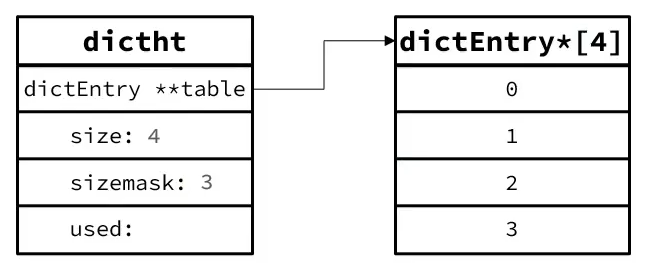
// 节点 typedefstructdictEntry { void *key; // 键 union { void *val; uint64_t u64; int64_t s64; double d; } v; // 值,并且可以存储不同的数据类型 structdictEntry *next;/* Next entry in the same hash bucket. */// 下一个entry的指针 void *metadata[]; /* An arbitrary number of bytes (starting at a * pointer-aligned address) of size as returned * by dictType's dictEntryMetadataBytes(). */ } dictEntry;
// 哈希函数 typedefstructdictType { uint64_t (*hashFunction)(constvoid *key); void *(*keyDup)(dict *d, constvoid *key); void *(*valDup)(dict *d, constvoid *obj); int (*keyCompare)(dict *d, constvoid *key1, constvoid *key2); void (*keyDestructor)(dict *d, void *key); void (*valDestructor)(dict *d, void *obj); int (*expandAllowed)(size_t moreMem, double usedRatio); /* Allow a dictEntry to carry extra caller-defined metadata. The * extra memory is initialized to 0 when a dictEntry is allocated. */ size_t (*dictEntryMetadataBytes)(dict *d); } dictType;
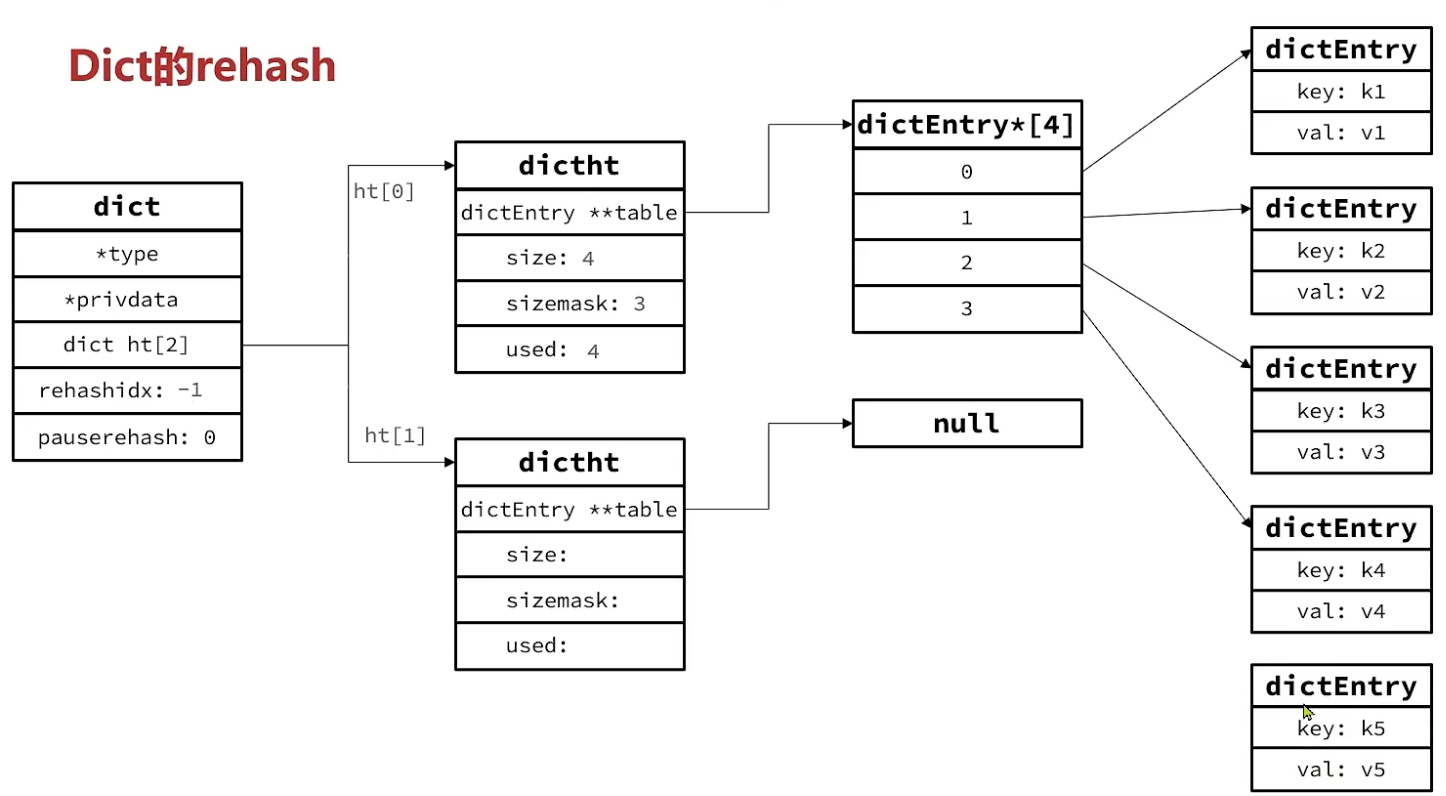
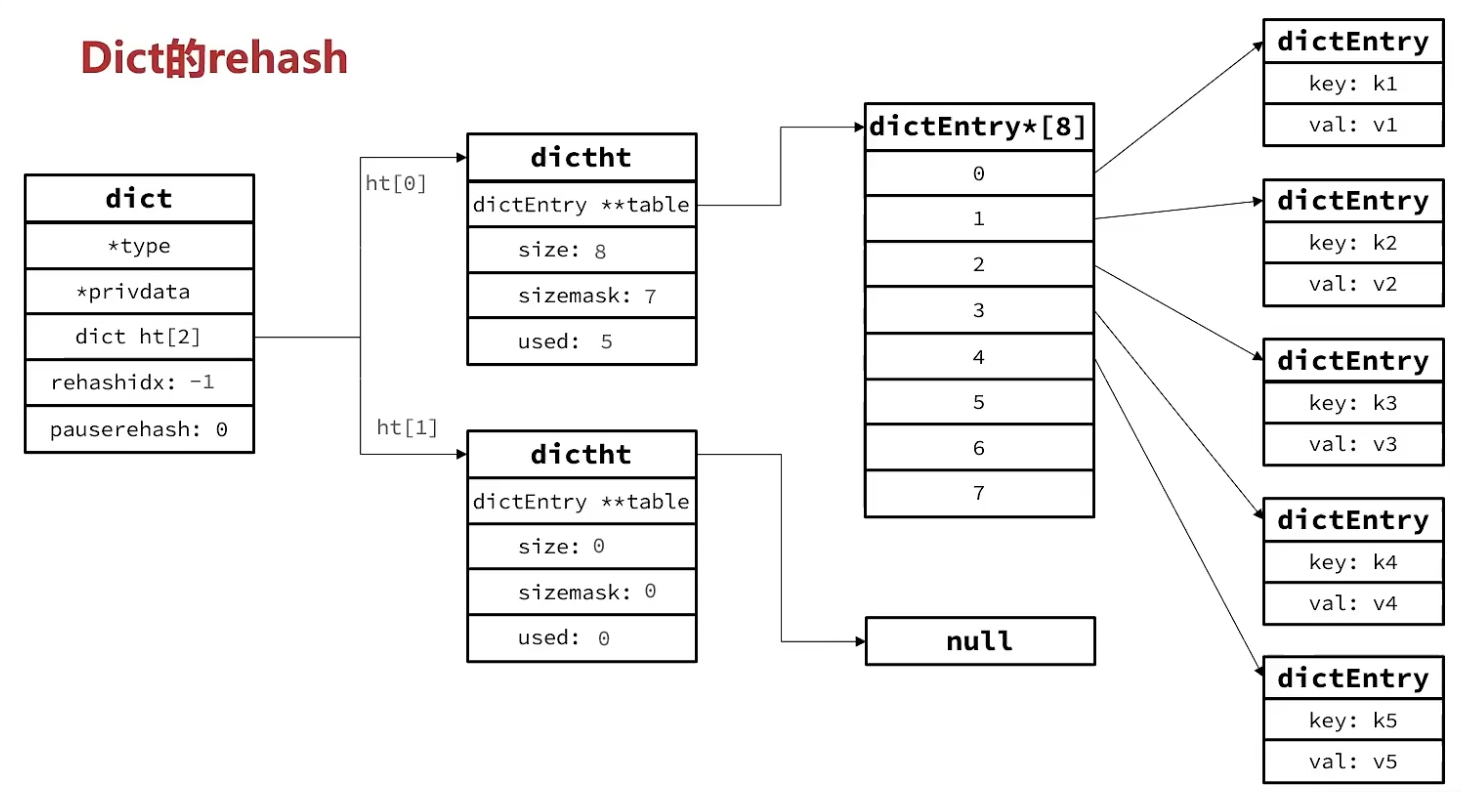
long rehashidx; /* rehashing not in progress if rehashidx == -1 */// rehash进度
/* Keep small vars at end for optimal (minimal) struct padding */ int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */// hash是否暂停, >0 代表暂停 signedchar ht_size_exp[2]; /* exponent of size. (size = 1<<exp) */ };
// 字典迭代器,用于迭代dict /* If safe is set to 1 this is a safe iterator, that means, you can call * dictAdd, dictFind, and other functions against the dictionary even while * iterating. Otherwise it is a non safe iterator, and only dictNext() * should be called while iterating. */ typedefstructdictIterator { dict *d; long index; int table, safe; dictEntry *entry, *nextEntry; /* unsafe iterator fingerprint for misuse detection. */ unsignedlonglong fingerprint; } dictIterator;
/* Expand the hash table if needed */ staticint _dictExpandIfNeeded(dict *d) { /* Incremental rehashing already in progress. Return. */ if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */ if (DICTHT_SIZE(d->ht_size_exp[0]) == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
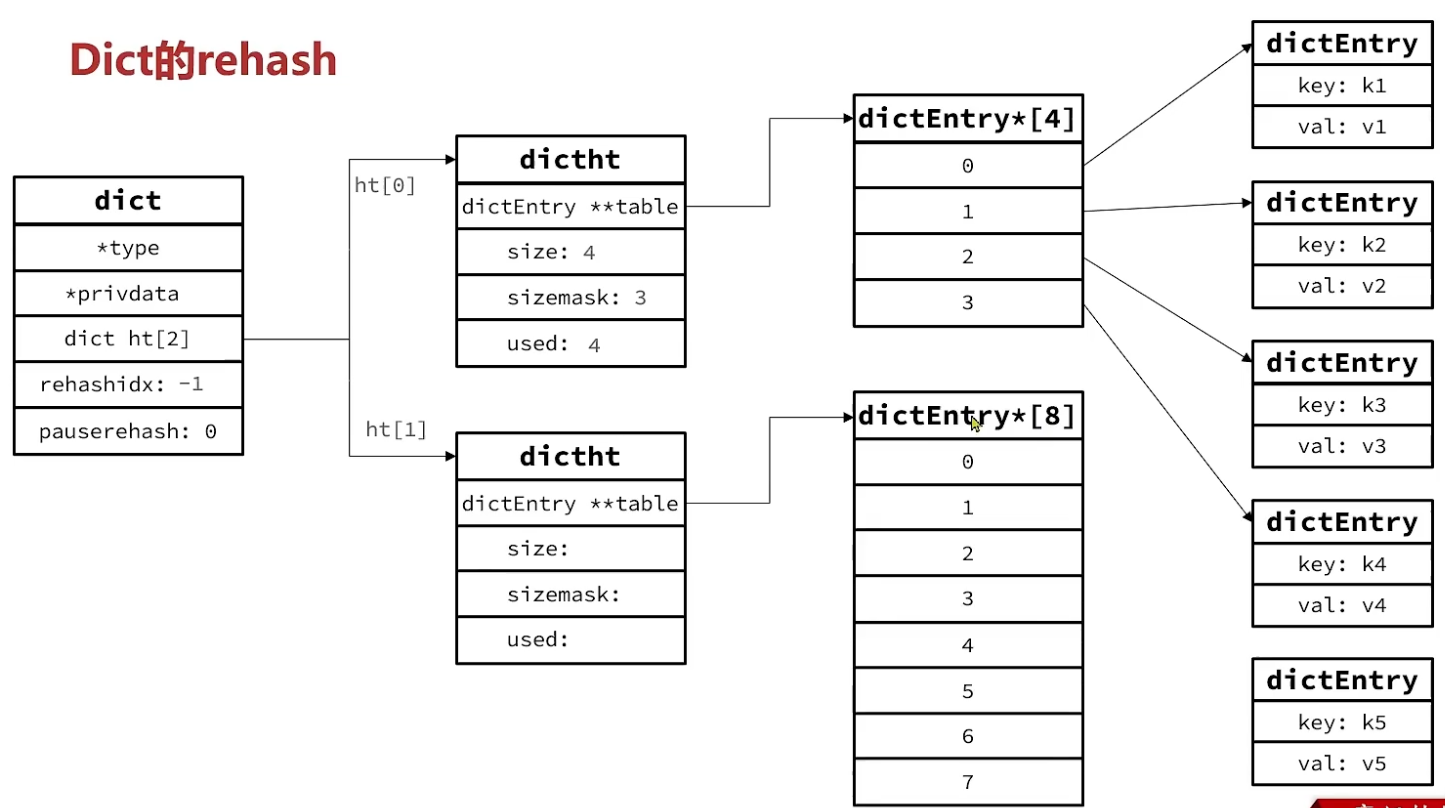
/* If we reached the 1:1 ratio, and we are allowed to resize the hash * table (global setting) or we should avoid it but the ratio between * elements/buckets is over the "safe" threshold, we resize doubling * the number of buckets. */ if (d->ht_used[0] >= DICTHT_SIZE(d->ht_size_exp[0]) && (dict_can_resize || d->ht_used[0]/ DICTHT_SIZE(d->ht_size_exp[0]) > dict_force_resize_ratio) && dictTypeExpandAllowed(d)) { return dictExpand(d, d->ht_used[0] + 1); } return DICT_OK; }
/* Resize the table to the minimal size that contains all the elements, * but with the invariant of a USED/BUCKETS ratio near to <= 1 */ intdictResize(dict *d) { unsignedlong minimal;
if (!dict_can_resize || dictIsRehashing(d)) return DICT_ERR; minimal = d->ht_used[0]; if (minimal < DICT_HT_INITIAL_SIZE) minimal = DICT_HT_INITIAL_SIZE; return dictExpand(d, minimal); }
/* Each entry in the ziplist is either a string or an integer. */// 记录ZipList中的节点信息 typedefstruct { /* When string is used, it is provided with the length (slen). */ unsignedchar *sval; unsignedint slen; /* When integer is used, 'sval' is NULL, and lval holds the value. */ longlong lval; } ziplistEntry;
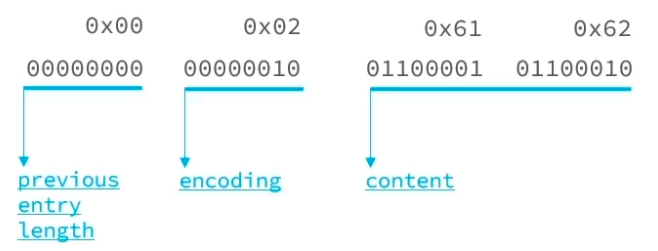
/* We use this function to receive information about a ziplist entry. * Note that this is not how the data is actually encoded, is just what we * get filled by a function in order to operate more easily. */ typedefstructzlentry { unsignedint prevrawlensize; /* Bytes used to encode the previous entry len*/// 记录前一个节点长度的字节数 unsignedint prevrawlen; /* Previous entry len. */// 前一个节点长度 unsignedint lensize; /* Bytes used to encode this entry type/len. // 记录当前字节长度的字节数 For example strings have a 1, 2 or 5 bytes header. Integers always use a single byte.*/ unsignedint len; /* Bytes used to represent the actual entry. // 当前字节长度 For strings this is just the string length while for integers it is 1, 2, 3, 4, 8 or 0 (for 4 bit immediate) depending on the number range. */ unsignedint headersize; /* prevrawlensize + lensize. */// 头信息占用字节长度 unsignedchar encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on // 编码,确定数据时数字还是字符串 the entry encoding. However for 4 bits immediate integers this can assume a range of values and must be range-checked. */ unsignedchar *p; /* Pointer to the very start of the entry, that // ZipList中起始节点指针 is, this points to prev-entry-len field. */ } zlentry;
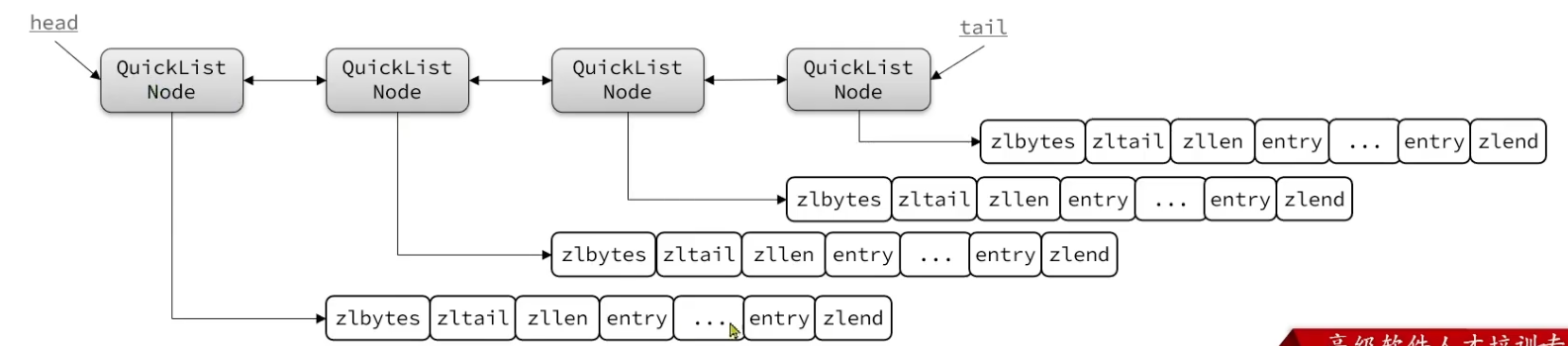
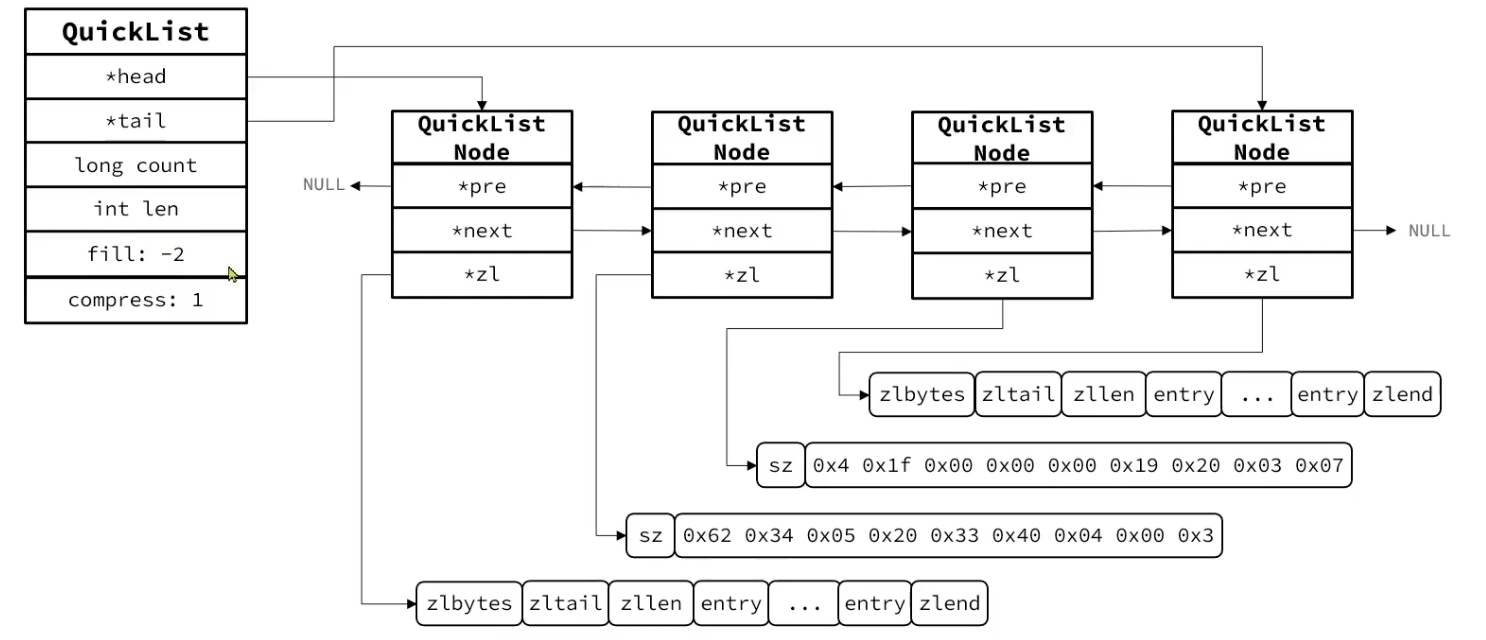
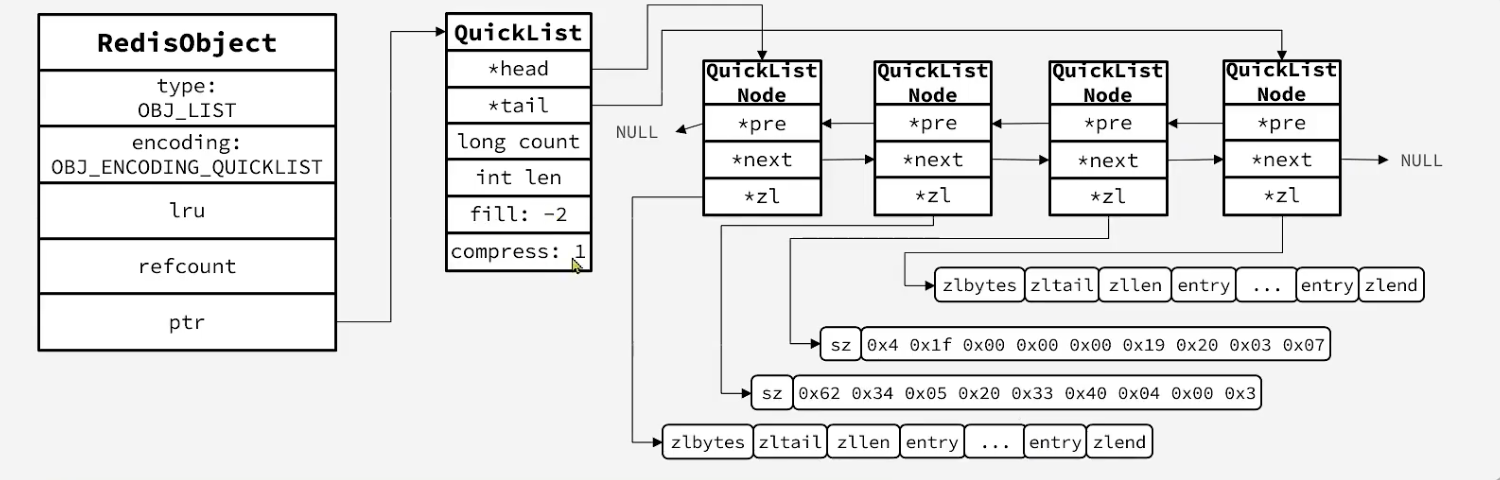
/* quicklistNode is a 32 byte struct describing a listpack for a quicklist. * We use bit fields keep the quicklistNode at 32 bytes. * count: 16 bits, max 65536 (max lp bytes is 65k, so max count actually < 32k). * encoding: 2 bits, RAW=1, LZF=2. * container: 2 bits, PLAIN=1 (a single item as char array), PACKED=2 (listpack with multiple items). * recompress: 1 bit, bool, true if node is temporary decompressed for usage. * attempted_compress: 1 bit, boolean, used for verifying during testing. * extra: 10 bits, free for future use; pads out the remainder of 32 bits */ typedefstructquicklistNode {// QuickList中的节点结构体 structquicklistNode *prev;// 前一个节点指针 structquicklistNode *next;// 后一个节点指针 unsignedchar *entry; // 当前节点指针 size_t sz; /* entry size in bytes */// 当前节点ZipList的字节大小 unsignedint count : 16; /* count of items in listpack */// 当前节点ZipList中entry的个数 unsignedint encoding : 2; /* RAW==1 or LZF==2 */// 编码方式,1是ZipList,2是LZP压缩模式 unsignedint container : 2; /* PLAIN==1 or PACKED==2 */// 数据容器类型,1是PLAIN,2是PACKED unsignedint recompress : 1; /* was this node previous compressed? */// 是否被压缩,1说明被解压了,后续要重新压缩 unsignedint attempted_compress : 1; /* node can't compress; too small */// 测试用 unsignedint dont_compress : 1; /* prevent compression of entry that will be used later */ unsignedint extra : 9; /* more bits to steal for future usage */// 预留字段 } quicklistNode;
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist. * 'count' is the number of total entries. * 'len' is the number of quicklist nodes. * 'compress' is: 0 if compression disabled, otherwise it's the number * of quicklistNodes to leave uncompressed at ends of quicklist. * 'fill' is the user-requested (or default) fill factor. * 'bookmarks are an optional feature that is used by realloc this struct, * so that they don't consume memory when not used. */ typedefstructquicklist {// QuickList 结构体 quicklistNode *head; // 头节点指针 quicklistNode *tail; // 尾结点指针 unsignedlong count; /* total count of all entries in all listpacks */// 所有ZipList中entry数量 unsignedlong len; /* number of quicklistNodes */// ZipList的数量 signedint fill : QL_FILL_BITS; /* fill factor for individual nodes */// ZipList上限,默认值 -2 unsignedint compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */// 首位不压缩的节点数量 unsignedint bookmark_count: QL_BM_BITS; // 内存重分配时的书签数量及数组,一般用不到 quicklistBookmark bookmarks[]; } quicklist;
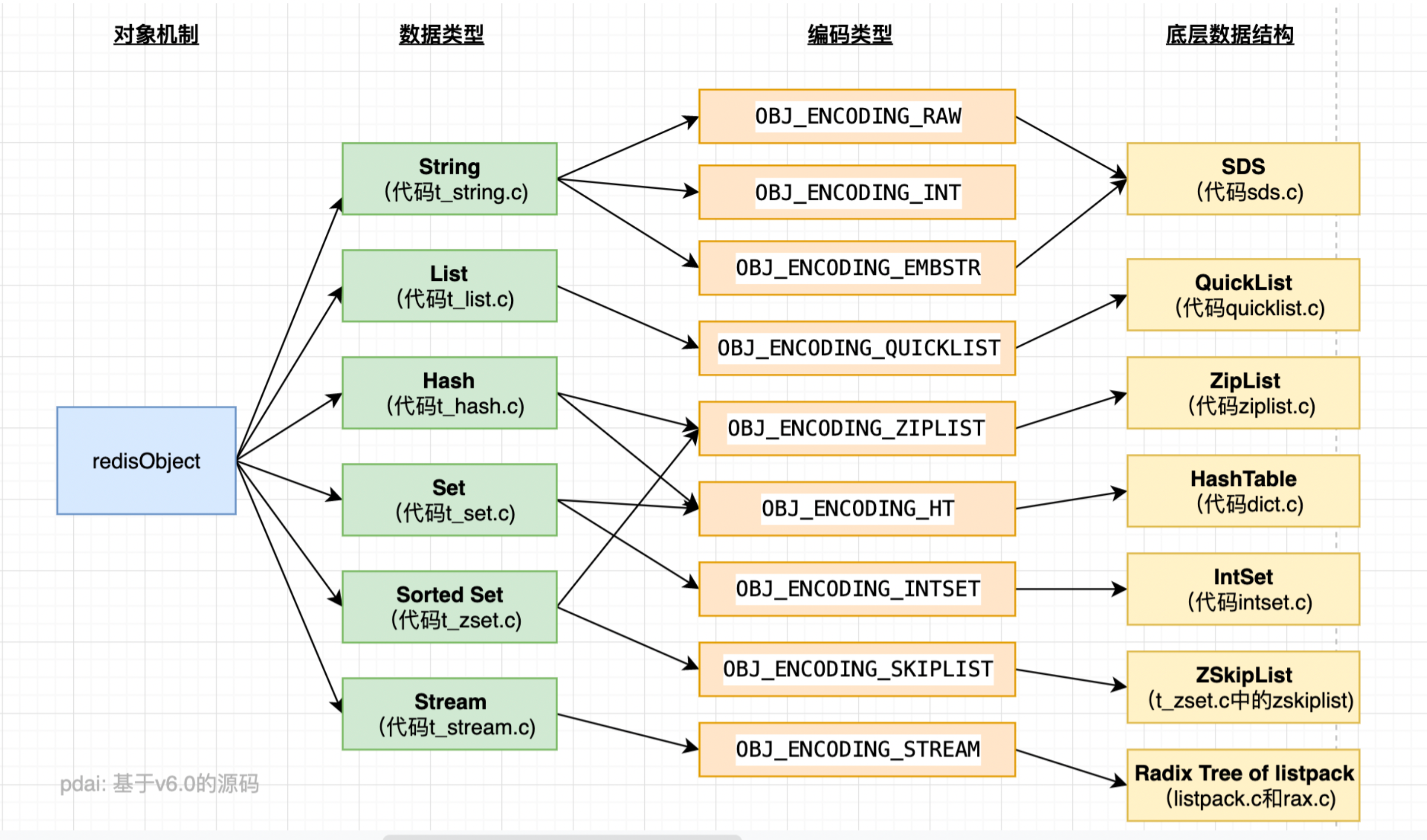
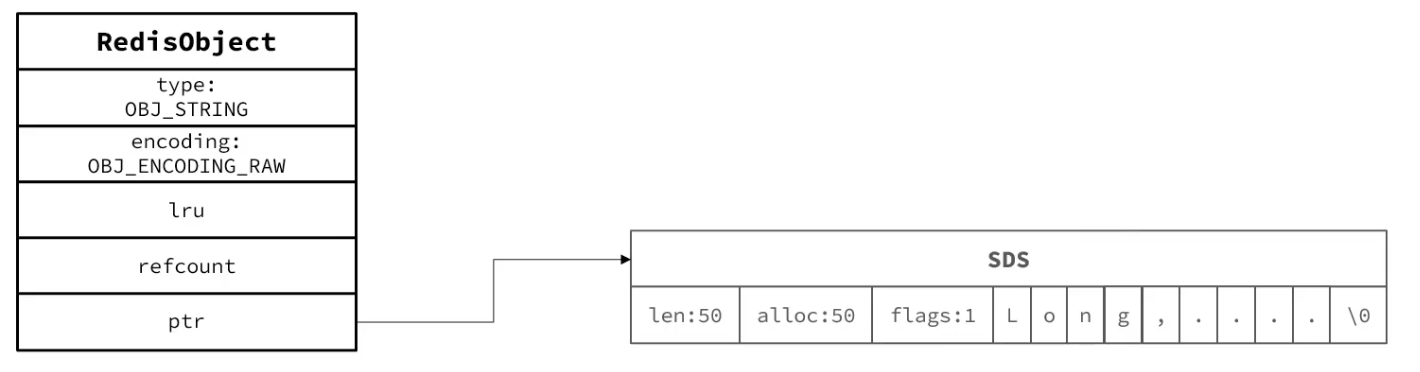
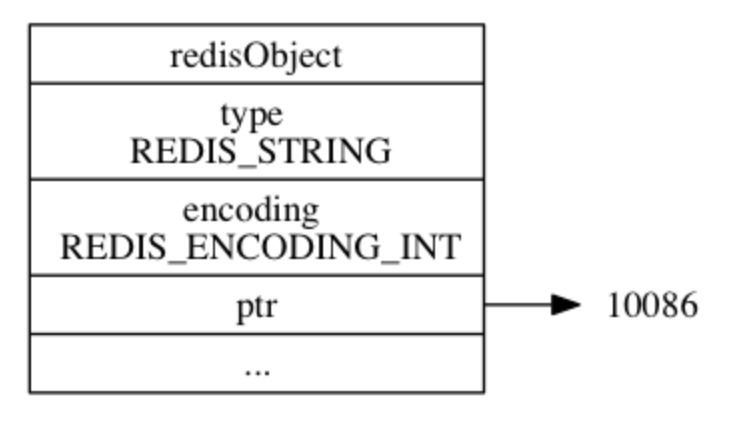
typedefstructredisObject { unsigned type:4; // 对象类,数据类型,从0-4有5种,占4个bit unsigned encoding:4; // 数据编码,同一个数据类型,也会有不同的数据编码,占4个bit unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or // 表示该对象最后一次被访问的时间,占用24个bit,便于判断空闲时间太久的key * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */ int refcount; // 对象引用计数器,有对象引用+1,没有对象引用-1,为0代表没有应用引用,则可回收 void *ptr; // 指针,指向实际存放数据的空间 } robj; // 对象头部,占用16个字节
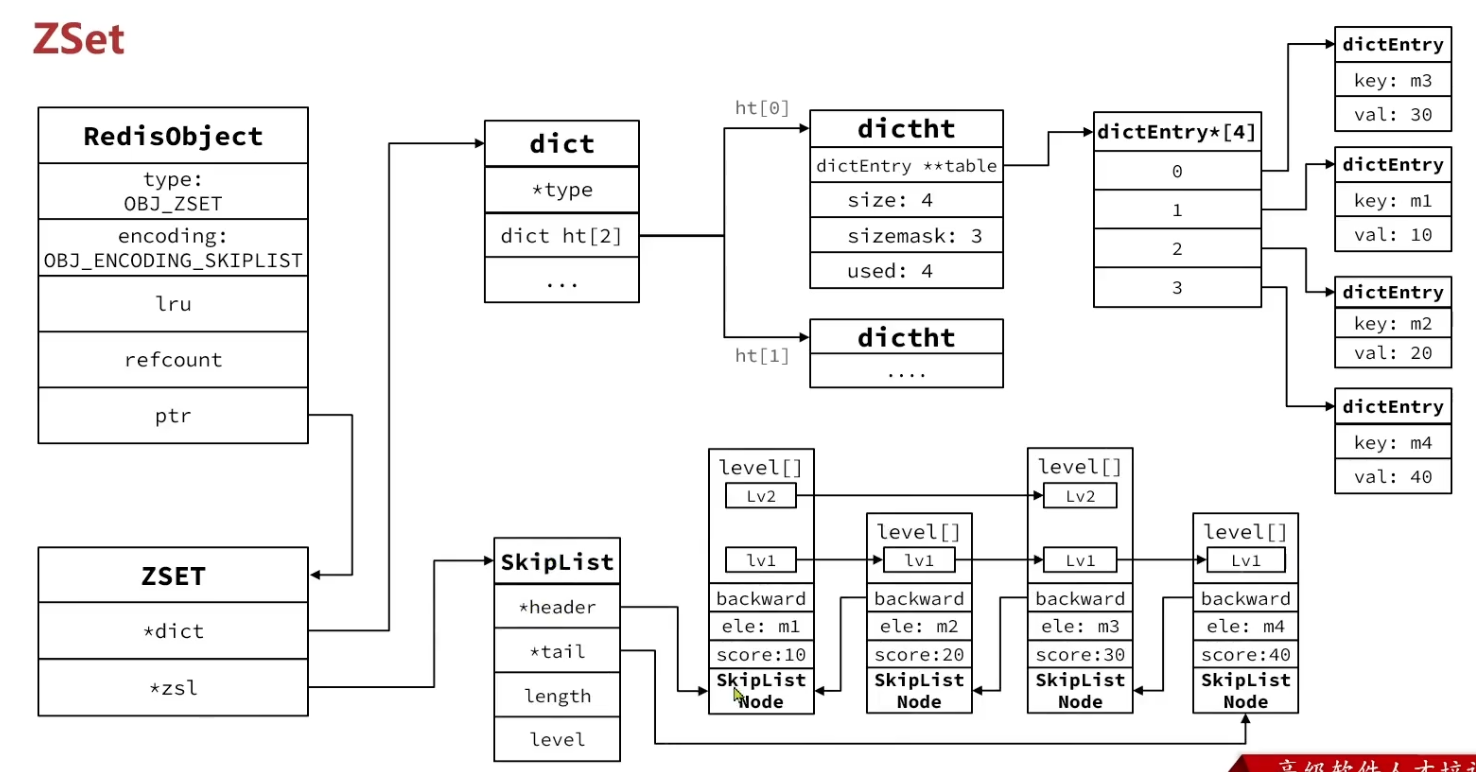
// type 数据类型 /* The actual Redis Object */ #define OBJ_STRING 0 /* String object. */// int embstr raw #define OBJ_LIST 1 /* List object. */// QuickList #define OBJ_SET 2 /* Set object. */// IntSet,HashTable #define OBJ_ZSET 3 /* Sorted set object. */// ListPack,SkipList #define OBJ_HASH 4 /* Hash object. */// ListPack,HashTable
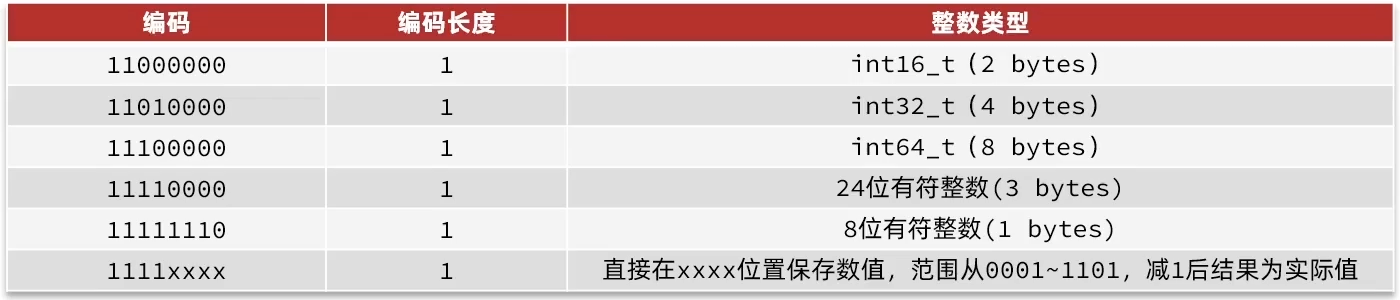
// 数据编码 /* Objects encoding. Some kind of objects like Strings and Hashes can be * internally represented in multiple ways. The 'encoding' field of the object * is set to one of this fields for this object. */ #define OBJ_ENCODING_RAW 0 /* Raw representation */// 动态字符串的一种方式 #define OBJ_ENCODING_INT 1 /* Encoded as integer */// long类型的整数的字符串 #define OBJ_ENCODING_HT 2 /* Encoded as hash table */// hash表,也就是字典dict #define OBJ_ENCODING_ZIPMAP 3 /* No longer used: old hash encoding. */// 已废弃 #define OBJ_ENCODING_LINKEDLIST 4 /* No longer used: old list encoding. */// 双端链表,已废弃 #define OBJ_ENCODING_ZIPLIST 5 /* No longer used: old list/hash/zset encoding. */// Redis 7中已经不使用ZipList #define OBJ_ENCODING_INTSET 6 /* Encoded as intset */// 整数集合 #define OBJ_ENCODING_SKIPLIST 7 /* Encoded as skiplist */// 跳表 #define OBJ_ENCODING_EMBSTR 8 /* Embedded sds string encoding */// 动态字符串的一种方式 #define OBJ_ENCODING_QUICKLIST 9 /* Encoded as linked list of listpacks */// 快速列表 #define OBJ_ENCODING_STREAM 10 /* Encoded as a radix tree of listpacks */// Stream 流 #define OBJ_ENCODING_LISTPACK 11 /* Encoded as a listpack */// Redis 7中使用ListPack代替ZipList
127.0.0.1:6379> set raw aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa OK 127.0.0.1:6379> set emb abc OK 127.0.0.1:6379> set int 123 OK 127.0.0.1:6379> OBJECT encoding raw "raw" 127.0.0.1:6379> OBJECT encoding emb "embstr" 127.0.0.1:6379> OBJECT encoding int "int"
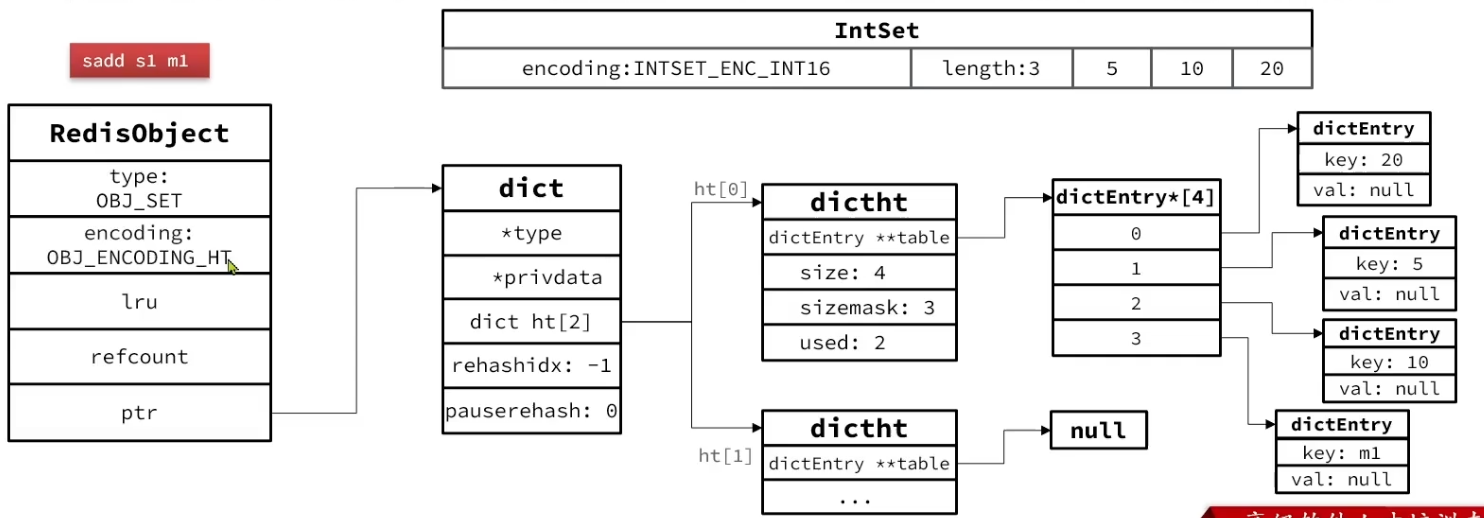
127.0.0.1:6379> CONFIG GET *max-intset* 1) "set-max-intset-entries" 2) "512"
src/t_set.c
1 2 3 4 5 6 7 8 9 10 11
/* Factory method to return a set that *can* hold "value". When the object has * an integer-encodable value, an intset will be returned. Otherwise a regular * hash table. */ robj *setTypeCreate(sds value) { // 判断value是否是数值类型 LongLong if (isSdsRepresentableAsLongLong(value,NULL) == C_OK) // 如果是数值类型,则采用IntSet编码 return createIntsetObject(); // 如果不是,则采用默认编码,也就是HT return createSetObject(); }
/* Add the specified value into a set. * * If the value was already member of the set, nothing is done and 0 is * returned, otherwise the new element is added and 1 is returned. */ // set中增加元素,会判断长度,过长会转变为OBJ_ENCODING_HT intsetTypeAdd(robj *subject, sds value) { longlong llval; // 已经是HT编码,直接添加元素 if (subject->encoding == OBJ_ENCODING_HT) { dict *ht = subject->ptr; dictEntry *de = dictAddRaw(ht,value,NULL); if (de) { dictSetKey(ht,de,sdsdup(value)); dictSetVal(ht,de,NULL); return1; } // 是 IntSet 编码 } elseif (subject->encoding == OBJ_ENCODING_INTSET) { // 判断数据类型,如果是LongLong if (isSdsRepresentableAsLongLong(value,&llval) == C_OK) { uint8_t success = 0; subject->ptr = intsetAdd(subject->ptr,llval,&success); if (success) { /* Convert to regular set when the intset contains * too many entries. */ // 当IntSet元素数量超出set_max_intset_entries,则转换成IntSet size_t max_entries = server.set_max_intset_entries; /* limit to 1G entries due to intset internals. */ if (max_entries >= 1<<30) max_entries = 1<<30; if (intsetLen(subject->ptr) > max_entries) setTypeConvert(subject,OBJ_ENCODING_HT); return1; } } else { /* Failed to get integer from object, convert to regular set. */ // 不是整数,直接转换成 HT setTypeConvert(subject,OBJ_ENCODING_HT);
/* The set *was* an intset and this value is not integer * encodable, so dictAdd should always work. */ serverAssert(dictAdd(subject->ptr,sdsdup(value),NULL) == DICT_OK); return1; } } else { serverPanic("Unknown set encoding"); } return0; }
/*----------------------------------------------------------------------------- * Sorted set commands *----------------------------------------------------------------------------*/
/* This generic command implements both ZADD and ZINCRBY. */ voidzaddGenericCommand(client *c, int flags) { staticchar *nanerr = "resulting score is not a number (NaN)"; robj *key = c->argv[1]; robj *zobj; sds ele; double score = 0, *scores = NULL; int j, elements, ch = 0; int scoreidx = 0; /* The following vars are used in order to track what the command actually * did during the execution, to reply to the client and to trigger the * notification of keyspace change. */ int added = 0; /* Number of new elements added. */ int updated = 0; /* Number of elements with updated score. */ int processed = 0; /* Number of elements processed, may remain zero with options like XX. */
/* Parse options. At the end 'scoreidx' is set to the argument position * of the score of the first score-element pair. */ scoreidx = 2; while(scoreidx < c->argc) { char *opt = c->argv[scoreidx]->ptr; if (!strcasecmp(opt,"nx")) flags |= ZADD_IN_NX; elseif (!strcasecmp(opt,"xx")) flags |= ZADD_IN_XX; elseif (!strcasecmp(opt,"ch")) ch = 1; /* Return num of elements added or updated. */ elseif (!strcasecmp(opt,"incr")) flags |= ZADD_IN_INCR; elseif (!strcasecmp(opt,"gt")) flags |= ZADD_IN_GT; elseif (!strcasecmp(opt,"lt")) flags |= ZADD_IN_LT; elsebreak; scoreidx++; }
/* Turn options into simple to check vars. */ int incr = (flags & ZADD_IN_INCR) != 0; int nx = (flags & ZADD_IN_NX) != 0; int xx = (flags & ZADD_IN_XX) != 0; int gt = (flags & ZADD_IN_GT) != 0; int lt = (flags & ZADD_IN_LT) != 0;
/* After the options, we expect to have an even number of args, since * we expect any number of score-element pairs. */ elements = c->argc-scoreidx; if (elements % 2 || !elements) { addReplyErrorObject(c,shared.syntaxerr); return; } elements /= 2; /* Now this holds the number of score-element pairs. */
/* Check for incompatible options. */ if (nx && xx) { addReplyError(c, "XX and NX options at the same time are not compatible"); return; } if ((gt && nx) || (lt && nx) || (gt && lt)) { addReplyError(c, "GT, LT, and/or NX options at the same time are not compatible"); return; } /* Note that XX is compatible with either GT or LT */
if (incr && elements > 1) { addReplyError(c, "INCR option supports a single increment-element pair"); return; }
/* Start parsing all the scores, we need to emit any syntax error * before executing additions to the sorted set, as the command should * either execute fully or nothing at all. */ scores = zmalloc(sizeof(double)*elements); for (j = 0; j < elements; j++) { if (getDoubleFromObjectOrReply(c,c->argv[scoreidx+j*2],&scores[j],NULL) != C_OK) goto cleanup; }
/* Lookup the key and create the sorted set if does not exist. */ // zadd 添加元素时,先根据key找到zset,不存在则创建新的key zobj = lookupKeyWrite(c->db,key); if (checkType(c,zobj,OBJ_ZSET)) goto cleanup; // zset不存在时 if (zobj == NULL) { if (xx) goto reply_to_client; /* No key + XX option: nothing to do. */ if (server.zset_max_listpack_entries == 0 || server.zset_max_listpack_value < sdslen(c->argv[scoreidx+1]->ptr)) // zset_max_listpack_entries 为0,则是仅用了ListPack // 或者超过 zset_max_listpack_value ,使用createZsetObject,也就是 HT + SkipList { zobj = createZsetObject(); } else { // 反之,则使用ListPack zobj = createZsetListpackObject(); } dbAdd(c->db,key,zobj); }
for (j = 0; j < elements; j++) { double newscore; score = scores[j]; int retflags = 0;
ele = c->argv[scoreidx+1+j*2]->ptr; int retval = zsetAdd(zobj, score, ele, flags, &retflags, &newscore); if (retval == 0) { addReplyError(c,nanerr); goto cleanup; } if (retflags & ZADD_OUT_ADDED) added++; if (retflags & ZADD_OUT_UPDATED) updated++; if (!(retflags & ZADD_OUT_NOP)) processed++; score = newscore; } server.dirty += (added+updated);
reply_to_client: if (incr) { /* ZINCRBY or INCR option. */ if (processed) addReplyDouble(c,score); else addReplyNull(c); } else { /* ZADD. */ addReplyLongLong(c,ch ? added+updated : added); }
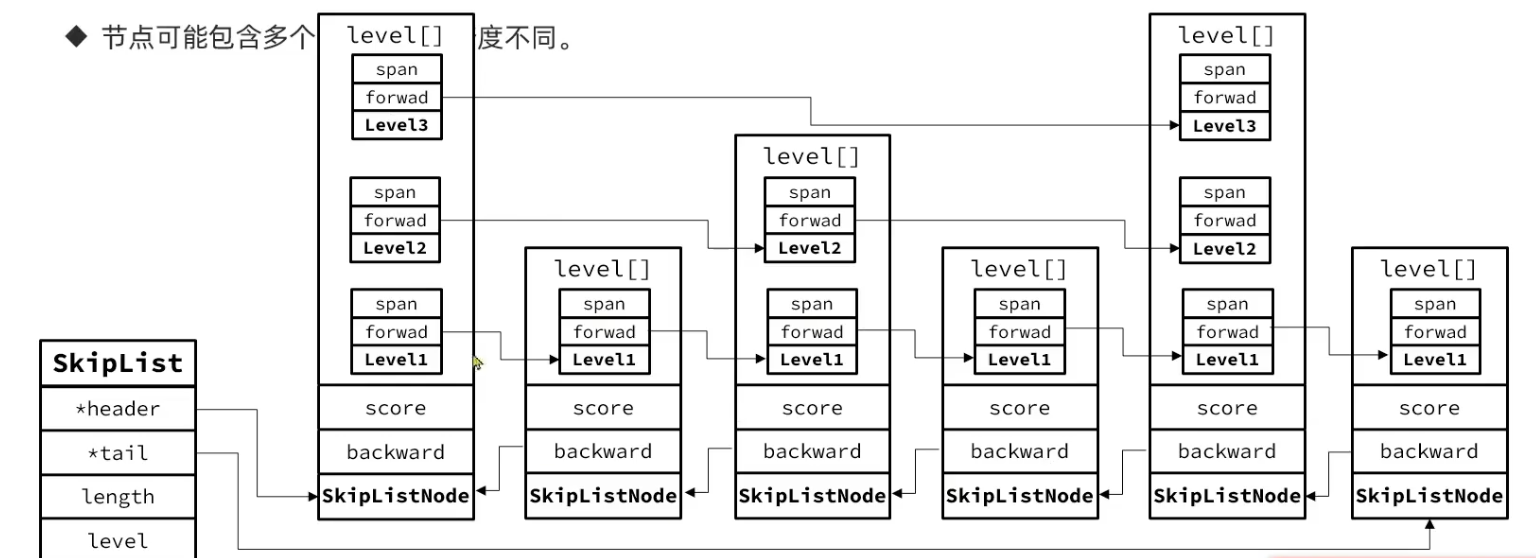
/* Add a new element or update the score of an existing element in a sorted * set, regardless of its encoding. * * The set of flags change the command behavior. * * The input flags are the following: * * ZADD_INCR: Increment the current element score by 'score' instead of updating * the current element score. If the element does not exist, we * assume 0 as previous score. * ZADD_NX: Perform the operation only if the element does not exist. * ZADD_XX: Perform the operation only if the element already exist. * ZADD_GT: Perform the operation on existing elements only if the new score is * greater than the current score. * ZADD_LT: Perform the operation on existing elements only if the new score is * less than the current score. * * When ZADD_INCR is used, the new score of the element is stored in * '*newscore' if 'newscore' is not NULL. * * The returned flags are the following: * * ZADD_NAN: The resulting score is not a number. * ZADD_ADDED: The element was added (not present before the call). * ZADD_UPDATED: The element score was updated. * ZADD_NOP: No operation was performed because of NX or XX. * * Return value: * * The function returns 1 on success, and sets the appropriate flags * ADDED or UPDATED to signal what happened during the operation (note that * none could be set if we re-added an element using the same score it used * to have, or in the case a zero increment is used). * * The function returns 0 on error, currently only when the increment * produces a NAN condition, or when the 'score' value is NAN since the * start. * * The command as a side effect of adding a new element may convert the sorted * set internal encoding from listpack to hashtable+skiplist. * * Memory management of 'ele': * * The function does not take ownership of the 'ele' SDS string, but copies * it if needed. */ intzsetAdd(robj *zobj, double score, sds ele, int in_flags, int *out_flags, double *newscore) { /* Turn options into simple to check vars. */ int incr = (in_flags & ZADD_IN_INCR) != 0; int nx = (in_flags & ZADD_IN_NX) != 0; int xx = (in_flags & ZADD_IN_XX) != 0; int gt = (in_flags & ZADD_IN_GT) != 0; int lt = (in_flags & ZADD_IN_LT) != 0; *out_flags = 0; /* We'll return our response flags. */ double curscore;
/* NaN as input is an error regardless of all the other parameters. */ if (isnan(score)) { *out_flags = ZADD_OUT_NAN; return0; }
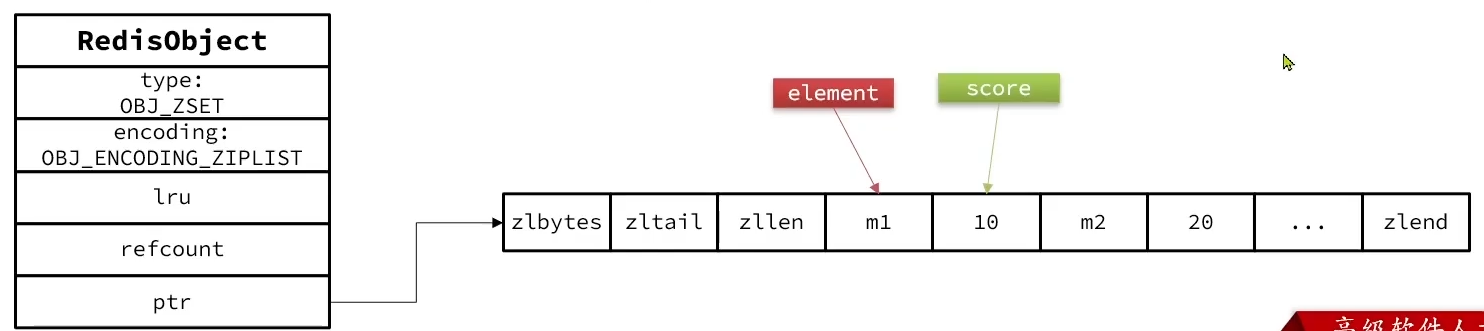
/* Update the sorted set according to its encoding. */// 判断编码方式,如果是ListPack if (zobj->encoding == OBJ_ENCODING_LISTPACK) { unsignedchar *eptr; // 判断当前元素是否已经存在,已经存在 if ((eptr = zzlFind(zobj->ptr,ele,&curscore)) != NULL) { /* NX? Return, same element already exists. */ if (nx) { *out_flags |= ZADD_OUT_NOP; return1; }
/* Prepare the score for the increment if needed. */ if (incr) { score += curscore; if (isnan(score)) { *out_flags |= ZADD_OUT_NAN; return0; } }
/* GT/LT? Only update if score is greater/less than current. */ if ((lt && score >= curscore) || (gt && score <= curscore)) { *out_flags |= ZADD_OUT_NOP; return1; }
if (newscore) *newscore = score;
/* Remove and re-insert when score changed. */ if (score != curscore) { zobj->ptr = zzlDelete(zobj->ptr,eptr); zobj->ptr = zzlInsert(zobj->ptr,ele,score); *out_flags |= ZADD_OUT_UPDATED; } return1; } elseif (!xx) { // 如果元素不存在 /* check if the element is too large or the list * becomes too long *before* executing zzlInsert. */ // 判断新增1个元素之后,ziplist长度,如果大于zset_max_listpack_entries,或者值大于zset_max_listpack_value if (zzlLength(zobj->ptr)+1 > server.zset_max_listpack_entries || sdslen(ele) > server.zset_max_listpack_value || !lpSafeToAdd(zobj->ptr, sdslen(ele))) { // 转换成SkipList zsetConvert(zobj,OBJ_ENCODING_SKIPLIST); } else { zobj->ptr = zzlInsert(zobj->ptr,ele,score); if (newscore) *newscore = score; *out_flags |= ZADD_OUT_ADDED; return1; } } else { *out_flags |= ZADD_OUT_NOP; return1; } }
/* Note that the above block handling listpack would have either returned or * converted the key to skiplist. */// 编码方式,如果是SkipList,无需转换 if (zobj->encoding == OBJ_ENCODING_SKIPLIST) { zset *zs = zobj->ptr; zskiplistNode *znode; dictEntry *de;
de = dictFind(zs->dict,ele); if (de != NULL) { /* NX? Return, same element already exists. */ if (nx) { *out_flags |= ZADD_OUT_NOP; return1; }
curscore = *(double*)dictGetVal(de);
/* Prepare the score for the increment if needed. */ if (incr) { score += curscore; if (isnan(score)) { *out_flags |= ZADD_OUT_NAN; return0; } }
/* GT/LT? Only update if score is greater/less than current. */ if ((lt && score >= curscore) || (gt && score <= curscore)) { *out_flags |= ZADD_OUT_NOP; return1; }
if (newscore) *newscore = score;
/* Remove and re-insert when score changes. */ if (score != curscore) { znode = zslUpdateScore(zs->zsl,curscore,ele,score); /* Note that we did not removed the original element from * the hash table representing the sorted set, so we just * update the score. */ dictGetVal(de) = &znode->score; /* Update score ptr. */ *out_flags |= ZADD_OUT_UPDATED; } return1; } elseif (!xx) { ele = sdsdup(ele); znode = zslInsert(zs->zsl,score,ele); serverAssert(dictAdd(zs->dict,ele,&znode->score) == DICT_OK); *out_flags |= ZADD_OUT_ADDED; if (newscore) *newscore = score; return1; } else { *out_flags |= ZADD_OUT_NOP; return1; } } else { serverPanic("Unknown sorted set encoding"); } return0; /* Never reached. */ }
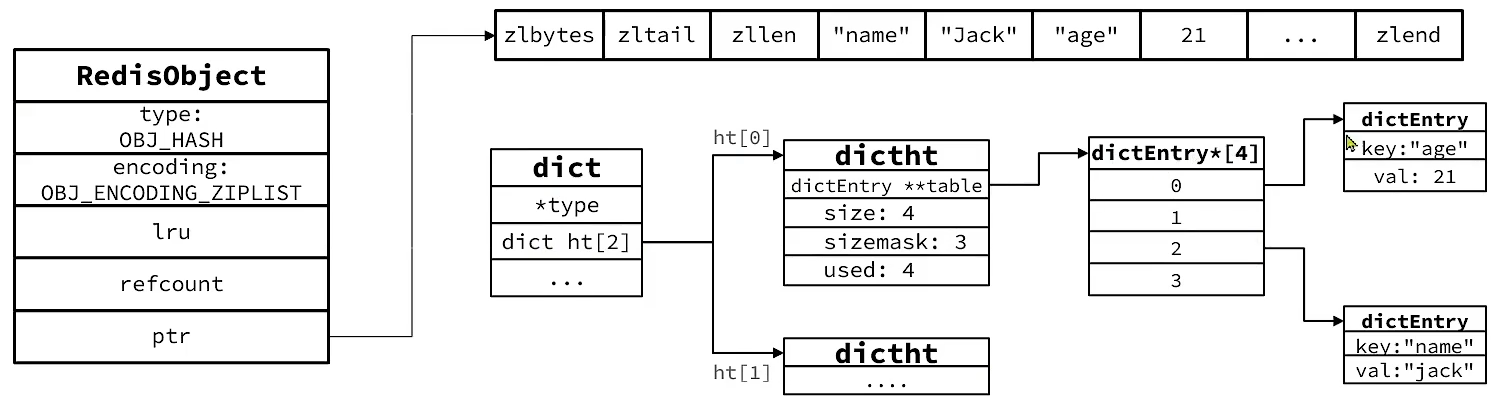
robj *hashTypeLookupWriteOrCreate(client *c, robj *key) { // 查询key robj *o = lookupKeyWrite(c->db,key); // 判断类型,如果是Hash,则返回 if (checkType(c,o,OBJ_HASH)) returnNULL; // 如果没找到,则创建Hash if (o == NULL) { o = createHashObject(); dbAdd(c->db,key,o); } return o; }
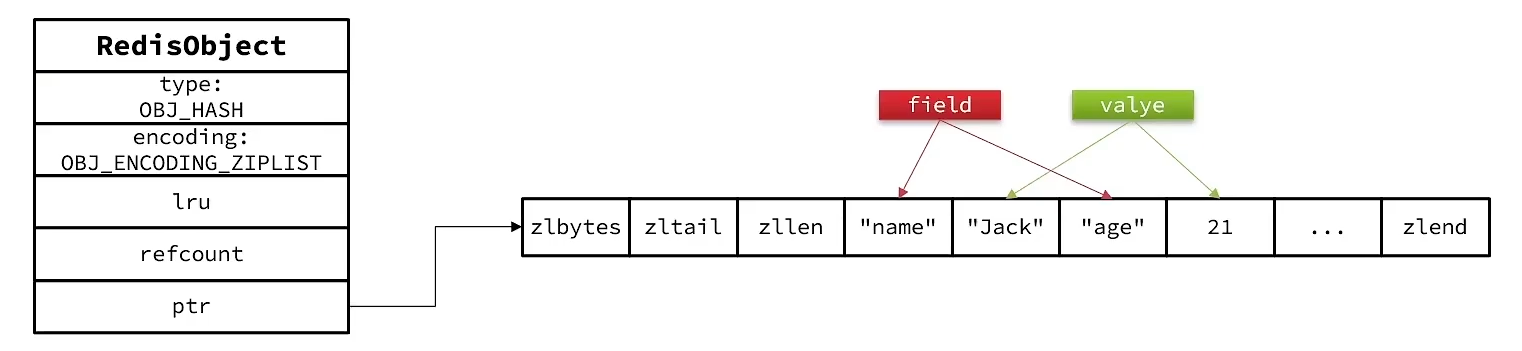
/* Check the length of a number of objects to see if we need to convert a * listpack to a real hash. Note that we only check string encoded objects * as their string length can be queried in constant time. */ voidhashTypeTryConversion(robj *o, robj **argv, int start, int end) { int i; size_t sum = 0; // 先判断是不是ListPack if (o->encoding != OBJ_ENCODING_LISTPACK) return;
// 依次遍历添加进来的元素中的field和value for (i = start; i <= end; i++) { if (!sdsEncodedObject(argv[i])) continue; size_t len = sdslen(argv[i]->ptr); // 判断长度 如果大于 hash_max_listpack_value ,则将类型转换成HT if (len > server.hash_max_listpack_value) { hashTypeConvert(o, OBJ_ENCODING_HT); return; } sum += len; } // 如果 总大小,超过1G,也转为HT if (!lpSafeToAdd(o->ptr, sum)) hashTypeConvert(o, OBJ_ENCODING_HT); }
/* Add a new field, overwrite the old with the new value if it already exists. * Return 0 on insert and 1 on update. * * By default, the key and value SDS strings are copied if needed, so the * caller retains ownership of the strings passed. However this behavior * can be effected by passing appropriate flags (possibly bitwise OR-ed): * * HASH_SET_TAKE_FIELD -- The SDS field ownership passes to the function. * HASH_SET_TAKE_VALUE -- The SDS value ownership passes to the function. * * When the flags are used the caller does not need to release the passed * SDS string(s). It's up to the function to use the string to create a new * entry or to free the SDS string before returning to the caller. * * HASH_SET_COPY corresponds to no flags passed, and means the default * semantics of copying the values if needed. * */ #define HASH_SET_TAKE_FIELD (1<<0) #define HASH_SET_TAKE_VALUE (1<<1) #define HASH_SET_COPY 0 inthashTypeSet(robj *o, sds field, sds value, int flags) { int update = 0;
/* Check if the field is too long for listpack, and convert before adding the item. * This is needed for HINCRBY* case since in other commands this is handled early by * hashTypeTryConversion, so this check will be a NOP. */ // 判断编码是ListPack if (o->encoding == OBJ_ENCODING_LISTPACK) { // 判断长度是否大于 hash_max_listpack_value ,或者值大于 hash_max_listpack_value if (sdslen(field) > server.hash_max_listpack_value || sdslen(value) > server.hash_max_listpack_value) hashTypeConvert(o, OBJ_ENCODING_HT); } if (o->encoding == OBJ_ENCODING_LISTPACK) { unsignedchar *zl, *fptr, *vptr;
zl = o->ptr; fptr = lpFirst(zl); if (fptr != NULL) { fptr = lpFind(zl, fptr, (unsignedchar*)field, sdslen(field), 1); if (fptr != NULL) { /* Grab pointer to the value (fptr points to the field) */ vptr = lpNext(zl, fptr); serverAssert(vptr != NULL); update = 1;
if (!update) { /* Push new field/value pair onto the tail of the listpack */ zl = lpAppend(zl, (unsignedchar*)field, sdslen(field)); zl = lpAppend(zl, (unsignedchar*)value, sdslen(value)); } o->ptr = zl;
/* Check if the listpack needs to be converted to a hash table */ // 插入之后,再次校验长度是否大于hash_max_listpack_entries if (hashTypeLength(o) > server.hash_max_listpack_entries) hashTypeConvert(o, OBJ_ENCODING_HT); } elseif (o->encoding == OBJ_ENCODING_HT) { dictEntry *de = dictFind(o->ptr,field); if (de) { sdsfree(dictGetVal(de)); if (flags & HASH_SET_TAKE_VALUE) { dictGetVal(de) = value; value = NULL; } else { dictGetVal(de) = sdsdup(value); } update = 1; } else { sds f,v; if (flags & HASH_SET_TAKE_FIELD) { f = field; field = NULL; } else { f = sdsdup(field); } if (flags & HASH_SET_TAKE_VALUE) { v = value; value = NULL; } else { v = sdsdup(value); } dictAdd(o->ptr,f,v); } } else { serverPanic("Unknown hash encoding"); }
/* Free SDS strings we did not referenced elsewhere if the flags * want this function to be responsible. */ if (flags & HASH_SET_TAKE_FIELD && field) sdsfree(field); if (flags & HASH_SET_TAKE_VALUE && value) sdsfree(value); return update; }
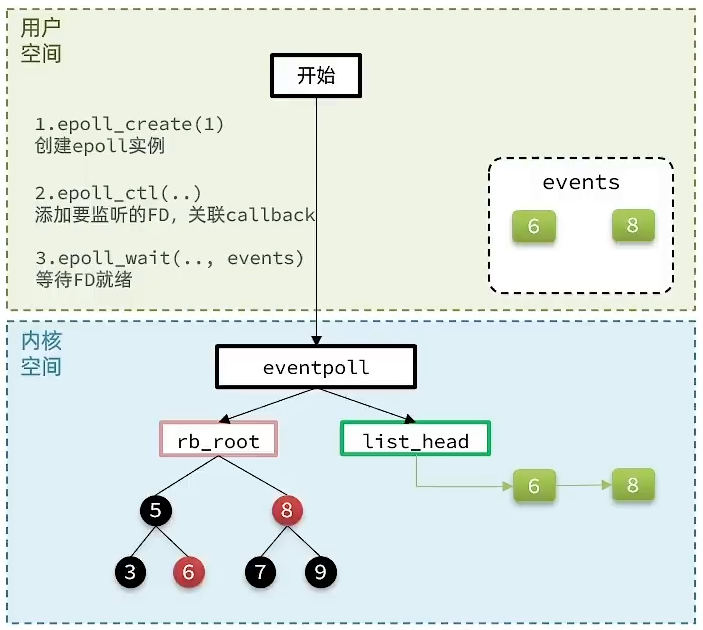
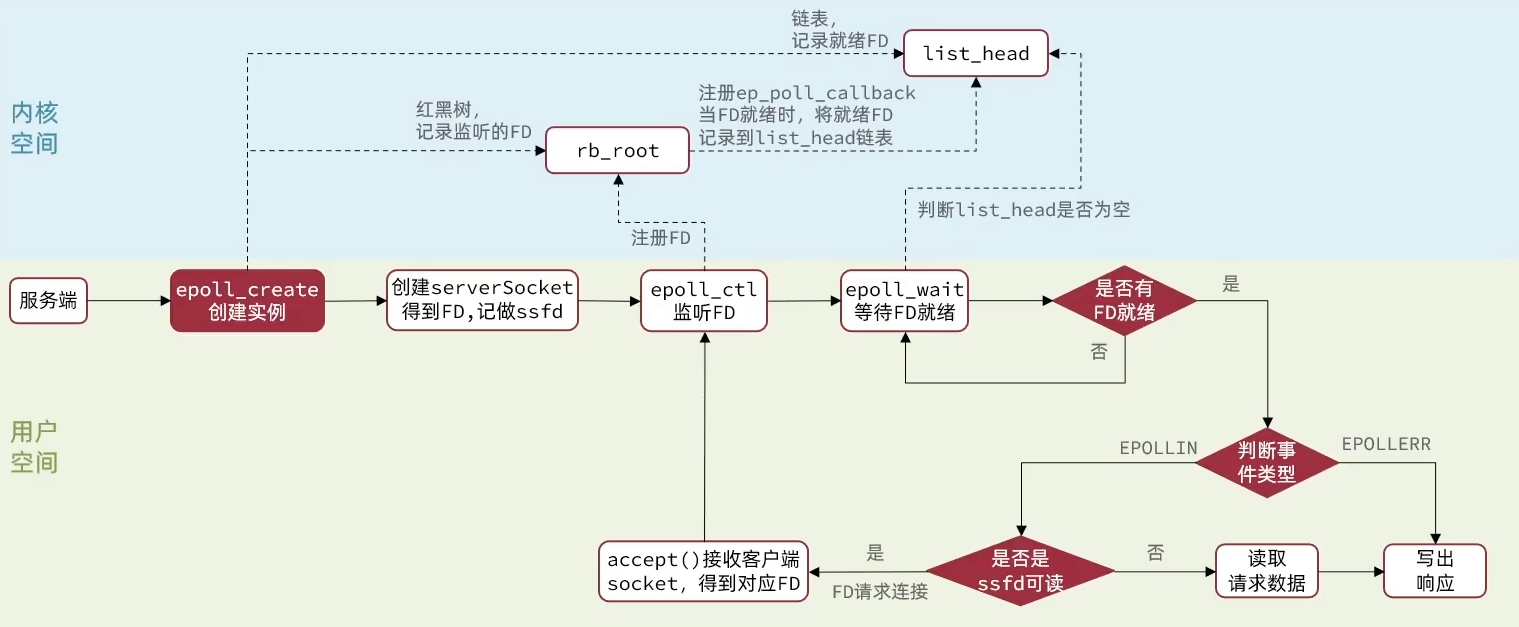
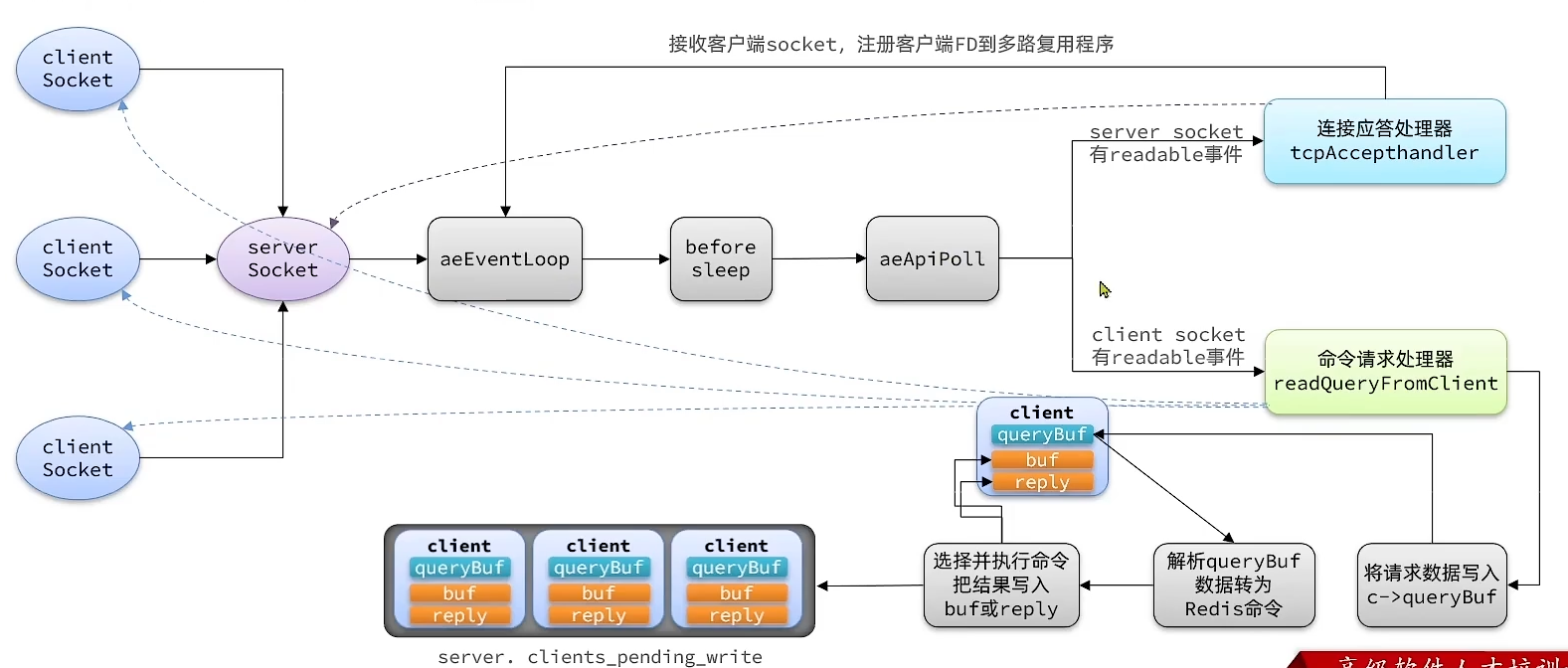
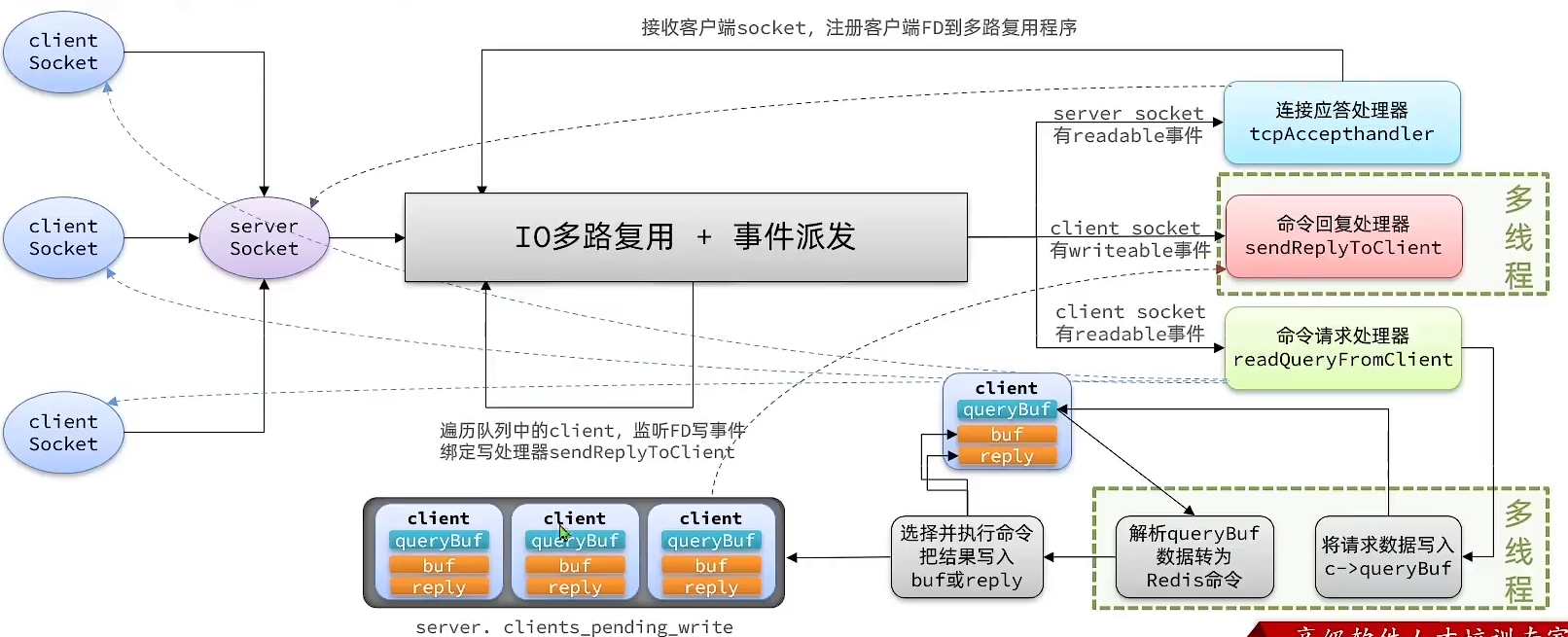
structeventpoll { // 截取部分 /* List of ready file descriptors */ structlist_headrdllist;// 一个链表,记录就绪的FD /* RB tree root used to store monitored fd structs */ structrb_rootrbr;// 一颗红黑树,记录要监听的FD };
/* Include the best multiplexing layer supported by this system. * The following should be ordered by performances, descending. */ #ifdef HAVE_EVPORT // 判断是否支持HAVE_EVPORT,如果支持,调用ae_evport.c,下面的代码同理 #include"ae_evport.c" #else #ifdef HAVE_EPOLL // 判断是否支持HAVE_EPOLL,如果支持,调用ae_epoll.c, #include"ae_epoll.c" #else #ifdef HAVE_KQUEUE // 判断是否支持HAVE_KQUEUE,如果支持,调用ae_kqueue.c, #include"ae_kqueue.c" #else// 如果以上都不支持,就调用ae_select.c #include"ae_select.c" #endif #endif #endif
127.0.0.1:6379> CONFIG GET *maxmemory* 1) "maxmemory" 2) "0"
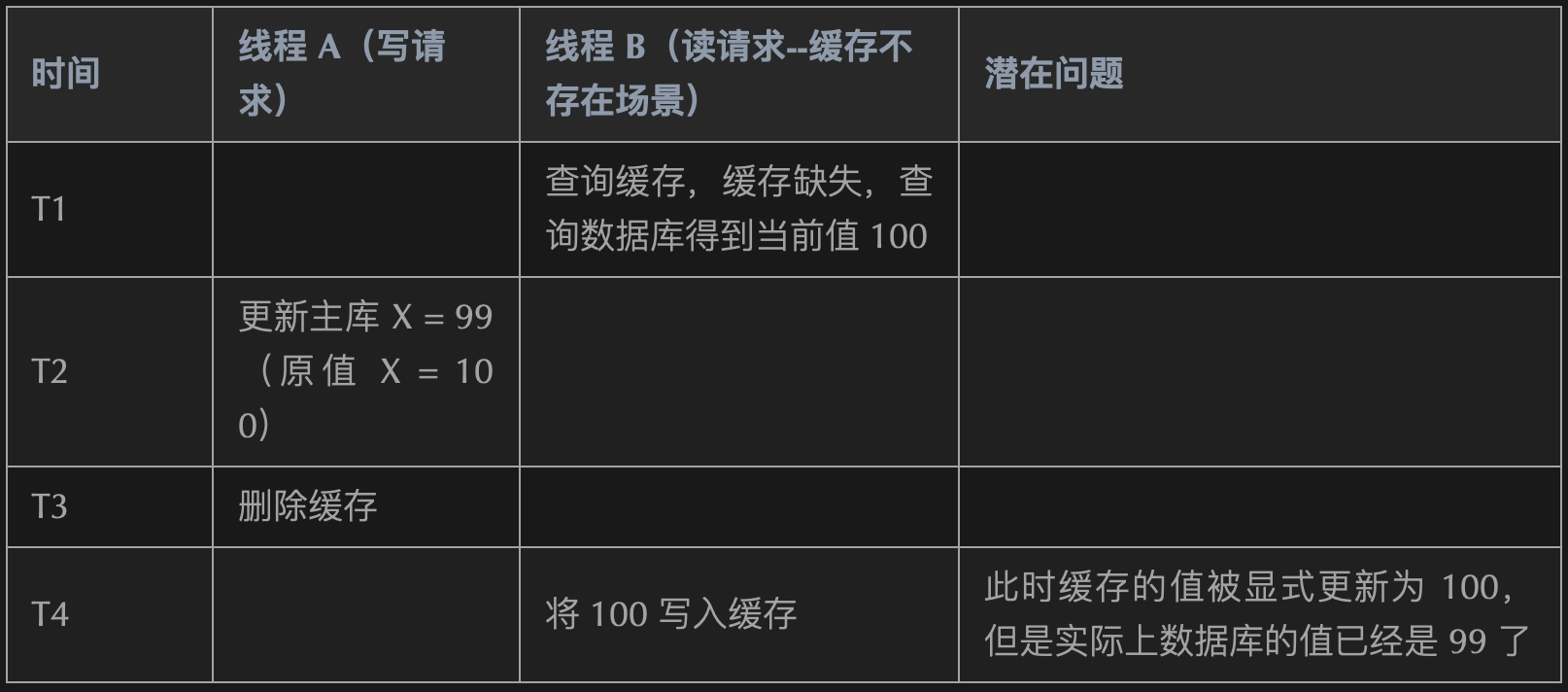
当内存使用达到上限时,就无法存储更多数据。
内存过期
通过ttl获取数据过期时间,当数据过期时,则删除该数据
1 2 3 4 5 6 7 8
127.0.0.1:6379> set name mitaka // 设置key value OK 127.0.0.1:6379> EXPIRE name 5 // 设置过期时间 5s (integer) 1 127.0.0.1:6379> get name // 立即获取 "mitaka" 127.0.0.1:6379> get name // 过5s之后再获取 (nil)
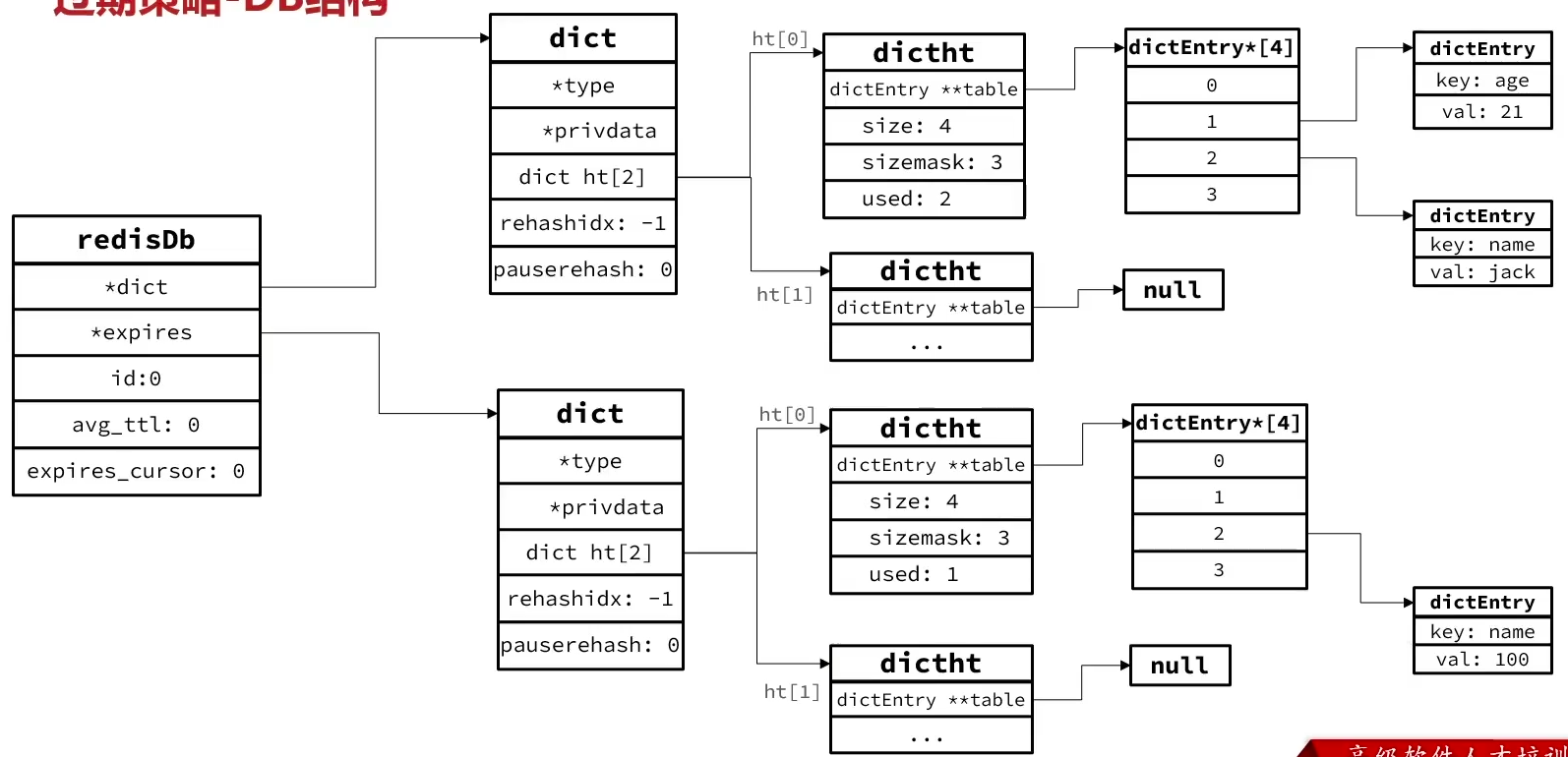
/* Redis database representation. There are multiple databases identified * by integers from 0 (the default database) up to the max configured * database. The database number is the 'id' field in the structure. */ typedefstructredisDb { // 存放所有key及value的地方,也称为keyspace dict *dict; /* The keyspace for this DB */ // 存放每一个key及其对应的TTL存活时间,只包含设置了TTL的key dict *expires; /* Timeout of keys with a timeout set */ dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/ dict *ready_keys; /* Blocked keys that received a PUSH */ dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */ int id; /* Database ID */ // 记录平均TTL时长 longlong avg_ttl; /* Average TTL, just for stats */ // expire检查时,在dict中抽样的索引位置 unsignedlong expires_cursor; /* Cursor of the active expire cycle. */ // 等待碎片整理的key列表 list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */ } redisDb;
/* Lookup a key for write operations, and as a side effect, if needed, expires * the key if its TTL is reached. * * Returns the linked value object if the key exists or NULL if the key * does not exist in the specified DB. */ // 查找一个key执行写操作 robj *lookupKeyWriteWithFlags(redisDb *db, robj *key, int flags) { // 检查是否过期 expireIfNeeded(db,key); return lookupKey(db,key,flags); }
/* Lookup a key for read operations, or return NULL if the key is not found * in the specified DB. * * As a side effect of calling this function: * 1. A key gets expired if it reached it's TTL. * 2. The key last access time is updated. * 3. The global keys hits/misses stats are updated (reported in INFO). * 4. If keyspace notifications are enabled, a "keymiss" notification is fired. * * This API should not be used when we write to the key after obtaining * the object linked to the key, but only for read only operations. * * Flags change the behavior of this command: * * LOOKUP_NONE (or zero): no special flags are passed. * LOOKUP_NOTOUCH: don't alter the last access time of the key. * * Note: this function also returns NULL if the key is logically expired * but still existing, in case this is a slave, since this API is called only * for read operations. Even if the key expiry is master-driven, we can * correctly report a key is expired on slaves even if the master is lagging * expiring our key via DELs in the replication link. */ // 查找一个key执行读取操作 robj *lookupKeyReadWithFlags(redisDb *db, robj *key, int flags) { robj *val; // 检查key是否过期 if (expireIfNeeded(db,key) == 1) { /* If we are in the context of a master, expireIfNeeded() returns 1 * when the key is no longer valid, so we can return NULL ASAP. */ if (server.masterhost == NULL) goto keymiss;
/* However if we are in the context of a slave, expireIfNeeded() will * not really try to expire the key, it only returns information * about the "logical" status of the key: key expiring is up to the * master in order to have a consistent view of master's data set. * * However, if the command caller is not the master, and as additional * safety measure, the command invoked is a read-only command, we can * safely return NULL here, and provide a more consistent behavior * to clients accessing expired values in a read-only fashion, that * will say the key as non existing. * * Notably this covers GETs when slaves are used to scale reads. */ if (server.current_client && server.current_client != server.master && server.current_client->cmd && server.current_client->cmd->flags & CMD_READONLY) { goto keymiss; } } val = lookupKey(db,key,flags); if (val == NULL) goto keymiss; server.stat_keyspace_hits++; return val;
/* This function is called when we are going to perform some operation * in a given key, but such key may be already logically expired even if * it still exists in the database. The main way this function is called * is via lookupKey*() family of functions. * * The behavior of the function depends on the replication role of the * instance, because slave instances do not expire keys, they wait * for DELs from the master for consistency matters. However even * slaves will try to have a coherent return value for the function, * so that read commands executed in the slave side will be able to * behave like if the key is expired even if still present (because the * master has yet to propagate the DEL). * * In masters as a side effect of finding a key which is expired, such * key will be evicted from the database. Also this may trigger the * propagation of a DEL/UNLINK command in AOF / replication stream. * * The return value of the function is 0 if the key is still valid, * otherwise the function returns 1 if the key is expired. */ // 判断是否过期 intexpireIfNeeded(redisDb *db, robj *key) { // key过期,则直接返回0 if (!keyIsExpired(db,key)) return0;
/* If we are running in the context of a slave, instead of * evicting the expired key from the database, we return ASAP: * the slave key expiration is controlled by the master that will * send us synthesized DEL operations for expired keys. * * Still we try to return the right information to the caller, * that is, 0 if we think the key should be still valid, 1 if * we think the key is expired at this time. */ if (server.masterhost != NULL) return1;
/* If clients are paused, we keep the current dataset constant, * but return to the client what we believe is the right state. Typically, * at the end of the pause we will properly expire the key OR we will * have failed over and the new primary will send us the expire. */ if (checkClientPauseTimeoutAndReturnIfPaused()) return1;
/* Delete the key */ // 删除过期key deleteExpiredKeyAndPropagate(db,key); return1; }
/* Check if the key is expired. */ intkeyIsExpired(redisDb *db, robj *key) { mstime_t when = getExpire(db,key); mstime_t now;
if (when < 0) return0; /* No expire for this key */
/* Don't expire anything while loading. It will be done later. */ if (server.loading) return0;
/* If we are in the context of a Lua script, we pretend that time is * blocked to when the Lua script started. This way a key can expire * only the first time it is accessed and not in the middle of the * script execution, making propagation to slaves / AOF consistent. * See issue #1525 on Github for more information. */ if (server.lua_caller) { now = server.lua_time_snapshot; } /* If we are in the middle of a command execution, we still want to use * a reference time that does not change: in that case we just use the * cached time, that we update before each call in the call() function. * This way we avoid that commands such as RPOPLPUSH or similar, that * may re-open the same key multiple times, can invalidate an already * open object in a next call, if the next call will see the key expired, * while the first did not. */ elseif (server.fixed_time_expire > 0) { now = server.mstime; } /* For the other cases, we want to use the most fresh time we have. */ else { now = mstime(); }
/* The key expired if the current (virtual or real) time is greater * than the expire time of the key. */ return now > when; }
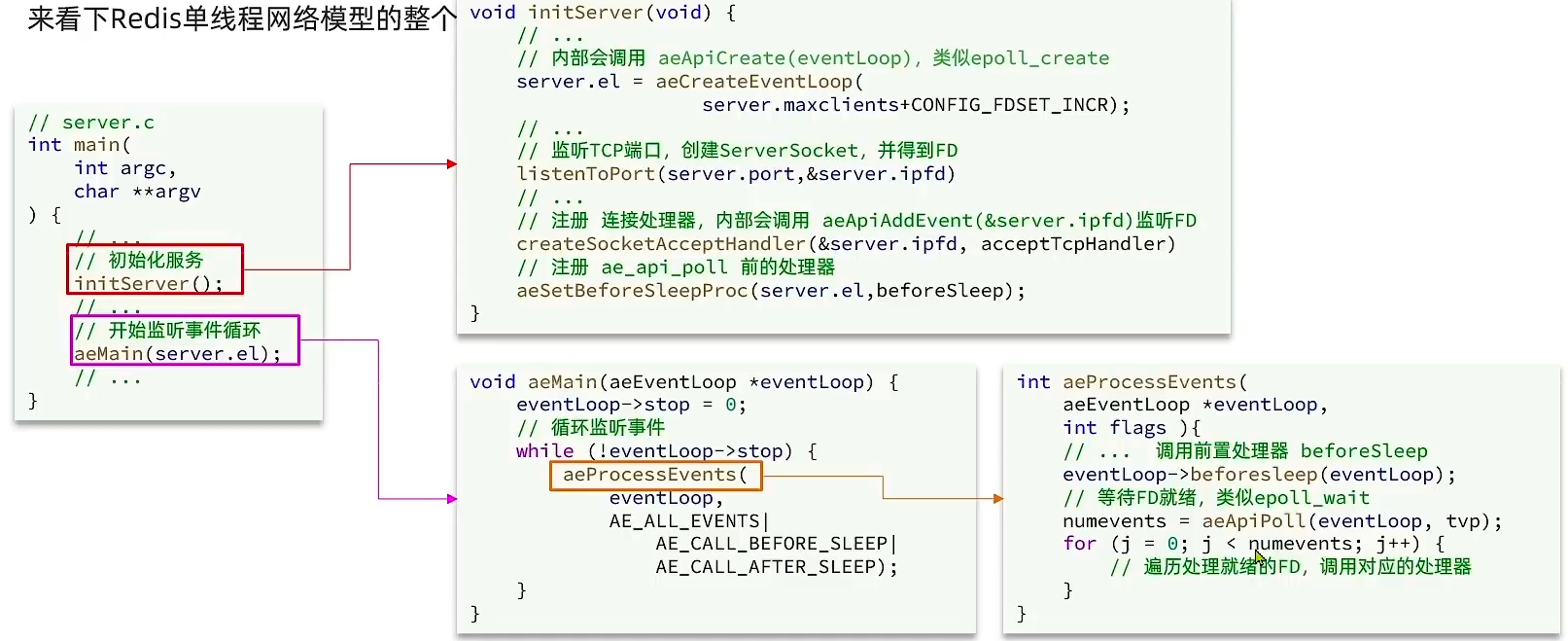
voidinitServer(void) { /* Create the timer callback, this is our way to process many background * operations incrementally, like clients timeout, eviction of unaccessed * expired keys and so forth. */ // 创建定时器,关联回调函数serverCron,处理周期取决于server.hz,默认10 if (aeCreateTimeEvent(server.el, 1, serverCron, NULL, NULL) == AE_ERR) { serverPanic("Can't create event loop timers."); exit(1); } // ... }
intserverCron(struct aeEventLoop *eventLoop, longlong id, void *clientData) { /* We have just LRU_BITS bits per object for LRU information. * So we use an (eventually wrapping) LRU clock. * * Note that even if the counter wraps it's not a big problem, * everything will still work but some object will appear younger * to Redis. However for this to happen a given object should never be * touched for all the time needed to the counter to wrap, which is * not likely. * * Note that you can change the resolution altering the * LRU_CLOCK_RESOLUTION define. */ // 更新lrulock到当前时间,为后期的LRU和LFU做准备 unsignedint lruclock = getLRUClock(); atomicSet(server.lruclock,lruclock); /* Handle background operations on Redis databases. */ // 执行database的数据清理,例如过期key处理 databasesCron(); return1000/server.hz; // ... }
/* This function handles 'background' operations we are required to do * incrementally in Redis databases, such as active key expiring, resizing, * rehashing. */ voiddatabasesCron(void) { /* Expire keys by random sampling. Not required for slaves * as master will synthesize DELs for us. */ // 清理过期key if (server.active_expire_enabled) { if (iAmMaster()) { // 使用SLOW模式 activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW); } else { expireSlaveKeys(); } } // ... }
/* This function gets called every time Redis is entering the * main loop of the event driven library, that is, before to sleep * for ready file descriptors. * * Note: This function is (currently) called from two functions: * 1. aeMain - The main server loop * 2. processEventsWhileBlocked - Process clients during RDB/AOF load * * If it was called from processEventsWhileBlocked we don't want * to perform all actions (For example, we don't want to expire * keys), but we do need to perform some actions. * * The most important is freeClientsInAsyncFreeQueue but we also * call some other low-risk functions. */ voidbeforeSleep(struct aeEventLoop *eventLoop) { /* Run a fast expire cycle (the called function will return * ASAP if a fast cycle is not needed). */ // 尝试清理部分过期key,清理模式默认为FAST if (server.active_expire_enabled && server.masterhost == NULL) activeExpireCycle(ACTIVE_EXPIRE_CYCLE_FAST); // ... }
src/ae.c
1 2 3 4 5 6 7 8 9 10 11 12
voidaeMain(aeEventLoop *eventLoop) { eventLoop->stop = 0; while (!eventLoop->stop) { // beforeSleep() --> FAST 模式清理 // n = aeApiPoll() // 如果 n > 0 ,FD就绪,处理IO事件 // 如果到了执行时间,则调用serverCron() --> SLOW 模式清理 aeProcessEvents(eventLoop, AE_ALL_EVENTS| AE_CALL_BEFORE_SLEEP| AE_CALL_AFTER_SLEEP); } }
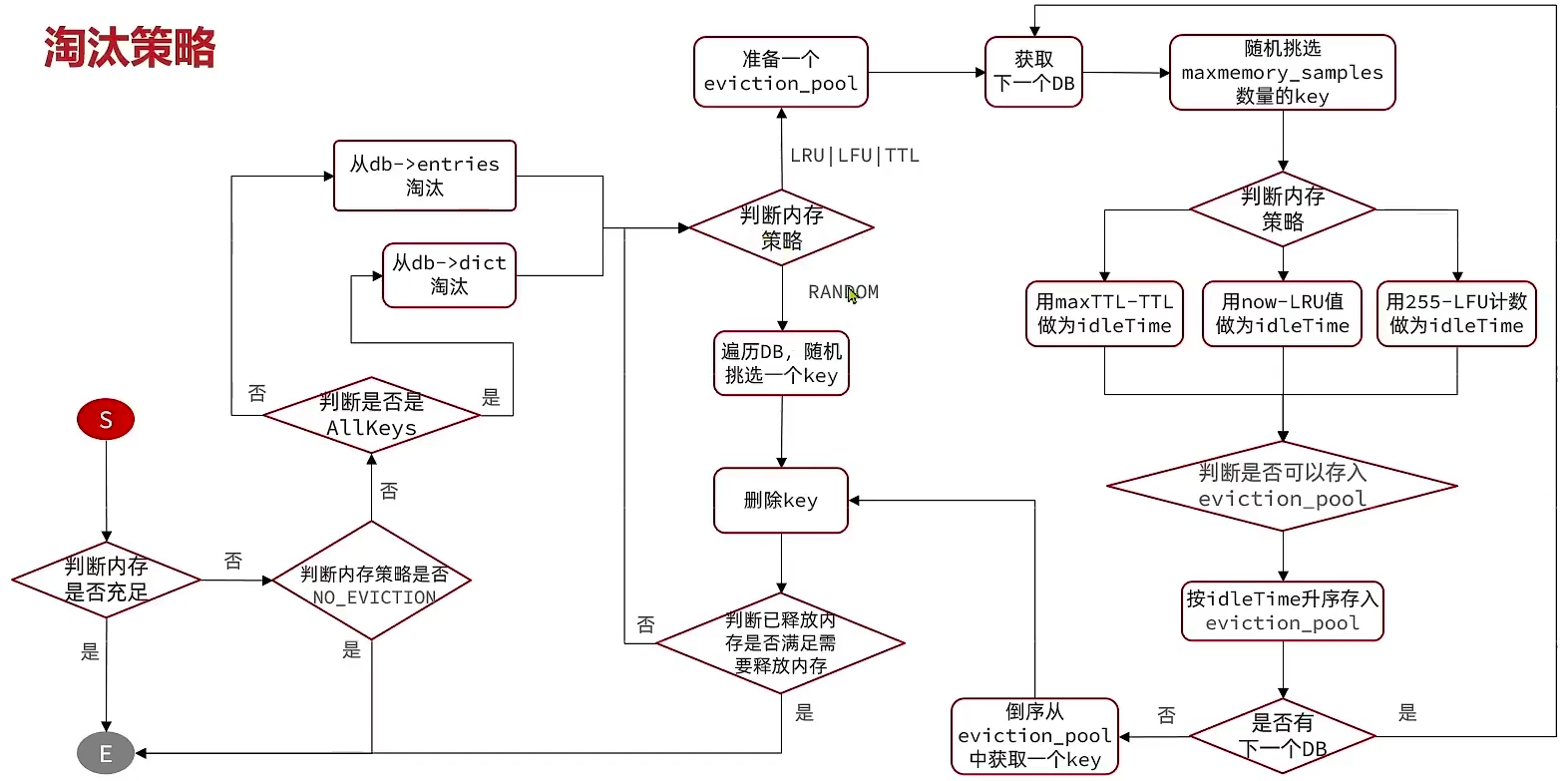
/* If this function gets called we already read a whole * command, arguments are in the client argv/argc fields. * processCommand() execute the command or prepare the * server for a bulk read from the client. * * If C_OK is returned the client is still alive and valid and * other operations can be performed by the caller. Otherwise * if C_ERR is returned the client was destroyed (i.e. after QUIT). */ intprocessCommand(client *c) { /* Handle the maxmemory directive. * * Note that we do not want to reclaim memory if we are here re-entering * the event loop since there is a busy Lua script running in timeout * condition, to avoid mixing the propagation of scripts with the * propagation of DELs due to eviction. */ // 尝试进行内存淘汰 performEvictions,如果失败,则会有 out_of_memory if (server.maxmemory && !server.lua_timedout) { int out_of_memory = (performEvictions() == EVICT_FAIL); // 当 out_of_memory 时,会拒绝命令 if (out_of_memory && reject_cmd_on_oom) { rejectCommand(c, shared.oomerr); return C_OK; } // ... }
/* Check that memory usage is within the current "maxmemory" limit. If over * "maxmemory", attempt to free memory by evicting data (if it's safe to do so). * * It's possible for Redis to suddenly be significantly over the "maxmemory" * setting. This can happen if there is a large allocation (like a hash table * resize) or even if the "maxmemory" setting is manually adjusted. Because of * this, it's important to evict for a managed period of time - otherwise Redis * would become unresponsive while evicting. * * The goal of this function is to improve the memory situation - not to * immediately resolve it. In the case that some items have been evicted but * the "maxmemory" limit has not been achieved, an aeTimeProc will be started * which will continue to evict items until memory limits are achieved or * nothing more is evictable. * * This should be called before execution of commands. If EVICT_FAIL is * returned, commands which will result in increased memory usage should be * rejected. * * Returns: * EVICT_OK - memory is OK or it's not possible to perform evictions now * EVICT_RUNNING - memory is over the limit, but eviction is still processing * EVICT_FAIL - memory is over the limit, and there's nothing to evict * */ intperformEvictions(void) { // ... }