MySQL学习笔记高可用篇
数据库日志
除了前面在用于支持事务的redo log和undo log,数据库系统还有其他的日志。例如系统运行过程中的错误日志、同步日志等。
MySQL 8.0官网日志地址:https://dev.mysql.com/doc/refman/8.0/en/server-logs.html

日志的分类:
Slow query log:慢查询日志,记录所有执行时间超过long_query_time的所有查询,方便对查询进行优化General query log:通用查询日志,记录所有连接的其实时间和终止时间,以及连接发送给数据库服务器的所有指令,对复原操作的实际场景、发现问题,甚至是对数据库操作的审计都有很大的帮助Error log:记录MySQL服务的启动、运行或停止MySQL服务时出现的问题,方便了解服务器状态,从而维护服务器Binary log:二进制日志,记录所有更改数据的语句(可选择是语句还是修改数据的行数),可以用于主从服务器之间的数据同步,以及服务器遇到故障时数据的无损失恢复Relay log:中继日志,用于主从服务器架构中,从服务器用来存放主服务器二进制日志内容的一个中间文件。从服务器通过读取终极日志的内容,来同步主服务器上的操作DDL log:数据定义语句日志:记录数据定义语句执行的元数据操作。
除了二进制文件外,其他日志都是文本文件。默认情况下,所有日志创建与MySQL数据目录中。
日志的弊端:
- 日志会降低MySQL数据库的性能
- 日志会占用大量的磁盘空间
慢查询日志(slow query log)
详细使用:定位执行慢的SQL:慢查询日志
通用查询日志(general query log)
通用查询日志用来记录用户的所有操作,包括启动和关闭MySQL服务、所有用户的连接开始时间和截止时间、发给MySQL数据库服务器的所有SQL指令等。当数据发生异常时,查看通用查询日志,还原操作时的具体场景,帮助定位问题。
1 | -- 查看通用查询日志 |
例如查看表中的数据和删除记录
1 | 2022-11-27T12:11:06.511669Z 32 Query SET PROFILING = 1 |
1 | -- 关闭日志 |
1 | -- 删除、刷新日志 |
1 | 在shell中操作,将原先的日志文件删除或者备份,执行命令之后会重新生成一个新的日志文件 |
错误日志(error log)
记录出现的错误、警告和提示等。
错误日志默认是开启的,而且错误日志无法被禁止。默认路径是mysqld.log(Linux系统)
1 | SHOW VARIABLES LIKE 'log_err%'; |
1 | cat /var/log/mysqld.log |
1 | cat 87e36d56e6fe.err |
删除、刷新过程,与上面一样,重命名之后。
1 | -- 首先需要执行,然后再刷新。这是由于MySQL新版本备份操作要多做一步。 |
二进制日志(binlog)
二进制日志,也就是 binary log,也做叫变更日志(update log),记录了数据库所有执行的DDL和DML等数据库更新事件的语句,但是不包含没有修改任何数据的语句。
主要应用场景:
- 用于数据恢复
- 用于数据复制,主从复制中
master将二进制日志传递给slaves来达到master-slave数据一致的目的
使用
MySQL数据库的数据备份、主备、主主、主从都离不开binlog,都需要依靠binlog来同步数据,保证数据一致性。
1 | SHOW VARIABLES LIKE 'log_bin%'; |
1 | cd /var/lib/mysql |
修改配置,持久化修改需要修改 my.cnf 配置文件,临时修改改配置文件,而且只能用session级别。
1 | [mysqld] |
数据库文件最好不要与二进制文件放在同一个磁盘上,避免磁盘损坏导致数据无法恢复。使用新的目录要修改目录所属用户和所属用户组。
查看日志
1 | SHOW BINARY LOGS; |
查看日志具体信息
1 | mysqlbinlog "/var/bin/log/binlog.000020" |
查看到的日志具体数据都是二进制的,通过参数 -v可以看到具体操作
1 | mysqlbinlog -v "/var/bin/log/binlog.000020" |

binlog一些用法
1 | 查看帮助 |
更方便的查询
1 | show binlog events [IN 'log_name'] [from pos] [limit [offset,] row_count]; |
[IN 'log_name']:指定查询binlog文件名[from pos]:指定从哪个pos起始点开始查limit [offset,]:偏移量row_count:查询总条数
1 | show binlog events IN 'binlog.000020' limit 10; |
binlog格式查看
1 | SHOW VARIABLES LIKE '%binlog_format%'; |
Statement:每一条会修改数据的sql都会记录在binlog中。Row:不记录sql语句上下文相关信息,仅保存记录被修改的信息Mixed:Statement和Row的结合
使用binlog恢复数据,例如误删除一些操作,此时可以使用binlog将误删除的数据恢复出来
1 | -- 先刷新日志,创建出一个新的二进制日志文件,避免单个文件写入又读取 |
恢复
1 | mysqlbinlog --start-position=100 --stop-position=800 --database=dbtest2 /var/lib/mysql/binlog.000020 | mysql -uroot -p123456 -v student; |
起止时间
1 | mysqlbinlog --start-datetime="2022-11-27 21:00:00" --stop-datetime="2022-11-27 21:01:00" --database=dbtest2 /var/lib/mysql/binlog.000020 | mysql -uroot -p123456 -v student; |
删除二进制文件
可以选择部分删除或者全部都删
1 | -- PURGE MASTER LOGS:删除指定 ,将11 之前(不包含11)的都删掉 |
全部删除,(慎用)
1 | RESET MASTER; |
写入机制
binlog是在事务执行过程中,先将binlog写入binlog cache,再提交事务,再把binlog cache写到binlog文件中。因为一个事务的binlog不能被拆开,无论这个事务多大,也要确保一次性写入,所以系统会给每个线程分配一个块内存作为binlog cache。
可以通过 binlog_cache_size 参数控制单个线程binlog cache大小,存储内容超过这个参数,就会暂存到磁盘。
刷盘流程:
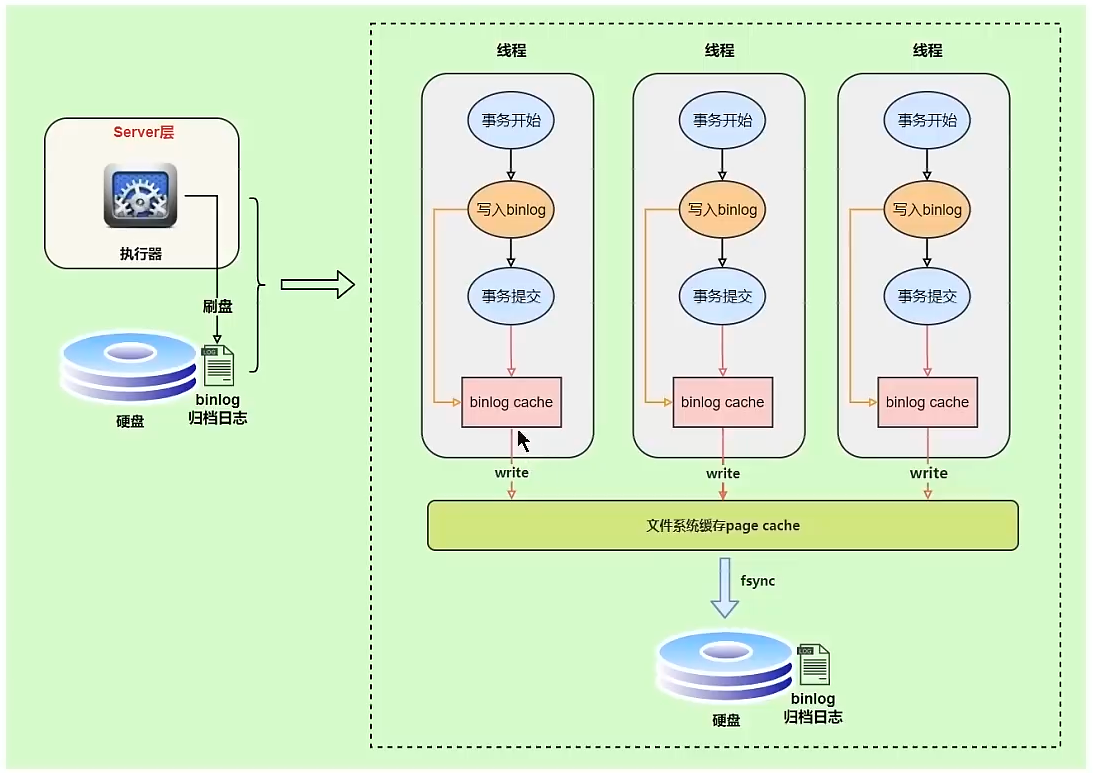
write是将binlog cache写入page cache,fsync是将page cache同步到磁盘。
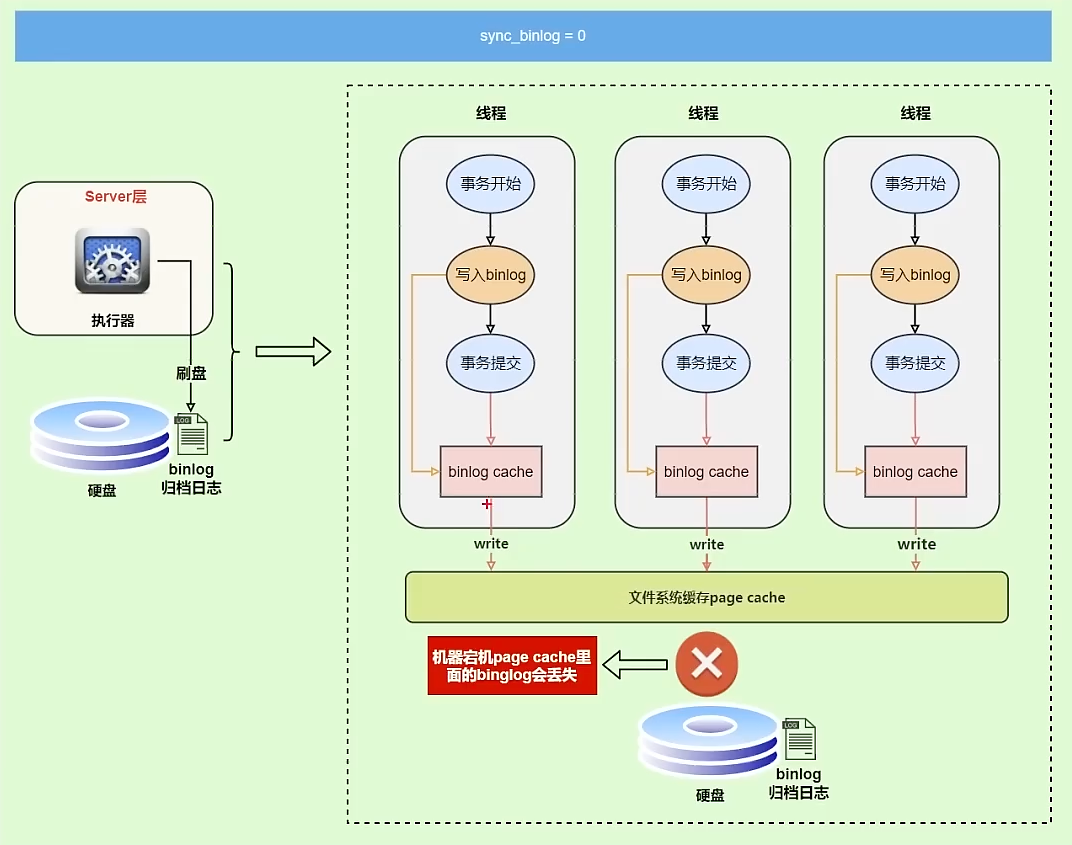
write和fsync的时机可以由参数 sync_binlog 控制,默认是0,代表每次提交事务都只write,由系统判断fsync的执行时机。性能会提升,但是可能有丢失数据的风险
为了安全,可以设置为1,每次提交事务都会执行fsycn,如同redo log刷盘流程一样。
也可以改成N(>1),每次提交事务都write,积累N个事务之后才fsync。性能更高,但是风险也更高。
binlog和redolog对比
redo log是物理日志,记录的是某个数据页上的改动,属于InnoDB存储引擎产生的bin log是逻辑日志,记录语句的原始逻辑,属于MySQL server层- 都可以持久化,但是侧重点不同
redo log让InnoDB存储引擎有了崩溃恢复能力bin log保证MySQL集群架构的数据一致性
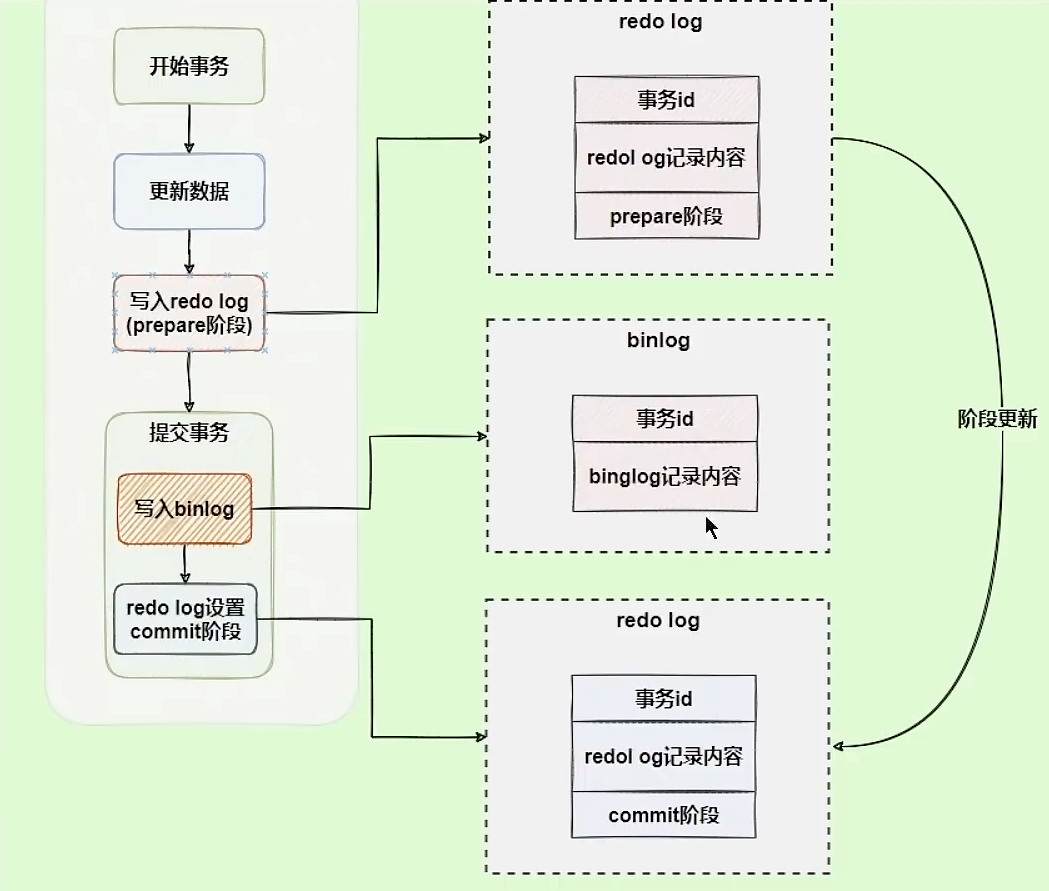
二阶段提交
更新语句会更新redo log和bin log,以基本事务为单位,redo log在事务执行过程中可以不断写入,bin log只有在事务提交才会写入
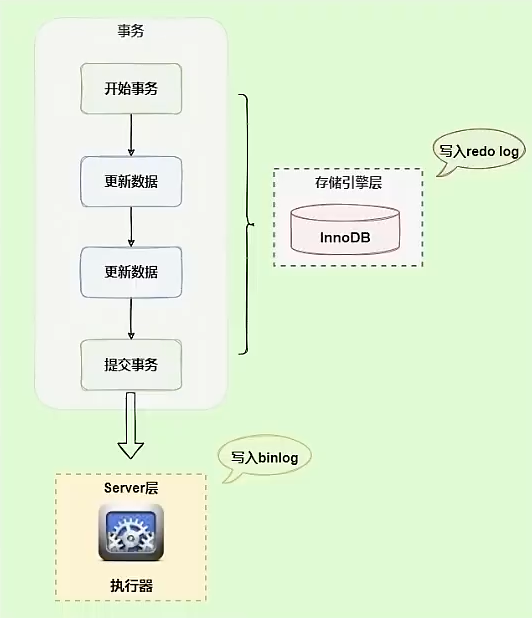
如果两份日志不一致,会出现什么问题?
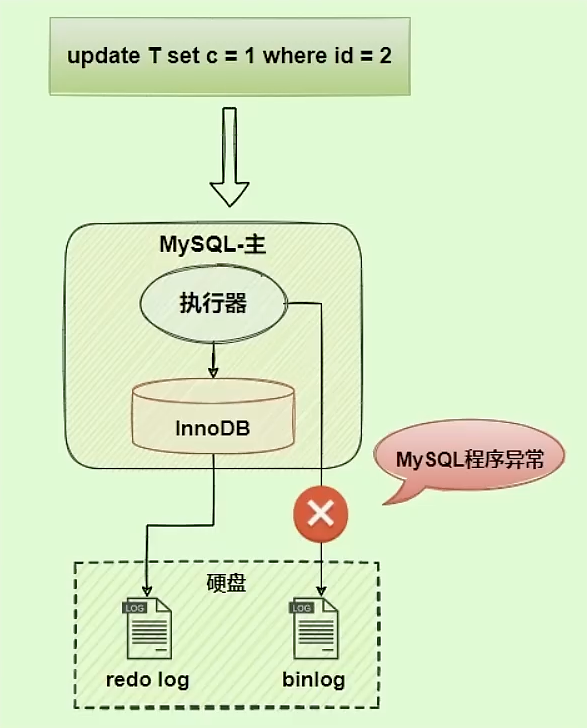
bin log没写完就异常,而 redo log正常,恢复之后,会出现 c 这一行的数据不一致。
此时,通过bin log做数据同步,数据会不一致。
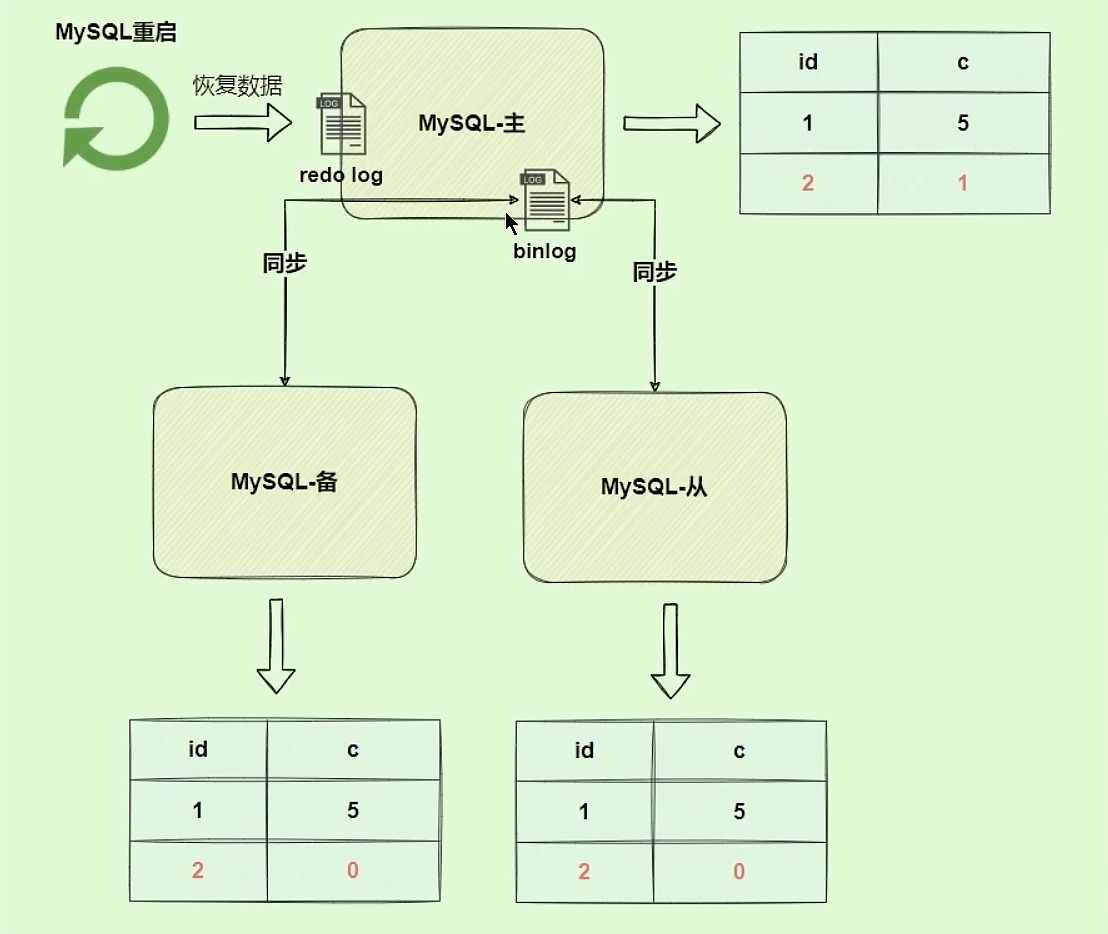
为了解决数据之间不一致的问题,InnoDB存储引擎使用两阶段提交的方案,原理是将redo log的写入拆成两个步骤,prepare和commit,这就是两阶段提交
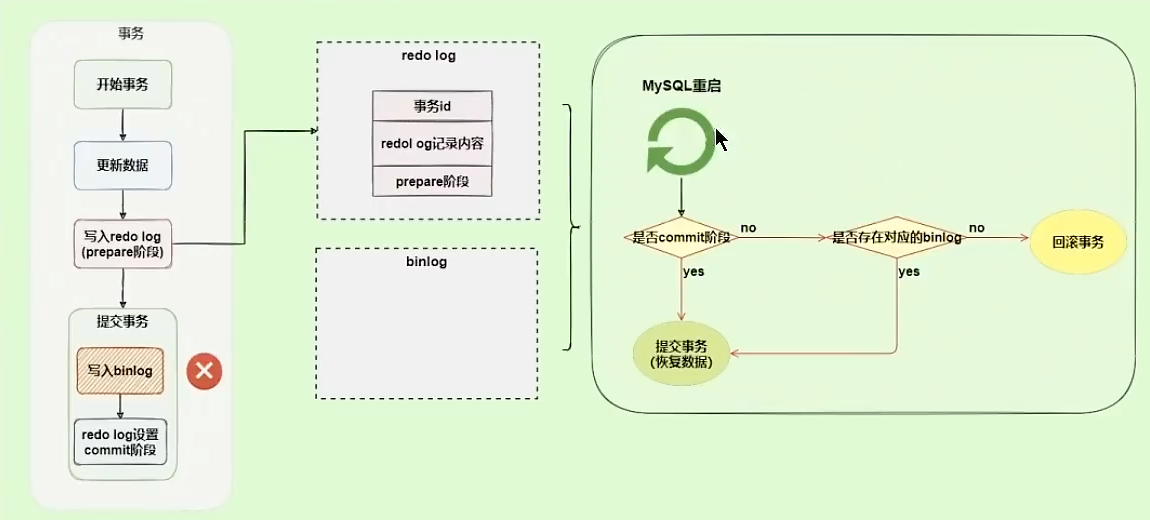
通过redo log恢复数据时,发现redo log处于prepare阶段,并且没有对应binlog日志,就会回滚该事务
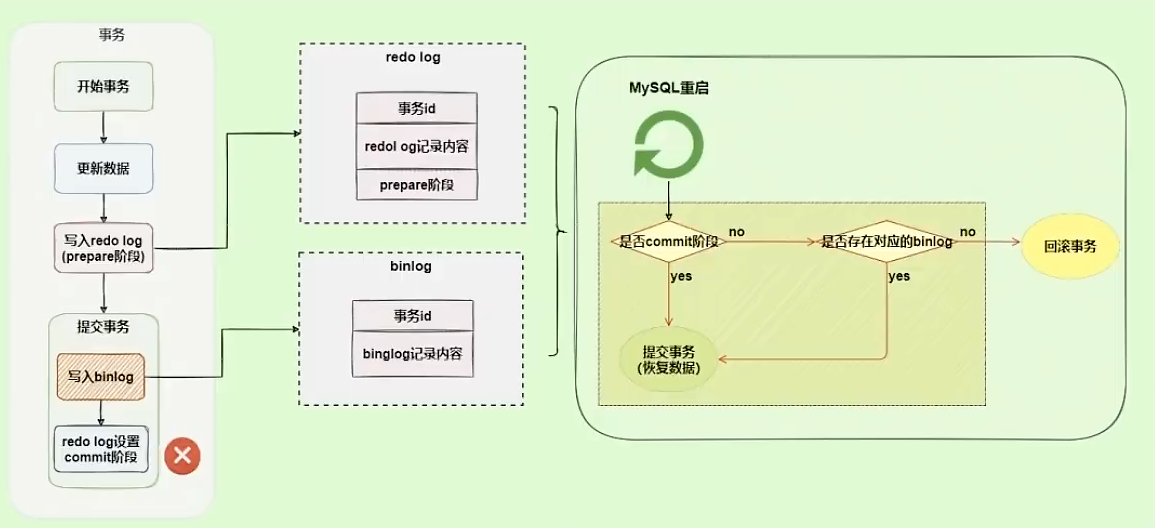
如果是 redo log设置commit阶段发生异常,此时就不会回滚,虽然redo log处于prepare阶段,但是能通过事务id找到对应的binlog,所以MySQL认为是完整的,就会提交事务恢复数据。
中继日志(relay log)
中继日志只在主从服务器架构中的从服务器上存在。例如一主一从架构中,为了与主服务保持一致,需要从服务器读取二进制的内容,并且把读取到的信息写入本地的日志文件中,这个就是中继日志。然后从服务器读取中继日志,数据更新,完成数据同步。
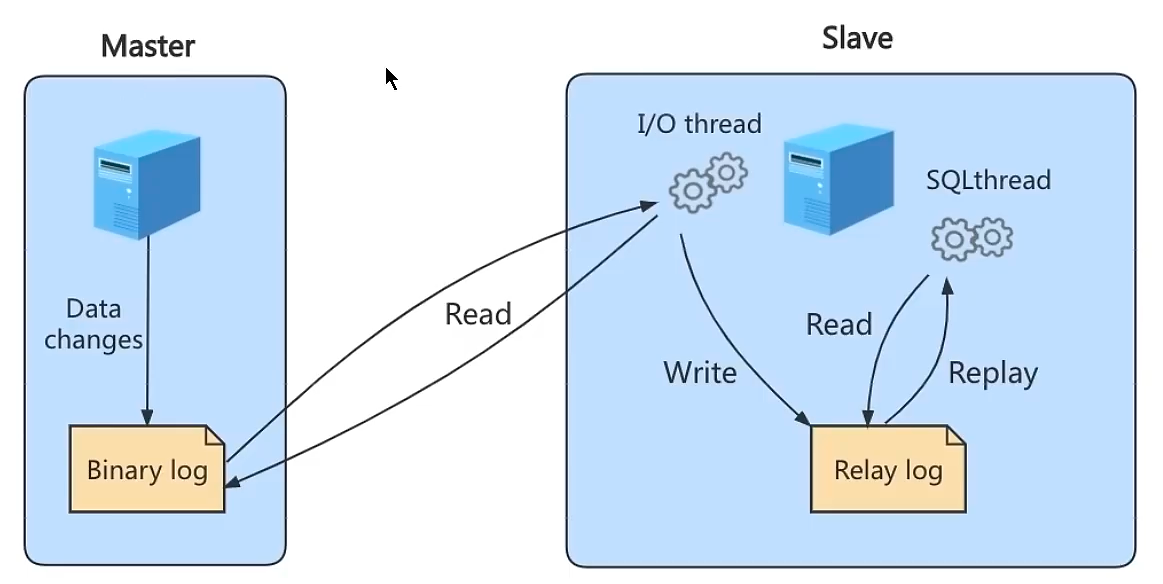
文件格式是 从服务器名-relay-bin.序号。中继日志还有一个索引文件:从服务器名-relay-bin.index,用来定位当前使用的中继日志。
查看方式可以使用mysqlbinlog
如果从服务器宕机,并且从服务器宕机,从中继日志恢复数据,可能导致数据不一致,这可能由于日志中的从服务器名不一致。
主从复制
提升数据库的并发能力常常会采用redis作为缓存与MySQL配合使用,可以提高读取的效率,也降低数据库的压力。
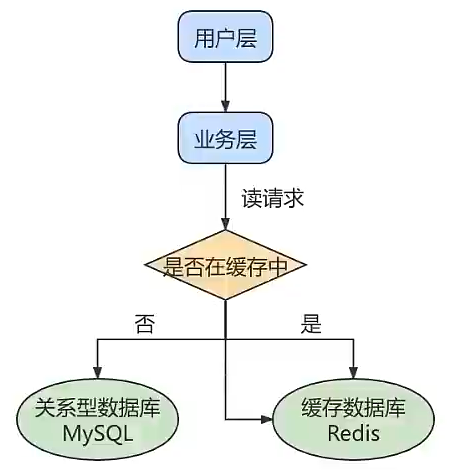
一般应用对数据库而言都是读多写少,也就是对数据库读取数据的压力比较大,这个时候就可以通过主从架构、进行读写分离,提升服务器的读取能力。
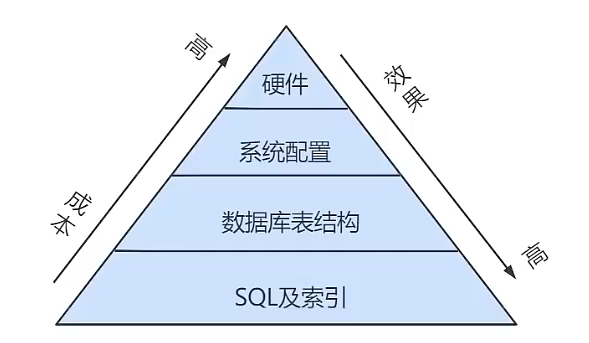
但是数据库调优的过程,是先从成本考虑,从成本低到成本高,因此,从硬件方面实现主从架构,是最后的方案
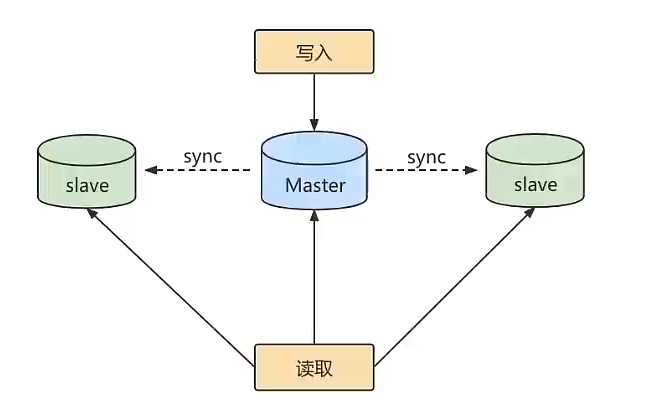
主从复制作用
读写分离
![image-20221127215122649]()
其中一个是Master主库,负责写入数据,称之为写库
其他都是Slave从库,负责读取数据,称之为读库。
这种方式可以实现更高的并发访问,不仅可负载均衡,还减少了锁表的影响,当主库负责写,主库出现写锁的时候,不影响从库读取。
数据备份
将数据从主库复制到从库,相当于是一种热备。
具有高可用性
是一种冗余的机制,通过这种冗余的机制,可以换取数据库的高可用性,当服务器出现故障或者宕机的情况下,可以切换到从服务器上。
主从复制的原理
Slave会从Master读取bin log来同步。
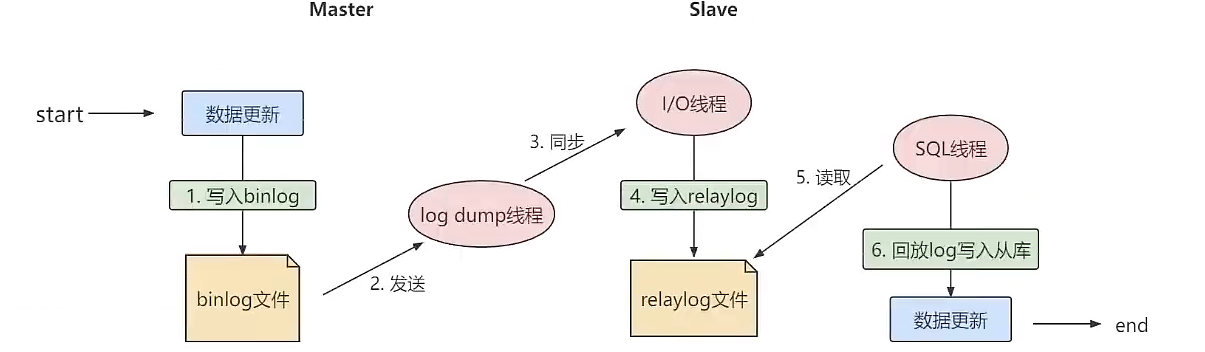
实际上是有三个线程:
主库二进制转储线程将二进制发送给从库,主库读取时间的时候,会在binlog上加锁,读取完成之后,再将锁释放。
从库**I/O线程**会连接主库,向主库发送请求更新binlog,从库的I/O线程将读取到主库的二进制日志转储binlog的更新部分,并且拷贝到本地的中继日志。
从库SQL线程会读取从库中的中继日志,并且执行日志中的事件,将从库中的数据与主库保持同步。
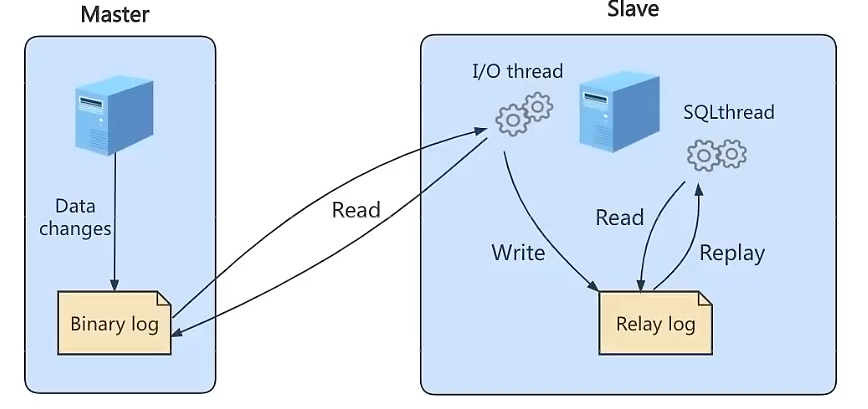
注意:不是所有
MySQL版本都默认开启服务器的二进制日志,进行主从同步的时候,需要先检查服务器是否已经开启二进制日志。
复制的最大问题,就是延迟。写入主库和读取从库中间需要时间。
复制的原则:
- 每个
Slave只有一个Master - 每个
Slave只能有一个唯一的服务器ID - 每个
Master可以有多个Slave
准备环境
搭建两台MySQL服务器,一主一从。
这里使用两个容器搭建。
1 | # 两个 UUID |
主机配置
必选
1
2
3[mysqld]
server-id = 1
log-bin=binlog可选
1
2
3
4
5
6
7
8
9
10
11
12
13[mysqld]
# 0 表示读写(主机),1表示只读(从机)
read-only=0
# 设置日志文件保留的时长,单位是秒
binlog_expire_logs_seconds=6000
# binlog日志最大大小
max_binlog_size=200M
# 不要复制的数据库
binlog-ignore-db=test
# 复制的数据库,不写默认全部
binlog-do-db=
# binlog格式 STATEMENT:基于SQL语句的配置
binlog_format=STATEMENTbinlog_format:binlog格式STATEMENT:默认,基于SQL语句的复制,每一条会修改数据的SQL语句都会记录到binlog中。(例如INSERT ... SELECT,记录的语句)。优点是减少
binlog日志,包含所有数据库的更改信息,可以实时还原,二不仅仅是复制。缺点是不是所有UPDATE语句都可以被复制,例如
UUID这样的函数;会产生更多的行级锁;复杂语句会消耗更多资源;ROW:基于行的格式,不记录每条SQL语句的上下文信息,仅记录哪条数据被修改了,修改成什么样。(例如INSERT ... SELECT,记录的插入的数据)。优点是安全可靠;可以采用多线程执行复制
缺点:日志大;复杂的回滚binlog中会包含大量的数据;
MIXED:二者集合一般的语句修改使用
STATEMENT格式保存binlog。比如一些函数,
STATEMENT无法完成主从复制,则采用row格式保存binlog。
从机配置
必选
1
2[mysqld]
server-id = 2可选
1
2# 启用中继日志
relay-log=mysql-relay
主机建立账户并授权
1 | CREATE USER 'slave1'@'172.17.0.3' IDENTIFIED BY '123456'; |
查询master状态,并记录File和Position信息
1 | SHOW MASTER STATUS; |
操作从机
1 | CHANGE MASTER TO MASTER_HOST='172.17.0.2',MASTER_USER='slave1',MASTER_PASSWORD='123456',MASTER_LOG_FILE='binlog.000002',MASTER_LOG_POS=1192; |
如果出现一些报错,例如前面配置过从机,则需要停止从机,然后再CHANGE MASTER ...
1 | STOP SLAVE; |
启动slave
1 | START SLAVE; |
如果启动报错,可能是由于已经有relay_log,此时reset,然后重新CHANGE MASTER ...
1 | RESET SLAVE; |
查看从机状态
1 | SHOW SLAVE STATUS\G |
测试:
主库操作
1 | create database dbtest10; |
从库操作
1 | show databases; |
可以看到同步成功。
停止同步
停止同步
1 | stop slave; |
重新配置主从,需要在主机上执行
1 | stop slave; |
数据一致性问题
主从同步的要求:
- 读库和写库的数据一致(最终一致);
- 写数据必须写到写库;
- 读数据必读到读库(不一定);
方法1:异步复制
异步模式就是客户端提交COMMIT之后,不需要等从库返回任何结果,而是直接将结果返回给客户端,这样的好处是不会影响主库写的效率,但是可能存在主库宕机,binlog还没有同步到从库的情况,也就是此时主库和从库数据不一致。这时候从从库中选择一个作为新主,那么新主则能缺少原来主服务器已提交的事务。所以,这种复制模式下的数据一致性是最弱的。
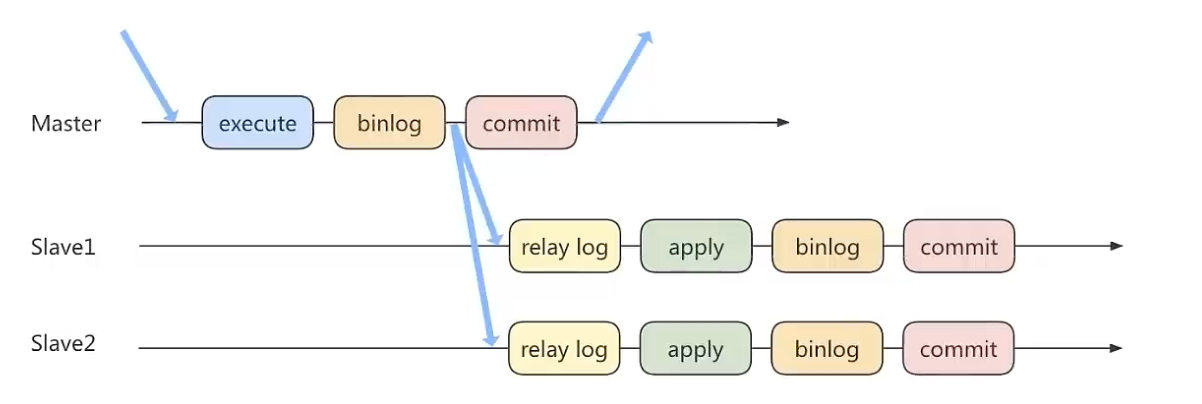
ps:图中commit在binlog之后,是表示系统宕机启动之后,通过redo log和bin log之后再判断这个事务是否会提交。
方法2:半同步复制
MySQL 5.5版本之后开始支持,当客户端提交COMMIT之后,不直接将结果返回给客户端,而是等待至少有一个从库收到了binlog,并且写入中继日志中,再返回给客户端。
好处是提高了数据一致性,相比异步复制,至少多增加了一个网络连接的延迟,降低了主从写的效率。
MySQL 5.7 版本增加一个 rpl_semi_sync_master_wait_for_slave_count 参数,可以设置应答的从库数量,默认为1,也就是有1个从库响应,就可以返回给客户端。
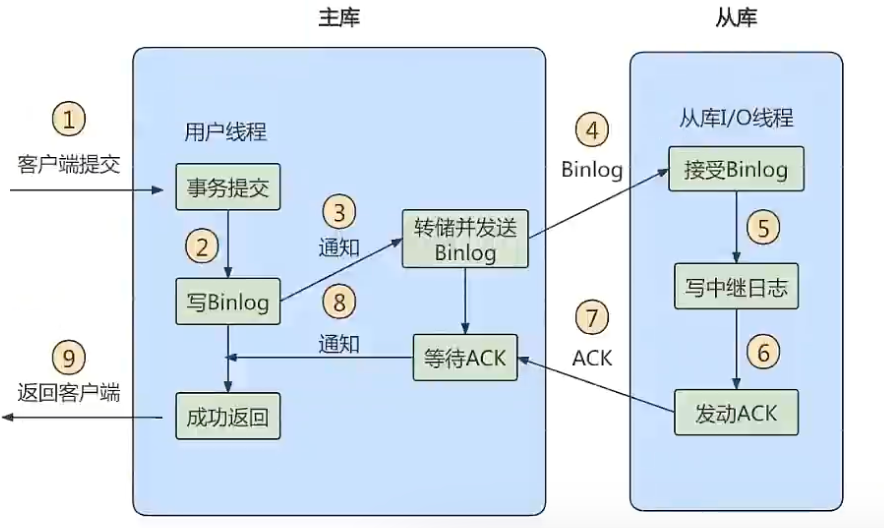
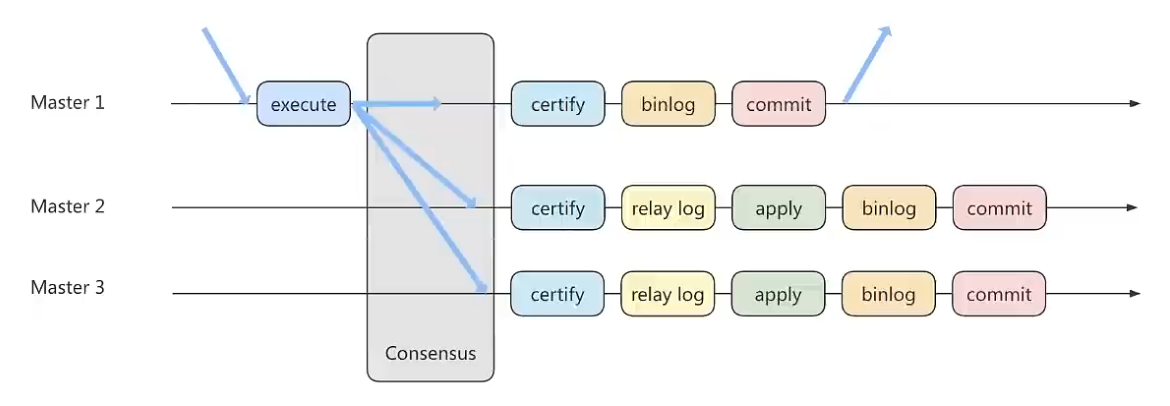
方法3:组复制
异步复制和半同步复制都无法最终保证数据的一致性问题,半同步复制是通过判断从库响应的个数来决定是否返回给客户端,虽然数据一致性相比于异步复制有提升,但仍然无法满足对数据一致性要求高的场景。
组复制技术,简称MGR(MySQL Group Replication),基于Paxos协议的状态机复制。
MGR工作原理:
首先将多个节点组成一个复制组,在执行读写事务的时候,通过一致性协议层的同意,也就是读写(RW)事务想要进行提交,必须要经过组里“大多数人”(x > N/2+1)的同意,才可以提交。针对只读(RO)事务,则不需要经过组内同意,直接COMMIT即可。
在一个复制组内有多个节点组成,各自维护了自己的数据副本,并且在一致性协议层实现了原子消息和全局有序消息,从而保证组内数据的一致性。
数据库备份
为了有效防止数据丢失,并将损失降到最低,应定期对MySQL数据库服务器做备份,如果数据库中的数据丢失或者出现错误,可以使用备份的数据进行恢复。主从服务器之间的数据同步问题可以通过复制功能实现。
物理备份与逻辑备份
物理备份:备份数据文件,转储数据库物理文件到某一目录。物理备份恢复速度快,但占用空间比较大,MySQL中可以用xtrabackup工具来进行物理备份。
逻辑备份:对数据库对象利用工具进行导出,汇总入备份文件内。逻辑备份恢复速度慢,但占用空间小,更灵活。MySQL中常用的备份工具为mysqldump。逻辑备份就是备份sql语句,在恢复的时候执行备份的sql语句实现数据库数据的重现。
逻辑备份
mysqldump执行时,可以即将数据库备份成一个文本文件,包含多个CREATE和INSERT语句,使用这些语句可以重新创建表和插入数据。
- 查出需要备份的表的结构,在文本文件中生成一个
CREATE语句 - 将表中的所有记录转换成一条
INSERT语句
基本语法:
备份指定数据库
1 | mysqldump -h127.0.0.1 -P3306 -uroot -p123456 dbtest2 > dbtest2_bak.sql |
备份出来的 dbtest2_bak.sql可以直接查看
1 | # 截取部分 |
备份全部数据库
1 | mysqldump -h127.0.0.1 -P3306 -uroot -p123456 --all_databases > all_databases_bak.sql |
备份多个数据库
1 | mysqldump -h127.0.0.1 -P3306 -uroot -p123456 --databases dbtest2 dbtest > dbtest2_dbtest1_bak.sql |
备份部分表
1 | mysqldump -h127.0.0.1 -P3306 -uroot -p123456 dbtest2 account student > dbtest2_account_student_bak.sql |
备份单表中的部分数据
1 | mysqldump -h127.0.0.1 -P3306 -uroot -p123456 dbtest2 account --where="id < 2" > dbtest2_account_id2_low_bak.sql |
排除某些表
1 | mysqldump -h127.0.0.1 -P3306 -uroot -p123456 dbtest2 --ignore-table=dbtest2.account > dbtest2_excloud_account_bak.sql |
只备份表结构
1 | mysqldump -h127.0.0.1 -P3306 -uroot -p123456 dbtest2 --no-data > dbtest2_nodata.sql |
只备份数据
1 | mysqldump -h127.0.0.1 -P3306 -uroot -p123456 dbtest2 --no-create-info > dbtest2_no_table.sql |
备份包含存储过程、函数、事件
1 | -- 查看函数和存储过程 |
-R :备份存储过程和函数
-E:备份事件
1 | mysqldump -h127.0.0.1 -P3306 -uroot -p123456 -R -E mitaka > mitaka_func.sql |
备份结果
1 | DELIMITER ;; |
数据库恢复
恢复时,通过备份出的.sql文件,用mysql命令恢复
单库备份中恢复单库
1 | -- 既可以恢复到原先的库中,没有指定库名,就恢复到原先的数据库中 |
全量恢复
1 | mysql -h127.0.0.1 -P3306 -uroot -p123456 < all_databases_bak.sql |
从全量备份中恢复单个数据库,从全局的sql文件中提取部分数据库的数据,放到一个新的文件中。
1 | sed -n '/^-- Current Database: `dbtest`/,/^-- Current Database: `/p' all_databases_bak.sql > dbtest_bak.sql |
然后再恢复
1 | mysql -h127.0.0.1 -P3306 -uroot -p123456 < dbtest_bak.sql |
从单库备份中恢复单表
1 | -- 表结构 |
然后再恢复
1 | -- 在sql中通过source命令恢复 |
物理备份
直接复制整个数据库,原理就是拷贝数据。
为了保证数据一致性:
- 方式1:备份前,将服务器停止
- 方式2:备份前,对相关表执行
FLUSH TABLES WITH READ LOCK操作
这种方式方便、快速,但不是最好的备份方法,因为实际情况可能不允许停止MySQL服务器或者锁表,而且这种方法对InnoDB存储引擎的表不适用。
注意,物理备份完毕后,执行UNLOCK TABLES来解锁。
说明:
在MySQL版本号中,第一个数字表示主版本号,主版本号相同的MySQL数据库文件格式相同。
此外,还可以考虑使用相关工具实现备份,比如MySQLhotcopy工具。MySQLhotcopy是一个Perl脚本,使用LOCK TABLES、FLUSH TABLES和cp或者scp来快速备份数据库。它是备份数据库或单个表最快的途径,但只能运行在数据库目录所在的机器上,并且只能备份MyISAM类型的表。
备份和恢复需要注意:备份和恢复的数据库版本的主版本号必须相同
1 | 备份 |
表的导出与导入
表的导出
将表的数据导出到某个文件
1 | -- 获取目录位置 |
查看文件
1 | cat /var/lib/mysql-files/account1.txt |
或者使用mysqldump将数据和表结构导出
1 | mysqldump -h127.0.0.1 -P3306 -uroot -p123456 -T "/var/lib/mysql-files/" dbtest2 account |
也可以使用FIELDS字段,将字段之间使用逗号 “,”间隔,所有字符类型字段值用双引号括起来
1 | mysqldump -h127.0.0.1 -P3306 -uroot -p123456 -T "/var/lib/mysql-files/" dbtest2 account --fields-terminated-by=',' --fields-optionally-enclosed-by='\"' |
使用mysql语句导出
1 | mysql -h127.0.0.1 -P3306 -uroot -p123456 --execute="SELECT * FROM account;" dbtest2 > ./account2.txt |
导入
1 | -- 先删除,再导入 |
使用mysqlimport导入
1 | mysqlimport -h127.0.0.1 -P3306 -uroot -p123456 dbtest2 "/var/lib/mysql-files/account.txt" --fields-terminated-by=',' --fields-optionally-enclosed-by='\"' |
数据库迁移
数据迁移(data migration)是指选择、准备、提取和转换数据,将数据从一个计算机存储系统永久地传输到另一个计算机存储系统。迁移完之后,还需要验证迁移数据的完整性和退役原来旧的数据存储。
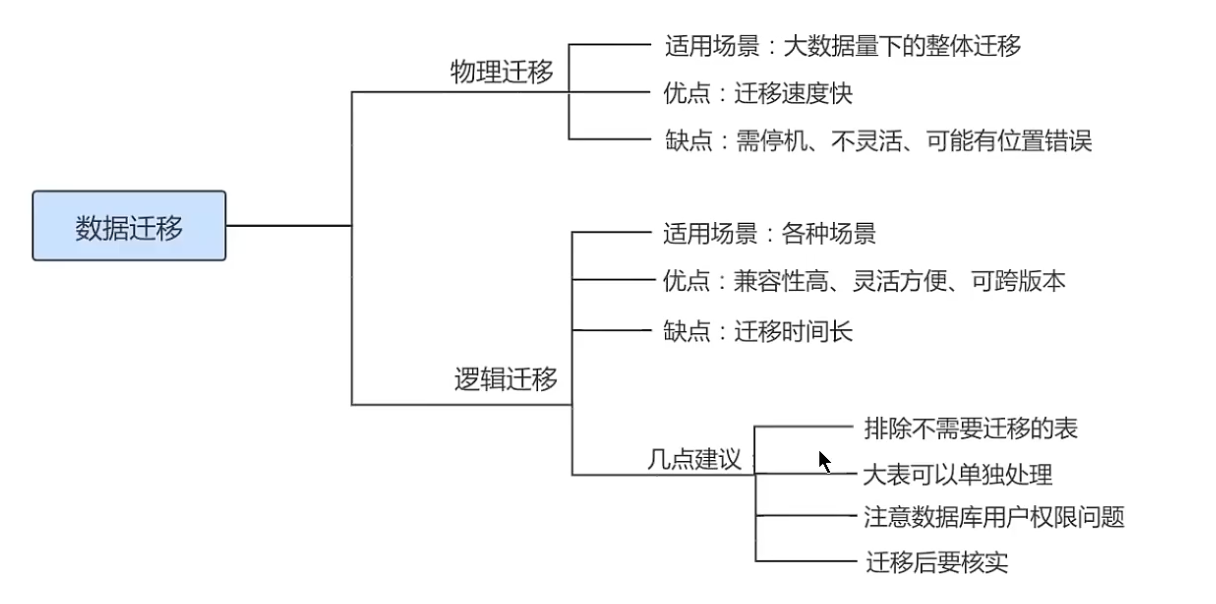
MySQL迁移方案通常有物理迁移和逻辑迁移两类,通常尽可能采用自动化的方式执行。
物理迁移
速度快,需要停机迁移,并且要求MySQL版本以及配置必须和元服务器相同。
物理迁移包括拷贝数据和使用
XtraBackup备份工具两种。不同服务器之间可以使用物理迁移,在新的服务器上安装相同的版本软件,创建相同的目录,建议配置文件也要和原数据库相同,然后从原数据库方拷贝来数据文件及日志文件,配置好文件组权限,之后在新服务器上使用
mysqld命令启动服务器。逻辑迁移
逻辑迁移适用范围更广,无论是部分迁移还是全量迁移,都可以使用逻辑迁移。逻辑迁移中使用最多的就是通过
mysqldump等备份工具
注意点
相同版本的数据库之间迁移注意点
方式1:迁移前后MySQL数据库的主版本号相同,可以拷贝数据库文件实现,但是物理迁移方式只适用于
MyISAM引擎。方式2:最常用的方案,还是使用
mysqldump导出数据,然后再在目标服务器上导入数据。
1 | 通过 | ,将前面的结果作为后面语句的输入 |
不同版本的数据库之间迁移注意点
例如从MySQL 5.5迁移到MySQL 8.0,不同版本之间迁移。
新旧版本可能使用不同的默认字符集,如果数据库中有中文数据,那么迁移过程中需要对默认字符集进行修改。
高版本的MySQL数据库通常会兼容低版本,因此可以从低版本的MySQL数据库迁移到高版本。
不同数据库之间迁移点
例如从
postgres或者sqlite迁移到MySQL,这种迁移没有普适的解决方法。迁移之前,需要了解不同数据库的架构,比较它们之间的差异。不同数据库中定义相同的数据的关键字可能会不同。
不同类型数据库之间的差异造成了互相迁移的困难,但是有些数据库之间是可以迁移的,例如用
MyODBC实现MySQL和SQLServer之间的迁移。MySQL官方提供的工具MySQL Migration Toolkit也可以在不同数据库之间进行数据迁移。MySQL迁移到Oracle时,需要使用mysqldump命令导出sql文件,然后,手动更改sql文件中的CREATE语句。
误操作后的一些操作
例如一些误删除操作:
- 使用
delete语句误删数据行 - 使用drop table或者truncate table语句误删除数据表
- 使用drop database语句误删除数据库
- 使用rm命令误删整个MySQL实例
误删行数据
使用Flashback工具恢复数据。
原理:修改bin log内容,拿回原库重放。如果误删数据涉及到了多个事务,需要将事务的顺序调过来再执行。
使用前提:binlog_format=row 和 binlog_row_image=FULL
最好的方案还是预防操作:代码做SQL审查、审计;打开安全模式,sql_safe_updates参数设置为on,删除时要求加where条件且where后需要时索引字段,否则必须使用limit,否则就会报错。
误删库、表
delete操作可以通过redolog、binlog恢复,使用truncate table或者drop table命令,在日志中也只有相同的命令记录,这个无法使用Flashback恢复。
这种情况,需要使用全量备份与增量日志结合的方式。
前提:有定期的全量备份,并且实时备份binlog
恢复步骤:
- 取最近一次全量备份
- 用备份恢复出一个临时库(这里是恢复临时库,不是操作主库)
- 取出备份时间之后的
binlog - 剔除误删除语句,将其他语句全部应用到临时库
- 然后恢复主库
预防:
- 权限分离:不给业务人员
drop、truncate权限,日常使用给只读权限;不同账号、不同数据之间进行权限分离 - 制定操作规范
- 设置延迟复制备库:例如设置1小时延迟时间再同步到备库,出现误操作1小时内,到这个备库执行
stop slave,再通过redo log恢复到误删之前的操作
误删MySQL实例
如果是有高可用实例的MySQL集群,删除一个节点之后,HA系统会重新选取一个主库,从而保证整个集群的正常工作。将这个节点上的数据恢复之后,再接入整个集群即可。
如果是删除集群,那就需要考虑跨机房备份,跨城市备份。