作为后端开发,Redis是必知必会的,而且越精通越好。无论是面试,还是平常使用,都离不开Redis,将Redis做一个总结和记录,覆盖比较常用的。比较高级的用法和底层存储结构有待后续补充。
NoSQL Not only SQL:MongoDB,Redis,elasticsearch
泛指非关系型的数据库(相对于关系型数据库管理系统RDBMS)
不支持SQL语法
存储结构跟关系型数据库中的关系表不同,NoSQL中存储的数据是KV形式(可以类比golang中的map)
每个NoSQL数据库都有自己通用的语法和api
与SQL的比较 适用场景不同,sql数据库适合用于关系特别复杂的数据查询场景,nosql反之
事务支持,sql对事务的支持非常完善,nosql基本不支持事务(Redis支持简单的事务)
简介 使用C语言编写,提供简单的TCP通信协议,支持集群,使用多路复用的I/O模型,可基于内存也可持久化的日志型、Key-Value数据库,并提供多种语言的API。
常用于缓存、队列系统。
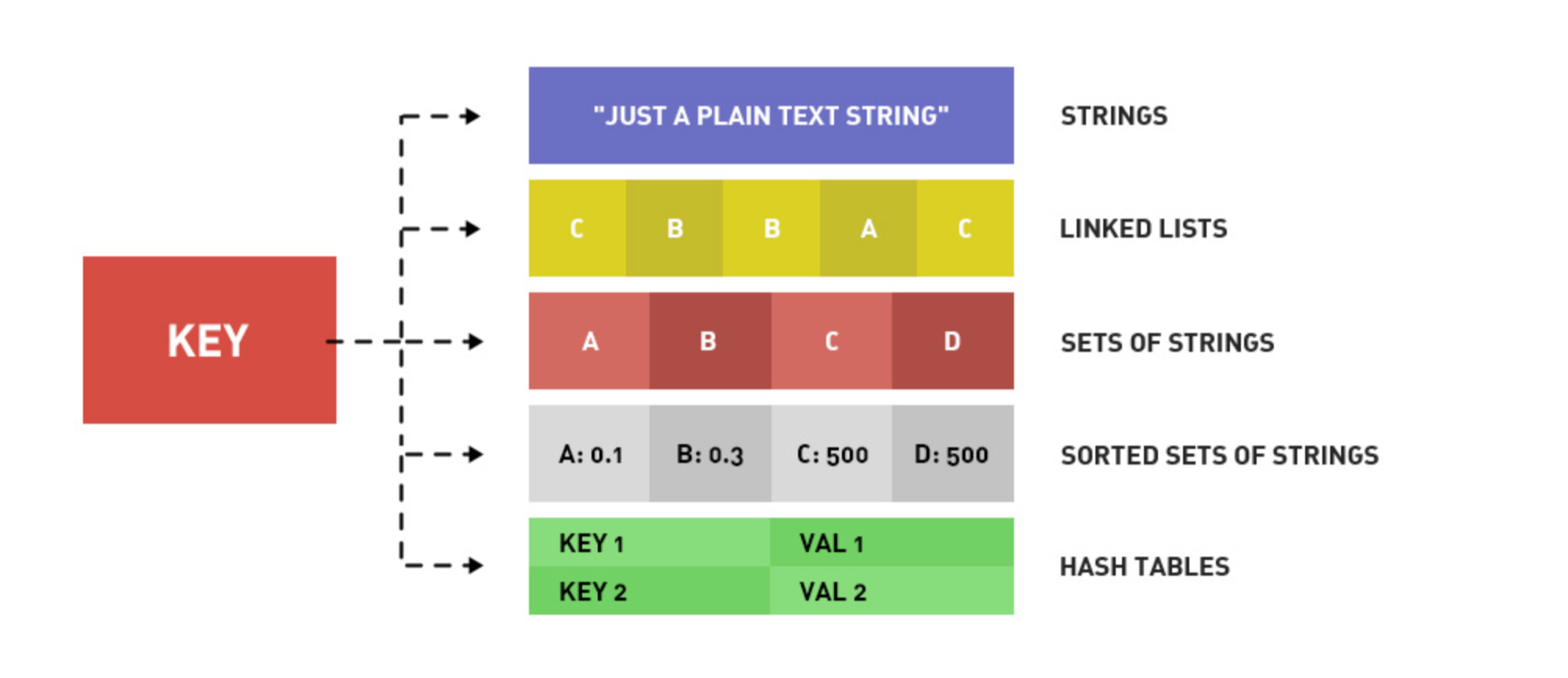
数据结构 Redis是key-value的数据结构,每条数据都是一个键值对。
键是字符串,值可以是字符串string、哈希hash、列表list、集合set、有序集合zset等数据结构。
需要注意,键不能重复,重复会覆盖。
内部编码
特性 速度快(基于内存、C语言编写、单线程处理请求、I/O多路复用)
支持持久化,将内存中的数据异步保存在磁盘中,重启的时候可以再次加载进行使用
不仅支持key-value类型的数据,还提供string,list,set,zset,hash(基础数据结构)等数据结构的存储
支持数据备份,支持master-slave模式主从复制以及分布式模式,哨兵模式
支持发布订阅、pipeline等消息队列的功能
优势 性能极高:单线程读速度和写速度都上十万次/秒
数据存储在内存中;
C语言实现;
单线程,通过非阻塞IO,epoll;同时避免线程切换和竞态消耗;
对于多路复用器的多路选择算法常见的有三种:select模型、poll模型、epoll模型
select模型,数据结构为数组,性能低,有限;
poll模型,采用链表,使用轮询算法,因此对客户端的处理有延迟
epoll模型,使用回调方式
因此Redis一次只执行一条命令,拒绝长命令,执行某个命令的时候,其他的命令会等待。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 127.0.0.1:6379> INFO server # Server redis_version:7.0.5 redis_git_sha1:00000000 redis_git_dirty:0 redis_build_id:d9291579292e26e3 redis_mode:standalone -- 单机版 os:Linux 5.15.49-linuxkit aarch64 arch_bits:64 monotonic_clock:POSIX clock_gettime multiplexing_api:epoll -- 多路复用方式 atomicvar_api:c11-builtin gcc_version:10.2.1 process_id:1 process_supervised:no run_id:e31a71241440cd4d671781b2e2de250ee7e7b23d tcp_port:6379 server_time_usec:1669692771253711 uptime_in_seconds:6616 uptime_in_days:0 hz:10 configured_hz:10 lru_clock:8748387 executable:/data/Redis-server config_file: io_threads_active:0
丰富的数据类型:string list set zset hash,二进制安全存储的
原子:Redis的所有操作都是原子性的,还支持对结合操作合并后的原子性执行
特性丰富:只是publish、subscribe,通知,key过期等特性
应用场景 用来做缓存系统;
计数器;单线程,快速计数
消息队列系统;
排行榜;有序集合
特定场景替代传统数据库:比如社交类应用
大型系统中实现一些特定的功能:session共享、购物车
高级功能 新版Redis提供额外的数据结构:
BitMaps:位图,通过极小的空间存储极多数据,例如布隆过滤器,通常用来做日活统计HyperLogLog:超小内存(12k),记录大量数据,并且实现唯一值技术,通常用于大数据去重GEO:地理信息位置定位(算精度维度、O2O、算距离较近的餐馆之类的)
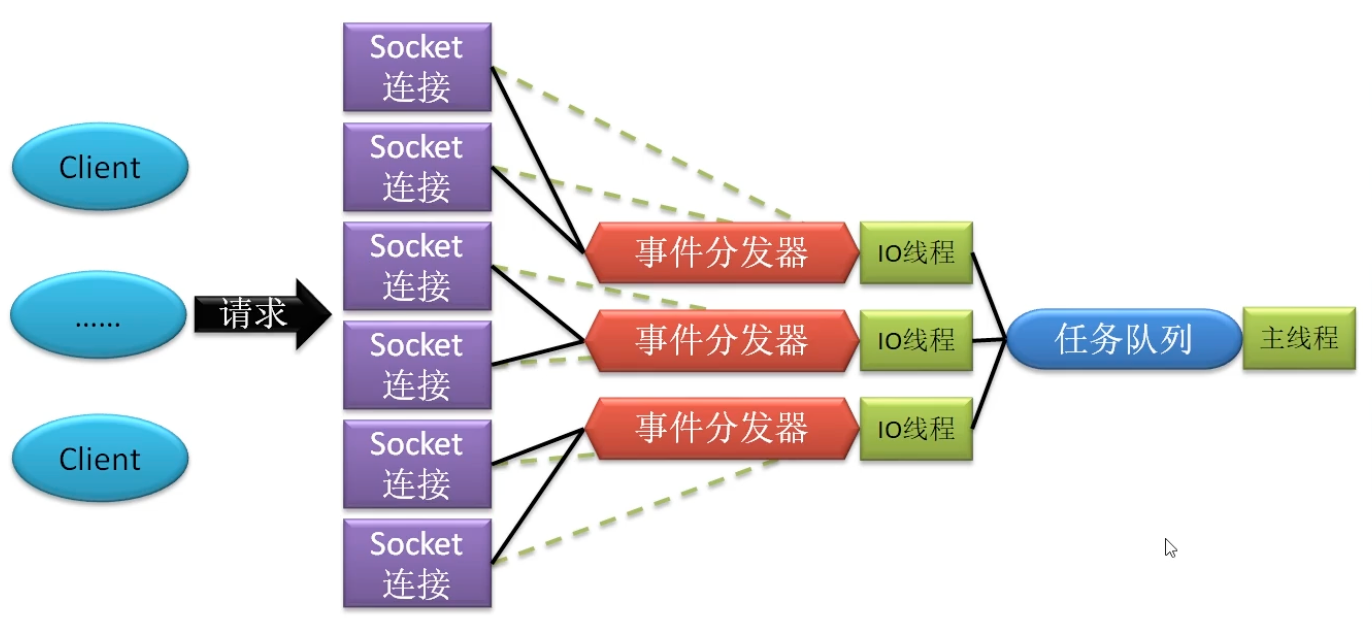
IO模型 Redis处理客户端提交的请求架构,也就是I/O模型,不同的Redis版本模型不同。
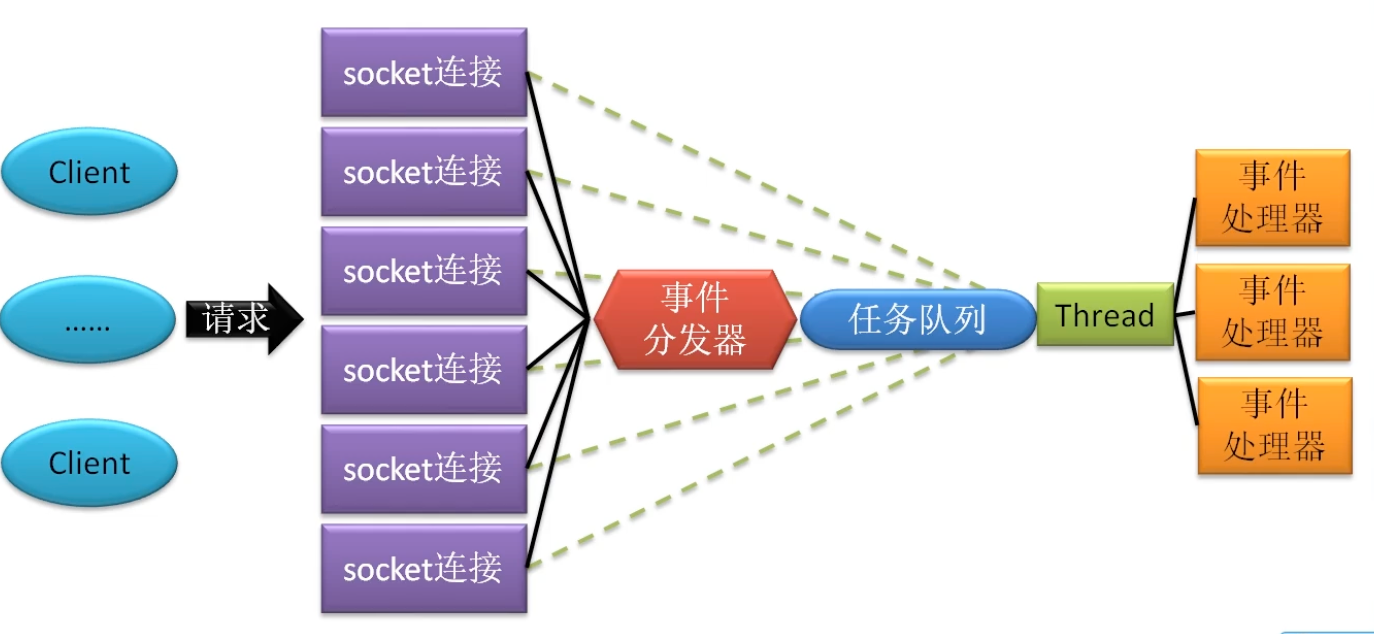
单线程模型 Redis 3.0及其之前版本,Redis的I/O模型采用的是纯粹的单线程模型。所有客户端的请求全部由一个线程处理。
混合线程模型 Redis 4.0版本开始,引入多线程元素。对于一些比较耗时但又不影响对客户端的响应的操作,就交由后台其他线程来处理,例如持久化、对AOF的rewrite、对失效连接的清理等。
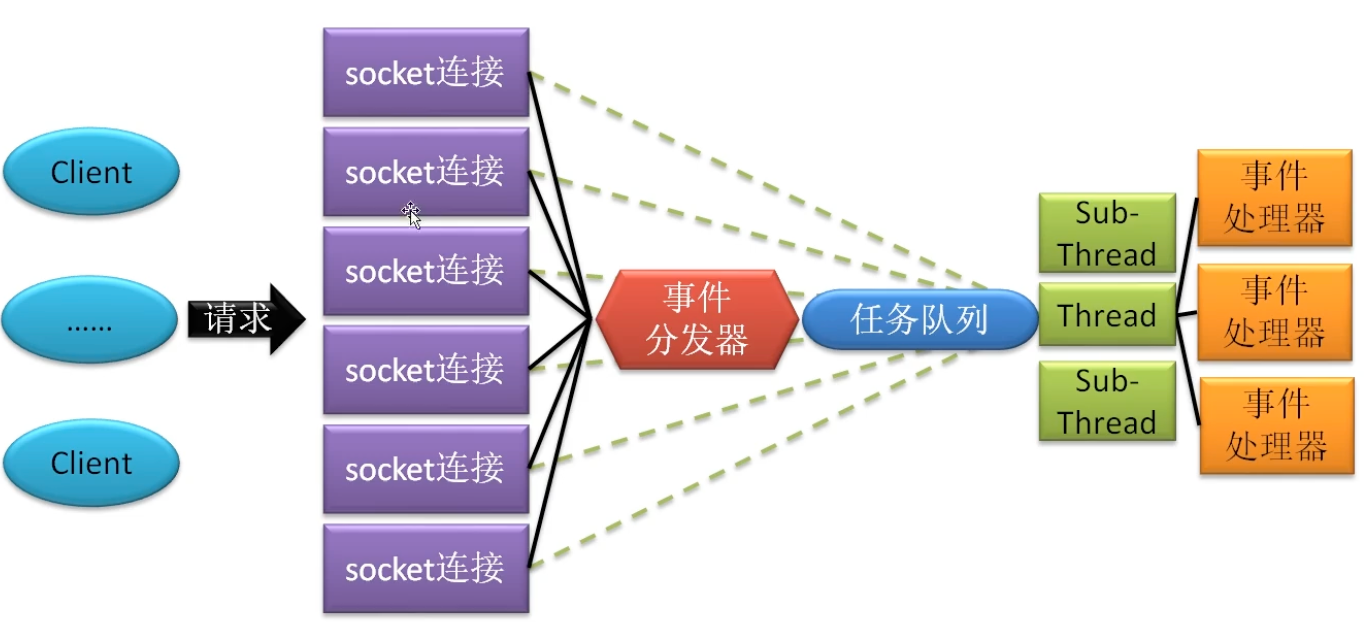
多线程模型 Redis 6.0版本开始,才是真正的多线程模型。因为对于客户端请求的处理采用的是多线程模型,多线程仅用于接受、解析客户端的请求,而对于具体任务的处理,仍然是由主线程处理。
对比 单线程模型
优点:可维护性高,性能高,不存在并发读写情况,也就不存在线程切换导致的开销、锁问题
缺点:只是用一个处理器,会形成处理器浪费
多线程模型
安装 学习的过程,服务端建议通过docker启动
1 docker run --name some-redis -d -p 6379:6379 redis redis-server --appendonly yes
配置 常用配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # cat /etc/Redis.conf bind 0.0.0.0 // 绑定地址,注释也代表监听所有网口 daemonsize yes // 后台运行 dir "/data" // 数据文件存储路径 port 6379 // 端口 pidfile /var/run/Redis.pid // pid 文件 loglevel notice // 日志级别 debug < verbose < notice < warning databases 16 // 数据库个数,默认16个,从0开始 logfile /var/log/Redis/Redis.log // 日志文件 protected-mode no // 关闭保护模式,没有密码时只能自身访问 requirepass 123 // 设置之后,需要通过 auth 123 命令,才可以获取和操作数据,或者连接Redis时,通过 -a 123 rename-command flushall "" // 禁用 flushall 命令,flushall会删除所有数据 rename-command flushall "flushall_alias" // 或者将flushall命令重命名 rename-command flushdb "" // 禁用 flushdb 命令,flushdb可以删除当前数据库的数据
其他配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ## INCLUDES ## 包含其他的一些配置文件,可以分模块管理,文件放在配置文件最末尾,其中的配置会覆盖主配置文件 ## GENARY ## 基本配置 ## MODULES ## 插件,和引用其他的库 ## NETWORK ## 设置和网络相关的配置 timeout 0 // 超时时间,客户端和服务端之间TCP的连接超时时间,默认TCP连接超时时间2h tcp-keepalive 300 // 服务端检测客户端的存活间隔,单位s,发送ACK,检测客户端是否存活,关闭连接需要两倍的连接 tcp-backlog 511 // TCP的连接队列长度,主要解决高并发场景下客户端慢连接的问题。该队列与TCP三次握手有关,完成三次握手之后,进入队列(Linux内核版本不同,队列中TCP连接状态有区别),与内核配置 somaxconn 共同决定,取最小值。高并发场景下,尽量设置比较大。 ## CLIENTS ## 客户端模块 maxclients 10000 // Redis 可并发处理得最大连接数,该值不能超过linxu系统支持的文件描述符阈值,ulimit -n ## MEMORY MANAGEMENT ## 内存管理 maxmemory // 设置内存使用限制,达到限制时,根据选择的驱逐策略 maxmemory-policy 尝试删除符合条件的key // 设置 noeviction 时,写入操作会报错,读取操作不影响 maxmemory-policy noeviction // 数据驱逐策略,默认不移除 maxmemory-samples 5 // 提升LRU算法精确度,通过过期算法之后,从5个选中1个。 maxmemory-evication-tenacity 10 // 移除容忍度 ## THREADED I/O ## 多线程配置 io-threads 4 // 多线程个数,当机器线程数大于4以上才建议开启,并且建议预留一个Core,超过8意义不大 io-threads-reads no // 多线程开启之后,默认线程只支持写请求,修改成yes,让线程支持读,意义不大
客户端连接 通过命令行连接
1 2 3 # redis-cli -h 172.16.211.68 -p 49153 -a Redispw 172.16.211.68:49153> ping PONG
选择数据库
1 2 3 4 172.16.211.68:49153> SELECT 10 OK 172.16.211.68:49153[10]> SELECT 0 OK
或者通过图形化工具,推荐使用RedisDesktopManager,通过github下载0.8.8版本可免费使用(更高版本收费)
官网:https://github.com/RedisInsight/RedisDesktopManager
0.8.8版本下载:https://github.com/RedisInsight/RedisDesktopManager/releases/tag/0.8.8
持久化 Redis的持久化方式有两种,AOF和RDB
安装之后的命令行
1 2 3 4 5 6 redis-benchmark // Redis性能测试工具 redis-check-aof // AOF修复工具 redis-check-rdb // RDB修复工具 redis-cli // 客户端 redis-sentinel // 哨兵模式 redis-server // 服务端
基本功能 帮助命令
1 172.16.211.68:49153> help @string
键的基本操作 切换数据库
1 2 127.0.0.1:6379[1]> SELECT 0 OK
查看所有key的个数,时间复杂度O(1)
1 2 172.16.211.68:49153> DBSIZE (integer) 4
获取某个key,时间复杂度O(1)
1 2 172.16.211.68:49153> KEYS z1 1) "z1"
删除全部数据或者部分数据库的数据
1 2 3 4 127.0.0.1:6379> FLUSHALL // 删除所有库所有数据 OK 127.0.0.1:6379> FLUSHDB // 删除当前库所有数据 OK
查找
1 2 3 4 5 6 7 8 9 10 172.16.211.68:49153> KEYS * // 通配符,获取所有的键(一般不在生产环境使用) ,时间复杂度o(n) 1) "k2" 2) "k3" 3) "k1" 4) "str1" 172.16.211.68:49153> KEYS k[1-2] // 通配符, 1) "k2" 2) "k1" 172.16.211.68:49153> KEYS *2 // 通配符, 1) "k2"
key * 在生产环境不适用,原因是如果数据非常多,此时Redis会处于阻塞状态,无法响应其他请求。解决方案:
判断是否存在,时间复杂度o(1)
1 2 3 4 172.16.211.68:49153> EXISTS k1 // 时间复杂度是o(1) (integer) 1 // 存在返回1 172.16.211.68:49153> EXISTS k10 (integer) 0 // 不存在返回0
查看键的类型,时间复杂度o(1)
1 2 3 4 5 6 7 8 9 10 11 12 172.16.211.68:49153> TYPE k1 string 172.16.211.68:49153> TYPE xu01 hash 172.16.211.68:49153> TYPE z1 zset 172.16.211.68:49153> TYPE a1 list 172.16.211.68:49153> TYPE s1 set 172.16.211.68:49153> TYPE s10 none // key不存在则为none
删除key,时间复杂度o(1)
1 2 3 4 172.16.211.68:49153> DEL k1 (integer) 1 // 返回删除的个数 172.16.211.68:49153> DEL k2 k3 // 删多个key value (integer) 2
重命名
1 2 3 4 127.0.0.1:6379> RENAME abc def OK 127.0.0.1:6379> RENAME age abc // 重命名不存在的key时,报错 (error) ERR no such key
移动到其他库
1 2 3 4 5 6 127.0.0.1:6379> MOVE def 3 (integer) 1 127.0.0.1:6379> SELECT 3 OK 127.0.0.1:6379[3]> KEYS * 1) "def"
设置过期时间expire,查看过期时间ttl,时间复杂度o(1)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 172.16.211.68:49153> SET str2 value2 EX 3 // set 的时候设置过期时间 OK 172.16.211.68:49153> GET str2 "value2" 172.16.211.68:49153> GET str2 (nil) // 第二种方法,通过setex 172.16.211.68:49153> SETEX str1 5 value1 OK 172.16.211.68:49153> GET str1 (nil) // 设置某个键的过期时间 172.16.211.68:49153> EXPIRE k4 100 (integer) 1 // 查看还有多久过期 172.16.211.68:49153> TTL k4 // 时间复杂度o(1) (integer) 86 172.16.211.68:49153> TTL k1 (integer) -2 // -2 代表已经过期 127.0.0.1:6379[3]> EXPIRE def 0 // 设置0 代表立马过期 (integer) 1 // 去掉过期时间 172.16.211.68:49153> EXPIRE k1 100 (integer) 1 172.16.211.68:49153> TTL k1 (integer) 95 172.16.211.68:49153> PERSIST k1 // 时间复杂度o(1) (integer) 1 172.16.211.68:49153> TTL k1 (integer) -1 // -1 表示存在,并且没有过期时间
随机返回一个key
1 2 127.0.0.1:6379> RANDOMKEY // 通常用来判断当前库是否为空 "a"
string
SDS: simple dynamic string
二进制安全的数据结构
内存预分配机制,避免了频繁的内存分配
Redis自动处理,每个字符串以\0结尾,兼容c语言函数库
当free不够,每次扩容,都是新增数据之后长度的两倍,扩容之后,将新的数据赋值到内存中;当业务数据达到1M,每次多分配1M;
1 2 3 free: // 这个buf剩余的空间 len: 11 // buf 已用空间 char buf[]="hello world" // 元素
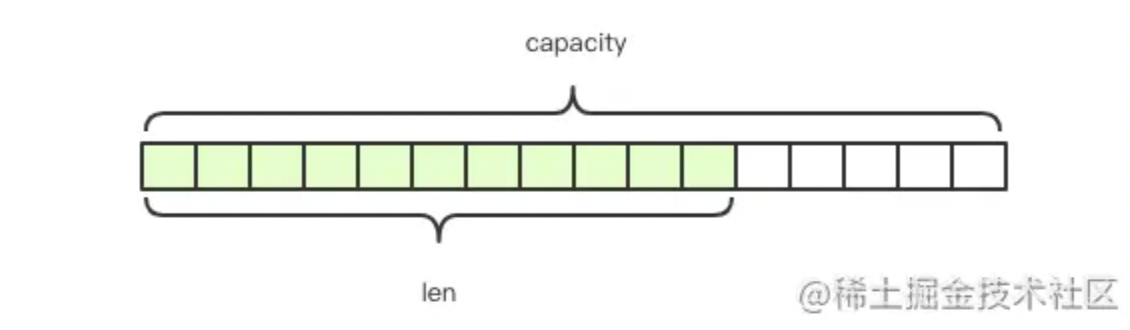
字符串,可以存string也可以存int,也可以是二进制,也可以是一个json、xml。**最大512MB**。
增,时间复杂度o(1)
1 2 3 4 5 6 7 8 172.16.211.68:49153> set str1 value1 // 设置 OK 172.16.211.68:49153> get str1 // 时间复杂度o(1) "value1" 172.16.211.68:49153> set str1 value2 // 修改 时间复杂度o(1) OK 172.16.211.68:49153> get str1 "value2"
set key value :无论key是否存在,都设置,存在则更新;时间复杂度o(1)
setnx key value :key不存在则设置,也就是创建;时间复杂度o(1)
setxx key value : key存在则设置,也就是更新;时间复杂度o(1)
1 2 3 4 5 6 7 8 9 10 11 12 // setnx 的两种用法 172.16.211.68:49153> SET string3 10 nx (nil) 172.16.211.68:49153> SET string5 10 nx OK 172.16.211.68:49153> SETNX string6 10 (integer) 1 // set xx 172.16.211.68:49153> GET string5 "10" 172.16.211.68:49153> SET string5 100 xx OK
字符串追加、获取长度
1 2 3 4 5 6 7 8 9 10 172.16.211.68:49153> APPEND k1 v1append // 追加在后面 (integer) 10 // 返回追加之后的长度 172.16.211.68:49153> get k1 "v1v1append" 172.16.211.68:49153> APPEND string7 你好 // 中文三个字节 (integer) 12 172.16.211.68:49153> STRLEN string7 (integer) 12 172.16.211.68:49153> get string7 // 中文存储方式 "xxxyyy\xe4\xbd\xa0\xe5\xa5\xbd"
设置值时,也设置过期时间
1 2 3 4 127.0.0.1:6379> SETEX abd 100 123 // 100 为过期时间 123为value OK 127.0.0.1:6379> PSETEX k2 10000 123 // 设置毫秒级别过期时间,10000ms,也就是10s OK
先设置,再获取
1 2 127.0.0.1:6379> GETSET k1 v1 (nil)
批量设置和获取多个
1 2 3 4 5 6 7 8 9 10 11 12 172.16.211.68:49153> MSET k1 v1 k2 v2 k3 v3 // 时间复杂度o(n) OK 172.16.211.68:49153> get k1 "v1" 172.16.211.68:49153> MGET k1 k2 k3 // 时间复杂度o(n) 1) "v1" 2) "v2" 3) "v3" 127.0.0.1:6379> MSETNX k1 v1 k2 v2 k3 v3 // 当全部不存在时,设置成功 (integer) 0 // 返回0 ,代表操作没有成功 127.0.0.1:6379> MSETNX k11 v1 k12 v2 k13 v3 (integer) 1
整形操作
自增
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 172.16.211.68:49153> set string1 a OK 172.16.211.68:49153> INCR string1 // 只能操作整形 (error) ERR value is not an integer or out of range 172.16.211.68:49153> set string2 1 OK 172.16.211.68:49153> INCR string2 // 自增1,o(1) (integer) 2 172.16.211.68:49153> INCR string3 // 如果key不存在,则从0自增1 (integer) 1 // 自增设置值 172.16.211.68:49153> INCRBY string3 10 // 按照10自增,o(1) (integer) 10 127.0.0.1:6379> INCRBY s -2 // 负数为自减 (integer) 25 127.0.0.1:6379> DECRBY s 10 // DECR 为自减,DECRBY 按照这个值自减 (integer) 15
浮点自增,浮点只有自增,没有自减,自减用负数
1 2 3 4 5 6 172.16.211.68:49153> set string10 1 // 可浮点数,可整数 OK 172.16.211.68:49153> INCRBYFLOAT string10 1.1 "2.1" 127.0.0.1:6379> INCRBYFLOAT f -1.1 "100.1"
自减
1 2 3 4 5 6 7 172.16.211.68:49153> DECR string3 (integer) 0 172.16.211.68:49153> DECR string4 // 不存在则从0自减1,o(1) (integer) -1 // 自减设置值 172.16.211.68:49153> DECRBY string3 2 // ,o(1) (integer) 8
获取老的值并且设置新的值
1 2 3 4 172.16.211.68:49153> GETSET string6 4 // o(1) "10" 172.16.211.68:49153> get string6 "4"
获取指定下标的值,设置指定下标的值,也就是获取子串
1 2 3 4 5 6 7 8 9 10 11 12 172.16.211.68:49153> SET string21 abcdefg OK 172.16.211.68:49153> SETRANGE string21 3 x // 将3位置设置为x (integer) 7 172.16.211.68:49153> GETRANGE string21 3 4 // 获取位置3到4 "xe" 127.0.0.1:6379> GETRANGE string21 -4 -3 // 也可以用负数 "de" 127.0.0.1:6379> SETRANGE string21 20 nihaoya // 如果设置角标超过长度,则会用 x00 补 (integer) 27 127.0.0.1:6379> GET string21 "abcnihaoyanihaoya\x00\x00\x00nihaoya"
使用场景
做缓存,从Redis获取,而不是数据库
做计数器:例如记录页面用户的访问量
1 INCR userid:pageview // 单线程,无竞争
共享Session,存放token之类的数据,来验证登录
限速器,限制1个IP不能在1秒内访问超过n次,结合过期时间与incr命令完成限速
set 192.168.10.10 1 ex 60 nx,设置1分钟访问10次,incr 192.168.10.10 1,如果返回10,代表已经访问10次,设置成功返回true,返回失败返回null或者0。可以防止DoS(Denial of Service)攻击,但是无法防止DDoS(Distributed Denial of Service)攻击。
分布式锁
1 2 3 4 SETNX product:10001 true // 返回1代表获取锁成功 SETNX product:10001 false // 返回0代表获取锁失败 SET porduct:10001 true ex 10 nx // 防止程序意外停止导致死锁
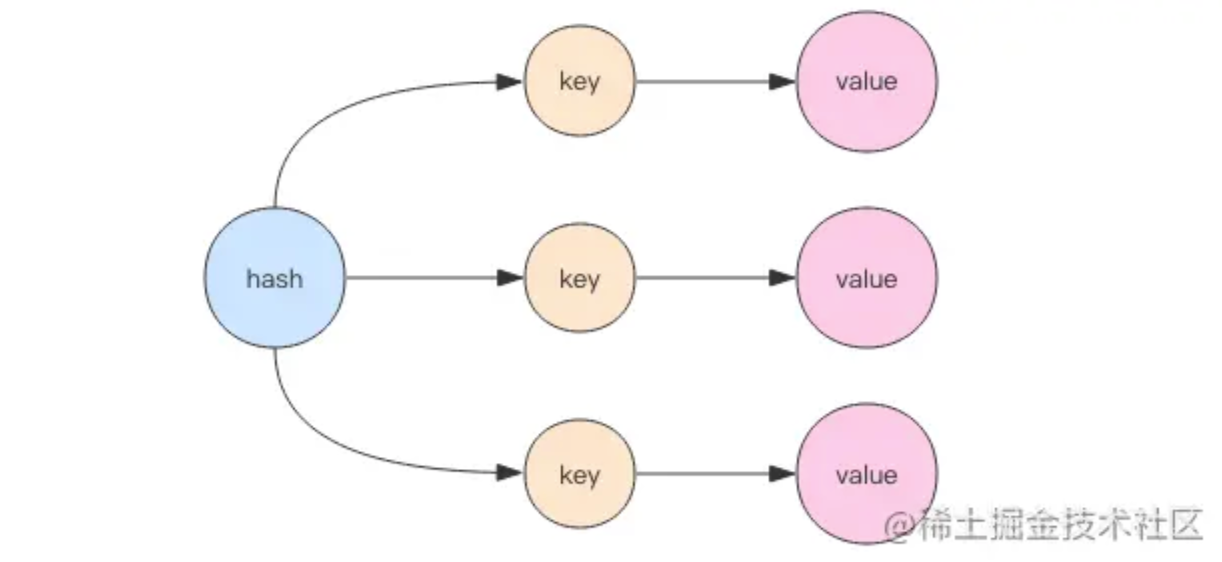
hash
哈希hash可以设置一个key多个属性,可以理解为一个map,map中有kv(称作field和value)(其实是一个小的Redis)
数据以hashtab的形式存储,dict[4]为key的长度,key被hash之后,与长度取模获得位置,如果出现溢出(取模之后结果一直)则放到已存在的value之前,通过链表的形式指向下一个。如果溢出过多,dict会扩容,按照1倍扩容,在hash被访问或者定时,会将key移动到新的hash中,移动之后删除老的hash中的map。
1 2 3 4 5 6 172.16.211.68:49153> HSET xu height 70 // 时间复杂度o(1) (integer) 1 172.16.211.68:49153> HSET xu weight 75 // 增加新的属性 (integer) 1 172.16.211.68:49153> HSET xu age 28 (integer) 1
获取
1 2 3 4 5 6 7 8 9 172.16.211.68:49153> HGET xu age // 时间复杂度o(1) "28" 172.16.211.68:49153> HGETALL xu // 获取所有属性,时间复杂度o(n),谨慎使用 1) "height" 2) "70" 3) "weight" 4) "75" 5) "age" 6) "28"
给key批量复制
1 2 3 4 5 6 7 8 9 172.16.211.68:49153> HSET xu01 k1 v2 k2 v2 k3 v3 // 时间复杂度o(n) (integer) 3 172.16.211.68:49153> HGETALL xu01 1) "k1" 2) "v2" 3) "k2" 4) "v2" 5) "k3" 6) "v3"
批量设置和批量获取
1 2 3 4 5 172.16.211.68:49153> HMSET xu02 k1 v1 k2 v2 k3 v3 // 时间复杂度o(n) OK 172.16.211.68:49153> HMGET xu02 k1 k2 // 时间复杂度o(n) 1) "v1" 2) "v2"
获取hash中的key
1 2 3 4 172.16.211.68:49153> HKEYS xu02 // 时间复杂度o(n) 1) "k1" 2) "k2" 3) "k3"
获取hash中的value
1 2 3 4 172.16.211.68:49153> HVALS xu02 // 时间复杂度o(n) 1) "v1" 2) "v2" 3) "v3"
删除hash中的某个key和value
1 2 3 4 5 172.16.211.68:49153> HDEL xu02 k1 // 时间复杂度o(1) (integer) 1 172.16.211.68:49153> HVALS xu02 1) "v2" 2) "v3"
判断field是否存在
1 2 3 4 172.16.211.68:49153> HEXISTS user:1:info age // 时间复杂度o(1) (integer) 1 172.16.211.68:49153> HEXISTS user:1:info agex (integer) 0
获取key field的数量
1 2 172.16.211.68:49153> HLEN user:1:info (integer) 2
与string类似,可以一次获取多个field或者一次设置多个field
1 2 3 4 5 172.16.211.68:49153> HMGET user:1:info name age // 时间复杂度o(n) 1) "xu" 2) "18" 172.16.211.68:49153> HMSET user:1:info name xu01 age 28 // 时间复杂度o(n) OK
HSETNX 当hash的key不存在则创建
1 2 172.16.211.68:49153> HSETNX user:1:info newpageview 2 // 时间复杂度o(1) (integer) 1
HINCRBY 自增
1 2 172.16.211.68:49153> HINCRBY user:1:info newpageview 1 // 时间复杂度o(1) (integer) 3
HINCRBYFLOAT 浮点自增
1 2 172.16.211.68:49153> HINCRBYFLOAT user:1:info newpageview 1.1 // 时间复杂度o(1) "4.1"
使用hash,将前面记录用户访问量的功能优化
1 2 172.16.211.68:49153> HINCRBY user:1:info pageview 1 (integer) 1
缓存视频的基本信息,如果是string,存入之前做一个序列化,读取后反序列化。使用hash则可以直接存储hash
方案
优点
缺点
string: set videoinfo:1 "{**"k1"**:**"v1"**}",序列化和反序列化变成简单;节约内存
序列化和反序列化开销;设置属性要更新所有
string:set videoinfo:1:k1 v1,每个field设置一个string直观;可以部分更新
内存占用大;key分散
hash:hset videoinfo:1 k1 v1 k2 v2直观;节省空间;可以部分更新
编程稍微复杂;ttl不好控制
使用场景:
购物车:用户id是key,商品id为field,商品数量为value
list 列表,或者说双向,一次性可以存储多个数据,里面元素类型是string,数据结构是一个有序队列,内容可以重复,可以从左右弹出插入
从左侧插入数据
1 2 3 4 172.16.211.68:49153> LPUSH a1 a b c d e f // 时间复杂度o(1~n) (integer) 6 127.0.0.1:6379> LPUSH lan Javascript Ruby Python Java Go (integer) 5
从列表中取
1 2 3 4 5 6 7 8 9 10 11 12 13 172.16.211.68:49153> LRANGE a1 0 100 // 序号从0到100取出来,-1代表所有 时间复杂度o(n) 1) "f" 2) "e" 3) "d" 4) "c" 5) "b" 6) "a" 127.0.0.1:6379> LRANGE lan 0 -1 1) "Go" 2) "Java" 3) "Python" 4) "Ruby" 5) "Javascript"
获取指定位置的值
1 2 172.16.211.68:49153> LINDEX a1 1 // 时间复杂度o(n) "e"
往右侧插入数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 172.16.211.68:49153> RPUSH a1 x y z // 时间复杂度o(1~n) (integer) 9 172.16.211.68:49153> LRANGE a1 0 -1 1) "f" 2) "e" 3) "d" 4) "c" 5) "b" 6) "a" 7) "x" 8) "y" 9) "z" 127.0.0.1:6379> RPUSH lan2 Go Java Python Ruby Javascript (integer) 5 127.0.0.1:6379> LRANGE lan2 0 -1 1) "Go" 2) "Java" 3) "Python" 4) "Ruby" 5) "Javascript"
当有列表时才插入
1 2 3 4 127.0.0.1:6379> LPUSHX sli1 1 2 3 (integer) 0 127.0.0.1:6379> LPUSHX lan2 PHP (integer) 6
弹出数据,每次弹出一个
1 2 3 4 5 6 7 8 9 10 11 12 13 172.16.211.68:49153> LPUSH list1 a b c d // d-c-b-a (integer) 4 172.16.211.68:49153> LPOP list1 // 左边弹出,时间复杂度o(n) "d" 172.16.211.68:49153> LRANGE list1 0 -1 // c-b-a 1) "c" 2) "b" 3) "a" 172.16.211.68:49153> RPOP list1 // 右边弹出,时间复杂度o(n) "a" 172.16.211.68:49153> LRANGE list1 0 -1 // c-b 1) "c" 2) "b"
在指定元素前或后插入新数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 172.16.211.68:49153> LINSERT a1 after a a1 // 在a后面加a1 时间复杂度o(n) (integer) 10 172.16.211.68:49153> LINSERT a1 before a b1 // 在a前面加b1 时间复杂度o(n) (integer) 11 172.16.211.68:49153> LRANGE a1 0 -1 1) "f" 2) "e" 3) "d" 4) "c" 5) "b" 6) "b1" 7) "a" 8) "a1" 9) "x" 10) "y" 11) "z"
设置指定位置的值
1 2 3 4 5 6 172.16.211.68:49153> LSET a1 1 f1 // 时间复杂度o(n) OK 172.16.211.68:49153> LRANGE a1 0 -1 1) "f" 2) "f1" 3) "d"
删除指定元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 172.16.211.68:49153> LRANGE a1 0 -1 1) "f" 2) "aaaaaa" 3) "d" 4) "aaaaaa" 5) "d" 6) "aaaaaa" 7) "a" 8) "aaaaaa" 9) "x" 10) "y" 11) "z" 172.16.211.68:49153> LREM a1 3 aaaaaa // 3代表从前往后数,删除3个aaaaaa;-3代表从后往前数,移除3个;0代表全部移除 时间复杂度o(n) (integer) 3 172.16.211.68:49153> LRANGE a1 0 -1 1) "f" 2) "d" 3) "d" 4) "a" 5) "aaaaaa" 6) "x" 7) "y" 8) "z"
裁剪列表,在操作大型列表时有优势
1 2 172.16.211.68:49153> LTRIM a1 2 5 // 保留a1从2到5号 时间复杂度o(n) OK
获取长度
1 2 172.16.211.68:49153> LLEN a1 // 时间复杂度o(1),因为数据结构内部保留了长度 (integer) 4
从链表1的右边推出一个,送入到链表2的左边
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 127.0.0.1:6379> RPUSH sour a b c (integer) 3 127.0.0.1:6379> RPUSH desc x y z (integer) 3 127.0.0.1:6379> RPOPLPUSH sour desc "c" 127.0.0.1:6379> LRANGE sour 0 -1 1) "a" 2) "b" 127.0.0.1:6379> LRANGE desc 0 -1 1) "c" 2) "x" 3) "y" 4) "z" // 以及阻塞版本 127.0.0.1:6379> BRPOPLPUSH sour desc 2 "b"
阻塞弹出,例如生产者消费者,如果有元素,则弹出,如果没有,则阻塞,直到超时时间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 172.16.211.68:49153> BLPOP a1 0 // 左边弹出 0 代表永不超时,一直阻塞 1) "a1" 2) "hello" (86.43s) 172.16.211.68:49153> BRPOP a1 0 // 右边弹出 1) "a1" 2) "hello" (2.48s) 127.0.0.1:6379> BLPOP lan lan1 lan2 5 // 先看 lan 中有没有数据,如果有,就弹出一个,就结束,如果没有就从lan1中获取,如果都没有,则阻塞5s 1) "lan" 2) "Go" 127.0.0.1:6379> BLPOP lan10 lan11 lan12 5 // 所有的list都没有数据 (nil) (5.10s)
使用场景,例如根据TimeLine查看更新
有新的数据,则往左边插入,用户查看某个时间节点的信息,通过获取一定范围内的数据
数据结构使用场景
LPUSH + LPOP = Stack 栈,先进后出LPUSH + RPOP = Queue 队列,先进先出LPUSH + LTRIM = Capped Collection ,动态有限集合,有固定长度列表LPUSH + BRPOP = Message Queue 阻塞式消息队列,生产者往队里推送消息,消费者监听队列
使用场景:
微博和微信公众号信息流
set 无序集合,元素为string类型,元素具有唯一性,底层是一个map,不重复,对于集合,没有修改操作,只能删除其中元素再增加元素。支持集合间的操作(交集,并集,差集)
添加
1 2 172.16.211.68:49153> SADD s1 a b c d e f // 时间复杂度o(n),添加1个就是o(1) (integer) 6
获取值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 172.16.211.68:49153> SMEMBERS s1 // 从集合中取出所有元素,无序,小心使用 1) "d" 2) "a" 3) "f" 4) "b" 5) "c" 172.16.211.68:49153> SCARD s1 // 返回集合中元素个数 (integer) 5 172.16.211.68:49153> SISMEMBER s1 f // 检查集合中是否有这个元素 (integer) 1 // 有则返回1 172.16.211.68:49153> SISMEMBER s1 ads (integer) 0 // 没有则返回0 172.16.211.68:49153> SRANDMEMBER s1 // 从集合中随机取出一个元素 "e" 127.0.0.1:6379> SRANDMEMBER p985 2 // 可以放多个,如果是 负数 ,则返回一个个数,但是可能会出现重复 1) "beida" 2) "fudan" 127.0.0.1:6379> SRANDMEMBER p985 -2 1) "jiaoda" 2) "jiaoda"
删除值
1 2 3 4 5 6 7 8 9 10 172.16.211.68:49153> SREM s1 a // 时间复杂度o(1) 可以一次性删除多个 (integer) 1 172.16.211.68:49153> SMEMBERS s1 1) "f" 2) "b" 3) "d" 4) "c" 5) "e" 172.16.211.68:49153> SPOP s1 // 从集合中随机弹出一个元素,弹出后删除,可用于抽奖,抽完后,将这个人从奖池中去掉 "c"
差集
1 2 3 4 5 6 7 172.16.211.68:49153> SADD set1 it his music sports (integer) 4 172.16.211.68:49153> SADD set2 it ent news sports (integer) 4 172.16.211.68:49153> SDIFF set1 set2 // 获取set1和set2的差集,取前一个的差集 1) "his" 2) "music"
交集
1 2 3 172.16.211.68:49153> SINTER set1 set2 // 获取set1和set2的交集 1) "sports" 2) "it"
并集
1 2 3 4 5 6 7 172.16.211.68:49153> SUNION set1 set2 // 获取set1和set2的并集 1) "music" 2) "news" 3) "sports" 4) "it" 5) "his" 6) "ent"
将一个集合中的数据移动到另外一个集合中
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> SADD p985 qinghua beida fudan jiaoda (integer) 4 127.0.0.1:6379> SMOVE p985 c9 qinghua // 只能移动1个 (integer) 1 127.0.0.1:6379> SMEMBERS c9 1) "qinghua" 127.0.0.1:6379> SMEMBERS p985 1) "jiaoda" 2) "beida" 3) "fudan"
将差集、交集、并集存入到另外一个set中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 172.16.211.68:49153> SINTERSTORE set11 set1 set2 // 将交集存入另一个set中 (integer) 2 172.16.211.68:49153> SMEMBERS set11 1) "it" 2) "sports" 127.0.0.1:6379> SDIFFSTORE set12 set1 set2 // 将 set1对于set2的差集,存放到set12中 (integer) 2 127.0.0.1:6379> SMEMBERS set12 1) "music" 2) "his" 127.0.0.1:6379> SUNIONSTORE set13 set1 set2 // 将 set1 和 set2 的并集,存放到 set13 中 (integer) 6 127.0.0.1:6379> SMEMBERS set13 1) "sports" 2) "ent" 3) "music" 4) "his" 5) "it" 6) "news"
使用场景:
动态黑白名单:用户访问时,通过黑名单判断用户是否具备在set中
抽奖 SPOP、SRANDMEMBER:可以选择抽取一个之后,是否放回set中
用户画像:将一些标签添加到用户的集合中,通过交集推荐好友、商品
Like、赞、踩(记录这个用户操作了哪个文件)SADD
标签,给用户加标签、给标签加用户(可以用一个事务实现) SADD
共同关注的好友、兴趣-交集 SADD SINTER
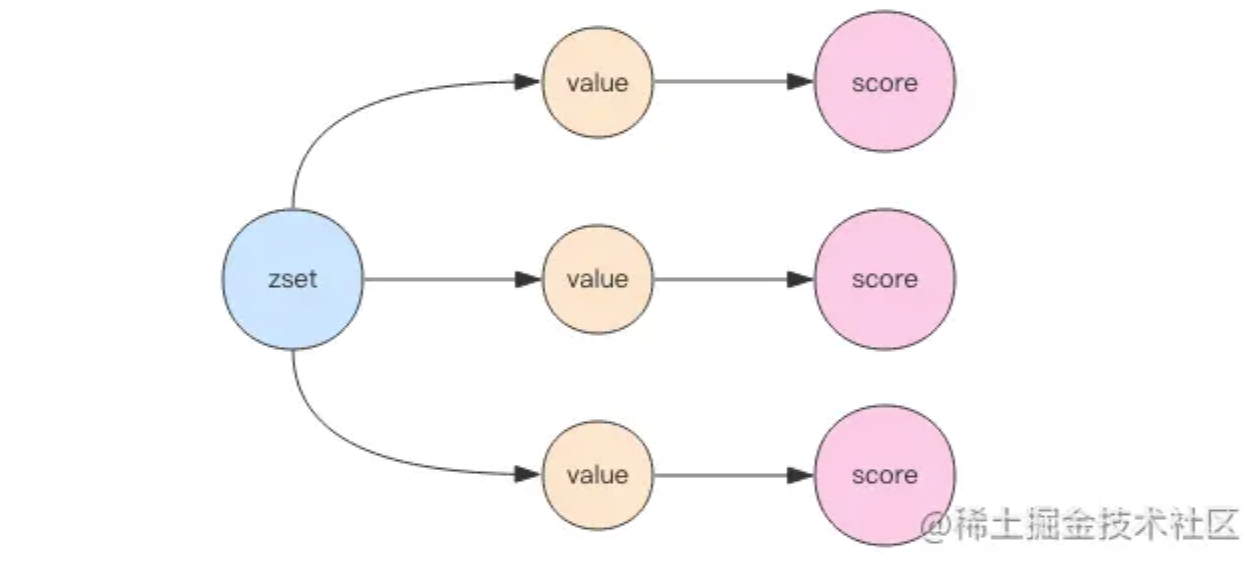
zset
sroted set,有序集合;元素为string;元素具有唯一性,不重复;每个元素关联一个double类型的score,表示权重,通过权重将元素从小到大排序。
添加
1 2 172.16.211.68:49153> ZADD z1 4 a 5 b 6 c 7 d // score可以重复 member不能重复 时间复杂度o(logN) (integer) 4
获取
返回指定范围内的元素;start、stop位元素的下标索引;索引从左侧开始,第一个元素为0,索引可以是负数,表示从尾部开始计数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 172.16.211.68:49153> ZRANGE z1 0 -1 //,时间复杂度o(log(n)+m) n是有序集合元素的个数,m是获取的个数,从0开始,到-1,也就是所有 1) "a" 2) "b" 3) "c" 4) "d" 172.16.211.68:49153> ZRANGE zsort1 0 2 WITHSCORES // 获得从0到2排名的元素,并且打印分值 1) "x" 2) "1" 3) "b" 4) "2" 5) "y" 6) "2" 172.16.211.68:49153> ZCARD zsort1 // 返回集合中数量,时间复杂度o(1) (integer) 6
获取指定权重范围的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 172.16.211.68:49153> ZRANGEBYSCORE z1 5 6 //时间复杂度o(log(n)+m) n是有序集合元素的个数,m是获取的个数 1) "b" 2) "c" 127.0.0.1:6379> ZRANGEBYSCORE z1 -inf +inf withscores // 负无穷到正无穷 1) "a" 2) "4" 3) "b" 4) "5" 5) "c" 6) "6" 7) "d" 8) "7" 127.0.0.1:6379> ZRANGEBYSCORE z1 -inf +inf withscores limit 1 2 // 排序之后,从1开始,选2个 1) "b" 2) "5" 3) "c" 4) "6"
获取分数范围内的个数
1 2 172.16.211.68:49153> ZCOUNT zsort1 0 2 //时间复杂度o(log(n)+m) n是有序集合元素的个数,m是获取的个数 (integer) 3
获取值的权重
1 2 172.16.211.68:49153> ZSCORE z1 b "5"
获取元素的排名
1 2 172.16.211.68:49153> ZRANK zsort1 a (integer) 5
删除
1 2 3 4 5 172.16.211.68:49153> ZREM z1 a b // 删除元素,删除一个时间复杂度o(1) (integer) 2 172.16.211.68:49153> ZRANGE z1 0 -1 1) "c" 2) "d"
删除权重范围的值
1 2 3 4 5 6 7 8 9 10 172.16.211.68:49153> ZSCORE z1 c "6" 172.16.211.68:49153> ZSCORE z1 d "7" 172.16.211.68:49153> ZREMRANGEBYSCORE z1 6 6 // 按照分数删除,删除权重是6到6的 时间复杂度o(log(n)+m) (integer) 1 172.16.211.68:49153> ZRANGE z1 0 -1 1) "d" 172.16.211.68:49153> ZREMRANGEBYRANK zsort1 1 2 // 按照排名删除,从排名1到排名2的都删除 时间复杂度o(log(n)+m) (integer) 2
给某个元素的score增加权重
1 2 172.16.211.68:49153> ZINCRBY zsort1 10 a // 给a这个元素的socre加10,传入负数就是减少 "11"
从高到低排序罗列,也就是倒着排序
1 2 3 4 5 172.16.211.68:49153> ZREVRANGE zsort1 0 -1 1) "a" 2) "z" 3) "c" 4) "x"
从高到低获取排名,也就是倒着的排名
1 2 172.16.211.68:49153> ZREVRANK zsort1 c (integer) 2 // 排名从0开始,2代表第三名
从高到低按照分数获取中间元素
1 2 3 4 172.16.211.68:49153> ZREVRANGEBYSCORE zsort1 4 1 1) "z" 2) "c" 3) "x"
分值相同时,按照字典序(lexicographical ordering)来进行排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 127.0.0.1:6379> ZADD z3 40 aa 40 ab 40 ac 40 ba 40 bb 40 bc 40 ca 40 cb 40 cc (integer) 9 127.0.0.1:6379> ZRANGE z3 0 -1 1) "aa" 2) "ab" 3) "ac" 4) "ba" 5) "bb" 6) "bc" 7) "ca" 8) "cb" 9) "cc" 127.0.0.1:6379> ZRANGEBYLEX z3 [ab (cb // 从 [ab 开始排序,包含ab,到cb排序结尾,不包含cb 1) "ab" 2) "ac" 3) "ba" 4) "bb" 5) "bc" 6) "ca" 127.0.0.1:6379> ZLEXCOUNT z3 - + // 计数 (integer) 9 127.0.0.1:6379> ZREMRANGEBYLEX z3 [bb (ca // 移除,从 [bb 开始移除,一直到 (ca (integer) 2 127.0.0.1:6379> ZRANGEBYLEX z3 - + 1) "aa" 2) "ab" 3) "ac" 4) "ba" 5) "ca" 6) "cb" 7) "cc"
将两个zset并集存入另一个zset中
1 2 3 4 5 172.16.211.68:49153> ZINTERSTORE zsort21 2 zsort1 zsort2 // 将zsort1和zsort2的并集存入zsort21中 (integer) 2 172.16.211.68:49153> ZUNIONSTORE zsort32 2 zsort1 zsort2 // 将zsort1和zsort2的交集存入zsort32中 (integer) 6
使用场景
性能测试工具 使用 redis-benchmark工具,对Redis进行性能测试工具
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 # redis-benchmark --help Usage: redis-benchmark [OPTIONS] [COMMAND ARGS...] Options: -h <hostname> Server hostname (default 127.0.0.1) -p <port> Server port (default 6379) -s <socket> Server socket (overrides host and port) -a <password> Password for Redis Auth --user <username> Used to send ACL style 'AUTH username pass'. Needs -a. -u <uri> Server URI. -c <clients> Number of parallel connections (default 50) // 并行连接客户端数量,默认50 -n <requests> Total number of requests (default 100000) // 接受请求总数 -d <size> Data size of SET/GET value in bytes (default 3) // 发送的数据量大小 ,默认3Byte --dbnum <db> SELECT the specified db number (default 0) -3 Start session in RESP3 protocol mode. --threads <num> Enable multi-thread mode. --cluster Enable cluster mode. If the command is supplied on the command line in cluster mode, the key must contain "{tag}". Otherwise, the command will not be sent to the right cluster node. --enable-tracking Send CLIENT TRACKING on before starting benchmark. -k <boolean> 1=keep alive 0=reconnect (default 1) // 如果是0,代表断链之后会重连 -r <keyspacelen> Use random keys for SET/GET/INCR, random values for SADD, random members and scores for ZADD. Using this option the benchmark will expand the string __rand_int__ inside an argument with a 12 digits number in the specified range from 0 to keyspacelen-1. The substitution changes every time a command is executed. Default tests use this to hit random keys in the specified range. Note: If -r is omitted, all commands in a benchmark will use the same key. -P <numreq> Pipeline <numreq> requests. Default 1 (no pipeline). -q Quiet. Just show query/sec values // 仅仅查看最终汇总测试报告 --precision Number of decimal places to display in latency output (default 0) --csv Output in CSV format -l Loop. Run the tests forever -t <tests> Only run the comma separated list of tests. The test // 测试具体命令,例如是 set,get,lpush names are the same as the ones produced as output. The -t option is ignored if a specific command is supplied on the command line. -I Idle mode. Just open N idle connections and wait. -x Read last argument from STDIN. --tls Establish a secure TLS connection. --sni <host> Server name indication for TLS. --cacert <file> CA Certificate file to verify with. --cacertdir <dir> Directory where trusted CA certificates are stored. If neither cacert nor cacertdir are specified, the default system-wide trusted root certs configuration will apply. --insecure Allow insecure TLS connection by skipping cert validation. --cert <file> Client certificate to authenticate with. --key <file> Private key file to authenticate with. --tls-ciphers <list> Sets the list of preferred ciphers (TLSv1.2 and below) in order of preference from highest to lowest separated by colon (":"). See the ciphers(1ssl) manpage for more information about the syntax of this string. --tls-ciphersuites <list> Sets the list of preferred ciphersuites (TLSv1.3) in order of preference from highest to lowest separated by colon (":"). See the ciphers(1ssl) manpage for more information about the syntax of this string, and specifically for TLSv1.3 ciphersuites. --help Output this help and exit. --version Output version and exit.
执行之后
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 redis-benchmark -h 127.0.0.1 -p 6379 -n 200000 -c 100 // 测试 PING_INLINE、PING_MBULK、SET、GET等命令,因此测试时间会比较长 ====== PING_INLINE ====== // 测试环境 200000 requests completed in 1.38 seconds // 200000 请求完成时间1.38s 100 parallel clients // 100 个并发客户端请求 3 bytes payload // 发送数据 3 Byte keep alive: 1 // keep alive配置打开 host configuration "save": 3600 1 300 100 60 10000 // 自动持久化的配置 host configuration "appendonly": no // AOF 开关,没有开启 multi-thread: no // 多线程是否打开 // 测试结果 // 延迟分布 Latency by percentile distribution: 0.000% <= 0.111 milliseconds (cumulative count 1) 50.000% <= 0.343 milliseconds (cumulative count 112596) // 50的分位数 0.343秒 75.000% <= 0.367 milliseconds (cumulative count 154893) 87.500% <= 0.399 milliseconds (cumulative count 176783) 93.750% <= 0.439 milliseconds (cumulative count 187763) 96.875% <= 0.495 milliseconds (cumulative count 194178) 98.438% <= 0.607 milliseconds (cumulative count 196933) 99.219% <= 0.815 milliseconds (cumulative count 198464) 99.609% <= 0.967 milliseconds (cumulative count 199238) 99.805% <= 1.055 milliseconds (cumulative count 199626) 99.902% <= 1.135 milliseconds (cumulative count 199817) 99.951% <= 1.311 milliseconds (cumulative count 199905) 99.976% <= 1.415 milliseconds (cumulative count 199952) 99.988% <= 1.471 milliseconds (cumulative count 199979) 99.994% <= 1.559 milliseconds (cumulative count 199989) 99.997% <= 1.623 milliseconds (cumulative count 199994) 99.998% <= 1.655 milliseconds (cumulative count 199997) 99.999% <= 1.679 milliseconds (cumulative count 199999) 100.000% <= 1.695 milliseconds (cumulative count 200000) 100.000% <= 1.695 milliseconds (cumulative count 200000) // 累计延迟分布 Cumulative distribution of latencies: 0.000% <= 0.103 milliseconds (cumulative count 0) 0.008% <= 0.207 milliseconds (cumulative count 16) 12.201% <= 0.303 milliseconds (cumulative count 24403) 89.836% <= 0.407 milliseconds (cumulative count 179672) 97.336% <= 0.503 milliseconds (cumulative count 194672) 98.466% <= 0.607 milliseconds (cumulative count 196933) 98.925% <= 0.703 milliseconds (cumulative count 197851) 99.215% <= 0.807 milliseconds (cumulative count 198430) 99.448% <= 0.903 milliseconds (cumulative count 198897) 99.716% <= 1.007 milliseconds (cumulative count 199433) 99.874% <= 1.103 milliseconds (cumulative count 199747) 99.933% <= 1.207 milliseconds (cumulative count 199867) 99.951% <= 1.303 milliseconds (cumulative count 199902) 99.975% <= 1.407 milliseconds (cumulative count 199950) 99.991% <= 1.503 milliseconds (cumulative count 199982) 99.996% <= 1.607 milliseconds (cumulative count 199992) 100.000% <= 1.703 milliseconds (cumulative count 200000) // 测试的总结 Summary: throughput summary: 144508.67 requests per second // 每秒钟处理 14W 请求 latency summary (msec): // 延迟汇总 avg min p50 p95 p99 max // 平均、最小、50分位、95分位、99分位、最大处理时间 0.354 0.104 0.343 0.455 0.727 1.695 ====== PING_MBULK ====== ... ====== SET ====== ... ====== GET ====== ...
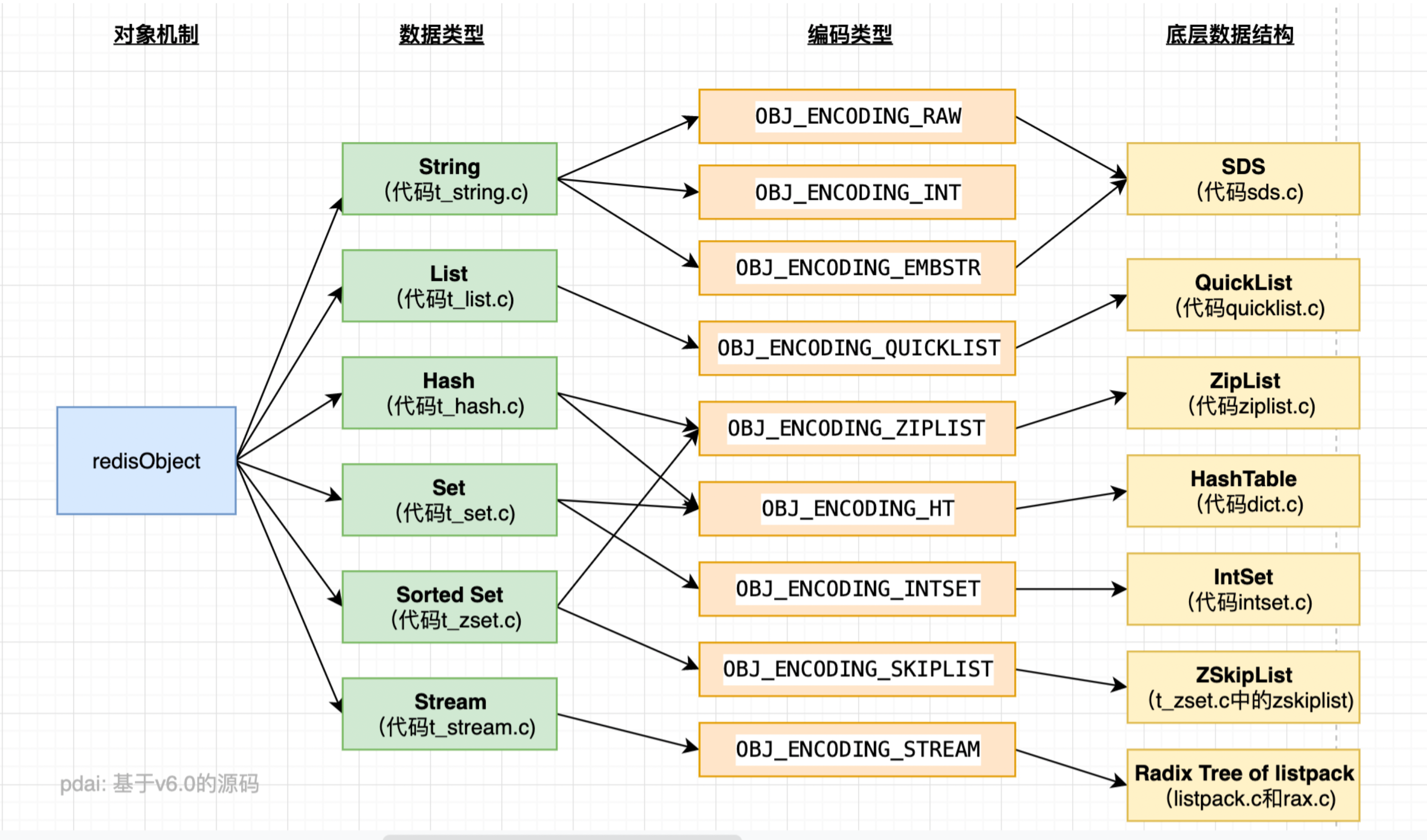
数据结构 下载Redis源码可以查看底层数据结构:https://github.com/redis/redis,在不同的分支(版本)具体的数据结构表现不一样。
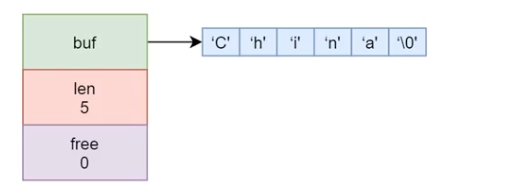
简单动态字符串 SDS 无论Key还是Value,基础数据类型都是字符串,这种字符串本身结构比较简单,但是功能非常强大,Simply Dynamic String,简称SDS
在源码 src/sds.h中
1 2 3 4 5 struct sdshdr { int len; int free ; char buf[]; };
例如
1 2 3 4 127.0.0.1:6379> SET country China // 此时的China是SDS存储 OK 127.0.0.1:6379> GET country "China" // 此时返回的China是c中的字符串。字符串会出现在“字面常量”中,并且该字符串不可能发生变更
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> TYPE country // 此时 country 的type 是string,但是数据结构是embstr string 127.0.0.1:6379> OBJECT encoding country "embstr" 127.0.0.1:6379> SET age 10 OK 127.0.0.1:6379> TYPE age // 此时 age 的type 是string,但是数据结构是int string 127.0.0.1:6379> OBJECT encoding age "int"
实际SDS结构
可以看到,buf一共占6个字节,len的个数不包含\0。
SDS采用空间预分配策略 与惰性空间释放策略 来避免内存再分配问题。
空间预分配策略:每次SDS进行空间扩展时,程序不但为其分配所需的空间,还会为其分配额外的未使用空间,以减少内存分配次数。
惰性空间释放策略:当删除字符串时,不回收内存,而是将空间放到free中,避免下次分配
优势:
防止字符串长度获取 性能瓶颈:获取长度和长度没关系
保障二进制安全:C语言中字符串只能包含某种编码格式的字符,例如UTF-8等,并且除了末尾,其他位置不能包含\0,因此不能存放图片、压缩文件、office文件等二进制数据。SDS中不是以 \0结尾,可以存放,而且还可以保证长度记录的准确性。因此数据读取、存储,都不会再过滤。
减少内存再分配次数:C语言中,字符串拼接会重新分配内存,用于存储新的字符串,但是在Redis中,SDS拼接字符串,不会重新分配内存。
兼容C函数:提供一些C语言函数,操作SDS中的字段,供二次开发,这也是为什么buf尾部以\0结尾的原因
集合的底层实现原理 zset集合,其底层的实现实际有两种:压缩列表ZipList,与跳跃列表SkipList。对于用户是透明的,一般情况下是ziplist,当数据满足某个条件时,改用skiplist。
1 2 3 4 5 127.0.0.1:6379> CONFIG GET zset-*-ziplist-* 1) "zset-max-ziplist-value" 2) "64" 3) "zset-max-ziplist-entries" 4) "128"
当zset中的元素个数不超过128个,并且每个元素的长度不超过64,则使用ziplist,否则使用skiplist。
1 2 3 4 5 127.0.0.1:6379> CONFIG GET hash-*-ziplist-* 1) "hash-max-ziplist-value" 2) "64" 3) "hash-max-ziplist-entries" 4) "512"
当hash中的元素个数不超过512个,并且每个元素的长度不超过64,则使用ziplist,否则使用skiplist。
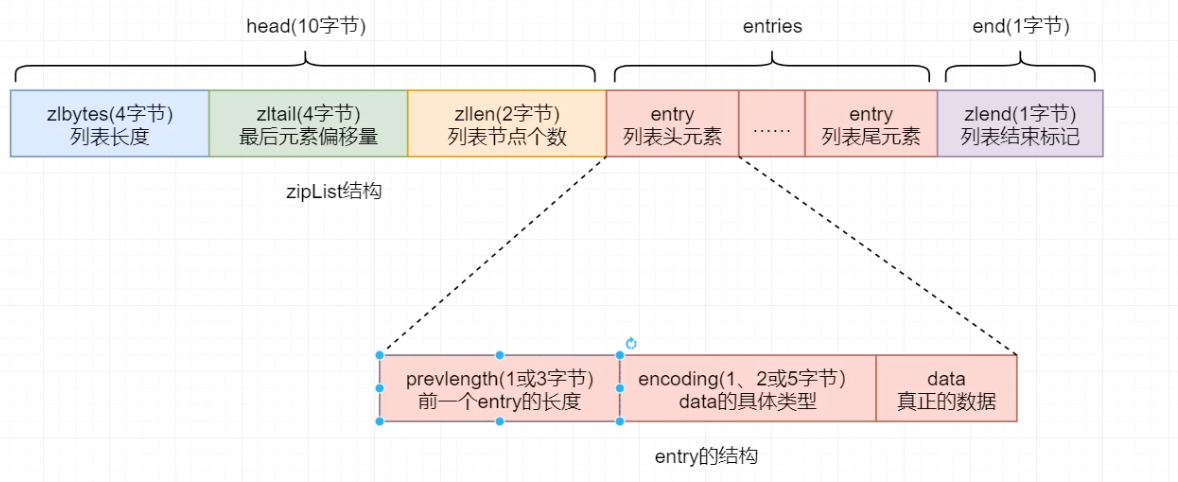
压缩列表ziplist 时一个经过特殊编码的用于存储字符串或整数的链表 ,在内存上占用一个连续的内存块。(因此可以说是一个双向链表,通过数据长度即可获取上、下一个数据的位置)
1 <zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
其底层数据结构主要由三个部分组成:head、entries、end,这三部分在内存中时连续存放的。
head:头部,主要布局
zlbytes:4个字节,列表长度zltail:4个字节,最后元素偏移量zllen:2个字节,列表中的节点个数
entries:主体
end:尾部
zlend:1个字节,放恒定值255,表明列表末尾
每一个entry也由三部分构成:
1 <prevlen> <encoding> <entry-data>
prevlength:记录上一个entry的长度,以实现逆序遍历,默认长度为1字节,只要上一个entry的长度 小于 254 字节,prevlength为1字节,否则会自动扩展为3字节长度。
255用于标记ziplist结尾;
254用于标记需要扩展;
encoding:用于标志后面的data的具体类型。
如果data为整数类型,encoding固定长度为1字节;
如果data为字符串类型,encoding长度可能会是1字节、2字节、5字节;
data:真正存储的数据,数据类型只能是整数类型或字符串类型,不同的数据占用的字节长度不同
通过三个字段的长度,当数据小时,占用内存小,体现出压缩的功能。
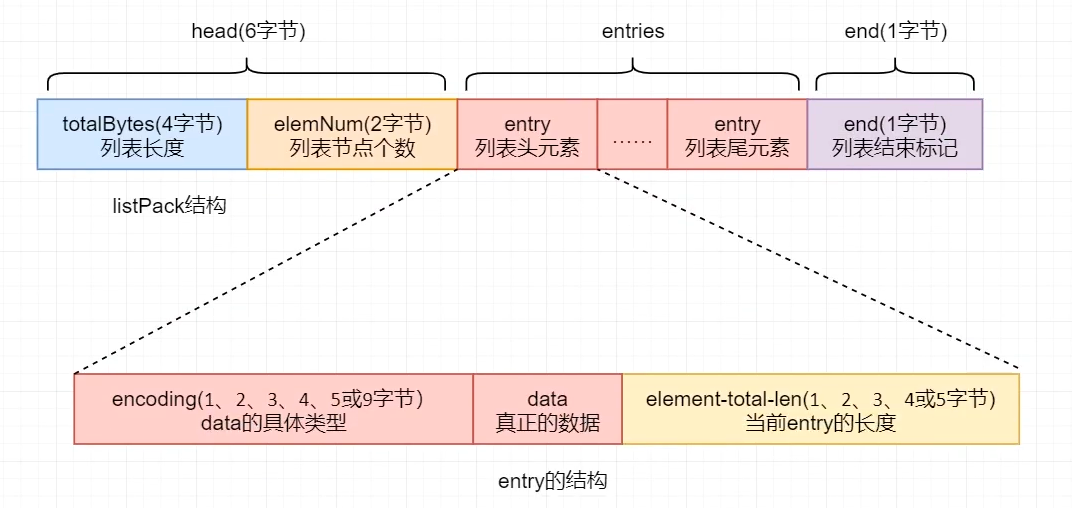
listPack为了优化ziplist中,为了逆序遍历,每一个entry记录了前一个entry的长度,这样会导致当修改或者插入元素时,要级联更新,更新后面元素信息,高并发下会降低性能。因此,在7.0版本中,将所有的ziplist更换了listPack,并且为了兼容性,保留了ziplist的相关属性。
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> OBJECT encoding l21 // list 是quicklist "quicklist" 127.0.0.1:6379> ZADD z21 1 a 1 b 1 c (integer) 3 127.0.0.1:6379> OBJECT encoding z21 // zset 是listpack "listpack" 127.0.0.1:6379> HSET h21 a 1 b 2 c 3 (integer) 3 127.0.0.1:6379> OBJECT encoding h21 // hash 是listpack "listpack"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 127.0.0.1:6379> CONFIG GET zset-* 1) "zset-max-ziplist-value" 2) "64" 3) "zset-max-listpack-entries" // zset中使用listpack 4) "128" 5) "zset-max-listpack-value" 6) "64" 7) "zset-max-ziplist-entries" 8) "128" 127.0.0.1:6379> CONFIG GET hash-* 1) "hash-max-listpack-value" // hash中使用listpack 2) "64" 3) "hash-max-ziplist-value" 4) "64" 5) "hash-max-listpack-entries" 6) "512" 7) "hash-max-ziplist-entries" 8) "512"
listpack也是一个经过特殊编码的用于存储字符串或整数的双向链表,底层数据结构也由三个部分组成:head、entry、entry
1 <totalBytes> <elemNum> <entry> <entry> ... <entry> <end>
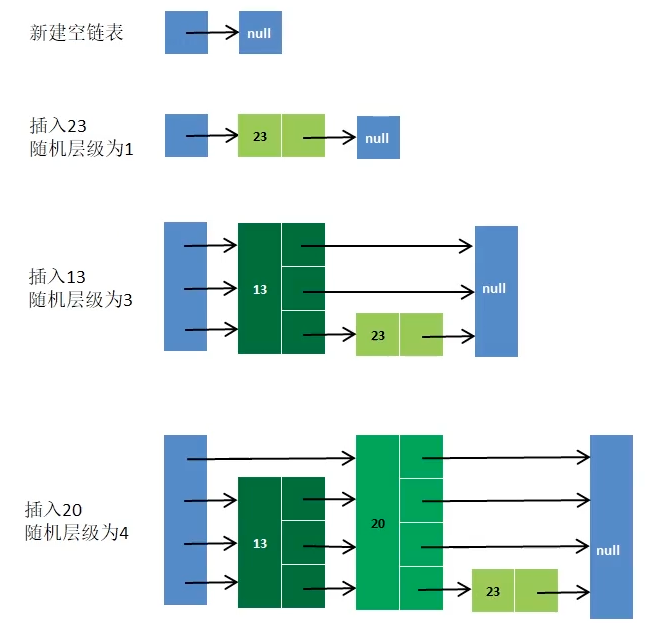
跳跃列表 skiplist 简称跳表,是一种随机化的数据结构,基于并联的链表,实现简单,查找效率较高。
简单来说,跳表也是链表的一种,只不过是在链表的基础上增加了跳跃功能,在查找元素时,能够提供更高的效率。
普通链表,插入数据时,需要一个一个比较,然后再插入
让偶数节点垫高相连,这个时候再进行比较,先通过高层链表,然后再查询底层链表,减少比较次数
再让3的倍数的节点增加高度,则又可以加快比较效率
好处是减少查询次数,增加效率。坏处是如果增加、删除节点,会影响后续的节点指针。解决方案就是通过随机层级。
快速列表quicklist 是一个双向无循环链表,每一个节点都是一个ziplist。
从Redis 3.2版本开始,对于List的底层实现,使用quicklist替代ziplist和linkedlist。quicklist是两者的集合和改进。
linkedlist:是一个双向链表,优点是增加、删除节点方便,缺点是需要存放上、下一个节点的指针,节点多了会出现内存碎片问题。
ziplist:在内存中连续,优点是没有浪费内存,确定是增加、删除节点,都会后面的节点。
quicklist则是将linkedlist按段切分,每一段使用ziplist来紧凑存储若干真正的数据元素,多个ziplist之间使用双向指针串联起来。每个ziplist中最多存放的数据个数,通过 list-max-ziplist-size指定
1 2 3 127.0.0.1:6379> CONFIG GET list-max-ziplist-size 1) "list-max-ziplist-size" 2) "-2" // -2 代表 8Kb,在Redis配置文件中可以看到配置的描述,代表整个ziplist大小不超过8Kb
查询过程,则是通过与head中的zllen进行比较,获取具体的ziplist节点,然后再在ziplist中遍历。
插入过程:
如果 插入的数据长度 + zlbytes <= list-max-ziplist-size,则直接将元素插入到当前找到的ziplist中即可
如果 插入的数据长度 + zlbytes > list-max-ziplist-size,
如果插入的位置是ziplist的首部,此时需要查看前一个ziplist的大小,是否可以插入到尾部(判断条件也是插入之后的长度是否小于等于list-max-ziplist-size);如果不可以,则将新的节点单独创建出一个ziplist节点,插入到两个ziplist之间
如果插入的位置是ziplist的尾部,此时需要查看后一个ziplist的大小,是否可以插入到首部(判断条件也是插入之后的长度是否小于等于list-max-ziplist-size);如果不可以,则将新的节点单独创建出一个ziplist节点,插入到两个ziplist之间
如果插入的位置是ziplist的中间,此时需要将该ziplist分割成两个ziplist,将元素插入到前一个ziplist的尾部
key和集合元素个数的限制Redis可以处理2^32个key,每一个Redis实例最少可以处理2.5亿个key。
每个hash、list、set、zset,可以容纳2^32个元素。
高级功能 流水线 pipeline 流水线是将多个命令打包一起发送到服务端,服务端执行之后将结果一次性返回。相比多个命令依次执行,节约了网络传递时间。
相比mget之类的操作,mget是原子性的,pipeline到达服务端会被拆开,中间可能会插入其他的命令。
注意每次pipeline携带数据量。
pipeline只会作用到一个节点上
1 2 3 4 5 6 7 8 9 10 11 12 13 14 pipelineClient := rdb.Pipeline() for i := 0; i < 100; i++ { pipelineClient.Set("string21", i, 0) } cmdres, err := pipelineClient.Exec() if err != nil { log.Fatal(err) } for index, cmd := range cmdres { if index == 0 { fmt.Printf("%#v", cmd) } }
发布/订阅 发布者 publisher:将消息发送到频道中
订阅者 subscriber:订阅者订阅频道,获取消息,可以订阅多个频道,
频道 channel:先进先出,可以同时发给多个订阅者
1 2 3 4 5 6 7 8 9 10 11 12 172.16.211.68:49153> PUBLISH mitaka:tv "hello wrold" // 发布消息,结果显示发布到多少个订阅者 (integer) 2 172.16.211.68:49153> SUBSCRIBE mitaka:tv // 订阅频道 Reading messages... (press Ctrl-C to quit) 1) "subscribe" // 订阅操作 2) "mitaka:tv" // 订阅的 channel 3) (integer) 1 // 订阅成功的 channel 编号,如果有多个,编号会增加 1) "message" // 获取消息操作 2) "mitaka:tv" // 订阅的 channel 3) "hello wrold" // 获取到的消息信息 172.16.211.68:49153> UNSUBSCRIBE mitaka:tv // 取消订阅
按照模式订阅,通过 * 通配符匹配
1 2 3 4 5 6 7 8 172.16.211.68:49153> PSUBSCRIBE *tv // 订阅 tv结尾的频道 Reading messages... (press Ctrl-C to quit) 1) "psubscribe" 2) "*tv" 3) (integer) 1 // 订阅的频道1 1) "psubscribe" 2) "mitaka*" 3) (integer) 2 // 订阅的频道2
查看至少有一个订阅者 的channel,以及相关channel操作
1 2 3 4 5 6 7 8 9 10 11 172.16.211.68:49153> PUBSUB channels 1) "mitaka:tv" // 列出给定channel订阅者数量 172.16.211.68:49153> PUBSUB numsub mitaka:tv 1) "mitaka:tv" 2) (integer) 1 // 列出被 使用通配符定于的 channel 的数量 172.16.211.68:49153> PUBSUB numpat (integer) 1
取消订阅
1 2 3 4 5 6 7 8 9 10 127.0.0.1:6379> UNSUBSCRIBE mitaka:tv 1) "unsubscribe" 2) "mitaka:tv" 3) (integer) 0 // 或者批量取消订阅 127.0.0.1:6379> PUNSUBSCRIBE mitaka* 1) "punsubscribe" 2) "mitaka*" 3) (integer) 0
消息队列
消息队列和发布订阅的区别是:发布订阅是发布者发布消息,订阅者都能收到;消息队列是发布者发布消息,消费者抢消息,只有一个消费者能抢到消息
缺点:
不支持数据持久化
无法避免消息丢失
消息堆积有上线,超出时数据丢失
位图 bitmap 通过ASCII码可以获取字符串bit对应二进制,也就是一个仅包含0和1的二进制字符串,string类型。描述该字符串的属性有三个:key、offset、bitValue
key:也就是Redis中key-value中的key
offset:每个bitmap都是一个字符串,字符串中的每个字符都有对应的索引,从0开始计数,这个索引就是偏移量offset。
offset的值的范围是[0,2^32 - 1],也就是最大值是4G-1。
bitValue:每个offset为上的字符就是该位的bitValue,非0即1。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 172.16.211.68:49153> set hello world OK 172.16.211.68:49153> GETBIT hello 1 // 获取偏移量的值,获取第1个偏移量的值。偏移量从0开始 (integer) 1 172.16.211.68:49153> SETBIT hello 1 0 // 设置偏移量的值,设置第1个偏移量的值为。如果超过字符串最大偏移量,会会自动伸展。但是需要注意,如果自动伸展过大,会导致redis阻塞,因此,一般会在启动时就设置最大偏移量,后续就不会扩展。 (integer) 1 172.16.211.68:49153> get hello "7orld" 172.16.211.68:49153> BITCOUNT hello 0 -1 // 获取位图指定范围位置为1的个数 (integer) 22 172.16.211.68:49153> BITOP and opkey hello string10 // 将多个bitmq的and交集,or并集,not非,xor异或操作并且将结果保存在destkey中 (integer) 5 172.16.211.68:49153> BITPOS hello 1 0 -1 // 计算位图指定范围第一个偏移量对应值等于1的位置,从0开始,到-1,第一个等于1的位置值是2 (integer) 2
需要注意,bitmap是从左到右的
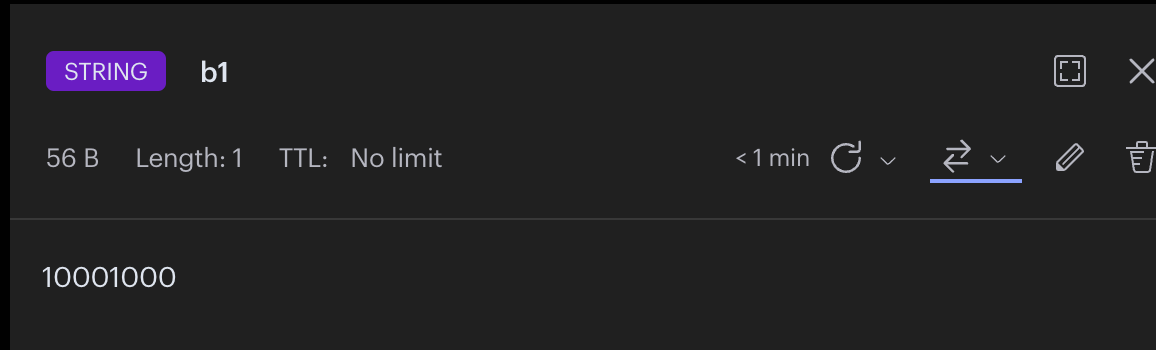
1 2 3 4 127.0.0.1:6379> SETBIT b1 0 1 (integer) 0 127.0.0.1:6379> SETBIT b1 4 1 (integer) 0
通过RDM可以看到从左到右,第0位和第4位是1,其他都是0,一共占用8位,1Byte。
使用场景:数据量非常大时很适合,数据量小的时候不适合,对于set和bitmap,可通过内存占用大小判断哪个更加合适。
真实使用时,为了计算连续登录天数,会将一个月的登录信息,获取成无符号整数出来,然后与1做位运算,然后1加1位,继续比较。
超级日志记录 HyperLogLog 意义是hyperlog log。可以理解为一个set集合,集合元素是string,基于hyperloglog算法,一种基数计算概率算法,通过该算法可以利用极小的内存(即使是上亿的量,占用也不会超过16KB)完成独立总数的计算;
所有相关命令都是对这个set集合的操作,为了纪念算法研究者Philippe Flajolet博士,命令使用首字母缩写PF开头。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 172.16 .211 .68 :49153 > PFADD string31 hello1 hello2 hello3 hello4 // 向HyperLogLog中添加元素(integer) 1 172.16 .211 .68 :49153 > PFCOUNT string31 // 计算独立总数(integer) 5 172.16 .211 .68 :49153 > PFADD string31 hello1 hello2 hello3 hello4 // 再次向HyperLogLog中添加元素(integer) 1 172.16 .211 .68 :49153 > PFCOUNT string31 // 计算独立总数,不会变化(integer) 5 127.0 .0 .1 :6379 > PFCOUNT string31 string32 // 记录多个HyperLogLog的集合的并集近似基数(integer) 5 172.16 .211 .68 :49153 > TYPE string31string 172.16 .211 .68 :49153 > get string31"HYLL\x01\x00\x00\x00\x05\x00\x00\x00\x00\x00\x00\x00C\x8e\x80Ru\x8cM\xf8\x80N2\x80B\x83\x88KE" 172.16 .211 .68 :49153 > PFMERGE string33 string31 string32 // 将两个HyperLogLog合并OK 172.16 .211 .68 :49153 > PFCOUNT string33(integer) 7
内存消耗相比位图更小
应用场景:
可对数据量超级庞大的日志数据做不精确(官方误差是0.81%)的去重计数统计,例如平台上每天的UV数据(独立访客数,一次API请求记录一次,一天可能上亿的访问),非常适合使用HyperLogLog进行记录。
UV:Unique Visitor,独立访问量,是指通过互联网访问、浏览这个网页的自然人。1天内,同一个用户访问多次该网站,只记录1次。
PV:Page View,页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
缺点:
地理空间 GEO Geospatial存储经纬度,计算两地距离,范围计算,类型是zset
集合中元素由三部分组成:
经度:longitude,有效经度为[-180, 180]。正的表示东经,负的表示西经
纬度:latitude,有效维度为 [-85.05112878, 85.05112878]。正的表示北纬,负的表示南纬
位置名称:为该经纬度锁标注的位置所命名的名称,也称为该Geospatial集合的空间元素名称
通过该类型,可以设置、查询某地理位置的经纬度,查询某范围内的空间元素,计算两空间元素间的距离等。
原理是将二维经纬度,以坐标的形式(0,0)``(0,1)``(1,0)``(1,1)存储,并且并且每一个块再进行细分,例如(0,0)的格子再分为四个区域,将所有的格子通过z阶曲线,从二维降低成一维。将经度和纬度通过二分,转换成二进制,经纬度组合成一个组合编码。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 172.16.211.68:49153> GEOADD cities:locations 100 30 beijing // 将位置添加进去,例如这个是经度为100,维度为30,地理位置名称是beijing (integer) 1 172.16.211.68:49153> GEOADD cities:locations 90 40 shanghai (integer) 1 172.16.211.68:49153> GEOADD cities:locations 40 30 wuhan (integer) 1 172.16.211.68:49153> GEOADD cities:locations 10 20 hangzhou (integer) 1 172.16.211.68:49153> GEOPOS cities:locations hangzhou // 获取经纬度 1) 1) "10.00000208616256714" 2) "20.00000058910486445" 172.16.211.68:49153> GEODIST cities:locations hangzhou wuhan m // 计算两个位置的距离,单位为m,默认单位 "3210283.5452" 172.16.211.68:49153> GEORADIUS cities:locations 40 30 4000 km // 计算某个经纬度范围内的地点,单位为km 1) "hangzhou" 2) "wuhan" 172.16.211.68:49153> GEORADIUSBYMEMBER cities:locations hangzhou 4000 km // 计算某个成员某个范围的地点 1) "hangzhou" 2) "wuhan" 127.0.0.1:6379> GEORADIUS cities:locations 40 30 4000 km withcoord withdist withhash count 2 desc // 选2个,由远及近 1) 1) "hangzhou" // 名称 2) "3210.2835" // 距离 3) (integer) 3403951602136190 // hash 4) 1) "10.00000208616256714" 2) "20.00000058910486445" 2) 1) "wuhan" 2) "0.0000" 3) (integer) 3499826602464945 4) 1) "40.00000029802322388" 2) "30.00000024997701331" 172.16.211.68:49153> TYPE cities:locations // 类型是zset zset 127.0.0.1:6379> GEOHASH cities:locations wuhan shanghai // 将二维空间经纬度编码成一个字符串,主要用于底层应用或者调试 1) "svk6wjr4et0" 2) "wp0581b0bh0"
使用场景:
主要应用地理位置相关的计算,例如微信发现中的“附近”功能、添加朋友中“雷达加朋友”功能、QQ动态中的“附近”功能、钉钉中的“签到”功能等。
流 Stream Stream是Redis 5.0引入的一种新的数据类型,可以实现一个功能非常完善的消息队列。
支持数据持久化。
1 XADD key ID field value [field value ...]
key:是Stream的名称ID:是这条消息的唯一ID,*代表由Redis自动生成,格式是时间戳-递增数字 ,例如1670419745548-0,
field value:发送到队列中的消息,称为entry,格式就是多个key-value键值对。
1 2 3 4 5 6 127.0.0.1:6379> XADD stream1 1 k1 v1 k2 v2 // 发送消息 "1-0" 127.0.0.1:6379> XADD stream1 * k1 v1 k2 v2 // 发送消息 "1670419745548-0" 127.0.0.1:6379> XLEN stream1 // 查看Stream长度 (integer) 2
读取消息
1 XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]
COUNT:读取的消息个数BLOCK:当没有消息时,是否阻塞,阻塞时长STREAMS key:从哪个队列读取消息,key就是队列名id:起始id,只返回大于该id的消息;0代表从第一个消息开始,$代表从最新的消息开始
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 127.0.0.1:6379> XREAD COUNT 1 STREAMS stream1 0 // 读取多次,可以无限重新读取 1) 1) "stream1" 2) 1) 1) "1-0" 2) 1) "k1" 2) "v1" 3) "k2" 4) "v2" 127.0.0.1:6379> XREAD COUNT 1 STREAMS stream1 0 1) 1) "stream1" 2) 1) 1) "1-0" 2) 1) "k1" 2) "v1" 3) "k2" 4) "v2" 127.0.0.1:6379> XREAD COUNT 1 BLOCK 0 STREAMS stream1 $ // 永久阻塞,获取最新消息时,如果有多条消息同时到达,也会获取最新消息,可能出现漏读消息
单消费模式特点:
消息可回溯
一个消息可以被多个消费者读取
可以阻塞读取
消息有漏读的风险
消费者组,将多个消费者划分到一个组中,监听同一个队列,可以解决消息漏读的风险。
消息分流:队列中消息会分流给组内的不同消费者,而不是重复消费,从而加快消息处理的速度
消息表示:消费组会维护一个表示,记录最后一个被处理的消息,即使消费者宕机重启,还会从表示之后读取消息,确保每一个消息都会被消费
消息确认:消费者获取消息后,消息处于pending状态,并存入一个pending-list,当处理完成后,需要通过XACK来确认消息,标记消息为已处理,才会从pending-list移除
1 XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername]
通过XGROUP命令创建、删除、管理消费者组。
1 2 127.0.0.1:6379> XGROUP CREATE stream1 g1 $ // 创建消费者组 OK
1 XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
通过消费者组消费消息,使用XREADGROUP
GROUP group:消费组组名称consumer:消费者名称,如果没有,则会自动创建一个BLOCK milliseconds:当没有消息时最长等待时间NOACK:无需手动ACK,获取到消息后自动确认STREAMS key:指定Steam名称ID:获取消息的其实ID:
>:从下一个未消费的消息开始其他:根据指定id从pending-list中获取已消费但未确认的消息。例如0,是从pending-list中的第一个消息开始
1 2 3 4 5 6 7 127.0.0.1:6379> XREADGROUP GROUP g1 c2 COUNT 1 BLOCK 2000 STREAMS stream1 > // 读取,但是不确认 1) 1) "stream1" 2) 1) 1) "1670421019592-0" 2) 1) "k1" 2) "v1" 3) "k2" 4) "v2"
1 XACK key group ID [ID ...]
通过XACK确认消息
key:是Stream的名称group:组名称ID:消息ID
1 2 127.0.0.1:6379> XACK stream1 g1 1670421019878-0 (integer) 1
获取pending-list中的数据
1 XPENDING key group [start end count] [consumer]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 127.0.0.1:6379> XPENDING stream1 g1 // 获取 stream1在g1的已经消费但未确认的消息 1) (integer) 6 // 一共6个数据 2) "1670420955080-0" // 列举最近的两个 3) "1670421019592-0" 4) 1) 1) "c1" // c1 有2个 2) "2" 2) 1) "c2" // c2 有4个 2) "4" 127.0.0.1:6379> XPENDING stream1 g1 0 1670421020440-0 200 c1 // 0代表开始的id,1670421020440-0代表结束的id,200代表个数,c1指定消费组 1) 1) "1670420955080-0" 2) "c1" 3) (integer) 568115 4) (integer) 1 2) 1) "1670421018454-0" 2) "c1" 3) (integer) 508701 4) (integer) 1 3) 1) "1670421020138-0" 2) "c1" 3) (integer) 69955 4) (integer) 1 4) 1) "1670421020440-0" 2) "c1" 3) (integer) 60509 4) (integer) 1
特点:
消息可回溯
可以多消费者争抢消息,加快消费速度
可以阻塞读取
没有消息漏读的风险
有消息确认机制,保证消息至少被消费一次
Redis消息队列的对比
List
PubSub
Stream
消息持久化
支持
不支持
支持
阻塞读取
支持
支持
支持
消息堆积处理
受限于内存空间,可以利用多消费者加快处理
受限于消费者缓冲区
受限于队列长度,可以利用消费者组提高消费速度,减少堆积
消息确认机制
不支持
不支持
支持
消息回溯
不支持
不支持
支持
事务 Redis的事务仅保证了数据的一致性,并不是像DBMS一样的ACID特性(原子性、一致性、隔离性、持久性)。
这组命令的某些命令的执行失败,不会影响其他命令的执行,不会引发回滚,也就是不具备原子性
这组命令通过乐观锁机制,实现简单的隔离性。没有复杂的隔离级别
这组命令的执行结果是被写入到内存的,是否持久取决于Redis的持久化策略,与事务无关
基本使用 Redis事务由三个命令进行控制
MULTI:开启事务exec:执行事务discard:取消事务
执行或者取消事务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 127.0.0.1:6379> MULTI // 开启事务 OK 127.0.0.1:6379> SET a 10 // 放到队列中 QUEUED 127.0.0.1:6379> get a // 再获取a,放到队列中 QUEUED 127.0.0.1:6379> exec // 提交 1) OK 2) "10" 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> set age 20 QUEUED 127.0.0.1:6379> DISCARD // 回滚 OK 127.0.0.1:6379> GET age "10"
中途出现报错
1 2 3 4 5 6 7 8 9 10 11 12 127.0.0.1:6379> get age "10" 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> INCR age QUEUED 127.0.0.1:6379> INCRBY abc (error) ERR wrong number of arguments for 'incrby' command // 执行过程中出现报错, 127.0.0.1:6379> exec (error) EXECABORT Transaction discarded because of previous errors. // 提交或者取消时,都会报错 127.0.0.1:6379> get age // 执行出错时,执行的命令不会生效 "10"
另外一种报错
1 2 3 4 5 6 7 8 9 10 11 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> set score A QUEUED 127.0.0.1:6379> INCRBY score 10 // 语法不会报错,但是执行会报错 QUEUED 127.0.0.1:6379> exec // 执行阶段报错 1) OK 2) (error) ERR value is not an integer or out of range 127.0.0.1:6379> GET score // 执行之后,没有报错的语句成功执行 "A"
隔离机制 多个客户端操作时,为了避免数据冲突,事务操作时,会通过乐观锁实现数据隔离
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 // 客户端1 127.0.0.1:6379> SET resouce 100 OK 127.0.0.1:6379> WATCH resource // 给资源加乐观锁 OK 127.0.0.1:6379> MULTI OK 127.0.0.1:6379> DECRBY resource 10 QUEUED // 客户端2 127.0.0.1:6379> DECRBY resource 10 (integer) 50 // 客户端1 127.0.0.1:6379> exec (nil) // 客户端1 提交,显示nil,代表操作失败
通过WATCH给resource加乐观锁之后,Redis会在内存中给resource加一个版本号,并且将 resource和version记录到对应client上;
当有其他的client操作resource之后,resource的版本号变成2;
事务EXEC时,会判断resource的版本号和记录的版本号,如果记录的版本号 < 当前版本号,则代表数据已经被修改,此时事务不会提交成功。
事务和流水线的对比
事务具有原子性,管道不具有原子性
管道一次性将多条命令发送到服务器,事务是一条一条的发,事务只有在接收到exec命令后才会执行,管道不会
执行事务时会阻塞其他命令的执行,而执行管道中的命令时不会
流水线是客户端的行为,对于服务器来说是透明的,可以认为服务器无法区分客户端发送来的查询命令是以普通命令的形式还是以流水线的形式发送到服务器的;而事务则是实现在服务器端的行为,用户执行MULTI命令时,服务器会将对应这个用户的客户端对象设置为一个特殊的状态,在这个状态下后续用户执行的查询命令不会被真的执行,而是被服务器缓存起来,直到用户执行EXEC命令为止,服务器会将这个用户对应的客户端对象中缓存的命令按照提交的顺序依次执行。
由于第4点,也就是说,Redis的事务,只有在EXEC之后才会真实执行,因此不存在脏读、脏写等问题,也没有写入时的排他锁机制。
持久化 Redis所有的数据都保留在内存中,但是数据会异步保存到磁盘上进行持久化,关机时数据不会丢失。
持久化的方式一般有两种:
快照:MySQL dump、Redis RDB
写日志:MySQL Binlog、redolog,Redis AOF
RDB和AOF可以都选,RDB是系统默认的。
Redis在启动之后,会首先判断AOF持久化是否开启,如果开启,则使用AOF持久化文件恢复数据。如果没有开启,再通过RDB持久化文件恢复数据。
持久化配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 127.0.0.1:6379> INFO Persistence # Persistence loading:0 async_loading:0 current_cow_peak:0 current_cow_size:0 current_cow_size_age:0 current_fork_perc:0.00 current_save_keys_processed:0 current_save_keys_total:0 rdb_changes_since_last_save:9 rdb_bgsave_in_progress:0 rdb_last_save_time:1669879766 rdb_last_bgsave_status:ok rdb_last_bgsave_time_sec:0 rdb_current_bgsave_time_sec:-1 rdb_saves:9 rdb_last_cow_size:716800 rdb_last_load_keys_expired:0 rdb_last_load_keys_loaded:30 aof_enabled:0 aof_rewrite_in_progress:0 aof_rewrite_scheduled:0 aof_last_rewrite_time_sec:-1 aof_current_rewrite_time_sec:-1 aof_last_bgrewrite_status:ok aof_rewrites:0 aof_rewrites_consecutive_failures:0 aof_last_write_status:ok aof_last_cow_size:0 module_fork_in_progress:0 module_fork_last_cow_size:0
RDB 将数据快照全量 保存到磁盘中,启动的时候加载。
RDB持久化文件即是.rdb文件
1 -rw------- 1 redis redis 15K Dec 1 07:29 dump.rdb
触发机制:
save :同步,执行save的时候,会阻塞 Redis的主进程,先备份出一个临时文件,如果存在老的文件,则会将新的文件替换老的文件,时间复杂度o(n)
1 2 172.16.211.68:49153> save OK
1 2 172.16.211.68:49153> BGSAVE Background saving started
1 2 3 172.16.211.68:49153> CONFIG GET save 1) "save" 2) "3600 1 300 100 60 10000"
配置自动bgsave,可以修改配置文件,在conf中的 SNAPSHOTTING 中
1 2 3 4 5 6 7 8 save 3600 1 300 100 60 10000 // 代表 3600s 有 1 次写入操作,或者 300s 有 100 次写入操作,或者 60s 有 10000写入操作,就会自动执行bgsave stop-writes-on-bgsave-error yes // 在有备份文件时,在bgsave出现报错的时候,停止接收写操作。这样让用户可以意识到数据没有持久化到磁盘。如果bgsave正常,则可以正常接受写操作。 rdbcompression yes // rdb时,是否使用字符串压缩算法,会消耗CPU,但是可以节省磁盘 rdbchecksum yes // rdb校验和,增强安全性,开启会影响bgsave和恢复的性能,大约10%。禁用的时候,校验和是0。 sanitize-dump-payload no // 全面安全检测开关,可以减少断言、crash的问题。no:从来不执行;yes:一直执行;client:客户端连接时检测;默认应该是client,但是会影响集群下数据迁移,因此改成no。 dbfilename dump.rdb // 生成备份的名称 rbd-del-sync-files no // 主从同步时,通过将rdb文件发给salve,当没有打开持久化时才有效果,yes代表同步后会被删除,no代表不删除。 dir ./ 工作目录,对于AOF(Append Only File)文件,也是创建在这个目录
查看最近一次持久化的时间
1 2 127.0.0.1:6379> LASTSAVE (integer) 1669879766
其他的触发方式:
主从复制,全量复制的时候会触发
debug reoloadshutdown
RDB文件结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 root@4991bfc67ce7:/data# cat dump.rdb REDIS0010� redis-ver7.0.5� redis-bits�@�ctime��W�cused-mem�(�/aof-base���.l21�c�b�a�s�z�a�b�c�d�z21�a�b�c�p985fudanbeidajiaodast hello worldset2entnewssportsitb�mylist@{�/Ja a �VXK�������������@l_� �c�VXK����������������������������������@l_� ... 中间删除内容相容的数据 �c�VXK����������������������������������@l_� �c�VXK���������������������������������k13v3countryChinak12v2k1v1lan''�Java�Python�Ruby�Javascript string32HYLLQ��DD�i�key:__rand_int__VXKdesc�b�c�x�y�z�f100.1z2++ �az a�aabbcc��z3�'11�aa(�ab`c@b`c�`c �zsort�ad_int__�VXK�counter:__rand_int__�@ �z�c�x(�age� set12musichisbbb�set13newsmusichisentsportsistring21�abcnihaoya�` yac9qinghualan2++�Go�Java�Python�Ruby�Javascript �abc�{sour �a�me�name�xu�age�a1�f�e�d�c�b�astring31HYLL�C��Ru�\,�B��KEyou�name�mi�set1musicsportsithistring33!HYLL�C��N/�DD�\,�B��KEh21'' �a�b�c�name�zs�age�ccc�cities:locations@S�hangzhou �~�>� �wuhan�Vj�o �beijin�;�Bk�G �shanghai �PQEPU �k11v1aaa�def���o|���Se
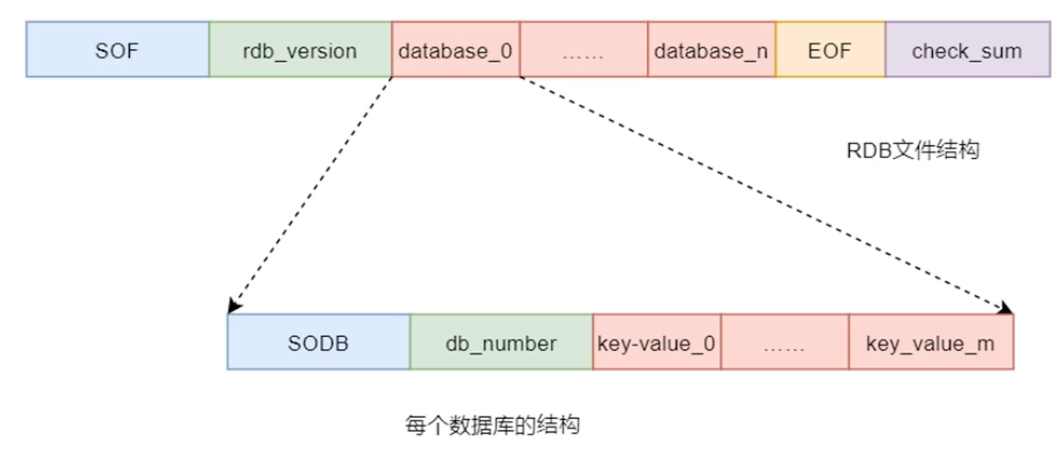
dump.rdb 整体上有五部分构成:
SOF:Start Of File,文件头,是一个常量,一个字符串REDIS,仅包含着5个字符,长度为5。用于标识RDB文件的开始,以便在加载RDB文件时,可以迅速判断出文件是否是RDB文件。
rdb_version:是一个整数,长度4字节,表示RDB文件的版本号,例如上面就是0010
databases:数据部分,包含任意多个非空数据库,由三个部分组成:
EOF:数据结束标识符
check_sum:校验和,检查文件完整性,采用CRC校验。
是将SOF、rdb_version以及数据快照这三者的二进制数据拼接起来,形成一个二进制数(假设是a),然后再使用a除以校验和check_sum,此时可获取到一个余数b,然后再将这个(check_sum-b)之后的值拼接到a的后面,形成databases。
加载时,首先通过check_sum进行文件完整性校验,将rdb文件中除EOF和check_sum之外的数据除以check_sum,如果余数不是0,则代表数据损坏,但是如果数据是0,也不一定代表数据没有损坏。
AOF Append Only File,解决RDB的问题:IO耗时、耗性能(数据解压缩、校验)、不可控、丢失数据可能性(只能恢复到save的时间节点,AOF可以将丢失数据的时间降低到1s)。
通过日志文件记录实时写操作到一个AOF文件中,恢复数据时通过AOF文件,将这些写操作重新执行一次;(如果RDB和AOF都开启,则使用AOF)
AOF会重写rewrite,例如一个key被set多次,重写后只记录一次,减少硬盘占用,加速恢复速度;
配置开启,在conf中的 APPEND ONLY MODE 中
1 2 3 4 5 6 appendonly yes // 开启AOF appendfilename "appendonly.aof" // Redis 7中,AOF文件是一组文件,这个配置是一个前缀,在Redis 6中,只有1个文件 appenddirname "appendonlydir" // AOF文件目录 aof-use-rdb-preamble yes // 混合持久化,AOF的base文件格式,yes代表二进制,也就是RDB格式,no代表不使用二进制,需要向后兼容的时候,使用no appendfsync everysec // 将AOF缓存中的数据同步到磁盘上的策略 aof-timestamp-enabled no // AOF文件是否记录时间戳,好处是恢复时按照时间恢复,但是加上之后,可能跟当前机器的AOF文件不兼容。
AOF同步策略:
alwayes:当写命令写入到AOF的缓冲区时,每条命令都同步到磁盘的AOF日志中,慢,但是安全。everysec:每一秒把缓冲区的数据记录到AOF日志中,默认no:根据操作系统决定,Linux默认同步的周期是30s
获取配置
1 2 3 4 5 6 7 8 9 10 11 12 13 127.0.0.1:6379> CONFIG GET appendonly 1) "appendonly" 2) "no" // 临时修改 127.0.0.1:6379> CONFIG SET appendonly yes OK 127.0.0.1:6379> CONFIG GET appendonly 1) "appendonly" 2) "yes" // 将内存中的配置保存到文件中 127.0.0.1:6379> CONFIG REWRITE // 前提条件是运行时指定配置文件
AOF文件
1 2 3 4 5 ls -ltrah total 28K -rw------- 1 redis redis 0 Dec 1 09:27 appendonly.aof.1.incr.aof // 增量文件,在base之后的操作记录到incr文件中 -rw------- 1 redis redis 15K Dec 1 09:27 appendonly.aof.1.base.rdb // 基本文件,创建这个文件当时的全状态数据,可以是二进制的方式,也可以是命令集的方式,rdb就是二进制格式,其实也就是rdb的持久化文件。文件创建之后,就不会变化。 -rw------- 1 redis redis 88 Dec 1 09:27 appendonly.aof.manifest // 清单文件,跟踪这些文件,当创建这些文件、使用文件恢复数据时使用的顺序
1 2 3 # cat appendonly.aof.manifest file appendonly.aof.1.base.rdb seq 1 type b // 文件、序号、类型、b是二进制 file appendonly.aof.1.incr.aof seq 1 type i // 按照顺序从上到下加载
.aof格式,其实就是Redis通讯协议格式,AOF持久化文件的本质就是基于Redis通讯协议的文本,将命令以纯文本的方式写入到文件中。
1 2 3 4 127.0.0.1:6379> set a abc OK 127.0.0.1:6379> set b def OK
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 cat appendonly.aof.1.incr.aof *2 // 表示当前消息体有2行 $6 // 表示下一行有6字字节长度 SELECT // 命令 $1 // 表示下一行有1个字节长度 0 // 0 -------- 到这里,也就是记录 SELECT 0 *3 $3 set $1 a $3 abc *3 $3 set $1 b $3 def
Redis协议规定,Redis文本是以行来划分,每行以\r\n行结束。每一行都有一个消息头,以表示消息类型。
消息头由六种不同的符号表示
*:表示消息体总共有多少行,不包含当前行$:表示下一行消息数据的长度,不包括换行符长度\r\n+:表示一个正确的状态信息-:表示一个错误信息``:空,表示一个消息数据
::表示返回一个数值
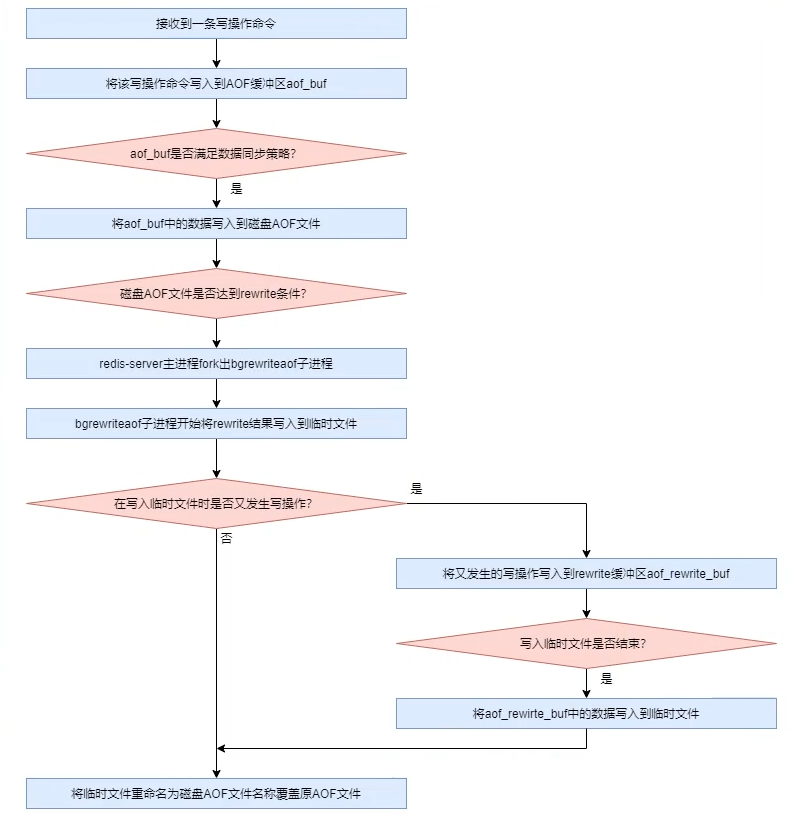
重写rewrite 当rewrite开启后,主进程会创建出一个子进程bgrewriteaof,用于完成rewrite过程。
rewrite相关配置
1 2 3 4 5 auto-aof-rewrite-percentage 100 // 自动rewrite判断条件,增加的日志,占当前rewrite后日志大小,超过这个百分比就rewrite,0表示禁用rewrite auto-aof-rewrite-min-size 64MB // rewrite之后,日志大小超过64MB,就rewrite no-appendfsync-on-rewrite no // 当策略设置的是always或者everysec是,在后台的bgrewrite、bgsave时会占用大量磁盘IO,此时是否同步rewrite的AOF,默认no。需要保持no aof-rewrite-incremental-fsync yes // bgrewriteaof执行时,将结果写到aof_rewrite_buf缓存中,缓存中数据达到一定量或者一定时间会通过fsync()进行刷盘操作,即数据同步,将数据写入临时文件中。该属性用于控制每次刷盘的数据量最大不超过4MB,可以避免单次刷盘两太大导致磁盘产生过大延迟 aof-load-truncated yes // 当AOF文件被截断,服务重启后如何处理。当操作系统crash可能出现这种情况。yes代表加载尽可能多的数据,并且记录日志,no代表报错退出,此时需要通过redis-check-aof工具修复。如果AOF文件中间异常,无论哪个选项,都会直接退出。
首先对AOF文件进行rewrite计算,将计算记过写入到一个临时文件,写入完毕后,在rename该临时文件为原AOF文件名,覆盖原文件
1 2 3 4 5 // rewrite 127.0.0.1:6379> set name tom OK 127.0.0.1:6379> set name jerry OK
1 2 3 4 5 6 7 8 9 10 11 12 13 14 *3 $3 set $4 name $3 tom *3 $3 set $4 name $5 jerry
rewrite计算也称为rewrite策略。rewrite计算遵循以下策略:
读操作命令不写入文件
无效命令不写入文件(先set,然后再修改,最后删除,此时修改命令就是无效命令)
过期数据不写入文件
多条命令合并写入文件(例如多个incre合并成一个,或者hash中多次加入元素会合并成一条命令,最大64条)
手动开启
1 2 127.0.0.1:6379> BGREWRITEAOF Background append only file rewriting started
开启之后
1 2 3 4 5 6 7 8 9 ls -ltrah total 28K -rw------- 1 redis redis 0 Dec 1 12:02 appendonly.aof.2.incr.aof -rw------- 1 redis redis 15K Dec 1 12:02 appendonly.aof.2.base.rdb -rw------- 1 redis redis 88 Dec 1 12:02 appendonly.aof.manifest cat appendonly.aof.manifest file appendonly.aof.2.base.rdb seq 2 type b file appendonly.aof.2.incr.aof seq 2 type i
重写实现方式:
bgrewriteaof:发送bgrewriteaof命令
AOF重写配置
检测和修复AOF
1 2 3 4 5 redis-check-aof appendonly.aof.3.incr.aof Start checking Old-Style AOF AOF analyzed: filename=appendonly.aof.3.incr.aof, size=145, ok_up_to=145, ok_up_to_line=27, diff=0 AOF appendonly.aof.3.incr.aof is valid
将文件最后一些内容删掉,再检查
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 redis-check-aof appendonly.aof.3.incr.aof Start checking Old-Style AOF 0x 7a: Expected to read 5 bytes, got 0 bytes AOF analyzed: filename=appendonly.aof.3.incr.aof, size=122, ok_up_to=105, ok_up_to_line=24, diff=17 AOF appendonly.aof.3.incr.aof is not valid. Use the --fix option to try fixing it. // 修复,修复之后,会尽量恢复更多的数据 redis-check-aof --fix appendonly.aof.3.incr.aof Start checking Old-Style AOF 0x 7a: Expected to read 5 bytes, got 0 bytes AOF analyzed: filename=appendonly.aof.3.incr.aof, size=122, ok_up_to=105, ok_up_to_line=24, diff=17 This will shrink the AOF appendonly.aof.3.incr.aof from 122 bytes, with 17 bytes, to 105 bytes // 从122字节,缩减17个字节,缩短到105个字节 Continue? [y/N]: y Successfully truncated AOF appendonly.aof.3.incr.aof // 再次查看 redis-check-aof appendonly.aof.3.incr.aof Start checking Old-Style AOF AOF analyzed: filename=appendonly.aof.3.incr.aof, size=105, ok_up_to=105, ok_up_to_line=20, diff=0 AOF appendonly.aof.3.incr.aof is valid
如果是在中间删除一些数据,就不一定能恢复数据。
AOF持久化过程:
RDB和AOF对比 RDB优势:
RDB劣势:
数据安全性较差
写时复制ROW会降低性能
RDB文件可读性差
AOF优势:
AOF劣势:
技术选型:
官方推荐RDB与AOF混合使用
若对数据安全性不高,则推荐使用纯RDB
不推荐纯使用AOF
若Redis仅用于缓存,则无需使用任何持久化技术
主从 Redis的主从集群是一个一主多从 的读写分离 集群。
master-slave:一个master可以拥有多个slave,一个slave也可以有多个slave;
master用来写数据,slave用来读数据,数据流向是单向的,master到slave。
通过主从配置实现读写分离。
一般来说,会通过搭建伪集群的方式搭建集群,也就是在单台物理服务器上运行多个Redis实例,充分将多核系统利用起来。
1 2 3 6379(master) | | 6380(slave0) 6381(slave1)
主服务器配置
1 2 3 4 5 bind 192.168.10.1 port 6379 // 可配置密码 masterauth xxx // 配置密码之后,salve连接需要使用密码 repl-disable-tcp-nodelay no // 关闭TCP延迟,可提升性能。默认情况下,TCP为了发送尽可能大的数据块,使用Nagle算法,当数据包比较小时,会汇总到一起发送,提升网络利用率。no代表nodelay,不使用Nagle算法,提高网络延迟。使用yes,Slave短会有40ms的延迟。
从服务进程1配置
1 2 3 4 5 bind 0.0.0.0 port 6380 slaveof 127.0.0.1 6379 // 表示是谁的slave replica-priority 110 // 设置slave的优先级,越小越优先,默认100。优先级高,在master挂掉之后,哨兵选择优先级高的成为master。0代表不竞争。 dbfilename dump6380.rdb
服务启动
1 redis-server redis_6380.conf
从服务进程2配置
1 2 3 4 5 bind 0.0.0.0 port 6381 slaveof 127.0.0.1 6379 replica-priority 90 // 这里配置优先级,为后面Sentinel做准备 dbfilename dump6381.rdb
服务启动
1 redis-server redis_6381.conf
查看配置信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 127.0.0.1:6379> INFO replication # Replication role:master // 角色master connected_slaves:2 // 连接了多少个slave slave0:ip=127.0.0.1,port=6380,state=online,offset=1358,lag=1 // 第一个 Slave 的信息 slave1:ip=127.0.0.1,port=6381,state=online,offset=1358,lag=0 // 第二个 Slave 的信息 master_failover_state:no-failover master_replid:b07439816e93bc83b257f72af222cc11f78a139a master_replid2:0000000000000000000000000000000000000000 master_repl_offset:1358 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:1358
或者将三个进程都启动,然后通过命令行的方式,加入到主从中
1 2 127.0.0.1:6379> SLAVEOF 127.0.0.1 6379 OK
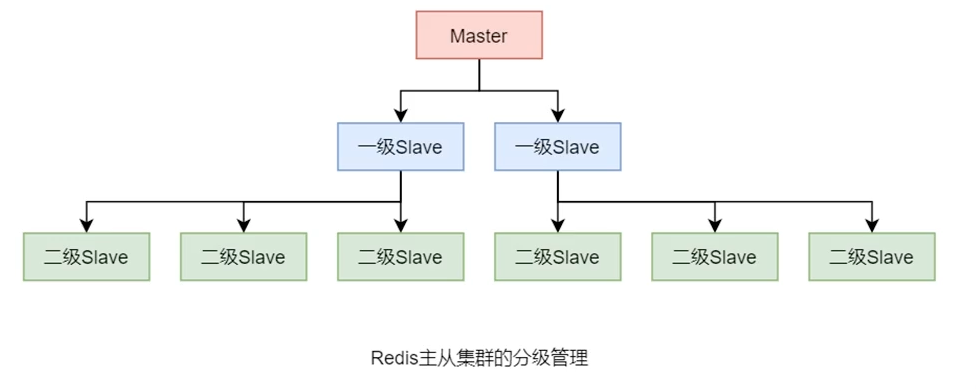
分级管理 Redis主从集群中的Slave较多时,数据同步过程会对Master形成较大的性能压力,此时可以对这些Slave进行分级管理。
6379(master)
|
6380(slave0)
|
6381(slave0)
此时,6380端口的进程是6379的Slave,6381端口的进程是6380的Slave,也就是将6381端口的redis的master改成6380即可
1 2 3 redis-cli -h 127.0.0.1 -p 6381 127.0.0.1:6381> SLAVEOF 127.0.0.1 6380 OK
此时查看6379的状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 127.0.0.1:6379> INFO replication # Replication role:master connected_slaves:1 // 只有1个slave ,是 6380 slave0:ip=127.0.0.1,port=6380,state=online,offset=1876,lag=0 master_failover_state:no-failover master_replid:1472948ec5d7430a59fab95e209cf66afe812736 master_replid2:b07439816e93bc83b257f72af222cc11f78a139a master_repl_offset:1876 second_repl_offset:1499 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:1876
查看6380的状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 127.0.0.1:6380> INFO replication # Replication role:slave // 是 6379的slave master_host:127.0.0.1 master_port:6379 master_link_status:up master_last_io_seconds_ago:8 master_sync_in_progress:0 slave_read_repl_offset:1932 slave_repl_offset:1932 slave_priority:100 slave_read_only:1 replica_announced:1 connected_slaves:1 // 自己也有slave,slave是6381 slave0:ip=127.0.0.1,port=6381,state=online,offset=1932,lag=1 master_failover_state:no-failover master_replid:1472948ec5d7430a59fab95e209cf66afe812736 master_replid2:b07439816e93bc83b257f72af222cc11f78a139a master_repl_offset:1932 second_repl_offset:1499 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1135 repl_backlog_histlen:798
当6380挂了,此时6381无法升级为主
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 127.0.0.1:6381> INFO replication # Replication role:slave master_host:127.0.0.1 master_port:6380 // 可以看到master的连接断开 master_link_status:down master_last_io_seconds_ago:-1 master_sync_in_progress:0 slave_read_repl_offset:2044 slave_repl_offset:2044 master_link_down_since_seconds:25 slave_priority:90 slave_read_only:1 replica_announced:1 connected_slaves:0 master_failover_state:no-failover master_replid:1472948ec5d7430a59fab95e209cf66afe812736 master_replid2:b07439816e93bc83b257f72af222cc11f78a139a master_repl_offset:2044 second_repl_offset:1499 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1275 repl_backlog_histlen:770
容灾冷处理 当Master出现宕机,有两种处理方式:
通过手工角色调整,使Slave晋升为Master的冷处理
使用哨兵模式,实现Redis集群的高可用HA,即热处理
无论Master是否宕机,Slave都可以通过 slaveof no one 将自己晋升为Master,如果其原本就有下一级的Slave,则其就直接成为这些Slave的Master
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 127.0.0.1:6381> SLAVEOF no one OK 127.0.0.1:6381> INFO replication # Replication role:master connected_slaves:0 master_failover_state:no-failover master_replid:9559c36cf9cc0363a09c8217364512f5c5758f38 master_replid2:1472948ec5d7430a59fab95e209cf66afe812736 master_repl_offset:2044 second_repl_offset:2045 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1275 repl_backlog_histlen:770
这种情况下,即使原先的Master恢复,也会失去原来的Slave,新的Master也不会成为原Master的Slave。
主从复制原理 主从复制的过程,从Slave上配置开始
客户端通过 slaveof <master_ip> <master_port>命令给Slave
Slave将Master地址保存到本地
Slave中的定时任务会向Master发出连接请求
连接成功后,会发送ping命令进行首次通信;没有连接成功,则在下次定时任务时再次尝试连接
如果Slave接受到 slaveof no one,则停止向Master的连接
Master接受到Slave的ping命令后对Slave进行身份验证
如果通过,则发送连接成功响应;如果没有成功,则拒绝连接
Slave接受到了Master响应,则向Master发出数据同步请求;如果没有接受到响应,则在下次定时任务时再次尝试连接
Master在接受到数据同步请求后,fork出一个子进程进行数据持久化
持久化完毕后,Master再fork出一个子进程,将其持久化文件发送给Slave(首次同步,需要做全量同步)
Slave接受Master的数据并写入到本地持久化文件
数据同步过程中,如果Master又有写操作,Master会将数据写入本地内存同时,又将数据写入到同步缓存
写入缓存的过程中,会判断Master的持久化数据是否发送完毕,如果发送完毕,则将同步缓存中的数据发送给Slave;没有发送完毕,则继续将数据写入同步缓存
数据同步过程中,如果Master没有写操作,Slave读取本地持久化文件,恢复内存数据,对外服务
数据第一次同步后,Master的后续写操作,会以增量方式发送给Slave
数据同步演变过程 sync同步 Redis 2.8版本之前,首次通信成功后,Slave会向Master发送sync数据同步请求,也就是全量同步。在复制过程中,如果网络出现抖动,Slave会重新发送sync,重新开始同步。
不完全同步 psync Redis 2.8版本之后,全量复制采用psync(Partial Sync,不完全同步)同步策略,可以断点续传 ,当连接成功后,如果出现网络抖动,则从断开的地方继续复制。
为了实现psync,需要满足以下三点:
复制偏移量
系统为每个要传送数据赋予一个编号,同步时,Master和Slave都会记录同步到的编号,这个编号就是复制偏移量。
1 2 3 4 5 127.0.0.1:6380> INFO replication # Replication role:slave slave_read_repl_offset:2156 // Slave同步到2156 slave_repl_offset:2156
1 2 3 4 5 6 127.0.0.1:6379> INFO replication # Replication role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6380,state=online,offset=2142,lag=1 // Master上记录Slave同步到的编号 slave1:ip=127.0.0.1,port=6381,state=online,offset=2142,lag=0
主节点复制ID
Master启动后会动态生成一个长度为40位的16进制字符串作为当前Master的复制ID,在进行数据同步时Slave通过这个ID识别Master
1 2 3 4 5 127.0.0.1:6380> INFO replication # Replication role:slave master_replid:3903a868ede4dbd07073a3a1c04effb7536f0965 // 复制ID master_replid2:0000000000000000000000000000000000000000
Master重启之后,会重新进行主从同步,全量同步。这样做的好处是避免有数据不一致的情况。
复制积压缓冲区
当Master有连接的Slave时,Master中会创建并维护一个队列backlog,默认大小1MB,这个队列被称为复制积压缓冲区。Master接受到了写操作数据不仅会写入到Master内存、写入到为每个Slave配置的发送缓存,还会写入到复制积压缓冲区,作用是用于保存最近操作的数据,以备断点续传时做数据补偿,防止数据丢失。例如Slave断开,此时写入的数据不会写入对应Slave的发送缓存,避免数据丢失,Slave连接时,会再次从发送缓存中获取数据。
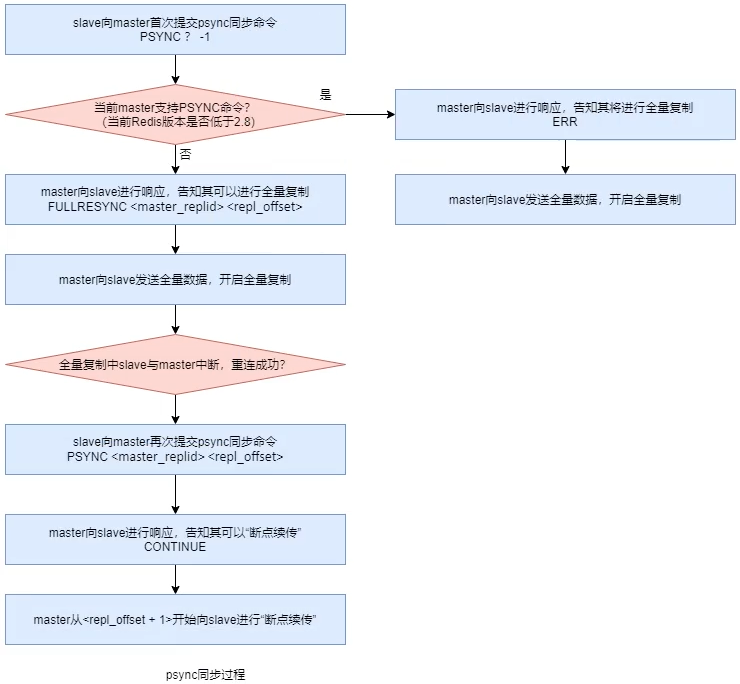
psync同步过程Slave在全量复制时,Slave会从offset+1处开始复制,以保证断线续传。但是最开始的过程是向Master发送psync -1的命令开始。
实际上在Slave提交psync之后,会根据Master提交的响应结果来执行复制操作:
FULLRESYNC <master_replid> <repl_offset>:告知Slave当前Master的动态ID及可以开始全量复制,这里repl_offset一般为0CONTINUE:告知Slave可以按照它提交的repl_offset后面的位置开始续传ERR:告知Slave当前Master版本低于Redis 2.8,不支持psync,需要全量复制
psync存在的问题
同步过程中,如果Slave重启,Slave内存中保存的master_replid和repl_offset都会消失,重启之后,需要全量复制
同步过程中,如果Master宕机,新的Master有新的动态master_replid,也需要进行全量复制
psync同步的改进Redis 4.0版本对psync进行改进,提出同源增量同步策略
1 2 3 4 5 127.0.0.1:6380> INFO replication # Replication role:slave master_replid:3903a868ede4dbd07073a3a1c04effb7536f0965 // master_replid2:0000000000000000000000000000000000000000 // 如果易主,则master_replid会放到master_replid2;也就是master_replid2记录的是老的Master动态ID
哨兵 对于Master宕机之后,冷处理方式是无法实现高可用的。Redis从2.6版本提供高可用解决方案Sentinel哨兵机制。
分布式中的CAP理论和BASE理论:分布式理论
在集群中再引入一个节点,该节点充当Sentinel哨兵,用于监控Master的运行装填,并在Master宕机后自动指定一个Slave作为新的Master。整个过程无需人工干预,完全有哨兵自动完成。
为了解决Sentinel的单点故障,也引入了Sentinel集群。
每个Sentinel都会向Master发送心跳信息进行监控,在固定时间内,收到Master的响应,即表示Master正常。在固定时间内,如果Sentinel中有quorum个哨兵没有收到响应,那么认为Master已经宕机,然后会有一个Sentinel做failover故障转移。
故障转移
多个Sentinel发现并确认Master有问题;选举一个Sentinel作为领导,选出一个是Slave作为Master,通知其余Slave成员成为新的Master的Slave;通知客户端主从变化;等待老的Master复活成为新Master的Slave;
部署 例如搭建一主两从三哨兵(三个哨兵是为了满足超过半数选举,宕机1个可正常使用。)
角色
端口号
Master
6380(这里使用6380作为master,因为模拟master宕机时停6379,主进程停止会导致docker也关闭)
Slave
6381,replica-priority为110
Slave
6382,replica-priority为90
Sentinel
26380
Sentinel
26381
Sentinel
26382
Sentinel配置文件,这里展示Sentinel1,其他Sentinel的配置文件除了端口,其他相同
1 2 3 sentinel monitor mymaster 127.0.0.1 6380 2 // sentinel中Master的名称、地址、端口,以及判断下线的Sentinel个数。这里3个哨兵,过半,则是2 // sentinel auth-pass mymaster pwd // 用于认证Master和Slave。注意,Master和Slave之间的密码要一致。如果Redis实例中有的需要密码验证,有的不需要密码验证,可以混合使用。 本例子中没有密码,则注释掉 port 26380 // 端口
注意:这里的2,是判断Master下线的Sentinel个数,这个个数不一定能代表可以进行failover的个数,可以failover的主Sentinel一定要超过半数。
如果添加Slave,或者Master进行变化,Sentinel的配置文件都会发生变化。
服务启动顺序:先启动Master,启动其他两个Slave,并且都 SLAVEOF 127.0.0.1 6380,启动Sentinel。
Master状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 127.0.0.1:6380> INFO replication # Replication role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6381,state=online,offset=120336,lag=1 slave1:ip=127.0.0.1,port=6382,state=online,offset=120336,lag=0 master_failover_state:no-failover master_replid:c4315b10b4ade9d01720e882c80e079c5eaea57a master_replid2:a8082df2f6dad9a85f9fa334eea5fafc6ae5b040 master_repl_offset:120336 second_repl_offset:101813 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:101813 repl_backlog_histlen:18524
Slave6381状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 127.0.0.1:6381> INFO replication # Replication role:slave master_host:127.0.0.1 master_port:6380 master_link_status:up master_last_io_seconds_ago:6 master_sync_in_progress:0 slave_read_repl_offset:120378 slave_repl_offset:120378 slave_priority:110 // 优先级为110 slave_read_only:1 replica_announced:1 connected_slaves:0 master_failover_state:no-failover master_replid:c4315b10b4ade9d01720e882c80e079c5eaea57a master_replid2:0000000000000000000000000000000000000000 master_repl_offset:120378 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:120337 repl_backlog_histlen:42
Slave6382状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # Replication role:slave master_host:127.0.0.1 master_port:6380 master_link_status:up master_last_io_seconds_ago:6 master_sync_in_progress:0 slave_read_repl_offset:120420 slave_repl_offset:120420 slave_priority:90 // 优先级为90 slave_read_only:1 replica_announced:1 connected_slaves:0 master_failover_state:no-failover master_replid:c4315b10b4ade9d01720e882c80e079c5eaea57a master_replid2:0000000000000000000000000000000000000000 master_repl_offset:120420 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:120337 repl_backlog_histlen:84
启动3个Sentinel
1 2 3 redis-sentinel sentinel_26380/sentinel_26380.conf redis-sentinel sentinel_26381/sentinel_26381.conf redis-sentinel sentinel_26382/sentinel_26382.conf
登录Sentinel,查看状态信息
1 2 3 4 5 6 7 8 9 10 root@4991bfc67ce7:/data# redis-cli -h 127.0.0.1 -p 26380 127.0.0.1:26380> INFO sentinel # Sentinel sentinel_masters:1 // Sentinel监控的Master的信息(Sentinel可以统计监控多个Master) sentinel_tilt:0 sentinel_tilt_since_seconds:-1 sentinel_running_scripts:0 sentinel_scripts_queue_length:0 sentinel_simulate_failure_flags:0 master0:name=mymaster,status=ok,address=127.0.0.1:6380,slaves=2,sentinels=3 // 状态,2个Slave,3个Sentinel
Sentinel启动之后,配置文件会被重写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 cat sentinel_26380/sentinel_26380.conf sentinel monitor mymaster 127.0.0.1 6380 2 port 26380 # Generated by CONFIG REWRITE // 这些配置,如果手动更换Master的信息,也需要手动修改 dir "/data" latency-tracking-info-percentiles 50 99 99.9 user default on nopass sanitize-payload ~* &* +@all sentinel myid 60d8fb564624e78cad1f5258de1b600e9698dc93 sentinel config-epoch mymaster 0 sentinel leader-epoch mymaster 0 sentinel current-epoch 0 sentinel known-sentinel mymaster 127.0.0.1 26381 944b65d38d7a5eac35dda6eb14c5b34c0d2738b4 sentinel known-replica mymaster 127.0.0.1 6381 sentinel known-replica mymaster 127.0.0.1 6382 sentinel known-sentinel mymaster 127.0.0.1 26382 5842293a166ce52efabb61dbb9d4dc2440849d43
模拟Master宕机,也就是关闭6380端口的服务
1 redis-cli -p 6380 shutdown
可以看到Sentinel日志切换
1 2 3 4 5 6 7 8 9 10 11 178:X 03 Dec 2022 04:47:27.727 * Sentinel new configuration saved on disk 178:X 03 Dec 2022 04:47:27.727 # +new-epoch 1 178:X 03 Dec 2022 04:47:27.736 * Sentinel new configuration saved on disk 178:X 03 Dec 2022 04:47:27.736 # +vote-for-leader 5842293a166ce52efabb61dbb9d4dc2440849d43 1 // 为leader投票,判断Master状态是否宕机 178:X 03 Dec 2022 04:47:27.737 # +odown master mymaster 127.0.0.1 6380 #quorum 3/2 // 3个Sentinel中有2票,认为6380宕机 178:X 03 Dec 2022 04:47:27.737 # Next failover delay: I will not start a failover before Sat Dec 3 04:53:28 2022 // failover有延迟时间 178:X 03 Dec 2022 04:47:28.455 # +config-update-from sentinel 5842293a166ce52efabb61dbb9d4dc2440849d43 127.0.0.1 26382 @ mymaster 127.0.0.1 6380 // 将6382作为新的master 178:X 03 Dec 2022 04:47:28.455 # +switch-master mymaster 127.0.0.1 6380 127.0.0.1 6382 // 将6382切换为master 178:X 03 Dec 2022 04:47:28.455 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ mymaster 127.0.0.1 6382 178:X 03 Dec 2022 04:47:28.455 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6382 178:X 03 Dec 2022 04:47:28.470 * Sentinel new configuration saved on disk
查看Slave6381状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 127.0.0.1:6381> INFO replication # Replication role:slave master_host:127.0.0.1 master_port:6382 // master切换 master_link_status:up master_last_io_seconds_ago:2 master_sync_in_progress:0 slave_read_repl_offset:191980 slave_repl_offset:191980 slave_priority:110 slave_read_only:1 replica_announced:1 connected_slaves:0 master_failover_state:no-failover master_replid:4a6ec11e5320d28a8f5130cc071f0037cecb0b7c master_replid2:c4315b10b4ade9d01720e882c80e079c5eaea57a master_repl_offset:191980 second_repl_offset:150168 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:120337 repl_backlog_histlen:71644
Master6382状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 127.0.0.1:6382> INFO replication # Replication role:master // 状态切换为Master connected_slaves:1 slave0:ip=127.0.0.1,port=6381,state=online,offset=199204,lag=1 master_failover_state:no-failover master_replid:4a6ec11e5320d28a8f5130cc071f0037cecb0b7c master_replid2:c4315b10b4ade9d01720e882c80e079c5eaea57a master_repl_offset:199204 second_repl_offset:150168 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:120337 repl_backlog_histlen:78868
此时查看Slave6381的配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 cat redis_6381/redis_6381.conf bind 0.0.0.0 port 6381 replica-priority 110 dbfilename dump6381.rdb # Generated by CONFIG REWRITE replicaof 127.0.0.1 6382 // 配置文件覆盖,将Master改为6382 dir "/data" latency-tracking-info-percentiles 50 99 99.9 save 3600 1 save 300 100 save 60 10000 user default on nopass ~* &* +@all
查看Sentinel26380的配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 cat sentinel_26380/sentinel_26380.conf sentinel monitor mymaster 127.0.0.1 6382 2 // 配置文件覆盖,将Master改为6382 port 26380 # Generated by CONFIG REWRITE dir "/data" latency-tracking-info-percentiles 50 99 99.9 user default on nopass sanitize-payload ~* &* +@all sentinel myid 60d8fb564624e78cad1f5258de1b600e9698dc93 sentinel config-epoch mymaster 1 sentinel leader-epoch mymaster 1 sentinel current-epoch 1 sentinel known-sentinel mymaster 127.0.0.1 26381 944b65d38d7a5eac35dda6eb14c5b34c0d2738b4 sentinel known-replica mymaster 127.0.0.1 6381 sentinel known-replica mymaster 127.0.0.1 6380 sentinel known-sentinel mymaster 127.0.0.1 26382 5842293a166ce52efabb61dbb9d4dc2440849d43
优化配置 主要跟配置文件相关
1 2 3 4 sentinel down-after-milliseconds mymaster 30000 // 30s没有回复心跳PING,则认为Master下线;同时也判断Slave和其他的Sentine的下线 sentinel parallel-syncs mymaster 1 // 在故障恢复期间,并行从Master同步数据的Slave的个数 sentinel failover-timeout mymaster 180000 // 故障转移超时时间,默认3分钟,超时之后,再过两个超时时间,则会换一个Master做故障转移 sentinel deny-scripts-reconfig yes // 是否会动态修改脚本(例如重新配置脚本/var/redis/reconfig.h)
哨兵机制原理 Sentinel维护者三个定时任务以检测Redis节点及其他Sentinel节点的状态。
Sentinel的三个任务
info任务
每个Sentinel节点每10s会向Redis集群中的每个节点 发送info命令,以获得最新的Redis拓扑结构。
Sentinel会向Master和Slave都发送info命令,但是配置Sentinel中只配置Master信息,因此Sentinel会从Master中获取Slave信息。
心跳任务
每个Sentinel节点每1s就会向所有Redis节点及其他Sentinel节点发送一条ping命令,以检测这些节点的存活状态。该任务时判断节点在线状态的重要依据。
发布、订阅任务
每个Sentinel节点在启动时,都会向所有Redis节点订阅__sentinel__:hello主题的消息,当Redis节点中该主题的信息发生变化,就会立即通知到所有订阅者。__sentinel__:hello主题的信息,该信息是当前Sentinel对每个Redis节点在线状态的判断结果及当前Sentinel节点信息。__sentinel__:hello主题信息后,就会读取并解析这些信息,然后完成以下三项工作:
如果发现有新的Sentinel节点加入,则记录下新加入Sentinel节点信息,并与其建立连接
如果发现有Sentinel Leader选举的投票信息,则执行Leader选举过程
汇总其他Sentinel节点对当前Redis节点在线状态的判断结果,作为Redis节点客观下线的判断依据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 127.0.0.1:6382> PUBSUB CHANNELS // channel 1) "__sentinel__:hello" 127.0.0.1:6382> PUBSUB NUMSUB __sentinel__:hello // 三个 Sentinel 有3个订阅者 1) "__sentinel__:hello" 2) (integer) 3 127.0.0.1:6382> SUBSCRIBE __sentinel__:hello // 获取channel的信息 Reading messages... (press Ctrl-C to quit) 1) "subscribe" 2) "__sentinel__:hello" 3) (integer) 1 1) "message" 2) "__sentinel__:hello" 3) "127.0.0.1,26380,60d8fb564624e78cad1f5258de1b600e9698dc93,1,mymaster,127.0.0.1,6382,1" // Sentinel 26380 的信息 1) "message" 2) "__sentinel__:hello" 3) "127.0.0.1,26382,5842293a166ce52efabb61dbb9d4dc2440849d43,1,mymaster,127.0.0.1,6382,1" // Sentinel 26382 的信息 1) "message" 2) "__sentinel__:hello" 3) "127.0.0.1,26381,944b65d38d7a5eac35dda6eb14c5b34c0d2738b4,1,mymaster,127.0.0.1,6382,1" // Sentinel 26381 的信息
Redis节点下线判断 每个Redis节点在线状态的监控由Sentinel完成。分为主观下线和客观下线。
主观下线
Sentinel往Redis节点发送ping命令之后,如果一定时间内没有收到回复,该Sentinel节点主观认为当前Redis下线。
客观下线
当Sentinel主观下线的节点是Master时,该Sentinel节点会向其他Sentinel节点发送sentinel is-master-down-by-addr 命令,询问其他节点与Master在线状态的判断结果。其他Sentinel收到命令后,会向这个发问的Sentinel节点响应0(在线)或1(下线)。当Sentinel收到超过quorum个下线判断后,就会对Master做出客观下线判断。
Sentinel Leader选举 当Sentinel节点对Master做出客观下线判断后,会由Sentinel Leader 来完成后续的故障转移 。即Sentinel集群中的节点也并非是对等节点,是存在Leader与Follower的。Leader的选举是通过Raft算法实现。
每个选举者都具有当选Leader资格,当完成了客观下线判断后,就会立即推荐自己做Leader,然后将自己的天发送给所有参与者。其他参与者收到提案后,只要自己手动的选票没有投出去,其就会立即通过该提案并将同意结果反馈给提案者,后续再过来的提案会由于该参与者没有选票而拒绝。当提案者收到了同意反馈数量大于等于max(quorm,SentinelNum/2 + 1,quorm个数和过半Sentinel个数取最大值),该提案者就是Leader。
一般,在没有网络问题的前提下,谁先做出客观下线判断,谁就首先发起Sentinel Leader的选举,也就会当选Leader。
Sentinel Leader选举会在首次故障转移发生之前进行
故障转移后Sentinel不再维护这种Leader-Follower关系,即Leader不再存在。下次如果再出现故障转移,会再次选举Leader
Master选择算法 进行故障转移时,Sentinel Leader会从所有Redis的Slave节点中选择出新的Master。
选择算法为:
过滤掉所有不可能成为Master节点的,也就是主观下线的,或心跳没有响应Sentinel的,或replica-priority为0的
在剩余Redis节点中选择出replica-priority最小的节点,放入La列表中(可能有多个相同的)
如果La列表中只有一个,则直接选取;如果包含多个,则选择复制偏移量slave_repl_offset最大的节点,放入Lb列表中(相同slave_repl_offset也可能有多个)
如果Lb列表中只有一个,则直接选取;如果包含多个,则选择动态ID最小的节点作为Master
故障转移过程 Leader选举出新的Master之后,需要同步其他的Slave。
Leader向新的Master发送slaveof no one命令,将其晋升为Master
Leader向新的Master发送info replication命令,获取其动态ID
Leader向其余Redis节点发送slaveof new_msater_ip new_master_port指令,使他们成为新Master的Slave
Leader从其余Redis中选择出parallel-syncs个Slave从新Master中同步数据(配置文件中获取并发同步Slave个数)
同步过程中,Leader会轮询询问所有Slave是否同步完毕,完毕,则结束;如果没有,则重复步骤4
节点上线 节点上线分为三种情况:原Redis节点上线,新Redis节点上线,Sentinel节点上线
原Redis节点上线
无论是原Master节点还是原Slave节点,只需要启动Redis即可。因为每个Sentinel中都保留原来监控的所有Redis列表 ,Sentinel会定时查看这些Redis节点是否恢复(所有Sentinel节点都会定时监控所有下线节点)。如果已经恢复,则会命起从当前Master进行数据同步。
如果是原Master上线,Leader会立即先将原Master节点更新为Slave,然后才会定时查看是否恢复。
新Redis节点上线
添加新的Redis,由于未曾出现在Redis集群中,上线后需要手动执行slaveof master_ip master_slave,进行数据同步
新Sentinel节点上线
添加新的Sentinel,无论是下线之后恢复,还是新添加Sentinel节点,都需要手动在配置文件中修改sentinel monitor属性,指定要监控的Master,然后启动Sentinel即可。
Raft算法 Raft算法是一种通过对日志复制管理 来达到集群一致性的算法 。这个日志复制管理发生在集群节点中的Leader与Follower之间。Raft通过选举出的Leader节点负责管理日志复制过程,以实现各个节点间数据的一致性。
动态演示:https://thesecretlivesofdata.com/raft/
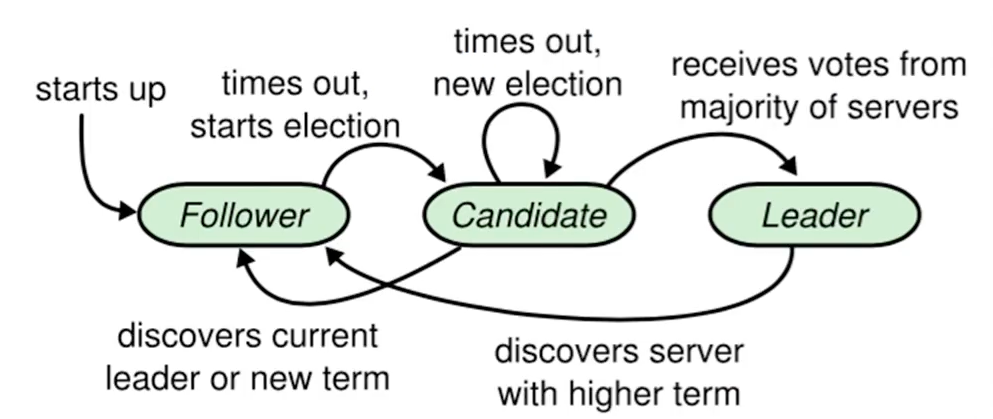
Raft算法中,有三种角色:
Leader:唯一负责处理客户端写请求的节点;也可以处理客户端读请求;同时负责日志复制工作
Candidate:Leader选举的候选人,其可能会成为Leader。是一个选举中的过程角色
Follower:可以处理客户端读请求;负责同步来自Leader的日志;当接受到其他Candidate的投票请求后可以进行投票;当发现Leader挂了,会转变为Candidate发起Leader选举。
可见,节点最终状态只有Leader和Follower,初始状态为所有节点都是Follower,当没有Leader时,Follower转变为中间角色Candidate,进行参加选举。
Leader选举 Follower进行选举 首先Follower在心跳超时范围内没有收到来自Leader的心跳,则认为Leader挂了。此时其首先会使其本地term增1(本地term来自于之前的Leader),然后Follower会完成以下步骤:
若接受到了其他Candidate的投票请求,则会将选票投给这个Candidate
由Follower转变为Candidate
若之前尚未投票,则投自己一票(每个Follower节点只有一票)
向其他节点发出投票请求,然后等待相应
Follower进行投票 Follower在接受到投票请求后,会根据以下情况判断是否投票:
发来投票请求的Candidate的term不能小于自己的term
在当前term内,自己的票没有投出去
若接受到多个Candidate请求,采取first-come-first-served方式投票(也就是先到先获取投票)
等待响应 当Candidate发出投票请求之后,会等待其他节点的响应结果,这个结果可能有三种情况:
收到过半选票,称为新的Leader,然后会将消息广播给所有其他节点,告诉其他节点自己称为新的Leader
接受到别的Candidate发来的新的Leader通知,比较新Leader的term,比自己大,则自己转换为Follower
经过一段时间,没有收到过半选票,也没有收到新Leader通知,则重新发出选举
选举时机 很多时候,当Leader真的挂了,Follower可能几乎同时感知到,所以会同时变成Candidate并且发起新的选举,可能导致很多Candidate的票数一样,导致无法选举出Leader。
为了防止这种情况,Raft采用randomized election timeouts策略来解决这个问题。(随机选举超时)
每个Follower都有一个随机的election timeouts,选举超时时间,范围是150-300ms,到达了election timeouts时间的Follower,才会变成Candidate。此时较小election timeouts的Follower会最可能成为Leader。
数据同步 Leader选举出来后,会通过日志复制管理 实现集群中各节点数据的同步。
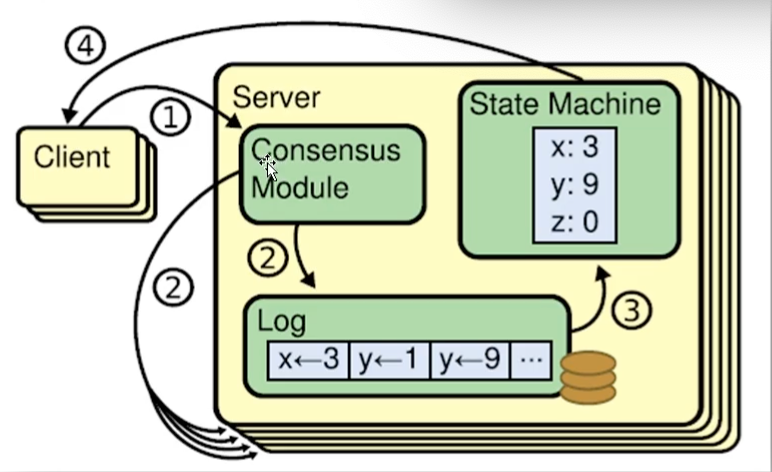
状态机 Raft算法一致性的实现,是基于日志复制状态机 。
状态机的最大特征:不同Server中的状态机若当前状态相同,然后接受到了相同的输入,则一定会得到相同的输出。
数据写入、修改过程:
Leader收到client写、修改操作请求data
Leader将data域自己的term封装为一个box
Leader将box随下一次心跳发送给所有Follower;并且将data在本地封装为日志Log
Follower接受到box之后,判断term是否 >= 本地term(接收数据写入请求需要超过半数节点响应)
如果大于或者等于,则向Leader回复同意;并且将box中的data封装为本地日志Log
Leader接受Follower的同意响应,判断响应数量是否过半
如果过半,则Leader将日志COMMIT到状态机,日志状态变为COMMIT
Leader发送COMMIT指令给所有Follower;并且向client回复成功处理响应
Follower接受到COMMIT指令后,将日志COMMIT到状态机
也就是说,Raft不是强一致性,而是最终一致性,在CAP理论中,是AP。
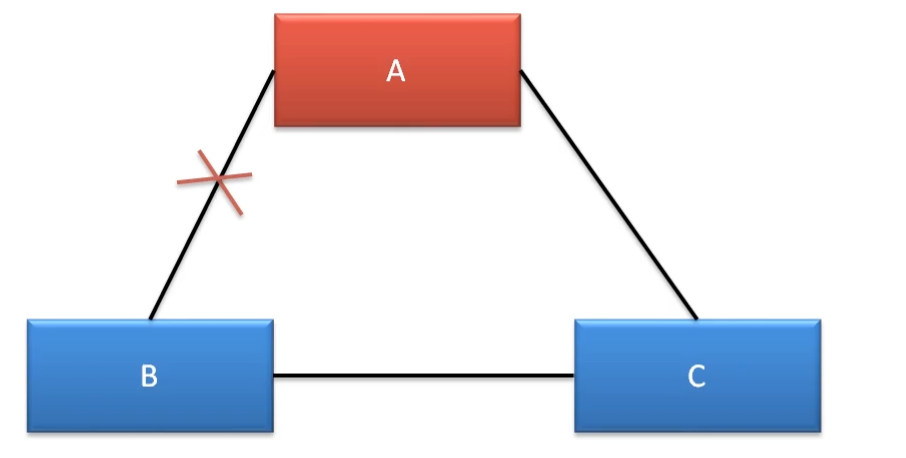
脑裂 Raft集群存在脑裂问题,在多机房部署情况下,容易出现网络连接问题,形成多个分区。而形成多个分区的,就容易产生脑裂,从而导致数据不一致。例如使用三机房部署,
此时A机房到B机房的网络断开,B会进行Leader选举,而且term+1,此时C会将选票投给B,此时B会成为新Leader,与C组成一个集群。A也存在Leader,但是不能处理写请求。(写请求需要超过半数同意)此时出现脑裂。
处理方案是给Leader增加自动下课功能,当无法处理写请求,则自动降级为Follower。
此时A机房到B机房、C机房的网络断开,B或者C会进行Leader选举,而且term+1,两个里面会有一个Leader,并且可以正常对外提供服务。但此时A机房也有Leader,只能提供读请求,出现脑裂。
处理方案也是自动降级。
此时B机房到A机房、C机房的网络断开,B会进行Leader选举,变成Candidate状态,此状态下,无法提供读、写服务。A和C的集群可以正常工作。没有出现脑裂
此时B机房到C机房断开,不会对集群造成任何影响,也不会形成脑裂。
此时A到B、B到C、C到A全部断开,B机房和C机房会进行选举,一直处于Candidate状态,无法处理读、写请求,而A机房由于写入请求处理无法过半,无法处理写请求,只能处理读请求。此时没有出现脑裂。
Leader宕机处理 Leader宕机之后,集群的处理方式会根据状态有所不同
请求到达前,Leader宕机
此时client的写请求在到达Leader之前,Leader宕机,此时这个请求对于集群来说没存在过,对集群数据一致性没有影响。
集群重新选举Leader之后,client没有收到请求成功的响应,需要重新发送请求。前提是client能够重试。
未开始发送数据前,Leader宕机
client发送数据到Leader之后,Leader处理写入的数据。在写入到box之后,没有向Follower发送数据就宕机,此时集群会重新选择Leader,Stale Leader重启后会作为Follower重新加入集群,并同步新Leader中的数据以保证数据一致性。之前收到client的数据被丢弃。
由于client没有收到请求成功的响应,需要重新发送请求。前提是client能够重试。
发送了部分数据,Leader宕机
client发送数据到Leader之后,Leader封装成box,将box发送给Follower,但是只发送给了部分Follower,此时Leader宕机,集群重新选举Leader
若Leader产生于已完成数据接受的Follower,其会继续将前面接受到的写操作请求转换为日志,并写入本地状态机,并向所有Follower发出询问,在获取半数同意响应后,COMMIT到状态机,并且向所有Follower发送COMMIT指令,同时向client进行相应。
若Leader产生于没有完成数据接受的Follower,那么原来已完成接受的Follower则会放弃曾接受到的数据,由于client没有收到响应,需要重新发送请求。
COMMIT通知发出后,Leader宕机
client发送写操作给Leader,Leader也成功向其他Follower发出COMMIT通知,写入状态机,并向client响应后,Leader宕机。
由于Stale Leader已经向client发送成功接手响应,且COMMIT通知已经发出,说明这个写操作已经被Server成功处理。
集群 相比主从集群来讲,写入请求只有Master可以处理。为了进一步提升性能,Redis也支持分布式系统,官方成为Redis Cluster,Redis集群。是Redis 3.0开始推出的分布式解决方案,可以很好的解决不同Redis节点存放不同数据,并将用户请求方便的路由到不同的Redis。
数据分区算法 分布式数据库系统会根据不同的数据分区算法,将数据分散存储到不同的数据库服务器节点上,每个节点管理着整个数据集合中的一个子集。
数据写入,通过分区算法,将数据子集写入到不同的数据服务器节点
数据读取,通过路由器,从不同的服务器节点读取到不同的数据
常见的数据分区规则有两大类:顺序分区与哈希分区。
顺序分区
将数据按照某种顺序平均分配到不同的节点。不同的顺序方式,产生不同的分区算法。例如:
轮询分区算法:需要client与Server保持长连接
时间片轮转分区算法:好处是client与Server不需要长连接,在固定时间片内连接即可
数据块分区算法:需要确定数据总量,根据各个节点的存储能力,将连续的数据块分配到某一节点
业务主题分区算法
哈希分区
利用数据哈希值完成分配。对数据哈希值的不同使用方式产生不同的哈希分区算法。例如:
节点取模分区算法:前提是每一个节点分配好一个唯一的序号,选取数据特值作为key,计算hash(key)取模节点总数,按照取模的结果放到对应的节点。优势是简单,劣势是缩容扩容时,需要做数据迁移,一般情况下,扩容一般采用翻倍,缩容一般采用缩小一半,以减少数据迁移的比例。
一致性哈希分区算法:利用一个哈希环,从0开始,到2^32-1结尾。选取节点特征值作为key,计算hash(key),放到环上。存储数据时,也按照数据存储特征值的key计算hash(key),在环上顺时针(或者逆时针)查询节点,将数据存储到对应节点上。好处是扩容时,只需要对顺时针(或逆时针)的节点上的数据有影响;缺点是节点比较少的时候,容易出现数据倾斜。
虚拟槽分区
首先虚拟出一个固定数量的整数集合,该集合中每个整数称为一个slot槽。这个槽的数量一般是远远大于节点数量的值,然后在将所有slot槽平均映射到各个节点上。Redis集群就是使用这种方式,Redis会虚拟出16384个槽,范围为[0,16383],假设有3个节点,槽和节点的对应关系如下:
而数据只与槽有关系,与节点没有直接关系。通过数据hash(key)与槽取模,确定存储槽位。
优势是解耦数据与节点,客户端不维护节点,只需维护与slot槽的关系。
Redis计算槽点的公式:slot = CRC16(key) % 16384 ,当然,实际上的运算过程是 slot = CRC16(key) & 16383 ,采用位运算,更快。(采用位运算的前提是总数需要是2的指数倍)
搭建 通过6个节点搭建集群,端口从6381-6386,并且选择一个Master有一个Slave的模式。
节点配置
1 2 3 4 5 6 7 cat redis_6381.conf port 6381 cluster-enabled yes // 打开 cluster 模式 cluster-config-file node-6381.conf // Cluster 配置文件,会自动生成,存放集群信息 cluster-node-timeout 15000 // Cluster 节点超时时间,默认15s dbfilename dump6381.rdb
1 2 3 4 5 6 7 cat redis_6382.conf port 6382 cluster-enabled yes cluster-config-file node-6382.conf cluster-node-timeout 15000 dbfilename dump6382.rdb
1 2 3 4 5 6 7 cat redis_6383.conf port 6383 cluster-enabled yes cluster-config-file node-6383.conf cluster-node-timeout 15000 dbfilename dump6383.rdb
1 2 3 4 5 6 7 cat redis_6384.conf port 6384 cluster-enabled yes cluster-config-file node-6384.conf cluster-node-timeout 15000 dbfilename dump6384.rdb
1 2 3 4 5 6 7 cat redis_6385.conf port 6385 cluster-enabled yes cluster-config-file node-6385.conf cluster-node-timeout 15000 dbfilename dump6385.rdb
1 2 3 4 5 6 7 cat redis_6386.conf port 6386 cluster-enabled yes cluster-config-file node-6386.conf cluster-node-timeout 15000 dbfilename dump6386.rdb
分别启动服务
1 2 3 4 5 6 redis-server redis_6381.conf redis-server redis_6382.conf redis-server redis_6383.conf redis-server redis_6384.conf redis-server redis_6385.conf redis-server redis_6386.conf
创建集群
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 redis-cli --cluster create --cluster-replicas 1 127.0.0.1:6381 127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 127.0.0.1:6385 127.0.0.1:6386 // 通过命令创建Cluster,--cluster-replicas 1代表每个Master有1个Slave,后面指定每个节点的地址和端口 >>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 // 将slot 0 - 5460 分配给Master0 Master[1] -> Slots 5461 - 10922 // 将slot 5461 - 10922 分配给Master1 Master[2] -> Slots 10923 - 16383 // 将slot 10923 - 16383 分配给Master2 Adding replica 127.0.0.1:6385 to 127.0.0.1:6381 // 预备将6385分配给6381作为Slave Adding replica 127.0.0.1:6386 to 127.0.0.1:6382 // 预备将6386分配给6382作为Slave Adding replica 127.0.0.1:6384 to 127.0.0.1:6383 // 预备将6384分配给6383作为Slave >>> Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their master // 下面是ID信息和Master、Slave信息 M: a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381 slots:[0-5460] (5461 slots) master M: 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382 slots:[5461-10922] (5462 slots) master M: 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383 slots:[10923-16383] (5461 slots) master S: 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384 replicates a410096f39bd4487b15635420221f0d59e9abdf2 S: 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385 replicates 41e4024747281db14a8c400d826cf5f94e53a7d2 S: ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386 replicates 3a74a2be2d5d06a07df63fc57d4641104c3f728a Can I set the above configuration? (type 'yes' to accept): yes // 应用上述配置 >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join . >>> Performing Cluster Check (using node 127.0.0.1:6381) // 实际分配信息 M: a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385 // 6385 是 6382的Slave slots: (0 slots) slave replicates 41e4024747281db14a8c400d826cf5f94e53a7d2 M: 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384 // 6384 是 6381 的Slave slots: (0 slots) slave replicates a410096f39bd4487b15635420221f0d59e9abdf2 S: ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386 // 6386 是 6383 的Slave slots: (0 slots) slave replicates 3a74a2be2d5d06a07df63fc57d4641104c3f728a [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
获取集群状态
1 2 3 4 5 6 7 8 9 redis-cli -c -p 6381 // 使用 -c 表示连接集群 127.0.0.1:6381> CLUSTER nodes // 获取集群信息 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383@16383 master - 0 1670231906979 3 connected 10923-16383 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385@16385 slave 41e4024747281db14a8c400d826cf5f94e53a7d2 0 1670231905952 2 connected 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382@16382 master - 0 1670231905000 2 connected 5461-10922 a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381@16381 myself,master - 0 1670231906000 1 connected 0-5460 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384@16384 slave a410096f39bd4487b15635420221f0d59e9abdf2 0 1670231904932 1 connected ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386@16386 slave 3a74a2be2d5d06a07df63fc57d4641104c3f728a 0 1670231904000 3 connected
集群操作 集群操作,需要通过参数 -c指定使用集群模式
分布到不同的slot
1 2 3 4 5 6 7 8 9 10 11 12 13 127.0.0.1:6381> SADD names mitaka xu shepher -> Redirected to slot [6659] located at 127.0.0.1:6382 // 重定向到slot 6659,也就是6382 (integer) 0 127.0.0.1:6382> SET name mitaka OK 127.0.0.1:6382> SET age 18 // 可以看到,重定向之后,端口改成6382 -> Redirected to slot [741] located at 127.0.0.1:6381 // 再次重定向到6381 OK // 注意,批量写入数据时,要注意是否能写入到同一个slot中 127.0.0.1:6381> MSET name mitaka age 18 sex male (error) CROSSSLOT Keys in request don't hash to the same slot // hash之后,无法放到同一个slot 127.0.0.1:6383> MSET name{0} mitaka age{0} 18 sex{0} male // 可以采用相同的字符串做hash OK
获取key所在的slot
1 2 3 4 5 6 7 8 127.0.0.1:6383> CLUSTER KEYSLOT name // 几个key在不同的slot中 (integer) 5798 127.0.0.1:6383> CLUSTER KEYSLOT age (integer) 741 127.0.0.1:6383> CLUSTER KEYSLOT sex (integer) 2584 127.0.0.1:6383> CLUSTER KEYSLOT 0 // 都是用0作为key,则会放到同一个slot,slot号为13907,也就是Master 3的6383中 (integer) 13907
获取slot中的key数量和数据
1 2 3 4 5 6 127.0.0.1:6383> CLUSTER COUNTKEYSINSLOT 13907 // 注意,这里只能查询当前主机的slot信息,无法查询其他的slot信息 (integer) 3 // 这个slot中有3个key 127.0.0.1:6383> CLUSTER GETKEYSINSLOT 13907 3 // 获取这个slot中的3个key信息 1) "sex{0}" 2) "age{0}" 3) "name{0}"
故障转移 单Master宕机,后续再启动 当1个Master宕机,例如6381宕机
1 redis-cli -p 6381 shutdown
查看集群信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 redis-cli -c -p 6382 127.0.0.1:6382> CLUSTER NODES 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385@16385 slave 41e4024747281db14a8c400d826cf5f94e53a7d2 0 1670233857638 2 connected 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383@16383 master - 0 1670233856000 3 connected 10923-16383 ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386@16386 slave 3a74a2be2d5d06a07df63fc57d4641104c3f728a 0 1670233855000 3 connected a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381@16381 master - 1670233844253 1670233840157 1 disconnected 0-5460 // 6381断开 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382@16382 myself,master - 0 1670233857000 2 connected 5461-10922 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384@16384 slave a410096f39bd4487b15635420221f0d59e9abdf2 0 1670233856610 1 connected 127.0.0.1:6382> CLUSTER NODES 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385@16385 slave 41e4024747281db14a8c400d826cf5f94e53a7d2 0 1670233966568 2 connected 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383@16383 master - 0 1670233967586 3 connected 10923-16383 ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386@16386 slave 3a74a2be2d5d06a07df63fc57d4641104c3f728a 0 1670233964000 3 connected a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381@16381 master,fail - 1670233844253 1670233840157 1 disconnected // 6381 状态为fail 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382@16382 myself,master - 0 1670233965000 2 connected 5461-10922 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384@16384 master - 0 1670233966000 7 connected 0-5460 // 6384 晋升为master
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 redis-cli -c -p 6384 127.0.0.1:6384> INFO replication # Replication role:master // 6384 晋升为Master connected_slaves:0 master_failover_state:no-failover master_replid:d759ccebae01fcab1c3dc2da4983af9447712e16 master_replid2:de3260b0b42199372d1ca640ca7a0c2a5c70dd90 master_repl_offset:3271 second_repl_offset:3272 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:3271
再将6381启动起来
1 2 3 4 5 6 7 127.0.0.1:6384> CLUSTER NODES 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384@16384 myself,master - 0 1670234637000 7 connected 0-5460 ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386@16386 slave 3a74a2be2d5d06a07df63fc57d4641104c3f728a 0 1670234636000 3 connected 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385@16385 slave 41e4024747281db14a8c400d826cf5f94e53a7d2 0 1670234637756 2 connected a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381@16381 slave 66b0423f7cfa7168bf9a4f73d49f289982712a76 0 1670234638787 7 connected // 6381 起来之后,作为Slave加入到集群中 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383@16383 master - 0 1670234635000 3 connected 10923-16383 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382@16382 master - 0 1670234636719 2 connected 5461-10922
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 redis-cli -c -p 6381 127.0.0.1:6381> INFO replication # Replication role:slave // 6381 是Slave master_host:127.0.0.1 master_port:6384 // 主事6384 master_link_status:up master_last_io_seconds_ago:7 master_sync_in_progress:0 slave_read_repl_offset:3313 slave_repl_offset:3313 slave_priority:100 slave_read_only:1 replica_announced:1 connected_slaves:0 master_failover_state:no-failover master_replid:d759ccebae01fcab1c3dc2da4983af9447712e16 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:3313 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:3286 repl_backlog_histlen:28
一对Master、Slave宕机 对于通过slot分配数据,当节点宕机,部分slot无法获取,此时数据无法访问。
但是Redis提供配置,可提供存在的slot的查询操作。
1 cluster-require-full-coverage no // 当部分hash槽不可用,是否继续提供服务,no代表不提供,yes代表可提供存在的slot上的查询操作。
扩容 一次性添加两个节点,一个做Master,一个做Slave
1 2 3 4 5 6 7 cat redis_6387.conf port 6387 cluster-enabled yes cluster-config-file node-6387.conf cluster-node-timeout 15000 dbfilename dump6387.rdb
1 2 3 4 5 6 7 cat redis_6388.conf port 6388 cluster-enabled yes cluster-config-file node-6388.conf cluster-node-timeout 15000 dbfilename dump6388.rdb
启动服务
1 2 redis-server redis_6387.conf redis-server redis_6388.conf
先将6387加入到集群中,通过Slave的节点加入,会成为Slave
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 redis-cli -c --cluster add-node 127.0.0.1:6387 127.0.0.1:6381 >>> Adding node 127.0.0.1:6387 to cluster 127.0.0.1:6381 >>> Performing Cluster Check (using node 127.0.0.1:6381) S: a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381 slots: (0 slots) slave replicates 66b0423f7cfa7168bf9a4f73d49f289982712a76 S: ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386 slots: (0 slots) slave replicates 3a74a2be2d5d06a07df63fc57d4641104c3f728a S: 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385 slots: (0 slots) slave replicates 41e4024747281db14a8c400d826cf5f94e53a7d2 M: 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382 slots:[5461-10922] (5462 slots) master 1 additional replica(s) M: 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383 slots:[10923-16383] (5461 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. >>> Getting functions from cluster >>> Send FUNCTION LIST to 127.0.0.1:6387 to verify there is no functions in it >>> Send FUNCTION RESTORE to 127.0.0.1:6387 >>> Send CLUSTER MEET to node 127.0.0.1:6387 to make it join the cluster. [OK] New node added correctly.
此时查看集群状态
1 2 3 4 5 6 7 8 9 redis-cli -c -p 6381 127.0.0.1:6381> CLUSTER NODES ecce086b7d3b81bd846a0db374ea2e09733863e9 127.0.0.1:6387@16387 slave 3a74a2be2d5d06a07df63fc57d4641104c3f728a 0 1670241540374 3 connected // 此时,新加的节点为Slave a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381@16381 myself,slave 66b0423f7cfa7168bf9a4f73d49f289982712a76 0 1670241541000 7 connected ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386@16386 slave 3a74a2be2d5d06a07df63fc57d4641104c3f728a 0 1670241543448 3 connected 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385@16385 slave 41e4024747281db14a8c400d826cf5f94e53a7d2 0 1670241542429 2 connected 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382@16382 master - 0 1670241541402 2 connected 5461-10922 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384@16384 master - 0 1670241539000 7 connected 0-5460 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383@16383 master - 0 1670241540000 3 connected 10923-16383
踢掉6387
1 2 3 4 5 redis-cli -c --cluster del-node 127.0.0.1:6387 ecce086b7d3b81bd846a0db374ea2e09733863e9 >>> Removing node ecce086b7d3b81bd846a0db374ea2e09733863e9 from cluster 127.0.0.1:6387 >>> Sending CLUSTER FORGET messages to the cluster... >>> Sending CLUSTER RESET SOFT to the deleted node.
通过Master节点加入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 redis-cli -c --cluster add-node 127.0.0.1:6387 127.0.0.1:6382 >>> Adding node 127.0.0.1:6387 to cluster 127.0.0.1:6382 >>> Performing Cluster Check (using node 127.0.0.1:6382) M: 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386 slots: (0 slots) slave replicates 3a74a2be2d5d06a07df63fc57d4641104c3f728a S: a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381 slots: (0 slots) slave replicates 66b0423f7cfa7168bf9a4f73d49f289982712a76 M: 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384 slots:[0-5460] (5461 slots) master 1 additional replica(s) S: 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385 slots: (0 slots) slave replicates 41e4024747281db14a8c400d826cf5f94e53a7d2 M: 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383 slots:[10923-16383] (5461 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. // 所有的slot已经分配 >>> Getting functions from cluster >>> Send FUNCTION LIST to 127.0.0.1:6387 to verify there is no functions in it >>> Send FUNCTION RESTORE to 127.0.0.1:6387 >>> Send CLUSTER MEET to node 127.0.0.1:6387 to make it join the cluster. [OK] New node added correctly.
获取集群状态
1 2 3 4 5 6 7 8 127.0.0.1:6381> CLUSTER NODES ecce086b7d3b81bd846a0db374ea2e09733863e9 127.0.0.1:6387@16387 master - 0 1670241883522 0 connected // 6387以Master的角色加进来,但是没有分配slot a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381@16381 myself,slave 66b0423f7cfa7168bf9a4f73d49f289982712a76 0 1670241880000 7 connected ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386@16386 slave 3a74a2be2d5d06a07df63fc57d4641104c3f728a 0 1670241882000 3 connected 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385@16385 slave 41e4024747281db14a8c400d826cf5f94e53a7d2 0 1670241882497 2 connected 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382@16382 master - 0 1670241881000 2 connected 5461-10922 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384@16384 master - 0 1670241882000 7 connected 0-5460 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383@16383 master - 0 1670241881000 3 connected 10923-16383
此时,需要将一部分slot移动到6387
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 redis-cli -c --cluster reshard 127.0.0.1:6387 // 127.0.0.1:6387重新分区 > >> Performing Cluster Check (using node 127.0.0.1:6387) M: ecce086b7d3b81bd846a0db374ea2e09733863e9 127.0.0.1:6387 slots: (0 slots) master S: a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381 slots: (0 slots) slave replicates 66b0423f7cfa7168bf9a4f73d49f289982712a76 M: 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386 slots: (0 slots) slave replicates 3a74a2be2d5d06a07df63fc57d4641104c3f728a M: 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385 slots: (0 slots) slave replicates 41e4024747281db14a8c400d826cf5f94e53a7d2 [OK] All nodes agree about slots configuration. > >> Check for open slots... > >> Check slots coverage... [OK] All 16384 slots covered. How many slots do you want to move (from 1 to 16384)? 2000 // 分多少slot给6387 What is the receiving node ID? ecce086b7d3b81bd846a0db374ea2e09733863e9 // 确定6387的节点ID Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node #1: all // 分slot的方式,all代表从所有的slot分,done则需要输入指定slot,从指定的slot中分 Ready to move 2000 slots. // 开始数据迁移 Source nodes: M: 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382 slots:[5461-10922] (5462 slots) master 1 additional replica(s) M: 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383 slots:[10923-16383] (5461 slots) master 1 additional replica(s) Destination node: M: ecce086b7d3b81bd846a0db374ea2e09733863e9 127.0.0.1:6387 slots: (0 slots) master Resharding plan: Moving slot 5461 from 41e4024747281db14a8c400d826cf5f94e53a7d2 Moving slot 5462 from 41e4024747281db14a8c400d826cf5f94e53a7d2 ... 省略部分数据 Moving slot 6126 from 127.0.0.1:6382 to 127.0.0.1:6387: Moving slot 6127 from 127.0.0.1:6382 to 127.0.0.1:6387: Moving slot 0 from 127.0.0.1:6384 to 127.0.0.1:6387: Moving slot 1 from 127.0.0.1:6384 to 127.0.0.1:6387: ... 省略部分数据 Moving slot 11587 from 127.0.0.1:6383 to 127.0.0.1:6387: Moving slot 11588 from 127.0.0.1:6383 to 127.0.0.1:6387:
分后,查看集群状态
1 2 3 4 5 6 7 8 127.0.0.1:6381> CLUSTER NODES ecce086b7d3b81bd846a0db374ea2e09733863e9 127.0.0.1:6387@16387 master - 0 1670242366000 8 connected 0-665 5461-6127 10923-11588 // 3个段,从3个Master中分 a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381@16381 myself,slave 66b0423f7cfa7168bf9a4f73d49f289982712a76 0 1670242364000 7 connected ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386@16386 slave 3a74a2be2d5d06a07df63fc57d4641104c3f728a 0 1670242367000 3 connected 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385@16385 slave 41e4024747281db14a8c400d826cf5f94e53a7d2 0 1670242369636 2 connected 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382@16382 master - 0 1670242368000 2 connected 6128-10922 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384@16384 master - 0 1670242367592 7 connected 666-5460 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383@16383 master - 0 1670242368613 3 connected 11589-16383
将另一个新节点加入
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 redis-cli -c --cluster add-node 127.0.0.1:6388 127.0.0.1:6382 > >> Adding node 127.0.0.1:6388 to cluster 127.0.0.1:6382 > >> Performing Cluster Check (using node 127.0.0.1:6382) M: 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382 slots:[6128-10922] (4795 slots) master 1 additional replica(s) S: ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386 slots: (0 slots) slave replicates 3a74a2be2d5d06a07df63fc57d4641104c3f728a S: a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381 slots: (0 slots) slave replicates 66b0423f7cfa7168bf9a4f73d49f289982712a76 M: 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384 slots:[666-5460] (4795 slots) master 1 additional replica(s) S: 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385 slots: (0 slots) slave replicates 41e4024747281db14a8c400d826cf5f94e53a7d2 M: 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383 slots:[11589-16383] (4795 slots) master 1 additional replica(s) M: ecce086b7d3b81bd846a0db374ea2e09733863e9 127.0.0.1:6387 slots:[0-665],[5461-6127],[10923-11588] (1999 slots) master [OK] All nodes agree about slots configuration. > >> Check for open slots... > >> Check slots coverage... [OK] All 16384 slots covered. > >> Getting functions from cluster > >> Send FUNCTION LIST to 127.0.0.1:6388 to verify there is no functions in it > >> Send FUNCTION RESTORE to 127.0.0.1:6388 > >> Send CLUSTER MEET to node 127.0.0.1:6388 to make it join the cluster. [OK] New node added correctly.
查看集群状态
1 2 3 4 5 6 7 8 9 127.0.0.1:6381> CLUSTER NODES ecce086b7d3b81bd846a0db374ea2e09733863e9 127.0.0.1:6387@16387 master - 0 1670242493495 8 connected 0-665 5461-6127 10923-11588 a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381@16381 myself,slave 66b0423f7cfa7168bf9a4f73d49f289982712a76 0 1670242489000 7 connected edfa029afbb771c7082d85897d28f17891e48e98 127.0.0.1:6388@16388 slave 3a74a2be2d5d06a07df63fc57d4641104c3f728a 0 1670242493000 3 connected // 新节点为Slave,Master为6383 ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386@16386 slave ecce086b7d3b81bd846a0db374ea2e09733863e9 0 1670242490531 8 connected 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385@16385 slave 41e4024747281db14a8c400d826cf5f94e53a7d2 0 1670242490428 2 connected 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382@16382 master - 0 1670242491000 2 connected 6128-10922 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384@16384 master - 0 1670242491454 7 connected 666-5460 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383@16383 master - 0 1670242492480 3 connected 11589-16383
也可以在添加过程中指定角色Slave和对应的Master
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 redis-cli -c --cluster add-node 127.0.0.1:6388 127.0.0.1:6382 --cluster-slave --cluster-master-id ecce086b7d3b81bd846a0db374ea2e09733863e9 > >> Adding node 127.0.0.1:6388 to cluster 127.0.0.1:6382 > >> Performing Cluster Check (using node 127.0.0.1:6382) M: 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382 slots:[6128-10922] (4795 slots) master 1 additional replica(s) S: ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386 slots: (0 slots) slave replicates ecce086b7d3b81bd846a0db374ea2e09733863e9 S: a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381 slots: (0 slots) slave replicates 66b0423f7cfa7168bf9a4f73d49f289982712a76 M: 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384 slots:[666-5460] (4795 slots) master 1 additional replica(s) S: 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385 slots: (0 slots) slave replicates 41e4024747281db14a8c400d826cf5f94e53a7d2 M: 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383 slots:[11589-16383] (4795 slots) master M: ecce086b7d3b81bd846a0db374ea2e09733863e9 127.0.0.1:6387 slots:[0-665],[5461-6127],[10923-11588] (1999 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. > >> Check for open slots... > >> Check slots coverage... [OK] All 16384 slots covered. > >> Send CLUSTER MEET to node 127.0.0.1:6388 to make it join the cluster. Waiting for the cluster to join > >> Configure node as replica of 127.0.0.1:6387. [OK] New node added correctly.
查看集群状态
1 2 3 4 5 6 7 8 9 127.0.0.1:6381> CLUSTER NODES ecce086b7d3b81bd846a0db374ea2e09733863e9 127.0.0.1:6387@16387 master - 0 1670242681168 8 connected 0-665 5461-6127 10923-11588 // 虽然写2000,但是实际上slot个数是1999个 a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381@16381 myself,slave 66b0423f7cfa7168bf9a4f73d49f289982712a76 0 1670242677000 7 connected edfa029afbb771c7082d85897d28f17891e48e98 127.0.0.1:6388@16388 slave ecce086b7d3b81bd846a0db374ea2e09733863e9 0 1670242680000 8 connected // 6388和6386 都是6387的Slave ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386@16386 slave ecce086b7d3b81bd846a0db374ea2e09733863e9 0 1670242682189 8 connected 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385@16385 slave 41e4024747281db14a8c400d826cf5f94e53a7d2 0 1670242679000 2 connected 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382@16382 master - 0 1670242681000 2 connected 6128-10922 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384@16384 master - 0 1670242679123 7 connected 666-5460 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383@16383 master - 0 1670242680143 3 connected 11589-16383
缩容 如果移除Slave,则直接移除即可
1 2 3 4 5 redis-cli --cluster del-node 127.0.0.1:6388 edfa029afbb771c7082d85897d28f17891e48e98 > >> Removing node edfa029afbb771c7082d85897d28f17891e48e98 from cluster 127.0.0.1:6388 > >> Sending CLUSTER FORGET messages to the cluster... > >> Sending CLUSTER RESET SOFT to the deleted node.
如果移除Master,缩容之前,需要先将数据转移到其他节点的slot上
1 2 3 4 redis-cli --cluster del-node 127.0.0.1:6387 ecce086b7d3b81bd846a0db374ea2e09733863e9 >>> Removing node ecce086b7d3b81bd846a0db374ea2e09733863e9 from cluster 127.0.0.1:6387 [ERR] Node 127.0.0.1:6387 is not empty! Reshard data away and try again.
移除slot
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 redis-cli --cluster reshard 127.0.0.1:6382 // 数据重新分配,随便选定一个节点,需要获取集群信息 > >> Performing Cluster Check (using node 127.0.0.1:6382) M: 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382 slots:[6128-10922] (4795 slots) master 1 additional replica(s) S: ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386 slots: (0 slots) slave replicates ecce086b7d3b81bd846a0db374ea2e09733863e9 S: a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381 slots: (0 slots) slave replicates 66b0423f7cfa7168bf9a4f73d49f289982712a76 M: 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384 slots:[666-5460] (4795 slots) master 1 additional replica(s) S: 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385 slots: (0 slots) slave replicates 41e4024747281db14a8c400d826cf5f94e53a7d2 M: 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383 slots:[11589-16383] (4795 slots) master M: ecce086b7d3b81bd846a0db374ea2e09733863e9 127.0.0.1:6387 // 6387上slot的个数是1999 slots:[0-665],[5461-6127],[10923-11588] (1999 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. > >> Check for open slots... > >> Check slots coverage... [OK] All 16384 slots covered. How many slots do you want to move (from 1 to 16384)? 1999 // 移动slot的个数,是1999 What is the receiving node ID? 66b0423f7cfa7168bf9a4f73d49f289982712a76 // 接受slot的ID,只能选择Master,这里随便选一个 Please enter all the source node IDs. Type 'all' to use all the nodes as source nodes for the hash slots. Type 'done' once you entered all the source nodes IDs. Source node #1: ecce086b7d3b81bd846a0db374ea2e09733863e9 // 从哪个节点上移动,选择6387 Source node #2: done // 结束 Ready to move 1999 slots. // 开始移动数据 Source nodes: M: ecce086b7d3b81bd846a0db374ea2e09733863e9 127.0.0.1:6387 slots:[0-665],[5461-6127],[10923-11588] (1999 slots) master 1 additional replica(s) Destination node: M: 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384 slots:[666-5460] (4795 slots) master 1 additional replica(s) Resharding plan: Moving slot 0 from ecce086b7d3b81bd846a0db374ea2e09733863e9 ... 省略信息
获取集群信息
1 2 3 4 5 6 7 8 redis-cli -c -p 6381 cluster nodes ecce086b7d3b81bd846a0db374ea2e09733863e9 127.0.0.1:6387@16387 slave 66b0423f7cfa7168bf9a4f73d49f289982712a76 0 1670243556963 9 connected // 6387没有slot,降级为Slave,是6384的Slave a410096f39bd4487b15635420221f0d59e9abdf2 127.0.0.1:6381@16381 myself,slave 66b0423f7cfa7168bf9a4f73d49f289982712a76 0 1670243555000 9 connected ce3eda8aaf67141cdddcc38cb1fb4e976847600a 127.0.0.1:6386@16386 slave 66b0423f7cfa7168bf9a4f73d49f289982712a76 0 1670243555000 9 connected 4d6e600a5d55cf552d27ec19fcd50c5415eb0bcc 127.0.0.1:6385@16385 slave 41e4024747281db14a8c400d826cf5f94e53a7d2 0 1670243557000 2 connected 41e4024747281db14a8c400d826cf5f94e53a7d2 127.0.0.1:6382@16382 master - 0 1670243552837 2 connected 6128-10922 66b0423f7cfa7168bf9a4f73d49f289982712a76 127.0.0.1:6384@16384 master - 0 1670243555936 9 connected 0-6127 10923-11588 3a74a2be2d5d06a07df63fc57d4641104c3f728a 127.0.0.1:6383@16383 master - 0 1670243557985 3 connected 11589-16383
删除6387
1 2 3 4 5 redis-cli --cluster del-node 127.0.0.1:6387 ecce086b7d3b81bd846a0db374ea2e09733863e9 >>> Removing node ecce086b7d3b81bd846a0db374ea2e09733863e9 from cluster 127.0.0.1:6387 >>> Sending CLUSTER FORGET messages to the cluster... >>> Sending CLUSTER RESET SOFT to the deleted node.
集群模式下的限制
不能切换数据库,仅支持0号数据库
不能将hash、list、set、zset等数据拆分到不同的slot,分区仅限于key
批量操作支持有限
事务只支持一个节点,不能跨节点,不是分布式事务
不支持分级管理,没有多层级Slave
客户端 golang选择go-Redis
因为go-Redis原生支持连接哨兵及集群模式的Redis,并且是类型安全的。
官方文档:redis.uptrace.dev
这里Redis版本是7.0,客户端使用v9版本
普通模式,单主或者主从模式,连接MasterIP和端口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import ( "github.com/go-redis/redis/v9" "log" ) func main () rdb := redis.NewClient(&redis.Options{ Addr: "172.16.211.68:49153" , Password: "Redispw" , DB: 0 , }) res, err := rdb.WithContext(rdb.Context()).Ping().Result() if err != nil { log.Fatal(err) } log.Println(res) num, err := rdb.Set("string21" , "a" , 0 ).Result() if err != nil { log.Fatal(err) } log.Println(num) }
Sentinel模式,连接Sentinel的IP以及MasterName
1 2 3 4 5 6 import "github.com/go-redis/redis/v9" rdb := redis.NewFailoverClient(&redis.FailoverOptions{ MasterName: "master-name" , SentinelAddrs: []string {":9126" , ":9127" , ":9128" }, })
集群模式,连接集群中所有节点
1 2 3 4 5 6 7 8 9 import "github.com/go-redis/redis/v9" rdb := redis.NewClusterClient(&redis.ClusterOptions{ Addrs: []string {":7000" , ":7001" , ":7002" , ":7003" , ":7004" , ":7005" }, })
常见问题 1、慢查询阻塞:池子连接都被hang住
Redis处理请求是单线程,慢查询出现在执行命令期间
解决方案:首先避免出现慢查询,其次设置超时时间
2、资源池参数不合理,QPS高,池子小
3、连接泄漏:没有close()
4、DNS异常
慢查询队列 1 2 slowlog-max-len 128 // 慢查询是一个先进先出的队列;队列长度固定;保存在内存中 slowlog-log-slower-than 10000 // 慢查询阈值;0代表记录所有命令,<0代表不记录所有命令,默认10ms,通常1ms
1 2 3 4 5 6 172.16.211.68:49153> CONFIG GET slowlog-max-len // 通常设置在1000左右 1) "slowlog-max-len" 2) "128" 172.16.211.68:49153> CONFIG GET slowlog-log-slower-than // 默认10ms,通常1ms 1) "slowlog-log-slower-than" 2) "10000"
配置方式:
1、修改配置文件,重启(不支持)
2、动态配置
1 2 172.16.211.68:49153> CONFIG SET slowlog-max-len 256 OK
慢查询
1 2 3 4 5 6 172.16.211.68:49153> SLOWLOG get 1 // 获取慢查询个数 (empty array) 172.16.211.68:49153> SLOWLOG len // 获取慢查询队列长度 (integer) 0 172.16.211.68:49153> SLOWLOG reset // 清空慢查询 OK
可以定期持久化慢查询,存储到MySQL中。
扩展 Redis虽然可以作为缓存,减小数据库压力,但是在高并发场景下,也会有一些问题。
缓存穿击 当用户的数据既不在缓存中,也不在数据库中,导致查询都会穿透缓存,直达数据库,这种情况成为缓存击穿。
缓存击穿的原因主要有两个:一是在数据库中没有相应的查询结果;二是查询结果为空时,不对查询结果进行缓存。
解决方案也有两个:
对非法请求进行限制(比如布隆过滤器)
对结果为空的查询结果给出默认值
即使是空值,也在缓存中表示出来
缓存穿透 对于某一个缓存,在高并发情况下若其访问量特别巨大,当该缓存的有效时限到达时,可能会出现大量的访问都要重建该缓存,这些访问请求发现缓存中没有数据,则记录到数据库中进行查询,有可能引发对数据库的高并发查询,从而导致数据库崩溃。这种情况称为缓存击穿透,而该缓存数据称为热点数据。
对于缓存穿透的解决方案,较典型的是使用双重检测锁 机制。(简单操作就是从缓存中获取一次,如果没有,则上锁,然后再获取一次,没有的话再查询数据库,其他的线程由于锁机制,就无法再次查询数据库。)(复杂点,可以使用收敛模型。)也就是单飞模式。
缓存雪崩 对于缓存中的数据,很多都是有过期时间的。若大量缓存的过期时间在同一很短的时段内几乎同时到达,那么高并发场景下可能引发数据库的高并发查询,而这将可能直接导致数据库的崩溃。这种情况称为缓存雪崩。
缓存雪崩没有很直接的解决方案,最好的方案就是预防,即提前规划好缓存的过期时间。要么就是缓存永久有效,当数据库中数据发生变更时,更新缓存。如果数据库采用的是分布式部署,则将热点数据均匀分布在不同数据库节点中,将可能到来的访问负载均衡开来。
数据库缓存双写不一致的问题 数据库作为数据存储,可能出现与缓存中数据不一致的问题,可能出现的场景有如下几种:
修改DB更新缓存
对于具有warmup(缓存预热)功能系统,提供对外访问能力之前,先将所有数据写入到缓存。高并发写入场景 下,如果多个请求对数据库中同一个数据进行修改,修改完数据库再修改缓存数据,可能导致数据库中的数据和缓存中数据修改不一致。
修改DB删除缓存
对于没有warmup(缓存预热)功能系统,高并发读写场景 下,若这些请求对数据库发送修改和读取请求,可能出现写入之后删除对应缓存,但是读取的是删除之前的缓存,就可能导致数据不一致。
解决方案:延迟双删 针对修改DB删除缓存 的场景的解决方案,但是并不能彻底解决数据不一致的状况,只可能降低概率。
延迟双删的方案是指,在写操作完毕后会立即执行一次缓存的删除操作,然后再停上一段时间(一般为几秒)后再进行一次删除。两次删除中间的间隔时长,要大于一次缓存写操作的时长。
解决方案:队列 以上两种问题,本质上是由于并行处理请求。只要将请求写入一个统一的队列,只有处理完一个请求之后,才可处理下一个请求,使系统对于请求的处理串行化,就可以完全解决数据不一致的问题。但是会降低高并发的性能。
解决方案:分布式锁 使用分布式锁可以在不影响并发性的前提下,协调各处理线程间的关系,使数据库与缓存中的数据打成一致性。
对数据库中的这个共享数据的访问通过分布式锁来协调对其的操作访问即可。
布隆过滤器 * 例如查看当前字符串是否在缓存中,例如电话号码,范围很大。首先将号码通过`m`个`hash`函数,在一个长串二进制字符串中获取位置,命中的位置为1,如果经过了`m`个函数之后,都是1,则命中缓存。这样做可以避免布隆过滤器的误差。
* 解决缓存穿透的问题,攻击者查询一大堆既没有在缓存中,也不在数据库中的数据,导致所有的请求穿透缓存,直接打到数据库上。可以在服务启动之前,将所有的信息全部放到布隆过滤器上,先通过布隆过滤器获取数据是否存在,如果存在,再查询缓存,再查询数据库。
分段锁 在秒杀场景下,如果每次按照1个商品获取一次分布式锁,性能可能会下降,此时可以将商品进行分段,放在不同的节点上,例如第1-100个商品放到节点0上,第101-200个商品放到节点1上,然后在节点上内存中使用锁或者一些原子操作实现可提高性能,这个就是分段锁。分段锁的思想实际上可以理解为大锁划小锁。
可重入锁 当一个线程获取到锁之后,这个线程可以再次获取本对象上的锁,而且他的线程是不可以的,这个过程就是重入锁。例如在一些回调的接口中使用锁,可能会出现本线程回调自身,导致死锁,为了解决这种死锁的情况,将锁重入,再次加锁,一般通过value中存储锁次数,重入一次次数+1,解锁时,一层一层解锁,需要锁次数为0才能解锁。
公平锁 当多个线程同时申请锁时,这这些线程会进入到一个FIFO队列,只有队首元素才会获取到锁,其他元素等待。只有当锁被释放后,才会再将锁分配给当前的队首元素。有些线程会一直抢不到锁,这个就不是一个公平锁,而是非公平锁。
联锁 当一个线程需要同时处理多个共享资源时,可使用联锁。即一次性申请多个锁,同时锁定多个共享资源。联锁可预防死锁。
相当于对共享资源实现了原子性,要么都申请到,只要缺少一个资源,则将申请到的所有资源全部释放。
红锁 红锁由多个锁构成,只有当这些锁种的大部分锁申请成功时,红锁才申请成功。红锁一般用于解决Redis主从集群锁丢失的问题。
读写锁 读写锁就是包含读锁和写锁,读锁和写锁分别实现了RLock的可重入锁。
一个共享资源,在没有写锁的情况下,允许同时添加多个读锁。
只要添加了写锁,任何读锁与写锁都不能再次添加。
即读锁是共享锁,写锁是排它锁。
信号量 信号量的使用场景有两种:
无论谁添加的锁,任何其他线程都可以解锁
当一个线程需要一次申请多个资源时,可使用信号量。
可过期信号量 可过期信号量是在信号量的基础上,为每个信号增加一个过期时间,且每个信号都可以通过独立的ID来辨识。释放时也只能通过提交该ID才能释放。
不过,一个线程每次只能申请一个可过期信号量,每次也只会释放一个信号量。这是与信号量不同的地方。
该信号量为互斥信号量,其就等同于可重入锁。或者说,可重入锁就相当于信号量为1的可过期信号量。
可过期信号量与可重入锁的区别:
可重入锁:相当于用户每次只能申请1个信号量,且只有一个用户可以申请成功。
可过期信号量:相当于用户每次只能申请1个信号量,但可以有多个用户申请成功。
分布式闭锁 常用于一个或者多个线程的执行必须在其他某些任务执行完毕的场景。例如,大规模分布式并行计算中,最终的合并计算必须基于很多并行计算的运行完毕。
闭锁中定义了一个计数器和一个阻塞队列。阻塞队列中存放着待执行的线程。没当一个冰箱任务执行完毕,计数器减一。当计数器递减到0时,就会唤醒阻塞队列的所有线程。
推荐阅读 Raft共识算法
Raft Algorithm, Explained
In Search of an Understandable Consensus Algorithm