IO模型
网络编程中绕不过去的IO模型,从同步阻塞、同步非阻塞到IO多路复用,不同的IO模型有不同的特点。Redis、Nginx的高性能就是建立在IO多路复用的基础上。
Linux中一切都是文件,对网络I/O的操作就是操作文件描述符,也就是fd。
网卡接受到网络流量,会经过DMA处理,放到内存指定空间,当处理一个I/O的数据时,其他的I/O的数据不会丢失。
同步阻塞
服务端:创建socket之后,监听端口,监听连接,阻塞住
1 | func read(conn *net.TCPConn) { |
客户端1:创建socket,与服务端建立连接,TCP三次握手过程会出现阻塞,socket链接成功建立之后,写入消息,写入消息之后阻塞住,等待服务端读取消息,服务端读取消息,客户端结束,服务端处理逻辑,继续监听
1 | func main() { |
客户端2:由于服务端在处理其他客户端的消息,服务响应,会一直阻塞住,无法写入消息。等其他的客户端处理完之后,才会处理这个客户端
同步阻塞单线程:如果有一个线程阻塞,会影响到其他的socket的处理
同步阻塞多线程:客户端较多的时候,会造成资源浪费,真正就绪的socket可能只有少数几个。同时,线程的调度、上下文切换都会有资源浪费。
同步非阻塞 NIO
服务端:监听过程是非阻塞,一直循环监听链接,当链接上,则读取文件句柄,处理逻辑。如果没有链接,则返回一个非法的结果,继续下一轮监听
Golang中通过协程模拟同步非阻塞(只是模拟非阻塞过程,无法模拟对fd的检查)
1 | func read(conn *net.TCPConn) { |
客户端:创建socket,与服务端建立连接,写入数据
服务端会一直轮训监听是否建立socket链接,当没有建立链接,则返回非法函数,跳过,当建立链接,则处理逻辑。
主线程检查fd,当有fd就绪,开启一个新的线程处理这个fd的逻辑
优点:单个socket阻塞时,不影响其他的socket
缺点:需要不断的便利进行系统调用,有一定的开销。多线程的方式在线程切换的时候,会有上下文切换的开销。
IO多路复用
网络编程中,当 client 和 server 建立连接之后,通过 socket 通信。那么,核心点就在于,如何从一大堆创建好的文件描述符中,挑选出符合条件的文件描述符?例如,client发送消息之后,server 需要从特别多的 client 中获取到这个特定的 client 的数据。
思考:
- 每次都便利所有创建好的文件描述符,挨个检查是否符合条件。将可读的连接返回;
- 便利所有的文件描述符比较耗时。可以尝试在文件描述符满足条件时,将它们挪动到一个队列里面,如果接收到通知询问是否有满足条件的文件描述符,则直接返回这个队列里的数据;
select
每次都便利所有创建好的连接,挨个检查是否可读。把可读的连接返回。
select接收三个文件描述符集合:可读、可写和异常文件描述符集合,作为它监听的对象(遍历的对象)

- 文件描述符集合是一个
bitset,每一个比特位表达垓文件描述符的状态,默认容量是 1024
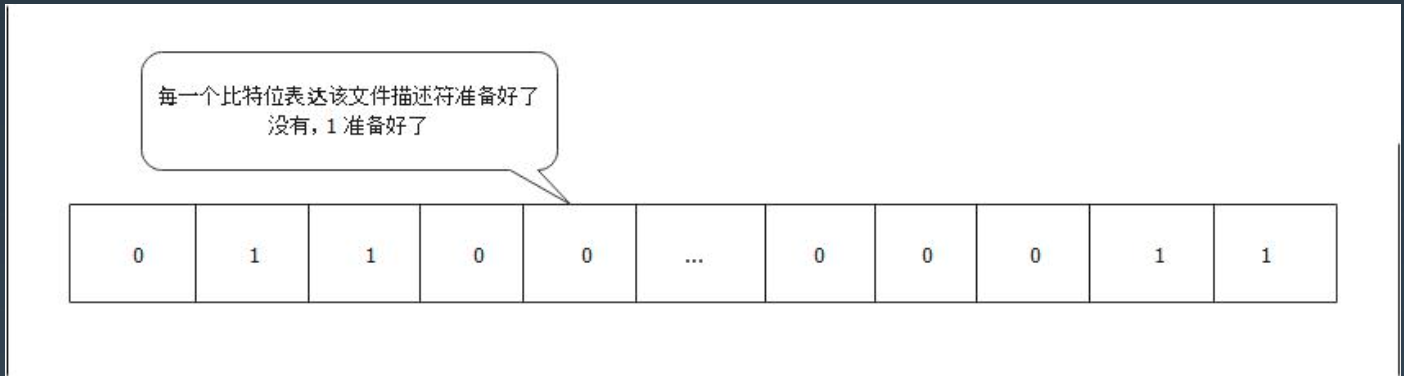
- 发起
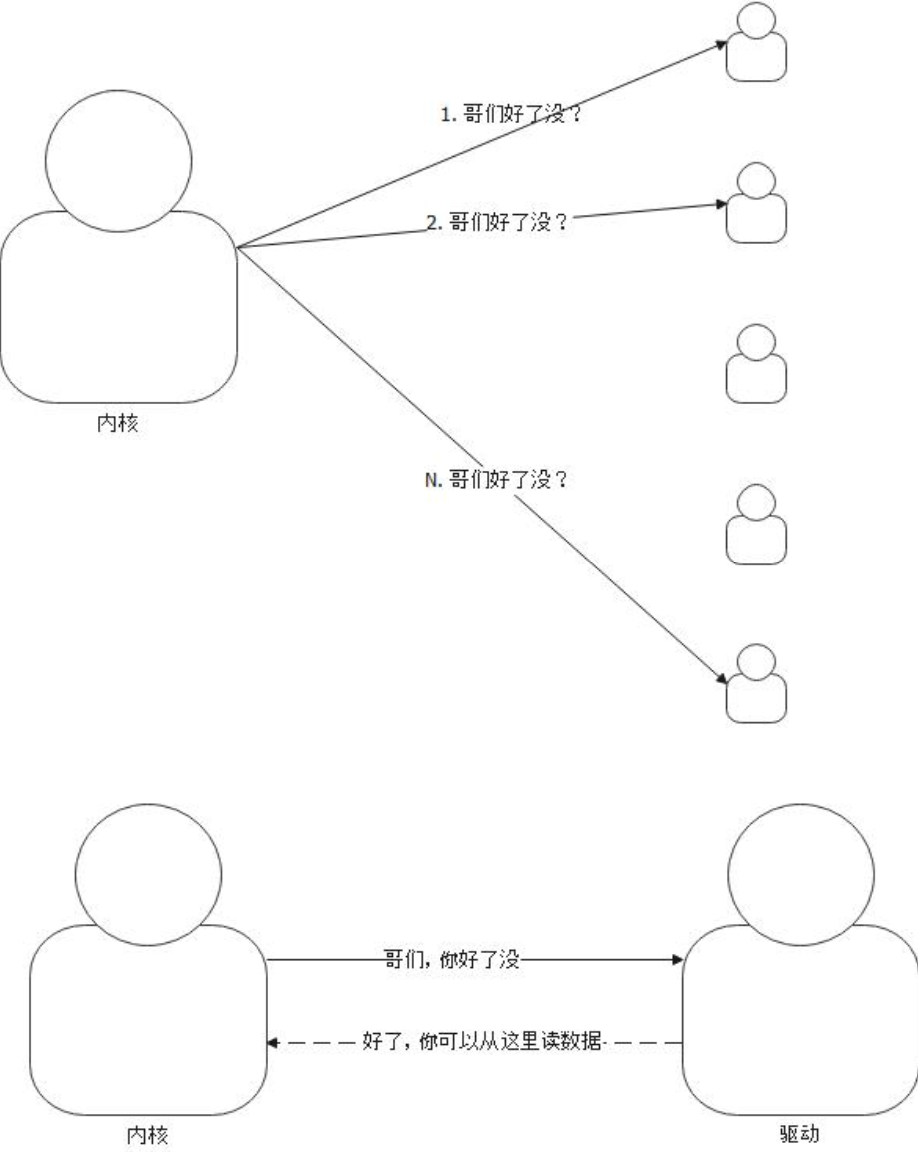
select调用,则需要传入我们希望select监听的文件描述符集合,select遍历这些文件描述符,根据文件描述符去找驱动,驱动会回答这些问题
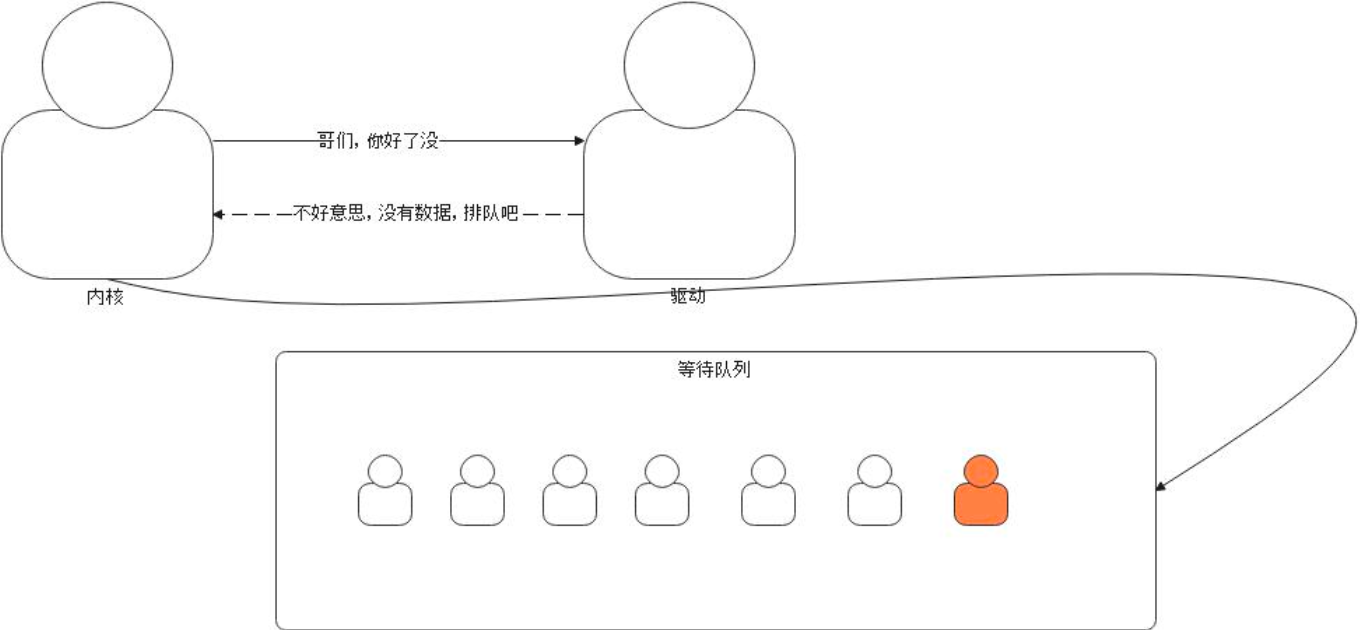
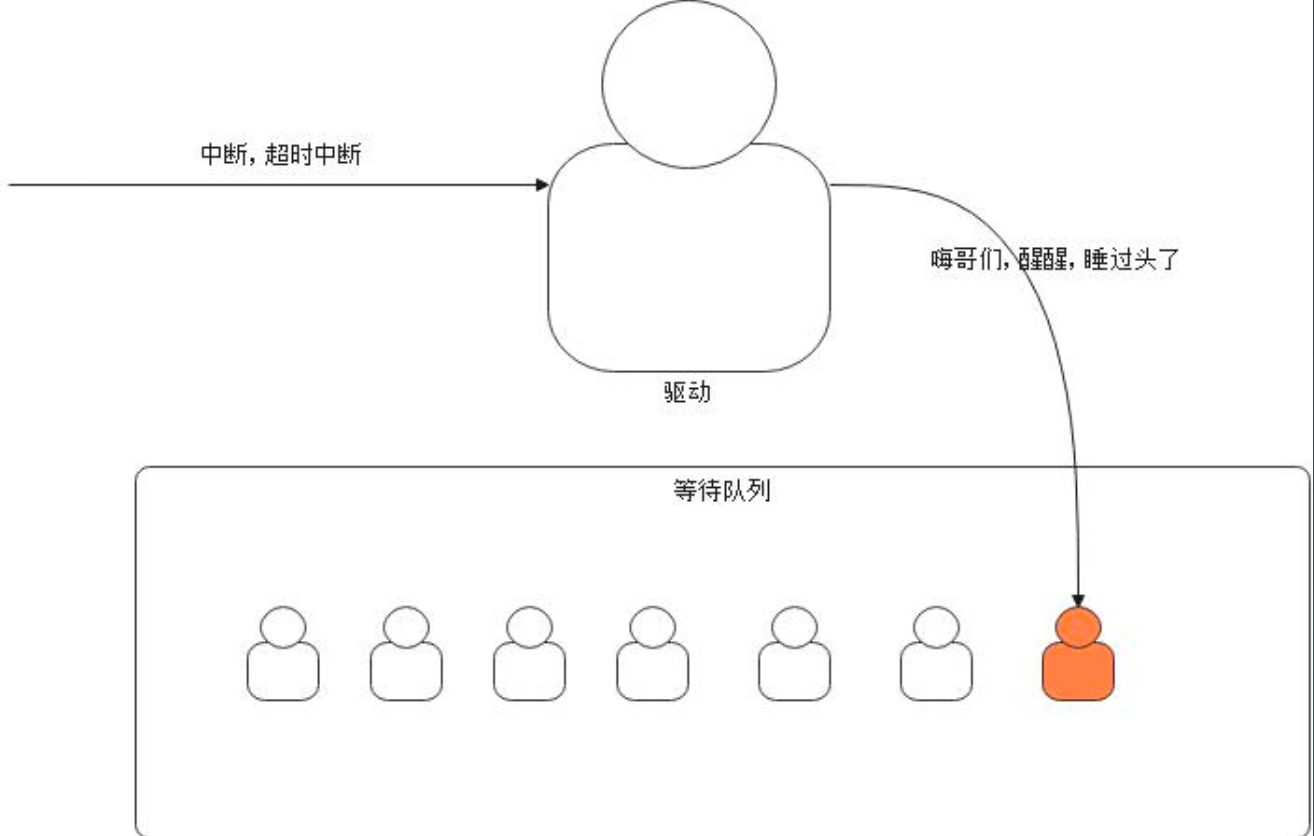
- 如果没有数据,并且设置了超时,那么会进入等待队列(如果设置了超时机制,超时后,则会进入到等待队列,等待队列也是驱动维护。)
- 如果超时之前等待了,驱动会唤醒内核线程。(当数据到达,网卡收到数据,硬件会通过中断提醒驱动,驱动检查等待队列之后获取就绪的文件描述符)
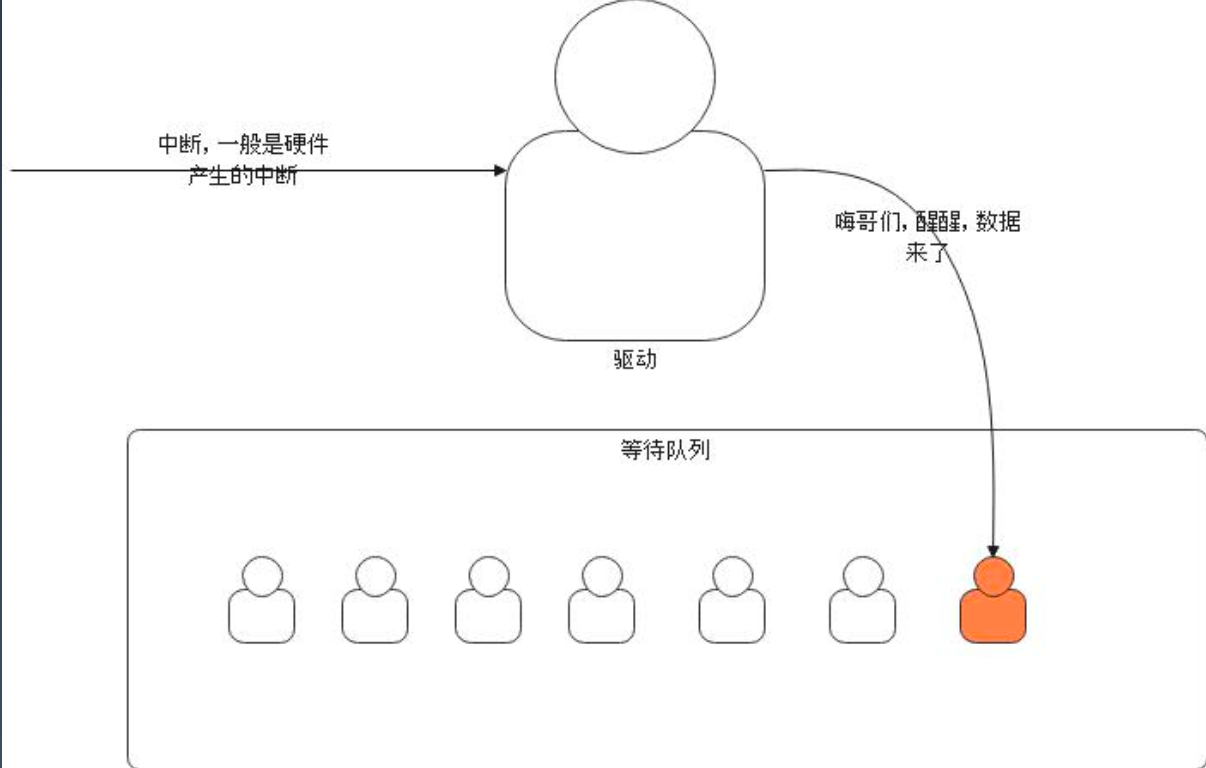
- 定时的时钟中断会通过操作系统通知内核检测,如果发生超时,那么驱动会将文件描述符从等待队列中拿出来;
用户使用方法:
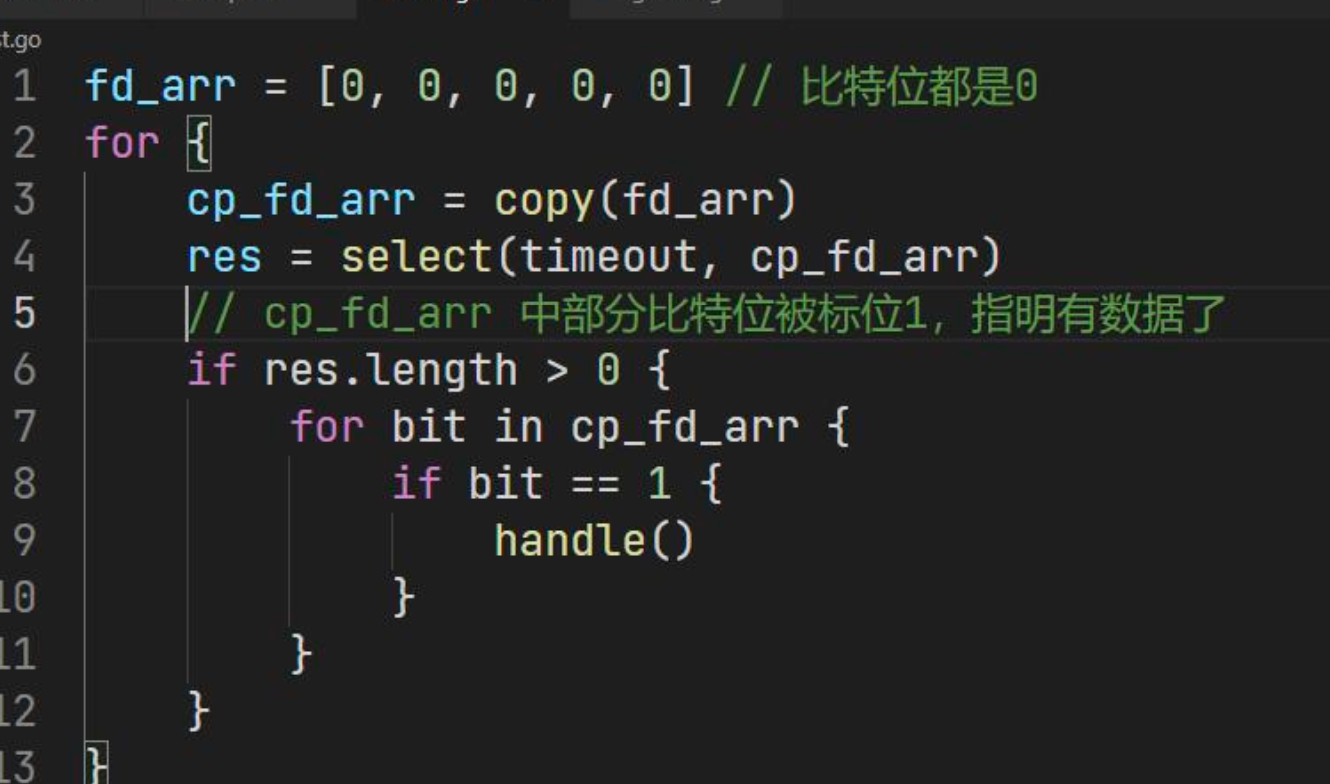
- 准备需要
select的文件描述符集合fd_arr - 复制文件描述符集合,作为参数传递给
select系统调用 - 检查每一个比特位,确认有没有就绪的文件描述符
- 处理就绪的文件描述符
解决同步非阻塞中频繁系统调用的问题
1 | // 获取就绪事件 |
服务端同时监听多个fd,将fd存放在bitmap中,也就是fd_set,监听不同的类型使用不同的fs_set,这个bitmap默认1024位(例如fd序号[1,2,3],则fd_set记录的就是01110000,表示1、2、3号位的fd需要监听,同时nfds是10)。
服务端将fd_set从用户态拷贝一份到内核态,内核在检查fd的过程中,如果没有数据,则阻塞住,如果有数据,有fd已经就绪,则将fd置位,将fd_set返回到用户态,用户态便利fd,获取对应就绪的fd,进行处理。
内核空间在检查fd的过程中,检查一次之后,如果没有fd就绪,则进入阻塞状态,当网卡收到流量,经过DMA处理,放到指定内存,CPU通过中断获取对应fd,内核再次检查所有fd,将就绪fd的数量返回用户态。
select是将socket是否就绪的检查逻辑下沉到操作系统层面,避免大量系统调用。
优点:不需要每个fd都进行一次系统调用,解决了频繁的用户态内核态切换的问题;
缺点:单进程监听的fd有限制,默认1024,但是有上线;不知道具体哪个文件描述符就绪,需要便利全部文件描述符;由于内核置位了fs_set,每次进入select的时候,都需要重新将入参的3个fd_set集合重置;以及每次调用需要将fd_set从用户态拷贝到内核态;
poll
1 | // 获取就绪事件 |
跟select类似,不使用bitmap,使用pollfd。将pollfd从用户态空间拷贝到内核态,poll过程也是阻塞,当事件就绪,内核态将revents置位。poll便利pollfds,当pollfd的revent发生改变,则进行处理以及恢复成默认状态,下次循环将默认的pollfd拷贝到内核态空间。
pollfd数组解决了bitmap的大小限制。
通过数组中的revent解决解决了每次复制到内核态的fd无法重用的问题。
优点:不需要每个fd都进行一次系统调用,导致频繁的用户态内核态切换
缺点:单进程监听的fd有限制,默认1024;每次调用需要将fd从用户态拷贝到内核态;不知道具体哪个文件描述符就绪,需要便利全部文件描述符;入参的3个fd_set集合每次调用都需要重置
epoll
event poll,事件驱动
epoll 不需要遍历所有的文件描述符,因为很耗时。尝试在文件描述符满足条件的时候,将它们挪到一个队列里面,如果用户询问,就可以直接返回这个队列里的数据。
解决poll中无法知道具体哪个fd就绪的问题
1 | // 创建一个epoll |
核心在于三个方法 epoll_create,epoll_ctl,epoll_wait
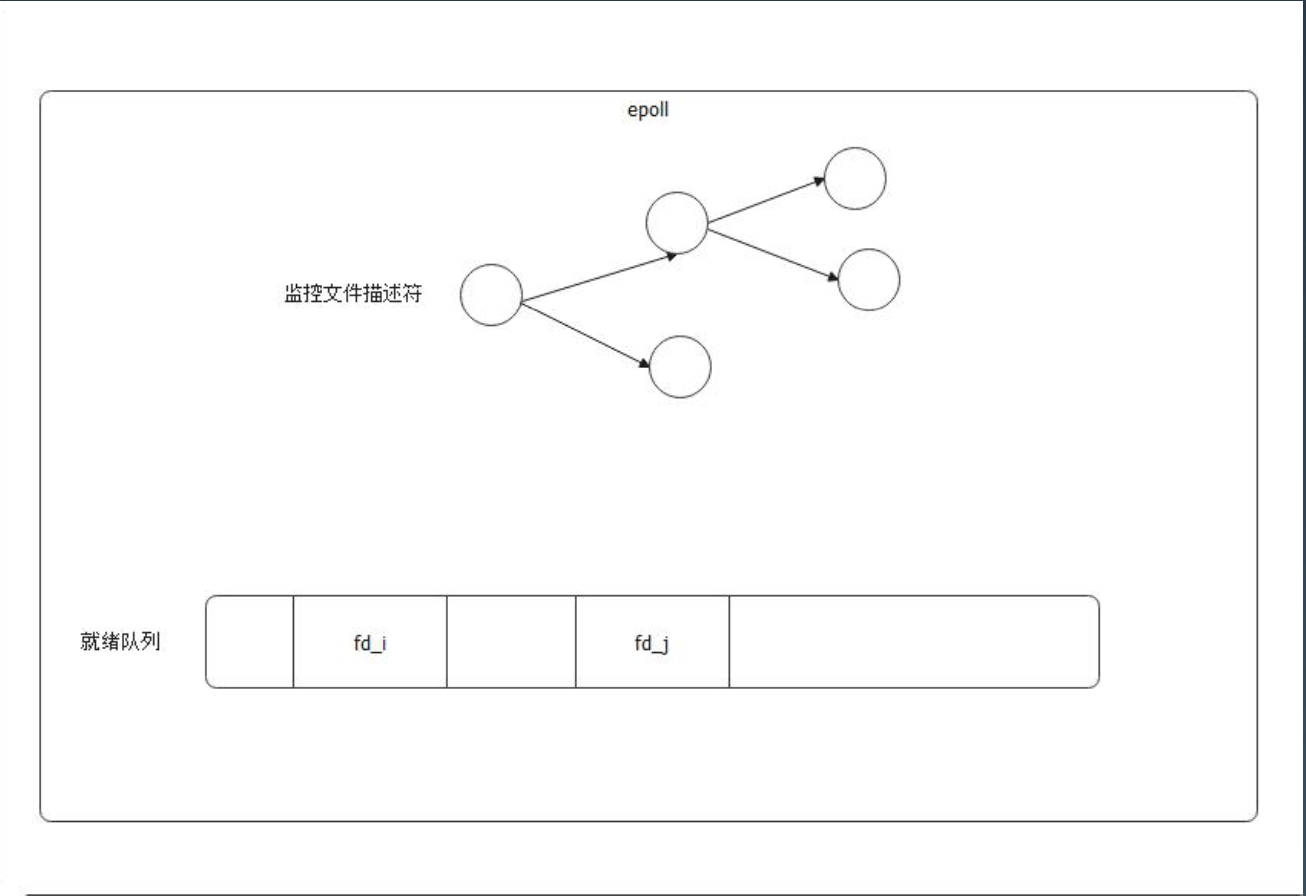
一个 epoll 对象主要有两个结构,一个是用红黑树来存储被监控文件描述符,一个就是就绪队列,存储就绪文件描述符。
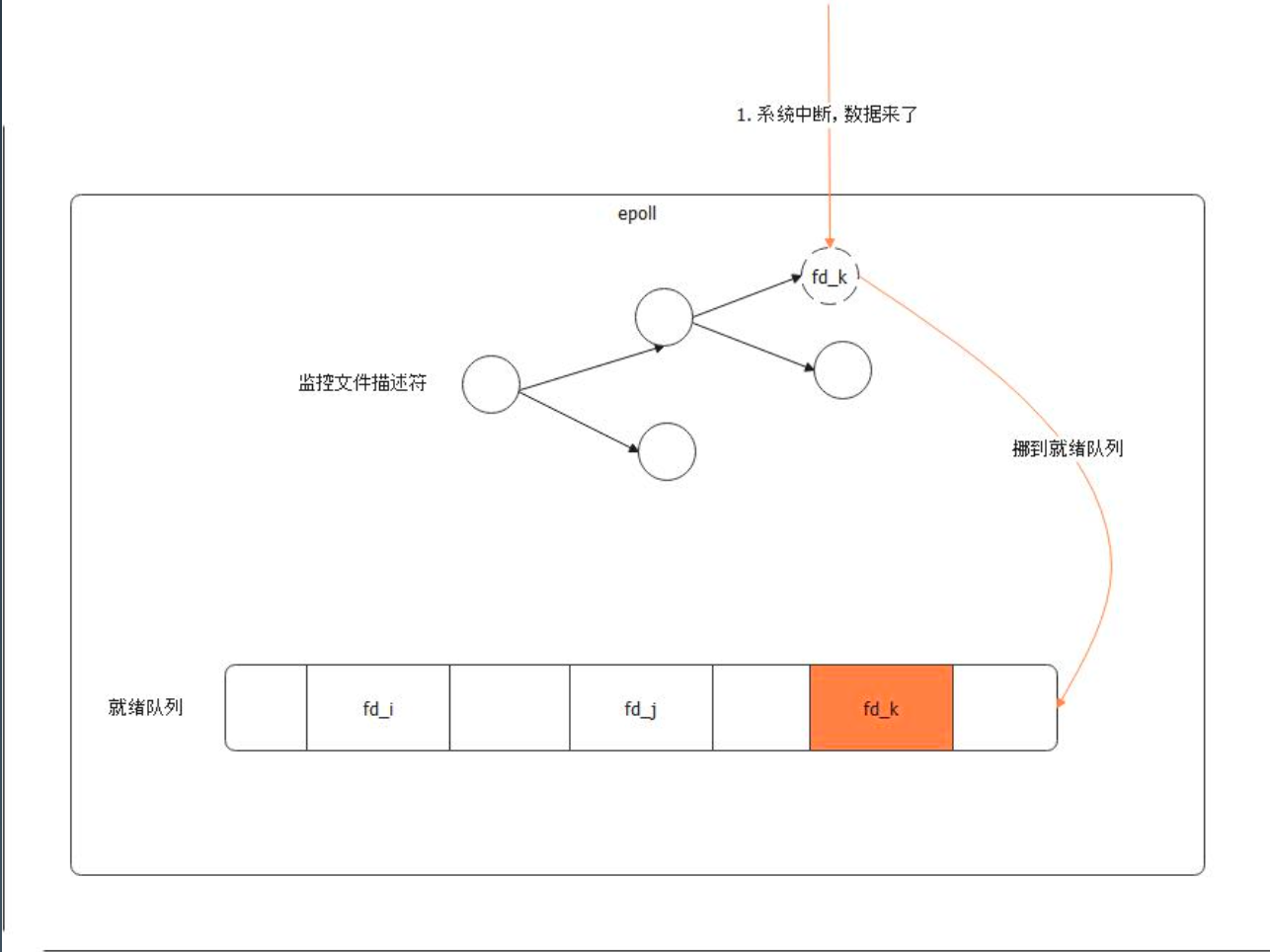
epoll 会监听系统中断,而后将文件描述符挪动到就绪队列。(这也是 epoll 比 select 高效的主要原因,次要原因是文件描述符的处理。)
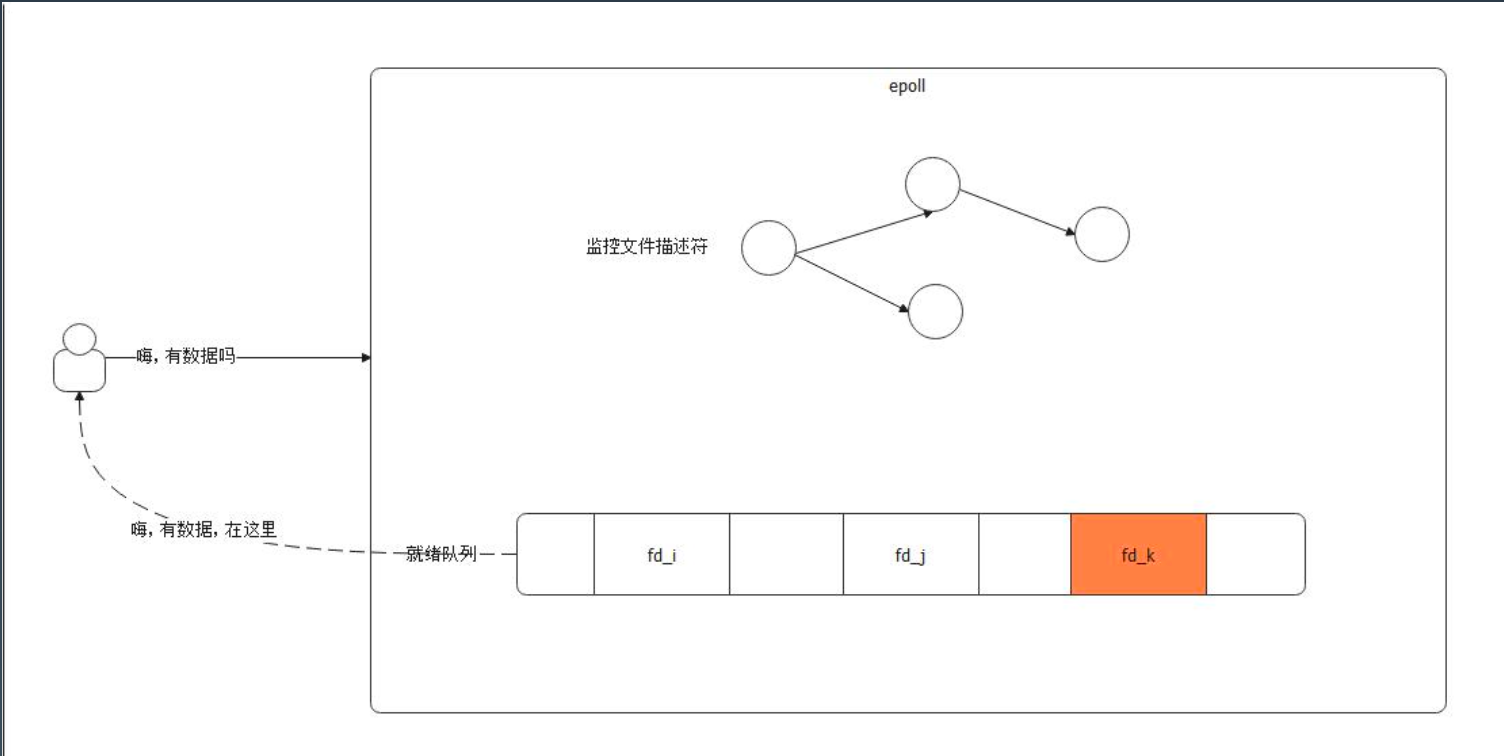
用户查询的时候,直接返回就绪队列。
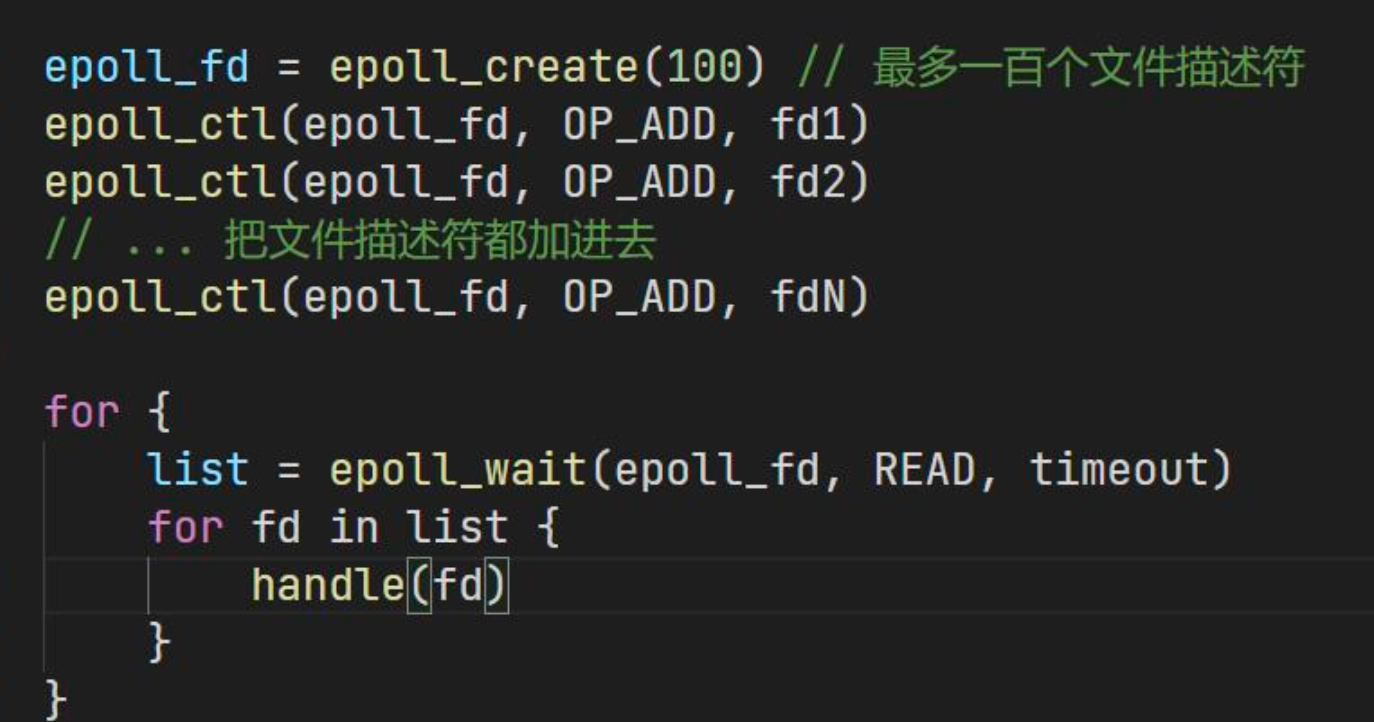
用户使用代码:
- 创建
epoll - 往
epoll里面添加文件描述符 - 不断从
epoll里面找数据
golang中的调用如下
1 | func epollcreate(size int32) int32 |
创建产生epollfd,可以是一个有容量的空白的空间,并且这个epfd是内核态和用户态共享的
1 | // 时间注册 |
golang中的调用如下
1 | //go:noescape |
epoll_ctl,循环注册,将需要监听的fd注册到epfd中,每次以fd-epoll_event的形式注册到epollfd
1 | // 获取就绪事件 |
golang中的调用如下
1 | //go:noescape |
内核态检测到有数据,通过重排的方式,将就绪状态的fd排列在epfd前面,并且返回就绪个数。
用户态在处理的时候,便利前面就绪个数的元素。
解决了poll中用户态到内核态拷贝的开销;解决了便利fd的时间复杂度。
高效处理高并发下的大量连接,同时有非常高的性能。
Redis和Nginx,都是使用的epoll。