微服务可用性设计之降级、重试和负载均衡
降级
通过降级回复来减少工作量,或者丢弃不重要的请求。而且需要了解哪些流量可以降级,并且有能力区分不同的请求。我们通常提供降低回复的质量来答复减少所需的计算量或者时间。自动降级通常需要考虑几个点:
- 确定具体采用哪个指标作为流量评估和优雅降级的决定性指标(如:CPU、延迟、队列长度、线程数量、下游服务的报错等)
- 当服务进入降级模式时,满足降级服务,可以从缓存(
local cache、remote cache)中捞取一批过期的数据或者空回复 - 流量抛弃或者优雅降级应该在服务的最上层(入口)实现(一般是
BFF、Gateway层),不需要在整个服务的每一层都实现,成本会比较高
同时我们要考虑以下几点:
- 优雅降级不应该被经常触发:通常触发条件实现了容量规划的失误,或者是意外的负载,比如说突然的大负载流量
- 演练:代码平时不会触发和使用,需要定期针对一小部分的流量进行演练,保证模式的正常
- 应该足够简单
本质
降级本质为:提供有损服务。
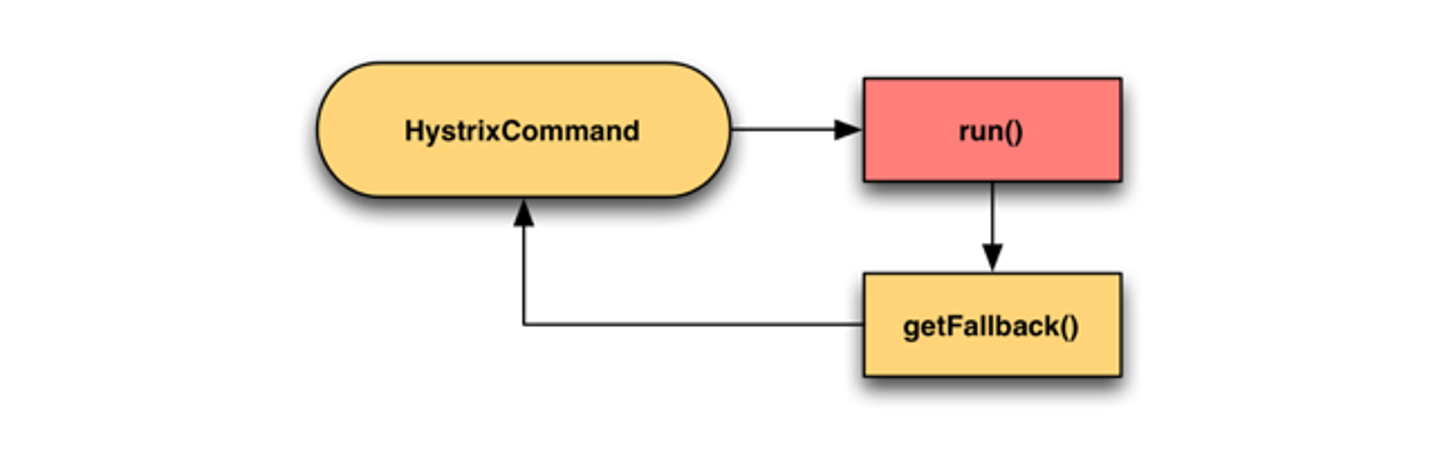
- UI 模块化,非核心模块降级:比如标签、评论等不重要的模块
- BFF 层聚合 API,模块降级
- 页面上一次缓存副本:刷新的时候如果报错,则返回上次成功的数据,避免出现白屏
- 默认值、热门推荐等:出现报错就使用默认值,一些会有大型流量的接口比如推荐,出现报错就推荐降级推荐的数据,例如抛去相关性
- 流量拦截 + 定期数据缓存(过期副本策略):比如截取
metadata里面或者url的值,来设定缓存的内容,返回过期降级数据
处理策略
- 页面降级、延迟服务(例如异步消费数据)、写/读降级、缓存降级
- 抛异常、返回的约定协议、
Mock数据(装饰器模式,下游返回报错,则使用Mock数据)、Fallback处理
Case Study
- 客户端解析协议失败,
app崩溃:需要与客户端协商约定,降级字段 - 客户端部分协议不兼容,导致页面失败
local cache数据源缓存,发版失效 + 依赖接口故障,引起的白屏:要保障local cache数据,可以在发版之前缓存,也可以cache失效再次降级- 没有操作白皮书(
playbook),导致的平均修复时间(MTTR) 上升:当故障时,有应急手册处理
重试
当请求返回错误(例:配额不足、超时、内部错误等),对于 backend 部分(需要留存部分后端资源)节点过载的情况下,倾向于立刻重试,但是需要留意重试带来的流量放大:
- 限制重试次数和基于重试分布的策略(重试比率:10%)
- 随机化、指数递增的重试周期:
exponential ackoff+jitter client侧记录重试次数直方图,传递到server,进行分布判定,交由server判定拒绝:server可以知道全局请求失败情况,进行判断是否重试- 只应该在失败的这层进行重试,当重试仍然失败,全局约定错误码,过载,无须重试,避免级联重试:重试失败之后,返回约定全局错误码,上游获得失败之后,不会重试,如果返回的不是全局错误码,说明下游没有重试,上游可以开始重试。
Case Study
Nginx upstream retry 过大,导致服务雪崩:可以约定最大值
业务不幂等,导致的重试,数据重复:写请求最好不要重试,读取请求也最好不要用在客户端
全局唯一
ID:根据业务生成一个全局唯一 ID,在调用接口时会传入该ID,接口提供方会从响应的存储系统比如redis中去检索这个全局 ID 是否存在如果存在,则说明该操作已经执行过了,将拒绝本次服务请求;
否则将响应该服务请求,并将全局ID存入存储系统中,之后包含相同业务 ID 参数的请求将被拒绝
去重表:这种方法适用于在业务中有唯一标识的插入场景。
比如在支付场景中,一个订单只会支付一次,可以建立一张去重表,将订单ID作为唯一索引。把支付并且写入支付单据到去重表放入一个事务中,这样当出现重复支付时,数据库就会抛出唯一约束异常,操作就会回滚。这样保证了订单只会被支付一次。
多版本并发控制:适合对更新请求作幂等性控制,比如要更新商品的名字,这时就可以在更新的接口中增加一个版本号来做幂等性控制
多层级重试传递,放大流量引起雪崩:约定全局错误码,避免多层级重试
负载均衡
负载均衡是数据中心内部的负载均衡。(负载均衡的本质是挑选一个最优的节点)
在理想情况下,某个服务的负载会完全均匀地分发给所有的后端任务。在任何时刻,最忙的和最不忙的节点永远消耗同样数量的 CPU 。
目标:
- 均衡的流量分发(长连接时,新节点无法平摊流量)
- 可靠的识别异常节点(节点无法处理请求,或者服务发现节点通,但是请求到节点网络不通)
- Scale-out,增加同质节点扩容
- 减少错误,提高可用性
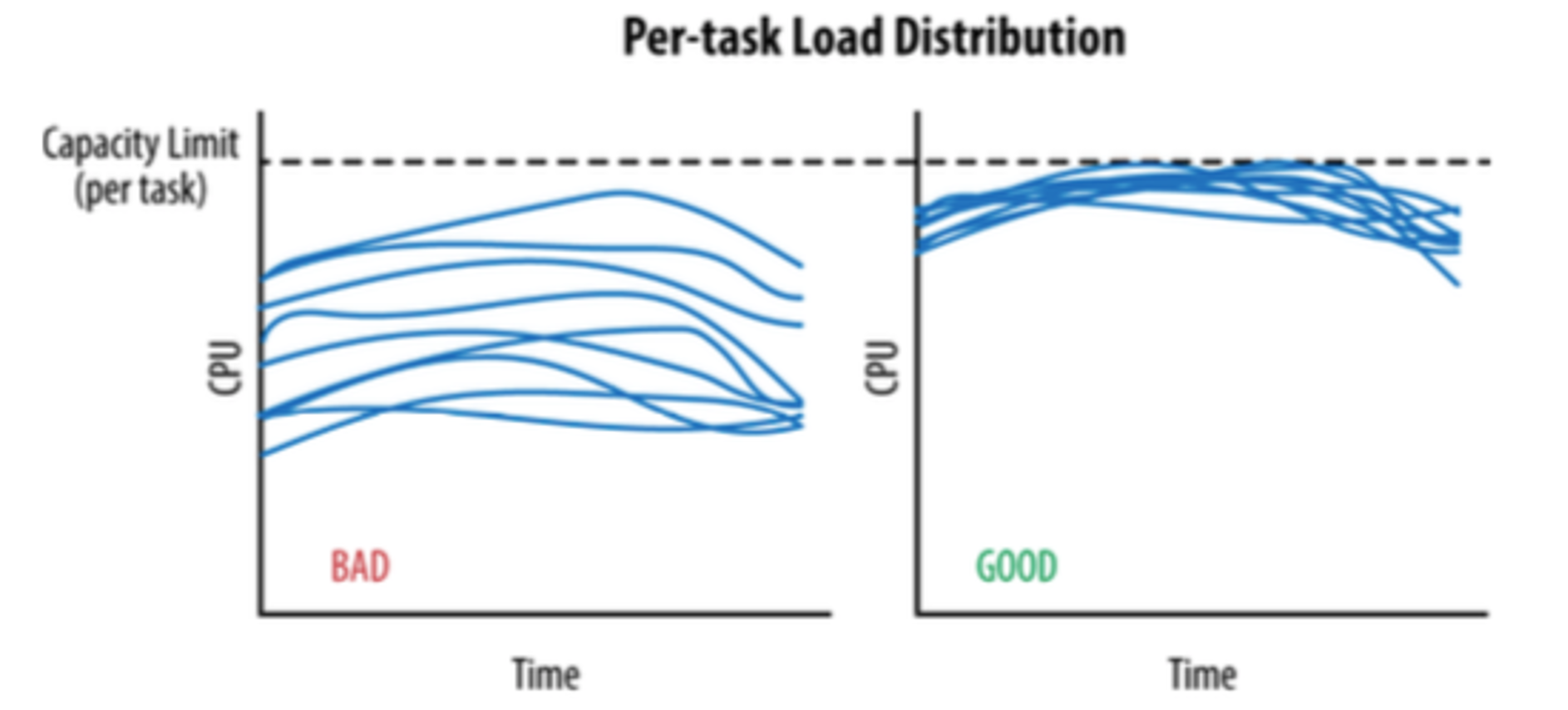
在实际情况中,backend 之间的 load 差异比较大:
- 每个请求的处理成本不同
- 物理机环境的差异
- 服务器很难强同质性(物理硬件、运行时长等)
- 存在共享资源争用(内存缓存、带宽、IO等)
- 性能因素
FullGCJVM JIT
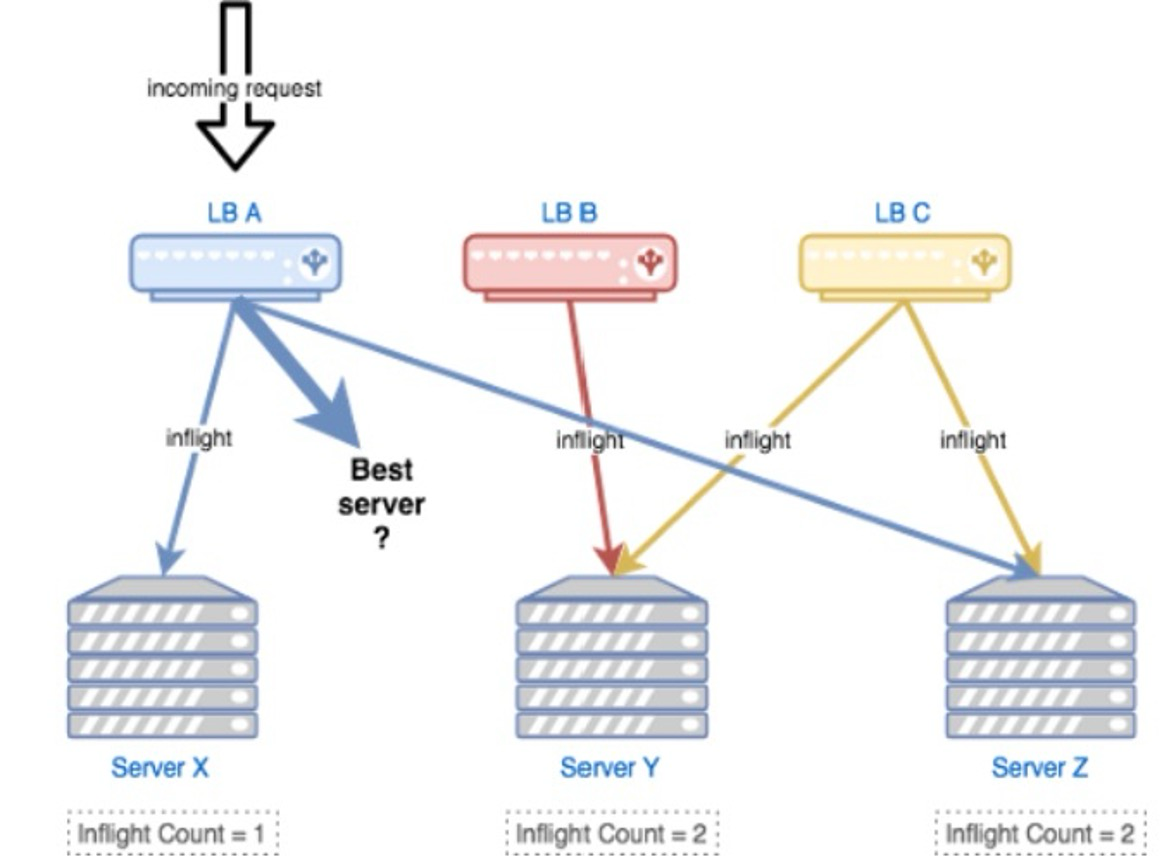
参考 JSQ(最闲轮询)负载均衡算法带来的问题,缺乏的是服务端全局视图,因此目标是需要综合考虑:负载 + 可用性。
参考The Power of Two Choices in Randomized Load Balancing的思路,使用 the choice-of-2 算法,随机选取两个节点进行打分,选择更优的节点:
- 选择
backend:CPU,client:health、inflight、latency作为指标,使用一个简单的线性方程进行打分 - 对新启动的节点使用常量惩罚值(
penalty),以及使用探针方式最小化放量,进行预热 - 打分比较低的节点,避免进入 永久黑名单 而无法恢复,使用统计衰减的方式,让节点指标逐渐恢复到初始状态(即默认值)
指标计算结合 moving average,使用时间衰减,计算 vt = v(t-1) * β + at * (1-β) 。(上一个时间节点的值,乘以β ,加上本次时间节点的值,乘以 1-β )
β 为若干次幂的倒数,即:Math.Exp((-span) / 600ms)
最终的状态,所有 backend 节点的负载趋于一样。
算法
- 轮询
- 有一些前提
- 所有服务器的处理能力是一样的
- 所有请求所需的资源也是一样的
- 有一些前提
- 加权轮询
- 权重大的多分,权重少的少分
- 用权重来代表服务器的处理能力
- 所有请求所需的资源也是一样的
- 随机
- 瞎选
- 所有服务器的处理能力是一样的
- 所有请求所需的资源也是一样的
- 每台服务器被随机到的概率一样,因而大量请求的情况下,服务器之间的负载会一样
- 相比之下,轮询的可控性更强。但是大多数情况下效果差不多
- 加权随机
- 根据权重来确定选中率
- 用权重来代表服务器的处理能力
- 所有请求所需的资源也是一样的
- 哈希
- 所有服务器的处理能力是一样的
- 所有请求所需的资源也是一样的
- 哈希值是均匀的
- 哈希值不均匀会导致请求堆积在一个地方
- 最小连接数
- 加设
- 用连接数来代表服务器负载
- 所有服务器的处理能力是一样的
- 请求所需资源都一样
- 可能会短时间内把所有的请求都发过去同一台服务器
- 连接复用的情况下,连接数不能很好代表服务器的负载
- 加设
- 最小活跃数(最少请求数)
- 加设:
- 用服务器上的请求数量代表负载
- 所有服务器的处理能力是一样的
- 请求所需资源都一样
- 可能会短时间内把所有的请求都发去同一台服务器
- 加设:
总结
- 要不要考虑服务器处理能力
- 轮询、随机、哈希、最小连接数、最少活跃数都没有考虑上限
- 选择什么指标来表达服务器当前负载
- (加权)轮询、(加权)随机、哈希什么都没有选,依赖于统计
- 选择连接数、请求数、响应时间、错误数
- 是不是所有的请求所需资源都是一样的?显然不是
- 大商家品类极多,大买家订单极多
- 不考虑请求消耗资源的负载均衡容易出现偶发性的大爆某一台实例的情况
微服务下的额外约束
- 微服务客户端不同于网关,它不具备全局信息
- 最小连接数负载均衡:客户端只能知道自己和服务器之间有多少连接
- 最少活跃负载均衡:客户端只能知道自己发过去多少的请求,还有多少个没有返回
- 微服务框架很少设计为要获取全局信息,难点在于:
- 这本质上是一个分布式一致性问题
- 即便借助于注册中心交换信息,会导致注册中心频繁通知客户端
- 在缺乏全局信息的情况下,客户端会选择服务端1作为服务提供者
- 在微服务中选择负载均衡算法,这种需要全局信息的算法可能抖动会比较厉害
- 那么为什么它们运作得还是很好呢?因为请求数量多了,慢慢会收敛到一种比较均匀的状态
负载均衡的业务相关性
- 业务相关负载均衡:根据业务的某些特征来进行负载均衡,典型的如根据用户ID来进行负载均衡
- 但是往往一个请求所需多少资源和业务是强相关的,于是容易出现热点问题,或者大请求永远落在一部分机器上两个问题
- 业务相关的负载均衡可以结合本地缓存,避免本地缓存同步的问题
负载均衡和本地缓存
- 业务无关的负载均衡和本地缓存搭配,效果很差:
- 缓存命中率低
- 缓存占据内存更大
- 业务相关负载均衡,例如根据用户ID来做负载均衡(分库分表大部分都可以看作是业务相关的),存在热点问题
推荐阅读
实施微服务,我们需要哪些基础框架?
开源 Linkerd 项目庆祝一周年纪念日
Rethinking Netflix’s Edge Load Balancing
亿级Web系统的容错性建设实践
分布式系统常见负载均衡算法
predictive_load_balancing
“Predictive Load-Balancing: Unfair but Faster & more Robust” by Steve Gury
(转)深入解析TensorFlow中滑动平均模型与代码实现