Go工程化实践之API设计
API设计
gRPC
gRPC 可以用官网的一句话来概括:
A high-performance, open-source universal RPC framework
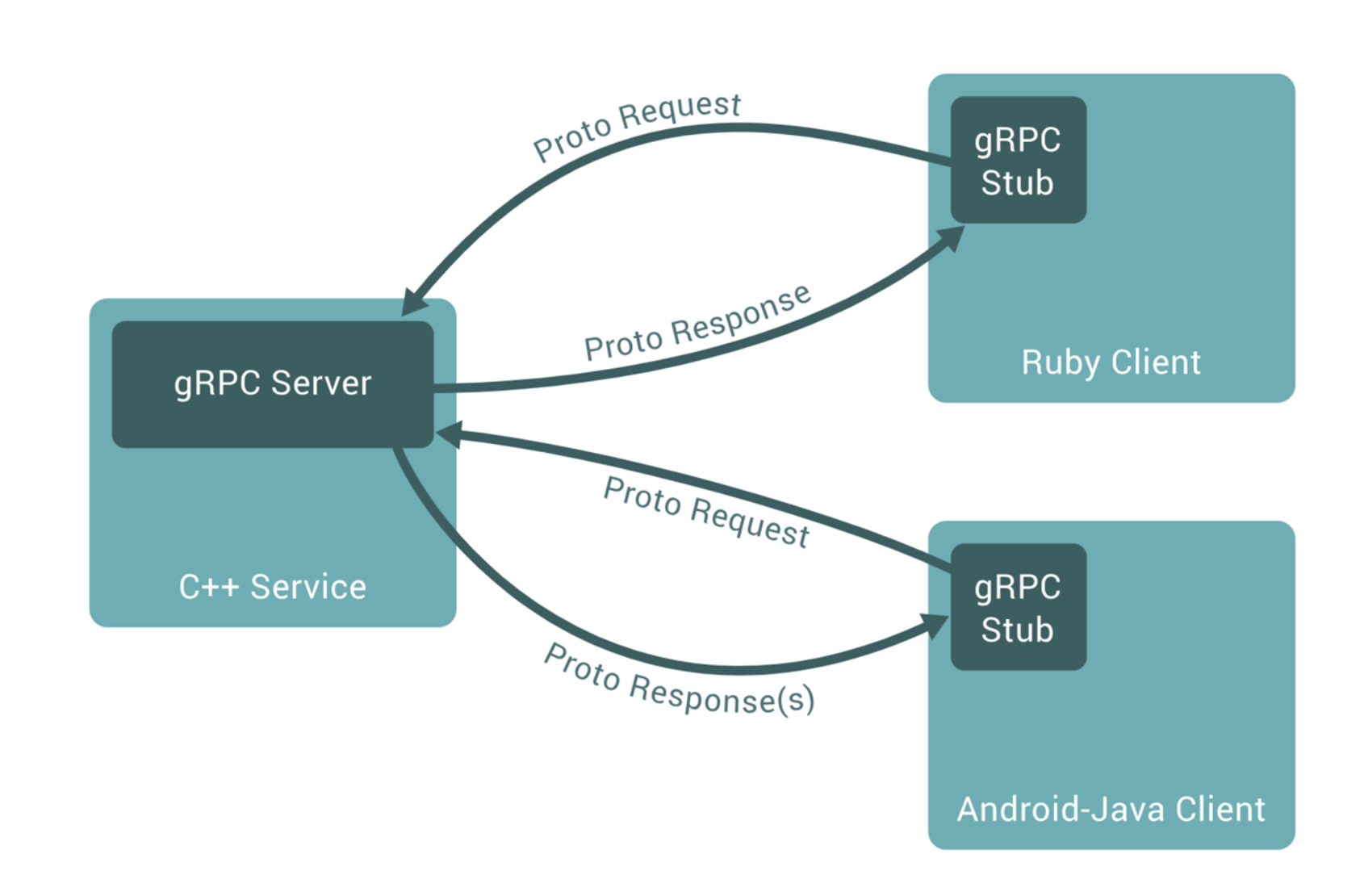
gRPC 有这几个特点:
多语言支持:语言中立,支持多种语言
轻量级、高性能:序列化支持
PB(Protocol Buffer)和JSON,PB是一种语言无关的高性能序列化框架可插拔:支持很多组件,原生有很多
middleware,支持很多扩展IDL:基于文件定义服务,通过
protoc3工具生成指定语言的数据结构、服务端接口以及客户端Stub设计理念:支持超时传递、
RPC取消、元数据传递移动端:基于标准的
HTTP2设计,支持双向流、消息头压缩、单TCP的多路复用、服务端推送等特性。这些特性使得gRPC在移动端设备上更加省电和节省网络流量服务而非对象、消息而非引用:促进微服务的系统间粗粒度消息交互设计理念,这是基于
proto语法,定义service和message负载无关的:不同的服务需要使用不同的消息类型和编码,例如
protocol buffers、JSON、XML和Thrift流:支持
Streaming API阻塞式和非阻塞式:支持异步和同步处理在客户端和服务端交互的消息序列
元数据交换:常见的横切关注点,如认证或跟踪,依赖数据交换
标准化状态码:客户端通常以有限的方式响应 API 调用返回的错误
![image-20231016164842712]()
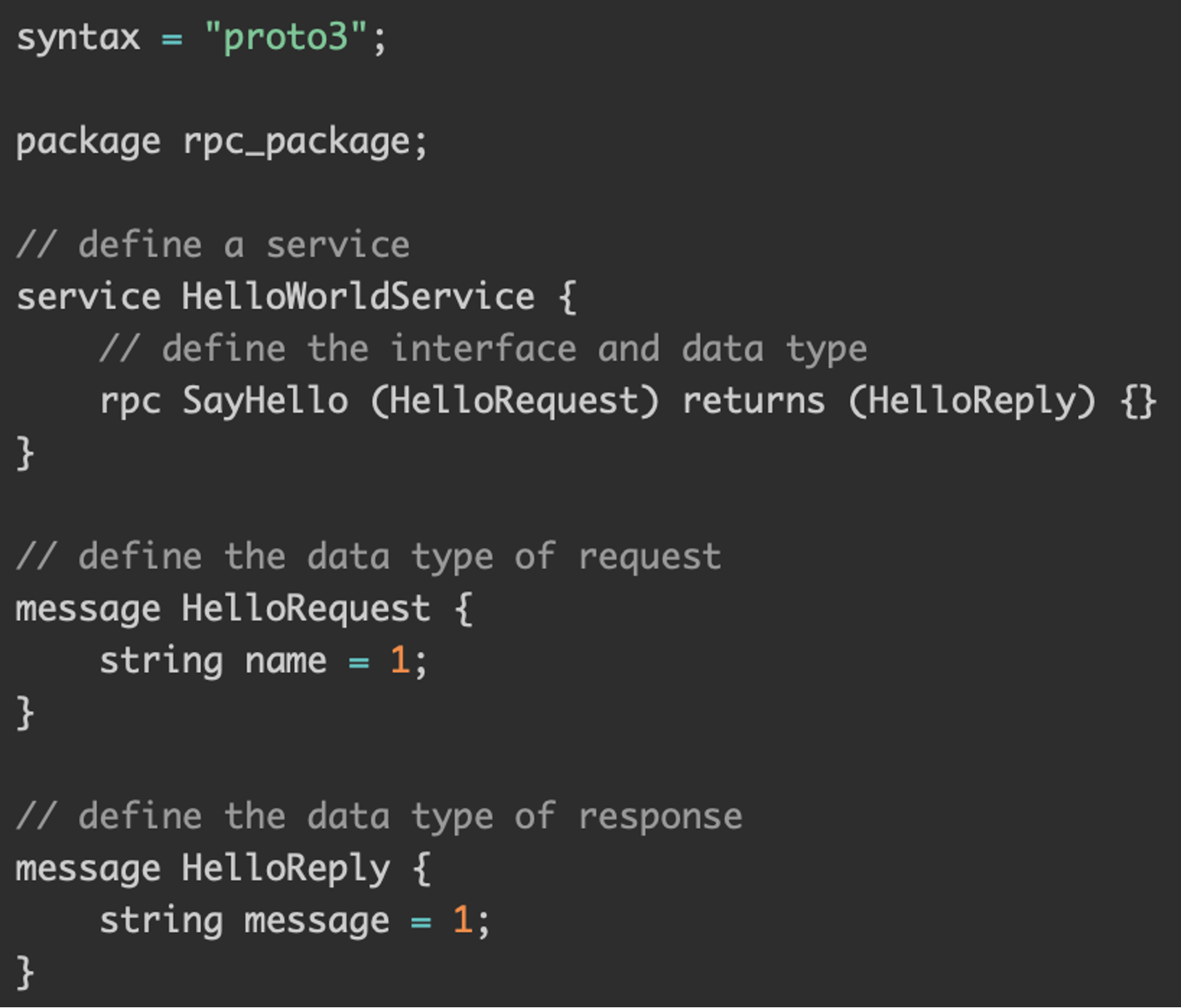
1 | protoc --go_out=. --go_opt=paths=source_relative \ |
API Project
例如在对接开发时,一般情况下需要根据对方的文档进行开发对接,很容易因为文档与线上环境不一致导致问题。而一些大厂为了统一检索和规范 API,会在内部建议一个统一的 apis 仓库,整合所有对内对外 API。
例如:
https://github.com/googleapis/googleapis
https://github.com/envoyproxy/data-plane-api
https://github.com/istio/api
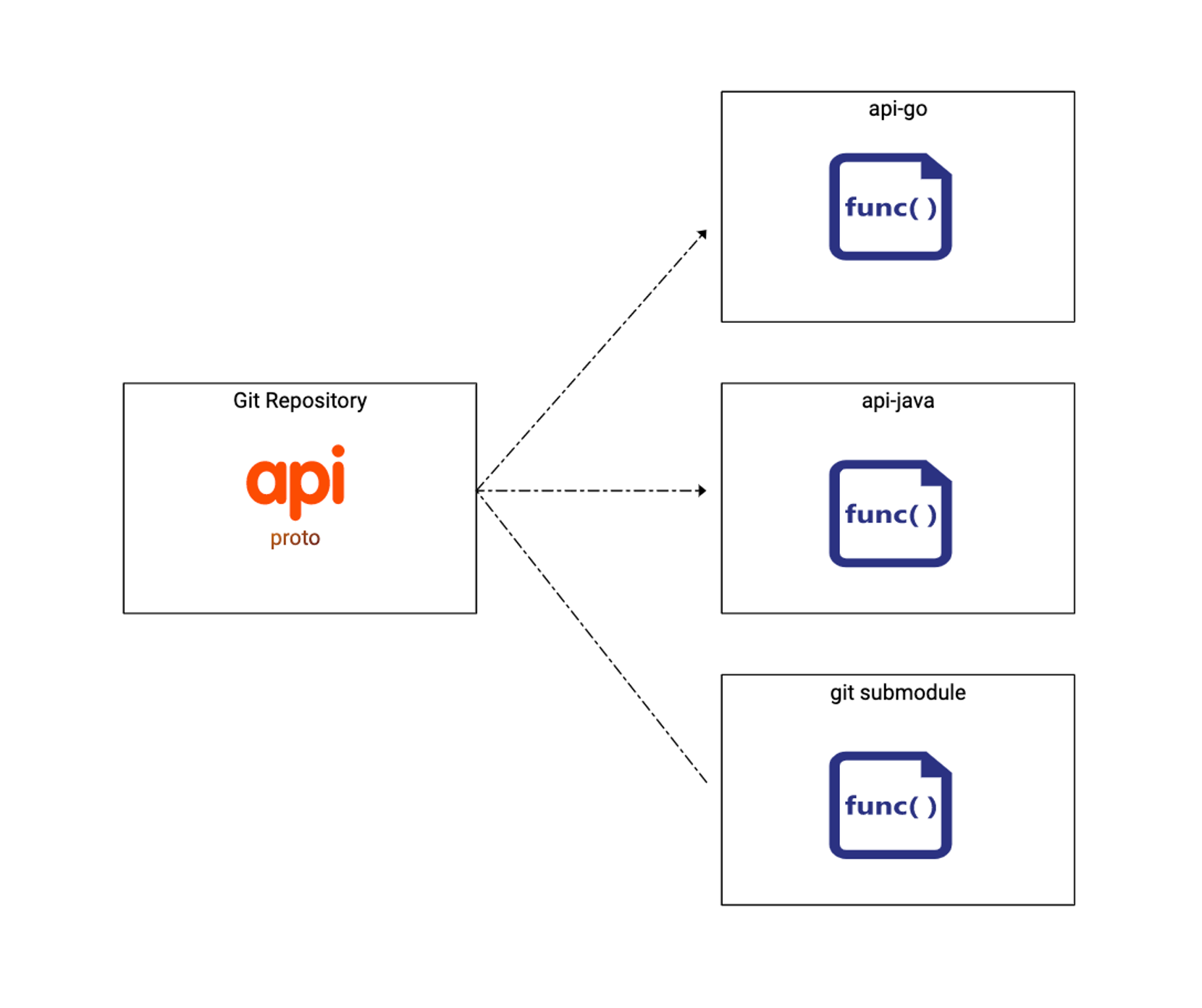
- API 仓库,方便跨部门协作
- 版本管理,基于 git 控制
- 规范化检查,API lint
- API design review,变更 diff
- 权限管理,目录 OWNERS
API Project Layout
以B站代码层级做实例。
项目中定义 proto,以 api 为包名根目录:

在统一仓库中管理 proto,以仓库为包名根目录:

在 apis 仓库中的目录:

在修改或者更新之后,可以将 api 目录拷贝到 apis 仓库的目录中。
API Compatibility
向后兼容(非破坏性)的修改
给API服务定义添加 API 接口
从协议的角度来看,这始终是安全的
给请求消息添加字段
只要客户端在新版和旧版中对该字段的处理不保持一致,添加请求字段就是兼容的。
给响应消息添加字段
在不改变其他响应字段的行为的前提下,非资源(例如,ListBooksResponse)的响应消息可以扩展而不必破坏客户端的兼容性。即使会引入冗余,先前在响应中填充的任何字段应继续使用相同的语义填充。
向后不兼容(破坏性)的修改
删除或重命名服务、字段、方法或枚举值
从根本上说,如果客户端代码可以引退某些东西,那么删除或重命名它都是不兼容的变化,这时必须修改 major 版本号。
修改字段的类型
即使新类型是传输格式兼容的,这也可能会导致客户端库的代码发生变化,因此必须增加 major 版本号。对于编译型静态语言来说,会容易引入编译错误。
修改现有请求的可见行为
客户端通常依赖于 API 行为和语义,即使这样的行为没有被明确支持或记录。因此,在大多数情况下,修改 API 数据的行为或语义将被消费者视为是破坏性的。如果行为没有加密隐藏,编码者应该加设用户已经发现它,并将依赖于它。
给资源消息添加 读取/写入 字段
API Naming Comventions
包名为应用的标识(APP_ID),用于生成 gRPC 请求路径,或者 proto 之间进行引用 Message。文件中声明的包名称应该于产品和服务名称保持一致。带有版本的 API 的软件包名称必须以此版本结尾。
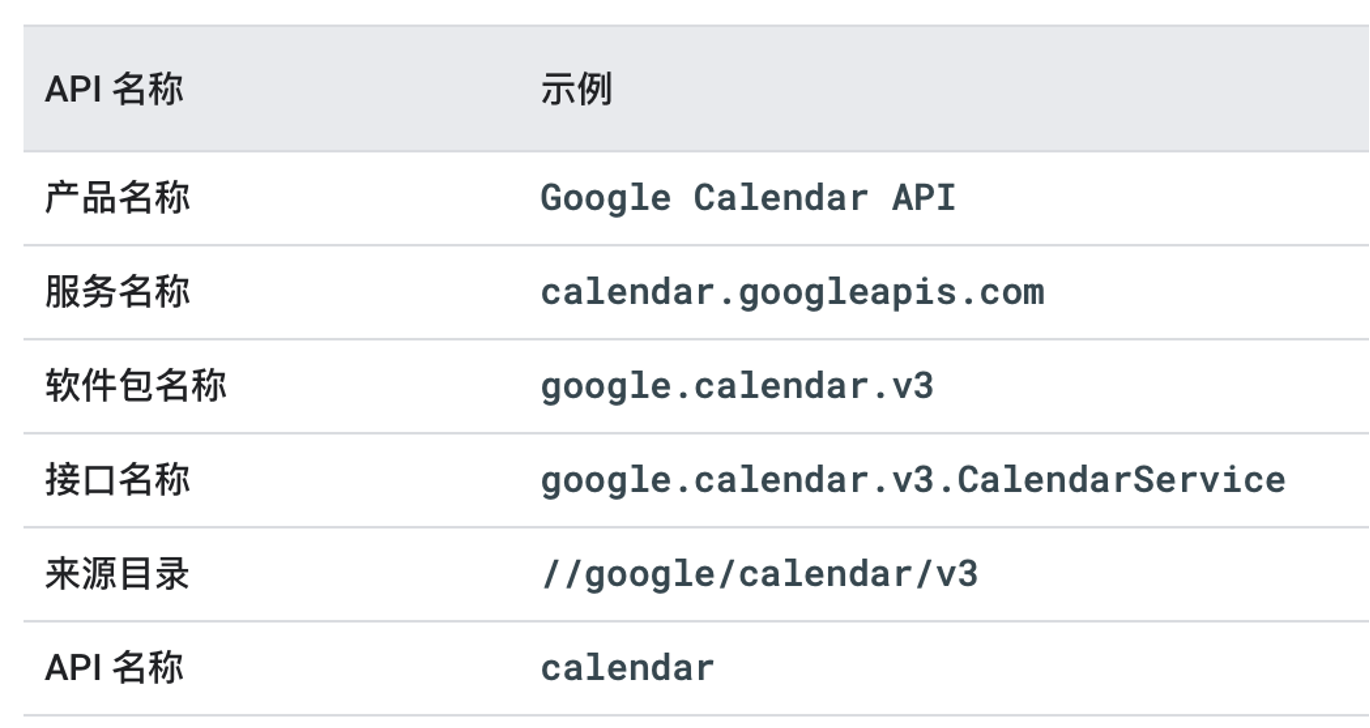
my.package.v1,为 API 目录,定义service相关接口,用于提供业务使用。
1 | // RequestURL: |
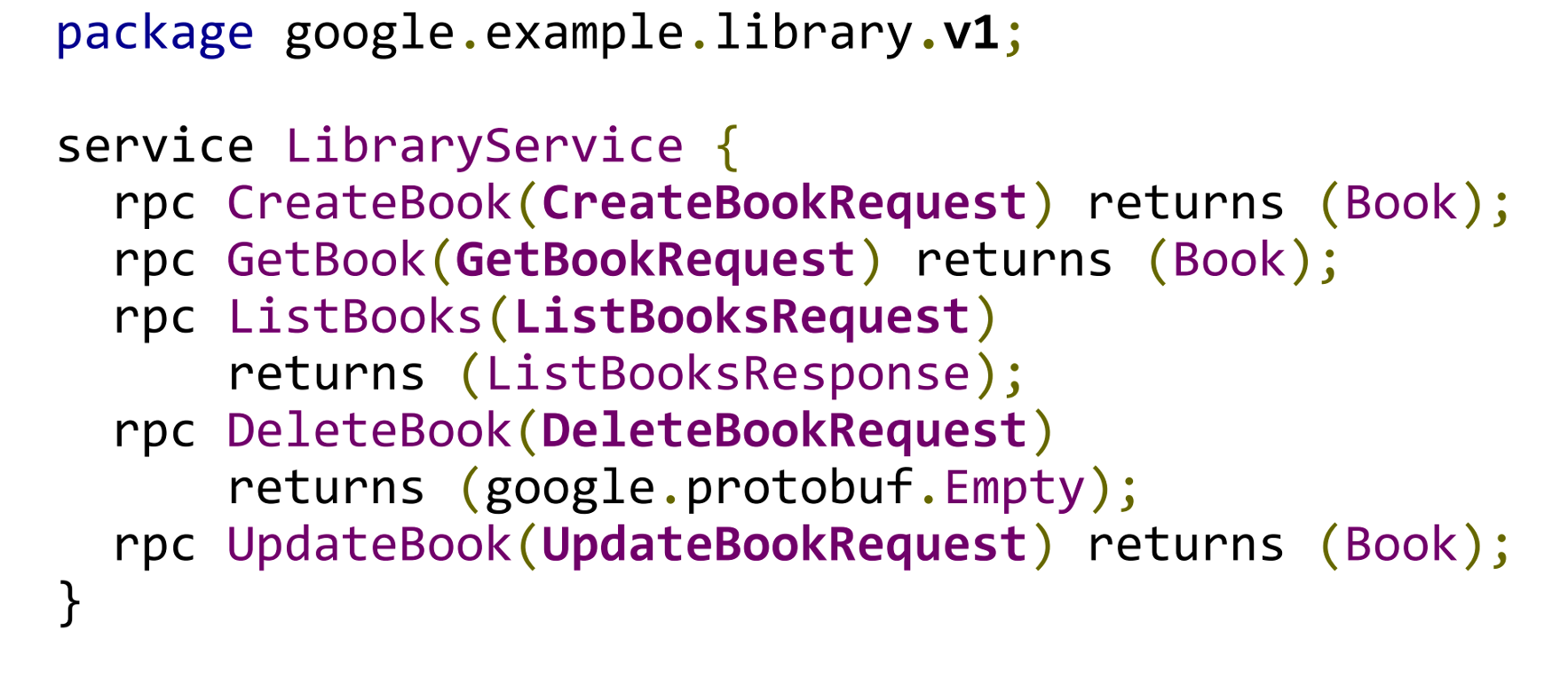
API 设计推荐阅读:Google API 设计指南
API Primitive Fields
gRPC 默认使用 Protobuf v3 格式,因为去除了 required 和 optional 关键字,默认全部都是 optional 字段。如果没有赋值的字段,默认会基础类型字段的默认值,比如 0 或者 “”。
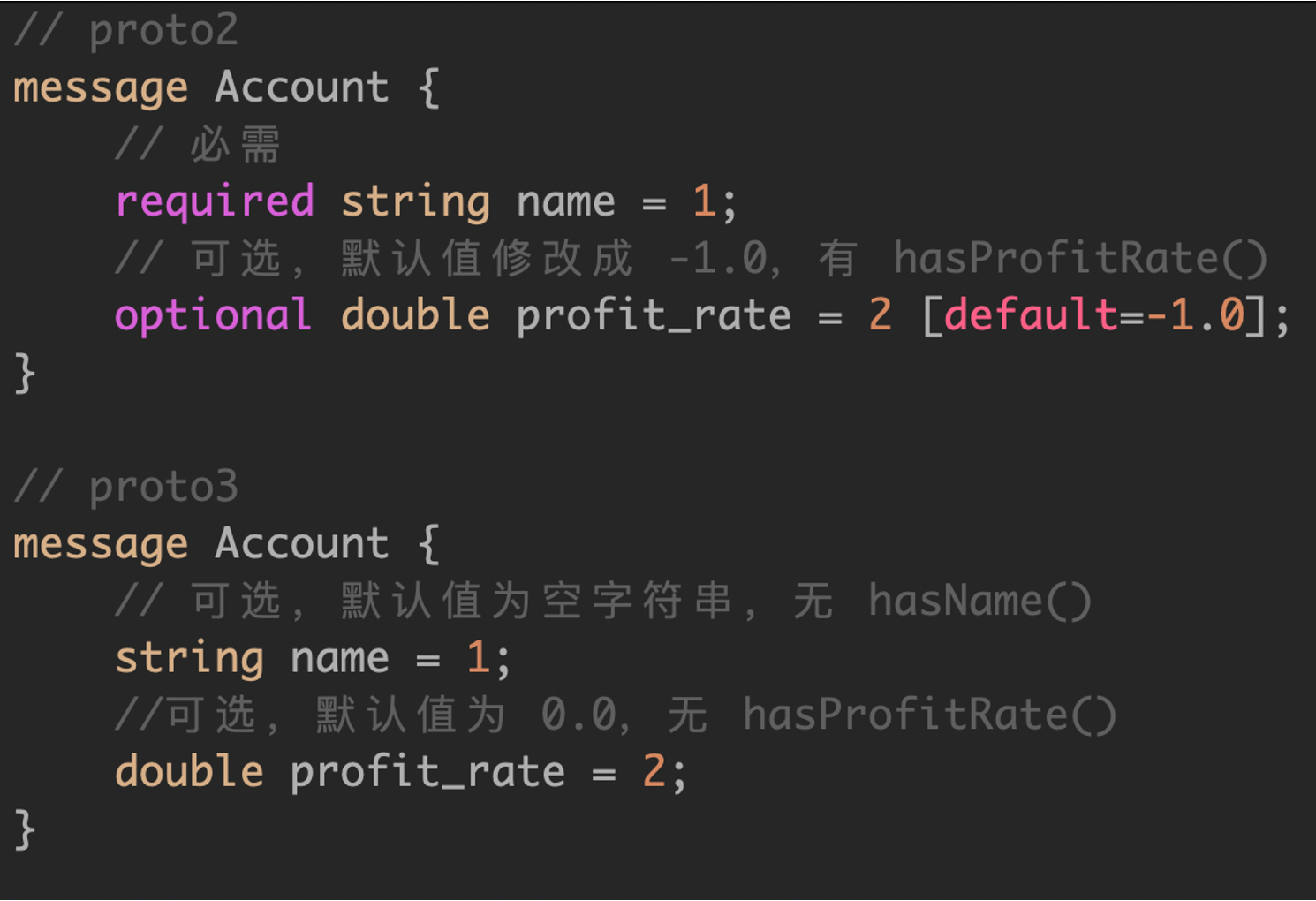
Protobuf v3 中,建议使用:
https://github.com/protocolbuffers/protobuf/blob/master/src/google/protobuf/wrappers.proto
Wrapper 类型的字段,即包装一个 message,使用时变为指针
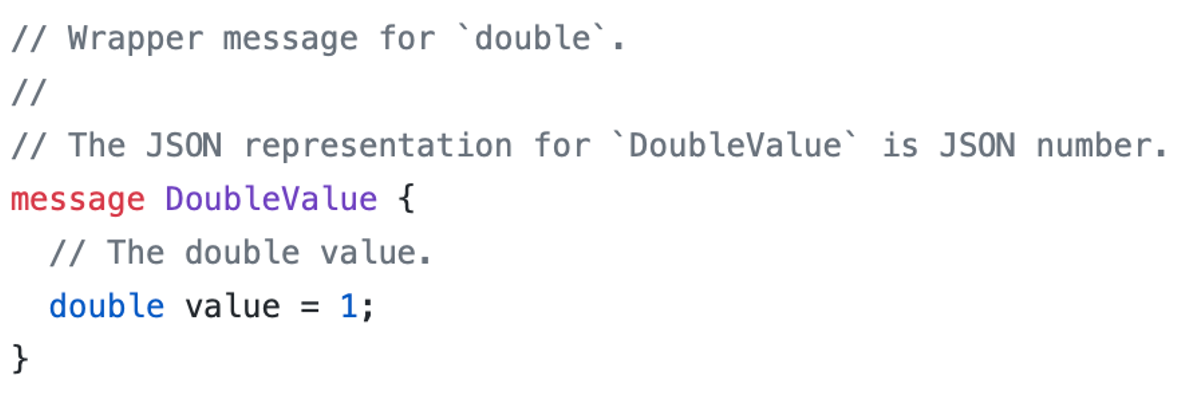

Protobuf作为强schema的描述文件,也可以方便扩展,也可以用于配置文件。
API Errors
使用一小组标准错误配合大量资源
- 例如,服务器没有定义不同类型的 “找不到” 错误,而是使用一个标准
google.rpc.Code.NOT_FOUND错误代码并包俗客户端找不到哪个特定资源。状态空间变小降低了文档的复杂性,在客户端库中提供了更好的惯用映射,并降低了客户端的逻辑复杂性,同时不限制是否包含可操作信息(/google/rpc/error_details
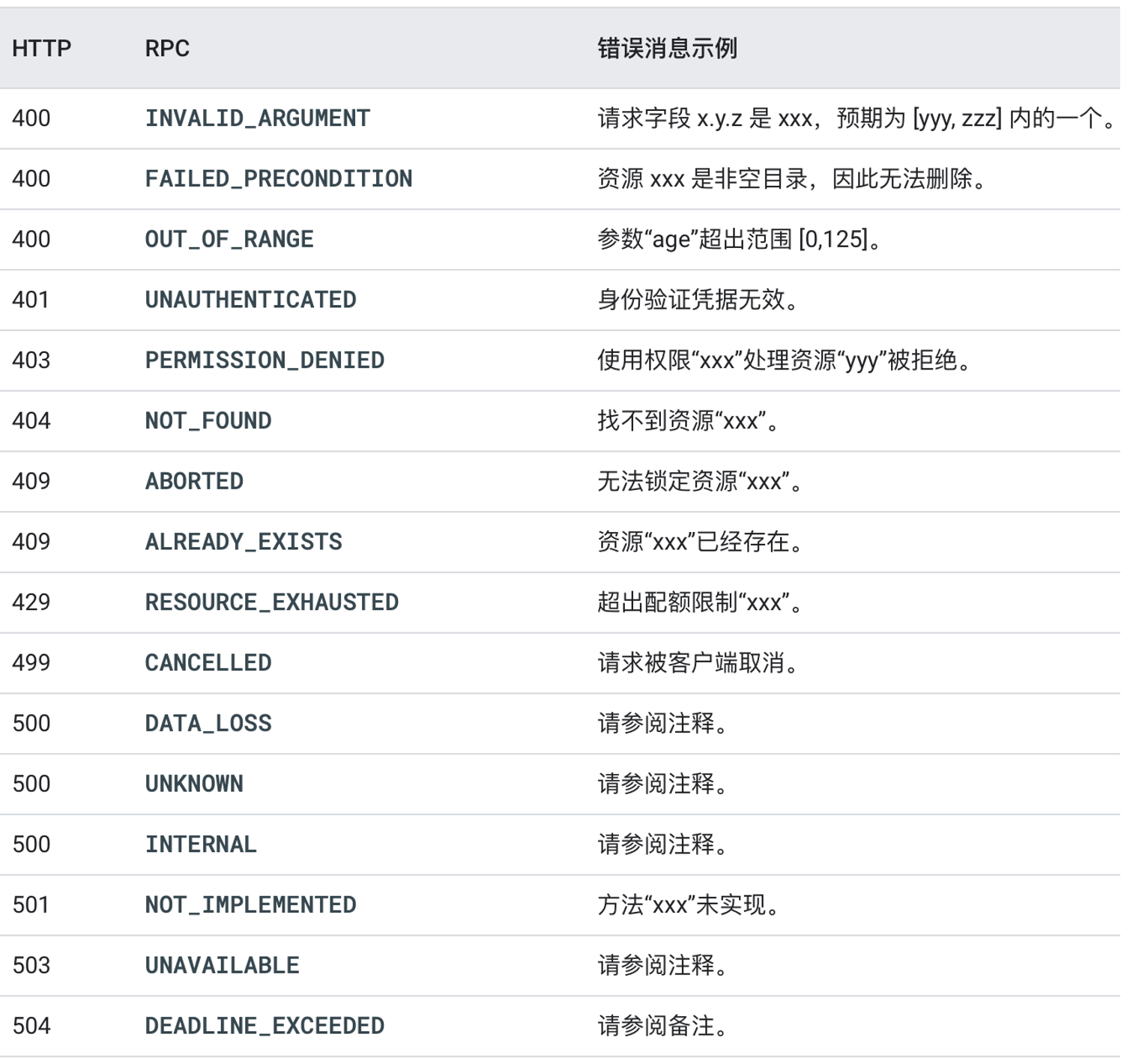
错误传播
如果 API 服务依赖于其他服务,则不应盲目地将这些服务的错误传播到上游的客户端。在翻译错误时,建议执行以下操作:
- 隐藏实现详细信息和机密信息
- 调整负责该错误的一方。例如,从另一个服务接受
INVALID_ARGUMENT错误的服务器应该将INTERNAL传播给它自己的调用者
全局错误码
全局错误码,是松散、易被破坏契约的,基于上述讨论,在每个服务传播错误的时候,做一次翻译,这样保证每个服务 + 错误枚举,应该是唯一的,而且在 proto 定义中是可以写出来文档的。
自定义错误:

rpc
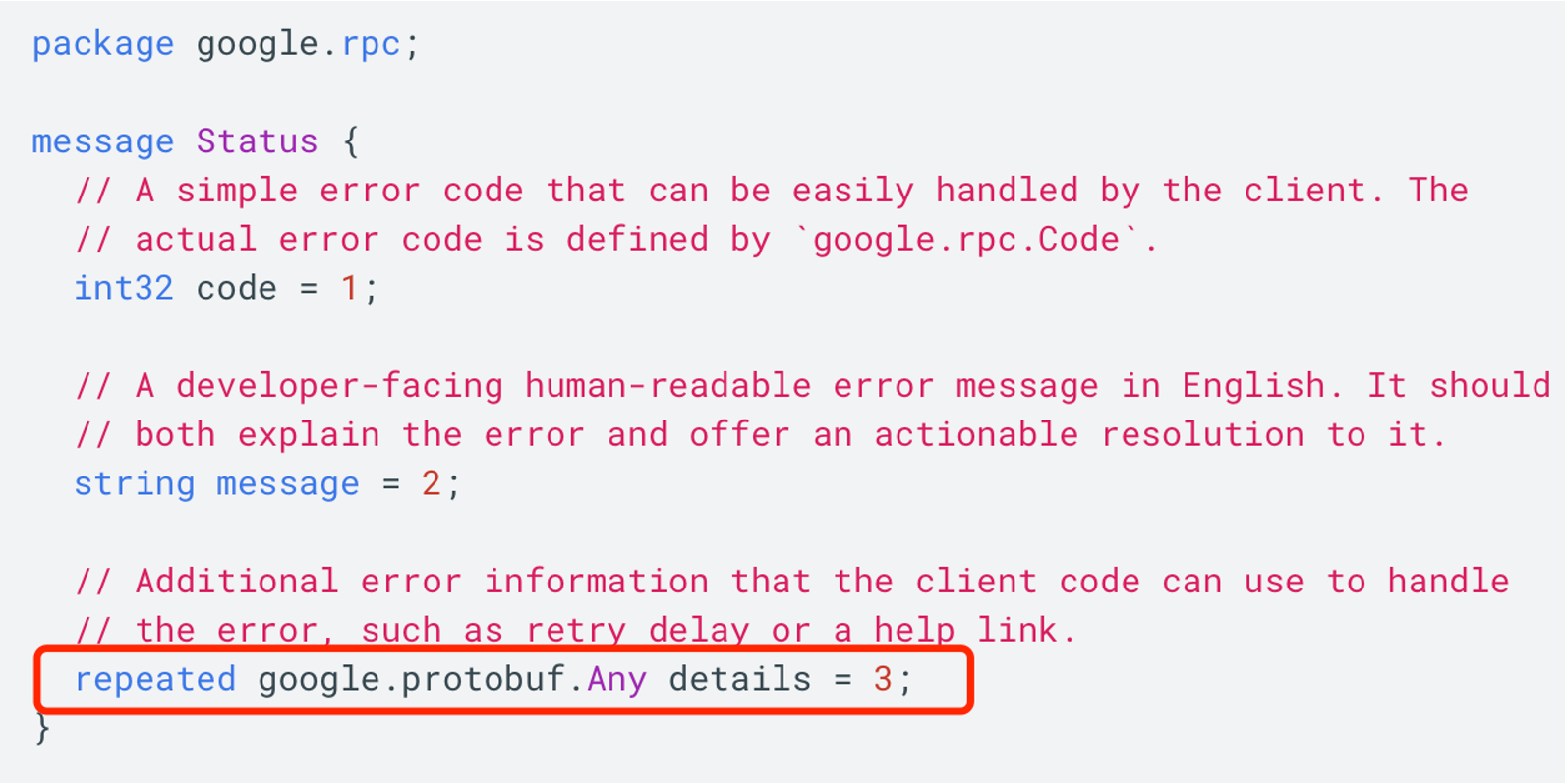
根据这个结构体,定义一些全局错误。可以将业务层返回的 error 包裹在结构体中。
API Design
API 接口设计

如果需要返回 Book 是否已经被读过,可能需要增加一个字段

此时,如果 Book 字段被其他接口引用,很容易影响到其他接口的返回。
FieldMask 部分更新的方案:
客户端可以执行需要更新的字段信息:
paths: "author"paths: "submessage.submessage.field"空
FieldMask默认应用到所有字段

错误码实践
错误码可以分为三种:
- 下游错误码
- 内部业务错误码
- 上游可感知错误码
可以从这三个角度考虑如何处理
- 是否希望上游的游服务知道下游的错误?如果不希望,则将下游的错误码转换,去掉敏感信息
- 上游的服务能否理解下游的错误?如果不能,则转换成能理解的错误
- 是否信任上游?不信任,则将内部业务错误码转换成安全的错误码,这样不会爆率过多的细节
中间件 API 设计方法论
一般情况下,写中间件的过程会通过个人经验来逐步优化,一般是从自底向上到自顶向下。
自底向上

- 一般就是最开始不清楚如何设计,所以直接写实现,没有接口设计
- 在实现过程中,发现某个地方可能存在变更的可能,于是将这个地方抽象出来,做成了一个接口
- 在不断抽象接口的时候,会发现有一些接口比另外一些接口更加抽象,也就是更为高级,最终组成一个类似金字塔的层级
- 难点在于知识变更点 - 依赖于个人见识和经验
自顶向下
在有了比较丰富的经验之后,就可以自顶向下

- 设计核心
API- 一组能够描述清楚自己整个功能的API - 在实现核心
API的时候,发现某种实现,需要引入新的接口,这些接口就是支撑核心接口的次级接口 - 围绕着次级接口的实现设计次次级接口
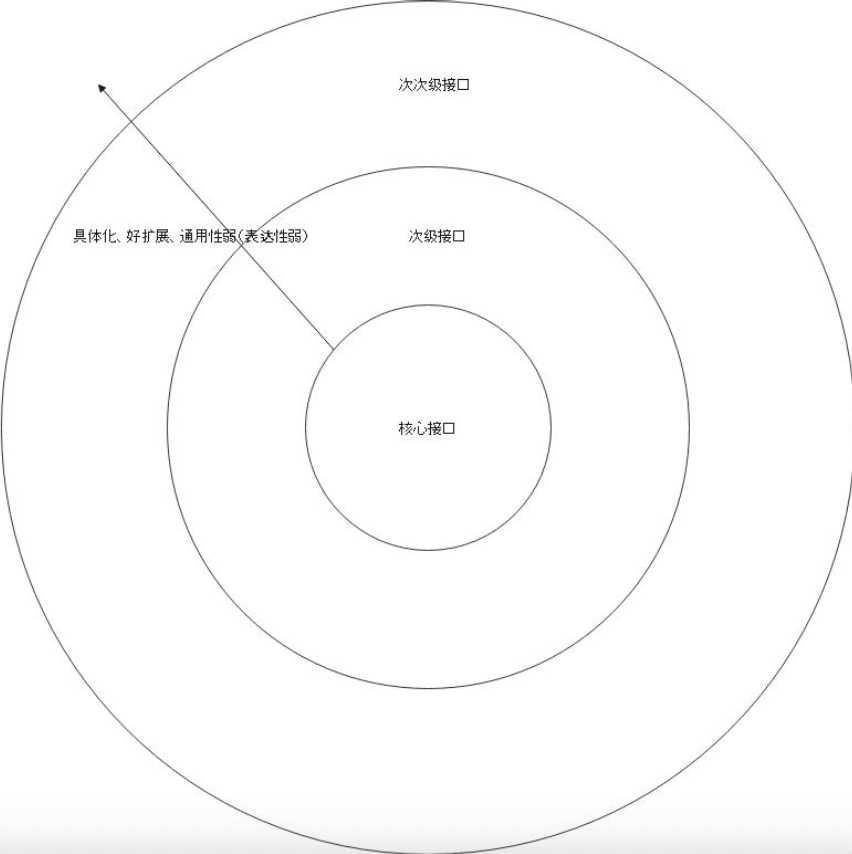
随着接口不断向外扩张,其表达性开始减弱。
比如说核心接口表达了整个模块的功能,那么次级接口可能只是表达了模块的某个方便的功能。
最外围的接口可能只是这个模块一个非常具体的点可以有不同的做法
同时抽象性下降,愈发具体。接口更加具体带来的好处就是 好理解,易扩展。
比如说大多数中间件,直接设计出来就是为了用户扩展的接口,普遍都是外围接口,例如各种
Filter接口,Interceptor接口越是靠近核心的接口,开发者越不想你扩展,甚至可能根本没有提供接入自定义实现的手段
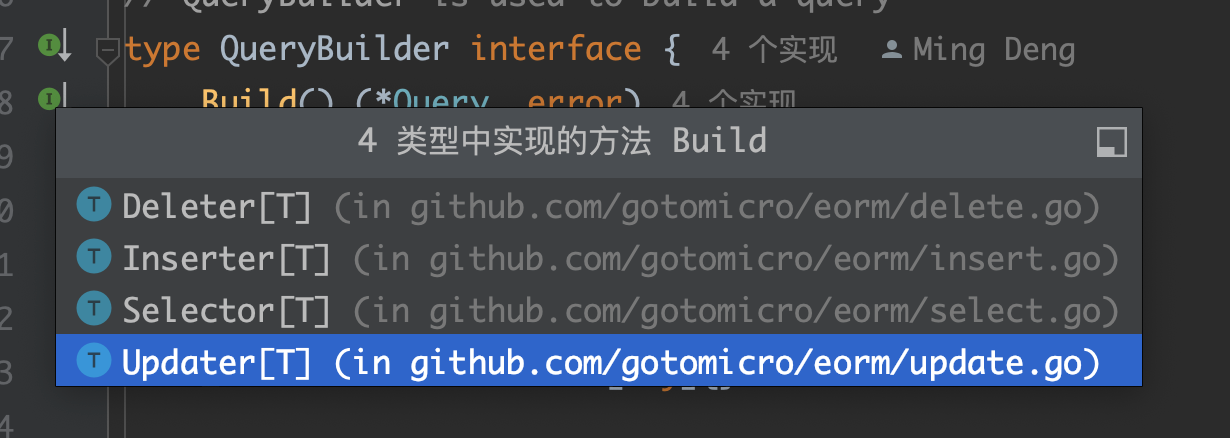
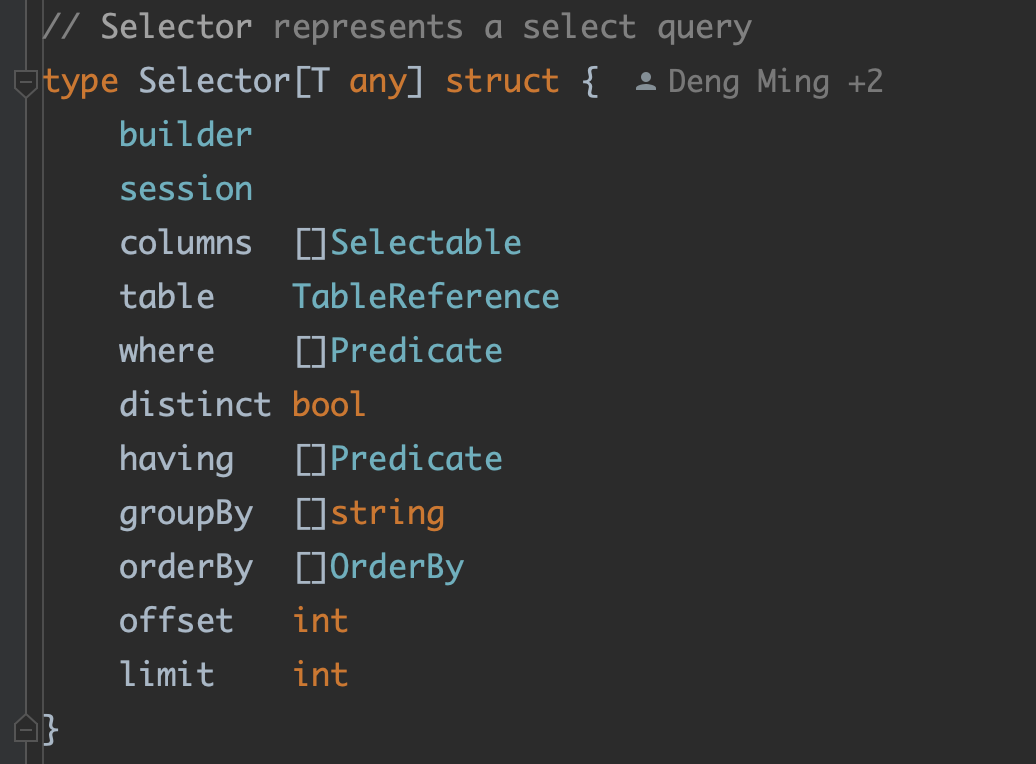
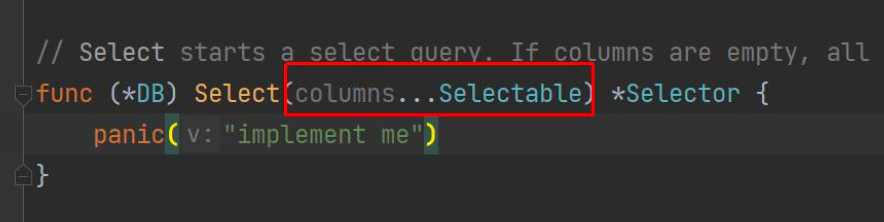
例如,在 ORM 中间件中,一个检索构建对象的接口。

核心接口:
QueryBuilder,描述了整个模块是干啥的:也就是构建一个查询,返回SQL和查询参数。剩下的不管是实现,还是别的接口,都是服务于这个接口的。
![image-20231019161005303]()
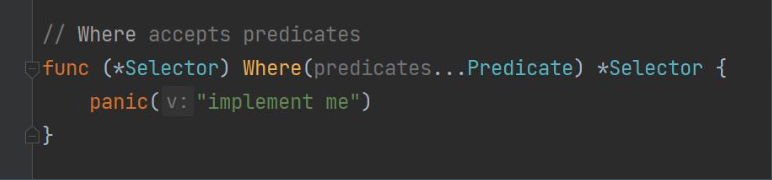
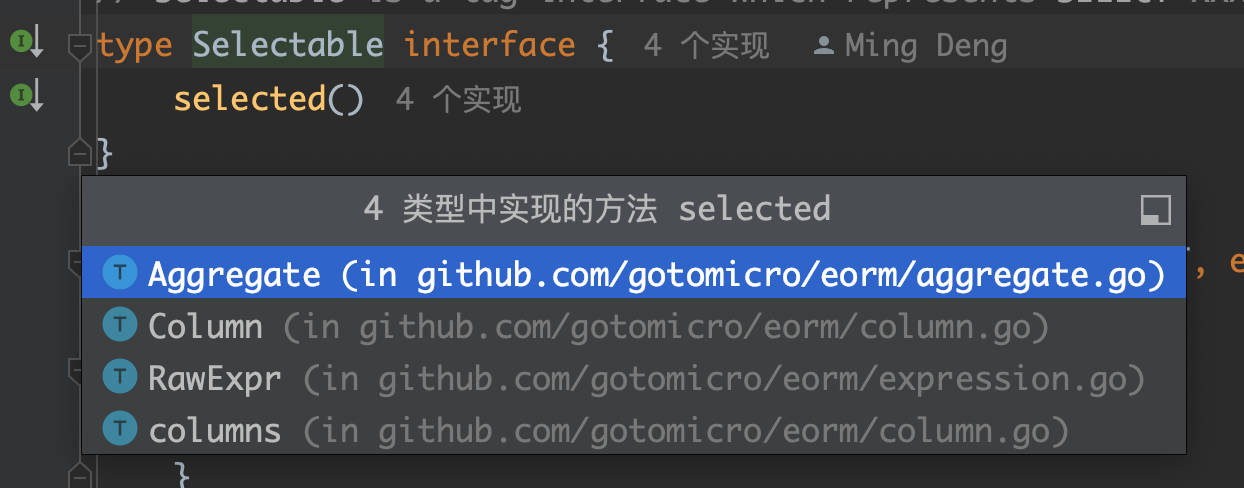
次级接口:
Selector是QueryBuilder的直接实现,为了支撑Selector的实现,引入了新的接口![image-20231019161207678]()
![image-20231019155806717]()
![image-20231019155815182]()
![image-20231019161314900]()
参考
错误数
区分 Protobuf 中缺失值和默认值
protobuf/src/google/protobuf/wrappers.proto
Functional options for friendly APIs
Self-referential functions and the design of options
Creating Good API Errors in REST, GraphQL and gRPC