Kubernetes 控制平面组件:etcd
etcd 简介
Etcd 是 CoreOS 基于 Raft 开发的分布式 key - value 存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)。
在分布式系统中,如何管理节点间的状态一直是一个难题,etcd 像是专门为集群环境的服务发现和注册而设计,它提供了数据 TTL 失效、数据改变监视、多值、目录监听、分布式锁原子操作等功能,可以方便的跟踪并管理集群节点的状态。
- 键值对存储:将数据存储在分层组织的目录中,如同在标准文件系统中
- 检测变更:检测特定的键或目录以进行更改,并对值的更改做出反应
- 简单:
curl可访问的用户的API(HTTP+JSON) - 安全:可选的
SSL客户端证书认证 - 快速:单实例每秒 1000 次写操作,2000+ 次读操作
- 可靠:使用
Raft算法保证一致性(选举Leader;超过半数达成一致)
主要功能
- 基本的
key-value存储 - 监听机制
key的过期及续约机制,用于监控和服务发现- 原子
Compare And Swap和Compare And Delete,用于分布式锁和leader选举
使用场景
- 也可以用于键值对存储,应用程序可以读取和写入
etcd中的数据 etcd比较多的应用场景是用于服务注册与发现- 基于监听机制的分布式异步系统
键值对存储
etcd 是一个键值存储的组件,其他的应用都是基于其键值存储的功能展开。
- 采用
kv型数据存储,一般情况下比关系型数据库快 - 支持动态存储(内存)以及静态存储(磁盘)
- 分布式存储,可集成为多节点集群
- 存储方式,采用类似目录结构。(
B+tree)- 只有叶子节点才能真正存储数据,相当于文件
- 叶子节点的父节点一定是目录,目录不能存储数据
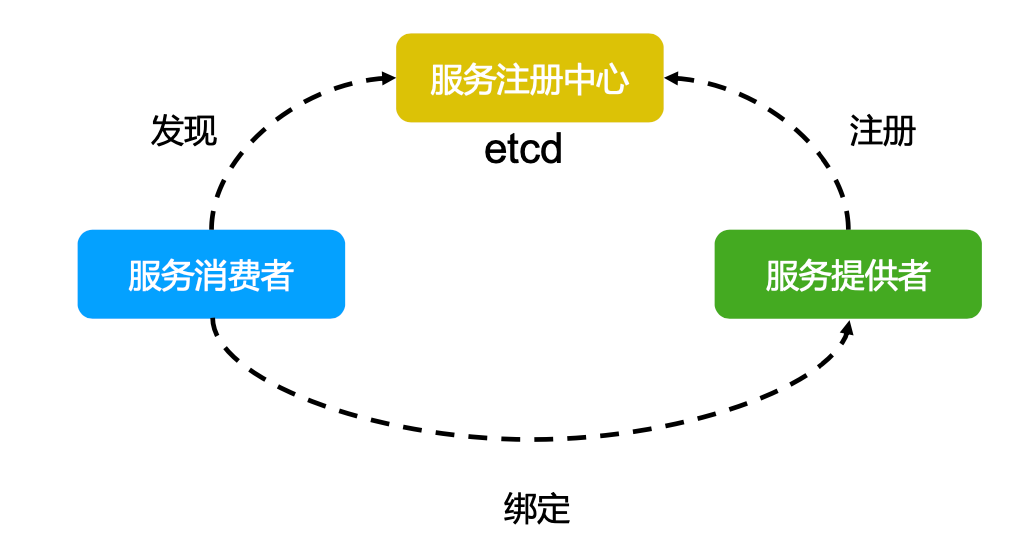
服务注册与发现
- 强一致性、高可用的服务存储目录
- 基于
Raft算法的etcd天生就是这样一个强一致性、高可用的服务存储目录
- 基于
- 一种注册服务和服务健康状况的机制
- 用户可以在
etcd中注册服务,并且对注册的服务配置key TTL,定时保持服务的心跳(续约)以达到监控健康状态的效果
- 用户可以在
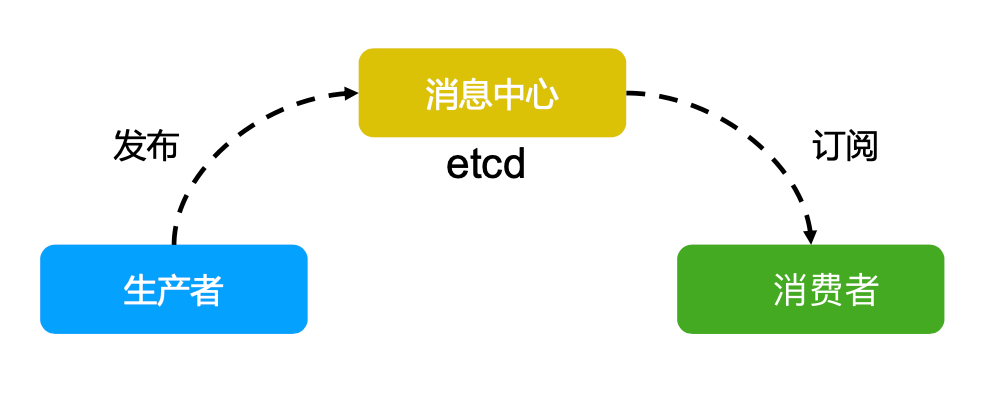
消息发布与订阅
- 在分布式系统中,最适用的一种组件间通信方式就是消息发布与订阅;
- 即构建一个配置共享中心,数据提供者在这个配置中心发布消息,而消息使用者则订阅他们关心的主题,一旦主题有消息发布,就会实时通知订阅者;
- 通过这种方式可以做到分布式系统配置的集中式管理与动态更新;
- 应用中用到的一些配置信息放到
etcd上进行集中管理; - 应用在启动的时候主动从
etcd获取一次配置信息,同时,在etcd节点上注册一个Watcher并等待,以后每次配置有更新的时候,etcd都会实时通知订阅者,以此达到获取最新配置信息的目的。
Etcd 的安装
下载安装包,参考 https://github.com/etcd-io/etcd/releases
1 | ETCD_VER=v3.4.29 |
为避免跟本地的 hostNetwork 的 etcd 容器冲突,我们需要修改 etcd 的监听端口
initial-cluster:初始化集群,需要列所有 member 地址What is the difference between listen-<client,peer>-urls, advertise-client-urls or initial-advertise-peer-urls?
listen-client-urls and listen-peer-urls specify the local addresses etcd server binds to for accepting incoming connections. To listen on a port for all interfaces, specify 0.0.0.0 as the listen IP address.
advertise-client-urls and initial-advertise-peer-urls specify the addresses etcd clients or other etcd members should use to contact the etcd server. The advertise addresses must be reachable from the remote machines. Do not advertise addresses like localhost or 0.0.0.0 for a production setup since these addresses are unreachable from remote machines.
listen-client-urls和listen-peer-urls指定etcd服务器绑定以接受传入连接的本地地址。要在所有接口上监听一个端口,请将0.0.0.0指定为监听IP地址。
advertise-client-urls和initial-advertise-peer-urls指定etcd客户端或其他etcd成员应使用的地址来联系etcd服务器。广告地址必须从远程机器可达。不要在生产环境中广告类似localhost或0.0.0.0的地址,因为这些地址对于远程机器是无法访问的。1
2
3
4
5etcd --listen-client-urls 'http://localhost:12379' \
--advertise-client-urls 'http://localhost:12379' \
--listen-peer-urls 'http://localhost:12380' \
--initial-advertise-peer-urls 'http://localhost:12380' \
--initial-cluster 'default=http://localhost:12380'Member list
获取集群成员
1
etcdctl member list --write-out=table --endpoints=localhost:12379
操作键值对
1
2
3
4
5etcdctl --endpoints=localhost:12379 put /key1 val1
etcdctl --endpoints=localhost:12379 put /key2 val2
etcdctl --endpoints=localhost:12379 get --prefix /
etcdctl --endpoints=localhost:12379 get --prefix / --keys-only
etcdctl --endpoints=localhost:12379 watch --prefix /1
2
3
4
5
6
7
8
9
10etcdctl --endpoints=localhost:12379 put /key val1
etcdctl --endpoints=localhost:12379 put /key val2
etcdctl --endpoints=localhost:12379 put /key val3
etcdctl --endpoints=localhost:12379 put /key val4
// 以更详细的方式获取 key
etcdctl --endpoints=localhost:12379 get /key -wjson
// 监听
etcdctl --endpoints=localhost:12379 watch --prefix / --rev 0
etcdctl --endpoints=localhost:12379 watch --prefix / --rev 1
etcdctl --endpoints=localhost:12379 watch --prefix / --rev 2第三方库和客户端工具
目前有很多支持
etcd的库和客户端工具- 命令行客户端工具
etcdctl(将命令转化成REST进行请求) Go客户端go-etcdJava客户端jetcdPython客户端python-etcd
- 命令行客户端工具
常用操作
查看集群成员状态
1 | etcdctl member list --write-out=table |
基本的数据读写操作:
写入数据
1 | etcdctl --endpoints=localhost:12379 put /a b |
读取数据(获取键值对)
1 | etcdctl --endpoints=localhost:12379 get /a |
按 key 的前缀查询数据
1 | etcdctl --endpoints=localhost:12379 get --prefix / |
只显示键值
1 | etcdctl --endpoints=localhost:12379 get --prefix / --keys-only --debug |
核心: TTL & CAS
TTL(time to live)指的是给一个 key 设置一个有效期,到期后这个 key 就会被自动删掉,这在很多分布式锁的实现上都会用到,可以保证锁的实时有效性。
Atomic Compare-and-Swap(CAS)指的是在对 key 进行赋值的时候,客户端需要提供一些条件,当这些条件满足后,才能赋值成功。这些条件包括:
prevExist:key当前赋值前是否存在prevValue:key当前赋值前的值prevIndex:key当前赋值前的Index
这样的话,key 的设置是有前提的,需要知道这个 key 当前的具体情况才可以对其设置
Raft 协议
Raft 协议概览
Raft 协议基于 quorum 机制,即大多数同意原则,任何的变更都需要超过半数的成员确认。
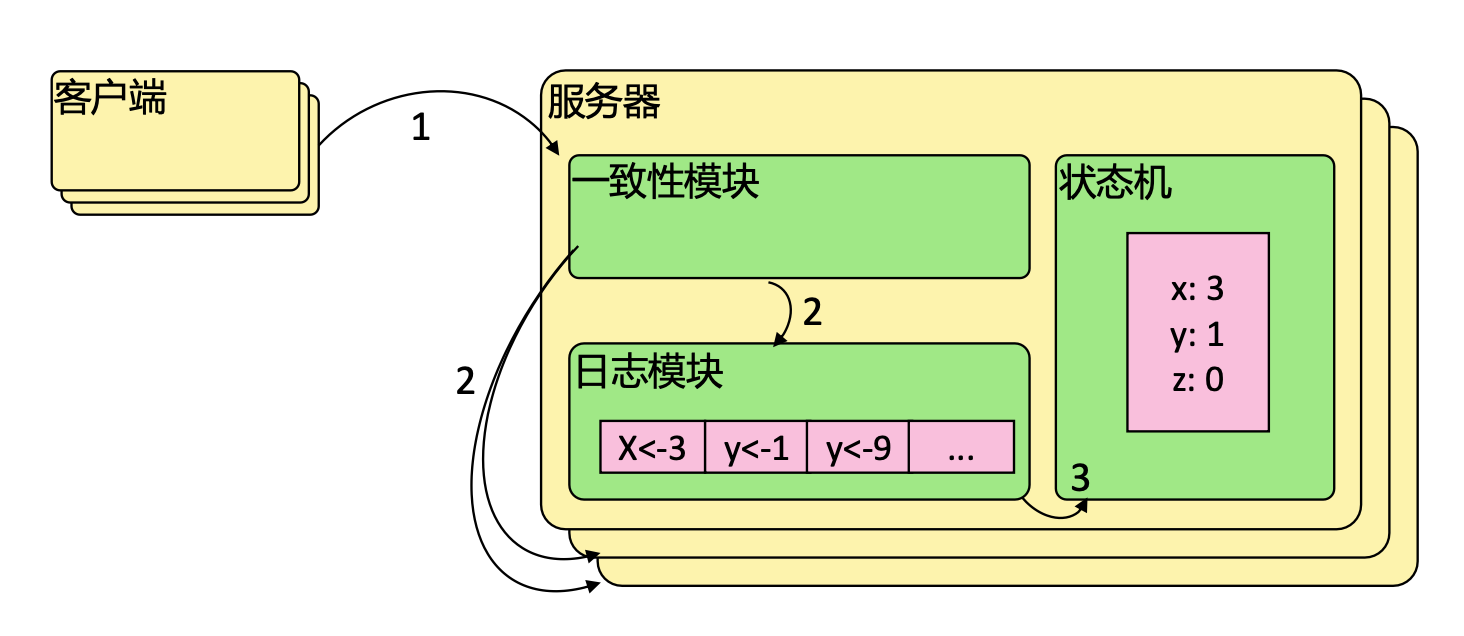
请求发送到服务器端,服务器中的一致性模块进行一致性协商,一致性模块将请求发送到另外两个服务器,并且将本次请求写入到本地的日志模块(临时存储)中,其他服务器接收到之后,记录到本地日志模块,记录完成之后,返回给第一个节点,当超过半数返回,则更新状态机(可以理解为持久化组件)。
理解 Raft 协议
https://thesecretlivesofdata.com/raft/
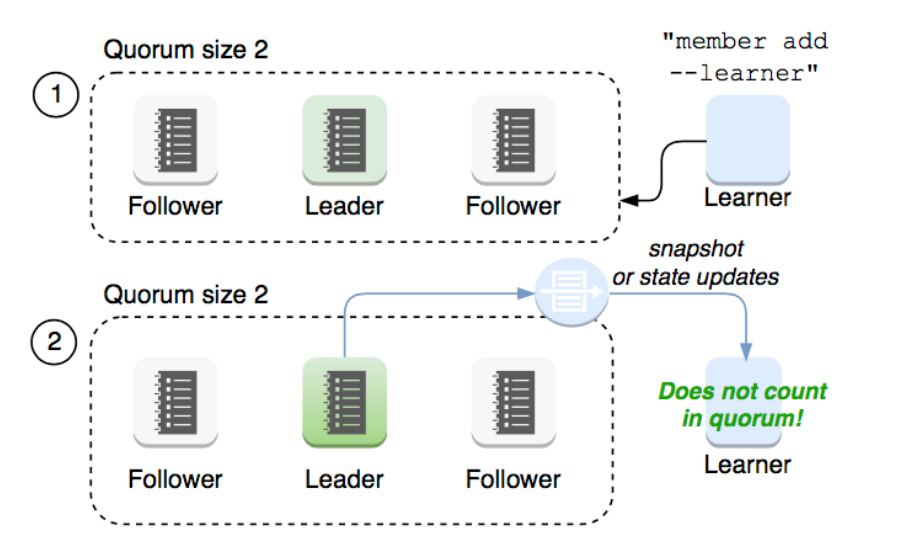
learner
Raft 4.2.1 引入的新角色
当出现一个 etcd 集群需要增加节点时,新节点与 Leader 的数据差异较大,需要较多数据同步才能跟上 leader 的最新的数据。
此时 Leader 的网络带宽很可能被用尽,进而使得 leader 无法正常保持心跳。
进而导致 follower 重新发起投票。
进而可能引发 etcd 集群不可用。
Learner 角色只接收数据而不参与投票,因此增加 learner 节点时,集群的 quorum 不变。
etcd 基于 Raft 的一致性
选举方法:
- 初始启动时,节点处于
follower状态并设定一个election timeout,如果在这一时间周期内没有收到来自leader的heartbeat,节点将会发起选择:将自己切换为candidate之后,向集群中其他candidate节点(满足1:自己没有leader,2:自己没有投票,才会投票)发送请求,询问其是否选举自己成为leader。 - 当收到来自集群中过半数节点的接收投票后,节点即为
leader,开始接收保存client的数据并向其他的follower节点同步日志。 - 如果没有达成一致,则
condidate随机选择一个等待间隔(150ms~300ms)再次发起投票,得到集群中半数以上follower接受的candidate将成为leader leader节点依靠定时向follower发送heartbeat来保持其地位- 任何时候如果其他
follower在election timeout期间都没有收到来自leader的heartbeat,同样会将自己状态切换为candidate并发起选举。每成功选举一次,新leader的任期(Term)都会比之前leader的任期大 1;
日志复制
- 当
Leader接收到客户端的日志(事务请求)后,先把该日志追加到本地的Log中 - 然后通过
heartbeat把该Entry同步给其他Follower Follower接收到日志后,记录日志然后向Leader发送ACK- 当
Leader收到大多数(n/2+1)Follower的ACK信息后将该日志设置为已提交并追加到本地磁盘中,通知客户端并在下个heartbeat中Leader将通知所有的Follower将该日志存储在自己的磁盘中。
安全性
安全性是用于保证每个节点都执行相同序列的安全机制。
- 如当某个
Follower在当前Leadercommit Log时变得不可用了,稍候可能该Follower又会被选举为Leader, - 这时新
Leader可能会用新的Log覆盖先前已committed的Log,这就是导致节点执行不同序列;
Safety 就是用于保证选举出来的 Leader 一定包含先前 committed Log 的机制。
选举安全性(Election Safety):每个任期(Term)只能选举出一个 Leader (数据同步由 Leader 管理。)
Leader 完整性(Leader Completeness):指 Leader 日志的完整性,当 Log 在任期 Term1 被 Commit 后,那么以后任期 Term2、Term3 … 等的 Leader 必须包含该 Log;
Raft 在选举阶段就使用 Term 的判断用于保证完整性:当请求投票的该 Candidate 的 Term 较大或 Index 更大,则投票,否则拒绝该请求。
失效处理
Leader失效:其他没有收到heartbeat的节点会发起新的选举,而当Leader恢复后由于步进数小会自动成为follower(日志也会被新leader的日志覆盖);follower节点不可用:follower节点不可用的情况相对容易解决。因为集群中的日志内容始终是从leader节点同步的,只要这一节点再次加入集群时重新从leader节点出复制日志即可;- 多个
candidate:冲突后candidate将随机选择一个等待间隔(150ms~300ms)再次发起投票,得到集群半数以上follower接受的candidate将会成为leader
wal 日志

https://chromium.googlesource.com/external/github.com/coreos/etcd/+/HEAD/raft/raftpb/raft.proto
wal 日志是二进制的,解析出来以后是以上数据结构 LogEntry。
1 | message Entry { |
第一个字段
type,现版本(v3.5)有三种:- 0: 表示
Normal - 1: 表示
ConfChange(ConfChange表示Etcd本身的配置变更同步,比如有新的节点加入等)。 - 2: 表示
ConfChangeV2
- 0: 表示
第二个字段是
term每个
term代表一个主节点的任期,每次主节点变更term就会变化。第三个字段是
index这个序号是严格有序递增的,代表变更序号
第四个字段是二进制的
data将
raft request对象的pb结构(使用protoc buffers二进制,相比json更加节省空间)整个保存下。
etcd 源码下有个 tools/etcd-dump-logs,可以将 wal 日志 dump 成文本查看,可以协助分析 Raft 协议。
Raft 协议本身不关心应用数据,也就是 data 中的部分,一致性都通过同步 wal 日志来实现,每个节点将从主节点收到的 data apply 到本地的存储,Raft 只关心日志的同步状态,如果本地存储实现的有 bug,比如没有正确的将 data apply 到本地,也可能会导致数据不一致。
etcd 使用
etcd v3 存储,Watch 以及过期机制
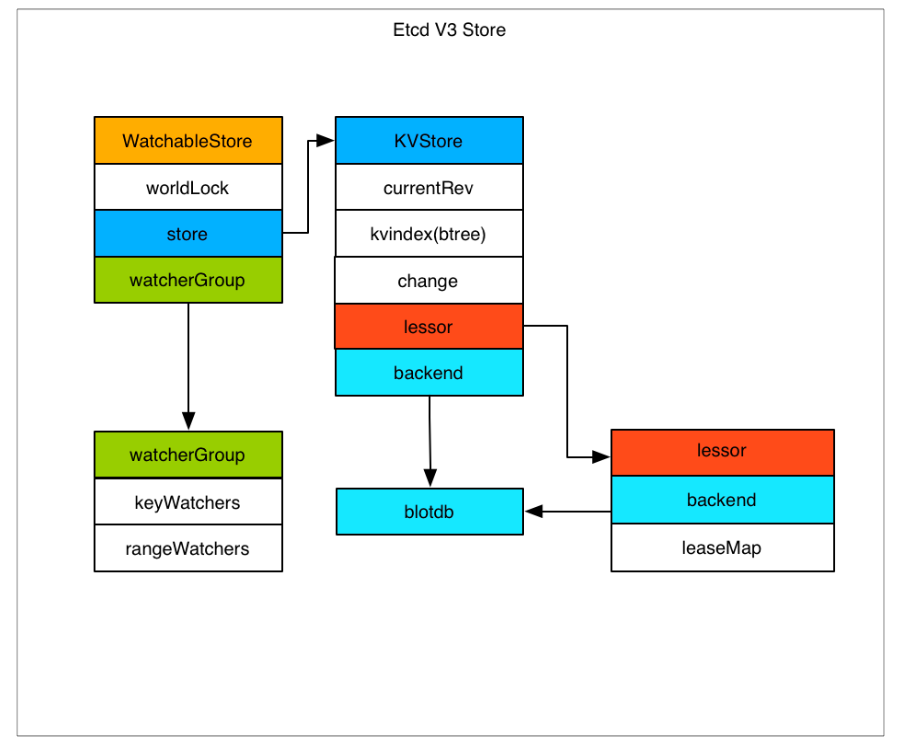
存储机制
etcd v3 store 分为两部分,一部分是内存中的索引,kvindex,是基于 Google 开源的一个 Golang 的 btree 实现的。
另一部分是后端存储。按照它的设计,backend 可以对接多种存储,当前使用的 boltdb。boltdb 是一个单机的支持事务的 kv 存储,etcd 的事务是基于 boltdb 的事务实现的。
etcd 在 boltdb 中存储的 key 是 reversion,value 是 etcd 自己的 key-value 组合,也就是说 etcd 会在 boltdb 中把每个版本都保存下,从而实现了多版本机制。(一个数据存储多份,也就是多份版本。)
reversion 主要由两部分组成,第一部分 main rev,每次事务进行加一,第二部分 sub rev,同一个事务中的每次操作加一。
1 | // set |
etcd 提供了命令和设置选项来控制 compact,同时支持 put 操作的参数来精确控制某个 key 的历史版本数。
内存 kvindex 保存的就是 key 和 reversion 之前的映射关系,用来加速查询。
etcd 写入数据的流程
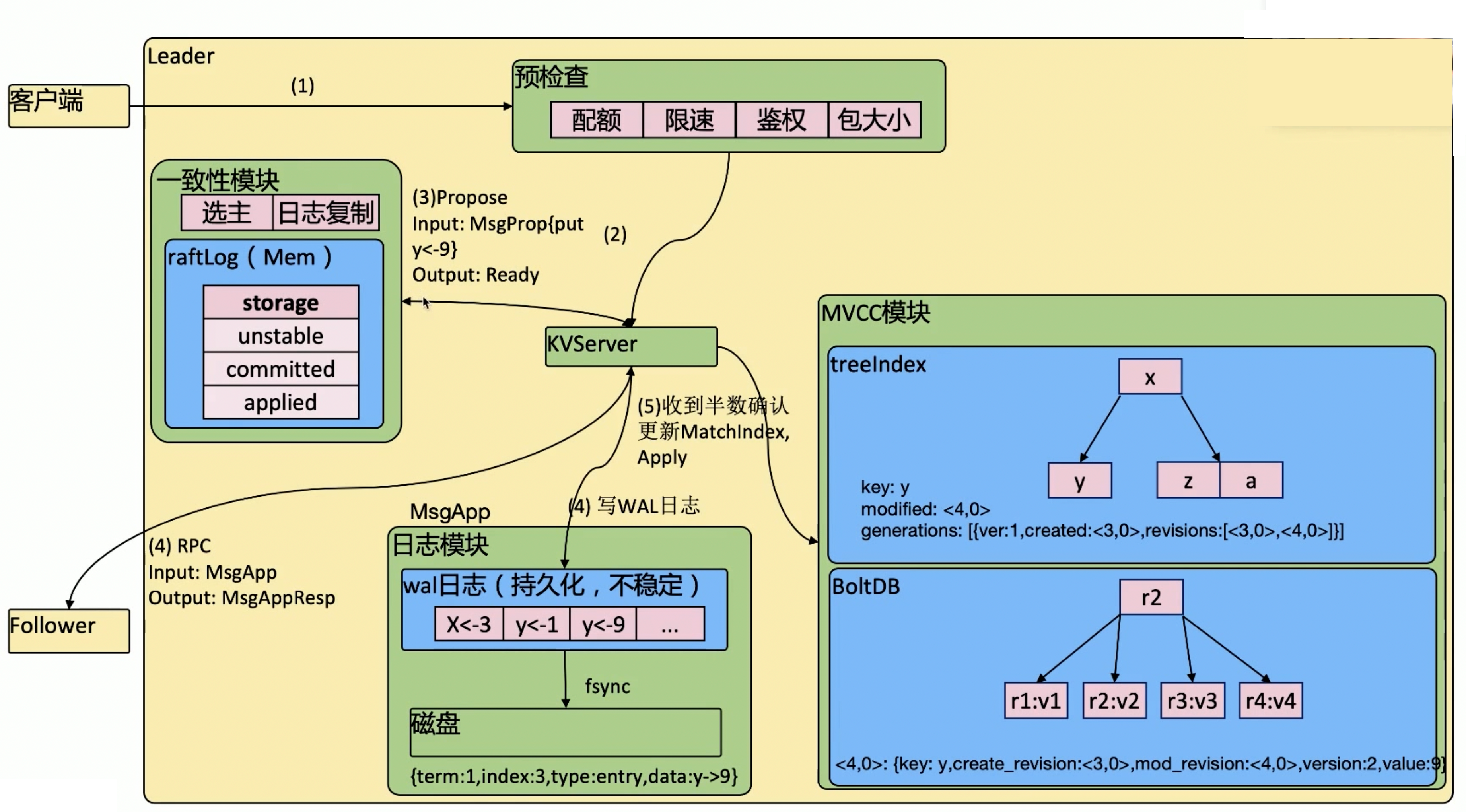
- 客户端写入数据
leader在预检查中做一系列的检测(配额、限速、鉴权、包大小例如1.5M等)- 检查通过之后,将数据发送到
KVServer KVServer发送到Raft的一致性模块,如果是发送到的Leader则直接处理,如果不是,则由一致性模块转发发送到Leader- 通过调用
Propose方法,将数据作为入参 - 内存中的
raftLog将数据放入unstable中作为临时存储 Leader将数据发送到Follower,并且同时将数据写入日志模块WAL日志(WAL是一个临时保障数据持久化的能力,防止宕机时内存中没有确认的数据丢失,虽然没有写入MVCC无法get出来。)- 后台
fsync会周期性将wal日志中的数据刷盘到磁盘中,存储完成后,数据才是稳定的 - 其他的
Follower收到请求之后,一样会将数据写入到WAL日志中,并且返回response KVServer判断是否收到超过半数确认- 如果确认了,则将数据从
unstable移动到committed(此时数据无法get到) - 最终操作
applied,通过MVCC模块操作索引,写入版本信息 - 在
treeIndex中会记录对应key的当前版本,创建版本,历史版本 - 在
BoltDB里面使用BTree存储,存储的key是版本信息,value是key-value的键值对,创建版本、修改版本、当前版本
也就是说,在 MVCC 模块中,要读取某个数据的某个版本,先从 treeIndex 中找到 key 对应数据,获取数据版本信息,在从 BoltDB 中通过 key 查对应版本,在 value 中获取值。
etcd 数据一致性
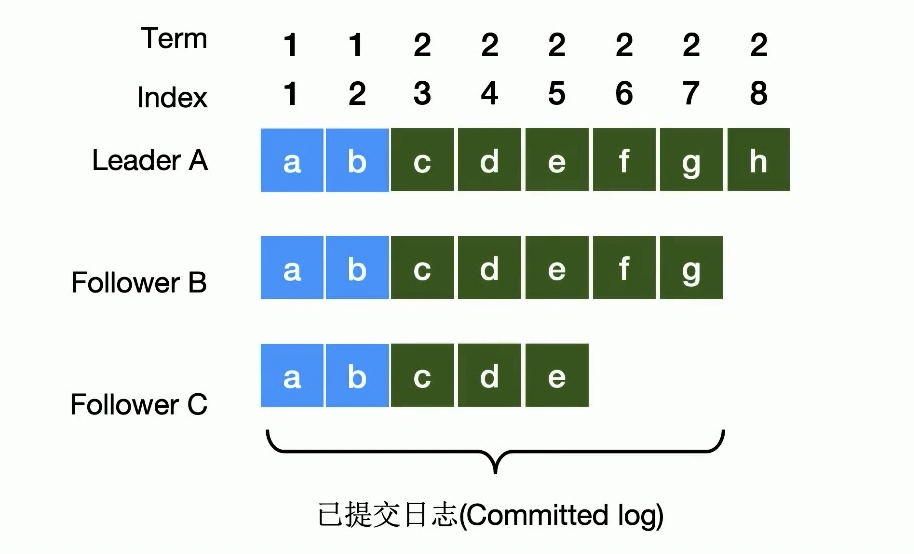
- 集群中有三个
node,Leader是A,Follower是B、C - 日志数据顺序写入,使用
Index单调递增 - 已经写入持久化的数据
a,b是已提交的 - 继续写入
c、d、e所有成员确认,可以提交 - 当出现数据
f、g,只有C没有收到,但是超过半数,也会提交 - 最后写入的
h,只有A收到,没有超过半数,h不会提交
Watch机制
etcd v3 的 watch 机制支持 watch 某个固定的 key,也支持 watch 一个范围(可以用于模拟目录的结构 watch),所以 watchGroup 包含两种 watcher:
- 一种是
key watchers,数据结构是每个key对应一组watcher; - 另外一种是
range watchers,数据结构是一个IntervalTree,方便通过区间查找到对应的watcher
同时,每个 WatchableStore 包含两种 watcherGroup:
- 一种是
synced,表示该group的watcher数据都已经同步完毕,在等待新的变更; - 一种是
unsynced,表示该group的watcher数据同步落后于当前最新变更,还在追赶;
当 etcd 收到客户端的 watch 请求,如果请求携带了 revision 参数,则比较请求的 revision 和 store 当前的 revision:
- 如果大于当前
revision,则放入synced组中; - 否则放入
unsynced组;(也就是请求老版本数据,需要从boltdb中读取)
同时 etcd 会启动一个后台的 goroutine 持续同步 unsynced 的 watcher ,然后将其迁移到 synced 组。
也就是这种机制下,etcd v3 支持从任意版本开始 watch,没有 v2 的 1000 条历史 event 表限制的问题(当然这是指没有 compact 的情况下)
watch 练习
查看集群成员状态
1 | etcdctl member list --write-out=table |
启动新 etcd 集群
1 | docker run -d registry.aliyuncs.com/google_containers/etcd:3.5.0-0 /usr/local/bin/etcd |
进入 etcd 容器
1 | docker ps|grep etcd |
存入数据
1 | etcdctl put x 0 |
读取数据
1 | etcdctl get x -w=json |
修改值
1 | etcdctl put x 1 |
查询最新值
1 | etcdctl get x |
查询历史版本值
1 | etcdctl get x --rev=2 |
etcd 重要参数
成员相关参数
1 | --name 'default' |
集群相关参数
1 | --initial-advertise-peer-urls 'http://localhost:2380' |
安全相关参数
1 | --cert-file '' |
客户端操作
1 | etcdctl --endpoints=https://192.168.239.128:2379 \ |
灾备
创建 Snapshot
1 | etcdctl \ |
恢复数据(可直接通过集群恢复,也可通过单节点恢复之后,再加入其他节点)
1 | etcdctl snapshot restore snapshot.db \ |
容量管理
单个对象不建议超过 1.5M
默认容量 2G
不建议超过 8G (除了本就存储在内存中的 kvindex,还会将 blotdb 映射到内存里面,加快访问速度。)
ALarm & Disarm ALarm
设置 etcd 存储大小
1 | etcd --quota-backend-bytes=$((16*1024*1024)) |
写爆磁盘
1 | while [ 1 ]; do dd if=/dev/urandom bs=1024 count=1024 | ETCDCTL_API=3 etcdctl put key || break; done |
写满了之后,数据库变成只读。
查看 endpoint 状态
1 | ETCDCTL_API=3 etcdctl --write-out=table endpoint status |
查看 alarm
1 | ETCDCTL_API=3 etcdctl alarm list |
清理碎片
1 | ETCDCTL_API=3 etcdctl defrag |
清理 alarm
1 | ETCDCTL_API=3 etcdctl alarm disarm |
碎片整理
1 | keep one hour of history |
高可用 etcd 解决方案
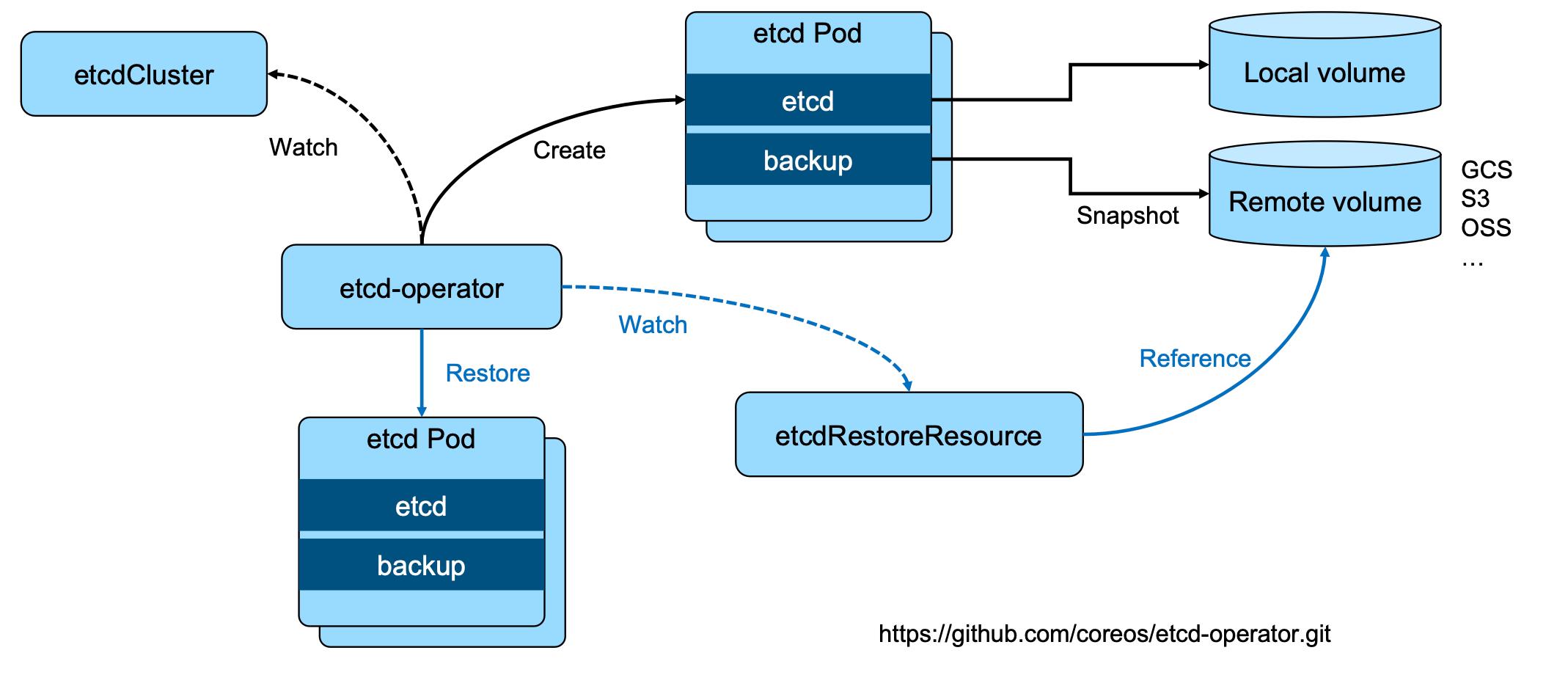
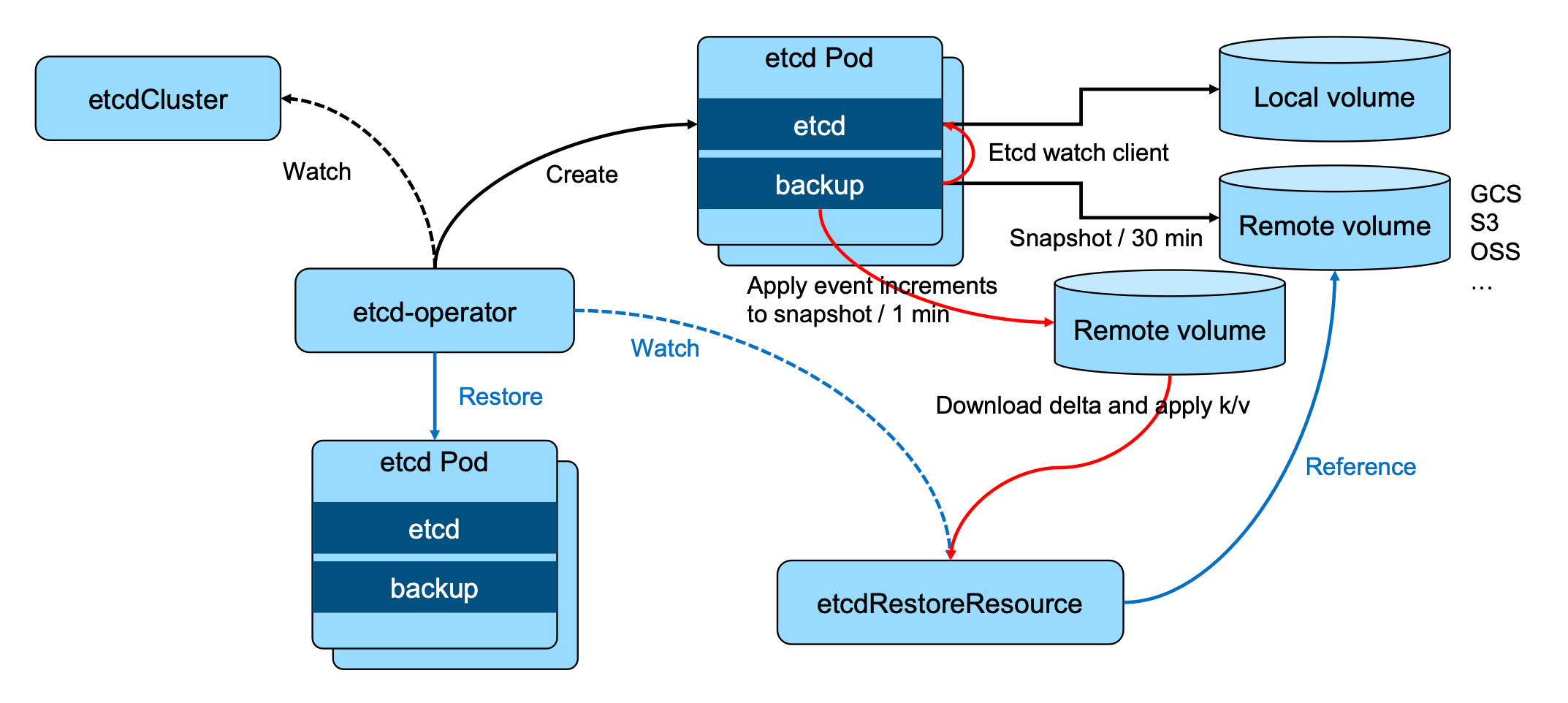
etcd-operator:coreos 开源的,基于 Kubernetes CRD 完成 etcd 集群配置。Archived:https://github.com/coreos/etcd-operator(该项目不再积极开发或维护)
Etcd statefulset Helm chart: Bitnami(powered by vmware)
https://bitnami.com/stack/etcd/helm
https://github.com/bitnami/charts/tree/main/bitnami/etcd
Etcd-Operator
https://github.com/coreos/etcd-operator
基于 Bitnami 安装 etcd 高可用集群
安装 heml
https://github.com/helm/helm/releases
通过 helm 安装 etcd
1 | helm repo add bitnami https://charts.bitnami.com/bitnami |
通过客户端与 serve 交互
1 | kubectl run my-release-etcd-client \ |
Kubernetes 使用 etcd
etcd 是 Kubernetes 的后端存储,对于每一个 Kubernetes Object,都有对应的 storage.go 负责对象的存储操作
pkg/registry/core/pod/storage/storage.go
API server 启动脚本中指定 etcd servers 集群
1 | spec: |
早期 API server 对 etcd 做简单的 Ping check,现在已经改为真实的 etcd api call。
Kubernetes 对象在etcd 中的存储路径
1 | ks exec -it etcd -cadminsh |
etcd 在集群中所处的位置
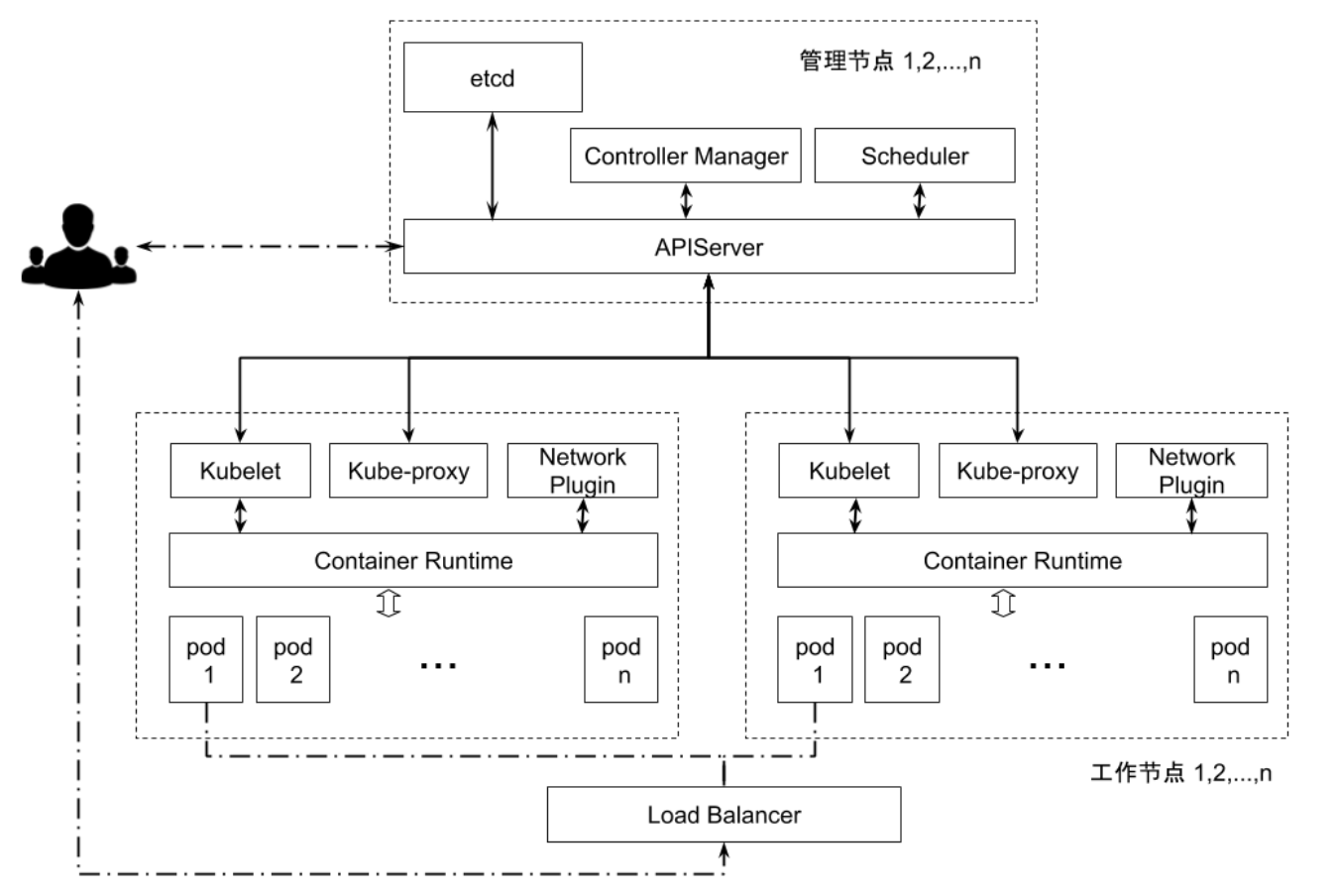
API server 启动脚本中指定 etcd servers 集群
1 | /usr/local/bin/kube-apiserver \ |
将变动频繁的(例如 events)的数据使用 overrides 指定到另外一个 etcd 集群。
etcd 集群
堆叠式 etcd 集群的高可用拓扑
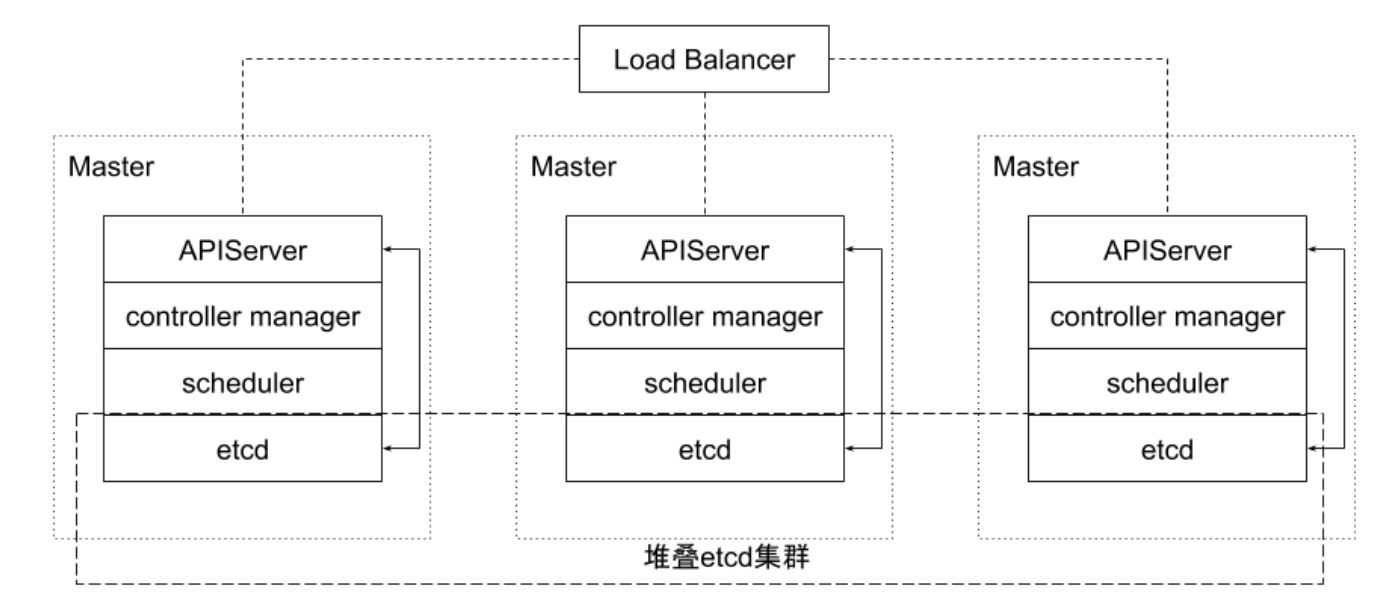
这种拓扑将相同节点上的控制平面和 etcd 成员耦合在一起。
优点在于建立起来非常容易,并且对副本的管理也更容易。但是,堆叠式存在耦合失败的风险。
如果一个节点发生故障,则 etcd 成员和控制平面实例都会丢失,并且集群冗余也会收到损害。可以通过添加更多控制平面节点来减轻这种风险。因此为实现集群高可用应该至少运行三个堆叠的 Master 节点。
外部 etcd 集群的高可用拓扑
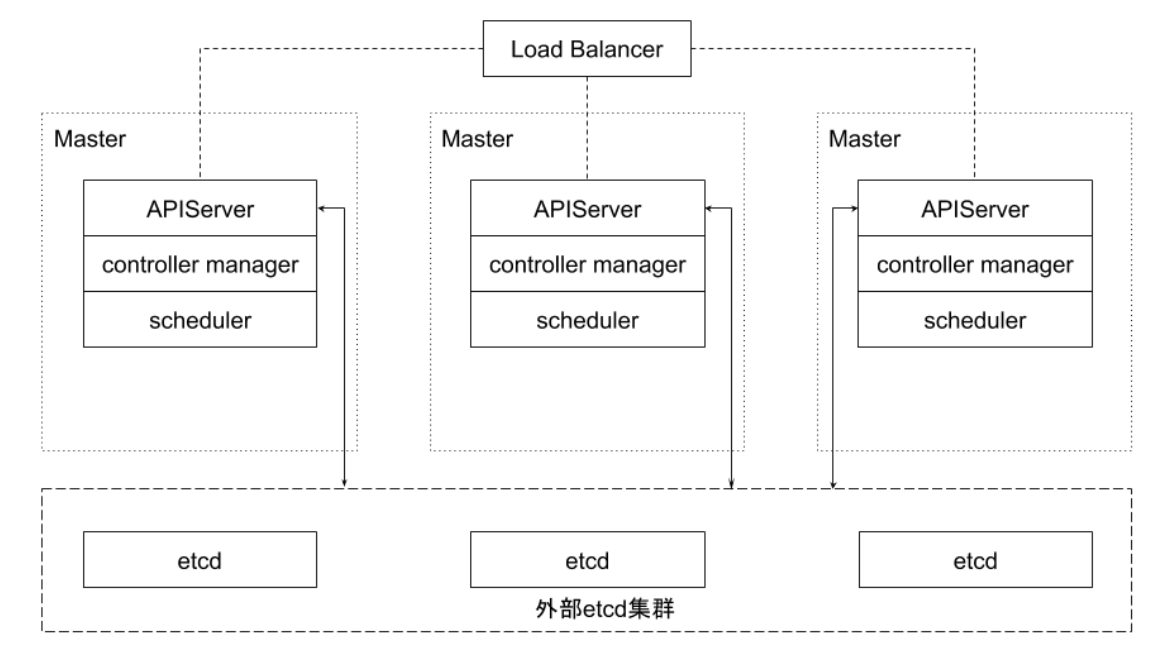
该拓扑将控制平面和 etcd 成员解耦。如果丢失一个 Master 节点,对 etcd 成员的影响较小,并且不会像堆叠式拓扑那样对集群冗余产生太大影响。
但是,此拓扑所需的主机数量是堆叠式拓扑的两倍。具有此拓扑的集群至少需要三个主机用于控制平面节点,三个主机用于 etcd 集群。
实践
多少个 peer 最合适?
- 1个?3个?5个?
- 保证高可用是首要目标,节点过多也会影响性能;但是3个节点时,一个节点故障,需要运维立马介入,而5个风险更小。
- 所有写操作都要经过
leader(如果 follower 接收请求也会转发给leader) peer多了是否能提升集群并读操作的并发能力?apiserver的配置直连本地的etcd peerapiserver的配置指定所有etcd peers,但只有当前连接的etcd member异常,apiserver才会换目标
- 需要动态
flex up吗?
保证 apiserver 和 etcd 之间的高效性通讯
apiserver和etcd部署在同一节点apiserver和etcd之间的通讯基于gRPC针对每一个
object,apiserver和etcd之间的Connection->stream共享http2的特性Stream quota带来的问题?对于大规模集群,会造成链路阻塞(本
grpc数据全部被占用,影响node的心跳数据发送)10000 个
pod,一次list操作需要返回的数据可能超过100M1
2
3
4
5k get pod --all-namespaces|wc–l
8520
k get pod -oyaml --all-namespaces > pods
ls -l pods
rw-r--r-- 1 root root 75339736 Apr 5 03:13 pods
本地
vs远程?Remote Storage- 优势是假设永远可用,现实真实如此吗?
- 劣势是
IO效率,可能带来的问题?
- 最佳实践
Local SSD- 利用
local volume分配空间
多少空间?
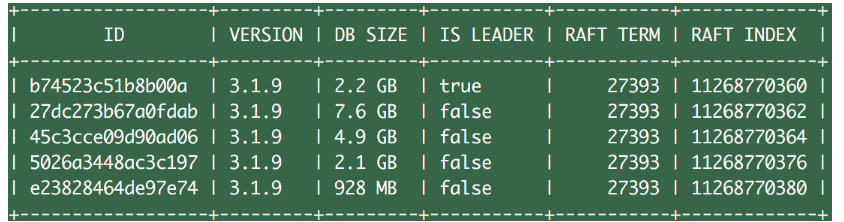
与集群规模相关,思考:为什么每个
member的DB size不一致?包含的碎片大小不一样,
defrag和snap。![image-20240112143519067]()
安全性
peer和peer之间的通讯加密是否有需求
TLS的额外开销- 运营复杂度增加
数据加密
是否有需求
Kubernetes 提供了针对
secret的加密https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/
事件分离
对于大规模集群,大量的事件会对
etcd造成压力API server启动脚本中指定etcd servers集群1
2
3
4/usr/local/bin/kube-apiserver \
--etcd_servers=https://localhost:4001 \
--etcd-cafile=/etc/ssl/kubernetes/ca.crt--storage-backend=etcd3 \
--etcd-servers-overrides=/events#https://localhost:4002
如何监控?
减少网络延迟
数据中心内的
RTT大概是数毫秒,国内的典型RTT约为50ms,两大洲之间的RTT可能慢至400ms。因此建议etcd集群尽量同地域部署。(外加异地备份)当客户端到
Leader的并发连接数量过多,可能会导致其他Follower节点发往Leader的请求因为网络拥塞而被延迟处理。在Follower节点上,可能会看到这样的错误:1
dropped MsgProp to 247ae21ff9436b2d since streamMsg's sending buffer is full
可以在节点上通过流量控制工具(
Traffic Control)提高etcd成员之间发送数据的优先级来避免。
减少磁盘 I/O 延迟
对于磁盘延迟,典型的旋转磁盘写延迟约为 10ms。对于 SSD(Solid State Drivers,固态硬盘),延迟通常低于 1ms。HDD(Hard Disk Drive,硬盘驱动器)或者网盘在大量数据读写操作的情况下延迟会不稳定。因此强烈建议使用 SSD。
同时为了降低其他应用程序的 I/O 操作对 etcd 的干扰,建议将 etcd 的数据存放在单独的磁盘内。也可以将不同类型的对象存储在不同的若干个 etcd 集群中,比如将频繁变更的 event 对象从主 etcd 集群中分离出来,以保证主集群的高性能。在 APIServer 处这是可以通过参数配置的。这些 etcd 集群最好也分别能有一块单独的存储磁盘。
如果不可避免地,etcd 和其他的业务共享存储磁盘,那么就需要通过下面 ionice 命令对 etcd 服务设置更高的磁盘 I/O 优先级,尽可能避免其他进程的影响。
1 | ionice -c2 -n0 -p 'pgrep etcd' |
保持合理的日志文件大小
etcd 以日志的形式保存数据,无论是数据创建还是修改,它都将操作追加到日志文件,因此日志文件大小会随着数据修改次数而线性增长。
当 Kubernetes 集群规模较大时,其对 etcd 集群中的数据更加也会很频繁,集群日志文件会迅速增长。
为了有效降低日志文件大小,etcd 会以固定周期创建快照保存系统的当前状态,兵移除旧日志文件。另外,当修改次数达到一定的数量(默认是 10000,通过参数 --snapshot-count 指定),etcd 也会创建快照文件。
如果 etcd 的内存使用和磁盘使用过高,可以先分析是否数据写入频度过大导致快照频度过高,确认后可通过调低快照触发的阈值来降低其对内存和磁盘的使用。
设置合理的存储配额
存储空间的配额用于控制 etcd 数据空间的大小。合理的存储配额可保证集群操作的可靠性。
如果没有存储配额,也就是 etcd 可以利用整个磁盘空间,etcd 的性能会因为存储空间的持续增长而严重下降,甚至有耗完集群磁盘空间导致不可预测集群行为的风险。
如果设置的存储配额太小,一旦其中一个节点的后台数据库的存储空间超出了存储配额,etcd 就会触发集群范围的告警,并将集群置于只接受读和删除请求的维护模式。
只有在释放足够的空间、消除后端数据库的碎片和清除存储配额告警之后,集群才能恢复正常操作。
自动压缩历史版本
etcd 会为每个键都保存了历史版本。为了避免出现性能问题或存储空间消耗完导致写不进去的问题,这些历史版本需要进行周期性地压缩。
压缩历史版本就是丢弃该键给定版本之前的所有信息,节省出来的空间可以用于后续的写操作。
etcd 支持自动压缩历史版本,在启动参数中指定参数 --auto-compaction,其值以小时为单位。也就是 etcd 会自动压缩该值设置的时间窗口之前的历史版本。
定期消除碎片化
压缩历史版本,相当于离散的抹去 etcd 存储空间某些数据,etcd 存储空间中将会出现碎片。
这些碎片无法被后台存储使用,却仍占据节点的存储空间。
因此定期消除存储碎片,将释放碎片化的存储空间,重新调整整个存储空间。
备份方案
etcd备份:备份完整的集群信息,灾难恢复https://github.com/coreos/etcd-operator
借鉴
operator的备份和恢复逻辑(通过创建pod来进行备份)1
etcdctl snapshot save
备份 Kubernetes event
备份频度
- 时间间隔太长:
- 能否接受
user data lost? - 如果有外部资源配置,如负载均衡等,能否接受数据丢失导致的
leak?
- 能否接受
- 间隔时间太短:
- 对
etcd的影响- 做
snapshot的时候,etcd会锁住当前数据 - 并发的写操作需要开辟新的空间进行增量写,导致磁盘空间增长
- 做
- 同时监控
wal,单独记录下来
- 对
如何保证备份的时效性,同时防止磁盘爆掉?
Auto defrag?
优化运行参数
当网络延迟和磁盘延迟固定的情况下,可以优化 etcd 运行参数来提升集群的工作效率。
etcd 基于 Raft 协议进行 Leader 选举,当 Leader 选定以后才能开始数据读写操作,因此频繁的 Leader 选举会导致数据读写性能显著降低。可以通过调整心跳周期(Heartbeat Interval)和选举超时时间(Election Timeout),来降低 Leader 选举的可能性。
心跳周期是控制 Leader 以何种频度向 Follower 发起心跳通知。心跳通知处表明 Leader 活跃状态之外,还带有待写入数据信息,Follower 依据心跳信息进行数据写入,默认心跳周期是 100ms。选举超时时间定义了当 Follower 多久没有收到 Leader 心跳,则重新发起选举,该参数的默认设置是 1000ms。
如果 etcd 集群的不同实例是部署在延迟较低的相同数据中心,通常使用默认配置即可。
如果不同实例部署在多数据中心或者网络延迟较高的集群环境,则需要对心跳周期和选举超时时间进行调整。建议心跳周期参数推荐设置为接近 etcd 多个成员之间平均数据往返周期的最大值,一般是平均 RTT 的 0.55 - 1.5 倍。
如果心跳周期设置得过低,etcd 会发送很多不必要的心跳信息,从而增加 CPU 和网络的负担。 如果设置得过高,则会导致选举频繁超时。
选举超时时间也需要根据 etcd 成员之间的平均 RTT 时间来设置。选举超时时间最少设置为 etcd 成员之间 RTT 时间的 10 倍,以便应对网络波动。
心跳间隔和选举超时时间的值必须对同一个 etcd 集群的所有节点都生效,如果各个节点配置不同,就会导致集群成员之间协商结果不可预知而不稳定。
etcd 备份存储
etcd 的默认工作目录下会生成两个子目录:wal 和 snap。
wal是用于存放预写式日志,其最大的作用是记录整个数据变化的全部历程。所有数据的修改在提交前,都要先写入wal中。snap是用于存放快照数据。为防止wal文件过多,etcd会定期(当wal中数据超过 10000 条记录时,由参数--snapshot-count设置)创建快照。当快照生成后,wal中数据就可以被删除了。
如果数据遭到破坏或错误修改需要回滚到之前某个状态时,方法就有两个:
- 一是从快照中恢复数据主体,但是未被拍入快照的数据会丢失
- 二是执行所有
wal中记录的修改操作,从最原始的数据恢复到数据损坏之前的状态,但恢复的时间较长
备份方案实践
官方推荐 etcd 集群的备份方式是定期创建快照。
- 和
etcd内部定期创建快照的目的不同,该备份方式依赖外部程序定期创建快照,并将快照上传到网络存储设备以实现etcd数据的冗余备份。 - 上传到网络设备的数据,都应进行了加密。
- 即使当所有
etcd实例都丢失了数据,也能允许etcd集群从一个已知的良好状态的时间点在任一地方进行恢复。
根据集群对 etcd 备份粒度的要求,可适当调节备份的周期。在生产环境中实测,拍摄快照通常会影响集群当时的性能,因此不建议频繁创建快照。但是备份周期太长,就可能导致大量数据的丢失。
这里可以使用增量备份的方式。
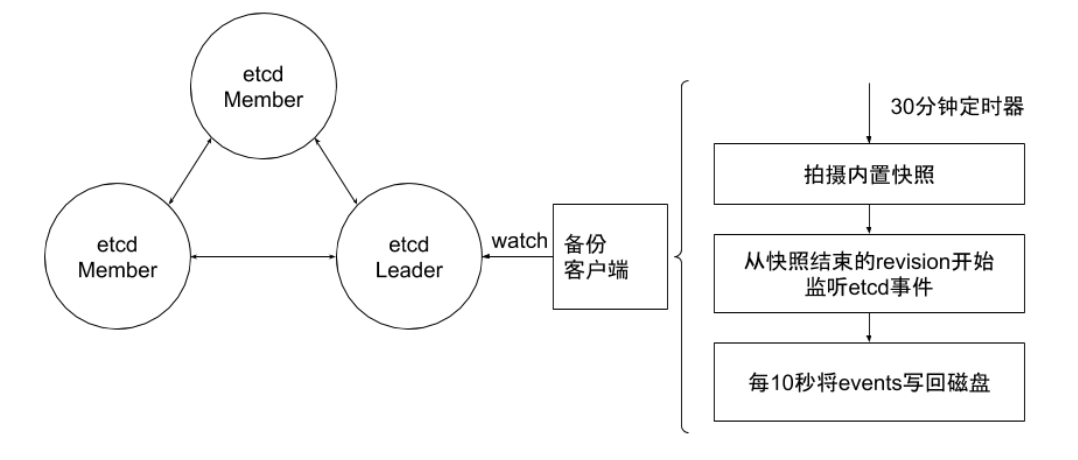
备份程序每 30 分钟触发一次快照的拍摄。
紧接着它从快照结束的版本(Revision)开始,监听 etcd 集群的事件,并每 10 秒钟将事件保存到文件中,并将快照和事件文件上传到网络存储设备中。
30分钟的快照周期对集群性能影响甚微。当大灾难来临时,也至多丢失 10s 的数据。
至于数据修复,首先把数据从网络设备存储中下载下来,然后从快照中恢复大块数据,并在此基础上依次应用存储的所有事件。这样就可以将集群数据恢复到灾难发生前。
增强版 backup 方案
etcd 数据加密
https://kubernetes.io/docs/tasks/administer-cluster/encrypt-data/
1 | apiVersion: apiserver.config.k8s.io/v1 |
Kubernetes 中数据分离
对于大规模集群,大量的事件会对
etcd造成压力API server启动脚本中指定etcd servers集群1
2
3
4
5/usr/local/bin/kube-apiserver \
--etcd-servers=https://localhost:4001 \
--etcd-cafile=/etc/ssl/kubernetes/ca.crt \
--storage-backend=etcd3 \
--etcd-servers-overrides=/events#https://localhost:4002
查询 APIServer
返回某 namespace 中的所有 Pod
1 | GET /api/v1/namespaces/test/pods |
从 10245 版本开始,监听所有对象变化
1 | GET /api/v1/namespaces/test/pods?watch=1&resourceVersion=10245 |
分页查询
1 | GET /api/v1/pods?limit=500 |
1 | GET |
ResourceVersion
单个对象的
resourceVersion- 对象的最后修改
resourceVersion
- 对象的最后修改
List对象的resourceVersion- 生成
list response时的resourceVersion
- 生成
List行为List对象时,如果不加resourceVersion,意味着需要Most Recent数据,请求会击穿APIServer缓存,直接发送至etcdAPIServer通过Label过滤对象查询时,过滤动作是在APIServer端,APIServer需要向etcd发起全量查询请求![image-20240112152340147]()

遭遇的陷阱
- 频繁的
leader election etcd分裂etcd不响应- 与
apiserver之间的链路阻塞 - 磁盘暴涨
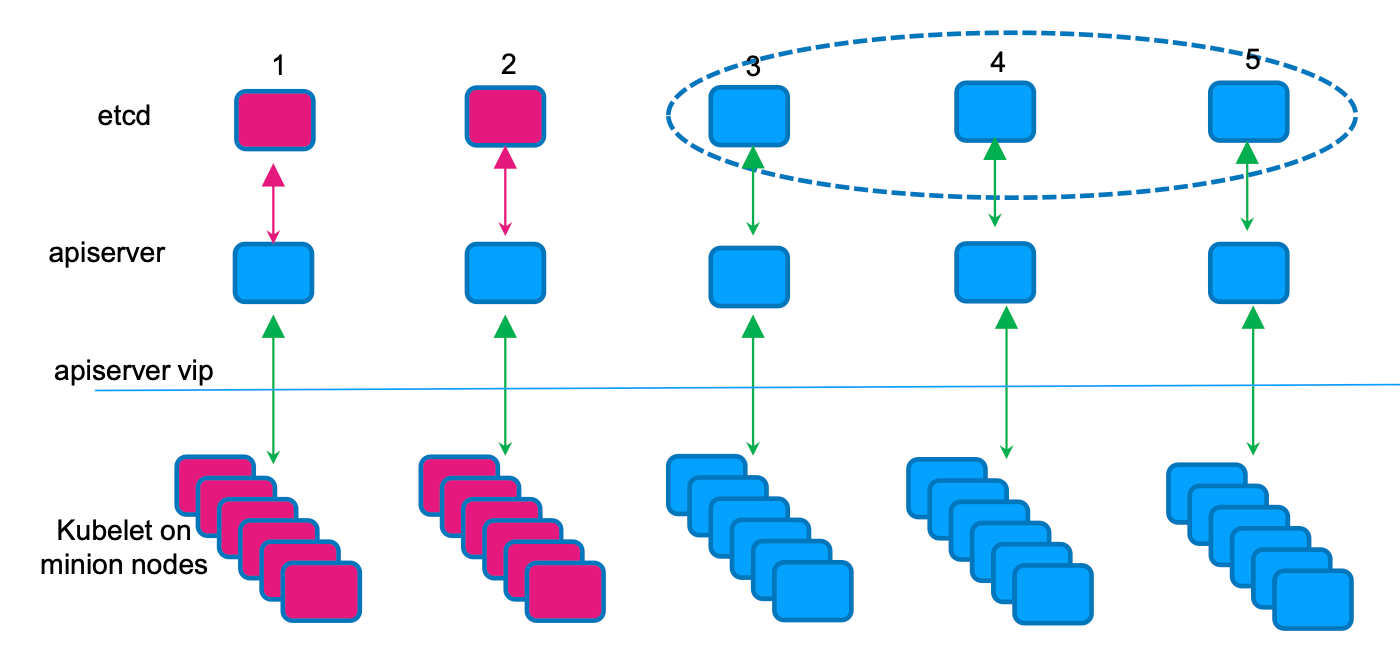
少数 etcd 成员 Down
老版本可能出现少数 etcd 异常,但是上层 apiserver 正常,可能会导致两个节点上的 pod 出现异常。
解决方法是健康检查,apiserver 检测 etcd 异常之后,自杀,让apiserver调用其他节点上的 etcd
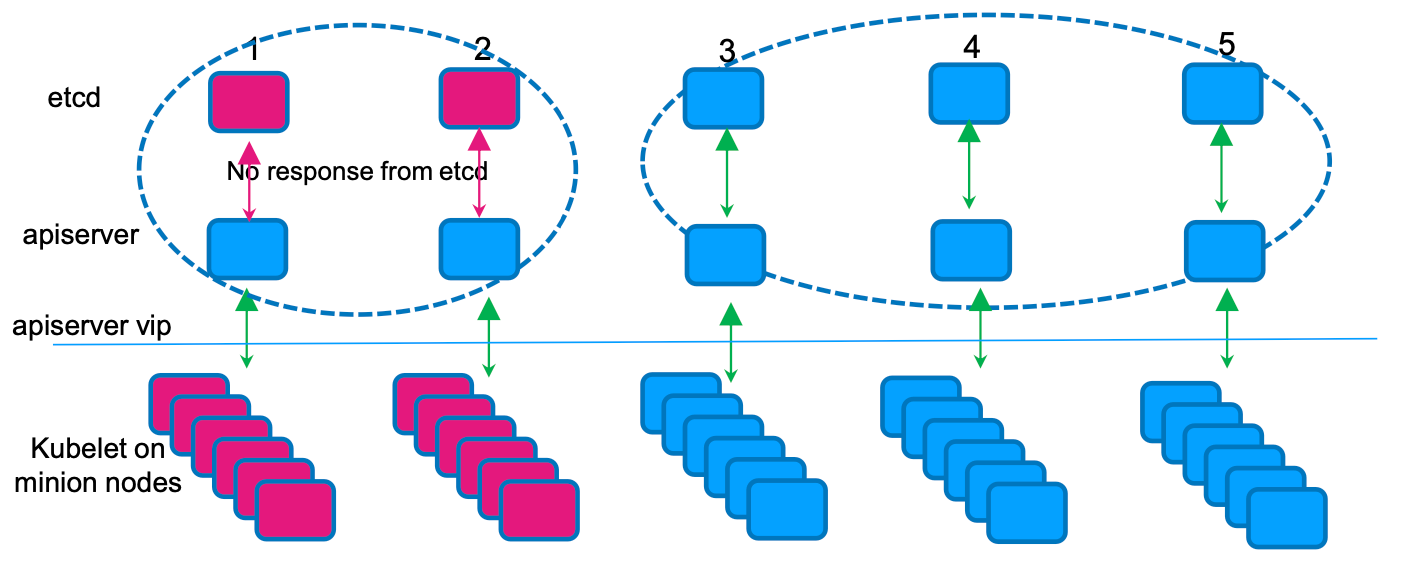
Master 节点出现网络分区
网络分区出现:
Group#1:master-1、master-2Group#2:master-3、master-4、master-5
references
ETCD如何处理读写请求
etcd-io/etcd
v3.5 docs
面试官问你B树和B+树,就把这篇文章丢给他
etcd教程(七)—读请求执行流程分析