错误码实践
错误码是基于Error实现,error是一个普通接口,错误码不仅仅需要实现error接口,还需要涉及到使用规范、分配、转换和记录。
设计规范
- 全局唯一(全公司唯一或者全部门唯一,视作用域和推动能力而定)
- 区别错误类型
- 输入错误还是内部错误 - client params error 、server intenrnel error
- A模块错误还是B模块错误
- 可扩展性
- 增加应用
- 增加模块
- 智能化错误码分配
- API平台或者项目管理平台统一分配错误段
- 应用内集中定义错误码
- 错误码转换,由code转换为可读的字符串
- error 记录:logging、tracing、metrics
实例
错误码可以由几个部分组成
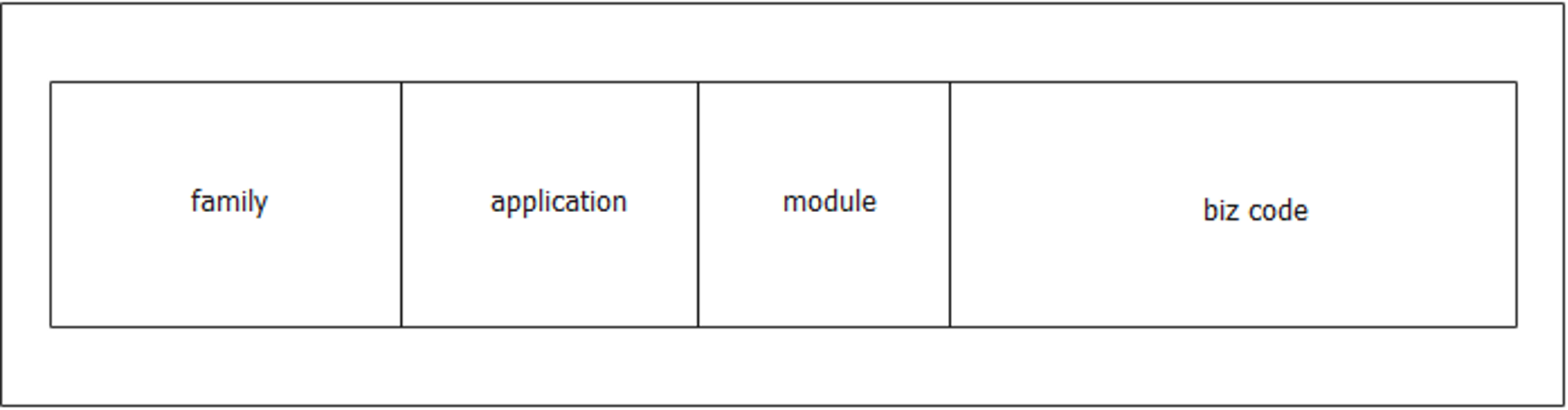
family:错误族,或者大类。用于标记整体装提啊。一般参考HTTP。
![image-20230731194245327]()
采用一位,例如HTTP,2xx 表示成功,4xx表示客户端错误,5xx表示系统错误
采用三位:例如直接使用HTTP的方案
https://datatracker.ietf.org/doc/html/rfc7231#section-6

注意:表达的是相似语义,比如说409是 Conflict 语义,那么这个时候可以考虑 409 来表达手机号码重复之类的错误。
可以根据需啊哟设计自己的族。例如用666代表不可挽回的严重错误,需要立刻人手工处理的错误。
application 和 module:应用和模块。
一般来说,只有超大型的服务才需要考虑两个都存在。一般情况下,使用一个字段就可以。结合自己公司的情况,一般来说是两位起步。
application 和 module 也可用domain来替换
biz code:具体代码层级错误。
要留出足够长度,两位起步
保留段。即全局范围内,具有特殊含义的一些错误码。
有一种实践是,永远用0来表达成功。这种情况下,调用方只需要简单判断是否为0就可以知道请求是否成功,能极大简化调用方代码。
注意:保留段的数量要少,方便开发记住。
错误码分配
案例1:用一个wiki,每次自己创建应用,或者设计模块的时候,去wiki上更新一下。
- X 01 0000 - X 01 9999 => 用户xxx
- X 02 0000 - X 02 9999 => 订单xxx
案例2:用一个数据库,每次创建应用,或者设计模块的时候,数据库更新一下错误码段
- 使用数据库方便后续智能分配
案例3:公司内部有创建项目脚本,运行时自动分配一个(使用代码脚手架,自动创建)
案例4:公公司有创建项目的平台和流程,自动分配好一个段(例如有开发平台,自动化能力高)
安全特性:
- 提交代码的时候有钩子检查错误码是否超出范围,是否符合规范
- 编译IDL文件(比如说proto)的时候,可以检查定义的错误码是否超出范围,是否符合规范
错误码转换
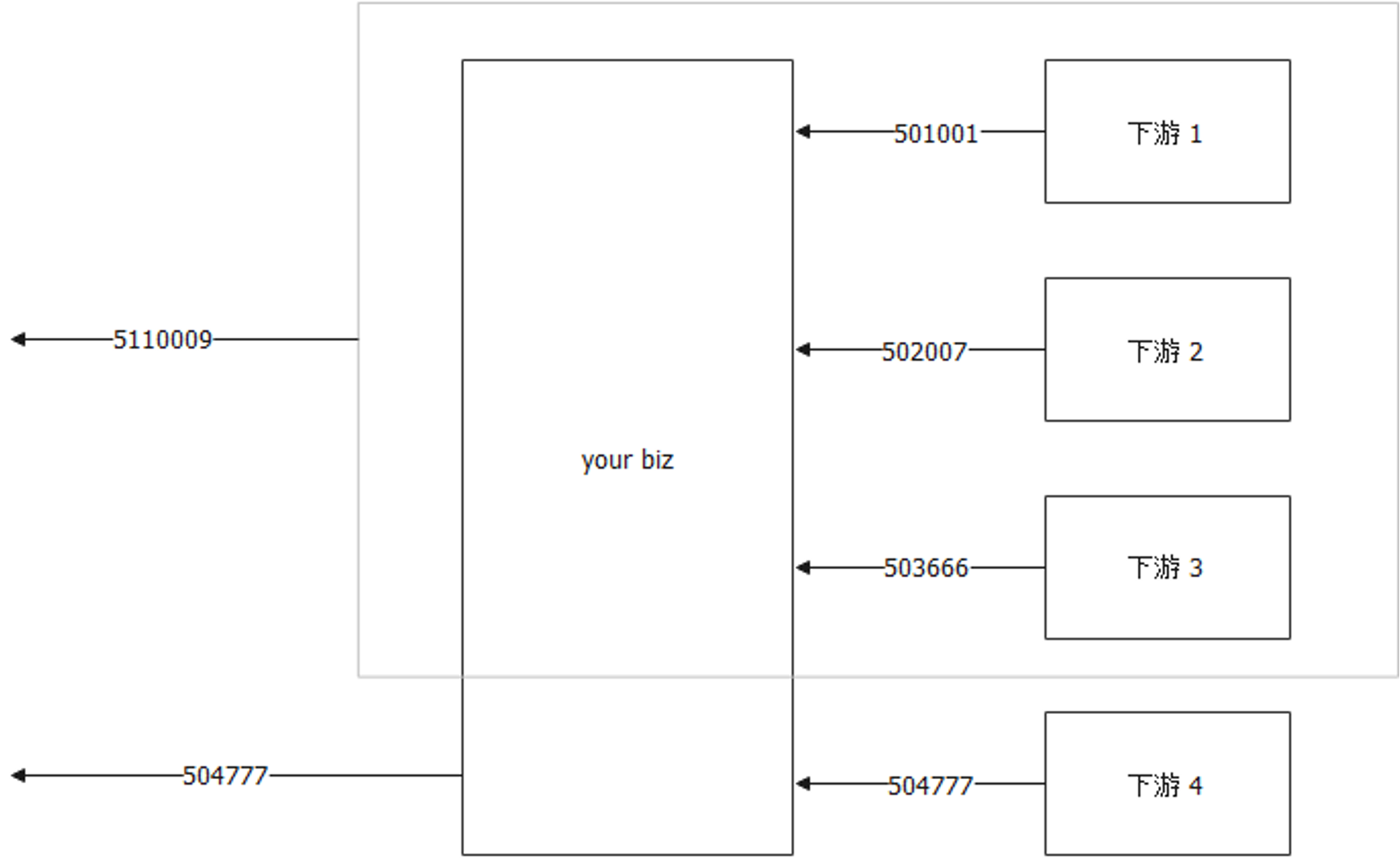
某些时候,下游好几个,对应于业务上的一种错误。这个时候可以尝试做转换
![image-20230731195918838]()
error跨端传递之后,在客户端这边是不能使用errors.Is来检测
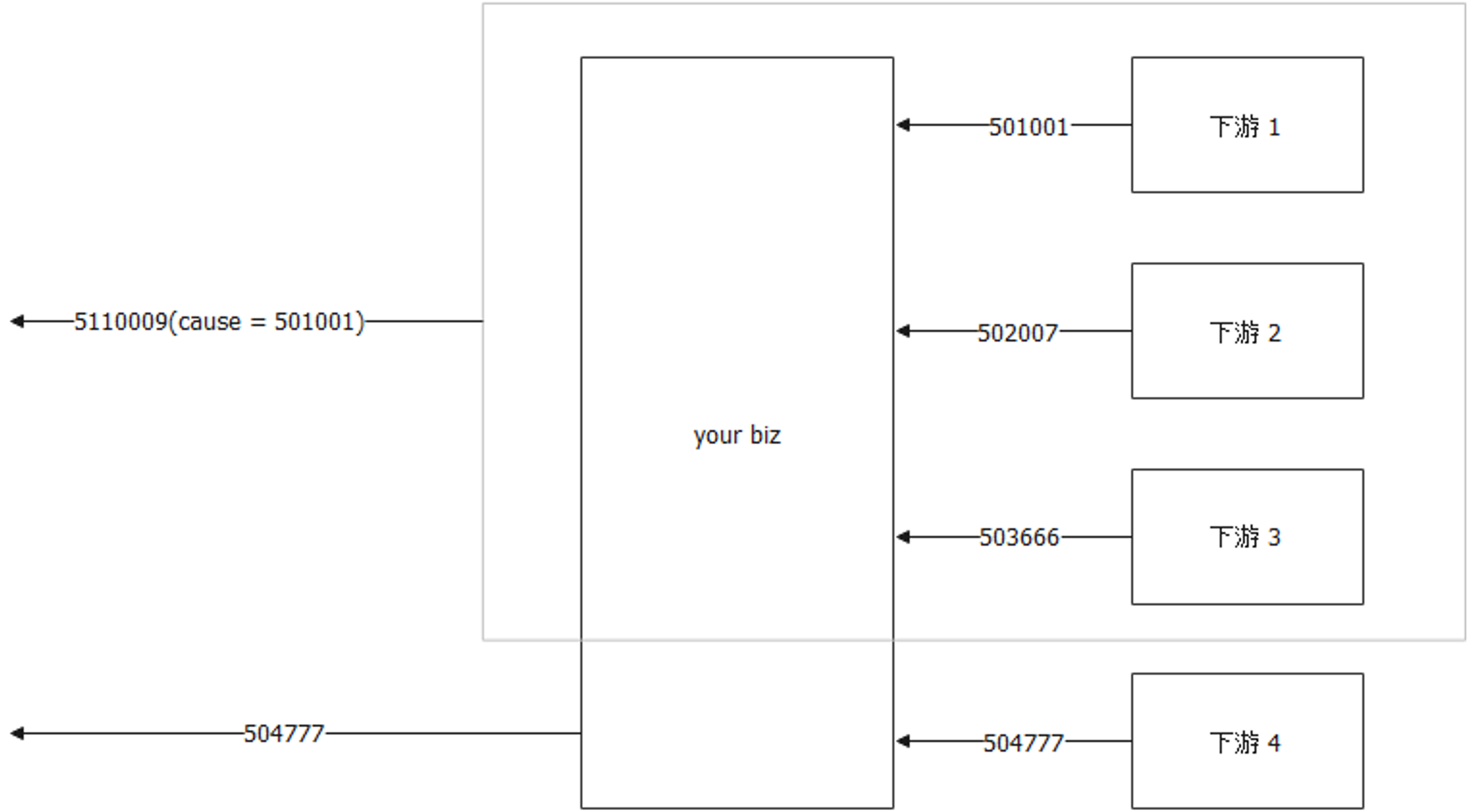
引入原因
引入Cause,实际上就是为了将error串起来,在某些时候会将下游的错误码转换为内部的状态码,然后暴露给上游,这个时候可能会期望在error里面保留了引起错误的原因。
例如下游某个应用来了 501001,在内部被转换成 502011,某些时候,在DEBUG的时候,可能需要判断是哪个下游错误,导致报错,因此需要知道cause(原因)
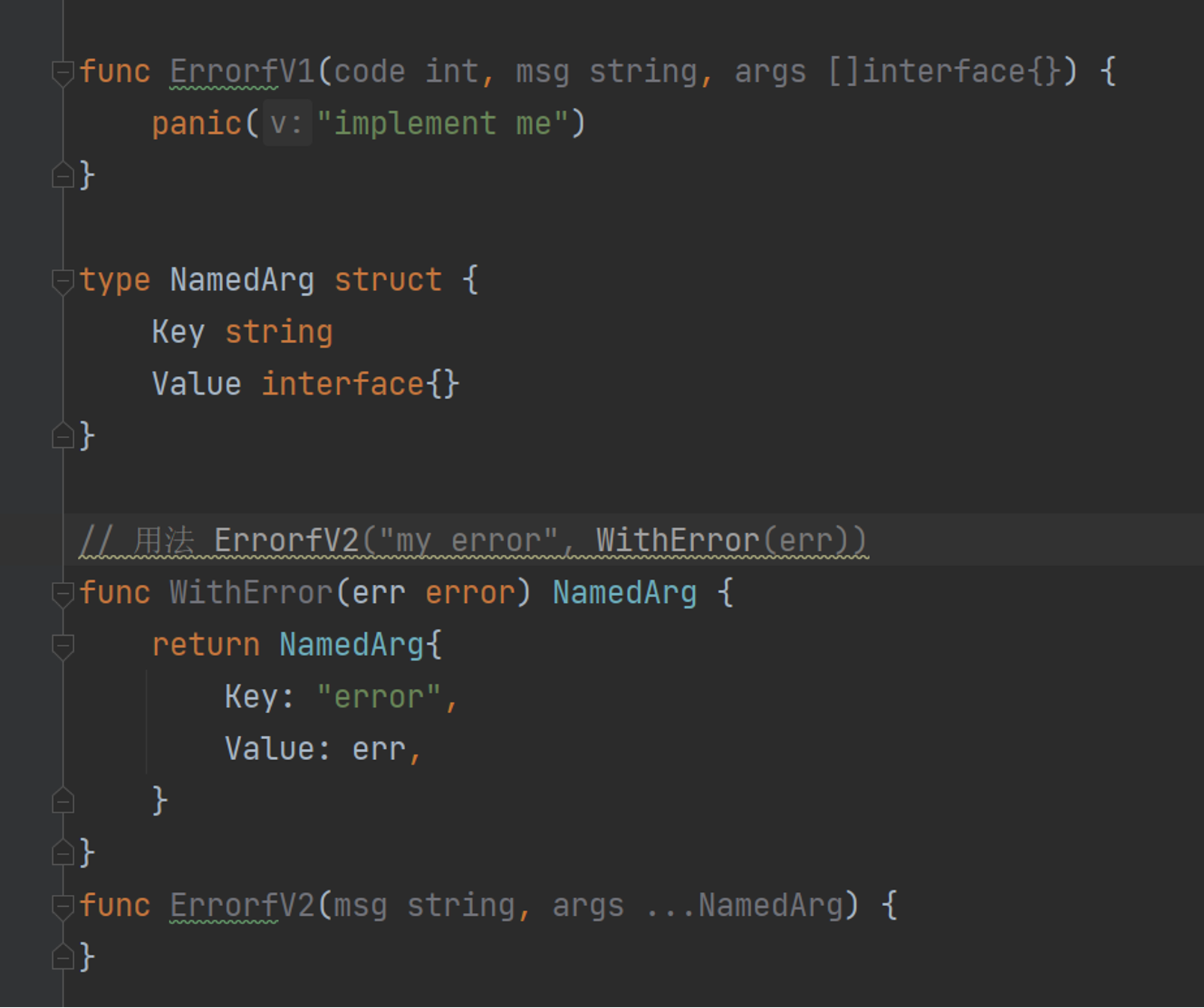
错误码记录
日志
规范记录日志格式,比如说提供类似于log.Errorf(code,msg,args)这种方法。要考虑将来是否存在日志分析的需求
使用时,可以使用编程结构体传入错误信息,也可以使用map
kratos/middleware/logging/logging.go
1 | if se := errors.FromError(err); se != nil { |
kratos/errors/errors.pb.go
1 | type Status struct { |
kratos/errors/errors.go
1 | // Error is a status error. |
tracing
在 tracing 里面记录下错误码。可能需要定义自己的错误结构体:
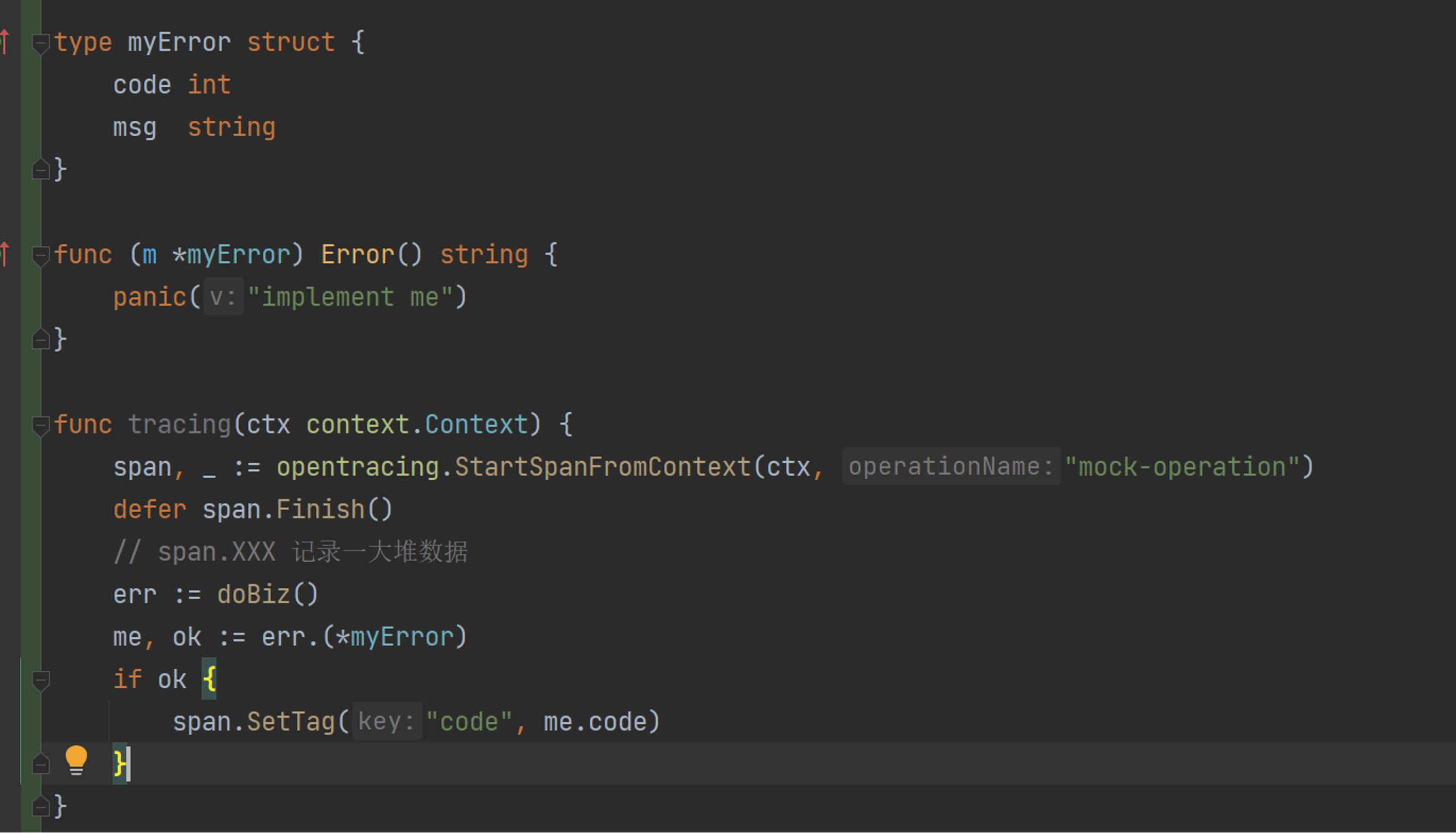
kratos/middleware/tracing/tracing.go
1 | // Server returns a new server middleware for OpenTelemetry. |
kratos/middleware/tracing/tracer.go
1 | // End finish tracing span |
使用tracing时,可以获取到全链路的报错
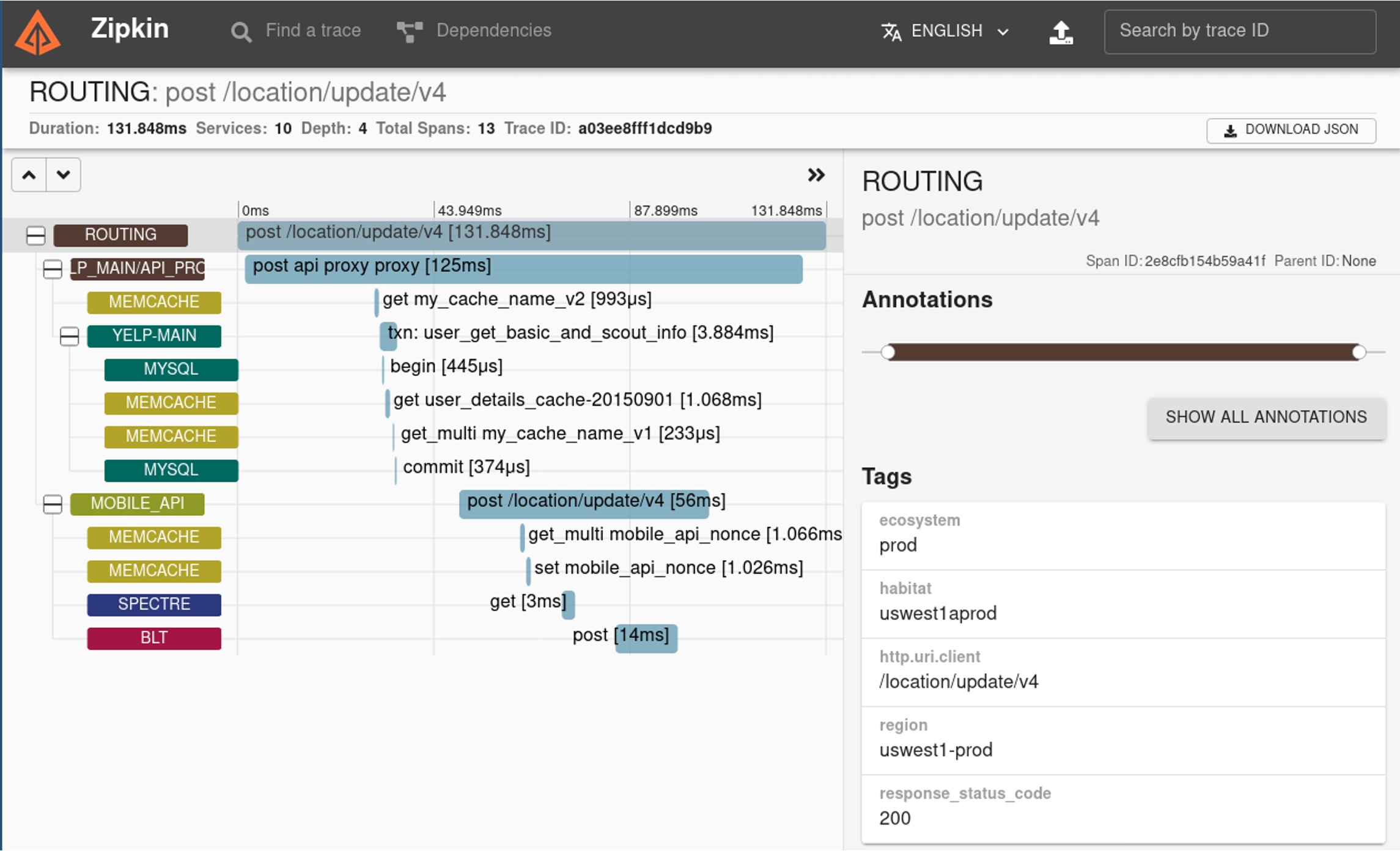
metrics
也可以把错误码记录到 metrics 里面。注意,error code 比较多的时候,不要记录到时序数据库里面
kratos/middleware/metrics/metrics.go
1 | // Server is middleware server-side metrics. |
总结
- 需要有Error的结构体,针对Error的辅助方法,例如从Error中提取原始error或者code
- 需要middleware,一般在中间件中都会提供,比如gin、gorm、gRPC中都会有
- 用middleware来实现logging、tracing、metrics
- 需要引入tracing框架,例如skywalking、zipkin
- 需要引入metrics框架,prometheus
- ELK等日志分析平台
一些注意事项
- OK vs Accepted:异步接口需要注意,返回Accept语义而不是OK(或者Success)
- 回调 or 消息也要带上错误码
- 要求苛刻的应用,错误码要入库。比如某个下单失败,失败原因作为错误码记录到数据库
- 为了统计或者离线分析,错误码本身可以存储到数据库里面
- tracing工具和metrics工具需要考虑错误码。prometheus要注意太多错误码可能会引发问题
- 错误码可以设计为数字,也可以设计为字符串–字符串更加灵活,例如可以使用缩写来表示,比如USR-LG-001,表达user应用,login模块的某个错误
- QPS没过百万,就不用担心错误码长度问题。(基本上高并发瓶颈不会在这里)
- 理论上,返回的错误码要详细,要细分
- 实际上,取决于是否可以按照规范设计延续下去
- 错误码只加不减
- 尽最大努力保持语义清晰并且正交
- API版本变化可能会引入新的错误码,要注意通知老用户处理新错误码
- 处理下游错误码的时候,要有default的分支,防止下游增加错误码自己没有处理
- 谨慎引入所谓通用错误码,比如说一个统一的错误码来表达“数据库错误”
HTTP code
使用HTTP错误码还是使用业务错误码?
比如HTTP code:
1 | http status : 200 |
http code 只表示收到了请求与否,但凡收到请求,返回的响应 http status 永远是成功。
1 | http status : 200 |
只用http code 来表达错误,无法细分具体业务错误,可能会导致请求错误误以为是业务逻辑错误
1 | http status: 400 |
http status 与 biz code 保持一致
思考
在纠结错误码的时候,到底争执的是什么
- 对错问题:比如说使用很明显的业界已经被证明是思路一条的方案,或者说这个方案无法解决掉业务的某个关键点的,这种属于对错问题
- 舍取问题:两个方案,在非功能性的偏向不同,比如说长期方案与短期打补丁的冲突;高性能与简单设计的冲突,方案本身都能解决问题,而且准确来说并没有高低优劣之分,只是侧重点不同
- 偏好问题:连取舍问题都说不上,完全是个人喜好。比如说代码风格,字段命名等
落地
先在组内试试,阻力小。如果组内同时都不愿意,那么可以遵循规范。这样出现BUG的时候,更容易理解。特别是如果公司有tracing或者metrics工具,错误码会显著加快定位问题的速度。
从新项目开始,老项目阻力一般都很大
要准备好各种辅助工具
- 错误码段分配要智能化
- 错误码辅助库,提供一些便利方法,比如判断状态码是否属于成功这一大类
折中、曲线方式
- 先建议规范创建项目的过程
- 新创建项目的脚本或者流程,完成错误码的创建
- 初始化项目结构
- 初始化git 钩子(pre-commit,pre-push)之类的
- 如果是用gitlab之类的,可以尝试直接接入代码质量检测工具
- 悄悄加上错误码分段,完善Error结构体方法,悄悄推进