微服务可观察性之链路追踪
设计目标
- 无处不在的部署
- 持续的监控
- 低消耗
- 应用级的透明
- 延展性
- 低延迟
Dapper
Dapper,大规模分布式系统的跟踪系统
参考 Google Dapper 论文实现,为每个请求都生成一个全局唯一的 traceid(cityhash + uuid 算法生成),端到端(跨进程通过 grpc 中的 metadata 传递,同进程使用 ctx 传递)传到上下游所有节点,每一层生成一个 spanid,通过 traceid 将不同系统孤立的调用日志和异常信息串联一起,通过 spanid 和 level 表达节点的父子关系。
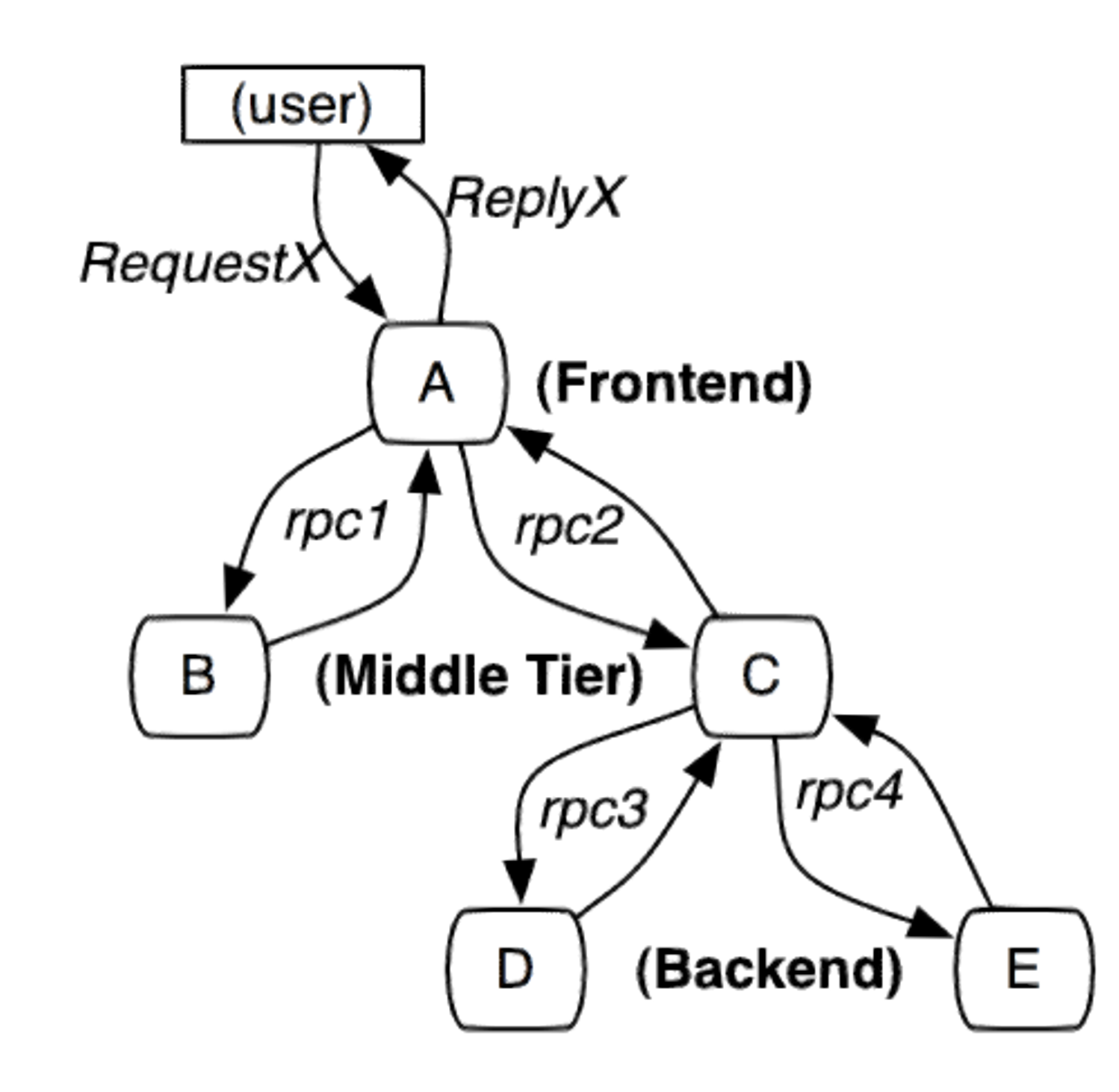
进程内传递和进程间传递:
进程内:使用 context 传递
进程间:例如 gRPC,可以放在 metadata里面;如果是 http,可以放在 header 里面(发起 HTTP
调用需要手动设置好头部。接下来,如果要将请求染色 A 的服务上,可以用七层负载均衡,也可以自己手动筛选服务器,比如说 a.yourcompany.com,或者用路径来区分。),一些基于 tcp 的 socket 通信,这种自定义实现方式,也需要自己实现。(例如 google的rpc协议约定放在 attachment里面)
初始染色可以是前端起步,也可以是 BFF 层,也可以是更加靠后的任何一个服务,取决于业务需要。
跨端传递核心就是在报文里面带上染色信息。普遍来说,要么是在 HTTP Header,要么是自定义协议的某个部分(那么自定义协议的头部,要么自定义协议的扩展部分)。重建 ctx 会在解析完报文之后第一时间建好,而后开始层层往下传。
这种元数据的使用方式,可以扩展到很多场景,例如 A/B 测试,多租户,压力测试,mock 测试。
核心概念:
Tree:整个调用过程Span:调用单元Annotation:调用单元中的挂载信息,例如ip、user之类的标签
调用链
在跟踪树结构中,树节点是整个架构的基本单元,而每一个节点又是对 span 的引用。虽然 span 在日志文件中知识简单的代表 span 的开始和结束时间,他们在整个树形结构中却是相对独立的。
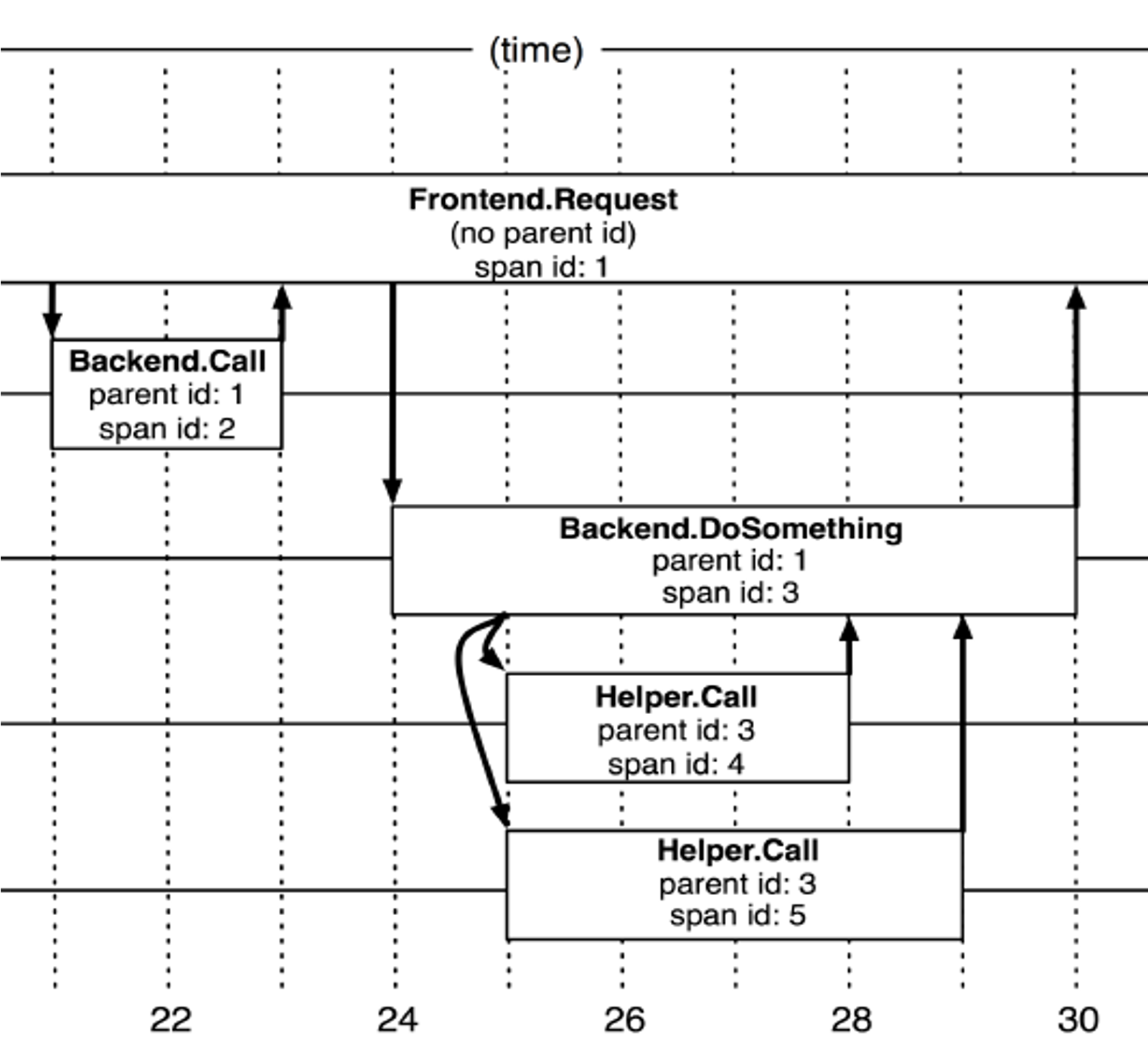
核心概念:
TraceID:一个完整的请求的idSpanID:其中一个节点的idParentID:上游服务的idFamily&Title:服务名 +rpc名称
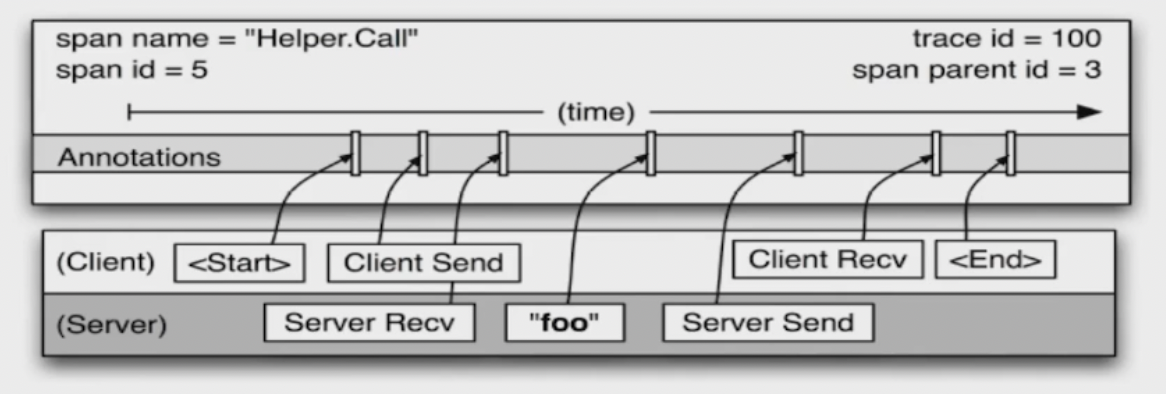
追踪信息
- 追踪信息包含时间戳、事件、方法名(
Family+Title)、注释(TAG/Comment) - 客户端和服务器上的时间戳来自不同的主机,因此必须考虑到时间偏差,
RPC客户端发送一个请求之后,服务端才能接收到,对于响应也是一样的(服务器先响应,然后客户端才能接收到这个响应)。这样一来,服务器端的RPC就有一个时间戳的上限和下限。
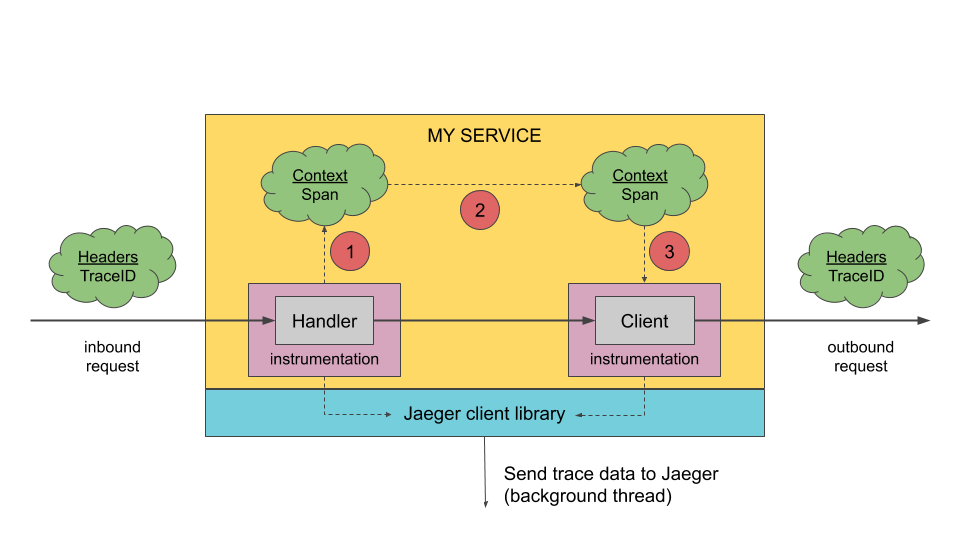
植入点
Dapper 可以对应用开发者近乎零侵入的成本对分布式控制路径进行跟踪,几乎完全依赖于少量通用组件库的改造。如下:
当一个线程在处理跟踪控制路径的过程中,Dapper 把这次跟踪的上下文在 ThreadLocal 中进行存储,在 Go 语言中,约定每个方法首参数为 context(上下文)
例如 gin 的 middware
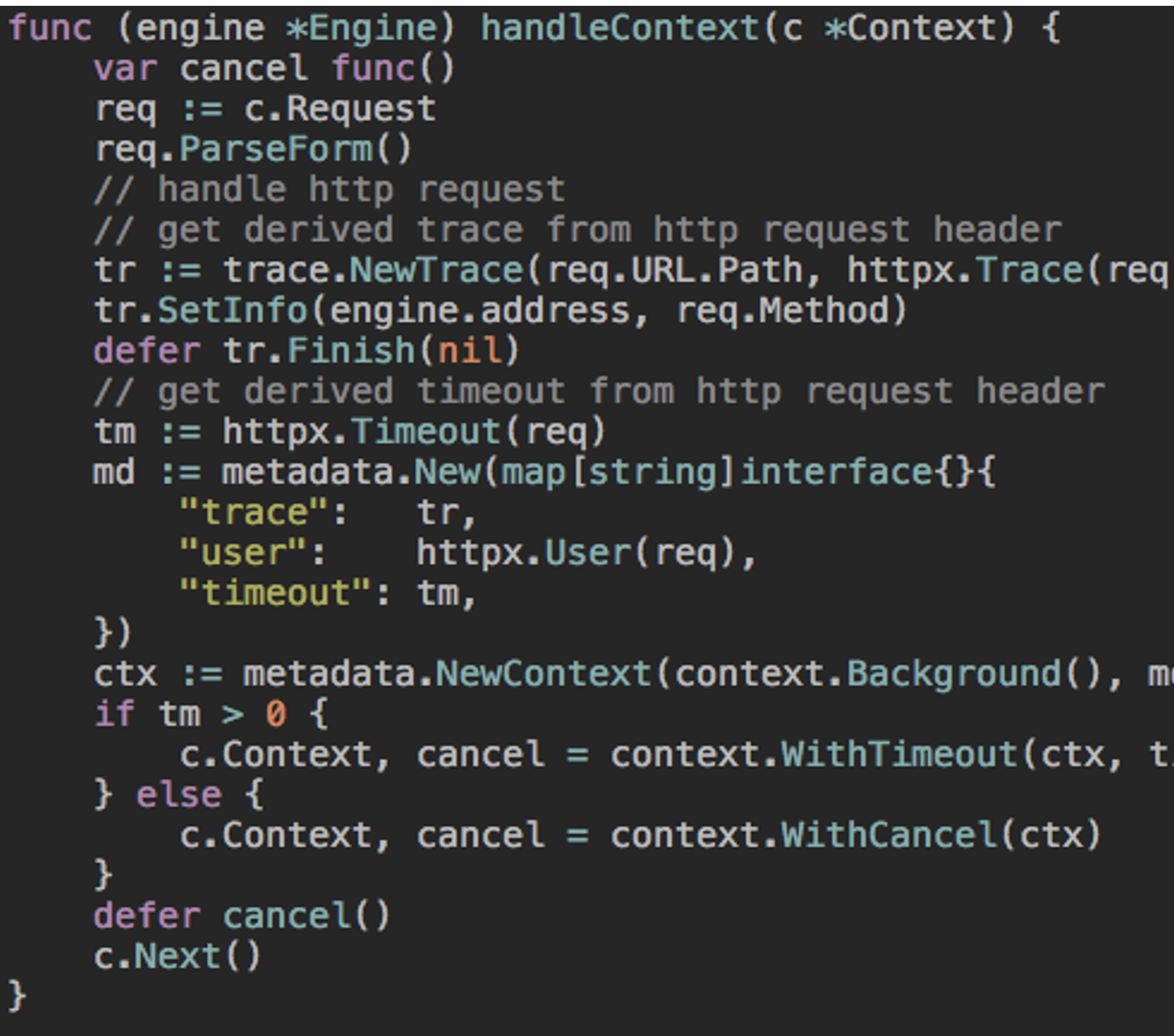
其实很多的中间件都有实现,在请求开始时创建一个 trace 或者 span
覆盖通用的中间件 & 通讯框架、不限于:redis、memcache、rpc、http、database、queue。
架构图
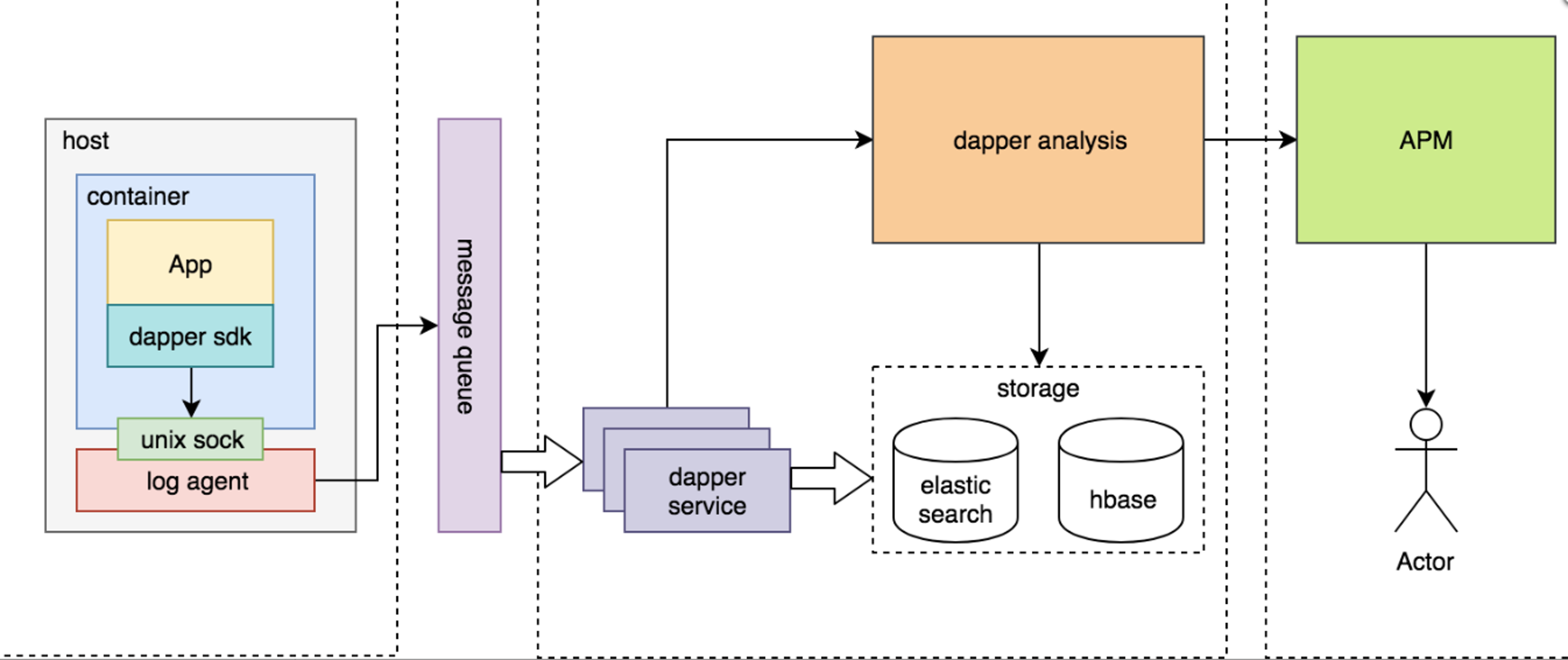
- 容器服务的日志经过
log agent通过unix sock将日志采集到消息队列(或者写入磁盘之后监控文件变化) - 消费者存储到
es和hbase,提供多种存储和检索手段,es中通过维度检索,hbase中rawkey作为traceid - 通过存储的数据,做
ui工具(推荐使用成熟的工具jaeger或者zipkin)
跟踪消耗
处理跟踪消耗:
- 正在被监控的系统在生成追踪和收集追踪数据的消耗导致系统性能下降
- 需要使用一部分资源来存储和分析跟踪数据,是
Dapper性能影响中最关键的部分:- 因为收集和分析可以更容易在紧急情况下被关闭(1、在紧急情况下可以自动降级,避免影响主要业务;2、生成
trace以及写入数据库的逻辑会引发gc),ID生成耗时、创建Span等 - 修改
agent nice值,以防在一台高负载的服务器上发生cpu竞争
- 因为收集和分析可以更容易在紧急情况下被关闭(1、在紧急情况下可以自动降级,避免影响主要业务;2、生成
采样:
如果一个显著的操作在系统中出现一次,他就会出现上千次。基于这个准则我们不全量收集数据。(不用担心出现问题的时候信息没有捕捉到。)
有意思的论文:Uncertainty in Aggregate Estimates from Sampled Distributed Traces
跟踪采样
固定采样,
1/1024:这个简单的方案是对高吞吐量的线上服务来说非常有用,因为那些感兴趣的事件(在大吞吐量的情况下)仍然很有可能经常出现,并且通常足以被捕捉到。
然而,在较低的采样率和较低的传输负载下可能会导致错过重要事件,而想用较高的采样率就需要能接受的性能损耗。
对于这样的系统的解决方案就是覆盖默认的采样率,这样需要手动干预的,这种情况是我们试图避免在
Dapper中出现的。应对积极采样:
我们理解为单位时间期望采集样本的条目,在高
QPS下,采样率自然下降,在低QPS下,采样率自然增加;比如1s内某个接口采集1条。二级采样:
容器节点数量多,即使使用积极采样仍然会导致采样样本非常多,所以需要控制写入中央仓库的数据的总规模,利用所有
span都来自一个特定的跟踪并分享同一个traceid这个事实,虽然这些span有可能横跨了数千个主机。对于在收集系统中的每一个
span,我们用hash算法把traceid转成一个标量Z,这里0<=Z<=1(然后将每一个请求生成一个浮点,大于Z的时候记录,不满足则不记录,按照请求来进行记录),我们选择了运行期采样率,这样就可以优雅的去掉我们无法写入到仓库中的多余数据,我们还可以通过调节收集系统中的二级采样率系数来调整这个运行期采样率,最终我们通过后端存储压力把策略下发给agent采集系统,实现精准的二级采样。下游采样:
越被依赖多的服务,网关层使用积极采样以后,对于
downstream的服务采样率仍然很高。
API
搜索
按照 Family(服务名)、Title(接口)、时间、调用者等维度进行搜索(例如直接查询耗时比较长的请求)
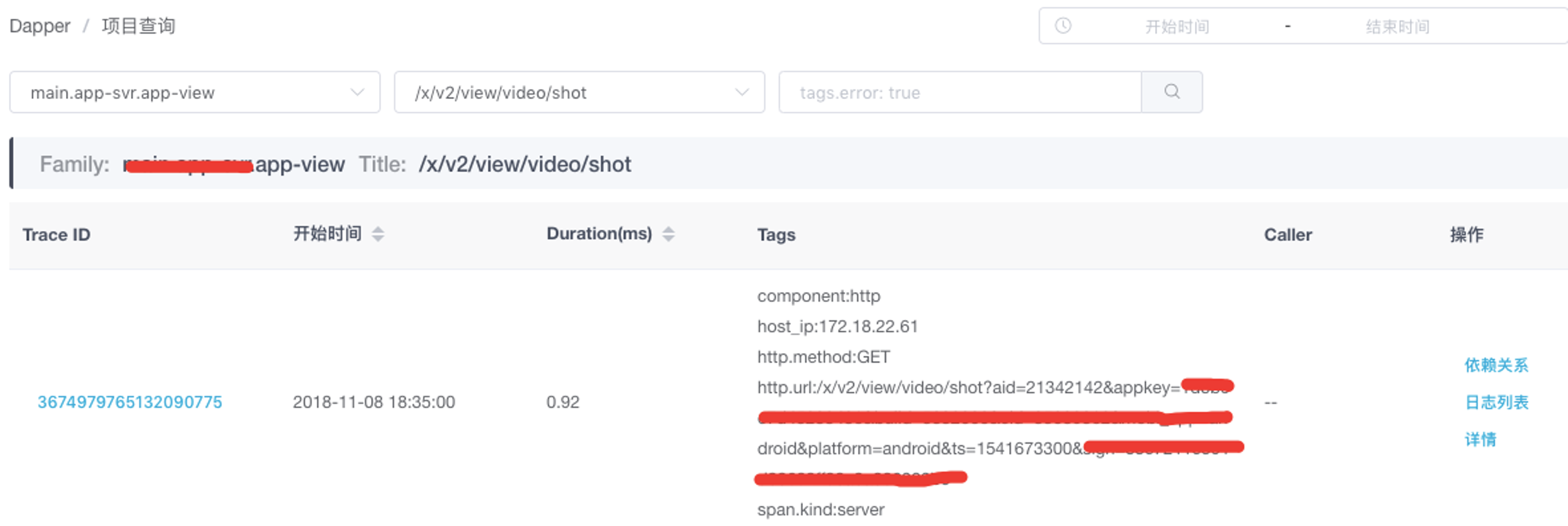
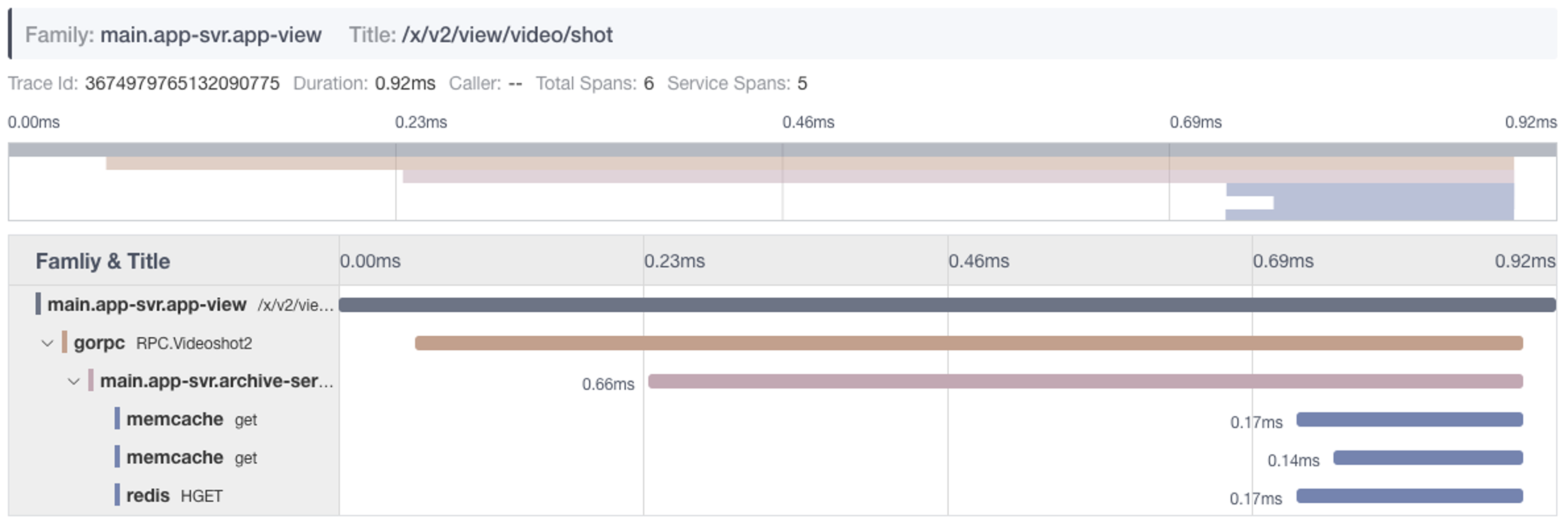
详情
根据单个traceid,查看整个链路信息,包含 span、level统计,span详情,依赖的服务、组件信息等;
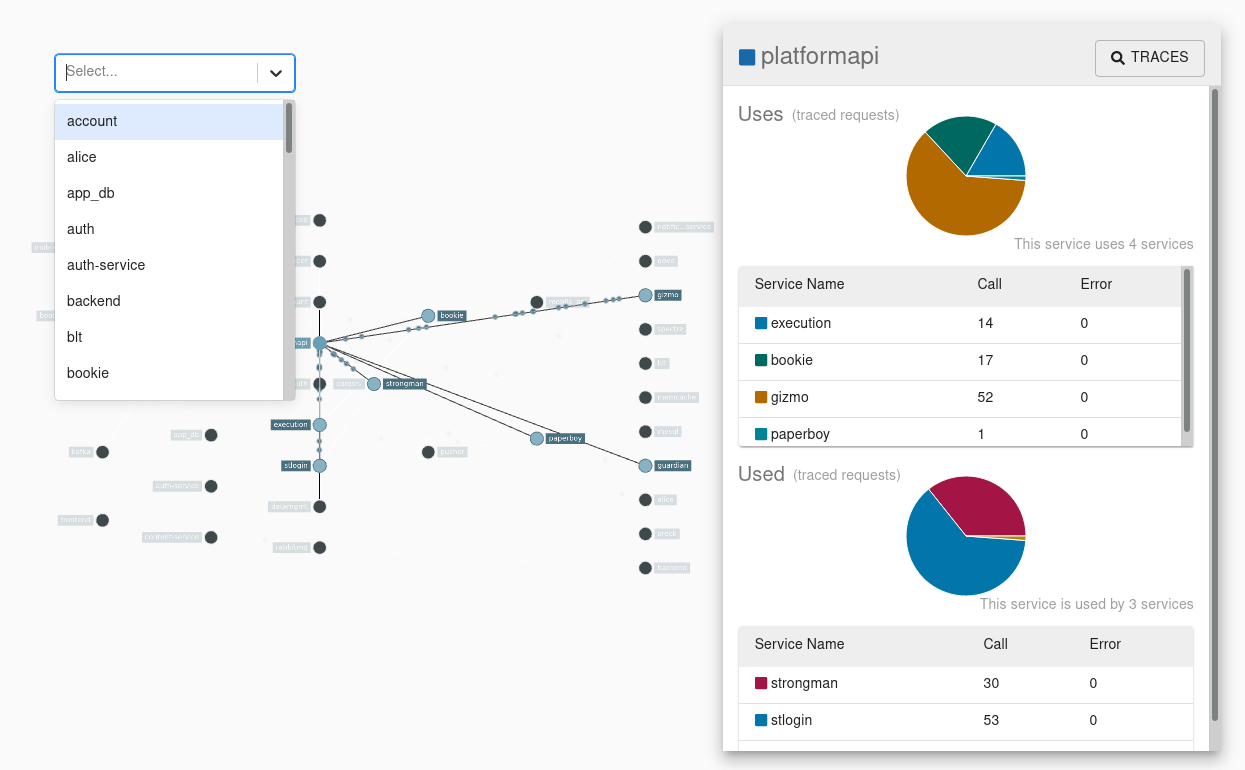
全局依赖图
由于服务之间的依赖是动态改变的,所以不可能仅从配置信息上推断出所有这些服务之间的依赖关系,能够推算出服务各自之间的依赖,以及服务和其他软件组件之间的依赖。
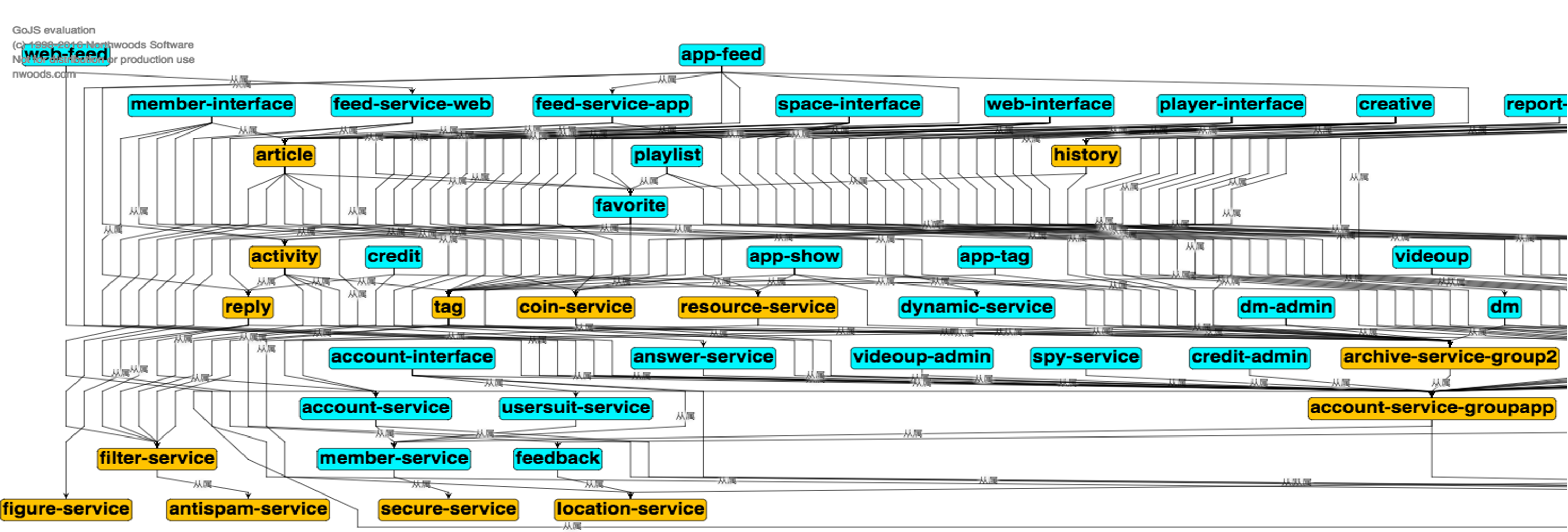
依赖搜索
搜索单个服务的依赖情况,方便我们做异地多活时候来全局考虑资源的部署情况,以及区分服务是否属于多活范畴,也可以方便我们经常性的梳理依赖服务和层级来优化我们的整体架构可用性。(还可以将服务之间的链路宽度通过请求量等比放大,作为服务扩展的依据)
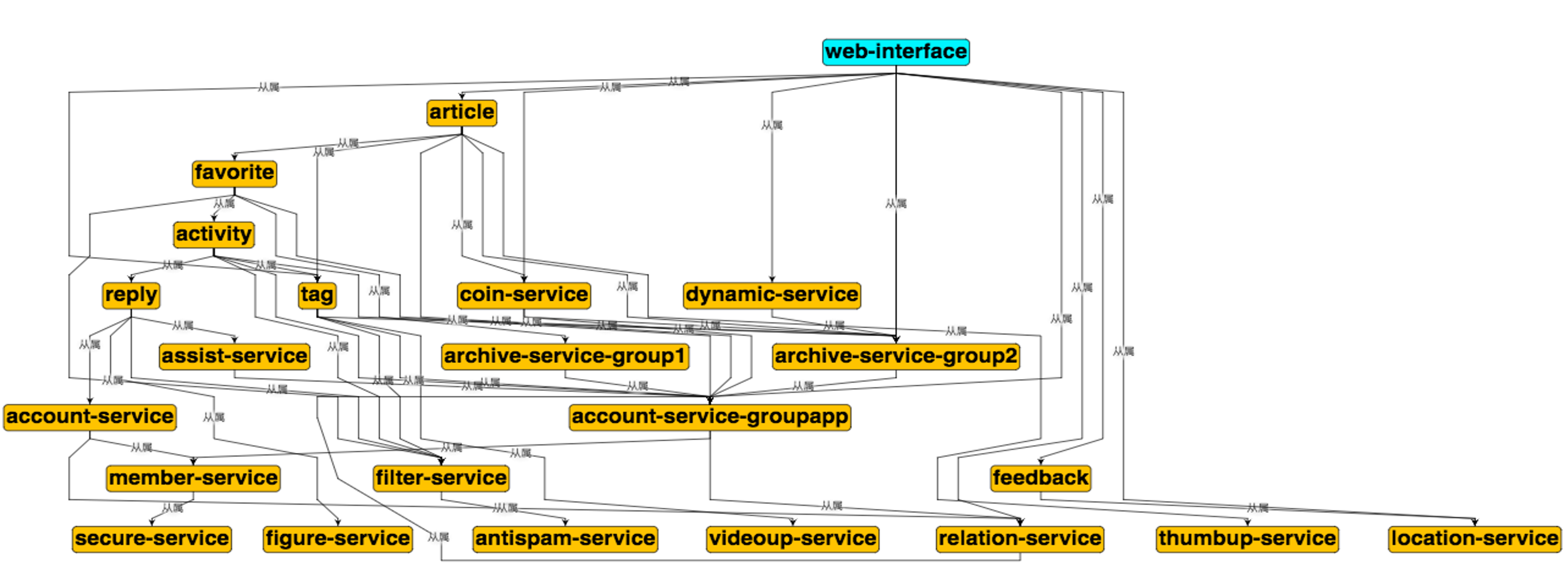
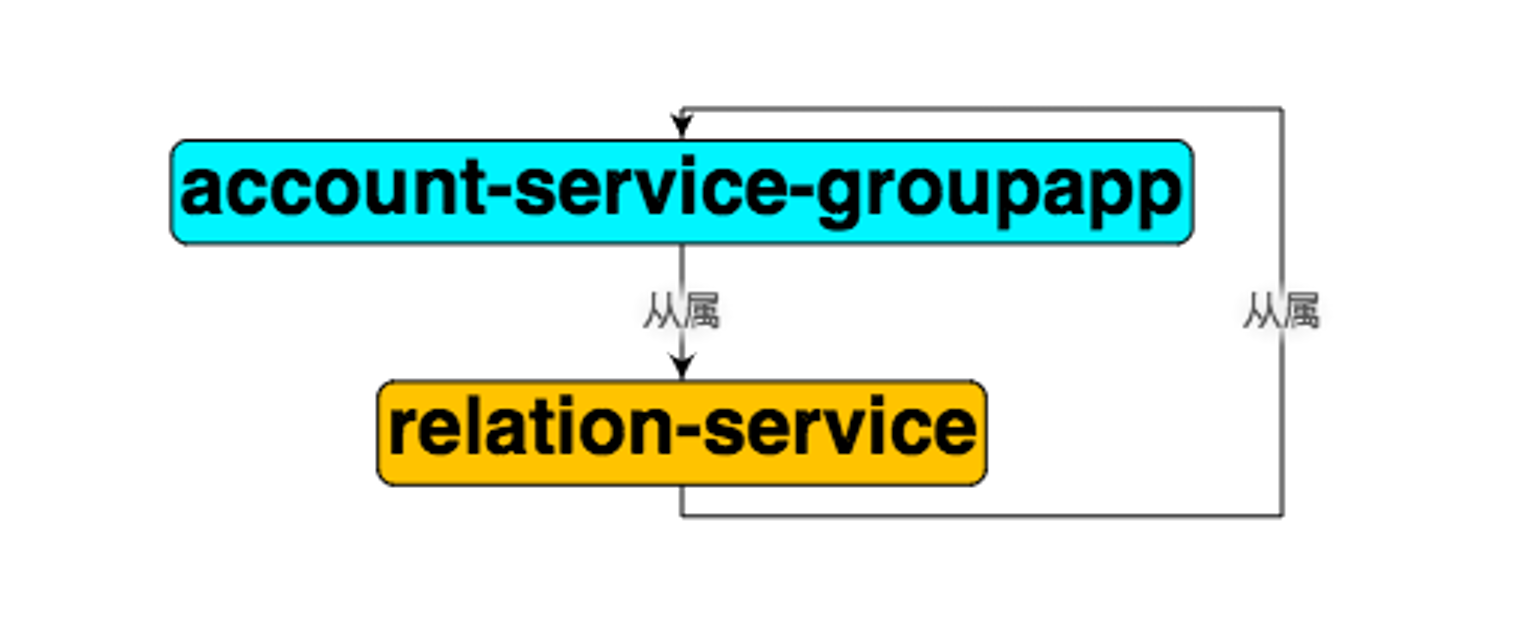
推断环依赖
一个复杂的业务架构,很难避免全部是层级关系的调用,但是我们要尽可能保证一点:调用栈永远向下,即:不产生环依赖。(产生环调用的时候,不好处理服务升级的顺序。)
经验&优化
性能优化
- 不必要的串行调用:分析能否改成并行调用,优化性能
- 缓存读放大;例如
for循环取cache - 数据库写放大:例如
for循环取 数据库 - 服务接口聚合调用:将高频调用一个接口改为批量低频调用
异常日志系统集成:
如果这些异常发生在 Dapper 跟踪采样的上下文中,那么相应的 traceid 和 spanid 也会作为元数据记录在异常日志中。异常监测服务的前端会提供一个链接,从特定的异常信息的报告直接导向到他们各自的分布式跟踪;
用户日志集成:
在请求的头中返回 traceid,当用户遇到故障或者上报客服可以根据 traceid 作为整个请求链路的关键字,再根据接口级的服务依赖接口所涉及的服务并行搜索 ES Index,聚合排序数据(将 es 中的日志数据还原成一个原始请求),就比较直观的诊断问题了;
容量预估
根据入口网关服务,推断整体下游服务的调用扇出来精确预估流量在各个系统的占比;
网络热点&易故障点:
我们内部 RPC 框架还不够统一,以及基础库的组件部分还没解决拿到应用层协议大小,如果收集起来,可以很简单的实现流量热点、机房热点、异常流量等情况。同理容易失败的 span,很容易统计出来,方便我们辨识服务的易故障点;
opentracing
标准化的推广,上面几个特性,都依赖 span TAG 来进行计算,因此我们会逐步完成标准化协议,也更方便我们开源,而不是一个内部特殊系统;
监控
Monitoring:
- 延迟、流量、错误、饱和度:监控需要关注的四个指标
- 长尾问题:少数服务占用大量资源或者少数服务、APP 接收大量请求
- 依赖资源(
Client/Server's view)
opentracing(Google Dapper)
jaegerzipkin
Logger:
traceid关联
Metric:
Prometheus+Granfana
日志级别
涉及到 net、cache、db、rpc 等资源类型的基础库,首先监控维度 4 个黄金指标:
- 延迟(耗时,需要区分正常还是异常)
- 流量(需要覆盖来源,即:
caller) - 错误(覆盖错误码或者
HTTP Status Code) - 饱和度(服务容量有多满)
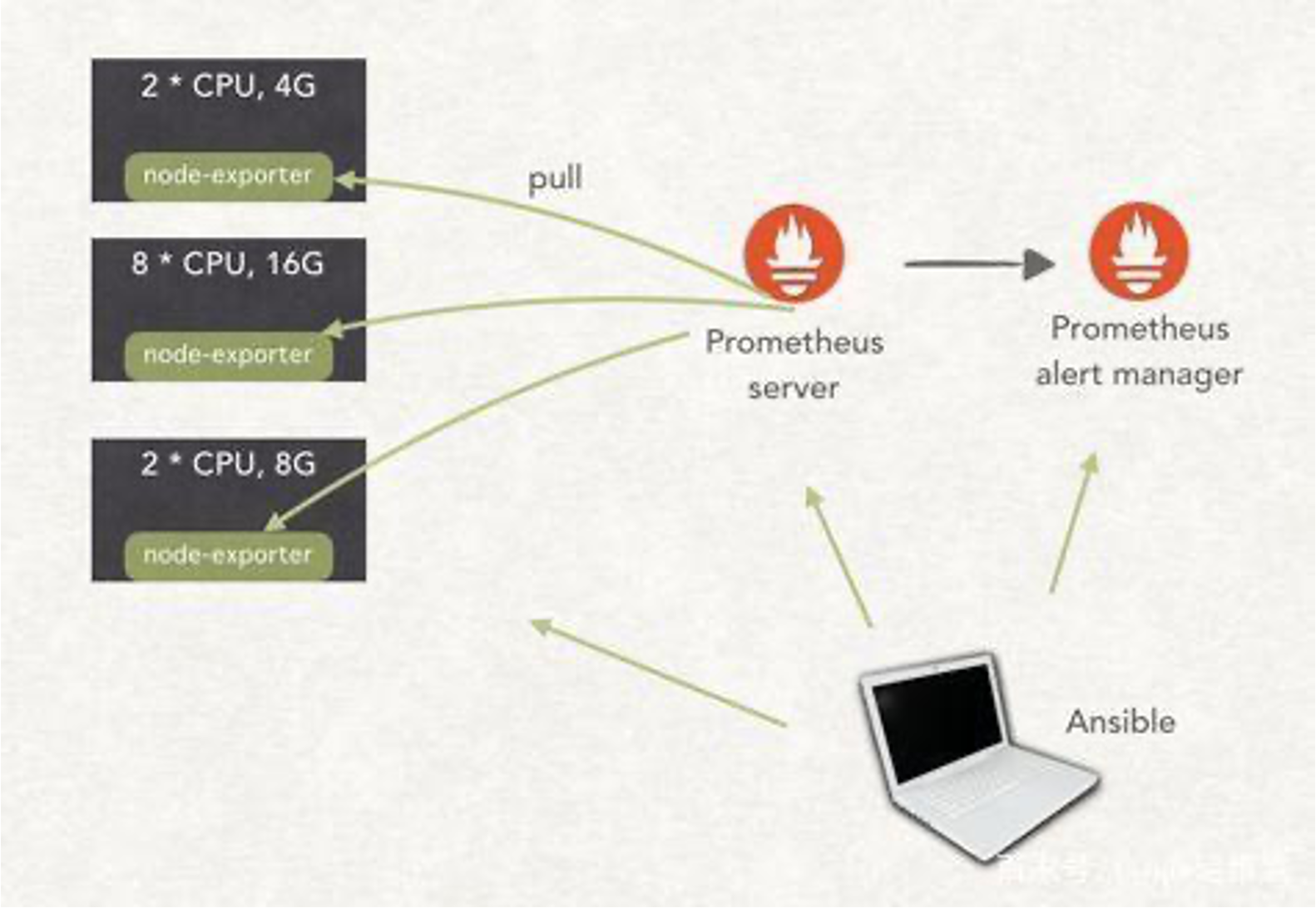
系统层面:
CPU,Memory,IO,Network,TCP/IP状态等,FD(等其他),Kernel:Context SwitchRuntime:各类GC、Mem内部状态等
监控方式
- 线上打开
Profiling的端口; - 使用服务发现找到节点信息,以及提供快捷的方式快速可以
WEB化查看进程的Profiling信息(火焰图等); watchdog,使用内存、CPU等信号量触发自动采集;

opentracing 基本用法
opentracing定义了一套API,很多tracing框架都支持这套APIgo get github.com/opentracing/opentracing-go@latest引入依赖
1 | func main() { |
1 | http.HandleFunc("/", func(w http.ResponseWriter, req *http.Request) { |
- 在程序入口处创建一个根
span。一般来说,是在HTTP服务器上接收用户请求的地方创建 span创建之后要记得Finish()
1 | func xyz(parentSpan opentracing.Span, ...) { |
- 在需要的打点创建子
span,进一步记录数据Log Field:发生了什么事情,有唯一时间戳Tag:贯穿整个span生命周期Baggage Item:贯穿tracing整个剩下的周期。会不断向下传递。
- 将
span和context.Context关联起来,向下传递
几个关键 API
StartSpan:创建根spanContextWithSpan:将span和context.Context结合在一起,以在进程内传递tracing信息StartSpanFromContext:视图从参数ctx里面拿到一个span作为父亲span。如果拿不到,则创建一个根spanContextWithSpan和StartSpanFromContext基本上是成对出现- 除非你明确知道自己是入口,否则使用
StartSpanFromContext
跨端传递
1 | func makeSomeRequest(ctx context.Context) ... { |
Span跨端传递核心是要把tracing的信息在端到端之间进行传递。也就是两个过程:在客户端把tracing信息写入到请求里面,也就是Inject(注入)过程:在服务端里面提取出来tracing信息,也就是extract过程- 对于
HTTP协议来说,一般是放在HTTP Header里面 - 对于
RPC协议来说,如果其本身依赖于HTTP,那么也是放在Header里面。但是如果本身是直接TCP通信,那么就会在自己协议的某个位置里面放下
配合 zipkin 或者 jeager
可以自己搭建一个 zipkin 或者 jeager 本地服务器作为 tracing 的采集服务器,收集采集信息。
1 | docker run -d -p 9411:9411 openzipkin/zipkin |
prometheus
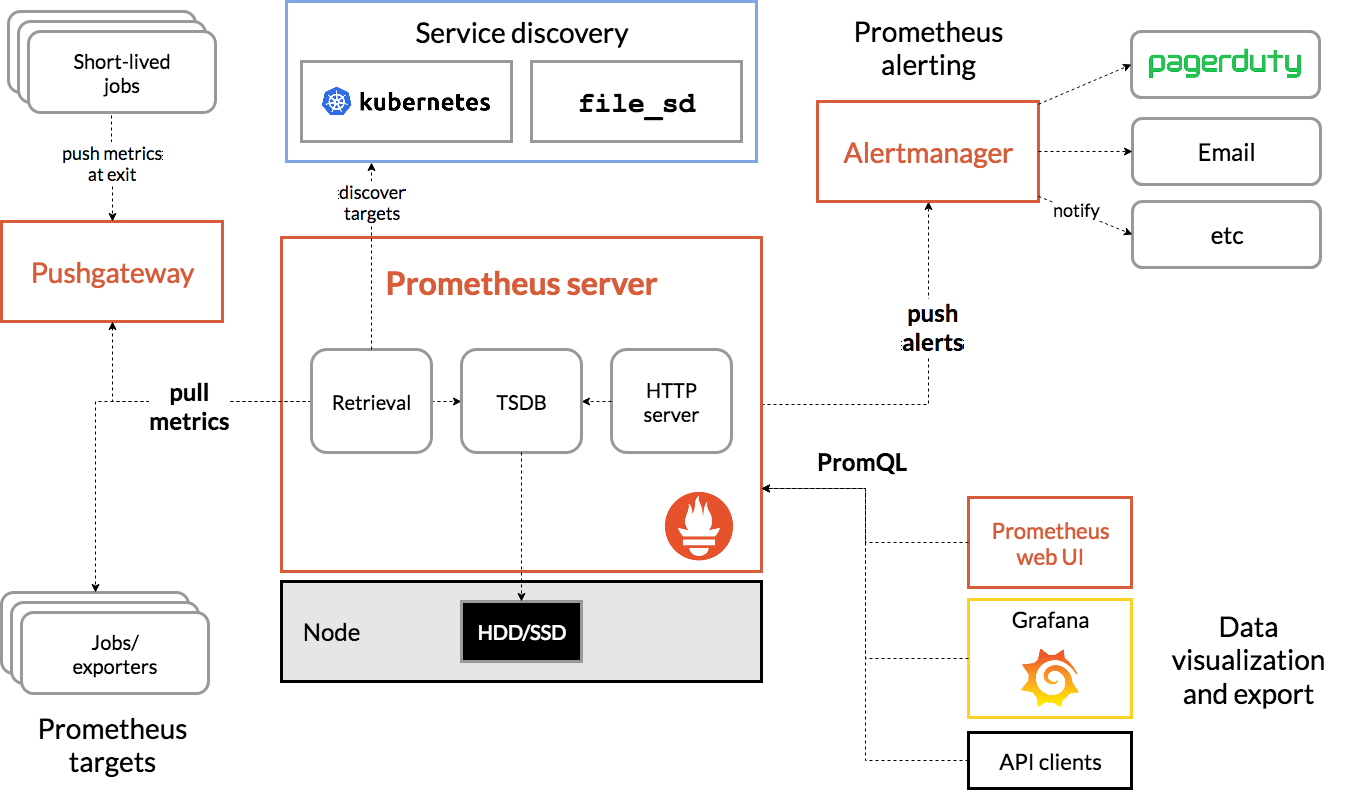
promtheus 是拖的模式,由服务端主动从客户端拖数据。避免客户端上的请求非常多,碎片信息多,导致请求大爆服务端。
指标
prometheus自身分为客户端和服务端。服务端也就是采集到的数据存储的地方,客户端就是使用prometheus的地方。prometheus metrics类型:Counter:计数器,统计次数,比如说某件事的发生次数Gauge:度量,可以增加也可以减少,比如说当前正在处理的请求数Histogram:柱状图,对观察对象进行采样,然后分到一个个桶里面Summary:采样点按照百分位进行统计,比如说 99 线,999 线等
配合 Grafana
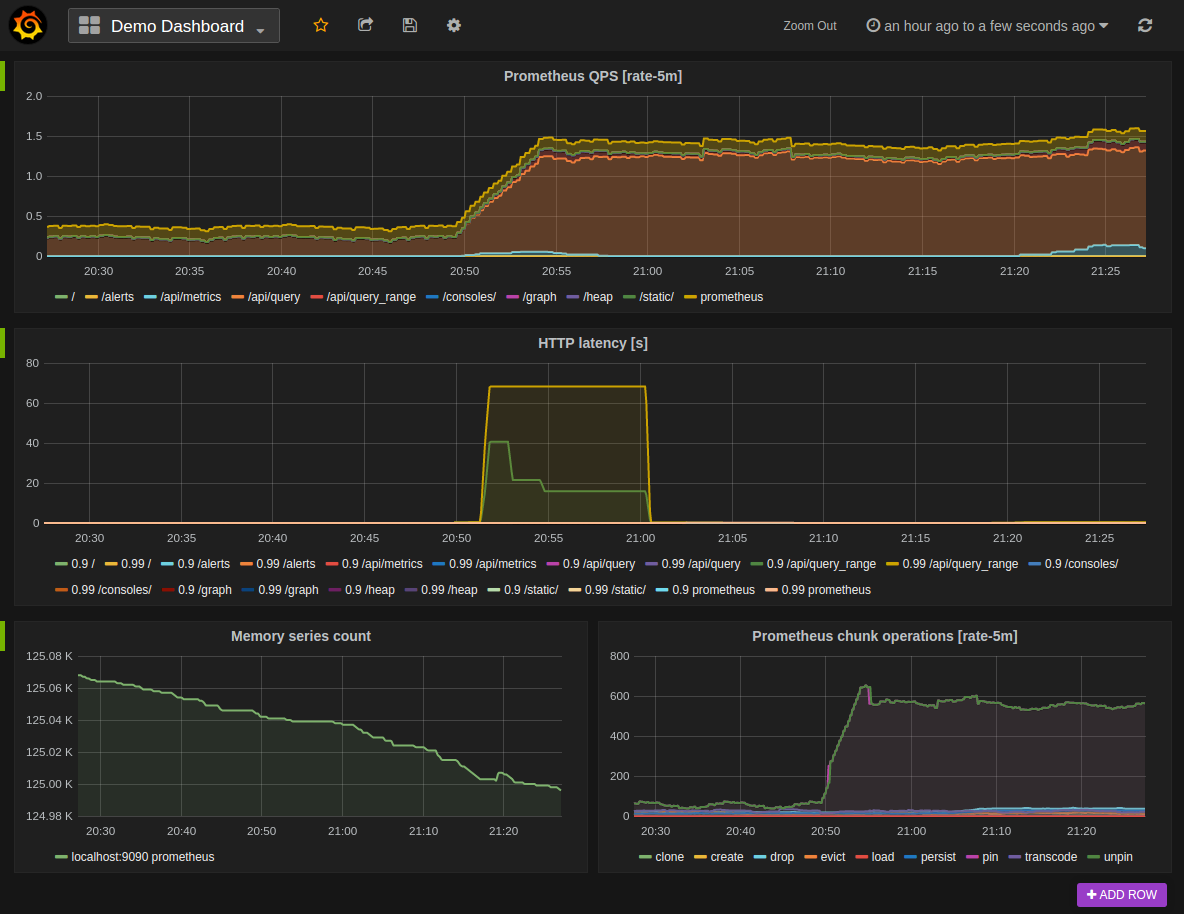
使用
1 | func NewPrometheusService() (*Service, error) { |
需要引入 github.com/prometheus/client_golang/prometheus
namespace可以是应用名subsystem:可以是一大类的东西,例如httpname:则是给指标的命名,根据需求来
向量用法
- 创建一个向量,可以使用
ConstLabels和Labels - 使用
WithLabelValues来获取具体的收集器
这种用法更加普遍
Histogram 和 Summary 区别
Histogram和Summary两者都会额外统计计数和总和- 区别:
summary是在客户端上(也就是我们的应用上)做计算的,所以性能损耗比较大histogram是在服务端上做计算的summary不支持聚合操作(因为上报的结果都是已经计算好了的)summary指标在客户端上硬编码,不灵活histogram严重依赖于设置合理的bucket
客户端和服务端启动
一般是采用客户端开启一个端口,由服务端来拉取数据。
1 | package main |
- 在客户端暴露采集数据端口:
prometheus会访问这个端口来拉数据 - 启动
prometheus服务器:本地实验可以使用docker来启动 - 推荐配置 CONFIGURATION
1 | docker run \ |
查询语言 PromQL
QUERYING PROMETHEUS
观测
HTTP 服务端观测
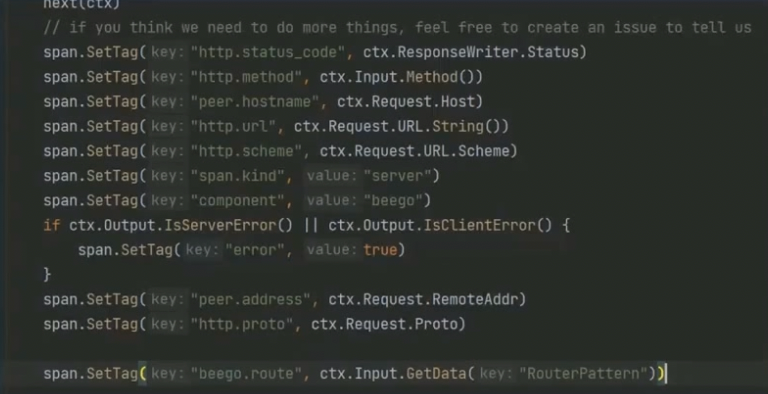
HTTP方法、状态、协议:GET,POST、200、HTTPSHTTP路由:不是记录路径,路径可能带参数,所以应该记录命中的路由。注意一些非法请求可能完全不能命中任何路由error:如果能够利用middleware之类的东西获得请求执行过程中的error,则可以记录下来。如果有错误码的设计,那么这一步应该记录下错误码- 请求和响应:在处于开发环境或者
DEBUG下,请求和响应整体都应该记录下来,用作DEBUG信息 - 业务ID:如果可以从
HTTP Header里面解析出来用户ID,或者订单ID,也可以记录下来,后面查找、分析都很有用 - 响应时间
HTTP 客户端观测
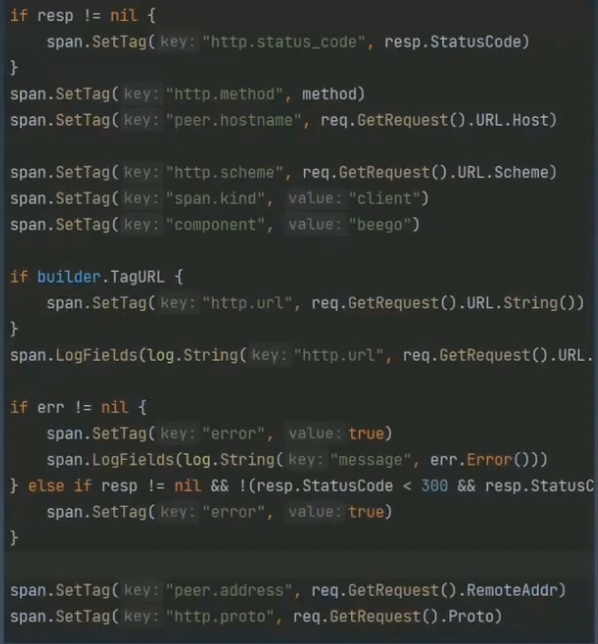
HTTP方法、状态、协议:GET,POST、200、HTTPSHTTP路由:如果要做聚合分析,那么应该记录可能命中的路由,否则直接记录整个路径(不含参数)error:如果能够利用middleware之类的东西获得请求执行过程中的error,则可以记录下来。如果有错误码的设计,那么这一步应该记录下错误码- 请求和响应:在处于开发环境或者
DEBUG下,请求和响应整体都应该记录下来,用作DEBUG信息 - 业务ID:如果可以从
HTTP Header里面解析出来用户ID,或者订单ID,也可以记录下来,后面查找、分析都很有用 - 响应时间
RPC 观测
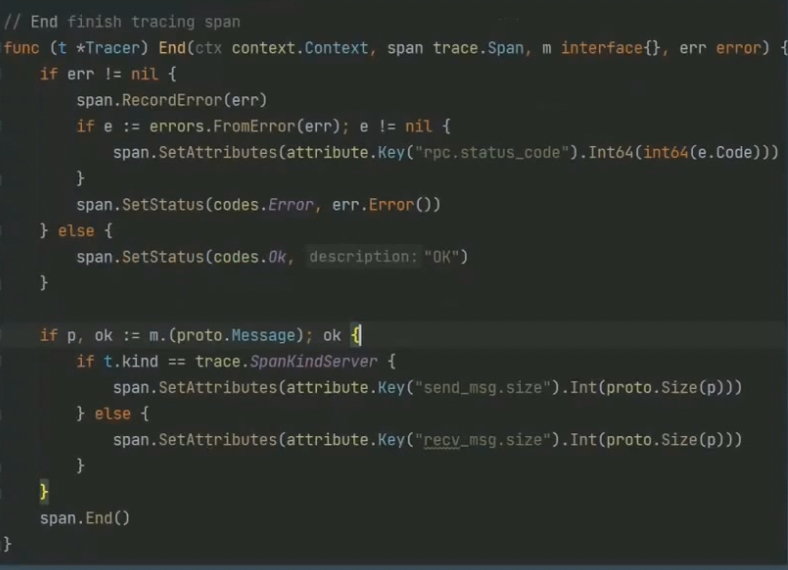
- 服务标志符:用于标记唯一服务的
- 目标主机名、IP 和端口:如果能够拿到目标主机的主机名、IP和端口都可以记录下来
RPC响应状态:取决于RPC框架设计和公司规范RPC请求和响应:开发环境或者DEBUG下可以完整记录error:如果能够获得error,则可以记录下来。如果有错误码的设计,那么这一步应该记录下错误码- 响应时间
- RPC 一般来说比较难获得业务ID,除非是约定了在整个链路中传递,例如放在
metadata里面
References
OpenTracing(已经弃用,合并到 OpenTelemetry 中)
分布式链路追踪
Zipkin