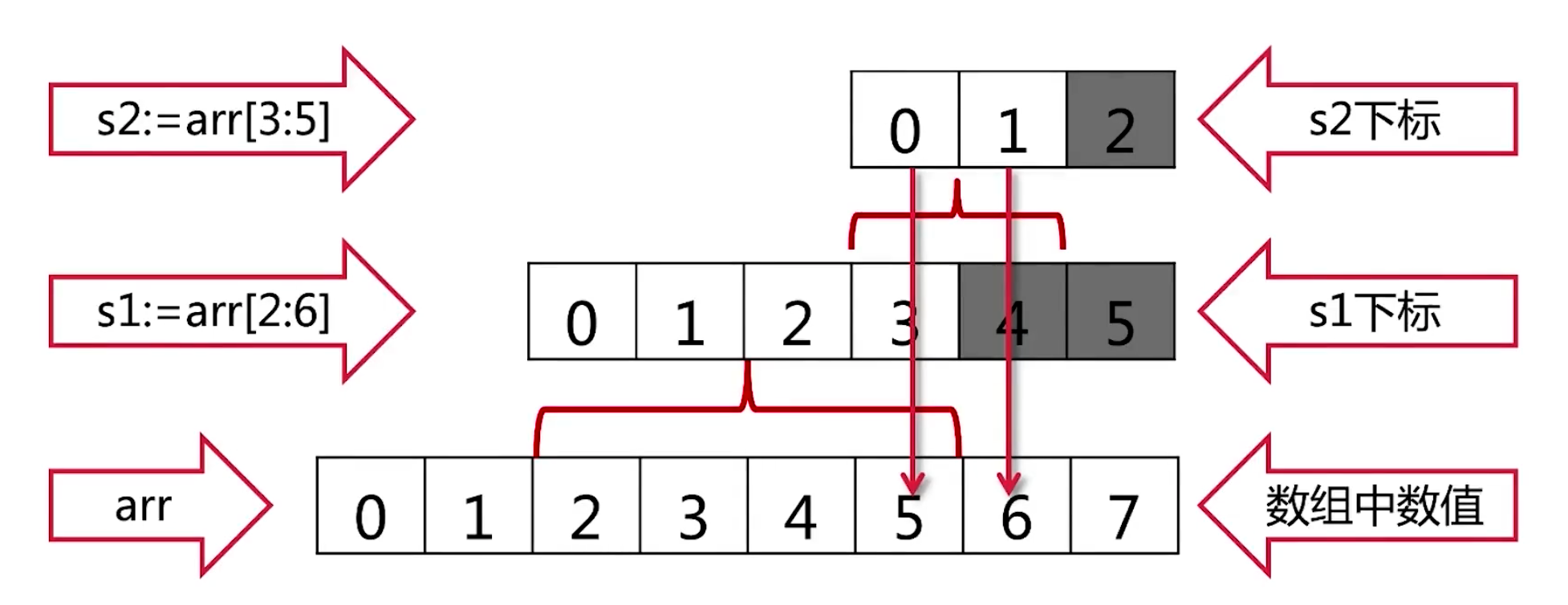
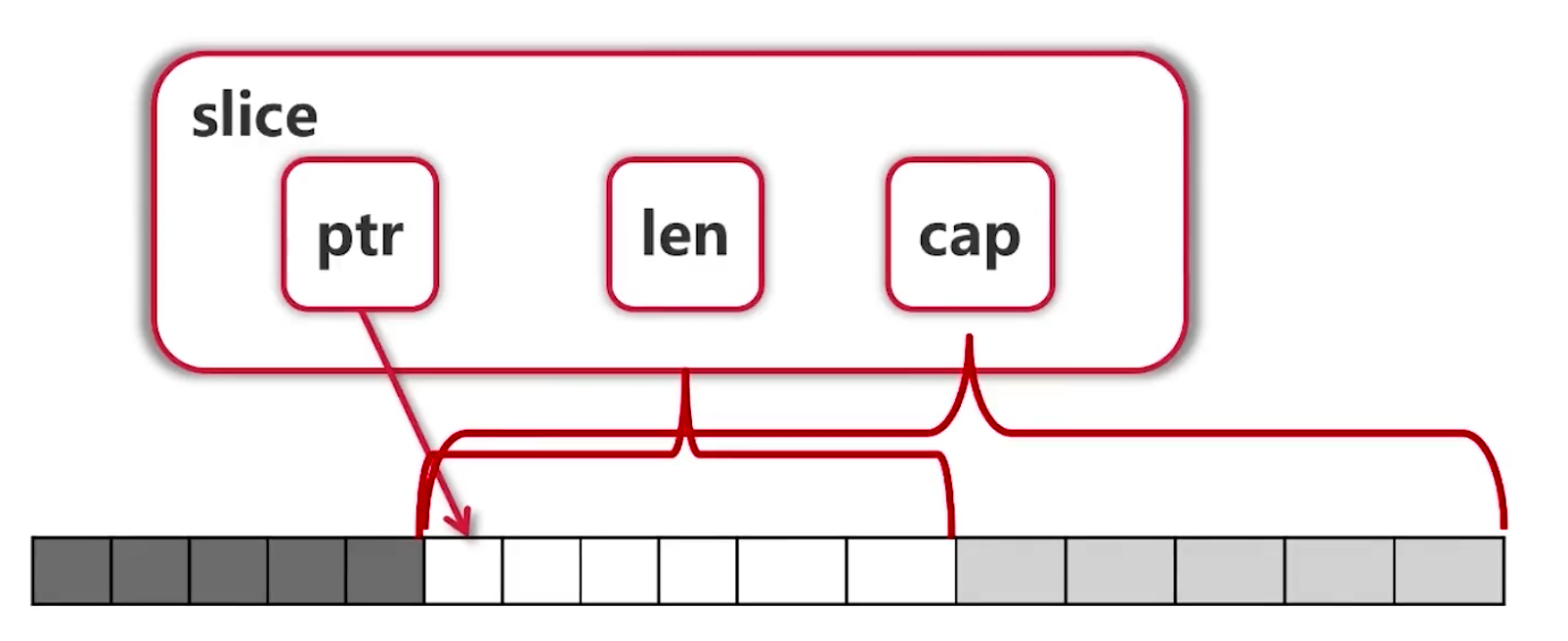
s := "hello世界!" fmt.Println(len(s)) // 获得字节长度 12,汉字6个字符 for i, j := range []byte(s) { fmt.Printf("(%d:%x)", i, j) // (0:68)(1:65)(2:6c)(3:6c)(4:6f)(5:e4)(6:b8)(7:96)(8:e7)(9:95)(10:8c)(11:21) // unicode编码,直接使用unicode编码转义,会出现错乱字符 } fmt.Println() for i, j := range s { fmt.Printf("(%d:%x)", i, j) // (0:68)(1:65)(2:6c)(3:6c)(4:6f)(5:4e16)(8:754c)(11:21) // UTF8编码,一个汉字占三个字节,因此无法获取索引为 6 7 9 10 } fmt.Println() for i, j := range []rune(s) { fmt.Printf("(%d:%c)", i, j) // (0:h)(1:e)(2:l)(3:l)(4:o)(5:世)(6:界)(7:!) // 类型转换,每一个rune占4个字节,重新分配内存 } fmt.Println() fmt.Println(utf8.RuneCountInString(s)) // 8 获得字符数
// A header for a Go map. type hmap struct { // Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go. // Make sure this stays in sync with the compiler's definition. count int // # live cells == size of map. Must be first (used by len() builtin) flags uint8 B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items) noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0. oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields }
// mapextra holds fields that are not present on all maps. type mapextra struct { // If both key and elem do not contain pointers and are inline, then we mark bucket // type as containing no pointers. This avoids scanning such maps. // However, bmap.overflow is a pointer. In order to keep overflow buckets // alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow. // overflow and oldoverflow are only used if key and elem do not contain pointers. // overflow contains overflow buckets for hmap.buckets. // oldoverflow contains overflow buckets for hmap.oldbuckets. // The indirection allows to store a pointer to the slice in hiter. overflow *[]*bmap oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket. nextOverflow *bmap }
// A bucket for a Go map. type bmap struct { // tophash generally contains the top byte of the hash value // for each key in this bucket. If tophash[0] < minTopHash, // tophash[0] is a bucket evacuation state instead. tophash [bucketCnt]uint8 // Followed by bucketCnt keys and then bucketCnt elems. // NOTE: packing all the keys together and then all the elems together makes the // code a bit more complicated than alternating key/elem/key/elem/... but it allows // us to eliminate padding which would be needed for, e.g., map[int64]int8. // Followed by an overflow pointer. }
var a int fmt.Printf("%p %v\n", &a, a) // 0x1400012c008 0 var b string fmt.Printf("%p %v\n", &b, b) // 0x14000110210 var c [1]int fmt.Printf("%p %v\n", &c, c) // 0x1400012c020 [0] var d []int fmt.Printf("%p %v %p\n", &d, d, d) // 0x1400011e018 [] 0x0 var e map[int]int fmt.Printf("%p %v %p\n", &e, e, e) // 0x14000126020 map[] 0x0 var f chan int fmt.Printf("%p %v %p\n", &f, f, f) // 0x14000126028 <nil> 0x0 var g func() fmt.Printf("%p %v %p\n", &g, f, g) // 0x14000126030 <nil> 0x0
var a int a = 1 b := &a *b = 2 fmt.Println("a:", a) // a: 2 defer fmt.Println("defer a:", a) // defer a: 2 defer fmt.Println("defer *b:", *b) // defer *b: 2 *b = 3 fmt.Println("last a:", a) // last a: 3
// chinese test case {"你好呀世界", 5}, {"你从哪里来,我的朋友,好像一只蝴蝶~", 12}, } for _, tt := range tests { if res := findlongeststr(tt.s); res != tt.num { t.Errorf("findlongeststr with str %s get %d inpect %d", tt.s, res, tt.num) // 测试结果通过t给出 } } }
➜ findLongestStr go test // 命令行 PASS ok gostudy/findLongestStr 0.093s
➜ findLongestStr go test -coverprofile=c.out // 将覆盖报告生成一个文件 PASS coverage: 100.0% of statements
➜ findLongestStr go tool cover -html=c.out // html的方式展示
1 2 3 4 5 6 7 8 9 10 11 12
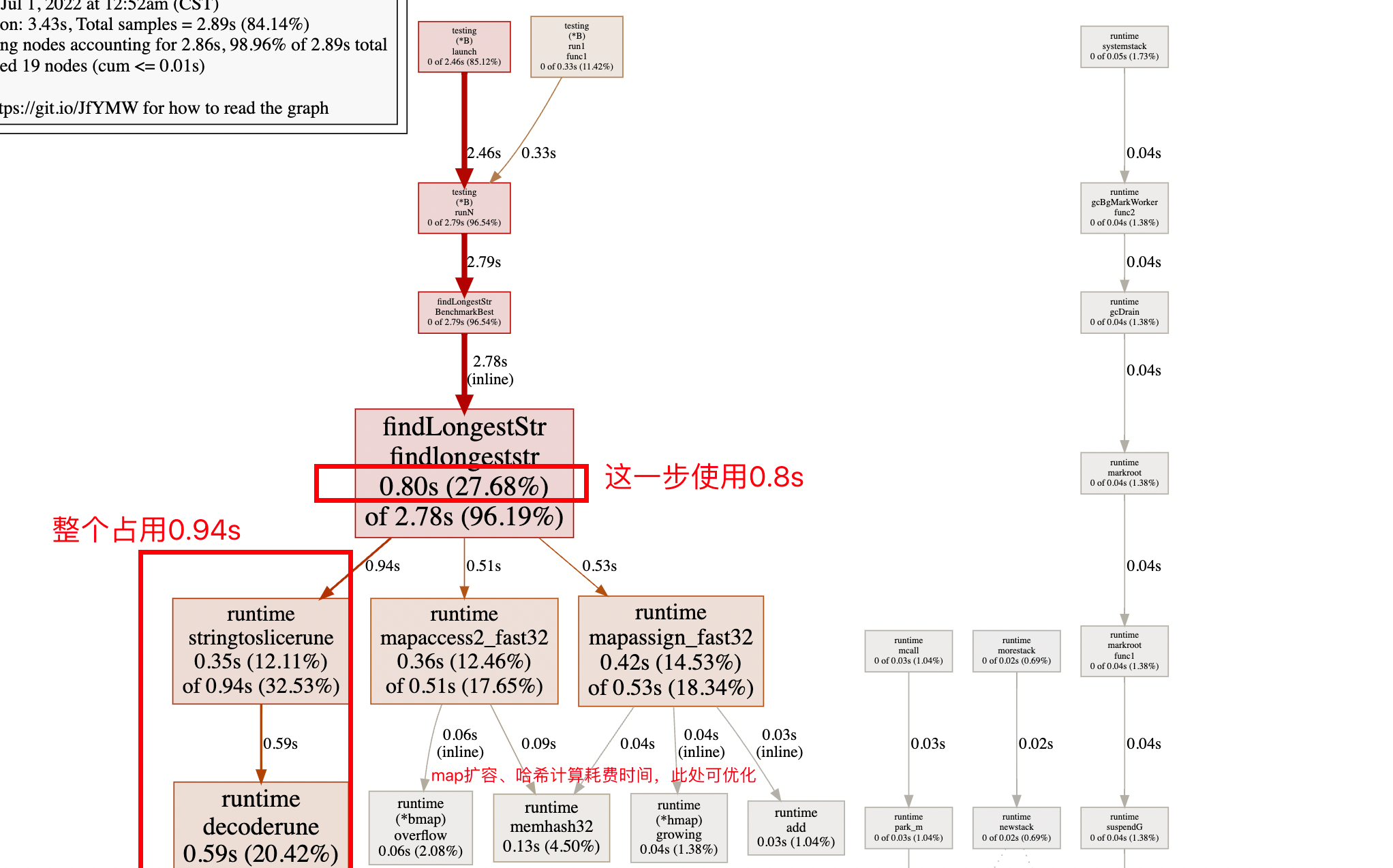
func BenchmarkBest(b *testing.B) { for i := 0; i < b.N; i++ { s, num := "你从哪里来,我的朋友,好像一只蝴蝶~", 12 if res := findlongeststr(s); res != num { b.Errorf("findlongeststr with str %s get %d inpect %d", s, res, num) } } }
func Println(a ...any) (n int, err error) Println formats using the default formats for its operands and writes to standard output. Spaces are always added between operands and a newline is appended. It returns the number of bytes written and any write error encountered.
func calc(a, b int) int { c := a + b x := c * 10 return x }
func cacl1(a int) int { var b int // b 是整形,通过返回值"逃出"了cacl1函数,但是是b的值的拷贝作为返回值,即使b被回收,也不影响在main()中使用返回值 b = a return b }
func none() {
}
func main() { var a int none() fmt.Println(calc(1, a)) fmt.Println(a, cacl1(10)) }
1
go run -gcflags "-m -l" main.go
-gcflags 编译参数,-m 进行内存分配分析 -l 表示避免程序内联,避免程序优化
1 2 3 4 5 6
./main.go:24:13: ... argument does not escape ./main.go:24:18: calc(1, a) escapes to heap // calc(1,a)逃逸到堆上,由于函数有返回值,被fmt.Println使用后还是会在main()函数中继续存在。 ./main.go:25:13: ... argument does not escape ./main.go:25:13: a escapes to heap // a 逃逸到堆上 ./main.go:25:22: cacl1(10) escapes to heap
除了通过逃逸分析,还可以通过取地址
1 2 3 4 5 6 7 8 9 10 11
type Data struct { }
func NewData() *Data { var a Data // moved to heap: a return &a }
func main() { fmt.Println(NewData()) }
1 2 3
go run -gcflags "-m -l" main.go ./main.go:25:6: moved to heap: a // 变量a在函数外部也会被使用,移动到堆上 ./main.go:30:13: ... argument does not escape
for i := 0; i < 10; i++ { go func() { for { fmt.Println("hello go routine: ", i) // 闭包,当外部i变更,函数内部i的值也会随着变化。fmt.Println需要调用io,会发生goroutine切换,切换到main goroutine会终止主进程 } }() } time.Sleep(1 * time.Second)
1 2 3 4 5 6 7 8 9 10 11
func main() { slice1 := make([]int, 11) // 此处需要注意,如果是10,则当i最终加到10的时候,无法访问slice1[10],会出现报错。现在的CPU for i := 0; i < 10; i++ { go func() { for { slice1[i]++ // 闭包,外部i改变,影响函数内部,最终i的值是10,当slice1的len是10,则会出现out of range } }() } time.Sleep(1 * time.Second) }
去掉闭包的影响
1 2 3 4 5 6 7 8 9
runtime.GOMAXPROCS(2) // 指定GOMAXPROCS个数2 slice1 := make([]int, 10) for i := 0; i < 10; i++ { go func(i int) { for { slice1[i]++ // 在go 1.12.17版本中,协程进入死循环,无法被抢占,main goroutine无法被调度,会导致进程阻塞。 ps: 实测1.14.15以及后续版本不会,需要进一步考究golang版本更新。 } }(i) }
解决goroutine死循环无法被调度,可以手动调度,通过runtime.Gosched()
1 2 3 4 5 6 7 8 9
slice1 := make([]int, 10) for i := 0; i < 10; i++ { go func(i int) { for { slice1[i]++ runtime.Gosched() // 强制该goroutine被调度 } }(i) }
竞态检测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
go run -race goroutine.go slice1 address: 0xc0000be000================== WARNING: DATA RACE Read at 0x00c0000be000 by main goroutine: Previous write at 0x00c0000be000 by goroutine 7:
for i := 0; i < 10; i++ { go func(i int) { for { slice1[i]++ // write at 0x00c0000be000 by goroutine 7: runtime.Gosched() } }(i) } time.Sleep(1 * time.Second) fmt.Println(slice1) // Read at 0x00c0000be000 by main goroutine:
for i := 0; i < 10; i++ { // main goroutine 写i fmt.Printf("i address: %p", i) go func() { for { slice1[i]++ // goroutine 读i runtime.Gosched() } }() }
Goroutine 间通信
Goroutine 通过channel实现通信
channel分为有缓冲channel和无缓冲channel
1 2
c := make(chan int) c <- 1 // fatal error: all goroutines are asleep - deadlock! 无缓冲channel没有协程接收时会发生死锁
channel有方向区分,默认可接受可发送,定义时可定义只能接收或只能发送
1 2
c := make(chan<- int) d := make(<-chan int)
关闭的channel
1 2 3
ch := make(chan int) close(ch) fmt.Printf("get %d from close channel", <-ch) // get 0 from close channel
从关闭的channel种可以一直获取值,获取到的是类型的零值
1 2 3 4 5 6 7 8 9 10 11 12 13 14
ch := make(chan int) go func() { for { data, ok := <-ch if ok { fmt.Printf("get %d from channel\n", data) // get 1 from channel } else { fmt.Printf("get %d from close channel\n", <-ch) // get 0 from close channel break } } }() ch <- 1 close(ch)
通过range可以检测到channel关闭
1 2 3 4 5 6 7 8
ch := make(chan int) go func() { for data := range ch { fmt.Printf("get %d from channel\n", data) } }() ch <- 1 close(ch) // 当ch关闭,range也结束完成
当chanel不关闭
1 2 3 4 5 6 7
ch := make(chan int) go func() { ch <- 1 }() for data := range ch { // fatal error: all goroutines are asleep - deadlock! fmt.Printf("get %d from channel\n", data) }
go routine 乱序执行,即使channel有序推送信息,不同的go routine接收也是乱序的,如果要顺序执行,可以借助另外的channel实现
1 2 3 4 5 6 7 8 9 10 11
func WorkerDo(id int, c chan int, done chan struct{}) { for i := range c { fmt.Printf("get %c from worker %d\n", i, id) // 先接收 done <- struct{}{} // 再发送 } }
for i, w := range workers { w.in <- 'a' + i // 一个发送,发送完成之后,对端有人接收 <-w.done // 一个接收,接收到了之后再处理下一个,实现顺序执行 }
乱序,将发送和接收错开
1 2 3 4 5 6 7 8
for i, w := range workers { w.in <- 'a' + i // 直接发送,对端接受乱序 }
wg := &sync.WaitGroup{} wg.Add(10) // 10个 wg.Wait() // 等待所有的wg.Done
func WorkerDo(id int, c chan int, wg *sync.WaitGroup) { for i := range c { fmt.Printf("get %c from worker %d\n", i, id) wg.Done() } }
一般会将wg封装到对象中,也可以通过函数式编程封装done的功能为一个函数
1 2 3 4 5 6 7 8 9 10 11 12 13
type Worker struct { id int in chan int done func() }
workers = append(workers, Worker{ id: i, in: in, done: func() { wg.Done() }, })
select
可以同时从多个channel中接收数据,哪个channel先有数据则先接收哪个。
阻塞式
1 2 3 4 5 6
select { case n := <-ch1: fmt.Printf("get %d from ch1\n", n) case n := <-ch2: fmt.Printf("get %d from ch2\n", n) }
通过default非阻塞式
1 2 3 4 5 6 7 8
select { case n := <-ch1: fmt.Printf("get %d from ch1\n", n) case n := <-ch2: fmt.Printf("get %d from ch2\n", n) default: fmt.Println("select default get nothing") }
一般配合for使用,循环监听
1 2 3 4 5 6 7
for { select { case n := <-ch1: fmt.Printf("get %d from ch1\n", n) case n := <-ch2: fmt.Printf("get %d from ch2\n", n) }