-- 隐藏索引 -- 创建表时,隐藏索引 CREATETABLE index_test22( id INT, `name` VARCHAR(100), info VARCHAR(100), -- 创建不可见索引 INDEX idx_info(info) INVISIBLE );
show index from index_test22\G ***************************1.row*************************** Table: index_test22 Non_unique: 1 Key_name: idx_info Seq_in_index: 1 Column_name: info Collation: A Cardinality: 0 Sub_part: NULL Packed: NULL Null: YES Index_type: BTREE Comment: Index_comment: Visible: NO-- 不可见 Expression: NULL 1rowinset (0.01 sec)
-- 创建表之后 ALTERTABLE index_test22 ADDUNIQUE INDEX uk_idx_test22(`name`) INVISIBLE; CREATE INDEX uk_idx_test22_1 ON index_test22(id) INVISIBLE; -- 修改可见性 -- 修改成不可见 ALTERTABLE index_test22 ALTER INDEX uk_idx_test22 INVISIBLE; -- 修改成可见 ALTERTABLE index_test22 ALTER INDEX uk_idx_test22 VISIBLE;
-- 连接MySQL服务器的次数 SHOW STATUS LIKE'connections'; -- MySQL服务器的上线时间 SHOW STATUS LIKE'uptime'; -- 慢查询次数 SHOW STATUS LIKE'slow_queries'; -- SELECT 查询返回的行数,也就是查询操作返回的行数的叠加 SHOW STATUS LIKE'innodb_rows_read'; -- 执行 INSERT 操作插入的行数 SHOW STATUS LIKE'innodb_rows_inserted'; -- 执行 UPDATE 操作更新的行数 SHOW STATUS LIKE'innodb_rows_updated'; -- 执行 DELETE 操作删除的行数 SHOW STATUS LIKE'innodb_rows_deleted'; -- 查询操作的次数 SHOW STATUS LIKE'com_select'; -- 插入操作的次数,对于批量插入的insert操作,只累加一次 SHOW STATUS LIKE'com_insert'; -- 更新操作的次数 SHOW STATUS LIKE'com_update'; -- 删除操作的次数 SHOW STATUS LIKE'com_delete';
delimiter // DROPPROCEDURE IF EXISTS proc_batch_insert; CREATEPROCEDURE proc_batch_insert() BEGIN DECLARE pre_name BIGINT; DECLARE ageVal INT; DECLARE i INT; SET pre_name=187635267; SET ageVal=100; SET i=1; -- 循环 100 0000 次 WHILE i <=1000000 DO INSERTINTO t_user(`name`,age,create_time,update_time) VALUES(CONCAT(pre_name,'@qq.com'),(ageVal+1)%30,NOW(),NOW()); SET pre_name=pre_name+100; SET i=i+1; SET ageVal=ageVal+1; END WHILE; END// delimiter ;
-- 如果包含子查询的查询语句不能转为对应的多表连接的形式,并且子查询是不相关子查询 -- 该子查询的第一个SELECT关键字代表的查询是SUBQUERY -- 例如两个字段没有任何联系 use mitaka; Reading table information for completion oftableandcolumn names You can turn off this feature toget a quicker startup with-A
EXPLAIN SELECT*FROM employee WHERE emp_id IN (SELECT dept_id FROM department) OR lname ='a'; +----+-------------+------------+------------+-------+---------------+---------+---------+------+------+----------+-------------+ | id | select_type |table| partitions | type | possible_keys | key | key_len |ref|rows| filtered | Extra | +----+-------------+------------+------------+-------+---------------+---------+---------+------+------+----------+-------------+ |1|PRIMARY| employee |NULL|ALL|NULL|NULL|NULL|NULL|17|100.00|Usingwhere| |2| SUBQUERY | department |NULL| index |PRIMARY|PRIMARY|2|NULL|3|100.00|Using index | +----+-------------+------------+------------+-------+---------------+---------+---------+------+------+----------+-------------+ 2rowsinset, 1 warning (0.00 sec)
-- 如果包含子查询的查询语句不能转为对应的多表连接的形式,并且子查询是相关子查询 -- 该子查询的第一个SELECT关键字代表的查询是 DEPENDENT SUBQUERY EXPLAIN SELECT*FROM s1 WHERE id IN (SELECT id FROM s2) OR name ='12'; +----+--------------------+-------+------------+-----------------+---------------+---------+---------+------+------+----------+-------------+ | id | select_type |table| partitions | type | possible_keys | key | key_len |ref|rows| filtered | Extra | +----+--------------------+-------+------------+-----------------+---------------+---------+---------+------+------+----------+-------------+ |1|PRIMARY| s1 |NULL|ALL|NULL|NULL|NULL|NULL|1|100.00|Usingwhere| |2| DEPENDENT SUBQUERY | s2 |NULL| unique_subquery |PRIMARY|PRIMARY|4| func |1|100.00|Using index | +----+--------------------+-------+------------+-----------------+---------------+---------+---------+------+------+----------+-------------+ 2rowsinset, 1 warning (0.00 sec)
-- DEPENDENT SUBQUERY 的查询可能会被执行多次
-- 在包含 UNION 或者 UNION ALL 的大查询中,如果各个小查询都依赖于外层查询的话 -- 除了最左边的小查询之外,其余小查询的类型是 DEPENDENT UNION EXPLAIN SELECT*FROM s1 WHERE name IN (SELECT `name` FROM s2 WHERE name ='a'UNIONSELECT `name` FROM s1 WHERE `name` ='a'); +----+--------------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+ | id | select_type |table| partitions | type | possible_keys | key | key_len |ref|rows| filtered | Extra | +----+--------------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+ |1|PRIMARY| s1 |NULL|ALL|NULL|NULL|NULL|NULL|1|100.00|Usingwhere| |2| DEPENDENT SUBQUERY | s2 |NULL|ALL|NULL|NULL|NULL|NULL|1|100.00|Usingwhere| |3| DEPENDENT UNION| s1 |NULL|ALL|NULL|NULL|NULL|NULL|1|100.00|Usingwhere| |4|UNIONRESULT|<union2,3>|NULL|ALL|NULL|NULL|NULL|NULL|NULL|NULL|Using temporary | +----+--------------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+ 4rowsinset, 1 warning (0.01 sec)
-- 对于包含派生表的查询,该派生表对应的子查询的类型就是 DERIVED,例如 子查询出的零时表就是派生 EXPLAIN SELECT*FROM (SELECT `name`,COUNT(*) AS c FROM s1 GROUPBY `name`) AS derived_s1 WHERE c >2; +----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+ | id | select_type |table| partitions | type | possible_keys | key | key_len |ref|rows| filtered | Extra | +----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+ |1|PRIMARY|<derived2>|NULL|ALL|NULL|NULL|NULL|NULL|2|100.00|NULL| |2| DERIVED | s1 |NULL|ALL|NULL|NULL|NULL|NULL|1|100.00|Using temporary | +----+-------------+------------+------------+------+---------------+------+---------+------+------+----------+-----------------+ 2rowsinset, 1 warning (0.01 sec)
-- 当查询优化器在执行包含子查询的语句时,选择将子查询物化之后与外层查询进行连接查询时,属性是 MATERIALIZED EXPLAIN SELECT*FROM employee WHERE lname IN (SELECT `name` FROM department); -- 子查询转为了物化表 +----+--------------+-------------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+ | id | select_type |table| partitions | type | possible_keys | key | key_len |ref|rows| filtered | Extra | +----+--------------+-------------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+ |1| SIMPLE |<subquery2>|NULL|ALL|NULL|NULL|NULL|NULL|NULL|100.00|NULL| |1| SIMPLE | employee |NULL|ALL|NULL|NULL|NULL|NULL|17|10.00|Usingwhere; Usingjoin buffer (hash join) | |2| MATERIALIZED | department |NULL|ALL|NULL|NULL|NULL|NULL|3|100.00|NULL| +----+--------------+-------------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+ 3rowsinset, 1 warning (0.00 sec)
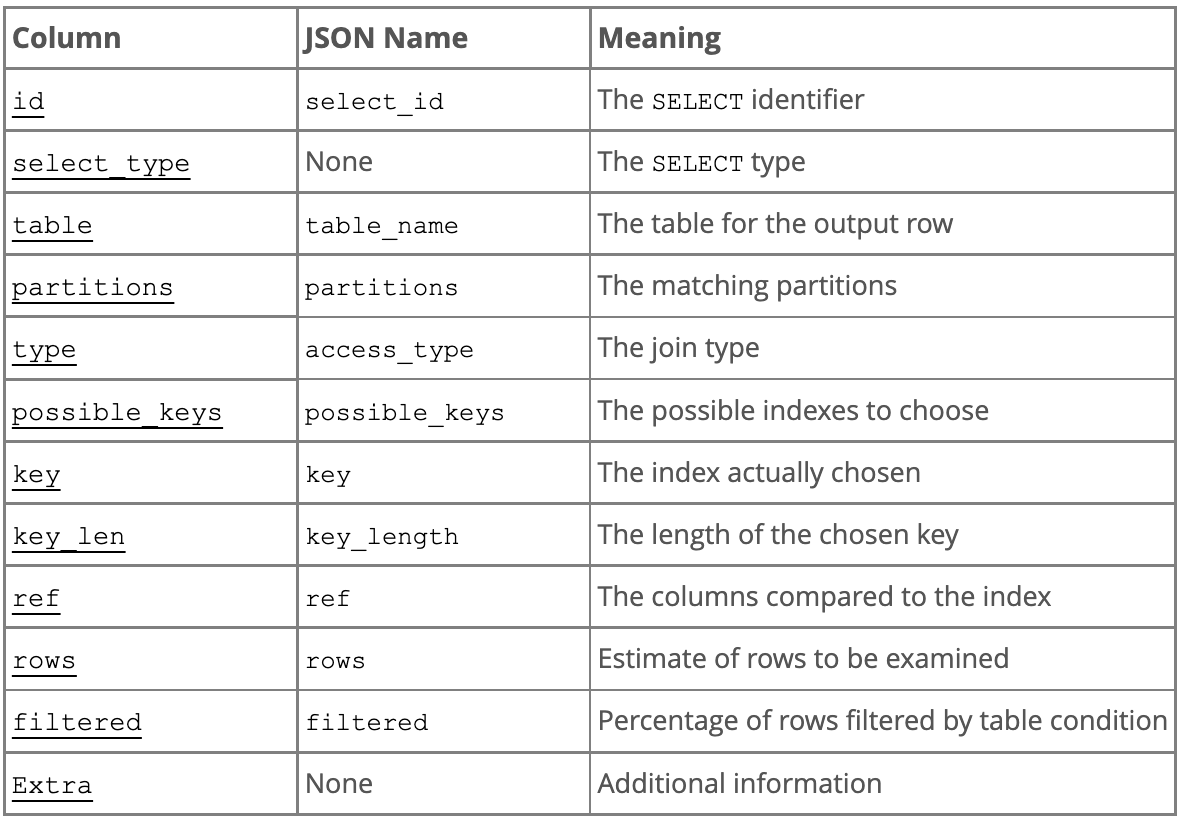
partitions 分区命中情况
可略,代表分区表中的命中情况,非分区表,该项为NULL。(将表创建在不同的区中)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
-- 按照id分区,id < 100 p0分区 ,其他 p1 分区 CREATETABLE user_partitions ( id INT,`name` VARCHAR(25)) PARTITIONBYRANGE(id)( PARTITION p0 VALUES less than(100), PARTITION p1 VALUES less than MAXVALUE );
DESCSELECT*FROM user_partitions WHERE id >200; +----+-------------+-----------------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type |table| partitions | type | possible_keys | key | key_len |ref|rows| filtered | Extra | +----+-------------+-----------------+------------+------+---------------+------+---------+------+------+----------+-------------+ |1| SIMPLE | user_partitions | p1 |ALL|NULL|NULL|NULL|NULL|1|100.00|Usingwhere| +----+-------------+-----------------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1rowinset, 1 warning (0.01 sec)
-- unique_subquery 针对一些包含IN子句的查询语句中,如果查询优化器决定将IN子查询转换为EXISTS子查询,而且子查询可以使用到的主键进行等值匹配的话, -- 那么该子查询执行计划的type列的值就是 unique_subquery EXPLAIN SELECT*FROM s1 WHERE sid IN (SELECT id FROM s2 WHERE s1.sid = s2.sid) OR key3 ='c'; +----+--------------------+-------+------------+-----------------+------------------+---------+---------+------+------+----------+-------------+ | id | select_type |table| partitions | type | possible_keys | key | key_len |ref|rows| filtered | Extra | +----+--------------------+-------+------------+-----------------+------------------+---------+---------+------+------+----------+-------------+ |1|PRIMARY| s1 |NULL|ALL| idx_key3 |NULL|NULL|NULL|2|100.00|Usingwhere| |2| DEPENDENT SUBQUERY | s2 |NULL| unique_subquery |PRIMARY,s1_id_fk |PRIMARY|4| func |1|100.00|Usingwhere| +----+--------------------+-------+------------+-----------------+------------------+---------+---------+------+------+----------+-------------+ 2rowsinset, 2 warnings (0.01 sec)
-- range 如果使用索引获取某些 范围区间 的记录,那么就可能使用到 range 访问方法 EXPLAIN SELECT*FROM s1 WHERE sid IN (1,3,4,5); +----+-------------+-------+------------+-------+---------------+--------+---------+------+------+----------+-----------------------+ | id | select_type |table| partitions | type | possible_keys | key | key_len |ref|rows| filtered | Extra | +----+-------------+-------+------------+-------+---------------+--------+---------+------+------+----------+-----------------------+ |1| SIMPLE | s1 |NULL|range| un_sid | un_sid |5|NULL|4|100.00|Using index condition| +----+-------------+-------+------------+-------+---------------+--------+---------+------+------+----------+-----------------------+ 1rowinset, 1 warning (0.01 sec)
EXPLAIN SELECT*FROM s1 WHERE sid >3AND sid <10; +----+-------------+-------+------------+-------+---------------+--------+---------+------+------+----------+-----------------------+ | id | select_type |table| partitions | type | possible_keys | key | key_len |ref|rows| filtered | Extra | +----+-------------+-------+------------+-------+---------------+--------+---------+------+------+----------+-----------------------+ |1| SIMPLE | s1 |NULL|range| un_sid | un_sid |5|NULL|1|100.00|Using index condition| +----+-------------+-------+------------+-------+---------------+--------+---------+------+------+----------+-----------------------+ 1rowinset, 1 warning (0.00 sec)
-- index 如果可以使用索引覆盖,但需要扫描全部的索引记录时,该表的访问方法就是 index CREATE INDEX idx_sid_key2_key3 ON s1(sid,key2,key3); DROP INDEX idx_key3 ON s1; -- 使用了联合索引idx_sid_key2_key3,但是还会扫描全部的索引记录 -- 索引覆盖:使用了联合索引,而且不需要回表操作,例如本次查询过程通过联合索引,但是扫描了全部的索引记录,在索引记录中包含key2,不需要回表再查,这个就是覆盖索引 EXPLAIN SELECT key2 FROM s1 WHERE key3='a'; +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+--------------------------+ | id | select_type |table| partitions | type | possible_keys | key | key_len |ref|rows| filtered | Extra | +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+--------------------------+ |1| SIMPLE | s1 |NULL| index | idx_sid_key2_key3 | idx_sid_key2_key3 |811|NULL|2|50.00|Usingwhere; Using index | +----+-------------+-------+------------+-------+-------------------+-------------------+---------+------+------+----------+--------------------------+ 1rowinset, 1 warning (0.00 sec)
-- 如果查询 name,则没有用到联合索引,就变成all EXPLAIN SELECT `name`,key2 FROM s1 WHERE key3='a'; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ | id | select_type |table| partitions | type | possible_keys | key | key_len |ref|rows| filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ |1| SIMPLE | s1 |NULL|ALL|NULL|NULL|NULL|NULL|2|50.00|Usingwhere| +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+ 1rowinset, 1 warning (0.00 sec)
-- ALL 全表扫描 EXPLAIN SELECT*FROM s1; +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+ | id | select_type |table| partitions | type | possible_keys | key | key_len |ref|rows| filtered | Extra | +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+ |1| SIMPLE | s1 |NULL|ALL|NULL|NULL|NULL|NULL|2|100.00|NULL| +----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------+ 1rowinset, 1 warning (0.00 sec)
结果值从最好到最坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
-- 没有使用表 No tables used EXPLAIN SELECT1; -- Impossible WHERE,where子句永远为FALSE EXPLAIN SELECT*FROM s1 WHERE1!=1;
-- Using where 使用全表扫描来执行某个表的查询,并且该语句的where子句中有针对该表的搜索条件时 EXPLAIN SELECT*FROM s1 WHERE key3 ='a'; -- Using where 使用索引访问来执行某个表的查询,并且语句的 where 子句有针对该表的搜索条件之外,还有其他的搜索条件时 EXPLAIN SELECT*FROM s1 WHERE `name` ='a'AND key3 ='a';
-- No matching min/max row 当查询列表有 MIN 或者 MAX 聚合函数,但是并没有符合 WHERE 子句中的搜索条件的记录时 EXPLAIN SELECTMIN(`name`) FROM s1 WHERE name ='abc';
-- Select tables optimized away 查询时有值 EXPLAIN SELECTMIN(`name`) FROM s1 WHERE name ='a';
-- Using index 当查询列表以及搜索条件中只包含属于某个索引的列,也就是在可以使用覆盖索引的情况下 EXPLAIN SELECT `name` FROM s1 WHERE `name`='a'; EXPLAIN SELECT `name`,id FROM s1 WHERE `name`='a';
-- Using index condition 条件索引,也就是索引下推,搜索条件中出现了索引列,但是不能使用到索引 EXPLAIN SELECT*FROM s1 WHERE `name` >'z'AND `name` LIKE'%a';
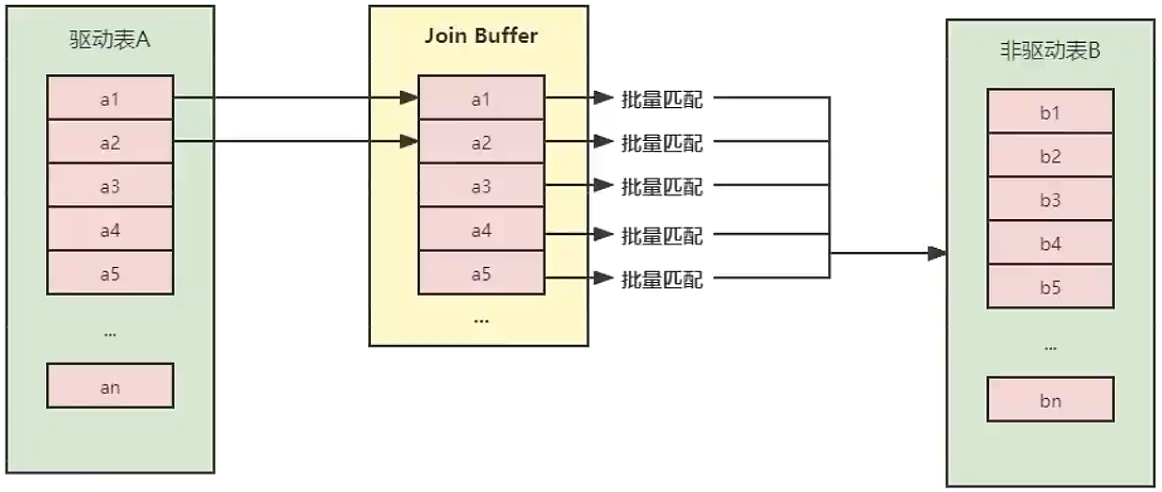
-- Using where; Using join buffer (hash join) 连接查询时,被驱动表不能有效的利用索引加快访问速度,MySQL会为其分配一块叫 JOIN Buffer 的内存块来加快查询速度,也就是 基于块的嵌套循环算法 DROP INDEX normal_idx ON s1; -- 删除 name 上的索引 EXPLAIN SELECT*FROM s1 INNERJOIN s2 ON s1.`name` = s2.`name`;
-- Using where; Not exists; Using join buffer (hash join) -- 当使用作为连接时,where子句包含要求被驱动表的某个列等于 NULL 值的搜索条件 -- 而且那个列又是不允许存储 NULL 值的,那么在该表的执行计划的EXTRA列会出现 not exist EXPLAIN SELECT*FROM s1 LEFTJOIN s2 ON s1.`name` = s2.`name` WHERE s2.id ISNULL;
-- 如果执行计划的 extra 列出现 using intersct(...) 的提示,说明准备使用 intersect 索引合并的方式执行查询 -- 括号中的 ... 表时需要进行索引合并的索引名称 -- 如果出现了 using union(...) 提示,说明准备使用 union 索引合并的方式执行查询 -- 出现了 Using sort_union(...) 提示,说明准备使用 sort_union 索引合并的方式查询 -- 例如 Using union(idx_key4,idx_key2); Using where ,使用两个索引,也就是说会用索引合并 EXPLAIN SELECT*FROM s1 WHERE key4 ='a'OR key2 ='a';
SHOW VARIABLES LIKE'%optimizer_trace%'; -- 打开 optimizer_trace,并将格式设置为json SET optimizer_trace="enabled=on",end_markers_in_json=on; -- 设置最大内存大小,避免由于信息过多,内存小导致截断 SET optimizer_trace_max_mem_size =1000000;
-- 全值匹配 -- 没有使用索引 EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE age =11; EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE age =11AND name ='187635267@qq.com'; EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE age =11AND name ='187635267@qq.com'AND create_time ='2022-11-16 05:47:16' ; -- 创建索引 CREATE INDEX id_age ON t_user(age); CREATE INDEX id_age_name ON t_user(age,name); CREATE INDEX id_age_name_ctime ON t_user(age,name,create_time); -- 使用索引 EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE age =11; EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE age =11AND name ='187635267@qq.com'; EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE age =11AND name ='187635267@qq.com'AND create_time ='2022-11-16 05:47:16' ;
-- 最佳左前缀匹配,在联合索引中,优先匹配最左侧的索引列 -- 过滤条件要使用索引必须按照索引建立时的顺序,一次满足,一旦跳过某个字段,索引后面的字段都无法被使用 -- 使用到 id_age_name_ctime EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE age =11AND name ='187635267@qq.com'; -- 没有匹配上索引,由于没有创建 name 的索引 EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE update_time ='2022-11-16 05:47:16'AND name ='187635267@qq.com';
-- 范围条件右边的列索引失效 -- 范围右侧的列不能使用,< <= > >= 和 BETWEEN . -- 因此,创建联合索引,务必把范围(时间、金额)放在索引后面 -- 删除除了主键之外的索引 -- 创建索引 CREATE INDEX idx_age_ctime_name ON t_user(age,create_time,name); -- 使用到索引 ,使用到了 age字段 和 create_time 字段 ,没有使用到 `name` 字段,这是由于使用了范围字段 EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE age =11AND create_time >'2022-11-16 05:47:16'AND `name` ='187635267@qq.com'; -- 要使用到索引,就需要将等值关系的索引放到前面 CREATE INDEX idx_age_name_ctime ON t_user(age,name,create_time); -- 使用到idx_age_name_ctime的全部字段 EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE age =20AND create_time >'2022-11-16'AND `name` ='abc';
-- 不等于 索引失效 CREATE INDEX idx_name ON t_user(`name`); -- 没有使用到索引 EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE `name` <>'abc'; EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE `name` !='abc';
-- IS NULL 可以使用索引 -- IS NOT NULL 无法使用索引 EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE `name` ISNULL; EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE `name` ISNOTNULL; -- 因此,最好在设计数据表时,就将字段设置为 NOT NULL 约束。INT类型默认值0,字符串类型默认值空字符串'' -- 同理,NOT LIKE 也一样无法使用索引,会全表扫描
-- LIKE 以 %开头索引失效 -- 用索引 EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE `name` LIKE'abc%'; -- 不用索引 EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE `name` LIKE'%abc';
-- OR 前后存在非索引的列,索引失效 -- 删除除主键索引其他的索引 -- 创建索引 CREATE INDEX idx_age ON t_user(age); -- 索引失效 EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE age =10OR `name` ='abc'; -- 如果要使用索引,则要将另外一个字段也创建索引 CREATE INDEX idx_name ON t_user(name); -- 此时会使用索引集合 Using union(idx_age,idx_name); Using where EXPLAIN SELECT SQL_NO_CACHE *FROM t_user WHERE age =10OR `name` ='abc';
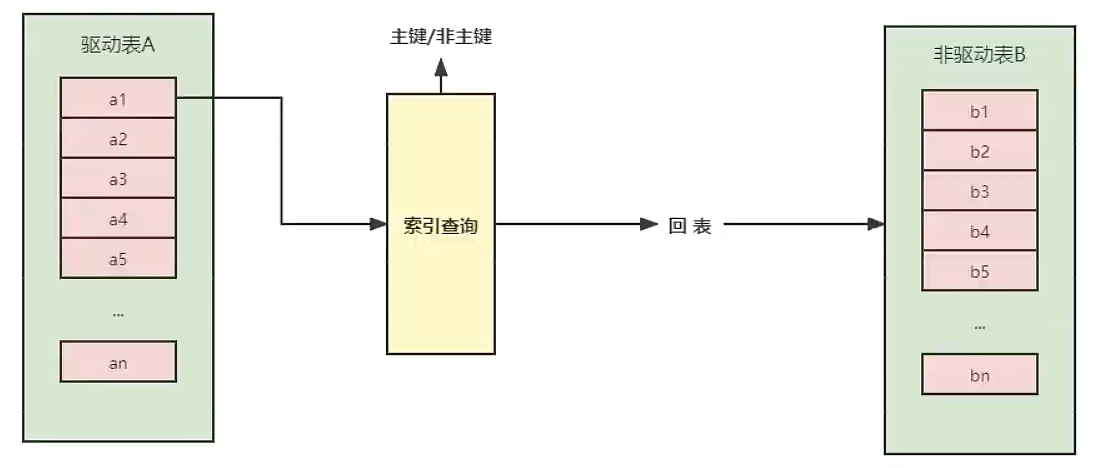
-- 外连接 -- 没有使用索引 EXPLAIN SELECT SQL_NO_CACHE *FROM employee LEFTJOIN department ON employee.dept_id = department.dept_id; -- 添加索引 CREATE INDEX idx_dept ON department(dept_id); -- 被驱动表有索引之后,使用被驱动表的索引。(驱动表不需要索引,因为要全表扫描)(字段类型如果不一样,会有隐式转换,会导致索引失效) EXPLAIN SELECT SQL_NO_CACHE *FROM employee LEFTJOIN department ON employee.dept_id = department.dept_id;
-- 内连接 EXPLAIN SELECT SQL_NO_CACHE *FROM employee INNERJOIN department ON employee.dept_id = department.dept_id; -- 添加索引 CREATE INDEX idx_dept ON department(dept_id); CREATE INDEX idx_dept ON employee(dept_id); -- 此时两个表的权重一样,可能驱动表和被驱动表的角色会互换 -- 查询优化器会根据表中的数据量,会选择数据量少的表作为驱动表,数据量大的座位被驱动表 EXPLAIN SELECT SQL_NO_CACHE *FROM employee INNERJOIN department ON employee.dept_id = department.dept_id; -- 删除 department 的索引 DROP INDEX idx_dept ON department; EXPLAIN SELECT SQL_NO_CACHE *FROM employee INNERJOIN department ON employee.dept_id = department.dept_id; -- 对于内连接,如果表中的连接条件只能有一个字段有索引,则有索引的字段所在的表会被作为被驱动表
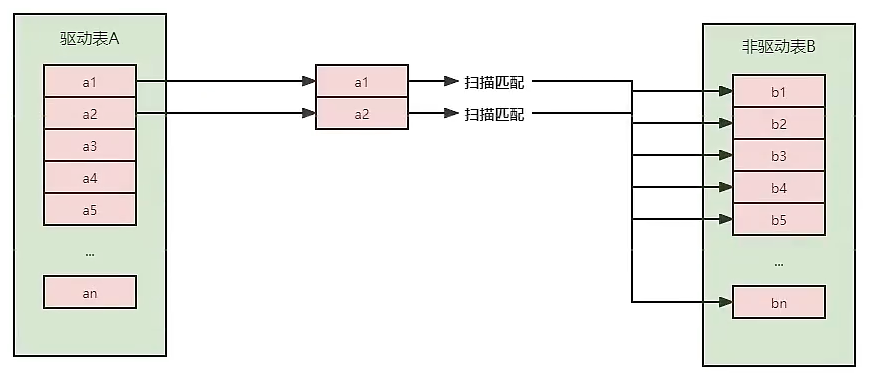
-- JOIN 语句原理 -- JOIN 方式连接多表,本质是各个表之间的数据的循环匹配。如果关联表的数据量很大,JOIN 关联的执行时间会很长。 -- 在MySQL 5.5之前,只支持嵌套循环算法 (nested loop join) -- 在MySQL 通过引入 BNLJ 算法来优化嵌套执行 -- 所谓驱动表,是指优化器优化之后的选择 -- 驱动表就是主表,被驱动表就是外表 -- 内连接可能会换角色,外连接也会 CREATETABLE a(f1 INT,f2 INT, INDEX(f1)) ENGINE = INNODB; CREATETABLE b(f1 INT,f2 INT)ENGINE=INNODB; INSERTINTO a VALUES(1,1),(2,2),(3,3),(4,4),(5,5),(6,6); INSERTINTO b VALUES(3,3),(4,4),(5,5),(6,6),(7,7),(8,8); -- 此时 b 是驱动表,a是被驱动表,尽管是 a LEFT JOIN b ,实际上,查询优化器是将外连接改成了一个内连接 EXPLAIN SELECT*FROM a LEFTJOIN b ON a.f1=b.f1 WHERE a.f2=b.f2; -- 此时还是一个外连接 EXPLAIN SELECT*FROM a LEFTJOIN b ON a.f1=b.f1 AND a.f2=b.f2; -- 内连接,b是驱动表,a是被驱动表 EXPLAIN SELECT*FROM a INNERJOIN b ON a.f1=b.f1 WHERE a.f2=b.f2;
-- 子查询 EXPLAIN SELECT*FROM employee emp WHERE emp.dept_id IN (SELECT dept_id FROM department dep WHERE `name` ISNOTNULL); -- 改造成多表查询 EXPLAIN SELECT emp.*FROM employee emp JOIN department dep ON emp.dept_id = dep.dept_id WHERE dep.`name` ISNOTNULL;
尽量不要使用 NOT IN 或者NOT EXISTS,用LEFT JOIN xxx ON xx WHERE xx IS NULL 替代。
-- 索引下推 CREATE INDEX idx_fname ON employee(fname); -- 首先通过 > 条件查询,查询出结果后,不回表,而是直接使用索引 再进行判断 LIKE ,最后再回表,这个就是索引下推,下推到下一个条件 EXPLAIN SELECT*FROM employee WHERE fname >'z'AND fname LIKE'%m'; -- 索引下推主要针对联合索引 CREATE INDEX idx_dept_fname_lname ON employee(dept_id,fname,lname); -- Using index condition; Using where -- 先通过索引 dept_id 查询,然后查询出来之后,索引中包含 后续fname的判断 内容,最后筛选出一部分之后,再进行回表判断 第三个不在索引中的条件,使用 where EXPLAIN SELECT*FROM employee WHERE dept_id =2AND fname LIKE'%m%'AND title LIKE'%h%';
-- 开启和关闭ICP SHOW VARIABLES LIKE'%optimizer_switch%'; SET optimizer_switch ='index_condition_pushdown=on'; SET optimizer_switch ='index_condition_pushdown=off';
ICP使用条件
表访问的类型为range、ref、eq_ref和ref_or_null可以使用ICP
ICP可以用于InnoDB和MyISAM表,包括分区表InnoDB和MyISAM表
对于InnoDB,ICP仅用于二级索引,ICP的目标是减少全行读取次数,从而减少IO操作
当SQL使用覆盖索引时,不支持ICP,因为这种情况下使用ICP不会减少IO
相关子查询的条件不能使用ICP
其他查询优化策略
EXISTS和IN的区分
1 2 3 4 5
-- 使用 IN 还是 EXISTS 主要取决于数据量,小表驱动大表,这种方式效率最高 -- A表大,B表小,是用这种方式,先获取B中数据,然后使用A表 SELECT*FROM A WHERE cc IN (SELECT cc FROM B); -- A表小,B表大,通过A表驱动B表 SELECT*FROM A WHEREEXISTS (SELECT cc FROM B WHERE B.cc = A.cc);