Go runtime之内存分配
堆栈 & 逃逸分析
堆和栈的定义
堆和栈都是编程语言里的虚拟概念,并不是说在物理内存上有堆和栈之分,两者的主要区别是栈是每个线程或者协程独立拥有的,从栈上分配内存时不需要加锁。
而整个程序在运行时只有一个堆,从堆中分配内存时需要加锁防止多个线程造成冲突,同时回收堆上的内存块时还需要运行可达性分析、引用计数等算法来决定内存块是否能被回收,所以从分配和回收内存的方面来看栈内存效率更高。

Go 有两个地方可以分配内存:一个全局堆空间用来动态分配内存,一个是每个 goroutine 都有的自身栈空间(例如goroutine占用2k)。
栈
栈区的内存一般由编译器自动进行分配和释放(例如在函数内使用局部变量
var a = 1),其中存储的入参以及局部变量,这些参数会随着函数的创建而创建,函数的返回而销毁。(通过CPU push & release两个指令)。stack的内存从高位增长,往低位使用。A function has direct access to the memory inside its frame, through the frame pointer, but access to memory outside its frame requires indirect access.
函数可以通过帧指针直接访问其帧内的内存,但访问其帧外的内存需要间接访问。

在 main frame 中声明的一个变量 u2,需要被外部访问,u2 会被分配到堆上,外面的 createUserV2 Frame 通过指针访问堆上的 u2,
堆
堆区的内存一般由编译器和工程师自己共同进行管理分配,交给
runtime GC来释放。堆上分配必须找到一块足够大的内存来存放新的变量数据。后续释放时,垃圾回收器扫描堆空间寻找不再被使用的对象。
Anytime a value is shared outside the scope of a function’s stack frame, it will be placed (or allocated) on the heap.
在函数栈帧范围之外共享值时,该值将被放置(或分配)到堆上。
stack allocation is cheap and heap allocation is expensive.
栈分配廉价,堆分配昂贵。(堆的内存分配比栈慢;成本更高;)
变量是在堆还是栈上?
写过其他语言,比如 C ,有明确的栈和堆的相关概念。而 Go 声明语法并没有提到栈和堆,而是交给 Go 编译器决定在哪分配内存,保证程序的正确性,在 Go FAQ 里面提到这么一段解释:
From a correctness standpoint, you don’t need to know. Each variable in Go exists as long as there are references to it. The storage location chosen by the implementation is irrelevant to the semantics of the language.
The storage location does have an effect on writing efficient programs. When possible, the Go compilers will allocate variables that are local to a function in that function’s stack frame. However, if the compiler cannot prove that the variable is not referenced after the function returns, then the compiler must allocate the variable on the garbage-collected heap to avoid dangling pointer errors. Also, if a local variable is very large, it might make more sense to store it on the heap rather than the stack.
In the current compilers, if a variable has its address taken, that variable is a candidate for allocation on the heap. However, a basic escape analysis recognizes some cases when such variables will not live past the return from the function and can reside on the stack.
从正确的角度来看,你不需要知道。Go 中的每个变量只要有引用就会一直存在。变量的存储位置(堆还是栈)和语言的语义无关。
存储位置对于写出高性能的程序确实有影响。如果可能,Go 编译器将为该函数的堆栈侦(``stack frame`)中的函数分配本地变量。但是如果编译器在函数返回后无法证明变量未被引用,则编译器必须在会被垃圾回收的堆上分配变量以避免悬空指针错误。此外,如果局部变量非常大,将它存储在堆而不是栈上可能更有意义。
在当前编译器中,如果变量存在取址,则该变量是堆上分配的候选变量。但是基础的逃逸分析可以将那些生存不超过函数返回值的变量识别出来,并且因此可以分配在栈上。
逃逸分析

go build -gcflags '-m' 可以看到是否有栈逃逸。例如 tmp 分配在栈上,但是返回了地址,因此会逃逸到堆上。
通过检查变量的作用域是否超出了它所在的栈来决定是否将它分配在堆上 的技术,其中 变量的作用域超出了它所在的栈 这种行为即被称为逃逸。
逃逸分析在大多数语言里属于静态分析:
在编译器由静态代码分析来决定一个值是否能被分配在栈帧上,还是需要 逃逸 到堆上。
- 减少 GC 压力,栈上的变量,随着函数退出后系统直接回收,不需要标记后再清除
- 减少内存碎片的产生
- 减轻分配堆内存的开销,提高程序的运行速度
超过栈帧(stack frame)
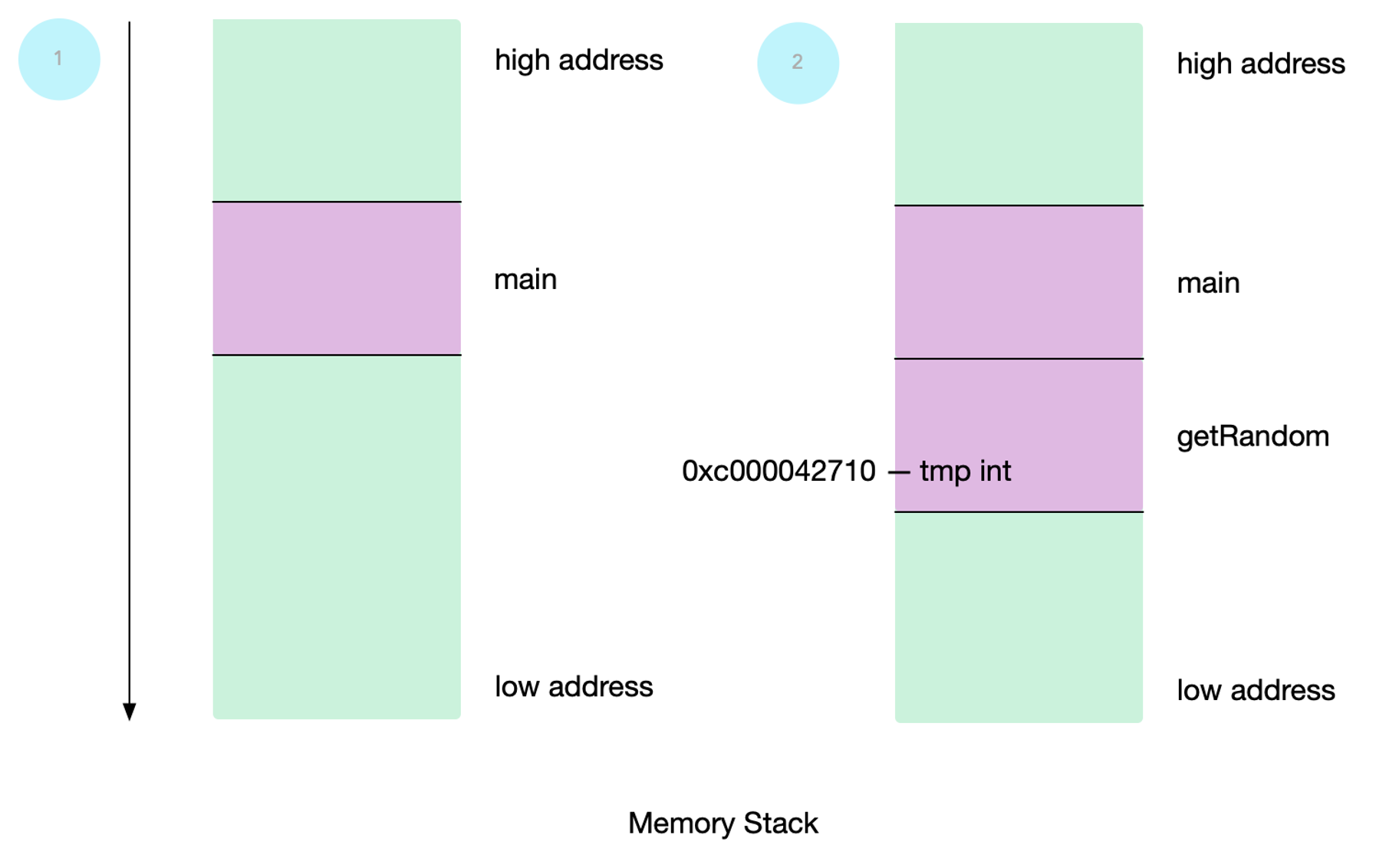
- 声明一个
main函数,在栈上分配内存 - 声明一个
getRandom函数,栈上新开一块内存进行分配;getRandom函数中声明一个局部变量tmp,并且初始化对应内存地址
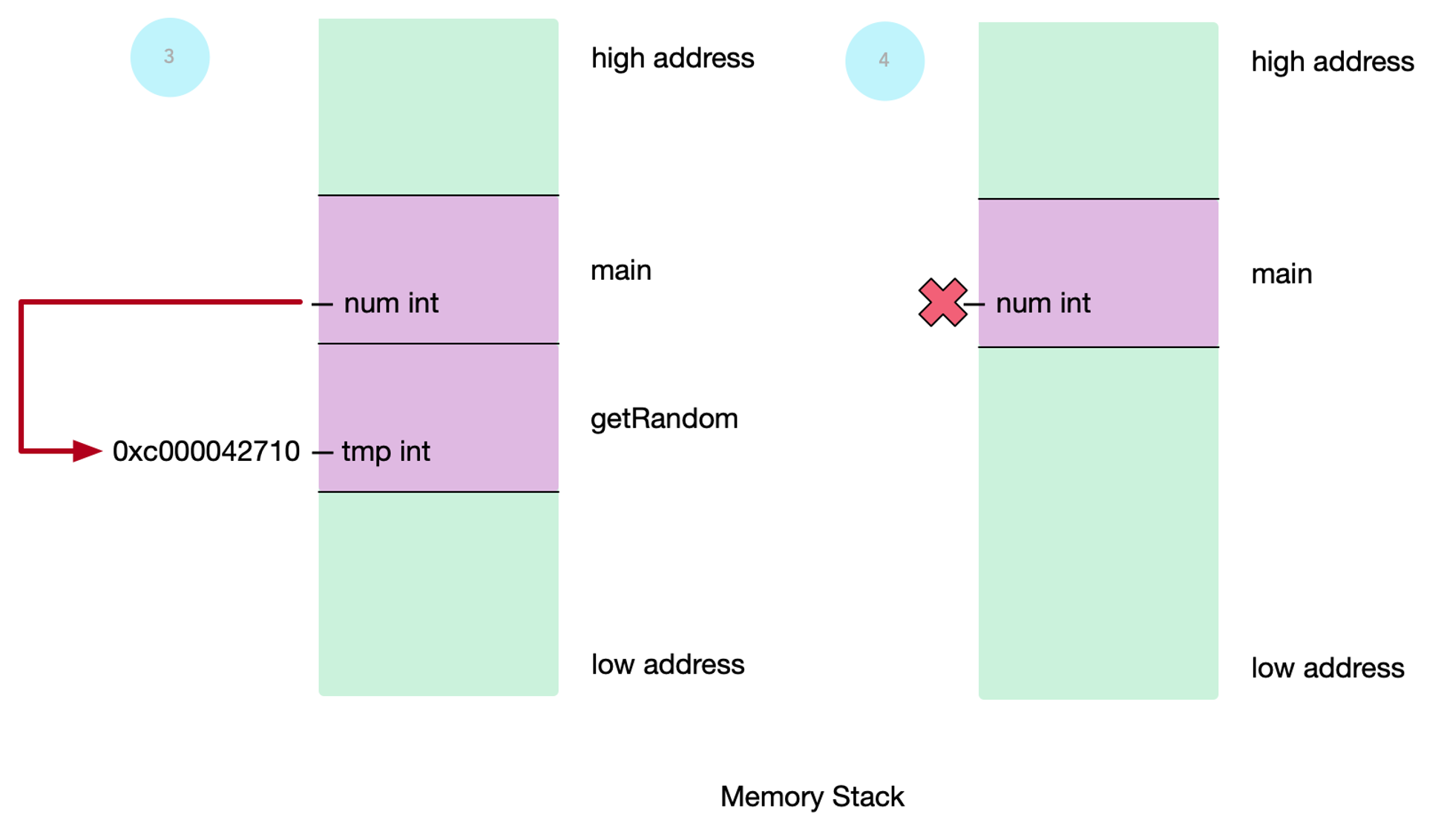
- 在
main函数中访问getRandom中的局部变量,赋值给自己的num变量,指向tmp的地址 - 跨栈访问内存中的变量会出现报错
因此 tmp 会被分配到 堆 上,在调用 getRandom 函数返回地址的时候,返回的是堆上的地址。
当一个函数被调用时,会在两个相关的帧边界间进行上下文切换。
从调用函数缺换到被调用函数,如果函数调用时需要传递参数,那么这些参数值也要传递到被调用函数的帧边界中。
Go 语言中帧边界间的数据传递是按值传递的。任何在函数 getRandom 中的变量在函数返回时,都将不能访问。
Go 查找所有变量超过当前函数栈帧的,把它们分配到堆上,避免 outlive 变量。
上述情况中 num 变量不能指向之前的栈。
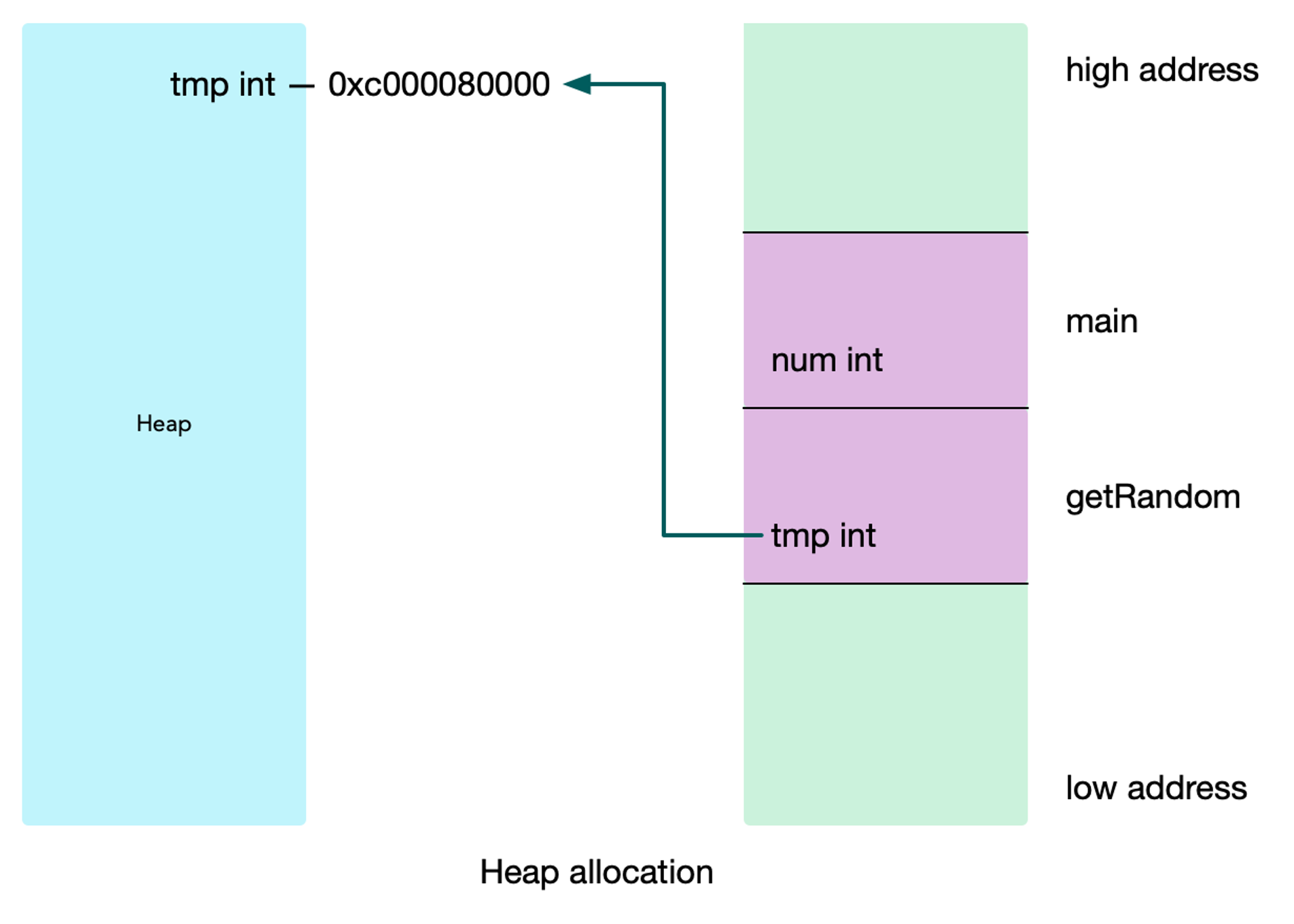
Go 查找所有变量超过当前函数栈帧的,把它们分配到堆上,避免 outlive 变量。
变量 tmp 在栈上分配,但是它包含了指向堆内存的地址,所以可以安全的从一个函数的栈帧复制到另外一个函数的栈帧。
逃逸案例
还存在大量其他的 case 会出现逃逸,比较典型的就是 多级间接赋值容易导致逃逸,这里的多级简介指的是,对某个应用类对象中的引用类成员进行赋值。Go 语言中的引用类数据类型有 func,interface,slice,map,chan,*Type:
- 一个值被分享到函数栈帧范围之外
- 在
for循环外声明,在for循环内分配,同理闭包 - 发送指针或者带有指针的值到
channel中 - 在一个切片上存储指针或带指针的值
slice的背后数组被重新分配了- 在
interface类型上调用方法 - …
go bulid -gcflags '-m'
连续栈
分段栈
Go 应用程序运行时,每个 goroutine 都维护着一个自己的栈区,这个栈区只能自己使用不能被其他 goroutine 使用。
栈区的初始大小是 2KB(比 x86_64 架构下线程的默认栈 2M 要小很多),在 goroutine 运行的时候栈区会按照需要增长和收缩,占用的内存最大限制的默认值在 64 位系统上是 1GB。
老栈会通过指针,指向新增长的栈,这就是分段栈。
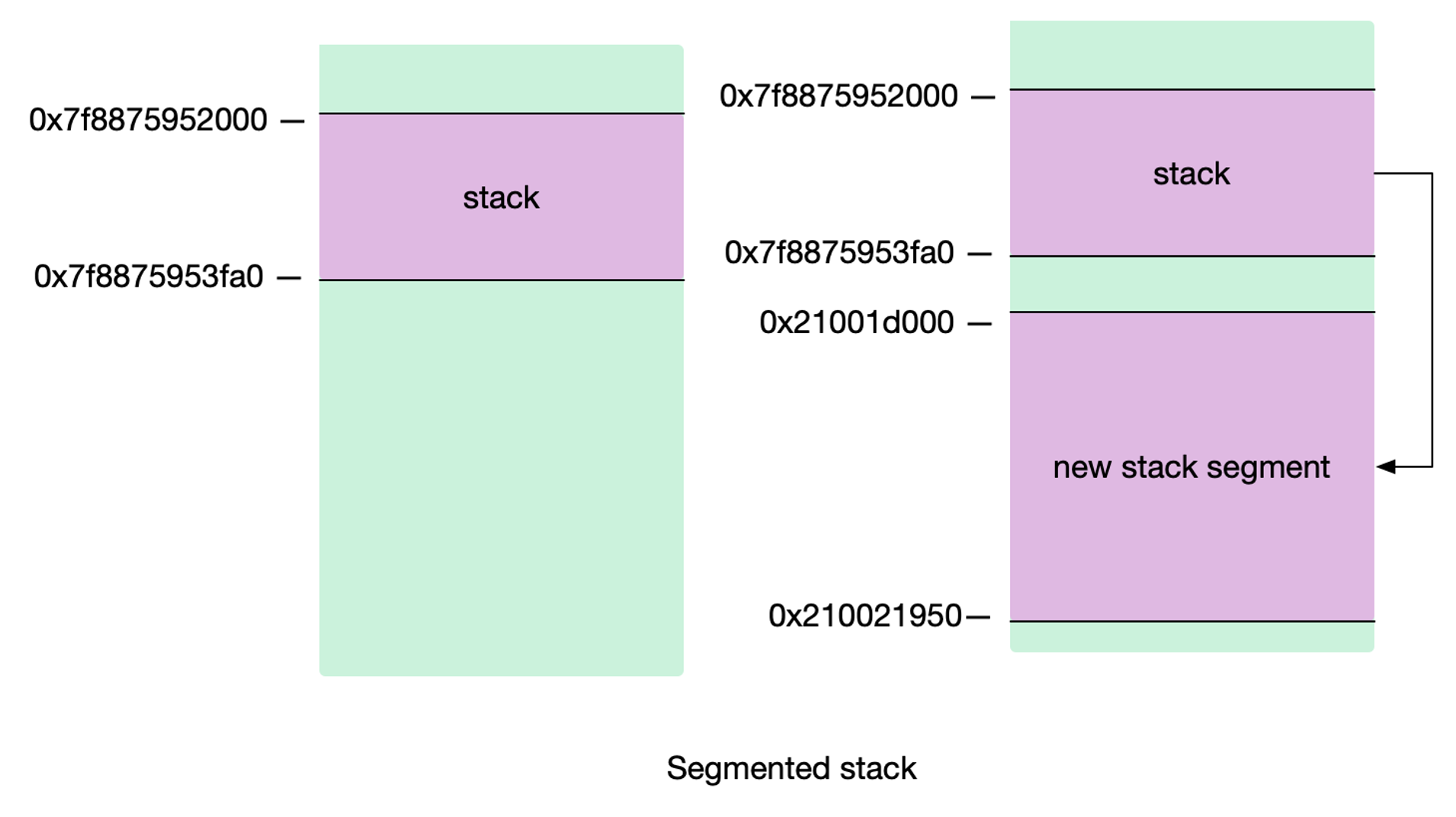
- v1.0 ~ v1.1 :最小栈内存空间为 4KB
- v1.2 :将最小栈内存提升到了 8KB
- v1.3 :使用连续栈替换之前版本的分段栈
- v1.4 :将最小栈内存降低到了 2KB
Hot split 问题
分段栈的实现方式存在 hot split 问题,如果栈快满了,那么下一次的函数调用会强制触发栈扩容。
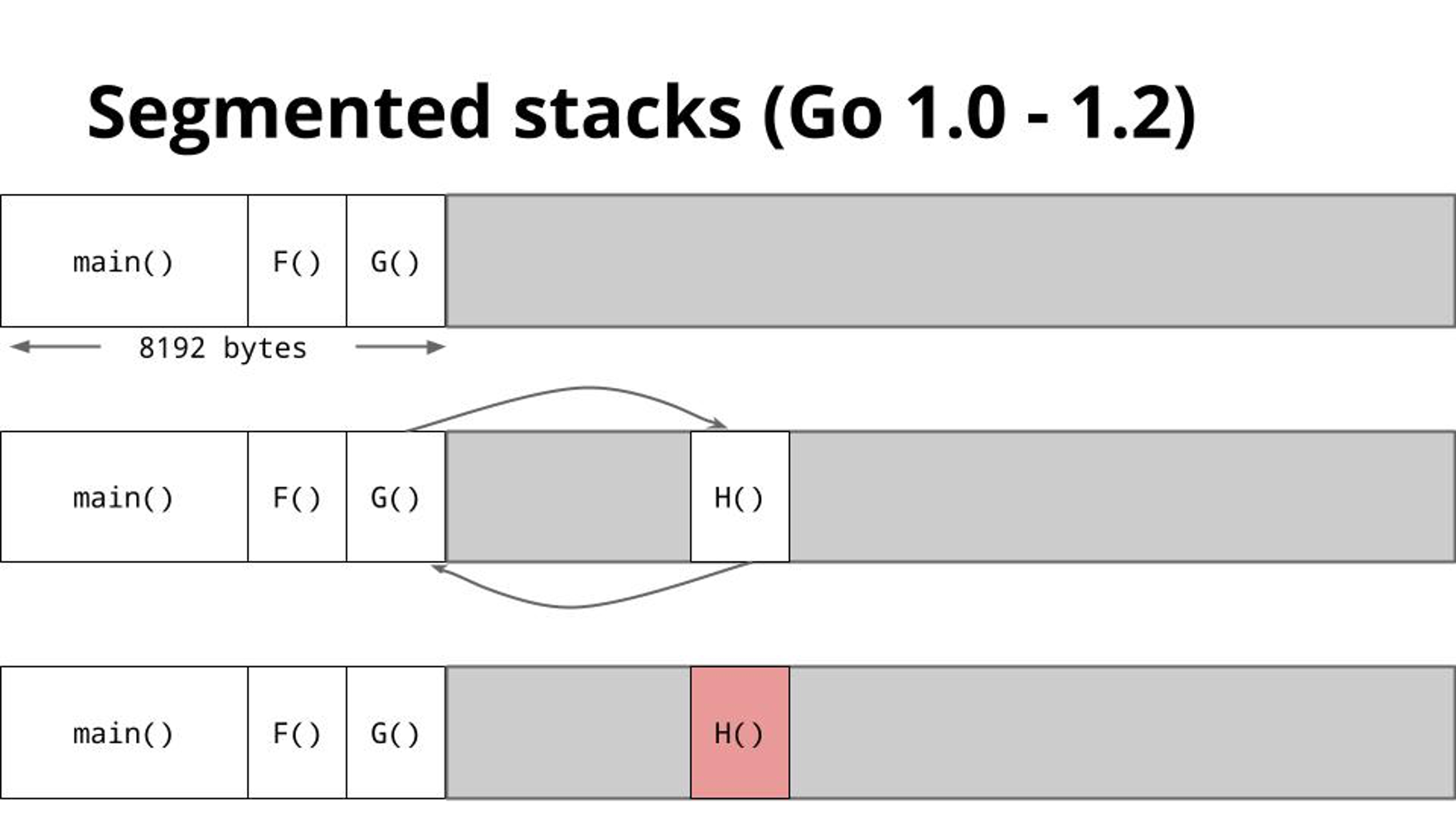
当函数返回时,新分配的 stack chunk 会被清理掉。
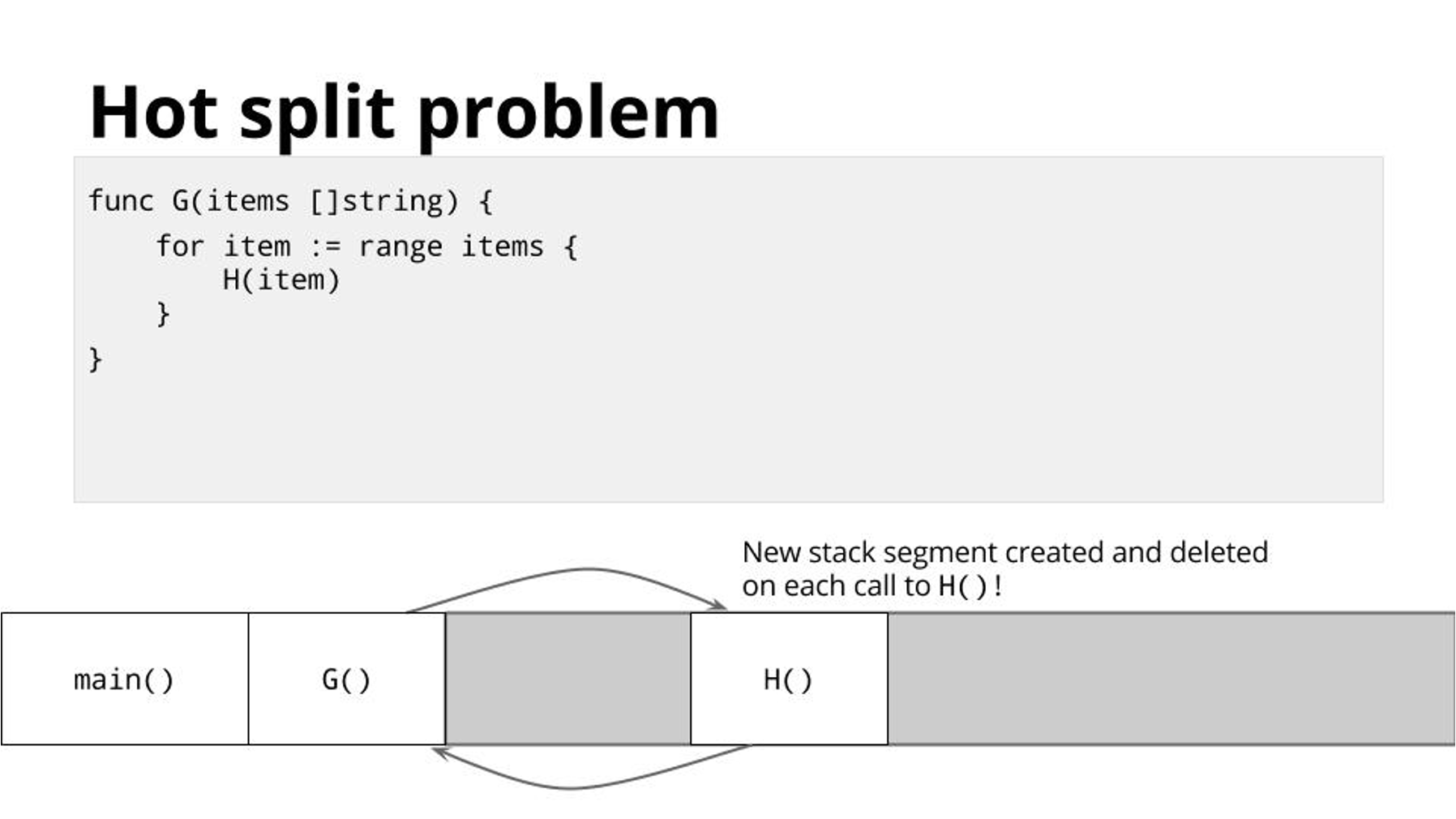
如果这个函数调用产生的范围是在一个循环中,会导致严重的性能问题,频繁的 alloc/free。
Go 不得不在 1.2 版本把栈默认大小改为 8KB,降低出发热分裂的问题,但是每个 goroutine 内存开销就比较大了。直到实现了连续栈(contiguous stack),栈大小才改为 2KB。
连续栈
采用复制栈的实现方式,在热分裂场景中不会频繁释放内存,即不像分配一个新的内存块并链接到老的栈内存块,而是会分配一个两倍大的内存块并把老的内存块内容复制到新的内存块里,当栈缩减回之前大小时,我们不需要做任何事情。
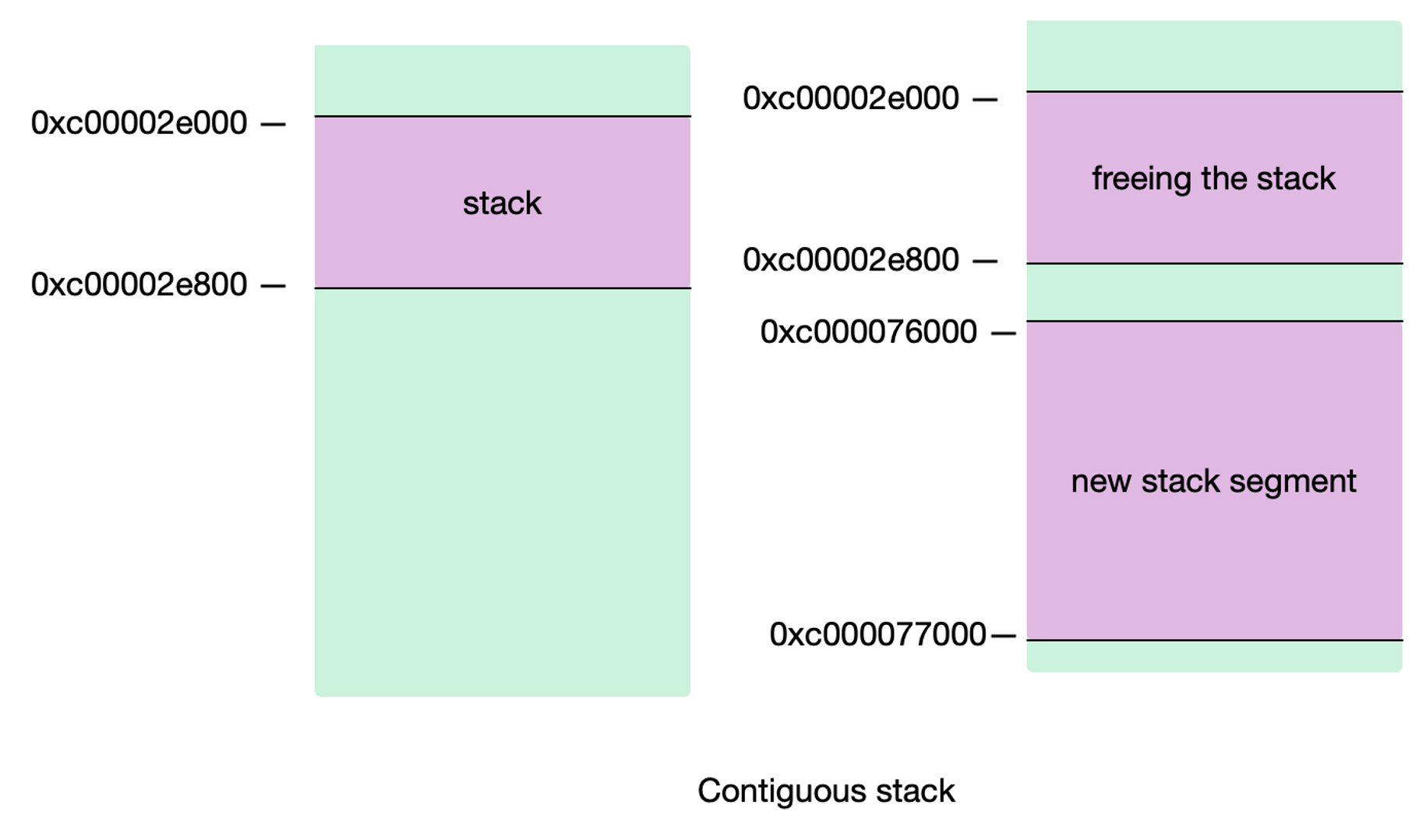
runtime.newstack:分配更大的栈内存空间runtime.copystack:将旧栈中的内容复制到新栈中- 将指向旧栈对应变量的指针重新指向新栈(这块代码比较复杂。)
runtime.stackfree:销毁并回收旧栈的内存空间
如果栈区的空间使用率不超过 1/4,那么在垃圾回收的时候使用 runtime.shrinkstack 进行栈锁容,同样使用 copystack。
栈扩容
Go 运行时判断栈空间是否足够,所以在 call function 中会插入 runtime.morestack,但每个函数调用都判定的话,成本比较高。
在编译期间通过计算 sp、func stack framesize 确定需要哪个函数调用中插入 runtime.morestack。
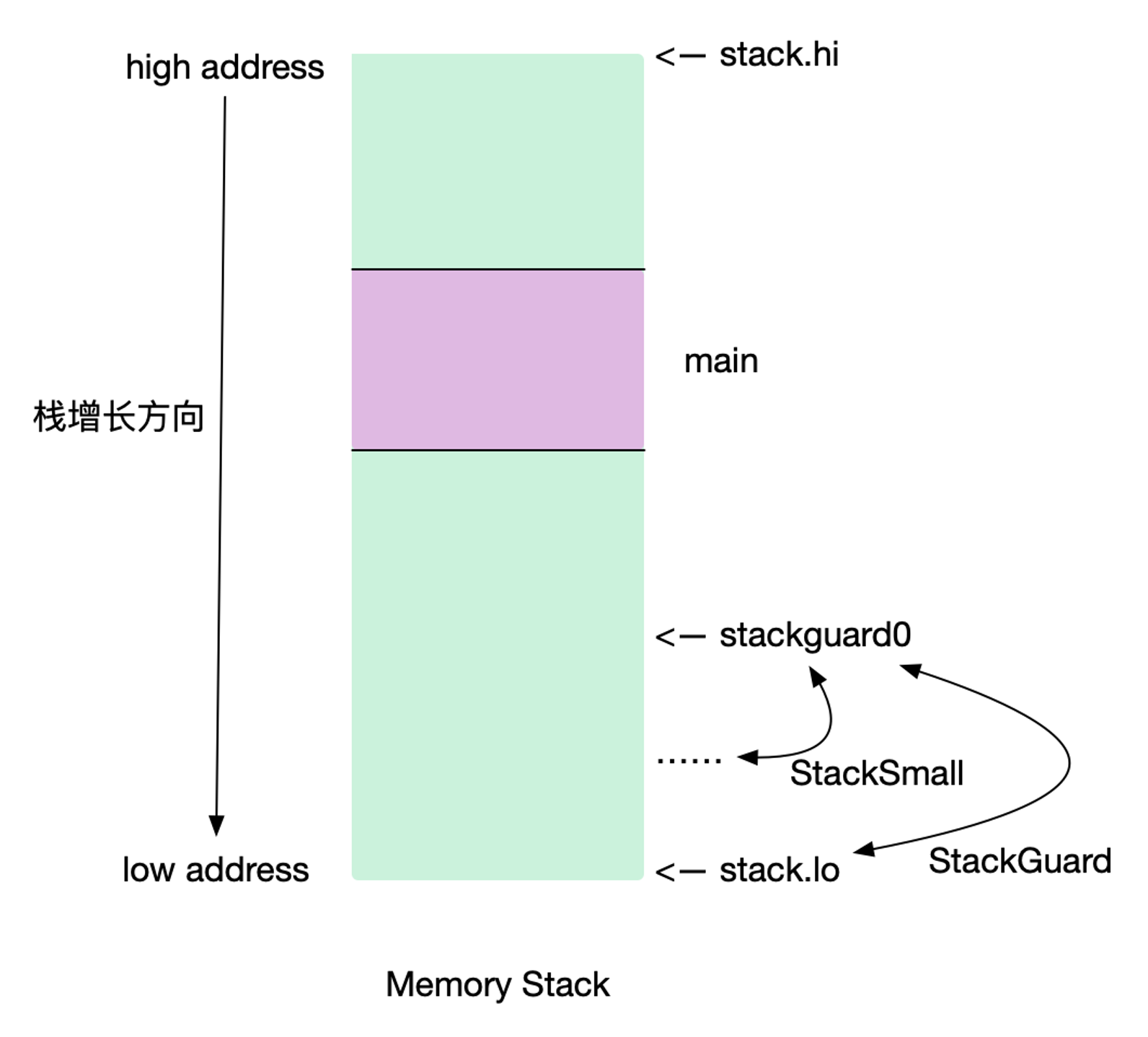
针函数 framesize 的判定:
当函数是叶子节点,且栈帧小于等于 112 字节(
StackSmall为120字节),不插入指令(因为不会超过stack.lo极限值)当叶子函数栈帧大小为 120-128 或者 非叶子函数栈帧大小为 0 - 128,则需要判断与
stackguard0进行比较。小,则需要插入(有风险超过stack.lo)SP < stackguard0大于
StackSmall,当函数栈帧大小为 128-4096,则需要计算SP - framesize < stackguard0 - StackSmall大于
StackBig,需要插入指令SP - stackguard + StackGuard <= framesize + (StackGuard - StackSmall)
内存结构
内存管理
TCMalloc 是 Thread Cache Malloc 的简称,是 Go 内存管理的起源,Go 的内存管理是借鉴了 TCMalloc,解决了下面两个问题:
内存碎片
随着内存不断的申请和释放,内存上会存在大量的碎片,降低了内存的使用率。为了解决内存碎片,可以将2个连续的未使用的内存块合并,减少碎片。
大锁
同一进程下的所有线程共享相同的内存空间,他们申请内存时需要加锁,如果不加锁就存在同一块内存被2个线程同时访问的问题。(因此可以在线程上申请内存,线程内部使用,就无须全局大锁)
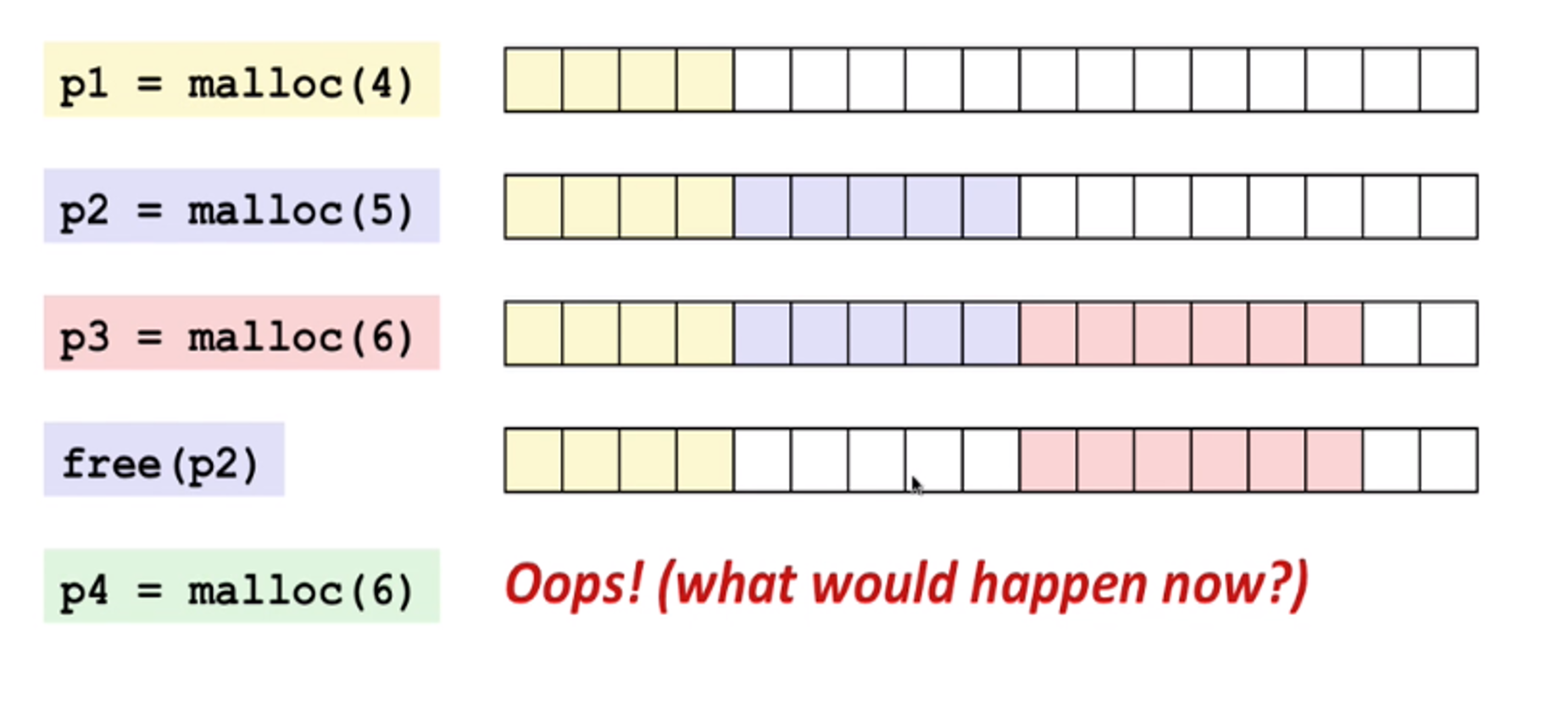
例如上图,在一块连续内存中,p1、p2、p3 申请内存之后,释放 p2,p4 再去申请内存,虽然内存容量够,但是没有足够的连续内存,出现内存碎片,导致实际使用内存不够。
因此,在分配内存的时候有多种内存分配方式
内存概念
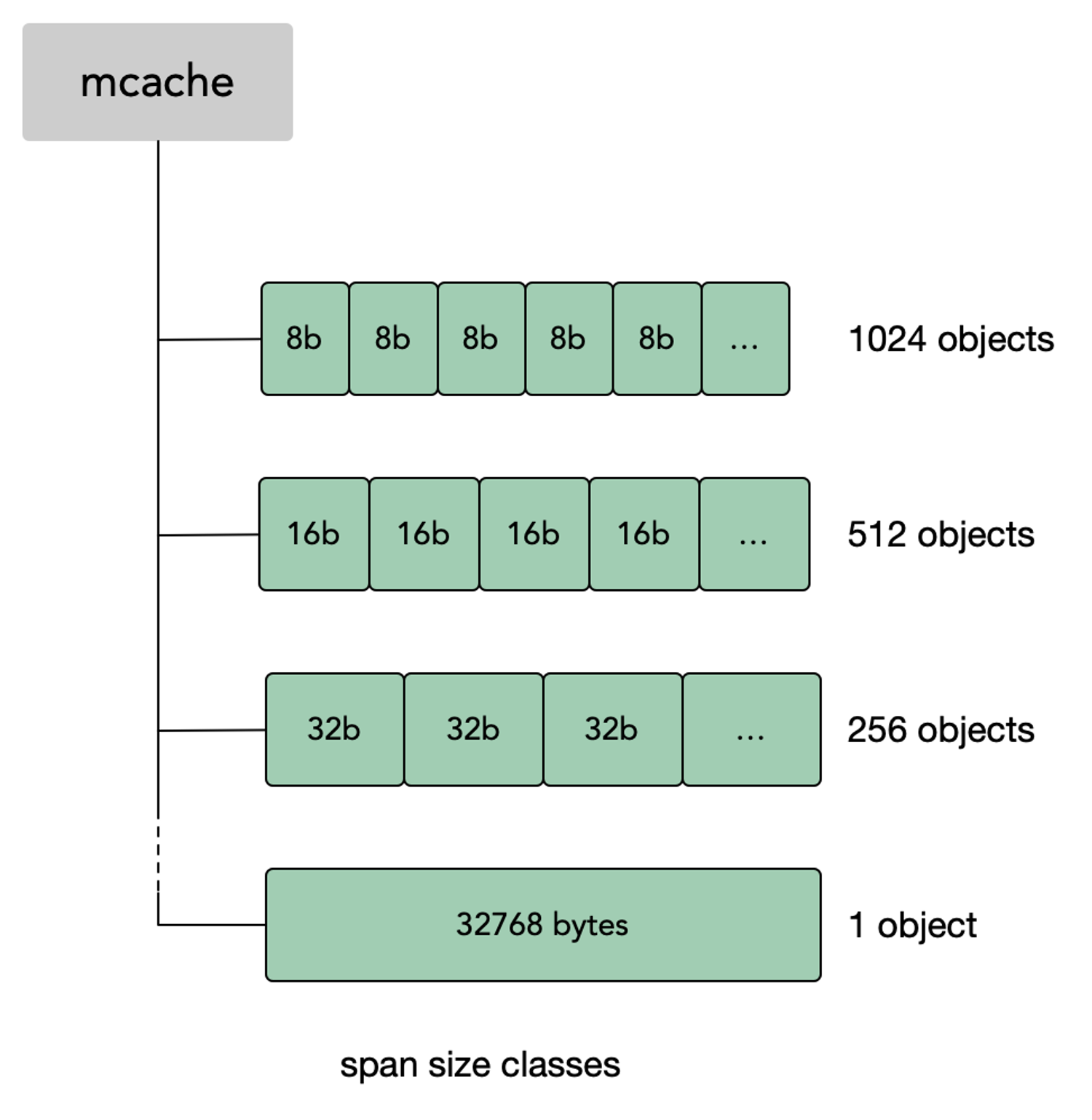
首先需要先知道几个重要的概念:
page:内存页,一块 8K 大小的内存空间。Go 与操作系统之间的内存申请和释放,都是以page为单位的。span:内存块,一个或多个连续的page组成一个spansizeclass:空间规格,每个span都带有一个sizeclass,标记着该span中的page应该如何使用object:对象,用来存储一个变量数据内存空间,一个span在初始化时,会被切割成一堆等大的object。假设object的大小是 16B,span大小是 8K,那么就会把span中的page就会被初始化8K/16B = 512个object
scan & noscan: Each span exists twice: one list for objects that do not contain pointer and another one that contains pointer. This distinction will make the life of the garbage collector easier since it will not have to scan the spans that do not contain any pointer.
扫描和不扫描: 每个跨度存在两次:一个是不包含指针的对象列表,另一个是包含指针的对象列表。这种区别将使垃圾回收器的工作变得更轻松,因为它不必扫描不包含任何指针的跨度。
小于 32KB 内存分配
当程序里发生了 32KB 以下的小块内存申请时,Go 会从一个叫作 mcache 的本地缓存给程序分配内存。
这样的一个内存块里叫作 mspan,它是要给程序分配内存时的分配单元。
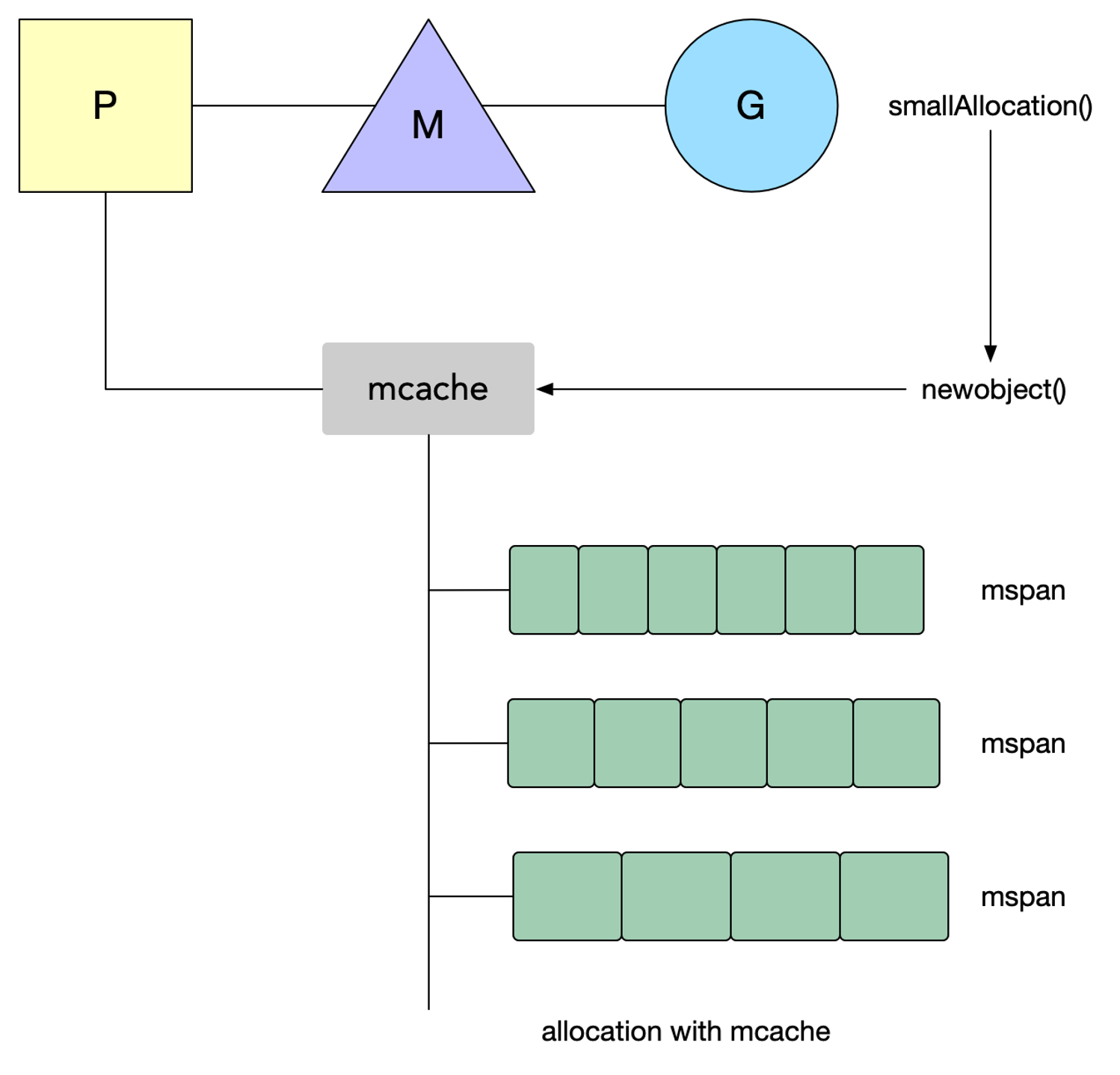
在 Go 的调度器模型里,每个线程 M 会绑定给一个处理器 P,在单一粒度的时间里只能最多处理运行一个 goroutine,每个 P 都会绑定一个上面说的本地缓存 mcache。
当需要进行内存分配时,当前运行的 goroutine 会从 mcache 中查找可用的 mspan。
从本地 mcache 里分配内存时不需要加锁,这种分配策略效率更高。
mspan的使用
申请内存时,都会给他们一个 mspan 这样的单元会不会产生浪费?
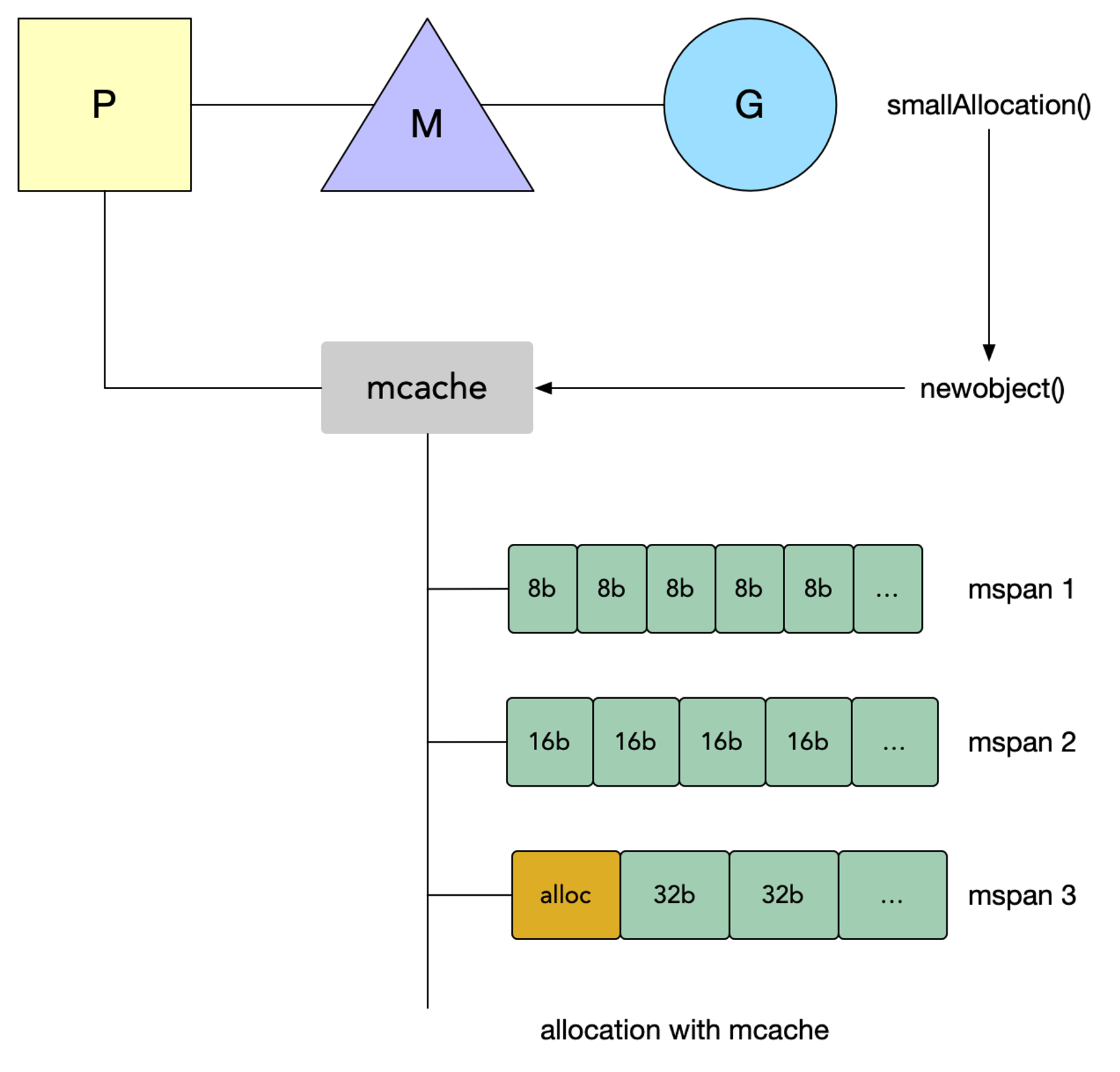
并不会。其实 mcache 持有的这一系列的 mspan 并不都是统一大小的,而是按照大小,从 8kb 到 32kb 分了大概 67 * 2 类的 mspan。
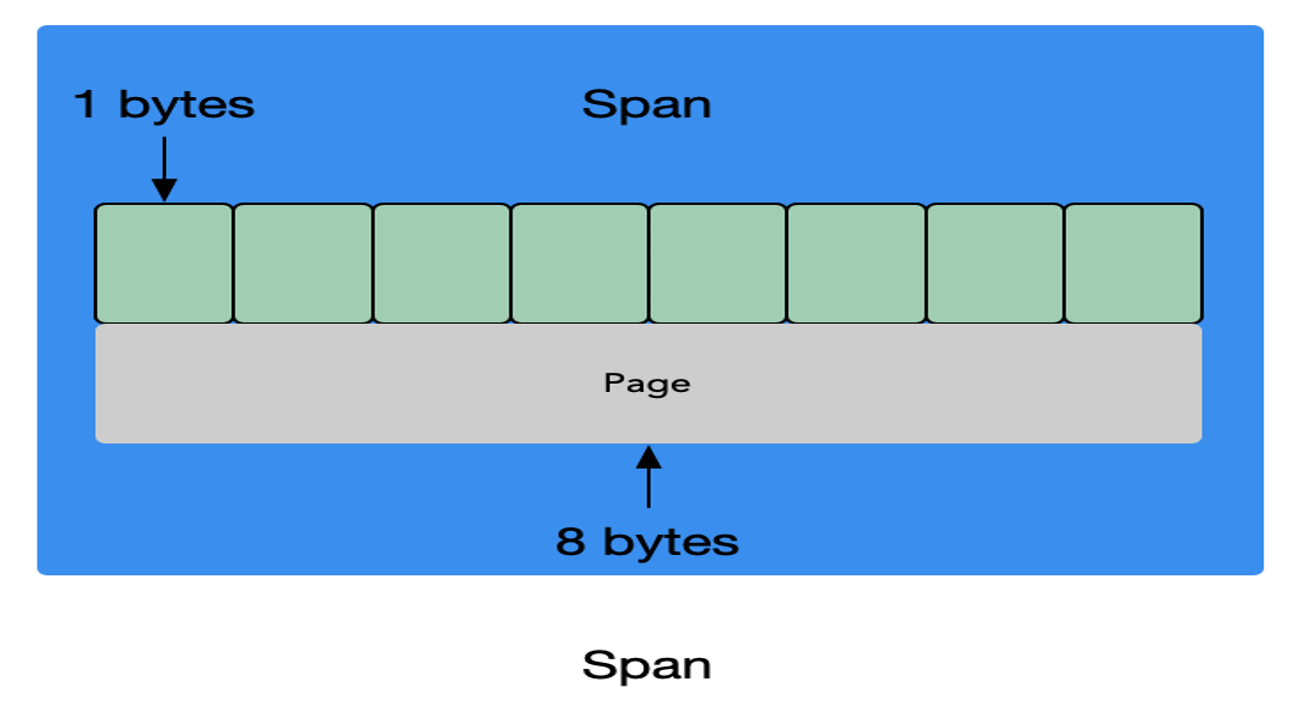
每个的思路在 Linux Kernel、Memcache 都可以见到 Slab 内存页分为多级固定大小的 空闲列表,着有助于减少碎片。类似 Allactor。
mcentral
如果分配内存时,mcache 里没有空闲的对口 sizeclass 的 mspan 了,Go 里还为每种类别的 mspan 维护着一个 mcentral。
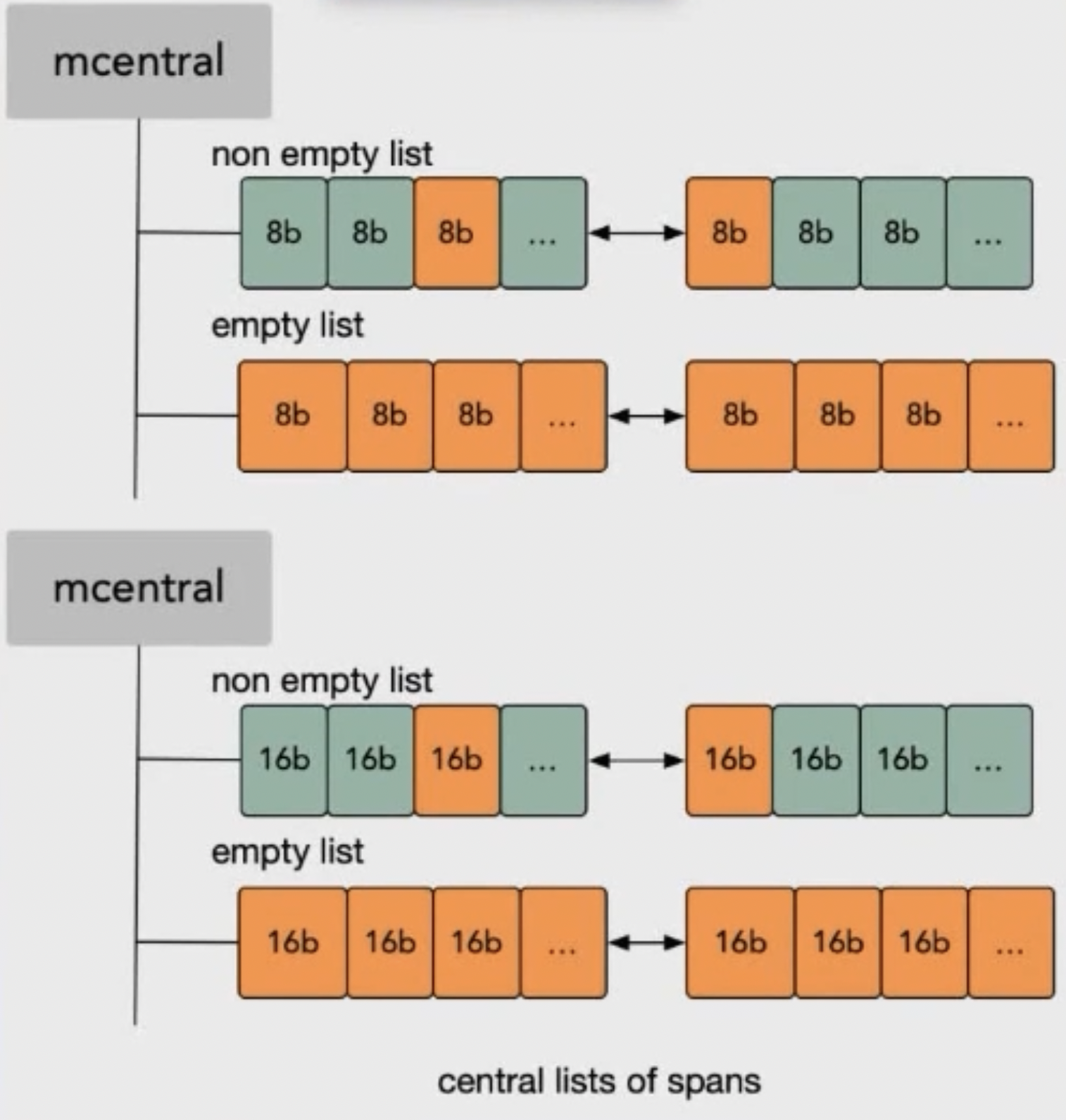
mcentral 的作用是为所有的 mcache 提供切分好的 mspan 资源。
每个 central 会持有一种特定大小的全局 mspan 列表,包括已分配出去的和未分配出去的。每个 mcentral 对应一种 mspan,当工作线程的 mcache 中没有合适(也就是特定大小的)的 mspan 时就会从 mcentral 去获取。
mcentral 被所有的工作线程共同享有,存在多个 goroutine 竞争的情况,因此从 mcentral 获取资源时需要加锁。
mcentral 里维护着两个双向链表,nonempty 表示链表里还有空闲的 mspan 待分配。empty 表示这条链表里的 mspan 都被分配了 object 或缓存 mcache 中。
mcentral 的使用
程序申请内存的时候,mcache 里已经没有合适的空闲 mspan 了,那么工作线程就会像下图这样去 mcentral 里去申请。
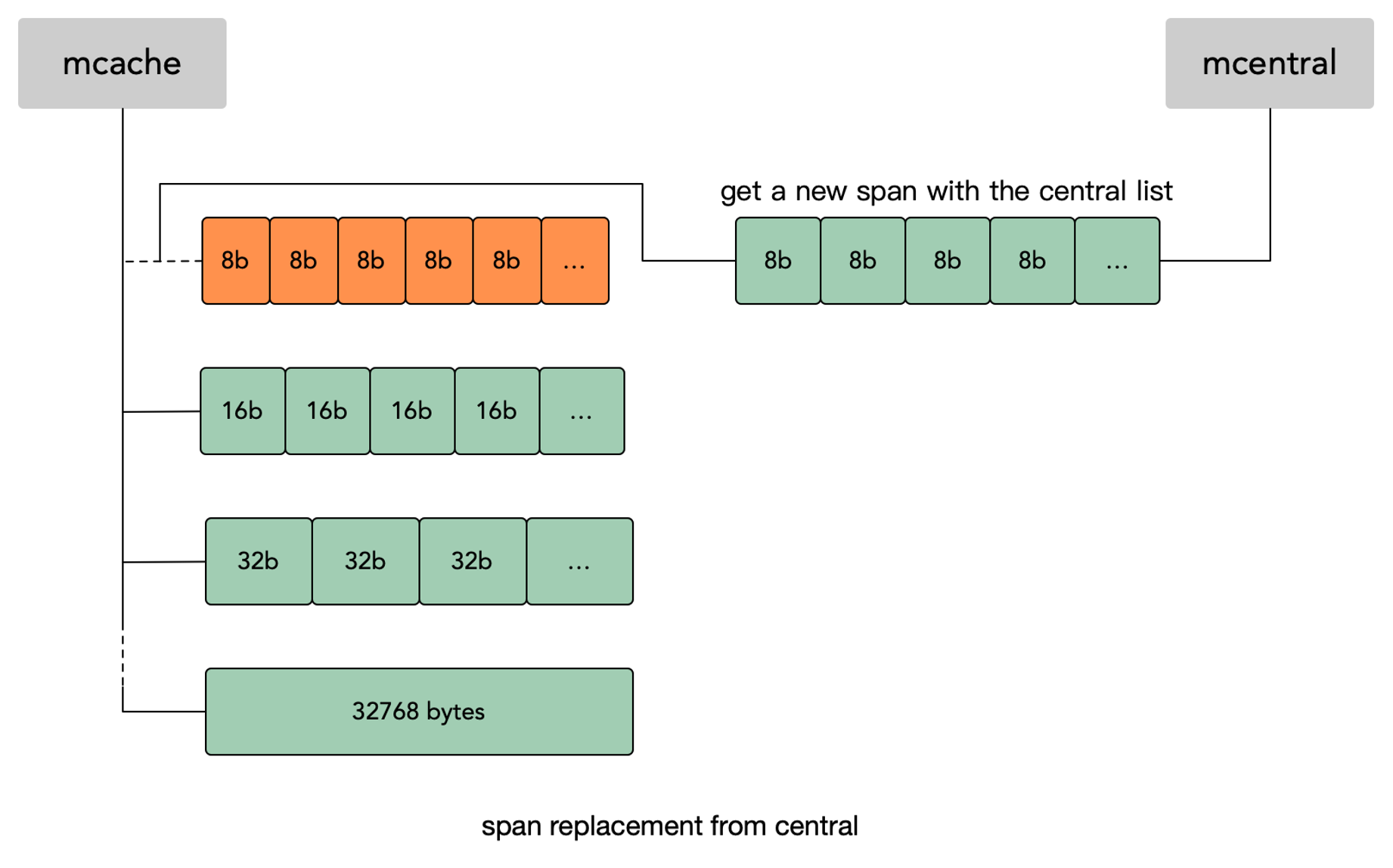
mcache 从 mcentral 获取和归还 mspan 的流程:
- 获取
- 加锁;
- 从
nonempty链表找到一个可用的mspan; - 并将其从
nonempty链表删除; - 将取回的
mspan加入到empty链表; - 将
mspan返回给工作线程; - 解锁
- 归还
- 加锁
- 将
mspan从empty链表删除; - 将
mspan加入到nonempty链表 - 解锁
mcentral 是 sizeclass 相同的 span 会以链表的形式组织在一起,就是指该 span 用来存储哪种大小的对象。
mcentral 内存扩容
当 mcentral 没有空闲的 mspan 时,会向 mheap 申请。而 mheap 没有资源时,会向操作系统申请新内存。mheap 主要用于大对象的内存分配,以及管理未切割的 mspan,用于给 mcentral 切割成小对象。
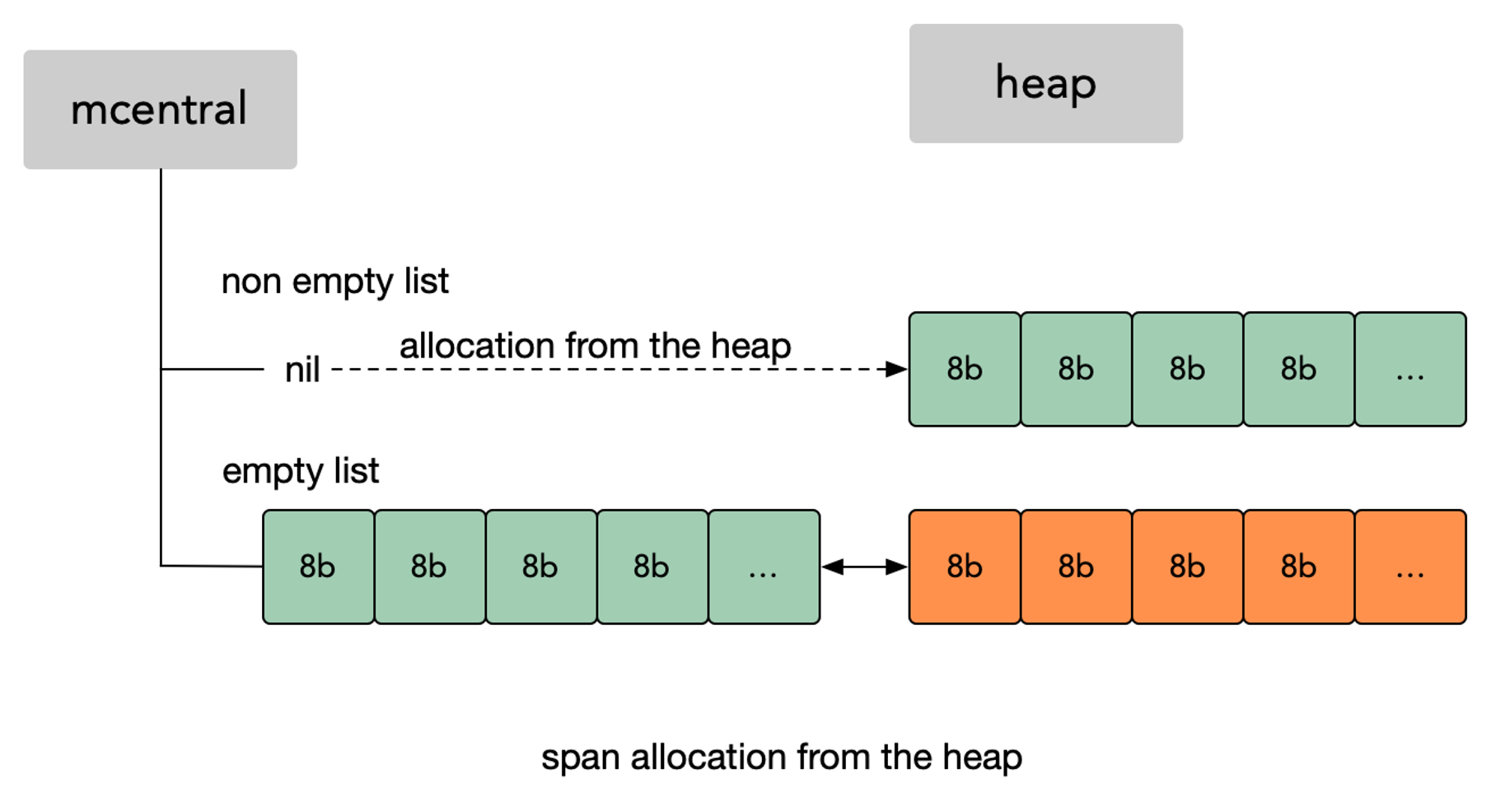
mheap 中含有所有规格的 mcentral,所以当一个 mcache 从 mcentral 申请 mspan 时,只需要在独立的 mcentral 中使用锁,并不会影响申请其他规格的 mspan。
- mcentral in mheap;
- cacheline padsize(false sharing)
mheap
所有 mcentral 的集合则是存放于 mheap 中的。
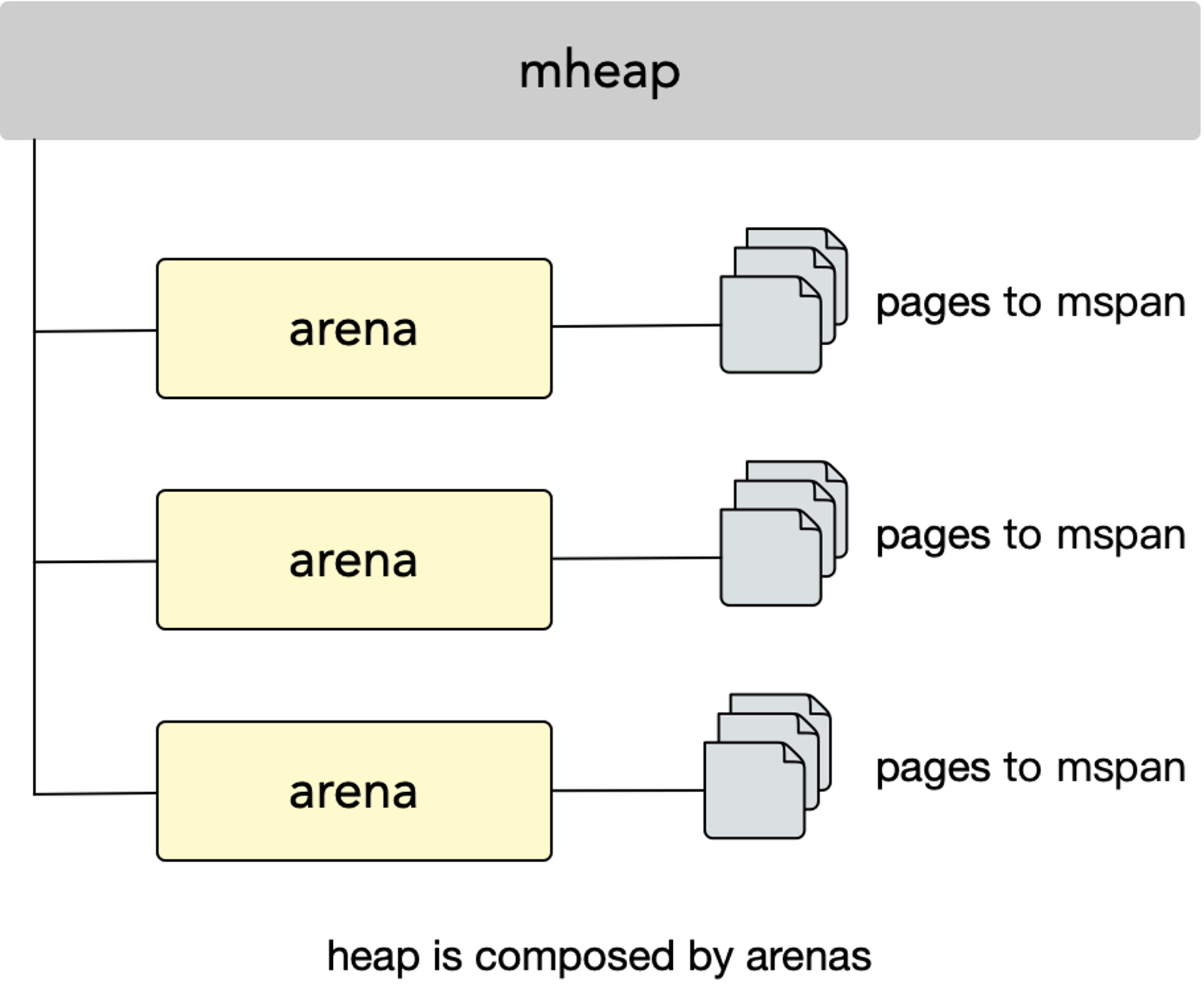
mheap 里的 arena 区域是真正的堆区,运行时会将 8KB 看作一页,这些内存页中存储了所有在堆上初始化的对象。
运行时使用二维的 runtime.heapArena 数组管理所有的内存,每个 runtime.heapArena 都会管理 64MB 的内存。
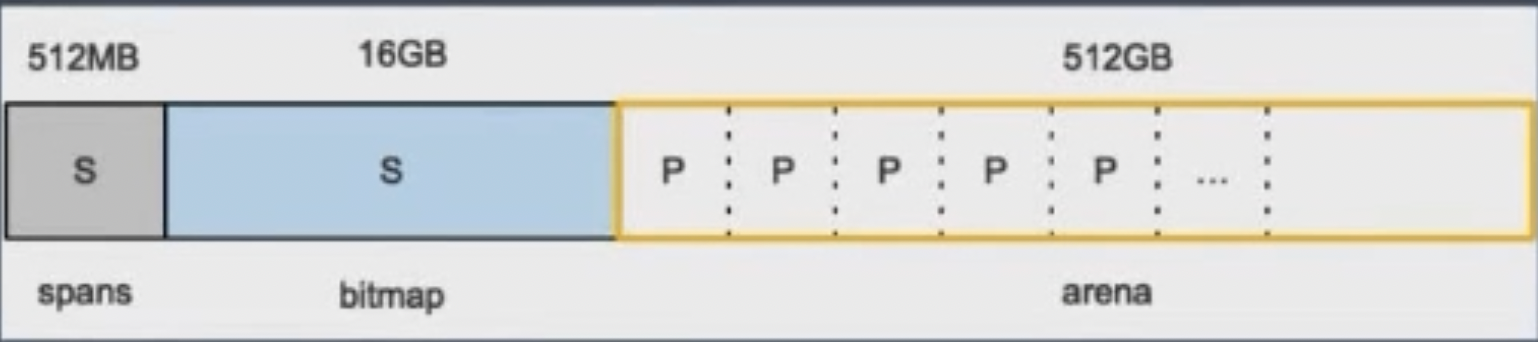
如果 arena 区域没有足够的内存,会调用 runtime.mheap.sysAlloc 从操作系统中申请更多的内存。(如下图: Go 1.11 前的内存布局)
小于 16B 内存分配
主要是 Go 做的一个优化。
对于小于 16字节的对象(且无指针),Go 语言将其划分为了 tiny 对象。划分 tiny 对象的目的是为了处理极小的字符串和独立的转义变量。
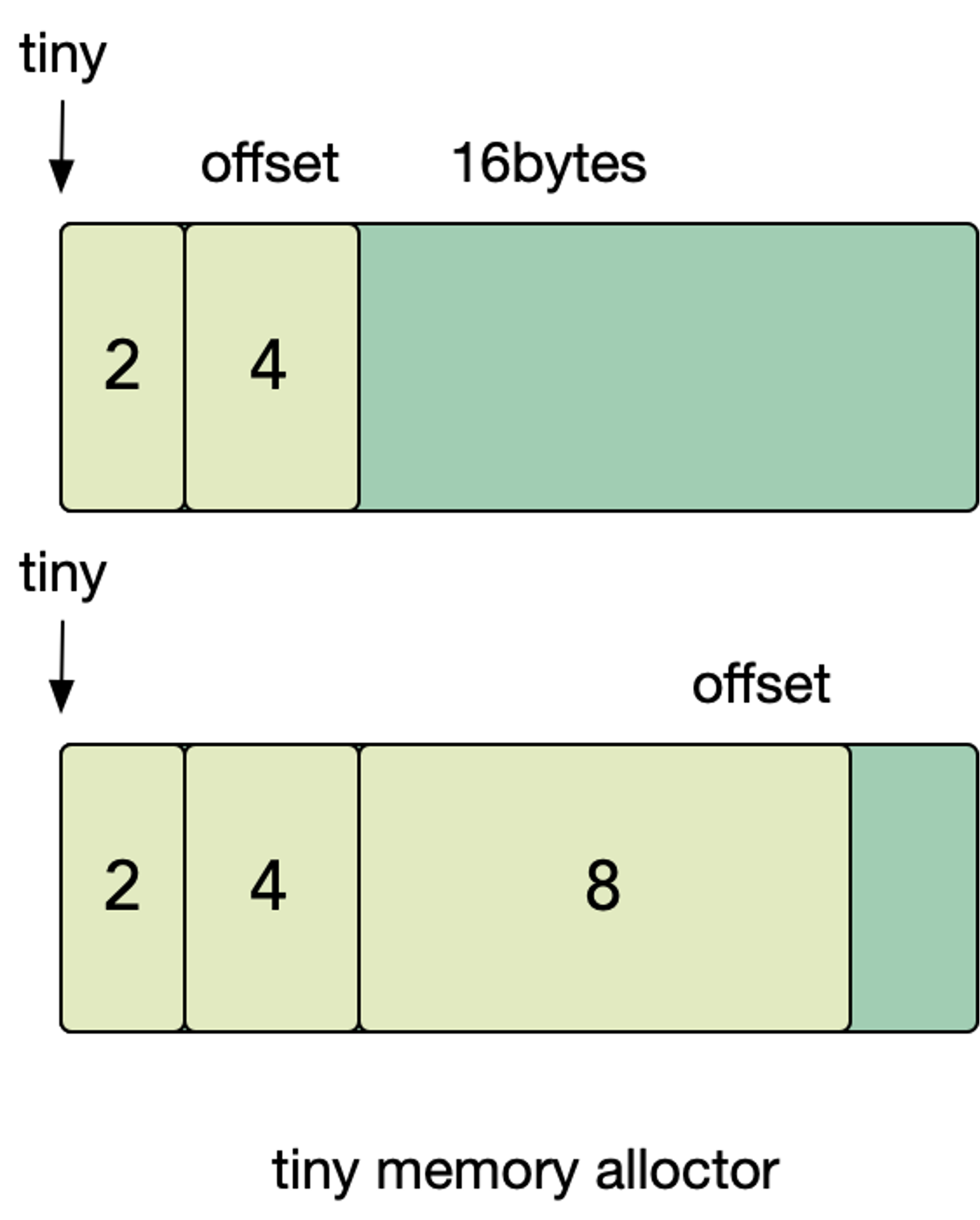
对 json 的基准测试表明,使用 tiny 对象减少了 12% 的分配次数和 20% 的堆大小。
tiny 对象会被放入 class 为 2 的 span 中。
- 首先查看之前分配的元素中是否有空余的空间
- 如果当前要分配的大小不够,例如要分配 16字节 的大小,这时就需要找到下一个空闲的元素
tiny 分配的第一步是尝试利用分配过的前一个元素的空间,达到节约内存的目的。
大于 32KB 内存分配
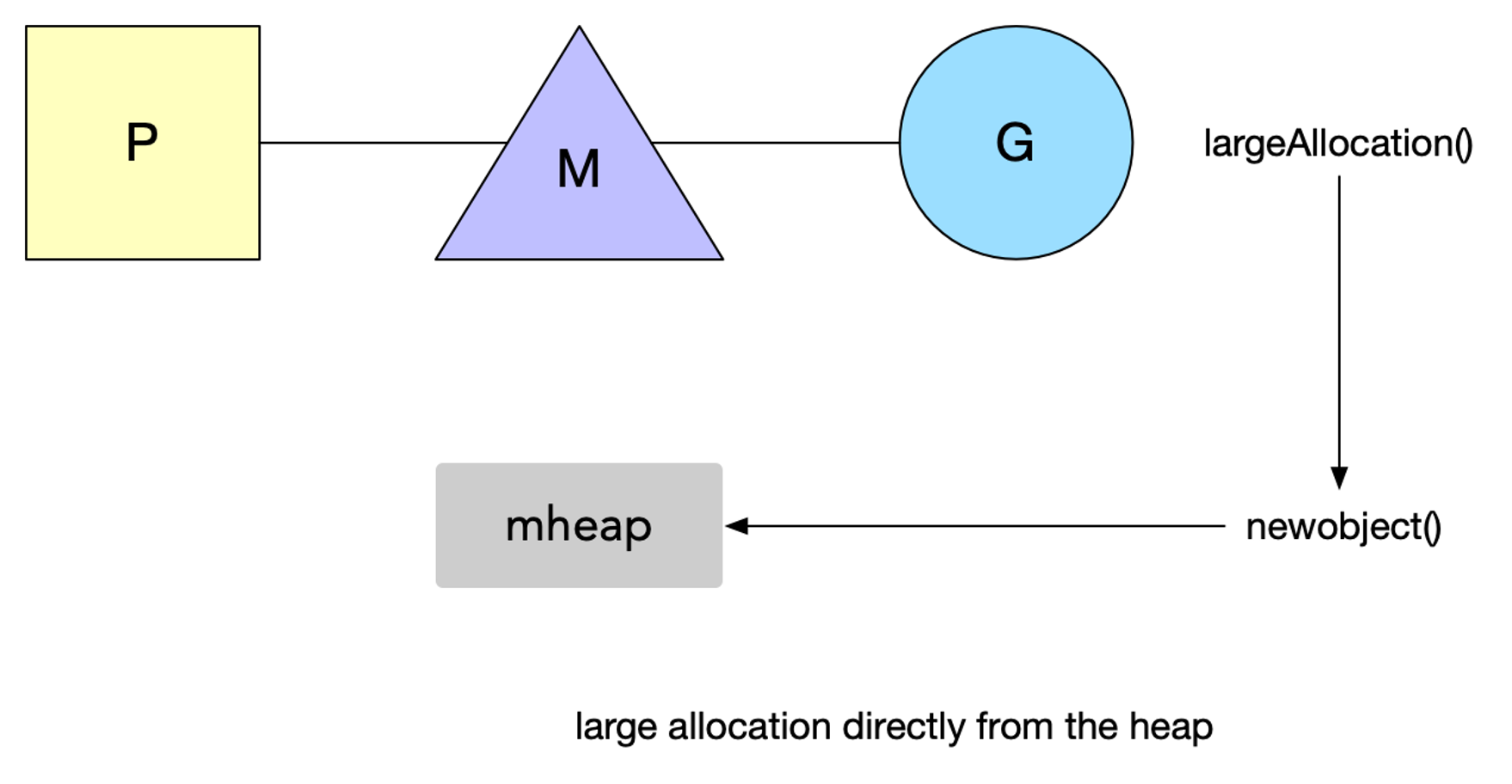
Go 没法使用工作线程的本地缓存 mcache 和全局中心缓存 mcentral 上管理超过 32KB 的内存分配,所以对于那些超过 32KB 的内存申请,会直接从堆(mheap)上分配对应的数量的内存页(每页大小是 8KB)给程序。
freelist:Go 早期版本,在分配和归还内存时,存储到链表中treap:后来改成二叉树维护,找到具体可以分配的内存,满足空间要求radix tree:1.14 之后,使用基数树,更迅速找到可以分配的内存
内存分配
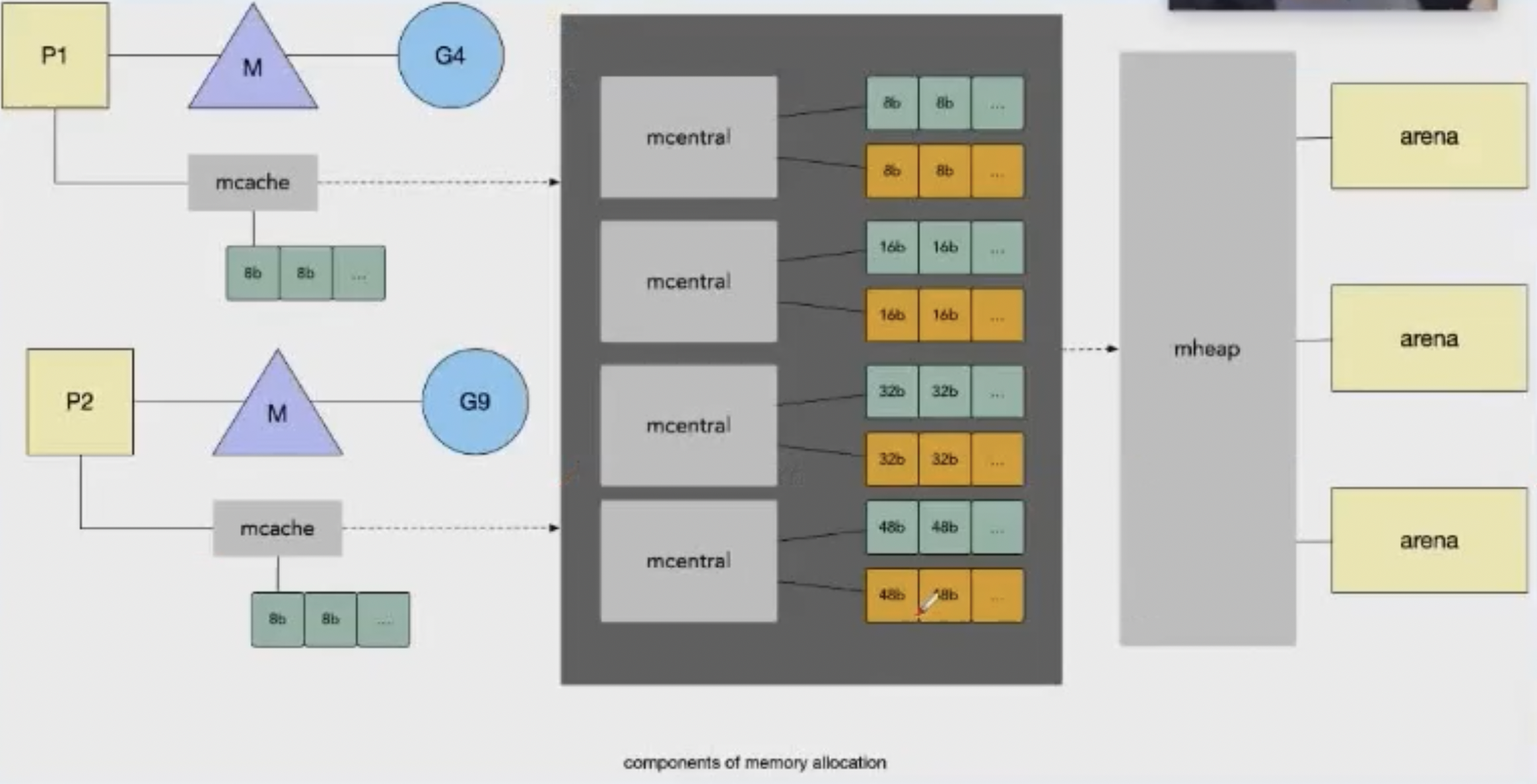
一般小对象通过 mspan 分配内存;大对象则直接由 mheap 分配内存。
- Go 在程序启动时,会向操作系统申请一大块内存,由
mheap结构全局管理(现在 Go 版本不需要连续地址了,所以不会申请一大堆地址) - Go 内存管理的基本单元是
mspan,每种mspan可以分配特定大小的object mcache、mcentral、mheap是 Go 内存管理的三大组件:mcache管理线程在本地缓存的mspanmcentral管理全局的mspan供所有线程
优化实践
1、使用缓存提高效率。在存储的整个体系中到处可见缓存的思想,Go 利用缓存一是减少了系统调用的次数,二是降低了锁的粒度、减少加锁的次数。
2、以空间换时间,提高内存管理效率。空间换时间是一种常用的性能优化思想,这种思想其实非常普遍,比如Hash、Map、二叉排序树等数据结构的本质就是空间换时间。
Reference
栈溢出的检测
Go 语言内存管理(一):系统内存管理
高性能 Go 服务的内存优化(译)
Go 语言内存管理(二):Go 内存管理
Go 语言内存管理(三):逃逸分析
图解Go语言内存分配
聊一聊goroutine stack
golang goroutine 堆栈
Language Mechanics On Stacks And Pointers
Language Mechanics On Escape Analysis
白话Go语言内存管理三部曲(二)解密栈内存管理
Language Mechanics On Stacks And Pointers
浅窥关于golang reflect获取interface值的性能问题以及用interface传递参的变量逃逸问题
Go 内存逃逸详细分析
Go语言的栈空间管理
Contiguous stacks in Go
Precise Stack Roots
Go 1.2 Runtime Symbol Information
Go内存管理三部曲[1]- 内存分配
Writing a Memory Allocator
从源码讲解 golang 内存分配
详解Go语言的内存模型及堆的分配管理
图解golang内存分配机制 (转)
内存分配
golang 内存分配深度分析
golang源码解析–内存mspan,mcache结构体
Manual Memory Management in Go using jemalloc