Go的concurrency之Memory model
简介
如何保证在一个 goroutine 中看到在另一个 goroutine 修改的变量的值,如果程序中修改数据时,有其他 goroutine 同时读取,那么必须将读取串行化。为了串行化访问,请使用 channel 或其他同步原语,例如 sync 和 sync/atomic 来保护数据。
Programs that modify data being simultaneously accessed by multiple goroutines must serialize such access.
To serialize access, protect the data with channel operations or other synchronization primitives such as those in the
syncandsync/atomicpackages.If you must read the rest of this document to understand the behavior of your program, you are being too clever.
https://go.dev/ref/mem
先行发生
Happens-Before
在 Go 语言中,如果一个操作 A happens-before 另一个操作 B,那么 A 对 B 的执行具有一定的顺序保证。这种顺序保证可以用于推断 Goroutine 之间的同步关系。
在一个 goroutine 中,读和写一定是按照程序中的顺序执行的。即编译器和处理器只有在不会改变这个 goroutine 的行为时才可能修改读和写的执行顺序。由于重排,不同的 goroutine 可能会看到不同的执行顺序。
比如
1 | a := 1 |
在编译器重排之后,可能会变成
1 | b := 2 |
ps: 这个可能是为了执行效率和性能优化考虑。
例如,一个 goroutine 执行 a = 1; b = 2;,另一个 goroutine 可能看到 b 在 a 之前更新。

这个结果,可能会看到 (0,1) 或者 (1,1),也可能会打印(0,0),也就是产生内存重排。
用户写下的代码,先要编译成汇编代码,也就是各种指令,包括读写内存的指令。CPU的设计者们,为了榨干CPU的性能,无所不用其极,各种手段都用上,例如流水线、分支预测等等。
其中,为了提高读写内存的效率,会对读写指令进行重新排列,这就是所谓的内存重排,英文为 MemoryReordering 。
除了上面的 CPU 重排,其实还有编译器重排。比如

同一个变量相同赋值、并且打印多次,编译器会通过分支预测,将代码重排成下面这样:

但是,如果这时有另外一个线程同时执行

在多核场景下,没有办法轻易地判断两段程序是否是“等价”的。
内存重排
Memory Reordering
现代CPU为了“抚平”内核、内存、硬盘之间的速度差异,通过各种策略,例如多级缓存(CPU的三级缓存)。
例如下图,为了让 (2) 不必等待 (1) 的执行“效果”可见之后才能执行,我们可以把 (1) 的效果保存到 store buffer:
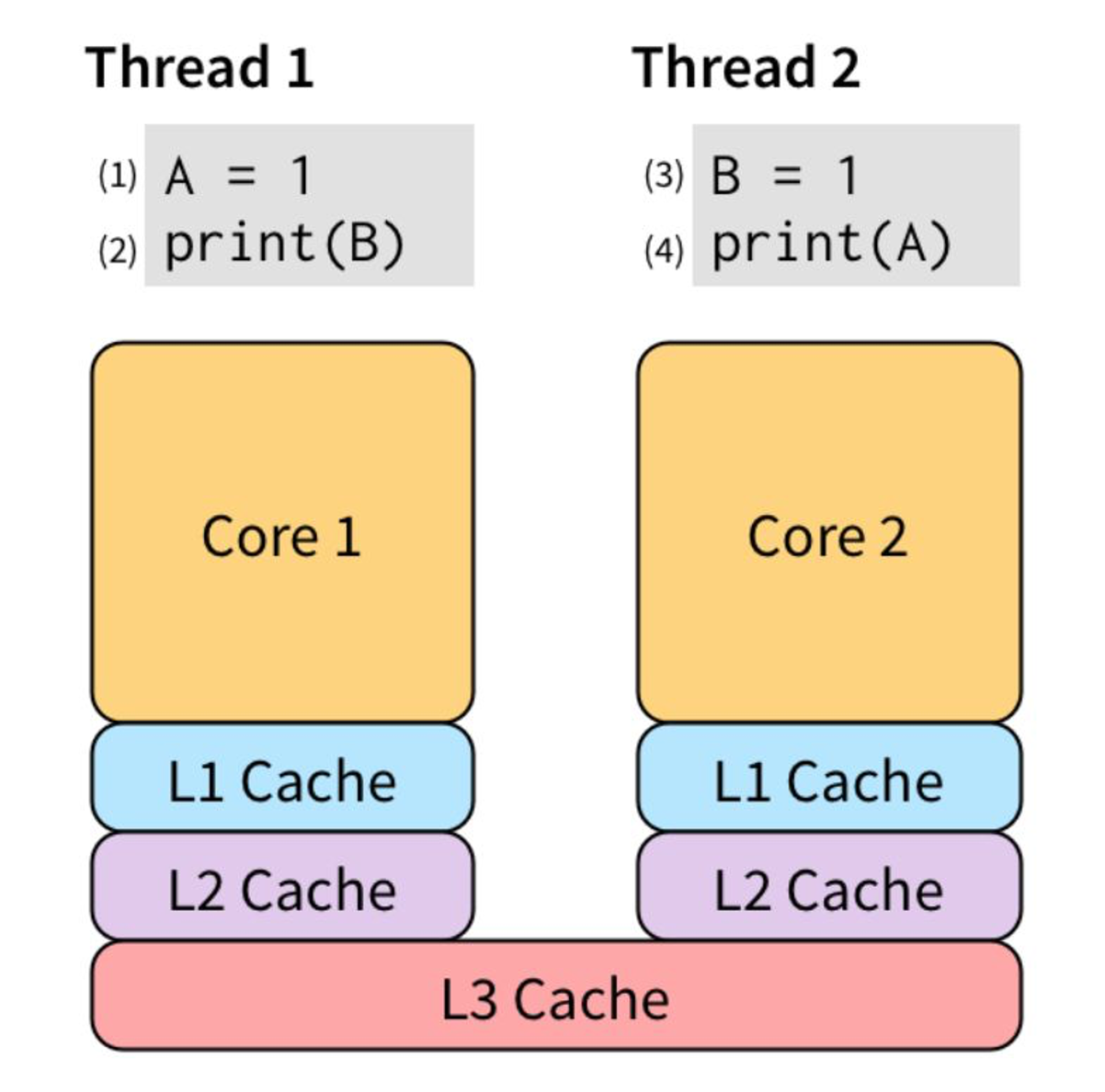
为了让 (2) 不必等待 (1) 的执行“效果”可见之后才能执行,我们可以把 (1) 的效果保存到 store buffer:
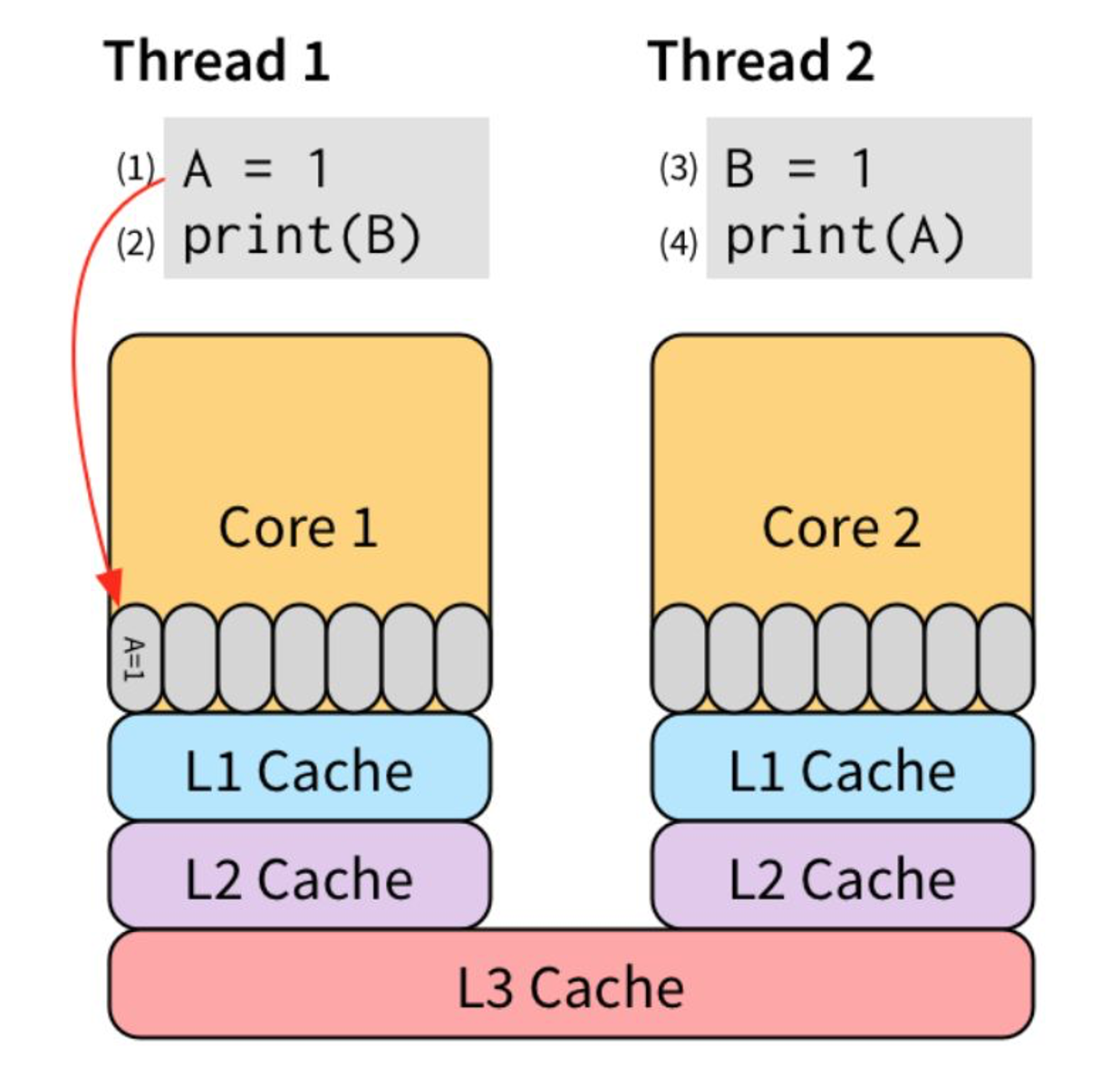
store buffer 对单线程是完美的。
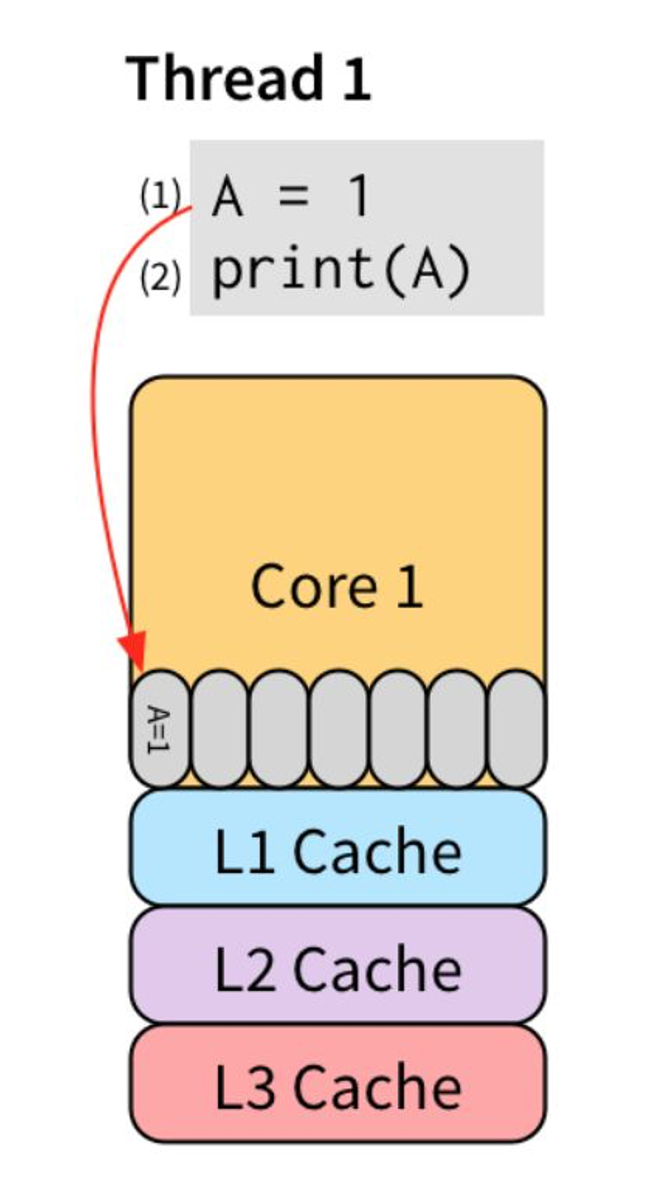
但是在多线程上,先执行(1)和(3),将他们直接写入 store buffer,接着执行(2)和(4)。
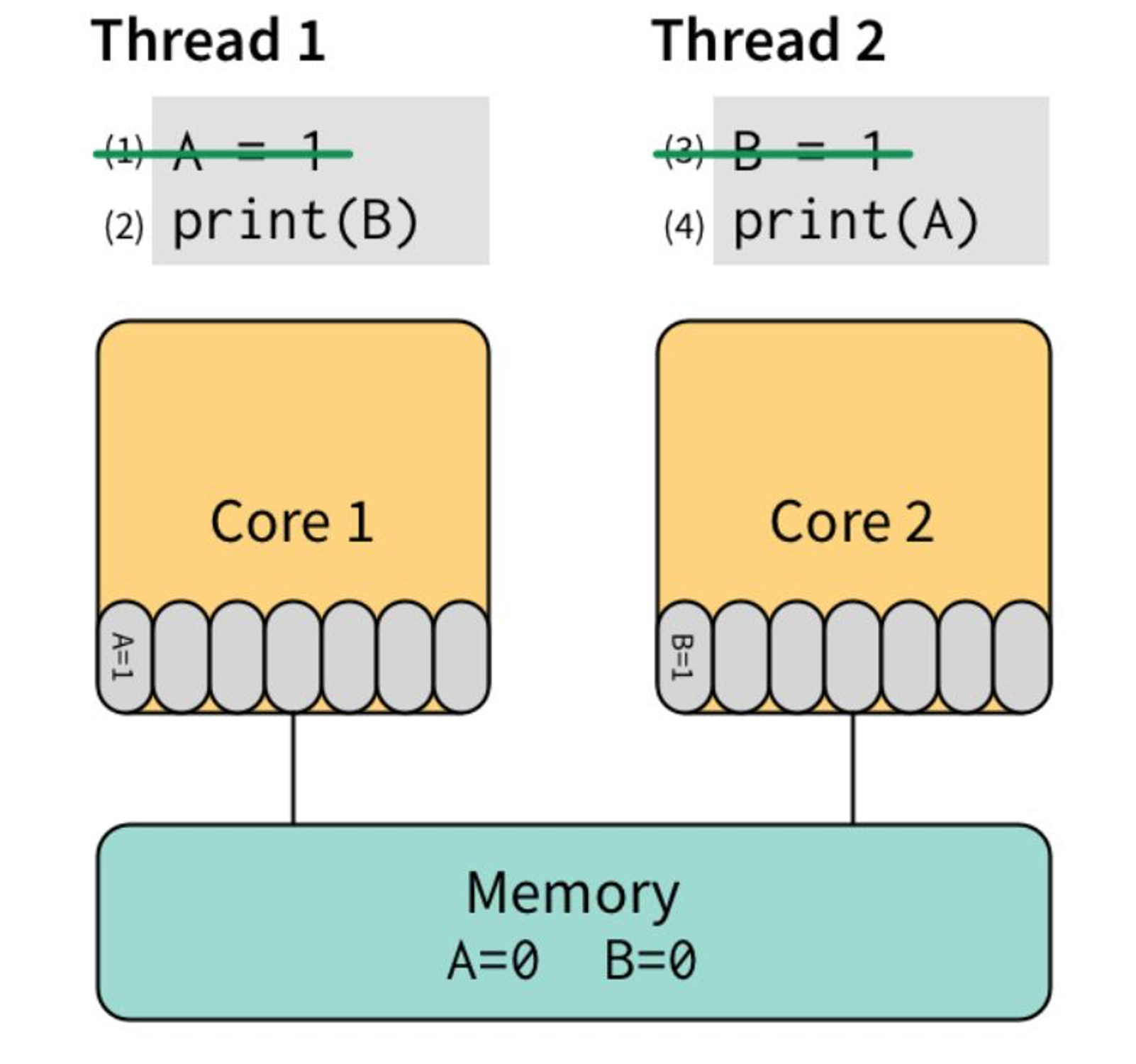
这个时候,(2)看了 store buffer 中的内容,没有发现B的值,于是从Memory读出了0,(4)同样从Memory读出了0,最后,打印出(0,0)
因此,对于多线程的程序,所有的CPU都会提供“锁”支持,称之为 barrier(内存屏障),或者fence。它要求:barrier 指令要求所有对内存的操作都必须要扩散到memory之后才能继续执行其他对 memory 的操作(也就是修改A的值之后,需要往内存中刷新)。因此,我们可以用高级点的 atomic compare-and-swap,或者直接用更高级的锁,通常是标准库提供。(锁、原子操作,基本上都是利用这套机制)
内存模型
Memory model
为了说明读和写的必要条件,我们定义了先行发生(Happens Before):如果事件 e1 发生在 e2 前,我们可以说 e2 发生在 e1 后。如果 e1 不发生在 e2 前也不发生在 e2 后,我们就说 e1 和 e2 是并发的。
在单一的独立的 goroutine 中,先行发生的顺序即是程序中表达的顺序。
当下面条件满足时,对变量 v 的读操作 r 是被允许看到对 v 的写操作 w 的:
- r 不先行发生于 w
- 在 w 后 r 前,没有对 v 的其他写操作
为了保证对变量 v 的读操作 r 看到对 v 的写操作 w,要确保 w 是 r 允许看到的唯一写操作。即当下面条件满足时,r 被保证看到 w :
- w 先行发生于 r
- 其他对共享变量 v 的写操作要么在 w 前,要么在 r 后
这一对条件,比前面的条件更严格,需要没有其他写操作与 w 或 r 并发发生。
单个 goroutine 中没有并发,所以上面两个定义是相同的:
读操作 r 看到最近一次的写操作 w 写入 v 的值。
当多个 goroutine 访问共享变量 v 时,它们必须使用同步事件来建立先行发生这一条件来保证读操作能看到需要的写操作。
- 对变量 v 的零值初始化在内存模型中变现的与写操作相同
- 对大量 single machine word 的变量的读写操作表现的像以不确定顺序对多个 single machine word 的变量的操作。(比如在 32 位的机器上,机器字是 4byte, 在赋值一个指针时,是需要两步操作,不是一个原子操作的。)
内存模型文章推荐:Go的内存模型
参考
The Go Memory Model
Go的内存模型
理解Memory Barrier(内存屏障)
曹大谈内存重排
从 Memory Reordering 说起