微服务可用性设计之超时控制
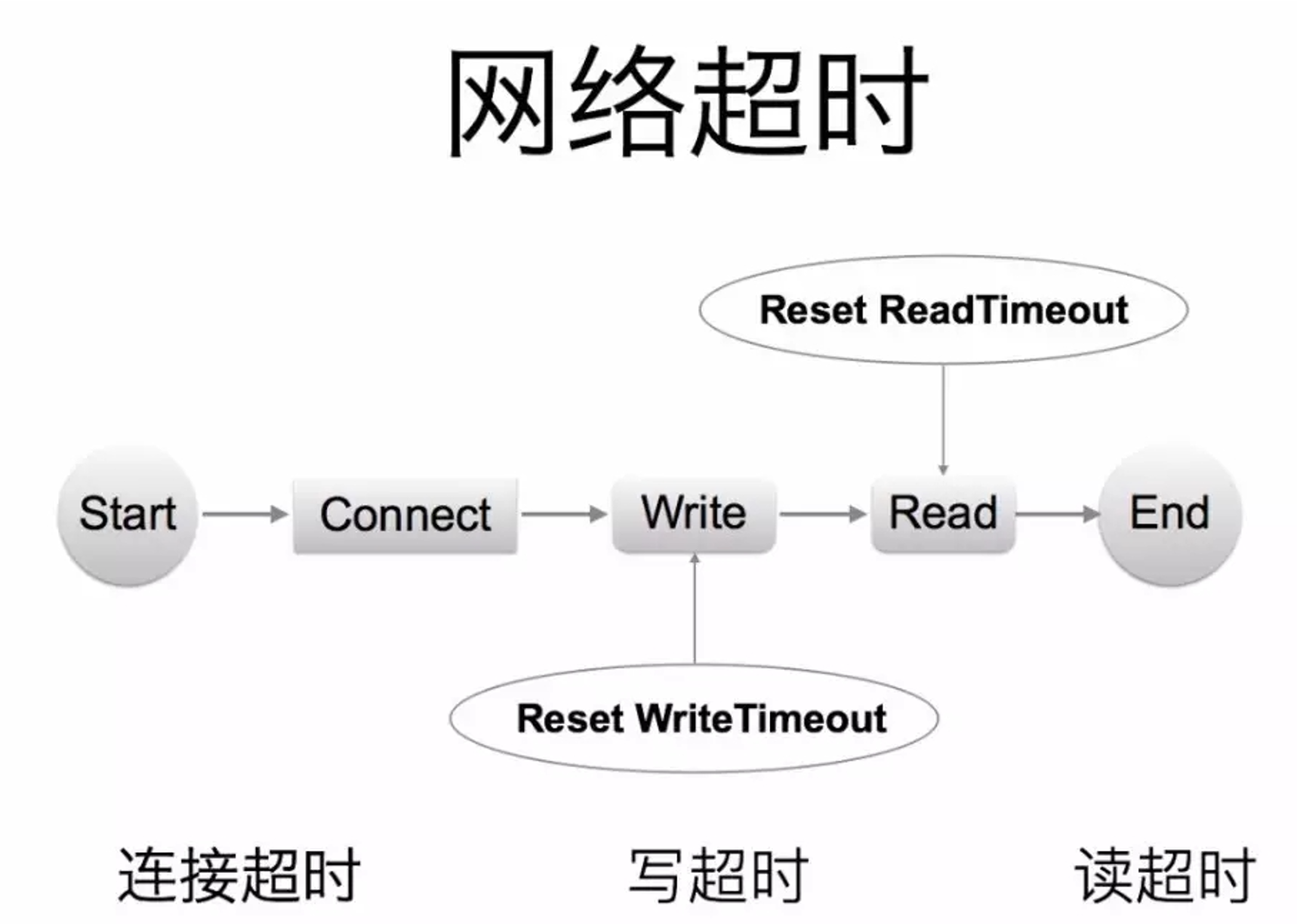
超时控制
超时控制,本质就是 快速失败(fail fast),因为我们不希望等到断开的实例直到超时。没有什么比挂起的请求和无响应的页面更令人失望。这不仅仅浪费资源,而且还会让用户体验变得更差。
我们的服务是相互调用的,所以在这些延迟叠加前,应该特别注意防止那些超时的操作。
网路传递具有不确定性
例如网络断开,client 收不到
syn报文或者ack报文,会一直处于等待客户端和服务端不一致的超时策略导致资源浪费
默认值策略
高延迟服务导致
client浪费资源等待,使用超时传递:进程间传递 + 跨进程传递
超时控制是微服务可用性的第一道关,良好的超时策略,可以尽可能让服务不堆积请求,尽快清空高延迟的请求,释放 Goroutine
依赖超时
实际业务开发中,我们依赖的微服务的超时策略并不清除,或者随着业务迭代耗时超生了变化,意外的导致依赖者出现了超时。
例如下游服务的耗时增加,导致上游服务的超时时间不够。
服务提供者定义好
latency SLO,更新到gRPC Proto定义中,服务后续迭代,都应保证SLO![image-20231020105228897]()
也就是服务提供者的性能指标,将指标放到服务中
1
2
3
4
5
6
7
8package google.example.library.v1;
service LibraryService {
// Lagency SLO: 95th in 100ms, 99th in 150ms.
rpc CreateBook(CreateBookRequest) returns (Book);
rpc GetBook(GetBookRequest) returns Book);
rpc ListBooks(ListBooksRequest) returns (ListBooksResponse);
}避免出现意外的默认超时策略,或者意外的配置超时策略。
kit 基础库兜底默认超时,比如
100ms,进行配置防御保护,避免出现类似60s之类的超大超时策略。配置中心公共模板,对于未配置的服务使用公共配置。

超时传递
超时传递:当上游服务已经超时返回504,但下游服务仍然在执行,会导致浪费资源做无用功。超时传递指的是把当前服务的剩余 Quota 传递到下游服务中,继承超时策略,控制请求级别的全局超时控制。
进程内超时传递
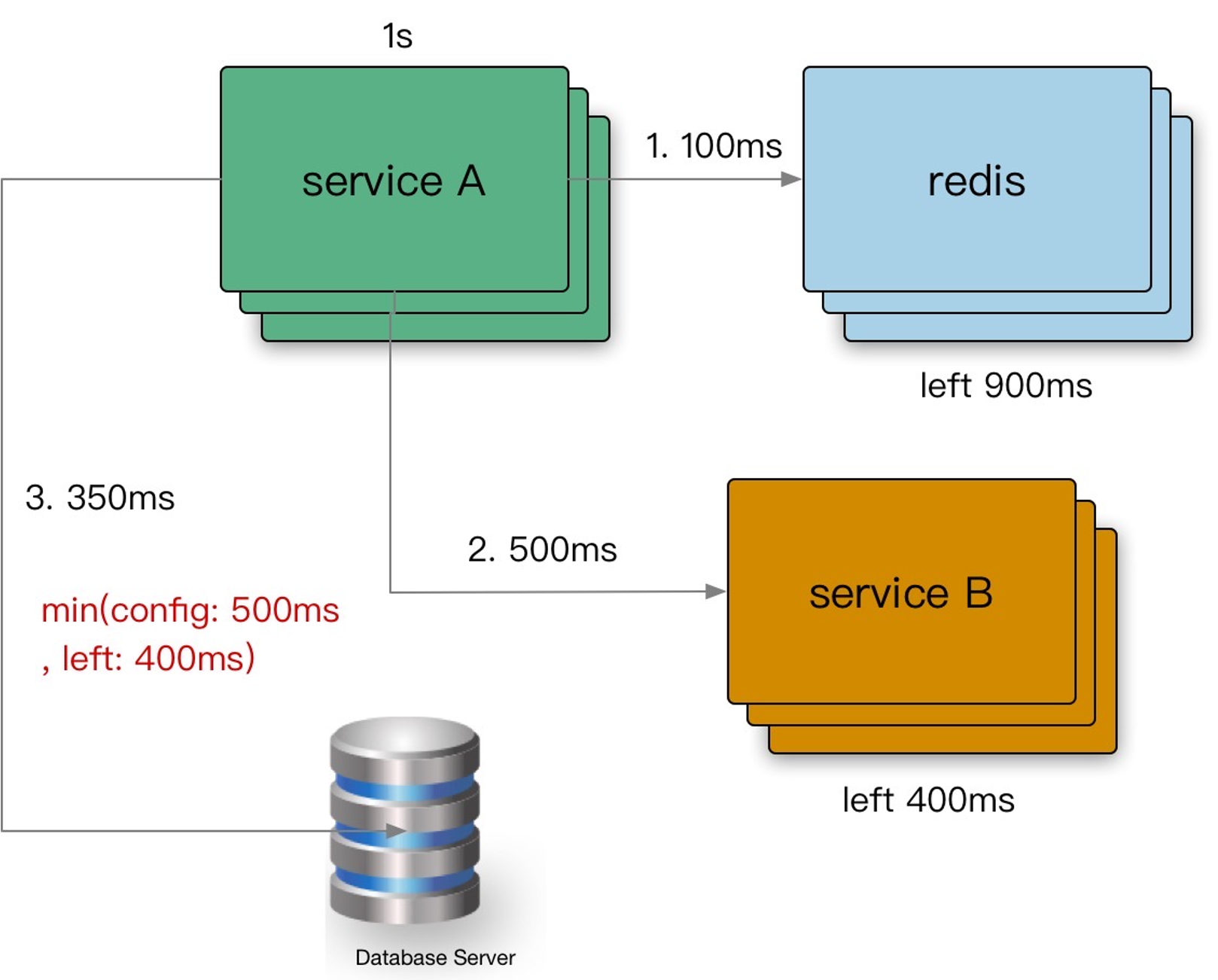
前提是实现进程内超时控制:
一个请求在每个阶段(网络请求)开始前,就要检查是否还有足够的剩余来处理请求,以及继承他的超时策略,使用 Go 标准库的 context.WithTimeout。
1 | func (c *asiiConn) Get(ctx context.Context, key string) (result *Item, err error) { |
进程间超时传递
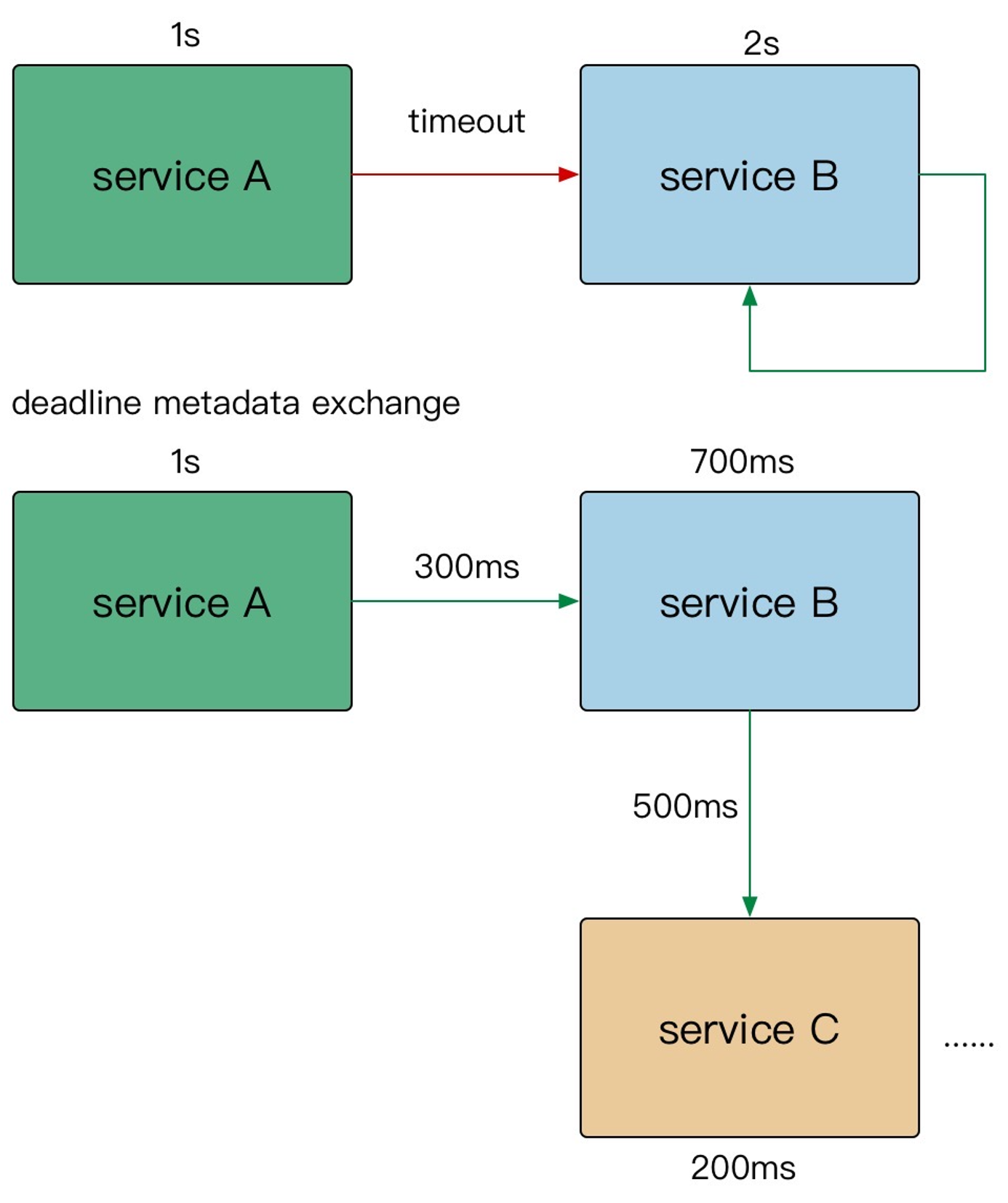
- A
gRPC请求 B,1s超时 - B 使用了
300ms处理请求,再转发请求 C - C 配置了
600ms超时,但是实际只用了500ms - 到其他的下游,发现余量不足,取消传递
在需要强制执行时,下游的服务可以覆盖上游的超时传递和配额。
在 gRPC 框架中,会依赖 gRPC Metadata Exchage ,基于 HTTP2 的 Headers 传递 grpc-timeout 字段,自动传递到下游,构建带 timeout 的 context
监控观察
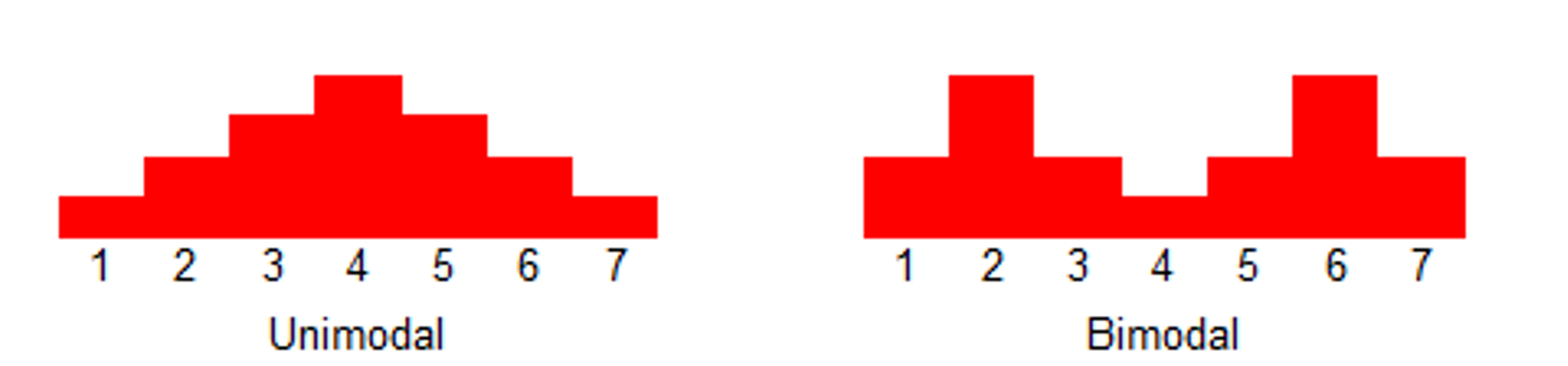
- 双峰分布:95% 的请求耗时在 100ms 内,5% 的请求可能永远不会完成(长超时)
- 对于监控不要只看 mean,可以看看耗时分布统计,比如 95th,99th
- 设置合理的超时,拒绝超长请求,或者当
Server不可用要主动失败
超时决定着服务线程能否被耗尽。
Case Study
SLB 入口
Nginx没有配置超时,导致连锁故障在
Nginx中配置timeout服务依赖的 DB 连接池漏配超时,导致请求阻塞,最终服务集体 OOM
下游服务发版本耗时增加,而上游服务配置超时过短,导致上游请求失败