Nginx架构、阶段、模块
初识 Nginx
Nginx 三个主要应用场景
- mir静态资源服务
- 通过本地文件系统提供服务:例如直接提供一些 h5 资源(html,css)或者图片等静态资源
- 反向代理服务
- Nginx 的强大性能:作为多个应用服务组成的集群的网关,提供高性能
- 缓存:将一段时间内看起来不变的内容缓存到 Nginx,加速访问
- 负载均衡:同一台 Nginx 可以同时支持多个后台服务器,并且做负载均衡
- API 服务
- OpenResty:直接访问数据库,提供完整的 API 服务
Nginx 出现原因
- 互联网的数据量快速增长,对高并发要求越来越高
- 互联网的快速普及
- 全球化
- 物联网
- 摩尔定律:性能提升
- 物理硬件 CPU、内存提升之后,操作系统和应用也需要配套提升
- 低效的 Apache
- 一个连接对应一个进程:操作系统进程间切换,导致并发数上不来,并发上来之后,使用进程处理,会导致大量进程创建、删除、切换,从而产生很大的开销
Nginx 的优点
- 高并发,高性能:可以达到百万QPS
- 可扩展性好:生态圈法阵非常好
- 高可靠性:可以持续不间断运行数年不重启
- 热部署:修改配置、升级后可以热加载,不需要重启
- BSD 许可证:开源、免费,而且可以修改代码之后做商业化
Nginx 组成部分
- Nginx 二进制可执行文件
- 由各模块源码编译出的一个文件
nginx.conf配置文件- 控制 Nginx 的行为
access.log访问日志- 记录每一条
http请求信息和相应信息
- 记录每一条
error.log错误日志- 用于定位问题
Nginx 版本发布
https://nginx.org/
一些版本推荐:https://openresty.org/cn/ (开源版)
编译适合自己的包
下载源码
https://nginx.org/en/download.html
目录介绍
1 | total 1624 |
auto 目录
1 | total 376 |
Configure 文件介绍
1 | ./configure --help |
- 可以指定一些模块的文件存放位置
- 可以指定使用哪些模块和不适用哪些模块
- 可以指定哪些特殊参数,例如是否打印
debug日志,或者是否加入第三方模块
中间文件介绍
执行 configure 后,会将中间文件生成在 objs 目录中。里面存放编译的一些配置信息
编译
执行 make 进行编译,会生成二进制可执行文件在 objs 目录中
安装
执行 make install。将指定的安装目录中,src 目录下的二进制文件拷贝出去执行即可。
Nginx 配置语法
- 配置文件由指令与指令块构成:指令以
;结尾,指令块在{}中 - 每条指令以
;号结尾,指令与参数间以空格符号分割 - 指令快以
{}大括号将多条指令组织在一起 include语句允许组合多个配置文件以提升可维护性- 使用
#符号添加注释,提高可读性 - 使用
$符号使用变量 - 部分指令的参数支持正则表达式
官方文件,一些模块:https://nginx.org/en/docs/
例如:

配置参数:时间的单位
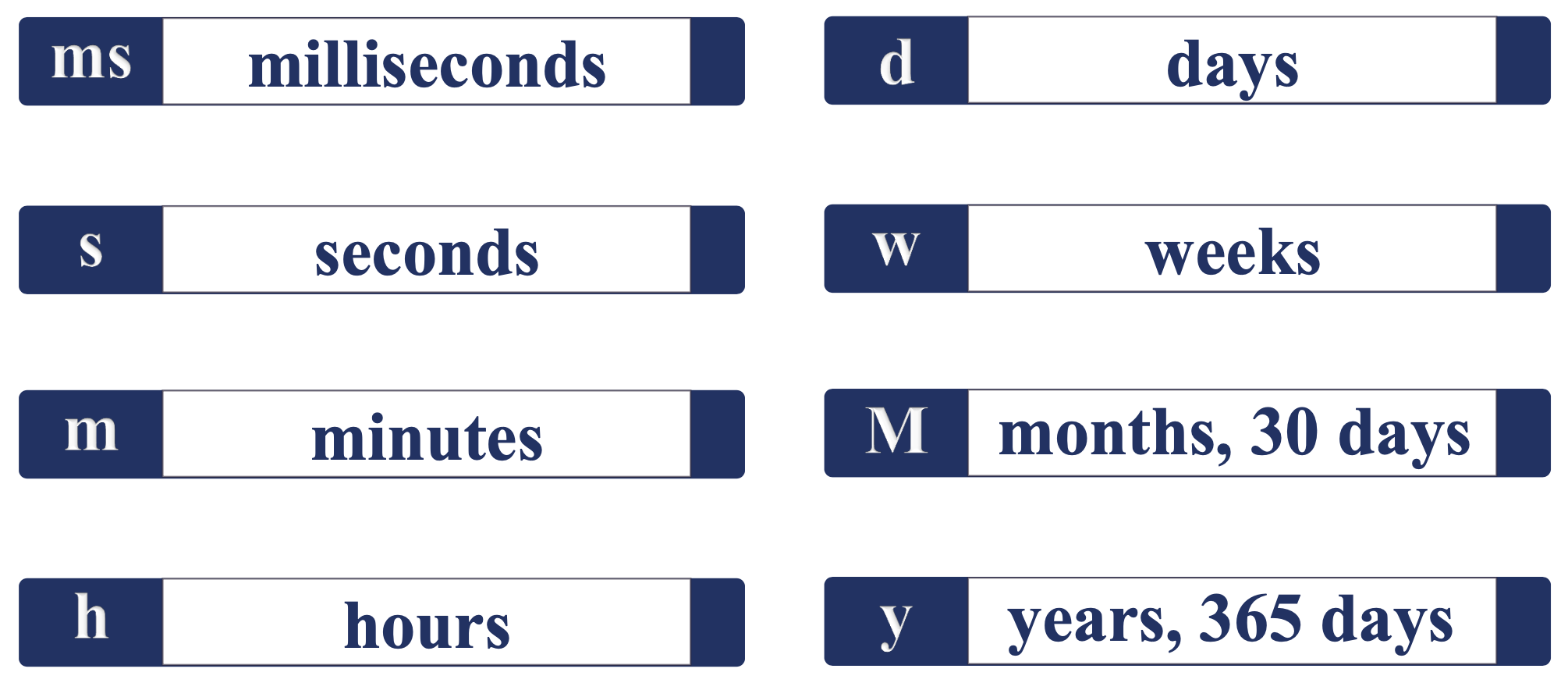
配置参数:空间的单位

http 配置的指令快
http:表示所有的指令由http模块解析server:对应一个域名或者一组域名location:一个url表达式upstream:表示上游服务,例如内网其他服务
Nginx 命令行
- 格式:
nginx -s reload - 帮助:
-? -h - 使用指定的配置文件:
-c - 指定配置指令:
-g,主要用于forget中间的指令 - 指定运行目录:
-p - 发送信号:
-s- 立即停止服务:
stop - 优雅的停止服务:
quit - 重载配置文件:
reload - 重新开始记录日志文件:
reopen
- 立即停止服务:
- 测试配置文件是否有语法错误:
-t、-T - 打印
nginx的版本信息、编译信息等:-v、-V
示例
重载配置文件
1 | # 修改配置文件后 |
热部署
1 | # 当 nginx 正在运行,需要更新nginx,先备份二进制文件,将新的二进制nginx可执行文件拷贝到对应目录中替换原文件 |
切割日志文件
1 | # 先拷贝 access.log 到另外一个地方 |
静态资源服务演示
例如一个 index.html 文件
1 | # 记录日志的格式,将这个格式命名成 main |
变量解释:https://nginx.org/en/docs/
带有缓存的反向代理
1 | http { |
使用 Go access 实时分析 accesslog 日志
通过 websocket 监听 accesslog 的实施变更,以图形化的方式分析 accesslog
https://goaccess.io/

1 | goaccess access.log -o report.html --log-format=COMBINED |
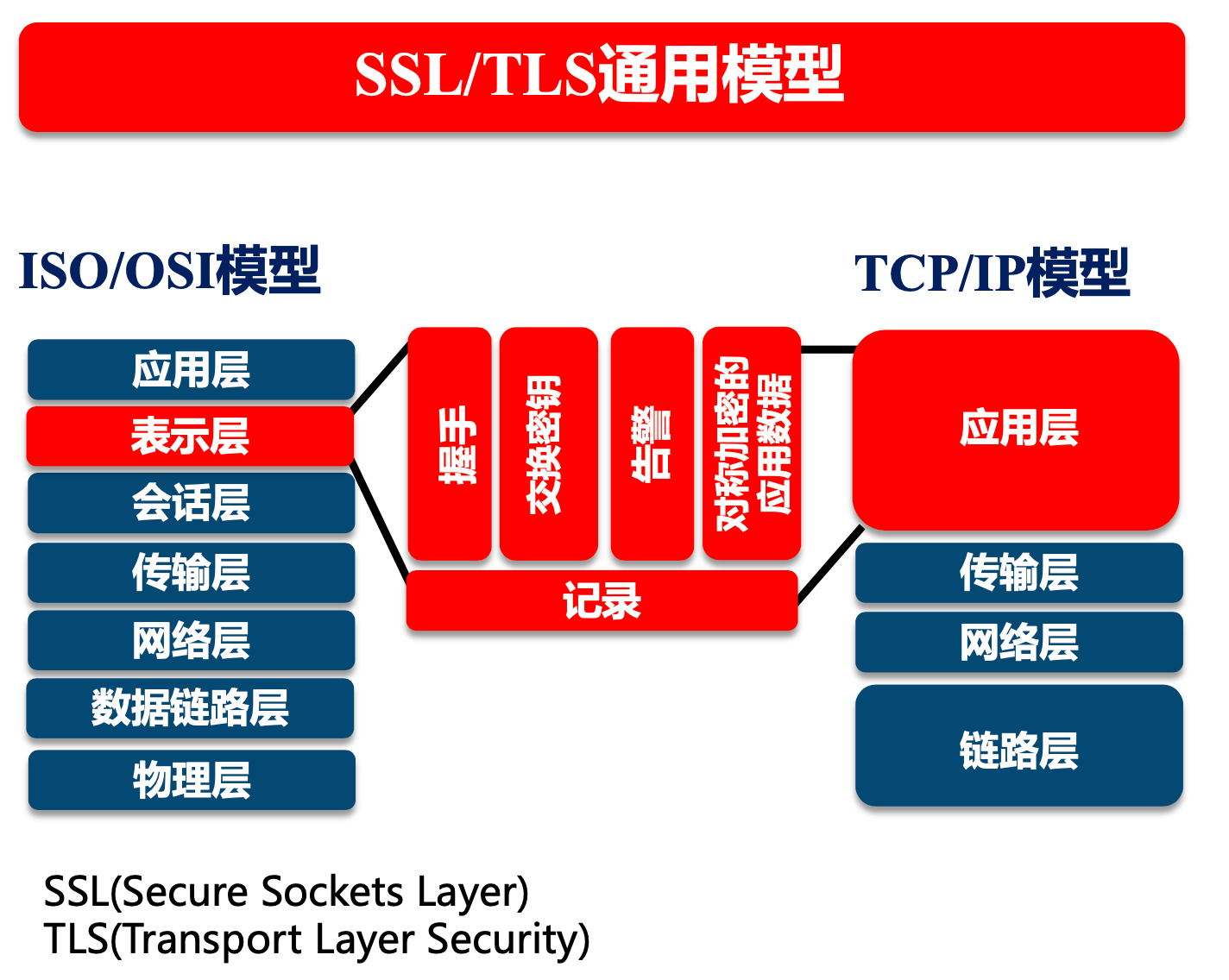
TLS/SSL 发展
站点通过 HTTPS 保障安全。
TLS 安全密码套件解读
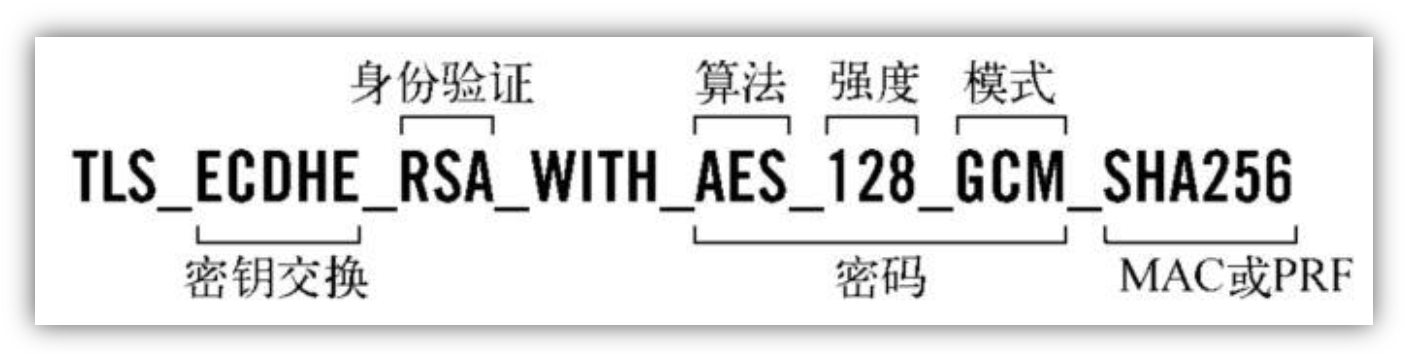
- 密钥交换算法:解决浏览器和服务器之间各自独立生成密钥,并且密钥相同
- 身份验证:浏览器和服务器之间交换密钥后验证身份
- 对称加密算法、强度、分组模式
- 签名 hash 算法
对称加密
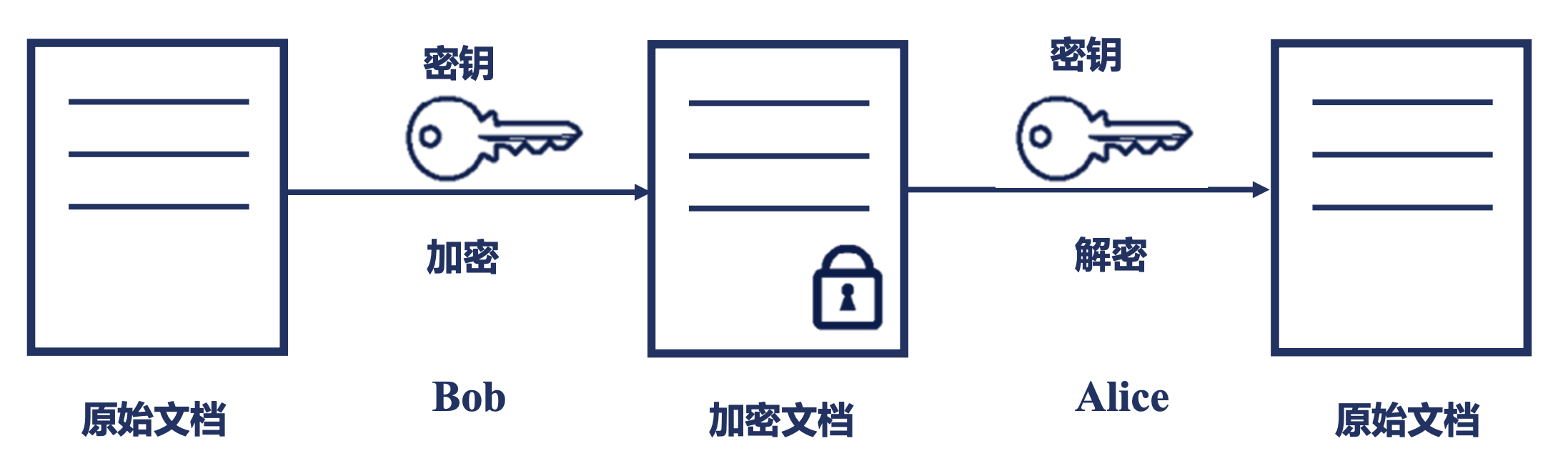
通常说:加密和解密,使用同一份密钥,其他人就算有密钥,但是没有加密算法也无法破译。
例如使用 RC4 的加密算法
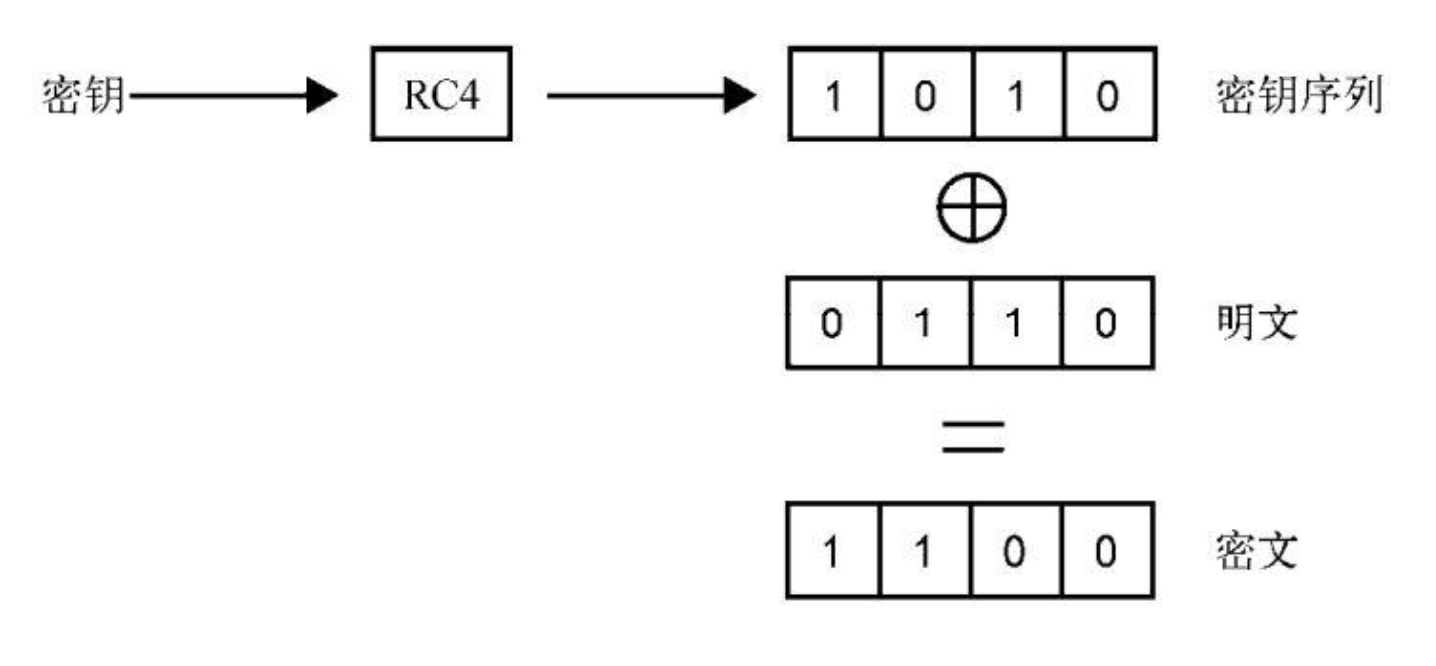
使用或运算,可以加密和解密,特点是性能好。
非对称加密
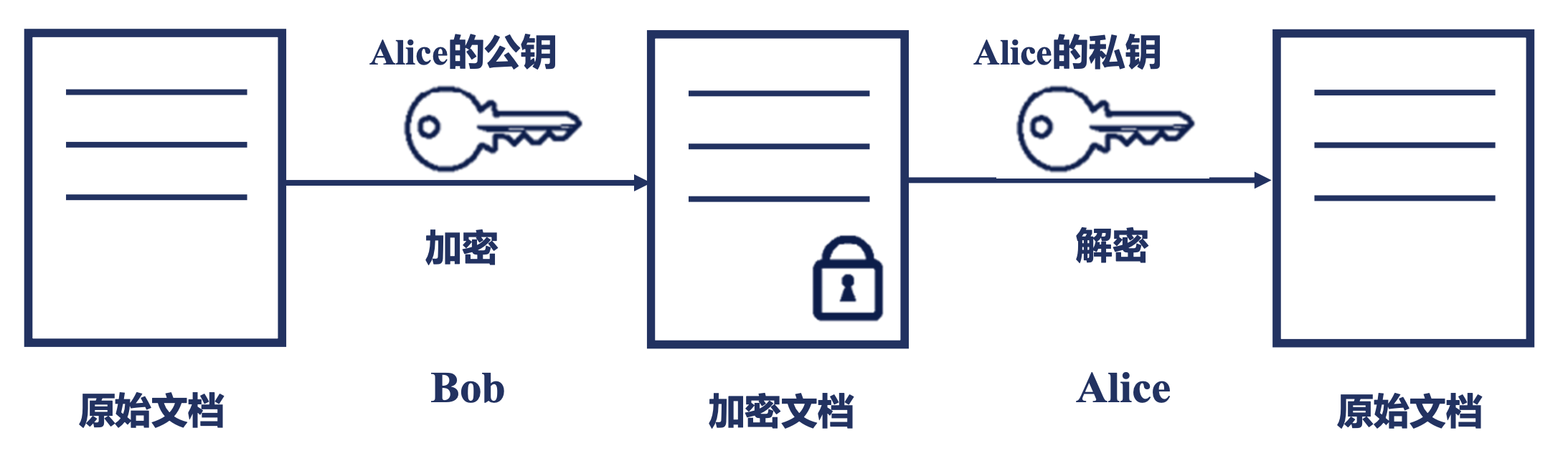
根据授权原理,生成一对密钥,分为私钥和公钥。使用公钥加密,则使用私钥解密,使用私钥加密,则使用公钥解密。
PKI 公钥基础设施
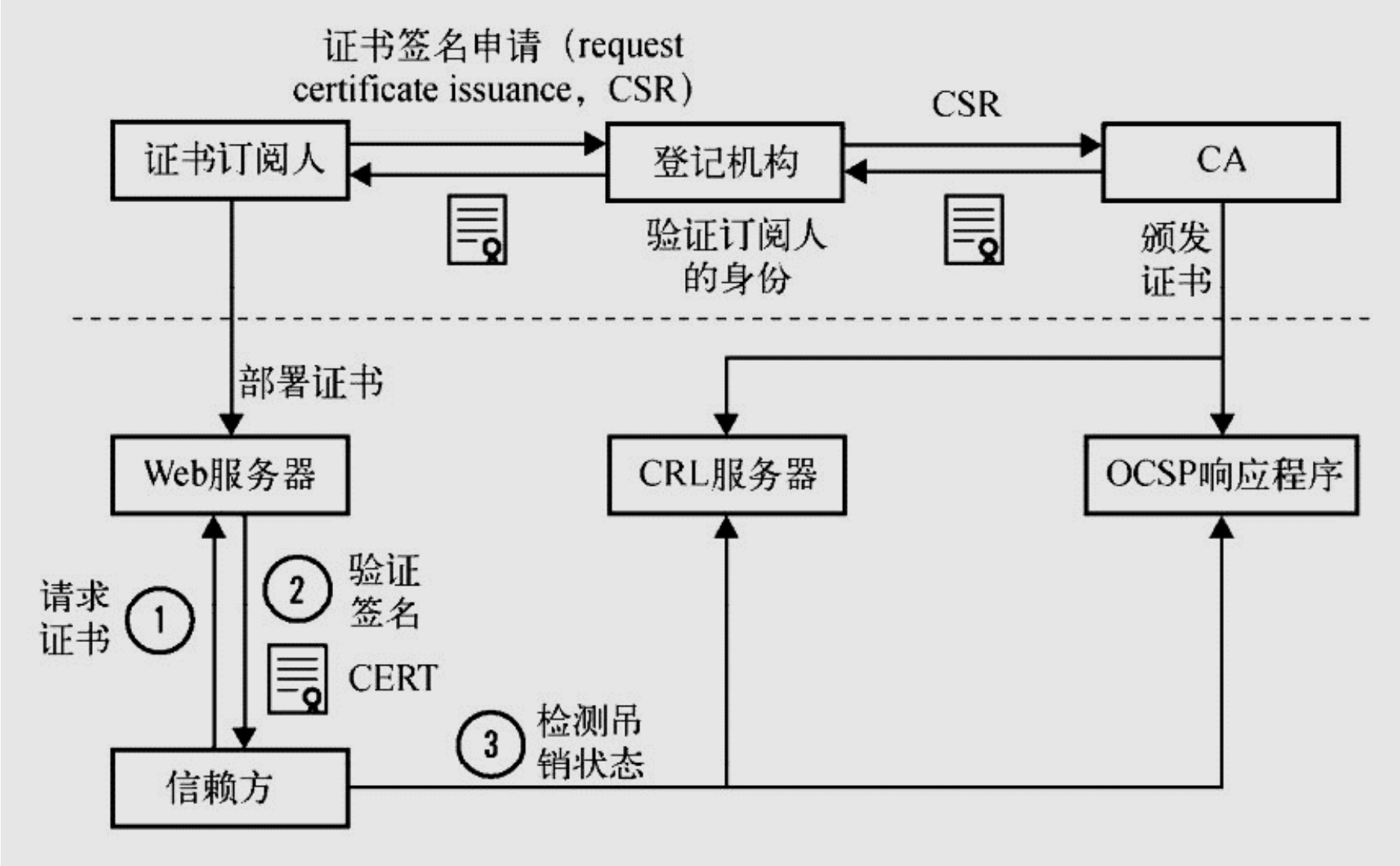
站点在 CA 申请证书,CA 生成一对公钥和私钥,颁发给网站站点。
浏览器请求时,站点会将证书发送给浏览器,浏览器会验证证书是否合法。
证书类型
域名验证(domain validated,DV)证书,验证证书归属是否正确
https://www.xiaoyeshiyu.com组织证书(organization validated,OV)证书,验证机构企业名称是否正确
https://www.baidu.com扩展验证(extended validation,EV)证书,严格,但是浏览器显式支持好
![image-20240319213954908]()

证书链
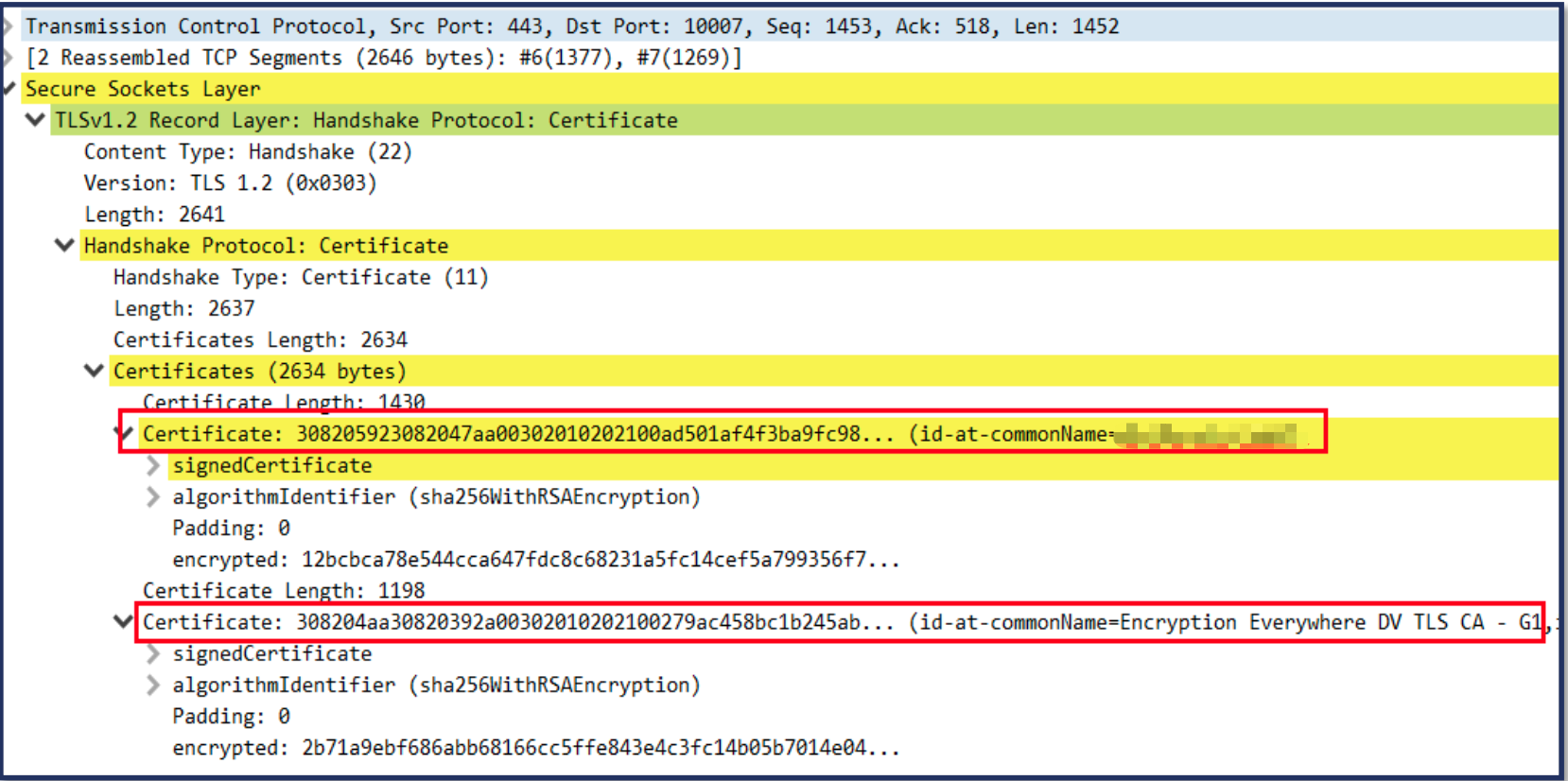
TLS 通讯过程
主要分为四个部分
- 验证身份
- 达成安全套件共识
- 传递密钥
- 加密通讯
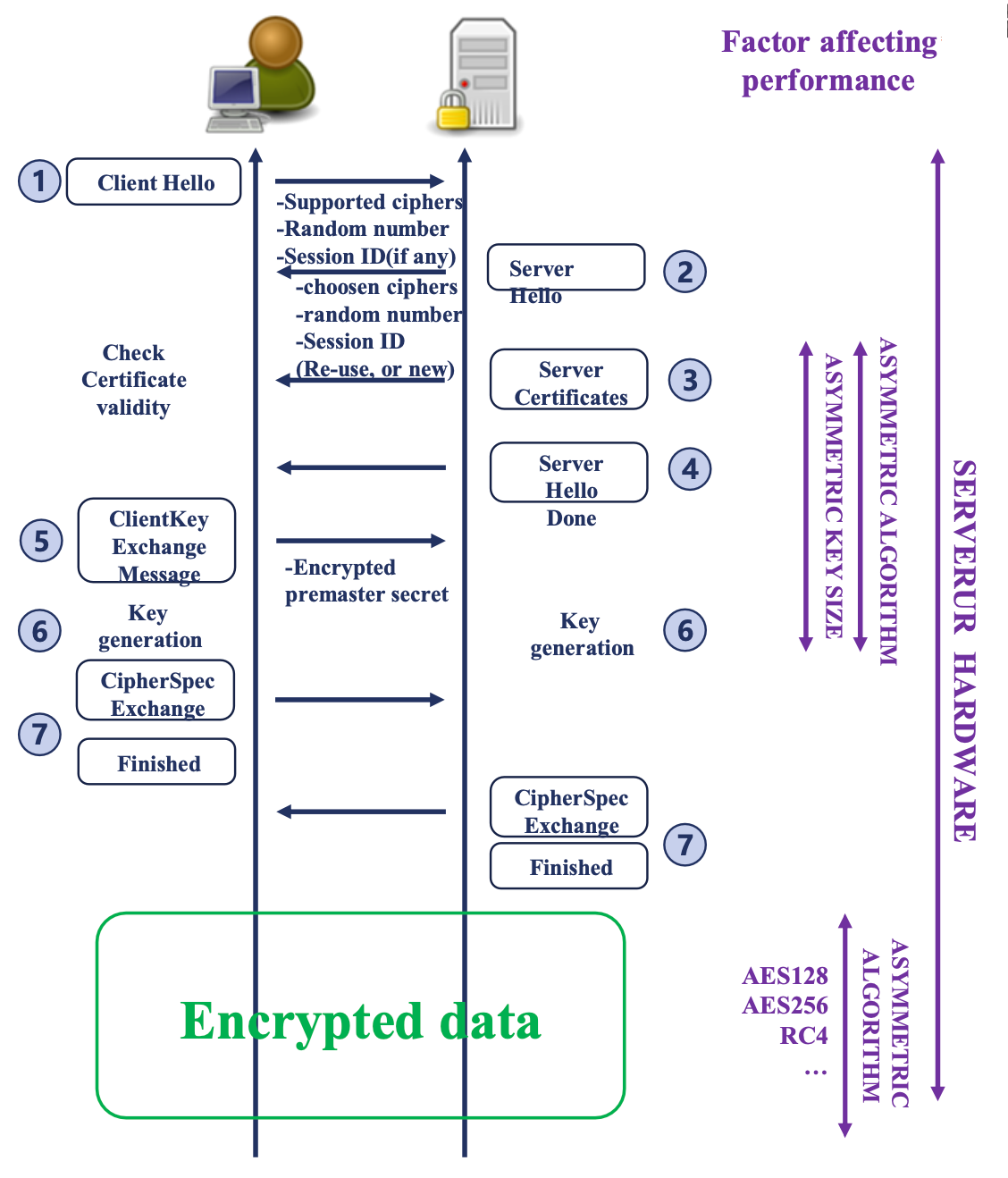
TLS主要做两件事:交换密钥,加密通讯。
OpenResty 安装
https://openresty.org/cn/installation.html
官网全中文,国人开源,非常友好。
扩展性更好,可以使用 lua 直接处理请求中的内容。
Nginx 架构基础
Nginx 运行在企业内网的最外层,处理的流量非常庞大,这也是 Nginx 的架构非常重要的原因。
Nginx 请求处理流程

- 外部流量大约可以分为三种:
WEB、EMAIL、TCP - Nginx 中处理这三种流量是通过非阻塞模型处理,
epoll,处理请求通过不同的状态机实现 - 当请求需要处理静态资源,则通过磁盘缓存处理,如果是反向代理的缓存内容也是从磁盘缓存中读取
- 当缓存中数据不存在,则会进入
IO阻塞调用,为了提高性能,还需要使用线程池处理磁盘阻塞调用 - 请求完成后,会记录日志,也可以通过
syslog协议记录到远程机器上 - Nginx 作为负载均衡或者反响代理,将请求以协议级传递给上游服务器
- 也可以通过应用层的协议,例如 FastCGI 等代理到相应的应用服务器
Nginx 进程结构
Nginx 进程结构分为:
- 单进程结构:不适合于生产环境,适合开发、调试
- 多进程结构
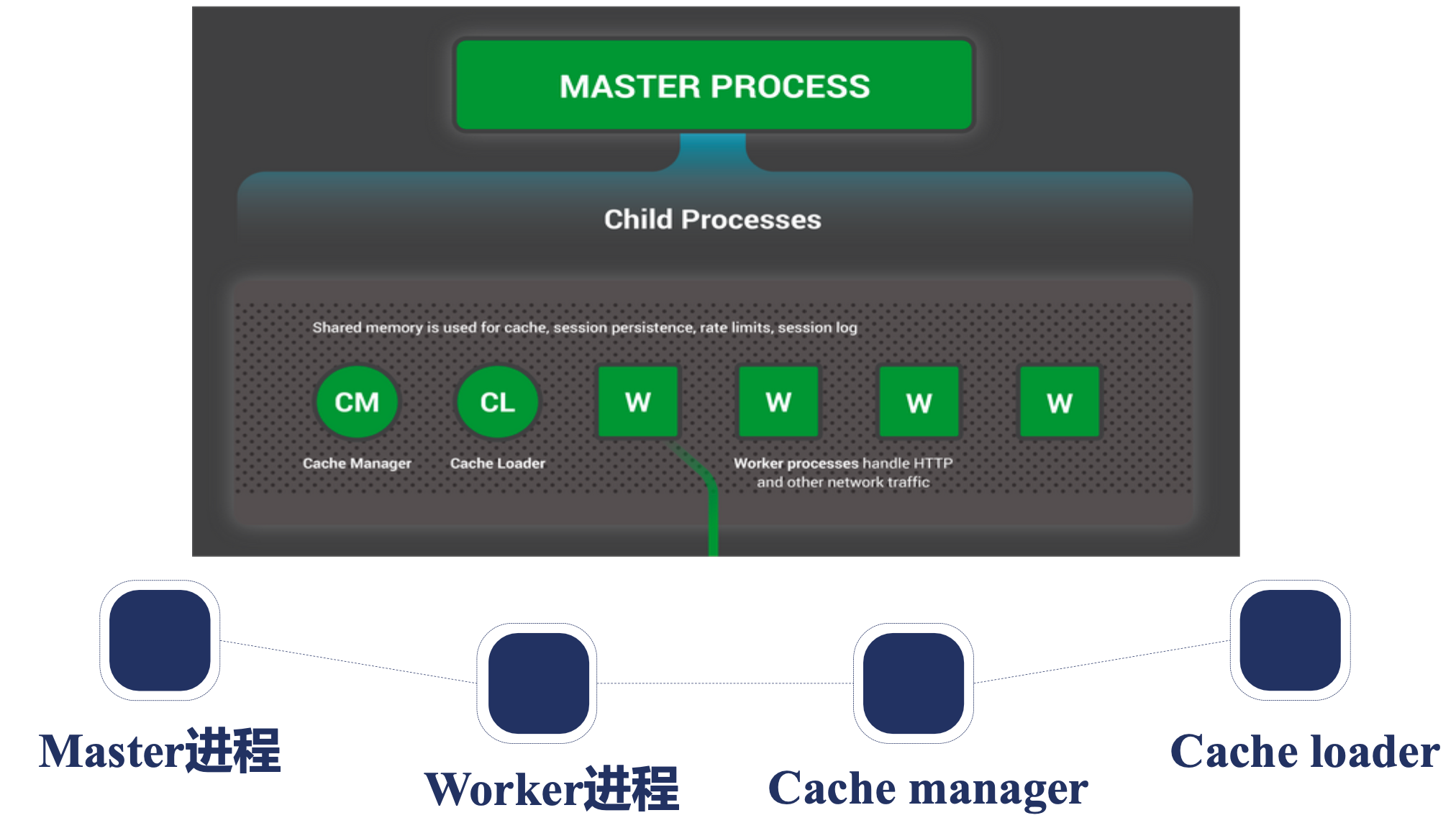
多进程结构分为:
- 一个父进程,Master 进程
- 多个子进程,分为两类:
Worker进程Cache相关的进程
Nginx 采用多进程的原因是为了高可靠性。如果是多线程模型,共用一个地址空间,当其他进程出现越界时,会影响 Nginx 进程。
第三方开发时,通常也不会在 Master 进程中加入模块,即使 Nginx 允许。
Master 进程用于做管理、监控其他 Worker 进程是否正常工作,监听热部署、重加载配置等信号,其他的 Worker 进程用于管理。
Cache 需要让缓存在多个进程间共享,不仅需要让 Master 进程使用,还需要在 Cache manager、Cache loader 进程使用。
Cache manager、Cache loader 则负责使用反向代理时的缓存,Cache manager 负责管理缓存,Cache loader 负责加载缓存。
Nginx 的进程间通讯,使用共享内存解决。
为了实现高性能,Nginx 的 worker 数量通常与 CPU 个数一致,并且当 CPU 核和 worker 进程绑定后,还可以减少缓存失效,提高缓存效率。
Nginx 进程管理:信号
Nginx 父子进程之间,通过信号进行管理。(数据共享还是通过共享内存)
Master 进程
监控 Worker 进程
- CHLD:当 Worker 进程出现异常,会向 Master 进程发送信号,Master 检测到信号之后,会立刻将 Worker 进程拉起
管理 Worker 进程
接收信号
TERM,INT:立刻停止 Nginx 进程
QUIT:优雅的停止 Nginx 进程,不会向用户发送 RESET 这样的 TCP 请求
HUP:重载配置文件
USR1:重新打开日志文件,做日志文件切割
上面四个可以通过
nginx命令行发送,下面两个只能使用kill发送信号USR2:热部署使用,生成一个新的 Nginx Master 进程,也会新启动一些 Worker 进程,老的 Worker 进程的请求会过渡到新的 Worker 中
WINCH:热部署使用,让老 nginx Master 进程优雅关闭老的 Worker 进程
Worker 进程:接受来自 Master 的信号(通常不会直接向 Worker 进程发送信号,而是使用 Master 进程管理,虽然直接发送也可以)
- TERM,INT
- QUIT
- USR1
- WINCH
nginx命令行:Nginx 使用命令行启动时,会将pid记录到文件中,命令行会通过文件读取pid,发送相应的命令。reload:HUPreopen:USR1stop:TERM
使用 nginx 命令行,跟向 master 进程发送信号的作用一样。
reload 流程
Nginx 可以不停止当前进程,启动新进程,避免当前请求中断。
- 向 Master 进程发送 HUP 信号(
reload命令) - Master 进程校验配置语法是否正确(也可以提前使用
-t先检查) - Master 进程打开新的监听端口(如果引入了新的端口,则会新打开端口,让子进程继承)
- Master 进程用新配置启动新的 Worker 子进程(Nginx 保证平滑,因此会先启新进程,然后再向老子进程发送信号)
- Master 进程向老 Worker 子进程发送 QUIT 信号(先结束请求,优雅关闭子进程,即使是一些
keep-alive请求) - 老 Worker 进程关闭监听句柄,处理完当前连接后结束进程(新的连接到新的子进程)
有些时候,reload 之后,子进程数量不会减少,这种场景出现在 upstream 中比较多,例如一些连接没有被客户端处理,或者 websocket。
不停机载入新配置:

当出现老 Worker 进程无法停止,Nginx 提供 worker_shutdown_timeout 参数来及时强制结束子进程。
热升级流程
- 将旧 Nginx 二进制可执行文件替换成新 Nginx 二进制可执行文件(注意备份)
- 向 Master 进程发送 USR2 信号(其实是相当于老 Master 进程以子进程的方式启动新的 Master 进程)
- Master 进程修改
pid文件名,加后缀.oldbin(给新的 Master 进程让路) - Master 进程用新 Nginx 文件启动新 Master 进程
- 向老 Master 进程发送 WINCH 信号,关闭老 Master
- 回滚:向老 Master 发送 HUP 信号,向新 Master 发送 QUIT 信号
不停机更新 Nginx 二进制文件:

Worker 进程:优雅的关闭
使用 QUIT 信号,主要针对 HTTP 请求
- 设置定时器
worker_shutdown_timeout(针对websocket这类无法检测是否完成的请求) - 关闭监听句柄
- 关闭空闲连接(为了保证高效,有些连接不会关闭。类似连接池原理)
- 在循环中等待全部连接关闭(发现请求完毕,则将该请求的连接关闭)
- 退出进程
网络收发与 Nginx 事件间的对应关系
网络数据包被解封装出内部的数据载荷后,进入操作系统处理

操作系统处理事件会定义一个事件收集、分发器,通过定义的一系列消费者来处理。
例如 Nginx 会建立很多对应的消费者处理事件,例如 连接建立事件消费者、读事件消费者、写事件消费者 等等。。。
读事件:
- Accept 建立连接(TCP 建立连接、关闭连接都是接受报文读取里面的消息)
- Read 读消息
写事件:
- Write 写消息
Nginx 事件循环

- Nginx 等待连接:此时处于
epoll_wait - 当三次握手完成,操作系统 Kernel 通知 Nginx 开始处理请求
- Worker 从 Kernel 中获取事件,操作系统将处理好的事件放在队列中:比如建立连接、TCP 报文

- 处理事件是一个循环,通过判断事件队列是否为空
- 在处理事件过程中,可能还会添加一个事件,例如超时时间(浏览器在超时时间内没有发送心跳,则将这个连接关闭)
epoll
网络事件收集器模型对比:

使用 Libevent 测试,当连接数增加,Select 和 Poll 所需要的时间增加都很多。
这是由于 Poll 和 Select 在有大并发连接的时候,Select 一次所能处理的句柄数有限,而 Poll 无法直接处理就绪的句柄,而需要便利所有的句柄,拿到活跃的连接。而 Epoll 则可以直接处理活跃的连接。

- 前提
- 高并发连接中,每次处理的活跃连接数量占比很小
- 实现
- 红黑树:任何的操作放到、取出红黑树中,操作是
log(n) - 链表:当网卡接受到报文,链表新增元素,从内核态读取到用户态,只读取一个节点,效率高
- 红黑树:任何的操作放到、取出红黑树中,操作是
- 使用
- 创建
- 操作:添加/修改/删除
- 获取句柄
- 关闭
请求切换

相比传统服务的处理模型,一个进程同时只能处理一种请求,一个请求可能会在不同的阶段交由不同的进程处理,导致频繁的进程间切换。是一个线程仅处理一个连接。不做连接切换(而是进程切换),依赖 OS 的进程调度实现并发。
Nginx 的 Worker 处理模型,是一线程同时处理多连接。当网络事件不满足时,则切换到另外一个事件处理。用户态代码完成连接切换;也尽量减少 OS 进程切换。
阻塞调用
操作系统在执行进程时,如果进程是阻塞调用,则当无法执行下去的时候,例如 IO 阻塞,CPU 会切换执行其他线程,将该线程置于睡眠状态。而非组赛则是当线程的 CPU 时间片没有使用完之前,CPU 是不会切换进程执行其他进程的。
而异步或者非异步,则是从编码角度和业务处理角度来说的。
以 accept 为例

已经完成三次握手,建立连接后,阻塞 accept 下,调用 accept 时,会直接读取套接字,而不会阻塞。但是,如果 accept 队列为空,则操作系统会等待新的三次握手连接到达内核中,然后再唤醒 accept 调用。虽然超时时间可以设置,但是阻塞过程中,也就是等待 IO 完成,会让操作系统进行进程间切换。

因此 Nginx 不会使用这种调用模型。
非阻塞调用

如果使用非阻塞 accept 调用套接字,当 ACCEPT 队列为空,不会等待,而是立刻返回一个 EAGAIN 错误码。此时会再次调用 accept,如果 ACCEPT 队列不为空,则将套接字从 ACCEPT 队列中移出并拷贝给进程。
那么,当接受到 EAGAIN 错误码的时候,是直接再次调用 accept 还是处理其他的请求,会根据代码逻辑来实现。
Nginx 会通过异步调用其他的业务逻辑。
非阻塞调用下的同步与异步
例如反响代理的实例:
1 | rc = ngx_http_read_request_body(r, ngx_http_upstream_init) ; |
Nginx 反向代理考虑到上游服务的处理能力通常不足,所以如果携带 body 请求,Nginx 会先接收完 body,再去向上游服务器发起连接。
ngx_http_read_request_body 方法执行完时调用 post_handler 异步方法
1 | ngx_int_t |
最终读取完 body 后调用 ngx_http_upstream_init 方法
1 | void |
整个过程比较复杂难懂。
相比而言,Openresty 提供同步调用代码
1 | local client = redis:new() |
Nginx 模块
Nginx 模块设计非常精良。在编译期可以将模块编译进去,而有些模块还需要在使用时打开才能使用该模块。
官方模块文档:https://nginx.org/en/docs/
nginx 模块的伪代码:

可以看到,模块之间高内聚,相同的功能在一个模块中。
模块内部高度抽象,都提供通用方法:
- 配置
- 启停回调方法
- 子模块抽象
httpeventmailstream
模块分类
Nginx 模块划分为不同的子模块

NGX_CORE_MODULE:Nginx 核心模块
一下几个,本身会定义出子类型模块
events: Nginx 事件通用处理方法,内聚成events方法- NGX_EVENT_MODULE:每一个模块通过下划线后缀表示具体
event信息,相同的核心模块排在最前面(类似于继承和封装的思想)
- NGX_EVENT_MODULE:每一个模块通过下划线后缀表示具体
http- NGX_HTTP_MODULE
streammail
NGX_CONF_MODULE:一个独立模块,负责解析 Nginx 的
conf文件
连接池

在配置文件中有参数 worker_connections,代表创建对应长度的数组。https://nginx.org/en/docs/ngx_core_module.html#worker_connections
1 | Syntax: worker_connections number; |
It should be kept in mind that this number includes all connections (e.g. connections with proxied servers, among others), not only connections with clients.
数组中每一位,都代表某一个事件,不同的事件维护不同的结构体。例如 connections,read_events,write_events。
并且由于读和写是不同的事件连接,因此,当分配较大的 worker_connections 时,占用内存也很多。
核心数据结构
1 | struct ngx_event_s { |
1 | struct ngx_connection_s { |

内存池

虽然 Nginx 使用 C语言写,自带内存池管理,不需要关注内存的申请和释放,但是也提供修改内存池大小,以供在特殊情况下处理请求和连接所需要的内存分配。
在 ngx_connection_s 中,ngx_pool_t 字段指向内存池,使用内存池的优势是减少内存碎片的大小。
当使用小块内存时,使用 next 指针连接在一起。
当分配大块内存时,还是会经过操作系统的 alloc 来进行分配。
内存池分为两种:
- 连接内存池:当处理
keep-alive请求时,一个连接会重复使用处理多个请求,当请求结束时,连接才关闭。 - 请求内存池:对于 HTTP 1.1 请求而言,一般会分配
4k大小的内存,用于存放uri和header。
对于第三方开发而言,实现内存池后,无需管理内存,而只需要知道是从连接内存池获取内存还是请求内存池获取内存。
通过设置内存池大小,可以提前预分配,减少后续分配的次数。
https://nginx.org/en/docs/http/ngx_http_core_module.html#connection_pool_size
1 | Syntax: connection_pool_size size; |
https://nginx.org/en/docs/http/ngx_http_core_module.html#request_pool_size
1 | Syntax: request_pool_size size; |
connection_pool_size 默认 512 字节(64位),这是由于连接需要保存的上下文信息较少。
request_pool_size 默认 4k,是由于对于连接而言,请求需要保存 uri 和 header 之类的。
Nginx 进程间的通讯方式
也就是所有 Worker 进程协同工作的关键。
Nginx 进程间通讯的方式有两种:
- 信号:Master 进程管理 Worker 进程
- 共享内存:开辟一块内存空间,所有的 Worker 共享使用,可以读取写入
为了使用好一块内存空间,则会引发两个问题:
- 锁:解决数据竞态(使用自旋锁替代信号量,避免进程陷入阻塞和进程切换,再切换回来导致上下文切换)
- Slab 内存管理器:降低进程使用内存的复杂性
共享内存:跨 Worker 进程通讯
共享内存使用者:
官方模块
ngx_http_lua_api
rbtree
![image-20240320174200080]()
单链表
![image-20240320174217530]()


OpenResty 共享内存代码示例

Slab 内存管理
虽然可以通过共享内存,将数据存储在红黑树中,但是,具体实现小块内存分配还需要一些方法。一般来说,为了高效管理内存,还需要将内存划分为不同大小的小块,以便更好的利用内存,
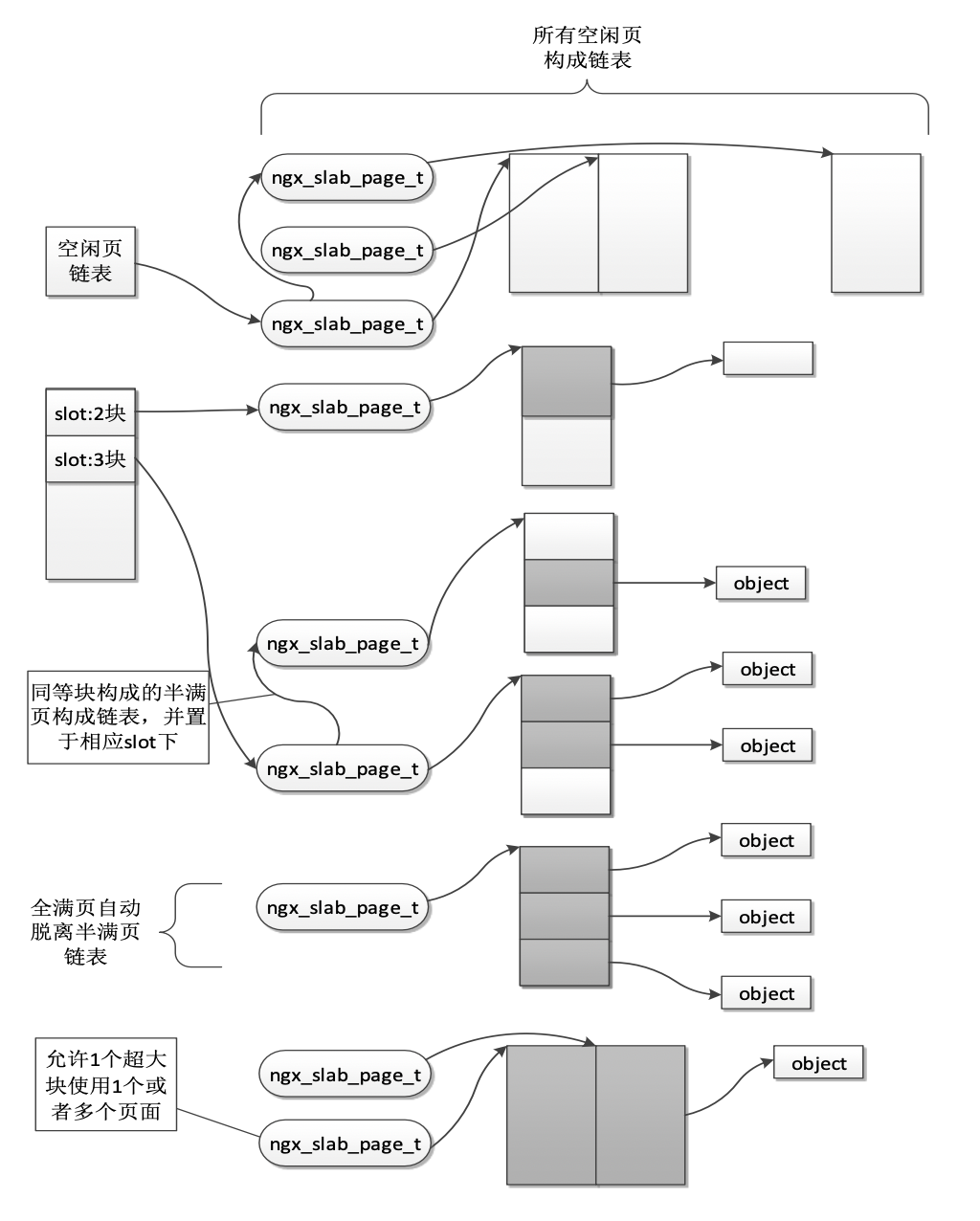
大片内存按照 slot 分配,slot 按照两倍增加,8byte、16byte等。
Bestfit分配方式- 最多两倍内存分配
Bestfit优势- 适合小对象
- 避免碎片
- 避免重复初始化
ngx_slab_stat 统计 Slab 使用状态
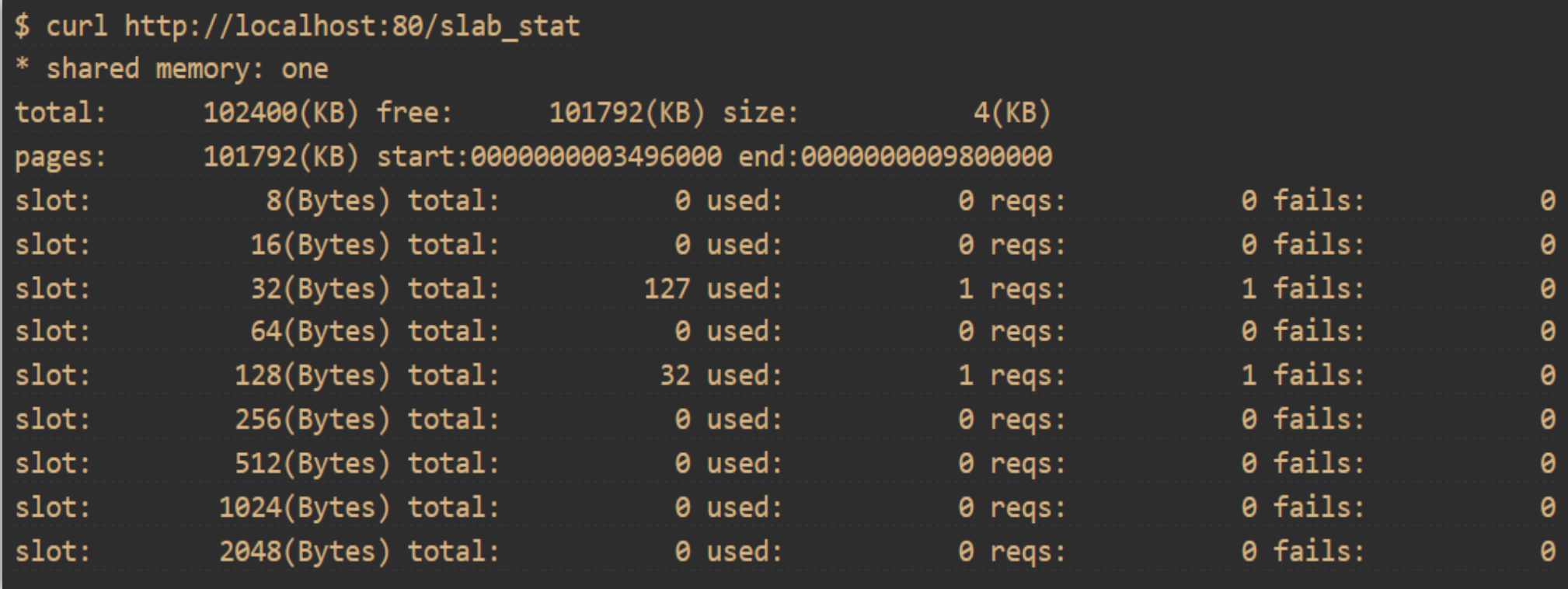
https://tengine.taobao.org/document_cn/ngx_slab_stat_cn.html
Nginx 容器
Nginx 容器是很多高级功能的基础。
- 数组:多块连续内存
- 链表
- 队列
- 哈希表
- 红黑树
- 基数树
Nginx 哈希表
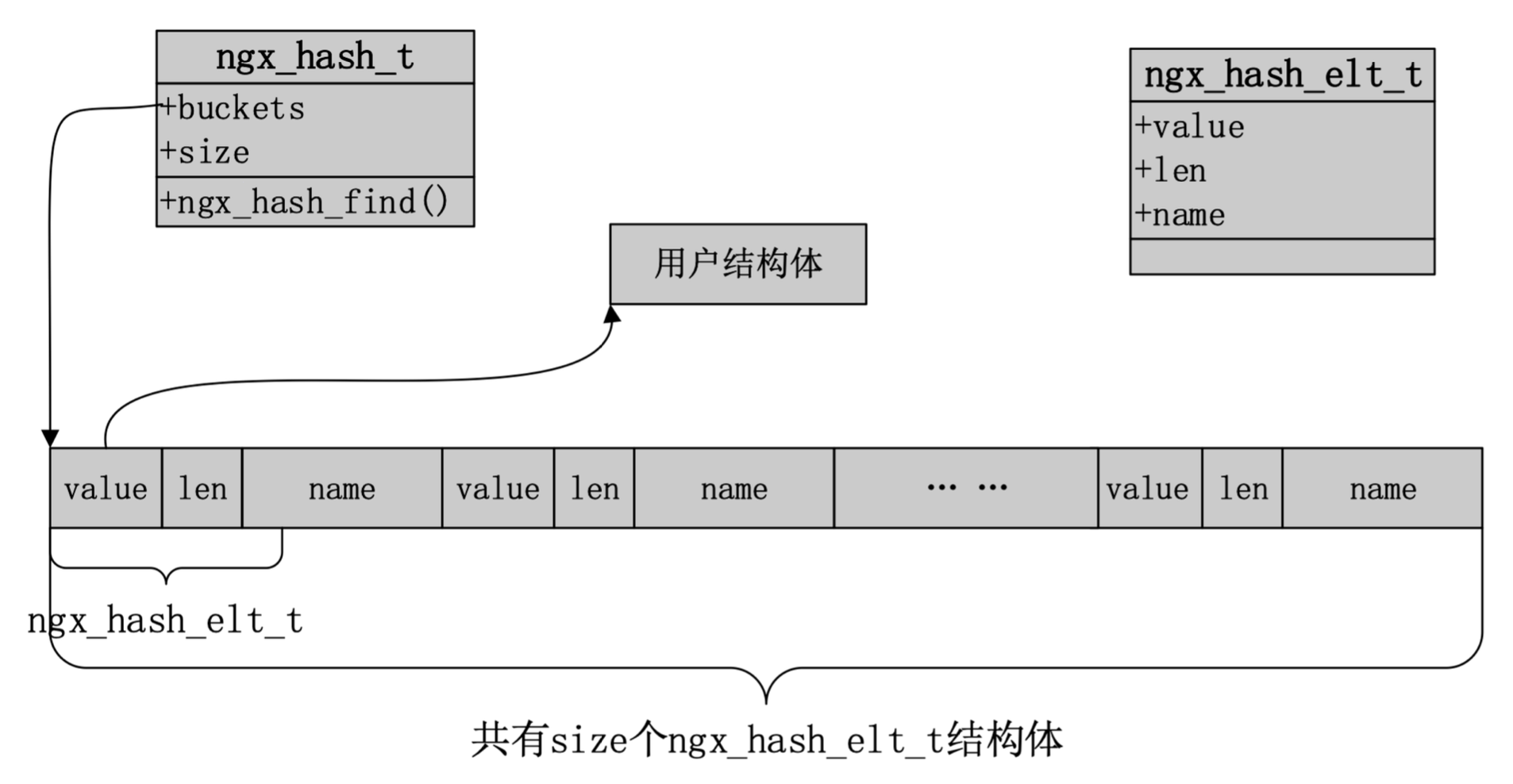
将用户结构体放在一块连续的内存中。
哈希表配置
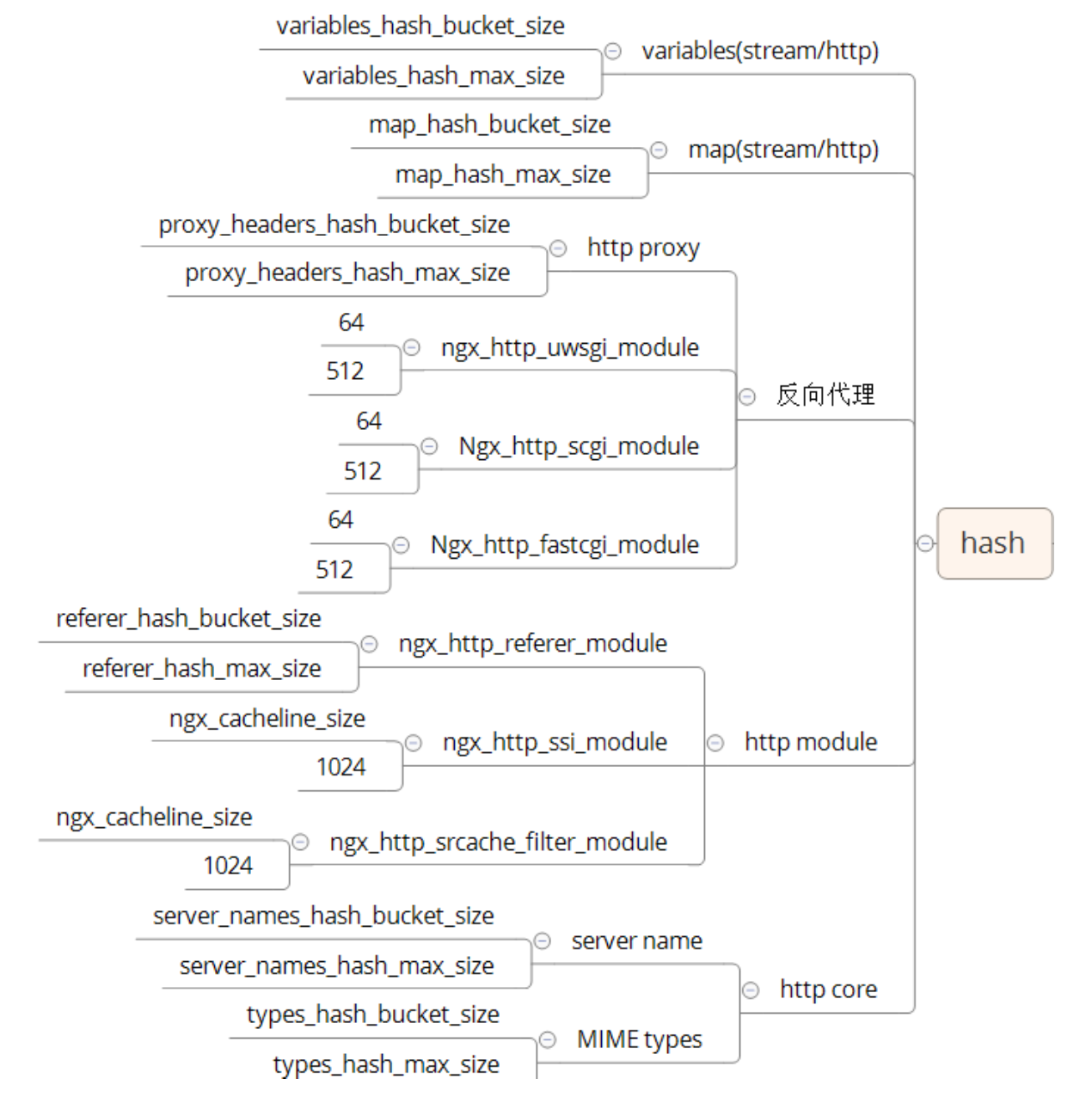
一般应用于静态不变的内容。不会删除和移动。
在开始使用的时候,就可以确定 Bucket size 和 Max size。
使用场景:例如 Nginx 中的一些变量,反向代理的数据等。
由于 CPU 往 L1、L2、L3 Cache 中读取数据按照机器字为单位,所以 Bucket size 会有 CPU 内存对齐。
红黑树
红黑树是一个查找二叉树。同时,高度差不会太大。
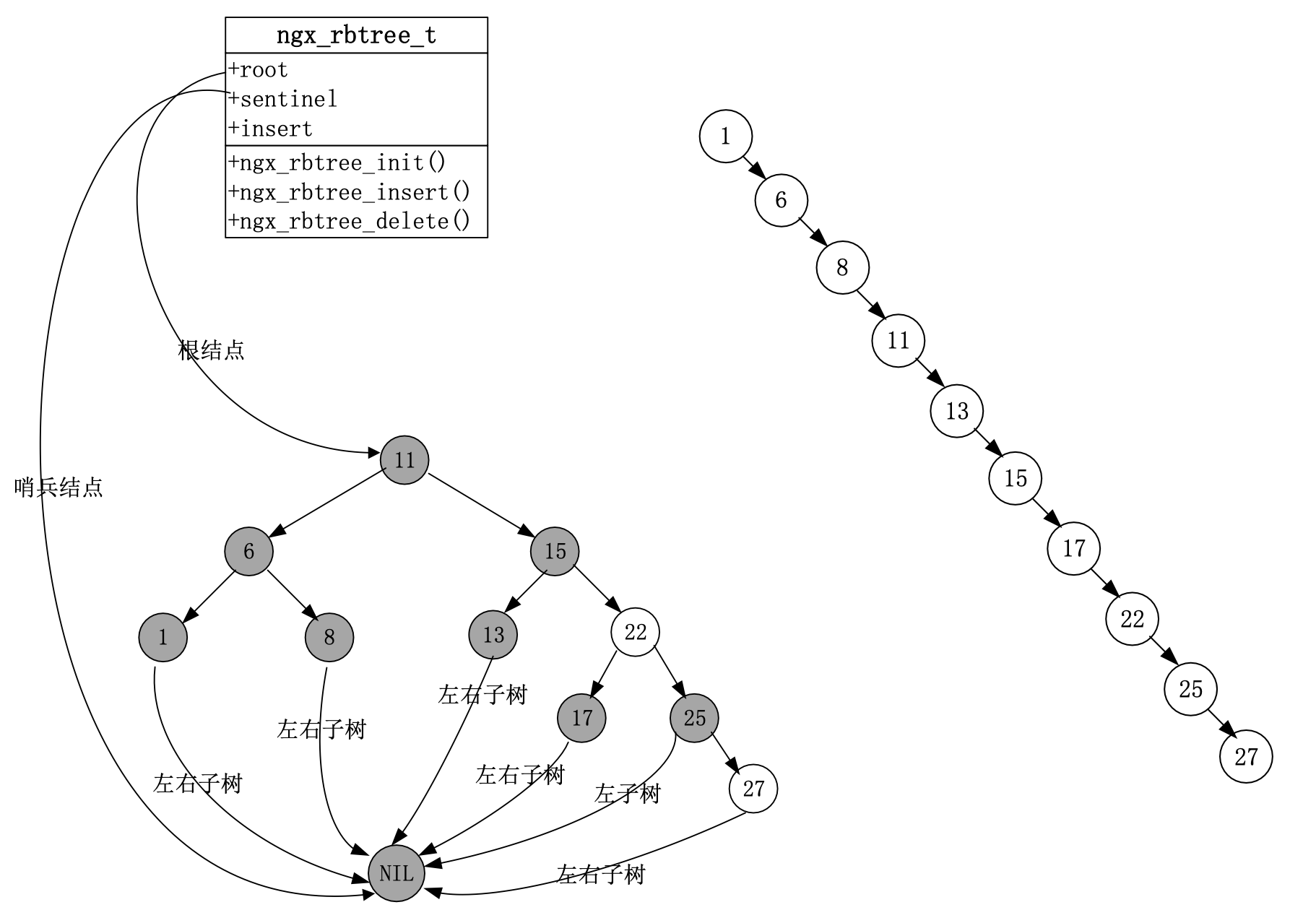
自平衡二叉查找树:
- 高度不会超过 2 倍数
log(n) - 增删改查算法复杂度
O(log(n)) - 便利复杂度
O(n)
红黑树的使用模块

红黑树一般会用于:
- 管理定时器计时器
- 管理共享内存的红黑树
动态模块-减少编译环节
在不使用动态模块时,编译 Nginx 的过程:
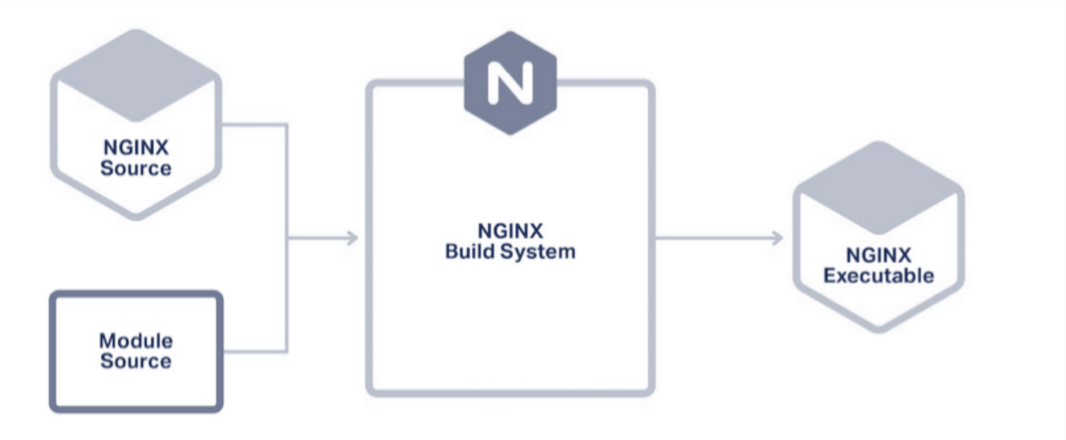
将 Nginx 官方模块源码和第三方模块源码放在一起编译。
使用动态模块:load_module modules/ngx_http_image_filter_module.so;
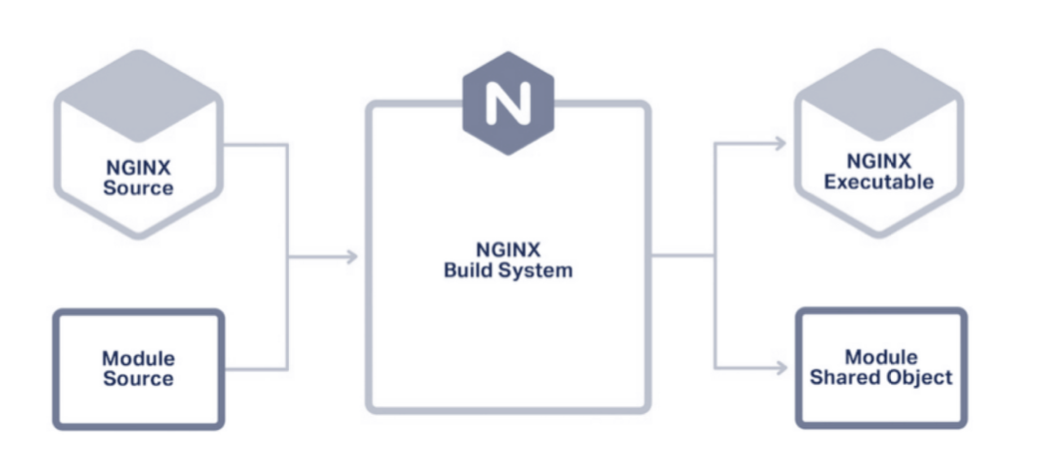
除了生成可执行二进制文件,还会生成一个共享的动态库。
静态库:将所有源代码编译到可执行文件中
动态库:在二进制可执行文件中保留库文件位置,在需要用到动态库功能时,需要 Nginx 可执行文件调用动态库文件
好处是:如果编译了大量第三方文件,可以仅仅编译第三方动态库文件进行替换,Nginx reload 就行,而不需要重新编译和启动 Nginx。
- Configure 加入动态模块(不是所有的模块可以以动态模块的方式加入);
- 编译进 binary(调用 make 命令)
- 启动时初始化模块数组
- 读取
load_module配置 - 打开动态库并加入模块数组
- 基于模块数组开始初始化
详解 HTTP 模块
配置文件中核心的配置模块。
配置块的嵌套
例如下面的配置块,存在嵌套关系。
1 | # 在大括号外面的是 main,一般放整个系统的配置,例如 日志、worker 数 |
指令的 Context
例如下面管理 log 的模块指令
1 | Syntax: log_format name [escape=default|json|none] string ...; |
Context 代表指令能出现的块。例如 log_format 只能出现在 http 块下,access_log 则可以出现在 http, server, location, if in location, limit_except 中。出现在其他地方就会报错。
指令的合并
指令出现在多个块中,可以合并。
值指令:存储配置项的值。可以合并,例如:
rootaccess_loggzip
动作类指令:指定行为。不可以合并,例如:
rewriteproxy_pass
生效阶段
server_rewrite阶段rewrite节点content阶段
存储值的指令继承规则:向上覆盖
子配置不存在时,直接使用父配置块。
子配置存在时,直接覆盖父配置块。
例如
1 | server { |
HTTP 模块合并配置的实现
当第三方模块没有详细文档说明模块配置是否可以合并时,可以通过下面的方法判断:
指令在哪个块下生效
指令允许出现在哪些块下
在
server块内生效,从http向server合并指令1
char *(*merge_srv_conf)(ngx_conf_t *cf, void *prev, void *conf);
配置缓存在内存
1
char *(*merge_loc_conf)(ngx_conf_t *cf, void *prev, void *conf);
常用指令
Listen 指令
一般用于指定监听端口或者地址
https://nginx.org/en/docs/http/ngx_http_core_module.html#listen
1 | Syntax: listen address[:port] [default_server] [ssl] [http2 | quic] [proxy_protocol] [setfib=number] [fastopen=number] [backlog=number] [rcvbuf=size] [sndbuf=size] [accept_filter=filter] [deferred] [bind] [ipv6only=on|off] [reuseport] [so_keepalive=on|off|[keepidle]:[keepintvl]:[keepcnt]]; |
1 | // 地址和端口 |
接收请求事件模块
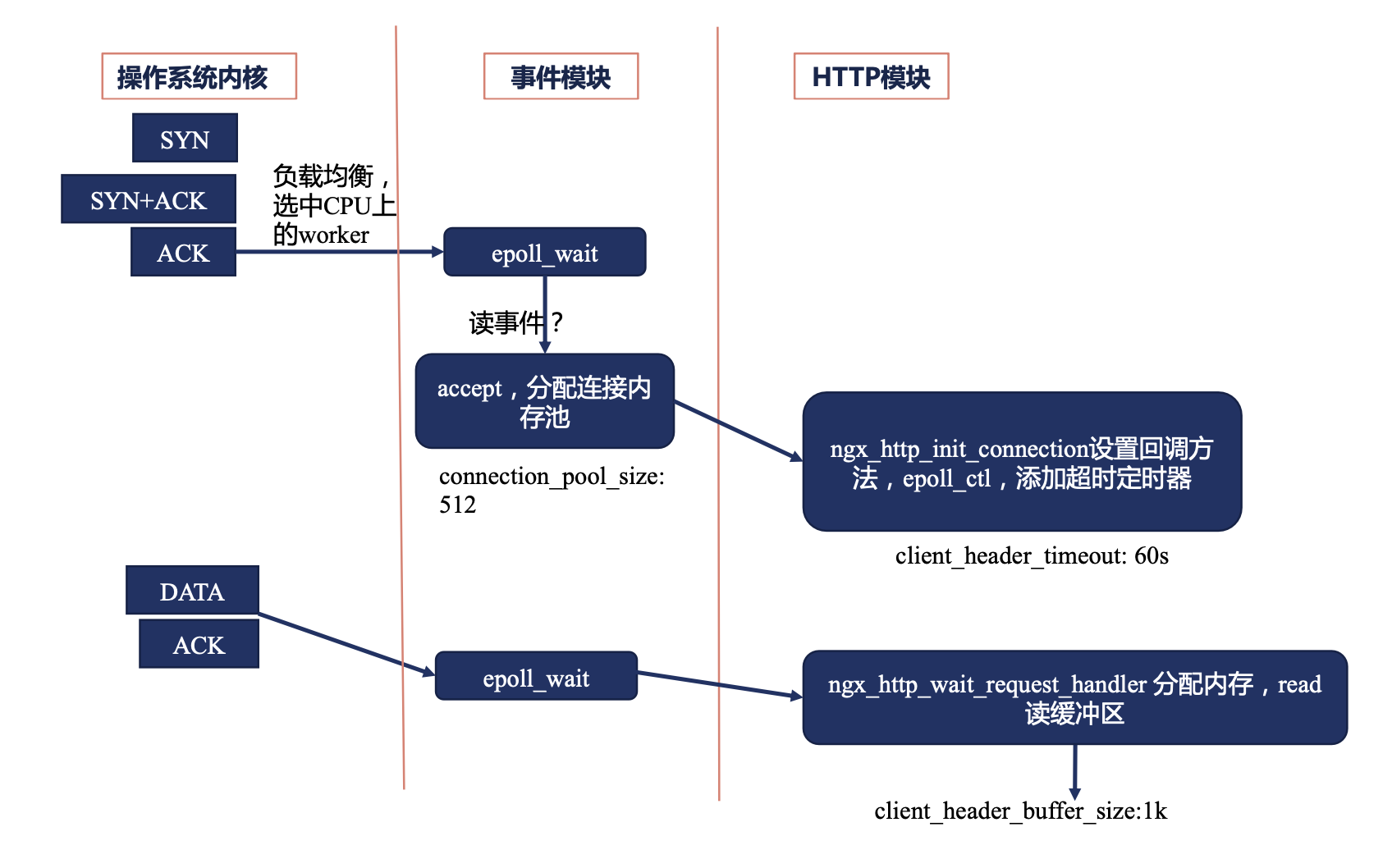
三次握手成功后,建立连接后,Worker 会根据自身负载均衡算法,选择一个 Worker 处理请求。
Worker 进程通过 Epoll_wait 方法获取连接好的句柄,通过这个读事件,调用 accept 方法,给这个连接分配 512 字节(初始大小)大小的连接内存池。
HTTP 模块从事件模块接手请求处理过程,此时会通过 ngx_http_init_connection 设置回调方法(ngx_http_wait_request_handler 方法,是为后续处理数据时执行),加入到 读事件中,并且添加超时定时器(client_header_timeout)。完后 Nginx 切换到其他的 fd 事件处理。
浏览器开发发送请求,通过监听 epoll_wait 事件,执行前面的回调函数,将内核中的 data 读取到用户态的内存中,从连接内存池中分配 1k(client_header_buffer_size)的内存大小。
当数据超过 1k,则需要在处理请求时解决。
接收请求 HTTP 模块
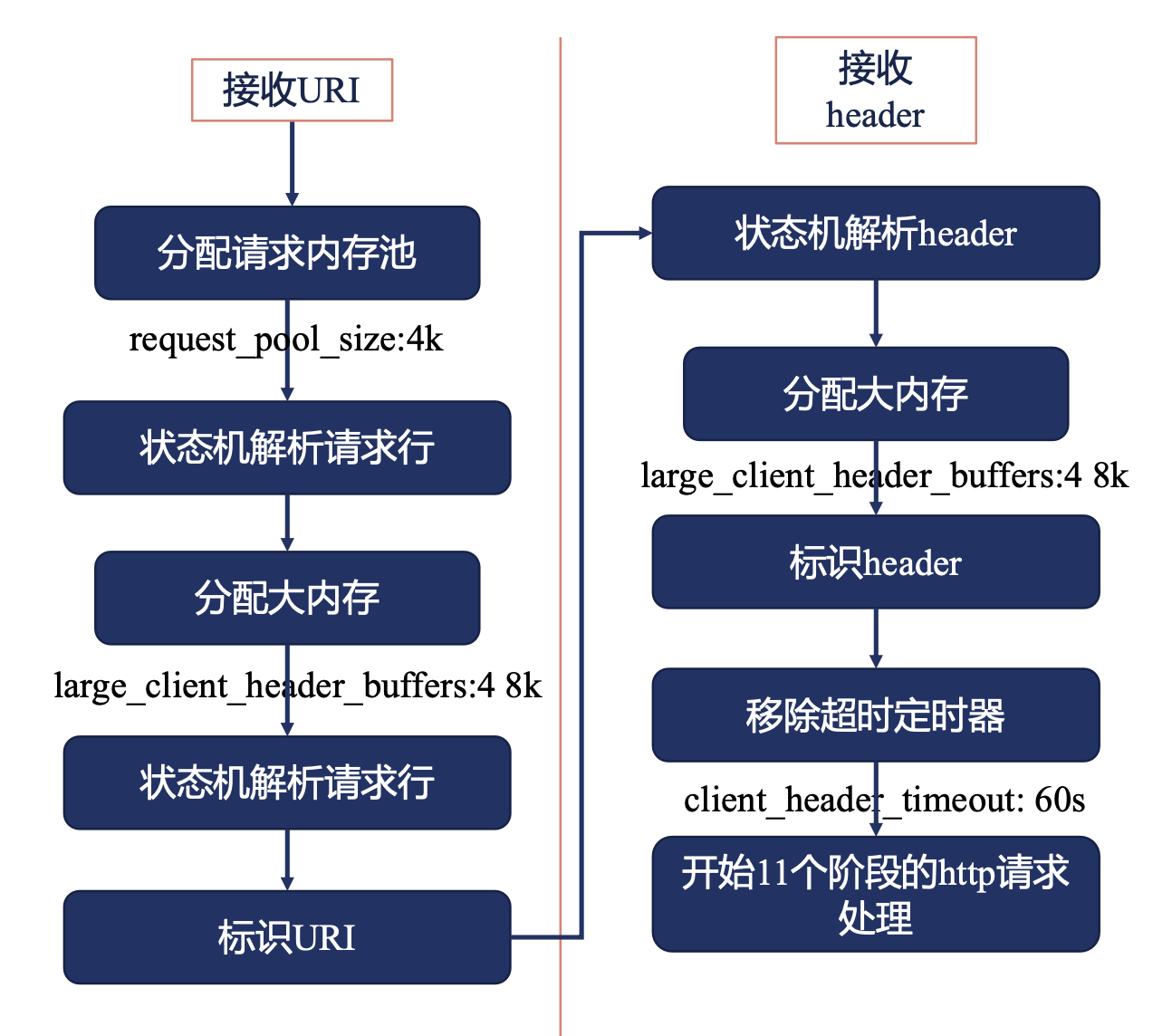
- 先分配请求内存池,默认 4k(
client_header_buffer_size的8倍 ),不能过多,否则性能会下降 - 在状态机中,解析请求行(
uri、协议等) - 如果超过 1k 的内存大小,则分配更大的内存。(一般用于解决
uri太长)large_client_header_buffers:4 8k的意思是先分配 8k,然后将前面 1k 的内容拷贝过来,再用剩下的 7k 接受请求。如果uri很长,还没有接受完,则分配第二个 8k,继续在状态机中解析请求行。最多分配32k - 解析完
uri之后,例如解析到\r\n,就标识uri,标识的目的是使用指针指向uri(性能高) - 开始接收
header,header可能很长,例如有cookie、host等字段 - 状态机中解析
header - 开始分配大内存,分配的内容会复用
large_client_header_buffers的配置,跟uri公用这个内容大小 - 标识
header,代表收到所有的header - 移除超时定时器,也就是连接建立后,还没有开始处理请求前设置的
client_header_timeout - 开始核心的过程,11个阶段的
http请求处理
正则表达式
在写域名或者 location 时,可以通过正则表达式提供更强大的用法。
元字符
常用的元字符:
.:匹配除换行符意外的任意字符\w:匹配字母数字或下划线或汉字\s:匹配任意的空白符\d:匹配数字\b:匹配单词的开始或结束^:匹配字符串的开始&:匹配字符串的结束
重复
*:重复零次或更多次+:重复一次或更多次?:重复零次或一次{n}:重复 n 次{n,}:重复 n 次或更多次{n,m}:重复 n 到 m 次
其他
\:转义符号,取消元字符的特殊含义():分组与取值
1 | 示例: |
避免测试需要重复重启 Nginx,可以使用 pcre 工具进行校验:https://www.pcre.org/original/doc/html/pcretest.html
server 指令块
server_name 指令
跟多个域名,第 1 个是主域名
1
server_name www.xiaoyeshiyu.com
当有多个域名时,可以通过
server_name_in_redirect on将返回的Location为主域名。泛域名:仅支持在最前或者最后
1
server_name *.xiaoyeshiyu.com www.xiaoyeshiyu.*
正则表达式:加
~前缀1
server_name www.xiaoyeshiyu.com ~^www\d+\.xiaoyeshiyu\.com$;
用正则表达式创建变量:用小括号
1
2
3
4
5server {
server_name ~^(www\.)?(.+)$;
# $2 指的是上面命令产生的两个变量中的第二个,例如如果是 www.xiaoyeshiyu.com,则 $2 是 xiaoyeshiyu.com
location / { root /sites/$2; }
}1
2
3
4
5server {
# 命名变量,后面可以使用 $domain 这个变量
server_name ~^(www\.)?(?<domain>.+)$;
location / { root /sites/$domain; }
}.xiaoyeshiyu.com可以匹配xiaoyeshiyu.com,*.xiaoyeshiyu.com_匹配所有""匹配没有传递 Host 头部
server 匹配顺序
- 精确匹配
*在前的泛域名*在后的泛域名- 按文件中的顺序匹配正则表达式域名
default server- 第一个
listen指定default
HTTP 请求处理时的 11 个阶段
Nginx 所有的模块只能在定义的 11 个阶段生效。

- 当一个请求进入到 Nginx 中,首先获取请求头,并且决定用哪个
server块指令处理 - 确认哪个配置块生效
- 判断是否限流
- 验证请求是否是盗链,或者通过
auth协议验证 - 生成用户响应信息
- 如果是转发请求到上游,还需要上游返回结果生成用户响应信息
- 如果这个过程中产生子请求或者重定向,那么接续前面几个阶段
- 返回请求时,会经过过滤模块,例如压缩、图片处理
- 返回给用户时,也会记录日志信息
具体流程以及对应的模块:

请求会从上到下,依次一个一个执行。
11 个阶段顺序处理

灰色由 Nginx 框架执行,蓝色由其他框架或者第三方框架执行。
POSTREAD 阶段
在这个阶段可以获取到真实的用户 IP 地址。

- TCP 连接四元组(
src ip, src port, dst ip, dst port) - HTTP 头部
X-Forwarded-For用于传递 IP,会往后面加 IP - HTTP 头部
X-Real-IP用于传递用户 IP,只能存放一个 IP - 网络中存在许多反响代理
拿到用户真实 IP 后,可以基于变量来使用,做一些限流的作用。
如 binary_remote_addr、remote_addr 这样的变量,其值就为真实的 IP(X-Real-IP),这样做连接限制(limit_conn 模块)。
realip 模块
用于将客户端地址和可选端口更改为指定标头字段中发送的地址。
默认情况下,realip 模块不会编译进 Nginx,通过 --with-http_realip_module 启用功能。
https://nginx.org/en/docs/http/ngx_http_realip_module.html
realip 模块生效的前提是:直接连接 nginx 的ip是在set_real_ip_from中指定的。
1 | # 定义已知发送正确替换地址的受信任地址。如果指定了特殊值 unix:,则所有 UNIX 域套接字将被信任。也可以使用主机名来指定受信任地址(1.13.1)。 |
REWRITE 阶段
会在 SERVER_REWRITE 阶段(对应 server 配置块下)、REWRITE (对应 location 配置块下)、POST_REWRITE阶段生效
https://nginx.org/en/docs/http/ngx_http_rewrite_module.html#rewrite
1 | Syntax: rewrite regex replacement [flag]; |
return 指令
https://nginx.org/en/docs/http/ngx_http_rewrite_module.html#return
1 | Syntax: return code [text]; |
- 返回状态码
- Nginx 自定义
- 例如 444: 关闭连接
- HTTP 1.0 标准
- 301: http 1.0 永久重定向,缓存在浏览器中
- 302: 临时重定向,禁止被缓存
- HTTP 1.1 标准
- 303: 临时重定向,允许改变方法,禁止被缓存
- 307: 临时重定向,不允许改变方法,禁止被缓存
- 308: 永久重定向,不允许改变方法
- Nginx 自定义
error_page 指令
https://nginx.org/en/docs/http/ngx_http_core_module.html#error_page
1 | Syntax: error_page code ... [=[response]] uri; |
与 return 有关联。用法是收到(这里注意是收到,而不是产生)一个返回码时,可以重定向为另外一个 URL 或者指定返回不一样的内容。
例如:
1 | error_page 404 /404.html; |
当出现 return 的时候,error_page 的 404 是否能执行
在 server 下和在 location 下出现 return,是否合并和如何生效。
例如
1 | server { |
- 如果有
return指令,则直接返回对应信息,而不会返回error_page;没有return指令,而是直接返回 404 状态码,则会被rewrite到error_page - 在
server模块下的return指令,是在SERVER_REWRITE阶段执行,先于location模块下的return指令在REWRITE阶段执行
rewrite 指令
https://nginx.org/en/docs/http/ngx_http_rewrite_module.html#rewrite
1 | Syntax: rewrite regex replacement [flag]; |
- 将
regex指定的url替换成replacement这个新的url- 可以使用正则表达式及变量提取
- 当
replacement以http://或者https://或者$schema开头,则直接返回302重定向 - 替换后的 url 根据 flag 指定的方式进行处理
--last:意思是持续,用replacement这个URI进行新的location匹配--break:表示停止,停止当前脚本指令的执行,等价于独立的break指令,break后面的指定都不会执行--redirect:返回 302 重定向--permanent:返回 301 重定向
rewrite_log 指令
https://nginx.org/en/docs/http/ngx_http_rewrite_module.html#rewrite_log
1 | Syntax: rewrite_log on | off; |
将 rewrite 的信息记录到 error_log 中
if 指令
可以根据请求中的变量的值,判断是否满足某个条件之后是否执行下面的配置指令。
https://nginx.org/en/docs/http/ngx_http_rewrite_module.html#if
1 | Syntax: if (condition) { ... } |
条件 condition 为真,则执行大括号内的指令;遵循值指令的继承规则。
表达式:
- 检查变量为空或者值是否为 0,直接使用
- 将变量与字符串做完全匹配,使用
=或者!= - 将变量与正则表达式做匹配
- 大小写敏感,
~或者!~ - 大小写不敏感,
~*或者!~*
- 大小写敏感,
- 检查文件是否存在,使用
-f或者!-f - 检查目录是否存在,使用
-d或者!-d - 检查文件、目录、软链接是否存在,使用
-e或者!-e - 检查是否为可执行文件,使用
-x或者!-x
1 | if ($http_user_agent ~ MSIE) { # 判断是否是 ie 浏览器 |
FIND_CONFIG 阶段
FIND_CONFIG 阶段主要是匹配 location,决定用哪个代码块处理。
https://nginx.org/en/docs/http/ngx_http_core_module.html#location
1 | Syntax: location [ = | ~ | ~* | ^~ ] uri { ... } |
https://nginx.org/en/docs/http/ngx_http_core_module.html#merge_slashes
1 | Syntax: merge_slashes on | off; |
当两个 / 在一起时,xxx//xxx.html,打开 merge_slashes 则可以合并成一个 /
Location 匹配规则
仅匹配 URI,忽略参数
- 前缀字符串
- 常规,例如
xxx/xxx.html =:精确匹配^~:匹配上后则不再进行正则表达式匹配
- 常规,例如
- 正则表达式
~:大小写敏感的正则匹配~*:忽略大小写的正则匹配
- 合并连续的
/符号merge_slashes on
- 用于内部跳转的命名
location@
匹配顺序:

Nginx 中会使用 二叉树 放置全部的 location。
匹配时,有三种情况:
- 匹配
=字符串,则停止匹配 - 再进行其他的前缀匹配,匹配上的话,对应最长的匹配
- 如果是
^~字符串,匹配上之后,则不会进行正则表达式匹配,如果多个匹配上,则用最长匹配上的url的location,此时如果最长location没有^~,因此后续还会进行正则表达式匹配 - 如果上面两个都没有,则先记住最长匹配的前缀字符串
location,并且再按照正则表达式匹配,如果正则表达式没有匹配上,则用这一个 - 使用正则表达式匹配是按照顺序的,如果匹配上,就直接使用,而不再继续往下匹配
PREACCESS 阶段
用于限制每个客户端的并发连接数
ngx_http_limit_conn_module 模块,默认编译进 Nginx
https://nginx.org/en/docs/http/ngx_http_limit_conn_module.html
生效范围:
- 全部
worker进程(基于共享内存) - 进入
preaccess阶段前不生效 - 限制的有效性取决于
key的设计:依赖postread阶段的realip模块取到真实ip(例如前面有 SLB 做负载均衡,此时连接数限制会失效,因此可以基于realip来做限制连接数)
limit_conn 指令
https://nginx.org/en/docs/http/ngx_http_limit_conn_module.html#limit_conn_zone
1 | Syntax: limit_conn_zone key zone=name:size; |
定义共享内存(包括大小)以及 key 关键字,一般 key 取值于用户的 IP 地址(remote_addr)
https://nginx.org/en/docs/http/ngx_http_limit_conn_module.html#limit_conn
1 | Syntax: limit_conn zone number; |
限制并发连接数
https://nginx.org/en/docs/http/ngx_http_limit_conn_module.html#limit_conn_log_level
1 | Syntax: limit_conn_log_level info | notice | warn | error; |
限制发生时的日志级别
https://nginx.org/en/docs/http/ngx_http_limit_conn_module.html#limit_conn_status
1 | Syntax: limit_conn_status code; |
限制发生时向客户端返回的错误码
limit_req 指令
默认编译进 Nginx,用于限制请求数和大小。
生效算法:leaky bucket 算法(漏桶):有一个一定容量的桶,请求来了之后,以固定的速度处理,如果桶满了,则直接返回报错
生效范围:
- 全部
worker进程(基于共享内存) - 进入
preaccess阶段前不生效 - 限制的有效性取决于
key的设计,依赖postread阶段的realip模块取到真实ip(例如前面有 SLB 做负载均衡,此时连接数限制会失效,因此可以基于realip来做限制连接数)
https://nginx.org/en/docs/http/ngx_http_limit_req_module.html#limit_req_zone
1 | Syntax: limit_req_zone key zone=name:size rate=rate [sync]; |
定义共享内存(包括大小),以及 key 关键字和限制速率。
rate 单位为 r/s 或者 r/m,代表每秒/分钟的请求数
https://nginx.org/en/docs/http/ngx_http_limit_req_module.html#limit_req
1 | Syntax: limit_req zone=name [burst=number] [nodelay | delay=number]; |
限制并发连接数。
burst 默认为0,代表盆中容纳多少个请求
nodelay ,对 burst 中的请求不再采用延时处理的做法,而是立刻处理(立刻返回错误),如果设置了,则会等待延迟处理,如果超过了设置的 number,则会立刻返回错误。
https://nginx.org/en/docs/http/ngx_http_limit_req_module.html#limit_req_log_level
1 | Syntax: limit_req_log_level info | notice | warn | error; |
限制发生时的日志级别
https://nginx.org/en/docs/http/ngx_http_limit_req_module.html#limit_req_status
1 | Syntax: limit_req_status code; |
当 limit_req 与 limit_conn 配置同时生效,limit_req 会优先生效,这是基于 HTTP 处理流程的。
ACCESS 阶段
控制请求是否可以继续向下访问,按照顺序,有 access、 auth_basic、 auth_request 三个模块
access 模块
默认编译到 Nginx,生效范围:进入 access 阶段前不生效
https://nginx.org/en/docs/http/ngx_http_access_module.html
allow 指令
允许哪些地址访问
https://nginx.org/en/docs/http/ngx_http_access_module.html#allow
1 | Syntax: allow address | CIDR | unix: | all; |
deny 指令
https://nginx.org/en/docs/http/ngx_http_access_module.html#deny
不允许哪些地址访问
1 | Syntax: deny address | CIDR | unix: | all; |
例如
1 | location / { |
auth_basic 模块
对用户名、密码做限制。默认编译进 Nginx
使用 RFC2671 的 HTTP Basic Authentication 协议进行用户名密码的认证。
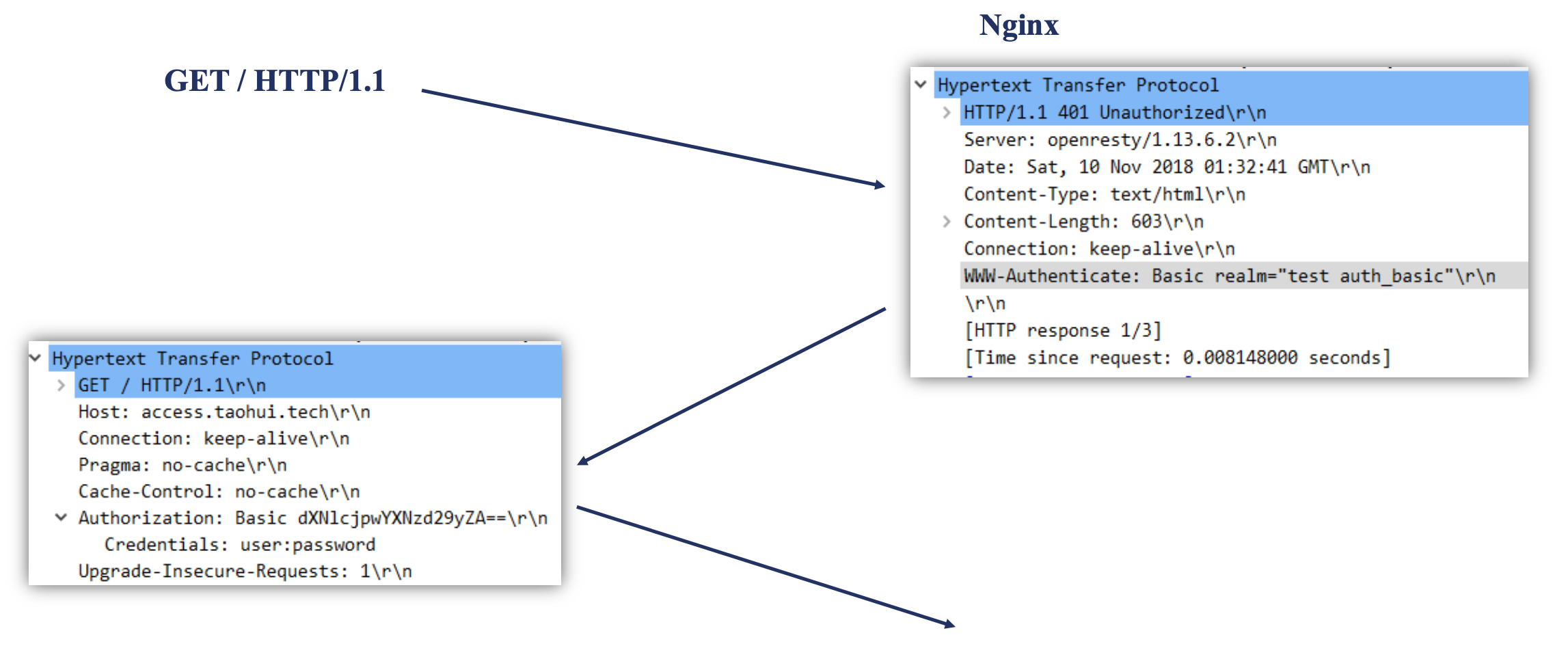
浏览器访问浏览器时,浏览器返回一个 401 的响应,这个响应不会在客户端显式,浏览器会弹出对话框,输入用户名密码。浏览器通过明文将用户名密码发给服务端,因此可以使用 HTTPS。
https://nginx.org/en/docs/http/ngx_http_auth_basic_module.html
1 | Syntax: auth_basic string | off; |
生成密码文件:
文件格式
1
2
3
4# comment
name1:password1
name2:password2:comment
name3:password3生成工具:
htpasswd安装依赖包:
httpd-tools,命令行:htpasswd –c file –b user pass
auth_request 模块
默认未编译进 Nginx。
功能:向上游的服务转发请求,若上游服务返回的响应码时 2xx,则继续执行,若上游服务返回的是 401 或者 403,则将响应返回给客户端。可以理解为向第三方验证,但是验证完成后由自己执行后面的操作。
原理:收到请求后,生成子请求(子请求与请求一致),通过反向代理技术把请求传递给上游服务。
https://nginx.org/en/docs/http/ngx_http_auth_request_module.html
1 | Syntax: auth_request uri | off; |
satisfy 指令
限制所有 access 阶段模块的 satisfy 指令
https://nginx.org/en/docs/http/ngx_http_core_module.html#satisfy
1 | Syntax: satisfy all | any; |
access 阶段的模块:
access模块auth_basic模块auth_request模块- 其他模块
satisfy all 代表所有的 access 模块都满足,请求才可以放行。
satisfy any 代表只要有任意一个 access 模块放行了,那么这个请求就可以放行。
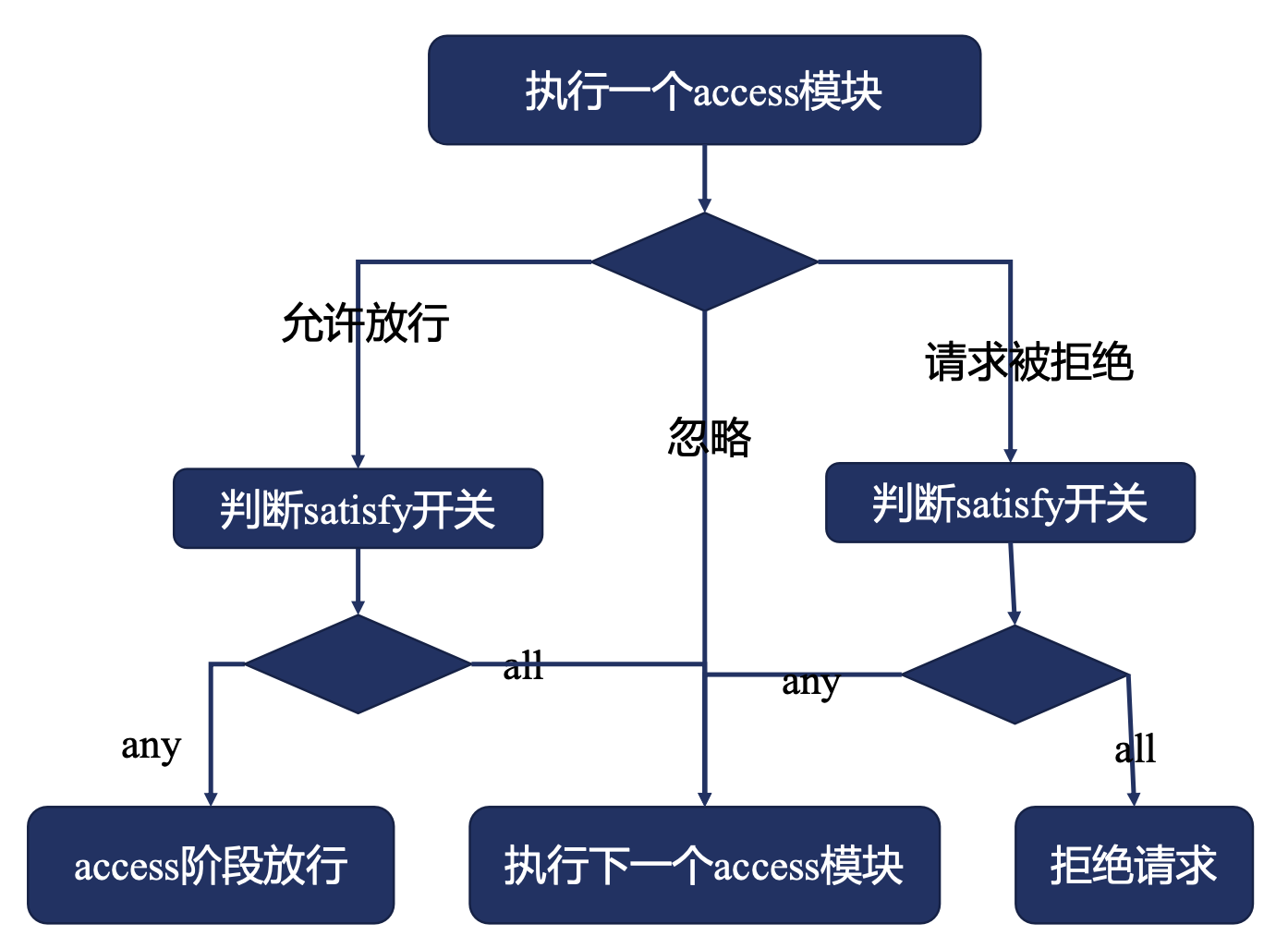
- 如果有
return指令,access阶段不会生效。这是由于return的REWRITE阶段在前面 - 多个
access模块的顺序的影响,会按照执行顺序,如果放行则直接放行,如果拒绝则直接拒绝
1 | location /{ |
例如上面,输入密码,可以访问文件;这是由于 satisfy any 作用于 access 模块之前,输入密码之后即可访问
1 | location /{ |
即使是这样,输入密码也可以
1 | location /{ |
如果改为这样,则不需要输入密码,即可访问。这是由于 access 模块在 auth_basic 之前。
PRECONTENT 阶段
try_files 指令
https://nginx.org/en/docs/http/ngx_http_core_module.html#try_files
默认编译到 Nginx 中,也无法取消。
1 | Syntax: try_files file ... uri; |
依次殊途访问多个 url 对应的文件(由 root 或者 alias 指令指定),当文件存在时直接返回文件内容,如果所有文件都不存在,则按最后一个 URL 结果或者 code 返回。
一般可以用于解决反向代理服务器的缓存,当存在文件则返回,如果不存在文件,则转发到上游服务器中。
mirror 指令
https://nginx.org/en/docs/http/ngx_http_mirror_module.html#mirror
一般用于创造一份镜像流量,例如生产环境中,可以将请求 copy 一份发送到测试环境或者生产环境中做处理。
默认编译进 Nginx,处理请求时,生成子请求访问其他服务,对子请求的返回值不做处理。
1 | Syntax: mirror uri | off; |
CONTENT 阶段
static 模块
有两个指令,功能都是将 url 映射为文件路径,以返回静态文件内容。
root 指令
https://nginx.org/en/docs/http/ngx_http_core_module.html#root
1 | Syntax: root path; |
差别是:root 就将完整 url 映射进文件路径中;由默认配置,并且上下文很多
alias 指令
https://nginx.org/en/docs/http/ngx_http_core_module.html#alias
1 | Syntax: alias path; |
差别:alias 只会将 location 后的 URL 映射到文件路径;没有默认配置
三个变量
除了 root 和 alias 之外,static 模块还提供三个变量。
request_filename:待访问文件的完整路径(绝对路径)document_root:由 URI 和root/alias规则生成的文件夹路径(目录的绝对路径)realpath_root:将document_root中的软链接等换成真实路径(软连接对应目录的绝对目录)
content-type
当读取磁盘上的文件时,会根据文件的扩展名做一次映射,放在 hash 表中
1 | # 将扩展名和 content-type 做映射,放在 hash 表中 |
log_not_found
当找不到文件时,打印日志。
1 | Syntax: log_not_found on | off; |
例如
1 | [error] 10156#0: *10723 open() "/html/first/2.txt/root/2.txt" failed (2: No such file or directory) |
重定向
static 模块实现了 root/alias 功能时,发现访问目标是目录,但 URL 末尾未加 / 时,会返回 301 重定向。
此时可以根据不同的配置实现不同的效果:
打开之后,重定向的 Location 内的内容就是主域名中的域名
https://nginx.org/en/docs/http/ngx_http_core_module.html#server_name_in_redirect
1 | Syntax: server_name_in_redirect on | off; |
打开之后,在 Location 中显示出端口
https://nginx.org/en/docs/http/ngx_http_core_module.html#port_in_redirect
1 | Syntax: port_in_redirect on | off; |
绝对路径打开,会返回一个域名,返回的域名默认是请求的域名,或者当请求的 header 中携带 Host,则是对应 Host 中的值,也可以由 server_name_in_redirect 控制,端口是否显式,由 port_in_redirect 控制。如果不打开,则返回的 Location 中不会携带 http://xxx 等,而是直接返回一个绝对路径
https://nginx.org/en/docs/http/ngx_http_core_module.html#absolute_redirect
1 | Syntax: absolute_redirect on | off; |
index 模块
指定/访问时返回 index 文件内容(当访问的 url 以 / 结尾时,会去查找目录下是否有 index.html 文件)
https://nginx.org/en/docs/http/ngx_http_index_module.html#index
1 | Syntax: index file ...; |
randomindex 模块
随机选择 index 指令指定的一系列 index 文件中的一个,作为 / 路径的返回文件内容。默认编译进 Nginx。
https://nginx.org/en/docs/http/ngx_http_random_index_module.html#random_index
1 | Syntax: random_index on | off; |
autoindex 模块
https://nginx.org/en/docs/http/ngx_http_autoindex_module.html#autoindex
1 | # 开启或者关闭 |
index 的执行顺序是先于 autoindex。
当 URL 以 / 结尾时,尝试以 html/xml/json/jsonp 等格式返回 root/alias 中指向目录的目录结构。默认编译进 Nginx
concat 模块
https://github.com/alibaba/nginx-http-concat
当页面需要访问多个小文件时,把它们的内容合并到一次 http 响应中返回,提升性能
使用:
在 uri 后面加上 ??,后通过多个 , 号分隔文件。如果还有参数,则在最后通过 ? 添加参数
1 | http://example.com/??style1.css,style2.css,foo/style3.css |
LOG 阶段
记录请求访问日志的 log 模块
将 HTTP 请求相关信息记录到日志。ngx_http_log_module 无法禁用
access_log 模块
https://nginx.org/en/docs/http/ngx_http_log_module.html#access_log
1 | # 定义格式 |
1 | # 定义日志文件 |
path路径可以包含变量(比如host根据不同主机写入不同文件):不打开cache时每记录一条日志都需要打开、关闭日志文件(这种情况性能很低)if通过通过变量值控制请求日志是否记录format不填,默认使用combined- 日志缓存
- 批量将内存中的日志写入磁盘(也就是使用
cache批量写入,节省性能) - 写入磁盘的条件
- 所有待写入磁盘的日志大小超出缓存文件
- 达到
flush指定的过期时间(过长的话,中途宕机可能导致日志丢失) worker进程执行reopen命令,或者正在关闭
- 批量将内存中的日志写入磁盘(也就是使用
- 日志压缩
- 批量压缩内存中的日志,再写入磁盘
buffer大小默认为64KB- 压缩级别默认为1(1最快压缩率最低,9最慢压缩率最高)
对日志文件名包含变量时的优化,使用缓存,避免每次写入日志都要先关闭当前文件,再打开要写入的文件。
1 | Syntax: open_log_file_cache max=N [inactive=time] [min_uses=N] [valid=time]; |
max:缓存内的最大文件句柄数,超出后用 LRU 算法淘汰inactive:文件访问完后在这段时间内不会被关闭。默认 10 秒min_uses:在inactive时间内使用次数超过min_uses才会继续存在内存中。默认1valid:超出valid时间后,将对缓存的日志文件检查是否存在。默认 60 秒off:关闭缓存功能
过滤模块的位置
在将结果返回给客户端之前,对返回的结果还要进行过滤操作。这个操作的位置在 LOG 之前,CONTENT 阶段之后。
1 | limit_req zone=req_one burst=120; |
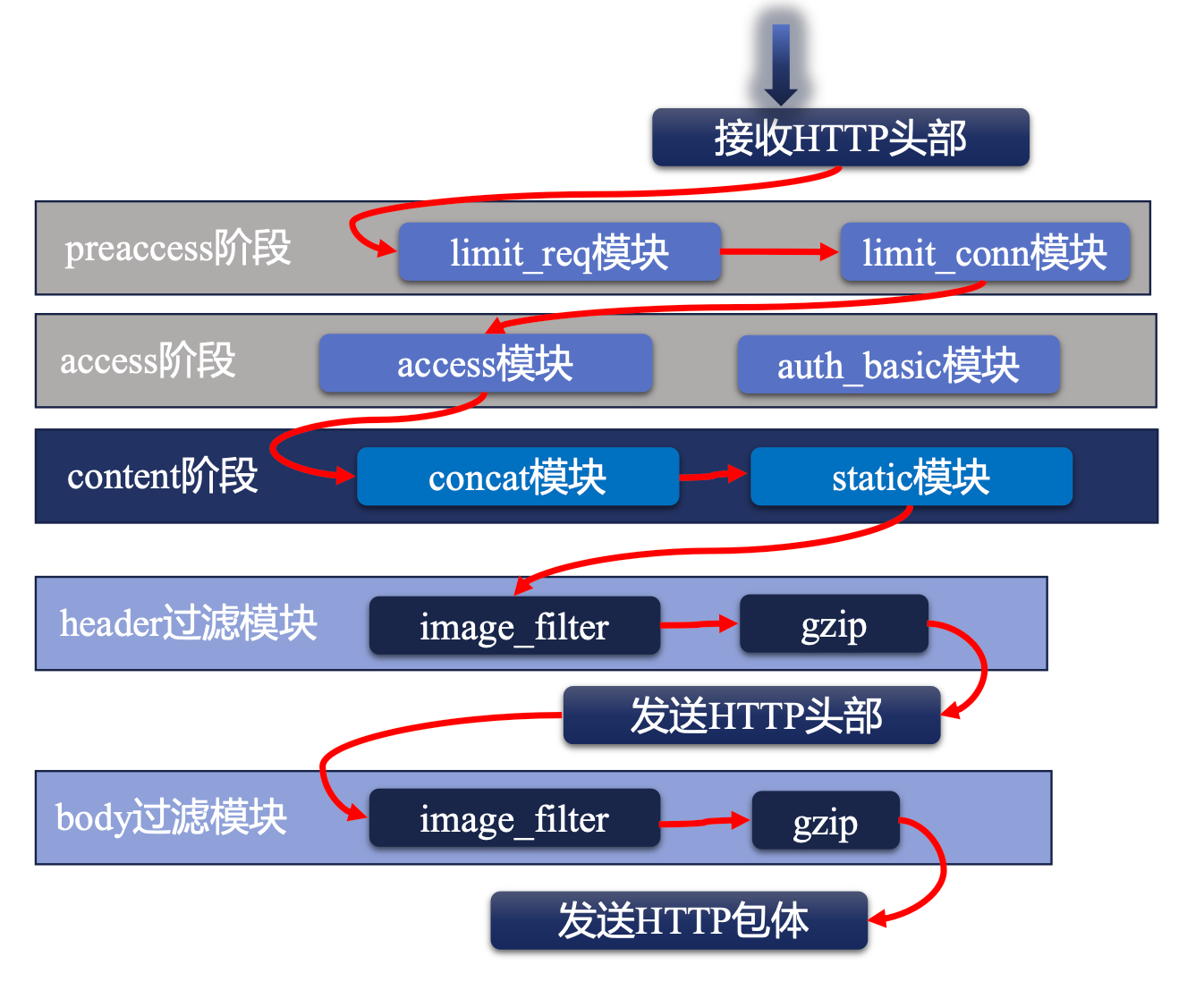
在返回请求时,会先发送 header,发送完后,才发送 body,因此,不同的过滤模块的位置不同。
加工响应内容
过滤模块中,不同模块的处理顺序:
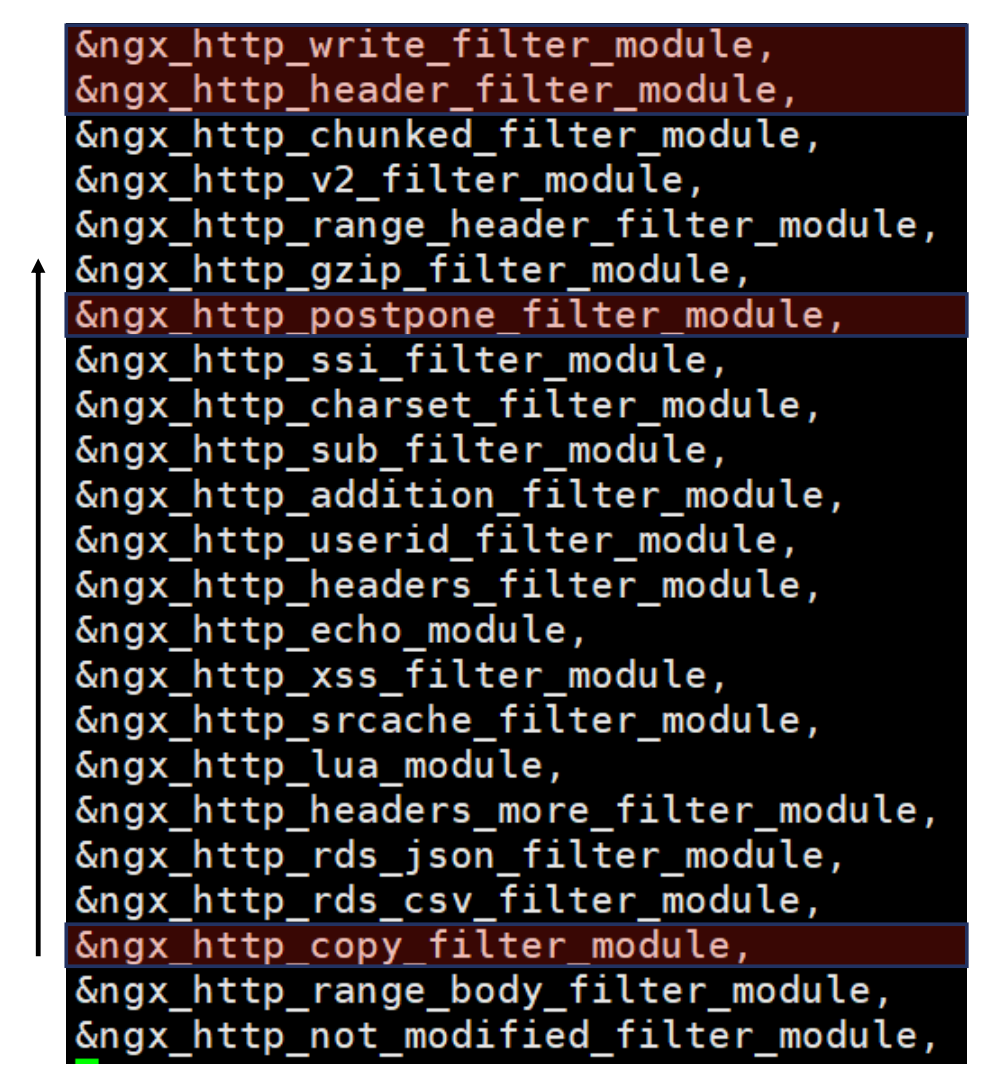
- HTTP 过滤模块:
copy_filter:复制包体内容(零拷贝技术,不经过用户态,直接拷贝给用户。但是如果使用gzip,则需要拷贝到内存中处理) - HTTP 过滤模块:
postpone_filter:处理子请求(例如需要关注一些子请求的结果) - HTTP 过滤模块:
header_filter:构造响应头部(例如增加 Nginx 版本信息到header中)write_filter:发送响应(调用系统 WRITE,发送数据到客户端)
sub 模块
将响应中指定的字符串,替换成新的字符串。默认未编译进 Nginx
https://nginx.org/en/docs/http/ngx_http_sub_module.html
1 | # 匹配后换成新的字符串,忽略大小写 |
addition 模块
在响应的 body 内容前或者响应的 body 后增加内容,而增加内容的方式时通过新 url 响应完成。默认为编译进 Nginx
https://nginx.org/en/docs/http/ngx_http_addition_module.html
1 | # 在响应之前添加内容,添加的内容是 uri 这个子请求返回的内容 |
Nginx 变量的运行原理
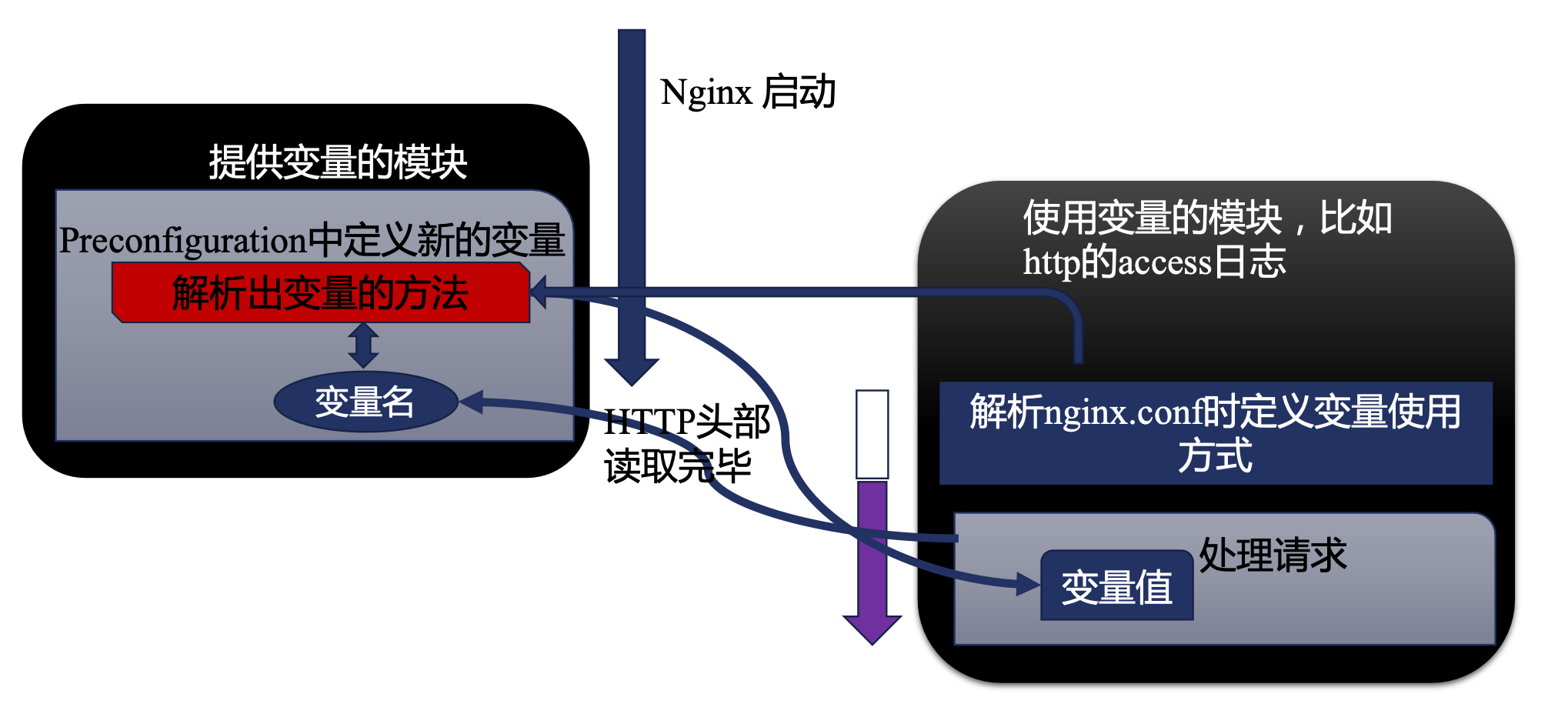
Nginx 中分为提供变量的模块和使用变量的模块,Preconfiguration 是 HTTP 模块读取配置模块之前添加的新变量。定义的变量是变量名和解析出变量的方法,目的是定义规则,当需要使用这个变量时,输入对应的变量名得到对应的值。
使用变量时,则解析 nginx.conf 时定义变量的使用方法,在处理请求时,通过变量名获取这个请求对应的变量值。
变量的特性:
惰性求值
只有当前请求处理完之后,才能通过变量名获取对应变量值
变量值可以时刻变化,其值为使用的那一时刻的值
存放变量的哈希表:
https://nginx.org/en/docs/http/ngx_http_core_module.html#variables_hash_bucket_size
通过参数配置变量大小和容量
1 | Syntax: variables_hash_bucket_size size; |
HTTP 框架提供的变量
一些系统提供的变量
HTTP 请求相关的变量
arg_参数名:URL中某个具体参数的值query_string:与args变量完全相同args:全部 URL 参数is_args:如果请求 URL 中有参数则返回?否则返回空content_length:HTTP 请求中标识包体长度的Content-Length头部的值content_type:标识请求包体类型的Content-Type头部的值uri:请求的 URI(不同于 URL,不包括?后的参数)document_uri:与uri完全相同request_uri:请求的 URL(包含 URI 以及完整的参数)sheme:协议名,例如 HTTP 或者 HTTPSrequest_method:请求方法,例如 GET、POSTrequest_length:所有请求内容的大小,包括请求行、头部、包体等remote_user:由 HTTP Basic Authentication 协议传入的用户名request_body_file:临时存放请求包体的文件- 如果包体非常小则不会存文件
client_body_in_file_only强制所有包体存入文件,且可决定是否删除
request_body:请求中的包体,这个变量当且仅当使用反向代理,且设定用内存暂存包体时才有效request:原始的url请求,含有方法与协议版本,例如GET /?a=1&b=2 HTTP/1.1host:先从请求行中获取- 如果含有
Host的header,则用其值替换掉请求行中的主机名 - 如果前两者都取不到,则使用匹配上的
server_name
- 如果含有
http_头部名字:返回一个具体请求头部的值- 特殊的几个,Nginx 会做一些特殊处理
http_host、http_user_agent、http_referer、http_via、http_x_forwarded_for、http_cookie
- 通用:其他的不会做任何处理,直接从
Header中读取到内容就是变量的值
- 特殊的几个,Nginx 会做一些特殊处理
TCP 连接相关的变量
binary_remote_addr:客户端地址的整型格式,对于 IPv4 是 4 字节,对于 IPv6 是 16字节(一般会使用这个作为缓存的 key,效率高,但是写入日志可读性就不好)connection:递增的连接序号connection_requests:当前连接上执行过的请求数,对keepalive连接有意义remote_addr:客户端度地址remote_port:客户端端口proxy_protocol_addr:如果使用了proxy_protocol协议则返回协议中的地址,否则返回空proxy_protocol_port:如果使用了proxy_protocol协议则返回协议中的端口,否则返回空server_addr:服务器端地址server_port:服务器端端口TCP_INFO:tcp内核层参数,包括$tcpinfo_rtt, $tcpinfo_rttvar, $tcpinfo_snd_cwnd, $tcpinfo_rcv_spaceserver_protocol:服务器端协议,例如HTTP/1.1
Nginx 处理请求过程中产生的变量
request_time:请求处理到现在的耗时,单位为秒,精确到毫秒server_name:匹配上请求的server_name值https:如果开启了 TLS/SSL,则返回no,否则返回空request_completion:若请求处理完则返回OK,否则返回空request_id:以 16禁止输出的请求标识 id,该 id 公含有 16 个字节,是随机生成的request_filename:待访问文件的完整路径document_root:由 URI 和root/alias规则生成的文件夹路径realpath_root:将document_root中的软链接等换成真实路径limit_rate:返回客户端响应时的速度上限,单位为每秒字节数。可以通过set指令修改对请求产生效果
发送 HTTP 响应时相关的变量
body_bytes_sent:响应中body包体的长度bytes_sent:全部 http 响应的长度status:http响应中的返回码sent_trailer_名字:把响应结尾内容里值返回sent_http_头部名字:响应中某个具体头部的值- 特殊处理
sent_http_content_typesent_http_content_lengthsent_http_locationsent_http_last_modifiedsent_http_connectionsent_http_keep_alivesent_http_transfer_encodingsent_http_cache_controlsent_http_link
- 通用
- 特殊处理
Nginx 系统变量
time_local:以本地时间标准输出的当前时间,例如14/Nov/2022:15:55:37 +0800time_iso8601:使用 ISO 8601 标准输出的当前时间,例如2022-11-14T15:55:37+08:00nginx_version:Nginx 版本号pid:所属worker进程的进程idpipe:使用了管道则返回p,否则返回.hostname:所在服务器的主机名,与hostname命令输出一致msee:1970年1月1日到现在的时间,单位为秒,小数点后精确到毫秒
简单有效的防盗链手段 referer 模块
场景:当某网站通过 url 引用了你的页面,当用户在浏览器上点击 url 时,http 请求的头部会通过 referer 头部,将该网站当前页面的 url 带上,告诉服务器本次请求是由这个网页发起的。
目的:拒绝非正常的网站访问我们站点的资源
思路:通过 referer 模块,用 invalid_referer 变量根据配置判断 ``referer` 头部是否合法
https://nginx.org/en/docs/http/ngx_http_referer_module.html
默认编译进 Nginx
1 | Syntax: valid_referers none | blocked | server_names | string ...; |
valid_referers 可同时携带多个参数,标识多个 referer 头部都生效。
none:允许缺失referer头部的请求访问blocked:referer字段存在于请求头中,允许referer头部没有对应的值的请求访问(可能是通过了反向代理或者防火墙导致,但是不是以http://开头或者以https://开头)server_names:若referer中站点域名与server_name中本机域名某个匹配,则允许该请求访问- 标识域名及
URL的字符串,对域名可在前缀或者后缀中含有*通配符:若referer头部的值匹配字符串后,则允许访问 - 正则表达式:若
referer头部的值匹配正则表达式后,则允许访问
invalid_referers 变量:
- 允许访问时,变量值为空
- 不允许访问时,变量值为1
防盗链的一种解决方案 secure_link 模块
通过验证 URL 中哈希值的方式防盗链。
https://nginx.org/en/docs/http/ngx_http_secure_link_module.html
默认未编译进 Nginx
过程:
- 由某服务器(也可以是
nginx)生成加密后的安全连接url,返回给客户端 - 客户端使用安全
url访问nginx,由nginx的secure_link变量判断是否验证通过
原理:
- 哈希算法不可逆
- 客户端只能拿到执行过哈希算法的 URL
- 仅生成 URL 的服务器、验证 URL 是否安全的
nginx这二者,才保存执行哈希算法前的原始字符串 - 原始字符串通常由以下部分有序组成:
- 资源位置,例如 HTTP 中指定资源的 URI,防止攻击者拿到一个安全 URL 后可以访问任意资源
- 用户信息,例如用户 IP 地址,限制其他用户盗用安全 URL
- 时间戳,使安全 URL 及时过期
- 密钥,仅服务器端拥有,增加攻击者猜测出原始字符串的难度
1 | Syntax: secure_link expression; |
变量:
secure_link:- 值为空字符串:校验不通过
- 值为0: URL 过期
- 值为1: 验证通过
secure_link_expires:时间戳的值
例如一个变量值及带过期时间的配置:
通过命令行生成安全链接:
原始请求:
1 | /test1.txt?md5=md5生成值&expires=时间戳(例如147483647) |
生成 md5
1 | echo -n '时间戳URI客户端IP 密钥' | openssl md5 -binary | openssl base64 | tr +/ - | tr -d = |
Nginx 配置
1 | secure_link $arg_md5,$arg_expires; |
仅对 URI 进行哈希的简单办法:
- 将请求 URL 分为三个部分:
/prefix/hash/link - Hash 生成方式:对
link密钥做md5哈希求值 - 用
secure_link_secret secret配置密钥
例如:
原始请求
1 | link |
生成的安全请求
1 | /prefix/md5/link |
生成 md5
1 | echo -n 'linksecret' | openssl md5 –hex |
Nginx 配置
1 | secure_link_secret secret; |
map 模块的指令
https://nginx.org/en/docs/http/ngx_http_map_module.html
基于已有变量,使用类似 switch {case: ... default: ...} 的语法,创建新变量,为其他基于变量值实现功能的模块提供更多的可能性。
默认编译进 Nginx。
1 | Syntax: map string $variable { ... } |
例如
1 | # 语法的意思是,如果已有变量 $http_host 的值,匹配上下面左边,则生成一个新变量 $name 值对应右边 |
规则:
- 已有变量:
- 字符串
- 一个或者多个变量
- 变量与字符串的组合
case规则:匹配过程有优先级,先匹配则返回对应内容- 字符串严格匹配
- 使用
hostnames指令,可以对域名使用前缀*泛域名匹配 - 使用
hostname指令,可以idui域名使用后缀*泛域名匹配 ~和~*正则表达式匹配,后者忽略大小写
default规则- 没有匹配到任何规则时,使用
defualt - 缺失
defualt时,返回空字符串给新变量
- 没有匹配到任何规则时,使用
- 其他
- 使用
include语法提升可读性 - 使用
volatile禁止变量值缓存
- 使用
split_clients 模块
主要用于实现 AB 测试,让百分比的用户体验某一部分新功能,然后看反馈。
https://nginx.org/en/docs/http/ngx_http_split_clients_module.html
默认编译进 Nginx
也是基于已有变量创建新变量,为其他 AB 测试提供更多的可能性。(通过变量的值,以百分比的方式生成新的变量)
- 对已有变量的值执行
MurmurHash2算法得到 32 位整型哈希数字,记为hash - 32 位无符号整型的最大数字
2^32-1,记为 max - 哈希数字与最大数字相除
hash/max,可以得到百分比percent - 配置指令中指示了各个百分比构成的范围,如
0-1%、1%-5%等,及范围对应的值 - 当
percent落在哪个范围里,新变量的值就对应着其后的参数
规则:
- 已有变量
- 字符串
- 一个或者多个变量
- 变量与字符串的组合
case规则xx.xx%,支持小数点后 2 位,所有项的百分比相加不能超过 100%*,由它匹配剩余的百分比(100% 减去以上所有项相加的百分比)
1 | Syntax: split_clients string $variable { ... } |
例如
1 | http { |
geo 模块
https://nginx.org/en/docs/http/ngx_http_geo_module.html
可以基于 IP地址创建新变量,默认编译进 Nginx
1 | Syntax: geo [$address] $variable { ... } |
例如
1 | geo $country { |
- 如果
geo指令后不输入$address,那么默认使用$remote_addr变量作为 IP 地址 { }内的指令匹配:优先最长匹配- 通过 IP 地址及子网掩码的方式,定义 IP 范围,当 IP 地址在范围内时新变量使用其后的参数值
default指定了当以上范围都未匹配上时,新变量的默认值- 通过
proxy指令指定可信地址(参考realip模块),此时remote_addr的值为X-Forwarded_For头部值中最后一个 IP 地址 proxy_recursive允许循环地址搜索include,优化可读性delete删除指定网络
geoip 模块
基于 MaxMind 数据库从客户端地址获取变量,例如地域和所属相关信息。默认未编译进 Nginx
https://nginx.org/en/docs/http/ngx_http_geoip_module.html
依赖 MaxMind GeoIP 库,编译前需要先下载,然后编译时携带进去。
1 | # 国家信息 |
变量:
geoip_country_code:两个字母的国家代码,比如 CN 或者 USgeoip_country_code3:三个字母的国家代码,例如 CHNgeoip_country_name:国家名称:例如China
geoip_city 中的指令很多,例如经度、纬度、洲、国家、洲或者省编码、省、邮编等
keepalive 模块
是 HTTP 协议中的 keepalive,而不是 TCP 协议中的 keepalive。keepalive 本身包括对上游的和对下游的,对上游则是反向代理,自身相当于客户端。以下是对下游客户端而言。
https://nginx.org/en/docs/http/ngx_http_core_module.html#keepalive_disable
功能:多个 HTTP 请求通过复用 TCP 连接,实现以下功能:
- 减少握手次数
- 通过减少并发连接数减少了服务器资源的消耗
- 降低 TCP 拥塞控制的影响
协议:
Connection头部:取值为close或者keepalive,前者表示请求处理完即关闭连接,后者表示复用连接处理下一条请求。(这个header可以是客户端发给 Nginx,也可以是 Nginx 发给客户端)Keep-Alive头部:其值为timeout=n,后面的数字n单位是秒,告诉客户端连接至少保留n秒。(这个请求是 Nginx 发送给客户端)
1 | # 对某些浏览器关闭 keepalive |